spark intro @ analytics big data summit
TRANSCRIPT

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Apache Spark : Fast and Easy Data Processing
Sujee Maniyam Founder / Principal Elephant Scale LLC
[email protected] http://elephantscale.com

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Outline
r Background r Spark Architecture r Demo

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark
r Fast & Expressive Cluster computing engine r Compatible with Hadoop r Came out of Berkeley AMP Lab r Now Apache project r Version 1.2 just released (Dec 2014)

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Timeline Hadoop & Spark

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Hypo-meter J
2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
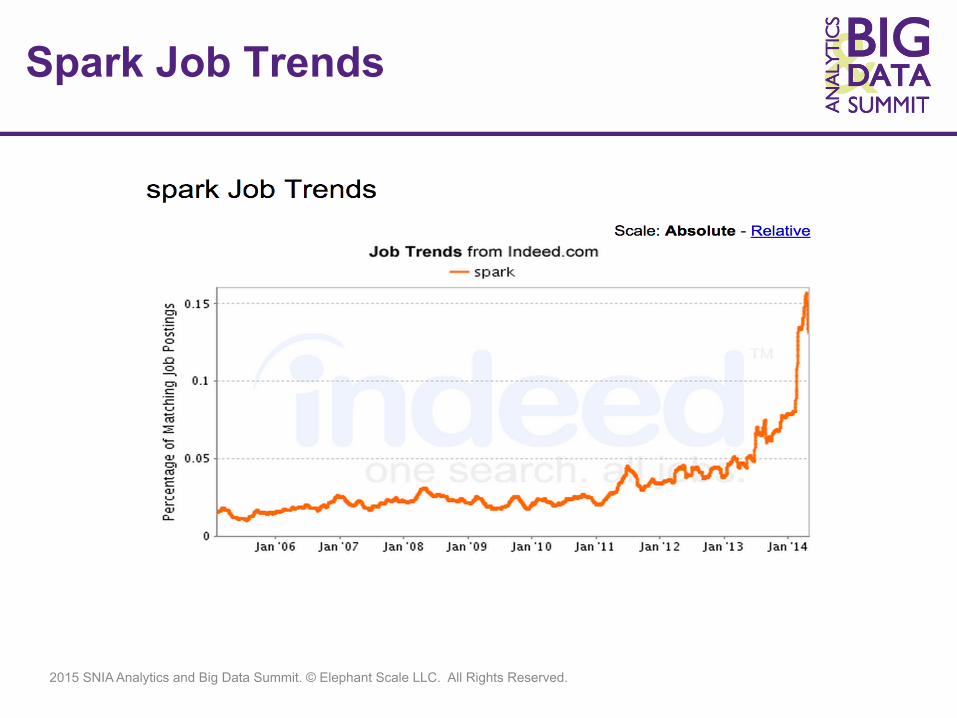
Spark Job Trends

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Comparison With Hadoop
Hadoop Spark
Distributed Storage + Distributed Compute
Distributed Compute Only
MapReduce framework Generalized computation
Usually data on disk (HDFS) On disk / in memory
Not ideal for iterative work Great at Iterative workloads (machine learning ..etc)
Batch process - Upto 2x -10x faster for data on disk - Upto 100x faster for data in memory
Compact code Java, Python, Scala supported
Shell for ad-hoc exploration
2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
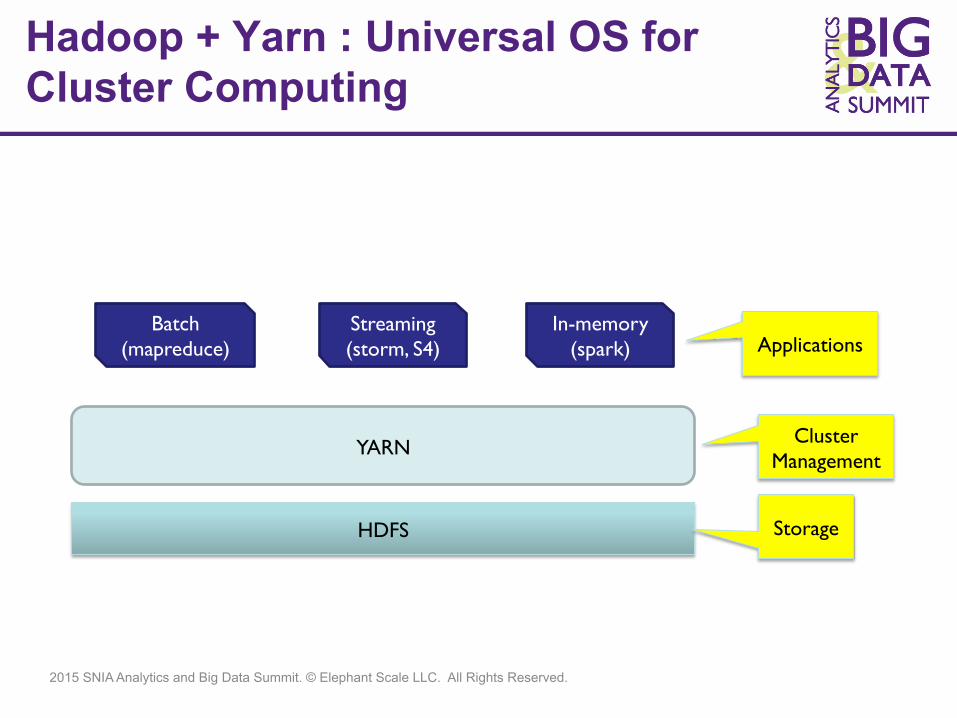
Hadoop + Yarn : Universal OS for Cluster Computing
HDFS
YARN
Batch (mapreduce)
Streaming (storm, S4)
In-memory (spark)
Storage
Cluster Management
Applications

