parallel distributed computing techniques
DESCRIPTION
Parallel distributed computing techniques. Sinh viên: Lê Trọng Tín Mai Văn Ninh Phùng Quang Chánh Nguyễn Đức Cảnh Đặng Trung Tín. GVHD: Phạm Trần Vũ. Pipelined Computations. Embarrassingly Parallel Computations. Partitioning and Divide-and-Conquer Strategies. - PowerPoint PPT PresentationTRANSCRIPT

Parallel distributed computing techniques
GVHD:
Phạm Trần Vũ
Sinh viên:
Lê Trọng Tín
Mai Văn Ninh
Phùng Quang Chánh
Nguyễn Đức Cảnh
Đặng Trung Tín

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 2
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 3
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Motivation of Parallel Computing Techniques
Demand for Computational Speed Continual demand for greater computational
speed from a computer system than is currently possible
Areas requiring great computational speed include numerical modeling and simulation of scientific and engineering problems.
Computations must be completed within a “reasonable” time period.
www.cse.hcmut.edu.vn 4

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 5
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Message-Passing Computing
Basics of Message-Passing Programming using user-level message passing libraries
Two primary mechanisms needed: A method of creating separate
processes for execution on different computers
A method of sending and receiving messages
www.cse.hcmut.edu.vn 6
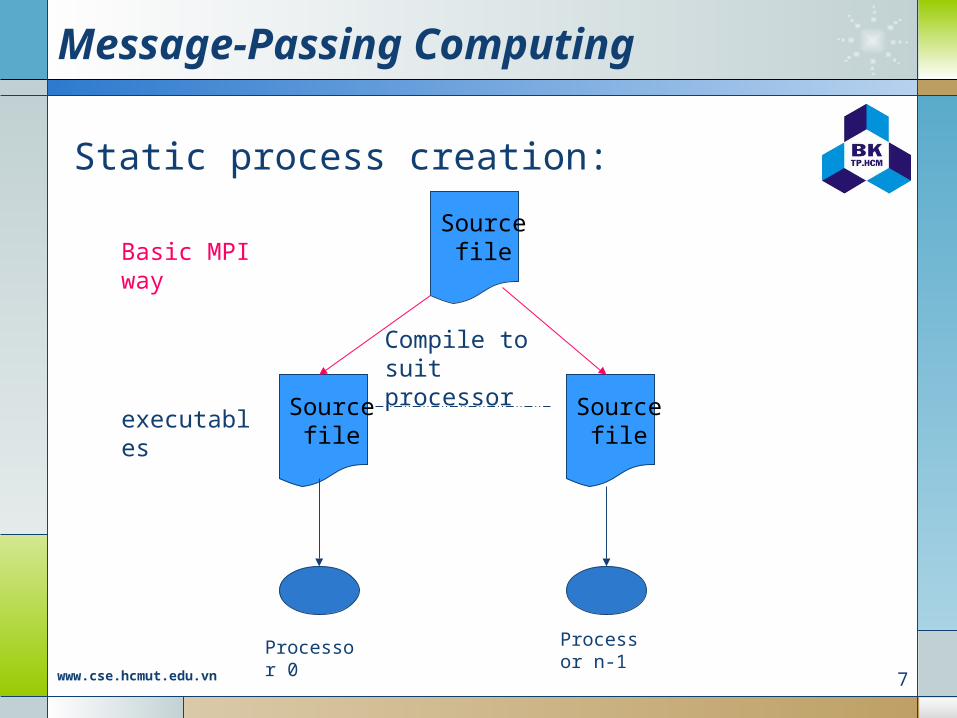
Message-Passing Computing
Static process creation:
Source file
Source file
Source file
Basic MPI way
executables
Compile to suit processor
Processor 0
Processor n-1
www.cse.hcmut.edu.vn 7

Message-Passing Computing
Dynamic process creation:
.
spawn().....
.
.
.
.
.
.
.
PVM way
time
Processor 1
Processor 2
Start executionof process 2
www.cse.hcmut.edu.vn 8

Message-Passing Computing
Method of sending and receiving messages?
www.cse.hcmut.edu.vn 9

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 10
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

