sparse representation based human action recognition using an action region-aware dictionary
DESCRIPTION
Sparse representation based human action recognition using an action region-aware dictionaryTRANSCRIPT

Sparse Representation-based Human Action Recognition using an Action Region-aware Dictionary
ISM 2013 December 11, 2013
Hyun-seok Min, Wesley De Neve, and Yong Man Ro
Image and Video Systems Lab Department of Electrical Engineering
Korea Advanced Institute of Science and Technology (KAIST)
e-mail: [email protected] web: http://ivylab.kaist.ac.kr
IEEE International Symposium on Multimedia 2013

Outline
• Introduction • Sparse representation-based human action recognition • Experiments • Conclusions and future research
IEEE International Symposium on Multimedia 2013 2

Outline
• Introduction – human action recognition – problems – contributions
• Sparse representation-based human action recognition • Experiments • Conclusions and future research
IEEE International Symposium on Multimedia 2013 3
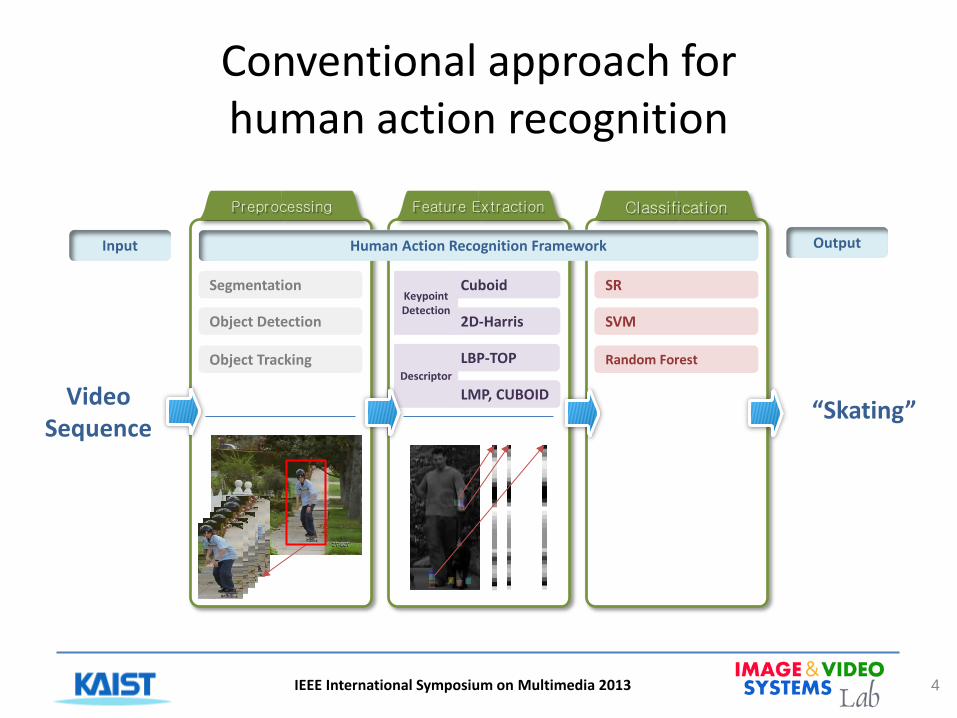
Conventional approach for human action recognition
4
Preprocessing Feature Extraction Classification
Input Human Action Recognition Framework
Video Sequence
“Skating”
Segmentation
Object Detection
Object Tracking
Cuboid
2D-Harris
LBP-TOP
SR
SVM
Random Forest
Input Output
LMP, CUBOID
Keypoint Detection
Descriptor
IEEE International Symposium on Multimedia 2013

Action detection vs. action recognition
• A video clip consists of a context region and an action region [1] – action detection (segmentation) is required for effective action recognition [2]
• Shortcomings of action detection – despite the great emphasis on action recognition, there is comparatively little
work available on action detection [2] – there is currently no general action detection method available that shows a
high level of effectiveness for every action
5
[1] K K. Reddy and M.Shah, “Recognizing 50 Human Action Categories of Web Videos,” Machine Vision and Applications Journal , vol. 24, no. 5, pp. 971-981, 2012. [2] S.Sadanand and J.J.Corso, “Action bank: A high-level representation of activity in video,” IEEE Conf. on Computer Vision and Pattern Recognition , pp.1234-1241, 2012.
Human action video clip Context region Action region
= +
IEEE International Symposium on Multimedia 2013

