spoken language translation by alexandra birch
TRANSCRIPT

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Spoken Language Translation
Alexandra Birch
School of InformaticsUniversity of Edinburgh
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
1
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 2
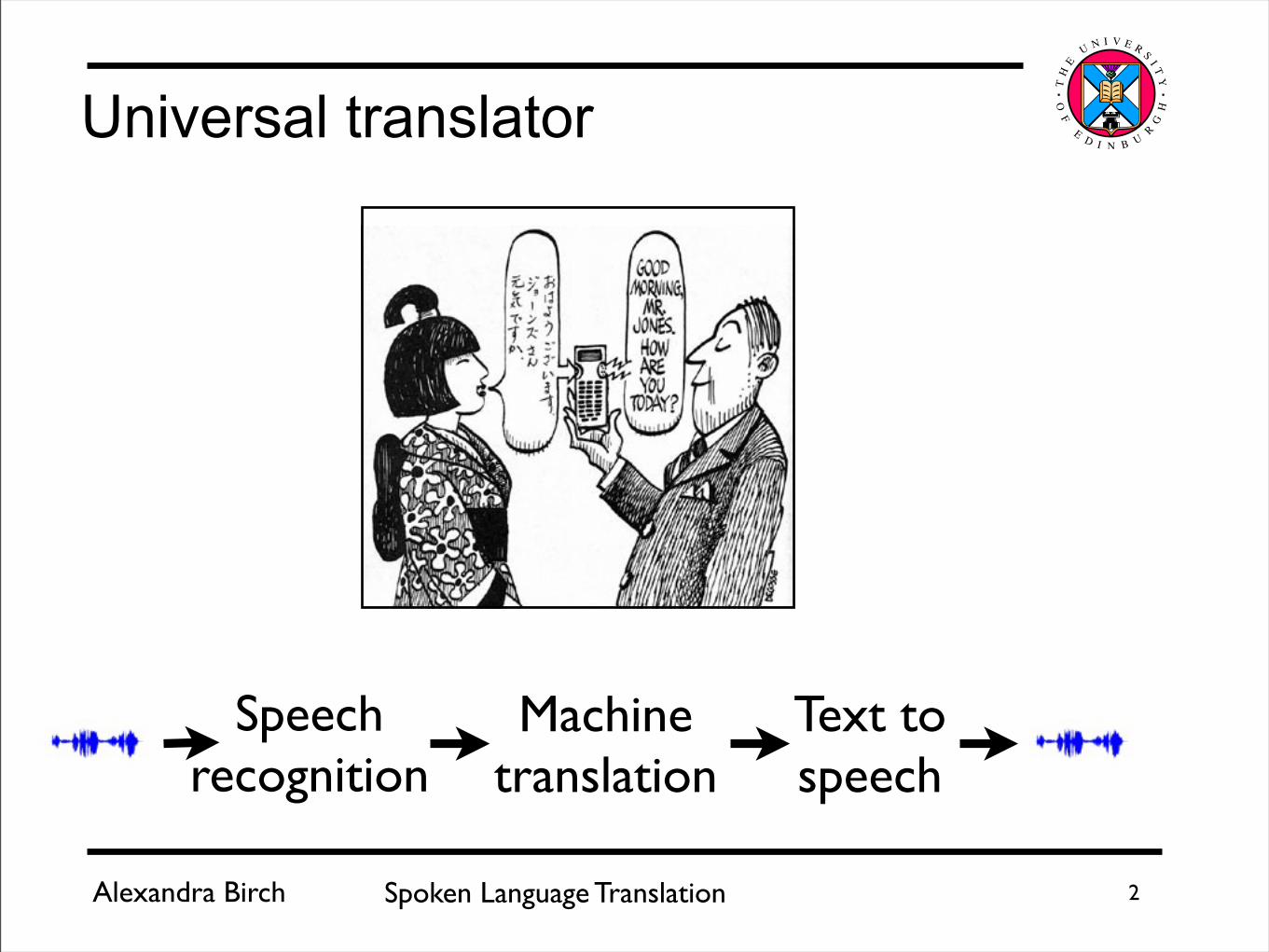
Universal translator
Speech recognition
Machine translation
Text to speech

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 3
Science fiction
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 4
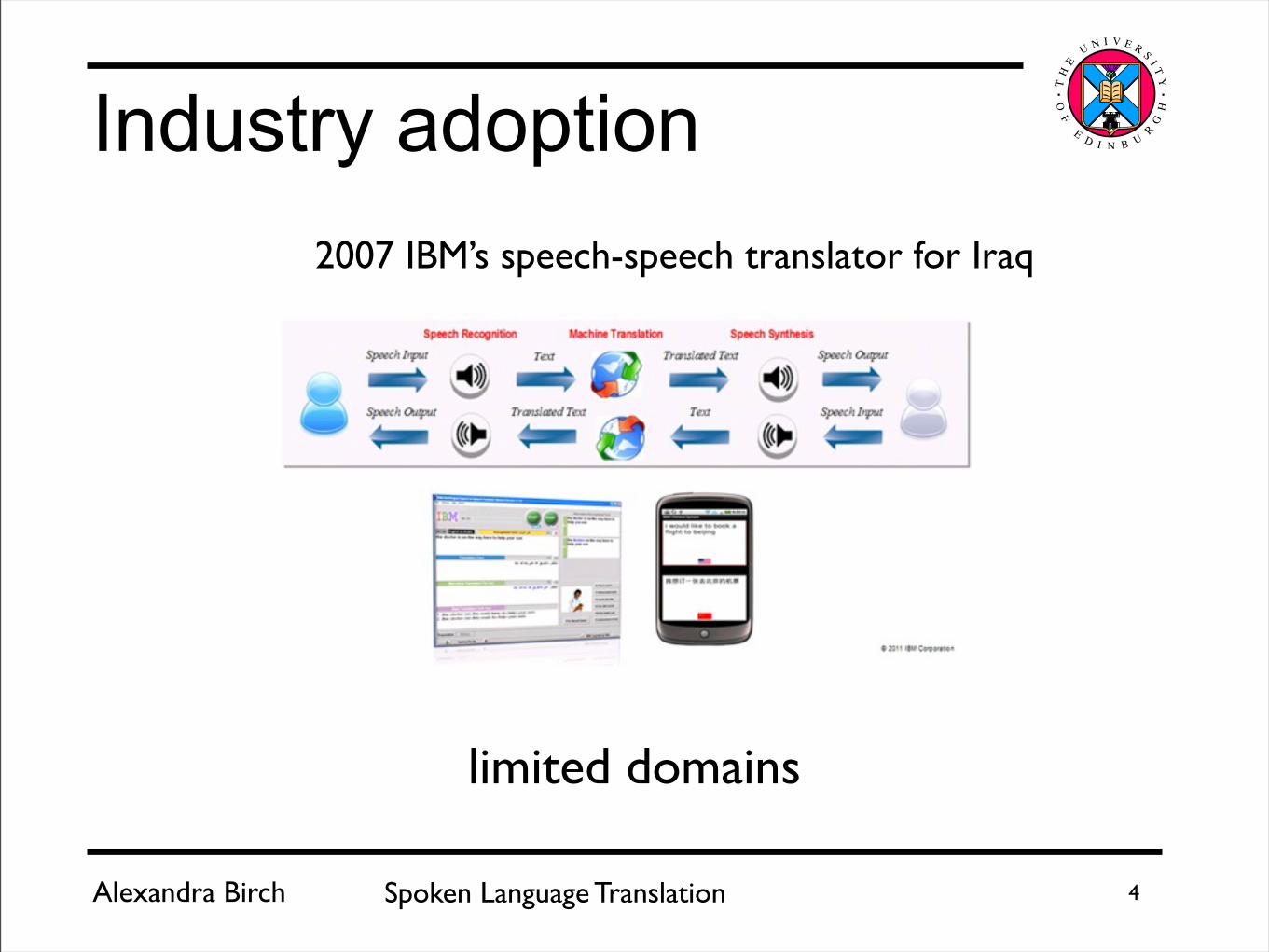
Industry adoption2007 IBM’s speech-speech translator for Iraq
limited domains

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 5
open domain - more language pairs
Industry adoption

