multiagent planning with factored mdps carlos guestrin daphne koller stanford university ronald parr...
Post on 21-Dec-2015
222 views
TRANSCRIPT

Multiagent Planning with Factored MDPs
Carlos Guestrin
Daphne KollerStanford University
Ronald ParrDuke University

Multiagent Coordination Examples
Search and rescue Factory management Supply chain Firefighting Network routing Air traffic control
Multiple, simultaneous decisions
Limited observability Limited communication
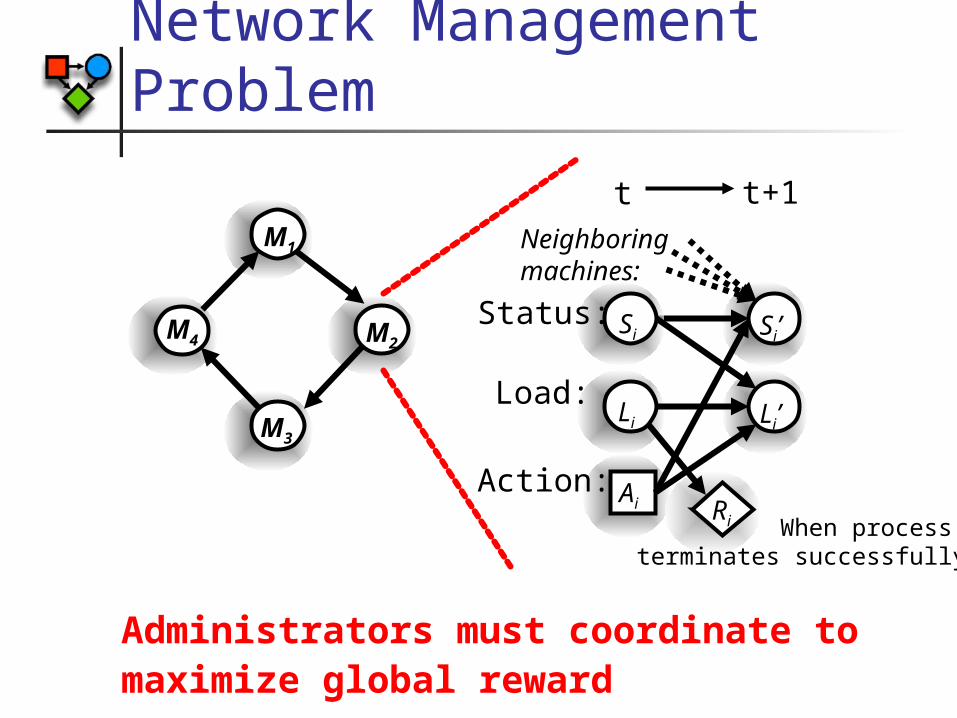
Network Management Problem
Administrators must coordinate to maximize global reward
M4
M1
M3
M2 Si’
Neighboring machines:
Li Li’Load:
SiStatus:
Ai Action:
Ri When process terminates successfully
t t+1

Joint Decision Space
Represent as MDP: Action space: joint action a= {a1,…, an} for all
agents State space: joint state x of entire system Reward function: total reward r
Action space is exponential in # agents
State space is exponential in # variables
Global decision requires complete observation

Long-term Utilities One step utility:
SysAdmin Ai receives reward ($) if process completes
Total utility: sum of rewards
Optimal action requires long-term planning Long-term utility Q(x,a):
Expected reward, given current state x and action a Optimal action at state x is:
),(max axa
Q

Q(A1,…,A4, X1,…,X4) ¼
Q1(A1, A4, X1,X4) + Q2(A1, A2, X1,X2) +
Q3(A2, A3, X2,X3) + Q4(A3, A4,
X3,X4)
Local Q function Approximation
M4
M1
M3
M2
Q3
Q(A1,…,A4, X1,…,X4)
Associated with Agent 3
Limited observability: agent i only observes variables in Qi
Observe only X2 and X3
Must choose action to maximize i Qi

Use variable elimination for maximization: [Bertele & Brioschi ‘72]
Maximizing i Qi: Coordination
Graph
Limited communication for optimal action choice
Comm. bandwidth = induced width of coord. graph
Here we need only 23, instead of 63 sum operations.
A1
A4
A2 A3
1Q
4Q 3Q
2Q
),(),(),(max 321312211,, 321
AAgAAQAAQA A A
),(),(max),(),(max 424433312211,, 4321
AAQAAQAAQAAQAA A A
),(),(),(),(max 424433312211,,, 4321
AAQAAQAAQAAQA A A A

