learning multifractal structure in large networks (purdue ml seminar)
TRANSCRIPT

Twitter: 3 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
LEARNING MULTIFRACTAL
STRUCTURE IN LARGE
NETWORKS
Austin Benson ([email protected])
Carlos Riquelme
Sven Schmit
Institute for Computational and Mathematical Engineering, Stanford University
Purdue Machine Learning Seminar, Sept. 11 2014
KDD 2014
Large-scale nonnegative matrix factorizationwith Jason Lee, Bartek Rajwa, David Gleich NIPS 2014
5000 10000 15000 2000012
13
14
15
16
17
18
19
20
dimension (N)
Eff
ective G
FL
OP
S /
co
re
Performance (24 cores) on N x 2800 x N
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
BINI
SCHONHAGE
Fast matrix multiplication:
bridging theory and practicewith Grey Ballard
sequential
shared memory
distributed memory
high-performance
arXiv: 1409.2908, 2014

Setting
• We want a simple, scalable method to model networks
and generate random (undirected) graphs
• Looking for graph generators that can mimic real world
graph structure: degree distribution, large number of
triangles, etc.
Why?
• Useful as null models
• Helps to understanding graphs
• Generate test problems

Lots of work in this area
• Erdős-Rényi model [1959]
• Watts-Strogatz model [1998]
• Chung-Lu [2000]
• Random Typing Graphs [Akoglu+2009]
• Stochastic Kronecker Graphs [Leskovec+2010]
• Mixed Kroncker Product Graph [Moreno+2010]
• Multifractal Network Generators [Palla+2011]
• Block two-level Erdős-Rényi [Seshadhri+2012]
• Transitive Chung-Lu [Pfeiffer+2012]

Multifractal Network Generators (MFNG)
• Simple, recursive model [Palla+ 2011]
Parameters:
• Symmetric probability matrix
• Set of lengths that sum to 1
• Number of recursive levels
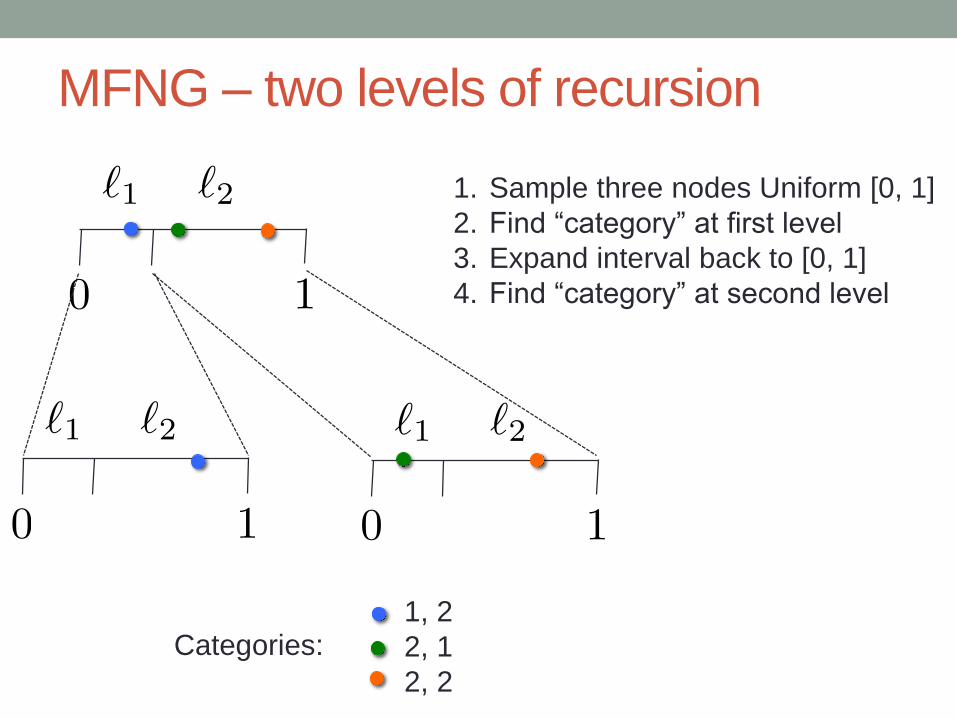
MFNG – two levels of recursion
1. Sample three nodes Uniform [0, 1]
2. Find “category” at first level
3. Expand interval back to [0, 1]
4. Find “category” at second level
1, 2
2, 1
2, 2
Categories:
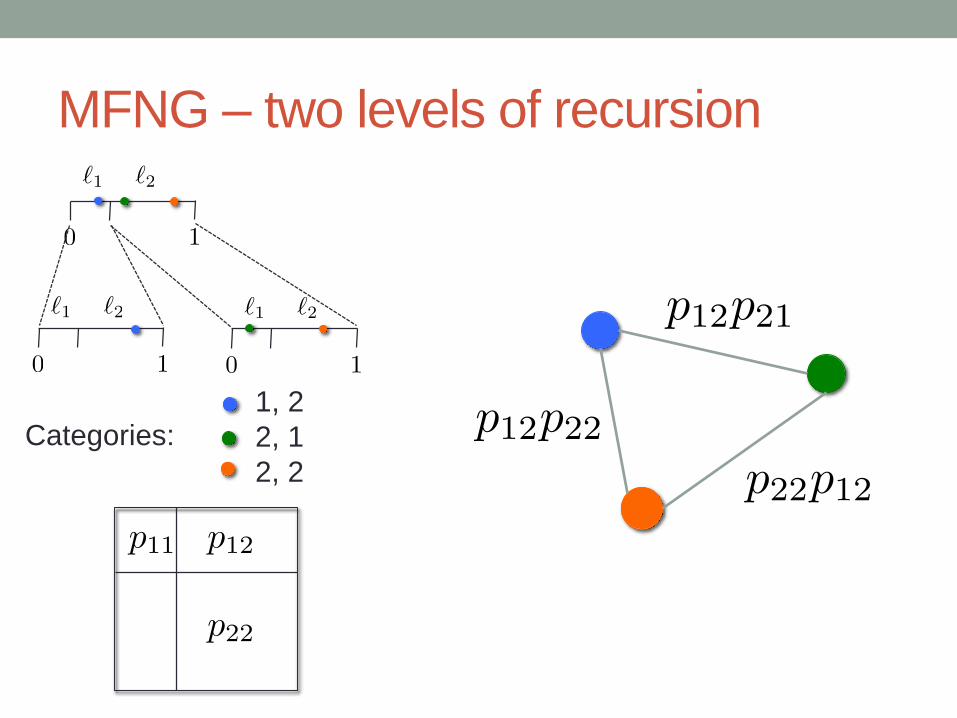
MFNG – two levels of recursion
1, 2
2, 1
2, 2
Categories:
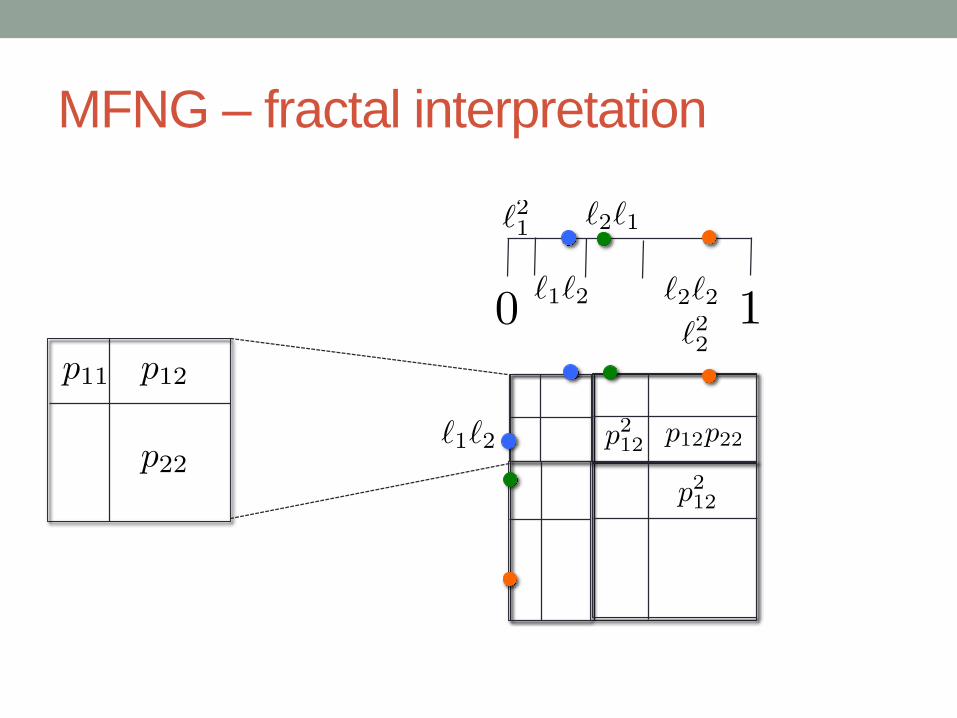
MFNG – fractal interpretation

