sql tuning 교육
DESCRIPTION
SQL Tuning 교육. 처리시간 (t). 자료량 (n) 사용자수 (n). Preface. Measurement for Tuning Response Time Throughput Time Resources for Tuning Memory CPU Disk Network. Query. Optimizer. Query Optimization. Query Rewrite. Parse. RBO CBO. Query Execution. QEP Generation. Results. - PowerPoint PPT PresentationTRANSCRIPT

SQL Tuning 교육SQL Tuning 교육

PrefacePreface
Measurement for Tuning• Response Time• Throughput Time
Resources for Tuning• Memory• CPU• Disk• Network
자료량 (n)
사용자수(n)
처리
시간
(t)

Query 처리흐름Query 처리흐름
Query Query
QEPGeneration
Query ExecutionResults
Optimizer
ParseQuery
Rewrite RBO CBO
Query Optimization

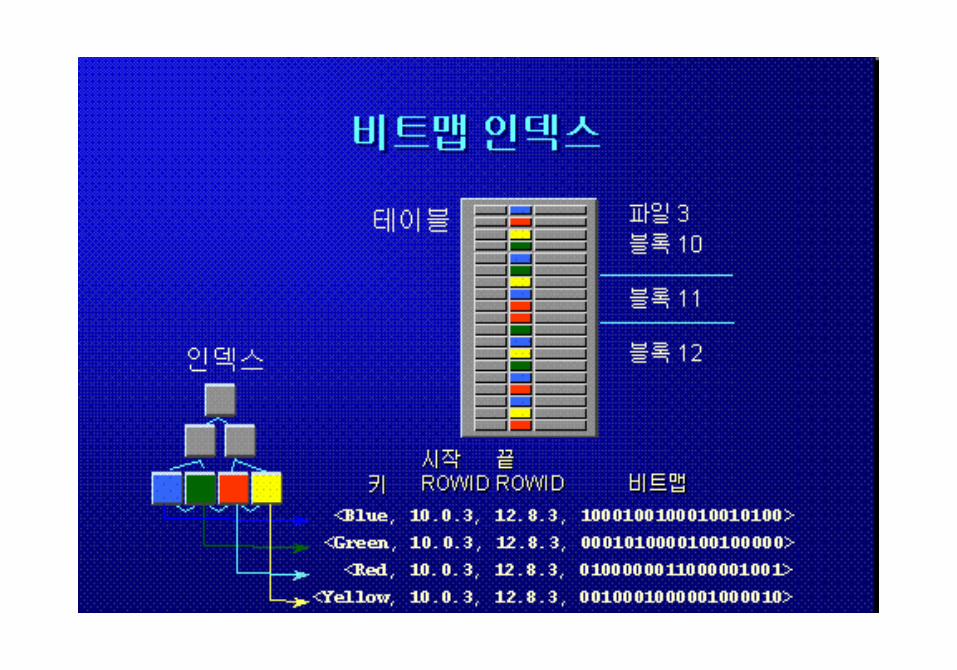
작가이름순 인덱스
책이름순 인덱스
도서분야 ( 종류 ) 인덱스
“ 도서관에서 필요한 책 찾기 ”
테이블 / 인덱스 개념

B*Tree 인덱스
A B C D E F G H I J K L
FA FB FC FD FE FF FG FH FI FJ FK FL FM FN FO FP
FII FIJ FIK FIL FIM FINFIA FIB FIC FID FIE FIF FIG FIH FIO FIP FIQ FIR FIS FIT
FIFA
DATA+ROWID
FIFB FIFC FIFD FIFE FIFH FIFI
DATA+ROWID
FIFJ FIFK FIFL FIFM FIFN FIFO
DATA+ROWID
FIFP FIFQ FIFR FIFS FIFT
ROOT
BRANCH
BRANCH
LEAF
Leaf block scan

테이블들어오는 순서대로 기록
인덱스인덱스 데이터 값을 정렬하여 기록
D page 1
103 D 92/06 D page 4
109 D 90/01
101 A 93/10
A page 7
고객번호 이름 생일 이름 ROWID
K page 2
100 K 93/10
105 93/10
page 6
K page 8
108 K 90/01
102 C 92/05
C page 3
104 F 93/01 F page 5
데이터 생성

테이블 액세스 ( 인덱스 없는 경우 )
고객번호 이름 생일 100 D 90/01
102 C 92/05
103 D 92/06
104 F 93/01
105 X 93/10
106 A 93/10
107 K 93/10
101 K 90/01
WHERE 이름 = ‘K’
FULL TABLE SCAN
Œ
O
O
X
X
X
X
X
X

