real time analytics with dse
TRANSCRIPT

Real Time Analytics with DataStax Enterprise
Ryan Knight @Knight_Cloud
Solution Engineer - Datastax

© 2014 DataStax, All Rights Reserved
Introduction to Spark

© 2014 DataStax, All Rights Reserved
Hadoop Limitations
• Master / Slave Architecture • Every Processing Step requires Disk IO • Difficult API and Programming Model • Designed for batch-mode jobs • No even-streaming / real-time • Complex Ecosystem

© 2014 DataStax, All Rights Reserved
Hadoop?

© 2014 DataStax, All Rights Reserved
Apps in the early 2000s were written for
Apps today are written for
Single machines Clusters of machinesSingle core processors Multicore processors
Expensive RAM Cheap RAMExpensive disk Cheap diskSlow networks Fast networks
Few concurrent users Lots of concurrent usersSmall data sets Large data sets
Latency in seconds Latency in milliseconds

What is Spark?• Fast and general compute engine for large-scale data
processing
• Fault Tolerant Distributed Datasets
• Distributed Transformation on Datasets
• Integrated Batch, Iterative and Streaming Analysis
• In Memory Storage with Spill-over to Disk

© 2014 DataStax, All Rights Reserved
Advantages of Spark• Improves efficiency through:
• In-memory data sharing • General computation graphs - Lazy Evaluates Data • 10x faster on disk, 100x faster in memory than
Hadoop MR
• Improves usability through: • Rich APIs in Java, Scala, Py..?? • 2 to 5x less code • Interactive shell


© 2014 DataStax, All Rights Reserved

10© 2015. All Rights Reserved.
•Functional Paradigm is ideal for Data Analytics
•Strongly Typed - Enforce Schema at Every Later
•Immutable by Default - Event Logging
•Declarative instead of Imperative - Focus on Transformation not Implementation
Scala for Data Analytics

© 2014 DataStax, All Rights Reserved
Spark Streaming

© 2014 DataStax, All Rights Reserved
Spark Versus Spark Streaming

© 2014 DataStax, All Rights Reserved
Spark Streaming General Architecture

© 2014 DataStax, All Rights Reserved
DStream Micro Batches

© 2014 DataStax, All Rights Reserved
Windowing

© 2014 DataStax, All Rights Reserved
Spark Cassandra Connector

Spark is about Data Analytics
• How do we get data into Spark?
• How can we work with large datasets?
• What do we do with the results of the analytics?

Spark Cassandra Connector

© 2014 DataStax, All Rights Reserved ●19
Spark Cassandra Connector uses the DataStax Java Driver to Read from and Write to C*
Spark C*
Full Token Range
Each Executor Maintains a connection to the C* Cluster
Spark Executor
DataStax Java Driver
Tokens 1-1000
Tokens 1001 -2000
Tokens …
RDD’s read into different splits based on sets of tokens
Spark Cassandra Connector

Connector Token Range Mapping
Spark Cassandra Connector uses the DataStax Java Driver to Read from and Write to C*
Spark C*
Full Token Range
Each Executor Maintains a connection to the C* Cluster
Spark Executor
DataStax Java Driver
Tokens 1-1000
Tokens 1001 -2000
Tokens …
RDD’s read into different splits based on sets of tokens
Spark Cassandra Connector

Spark Cassandra Connector • Data locality-aware (speed)
• Read from and Write to Cassandra
• Cassandra Tables Exposed as RDD and DataFrames
• Server-Side filters (where clauses)
• Cross-table operations (JOIN, UNION, etc.)
• Mapping of Java Types to Cassandra Types

Spark Cassandra Connector • Open Source Project
• Requires maintaining separate Cassandra and Spark Clusters
• Spark Master is not Highly Available without Zookeeper
• Submitting Spark Applications requires setting hard coded Spark Master and Cassandra Locations

© 2014 DataStax, All Rights Reserved
DataStax Enterprise Data Platform

© 2014 DataStax, All Rights Reserved.
Confidential
DataStax Enterprise Platform Workload Segregation w/out ETL
24
Cassandra OLTP Database
Analytics Streaming and Analytics
Search All Data Searchable
Graph Graph Data Structure - Coming this year
C*
C
C
S A
A

DataStax Enterprise Platform Workload Segregation w/out ETL
25© 2015. All Rights Reserved.

