mmds 6.3-6.5
TRANSCRIPT

MMDs 6.3-6.52014/2/19

前回の復習• アイテム : 商品,単語, …
• バスケットアイテムの集合 : カートの中身, Webページ, …
• supportバスケットの集合とアイテムの集合 I = {I1,I2,…} が与えられたときにIを含むバスケットの数
• やりたいこと:あるしきい値以上のsupportを持つアイテム集合を見つける

前回の復習• バスケットの集合は大きくなりがち
• Naive Algorithm : 全ペアを数える
• A-Priori Algorithm 1回目のパス : それぞれのアイテムの頻度を数える2回目のパス : 1回目で頻度がs以上のアイテム同士のペアの頻度を数える
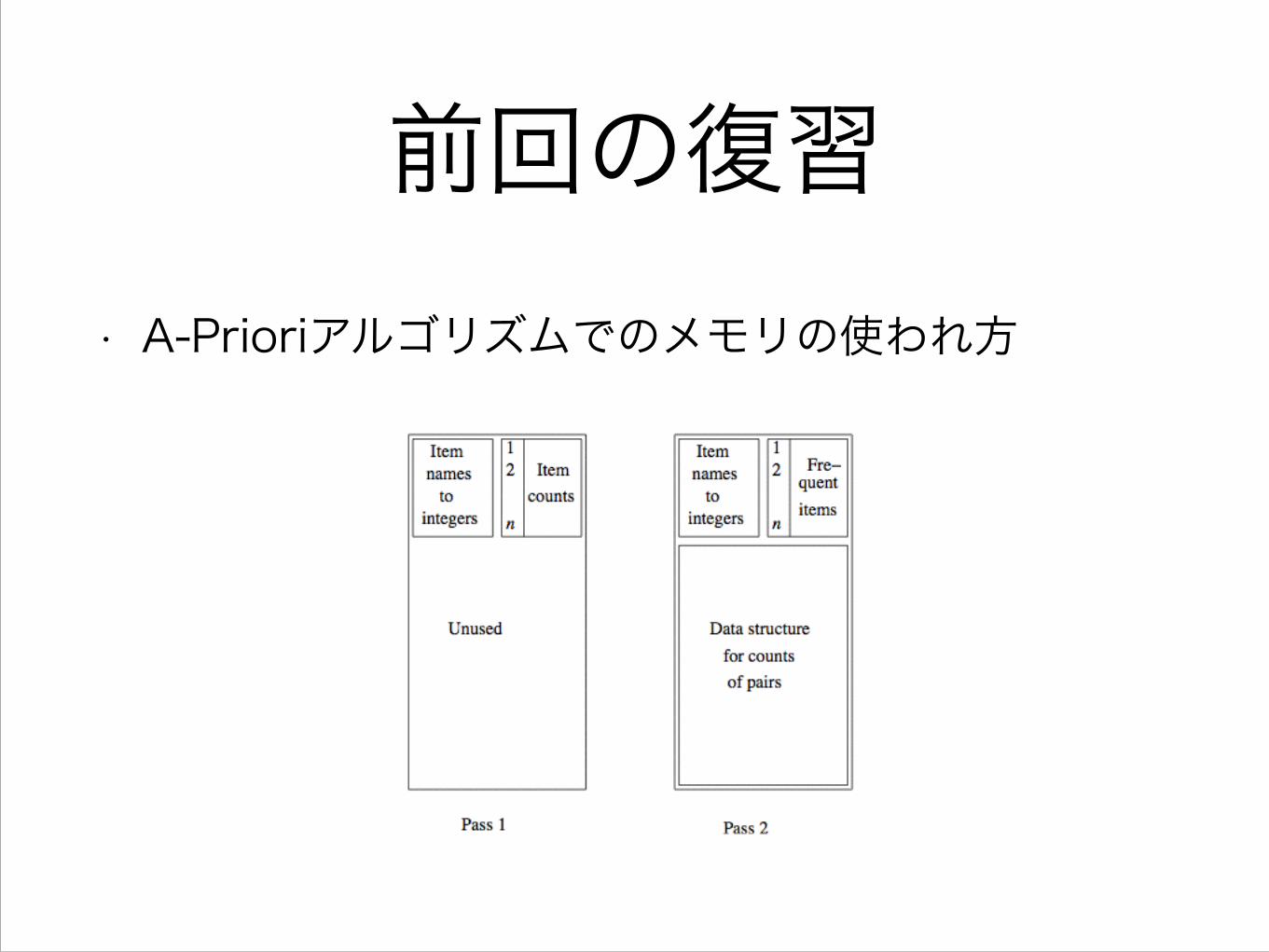
前回の復習• A-Prioriアルゴリズムでのメモリの使われ方