Where do the Qi come from?
Use function approximation to find Qi: Q(X1, …, X4, A1, …, A4) ¼ Q1(A1, A4, X1,X4) + Q2(A1, A2, X1,X2) +
Q3(A2, A3, X2,X3) + Q4(A3, A4, X3,X4)
Long-term planning requires Markov Decision Process # states exponential # actions exponential
Efficient approximation by exploiting structure!
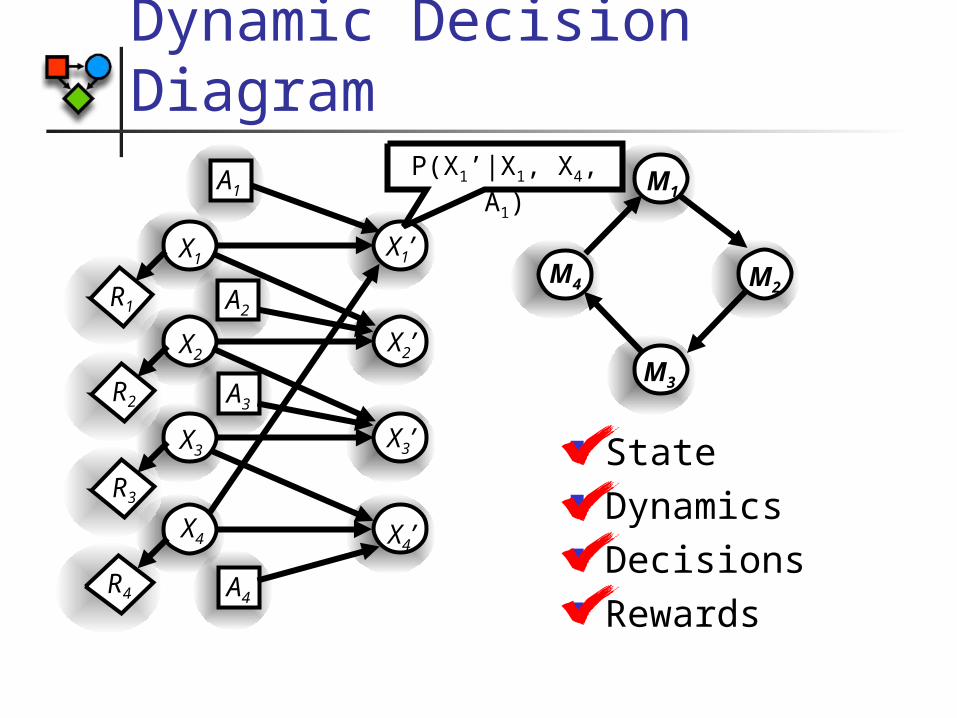
Dynamic Decision Diagram
M4
M1
M3
M2
A3
A4
A2
A1
X1
X3
X4
X2
R1
R2
R3
R4
X3’
X4’
X2’
X1’
State Dynamics Decisions Rewards
P(X1’|X1, X4, A1)

Long-term Utility = Value of MDP
Value computed by linear programming:
,
),()( :subject to
)(:minimize
⎩⎨⎧∀
≥
∑
ax
xax
xx
QV
V
One variable V (x) for each state One constraint for each state x and action a Number of states and actions exponential!

Linear combination of restricted domain functions [Bellman et al. ‘63][Tsitsiklis & Van Roy ’96][Koller & Parr ’99,’00][Guestrin et al. ’01]
Decomposable Value Functions
Each hi is status of small part(s) of a complex system: Status of a machine and neighbors Load on machine
Must find w giving good approximate value function
∑=i iihwV )()(
~xx

Single LP Solution for Factored MDPs
One variable wi for each basis function Polynomially many LP variables
One constraint for every state and action Exponentially many LP constraints
hi , Qi depend on small sets of variables/actions
,
),()( :subject to
:minimize
⎪⎩
⎪⎨⎧
∀
≥∑∑
∑
ax
xaxi
ii
ii
iii
Qhw
wα[Schweitzer and Seidmann
‘85]