26© 2015. All Rights Reserved.
•DSE Analytic Nodes configured to run Spark •No need to run separate Spark Cluster
•Simplified Deployment and Management •No need to specify Spark Master and Cassandra
Host
•High Availability of Spark Master
DSE Analytics with Spark Internal / Administrative Benefits

DataStax Enterprise Platform Integrated Spark Analytics
27© 2015. All Rights Reserved.

28© 2015. All Rights Reserved.
•High Availability Spark Master with automatic leader election
•Detects when Spark Master is down with gossip
•Uses Paxos to elect Spark Master
•Stores Spark Worker metadata in Cassandra
•No need to run Zookeeper
Spark Master High Availability

29© 2015. All Rights Reserved.
•Integration of Analytics and Search
•Spark Job Server
•SparkSQL and HiveQL access of Cassandra Data
•Streaming Resiliency with w/ Kafka Direct API via Cassandra File System
DSE Analytics with Spark Integration Benefits

DSE 4.8 Analytics + Search• Allows Analytics Jobs to use Solr Queries
• Allows searching for data across partitions
val table = sc.cassandraTable("music","albums")
val result = table.select(“id","artist_name")
.where(“solr_query='artist_name:Miles*'")
.collect

31
DSE Analytics Streaming Analysis
DSE Analytics Batch Analysis
Data Center 1 - US East
Data Center 2 - US West
replication
replication
Data Center Replication
Spark Streaming from Kafka
DSE Analytics Streaming Analysis
DSE Analytics Batch Analysis
Spark Streaming from Kafka
Passive Kafka
Active Kafka
Network Traffic Analysis Architecture

Common Use Cases
• Personalization
• Banking Fraud Detection
• Website Click Stream Analysis
• Login Monitoring

© 2014 DataStax, All Rights Reserved
Spark Streaming Demo

Spark Notebook
34© 2015. All Rights Reserved.
C*
C
C A
AANotebook
Notebook
Notebook
Spark Notebook ServerCassandra Cluster with Spark Connector

Apache Spark Notebook
35© 2015. All Rights Reserved.
•Reactive / Dynamic Graphs based on Scala, SQL and DataFrames
•Spark Streaming • Examples notebooks covering visualization, machine learning, streaming, graph analysis, genomics analysis
•SVG / Sliders - interactive graphs •Tune and Configure Each Notebook Separately •https://github.com/andypetrella/spark-notebook

