physicallybasedsimulationofclothondistributedmemory ...bernhard/pdf/thomasze07physically.pdf ·...
TRANSCRIPT

Physically Based Simulation of Cloth on Distributed MemoryArchitectures
Bernhard Thomaszewski a, Wolfgang Blochinger b
a WSI/GRIS,b WSI/SR
University of Tubingen, Wilhelm-Schickard-Institute, Sand 14,
D-72076 Tubingen, Germany
Abstract
Physically based simulation of cloth in virtual environments is a computationally demanding problem. It involvesmodeling the internal material properties of the textile (physical modeling) and also handling interactions with thesurrounding scene (collision handling).
In this paper, we present an approach to parallel cloth simulation designed for distributed memory parallel architec-tures, particularly clusters built of commodity components. We discuss parallel techniques for the physical modelingphase as well as the collision handling phase which are capable to significantly reduce the respective computation time.
To deal with the very fine granularity of the physical modeling phase we apply a static data decomposition approachbased on graph partitioning. In order to cope with the high irregularity of the collision handling phase we employtask parallel techniques based on fully dynamic problem decomposition.
We show how both techniques can be integrated to realize a robust parallel cloth simulation method which iscapable to deal with considerably complex scenes.
Key words: Parallel Cloth Simulation, Parallel Collision Handling, Irregular Problems, Distributed Memory Architectures
1. Introduction
In the last years, substantial research has beencarried out in the field of cloth simulation. Signif-icant improvements have been achieved on under-standing the physical behavior of textiles and onderiving appropriate mathematical models alongwith sophisticated simulation methods. However,this progress also resulted in enormous computa-tional demands, especially when we are dealingwith high quality animations which are based on
Email addresses:
[email protected] (BernhardThomaszewski),[email protected] (Wolfgang
Blochinger).
high resolution models. In this paper we investi-gate on employing parallel computing to meet thesecomputational requirements.
The simulation process of cloth comprises a largenumber of discrete time steps. Within each elemen-tary simulation step the computation can logicallybe divided into two different phases:– Physical Modeling Phase
In the first phase of a simulation step internalforces resulting from deformation and externalforces due to effects like gravity or wind are deter-mined. Based on these forces, updates for nodalvelocities and positions are computed accordingto Newton’s law of motion.
– Collision Handling PhaseThe second phase of a simulation step is respon-
Preprint submitted to Elsevier 11 April 2008

sible for detecting and handling interactions ofthe garment with other objects in the scene andalso interactions of the garment with itself (self-interference). Depending on the actual methodused, this results in motion constraints, repulsionforces or position and/or velocity updates for in-dividual nodes.One difficulty of parallel cloth simulation on
distributed memory architectures originates fromthe very fine granularity of the physical modelingphase. We employ a data-parallel method for themodeling part, especially designed for minimizinginter-processor communication. Specifically, thiswas achieved by data decomposition techniquesbased on advanced graph-partitioning algorithms.
Especially with textile simulation, several im-manent properties of collision handling make theparallelization of this phase most challenging. Basi-cally, collision handling is a global problem, becauseany pair of processors can own interfering elements.Thus, communication cannot be limited to proces-sors owning neighboring elements (as within thephysical modeling phase). During the course of sim-ulation, the geometry of the considered object canchange significantly. This means that also commu-nication partners are changing in a highly dynamicmanner. Moreover, interaction patterns cannot bepredicted and are often extremely unstructured. Inthis paper, we present a task parallel method forcollision handling which can cope with this highdegree of irregularity and which can tightly beintegrated with the physical modeling phase.
The rest of our paper is organized as follows: InSection 2 we report on related work. Section 3 givesa brief account of state-of-the-art cloth simulationmethods. In Section 4 we discuss our approach toparallel cloth simulation in detail. We report on per-formance measurements in Section 5.
2. Related Work
2.1. Cloth Simulation
Physically based simulation is a widely adoptedparadigm for reproducing the dynamic behavior ofdeformable surfaces like cloth. The research liter-ature on cloth modeling is abundant and we referthe interested reader to the textbooks [1] and [2].The seminal work of Baraff and Witkin [3] laid theground for fast and stable cloth simulation usingimplicit time stepping to solve the arising ordinary
differential equations. Later extensions and devel-opments addressed further physical as well as nu-merical aspects [4–8]. Despite these advances, evenon recent workstations the simulation of cloth withhigh resolution meshes (beyond 10000 vertices) isstill very time consuming.
2.2. Parallel Cloth Simulation
Gutierrez et al. [9] report on a cloth simulationmethod for NUMA parallel architectures which em-ploys an implicit integration method for the mod-eling phase. Lario et al. [10] describe a rapid par-allelization approach of a multilevel cloth simula-tor on shared-memory architectures using OpenMP.Zara et al. [11] deal with parallel cloth simulation on(distributed-memory) PC clusters employing both,explicit and implicit integration techniques.
The work of Zara et al. is the most related to theresearch presented in this paper, both in terms ofthe employed numerical algorithms and in terms ofthe target parallel architecture. The other two ap-proaches are based on shared address space paral-lel computers which are certainly more easy to pro-gram but do not scale well and/or have a worseprice/performance ratio compared to distributed-memory architectures, like clusters built of commod-ity components. A difference between our work andthe work of Zara et al. is the way problem decom-position and task mapping for the modeling phaseis carried out. While we perform a completely staticapproach based on data partitioning which mini-mizes inter-processor interaction, the work of Zaraet al. is based on partitioning dynamically generatedtask dependency graphs.
In contrast to our work, all other approaches toparallel cloth simulation do not explicitly addresscollision handling. This limits their usefulness tosimple scenes.