고객번호 이름 생일 100 D 90/01
102 C 92/05
103 D 92/06
104 F 93/01
105 X 93/10
106 A 93/10
107 K 93/10
101 K 90/01
이름 ROWID A page 7
D page 1
D page 4
F page 5
K page 8
K page 2
X page 6
C page 3
WHERE 이름 = ‘K’
INDEX SCAN TABLE ACCESS BY ROWID
X
테이블 액세스 ( 인덱스 있는 경우 )

인덱스 대상 컬럼
• 조건문에 자주 등장하는 컬럼
• 같은 값이 적은 컬럼 ( 분포도가 좁은 컬럼 )
• 조인에 참여하는 컬럼
인덱스 사용 시 손해 보는 경우
• 데이터가 적은 테이블 ( 16 Block 이내인 경우 )
• 같은 값이 많은 컬럼 ( 분포도가 넓은 컬럼 )
• 조회보다 DML 의 부담이 큰 경우
인덱스 사용 기준

고객번호 이름 생일
109 D 90/01
102 C 92/05
103 D 92/06
104 C 93/01
105 C 93/10
101 A 93/10
100 K 93/10
108 K 90/01
이름 생일 ROWID
A 93/10 page 7
C 92/05 page 3
C 93/01 page 5
C 93/10 page 6
D 90/01 page 1
D 92/06 page 4
K 90/01 page 2
K 93/10 page 8
WHERE 이름 = ‘C’ AND 생일 > ‘92/12’ AND 고객번호 = 105
O
X
CHECK인덱스 범위결정
X
스캔범위결정 조건과 검증조건

스캔범위결정 조건과 검증조건WHERE 이름 = ‘C’ AND 생일 like ‘%10’ AND 고객번호 = 105 check인덱스 범위결정
X
고객번호 이름 생일
109 D 90/01
102 C 92/05
103 D 92/06
104 C 93/10
105 C 93/10
101 A 93/10
100 K 93/10
108 K 90/01
이름 생일 ROWID
A 93/10 page 7
C 92/05 page 3
C 93/10 page 5
C 93/10 page 6
D 90/01 page 1
D 92/06 page 4
K 90/01 page 2
K 93/10 page 8
O
XX
check

• 인덱스 컬럼에 변형이 일어난 경우
• 부정형으로 조건을 기술한 경우
• NULL 을 비교하였을 경우
• 내부적인 변형이 일어난 경우
• 옵티마이져의 판단에 따라 (cost-based optimizer)
인덱스를 사용하지 못하는 경우

Select …
from department
where max_salary * 12 > 2500;
부서번호 부서명 max_salary
109 D 150
102 C 100
103 D 200
104 C 100
105 C 350
101 A 200
100 K 300
108 K 180
max_salary ROWID
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
150 xxxx.xxxx.xxxxxxxx
180 xxxx.xxxx.xxxxxxxx
200 xxxx.xxxx.xxxxxxxx
200 xxxx.xxxx.xxxxxxxx
300 xxxx.xxxx.xxxxxxxx
350 xxxx.xxxx.xxxxxxxx
O
X
X
X
X
X
O
X
인덱스 컬럼의 변형

O
O
Select …
from department
where max_salary > 2500/12 ;
부서번호 부서명 max_salary
109 D 150
102 C 100
103 D 200
104 C 100
105 C 350
101 A 200
100 K 300
108 K 180
max_salary ROWID
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
150 xxxx.xxxx.xxxxxxxx
180 xxxx.xxxx.xxxxxxxx
200 xxxx.xxxx.xxxxxxxx
200 xxxx.xxxx.xxxxxxxx
300 xxxx.xxxx.xxxxxxxx
350 xxxx.xxxx.xxxxxxxx
인덱스 컬럼의 변형

부서번호 부서명 max_salary
99 D 150
100 C 100
100 D 200
100 C 100
100 C 350
100 A 200
101 K 300
100 K 180
max_salary ROWID
99 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
101 xxxx.xxxx.xxxxxxxx
O
X
X
X
X
X
O
X
부정형 조건Select …
from Employee_TEMP
where 부서번호 <> ’100’ ;

부서번호 부서명 max_salary max_salary ROWID
99 D 150
100 C 100
100 D 200
100 C 100
100 C 350
100 A 200
101 K 300
100 K 180
O
O
Select …from Employee_TEMPwhere 부서번호 < ‘100’ OR 부서번호 >
‘100’ ;
99 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
100 xxxx.xxxx.xxxxxxxx
101 xxxx.xxxx.xxxxxxxx
부정형 조건

