Řízení prozodie řečového syntezátoru václav Šebesta, Ústav informatiky av Čr, v.v.i....
TRANSCRIPT

Řízení prozodie řečového syntezátoru
Václav Šebesta, Ústav informatiky AV ČR, v.v.i.
MFF UK 11.12.2009

MFF UK 11.12.2009
Content of contribution
1. Introduction
2. Speech synthesizer
3. Phonetic and phonologic features of speech units
4. GUHA method
5. Sensitivity approach
6. Weight approach
7. Combination of above mentioned approaches
8. Experimental results
9. Listening tests
MFF UK 11.12.2009
• The text-to-speech synthesizer of the Czech language The text-to-speech synthesizer of the Czech language is based on the is based on the concatenation of the elementary speech concatenation of the elementary speech unitsunits (phonemes, diphones or triphones)(phonemes, diphones or triphones). .
• The speech output from such a synthesizer, The speech output from such a synthesizer, represented by represented by fundamental frequencyfundamental frequency F F00 and duration and duration DD
of each of each speech unitspeech unit, is monotonous and sounds very , is monotonous and sounds very synthetically.synthetically.
• The naturalness of speech is considerably dependent on The naturalness of speech is considerably dependent on the implementation of the prosodic features.the implementation of the prosodic features.
• In this contribution In this contribution one can seeone can see severalseveral possible ways possible ways for for selection of suitable parameters for the training of Fselection of suitable parameters for the training of F
0 0
and Dand D and we will compare these ways.and we will compare these ways.
Introduction
MFF UK 11.12.2009
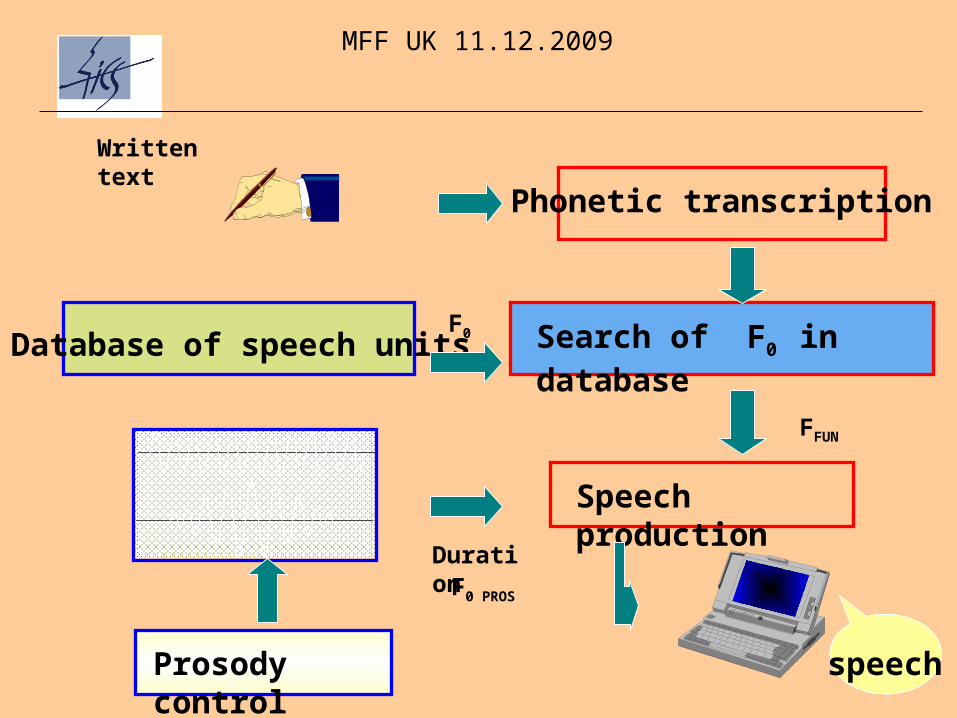
Phonetic transcription
Search of F0 in databaseDatabase of speech units
Speech production
FFUN
F0 PROS
Duration
Prosody control speech
Written text
F0
MFF UK 11.12.2009
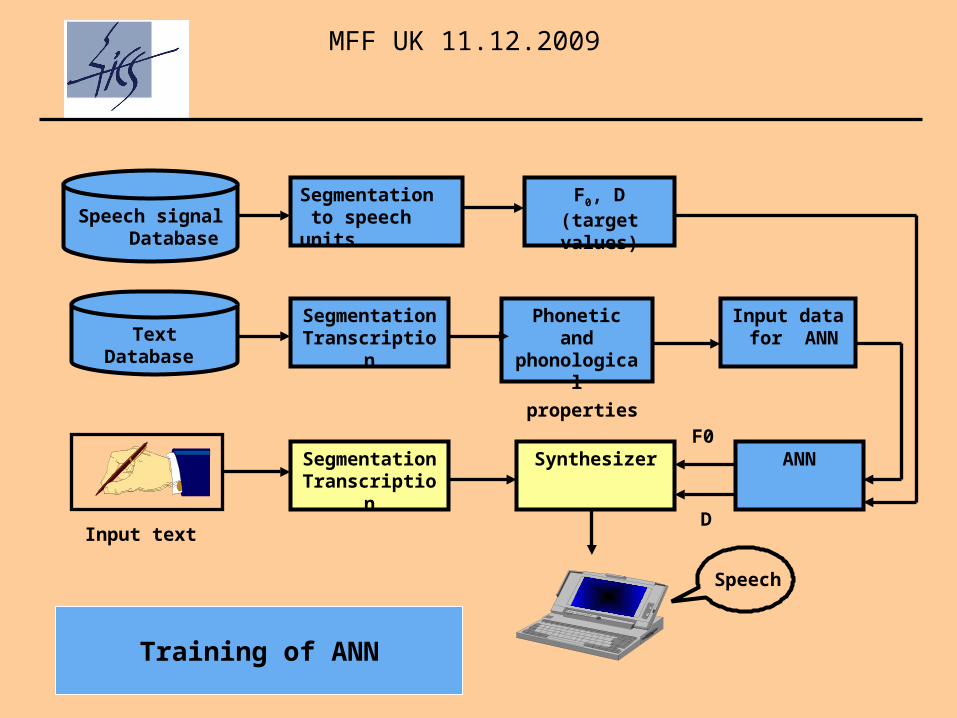
Speech signal Database
Segmentation to speech units
F0, D(target values)
TextDatabase
SegmentationTranscription
Phonetic andphonological
properties
Input data for ANN
SegmentationTranscription
Synthesizer
Input text
ANNF0
D
Speech
Training of ANN
MFF UK 11.12.2009
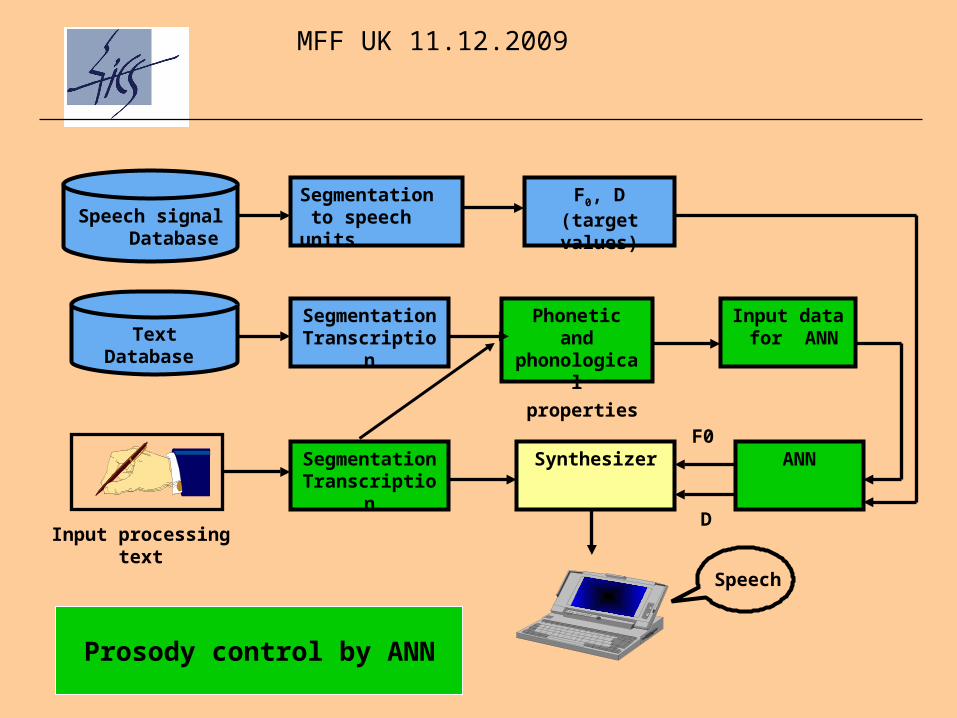
Speech signal Database
Segmentation to speech units
F0, D(target values)
TextDatabase
SegmentationTranscription
Phonetic andphonological
properties
Input data for ANN
SegmentationTranscription
Synthesizer
Input processingtext
ANNF0
D
Speech
Prosody control by ANN
MFF UK 11.12.2009
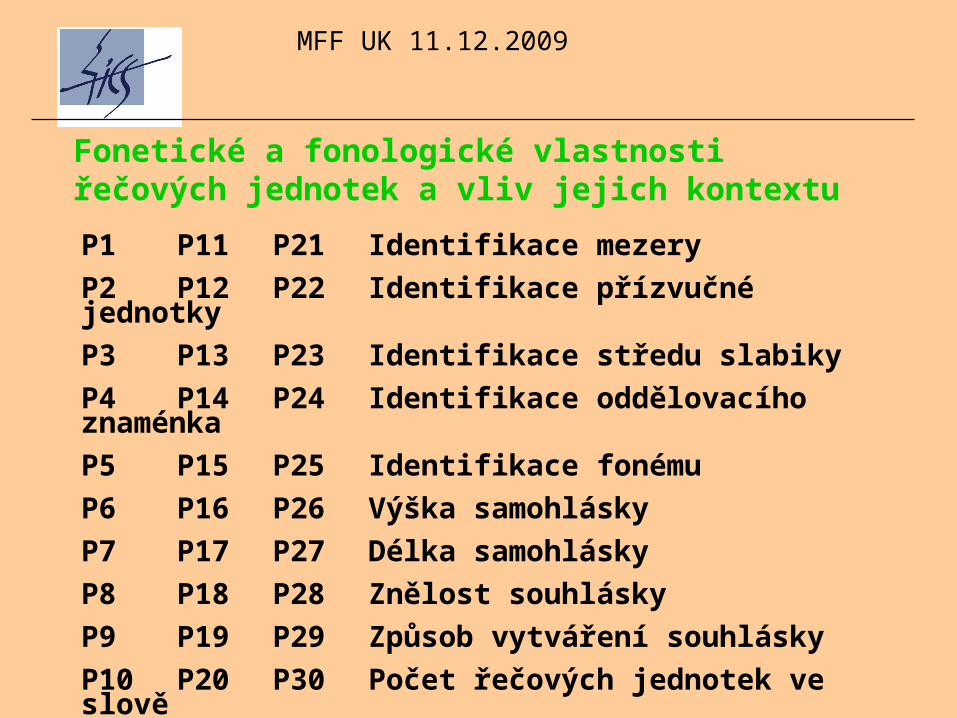
P1 P11 P21 Identifikace mezery
P2 P12 P22 Identifikace přízvučné jednotky
P3 P13 P23 Identifikace středu slabiky
P4 P14 P24 Identifikace oddělovacího znaménka
P5 P15 P25 Identifikace fonému
P6 P16 P26 Výška samohlásky
P7 P17 P27 Délka samohlásky
P8 P18 P28 Znělost souhlásky
P9 P19 P29 Způsob vytváření souhlásky