MFNG – general parameters
• Number of categories: c
• c x c symmetric probability matrix P
• Length-c vector of lengths
• Number of recursive levels, r
c = r = 3

Scalability issues
• Expanded probability matrix
grows exponentially with
number of recursive levels
• This makes it difficult to do
inference
• We only have c + c(c – 1) / 2
parameters with c categories

Recursive decomposition• Lemma [Benson+14]: Take r i.i.d. graph samples from
MFNG process with one level of recursion. The
distribution of the intersection of the graphs is identical to
the same MFNG process with r recursive levels.
• Proof: This follows from the fact that the categories of a
node at each recursive level are independent.
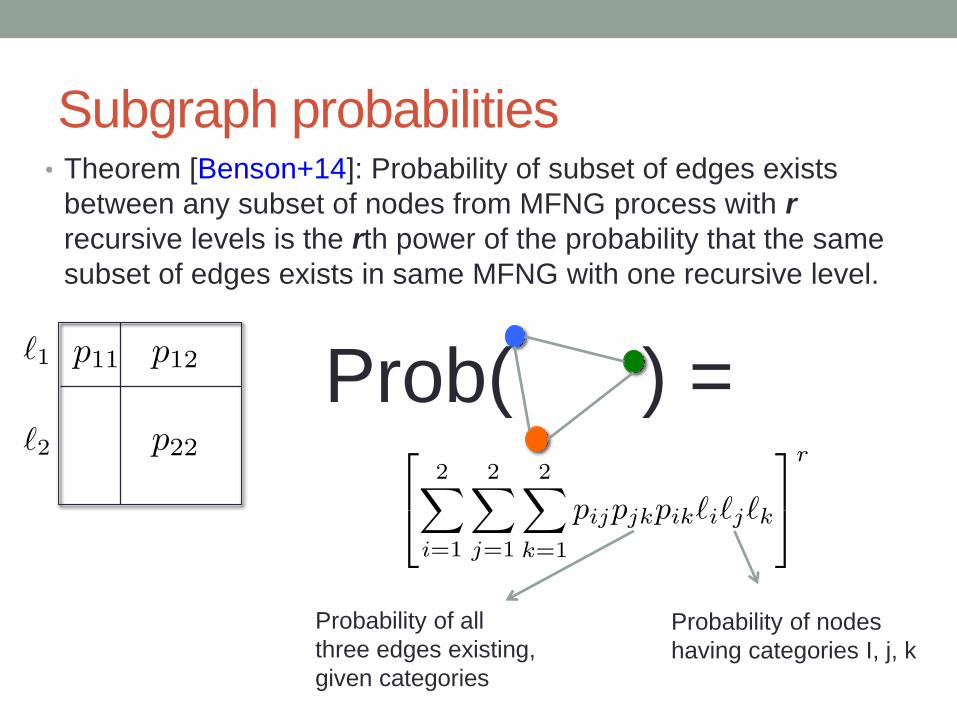
Subgraph probabilities• Theorem [Benson+14]: Probability of subset of edges exists
between any subset of nodes from MFNG process with r
recursive levels is the rth power of the probability that the same
subset of edges exists in same MFNG with one recursive level.
Prob( ) =
Probability of all
three edges existing,
given categories
Probability of nodes
having categories I, j, k