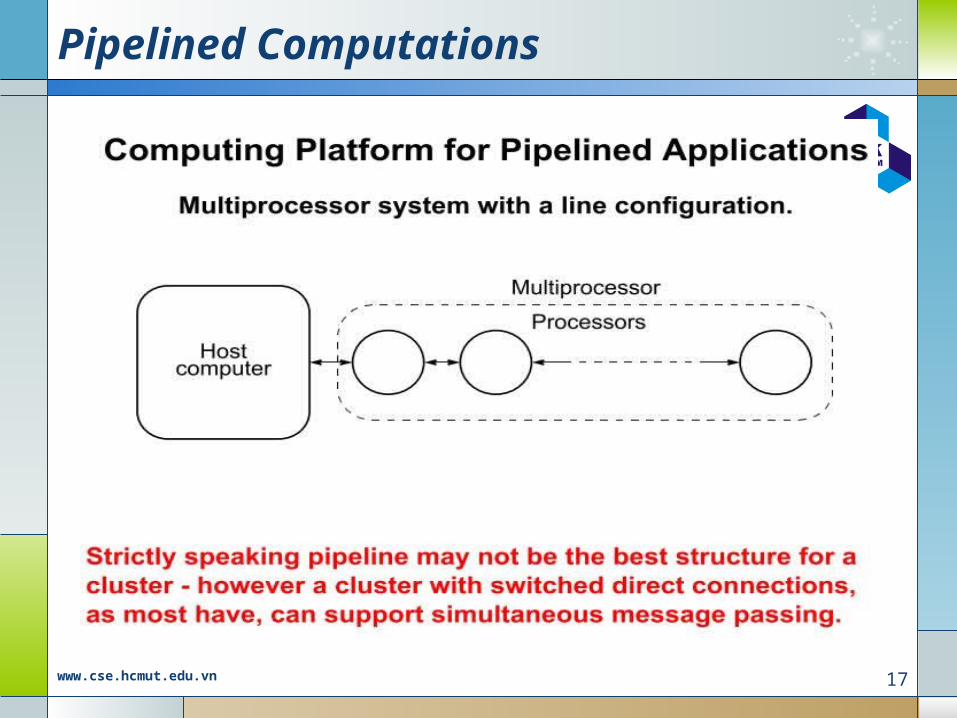
Pipelined Computation
Problem divided into a series of tasks that have to be completed one after the other (the basis of sequential programming).
Each task executed by a separate process or processor.
www.cse.hcmut.edu.vn 11

Pipelined Computation
Where pipelining can be used to good effect1-If more than one instance of the
complete problem is to be executed2-If a series of data items must be
processed, each requiring multiple operations
3-If information to start the next process can be passed forward before the process has completed all its internal operations
www.cse.hcmut.edu.vn 12

Pipelined Computation
Execution time = m + p - 1 cycles for a p-stage pipeline and m instances
www.cse.hcmut.edu.vn 13

Pipelined Computation
www.cse.hcmut.edu.vn 14

Pipelined Computation
www.cse.hcmut.edu.vn 15

Pipelined Computation
www.cse.hcmut.edu.vn 16
Pipelined Computations
www.cse.hcmut.edu.vn 17

Pipelined Computation
www.cse.hcmut.edu.vn 18

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 19
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Ideal Parallel Computation
A computation that can obviously be devided into a number of completely independent parts
Each of which can be executed by a separate processor
Each process can do its tasks without any interaction with other process
20www.cse.hcmut.edu.vn

Ideal Parallel Computation
Practical embarrassingly parallel computation with static process creation and master – slave approach
21www.cse.hcmut.edu.vn

Ideal Parallel Computation
Practical embarrassingly parallel computation with dynamic process creation and master – slave approach
22www.cse.hcmut.edu.vn

Embarrassingly parallel examples
Geometrical Transformations of ImagesMandelbrot setMonte Carlo Method
23www.cse.hcmut.edu.vn

Geometrical Transformations of Images
Performing on the coordinates of each pixel to move the position of the pixel without affecting its value
The transformation on each pixel is totally independent from other pixels
Some geometrical operations Shifting Scaling Rotation Clipping
24www.cse.hcmut.edu.vn

Geometrical Transformations of Images
Partitioning into regions for individual processes
Square region for each process Row region for each process
Map
Process
Map
Process
80
80
640
480 480
640
10
25www.cse.hcmut.edu.vn

Mandelbrot Set
Set of points in a complex plane that are quasi-stable when computed by iterating the function
where is the (k + 1)th iteration of the complex number z = a + bi and c is a complex number giving position of point in the complex plane. The initial value for z is zero.
Iterations continued until magnitude of z is greater than 2 or number of iterations reaches arbitrary limit. Magnitude of z is the length of the vector given by
26www.cse.hcmut.edu.vn