P10 P20 P30 Počet řečových jednotek ve slově
Fonetické a fonologické vlastnosti řečových jednotek a vliv jejich kontextu
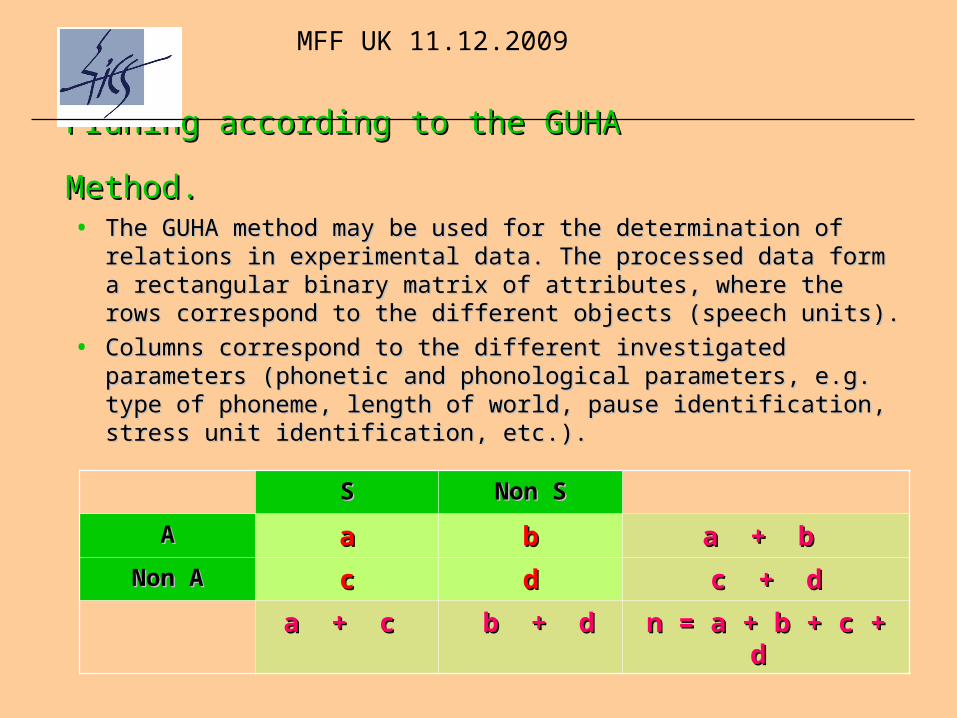
Pruning according to the Pruning according to the GUHA Method.GUHA Method. • The GUHA method may be used for the determination of relations The GUHA method may be used for the determination of relations
in experimental data. The processed data form a rectangular binary in experimental data. The processed data form a rectangular binary matrix of atmatrix of atttribribuutes, where the rows correspond to the different tes, where the rows correspond to the different objectsobjects (speech units) (speech units). .
• Columns correspond to the different investigated parameters Columns correspond to the different investigated parameters ((phonetic and phonological parameters, e.g.phonetic and phonological parameters, e.g. type of phonemetype of phoneme, , length of world, pause identificationlength of world, pause identification, , stress unit identificationstress unit identification, etc.), etc.). .
SS Non Non SS
AA aa bb a + b a + b
Non ANon A cc dd c + dc + d
a + ca + c b + db + d n = a + b + c + dn = a + b + c + d
MFF UK 11.12.2009
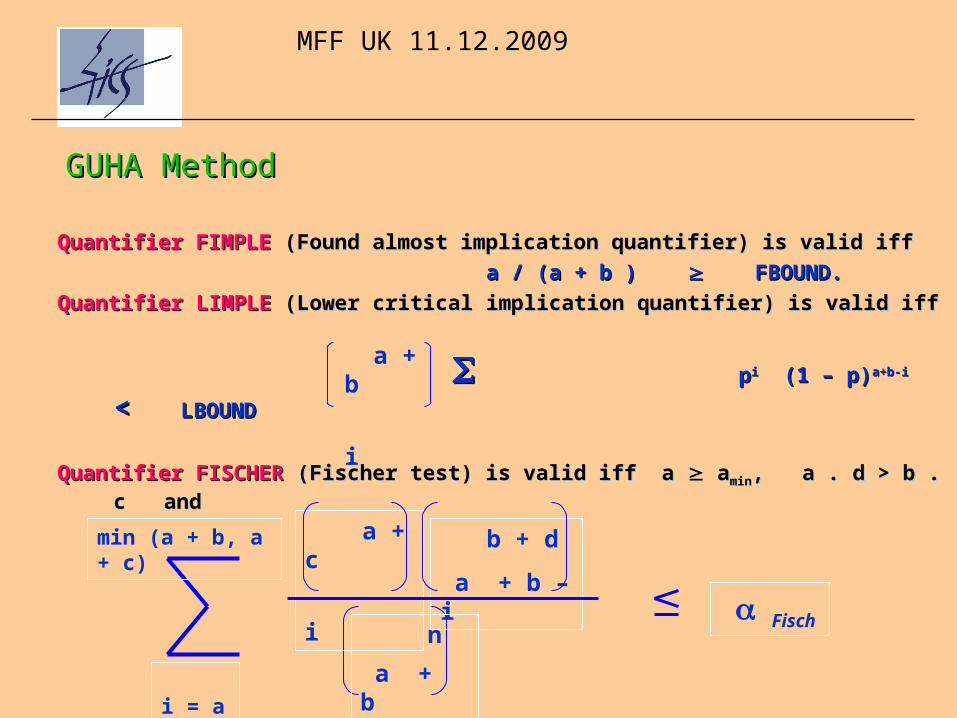
GUHA MethodGUHA Method
Quantifier FIMPLEQuantifier FIMPLE (Found almost implication quantifier) is valid iff (Found almost implication quantifier) is valid iff
a / (a + b ) a / (a + b ) FBOUND.FBOUND.