We can easily compute subgraph
moments
Any three nodes are equally likely to form
a triangle before Uniform [0, 1]
(before determining categories)
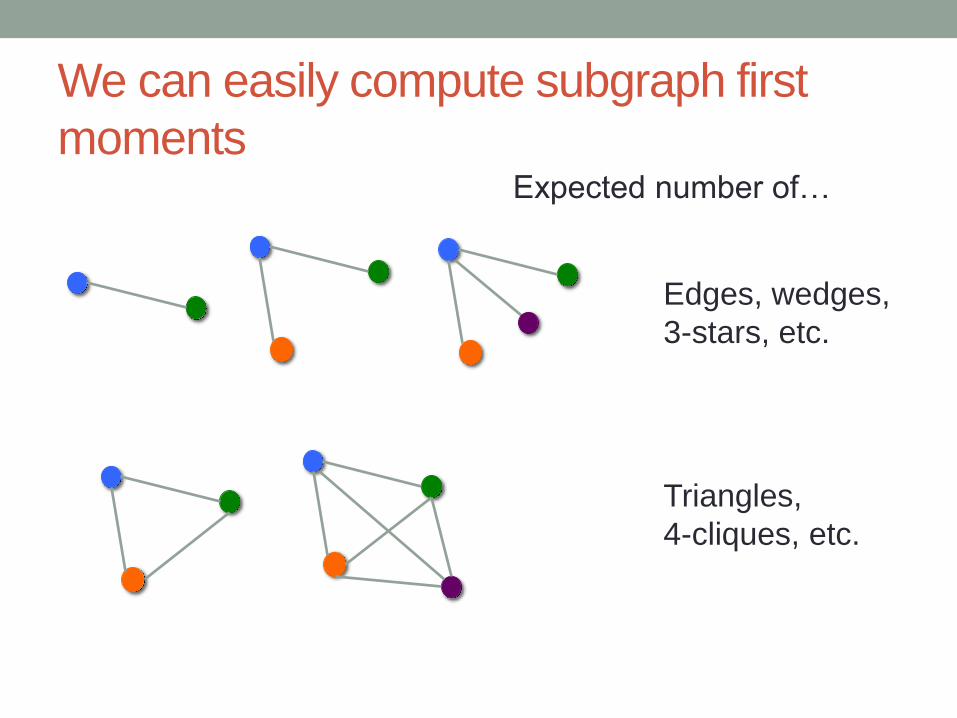
We can easily compute subgraph first
moments
Edges, wedges,
3-stars, etc.
Triangles,
4-cliques, etc.
Expected number of…
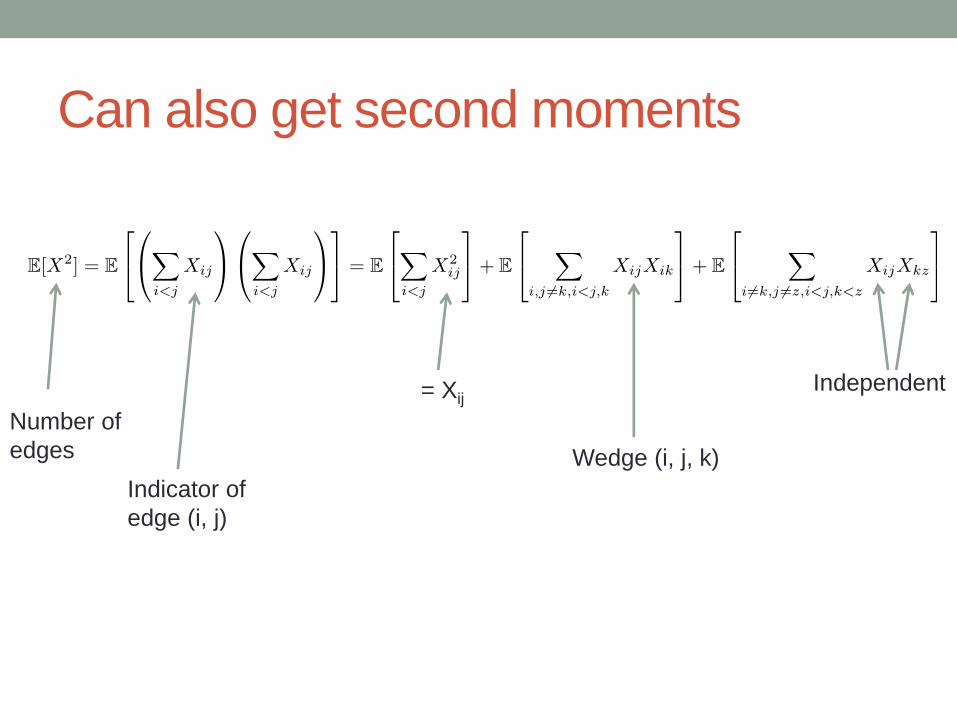
Can also get second moments
Number of
edges
Indicator of
edge (i, j)
= Xij
Wedge (i, j, k)
Independent

Open triangles
• We can only directly compute subgraph probabilities
where the edges exist
?
Prob( ) =
Prob( ) – Prob( )
x

Method of Moments
• Count number of wedges, 3-stars, triangles, 4-cliques,
etc. in network of interest (fi)
• Try to find parameters such that the expected values,
E[Fi], match the empirical counts, fi
Fast
computation
with our theory