Demo of Streaming in the Real World - Spark At Scale Project
36© 2015. All Rights Reserved.
•Based on Real World Use Cases
•Simulate a real world streaming use case
•Test throughput of Spark Streaming
•Best Practices for scaling
•https://github.com/retroryan/SparkAtScale
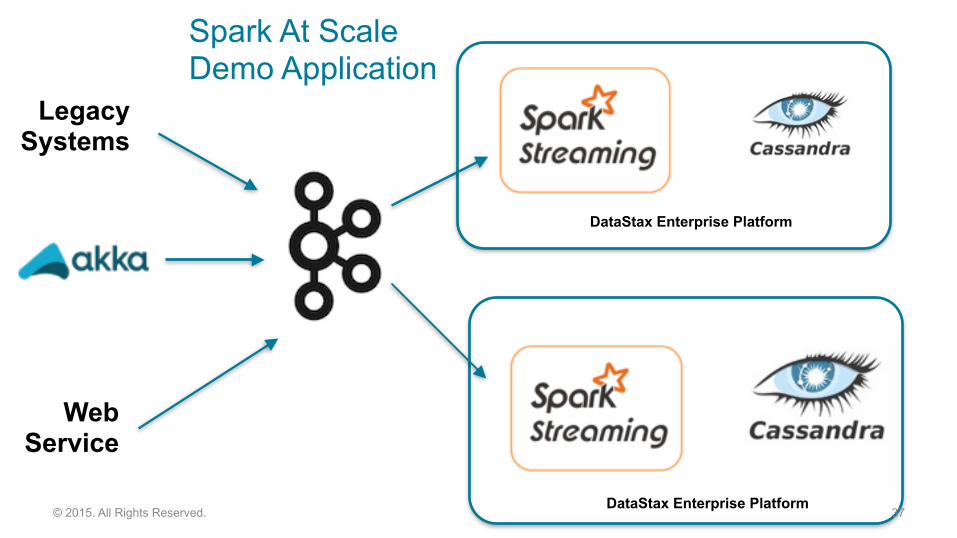
Spark At Scale Demo Application
37© 2015. All Rights Reserved.
DataStax Enterprise Platform
DataStax Enterprise Platform
Web Service
Legacy Systems

© 2014 DataStax, All Rights Reserved
Best Practices for Spark Streaming

Spark Streaming with Kafka Direct Approach
39© 2015. All Rights Reserved.
•Use Kafka Direct Approach (No Receivers)
•Queries Kafka Directly
•Automatically Parallelizes based on Kafka Partitions
•Exactly Once Processing - Only Move Offset after Processing
•Resiliency without copying data

Spark Streaming Deployment
40© 2015. All Rights Reserved.
•Don’t build fat jars!!!!
•spark-submit —package specify dependencies maven style
•Test submit options to match load •--executor-memory 4G •--total-executor-cores 15

How do we Scale for Load and Traffic?

42© 2015. All Rights Reserved.

Spark Streaming Monitoring
43© 2015. All Rights Reserved.
Processing Time
>Batch Duration
=Total Delay Grows
Out Of Memory Errors

Data Modeling using Event Sourcing
44© 2015. All Rights Reserved.
•Append-Only Logging
•Database of Facts
•Snapshots or Roll-Ups
•Why Delete Data any more?
•Replay Events

© 2014 DataStax, All Rights Reserved
Spark SQL and DataFrames

© 2014 DataStax, All Rights Reserved
• Creating and Running Spark Programs Faster • Write less code • Read less data • Let the optimizer do the hard work
• Spark SQL Catalyst optimizer
Why Spark SQL?

© 2014 DataStax, All Rights Reserved
• Distributed collection of data • Similar to a Table in a RDBMS • Common API for reading/writing data • API for selecting, filtering, aggregating
and plotting structured data • Similar to a Table in a RDBMS
DataFrame

© 2014 DataStax, All Rights Reserved
• Sources such as Cassandra, structured data files, tables in Hive, external databases, or existing RDDs.
• Optimization and code generation through the Spark SQL Catalyst optimizer
• Decorator around RDD • Previously SchemaRDD
DataFrame Part 2

© 2014 DataStax, All Rights Reserved
• Unified interface to reading/writing data in a variety of formats
• Spark Notebook Example
Write Less Code: Input & Output

© 2014 DataStax, All Rights Reserved
Configuring Kafka for Scaling

Key to Scaling - Configuring Kafka Topics
51© 2015. All Rights Reserved.
•Number of Partitions per Topic — Degree of parallelism
•Directly Affects Spark Streaming Parallelism
•bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic ratings

Populating Kafka Topics
52© 2015. All Rights Reserved.
val record = new ProducerRecord[String, String] (feederExtension.kafkaTopic, partNum, key, nxtRating.toString)
val future = feederExtension.producer.send(record, new Callback {

53© 2015. All Rights Reserved.