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 6
massive reach - uncertain quality
Industry adoption
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 7
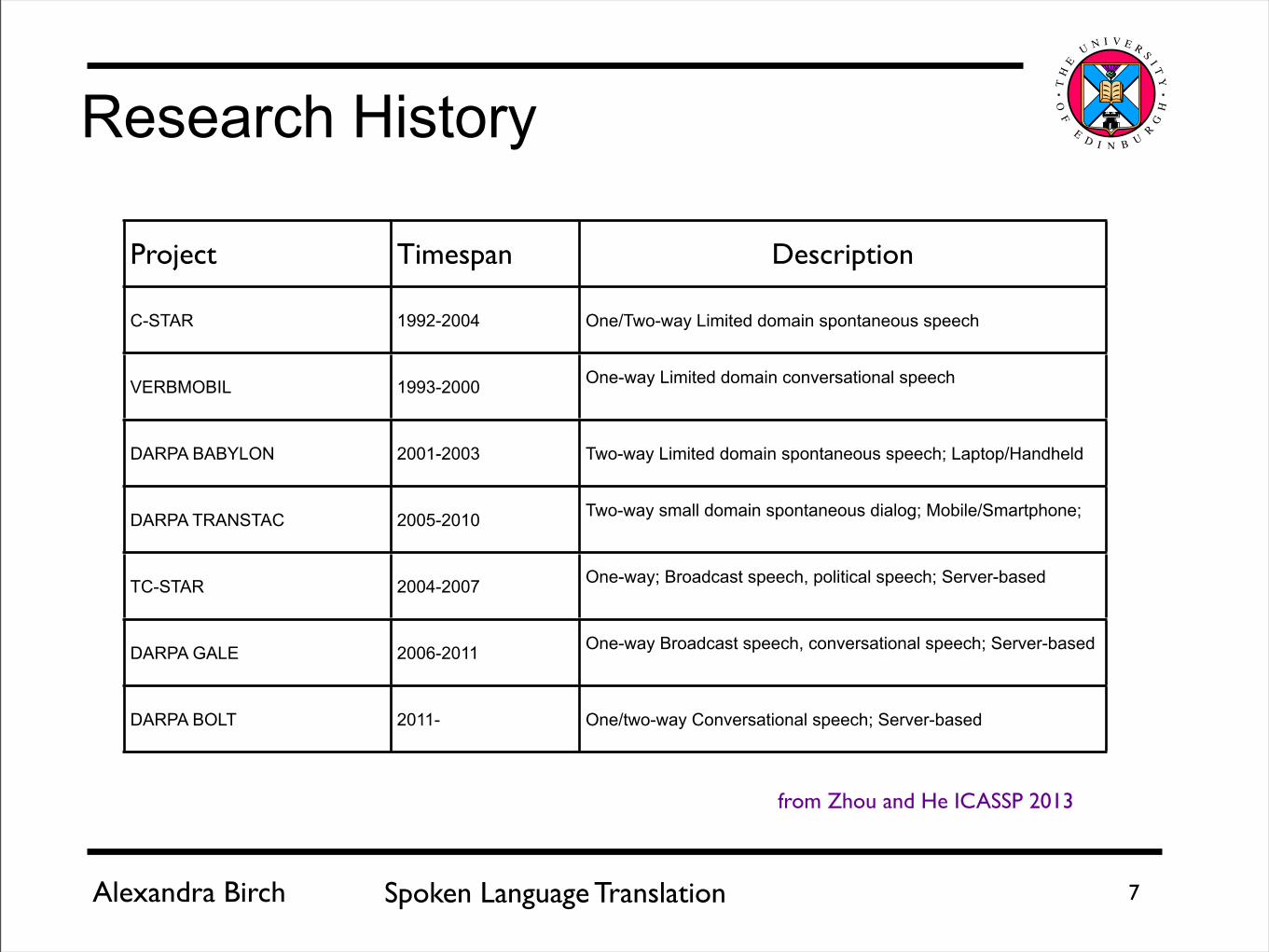
Research History
Project Timespan Description
C-STAR 1992-2004 One/Two-way Limited domain spontaneous speech
VERBMOBIL 1993-2000 One-way Limited domain conversational speech
DARPA BABYLON 2001-2003 Two-way Limited domain spontaneous speech; Laptop/Handheld
DARPA TRANSTAC 2005-2010 Two-way small domain spontaneous dialog; Mobile/Smartphone;
TC-STAR 2004-2007 One-way; Broadcast speech, political speech; Server-based
DARPA GALE 2006-2011 One-way Broadcast speech, conversational speech; Server-based
DARPA BOLT 2011- One/two-way Conversational speech; Server-based
from Zhou and He ICASSP 2013
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 8
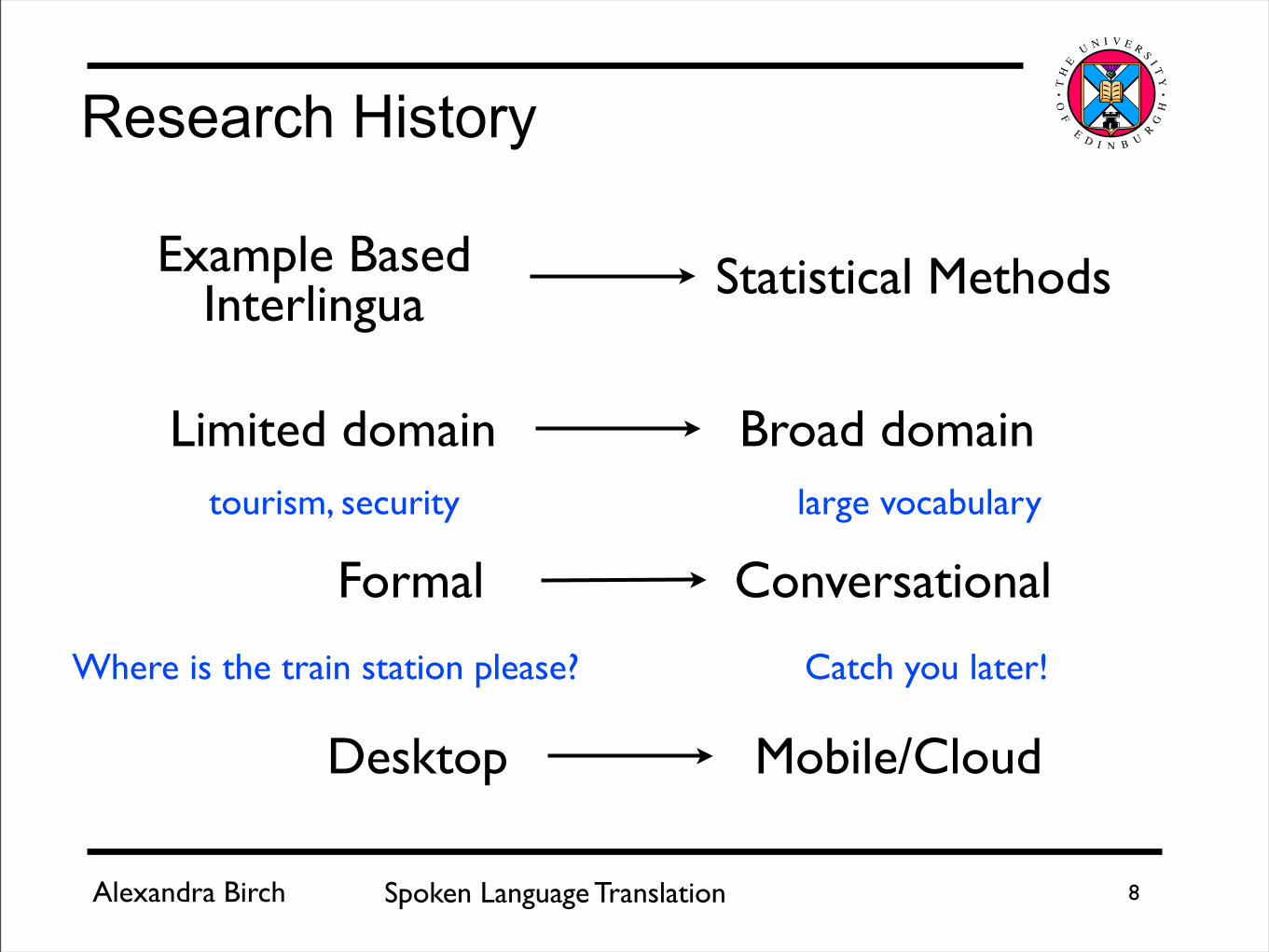
Research History
Desktop Mobile/Cloud
Limited domain Broad domaintourism, security large vocabulary
Formal Conversational
Where is the train station please? Catch you later!
Example BasedInterlingua Statistical Methods

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 9
Current Success
✦ Statistical models
✦ Large amounts of training data
✦ Discriminative training
✦ Better models (DNN for ASR)

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 10
Overview
• Spoken Language Translation✦ Background
✦ Challenges and opportunities
✦ Demos
• Experiments in SLT

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
THE HEAVIEST TRAIN IS GOING TO FALL IN A MY MANCHESTER AND THE SURROUNDING AREA
11
Automatic Speech Recognition
Challenges: accents, articulation, pronunciation, speed, recording quality, background noise