Context information for human action recognition
• Usefulness of context depends on the action class – e.g., context is
• helpful for making a distinction between (a) and (b) [3] • not helpful for making a distinction between (b) and (c)
6
[3] Tian Lan, Yang Wang, and Greg Mori, “Discriminative Figure-Centric Models for Joint Action Localization and Recognition,” IEEE International Conference on Computer Vision (ICCV), 2011
(a) (b) (c)
IEEE International Symposium on Multimedia 2013

Research challenges & contributions
• Challenges – lack of a general method for effective and efficient action detection – the usefulness of context information depends on the type of action
• Contributions – we propose a novel human action recognition method
• that does not require complex action detection during testing • that uses context information in an adaptive way
7 IEEE International Symposium on Multimedia 2013

Outline
• Introduction • Sparse representation-based human action recognition
– conventional method – proposed method
• construction of an action region-aware dictionary • use of an action region-aware dictionary • adaptive classification using split sparse coefficients
• Experiments • Conclusions and future research
IEEE International Symposium on Multimedia 2013 8
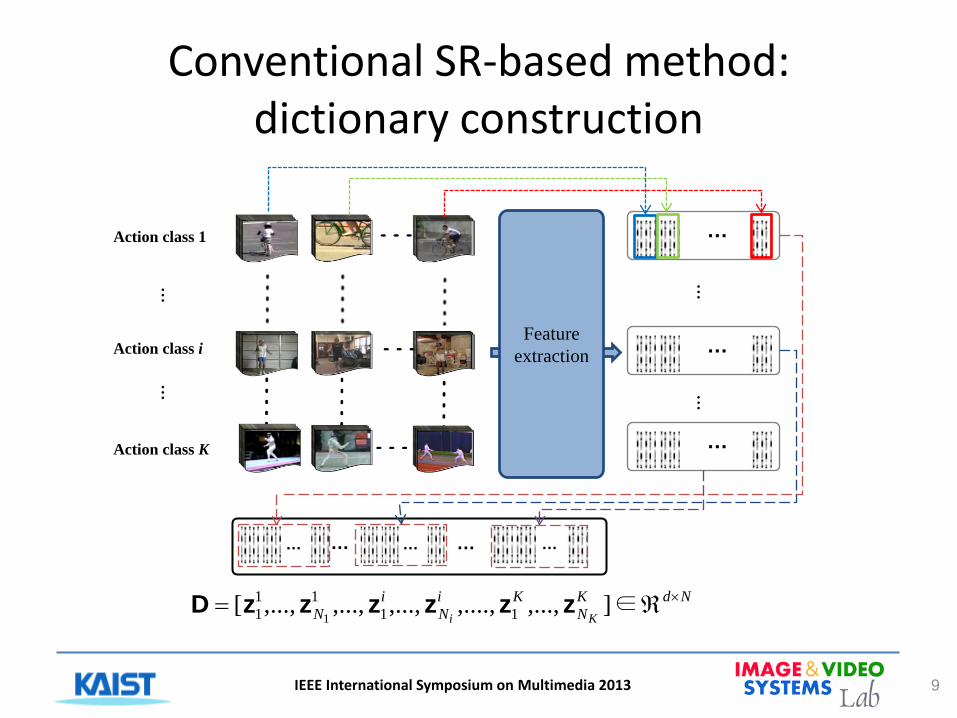
Conventional SR-based method: dictionary construction
9 IEEE International Symposium on Multimedia 2013
Action class 1
Action class i
Action class K
…
…
Feature extraction …
…
…
NdKN
KiN
iN Ki
×ℜ= ∈],...,,....,,...,,...,,...,[ 1111
1 1zzzzzzD
… … … …
…
…
…
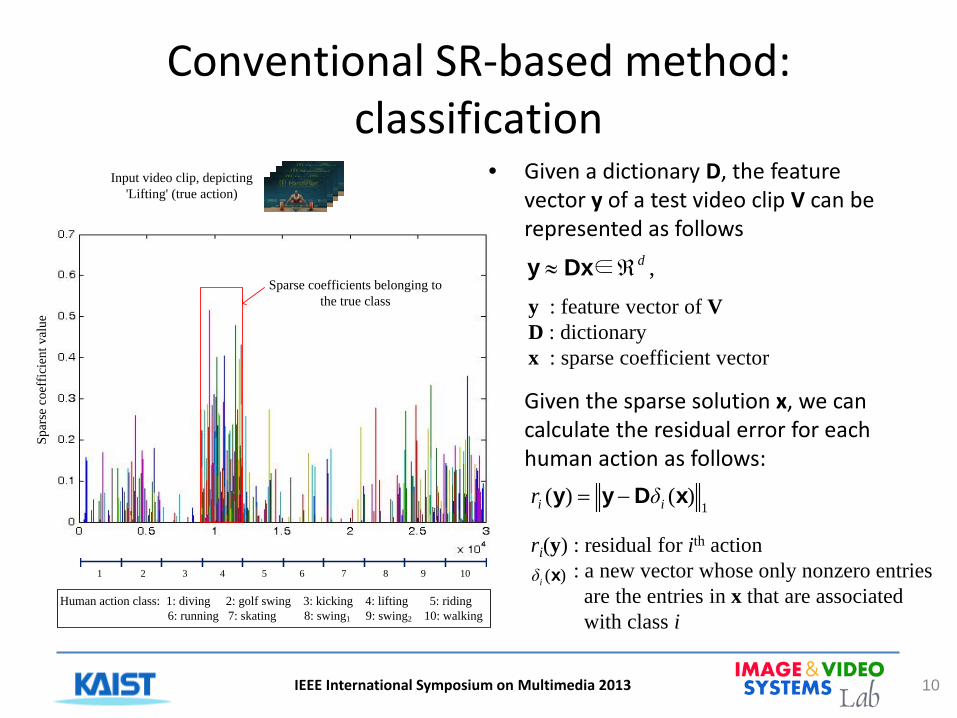
Conventional SR-based method: classification
• Given a dictionary D, the feature vector y of a test video clip V can be represented as follows
• Given the sparse solution x, we can calculate the residual error for each human action as follows:
10
,dℜ≈ ∈Dxy
IEEE International Symposium on Multimedia 2013
y : feature vector of V D : dictionary x : sparse coefficient vector
1)()( xDyy ii δr −=
ri(y) : residual for ith action : a new vector whose only nonzero entries are the entries in x that are associated with class i
)(xiδ
Spar
se c
oeff
icie
nt v
alue
Input video clip, depicting 'Lifting' (true action)
Sparse coefficients belonging to the true class
1 2 3 4 5 6 7 8 9 10
Human action class: 1: diving 2: golf swing 3: kicking 4: lifting 5: riding 6: running 7: skating 8: swing1 9: swing2 10: walking

