parallel computing platforms - androbenchcsl.skku.edu/uploads/sse3054s17/02-parahw.pdf · parallel...
TRANSCRIPT

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected])
Parallel Computing Platforms
Jinkyu Jeong ([email protected])Computer Systems Laboratory
Sungkyunkwan Universityhttp://csl.skku.edu

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 2
Elements of a Parallel Computer • Hardware
– Multiple processors– Multiple memories– Interconnection network
• System software– Parallel operating system– Programming constructs to express/orchestrate concurrency
• Application software– Parallel algorithms
• Goal: utilize the hardware, system and application software to – Achieve speedup: Tp = Ts/p– Solve problems requiring a large amount of memory
SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 3
Parallel Computing Platform
• Logical organization– The user’s view of the machine as it is being presented
via its system software • Physical organization– The actual hardware architecture
• Physical architecture is to a large extent independent of the logical architecture
– Ex) message passing on shared memory architecture, distributed shared memory system

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 4
Logical Organization Elements
• Control mechanism– Flynn’s taxonomy
SISDSingleInstructionstream
SingleDatastream
SIMDSingleInstructionstreamMultipleDatastream
MISDMultiple Instructionstream
SingleDatastream
MIMDMultiple Instructionstream
MultipleDatastream
not covered
Single-core processor
Multi-core processor
SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 5
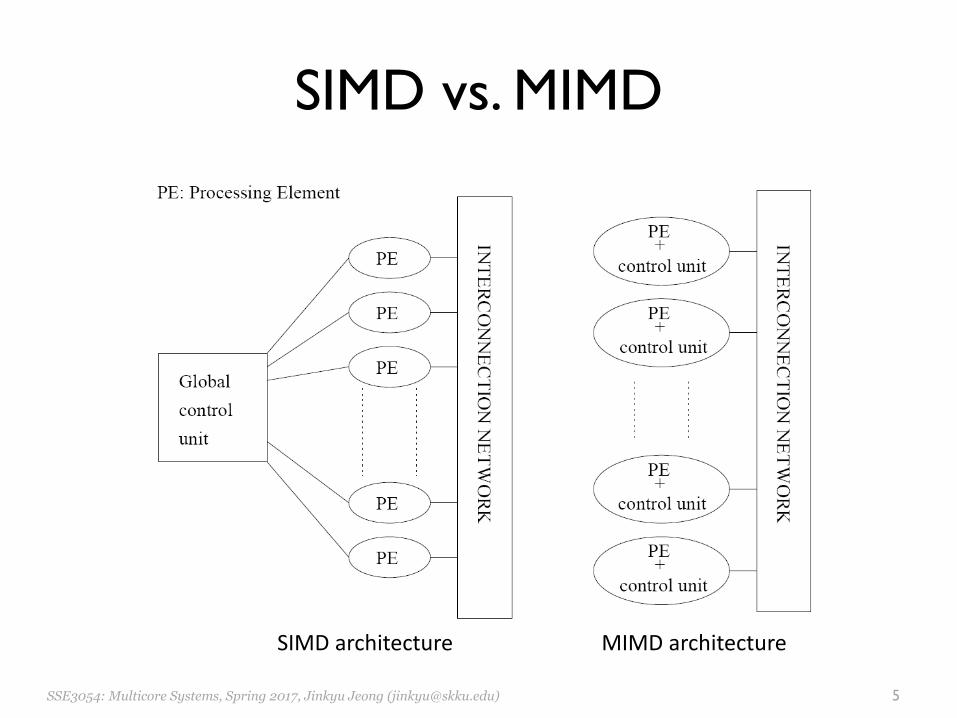
SIMD vs. MIMD
SIMDarchitecture MIMDarchitecture
SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 6
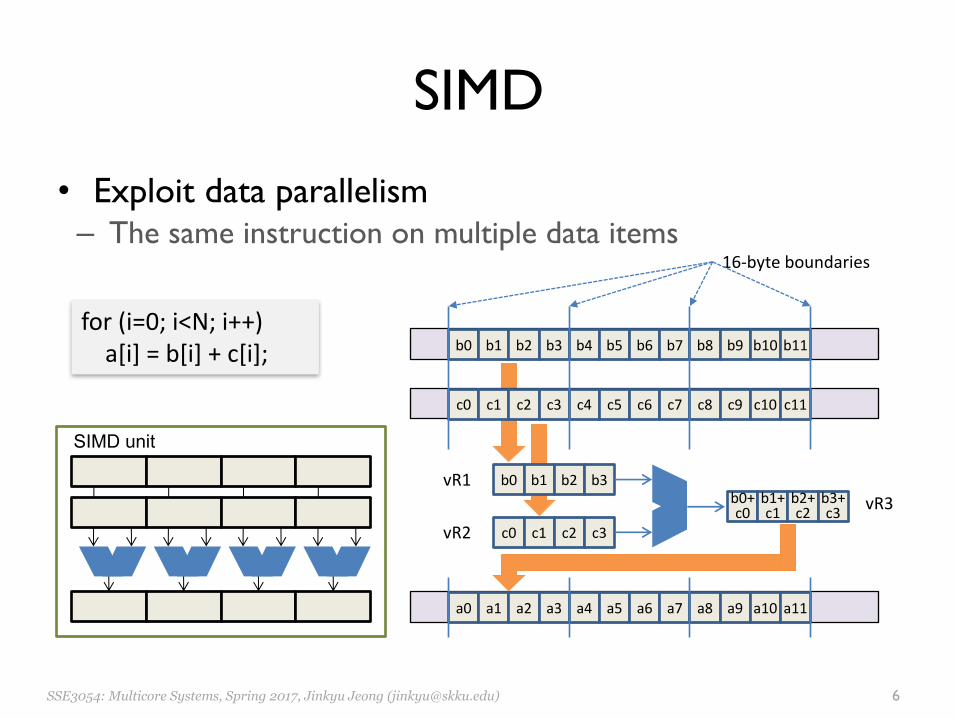
SIMD
• Exploit data parallelism– The same instruction on multiple data items
for(i=0;i<N;i++)a[i]=b[i]+c[i];
SIMD unit
...b0 b1 b2 b3 b4 b5 b6 b7 b8 b9 b10 b11
...c0 c1 c2 c3 c4 c5 c6 c7 c8 c9 c10 c11
b0 b1 b2 b3
c0 c1 c2 c3
16-byteboundaries
b0+c0
b1+c1
b2+c2
b3+c3
...a0 a1 a2 a3 a4 a5 a6 a7 a8 a9 a10 a11
vR1
vR2vR3