Mandelbrot Set
27www.cse.hcmut.edu.vn

Mandelbrot Set
28www.cse.hcmut.edu.vn

Mandelbrot Set
c.real = real_min + x * (real_max - real_min)/disp_widthc.imag = imag_min + y * (imag_max - imag_min)/disp_height
Static Task Assignment Simply divide the region into fixed number
of parts, each computed by a separate processor
Not very successful because different regions require different numbers of iterations and time
Dynamic Task Assignment Have processor request regions after
computing previouos regions
29www.cse.hcmut.edu.vn
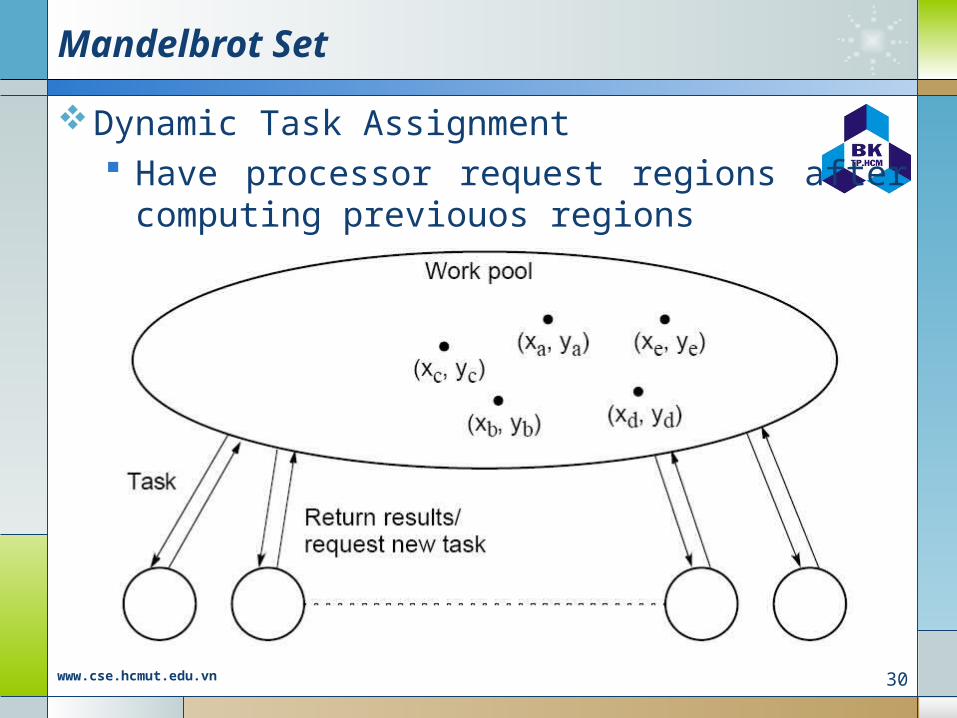
Mandelbrot Set
Dynamic Task Assignment Have processor request regions after
computing previouos regions
30www.cse.hcmut.edu.vn

Monte Carlo Method
Another embarrassingly parallel computationMonte Carlo methods use of random
selectionsExample – To calculate ∏
Circle formed within a square, with unit radius so that square has side 2x2. Ratio of the area of the circle to the square given by
31www.cse.hcmut.edu.vn

Monte Carlo Method
One quadrant of the construction can be described by integral
Random pairs of numbers, (xr,yr) generated, each between 0 and 1. Counted as in circle if
; that is,
32www.cse.hcmut.edu.vn

Monte Carlo Method
Alternative method to compute integralUse random values of x to compute f(x) and
sum values of f(x)
where xr are randomly generated values of x between x1 and x2
Monte Carlo method very useful if the function cannot be integrated numerically (maybe having a large number of variables)
33www.cse.hcmut.edu.vn

Monte Carlo Method
Example – computing the integral
Sequential code
Routine randv(x1, x2) returns a pseudorandom number between x1 and x2
34www.cse.hcmut.edu.vn

Monte Carlo Method
Parallel Monte Carlo integration
Master
Slaves
Request
Partial sum
Random number
Random-numberprocess
35www.cse.hcmut.edu.vn
Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 36
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

