prml reading 3.1 - 3.2
TRANSCRIPT

PATTERN RECOGNITIONand MACHINE LEARNING
READING3.1 Linear Basis Function Models
3.2 The Bias-Variance Decomposition
GSIS Tohoku Univ. Tokuyama Lab. M1 Yu Ohori
Korean-Japan Joint Workshop on General Optimization にて撮影Korean-Japan Joint Workshop on General Optimization にて撮影
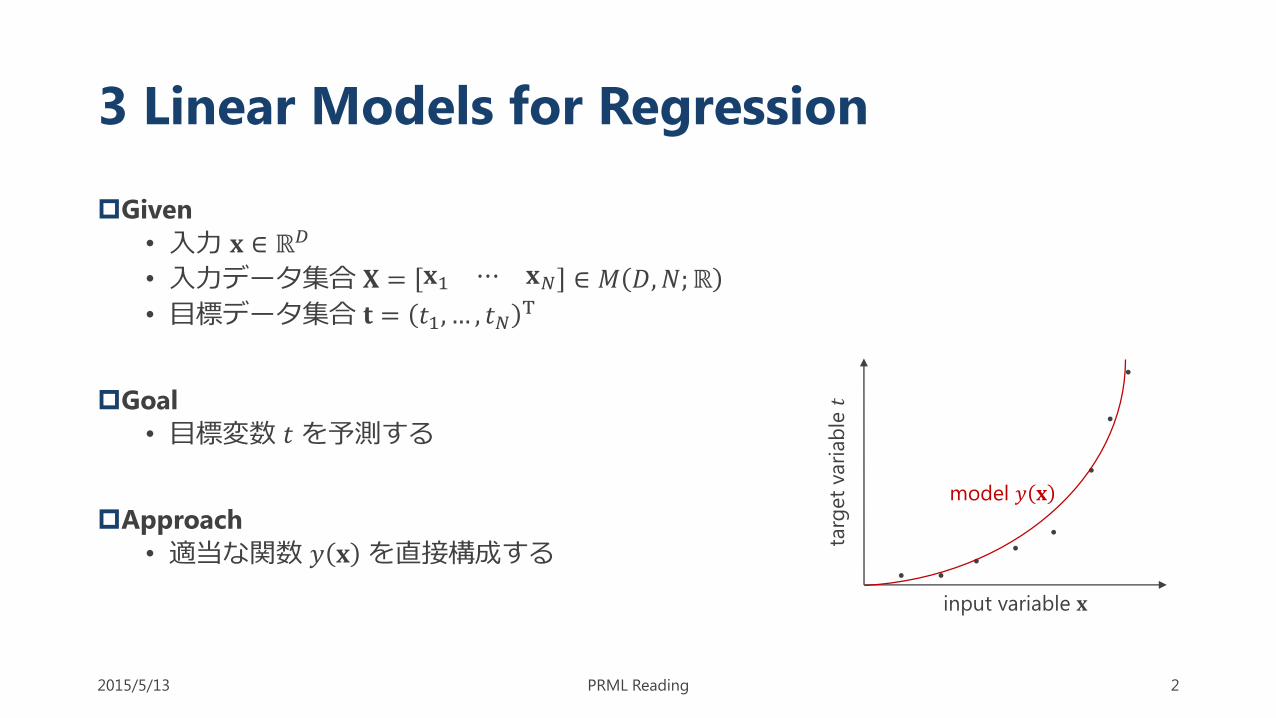
3 Linear Models for Regression
Given
• 入力 𝐱 ∈ ℝ𝐷
• 入力データ集合 𝐗 = 𝐱1 ⋯ 𝐱𝑁 ∈ 𝑀 𝐷,𝑁;ℝ
• 目標データ集合 𝐭 = 𝑡1, … , 𝑡𝑁T
Goal
• 目標変数 𝑡を予測する
Approach
• 適当な関数 𝑦 𝐱 を直接構成する
2015/5/13 PRML Reading 2
input variable 𝐱
targ
et
vari
ab
le 𝑡
model 𝑦 𝐱

3.1 Linear Basis Function Models
線形回帰モデル• 解析や計算において有用な性質を持つ
• 入力空間が高次元の問題に対しては不適 ( Sec. 1.4 )
• 最も単純な線形回帰モデル
• 𝑦 𝐱,𝐰 = 𝑤0 + 𝑗=1𝐷 𝑤𝑗𝑥𝑗
• 𝐷 次元の超平面
• 線形基底関数モデル
• 𝑦 𝐱,𝐰 = 𝑤0 + 𝑗=1𝑀−1𝑤𝑗𝜙𝑗 𝐱 = 𝐰T𝝓 𝐱
• 𝝓 = 𝜙0, … , 𝜙𝑀−1𝐓
• 𝜙𝑗 ( 𝜙0 = 1 ) : 基底関数