2.3. Parallel Contact Detection
Parallel contact detection has previously beenstudied in the context of various applications fromthe engineering domain, e.g. simulation of projectilepenetration [12] or simulation of foam compression[13]. The basic principle of these approaches is toidentify a subset of elements which can potentiallyget in contact. These elements are called surfaceelements and typically constitute only a small frac-tion of the total elements of the simulation. In
2

[13] a separate partitioning is used during the col-lision handling phase which exclusively considerssurface elements. Alternatively, multi-constraint,multi-objective graph partitioning algorithms areemployed to avoid expensive relocation actionsbetween the two phases [12]. In cloth simulation,every element is a surface element and it is notpossible to predict the set of elements which actu-ally interfere. Thus, approaches exclusively basedon graph-partitioning are not suitable for collisionhandling in parallel cloth simulation.
3. Physically Based Cloth Simulation
For the realistic simulation of complex dynamicsystems such as clothes there is virtually no alter-native to physically based modeling. The range ofexisting approaches in this area is still abundant.Methods vary from very simplified models for real-time scenarios (e.g. video games) to techniquesthat were designed to reproduce measured mate-rial parameters in an accurate way. These latterapproaches usually have high computational de-mands due do the numerical models used and theresolution of the meshes required. In the followingparagraphs we will briefly outline the (sequential)method which forms the basis for our parallel im-plementation. This involves the description of thephysical model, the numerical time integrationscheme and the collision handling algorithm.
3.1. Physical Model
For the physical model we rely on an approachbased on continuum mechanics. The basic quantitiesare strain which is a dimensionless deformation andstress which is a force per area or length. The twoare connected via a constitutive relation, i.e. a mate-rial law which in our case is linear. The result of thisapproach is a partial differential equation which hasto be discretized in space using numerical methods.To this end, we use a linear finite element approachas described in [7]. This yields a system (or stiffness)matrix relating nodal displacements of the mesh toforces acting on the nodes. Because only local neigh-bors have influence on the force on one node, thismatrix is sparse. The system is extended to accountfor dynamic motion according to Newton’s secondlaw, leaving the following system of coupled ODEs
x(t) = v(t)
v(t) = M−1f(x(t), v(t)) .
To obtain the dynamic evolution of the system theseequation have to be stepped forward in time. In thecase of cloth simulation the system equations areinherently stiff and are thus susceptible to instabil-ities when using explicit integration schemes. Sincethe work of Baraff et al. [3] the computer graph-ics community has settled on using implicit integra-tion schemes for cloth simulation. The heart of thismethod is the solution of a sparse LES which can becarried out in a convenient way using the conjugategradient (cg) method [14].
3.2. Collision Handling
Besides the simulation of the intrinsic propertiesof cloth the interaction with its environment hasto be modeled. This involves the detection of anycollisions and an adequate response to prevent theclothes from intersections. The proper treatment ofthese two components (to which we refer as collisionhandling in the remainder) is a very complex task[15]. While the physical simulation engine computesnew states at distinct intervals only, collisions canoccur at any instant in between such intervals. Al-gorithms that handle these cases in a robust way areoften very complex and time consuming such thatthe collision handling step soon becomes a bottle-neck in the simulation pipeline.
Basically, detecting interference between two ar-bitrarily shaped objects breaks down to determiningthe interference between all of the primitives (i.e.faces, edges, and vertices) of one mesh with everyprimitive of the meshs representing the other ob-jects. With complex objects comprising thousandsof faces, this naive approach soon becomes too ex-pensive, because of its quadratic complexity wrt thenumber of faces.
A common way to accelerate the interference testsis to structure the objects under consideration hier-archically with bounding volumes. Usually, a bound-ing volume hierarchy (BVH) is constructed for eachobject in the scene (including deformable as well asrigid objects) in a preprocessing step in the followingway (see Fig. 1 and 2 ): a bounding volume enclosingthe entire object is set as the root node of the treerepresenting the hierarchy. This node is then sub-divided recursively until a leaf criterion is reached.Usually, the leaves contain one single primitive.
3

Fig. 1. Interfering objects. Left : Different levels of the BVH.Right : Overlapping Faces.
Fig. 2. BVH structure for the two objects in Fig. 1. Over-
lapping leaf nodes are marked.
For our implementation we use the approach de-scribed in [16] which is based on a BVH with discreteoriented polytopes (k-Dops) as bounding volumes.More specifically, we use binary trees with 18-Dops,i.e. the bounding volumes are enclosed by 18 planeswith predefined (discrete) orientation. With a BVHconstructed, the test for intersection between twoobjects now proceeds as follows: first, the bound-ing volumes corresponding to the root nodes of thetwo hierarchies are tested for intersection. Only ifthese two overlap the corresponding children bound-ing volumes are recursively tested for intersections(see Fig. 3). Besides the interference with other ob-jects the cloth can also intersect with itself. Basi-cally, the same algorithms can be used to find theseself collisions but here, an efficient strategy is evenmore important. Usually, criterions based on surfacecurvature are used to rule out non-intersecting partsof the cloth quickly (cf. [17]). This interference testdelivers a pair of primitives that are close to eachother or intersect.
A robust method to prevent the imminent inter-section was presented by Bridson et al. [18]. Ourown collision reponse is based on this approach.The essence of this alogrithm is to apply a stoppingimpulse to approaching triangles (i.e. adjust theirnodal velocities) whenever their distance falls belowa certain threshold. We briefly outline this methodalong with some necessary extensions in the follow-ing.