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 12
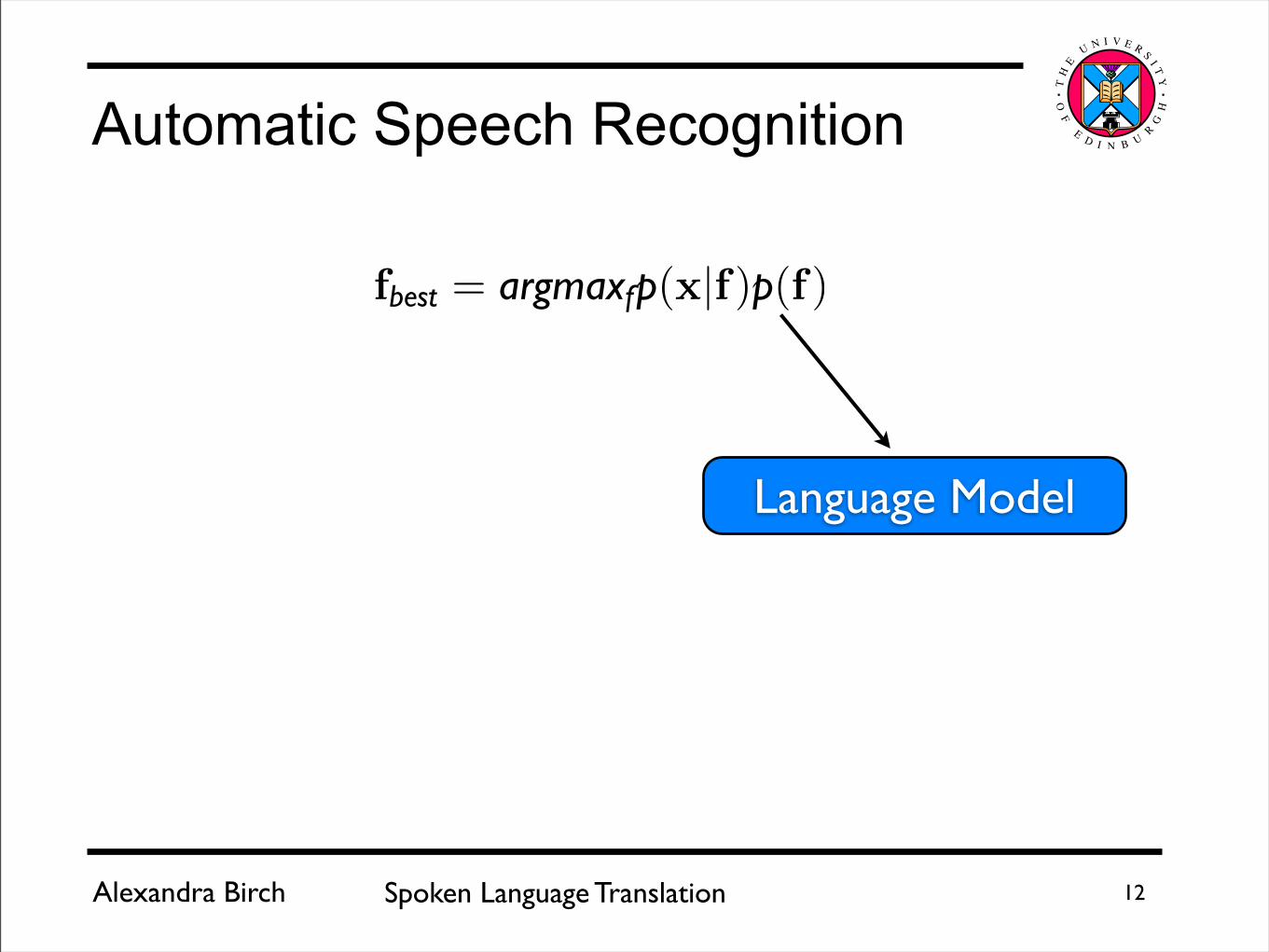
Automatic Speech Recognition
f = (x|f) (f)
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 12
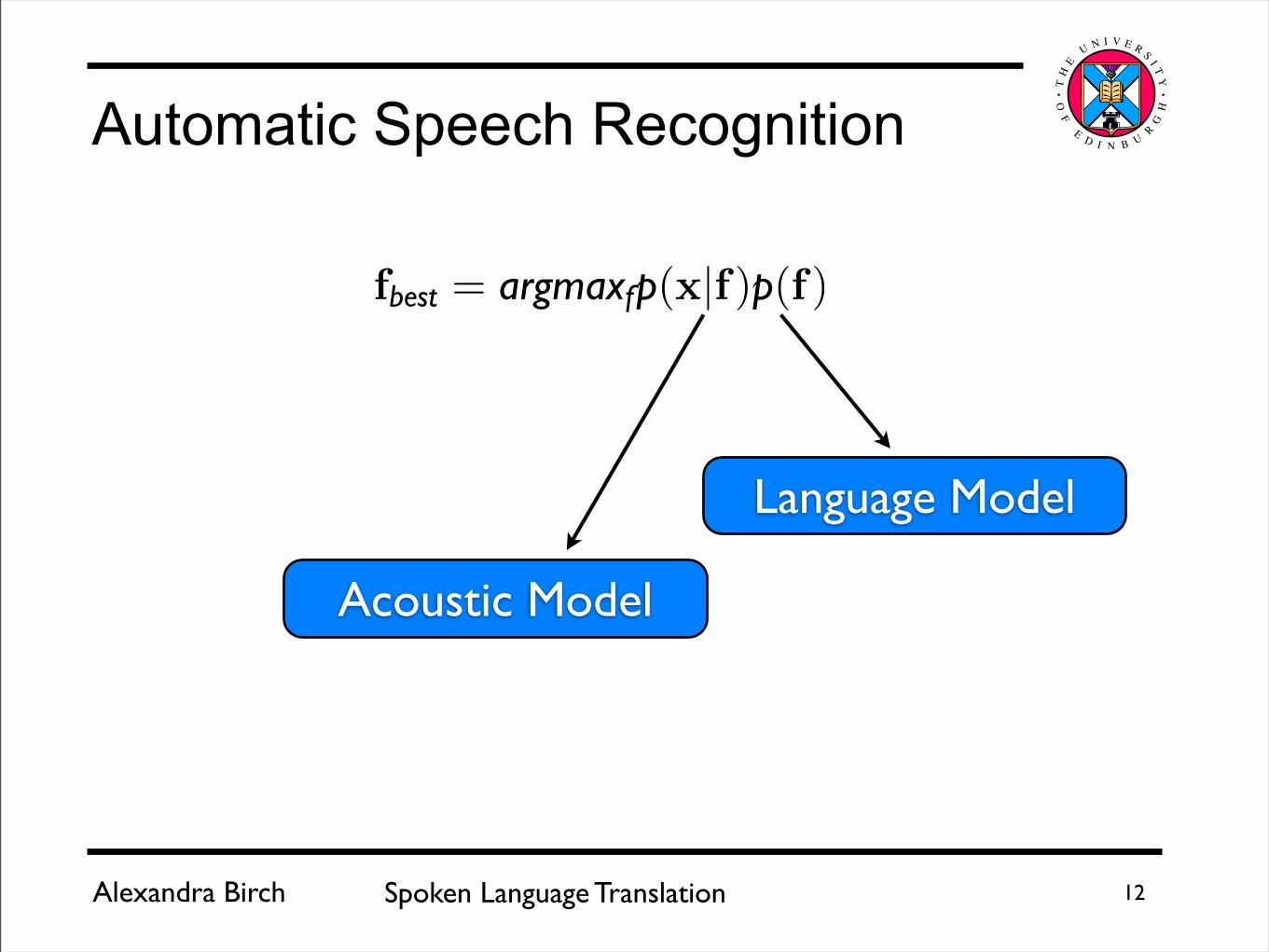
Automatic Speech Recognition
f = (x|f) (f)
Language Model
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 12
Automatic Speech Recognition
f = (x|f) (f)
Acoustic Model
Language Model
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
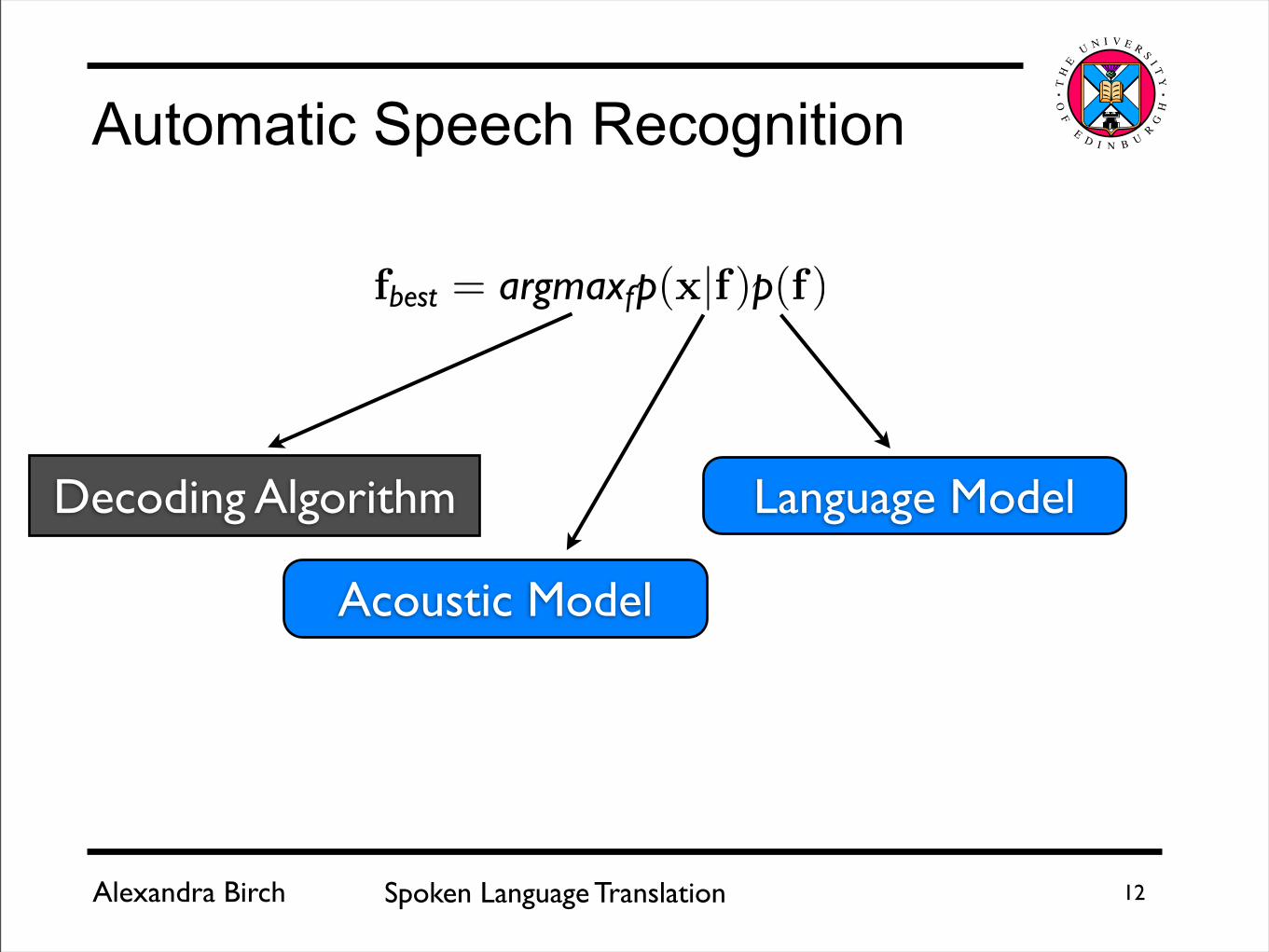
Alexandra Birch Spoken Language Translation 12
Automatic Speech Recognition
f = (x|f) (f)
Acoustic Model
Language ModelDecoding Algorithm
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
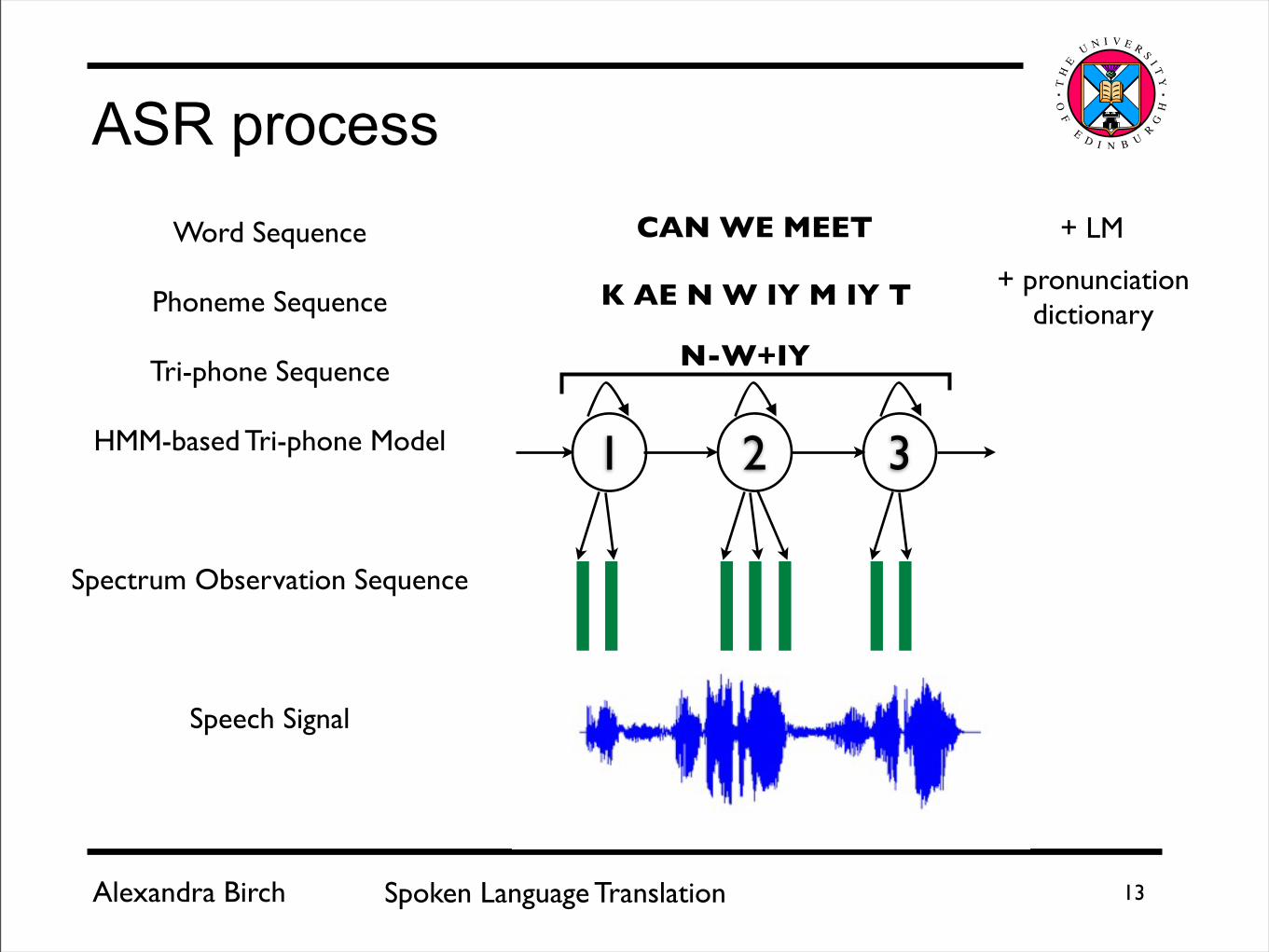
Alexandra Birch Spoken Language Translation 13
ASR processWord Sequence
Phoneme Sequence
Tri-phone Sequence
HMM-based Tri-phone Model
Spectrum Observation Sequence
Speech Signal
1 2 3
CAN WE MEET
K AE N W IY M IY T
N-W+IY
+ pronunciation dictionary
+ LM

