relaxed fd discoverer
TRANSCRIPT

Università di Salerno Corso di Basi Dati2
Relaxed FD Discoverer
Luciano Giuseppe

• Introduzione
• Dipendenze Funzionali
• Gli algoritmi esistenti
• Relaxed FD Discoverer
• Esperimenti
• Conclusioni
Overview

Introduzione
• Nel mondo del data analysis vi è la necessità di inferire delle dipendenze tra i dati presenti nei database: Dependency discovery
• Queste dipendenze possono non essere presenti nel modello relazionale del dataset.
• Il dependency discovery è utile per il DBA per la manutenzione e la ri-organizzazione degli schemi.

Introduzione
• Il dependency discovery ha alcune problematiche:
– Tempo di ricerca: la ricerca è esponenziale nel peggiore dei casi, a meno che non si effettuino tagli negli elementi da cerca
– Le dipendenze trovate devono sussistere: si deve testare la qualità dei dati analizzati.

Dipendenze Funzionali

Dipendenze Funzionali Definizioni di base
• R = {A1, . . . , Am} : schema di relazione di un database relazionale
• r : istanza di R. • t[X] : la proiezione di una tupla t Є r sul
sottoinsieme di attributi X R. • Una dipendenza funzionale (FD) è una relazione
tra attributi in un database. • Una FD si denota con X Y:
– X è detto lato sinistro o LHS – Y è detto lato destro o RHS

Dipendenze Funzionali Tipi
• Dipendenza Funzionale Esatta – X Y sussiste se: t1[X] = t2[X] e t1[Y] = t2[Y], per tutte
le coppie di tuple t1, t2 Є r.
• Dipendenza Funzionale Approssimata – Rappresentano dipendenze funzionali valide per quasi
tutte le tuple di una relazione r.
– E’ impostata una soglia di approssimazione
• Dipendenza Funzionale Condizionata – Introdotta per il data cleaning
– t[X] ≈ p[X], se per ogni A Є X: (p[A] =‘−’ o p[A] = t[A]).

Dipendenze Funzionali Tipi
• Dipendenze che rilassano sul paradigma di confronto tra attributi: catturano importanti relazioni semantiche tra gruppi di valori, che appaiono "simili"piuttosto che identici.
– Similarity Functional Dependency
• Tolleranza: ti θA tj ↔ |ti(A) − tj(A)| ≤ Є
• X Y sussiste se ti θX tj ti θY tj
Un valore reale ≥ O, che funge da soglia

Gli algoritmi esistenti

Algoritmi Esistenti
Ci sono già diversi algoritmi che rappresentano correntemente lo stato dell’arte e che usano diverse tecniche, col le quali cercano di diminuire il tempo di ricerca:
• Ricerca sul lattice: – Tane – FUN – FD_Mine
• Difference and agree set: – Dep-Miner – FastFDs
• Induzione delle dipendenze: – Fdep
Si approfondiranno

Algoritmi Esistenti Tane
• Tane si basa su due principi fondamentali
1. Partizioni degli attributi: per ogni valore in attributo si creano degli insiemi che contengono il numero di righe, che ne hanno un’occorrenza.
Algoritmi Esistenti Tane
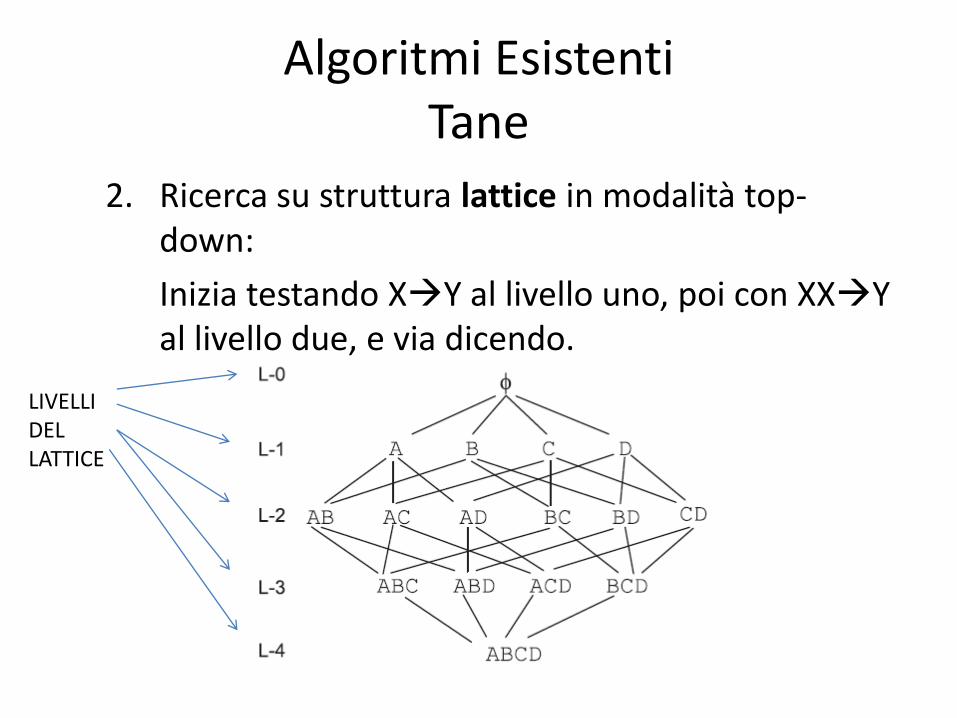
2. Ricerca su struttura lattice in modalità top-down:
Inizia testando XY al livello uno, poi con XXY al livello due, e via dicendo.
LIVELLI DEL LATTICE

