overview of cloud computing platforms -...
TRANSCRIPT

SALSASALSA
Overview of Cloud Computing Platforms
July 28, 2010 Big Data for Science Workshop
Judy [email protected]
http://salsahpc.indiana.edu
Pervasive Technology Institute
School of Informatics and Computing
Indiana University

SALSA
Important Trends
•Implies parallel computing important again
•Performance from extra cores – not extra clock speed
•new commercially supported data center model building on compute grids
•In all fields of science and throughout life (e.g. web!)
•Impacts preservation, access/use, programming model
Data DelugeCloud
Technologies
eScience
Multicore/
Parallel Computing •A spectrum of eScience or
eResearch applications (biology, chemistry, physics social science and
humanities …)
•Data Analysis
•Machine learning

SALSA
Challenges for CS Research
There’re several challenges to realizing the vision on data intensive systems and building generic tools (Workflow, Databases, Algorithms, Visualization ).
• Cluster/Cloud-management software
• Distributed execution engine
• Security and Privacy
• Language constructs e.g. MapReduce Twister …
• Parallel compilers
• Program Development tools
. . .
Science faces a data deluge. How to manage and analyze information?
Recommend CSTB foster tools for data capture, data curation, data analysis
―Jim Gray’sTalk to Computer Science and Telecommunication Board (CSTB), Jan 11, 2007

SALSA
Data We’re Looking at
• Public Health Data (IU Medical School & IUPUI Polis Center)
(65535 Patient/GIS records / 54 dimensions each)
• Biology DNA sequence alignments (IU Medical School & CGB)
(several million Sequences / at least 300 to 400 base pair each)
• NIH PubChem (Cheminformatics)
(60 million chemical compounds/166 fingerprints each)
• Particle physics LHC (Caltech)
(1 Terabyte data placed in IU Data Capacitor)
High volume and high dimension require new efficient computing approaches!
SALSA
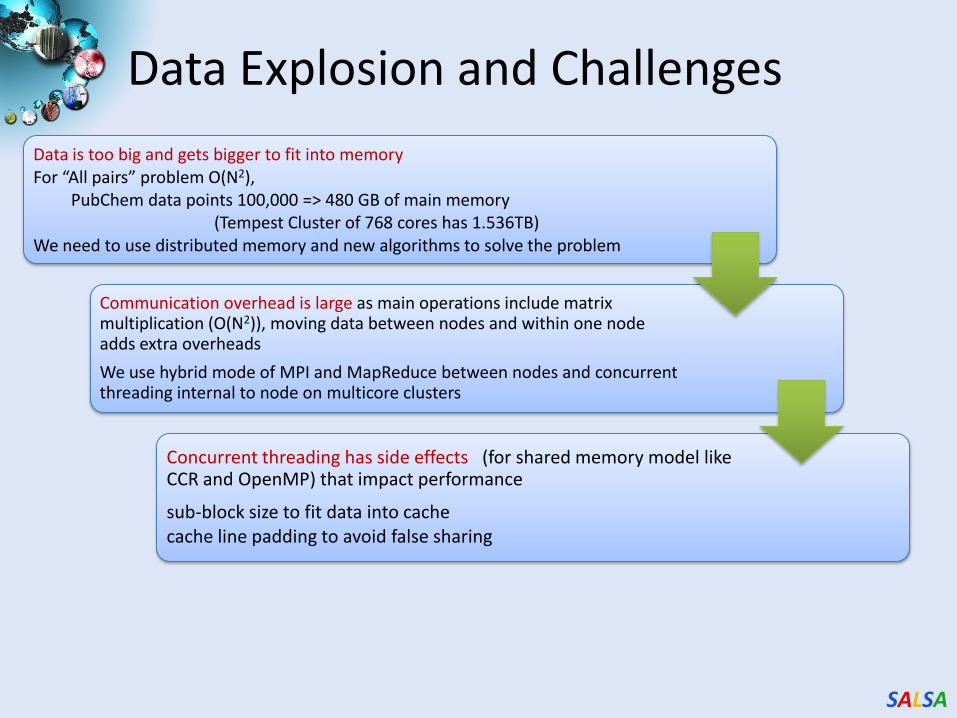
Data is too big and gets bigger to fit into memory For “All pairs” problem O(N2),
PubChem data points 100,000 => 480 GB of main memory(Tempest Cluster of 768 cores has 1.536TB)
We need to use distributed memory and new algorithms to solve the problem
Communication overhead is large as main operations include matrix multiplication (O(N2)), moving data between nodes and within one node adds extra overheads
We use hybrid mode of MPI and MapReduce between nodes and concurrent threading internal to node on multicore clusters
Concurrent threading has side effects (for shared memory model like CCR and OpenMP) that impact performance
sub-block size to fit data into cache cache line padding to avoid false sharing
Data Explosion and Challenges

SALSA
Gartner 2009 Hype CurveSource: Gartner (August 2009)
HPC?

SALSA
Clouds hide Complexity
7
SaaS: Software as a Service
(e.g. Clustering is a service)
IaaS (HaaS): Infrastructure as a Service
(get computer time with a credit card and with a Web interface like EC2)
PaaS: Platform as a Service
IaaS plus core software capabilities on which you build SaaS
(e.g. Azure is a PaaS; MapReduce is a Platform)
CyberinfrastructureIs “Research as a Service”

SALSA
Cloud Computing: Infrastructure and Runtimes
• Cloud Infrastructure: outsourcing of servers, computing, data, file space, utility computing, etc.
– Handled through (Web) services that control virtual machine lifecycles.
• Cloud Runtimes or Platform: tools (for using clouds) to do data-parallel (and other) computations.
– Apache Hadoop, Google MapReduce, Microsoft Dryad, Bigtable, Chubby (synchronization) and others
– MapReduce designed for information retrieval but is excellent for a wide range of science data analysis applications
– Can also do much traditional parallel computing for data-mining if extended to support iterative operations
– MapReduce not usually done on Virtual Machines

