programming with cuda, ws09 waqar saleem, jens müller programming with cuda and parallel algorithms...
Post on 20-Dec-2015
227 views
TRANSCRIPT

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Programming with CUDA and Parallel
AlgorithmsWaqar Saleem
Jens Müller

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Recap
•Organization
•GPGPU motivation and platforms: CUDA, Stream, OpenCL
•Simple ray tracing

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
GPU wars
•Nvidia is far more popular
•ATI reports more powerful number crunchersimage courtesy of Udeepta Bordoloi, AMD
Programming with CUDA, WS09
Waqar Saleem, Jens Müller
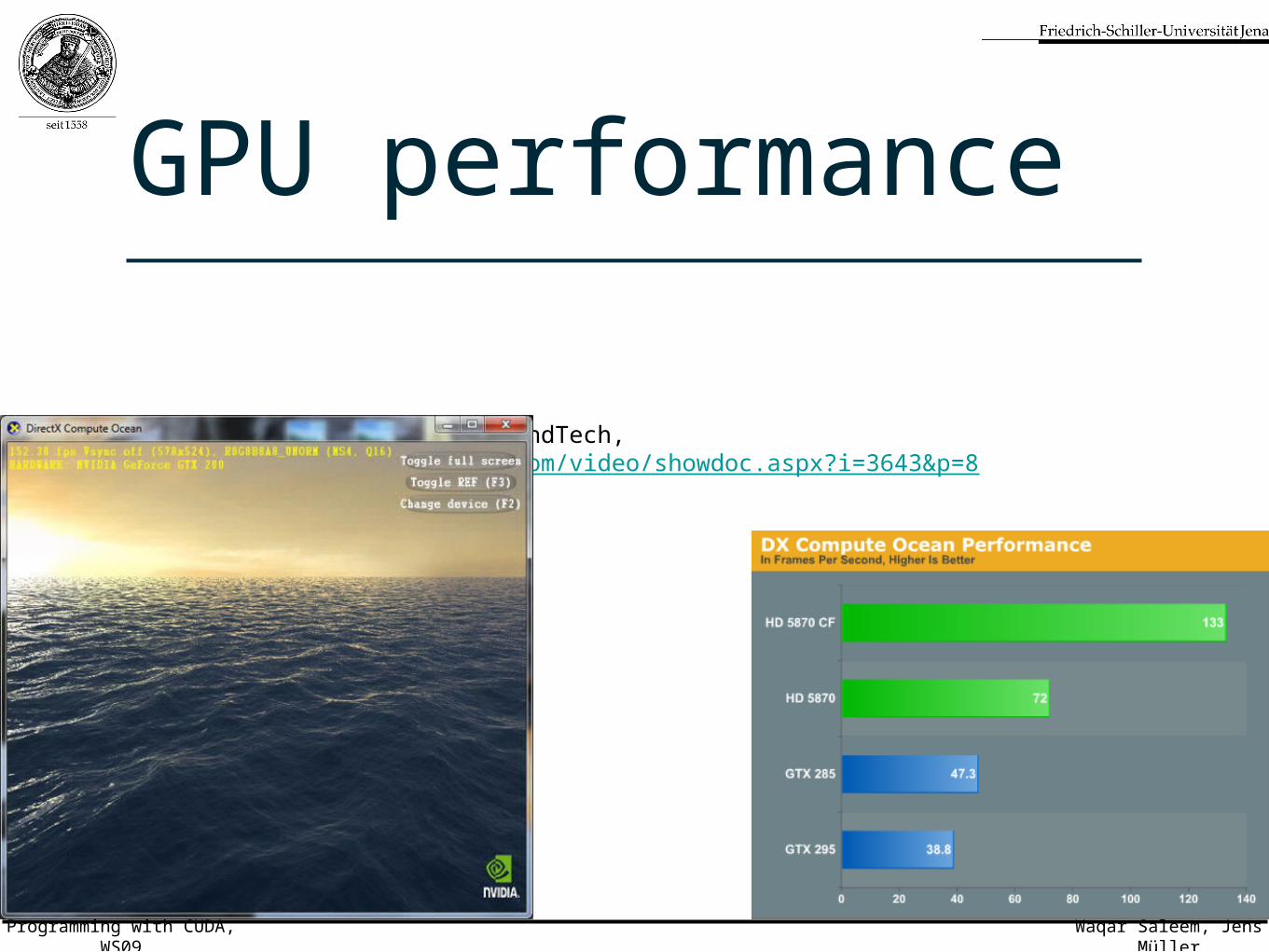
GPU performance
• images courtesy of AnandTech, http://www.anandtech.com/video/showdoc.aspx?i=3643&p=8