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 7
SIMD
• Exploit data parallelism– The same instruction on multiple data items
• SIMD units in processors– Supercomputers: BlueGene/Q– PC: MMX/SSE/AVX (x86), AltiVec/VMX (PowerPC),
…– Embedded systems: Neon (ARM), VLIW+SIMD DSPs– Co-processors: GPGPUs

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 8
MIMD• Multiple instructions on multiple
data items• A collection of independent
processing elements (or cores)– Usually exploits thread-level
parallelism– Modern parallel computing
platforms• E.g., multicore processors
– SIMD can also work on this system

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 9
Programming Model
• What programmer uses in coding applications– Specifies communication and synchronization– Instructions, APIs, defined data structure
• Programming model examples– Shared address space
• Load/store instructions to access the data for communication – Message passing
• Special system library, APIs for data transmission– Data parallel
• Well-structured data, same operation to multiple data in parallel • Implemented with shared address space or message passing

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 10
Shared Address Space Architecture
• Shared address space– Any processor can directly reference any memory location– Communication occurs implicitly as result of loads and
stores– Location transparency (flat address space)– Similar programming model to time-sharing on
uniprocessors• Except processes run on different processors• Good throughput on multi-programmed workloads
• Popularly known as shared memory machine/model– Memory may be physically distributed among processors