Algoritmi Esistenti FD_Mine
• FD_Mine è un’evoluzione di TANE. Utilizza le proprietà delle Dipendenze Funzionali per effettuare i tagli: – Simmetria:
Se X Y e Y X, allora X ↔ Y , i due attributi sono equivalenti.
– Assiomi di Amstrong: • Dato X Y , se XW Z vale, allora YW ↔ Z vale • Dato X Y , se ZW X vale, allora ZW ↔ Y vale.
In questo modo si tolgono attributi nella ricerca del
lattice per velocizzare.

Algoritmi Esistenti FD_Mine
• Miglioramento della ricerca con FD_Mine

Relaxed FD Discovery

Relaxed FD Discoverer
• Relaxed FD Discoverer è l’algoritmo implementato da noi per la ricerca di dipendenze nei dataset.
• L’algoritmo si basa sui principi di TANE e FD_Mine.
• Supporta vari tipi di Dipendenze Funzionali, tra cui: – Esatte
– Rilassate: per ogni attributo si può settare una soglia di similarità tra valori.

Relaxed FD Discoverer
• Permette la personalizzazione della funzione di aggregazione per la ricerca di diverse FD: – Fuzzy FD
– Type-M
– Altre…
• Scritto in Python e sfrutta la programmazione dinamica
• Permette un porting veloce su architettura distribuita

Relaxed FD Discoverer Ricerca
L’algoritmo effettua la ricerca di FD minimali sul lattice: ogni attributo Y appartenente al RHS viene analizzato da un codice tipo:
per ogni attributo come lato_destro:
per ogni livello del lattice:
per ogni combinazione_di_attributi dato il "livello" e lato_destro:
trova_dipendenza_funzionale (combinazione_di_attributi, lato_destro)

Relaxed FD Discoverer I passi della ricerca
L’algoritmo effettua la ricerca in due passi:
1. Viene effettuata la ricerca di FD a livello 1 del lattice.
2. Si effettua la ricerca dal livello 2 in poi del lattice. Si sfruttano le informazioni raccolte al primo passo per effettuare tagli locali o globali.

Relaxed FD Discoverer Pruning
Quando viene trovata una dipendenza funzionale X Y, l’algoritmo effettua un taglio diverso a seconda del passo in cui si trova.
Passo 1)
• Se si trova una riflessività tra attributi tipo: X Y e Y X, dall’insieme degli attributi su cui andare a cercare le dipendenze funzionali viene tolto un attributo, così da ridurne il numero su cui andare a cercare al passo due.
• Se non si trova una riflessività, al passo due, per il solo RHS Y vengono tagliati dalla ricerca tutte le combinazioni di attributi che contengono X.
Passo 2)
• Si cerca una riflessività e nel caso viene effettuato un taglio globale
• Se non vi è una riflessività, dall’albero di ricerca relativo al RHS Y vengono tagliati, per il livello successivo, tutti i rami che portano ai nodi contenenti X.

Relaxed FD Discoverer Pruning: Taglio globale
Si effettua al “passo 2” della ricerca di dipendenze funzionali.
Si sfrutta la regola di unione e si usano le FD trovate al passo 1.
Es:
1. Trovata una FD del tipo {X, Y} Z, si controlla se Z {X, Y}: se Z X e Z Y allora Z {X, Y}.
2. Nella ricerca si toglie da tutti i lati sinistri{X, Y} e si usa solo Z.

Relaxed FD Discoverer Partizioni e Programmazione Dinamica
• Dato il supporto delle FD approssimate non si possono usare le partizioni come viene effettuato in TANE.
• Viene usata la programmazione dinamica per salvare i confronti tra attributi effettuati a LHS.
Es: Se testiamo AB C : andiamo a trovare tutte le righe in cui i valori di AB sono simili e si salveranno in memoria, così quando si testerà AB D, non si dovrà più fare ricerche sui valori simili di AB.

Relaxed FD Discoverer Ontologie
• L’algoritmo permette di utilizzare le ontologie per confrontare gruppi di attributi.