SALSA
Gri
d/C
lou
dAuthentication and Authorization: Provide single sign in to both FutureGrid and
Commercial Clouds linked by workflow
Workflow: Support workflows that link job components between FutureGrid and
Commercial Clouds. Trident from Microsoft Research is initial candidate
Data Transport: Transport data between job components on FutureGrid and Commercial
Clouds respecting custom storage patterns
Software as a Service: This concept is shared between Clouds and Grids and can be
supported without special attention
SQL: Relational Database
Clo
ud
Program Library: Store Images and other Program material (basic FutureGrid facility)
Blob: Basic storage concept similar to Azure Blob or Amazon S3
DPFS Data Parallel File System: Support of file systems like Google (MapReduce), HDFS
(Hadoop) or Cosmos (Dryad) with compute-data affinity optimized for data processing
Table: Support of Table Data structures modeled on Apache Hbase (Google Bigtable) or
Amazon SimpleDB/Azure Table (eg. Scalable distributed “Excel”)
Queues: Publish Subscribe based queuing system
Worker Role: This concept is implicitly used in both Amazon and TeraGrid but was first
introduced as a high level construct by Azure
Web Role: This is used in Azure to describe important link to user and can be supported in
FutureGrid with a Portal framework
MapReduce: Support MapReduce Programming model including Hadoop on Linux, Dryad
Key Features of Cloud Platforms

SALSA
MapReduce “File/Data Repository” Parallelism
Instruments
Disks Map1 Map2 Map3
Reduce
Communication
Map = (data parallel) computation reading and writing dataReduce = Collective/Consolidation phase e.g. forming multiple global sums as in histogram
Portals/Users
MPI and Iterative MapReduceMap Map Map Map
Reduce Reduce Reduce
SALSA
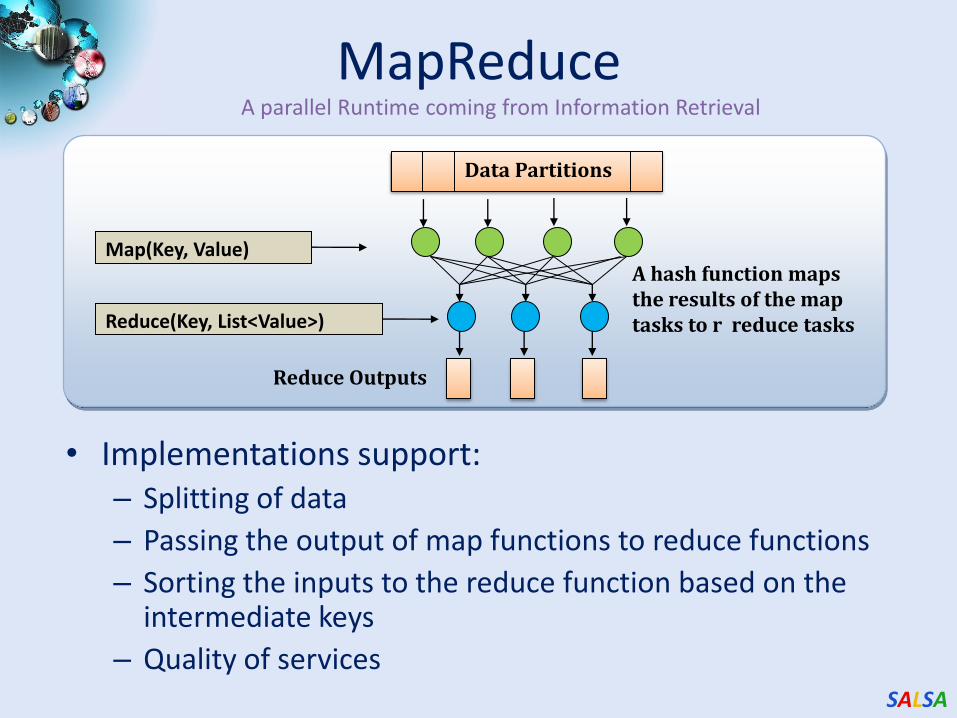
MapReduce
• Implementations support:– Splitting of data
– Passing the output of map functions to reduce functions
– Sorting the inputs to the reduce function based on the intermediate keys
– Quality of services
Map(Key, Value)
Reduce(Key, List<Value>)
Data Partitions
Reduce Outputs
A hash function maps the results of the map tasks to r reduce tasks
A parallel Runtime coming from Information Retrieval