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 14
Word Error Rate
• S is the number of substitutions,• D is the number of deletions,• I is the number of insertions and• N is the number of words in the reference
=+ +
Much easier to evaluate ASR than MT!
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
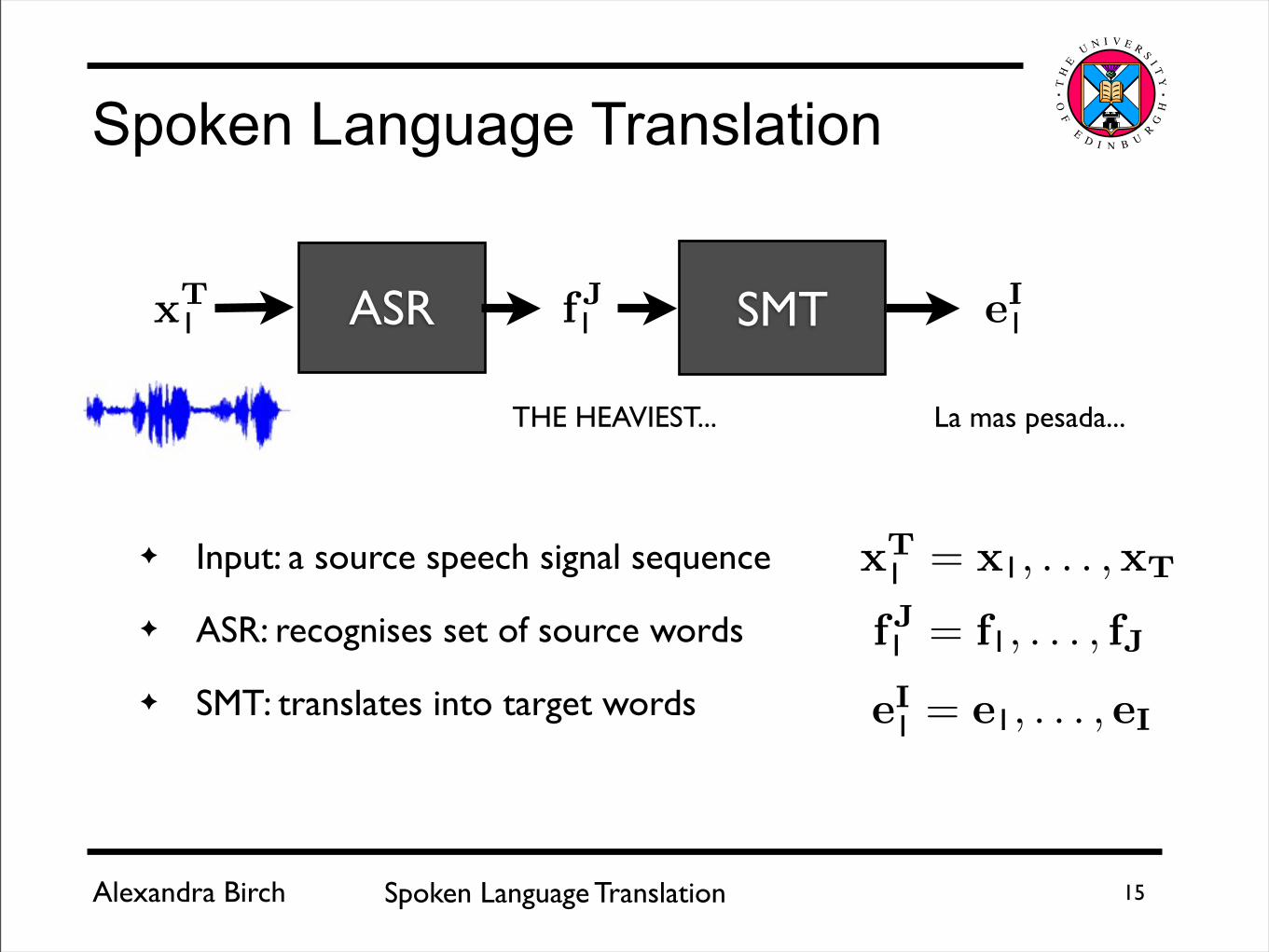
✦ Input: a source speech signal sequence
✦ ASR: recognises set of source words
✦ SMT: translates into target words
15
Spoken Language Translation
THE HEAVIEST... La mas pesada...
fJ = f , . . . , fJ
xT = x , . . . ,xT
eI = e , . . . , eI
ASR SMTxT eIfJ
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
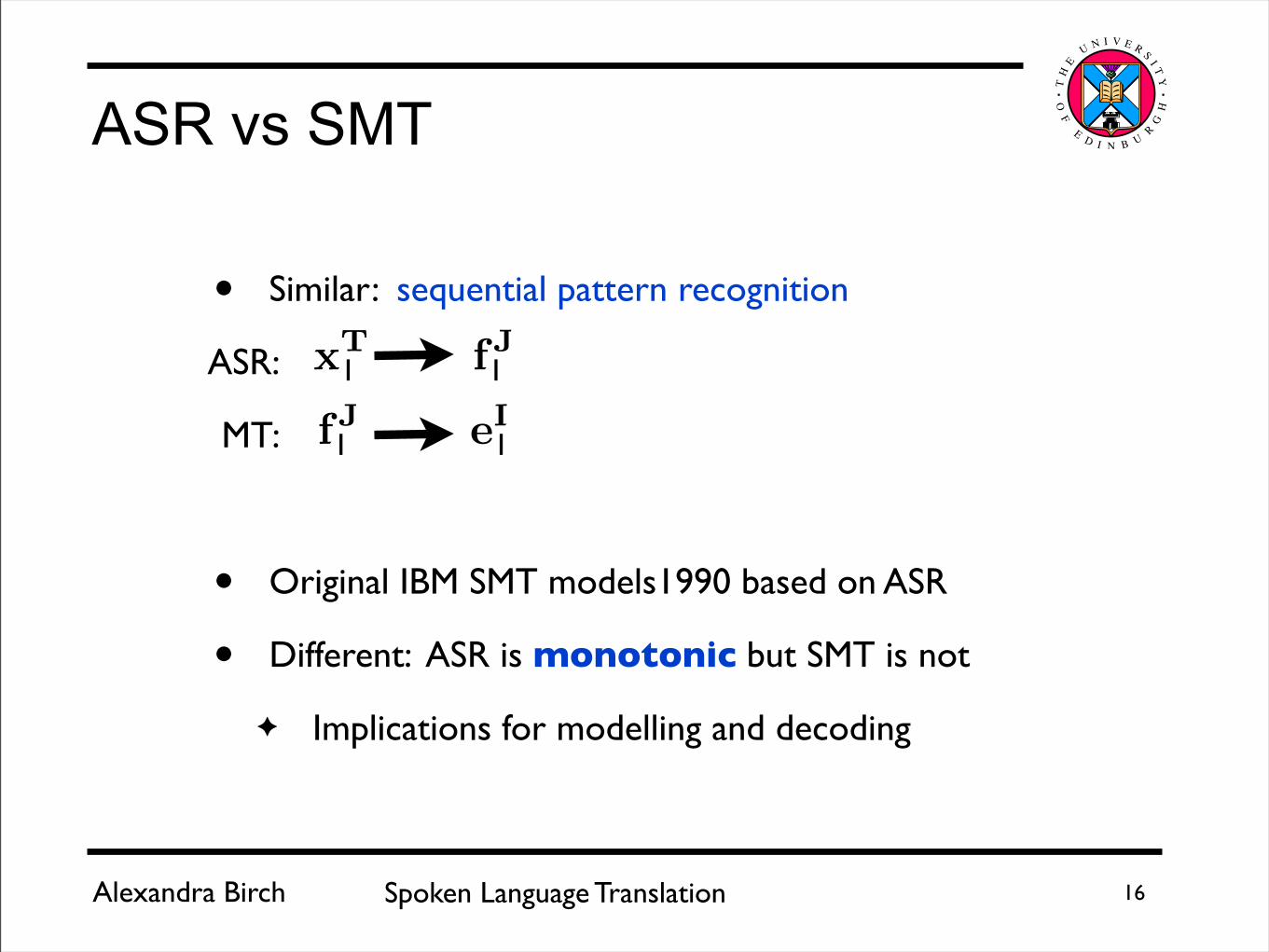
• Similar: sequential pattern recognition
ASR:
MT:
• Original IBM SMT models1990 based on ASR
• Different: ASR is monotonic but SMT is not
✦ Implications for modelling and decoding
16
ASR vs SMT
fJxT
eIfJ

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
ASR introduces errors
17
SLT Challenges
... RAIN IS GOING TO FALL IN ER MANCHESTER ...
Verbatim Speech:
ASR output:
... TRAIN IS GOING TO FALL IN A MY MANCHESTER ...

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Lack of case leads to ambiguities
ASR output: GEORGE BUSH IS VISITING NEW ORLEANS
Normal text:
George Bush is visiting New Orleans
18
SLT Challenges

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Lack of punctuation
ASR:
HE SAID YOU ARE NOT WELCOME
Normal text:
He said “You are not welcome?”
19
SLT Challenges

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Disfluencies and Restarts and repairs
I beg your pardon, but at the beginning of these uh human rights debatesI uh should have pointed out to im- uh important human rights uh defenders from Misses uh Estemirowafrom Chechnya and another from Russia are here they came along to visit uh group eh uh,uh they weren't here at the timeat the beginninguh uh when we began the debate,butthey've uh comethey've just come in now .
I beg your pardon, but at the beginning of these human
rights debates, I should have pointed out that two
important human rights defenders are here, Mrs
Estemirowa, from Chechnya, and Mr Lokshina, from
Russia.
They were not here at the beginning when we began
the debate, but they have just come in now.
20
Challenges
Verbatim Speech: Official transcript:

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Disfluencies and Restarts and repairs
I beg your pardon, but at the beginning of these uh human rights debatesI uh should have pointed out to im- uh important human rights uh defenders from Misses uh Estemirowafrom Chechnya and another from Russia are here they came along to visit uh group eh uh,uh they weren't here at the timeat the beginninguh uh when we began the debate,butthey've uh comethey've just come in now .
I beg your pardon, but at the beginning of these human
rights debates, I should have pointed out that two
important human rights defenders are here, Mrs
Estemirowa, from Chechnya, and Mr Lokshina, from
Russia.
They were not here at the beginning when we began
the debate, but they have just come in now.
20
Challenges
Verbatim Speech: Official transcript:

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Disfluencies and Restarts and repairs
I beg your pardon, but at the beginning of these uh human rights debatesI uh should have pointed out to im- uh important human rights uh defenders from Misses uh Estemirowafrom Chechnya and another from Russia are here they came along to visit uh group eh uh,uh they weren't here at the timeat the beginninguh uh when we began the debate,butthey've uh comethey've just come in now .
I beg your pardon, but at the beginning of these human
rights debates, I should have pointed out that two
important human rights defenders are here, Mrs
Estemirowa, from Chechnya, and Mr Lokshina, from
Russia.
They were not here at the beginning when we began
the debate, but they have just come in now.
20
Challenges
Verbatim Speech: Official transcript:

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Disfluencies and Restarts and repairs
I beg your pardon, but at the beginning of these uh human rights debatesI uh should have pointed out to im- uh important human rights uh defenders from Misses uh Estemirowafrom Chechnya and another from Russia are here they came along to visit uh group eh uh,uh they weren't here at the timeat the beginninguh uh when we began the debate,butthey've uh comethey've just come in now .
I beg your pardon, but at the beginning of these human
rights debates, I should have pointed out that two
important human rights defenders are here, Mrs
Estemirowa, from Chechnya, and Mr Lokshina, from
Russia.
They were not here at the beginning when we began
the debate, but they have just come in now.
20
Challenges
Verbatim Speech: Official transcript:

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Segmentation
• Je vais vous parler aujourd'hui de l'énergie et le climat.• Et ça peut sembler un peu surprenant parce que mon travail à temps plein à la Fondation est principalement sur les vaccins et les graines sur les choses que nous avons besoin d'inventer et d'aider les plus pauvres, deux milliards de vivre une vie meilleure.• Mais l'énergie et le climat sont extrêmement importantes pour ces gens, en fait, plus important que n'importe qui d'autre sur la planète.
• Je vais vous parler aujourd'hui.• L'énergie et le climat. • Ça peut sembler un peu surprenant, parce • Travail à temps plein à la Fondation.• Est principalement sur les vaccins et les graines sur les choses que nous avons besoin d'inventer et livrer.• Aider les plus pauvres deux milliards de dollars.• Vivre une vie meilleure.• Mais l'énergie et le climat sont extrêmement importantes pour ces gens, en fait.• Plus important.• À quelqu'un d'autre sur la planète.
Automatic segmentationHuman segmentation
21
Challenges
23.87 BLEU 18.30 BLEU

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Lack of data
22
Challenges
• Large quantities of parallel written text:
• Small quantities of transcribed, parallel speech:
Europarl: 48M words
Commoncrawl: 53M
TED: 3M
OPUS subtitles: 31M - noisy
For German-English

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
Variety of spoken language
23
Challenges
Europarl:
I declare resumed the session of the European Parliament, adjourned on Friday 17 December 1999, and I would like once again to wish you a happy new year in the hope that you enjoyed a pleasant festive period. .
TED:
It can be a very complicated thing, the ocean.And it can be a very complicated thing, what human health is.
OPUS subtitles:
Mewling quim!It's no sea serpent.Salamander?Yes?It's Fiks.What's up?I must return to Oslo.