Method of Moments
• Computing fi can be expensive (4-cliques)
can use estimators [Seshadhri+13]
• Not convex but fast
many random restarts
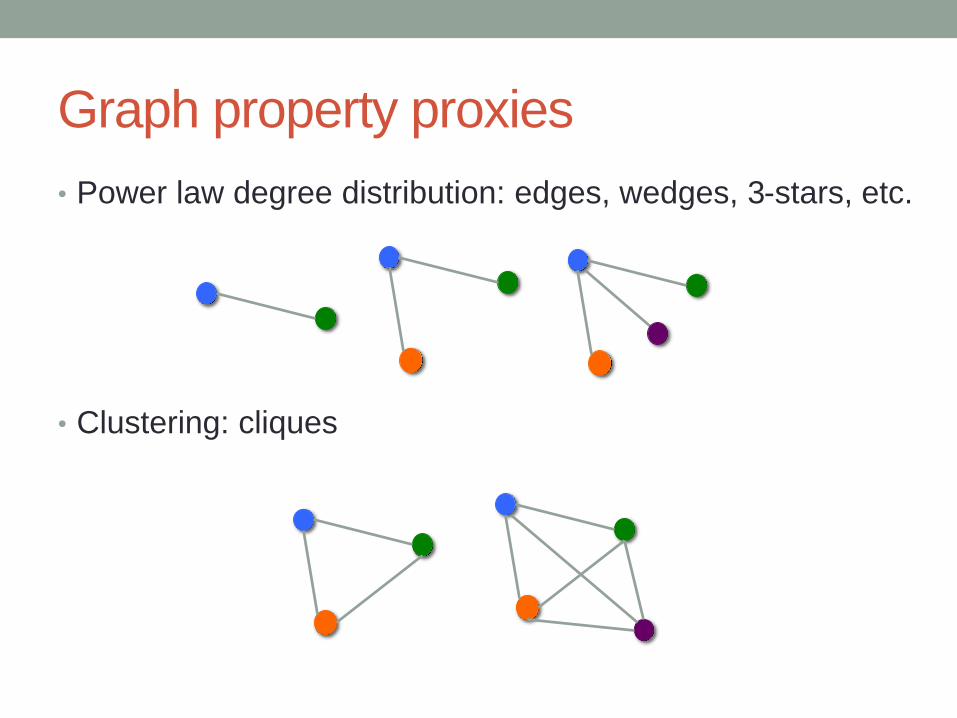
Graph property proxies
• Power law degree distribution: edges, wedges, 3-stars, etc.
• Clustering: cliques
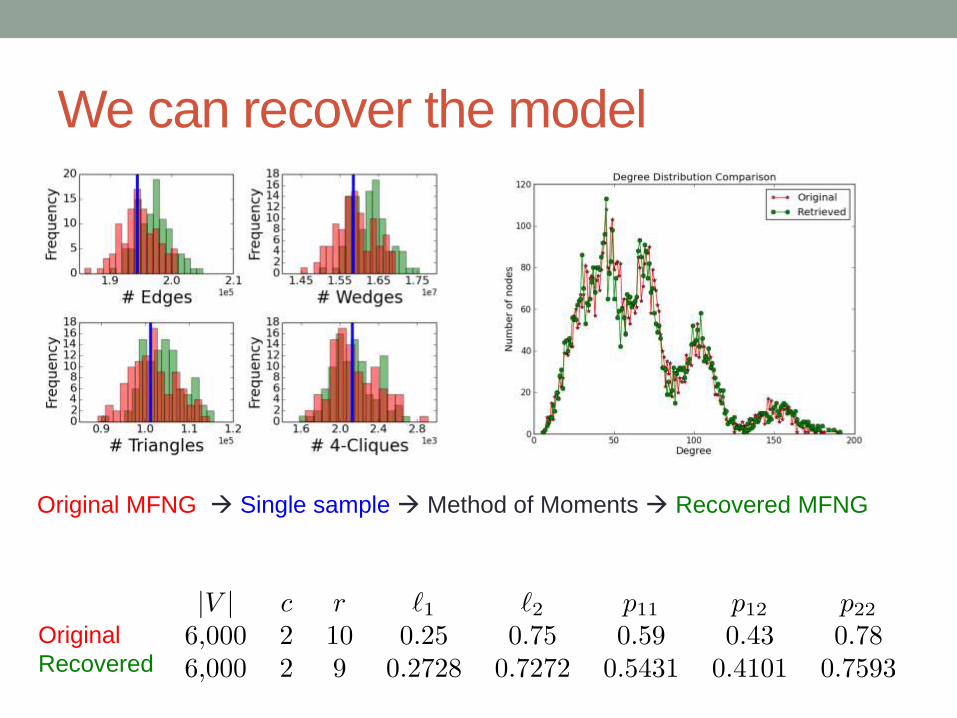
We can recover the model
Original
Recovered
Original MFNG Single sample Method of Moments Recovered MFNG
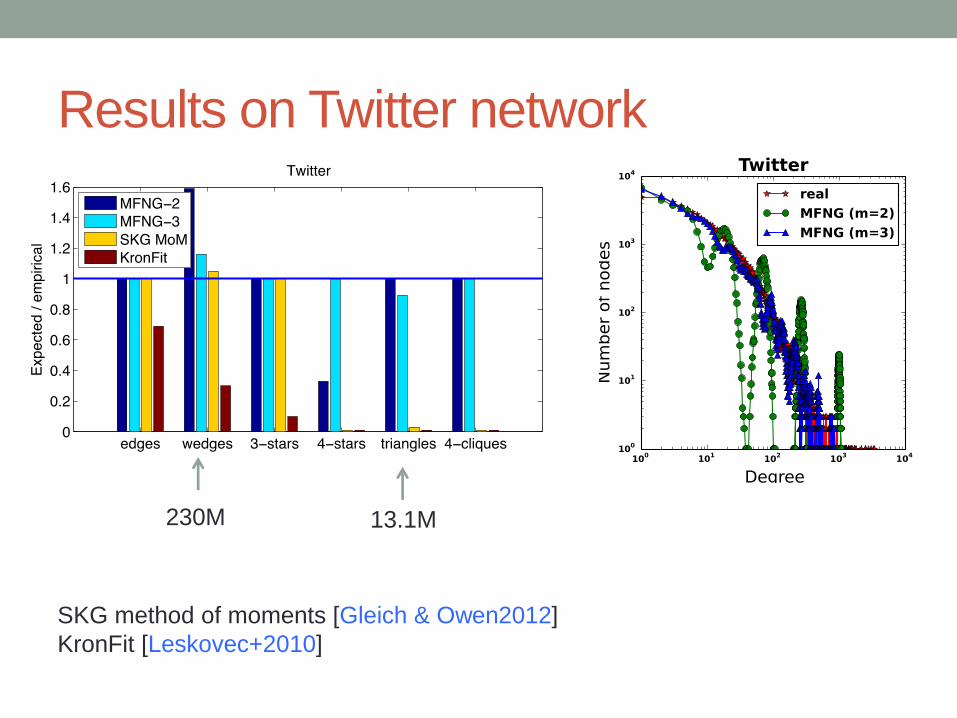
