moneyball in the classroom using baseball to teach statistics josh tabor
DESCRIPTION
Moneyball in the Classroom Using Baseball to Teach Statistics Josh Tabor Canyon del Oro High School [email protected]. Moneyball in the Classroom. Objectives By the end of the session, participants will: - PowerPoint PPT PresentationTRANSCRIPT

Moneyball in the ClassroomUsing Baseball to Teach Statistics
Josh TaborCanyon del Oro High School
Mo
ney
bal
l in
th
e C
lass
roo
m

ObjectivesBy the end of the session, participants will:• Obtain several classroom-tested examples
that promote the real-world applications of mathematics and help students meet the Common Core State Standards
• Understand that the goal of a model should be minimize the size of prediction errors
• Understand the properties of least-squares regression lines and how to interpret the slope and intercept
• Understand the concept of regression to the mean and what it reveals about future performances
Mo
ney
bal
l in
th
e C
lass
roo
m

Move over Brad Pitt, here is the real star of Moneyball:
Predicted winning percentage =
Created by Bill James and called the “Pythagorean” expected winning percentage, this formula uses a team’s runs scored (RS) and runs allowed (RA) to predict their winning percentage.
Does it work? Why did he use 2 for the exponent instead of some other value??
2
2 2
RS
RS RA
Mo
ney
bal
l in
th
e C
lass
roo
m

In 2012, the Oakland A’s scored 713 runs, allowed 614 runs, and won 94 games.
According to the Pythagorean formula, a team with this many runs scored and runs allowed would be expected to win about 57.4% of their games.
In a 162-game season, this is 0.574(162) = 92.99 expected wins.
This means that Oakland won 94 – 92.99 = 1.01 more games than expected, based on their runs scored and allowed.
2
2 2
7130.574 57.4%
713 614
Mo
ney
bal
l in
th
e C
lass
roo
m

The difference between an actual value and a predicted value is called a residual.
residual = actual value – predicted value
In the Common Core State Standards, our students are expected to “informally assess the fit of a function by plotting and analyzing residuals” (S-ID-6.b).
Mo
ney
bal
l in
th
e C
lass
roo
m

Team RS RA Wins Predicted Wins Residual
ARI 734 688 81 86.235 -5.23503ATL 700 600 94 93.3882 0.611765BAL 712 705 93 81.8003 11.1997BOS 734 806 69 73.4425 -4.44249CHC 613 759 61 63.954 -2.95396CHW 748 676 85 89.1701 -4.17012CIN 669 588 97 91.396 5.60403CLE 667 845 68 62.1893 5.81073COL 758 890 64 68.107 -4.10699
Here is a partial table showing how the formula worked for other teams:
Mo
ney
bal
l in
th
e C
lass
roo
m

So, why did Bill James use 2 for the exponent? Will another value for the exponent work better?
Here is a partial table using 1 for the exponent. Does this model work better?
Team RS RA Wins Predicted Wins Residual
ARI 734 688 81 83.6203 -2.62025ATL 700 600 94 87.2308 6.76923BAL 712 705 93 81.4001 11.5999BOS 734 806 69 77.213 -8.21299CHC 613 759 61 72.3805 -11.3805CHW 748 676 85 85.0955 -0.09551CIN 669 588 97 86.2196 10.7804CLE 667 845 68 71.4643 -3.46429COL 758 890 64 74.5121 -10.5121
Mo
ney
bal
l in
th
e C
lass
roo
m

Which model is better?
In general, we prefer models that produce smaller residuals.
To compare these two models, we can compare the sum of squared residuals (SSR).
For an exponent of 2,SSR = (-5.2)2 + (0.6)2 + … = 411
For an exponent of 1,SSR = (2.6)2 + (6.8)2 + … = 1300
Mo
ney
bal
l in
th
e C
lass
roo
m

The best model is the one that produces the smallest sum of squared residuals (SSR). This is called the least-squares criterion.
Here is a scatterplot showing different exponents from 1 to 3 along with their corresponding SSR. Which exponent looks best?
400
600
800
1000
1200
1400
1.0 1.5 2.0 2.5 3.0Exponent
SSR Scatter Plot
Mo
ney
bal
l in
th
e C
lass
roo
m

Interestingly, there is a different “ideal” exponent for each sport. (Class activity alert!)
For example, here is a scatterplot showing different exponents and SSR for NBA teams in 2009:
Mo
ney
bal
l in
th
e C
lass
roo
m