www.cse.hcmut.edu.vn 37

Partitioning simply divides the problem into parts.
It is the basic of all parallel programming.
Partitioning can be applied to the program data (data partitioning or domain decomposition) and the functions of a program
(functional decomposition).
It is much less mommon to find concurrent functions in a problem, but data partitioning is a main strategy for parallel programming.
www.cse.hcmut.edu.vn 38
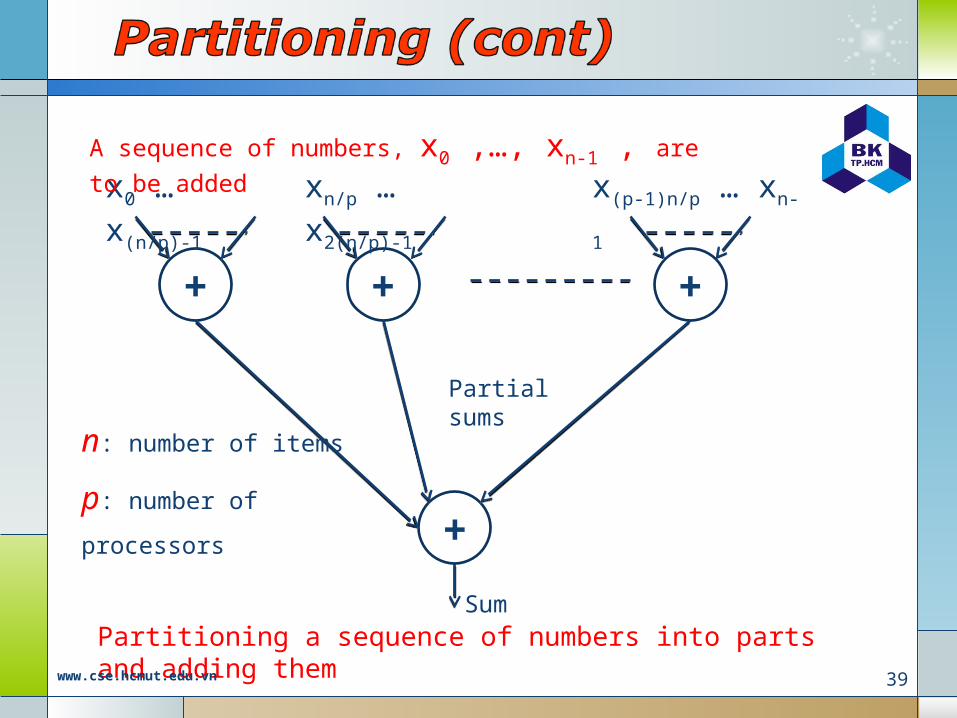
+ + +
+
Partial sums
Sum
x0 … x(n/p)-1 xn/p … x2(n/p)-1 x(p-1)n/p … xn-1
Partitioning a sequence of numbers into parts and adding them
n: number of items
p: number of processors
A sequence of numbers, x0 ,…, xn-1 , are to be added
www.cse.hcmut.edu.vn 39

Characterized by dividing problem into
subproblems of same form as larger
problem. Further divisions into still smaller
sub-problems, usually done by recursion.
Recursive divide and conquer amenable to
parallelization because separate processes
can be used for divided parts. Also usually
data is naturally localized.www.cse.hcmut.edu.vn 40

A sequential recursive definition for adding alist of numbers is
int add(int *s) // add list of numbers, s{
if(number(s) <= 2) return (n1 + n2);else {
Divide (s, s1, s2); // divide s into two part, s1, s2part_sum1 = add(s1);// recursive calls to add sub listspart_sum2 = add(s2);return (part_sum1 + part_sum2);
}}
www.cse.hcmut.edu.vn 41

42www.cse.hcmut.edu.vn
Divideproblem
Final task
Initial problem
Tree construction
www.cse.hcmut.edu.vn 42
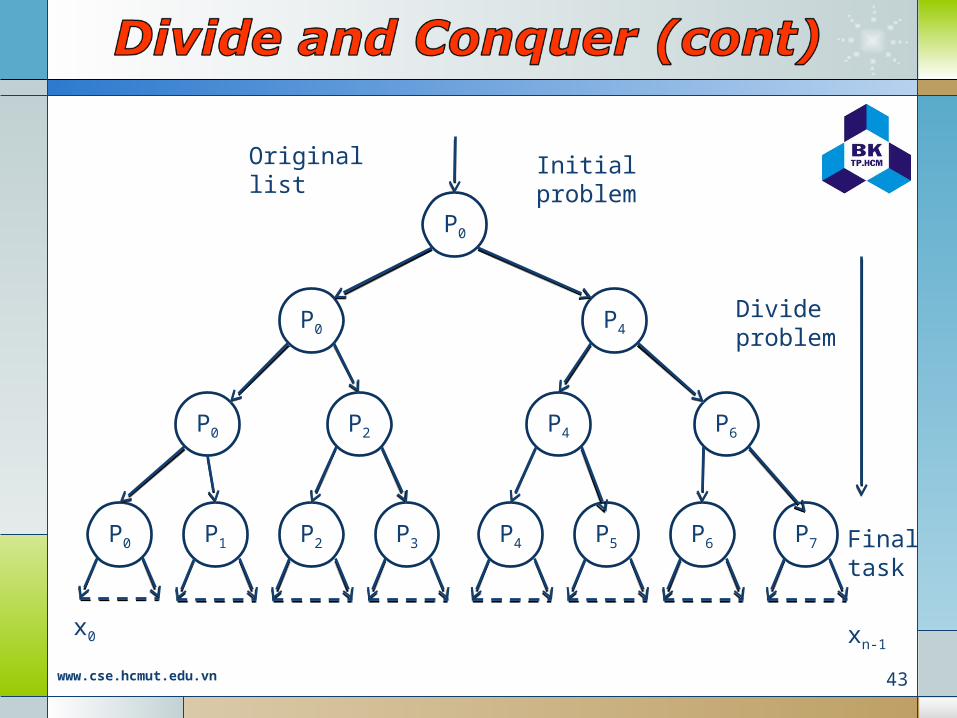
P0
P0 P4
P7P6P5P4P3P2P1P0
P2P0 P6P4
Original list
x0 xn-1
Divideproblem
Final task
Initial problem
www.cse.hcmut.edu.vn 43