2015/5/13 PRML Reading 3
𝑦 𝐱,𝐰
𝝓 𝐱
𝐱
𝑡
input vector
feature vector
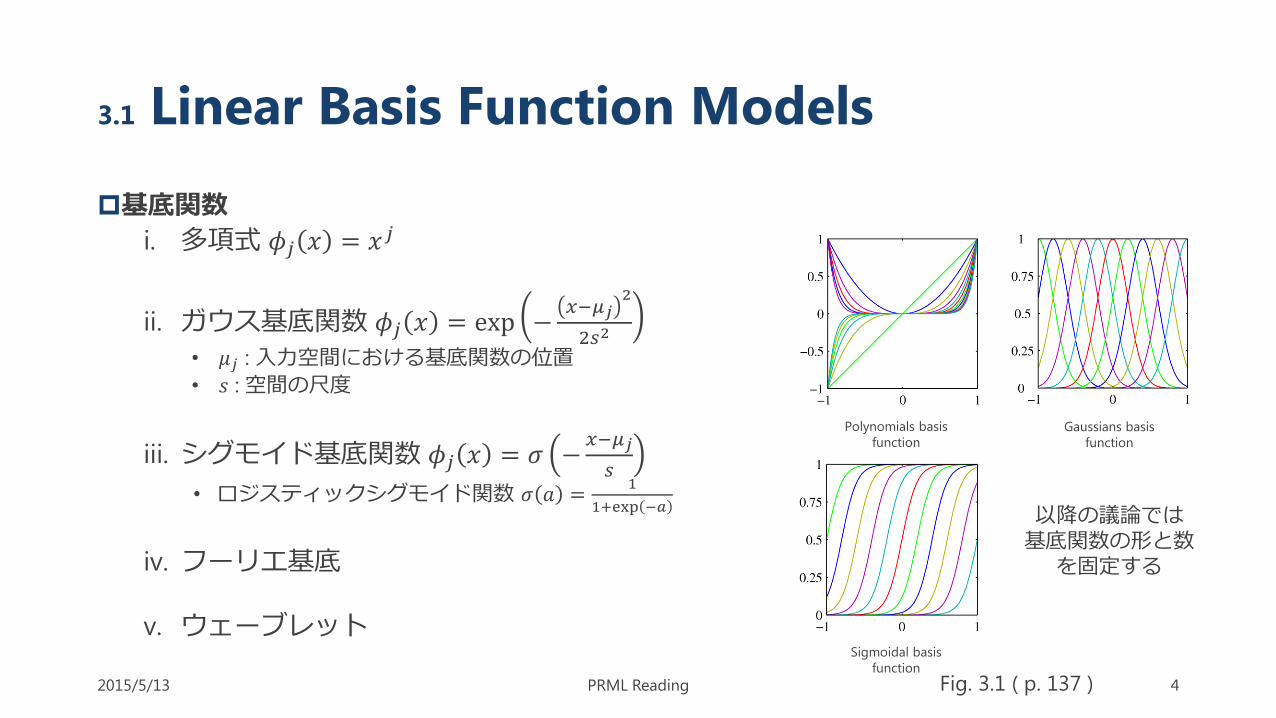
3.1 Linear Basis Function Models
基底関数
i. 多項式 𝜙𝑗 𝑥 = 𝑥𝑗
ii. ガウス基底関数 𝜙𝑗 𝑥 = exp −𝑥−𝜇𝑗
2
2𝑠2
• 𝜇𝑗 : 入力空間における基底関数の位置
• 𝑠 : 空間の尺度
iii. シグモイド基底関数 𝜙𝑗 𝑥 = 𝜎 −𝑥−𝜇𝑗
𝑠
• ロジスティックシグモイド関数 𝜎 𝑎 =1
1+exp −𝑎
iv. フーリエ基底
v. ウェーブレット
2015/5/13 PRML Reading 4
以降の議論では基底関数の形と数を固定する
Fig. 3.1 ( p. 137 )
Polynomials basis
function
Gaussians basis
function
Sigmoidal basis
function
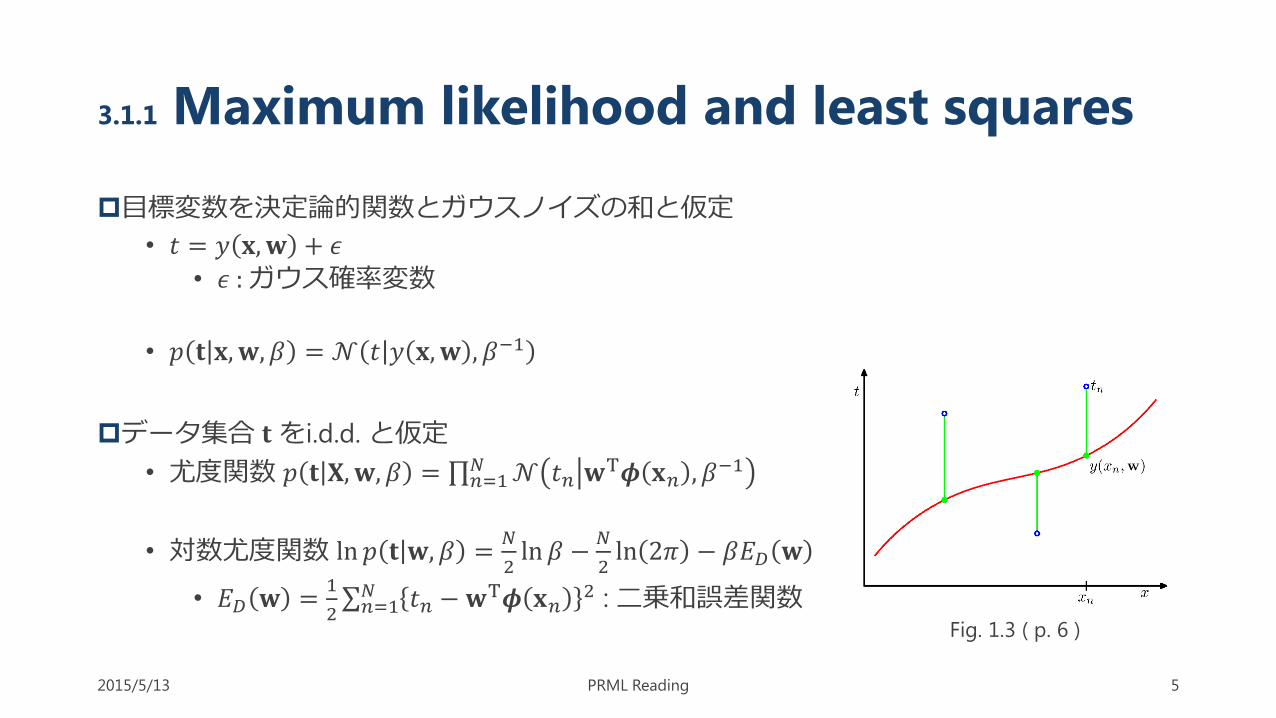
3.1.1 Maximum likelihood and least squares
目標変数を決定論的関数とガウスノイズの和と仮定
• 𝑡 = 𝑦 𝐱,𝐰 + 𝜖
• 𝜖 : ガウス確率変数
• 𝑝 𝐭 𝐱,𝐰, 𝛽 = 𝒩 𝑡 𝑦 𝐱,𝐰 , 𝛽−1
データ集合 𝐭をi.d.d. と仮定
• 尤度関数 𝑝 𝐭 𝐗,𝐰, 𝛽 = 𝑛=1𝑁 𝒩 𝑡𝑛 𝐰T𝝓 𝐱𝑛 , 𝛽−1
• 対数尤度関数 ln 𝑝 𝐭 𝐰, 𝛽 =𝑁
2ln 𝛽 −
𝑁
2ln 2𝜋 − 𝛽𝐸𝐷 𝐰
• 𝐸𝐷 𝐰 =1
2 𝑛=1
𝑁 𝑡𝑛 − 𝐰T𝝓 𝐱𝑛2 : 二乗和誤差関数