,),()( :subject to⎩⎨⎧
∀≥∑∑ axxaxi
ii
ii Qhw
Representing Exponentially Many Constraints [Guestrin et al ’01]
)(),( :subject to max0,⎩
⎨⎧
−∑≥i
iii hwQ xxaxa
Exponentially many linear = one nonlinear constraint
,)(),(0 :subject to⎩⎨⎧
∀−≥∑ axxxai
iii hwQ

Representing the Constraints
Functions are factored, use Variable Elimination to represent constraints:
[ ]),(),(max),(),(max0 4321,,
DBfDCfCAfBAfDCBA
+++≥
),(),(
),(),(max0
43),(
1
),(121
,,
DBfDCfg
gCAfBAf
CB
CB
CBA
+≥
++≥
Number of constraints exponentially smaller

Summary of Algorithm
1. Pick local basis functions hi
2. Single LP to compute local Qi’s in factored
MDP
3. Coordination graph computes maximizing
action
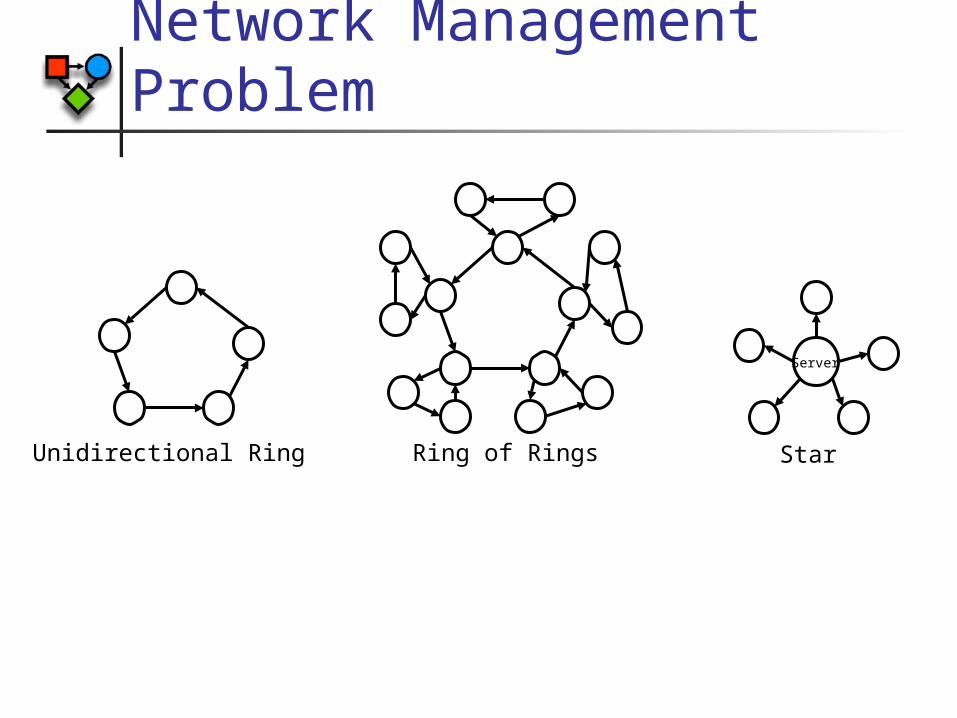
Network Management Problem