Quantifier Quantifier LLIMPLEIMPLE ( (Lower criticalLower critical implication quantifier) is valid iff implication quantifier) is valid iff
ppii (1 – (1 –
p)p)a+b-ia+b-i << LBOUND LBOUND
Quantifier FISCHERQuantifier FISCHER (Fischer test) is valid iff a (Fischer test) is valid iff a a aminmin, a . d > b . c , a . d > b . c and and
a + c
i
b + d
a + b – i
n
a + b i = a
min (a + b, a + c)
Fisch
a + b
i
MFF UK 11.12.2009
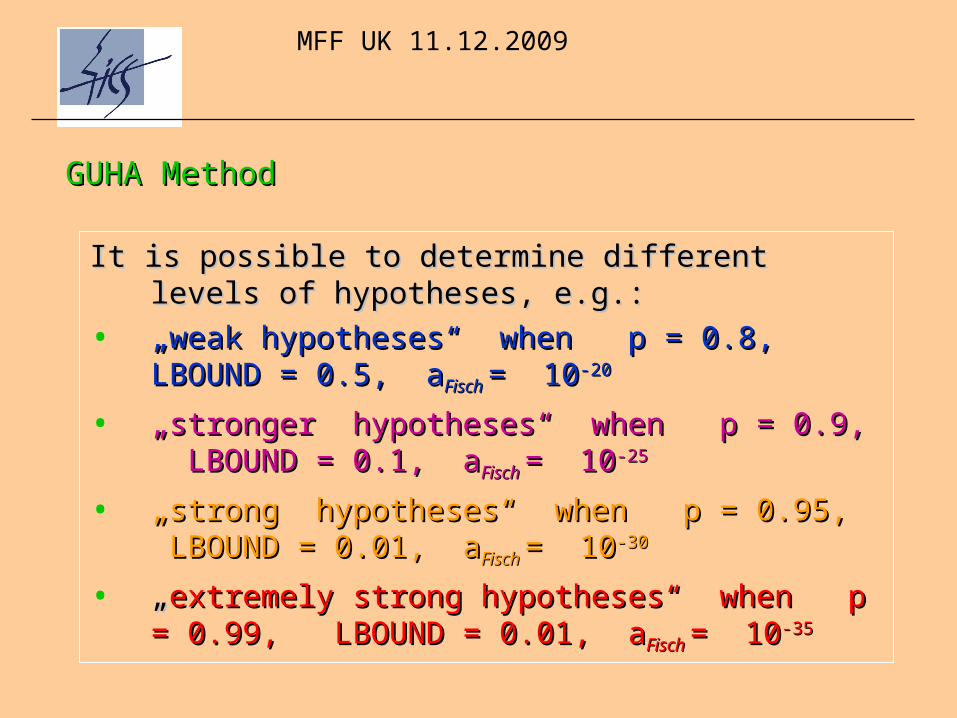
GUHA MethodGUHA Method
It is possible to determine different levels of hypotheses, It is possible to determine different levels of hypotheses, e.g.:e.g.:
• „„weak hypotheses“ when p = 0.8, LBOUND = weak hypotheses“ when p = 0.8, LBOUND = 0.5, a0.5, aFisch Fisch = 10= 10-20-20
• „„stronger hypotheses“ when p = 0.9, LBOUND stronger hypotheses“ when p = 0.9, LBOUND = 0.1, a= 0.1, aFisch Fisch = 10= 10--2525
• „„strong hypotheses“ when p = 0.9strong hypotheses“ when p = 0.955, LBOUND = , LBOUND = 0.0.001, a1, aFisch Fisch = 10= 10-30-30
• „„extremely strong hypotheses“ when p = 0.extremely strong hypotheses“ when p = 0.9999, , LBOUND = 0.LBOUND = 0.0101, a, aFisch Fisch = 10= 10--3535
MFF UK 11.12.2009

MFF UK 11.12.2009
Pruning according to the sensitivity approach
The determination of input parameters, which can be omitted according to the comparison of sums of absolute values of output signals derivatives :
k
n
xknnk x
yxySS
k
0
lim,
N
nkn
kprunedkn xySxyS
1_ ),(min,