The collision detection stage provides a set of closeface pairs. This set is the input for the subsequentcollision response phase. Every such colliding facepair is further decomposed into a set of lower levelcollisions among the geometric components of thefaces, i.e. triangles, edges and vertices. This results
in 6 vertex-triangle and 9 edge-edge collisions whichare then treated separately. For each of these ele-mentary collisions an impulse is calculated which,when applied to the involved components, preventsintersection. The direction and magnitude of the im-pulse is computed according to the geometric dis-tance of the entities. A drawback of this method isthat without further action multiple responses arecomputed for the same component. For example,an edge shared by two adjacent faces will receiveimpulses from both of the triangles. In the origi-nal sequential version of the algorithm this problemdoes not occur. Because impulses are applied im-mediately the resulting change in velocity influencesand thus weakens subsequently computed impulses.Such an approach, however, does not translate tothe parallel setting because it would lead to exces-sive communication. At first sight, it seems a possi-ble alternative to accumulate the impulses for everyvertex and normalize them afterwards. From our nu-merous experiments we learned that this approachdoes not lead to satisfying results. For some kindsof collisions the so generated impulses work well butfor most of them (especially large planar collisions)the impulses are too weak to prevent intersection.However, a maximum projection of the impulses forevery vertex yields good results in all cases. The ra-tionale behind this is that the impulses are basedon totally inelastic collisions and their magnitude istherefore always limited. Hence, the kinematic en-ergy (and thus the magnitude of the relative veloc-ities) of the involved vertices is never increased byapplying the maximum impulse.
4. Parallel Cloth Simulation
In this section, we discuss our approach to paral-lel cloth simulation in detail. The first part of thesection deals with the parallelization of the phys-ical modeling phase. In the second part, we turnto discussing parallel techniques we have developedto speed-up collision handling. For each phase weidentify specific requirements for problem decompo-sition and load balancing. Subsequently, we deriveappropriate parallelization strategies. It turns outthat to meet the identified requirements, for each ofthe two phases considerably different parallelizationtechniques have to be employed.
4

Fig. 3. Test tree for the colliding objects shown in Fig. 1.
4.1. Parallel Physical Modeling
4.1.1. Problem Decomposition and Load BalancingCompared to conceptually similar physically
based simulation applications from other domains(e.g. climate modeling), problem sizes in cloth an-imation (in terms of the number of unknowns tobe computed within each step) are typically muchsmaller. The resulting fine granularity represents asignificant challenge for parallelizing the physicalmodeling phase of a cloth simulator. In order tominimize parallel run-time overhead, we apply astatic problem decomposition and load balancingscheme based on data decomposition. The basicidea is to partition the vertices of the input meshinto groups vertices with the same size and stati-cally assign each group to one processor.
The position of neighboring vertices which belongto different processors have to be explicitly commu-nicated during the setup of the LES and also in ev-ery iteration of the cg procedure. Such vertices arecalled ghost-points, because they physically belongto one, but logically belong to two processors. To en-sure high parallel efficiency, it is crucial to minimizecommunication overhead, i.e. minimizing the num-ber of ghost-points. We employ graph partitioningtechniques to balance the load and at the same timeto minimize communication among the processors.Figure 4 shows an exemplary partitioning of a shirt,we obtained by applying a multilevel k-way graphpartitioning algorithm [19].
Conceptually, the partitioning process deliversa new ordering of the vertices, called the parallelnumbering. In the parallel numbering each proces-sor owns a consecutive range of vertex numbersresulting in a 1-dimensional, row-oriented parallellayout of the involved data structures (i.e. matricesand vectors). For generating output data, the re-spective data structures have to be permuted backto the application specific ordering.
After the initial decomposition stage, every pro-cessor holds a part of the global position, vertex and
Fig. 4. Partitioning of a shirt for 12 processors.
normal vector. The parallel simulation loop can nowbe executed in a synchronous SPMD fashion whereevery processor operates on the local parts of thedata structures and the ghost points. Algorithm 1shows the complete SPMD message passing algo-rithm for the physical modeling phase. It also servesus as the algorithmic framework for embedding theparallel collision handling phase (see Section 4.2).
4.1.2. ImplementationThe physical modeling phase is built on top of
the PETSc parallel toolkit [20,21]. PETSc is a suiteof parallel data structures and routines for buildingscalable parallel scientific applications. It is basedon the MPI (Message Passing Interface) standardand supports an SPMD (Single Program MultipleData) style of parallel programming which is locatedat a higher level of abstraction than the pure SPMDmessage passing programming model. For mesh par-titioning we use the parallel multilevel graph parti-tioning functionality provided by the ParMetis [19]graph partitioning library. PETSc features an inter-face which seamlessly provides access to ParMetisfunctionality.
4.2. Parallel Collision Handling
The specific challenge of parallelizing the colli-sion handling process originates from its high ir-regularity. As discussed subsequently, extending (in
5

Algorithm 1 SPMD based parallel algorithmpartition mesh
delivers (new) parallel numbering of verticesredistribute initial positions vector accord-ing to parallel numberingloop
communicate ghost pointssetup LES
compute the matrix A and the right handside vector b.solve LES
compute the new velocities by solving Av(t+h) = b with cg method
(requires communication of ghost values)compute new positions
x(t + h) = x(t) + hv(t + h)collision handling
see Section 4.2if (reached frame interval) then
all-to-one gather positions vectorif (NODE-ID = 0) then
permute position vector to applica-tion numberinggenerate frame
end ifend if
end loop
a straightforward manner) the data-parallel SPMDapproach of the physical modeling phase to the col-lision handling phase is not feasible. Depending onthe actual locations and types of the collisions, theamount of time spent in collision handling would dif-fer considerably among the processors. The result-ing high degree of processor idling can seriously de-grade parallel efficiency of the whole execution pro-cess. Moreover, the locations of collisions can changerapidly during the course of the simulation and can-not be predicted. Consequently, static techniques toproblem decomposition are not well suited. In orderto deal with the outlined issues, we propose a highlydynamic, task parallel approach for accelerating thecollision handling phase, which we describe in thissection.