6.3 Handling Larger Datasets in Main Memory
• メインメモリが十分でないとA-Prioriアルゴリズムは使えない (特にペアの数を数えるのが問題)→ PCY アルゴリズム Multistage アルゴリズム Multihash アルゴリズム

PCY アルゴリズム
• A-Priori アルゴリズムの1回目のパスにおいて大部分メモリは未使用(例) 100万(1M)のアイテム, 1GBのメモリ → 1回目のパスには100MBもあれば十分

PCY アルゴリズム(cond)• 未使用のメモリ領域をアイテムペアのハッシュ値のカウントに使用
• バケット : アイテムペアのハッシュ値のこと

PCY アルゴリズム(cond)• 1回目のパスは,
• アイテムの個数を数える
• アイテムのペアのハッシュを計算し,対応するバケットを1増やす
• 2回目の候補となるペア{i,j}は
• i,j がともにしきい値以上現れた
• {i,j}のハッシュがしきい値以上現れた

PCY アルゴリズム(cond)
• 1回目のパスと2回目のパスの間では,
• バケットをビット配列に変換する
• 1 は そのバケットがしきい値以上であったことを示す
• 4バイトの整数 → 1ビット (1/32になる)

PCY アルゴリズムは有用か?
• 使えるメモリ量によって1回目のパスでハッシュを使うべきかどうかはかわる
• もし全てのハッシュ値のカウントがしきい値以上なら普通にA-Priori アルゴリズムと一緒

PCY アルゴリズムは有用か?• Example 6.91GB = 10^9B : ハッシュテーブル用に使える領域 一つのハッシュのバケットの大きさ : 4B10個のアイテムを含む10億のバスケットがある全ペアの数: 10^9 * 10C2 = 4.5*10^10バケットの平均カウント数 = (4.5*10^10)/(2.5*10^8) = 180しきい値が180よりも大きければ(1000とか)意味がでてくる