Conventional SR-based method: dictionary shortcomings
• The dictionary only contains class information – we do not know the location and
size of the action region of a test video clip during classification
– however, we do know the location and size of the action regions in the training video clips
• Research question – how about putting the action
region information of the training video clips in the dictionary?
11
1 2 3 4 5 6 7 8 9 10
Human action class: 1: diving 2: golf swing 3: kicking 4: lifting 5: riding 6: running 7: skating 8: swing1 9: swing2 10: walking
Spar
se c
oeff
icie
nt v
alue
Input video clip, depicting 'Golf' (true action)
Sparse coefficients belonging to the true class
IEEE International Symposium on Multimedia 2013

Proposed SR-based method: construction of an action region-aware dictionary
• We propose to construct a dictionary that consists of two split dictionaries: – context region dictionary DC – action region dictionary DA
12
Training video clips
... ...
Segmented regions
...
Context regions
...
Action regions
Action region-aware dictionary
D =
Feature extraction
Segmentation during training
DC DA
... ...
IEEE International Symposium on Multimedia 2013
[ ] NdAC
×ℜ= ∈DDD |

Proposed SR-based method: use of an action region-aware dictionary (1/3)
• Given an action region-aware dictionary D and the feature vector y of a test video clip V, we can compute the sparse representation of y as follows – xi
j,C and xij,A: the sparse coefficient values that are associated with the
context and the action region of the jth training video clip of the ith human action
13
[ ] AACCA
CACR xDxD
xx
DDxDy +=
≅≈ | ],...,,...,,...,,...,,...,[ ,,1,,1
1,
1,1 1
KCN
KC
iCN
iCCNCC Ki
xxxxxx=x
],...,,...,,...,,...,,...,[ ,,1,,11
,1,1 1
KAN
KA
iAN
iAANAA Ki
xxxxxx=x
During testing, the proposed method for human action recognition is able to automatically make a distinction between information originating from the context region and information originating from the action region in a test video clip.
IEEE International Symposium on Multimedia 2013