4.2.1. Parallel Collision Handling FrameworkGenerally, we can distinguish between two differ-
ent types of collisions: external collisions and selfcollisions. To detect the first type we have to testour deformable object against every other (rigid ordeformable) object in the scene. For the latter case,
the deformable object has to be tested against itself.In this section, we show how this basic collision han-dling procedure can be integrated into the SPMDparallel framework of our cloth simulator. In the fol-lowing sections we describe how we tackle the highirregularity of collision handling by a task parallelapproach based on fully dynamic problem decom-position.
As explained in Section 3.2, we use a boundingvolume hierarchy to speed up the collision detec-tion stage. For embedding collision handling into theSPMD framework, the BV hierarchy is built as fol-lows: The problem decomposition stage of the phys-ical modeling phase supplies us with a number ofdisjoint partitions of the vertices of the input mesh.For each processor we now proceed in the followingway: a local mesh is constructed corresponding tothe assigned vertices. Then, a BVH hierarchy is setup on this mesh using a top-down approach. Oncethis is done, we combine the root nodes of the differ-ent processors to form a global hierarchy of the mesh.Testing a textile for interference with other objectsis now carried out in the standard manner. First, theroot node of the garment’s BVH is tested againstthe other object’s root node. If they overlap, thetrees of the processors are recursively tested. Thisapproach works well for standard collisions but forself collisions a different strategy has to be pursued.In our SPMD context we must distinguish betweentwo different types of self collisions: namely colli-sions between sub-meshes of different processors andthose that are real self collisions on the processor-local mesh. For the latter case we can use existingtechniques since this corresponds to the usual selfcollision problem. For the case of inter-processor selfcollisions we test the corresponding BVHs againsteach other, similar to the way standard collisions aretreated.
All discussed BVH tests form a set of top-leveltasks of our parallel collision handling method. How-ever, for scenes where collisions are not uniformlydistributed, the number of top-level tasks and alsothe amount of time to execute individual top-leveltasks can differ considerably among the processors.In Section 5.2 we present examples where such un-even processor load can be observed. In the follow-ing, we discuss a task-parallel approach which dy-namically decomposes top-level tasks into smallersub-tasks for evenly distributing the load among theprocessors.
6

Fig. 5. Dynamic problem decomposition. The arrow indicates the current state of the BVH testing procedure. The stack onthe right stores the root of untried branches.
4.2.2. Dynamic Problem DecompositionOur method for dynamic problem decomposition
is based on modifying the BVH testing procedure(see Section 3.2). We create sub-tasks which are re-sponsible for detecting a part of the collisions ofthe original task. As result, a sub-task computes anappropriate partial collision response (in the formof impulses for the involved geometric entities). Allpartial responses are combined at the end of the col-lision handling phase by one all-to-all broadcast op-eration and applied to the positions vector.
For dynamically generating new tasks, everyprocessors maintains a stack data structure whichrecords untried branches of the BVH testing treeof the current top-level task. In the BVH testingprocedure, expansion of a tree node results in twoadditional tree nodes each representing a refinedBVH test. As in the sequential procedure, the firsttest is carried out by starting a new recursion level.However, before entering the recursion, the secondtest is pushed onto the stack. In Section 4.2.3 wediscuss an appropriate representation of individ-ual BVH tests, which can be used for efficientlystoring them in a data structure. Figure 5 shows asnapshot of a BVH testing process along with thecorresponding state of the stack.
Tests which are recorded on the stack can be ex-ecuted in one of the following ways:– A test can be removed from the top of the stack
and executed sequentially when the recursion getsback to the current level. Conceptually, this caseis very similar to the procedure of the originalalgorithm.
– One or more Tests can be removed from the bot-tom of the stack and executed by a newly gener-ated (sub-)task. For each assigned test, this taskexecutes a BVH testing procedure for which theconsidered test defines the root of a BVH testingtree.In oder to prevent that tasks of too fine a granu-
larity are generated several tests can be removed atonce from the stack and assigned to a single task. For
the same reason tests are generally taken from thebottom of the stack for creating new tasks becausesuch tests have a higher potential of representing alarge testing tree since they are closer to the root.
Problem decomposition is steered by the load bal-ancing process (see Section 4.2.4). Before discussingspecific details of the load balancing process, we firstturn to the problem of finding a representation oftasks which enables efficient task transfers.
4.2.3. Task RepresentationFor dynamic load balancing tasks must be trans-
ferred between processors at run-time. In dis-tributed memory architectures, task transfers re-quire explicit communication operations. Depend-ing on the information associated with a task, tasktransfers can significantly contribute to the overallparallel overhead, especially when the computationto communication ratio of the tasks is poor. Findinga compact description of tasks is therefore crucialto minimize communication overhead. In our case,the cost for transferring a task is largely determinedby the representation of the associated BVH tests.
Including complete BVH information for eachindividual test (i.e. the entire representations oftwo sub-hierarchies defined by the test) with a taskwould lead to a considerable task size and thus isnot viable.
Consequently, we replicate on each node the BVhierarchy for every object in the scene such thaton all nodes the identical context is provided forexecuting BVH tests. Particularly, all objects andall DOPS are enumerated in the same order on allprocessors. This enables us to represent an individ-ual test simply as an array of integers of the form(obj1, dop1, obj2, dop2). The two BV hierarchies tobe tested are identified by obj1 and obj2, and theroot of the test is specified by dop1 and dop2.