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
CUDA or Stream?
•OpenCL is vendor independent
•OpenCL drivers provided by ATI and Nvidia for their cards
•OpenCL like initiative for Windows: Microsoft DirectCompute

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Why CUDA?• Many of the concepts from CUDA carry over almost
exactly to OpenCL
• CUDA has been around since Feb 2007 and is very well documented
• CUDA home,
http://www.nvidia.com/object/cuda_home.html
• links to programming guide, numerous university courses, multimedia presentations ...
• OpenCL v1.0 was released in Nov/Dec 2008
• GPU drivers are less than 6 months old
• A lot of our material will borrow heavily from the above

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Today• Motivational videos
• CUDA hardware and programming models
• Threads, blocks and grids
• CUDA memory hierarchy
• Device compute capability
• Example kernel
• Thread IDs
• Memory overhead

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Programming with CUDA•The G80 architecture, e.g. GeForce 8800
QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Simpler than graphics mode•G80 in graphics mode
QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
QuickTime™ and aBMP decompressor
are needed to see this picture.
QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Thinking CUDA• Break down the problem into serial and parallel
parts
• Serial parts execute on the host (few threads)
• Parallel parts execute on the device (massively parallel)
QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Program execution• The host launches a C program
• Compute intensive, data parallel computations are written in special functions, kernels, in extended C
• The host launches a kernel on the compute device with a grid configuration
• The device starts threads according to the provided configuration
• All threads run in parallel on the device
• All threads execute the same kernel

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Thread organization• A kernel launch specifies a
grid of thread blocks that execute the kernel
• A grid is a 1D or 2D array of blocks
• Each block is a 1D, 2D or 3D array of threads
• Blocks and threads have IDs
• Choose organization to suit your problem and optimize performance