NULL 로 비교시NULL 로 비교시 Select …from Employeewhere 생일 > ‘ ’;
Select …from Employeewhere 급여 > 0 ;
내부변형 발생시내부변형 발생시 Select …from Employeewhere 부서번호 =
to_char(10)
Select …from Employeewhere 생일 > to_char( today,
‘YYMMDD’)
Select …from Employeewhere 생일 is not
null;
Select …from Employeewhere 급여 is not
null;
Select …from Employeewhere 부서번호 =
10( 숫자 )
Select …from Employeewhere 생일 >
today( 일자 )
NULL 비교와 내부변형

조인 (JOIN)
• 조인과 서브쿼리의 차이
• 조인의 방법
• 조인의 속도

옵티마이져의 조인선택 조인 조건문 테이블 1 테이블 2 조인방법
한쪽만 인덱스가 있다 . XO 테이블 2 -> 테이블 1
X O 테이블 1 -> 테이블 2
양쪽에 인덱스가 있다 .OO
1. 조인순서에 상관없슴
2. 나머지 조건들로 판단
외부 (Outer) 조인인 경우 + 테이블 2 -> 테이블 1
“ 반드시 조인의 수를 줄일 수 있는 조인순서를 알아내고 이를
옵티마이져가 선택할 수 있도록 유도해야 한다 . “
양쪽에 인덱스가 없다 .XX
1. SORT+MERGE
2. HASH JOIN

Join Method – Nested Loop JoinJoin Method – Nested Loop Join
result = {};
for each row r in R do
for each row s in S do
if p(r.c, s.c) then result = result + {<r, s>};
end
end

Join Method – Sort Merge JoinJoin Method – Sort Merge Join
sort_merge(R, S, ci, cj)
{
sort(R, ci);
sort(S, cj);
merge(R, S, ci, cj);
}
MERGE
SORT
R
SORT
S

Sort-MergeSort-Merge
Internal Sort• in-memory sort• O(n2), O(nlog2n)
External Sort• internal sort 로 run 생성• m 개 run 들을 merge• O(n2) + O(mlog2m) + ?
R1 R2
R12
R4R3
R34
R1234
R5 R6
R56
R8R7
R78
R5678
R12345678
Internal Sort

Join Method – Hash JoinJoin Method – Hash Join
작은 row source 로 hash table 과 bitmap 을 만든다 .
다른 row source 를 hashing 하여 조사한다 .
bitmap 은 hash table 이 커 in-memory 에 모두 놓일 수 없을 때 , 사용된다 .
Table R(build input)
Disk
Memory 에 존재하는
hash table 과 bitmap
Result Set
Table S(probe)

조인의 종류 (Nested Loop)
Select a.col1, a.col2, b.col3 from TAB1 a, TAB2 b where a.PK = b.FK and a.col5 = ‘10’ and b.col6 like ‘AB%’
( 조인 조건 )1
Index(col5) TAB1 TAB2
●
●
●
●
●
●
●
●
●
●
●
Index(FK)
X
O
2
3 ( 결과 검증 )
2 ( 인덱스 SCAN )
OX
100 회 100 회 100회이상
100 회이상
13
50 건
1 : M

조인의 종류 (Nested Loop)
Select a.col1, a.col2, b.col3 from TAB1 a, TAB2 b where a.PK = b.FK and a.col5 = ‘10’ and b.col6 like ‘AB%’
( 조인 조건 )1
Index(col6) TAB2 TAB1
●
●
●
●
●
●
●
●
●
Index(PK)
X
O
3
3 ( 인덱스 SCAN)
2 ( 결과 검증 )
X
200 회 200 회 200회 200 회
12
50 건
1 : 1

조인의 종류 (Sort Merge)
( 인덱스 SCAN )
(SORT + 중복데이터 삭제 )
( 인덱스 SCAN )
Select a.col1, a.col2, b.col3 from TAB1 a, TAB2 b where a.PK = b.FK and a.col5 = ‘10’ and b.col6 like ‘AB%’
1
3
2
TAB1
●
●
●
●
●
●
Index(col5)
2
100100100 건
OXO
1SORTSORT
MERGEIndex(col6) TAB2
200
●
●
●
200
3
200 건

조인의 종류 (Hash Join)
( 인덱스 SCAN )
( 해쉬조인 )
( 인덱스 SCAN )
Select a.col1, a.col2, b.col3 from TAB1 a, TAB2 b where a.PK = b.FK and a.col5 = ‘10’ and b.col6 like ‘AB%’
1
3
2
Hash Function
100 건
TAB1
●
●
●
●
●
●
Index(PK)
2
100100
Index(col6) TAB2
200
●
●
●
200
3
200 건 Hashing