While this approach imposes additional costs forbuilding the copies of the BV hierarchies during ini-tialization, the overhead during the course of thesimulation is insignificant: Updating hierarchies (at
7

the beginning of every collision handling phase) re-quires one all-to-all broadcast operation to provideall processors the complete positions vector. (Notethat the structure of the BV hierarchy is kept fixduring the whole computation.)
4.2.4. Dynamic Load BalancingIn our application, the dynamic load balancing
process is responsible for triggering and coordinat-ing task creation and task transfer operations in or-der to prevent that processors run idle. Basically,load balancing can employ a central controller orcan be organized in a distributed manner. A centralcontroller can establish a more accurate view of thecurrent load of the processors, but also soon becomesthe sequential bottleneck of a parallel computation.In order to achieve high scalability, we employ a fullydistributed scheme. Specifically, our method is basedon the distributed task pool model, i.e. every pro-cessor maintains a local task pool. Upon creation,a task is first placed in the local task pool. Subse-quently, it can be instantiated and executed locally,when the processor gets idle. It also might be trans-fered to a remote task pool for load balancing pur-poses. As discussed subsequently, task creation andtask transfer operations are initiated autonomouslyby the processors.
Task Creation Basically, tasks are generated dy-namically employing the decomposition techniquesdiscussed in Section 4.2.2. To achieve a high de-gree of efficiency an (active) processor must be ableto satisfy task requests from other processors im-mediately. Additionally, we must ensure that taskswith sufficient granularity are generated. In our case,this means that when a task is to be created, thestack must contain a minimum number of BVH testswhich can be assigned to the task. In order to meetboth requirements, we generate tasks in a proac-tive fashion, i.e. independently of incoming tasks re-quests. Tasks are generated (and placed in the lo-cal task pool) when the size of the stack exceeds athreshold value τ . Since task generation generallyimposes an overhead (even when the new task issubsequently executed on the same processor) weincrease τ linearly with the current size of the taskpool σ: τ = aσ + b. This simple heuristics enablesus on the one hand to provide in a timely fashiontasks with a minimum granularity (determined byb) and ensures on the other hand that the overheadof additional task decomposition operations is com-
pensated by an increased granularity of the resultingtasks. The parameter values a and b largely dependon the parallel architecture used and should be de-termined experimentally. In our performance tests(see Section 5), choosing a = 2 and b = 8 deliveredthe best results.
A new task gets τ/2 tests, where the tests aretaken from the bottom of the stack as discussed pre-viously.
Task Transfer For transferring tasks between taskpools we employ a receiver initiated scheme. When aprocessor runs idle and the local task pool is empty,it tries to steal tasks from remote pools. First, avictim node is chosen to which a request for tasksis sent. If available, the victim transfers a task fromits pool to the local pool. Otherwise the request isrejected by sending a corresponding message. In thelatter case another victim node is chosen and a newrequest is issued. For selecting victims we apply around robin scheme, where each processor maintainsa local variable for c
4.2.5. ImplementationThe implementation of the previously described
methods is based on the parallel system platformDOTS [22]. DOTS provides extensive support forthe multithreading parallel programming model(not to be confused with the shared-memory model)which is particularly suited for task-parallel appli-cations that employ fully dynamic problem decom-position.
DOTS Programming Model The key concept ofthe DOTS programming model are thread group ob-jects which serve as links between different primi-tives of the API. Upon creation, a thread is eitherexplicitly or implicitly placed into a thread group,calling dots fork or dots hyperfork, respectively. Inthe former case, the thread group object has to besupplied as argument to dots fork. In the latter case,the thread is placed implicitly in the same threadgroup as its parent thread (which might have beencreated by a different processor). In both cases, aprocedure to be executed by the child thread and anargument-object has to be supplied. For all subse-quently applied primitives it is not relevant whethera thread has been placed explicitly or implicitly intoa thread group. Threads return result objects em-ploying dots return. The dots join primitive is used toretrieve results of threads from a given thread group
8

applying join-any semantics: The first result whichbecomes available from any thread in the group is de-livered. If no results are available, the calling threadis blocked until a thread of the group delivers a re-sult. If a thread has finished execution and all resultobjects of the thread have been joined, it is removedfrom the thread group. By checking the return valueof dots join, termination of a computation can bedetermined.
Parallel Collision Handling Using DOTS For ini-tiating the task-parallel execution process, we createon every processor threads which execute the top-level tasks of our parallel collision handling method(see Section 4.2.1). Threads that execute top-leveltasks are created using the dots fork primitive. Allthreads are placed into the same thread group.
Upon completion, each thread delivers a set of im-pulses which represent an appropriated collision re-sponse for the corresponding top-level collision han-dling task.
Tasks resulting from dynamic problem decom-position (see Section 4.2.2) are modeled by DOTSthreads that are created with the dots hyperforkprimitive. This approach enables us to easily syn-chronize with the completion of the collision han-dling phase regardless how many decompositionoperations took place. We simply apply dots joinoperations on the thread group until terminationof the execution is indicated. (Note that the ac-tual number of generated tasks largely dependson the considered scene and cannot be staticallydetermined.)
Using the load balancing extension framework ofDOTS we integrated the task transfer scheme de-scribed in Section 4.2.4.
5. Performance Measurements
5.1. Test Scenarios
We evaluate the performance of our approach us-ing two test scenarios. To demonstrate the robust-ness of our method we focused on problems with ahigh degree of irregularity.
Scene 1:For this test scene we let a round table cloth compris-ing 14033 vertices drape over a sphere with roughlyon third of the cloth’s diameter (see Figure 11). (Wecould as well use any other polygonal mesh as a col-lision object but the sphere is sufficient for our inter-
ests.) Initially, collisions only occur in a locally re-stricted region in the center of the cloth. As the sim-ulation proceeds, the distribution of the collisions inthe scene becomes more even. In the last part of thesequence the formation of folds exhibiting compli-cated self collisions can be observed. Finally, interprocessor self collisions occur at the border regionsof the cloth.