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
• smaller vocabulary
• simpler, shorter sentences
• structured dialog
24
Opportunities

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 25
• Daily BBC1 Weather report: limited domain
• Red Bee Media Limited
• Fully automated subtitling
Weatherview Demo

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 26
• TED talks
• Broad domain
• Large vocabularies
• Different speakers
• German ASR
TEDx Demo

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 27
DEMOS

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 28
Overview
• Spoken Language Translation✦ Background
✦ Challenges
✦ Demos
• Experiments in SLT✦ Retaining uncertainty from ASR
✦ Punctuation
✦ Segmentation

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 29
IWSLT
• Annual workshop on spoken language translation
• Running since 2003
• TED talks
• ASR, SLT, MT

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 30
• Match ASR output to MT input
✦ Punctuation before translation (Matusov et al. 2006)
IWSLT 2013 Edinburgh System
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
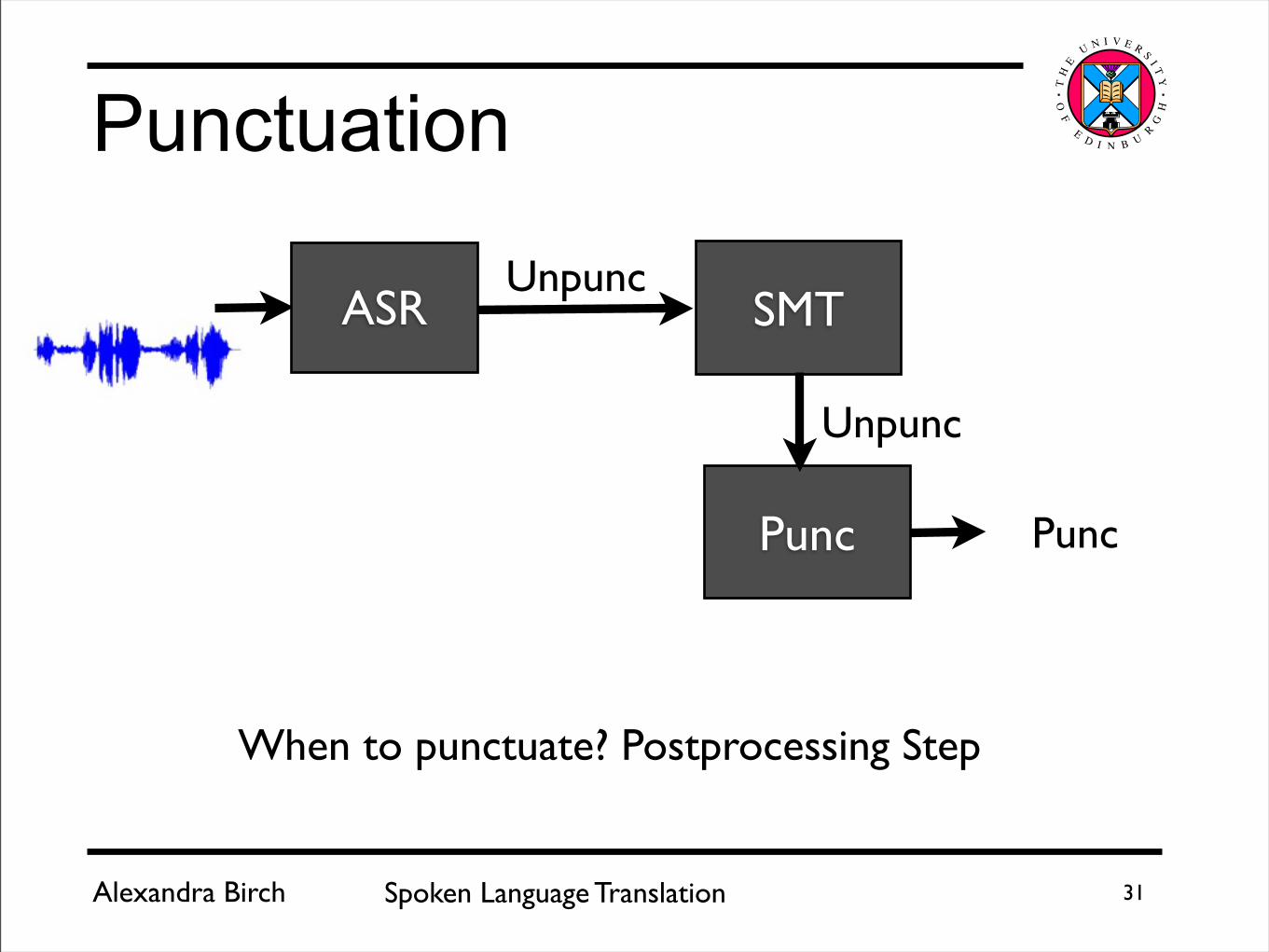
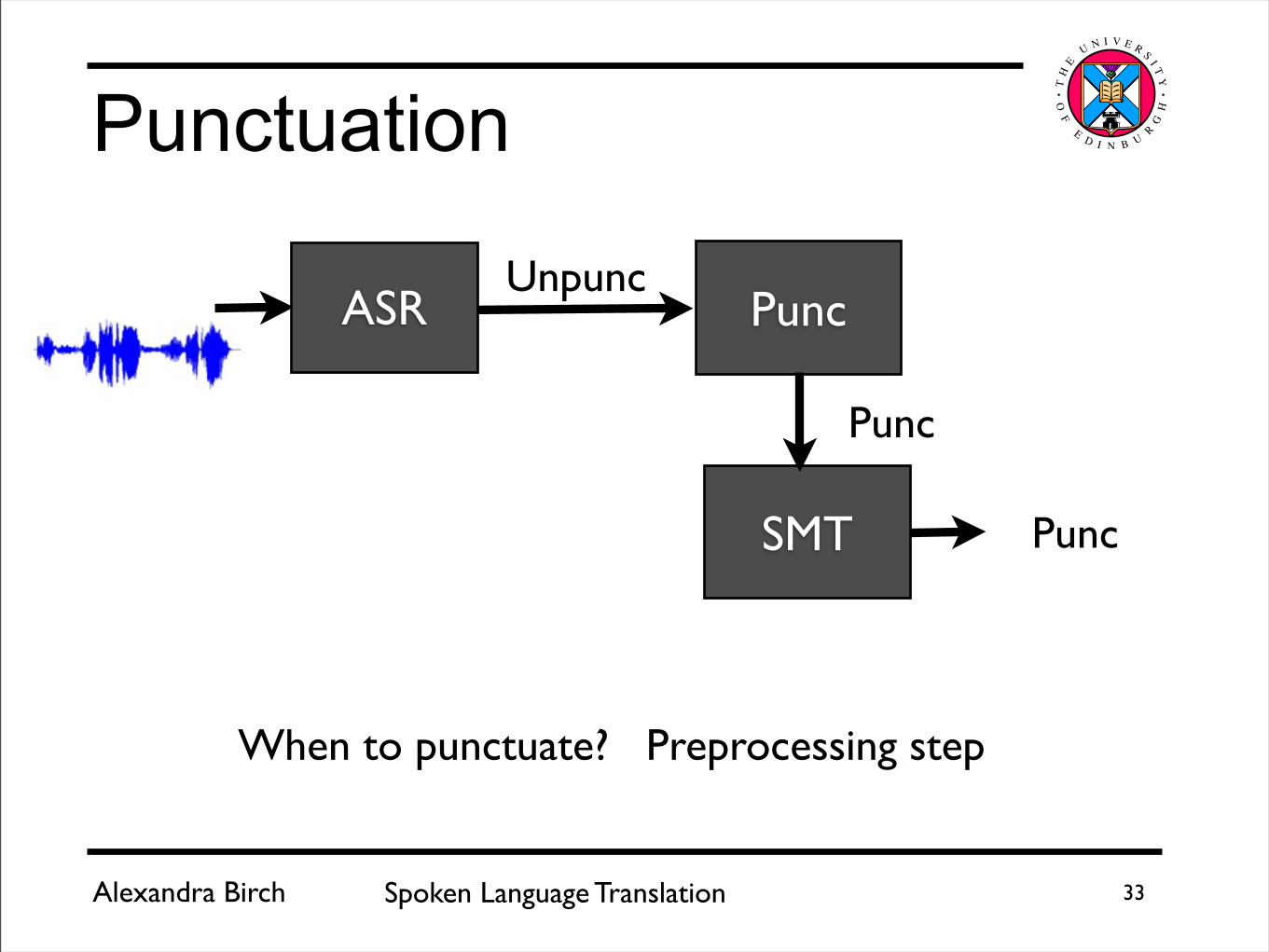
When to punctuate? Postprocessing Step
31
Punctuation
SMTASRUnpunc
Unpunc
Punc Punc
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
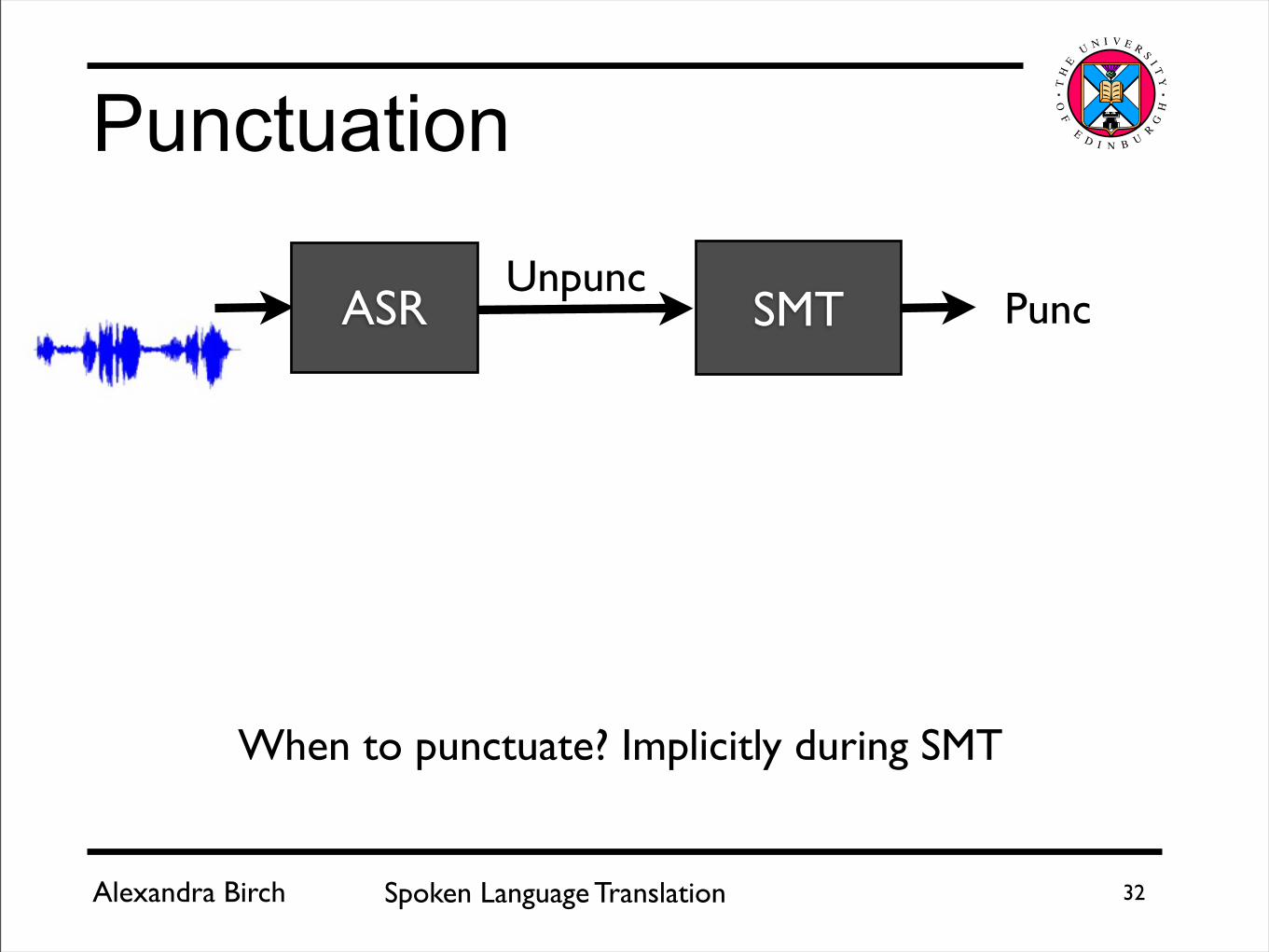
When to punctuate? Implicitly during SMT
32
Punctuation
SMTASRUnpunc
Punc
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
When to punctuate? Preprocessing step
33
Punctuation
PuncASRUnpunc
Punc
SMT Punc