MFF UK 11.12.2009
Standard pruning approach according to the weights
The determination of input parameters, which can be omitted according to the comparison of sums of absolute values of weights :
iik
kprunedk wsum ||min_
all inputs of neuronneuron

MFF UK 11.12.2009
Combination of above mentioned 3 approaches:
If some attributes of proposed ANN (for F0 and D) for 2 from 3 approaches give recommendation for pruning, then input parameter have been pruned.
We can prune the ANN by a lot of known methods:• Mozer, Smolensky (1989) „sensitivity calculation“• Karnin (1990) „sensitivity of error function“• Le Cun et all (1990) „saliency“• Chauvin (1989) „penalty terms“• Weigend, Rumelhard, Hubermann (1991)• Sietsma, Dow (1991) „heuristics“• Šebesta (1993) „statistical derivatives“
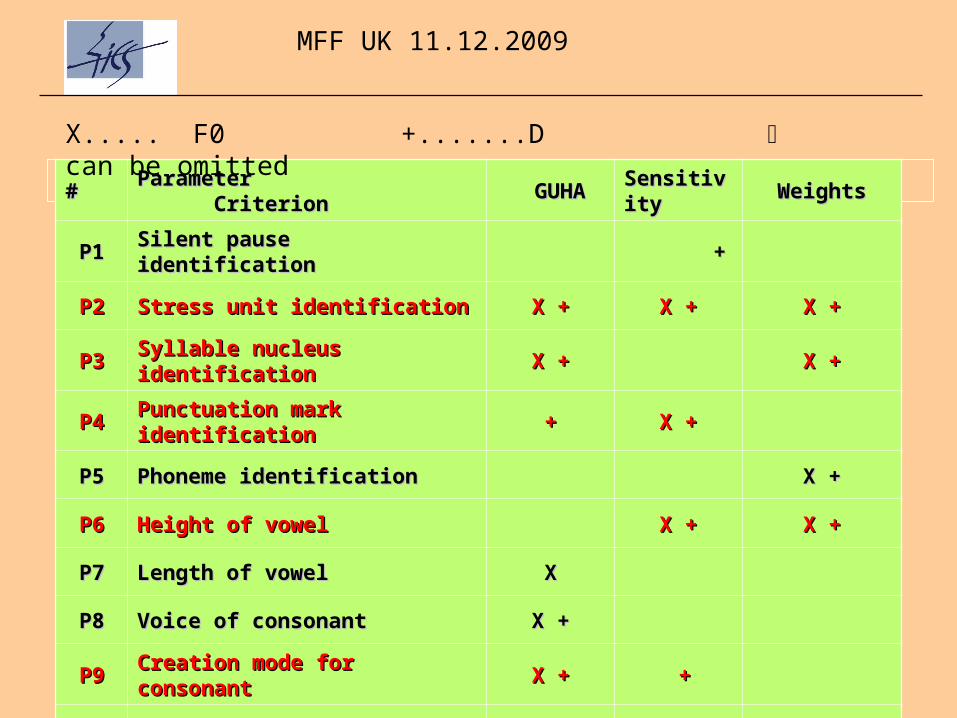
## Parameter Parameter CriterionCriterion GUHAGUHA Sensitivity Sensitivity
WeightsWeights
P1P1 Silent pause identificationSilent pause identification ++
P2P2 Stress unit identificationStress unit identification X +X + X +X + X +X +
P3P3 Syllable nucleus identificationSyllable nucleus identification X +X + X +X +
P4P4 Punctuation mark identificationPunctuation mark identification ++ X +X +
P5P5 Phoneme identificationPhoneme identification X +X +
P6P6 Height of vowelHeight of vowel X +X + X +X +
P7P7 Length of vowelLength of vowel XX
P8P8 Voice of consonantVoice of consonant X +X +
P9P9 Creation mode for consonantCreation mode for consonant X +X + ++