SALSA
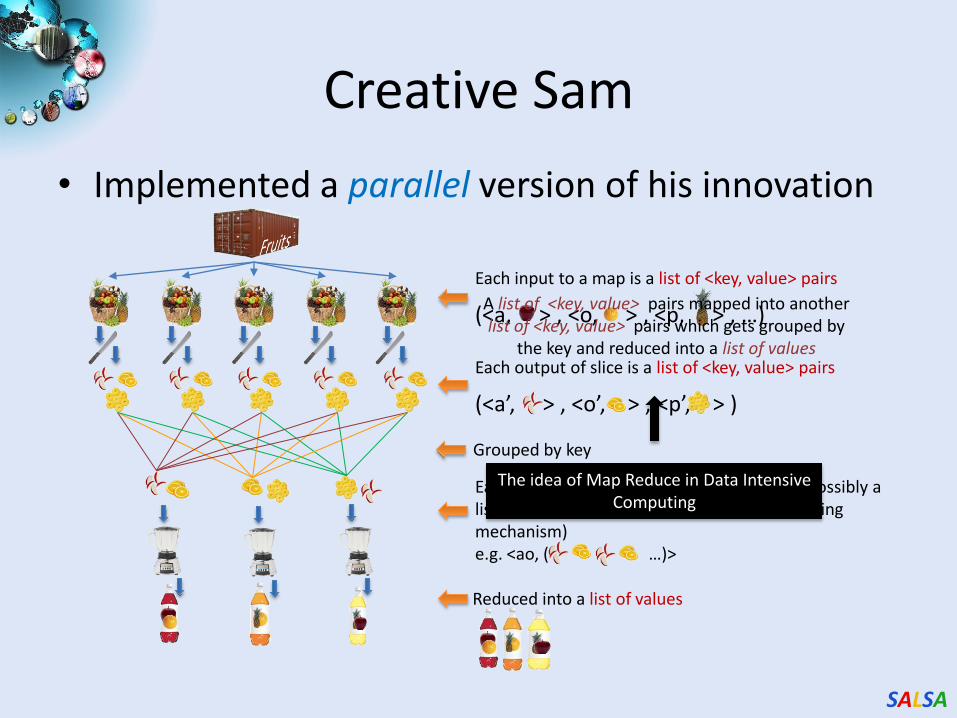
• Sam thought of “drinking” the apple
Sam’s Problem
He used a to cut the
and a to make juice.
SALSA
(<a’, > , <o’, > , <p’, > )
• Implemented a parallel version of his innovation
Creative Sam
(<a, > , <o, > , <p, > , …)
Each input to a map is a list of <key, value> pairs
Each output of slice is a list of <key, value> pairs
Grouped by key
Each input to a reduce is a <key, value-list> (possibly a list of these, depending on the grouping/hashing mechanism)e.g. <ao, ( …)>
Reduced into a list of values
The idea of Map Reduce in Data Intensive Computing
A list of <key, value> pairs mapped into another list of <key, value> pairs which gets grouped by
the key and reduced into a list of values
SALSA
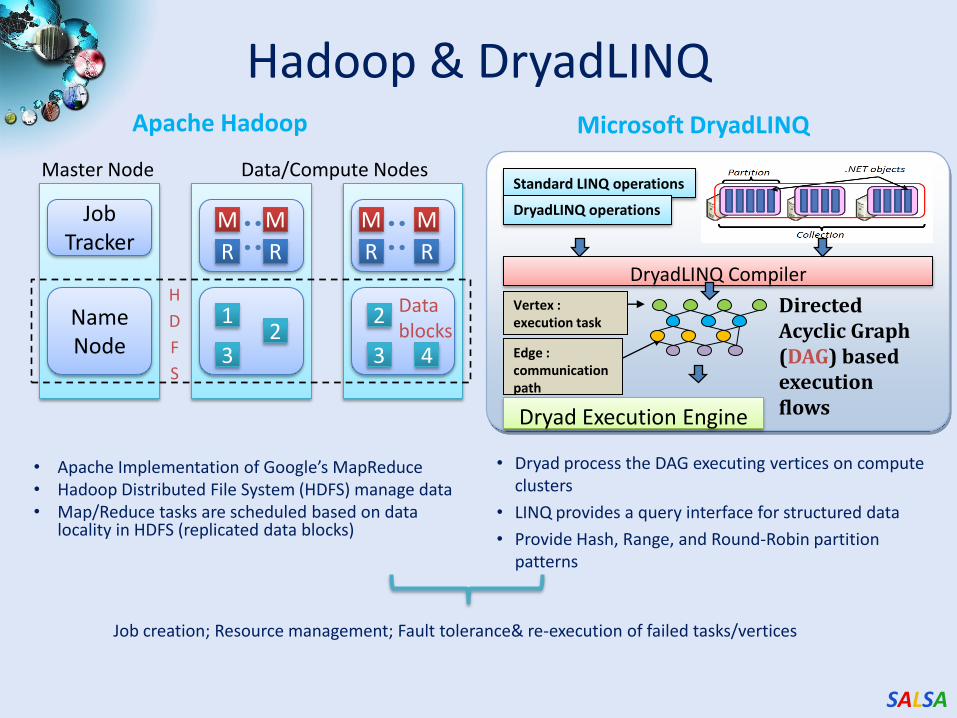
Hadoop & DryadLINQ
• Apache Implementation of Google’s MapReduce• Hadoop Distributed File System (HDFS) manage data• Map/Reduce tasks are scheduled based on data
locality in HDFS (replicated data blocks)
• Dryad process the DAG executing vertices on compute clusters
• LINQ provides a query interface for structured data
• Provide Hash, Range, and Round-Robin partition patterns
JobTracker
NameNode
1 2
32
3 4
M MM M
R R R R
H
D
F
S
Datablocks
Data/Compute NodesMaster Node
Apache Hadoop Microsoft DryadLINQ
Edge : communication path
Vertex :execution task
Standard LINQ operations
DryadLINQ operations
DryadLINQ Compiler
Dryad Execution Engine
Directed Acyclic Graph (DAG) based execution flows
Job creation; Resource management; Fault tolerance& re-execution of failed tasks/vertices

SALSA
Reduce Phase of Particle Physics “Find the Higgs” using Dryad
• Combine Histograms produced by separate Root “Maps” (of event data to partial histograms) into a single Histogram delivered to Client
• This is an example using MapReduce to do distributed histogramming.
Higgs in Monte Carlo

SALSA
High Energy Physics Data Analysis
Input to a map task: <key, value> key = Some Id value = HEP file Name
Output of a map task: <key, value> key = random # (0<= num<= max reduce tasks)
value = Histogram as binary data
Input to a reduce task: <key, List<value>> key = random # (0<= num<= max reduce tasks)
value = List of histogram as binary data
Output from a reduce task: value value = Histogram file
Combine outputs from reduce tasks to form the final histogram
An application analyzing data from Large Hadron Collider (1TB but 100 Petabytes eventually)

SALSA
AWS/ Azure Hadoop DryadLINQ
Programming patterns
“Master-worker” paradigm
Independent job execution
MapReduce DAG execution, MapReduce + Other
patterns
Fault Tolerance Task re-execution based on a time out
Re-execution of failed and slow tasks.
Re-execution of failed and slow tasks.
Data Storage S3/Azure Storage. HDFS parallel file system. Local files
Environments EC2/Azure clouds, local compute resources
Linux cluster, Amazon Elastic MapReduce
Windows HPCS cluster
Ease of Programming
EC2 : **
Azure: ******* ****
Ease of use EC2 : ***
Azure: ***** ****
Scheduling & Load Balancing
Dynamic scheduling through a global queue,
Good natural load balancing
Data locality, rack aware dynamic task scheduling through a global queue,
Good natural load balancing
Data locality, network topology aware
scheduling. Static task partitions at the node level, suboptimal load
balancing

SALSA
Some Life Sciences Applications
• EST (Expressed Sequence Tag) sequence assembly program using DNA sequence assembly program software CAP3.
• Metagenomics and Alu repetition alignment using Smith Waterman dissimilarity computations followed by MPI applications for Clustering and MDS (Multi Dimensional Scaling) for dimension reduction before visualization
• Mapping the 60 million entries in PubChem into two or three dimensions to aid selection of related chemicals with convenient Google Earth like Browser. This uses either hierarchical MDS (which cannot be applied directly as O(N2)) or GTM (Generative Topographic Mapping).
• Correlating Childhood obesity with environmental factors by combining medical records with Geographical Information data with over 100 attributes using correlation computation, MDS and genetic algorithms for choosing optimal environmental factors.