Scene 2:This scene consists of a square piece of cloth with14641 vertices draping over a thin ondulated barwhich is posed at some distance to a floor (see Figure10). Again, the collisions are locally restricted in thefirst part of the simulation. Due to the special shapeof the bar complicated folding patterns are formedas the cloth falls further downwards. When the clothreaches the floor, collision occur more widespread inthe mesh and the setting becomes more regular. Inthis scenario rigid collisions are inititally predomi-nant. As the simulation proceeds, fairly complex selfcollisions are produced: the cloth folds over itselfwhile it slides towards the troughs of the bar.
5.2. Tests and Results
We used a Linux based cluster for carrying outperformance measurements. All compute nodes areequipped with Intel Xeon processors (2.667 GHz)and with 2 GB of main memory. The nodes are con-nected by a Myrinet-2000 network.
All program runs compute 25 frames of our testscenes, where a single frame consists of 40 simula-tion steps. For each investigated setting, the pre-sented performance results are based on the arith-metic mean of the wall-clock times of three individ-ual parallel runs. Time values given for one processorare based on the sequential version of our applica-tion. (It employs sequential data structures and se-quential arithmetic operations for the physical mod-eling phase and performs no dynamic problem de-composition during the collision handling phase.)
Figure 6 and Figure 7 depict the results of theperformance measurements for our two test scenar-ios. Despite the high degree of irregularity of bothscenes, the overall computation time as well as theindividual run-times of the physical modeling andthe collision handling phases can be substantiallyreduced by parallel execution.
In all our test cases, the time required for collisionhandling is greater than the time spent in physicalmodeling. For both scenes, the run times of the phys-
9
ical modeling phases are comparable. Due to the in-creased occurrence of self-collisions in scene 1, timesneeded for collision handling (and thus the total runtimes) are noticeably greater than in scene 2.
Independently of the number of processors (andthe number of computed frames), we observe a con-stant amount of time (scene1: about 140 s, scene2:about 80 s) spent in preprocessing (essentially meshpartitioning and setting up BV hierarchies). Withan increased total run time (i.e. computing moreframes) this sequential fraction of the computationbecomes less dominant. In typical production runs(with several hundreds of frames) we can expectthat the individual speedups of the physical model-ing and of the collision handling phase contribute tothe overall speedup in a largely undiminished way.
Time (sec)
0100020003000400050006000700080009000
10000110001200013000
1 2 4 6 8 10 12Number of Processors
Physical Modeling Collision Handling Preprocessing
Speedups
0123456789
1011
1 2 4 6 8 10 12Number of Processors
Total Physical Modeling Collision Handling
Fig. 6. Results of performance measurements for scene 1.
Time (sec)
0100020003000400050006000700080009000
10000
1 2 4 6 8 10 12Number of Processors
Physical Modeling Collision Handling Preprocessing
Speedups
0123456789
10
1 2 4 6 8 10 12Number of Processors
Total Physical Modeling Collision Handling
Fig. 7. Results of performance measurements for scene 2.
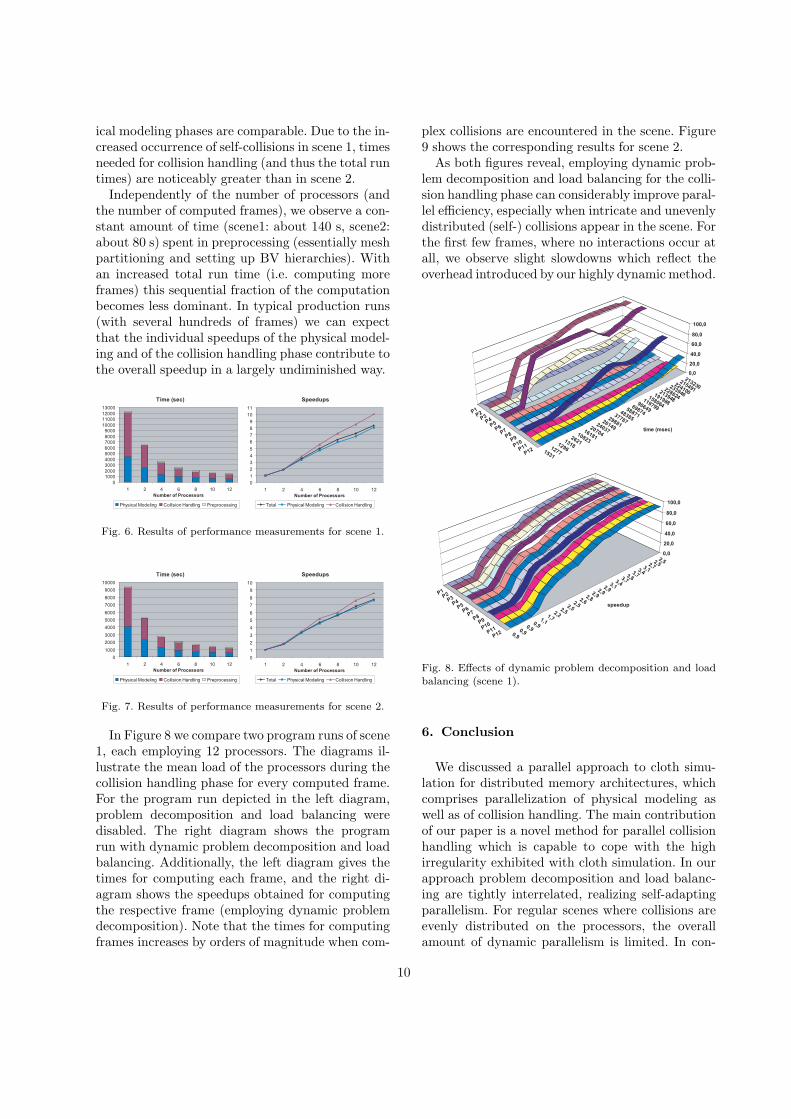
In Figure 8 we compare two program runs of scene1, each employing 12 processors. The diagrams il-lustrate the mean load of the processors during thecollision handling phase for every computed frame.For the program run depicted in the left diagram,problem decomposition and load balancing weredisabled. The right diagram shows the programrun with dynamic problem decomposition and loadbalancing. Additionally, the left diagram gives thetimes for computing each frame, and the right di-agram shows the speedups obtained for computingthe respective frame (employing dynamic problemdecomposition). Note that the times for computingframes increases by orders of magnitude when com-
plex collisions are encountered in the scene. Figure9 shows the corresponding results for scene 2.