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Vs Hadoop
r Spark is ‘easier’ than Hadoop r ‘friendlier’ for data scientists / analysts r Interactive shell
r fast development cycles r adhoc exploration
r API supports multiple languages r Java, Scala, Python
r Great for small (Gigs) to medium (100s of Gigs) data

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Vs. Hadoop
Fast!

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Is Spark Replacing Hadoop?
r Right now, Spark runs on Hadoop / YARN r Complimentary
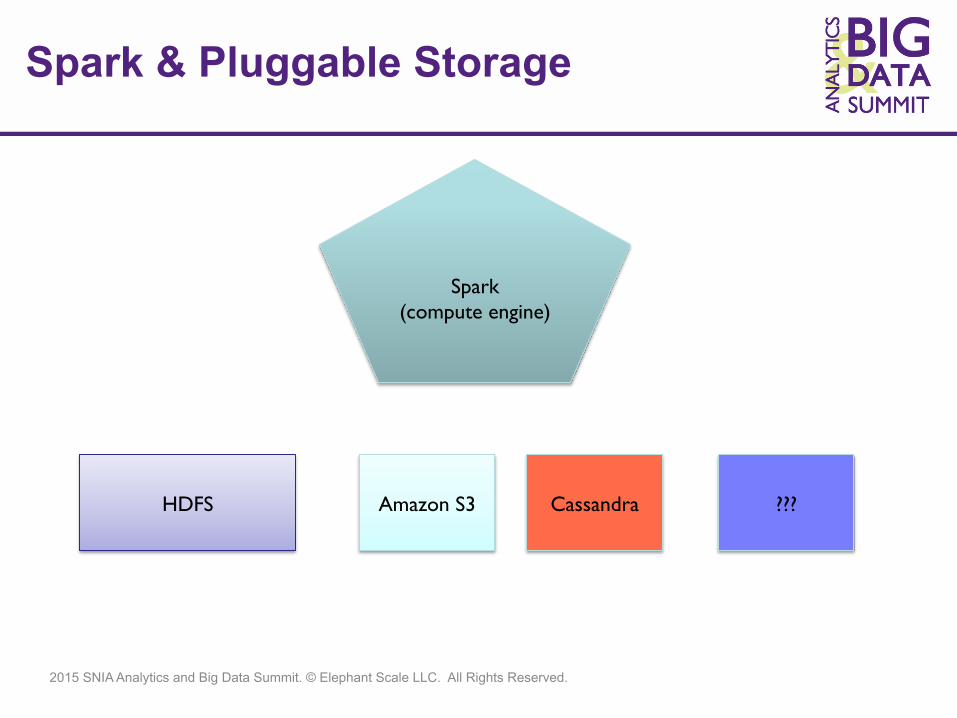
r Can be seen as generic MapReduce r Spark is really great if data fits in memory (few
hundred gigs), r Spark can be used as compute platform with
various storage types (see next slide)
2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark & Pluggable Storage
Spark (compute engine)
HDFS Amazon S3 Cassandra ???

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Hadoop & Spark Future ???