SALSA
DNA Sequencing Pipeline
Illumina/Solexa Roche/454 Life Sciences Applied Biosystems/SOLiD
Modern Commerical Gene Sequences
Internet
Read Alignment
Visualization
PlotvizBlocking
Sequence
alignment
MDS
Dissimilarity
Matrix
N(N-1)/2 values
FASTA File
N Sequences
block
Pairings
Pairwise
clustering
MapReduce
MPI
• This chart illustrate our research of a pipeline mode to provide services on demand (Software as a Service SaaS) • User submit their jobs to the pipeline. The components are services and so is the whole pipeline.

SALSA
Alu and Metagenomics Workflow
“All pairs” problem Data is a collection of N sequences. Need to calcuate N2 dissimilarities (distances) between
sequnces (all pairs).
• These cannot be thought of as vectors because there are missing characters• “Multiple Sequence Alignment” (creating vectors of characters) doesn’t seem to work if N larger than
O(100), where 100’s of characters long.
Step 1: Can calculate N2 dissimilarities (distances) between sequencesStep 2: Find families by clustering (using much better methods than Kmeans). As no vectors, use vector
free O(N2) methodsStep 3: Map to 3D for visualization using Multidimensional Scaling (MDS) – also O(N2)
Results: N = 50,000 runs in 10 hours (the complete pipeline above) on 768 cores
Discussions:• Need to address millions of sequences …..• Currently using a mix of MapReduce and MPI• Twister will do all steps as MDS, Clustering just need MPI Broadcast/Reduce
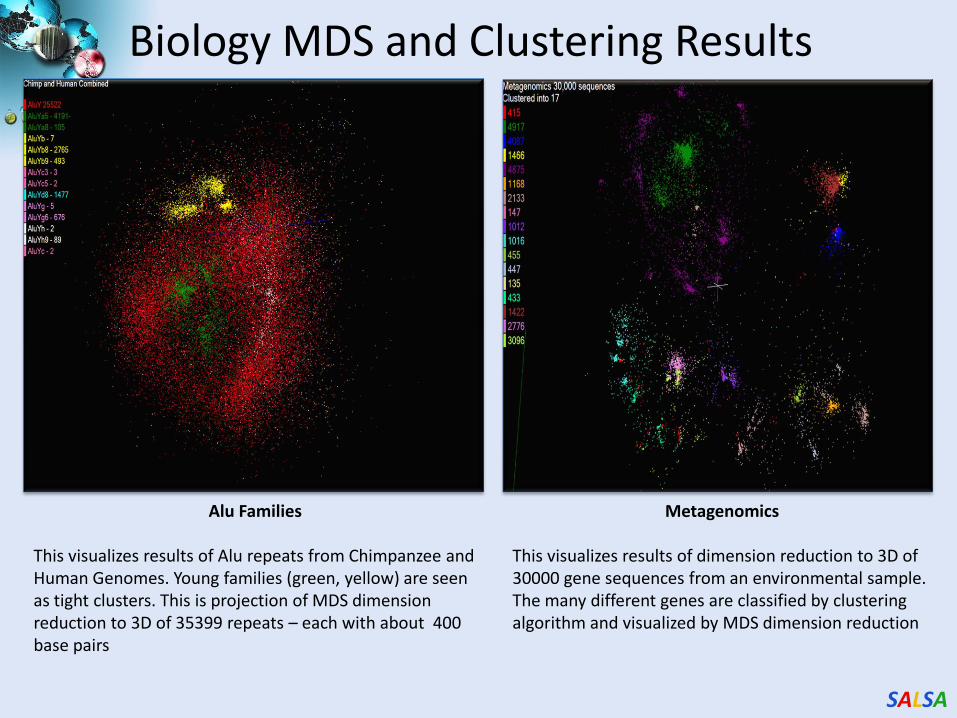
SALSA
Biology MDS and Clustering Results
Alu Families
This visualizes results of Alu repeats from Chimpanzee and Human Genomes. Young families (green, yellow) are seen as tight clusters. This is projection of MDS dimension reduction to 3D of 35399 repeats – each with about 400 base pairs
Metagenomics
This visualizes results of dimension reduction to 3D of 30000 gene sequences from an environmental sample. The many different genes are classified by clustering algorithm and visualized by MDS dimension reduction
SALSA
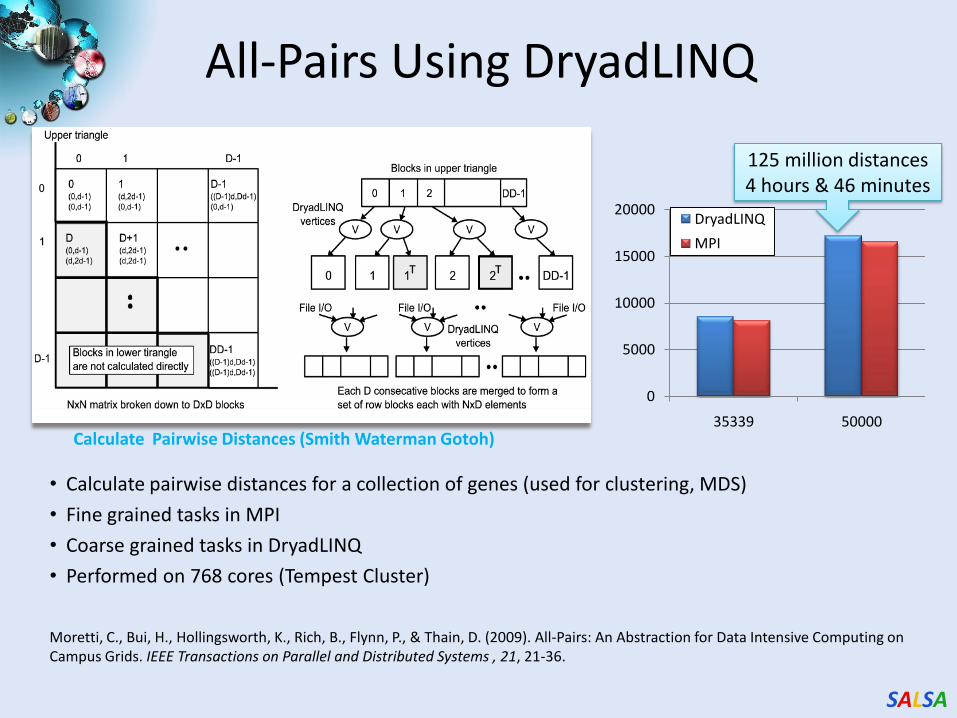
All-Pairs Using DryadLINQ
0
5000
10000
15000
20000
35339 50000
DryadLINQ
MPI
Calculate Pairwise Distances (Smith Waterman Gotoh)
125 million distances4 hours & 46 minutes
• Calculate pairwise distances for a collection of genes (used for clustering, MDS)
• Fine grained tasks in MPI
• Coarse grained tasks in DryadLINQ
• Performed on 768 cores (Tempest Cluster)
Moretti, C., Bui, H., Hollingsworth, K., Rich, B., Flynn, P., & Thain, D. (2009). All-Pairs: An Abstraction for Data Intensive Computing on Campus Grids. IEEE Transactions on Parallel and Distributed Systems , 21, 21-36.