Select a.col1, b.col2, b.col3, c.col4 From a, b, cWhere a.jcol1 = b.jcol1And a.jcol2 = c.jcol2And a.col1 = ‘KKK’And b.col2 > 10 And b.col3 like ‘a%’And c.col4 Between ‘20030101’ And ‘20030201’
Join 문 튜닝 예제
테이블 Row 수 Column 조건 선택도A 1,000,000 col1 = ‘KKK’ 0.1%
a.jcol1+a.Jol2 (# of Distinct Value : 100,000) 0.001%
B 10,000 b.col2 > 10 and b.col3 like ‘a%’ 5%
b.jcol1 (# of Distinct Value : 2,500) 0.04%
C 100,000 c.col4 between ‘20030101’ and ‘20030201’ 20%
c.jcol2 (# of Distinct Value : 20,000) 0.005%

Driving Table 의 결정 추출성능이 가장 좋은 테이블 *
1. 튜닝 시 드라이빙 테이블의 선택
조인절을 제외한 조건절에 의한 선택도가 가장 낮은 테이블
Cardinality = Table 의 전체 로우수 * 조건절 Selectiv-ity
And col2 > 10And col3 like ‘a%’
5%
And col4 between …20%
Driving Table
A
B
C
And col1 = ‘KKK’
0.1%10,000
100,000
1,000,000
1,000 = Cardinality

Next Join Table 의 결정
2. 튜닝 시 조인순서의 선택
비율 = Join Column 의 대응비 * 조건절 SelectivityCardinality = 결과건수 = Driving Table 의 전체 로우수 * 조건절 Se-lectivity
조인조건으로 연결이 되는 테이블 중에서 조인결과 비율이 가장 적은 테이블 ( 아래 결과 A, B, C 순서로 해석 )
1:4 (0.04%)
1: 5 (0.005%)
And col2 > 10And col3 like ‘a%’
5%
And col4 between …20%
결과건수
A
B
C
1,00010,000
100,000
a.jcol1 = b.jcol1
a.jcol2 = b.jcol2
Next Join Table
4 * 0.05 = 0.2 (20%)
5 * 0.2 = 1 (100%)

조인방법의 결정 조인을 통한 선택도가 조인대상 테이블의 일정비율 (5-10 %)를 초과 시 hash join, 반대의 경우에는 nested loop join
3. 튜닝 시 조인방법의 선택
비율 = ( (Cardinality * 대응비 ) / 대상테이블 전체로우수 ) * 100% = ( Cardinality * 조인 컬럼의 Selectivity ) * 100%Cardinality = 결과건수 = (Cardinality * 대응비 ) * 조건절 Se-lectivity
And col2 > 10And col3 like ‘a%’
5%
And col4 between …20%
B
C
1,000 10,000
100,000
a.jcol1 = b.jcol1
a.jcol2 = b.jcol2
대상 Table
1,000 * 4 / 10,000 = 0.4 (40%)1,000 * 4 * 0.05 = 200
200 * 5 / 100,000 = 0.01 (1%)
A
결과 건수
200
A+B
Hash Join
Nested Loop
1:4 (0.04%)
1: 5 (0.005%)

ROWS EXECUTION PLAN -------- ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 360 HASH JOIN 624 HASH JOIN 624 TABLE ACCESS (BY INDEX ROWID) OF 'BOFJMST’ 625 INDEX (RANGE SCAN) OF 'PK_BOFJMST' (UNIQUE) 1201800 TABLE ACCESS (FULL) OF 'BOFJBDEAL’ 7766 TABLE ACCESS (FULL) OF 'BMSMS'
조인방법과 순서 (예제 1)
인덱스 정보BOFJBDEAL(PK_BOFJBDEAL)- TRADE_DATE+STD_CODE
(UNIQUE)BMSMS (PK_BMSMS) - STD_CODE (UNIQUE)
SELECT A.std_code, B.sel_cnt+ B.buy_cnt, C.expire_kind …… FROM bofjmst A, bofjbdeal B, bmsms C WHERE A.std_code = B.std_code AND A.std_code = C.std_code AND A.trade_date= B.trade_date AND A.trade_date = :A AND C.expire_kind >= 5 AND C.expire_kind < 100;
Driving 테이블 : bofimst A(20,000)조인순서 : A -> C -> B조인방법 : ALL Nested Loop