2015/5/13 PRML Reading 5
Fig. 1.3 ( p. 6 )

3.1.1 Maximum likelihood and least squares
対数尤度関数を 𝐰 について最大化(二乗和誤差関数を最小化)
• 𝛻 ln 𝑝 𝐭 𝐰, 𝛽 𝐰=𝐰ML,𝛽=𝛽ML= 0を解くと
• 𝐰ML = 𝚽T𝚽−1
𝚽T𝐭 : 正規方程式
• 𝚽 : 計画行列
• 𝚽† ≡ 𝚽T𝚽−1
𝚽T : ムーア・ペンローズの疑似逆行列
対数尤度関数を 𝛽 について最大化
•𝜕
𝜕𝛽ln 𝑝 𝐭 𝐰, 𝛽
𝐰=𝐰ML,𝛽=𝛽ML
= 0を解くと
•1
𝛽ML=
1
𝑁 𝑛=1
𝑁 𝑡𝑛 − 𝐰T𝝓 𝐱𝑛2
2015/5/13 PRML Reading 6
𝚽 =
𝜙0 𝐱1 𝜙1 𝐱1 … 𝜙𝑀−1 𝐱1
𝜙0 𝐱2
⋮𝜙0 𝐱𝑁
𝜙1 𝐱2 … 𝜙𝑀−1 𝐱2
⋮ ⋱ ⋮𝜙1 𝐱𝑁 … 𝜙𝑀−1 𝐱𝑁
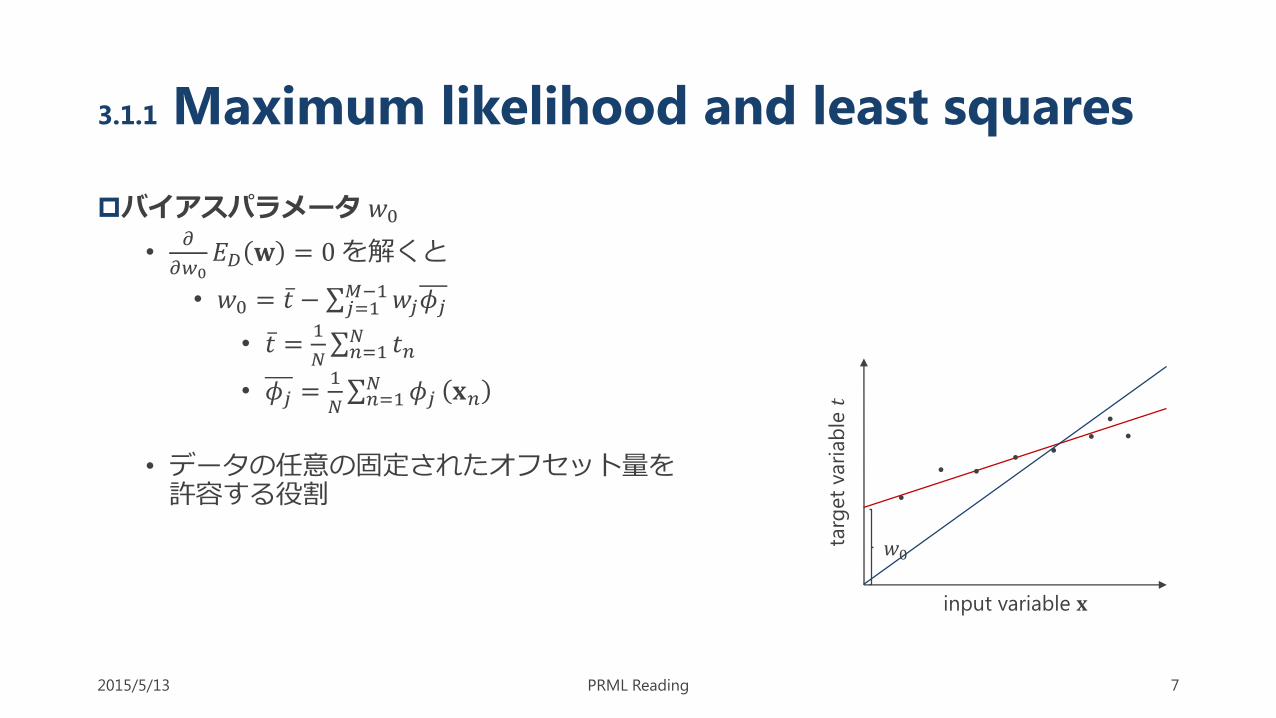
3.1.1 Maximum likelihood and least squares
バイアスパラメータ 𝑤0
•𝜕
𝜕𝑤0𝐸𝐷 𝐰 = 0を解くと
• 𝑤0 = 𝑡 − 𝑗=1𝑀−1𝑤𝑗𝜙𝑗
• 𝑡 =1
𝑁 𝑛=1
𝑁 𝑡𝑛
• 𝜙𝑗 =1
𝑁 𝑛=1
𝑁 𝜙𝑗 𝐱𝑛
• データの任意の固定されたオフセット量を許容する役割
2015/5/13 PRML Reading 7
input variable 𝐱
targ
et
vari
ab
le 𝑡
𝑤0

計画行列 𝚽
𝚽 =
𝜙0 𝐱1 𝜙1 𝐱1 ⋯ 𝜙𝑀−1 𝐱1
𝜙0 𝐱2
⋮𝜙0 𝐱𝑁
𝜙1 𝐱2 … 𝜙𝑀−1 𝐱2
⋮ ⋱ ⋮𝜙1 𝐱𝑁 ⋯ 𝜙𝑀−1 𝐱𝑁
= 𝝋0 ⋯ 𝝋𝑀−1 ∈ 𝑀 𝑁,𝑀;ℝ
ベクトル 𝐲
𝐲 =𝑦 𝐱1, 𝐰
⋮𝑦 𝐱𝑁 , 𝐰