Part 2: Modeling Runs Scored
Now that we understand how to use runs scored and runs allowed to model predicted winning percentage, how can we model runs scored and runs allowed?
Using team data from the 2012 season, we can look for variables that have a strong relationship with runs scored.
Here is a scatterplot showing hits vs. runs scored for the 30teams:
600
650
700
750
800
Hits1250 1350 1450 1550
Mo
ney
bal
l in
th
e C
lass
roo
m

Because the association appears linear, we should use a line to model the relationship between hits and runs scored.
But, which line is best?
Time for Fathom….
Mo
ney
bal
l in
th
e C
lass
roo
m

The “best” line is the one that makes the sum of squared residuals the least. Not surprisingly, it is called the least-squares regression line.
Here is the scatterplot again, along with the least-squares regression line:
predicted RS= -79 + 0.556(hits)
600
650
700
750
800
Hits1250 1300 1350 1400 1450 1500 1550
RS = -79 + 0.556Hits; r2 = 0.58Mo
ney
bal
l in
th
e C
lass
roo
m

CCSS: S-ID-7: Interpret the slope (rate of change) and the intercept (constant term) of a linear model in the context of the data.
The slope of the least-squares regression line is 0.556. How do we interpret this value? What about the intercept?
Slope: For each additional hit, the predicted number of runs increases by 0.556.
Intercept: If a team had 0 hits for the season, the predicted number of runs scored is -79. Realistic? Why not??
Mo
ney
bal
l in
th
e C
lass
roo
m

Suppose that Oakland has a chance to improve at one position and can expect to have 40 more hits. How many wins is that worth, assuming the performances of other players stay the same?
For each additional hit, we predict 0.556 more runs. So, 40 additional hits is worth 40(0.556) = 22.24 more runs.
This means Oakland would score 735.24 runs instead of 713. Using the Pythagorean formula:
58.9% of 162 is 95.42 wins. This means 2.43 additional expected wins (95.42 – 92.99 = 2.43).
2
2 2
735.240.589 58.9%
735.24 614
Mo
ney
bal
l in
th
e C
lass
roo
m

Which variable does the best job of modeling runs scored? Here are some scatterplots:
600
650
700
750
800
Hits1250 1300 1350 1400 1450 1500 1550
RS = -79 + 0.556Hits; r2 = 0.58
Team Offense Scatter Plot
600
650
700
750
800
HR100 120 140 160 180 200 220 240 260
RS = 513 + 1.14HR; r2 = 0.42
Team Offense Scatter Plot
600
650
700
750
800
OBP0.30 0.31 0.32 0.33 0.34
RS = -634 + 4182OBP; r2 = 0.62
Team Offense Scatter Plot
600
650
700
750
800
SLG0.36 0.38 0.40 0.42 0.44 0.46
RS = -236 + 2312SLG; r2 = 0.85
Team Offense Scatter Plot
Mo
ney
bal
l in
th
e C
lass
roo
m

The best model is the one with the smallest sum of squared residuals (SSR).
Here is a table showing the SSR when predicting runs scored using the following variables:
Variable SSR
Hits 40,603
Home runs 56,830
On-base percentage 37,138
Slugging average 14,237
OPS 10,109
Mo
ney
bal
l in
th
e C
lass
roo
m

Part 3: Modeling Runs Allowed
Modeling runs allowed is much more difficult. However, sabermatricians have been making good progress in the last decade after a revolutionary discovery by Voros McCracken.
He demonstrated that a pitcher has very little (if any) control over what happens to a ball once it is hit.
BABIP (batting average on balls in play) is a measure of what happens during at-bats that don’t end in strikeouts, walks, or home runs.
Voros showed that BABIP is essentially random from year to year.
Mo
ney
bal
l in
th
e C
lass
roo
m

Here is a scatterplot showing the BABIP for pitchers in two consecutive years (2008 and 2009):
0.26
0.28
0.30
0.32
0.34
0.22 0.24 0.26 0.28 0.30 0.32 0.34 0.36BABIP2008
2009,2008 Scatter Plot
Mo
ney
bal
l in
th
e C
lass
roo
m

Because the outcome of batted balls is basically random, McCracken suggested that the best way to model runs allowed is to use variables that pitchers do have control over. For example, strikeout rate, walk rate, and home run rate.
Here is a scatterplot of strikeout rate in 2008 and 2009 for these same pitchers:
3
4
5
6
7
8
9
10
11
3 4 5 6 7 8 9 10 11SOrate2008M
on
eyb
all i
n t
he
Cla
ssro
om

Part 4: Regression to the Mean
It’s difficult to make predictions, especially about the future.
–Yogi Berra
So far, we have been investigating relationships between variables within the same season.
What teams really want to know is how to make predictions about what will happen next year.
Before we do that, let’s flip some coins…
Mo
ney
bal
l in
th
e C
lass
roo
m