Unidirectional Ring
Server
StarRing of Rings
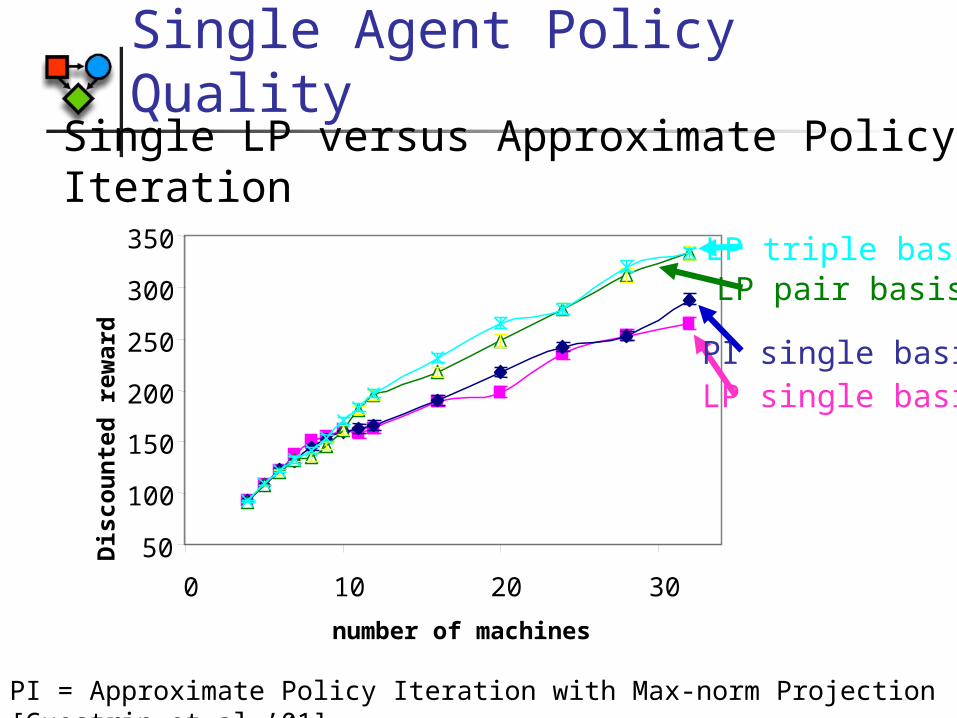
Single Agent Policy Quality
50
100
150
200
250
300
350
0 10 20 30
number of machines
Dis
cou
nte
d r
ewar
d
PI = Approximate Policy Iteration with Max-norm Projection [Guestrin et al.’01]
Single LP versus Approximate Policy Iteration
LP single basisPI single basis
LP pair basisLP triple basis
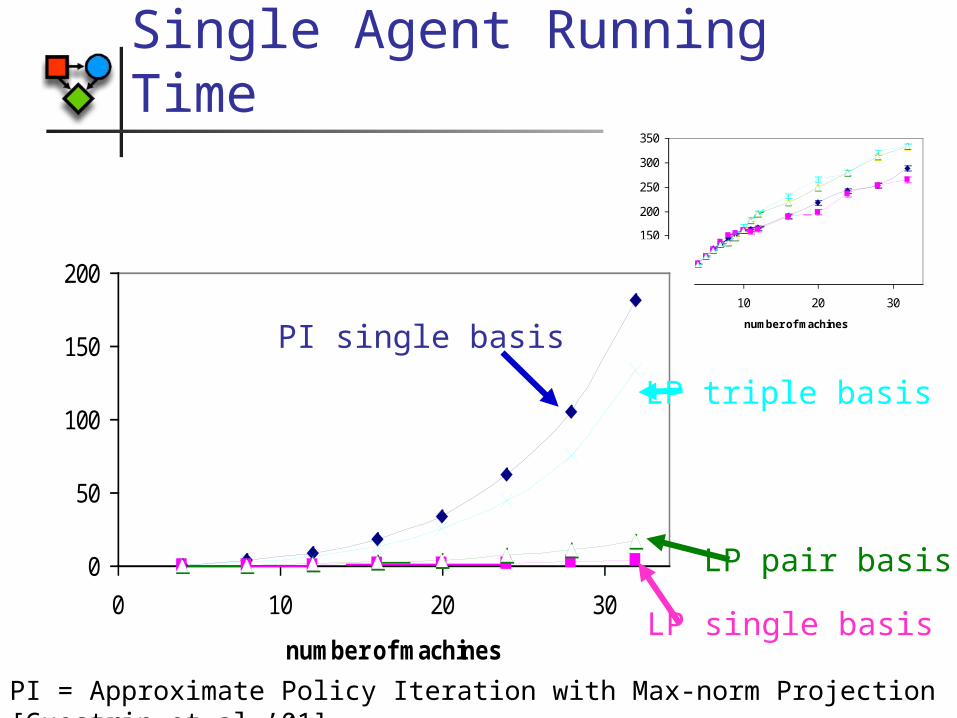
Single Agent Running Time
50
100
150
200
250
300
350
0 10 20 30
number of machines
Discounted reward
0
50
100
150
200
0 10 20 30
number of machines
Total running time (minutes)
LP single basis
PI single basis
LP pair basis
LP triple basis
PI = Approximate Policy Iteration with Max-norm Projection [Guestrin et al.’01]