=
𝑗=0
𝑀−1
𝑤𝑗𝜙𝑗 𝐱1
⋮
𝑗=0
𝑀−1
𝑤𝑗𝜙𝑗 𝐱𝑁
= 𝑗=0
𝑀−1
𝑤𝑗𝝋𝑗 = 𝚽𝐰 ∈ ℝ𝑁
二乗和誤差関数 𝐸𝐷 𝐰
𝐸𝐷 𝐰 =1
2
𝑛=1
𝑁
𝑡𝑛 − 𝐰T𝝓 𝐱𝑛2 =
1
2𝐭 − 𝐲 2
3.1.2 Geometry of least squares
2015/5/13 PRML Reading 8
𝐲と 𝐭の二乗ユークリッド距離
𝝋𝑗 の任意の線形結合

3.1.2 Geometry of least squares
最小二乗解の幾何学的解釈
• 各軸が目標値 𝑡𝑛 で与えられる 𝑁次元空間を考える
• 𝑀個のベクトル 𝝋𝑗 は 𝑀次元部分空間 𝑆を張る
• 最小二乗解は 𝐭の部分空間 𝑆の上への正射影に対応する
2015/5/13 PRML Reading 9
Fig. 3.2 ( p. 141 )

3.1.3 Sequential learning
バッチ手法
• 全ての訓練データ集合を一度に処理
• 大規模なデータ集合に対しては不適
逐次学習
• データ点を一度に一つだけ用いてパラメータを順次更新
• リアルタイムな応用の場面にも有効
• LMS アルゴリズム
• 𝐰 𝜏+1 = 𝐰 𝜏 − 𝜂𝛻𝐸𝑛 = 𝐰 𝜏 + 𝜂 𝑡𝑛 − 𝐰 𝜏 T𝝓 𝐱𝑛 𝝓 𝐱𝑛
• 𝐸 = 𝑛 𝐸𝑛 = 𝐸𝐷 𝐰
• 𝜏 :繰返し回数
• 𝜂 :学習率パラメータ
2015/5/13 PRML Reading 10

3.1.4 Regularized least squares
正則化
• 過学習を防ぐため誤差関数に罰金項を付加
• 𝐸 𝐰 = 𝐸𝐷 𝐰 + 𝜆𝐸𝑊 𝐰
• 𝐸𝐷 𝐰 : 二乗和誤差関数
• 𝐸𝑊 𝐰 =1
2𝐰 2 : 二次正則化項
• 𝜆 : 正則化係数
• 正則化誤差関数を 𝐰 について最小化
• 𝐰 = 𝜆𝐈 + 𝚽T𝚽−1