Results on Twitter network
SKG method of moments [Gleich & Owen2012]
KronFit [Leskovec+2010]
13.1M230M
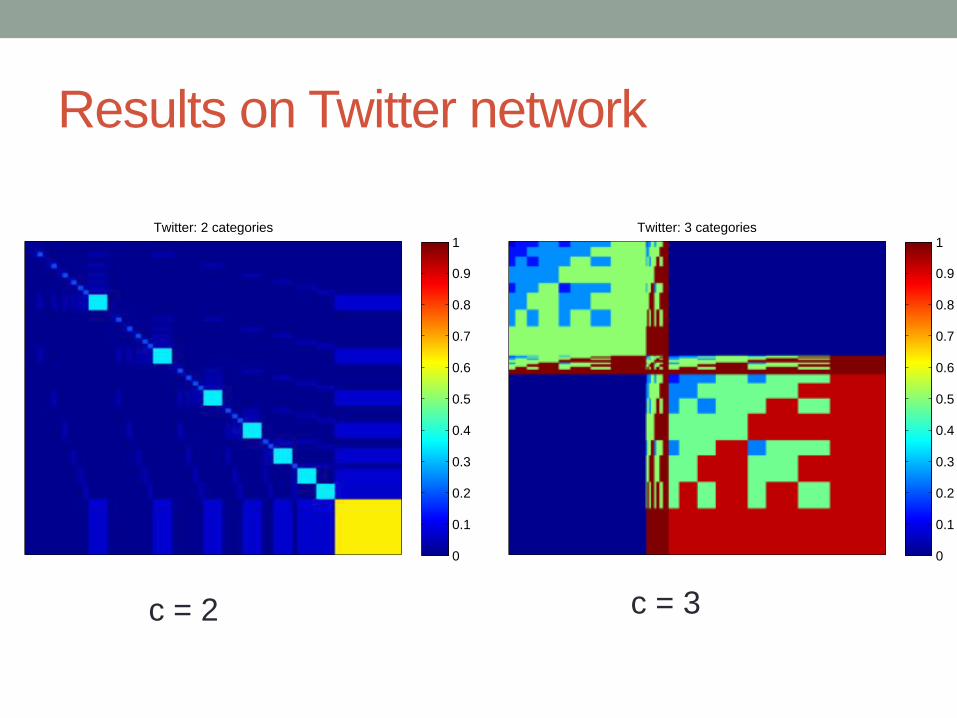
Results on Twitter network
Twitter: 2 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Twitter: 3 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
c = 2 c = 3
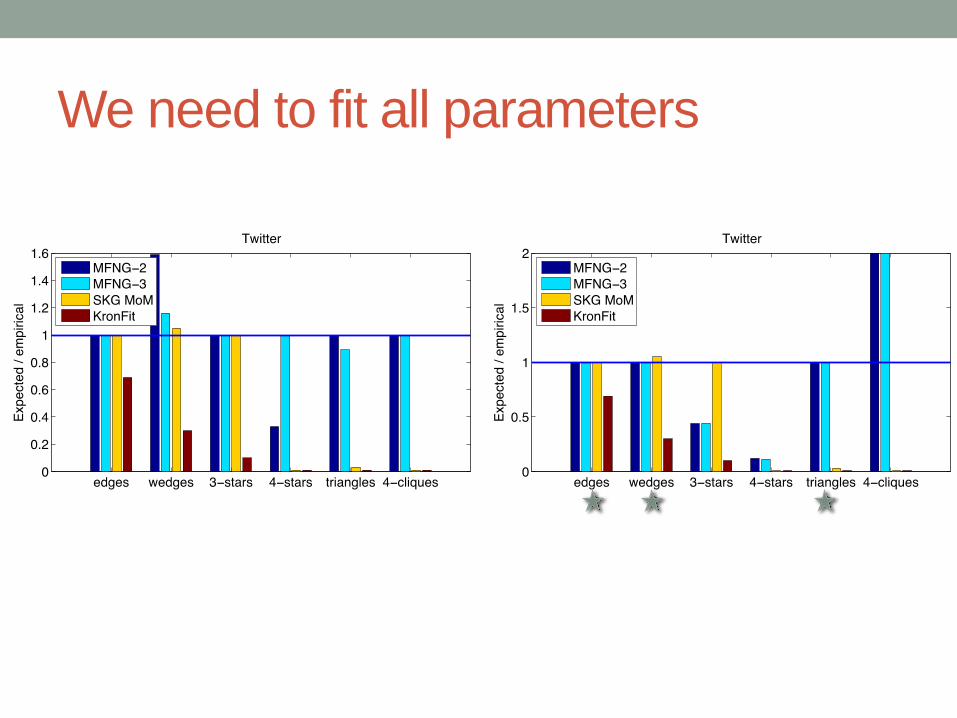
We need to fit all parameters
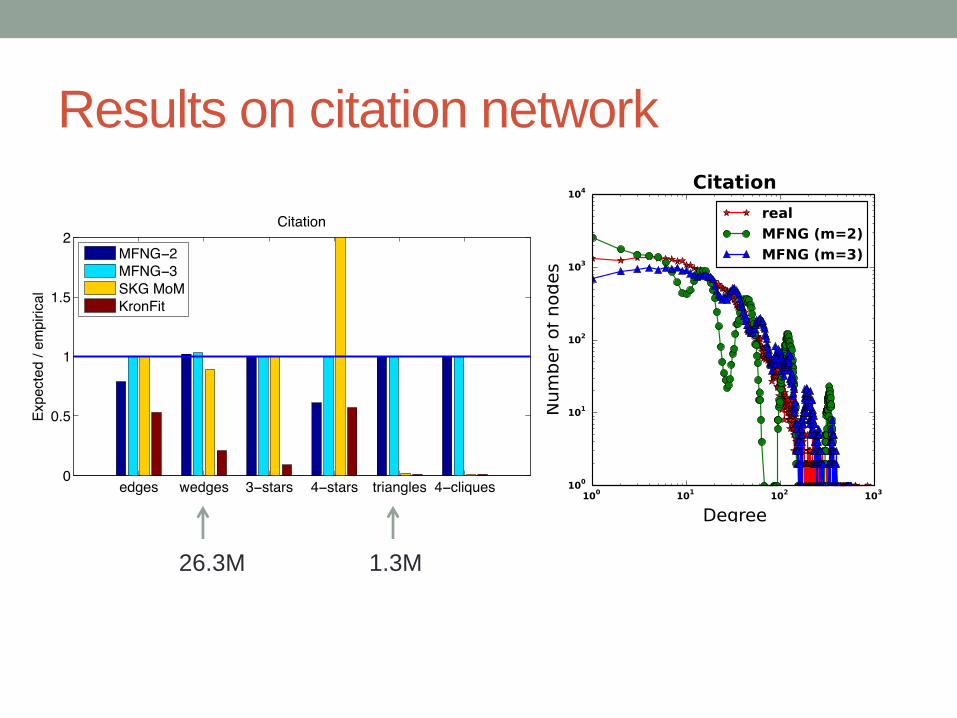
Results on citation network
1.3M26.3M
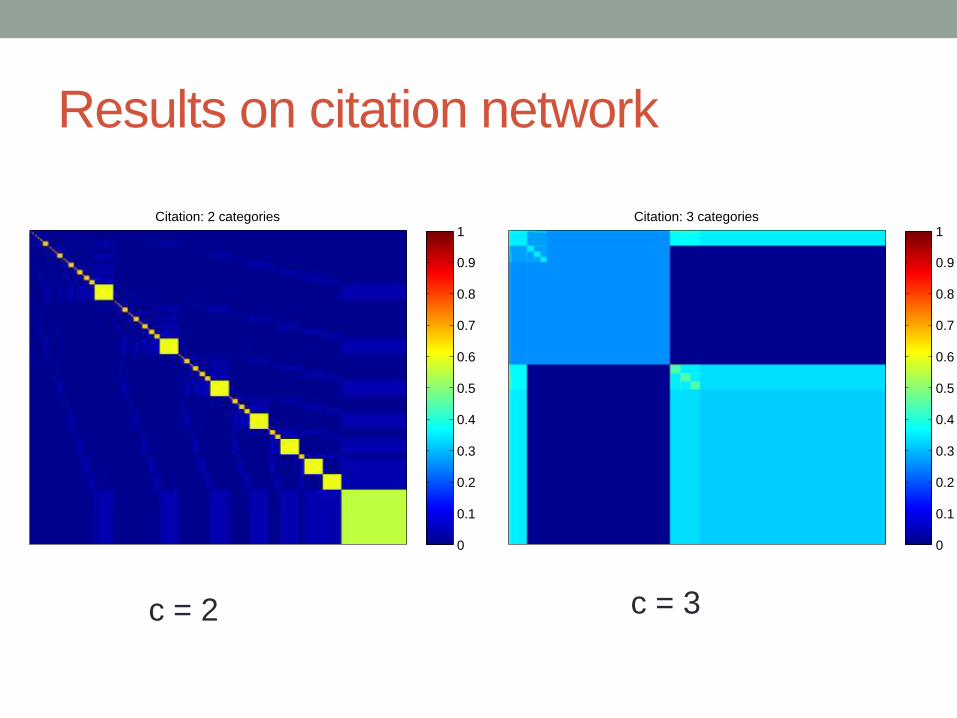