Here is a scatterplot showing the outcomes of two sets of 10 coin flips, along with the line y = x.
If we know a flipper did well the first time, what should we predict will happen the second time? What if a flipper did poorly the first time?
0
2
4
6
8
10
NumHeads10 2 4 6 8 10
NumHeads2 = x
Mo
ney
bal
l in
th
e C
lass
roo
m
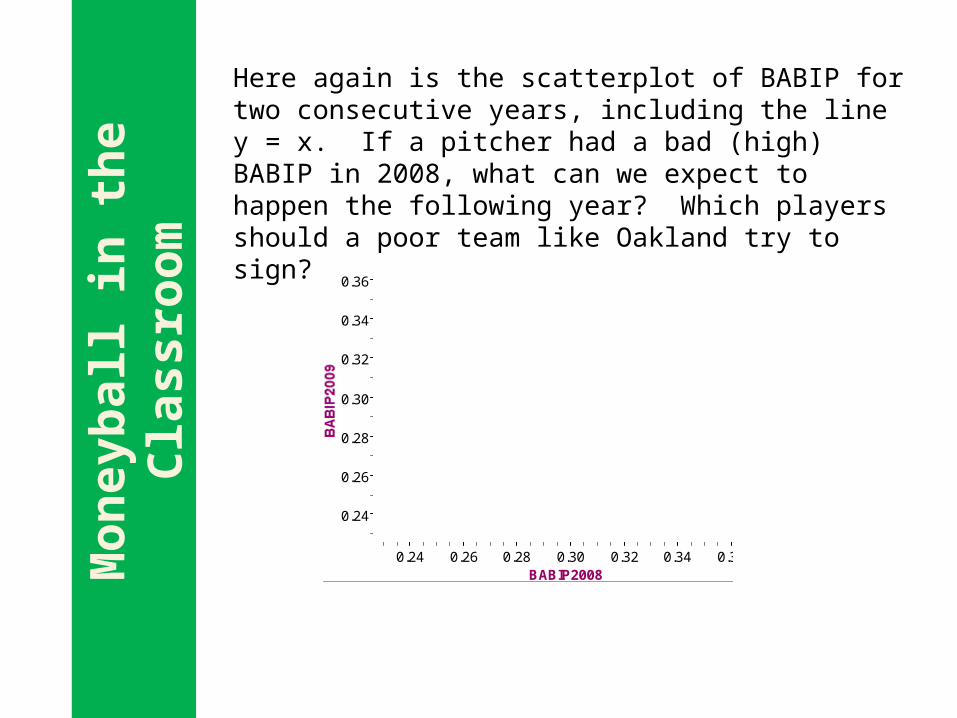
Here again is the scatterplot of BABIP for two consecutive years, including the line y = x. If a pitcher had a bad (high) BABIP in 2008, what can we expect to happen the following year? Which players should a poor team like Oakland try to sign?
0.24
0.26
0.28
0.30
0.32
0.34
0.36
0.24 0.26 0.28 0.30 0.32 0.34 0.36BABIP2008
BABIP2009 = x
Mo
ney
bal
l in
th
e C
lass
roo
m

Now, let’s look at hitters in two consecutive years. Here is a scatterplot showing batting average in 2008 and 2009, along with the line y = x. Do we see the same thing?
0.22
0.24
0.26
0.28
0.30
0.32
0.34
0.36
0.22 0.24 0.26 0.28 0.30 0.32 0.34 0.36AVG2008
AVG2009 = x
Mo
ney
bal
l in
th
e C
lass
roo
m

Now, here is the same scatterplot with the least-squares regression line added as well.
The line predicts that players who were above average in 2008 will be good, but not quite as good in 2009. Likewise, it predicts that players who were below average in 2008 will be bad, but not quite as bad in 2009. This is regression to the mean.
0.22
0.24
0.26
0.28
0.30
0.32
0.34
0.36
0.22 0.24 0.26 0.28 0.30 0.32 0.34 0.36AVG2008
Mo
ney
bal
l in
th
e C
lass
roo
m

What causes regression to the mean?
In sports,
performance = ability + random chance.
A good performance is usually a combination of good ability and good luck. In future performances, the good luck is unlikely to continue, even if his ability is the same.
This explains the SI Jinx and the Madden Curse.
Mo
ney
bal
l in
th
e C
lass
roo
m

This also applies to student performance on tests, especially MC tests—a good performance one year is likely due to good ability and good luck. What is likely to happen next year?
What about an intervention class for students with low scores the previous year??
Understanding regression to the mean is vital for making predictions about the future.
Evaluations: Session #466
Mo
ney
bal
l in
th
e C
lass
roo
m