Esperimenti

Esperimenti Test sui dataset UCI
Prima fase di validazione: test su dei dataset noti in letteratura e scaricabili dal sito UIC. Sono state trovare delle FD esatte.
• Iris: 150 istanze per 5 attributi
– (lunghezza sepalo, larghezza sepalo, lunghezza petalo) tipo iris – (lunghezza sepalo, larghezza sepalo, larghezza petalo) tipo iris – (lunghezza sepalo, lunghezza petalo, larghezza petalo) tipo iris – (larghezza sepalo, lunghezza petalo, larghezza petalo) tipo iris
• Balance-scale: 625 istanze per 5 attributi – (peso − a − sinistra, distanza − a − sinistra, peso − a − destra, distanza −
a − destra) tipo
• Chess: 28056 istanze per 7 attributi – (colonna Re bianco, riga Re bianco, Torre bianca colonna, Torre bianca
riga, Re nero colonna, Re nero riga) numero di mosse per la vittoria

Esperimenti Test sul dataset FuelEconomy.gov
FuelEconomy è un dataset delle auto, preso dal sito del dipartimento dell’energia degli Stati Uniti.
• Feature del dataset: a) Marca b) Modello c) Cilindrata in cm3 d) Numero di cilindri e) Tipo trasmissione f) Consumo in Città g) Consumo fuori Città h) Consumo combinato i) Trasmissione j) Numero di marce k) Drive System l) Drive Descriptiong m) Fuel Usage n) Annual Fuel Cost o) Viscosità dell’olio
K e L sono ridondanti: sono state usate per testare la ricerca di FD simmetriche.

Esperimenti Test sul dataset FuelEconomy.gov
• Vogliamo testare le FD rilassate. Per questi attributi abbiamo settato diverse soglie:
c) Cilindrata in cm3 : 0.5
d) Numero di cilindri: 2
f) Consumo in Città: 5
g) Consumo fuori Città : 5
h) Consumo combinato : 5
n) Annual Fuel Cost : 500

Esperimenti Test sul dataset FuelEconomy.gov
• Le funzioni testate:
– Max: per ogni attributo X, due tuple sono simili se la loro distanza è sotto la soglia prefissata.
– Funzione Aggregazione: è stata testata la seguente funzione
pesi Xi: elemento i-esimo della tupla X
soglie

Esperimenti Test sul dataset FuelEconomy.gov
• Uso dell’ontologia
E’ stata creata un’ontologia prendendo il tipo della macchina, data la marca e il modello. Questo per tutte le tuple del dataset.
Es: con marca: “fiat” e modello: “punto” si è avuto come tipo di macchina: “minicar”.

Esperimenti Test sul dataset FuelEconomy.gov
• Uso dell’ontologia
L’ontologia è stata usata in due modi:
1. Sul dataset: quando l’algoritmo testa una combinazione di attributi in cui ci sono marca e modello, va a confrontare i valori dell’ontologia.
2. Nel dataset: è stato creato un dataset dove al posto delle colonne marca e modello è stata inserita l’ontologia.

Esperimenti FuelEconomy: funzione Max
• Risultati sul dataset senza uso di ontologia, con approssimazione:
–0%: 42 FD trovate
–10%: 37 FD trovate
–20 %: 22 FD trovate

Esperimenti FuelEconomy: funzione Max
Alcune FD trovate dall’algoritmo

Relaxed FD Discoverer FuelEconomy: funzione Max
Risultati con uso di ontologia:
– Sul dataset:
• Non sono state trovate FD che contenesse l’ontologia
– Nel dataset: è stata trovata una nuova FD:
(’a’, ’c’, ’e’, ’f’, ’n’, ’o’) h
Dove ‘a’ è la colonna contenente l’ontologia

Relaxed FD Discoverer FuelEconomy:funzione di aggregazione
Risultati sul dataset senza uso dell’ontologia, con approssimazione dal 0% a 20 %:
– Una sola FD trovata al passo 2
(’b’, ’c’, ’o’) d
[(Carline, Eng Displ cm3, Oil Viscosity) # Cilindri]
Risultati sul dataset con l’uso dell’ontologia:
– 0 FD trovate

Conclusioni

Conclusioni
• Con i dataset della Uci l’algoritmo ha lavorato bene: ha trovato le FD indicate dal progetto Metanome.

Conclusioni
• Con il dataset FuelEconomy, sono state trovate diverse FD. – Al passo 1, per ogni versione dell’algoritmo sono state
trovate le stesse FD
– Al passo 2, a seconda della funzione di aggregazione usata sono state trovate diverse FD
– Cambiando la percentuale di approssimazione si sono trovate un numero minore di FD, man mano che questa aumentava.

Conclusioni Percentuale di approssimazione
• Aumentando l’approssimazione si sarebbero dovute trovare più funzioni di approssimazione, perché si ne sono trovate di meno?
– Sono state trovate le FD ad un livello più basso del lattice e quindi molte FD, trovate con approssimazione più bassa ma ad un livello più alto, sono state tagliate.

Conclusioni Percentuale di approssimazione
• Con un’approssimazione dello 0% sono state trovate:
– (Carline, City FE, Hwy FE, Transmission) Comb FE
– (Carline, City FE, Hwy FE, Drive Sys) Comb FE
– (Carline, City FE, Hwy FE, Fuel Usage) Comb FE
– (Carline, City FE, Hwy FE, Annual Fuel1 Cost) Comb FE
• Con un’approssimazione del 20% è stata trovata solo:
– (City FE, Hwy FE) Comb FE

FINE