Many possibilities.
Operations on sequences of number such as
simply adding them together
Several sorting algorithms can often be partitioned
or constructed in a recursive fashion
Numerical integration
N-body problem
www.cse.hcmut.edu.vn 44
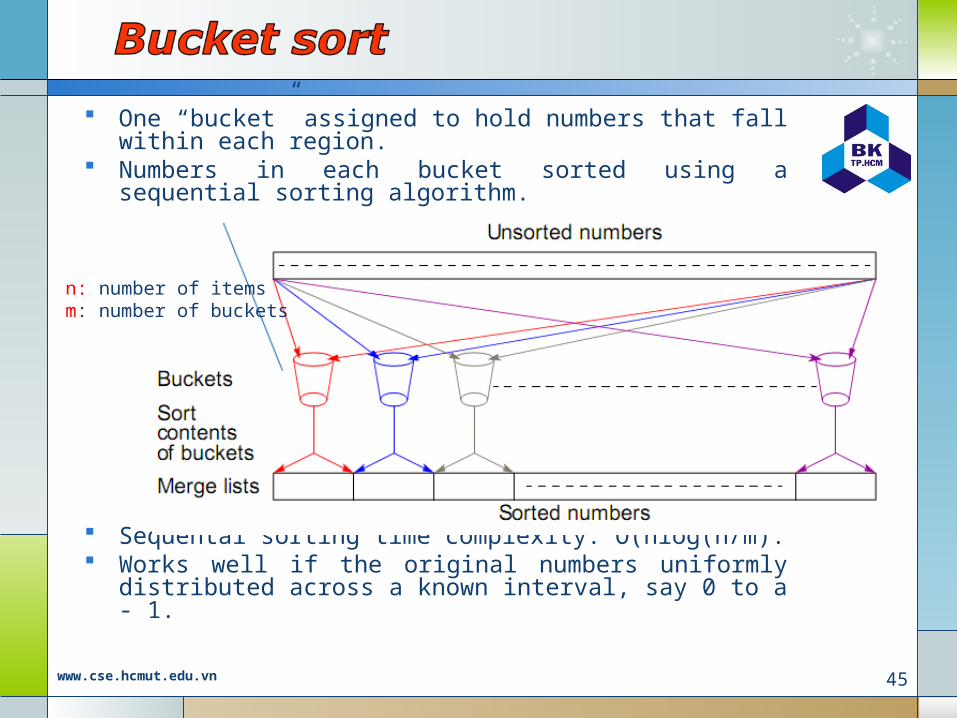
One “bucket” assigned to hold numbers that fall within each region.
Numbers in each bucket sorted using a sequential sorting algorithm.
Sequental sorting time complexity: O(nlog(n/m). Works well if the original numbers uniformly distributed
across a known interval, say 0 to a - 1.
n: number of itemsm: number of buckets
www.cse.hcmut.edu.vn 45

Simple approach Assign one processor for each bucket.
www.cse.hcmut.edu.vn 46

Partition sequence into m regions, one region for
each processor.
Each processor maintains p “small” buckets and
separates the numbers in its region into its own
small buckets.
Small buckets then emptied into p final buckets
for sorting, whichrequires each processor to send
one small bucket to each of the other processors
(bucket i to processor i).www.cse.hcmut.edu.vn 47

Introduces new message-passing operation - all-to-all broadcast.
www.cse.hcmut.edu.vn 48

Sends data from each process to every other process
www.cse.hcmut.edu.vn 49

“all-to-all” routine actually transfers rows of an array to columns:
Tranposes a matrix.
www.cse.hcmut.edu.vn 50

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 51
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Synchronous Computations
Synchronous• Barrier• Barrier Implementation
– Centralized Counter implementation– Tree Barrier Implementation– Butterfly Barrier
Synchronized Computations• Fully synchronous
– Data Parallel Computations– Synchronous Iteration(Synchronous Parallelism)
• Locally synchronous– Heat Distribution Problem– Sequential Code– Parallel Code
www.cse.hcmut.edu.vn 52

Barrier
A basic mechanism for synchronizing processes - inserted at the point in each process where it must wait.
All processes can continue from this point when all the processes have reached it
Processes reaching barrier at different times
www.cse.hcmut.edu.vn 53

Barrier Image
www.cse.hcmut.edu.vn 54

Barrier Implementation
Centralized Counter implementation ( linear barrier)
Tree Barrier Implementation.Butterfly BarrierLocal SynchronizationDeadlock
www.cse.hcmut.edu.vn 55