Results on citation network
Citation: 2 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Citation: 3 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
c = 2 c = 3
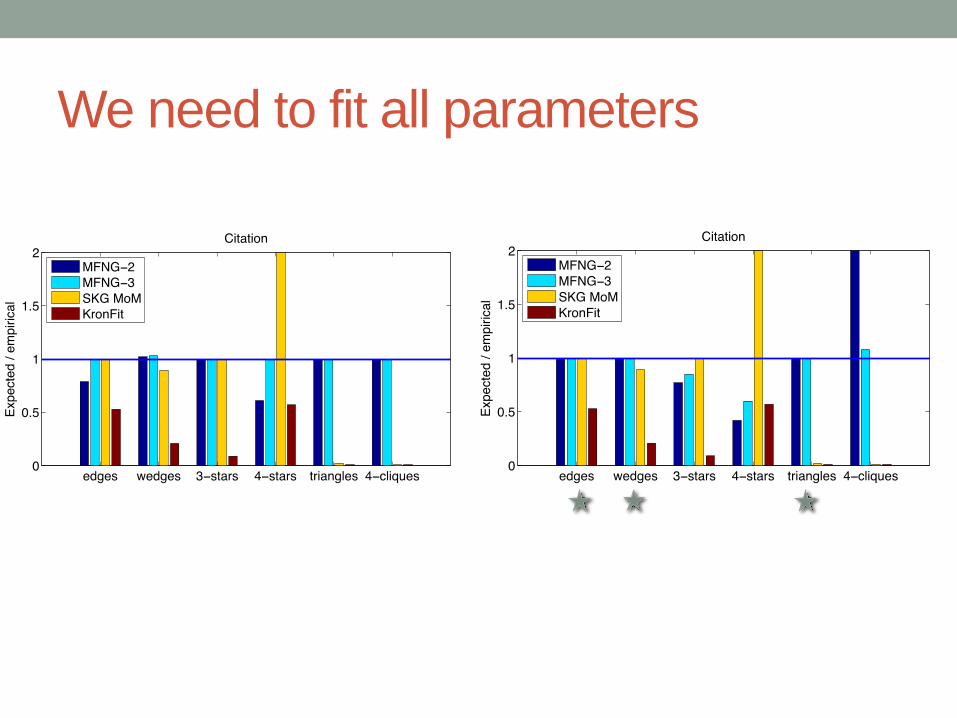
We need to fit all parameters
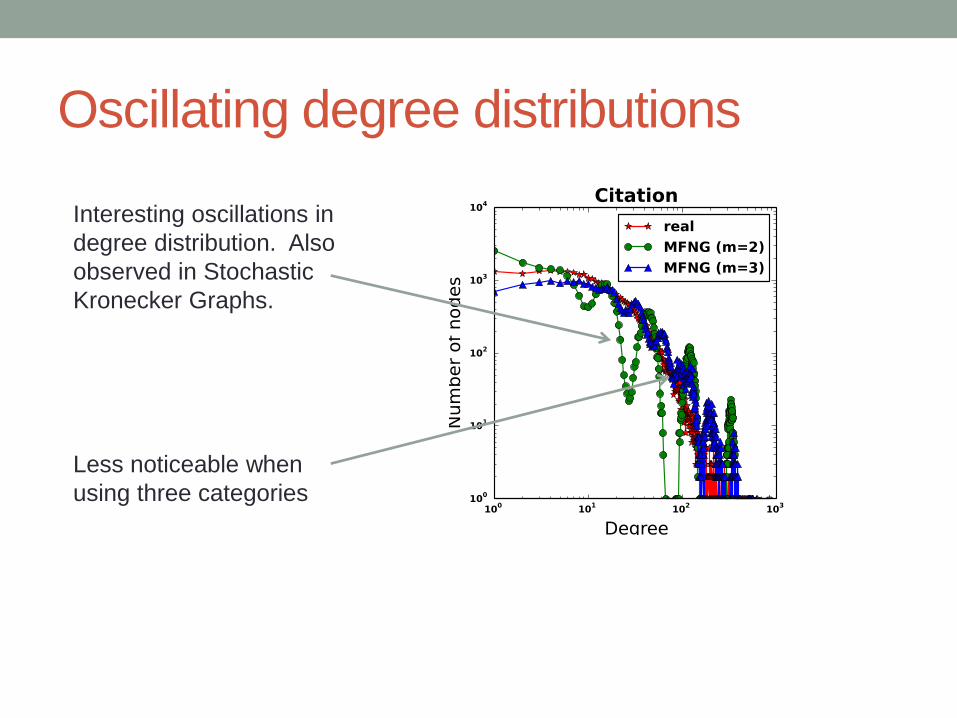
Oscillating degree distributions
Interesting oscillations in
degree distribution. Also
observed in Stochastic
Kronecker Graphs.
Less noticeable when
using three categories
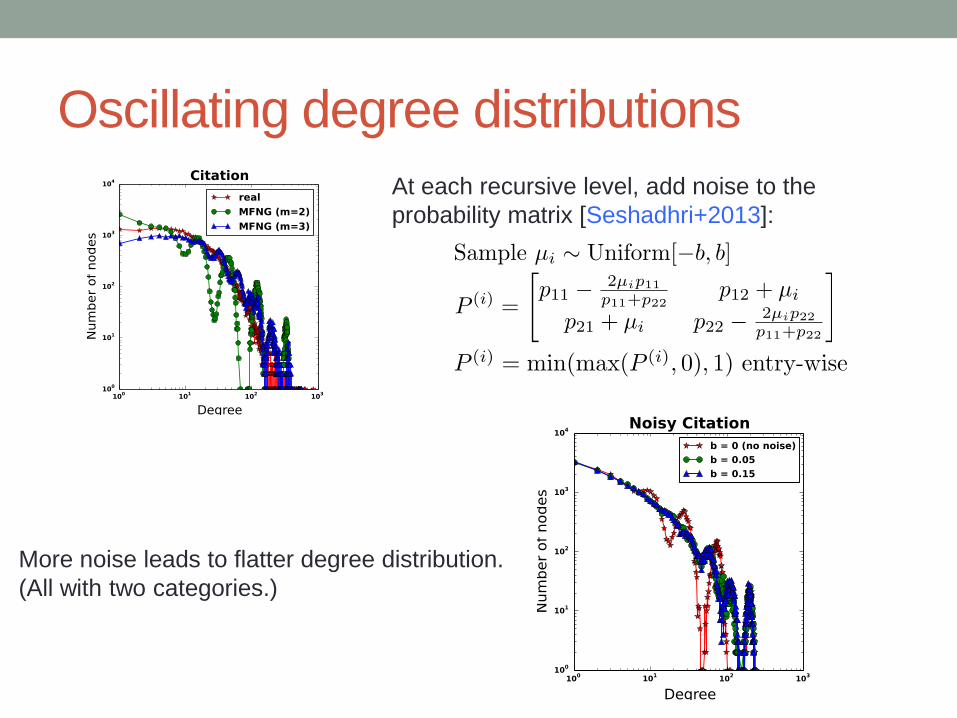