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
How much uncertainty is useful?
12 Chapter 2. Literature Review
(a) 0 1a
2b
3c
(b) 0 1a
!
2b
3c
y
(c) 0 1a
2
x
b3
c
y
Figure 2.1: Representations of (a) a sentence, (b) confusion network, and (c) word
lattice. Adapted from Dyer et al. (2008).
for the nodes in our lattices, as some of the algorithms we make use of rely on this
representation for efficient computation (Dyer et al., 2008).
Different authors refer to “lattices,” “word graphs,” “confusion networks,” “word
sausages,” etc. to describe data structures of this type, and specific terminology varies
from author to author. We define a confusion network as a special case of a word lattice
where all word arcs originating at tail node i in the ordered graph are connected only
to head node i+1. A sentence can be seen as a very simple lattice, where only one arc
connects each adjacent node. We show an example of these three types of structures in
Figure 2.1.
Word lattices are widely used in machine translation. The search graph of a phrase-
based decoder can be thought of as a word lattice (Ueffing et al., 2002). Recent work
has used this compact word lattice representation of the decoder’s search space to
perform more extensive Minimum Bayes-Risk decoding (Tromble et al., 2008) as well
to improve the MERT algorithm (Macherey et al., 2008).
Lattices can also be constructed from the output of translation systems. When a
pair of sentences is aligned at the word level, the correspondences between them can
be used to represent common nodes. Consensus decoding for system combination
(Section 2.4) is the most common use of this technique.
Lattices have also been used to represent input to translation systems. Their most
common use is in the translation of data generated by speech recognition systems.
Bertoldi and Federico (2005) construct confusion networks from the word graphs gen-
erated by ASR systems and show that using these inputs instead of k-best lists improve
translation scores in BLEU. This work is extended in Bertoldi et al. (2007).
ASR data used in this way passes on the ambiguity in the recognised speech to the
1best sentence
Confusion Network
Lattice
34
• Leverage uncertainty in ASR output
✦ Confusion Network (Bertoldi et al. 2007)
IWSLT 2013 Edinburgh System
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 35
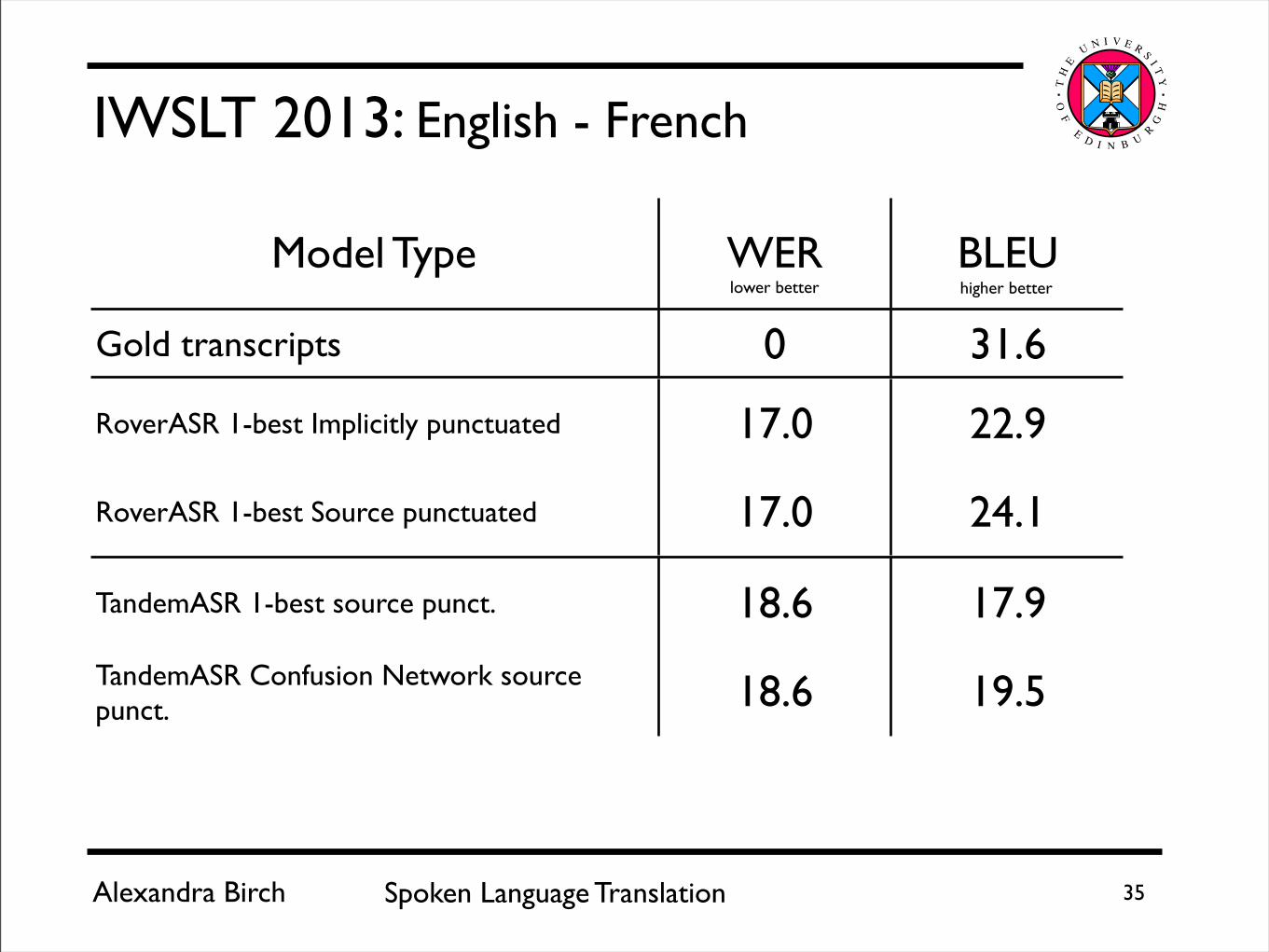
IWSLT 2013: English - French
Model Type WER BLEU
Gold transcripts 0 31.6
RoverASR 1-best Implicitly punctuated 17.0 22.9
RoverASR 1-best Source punctuated 17.0 24.1
TandemASR 1-best source punct. 18.6 17.9
TandemASR Confusion Network source punct. 18.6 19.5
lower better higher better
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
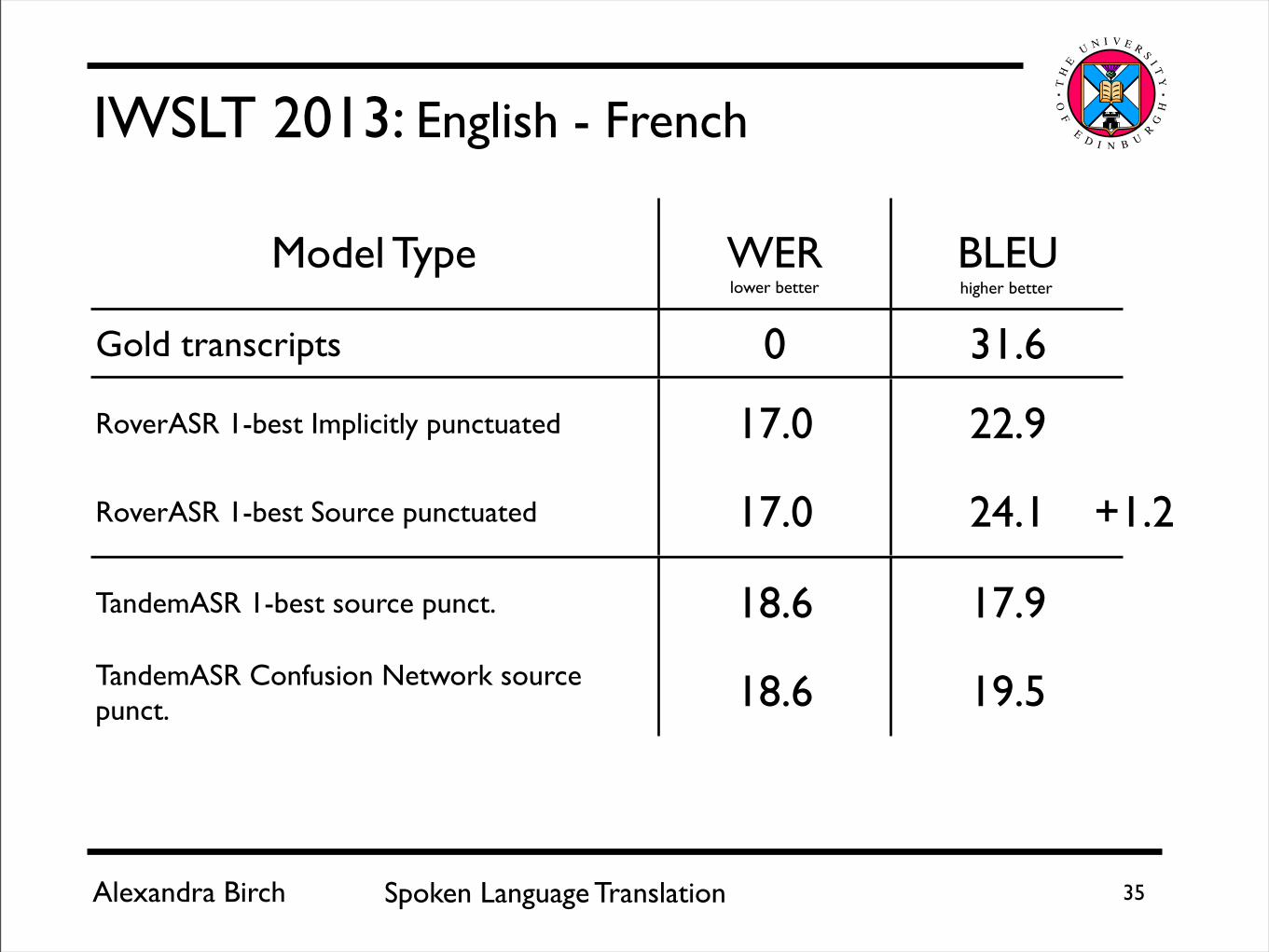
Alexandra Birch Spoken Language Translation 35
IWSLT 2013: English - French
Model Type WER BLEU
Gold transcripts 0 31.6
RoverASR 1-best Implicitly punctuated 17.0 22.9
RoverASR 1-best Source punctuated 17.0 24.1
TandemASR 1-best source punct. 18.6 17.9
TandemASR Confusion Network source punct. 18.6 19.5
lower better higher better
+1.2
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
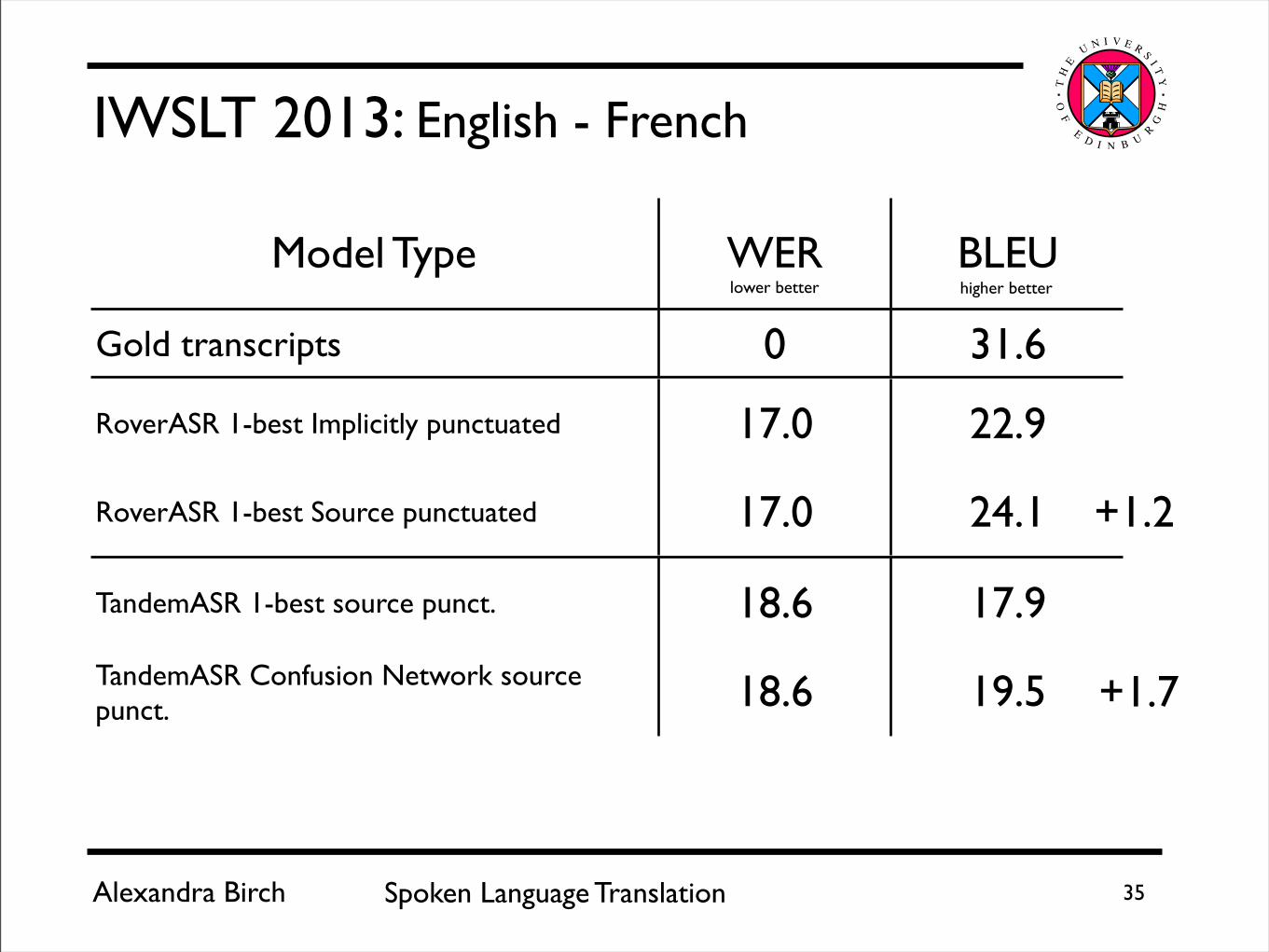
Alexandra Birch Spoken Language Translation 35
IWSLT 2013: English - French
Model Type WER BLEU
Gold transcripts 0 31.6
RoverASR 1-best Implicitly punctuated 17.0 22.9
RoverASR 1-best Source punctuated 17.0 24.1
TandemASR 1-best source punct. 18.6 17.9
TandemASR Confusion Network source punct. 18.6 19.5
lower better higher better
+1.2
+1.7