Centralized Counter implementation
Have two phase • Arrival phase (trapping) • Departure phase(release)
A process enters arrival phase and does not leave this phase until all processes have arrived in this phase
Then processes move to departure phase and are released
www.cse.hcmut.edu.vn 56
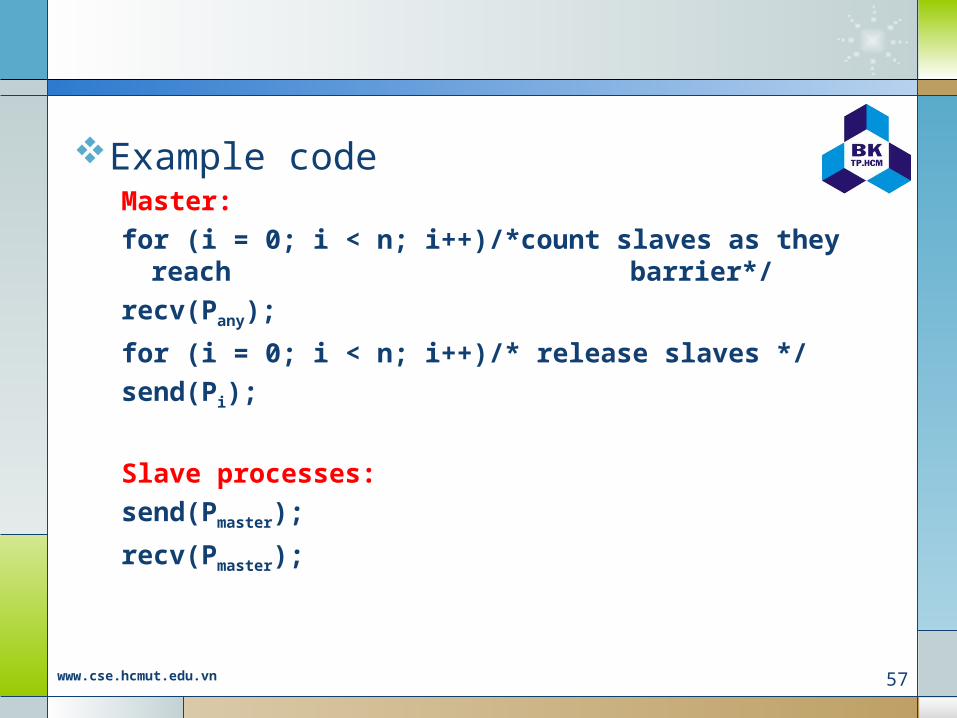
Example codeMaster:for (i = 0; i < n; i++)/*count slaves as they reach
barrier*/recv(Pany);
for (i = 0; i < n; i++)/* release slaves */send(Pi);
Slave processes:send(Pmaster);
recv(Pmaster);
www.cse.hcmut.edu.vn 57

Tree Barrier Implementation
Suppose 8 processes, P0, P1, P2, P3, P4, P5, P6, P7: First stage:
P1 sends message to P0; (when P1 reaches its barrier) P3 sends message to P2; (when P3 reaches its barrier) P5 sends message to P4; (when P5 reaches its barrier) P7 sends message to P6; (when P7 reaches its barrier)
Second stage: P2 sends message to P0; (P2 & P3 reached their barrier) P6 sends message to P4; (P6 & P7 reached their barrier)
Second stage: P4 sends message to P0; (P4, P5, P6, & P7 reached barrier) P0 terminates arrival phase;( when P0 reaches barrier &
received message from P4)
www.cse.hcmut.edu.vn 58

Tree Barrier Implementation
Release with a reverse tree construction.
Tree barrier
www.cse.hcmut.edu.vn 59

Butterfly Barrier
This would be used if data were exchanged between the processes
www.cse.hcmut.edu.vn 60

Local Synchronization
Suppose a process Pi needs to be synchronized and to exchange data with process Pi-1 and process Pi+1
Not a perfect three-process barrier because process Pi-1 will only synchronize with Pi and continue as soon as Pi allows. Similarly,process Pi+1 only synchronizes with Pi.
www.cse.hcmut.edu.vn 61

Synchronized Computations
Fully synchronous In fully synchronous, all processes involved in the computation
must be synchronized.
• Data Parallel Computations• Synchronous Iteration(Synchronous Parallelism)
Locally synchronous In locally synchronous, processes only need to synchronize
with a set of logically nearby processes, not all processes involved in the computation
• Heat Distribution Problem• Sequential Code• Parallel Code
www.cse.hcmut.edu.vn 62

Data Parallel Computations
Same operation performed on different data elements simultaneously (SIMD)
Data parallel programming is very convenient for two reasons The first is its ease of programming
(essentially only one program) The second is that it can scale easily to
larger problems sizes
www.cse.hcmut.edu.vn 63