SALSA
Hadoop/Dryad ComparisonInhomogeneous Data I
1500
1550
1600
1650
1700
1750
1800
1850
1900
0 50 100 150 200 250 300
Tim
e (
s)
Standard Deviation
Randomly Distributed Inhomogeneous Data Mean: 400, Dataset Size: 10000
DryadLinq SWG Hadoop SWG Hadoop SWG on VM
Inhomogeneity of data does not have a significant effect when the sequence lengths are randomly distributedDryad with Windows HPCS compared to Hadoop with Linux RHEL on Idataplex (32 nodes)
SALSA
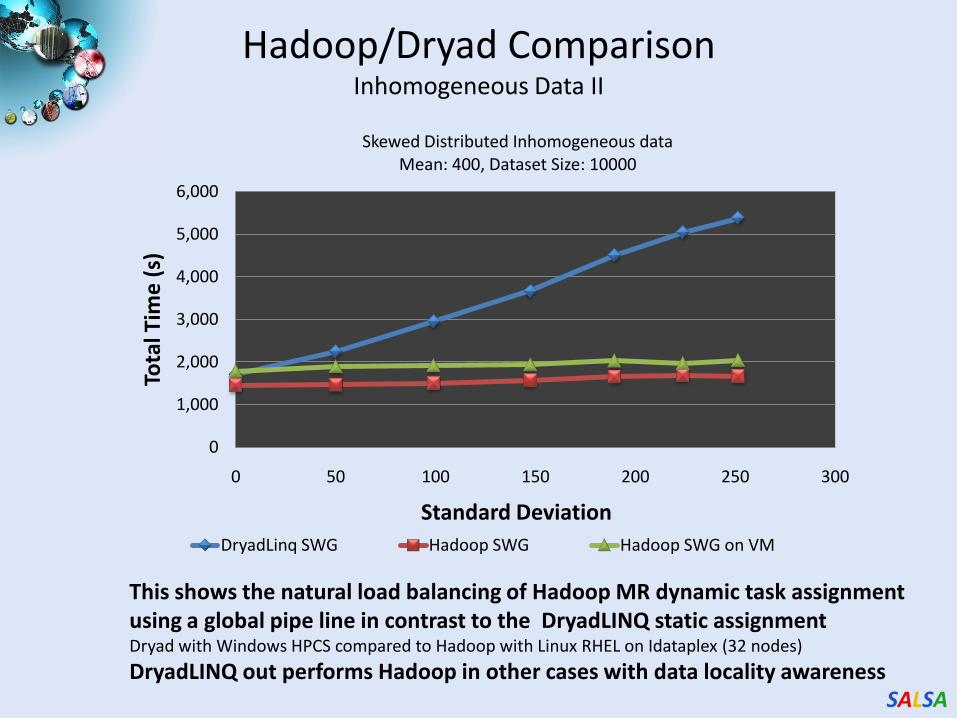
Hadoop/Dryad ComparisonInhomogeneous Data II
0
1,000
2,000
3,000
4,000
5,000
6,000
0 50 100 150 200 250 300
Tota
l Tim
e (
s)
Standard Deviation
Skewed Distributed Inhomogeneous dataMean: 400, Dataset Size: 10000
DryadLinq SWG Hadoop SWG Hadoop SWG on VM
This shows the natural load balancing of Hadoop MR dynamic task assignment using a global pipe line in contrast to the DryadLINQ static assignmentDryad with Windows HPCS compared to Hadoop with Linux RHEL on Idataplex (32 nodes)
DryadLINQ out performs Hadoop in other cases with data locality awareness
SALSA
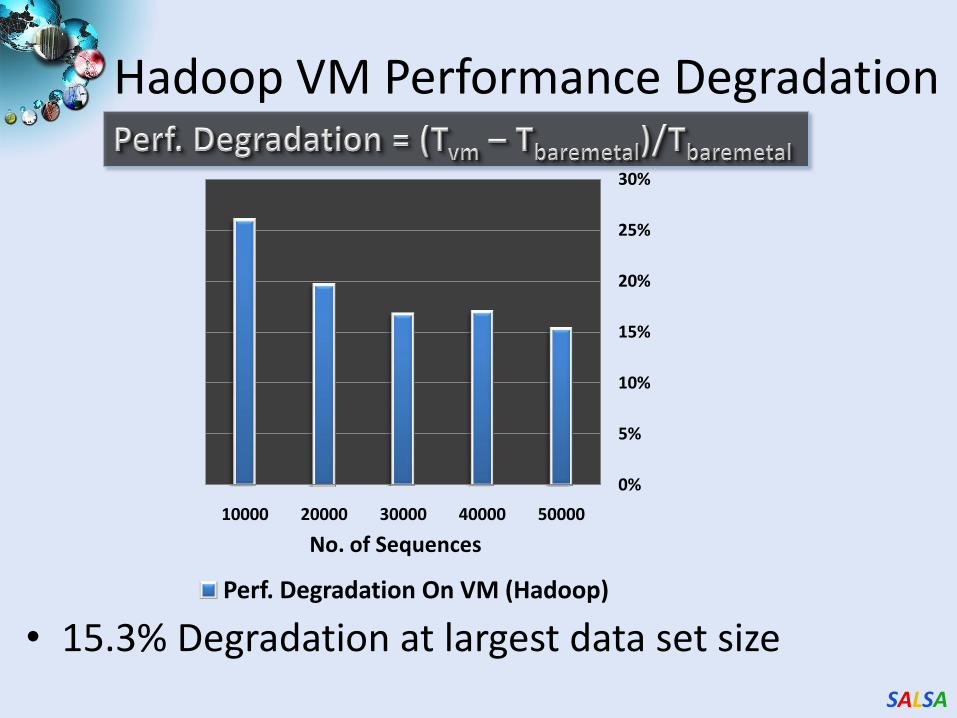
Hadoop VM Performance Degradation
• 15.3% Degradation at largest data set size
10000 20000 30000 40000 50000
0%
5%
10%
15%
20%
25%
30%
No. of Sequences
Perf. Degradation On VM (Hadoop)