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Outline
r Background r à Spark Architecture r Demo

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Eco-System
Spark Core
Spark SQL
Spark Streaming ML lib
Schema / sql Real Time Machine Learning

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Core
r Distributed compute engine r Sort / shuffle algorithms r Handles node failures -> re-computes missing
pieces

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark SQL
r Adhoc / interactive analytics r ETL workflow r Reporting r Natively understands
r JSON : {“name”: “mark”, “age”: 40} r Parquet : on disk columnar format, heavily
compressed

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark SQL Quick Example
{"name":"mark", "age":50, "sex":"M"}, {"name":"mary", "age":45, "sex":"F"}, {"name":"brian", "age":15, "sex":"M"}, {"name":"nancy", "age":17, "sex":"F"} // … setup … val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") è [brian, nancy]

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Streaming
r Process data streams in real time, in micro-batches
r Low latency, high throughput (1000s events / sec)
r Stock ticks / sensor data (connected devices / IoT – Internet of Things)
Streaming Sources
Storage

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Machine Learning (ML Lib)
r Machine learning at scale r Out of the box ML capabilities ! r Java / Scala / Python language support r Lots of common algorithms are supported
r Classification / Regressions r Linear models (linear R, logistic regression, SVM) r Decision trees
r Collaborative filtering (recommendations) r K-Means clustering r More to come

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Cluster Deployment
1) Standalone 2) Yarn
3) Mesos
Client
Node

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Cluster Architecture
r Multiple ‘applications’ can run at the same time r Driver (or ‘main’) launches an application r Each application gets its own ‘executor’
r Isolated (runs in different JVMs) r Also means data can not be shared across applications
r Cluster Managers: r multiple cluster managers are supported r 1) Standalone : simple to setup r 2) YARN : on top of Hadoop r 3) Mesos : General cluster manager (AMP lab)

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Spark Data Model : RDD
r Resilient Distributed Dataset (RDD) r Can live in
r Memory (best case scenario) r Or on disk (FS, HDFS, S3 …etc)
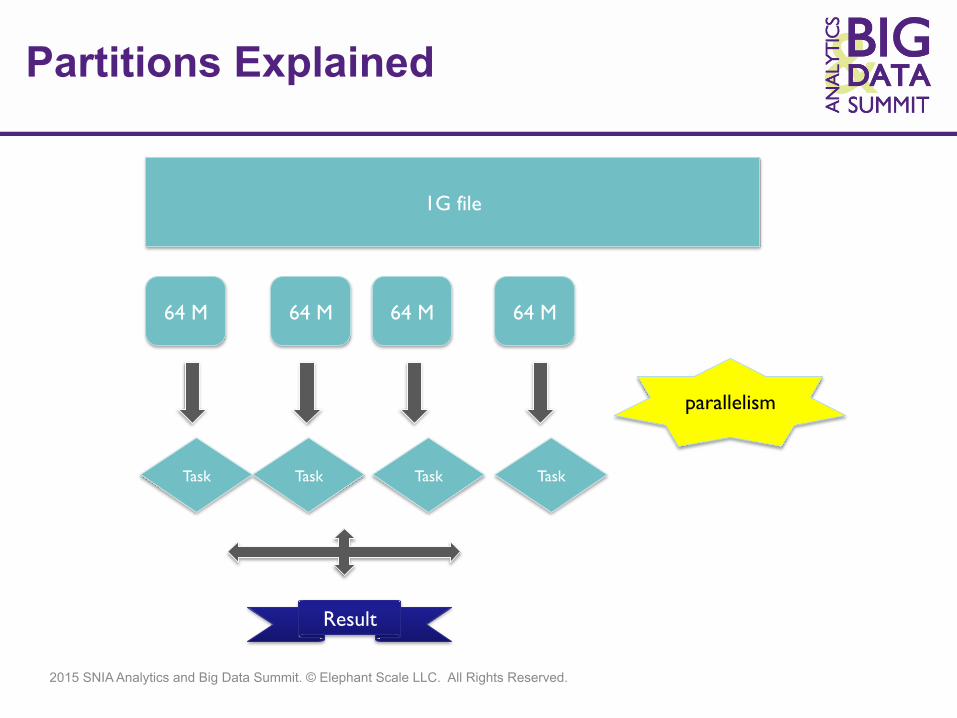
r Each RDD is split into multiple partitions r Partitions may live on different nodes r Partitions can be computed in parallel on
different nodes
2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Partitions Explained
1G file
64 M 64 M 64 M 64 M
Task Task Task Task
Result
parallelism

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
RDD : Loading
r Use Spark context to load RDDs from disk / external storage
val sc = new SparkContext(…) val f = sc.textFile(“/data/input1.txt”) // single file sc.textFile(“/data/”) // load all files under dir sc.textFile(“/data/*.log”) // wild card matching