P10P10 Number of phonemesNumber of phonemes X +X + X +X +
MFF UK 11.12.2009
X..... F0 +.......D can be omitted
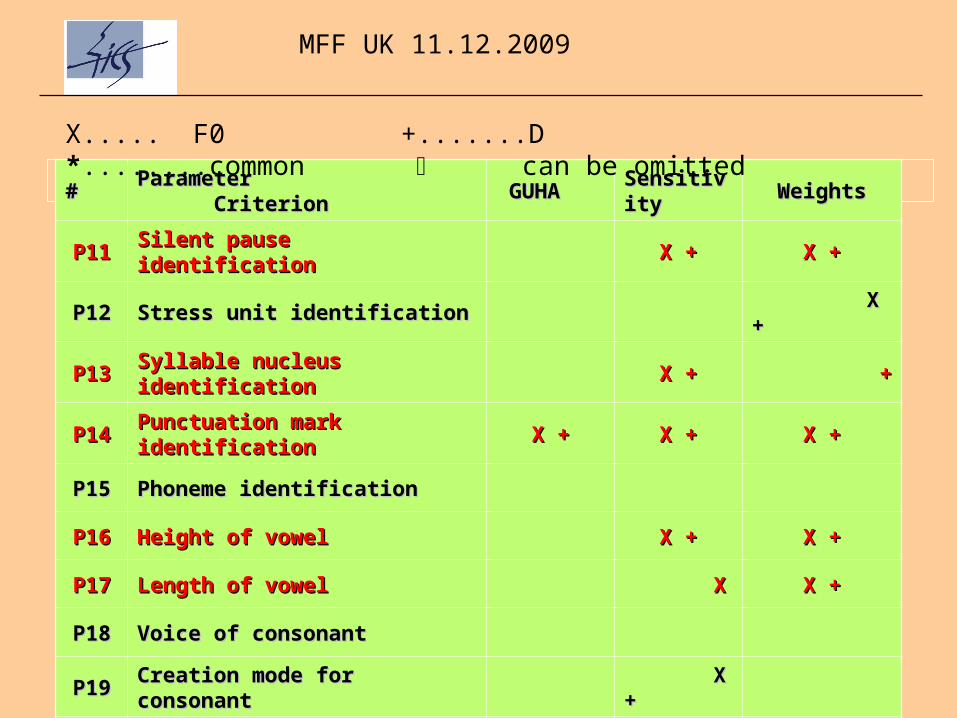
## Parameter Parameter CriterionCriterion GUHAGUHA Sensitivity Sensitivity
WeightsWeights
P1P111 Silent pause identificationSilent pause identification X +X + X +X +
PP1122 Stress unit identificationStress unit identification X +X +
PP1133 Syllable nucleus identificationSyllable nucleus identification X +X + ++
PP1144 Punctuation mark identificationPunctuation mark identification X +X + X +X + X +X +
PP1155 Phoneme identificationPhoneme identification
PP1166 Height of vowelHeight of vowel X +X + X +X +
PP1177 Length of vowelLength of vowel XX X +X +
PP1188 Voice of consonantVoice of consonant
PP1199 Creation mode for consonantCreation mode for consonant X +X +
PP2200 Number of phonemesNumber of phonemes
MFF UK 11.12.2009
X..... F0 +.......D *........common can be omitted
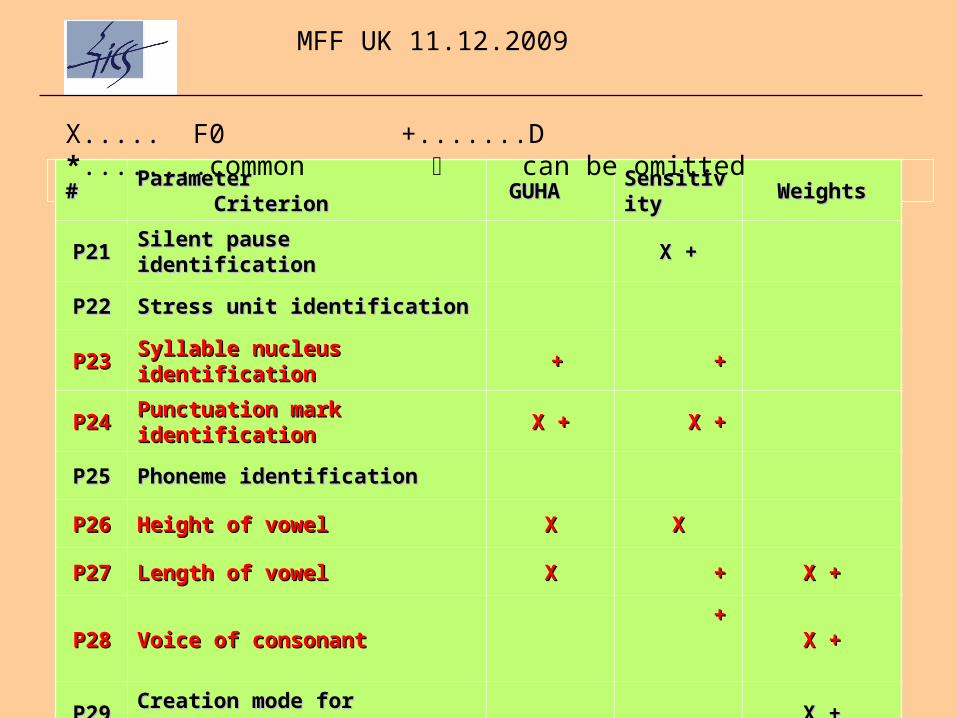
## Parameter Parameter CriterionCriterion GUHAGUHA Sensitivity Sensitivity
WeightsWeights
PP2211 Silent pause identificationSilent pause identification X +X +
PP2222 Stress unit identificationStress unit identification
PP2233 Syllable nucleus identificationSyllable nucleus identification ++ ++
PP2244 Punctuation mark identificationPunctuation mark identification X +X + X +X +
PP2255 Phoneme identificationPhoneme identification