As both figures reveal, employing dynamic prob-lem decomposition and load balancing for the colli-sion handling phase can considerably improve paral-lel efficiency, especially when intricate and unevenlydistributed (self-) collisions appear in the scene. Forthe first few frames, where no interactions occur atall, we observe slight slowdowns which reflect theoverhead introduced by our highly dynamic method.
15311277
12961318
262110823
16181
20704
24037
26149
29881
37787
48385
5887169874
90649
119799
158064
191988
213948
228624
233946
224100
215491
213230
P1P2
P3P4
P5P6
P7P8
P9P10
P11P12
0,0
20,0
40,0
60,0
80,0
100,0
time (msec)
0,90,90,90,91,11,72,22,52,52,52,62,82,92,92,93,13,43,73,83,73,43,12,72,52,5
P1P2P3P4P5P6P7P8P9
P10P11P12
0,0
20,0
40,0
60,0
80,0
100,0
speedup
Fig. 8. Effects of dynamic problem decomposition and load
balancing (scene 1).
6. Conclusion
We discussed a parallel approach to cloth simu-lation for distributed memory architectures, whichcomprises parallelization of physical modeling aswell as of collision handling. The main contributionof our paper is a novel method for parallel collisionhandling which is capable to cope with the highirregularity exhibited with cloth simulation. In ourapproach problem decomposition and load balanc-ing are tightly interrelated, realizing self-adaptingparallelism. For regular scenes where collisions areevenly distributed on the processors, the overallamount of dynamic parallelism is limited. In con-
10

15311277
12961318
262110823
16181
20704
24037
26149
29881
37787
48385
5887169874
90649
119799
158064
191988
213948
228624
233946
224100
215491
213230
P1P2
P3P4
P5P6
P7P8
P9P10
P11P12
0,0
20,0
40,0
60,0
80,0
100,0
time (msec)
0,90,90,90,91,11,72,22,52,52,52,62,82,92,92,93,13,43,73,83,73,43,12,72,52,5
P1P2P3P4P5P6P7P8P9
P10P11P12
0,0
20,0
40,0
60,0
80,0
100,0
speedup
Fig. 9. Effects of dynamic problem decomposition and loadbalancing (scene 2).
trast, if processors run idle due to an uneven dis-tribution of the collisions, additional parallelismis generated and balanced over the processors. Tothe best of our knowledge, our work represents thefirst research effort on parallel collision handlingfor textile simulation on distributed memory archi-tectures. We seamlessly integrated the task parallelcollision handling phase into the SPMD data par-allel framework imposed by the physical modelingphase. Thus, our parallel approach to cloth sim-ulation represents an example where considerablydissimilar types of parallelism could be beneficiallycombined within one application.
References
[1] P. Volino, N. Magnenat-Thalmann, Virtual Clothing,
Springer, 2000.
[2] D. H. House, D. E. Breen (Eds.), Cloth Modeling and
Animation, A K Peters, 2000.
[3] D. Baraff, A. Witkin, Large Steps in Cloth Simulation,
in: Computer Graphics (Proc. SIGGRAPH), 1998, pp.
43–54.
[4] B. Eberhardt, O. Etzmuß, M. Hauth, Implicit-Explicit
Schemes for Fast Animation with Particle Systems,in: Eurographics Computer Animation and Simulation
Workshop, 2000.
[5] P. Volino, N. Magnenat-Thalmann, Comparing
Efficiency of Integration Methods for Cloth Animation,
in: Computer Graphics International Proceedings, 2001.
[6] K.-J. Choi, H.-S. Ko, Stable but Responsive Cloth, in:
Computer Graphics (Proc. SIGGRAPH), 2002, pp. 604–611.
[7] O. Etzmuß, M. Keckeisen, W. Straßer, A Fast Finite
Element Solution for Cloth Modelling, Proc. PacificGraphics.
[8] M. Hauth, O. Etzmuß, A High Performance Solver forthe Animation of Deformable Objects using Advanced
Numerical Methods, in: Computer Graphics Forum,
2001, pp. 319–328.
[9] E. Gutierrez, S. Romero, L. F. Romero, O. Plata, E. L.
Zapata, Parallel techniques in irregular codes: clothsimulation as case of study, Journal of Parallel and
Distributed Computing 65 (4) (2005) 424–436.
[10] R. Lario, C. Garcia, M. Prieto, F. Tirado, RapidParallelization of a Multilevel Cloth Simulator Using
OpenMP, in: Third European Workshop on OpenMP,2001.
[11] F. Zara, F. Faure, J.-M. Vincent, Parallel simulation
of large dynamic system on a pcs cluster: Applicationto cloth simulation, International Journal of Computers
and Applications 26 (3).