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
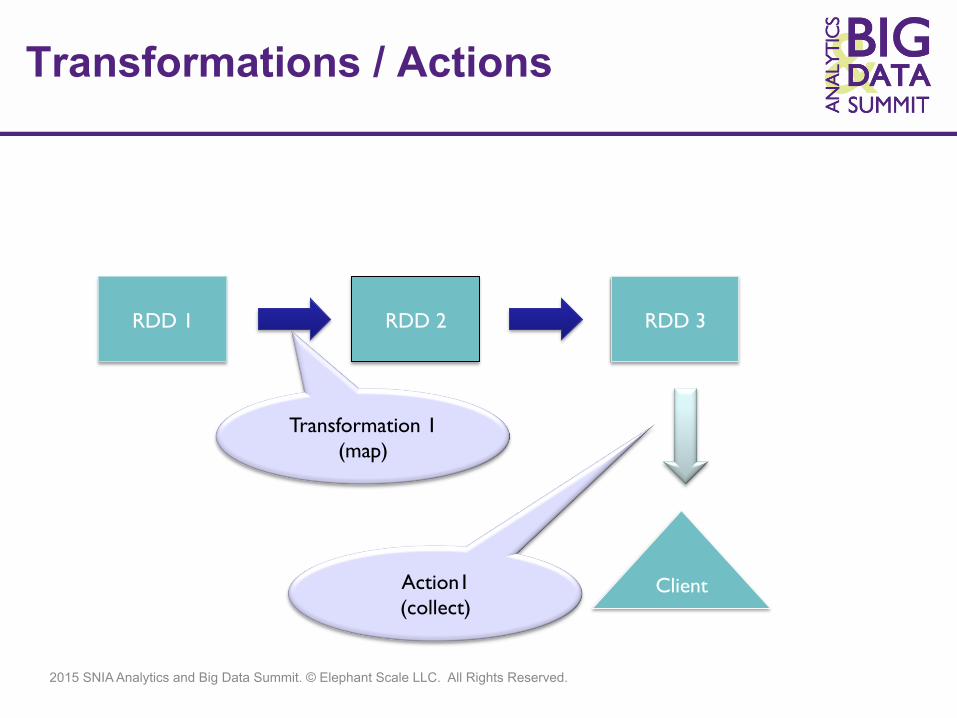
RDD Operations
r Two kinds of operations on RDDs r 1) Transformations
r Create a new RDD from existing ones (e.g. Map)
r 2) Actions r E.g. Returns the results to clients (e.g. Reduce)
r Transformations are lazy.. Actions force transformations
2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Transformations / Actions
RDD 1 RDD 2
Client
RDD 3
Transformation 1 (map)
Action1 (collect)

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
RDD Transformations
Transformation Description Example
filter Filters through each record (aka grep)
f.filter( line => line.contains(“ERROR”))
union Merges two RDDs rdd1.union(rdd2)
…see docs …

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
RDD Actions
Action Description Example
count() Counts all records in an rdd f.count()
first() Extract the first record f.first ()
take(n) Take first N lines f.take(10)
collect() Gathers all records for RDD. All data has to fit in memory of ONE machine (don’t use for big data sets)
f.collect()
…. See documentation ..

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
RDD : Saving
r saveAsTextFile () and saveAsSequenceFile() f.saveAsTextFile(“/output/directory”) // a directory r Output usually is a directory
r RDDs will be saved as multiple files in the dir r Each partition à one output file

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Caching of RDDs
r RDDs can be loaded from disk and computed r Hadoop mapreduce model
r Also RDDs can be cached in memory r Subsequent operations are much faster f.persist() // on disk or memory f.cache() // memory only r In memory RDDs are
great for iterative workloads r Machine learning algorithms

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Demo Time !

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Demo : Spark-shell
r Invoke spark shell r Load a data set r Do basic operations (count / filter)

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Demo: RDD Caching
r From Spark shell r Load an RDD r Demonstrate the difference between cached and
non-cached

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Demo : Map Reduce
r Quick Word count val input = sc.textFile(“…”) val counts = input.flatMap( line => line.split(“ “)). map(word => (word, 1)). reduceByKey(_+_)

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Thanks !
Sujee Maniyam [email protected] http://elephantscale.com
Expert consulting & training in Big Data

2015 SNIA Analytics and Big Data Summit. © Elephant Scale LLC. All Rights Reserved.
Credits
r http://spark.apache.org/ r http://www.strategictechplanning.com r Tuningpp.com r Kidzworld.com