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Thread specific information•Each thread may use block and
thread ID to access its data and make control decisions
QuickTime™ and aBMP decompressor
are needed to see this picture. QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
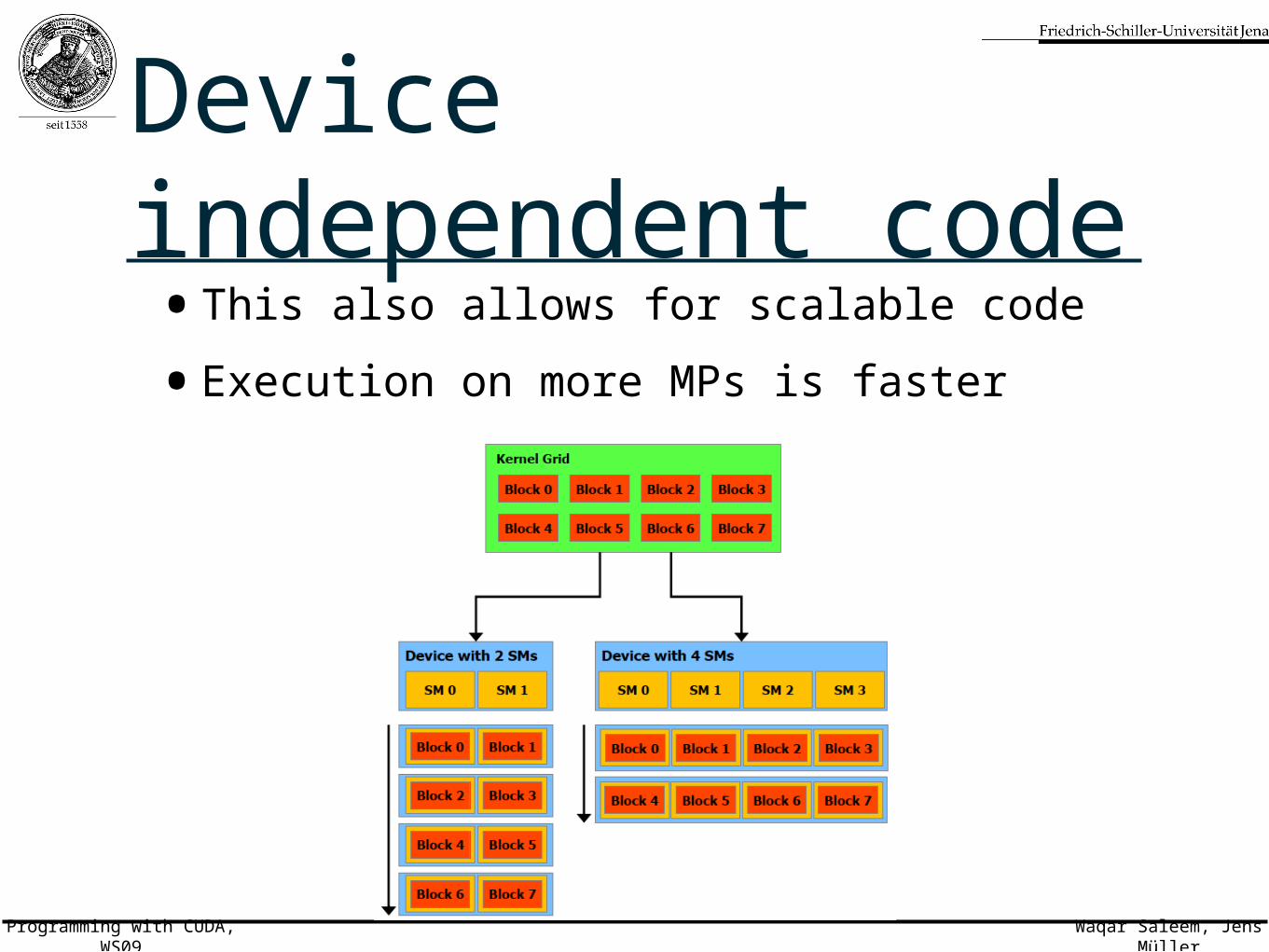
Thread execution• Each thread block is assigned to a single multiprocessor
(MP)
• If there are more blocks than MPs, multiple blocks are assigned to MPs
• An MP breaks assigned block(s) into warps
• The order of execution of blocks and warps is determined by the thread scheduler
• We can thus write code independent of our device specification
• Thread organization according to the problem rather than the hardware
• Caution: For optimum performance, device specification needs to be considered
Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Device independent code•This also allows for scalable code
•Execution on more MPs is faster
Programming with CUDA, WS09
Waqar Saleem, Jens Müller
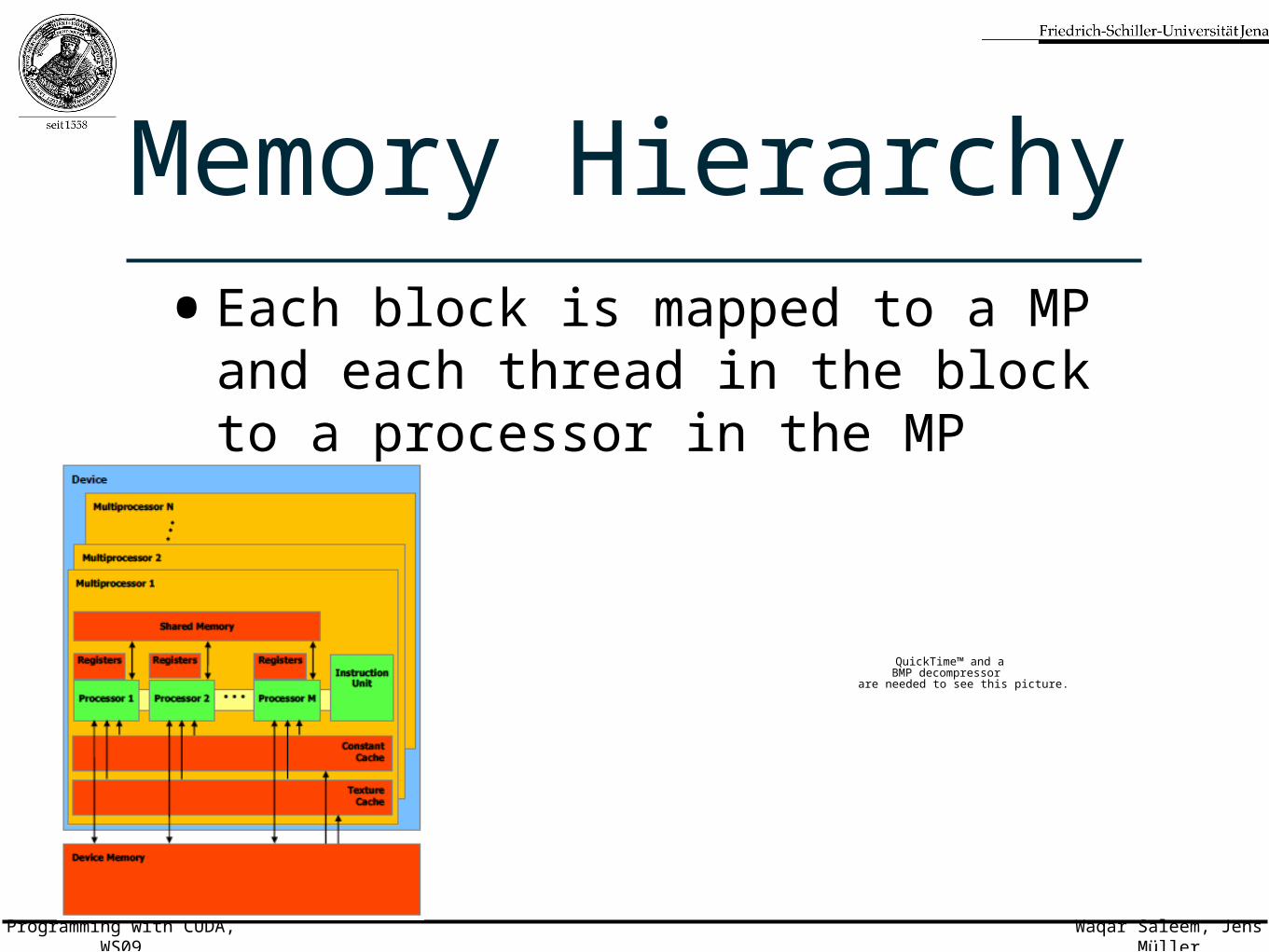
Memory Hierarchy•Each block is mapped to a MP and
each thread in the block to a processor in the MP
QuickTime™ and aBMP decompressor
are needed to see this picture.
Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Texture MemoryConstant Memory