SALSA
Application Classes
1 Synchronous Lockstep Operation as in SIMD architectures SIMD
2 Loosely Synchronous
Iterative Compute-Communication stages with independent compute (map) operations for each CPU. Heart of most MPI jobs
MPP
3 Asynchronous Compute Chess; Combinatorial Search often supported by dynamic threads
MPP
4 Pleasingly Parallel Each component independent MPP, Grids, Clouds
5 Metaproblems Coarse grain (asynchronous) combinations of classes 1)-4). The preserve of workflow.
Grids, Clouds
6 MapReduce++ It describes file(database) to file(database) operations which has subcategories including.
1) Pleasingly Parallel Map Only (e.g. Cap3)2) Map followed by reductions (e.g. HEP)3) Iterative “Map followed by reductions” –
Extension of Current Technologies that supports much linear algebra and datamining
Clouds
Hadoop/Dryad
Twister
Classification of Parallel software/hardware use in terms of “Application architecture” Structures

SALSA
Applications & Different Interconnection PatternsMap Only Classic
MapReduceIterative Reductions
MapReduce++Loosely
Synchronous
CAP3 AnalysisDocument conversion(PDF -> HTML)Brute force searches in cryptographyParametric sweeps
High Energy Physics (HEP) HistogramsSWG gene alignmentDistributed searchDistributed sortingInformation retrieval
Expectation maximization algorithmsClusteringLinear Algebra
Many MPI scientific applications utilizingwide variety of communication constructs including local interactions
- CAP3 Gene Assembly- PolarGrid Matlab data analysis
- Information Retrieval -HEP Data Analysis- Calculation of Pairwise Distances for ALU Sequences
- Kmeans - Deterministic Annealing Clustering- Multidimensional Scaling MDS
- Solving Differential Equations and - particle dynamics with short range forces
Input
Output
map
Input
map
reduce
Input
map
reduce
iterations
Pij
Domain of MapReduce and Iterative Extensions MPI
SALSA
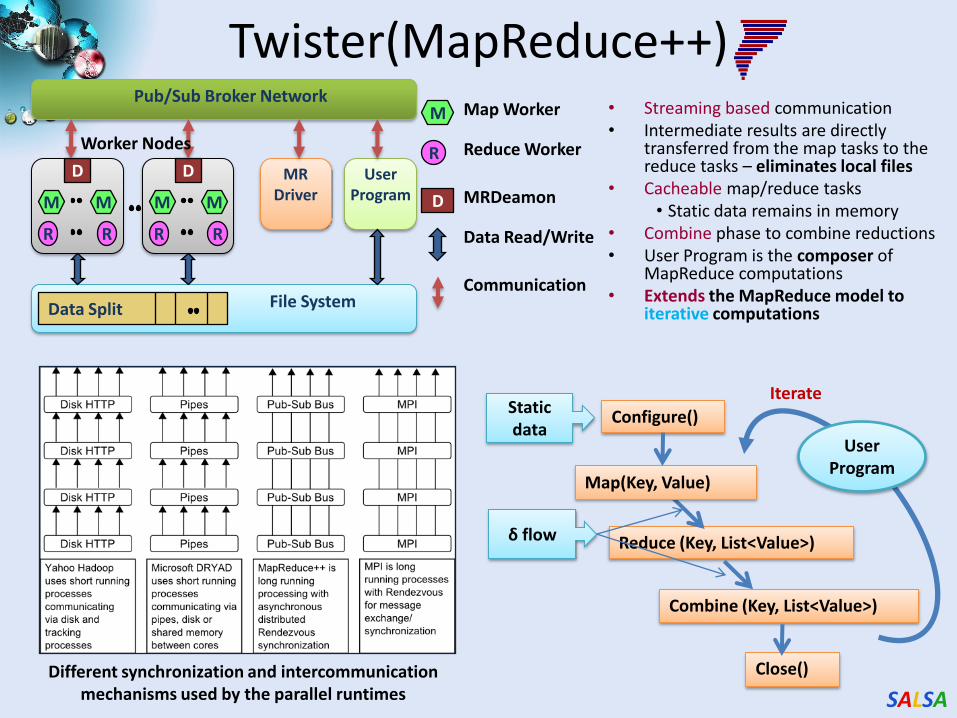
Twister(MapReduce++)• Streaming based communication• Intermediate results are directly
transferred from the map tasks to the reduce tasks – eliminates local files
• Cacheable map/reduce tasks• Static data remains in memory
• Combine phase to combine reductions• User Program is the composer of
MapReduce computations• Extends the MapReduce model to
iterative computationsData Split
D MRDriver
UserProgram
Pub/Sub Broker Network
D
File System
M
R
M
R
M
R
M
R
Worker Nodes
M
R
D
Map Worker
Reduce Worker
MRDeamon
Data Read/Write
Communication
Reduce (Key, List<Value>)
Iterate
Map(Key, Value)
Combine (Key, List<Value>)
User Program
Close()
Configure()Staticdata
δ flow
Different synchronization and intercommunication mechanisms used by the parallel runtimes

SALSA
Twister New Release

SALSA
Iterative Computations
K-meansMatrix
Multiplication
Performance of K-Means Parallel Overhead Matrix Multiplication
Smith Waterman