𝚽T𝐭
2015/5/13 PRML Reading 11
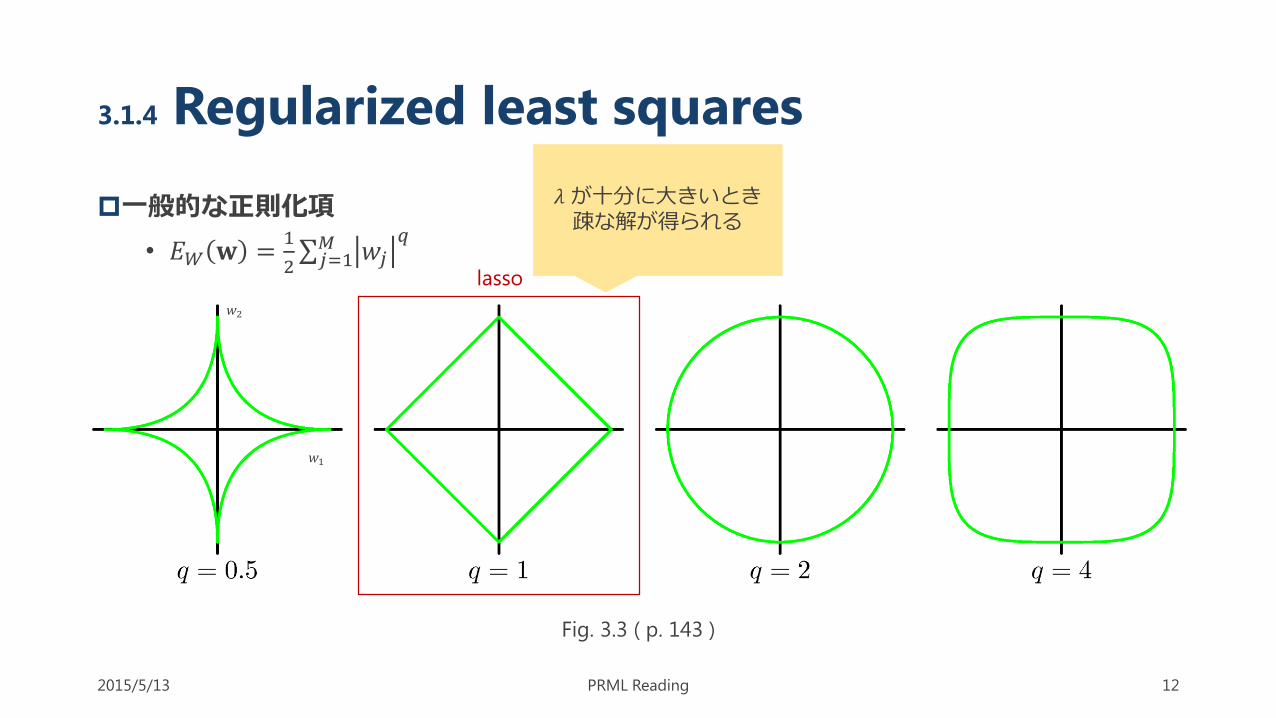
3.1.4 Regularized least squares
一般的な正則化項
• 𝐸𝑊 𝐰 =1
2 𝑗=1
𝑀 𝑤𝑗𝑞
2015/5/13 PRML Reading 12
𝜆が十分に大きいとき疎な解が得られる
Fig. 3.3 ( p. 143 )
lasso
𝑤1
𝑤2

3.1.5 Multiple outputs
Given
• 入力 𝐱 ∈ ℝ𝐷
• 入力データ集合 𝐗 = 𝐱1 ⋯ 𝐱𝑁 ∈ 𝑀 𝐷,𝑁;ℝ
• 目標データ集合 T= 𝐭1T ⋯ 𝐭𝑁
T T ∈ 𝑀 𝑁,𝐾;ℝ
Goal
• 目標変数 𝐭 ∈ ℝ𝐾 を予測する
Approach
• 𝐭の全ての要素に同じ基底関数を用いてモデル化
• 𝐲 𝐱,𝐰 = 𝐖T𝝓 𝐱𝑛 ∈ ℝ𝐾
2015/5/13 PRML Reading 13

3.1.5 Multiple outputs
目標変数の条件付分布を次の形の等方性ガウス分布と仮定
• 𝑝 𝐭 𝐱,𝐖, 𝛽 = 𝒩 𝐭 𝐖T𝝓 𝐱 , 𝛽−1𝐈
データ集合 Tをi.d.d. と仮定
• 𝑝 𝐓 𝐗,𝐖, 𝛽 = 𝑛=1𝑁 𝒩 𝐭𝑛 𝐖T𝝓 𝐱𝑛 , 𝛽−1𝐈
• ln 𝑝 𝐓 𝐗,𝐖, 𝛽 =𝑁𝐾
2ln
𝛽
2𝜋−
𝛽
𝟐 𝑛=1
𝑁 𝐭𝑛 − 𝐖T𝝓 𝐱𝑛2
対数尤度関数を 𝐖 について最大化
• 𝐖ML = 𝚽†𝐓
• 𝐰𝑘 = 𝚽†𝐭𝑘 (𝐭𝑘 ∈ ℝ𝑁 )
• 𝐾 個の独立な 1次元回帰問題に帰着可能
2015/5/13 PRML Reading 14
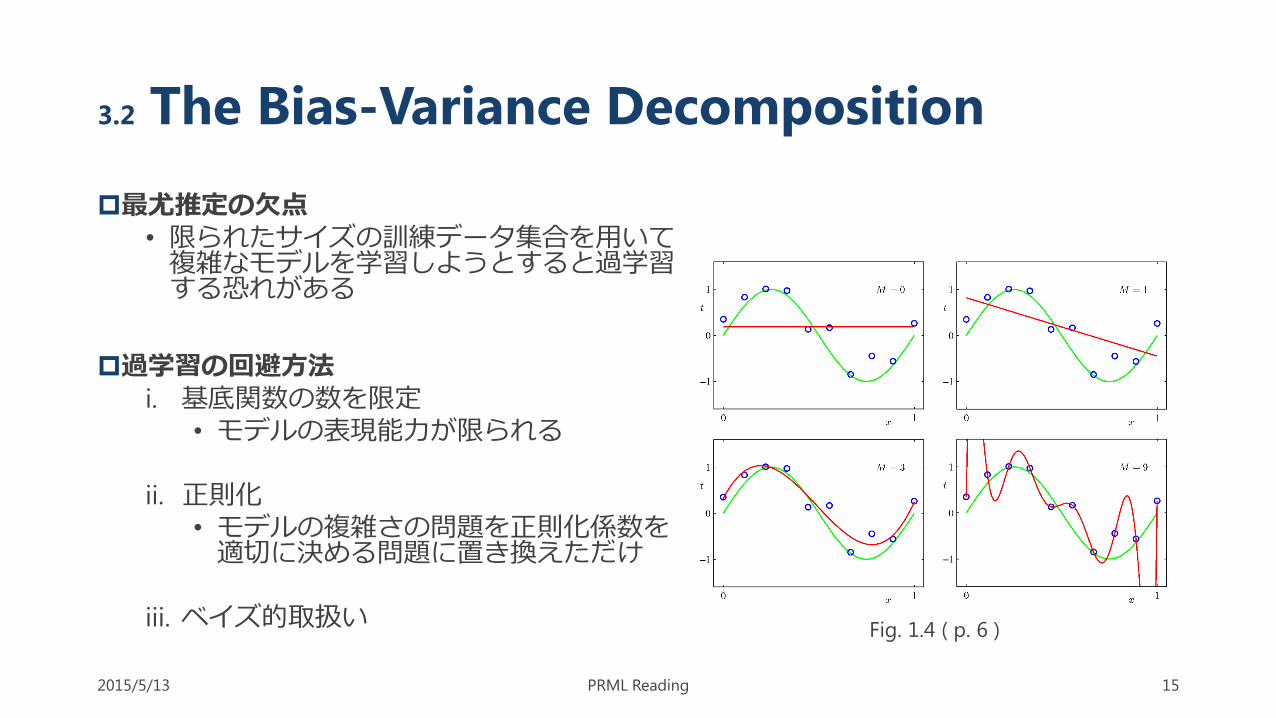
3.2 The Bias-Variance Decomposition