Streaming:collect tweets
Twitter API
HDFS:dataset
Spark SQL:ETL, queries
MLlib:train classifier
Spark:featurize
HDFS:model
Streaming:score tweets
language filter
Demo: Twitter Streaming Language Classifier
Cassandra
Cassandra

1. extract text from the tweet
https://twitter.com/andy_bf/status/
"Ceci n'est pas un tweet"
2. sequence text as
tweet.sliding(2).toSeq
("Ce", "ec", "ci", …, )
3. convert bigrams into
seq.map(_.hashCode())
(2178, 3230, 3174, …, )
4. index into sparse tf
seq.map(_.hashCode() % 1000)
(178, 230, 174, …, )
5. increment feature
Vector.sparse(1000, …)
(1000, [102, 104, …], [0.0455, 0.0455,
Demo: Twitter Streaming Language Classifier
From tweets to ML features, approximated as sparse vectors:

KMeans: Formal Definition (ignore this)
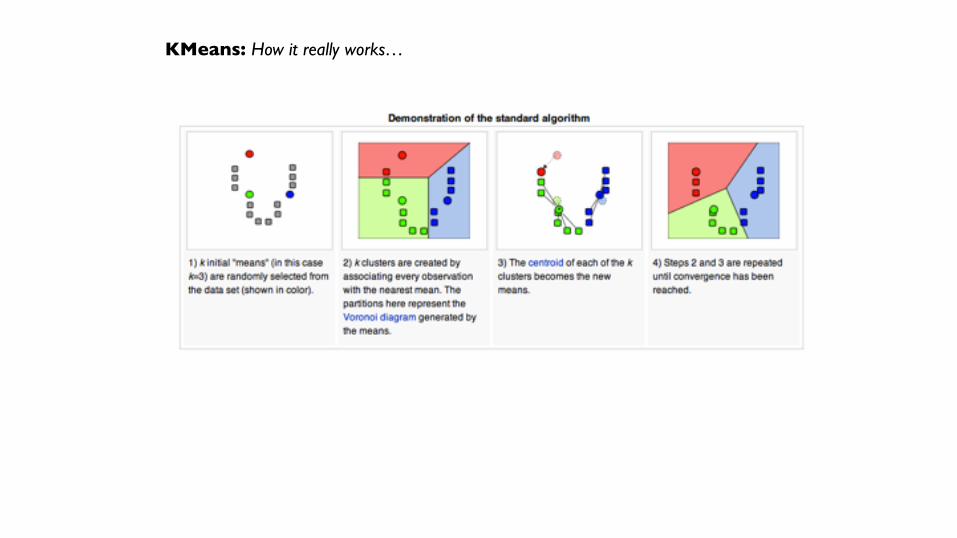
KMeans: How it really works…

KMeans: How it really works…

Demo: Twitter Streaming Language Classifier
Sample Code + Output: gist.github.com/ceteri/835565935da932cb59a2
val sc = new SparkContext(new SparkConf())
val ssc = new StreamingContext(conf, Seconds(5))
val tweets = TwitterUtils.createStream(ssc, Utils.getAuth)
val statuses = tweets.map(_.getText)
val model = new KMeansModel(ssc.sparkContext.objectFile[Vector]
(modelFile.toString).collect())
val filteredTweets = statuses
.filter(t =>
model.predict(Utils.featurize(t)) == clust)
filteredTweets.print()
ssc.start()
ssc.awaitTermination()
CLUSTER 1:TLあんまり⾒見ないけど@くれたっらいつでもくっるよ٩(δωδ)۶そういえばディスガイアも今⽇日か CLUSTER 4:قالوا العروبه روحت بعد صدامواقول مع سلمان تحيى العروبهRT @vip588: √ للمتواجدين االن √ زيادة متابعني √ فولو مي vip588
فولو باك √ رتويت للتغريدة √ فولو للي عمل رتويت √ اللي ما يلتزم ما √… بيستفيدن سورة

Thank you