Synchronous Iteration
Each iteration composed of several processes that start together at beginning of iteration. Next iteration cannot begin until all processes have finished previous iteration Using forall :
for (j = 0; j < n; j++) /*for each synch. iteration */forall (i = 0; i < N; i++) { /*N procs each using*/body(i); /* specific value of i */
}
www.cse.hcmut.edu.vn 64

Synchronous Iteration
Solving a General System of Linear Equations by Iteration Suppose the equations are of a general form with n
equations and n unknowns where the unknowns are x0, x1, x2, … xn-1 (0 <= i < n). an-1,0x0 + an-1,1x1 + an-1,2x2 … + an-1,n-1xn-1 = bn-1
.
.
.
.
a2,0x0 + a2,1x1 + a2,2x2 … + a2,n-1xn-1 = b2
a1,0x0 + a1,1x1 + a1,2x2 … + a1,n-1xn-1 = b1
a0,0x0 + a0,1x1 + a0,2x2 … + a0,n-1xn-1 = b0
where the unknowns are x0, x1, x2, … xn-1 (0<= i < n).
www.cse.hcmut.edu.vn 65

Synchronous Iteration
By rearranging the ith equation:ai,0x0 + ai,1x1 + ai,2x2 … + ai,n-1xn-1 = bi
toxi = (1/ai,i)[bi-(ai,0x0+ai,1x1+ai,2x2…ai,i-1xi-
1+ai ,i+1xi+1…+ai,n-1xn-1)]
Or
www.cse.hcmut.edu.vn 66

Heat Distribution Problem
An area has known temperatures along each of its edges. Find thetemperature distribution within. Divide area into fine mesh of points, hi,j. Temperature at an inside point taken to be average of temperatures of four neighboringpoints..
Temperature of each point by iterating the equation
(0 < i < n, 0 < j < n)www.cse.hcmut.edu.vn 67

Heat Distribution Problem
www.cse.hcmut.edu.vn 68

Sequential Code
Using a fixed number of iterationsfor (iteration = 0; iteration < limit; iteration++) {
for (i = 1; i < n; i++)for (j = 1; j < n; j++)
g[i][j] = 0.25*(h[i-1][j]+h[i+1][j]+h[i][j-1] +h[i][j+1]);
for (i = 1; i < n; i++)/* update points */for (j = 1; j < n; j++)
h[i][j] = g[i][j];
www.cse.hcmut.edu.vn 69

Parallel Code
With fixed number of iterations, Pi,j (except for the boundary points):for (iteration = 0; iteration < limit; iteration++) {
g = 0.25 * (w + x + y + z); send(&g, Pi-1,j); /* non-blocking sends */
send(&g, Pi+1,j); send(&g, Pi,j-1);send(&g, Pi,j+1);recv(&w, Pi-1,j); /* synchronous receives */recv(&x, Pi+1,j);recv(&y, Pi,j-1);recv(&z, Pi,j+1);
}
Local
Barrier
www.cse.hcmut.edu.vn 70

Contents
Pipelined Computations
Embarrassingly Parallel Computations
Partitioning and Divide-and-Conquer Strategies
Synchronous Computations
Load Balancing and Termination Detectionwww.cse.hcmut.edu.vn 71
Parallel Computing Techniques
Motivation of Parallel Computing Techniques
Message-passing computing

Load Balancing &Termination Detection

Load Balancing & Termination Detection
Load BalancingUsed to distribute computations fairly across processors in order to obtain the highest possible execution speed
Content
Termination Detection Detecting when a computation has beencompleted. More difficult when the computation is distributed.
www.cse.hcmut.edu.vn 73

Load Balancing
www.cse.hcmut.edu.vn 74

Load Balancing & Termination Detection
Static Load BalancingLoad Baclancing can be attemped statically before the execution of any process.
Load Balancing
Dynamic Load BalancingLoad Balancing can be attemped dynamically during the execution of the process.
www.cse.hcmut.edu.vn 75

Static Load Balancing
Round robin algorithm — passes out tasks in sequential order of processes coming back to the first when all processes have been given a task
Randomized algorithms — selects processes at random to
take tasks Recursive bisection — recursively divides the problem
into subproblems of equal computational effort while
minimizing message passing Simulated annealing — an optimization technique Genetic algorithm — another optimization technique,
described
www.cse.hcmut.edu.vn 76

Static Load Balancing
Several fundamental flaws with static load balancing even if a mathematical solution exists:
• Very difficult to estimate accurately the execution times of various parts of a program without actually executing the parts.
• Communication delays that vary under different circumstances
• Some problems have an indeterminate number of steps to reach their solution.
www.cse.hcmut.edu.vn 77

Dynamic Load Balancing
www.cse.hcmut.edu.vn 78

Centralized dynamic load balancing
Tasks handed out from a centralized location. Master-slave structure
Master process(or) holds the collection of tasks to be performed.
Tasks are sent to the slave processes. When a slave process completes one task, it requests another task from the master process.
(Terms used : work pool, replicated worker, processor farm.)
www.cse.hcmut.edu.vn 79