最尤推定の欠点• 限られたサイズの訓練データ集合を用いて複雑なモデルを学習しようとすると過学習する恐れがある
過学習の回避方法i. 基底関数の数を限定
• モデルの表現能力が限られる
ii. 正則化• モデルの複雑さの問題を正則化係数を適切に決める問題に置き換えただけ
iii. ベイズ的取扱い
2015/5/13 PRML Reading 15
Fig. 1.4 ( p. 6 )
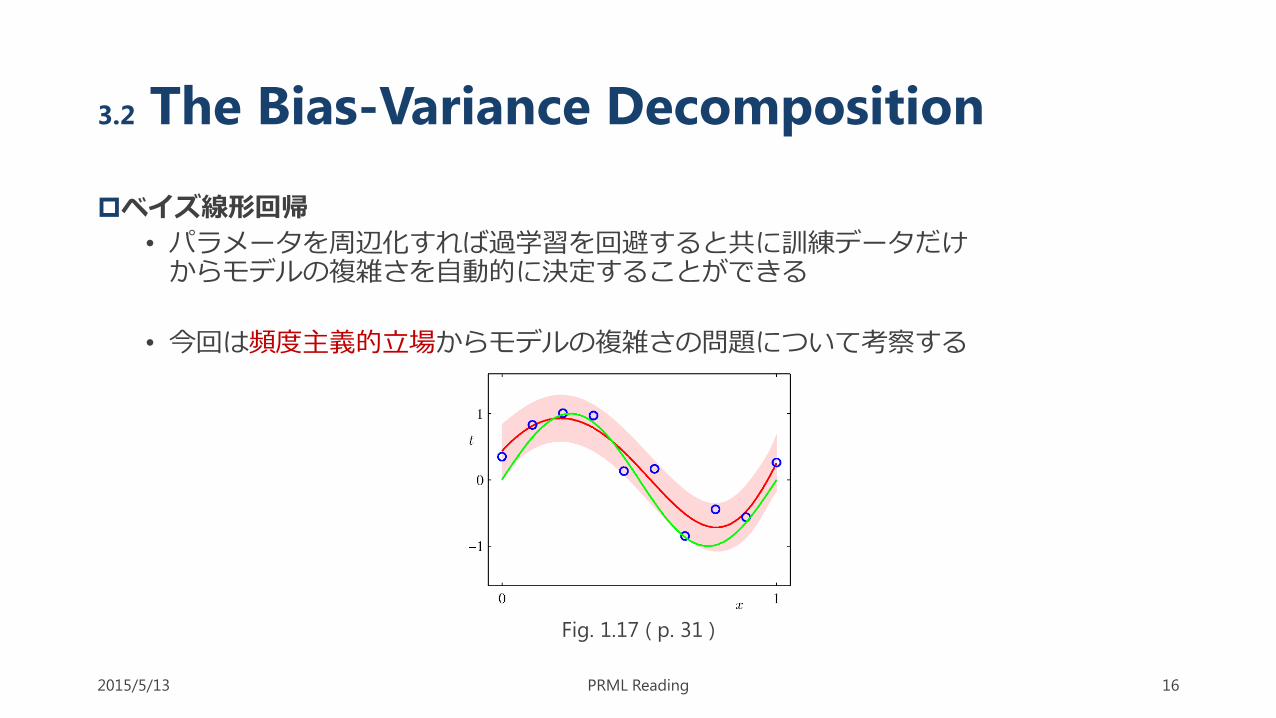
3.2 The Bias-Variance Decomposition
ベイズ線形回帰
• パラメータを周辺化すれば過学習を回避すると共に訓練データだけからモデルの複雑さを自動的に決定することができる
• 今回は頻度主義的立場からモデルの複雑さの問題について考察する
2015/5/13 PRML Reading 16
Fig. 1.17 ( p. 31 )

3.2 The Bias-Variance Decomposition
期待損失の最小化
• 𝔼 𝐿 = 𝑦 𝐱 − ℎ 𝐱 2𝑝 𝐱 ⅆ𝐱 + ℎ 𝐱 − 𝑡 2𝑝 𝐱, 𝑡 ⅆ𝐱ⅆ𝑡 ( Sec. 1.5.5 )
• 𝐿 𝑡, 𝑦 𝐱 = 𝑦 𝐱 − 𝑡 2 : 二乗損失関数
• ℎ 𝐱 = 𝔼𝑡 𝑡 𝐱 = 𝑡𝑝 𝑡 𝐱 ⅆ𝐱 : 回帰関数
• 第 1 項を 0 にするような関数 𝑦 𝐱 を求めたい
• 無数のデータ ℎ 𝐱 が利用可能
• 最適解 𝑦 𝐱 = ℎ 𝐱
• 有限個のデータ 𝒟 のみ利用可能
• 理想的な回帰関数を厳密に求めることは困難
2015/5/13 PRML Reading 17

3.2 The Bias-Variance Decomposition
頻度主義における推定値の不確実性の評価
• 𝑝 𝑡, 𝐱 に従う多数のデータ集合を用意