Multistage アルゴリズム
• PCY アルゴリズムの改良版
• 複数のハッシュテーブルを使うことで候補ペアの数を絞る
• パスが増える

Multistage アルゴリズム• 2回目のパスで使うハッシュ関数は1回目とは違うもの
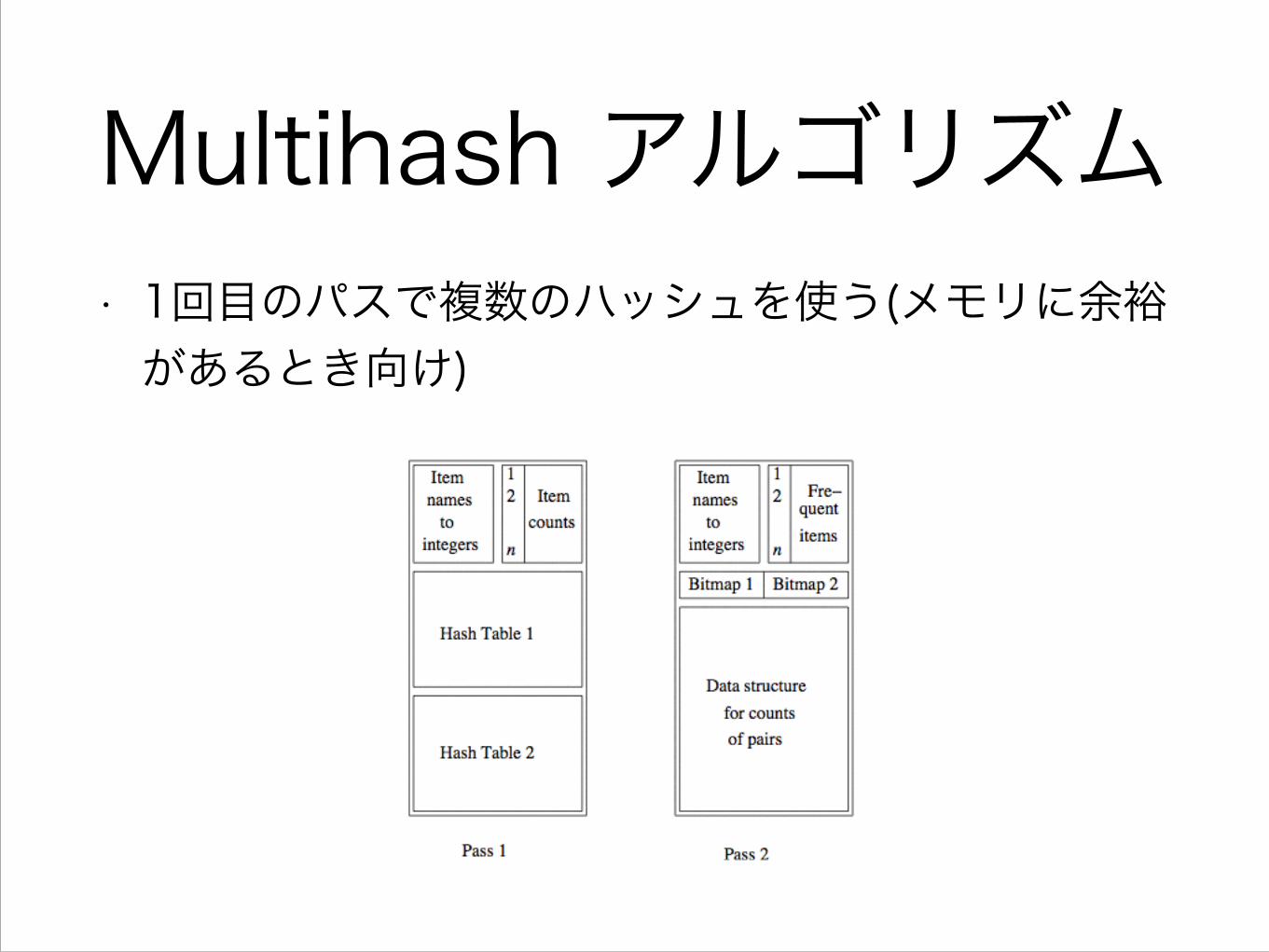
Multihash アルゴリズム• 1回目のパスで複数のハッシュを使う(メモリに余裕があるとき向け)

6.4 Limited-Pass Algorithms
• 常に全ての頻出するペアを見つける必要はない (例) スーパーでよく買われる商品ペアをセールしたい, だがそれら全てのペアでセールする訳ではない
• パスを少なくする(2回以下)の代わりに頻出ペアの大部分を見つけるアルゴリズム→ SONアルゴリズム, Toivonen’sアルゴリズム

単純な方法• バスケット全てを使わずバスケットのサブセットを使う
• このときしきい値はサブセットの大きさに合わせて調整する
• バスケットの抽出方法 • 全てのバスケット(m個)の中から確率pで抽出 • バスケットがランダムなら先頭mp個のバスケットを取れば良い
• ただしバスケットは一様とは限らないので注意

サンプリングの注意点• たまたま抽出したセットの中で頻出しただけかもしれない
• false postive を減らす: 全てのバスケットを走査し,抽出したセットで頻出と判断されたアイテムの数を数え,本当にそのアイテムが頻出か確認するただしこれでは false nagative は変わらず