PP2266 Height of vowelHeight of vowel XX XX
PP2277 Length of vowelLength of vowel XX ++ X +X +
PP2288 Voice of consonantVoice of consonant + + X +X +
PP2299 Creation mode for consonantCreation mode for consonant X +X +
PP3300 Number of phonemesNumber of phonemes X +X + X +X +
MFF UK 11.12.2009
X..... F0 +.......D *........common can be omitted
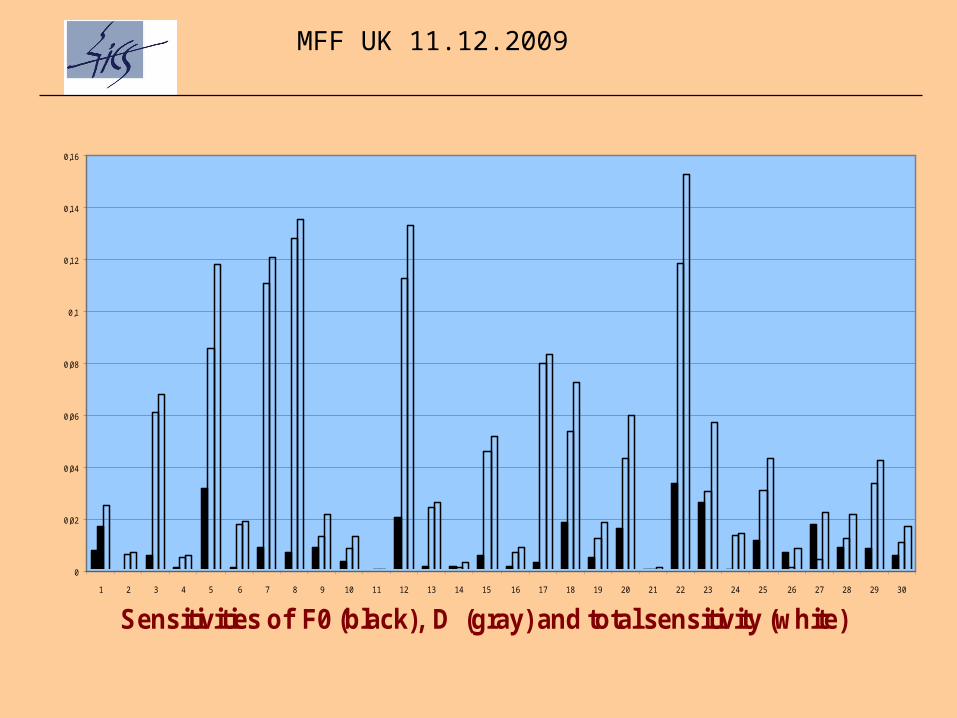
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Sensitivities of F0 (black), D (gray) and total sensitivity (white)
MFF UK 11.12.2009
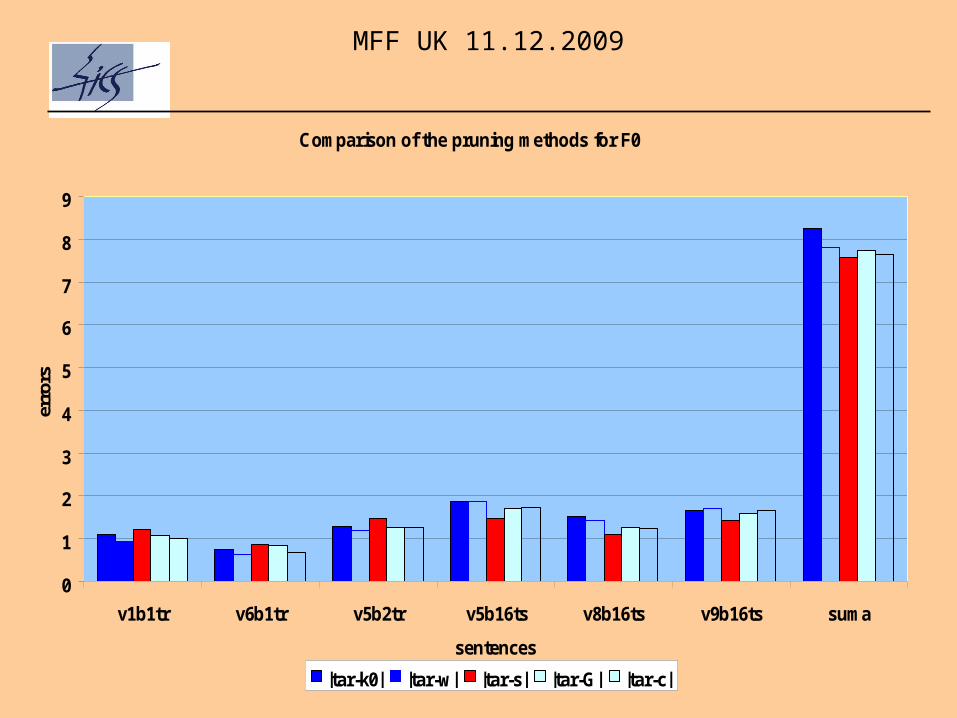
Comparison of the pruning methods for F0
0
1
2
3
4
5
6
7
8
9
v1b1tr v6b1tr v5b2tr v5b16ts v8b16ts v9b16ts suma
sentences
erro
rs
|tar-k0| |tar-w| |tar-s| |tar-G| |tar-c|
MFF UK 11.12.2009
MFF UK 11.12.2009
0
20
40
60
80
100
120
140
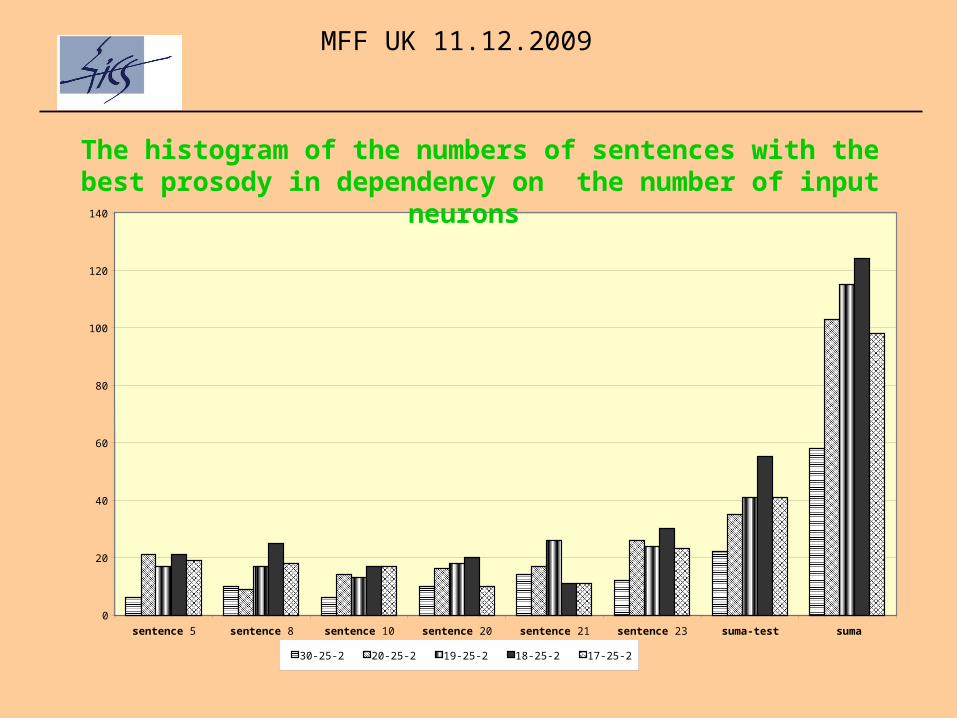
sentence 5 sentence 8 sentence 10 sentence 20 sentence 21 sentence 23 suma-test suma
30-25-2 20-25-2 19-25-2 18-25-2 17-25-2
The histogram of the numbers of sentences with the best prosody in dependency on the number of input neurons
MFF UK 11.12.2009
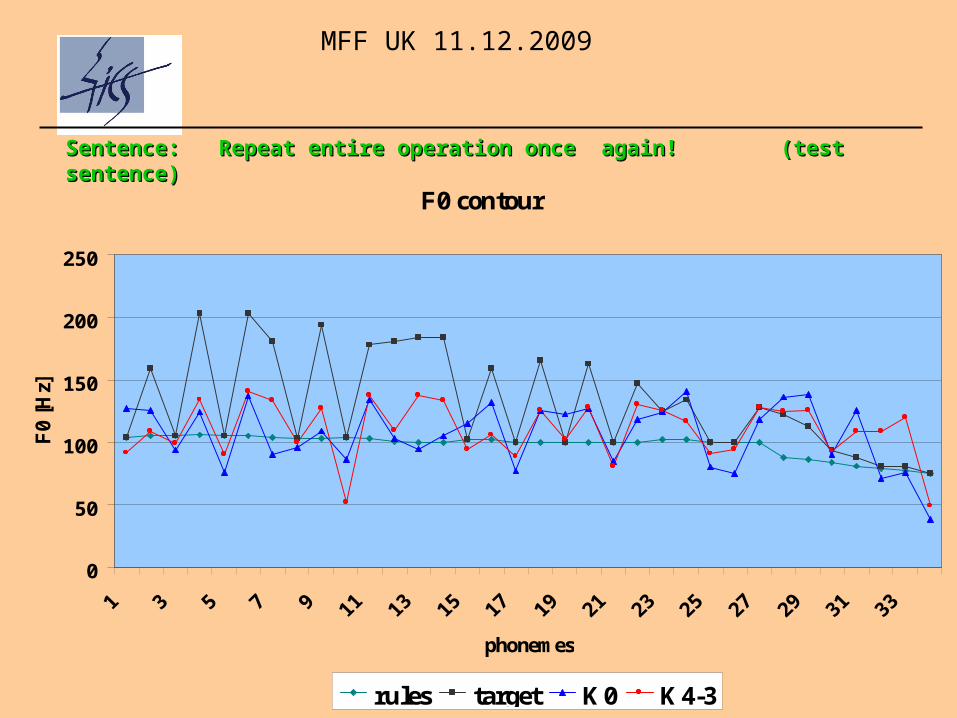
Sentence: Sentence: Repeat entire operation once again! Repeat entire operation once again! ((test sentencetest sentence))
F0 contour
0
50
100
150
200
250
phonemes
F0
[Hz]
rules target K0 K4-3
MFF UK 11.12.2009
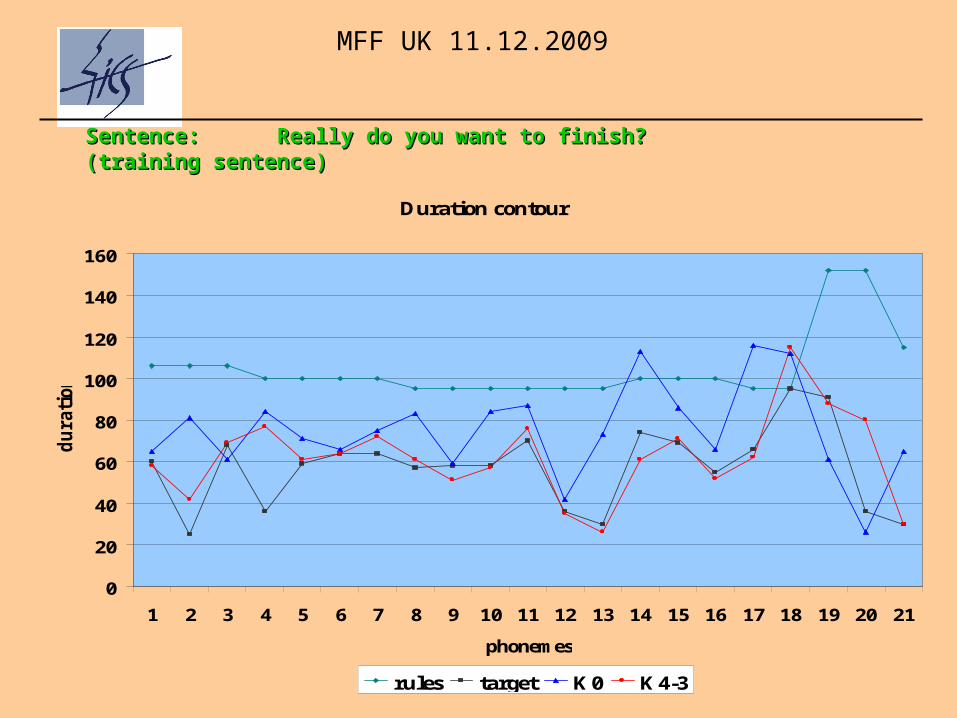
Sentence: Sentence: Really do you want to finish? Really do you want to finish? ((training training sentencesentence))