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 36
Segment ASR output
• Segmentation: end of a speech utterance
• Detecting pauses and non-speech: acoustic evidence
• Highly subjective
• Large effect on downstream processes:
Subtitling
Natural language understanding
SMT
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 37
Segment ASR output
• Segmentation model: semi-Markov model
• Combines:
✦ Acoustic pause information
✦ Sentence length distribution in domain
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 38
Segment ASR output
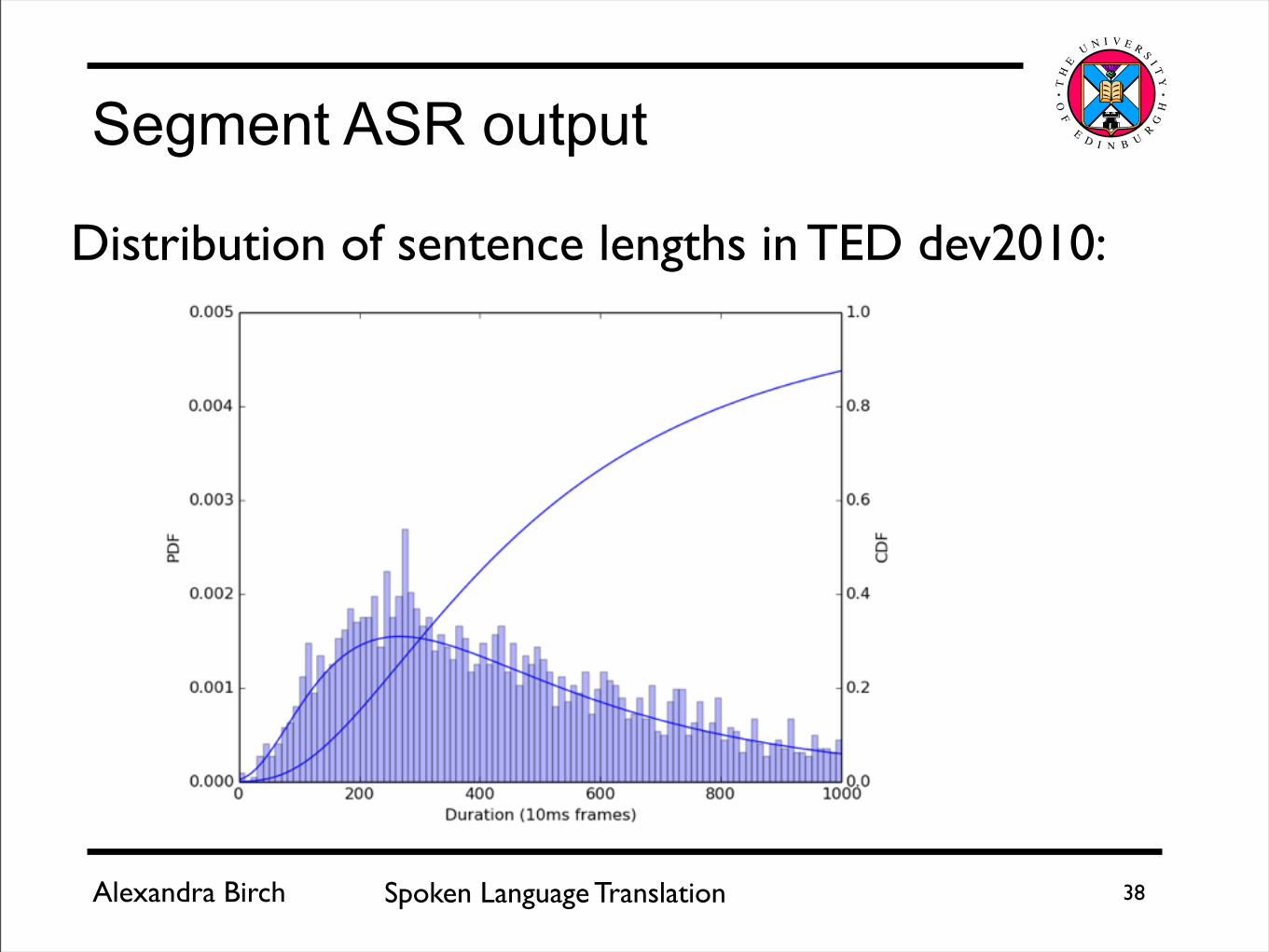
Distribution of sentence lengths in TED dev2010:
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 39
Segment ASR output
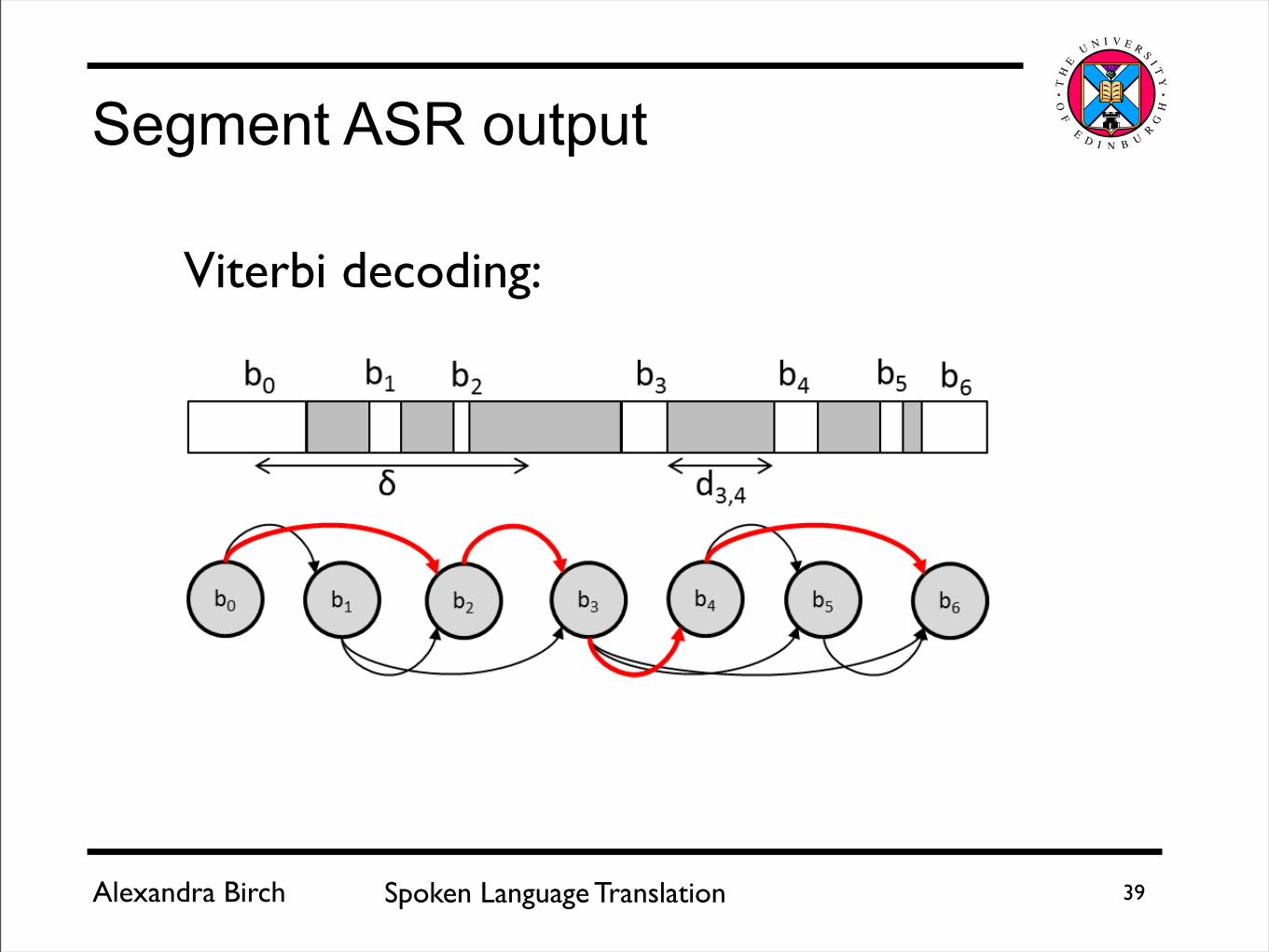
Figure 3: An example of a candidate break sequence and assos-ciated state topology. We can see that the states can only feedforward and some long-term transitions have been pruned suchas b0 → b3 as d0,3 > δ. The transitions highlighted in red showan example optimal break sequence B∗ = {b0, b2, b3, b4, b6}
3. Experiments3.1. Data
For evaluation, we used the data made available for the IWSLTevaluation campaigns[17]. This comprises a series of TED talksthat have been divided into development sets (dev2010 anddev2011) and a test set (tst2010), each containing 8-11 talks.The talks average just under 10mins in length and each containsa single English speaker (either native or non-native). The talksare manually segmented and transcribed at the utterance level.We also had manual English-French translations for evaluatingthe MT system component.
3.2. Speech Segmentation Systems
3.2.1. Manual
Here we simply pass the manual segmentation to the ASR andMT systems directly in order to form the oracle standard withwhich to compare our automatic speech segmenters.
3.2.2. SHOUT
This system makes use of the SHOUT Toolkit (v0.3)2[18]which is a widely-used off-the-shelf speech segmentation sys-tem. The tool uses a GMM-HMM-based Viterbi decoder,with an iterative sequence of parameter re-estimation and re-segmenting. Minimum speech and silence duration constraintsare enforced by the number of emitting states in the respectiveHMMs.
3.2.3. Baseline segmenter
Our baseline system, labelled “simple” in the tables, is identicalto that used for our recent lecture transcription system [19] andcomprises a GMM-HMM based model which is used to per-form a Viterbi decoding of the audio. Speech and non-speechare modelled with diagonal-covariance GMMs with 12 and 5mixture components respectively. We allow more mixture com-ponents for speech to cover its greater variability. Features arecalculated every 10ms from a 30ms analysis window and havea dimensionality of 14 (13 PLPs and energy). Models weretrained on 70 hours of scenario meetings data from the AMI cor-pus using the provided manual segmentations as a reference. Aheuristically optimised minimum duration constraint of 500msis enforced by inserting a series of 50 states per class that each
2http://shout-toolkit.sourceforge.net/download.html
have a transition weight of 1.0 to the next, the final state has aself transition weight of 0.9.
3.2.4. Break Smooth
Here we introduce our utterance-break prior model. In orderto establish the candidate break sequence we use the system inSection 3.2.3 to do an initial segmentation pass over the data.The only exception is that the minimum duration constraint isreduced to 100ms. If used directly, this would normally per-form very poorly as a VAD but when used as input to the sub-sequent break smoothing we have three advantages over theoriginal constraint: better guarantee of enough candidates tofind an optimal solution, the ability to find shorter speech seg-ments (≥100ms), and more accurate end-points for segmentsbetween 100-500ms. The break likelihood prior was trained onthe speech segment durations of the dev2010 and dev2011 sets.The maximum segment duration δ is set to 30 seconds.
We have also shown results for 2 different operating pointsof the scaling factor α, 30 and 80. While this parameter is de-signed to mitigate for the difference in dynamic range with theacoustic model, we found it subsequently functioned as a formof segment duration tuning whereby a greater α results in morebreak smoothing and hence longer segments.
3.2.5. Uniform
As well as our automatic methods we also considered segment-ing each talk into uniform speech segments of length N sec-onds, which is equivalent to having a break of zero length at ev-ery interval. This allowed us to check whether or not the benefitof our utterance-break prior may simply be due to an ’averag-ing’ of the break distribution. As the ASR system is still able todo decoder-based segmentation within each given segment, thisis also a way of measuring its influence. Here, longer uniformsegments leave more responsibility to the decoder for segmen-tation and at N = 300, the maximum segment length for theASR system, we effectively allow the decoder to do all the seg-mentation (with potentially a small error at the initial segmentboundaries).
3.3. Downstream System Descriptions
3.3.1. Automatic Speech Recognition (ASR)
ASR was performed using a system based on that described in[19]. Briefly, this comprises deep neural network acoustic mod-els used in a tandem configuration, incorporating out-of-domainfeatures. Models were speaker-adapted using CMLLR trans-forms. An initial decoding pass was performed using a 3-gramlanguage model, with final lattices rescored with a 4-gram lan-guage model.
3.3.2. Machine Translation (MT)
We trained an English-French phrase-based machine translationmodel using the Moses [20] toolkit. The model is described indetail in our 2013 IWSLT shared task paper [21]. It is the offi-cial spoken language translation system for the English-Frenchtrack. It uses large parallel corpora (80.1M English words and103.5M French words), which have been filtered for the TEDtalks domain. The tuning and filtering used the IWSLT dev2010set.
The goal of our machine translation experiments is to testthe effect that ASR segmentation has on the performance of adownstream natural language processing task. The difficulty
Viterbi decoding:
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 40
Segment ASR output
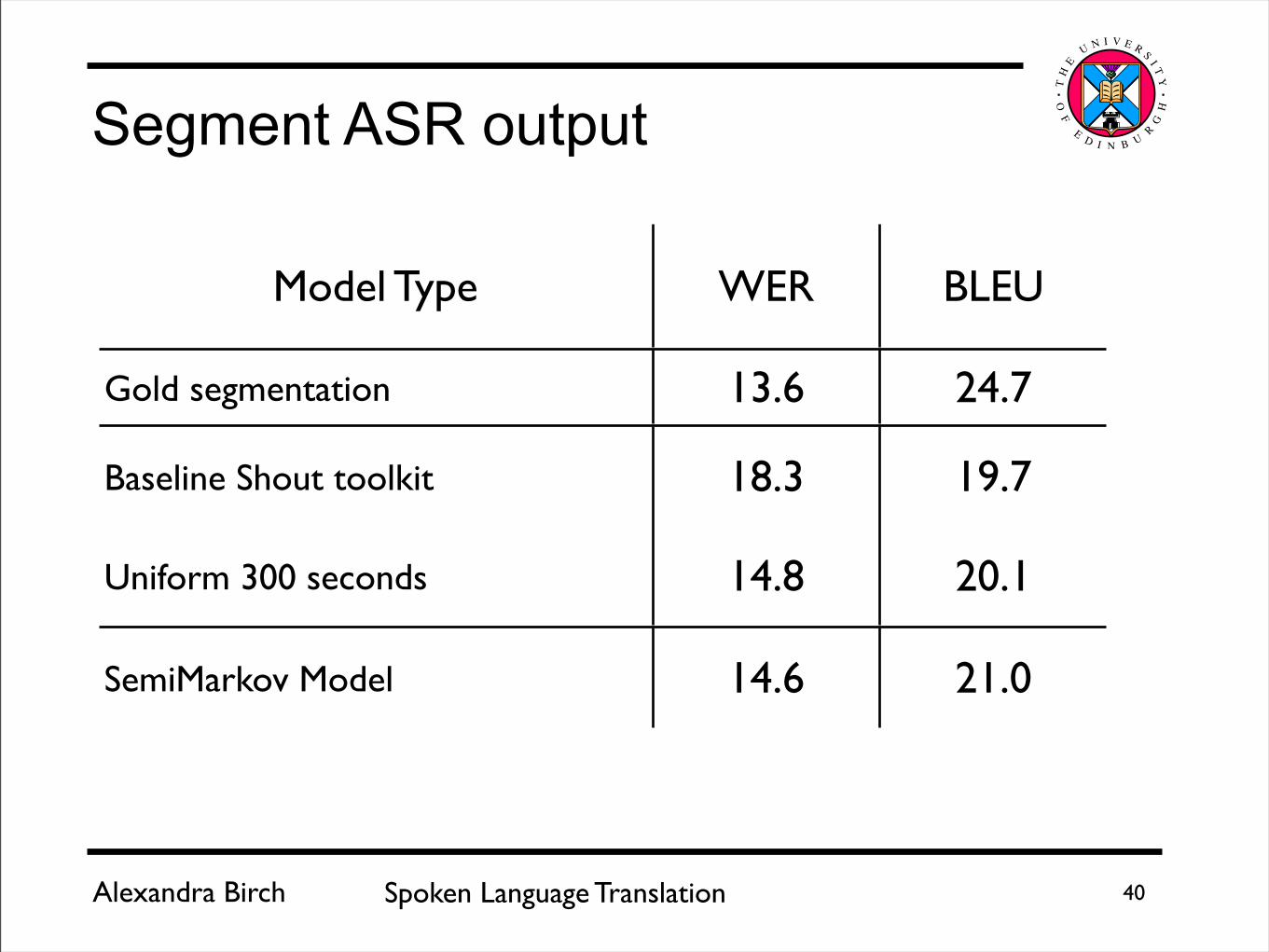
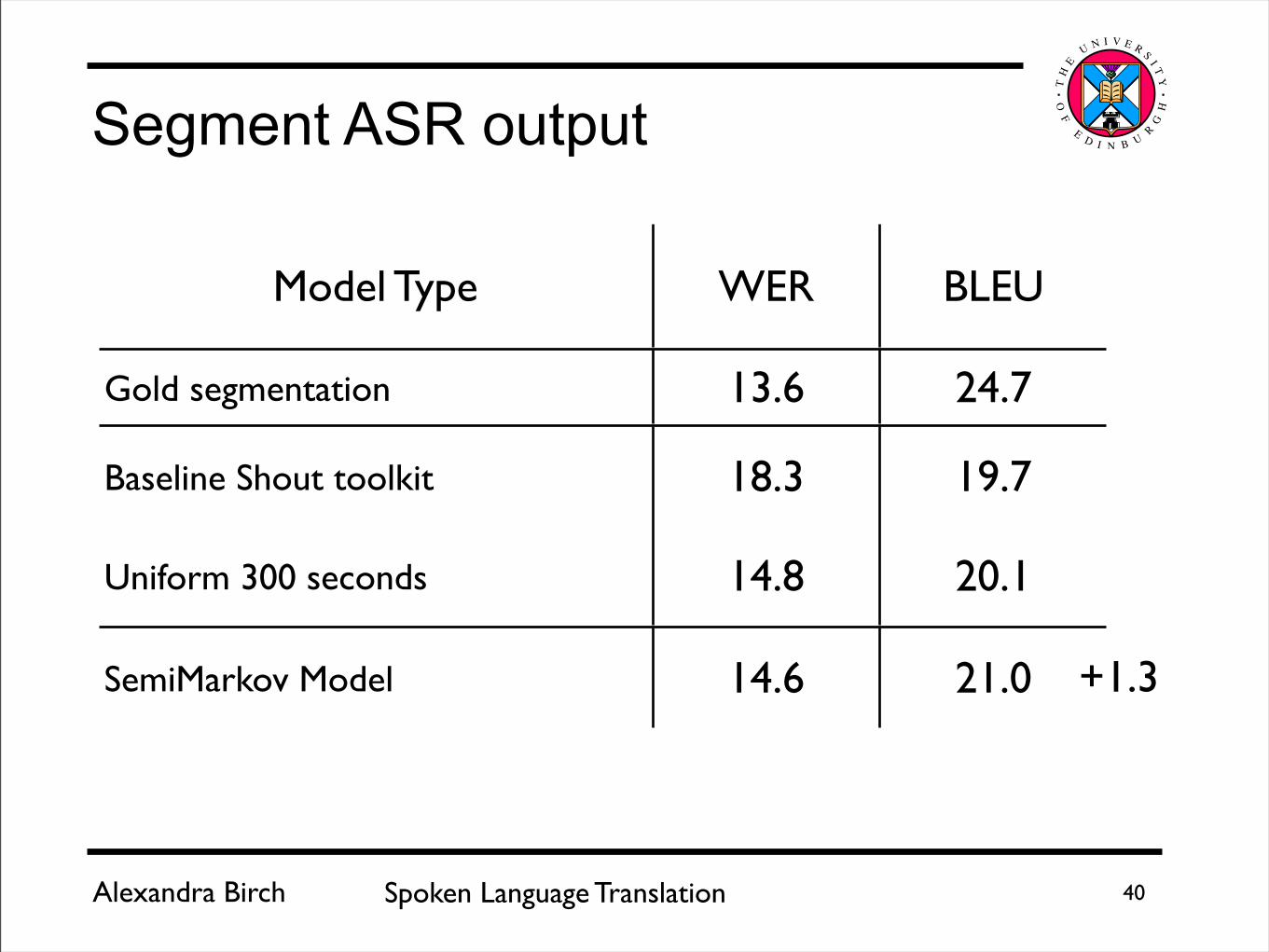
Model Type WER BLEU
Gold segmentation 13.6 24.7
Baseline Shout toolkit 18.3 19.7
Uniform 300 seconds 14.8 20.1
SemiMarkov Model 14.6 21.0
THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 40
Segment ASR output
Model Type WER BLEU
Gold segmentation 13.6 24.7
Baseline Shout toolkit 18.3 19.7
Uniform 300 seconds 14.8 20.1
SemiMarkov Model 14.6 21.0 +1.3