Centralized dynamic load balancing
www.cse.hcmut.edu.vn 80

Termination
Computation terminates when: • The task queue is empty and • Every process has made a request for
another task without any new tasks being generated
Not sufficient to terminate when task queue empty if one or more processes are still running if a running process may provide new tasks for task queue.
www.cse.hcmut.edu.vn 81

Decentralized dynamic load balancing
www.cse.hcmut.edu.vn 82

Fully Distributed Work Pool
Processes to execute tasks from each other
Task could be transferred by:
- Receiver-initiated - Sender-initiated
www.cse.hcmut.edu.vn 83

Process Selection
Algorithms for selecting a process: Round robin algorithm – process
Pi requests tasks from process Px,where x is given by a counter that is incremented after each request, using modulo n arithmetic (n processes), excluding x = i.
Random polling algorithm – process Pi requests tasks from process Px, where x is a number that is selected randomly between 0 and n- 1 (excluding i).
www.cse.hcmut.edu.vn 84

Distributed Termination Detection Algorithms
Termination Conditions
• Application-specific local termination conditions exist throughout the collection of processes, at time t.
• There are no messages in transit between processes at time t.
Second condition necessary because a message in transit might restart a terminated process. More difficult to recognize. The time that it takes for messages to travel between processes will not be known in advance.
www.cse.hcmut.edu.vn 85

Using Acknowledgment Messages
Each process in one of two states:
• Inactive - without any task to perform
• Active Process that sent task to
make it enter the active state becomes its “parent.”
www.cse.hcmut.edu.vn 86

Using Acknowledgment Messages
When process receives a task, it immediately sends an acknowledgment message, except if the process it receives the taskfrom is its parent process. Only sends an acknowledgment message to its parent when it is ready to become inactive, i.e. when:
• Its local termination condition exists (all tasks are completed, and It has transmitted all its acknowledgments for tasks it has received, and It has received all its acknowledgments for tasks it has sent out.
• A process must become inactive before its parent process. When first process becomes idle, the computation can terminate
www.cse.hcmut.edu.vn 87
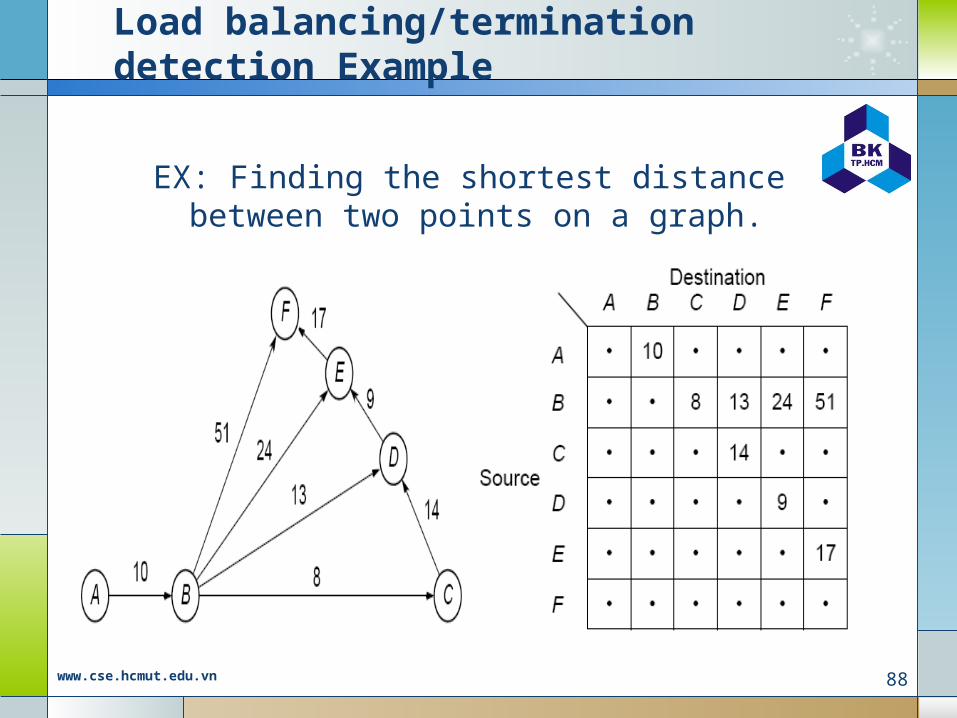
Load balancing/termination detection Example
EX: Finding the shortest distance between two points on a graph.
www.cse.hcmut.edu.vn 88

References:
Parallel Programming: Techniques and Applications Using Networked Workstations and Parallel Computers, Barry Wilkinson and MiChael Allen, Second Edition, Prentice Hall, 2005.