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
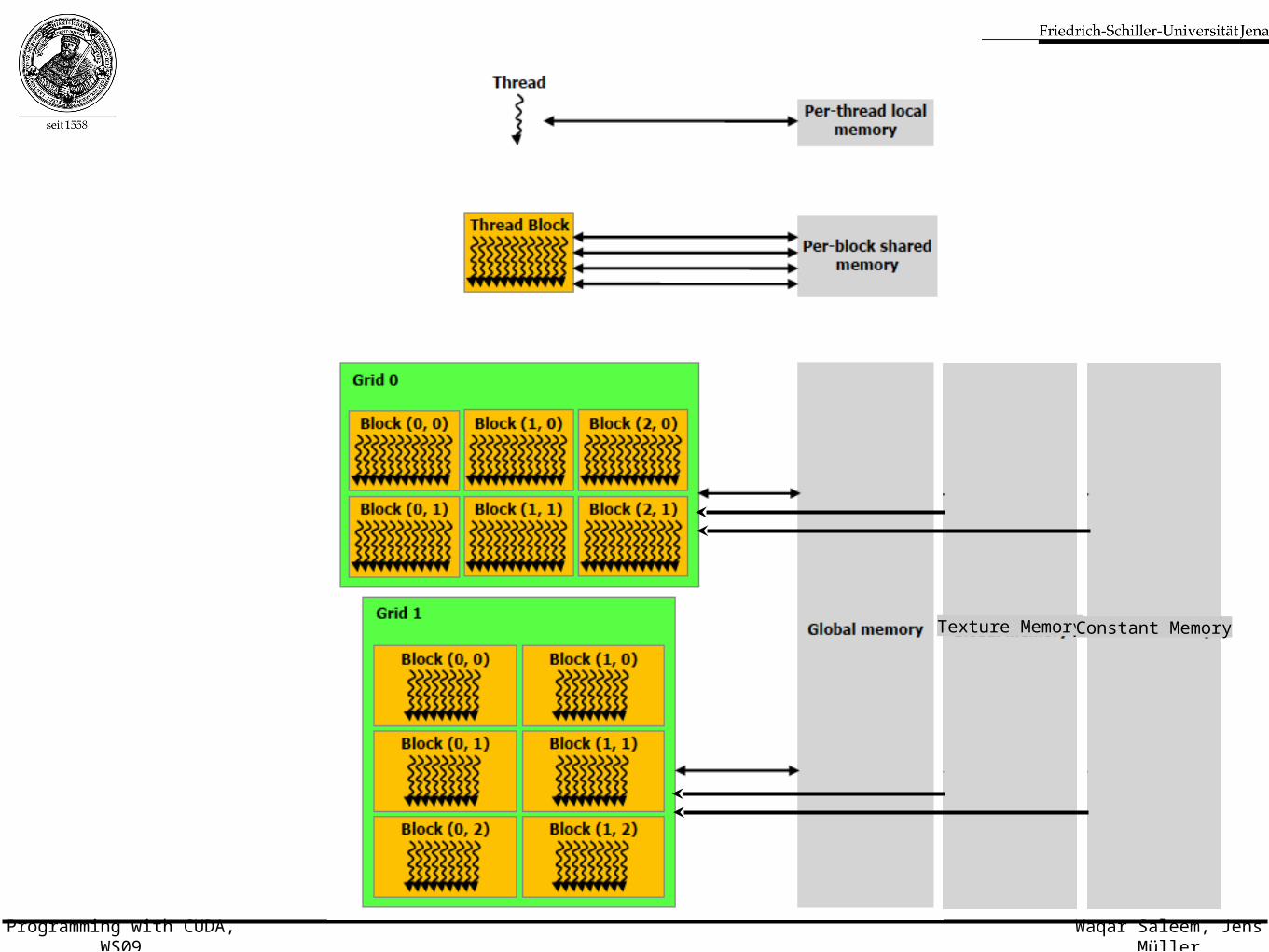
Thread communication• Threads in a block cooperate via shared memory,
barrier synchronization and atomic operations
• Threads from different blocks cannot cooperate
QuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Host and Device communication
• Host can read/write all device memories except registers and shared memory
• Device can read/write global memory
• large but slow (600 clocks)
• Device can read texture memory
• large, slow but cached after first read
• Device can read constant memory
• small, cached
• optimized for certain memory accessesQuickTime™ and aBMP decompressor
are needed to see this picture.