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 41
Segment/punctuate lexical clues
• using SMT Parallel corpus: English transcription stripped of punctuation on source side
Strong n-gram models
• using Decision TreesC.5 algorithm: split samples to max information gain. Uses boosting
Use interesting features: prosody = pitch + energy

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
WERStrip all punctuation 12.5SMT 6.7C5.0 5.6C5.0 + prosody 5.4C5.0 vs SMT 7.4
42
On development:
Weatherview

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation
GOOD EVENING.
SO FAR THIS WEEK OUR WEATHER HAS BEEN RELATIVELY SETTLED WITH MUCH OF THE COUNTRY UNDER THE INFLUENCE OF HIGH PRESSURE.
THERE HAVE BEEN SOME WEATHER FRONTS ACROSS THE SOUTHWEST CORNER AND IT'S THESE THAT ARE GOING TO TAKE OVER THROUGH THE NIGHT AND FOR THURSDAY'S WEATHER FORECAST, MOVING THAT HIGH OUT INTO THE NEAR CONTINENT AND BRINGING WITH IT SOME RAIN, AND THROUGH THE DAY SOME OF THAT RAIN IS GOING TO BE PARTICULARLY HEAVY ACROSS PARTS OF THE COUNTRY.
...
Good evening.
So far this week, our weather has been relatively settled, with much of the country under the influence of high pressure
there have been some weather fronts across the southwest corner and it's these that are going to take over through the night and for Thursday's weather forecast, moving that high out into the near continent and bringing with it some rain, and through the day, some of that rain is going to be particularly heavy across parts of the country
...
Gold Transcriptions SMT
43
Weatherview

THE
U NI V E R S
I TY
OF
ED I N B U
RGH
Alexandra Birch Spoken Language Translation 44
Summary
• Spoken Language Translation✦ Background
✦ Challenges
✦ Demos
• Experiments in SLT✦ Uncertainty
✦ Punctuation
✦ Segmentation