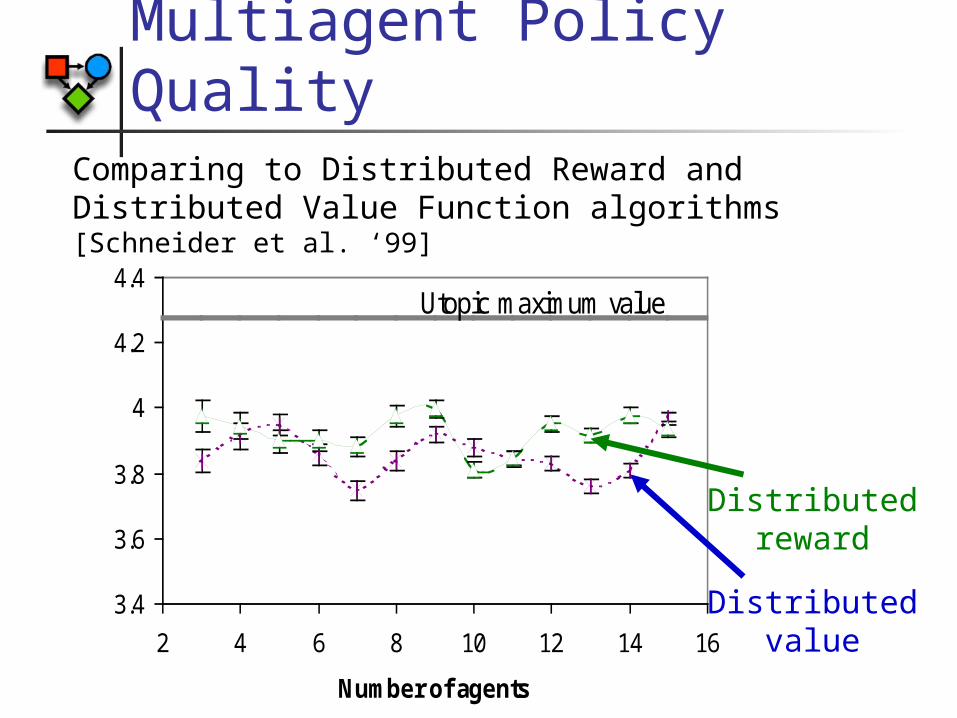
Multiagent Policy QualityComparing to Distributed Reward and Distributed Value Function algorithms [Schneider et al. ‘99]
3.4
3.6
3.8
4
4.2
4.4
2 4 6 8 10 12 14 16
Number of agents
Estimated value per agent
Utopic maximum value
Multiagent Policy QualityComparing to Distributed Reward and Distributed Value Function algorithms [Schneider et al. ‘99]
3.4
3.6
3.8
4
4.2
4.4
2 4 6 8 10 12 14 16
Number of agents
Estimated value per agent
Utopic maximum value
Distributedreward
Distributedvalue
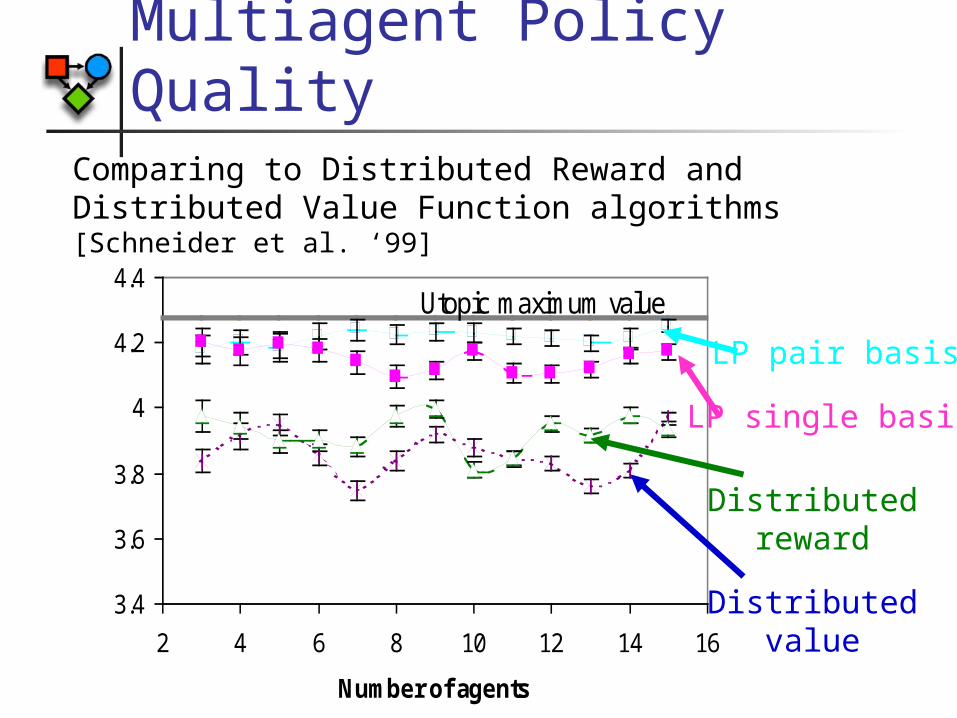
Multiagent Policy QualityComparing to Distributed Reward and Distributed Value Function algorithms [Schneider et al. ‘99]
3.4
3.6
3.8
4
4.2
4.4
2 4 6 8 10 12 14 16
Number of agents
Estimated value per agent
Utopic maximum value
LP single basis
LP pair basis
Distributedreward
Distributedvalue
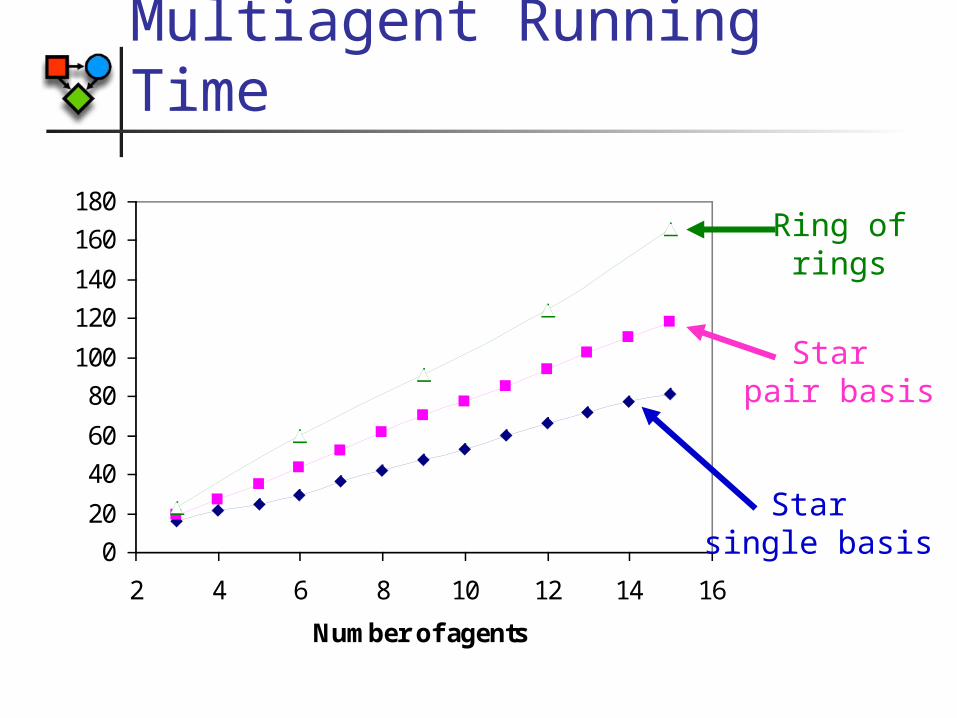
Multiagent Running Time
0
20
40
60
80
100
120
140
160
180
2 4 6 8 10 12 14 16
Number of agents
Total running time (seconds)Star
single basis
Star pair basis
Ring ofrings

Conclusions Multiagent planning algorithm:
Limited Communication Limited Observability
Unified view of function approximation and multiagent communication
Single LP solution is simple and very efficient
Exploit structure to reduce computation costs! Solve very large MDPs efficiently

14436596542203275214816766492036822682859734670489954077831385060806196390977769687258235595095458210061891186534272525795367402762022519832080387801477422896484127439040011758861804112894781562309443806156617305408667449050617812548034440554705439703889581746536825491613622083026856377858229022846398307887896918556404084898937609373242171846359938695516765018940588109060426089671438864102814350385648747165832010614366132173102768902855220001
Solve Very Large MDPs
Solved MDPs with :
states
1322070819480806636890455259752
over 10150 actions and
500 agents;

Conclusions Multiagent planning algorithm:
Limited Communication Limited Observability
Unified view of function approximation and multiagent communication
Single LP solution is simple and very efficient
Exploit structure to reduce computation costs! Solve very large MDPs efficiently