Duration contour
0
20
40
60
80
100
120
140
160
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
phonemes
du
rati
on
rules target K0 K4-3
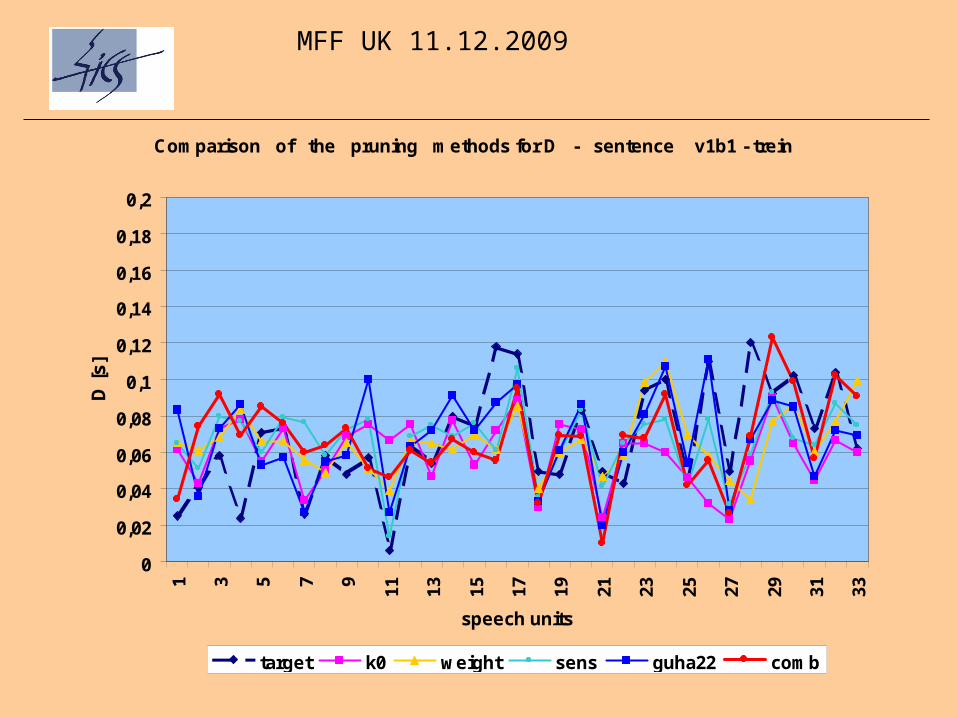
MFF UK 11.12.2009
Comparison of the pruning methods for D - sentence v1b1 - trein
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
0,18
0,21 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33
speech units
D [
s]
target k0 weight sens guha22 comb

Listening test Listening test ofof synthetic speech synthetic speech
1. Prosody controlled by non-pruned neural net.2. Prosody controlled by pruned neural net trained
according the weights.3. Prosody controlled by pruned neural net trained
according the GUHA method.4. Prosody controlled by pruned neural net trained
according the sensitivities.5. Prosody controlled by optimal values F0 and
durations.6. Direct speech.
MFF UK 11.12.2009

MFF UK 11.12.2009
1 2 3 4 5 6
1. Weather forecasting for the night and tomorrow. Předpověď počasí na noc a zítřek.
2. Eastern wind from two to five meters per second.
Východní vítr dva až pět metrů za sekundu.
3. Pressure tendency: week increase, afternoon week decrease.
Tlaková tendence: slabý vzestup, odpoledne slabý pokles.
4. Maximal value of ultra-violet index is five point eight.
Maximální hodnota UV-indexu pět celých osm.
5. There was the news of the Czech radio one-Radiojournal.
To byly zprávy Českého rozhlasu 1 – Radiožurnálu.