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 11
Shared Address Space Architecture
• Multi-Processing– One or more thread on a virtual address space– Portion of address spaces of processes are shared
• Writes to shared address visible to other threads/processes– Natural extension of uniprocessor model
• Conventional memory operations for communication• Special atomic operations for synchronization
Machinephysicaladdressspace
Virtualaddressspacesforacollectionofprocessescommunicatingviasharedaddresses

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 12
x86 Examples – Shared Address Space
• Quad core processors– Highly integrated, commodity systems– Multiple cores on a chip
• low-latency, high bandwidth communication via shared cache
Shared L3 Cache
Core Core Core Core
Inteli7(Nehalem)
Shared L2 Cache
Core Core
Core Core
AMDPhenom II(Barcelona)
SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 13
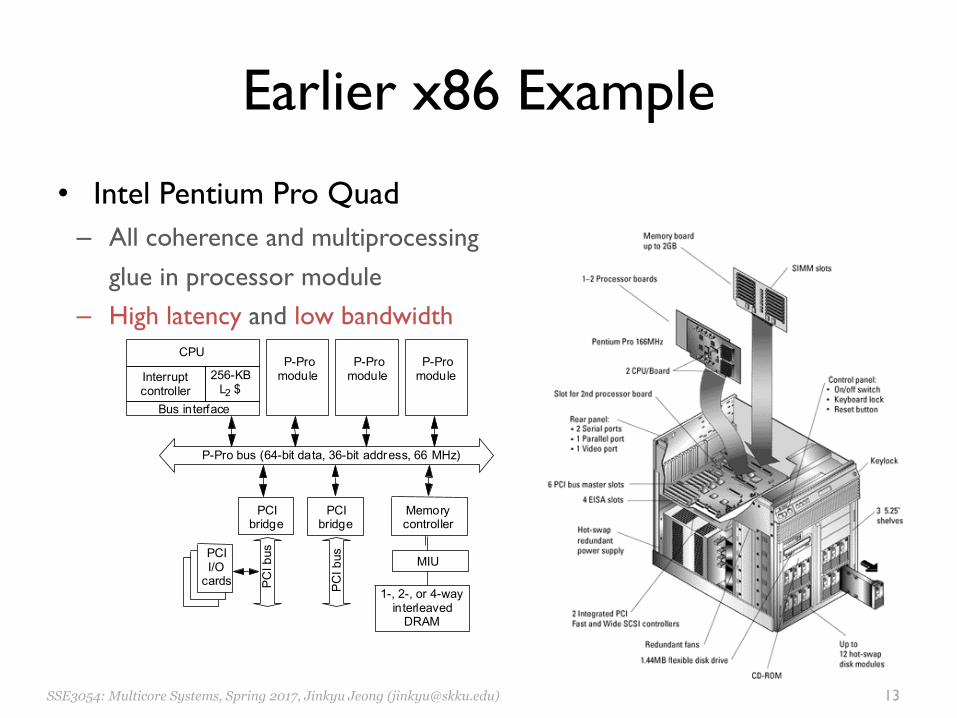
Earlier x86 Example
• Intel Pentium Pro Quad– All coherence and multiprocessing
glue in processor module– High latency and low bandwidth
P-Pro bus (64-bit data, 36-bit address, 66 MHz)
CPU
Bus interface
MIU
P-Promodule
P-Promodule
P-Promodule256-KB
L2 $Interruptcontroller
PCIbridge
PCIbridge
Memorycontroller
1-, 2-, or 4-wayinterleaved
DRAM
PCI b
us
PCI b
usPCII/O
cards

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 14
Shared Address Space Architecture
• Physical organization– Shared memory system
• Uniform memory access (UMA)• Non-uniform memory access (NUMA)
– Distributed memory system• Cluster of shared memory systems• Hardware- or software-based distributed shared memory (DSM)
UMAsystem NUMAsystem Distributedmemorysystem