• 任意のデータ集合 𝒟 から予測関数 𝑦 𝐱;𝒟 を求められると仮定
• 𝔼𝒟 𝔼 𝐿 = 𝔼𝒟 𝑦 𝐱;𝒟 − ℎ 𝐱 2 𝑝 𝐱 ⅆ𝐱 + ℎ 𝐱 − 𝑡 2𝑝 𝐱, 𝑡 ⅆ𝐱ⅆ𝑡
• 𝑦 𝐱;𝒟 − ℎ 𝐱 2を 𝔼𝒟 𝑦 𝐱;𝒟 の周りで展開
• 𝑦 𝐱;𝒟 − ℎ 𝐱 2
= 𝑦 𝐱;𝒟 − 𝔼𝒟 𝑦 𝐱;𝒟 + 𝔼𝒟 𝑦 𝐱;𝒟 − ℎ 𝐱 2
= 𝑦 𝐱;𝒟 − 𝔼𝒟 𝑦 𝐱;𝒟 2 + 𝔼𝒟 𝑦 𝐱;𝒟 − ℎ 𝐱 2
+2 𝑦 𝐱;𝒟 − 𝔼𝒟 𝑦 𝐱;𝒟 𝔼𝒟 𝑦 𝐱;𝒟 − ℎ 𝐱
2015/5/13 PRML Reading 18

3.2 The Bias-Variance Decomposition
期待損失の分解
• 𝔼𝒟 𝔼 𝐿 = 𝑏𝑖𝑎𝑠 2 + 𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 + 𝑛𝑜𝑖𝑠𝑒
• 𝑏𝑖𝑎𝑠 2 = 𝔼𝒟 𝑦 𝐱;𝒟 − ℎ 𝐱 2𝑝 𝐱 ⅆ𝐱
• 全てのデータ集合の取り方に関する予測値の平均と理想的な回帰関数の差の期待値
• 𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 = 𝔼𝒟 𝑦 𝐱;𝒟 − 𝔼𝒟 𝑦 𝐱;𝒟 2 𝑝 𝐱 ⅆ𝐱
• 各データ集合に対する解の特定のデータ集合の選び方に関する期待値の周りでの変動の度合い
• 𝑛𝑜𝑖𝑠𝑒 = ℎ 𝐱 − 𝑡 2𝑝 𝐱, 𝑡 ⅆ𝐱ⅆ𝑡
• 制御不可能
2015/5/13 PRML Reading 19
バイアスとバリアンスはトレードオフの関係!
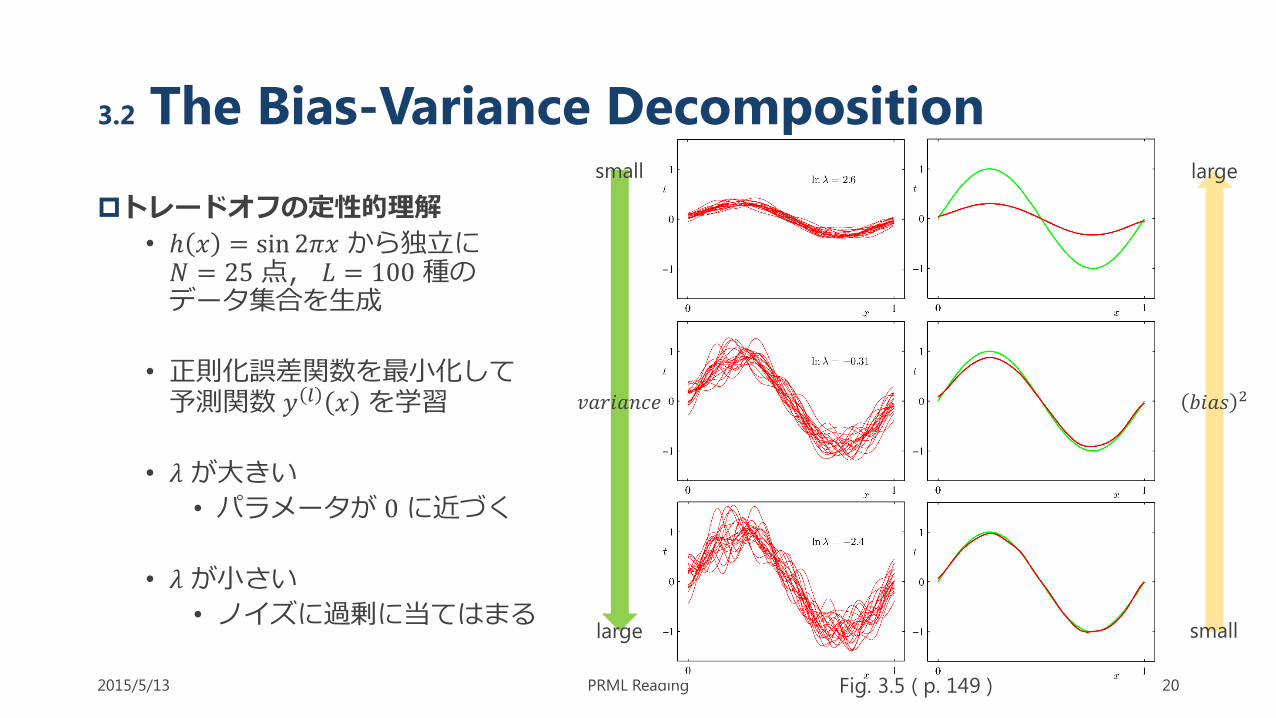
3.2 The Bias-Variance Decomposition
トレードオフの定性的理解