SALSA
Performance of Pagerank using
ClueWeb Data (Time for 20 iterations)
using 32 nodes (256 CPU cores) of Crevasse

SALSA
TwisterMPIReduce
• Runtime package supporting subset of MPI mapped to Twister
• Set-up, Barrier, Broadcast, Reduce
TwisterMPIReduce
PairwiseClusteringMPI
Multi Dimensional Scaling MPI
GenerativeTopographic Mapping
MPIOther …
Azure Twister (C# C++) Java Twister
Microsoft AzureFutureGrid Local
ClusterAmazon EC2

SALSA
Google MapReduce Apache Hadoop Microsoft Dryad Twister Azure Twister
Programming
Model
MapReduce MapReduce DAG execution,
Extensible to
MapReduce and
other patterns
Iterative
MapReduce
MapReduce-- will
extend to Iterative
MapReduce
Data Handling GFS (Google File
System)
HDFS (Hadoop
Distributed File
System)
Shared Directories &
local disks
Local disks
and data
management
tools
Azure Blob Storage
Scheduling Data Locality Data Locality; Rack
aware, Dynamic
task scheduling
through global
queue
Data locality;
Network
topology based
run time graph
optimizations; Static
task partitions
Data Locality;
Static task
partitions
Dynamic task
scheduling through
global queue
Failure Handling Re-execution of failed
tasks; Duplicate
execution of slow tasks
Re-execution of
failed tasks;
Duplicate execution
of slow tasks
Re-execution of failed
tasks; Duplicate
execution of slow
tasks
Re-execution
of Iterations
Re-execution of
failed tasks;
Duplicate execution
of slow tasks
High Level
Language
Support
Sawzall Pig Latin DryadLINQ Pregel has
related
features
N/A
Environment Linux Cluster. Linux Clusters,
Amazon Elastic
Map Reduce on
EC2
Windows HPCS
cluster
Linux Cluster
EC2
Window Azure
Compute, Windows
Azure Local
Development Fabric
Intermediate
data transfer
File File, Http File, TCP pipes,
shared-memory
FIFOs
Publish/Subscr
ibe messaging
Files, TCP

SALSA
High Performance Dimension Reduction and Visualization
• Need is pervasive
– Large and high dimensional data are everywhere: biology, physics, Internet, …
– Visualization can help data analysis
• Visualization of large datasets with high performance
– Map high-dimensional data into low dimensions (2D or 3D).
– Need Parallel programming for processing large data sets
– Developing high performance dimension reduction algorithms: • MDS(Multi-dimensional Scaling), used earlier in DNA sequencing application
• GTM(Generative Topographic Mapping)
• DA-MDS(Deterministic Annealing MDS)
• DA-GTM(Deterministic Annealing GTM)
– Interactive visualization tool PlotViz
• We are supporting drug discovery by browsing 60 million compounds in
PubChem database with 166 features each

SALSA
Dimension Reduction Algorithms
• Multidimensional Scaling (MDS) [1]o Given the proximity information among
points.
o Optimization problem to find mapping in target dimension of the given data based on pairwise proximity information while minimize the objective function.
o Objective functions: STRESS (1) or SSTRESS (2)
o Only needs pairwise distances ij between original points (typically not Euclidean)
o dij(X) is Euclidean distance between mapped (3D) points
• Generative Topographic Mapping (GTM) [2]o Find optimal K-representations for the given
data (in 3D), known as K-cluster problem (NP-hard)
o Original algorithm use EM method for optimization
o Deterministic Annealing algorithm can be used for finding a global solution
o Objective functions is to maximize log-likelihood:
[1] I. Borg and P. J. Groenen. Modern Multidimensional Scaling: Theory and Applications. Springer, New York, NY, U.S.A., 2005.[2] C. Bishop, M. Svens´en, and C. Williams. GTM: The generative topographic mapping. Neural computation, 10(1):215–234, 1998.

SALSA
GTM vs. MDS
MDS also soluble by viewing as nonlinear χ2 with iterative linear equation solver
GTM MDS (SMACOF)
Maximize Log-Likelihood Minimize STRESS or SSTRESSObjectiveFunction
O(KN) (K << N) O(N2)Complexity
• Non-linear dimension reduction• Find an optimal configuration in a lower-dimension• Iterative optimization method
Purpose
EM Iterative Majorization (EM-like)Optimization
Method

SALSA
MDS and GTM Example
37
Chemical compounds shown in literatures, visualized by MDS (left) and GTM (right)Visualized 234,000 chemical compounds which may be related with a set of 5 genes of interest (ABCB1, CHRNB2, DRD2, ESR1, and F2) based on the dataset collected from major journal literatures which is also stored in Chem2Bio2RDF system.