サンプリングの注意点
• false nagative を減らす:しきい値sを小さくする→ より多くのペアが選択されるメモリ容量とのトレードオフ

SON アルゴリズム• 2パスアルゴリズム
• 入力ファイルを複数のチャンクに分け,それぞれのチャンクに対して先ほどのサンプリングによる手法を適用
• どれか一つのチャンクで頻出と判断されたらそのアイテムは頻出と判断 (→ false negative は 0)
• 2回目のパスで false positive を排除

SONアルゴリズムとMapReduce
• SONアルゴリズムは並列計算と相性が良い
• それぞれのチャンクは並列に計算可能
• その後頻出アイテムをまとめればよい

SONアルゴリズムとMapReduce
• 1回目のMap Function バスケット集合のサブセットを受け取り頻出アイテムを探す.出力は (F,1)の集合, Fがアイテム
• 1回目のReduce Finction Mapから受け取ったキーをまとめる(値は無視)

SONアルゴリズムとMapReduce
• 2回目のMap Function 全ての頻出アイテム(1回目のreduceの出力)と入力ファイルの一部を受け取り,ペアのサポートを計算. 出力は(C,v),Cがペア, vがサポート
• 2回目のReduce FunctionMapの出力をまとめ,サポートの合計がしきい値以上のものを出力

Toivonen’s アルゴリズム
• 2パスアルゴリズム
• false positive も false negativeもない

Toivonen’s アルゴリズム• 1回目のパスでは,データの一部を抽出し,その中で頻出アイテムセットを探す.このときしきい値は小さくとる (サンプルが全バスケットの1%ならしきい値はs/100ではなくs/125ぐらいにする)
• このとき見つけたアイテムセットを元にnegative border を構築
• negative border にあるアイテムセットは,それ自体は頻出と考えられないものの,その全てのサブセットは頻出

Toivonen’s アルゴリズム• Example 6.11:アイテム: {A,B,C,D,E}頻出アイテムセット: {A},{B},{C},{D},{B,C},{C,D}
• まず,{E}はnegative border ({E}のサブセットφは頻出)
• {A,B},{A,C},{A,D},{B,D} も negative border 例えば{A,B}のサブセット{A,}{B}は共に頻出

Toivonen’s アルゴリズム• Toivonen’s アルゴリズムの2回目のパスでは全てのデータを使い,頻出と判断されたアイテム集合か,negative borderにあるアイテム集合の数を数える
• もし negative border のアイテムセットが一つも頻出と判断されなければ,それ以外で頻出と判断されたアイテムセットは確実に頻出
• もしnegative borderのアイテムセットが一つでも頻出と判断されたなら,パラメータ等を変えて最初からやり直す

Toivonen’s アルゴリズム
• 定理:全データでは頻出なのに,サンプルセットでは頻出でないアイテムセットがある場合,必ずnegative borderの中には全体で頻出となるものが存在する

Toivonen’s アルゴリズム• 証明:1. S を 全体で頻出かつサンプルで非頻出とする2. negative border の要素が一つも全体で頻出でなかったこのとき,TをSのサブセットの中で非頻出のもので最小のものする. Sが頻出なのでTも頻出のはず.またTはnegative borderに含まれる → 矛盾

6.5 Counting Frequent Items in an Stream
• ストリームの場合終わりがない→ 時間させあれば定期的にアイテムが現れる限りどのアイテムセットもいつかはしきい値に達する

ストリームに対するサンプルメソッド
• ストリームの要素をバスケットのアイテムだとする
• 単純な方法 : ストリームからいくつかの要素を集めてファイルに保存, これを分析

Decaying Windowsを使う
• Decaying Window (Section 4.7)
• score : あるアイテムのストリームの重みの和
• 最初の重みは1
• 1回のステップごとに重みに (1-c) 掛けられていく
• scoreが1/2より大きいものを記憶する