조인방법과 순서 (예제 1)
결과건수 = 전체 로우수 * 조건절 선택도 = Cardinality * 대응비 * 조건절 선택도조인결과비율 = 대응비 * 조건절 선택도조인비율 = (Cardinality * 대응비 ) / 대상테이블 전체로우수
1. Driving Table 위 선택 : 조건절에 의한 선택도가 가장 낮은 Table 2. Next 조인 Table 의 선택 : 조인결과 비율이 가장 낮은 Table3. 조인방법의 선택 : 조인비율이 10% 이상이면 Hah Join, 이하이면 Nested Loop
4:1( < 1:1 )
1: 1
expire_kind >= 5expire_kind < 100 50%
trade_date = :A
100%
C
B20,000
7,766
1,201,800
std_code = std_code
trade_date = trade_dateStd_code = std_code
A3%
bofjmst = A, bofjbdeal = B, bmsms = C

조인방법과 순서 ( 예제 1)
all count cpu elapsed disk query current rows------- ------ -------- ---------- ---------- ---------- ---------- ----------Parse 1 0.01 0.01 0 0 0 0Execute 1 0.01 0.01 0 0 0 0Fetch 5 4.82 5.60 4593 5949 8 360------- ------ -------- ---------- ---------- ---------- ---------- ----------Total 7 4.84 5.62 4593 5949 8 360
bofjdeal
2 차 hashing
Driving Table
HashFunction
HashFunction
bmsms
12018007766
Cost
Hig
h
1 차 hashing
pk_bofjmst
bofjmst
625

조인방법과 순서 ( 예제 1)
SELECT /*+ordered use_nl(bofjmst bmsms bofjbdeal) */ A.std_code, B.sel_cnt+ B.buy_cnt, C.expire_kind …… FROM bofjmst A, bmsms C, bofjbdeal B WHERE A.std_code = B.std_code AND A.std_code = C.std_code AND A.trade_date= B.trade_date AND A.trade_date = :A AND C.expire_kind >= 5 AND C.expire_kind < 100;
ROWS EXECUTION PLAN-------- ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=HINT: FIRST_ROWS 360 NESTED LOOPS 625 NESTED LOOPS 625 TABLE ACCESS (BY INDEX ROWID) OF 'BOFJMST’ 625 INDEX (RANGE SCAN) OF 'PK_BOFJMST' (UNIQUE) 360 TABLE ACCESS (BY INDEX ROWID) OF 'BMSMS' 625 INDEX (UNIQUE SCAN) OF 'PK_BMSMS' (UNIQUE) 360 TABLE ACCESS (BY INDEX ROWID) OF 'BOFJBDEAL’ 360 INDEX (UNIQUE SCAN) OF 'PK_BOFJBDEAL' (UNIQUE)

조인방법과 순서 ( 예제 1)조인순서 (Nested Loop)
bofidealDriving Table
pk_bofjmst
bofjmst
625 360 360
pk_bofidealbmsms
625
pk_bmsms
625
all count cpu elapsed disk query current rows------- ------ -------- ---------- ---------- ---------- ---------- ----------Parse 1 0.01 0.01 0 0 0 0Execute 1 0.00 0.00 0 0 0 0Fetch 5 0.52 0.60 572 4933 8 360------- ------ -------- ---------- ---------- ---------- ---------- ----------Total 7 0.53 0.61 572 4933 8 360
Cost Lo
w

Tuning Tips - OverviewTuning Tips - Overview
SQL 문의 성능저하에 대한 일반적인 원인• Sub-optimal access methods• 부적합한 통계정보• Bind 변수• 불필요한 sorting• Skewed data

Suboptimal Access MethodsSuboptimal Access Methods
필요 없는 rows 을 가급적 빨리 제거하라불필요한 FTS 을 피하라인덱스가 제대로 사용되는 지 확인하라• Leading 컬럼의 selectivity 가 좋은가 ?• Column 순서는 제대로인가 ?
Best plan 을 위해 다른 join 순서를 조사하라

부적합한 통계정보부적합한 통계정보
정기적으로 analyze• OLTP 환경에는 문제• Large table 에 대해서는 estimate 로 analyze
Query 에 있는 모든 테이블을 analyze
Join 컬럼에 대해서 analyze

Bind 변수Bind 변수
Bind 변수 사용시 trade-off:• 공유에 의한 parse time 절약• 최적화된 수행계획
원하는 access path 를 위해 hint 를 사용

SortingSorting
불필요한 sort 를 제거하라• 인덱스 Access 사용• UNION ALL 사용• Sort-Merge Join 을 피하라 (Hah Join, HASH_AREA_SIZE)
Sort 를 위한 튜닝• SORT_AREA_SIZE• TEMPORARY tablespaces