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 15
Scaling Up
• Problem is interconnect - cost (crossbar) or bandwidth (bus)– Share memory (uniform memory access, UMA)
• Latencies to memory uniform, but uniformly large– Distributed memory (non-uniform memory access, NUMA)
• Construct shared address space out of simple message transactions across a general-purpose network
– Cache: keeps shared data (local, and non-local data in NUMA)
M M M° ° °
° ° ° M ° ° °M M
NetworkNetwork
P
$
P
$
P
$
P
$
P
$
P
$
“DanceHall”(UMA) DistributedMemory(NUMA)

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 16
Example: SGI Altix UV 1000
• Scale up to 262,144 cores– 16TB shared memory– 15 GB/sec links– Multistate interconnection network– Hardware cache coherence– ccNUMA

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 17
Parallel Programming Models
• Shared Address Space
• Message Passing
• Data Parallel

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 18
Message Passing Architectures
• Message passing architectures– Complete computer as building block
• Communication via explicit I/O operations
– Programming model• Directly access only private address space (local memory)• Communicate via explicit messages (send/receive)
– High-level block diagram similar to distributed-memory shared address space system• But communication integrated to I/O level, not memory-level• Easier to build than scalable SAS

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 19
Message Passing Abstraction
• Message passing– Send specifies buffer to be transmitted and receiving process– Recv specifies sending process and buffer to receive
– Can be memory to memory copy, but need to name processes– Optional tag on send and matching rule on receive– Many overheads: copying, buffer management, protection
Process P Process Q
Address Y
Address X
SendX,Q,t
Receive Y, P, tMatch
Localpr ocessaddressspaceLocalpr ocess
address space

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 20
Message Passing Architectures
• Physical organization– Shared memory system
• Uniform memory access (UMA)• Non-uniform memory access (NUMA)
– Distributed memory system• Cluster of shared memory systems
UMAsystem NUMAsystem Distributedmemorysystem

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 21
Example: IBM Blue Gene/L
– Nodes: 2 PowerPC 400s– Everything (except DRAM) on one chip

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 22
Memory bus
MicroChannel bus
I/O
i860 NI
DMA
DR
AM
IBM SP-2 node
L2 $
Power 2CPU
Memorycontroller
4-wayinterleaved
DRAM
General interconnectionnetwork formed from8-port switches
NIC
Example: IBM SP-2
• Made out of essentially complete RS6000 workstation
– Network interface integrated in I/O bus – Bandwidth limited by I/O bus

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 23
Taxonomy of Common Systems
• Large-scale shared address space and message passing systemsLarge
multiprocessors
Shared address space
Distributed address space
Symmetric shared memory (SMP)
Ex) IBM eServer, SUN Sunfire
Distributed shared memory (DSM)
Commodity clusters
Ex) Beowulf, …Custom clusters
Cache coherent(ccNUMA)
Ex) SGI Origin/Altix
Non-cache coherent
Ex) Cray T3E, X1
Uniform cluster
Ex) IBM Blue Gene
Constellation cluster of DSMs or SMPs
Ex) SGI Altix, ASC Purple
aka“messagepassing”

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 24
Parallel Programming Models
• Shared Address Space
• Message Passing
• Data Parallel

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 25
Data Parallel Systems
• Programming model– Operations performed in parallel on each element of data structure– Logically single thread of control– Alternate sequential steps and parallel steps
• Architectural model– Array of many simple, cheap processors
with little memory each– Attached to a control processor that
issues instructions– Cheap global synchronization– Centralize high cost of instruction fetch & sequencing– Perfect fit for differential equation solver

SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong ([email protected]) 26
Evolution and Convergence
• Architecture converge to SAS/DAS architecture– Rigid control structure is minus for general purpose
• Simple, regular app’s have good locality, can do well anyway• Loss of applicability due to hardwired data parallelism
• Programming model converges with SPMD– Single Program Multiple Data (SPMD)
• Contributes need for fast global synchronization– Can be implemented on either shared address space or
message passing systems• Same program on different PEs, behavior conditional on thread
ID