Proposed SR-based method: use of an action region-aware dictionary (2/3)
14
DC DA1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
Spar
se c
oeff
icie
nt v
alue
Sparse coefficients belonging to the context region
Sparse coefficients belonging to the action region
...Input video clip, depicting 'golf swing' (true action)
Human action class: 1: diving 2: golf swing 3: kicking 4: lifting 5: riding 6: running 7: skating 8: swing1 9: swing2 10: walking
The sparse coefficients belonging to the context region of the ‘golf swing’ test video clip are dispersed over the different classes. This can be attributed to the fact that the background of ‘golf swing’ is visually similar to the background of ‘kicking’, ‘riding’, and ‘walking’.
IEEE International Symposium on Multimedia 2013

Proposed SR-based method: use of an action region-aware dictionary (3/3)
15
DC DA1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
Human action class: 1: diving 2: golf swing 3: kicking 4: lifting 5: riding 6: running 7: skating 8: swing1 9: swing2 10: walking
Spar
se c
oeff
icie
nt v
alue
Sparse coefficients belonging to the context region
Sparse coefficients belonging to the action region
Input video clip, depicting 'diving' (true action)
...
The sparse coefficients belonging to the context region of the ‘diving’ test video clip are concentrated in the true class. This means that the context region of ‘diving’ is different from the context regions of the other human actions.
IEEE International Symposium on Multimedia 2013

Adaptive classification using split sparse coefficients
• Given the above observations, we can hypothesize that – information originating from context regions can help in successfully classifying
human actions, on the condition that the sparse coefficients associated with the context regions are concentrated in the true class
• Measurement of the concentration of sparse coefficients
– Maximum Sparse Coefficient Concentration (MSCC)
• We can then use the following criterion to determine whether information
of context regions can help in successfully classifying human actions
16
1
1)(
max)(xx
x k
k
δMSCC =
ratioA
C ξMSCCMSCC
>)()(
xx
IEEE International Symposium on Multimedia 2013

Outline
• Introduction • Sparse representation-based human action recognition • Experiments
– experimental setup – experimental results
• Conclusions and future research
IEEE International Symposium on Multimedia 2013 17

Experimental setup (1/2)
• Use of the UCF Sports Action data set – contains 150 action video clips with a resolution of 720×480, collected
for various sports that are typically featured on broadcast television channels such as BBC and ESPN
– for each frame, a bounding box is available around the person performing the action of interest
– available action classes: diving, golf swinging, kicking, lifting, riding, running, skating, swinging, and walking
18
Diving Golf swinging Kicking Lifting Riding
Running Skating Swinging Walking
IEEE International Symposium on Multimedia 2013

Experimental setup (2/2)
• Comparison with – SR with action region
• only makes use of action regions in the test video clips considered, thus taking advantage of segmentation information
– SR with whole region • uses whole video frames, thus not exploiting segmentation information
19
SR with action region
SR with whole region
IEEE International Symposium on Multimedia 2013

Experimental results (1/2)
• The accuracy of the proposed SR-based method for human action recognition is more stable over the different human action classes
• The accuracy of the proposed method is highly independent of the type of human action – thanks to the use of a context-adaptive classification strategy
20 IEEE International Symposium on Multimedia 2013

Experimental results (2/2)
• We can observe that what method is most accurate depends on the human action class considered – “SR with action region” is usually more accurate when the concentration of
the sparse coefficients associated with the action region is higher than the concentration of the sparse coefficients associated with the context region
– Otherwise, “SR with whole region” or “Proposed method” are more effective
21 IEEE International Symposium on Multimedia 2013

Outline
• Introduction • Sparse representation-based human action recognition • Experiments • Conclusions and future research
– conclusions – future research directions
IEEE International Symposium on Multimedia 2013 22

Conclusions
• We proposed a novel SR-based method for human action recognition, having the following two major characteristics – first, classification does not have to apply explicit segmentation to a
given test video clip – second, classification is context adaptive in nature, only leveraging
information about the context in which the action took place when the concentration of the corresponding sparse coefficients is high
23 IEEE International Symposium on Multimedia 2013

Future research directions
• Use of dictionary learning techniques that allow for more effective and efficient construction of an overcomplete dictionary
• Perform experiments with actions that have a lower variation in background
• Study how to leverage SRC by means of an action region-aware dictionary in other application scenarios
24 IEEE International Symposium on Multimedia 2013

Thank you! Any questions?
e-mail: [email protected] .
web: http://ivylab.kaist.ac.kr
25 IEEE International Symposium on Multimedia 2013