• ℎ 𝑥 = sin 2𝜋𝑥 から独立に𝑁 = 25点, 𝐿 = 100種のデータ集合を生成
• 正則化誤差関数を最小化して予測関数 𝑦 𝑙 𝑥 を学習
• 𝜆が大きい
• パラメータが 0に近づく
• 𝜆が小さい
• ノイズに過剰に当てはまる
2015/5/13 PRML Reading 20
𝑏𝑖𝑎𝑠 2
large
small large
small
Fig. 3.5 ( p. 149 )
𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒
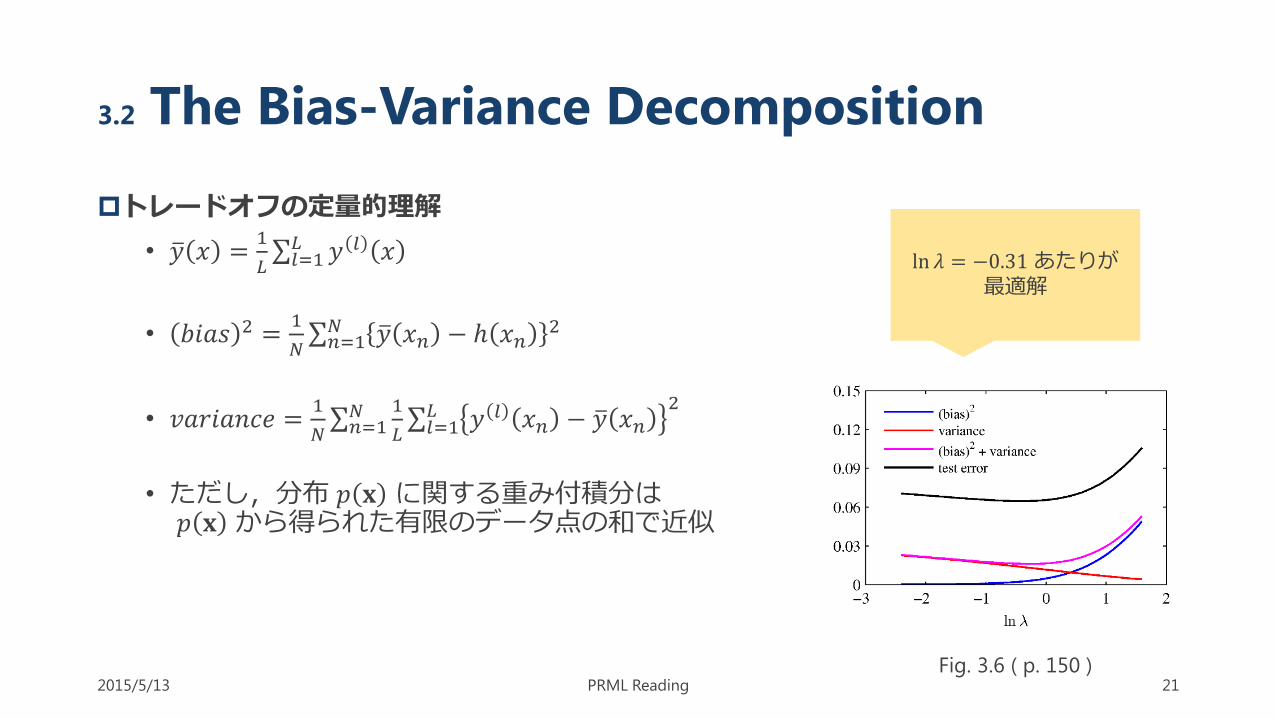
3.2 The Bias-Variance Decomposition
トレードオフの定量的理解
• 𝑦 𝑥 =1
𝐿 𝑙=1
𝐿 𝑦 𝑙 𝑥
• 𝑏𝑖𝑎𝑠 2 =1
𝑁 𝑛=1
𝑁 𝑦 𝑥𝑛 − ℎ 𝑥𝑛2
• 𝑣𝑎𝑟𝑖𝑎𝑛𝑐𝑒 =1
𝑁 𝑛=1
𝑁 1
𝐿 𝑙=1
𝐿 𝑦 𝑙 𝑥𝑛 − 𝑦 𝑥𝑛2
• ただし,分布 𝑝 𝐱 に関する重み付積分は𝑝 𝐱 から得られた有限のデータ点の和で近似
2015/5/13 PRML Reading 21
ln 𝜆 = −0.31あたりが最適解
Fig. 3.6 ( p. 150 )

Reference
Pattern Recognition and Machine Learning [ Christopher M. Bishop, 2006 ]
• English
• pp. 137 – 152
• Japanese ( vol. 1 )
• pp. 135 – 150
• Web site
• http://research.microsoft.com/en-us/um/people/cmbishop/prml/
2015/5/13 PRML Reading 22