Oscillating degree distributions
At each recursive level, add noise to the
probability matrix [Seshadhri+2013]:
More noise leads to flatter degree distribution.
(All with two categories.)
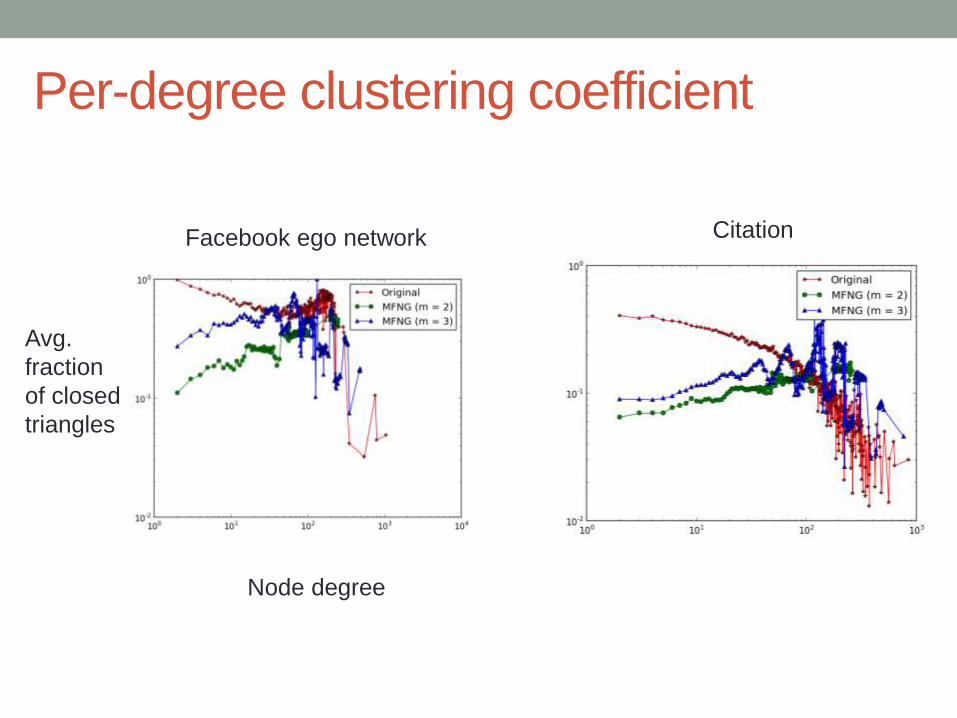
Per-degree clustering coefficient
CitationFacebook ego network
Avg.
fraction
of closed
triangles
Node degree
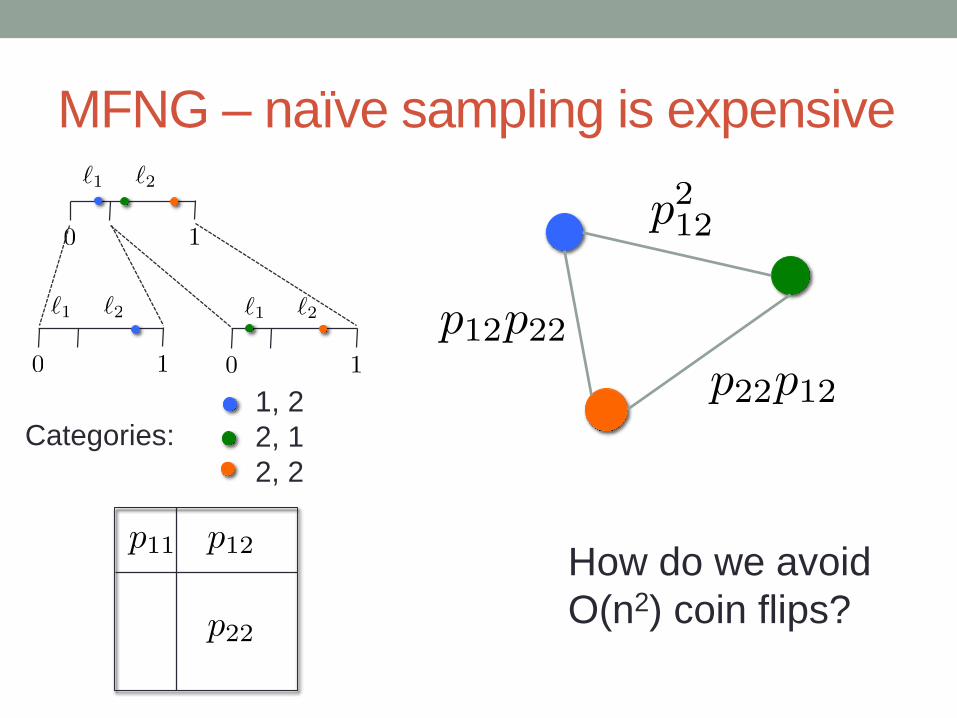
MFNG – naïve sampling is expensive
1, 2
2, 1
2, 2
Categories:
How do we avoid
O(n2) coin flips?