SALSA
Interpolation Method• MDS and GTM are highly memory and time consuming
process for large dataset such as millions of data points• MDS requires O(N2) and GTM does O(KN) (N is the number of
data points and K is the number of latent variables)• Training only for sampled data and interpolating for out-of-
sample set can improve performance• Interpolation is a pleasingly parallel application suitable for
MapReduce and Clouds
n in-sample
N-nout-of-sample
Total N data
Training
Interpolation
Trained data
Interpolated MDS/GTM
map
SALSA
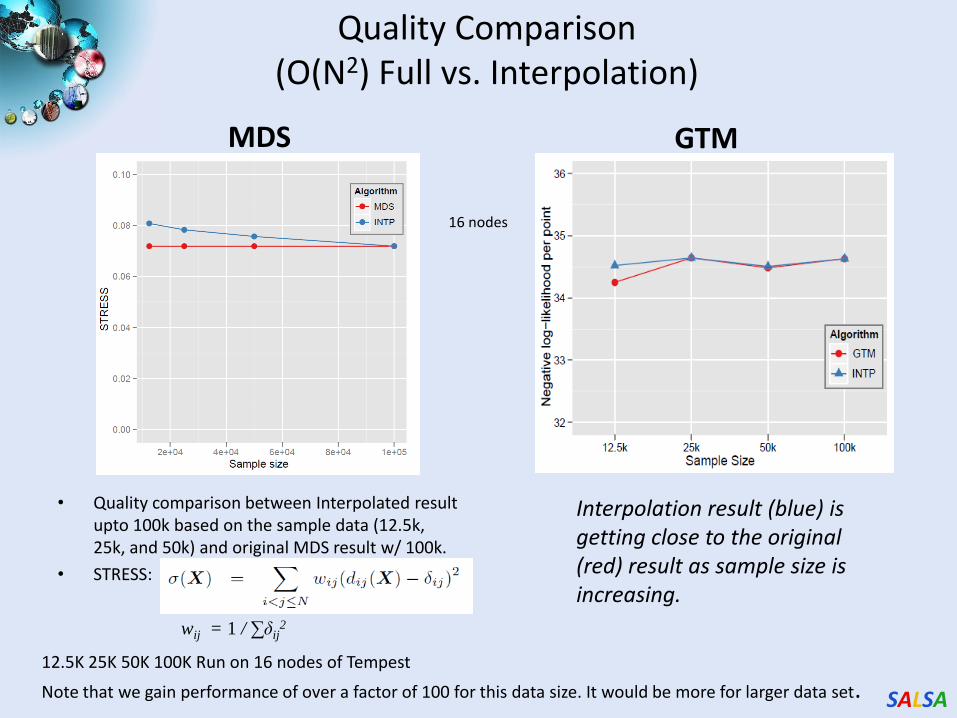
Quality Comparison (O(N2) Full vs. Interpolation)
MDS
• Quality comparison between Interpolated result upto 100k based on the sample data (12.5k, 25k, and 50k) and original MDS result w/ 100k.
• STRESS:
wij = 1 / ∑δij2
GTM
Interpolation result (blue) is getting close to the original (red) result as sample size is increasing.
16 nodes
12.5K 25K 50K 100K Run on 16 nodes of Tempest
Note that we gain performance of over a factor of 100 for this data size. It would be more for larger data set.

SALSA
Summary of Initial Results
• Cloud technologies (Dryad/Hadoop/Azure/EC2) promising for Life Science computations
• Dynamic Virtual Clusters allow one to switch between different modes
• Overhead of VM’s on Hadoop (15%) acceptable
• Twister allows iterative problems (classic linear algebra/datamining) to use MapReduce model efficiently
– Prototype Twister released
• Dimension Reduction is important for visualization
SALSA
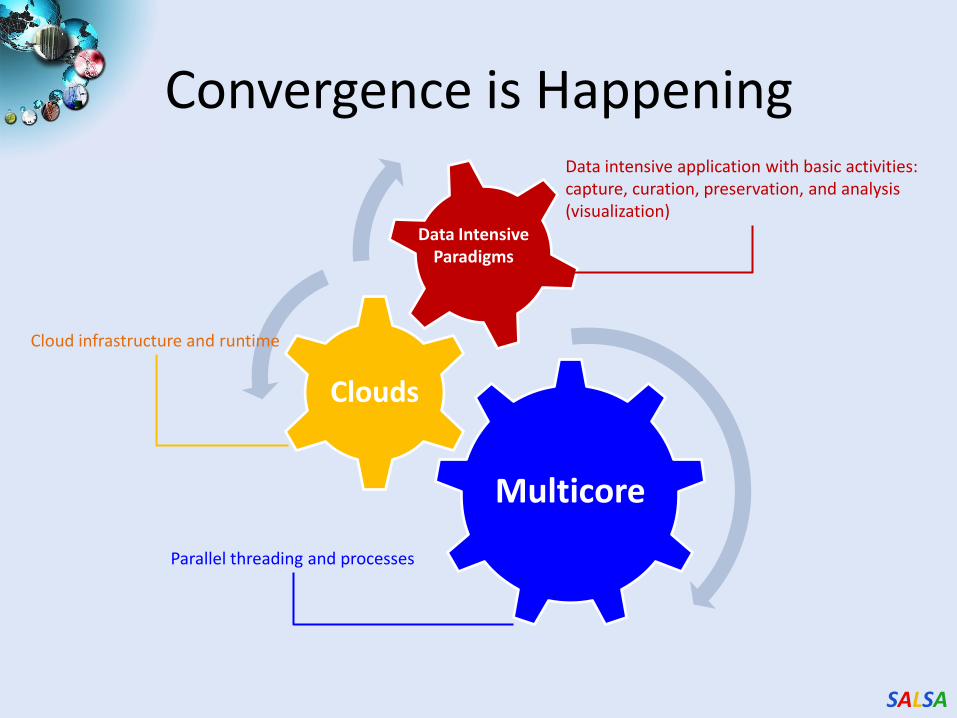
Convergence is Happening
Multicore
Clouds
Data IntensiveParadigms
Data intensive application with basic activities:capture, curation, preservation, and analysis (visualization)
Cloud infrastructure and runtime
Parallel threading and processes

SALSA
• Dynamic Virtual Cluster provisioning via XCAT• Supports both stateful and stateless OS images
iDataplex Bare-metal Nodes
Linux Bare-system
Linux Virtual Machines
Windows Server 2008 HPC
Bare-system Virtualization
Microsoft DryadLINQ / Twister / MPIApache Hadoop / Twister/ MPI
Smith Waterman Dissimilarities, CAP-3 Gene Assembly, PhyloD Using DryadLINQ, High Energy Physics, Clustering, Multidimensional Scaling,
Generative Topological Mapping
XCAT Infrastructure
Xen Virtualization
Applications
Runtimes
Infrastructure software
Hardware
Windows Server 2008 HPC
Science Cloud (Dynamic Virtual Cluster) Architecture
Services and Workflow

SALSA
Acknowledgements
SALSA Group
http://salsahpc.indiana.edu
Judy Qiu, Adam Hughes
Jaliya Ekanayake, Thilina Gunarathne, Jong Youl Choi, Seung-Hee Bae,
Yang Ruan, Hui Li, Bingjing Zhang, Saliya Ekanayake, Stephen Wu
Collaborators
Yves Brun, Peter Cherbas, Dennis Fortenberry, Roger Innes, David Nelson, Homer Twigg,
Craig Stewart, Haixu Tang, Mina Rho, David Wild, Bin Cao, Qian Zhu, Maureen Biggers, Gilbert Liu,
Neil Devadasan
Support by
Research Technologies of UITS and School of Informatics and Computing