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
CUDA devices•The compute capability of a device is
a number <major_rev>.<minor_rev>
•The major revision number represents a fundamental change in card architecture
•The minor revision number represents incremental changes within the major revision
•CUDA ready devices have compute capability >= 1.0

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Example kernel: Vector addition
•Time taken for the CPU version: N * 1 addition

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Example kernel: Vector addition
•Time taken for the GPU version: 1 addition

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Example kernel
• Host codefor ( int i = 0; i < N; i++ ) C[i] = A[i] + B[i];
• Device kernel__global__ void vAdd ( float* A, float* B, float* C ) { int i = threadIdx.x; C[i] = A[i] + B[i];}

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Kernel quantifier and thread ID•Kernels MUST be quantified as __global__
•Kernels MUST be declared void
• threadIdx is the 3 dimensional index of the thread in its block
•A thread with threadIdx (x,y,z) in a block of blockDim (Dx, Dy, Dz) has thread ID x + y.Dx + z.Dx.Dy
•For missing dimensions, the blockDim entry is 1 and the threadIdx entry is 0

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Kernel invocation• Host program
void main() { // allocate h_A, h_B,h_C, size N // assign values to host vectors for ( int i = 0; i < N; ++ ) h_C[i] = h_A[i] + h_B[i]; // output h_C // free host variables}
• Host + device programvoid main() { // allocate h_A, h_B,h_C, size N // assign values to host vectors // initialize device // allocate d_A,d_B,d_C, size N // copy h_A,h_B to d_A,d_B vAdd<<<1,N>>>(d_A,d_B,d_C) // copy d_C to h_C // output h_C // free host variables // free device variables}

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Memory overhead•Necessary evil: device needs data
in its own memory
•Overhead is justified if the kernel is compute intensive
•With multiple kernels, memory overhead can be overlaid with computation using streams
•Bandwidth between device and host is high

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Host-Device bandwidth
QuickTime™ and aBMP decompressor
are needed to see this picture.
Host
Device

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Memory usage•Host data is typically copied to/from
global memory on device
•Threads have to fetch their data from global memory (slow)
•If the data is to be operated on several times, copy it from global memory to shared memory or registers (fast)
•Write result back to global memory at the end of computation

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Memory usage
• __global__ void myKernel ( float* in1, float* in2, float* out ) { // initialize s_in1,s_in2,s_out in shared memory // copy in1,in2 to s_in1,s_in2 // perform heavy computations on s_in1,s_in2 // store result in s_out // copy s_out to out}

Programming with CUDA, WS09
Waqar Saleem, Jens Müller

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Other issues
•New time for exercises
•Some ray tracing issues: to be clarified in the next exercise session

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
Next time
•Copying memory between host and device
•Clarify grid parameters
•CUDA additions to C
•Memory limitations

Programming with CUDA, WS09
Waqar Saleem, Jens Müller
See you next time!