[12] G. Karypis, Multi constraint mesh partitioning for
contact/impact computations, in: Proc. of the 2003
ACM/IEEE Conf. on Supercomputing, IEEE ComputerSociety, Washington, DC, USA, 2003, p. 56.
[13] K. Brown, S. Attaway, S.J.Plimpton, B. Hendrickson,Parallel strategies for crash and impact simulations,
Computer Methods in Applied Mechanics and
Engineering 184 (2000) 375–390.
[14] J. R. Shewchuck, An Introduction to
the Conjugate Gradient Method Without the AgonizingPain, http://www.cs.cmu.edu/ quake-papers/painless-
conjugate-gradient.ps (1994).
[15] M. Teschner, B. Heidelberger, D. Manocha,N. Govindaraju, G. Zachmann, S. Kimmerle, J. Mezger,
A. Fuhrmann, Collision Handling in Dynamic
Simulation Environments, in: Eurographics Tutorials,2005, pp. 79–185.
[16] J. Mezger, S. Kimmerle, O. Etzmuß, HierarchicalTechniques in Collision Detection for Cloth Animation,
Journal of WSCG 11 (2) (2003) 322–329.
[17] P. Volino, N. Thalmann, Collision and Self-Collision
Detection: Efficient and Robust Solutions for Highly
Deformable Surfaces, in: Comp. Animation andSimulation, 1995.
[18] R. Bridson, R. P. Fedkiw, J. Anderson, RobustTreatment of Collisions, Contact, and Friction for ClothAnimation, in: Computer Graphics (Proc. SIGGRAPH),
2002, pp. 594–603.
[19] G. Karypis, V. Kumar, Parallel Multilevel k-wayPartitioning Schemes for Irregular Graphs, Tech. Rep.036, Minneapolis, MN 55454 (May 1996).
[20] S. Balay, W. D. Gropp, L. C. McInnes, B. F. Smith,Efficient management of parallelism in object orientednumerical software libraries, in: E. Arge, A. M. Bruaset,
H. P. Langtangen (Eds.), Modern Software Tools in
Scientific Computing, Birkhauser Press, 1997, pp. 163–202.
11

[21] S. Balay, K. Buschelman, W. D. Gropp, D. Kaushik,
M. Knepley, L. C. McInnes, B. F. Smith, H. Zhang,
PETSc users manual, Tech. Rep. ANL-95/11 - Revision2.1.5, Argonne National Laboratory (2002).
[22] W. Blochinger, W. Kuchlin, C. Ludwig, A. Weber,
An object-oriented platform for distributed high-performance Symbolic Computation, Mathematics and
Computers in Simulation 49 (1999) 161–178.
12
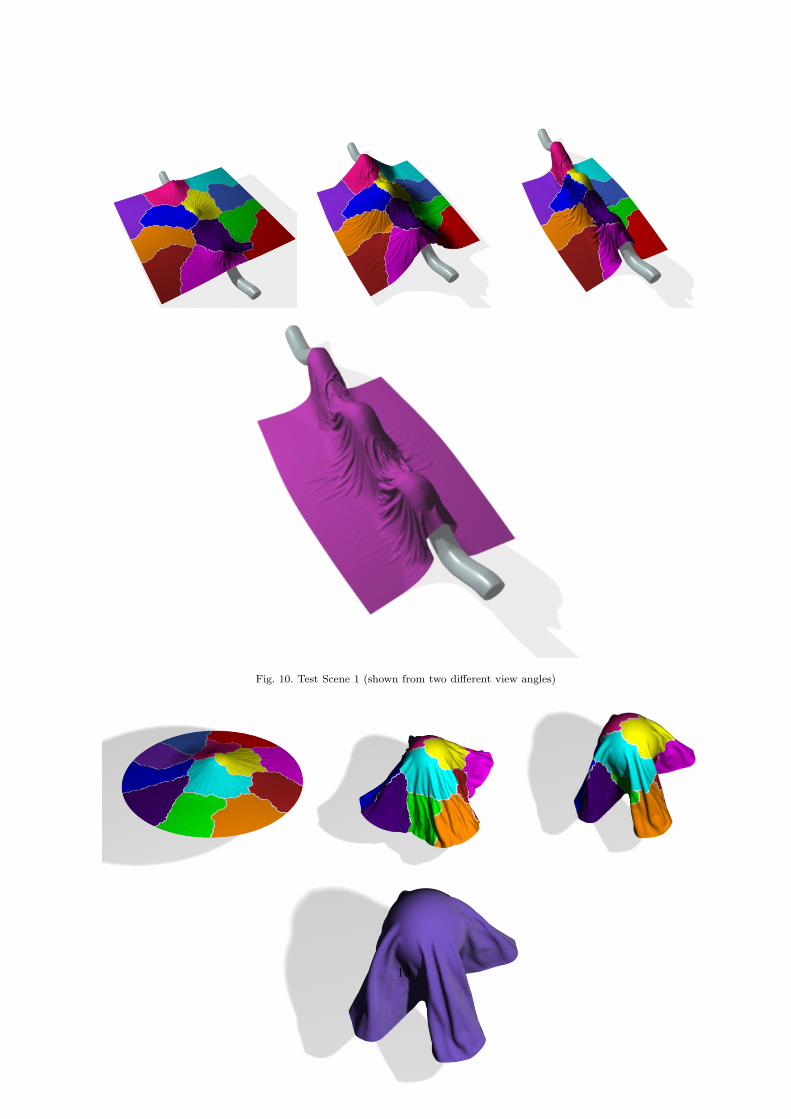
Fig. 10. Test Scene 1 (shown from two different view angles)
Fig. 11. Test Scene 2 (shown from two different view angles)
13