• First idea: Use recursive decomposition. Generate
r graphs and take the intersection.
• With one level of recursion and two categories,
there are four Erdős-Rényi components to
consider. We can sample each one quickly.
• When p22 isn’t close to 0 or close to 1, have to
store a dense graph.
Recursive decomposition does not help

“Ball dropping” does not quite work• Second idea: adapt “ball dropping” scheme from
SKG [Leskovec+2010].
Sample proportional to:
… at each level
Might get category pairs: (1, 1), (2, 2)
Choose random pair from (blue, green, orange)
Problem: just as likely to have 3 nodes fall into
box where yellow node is

Adapt for number of nodes per box
Sample proportional to:
… at each level
Might get category pairs: (1, 1), (2, 2)
3 actual nodes: 3 possible edges
Expected: 5(5 – 1)(1/4)^2 / 2 = 0.625
Sample e ~ Poisson(3 / 0.625λ)
Add e edges to the box
Larger λ need more samples, but less
dependency between edges.

Fast sampling heuristic: overview
Can compute these with methods presented earlier
Sample proportional to:
at each level
Sample e ~ Poisson(actual / expected * λ)
Add e edges to the box
1.
2.
3.
Repeat 2 and 3 until no more edges left

MFNG: what we have learned
• Method of Moments works
well to estimate MFNG
parameters for real networks
• Able to match degree
distribution, even though we
don’t explicitly fit for it
• Per-degree clustering
coefficient is still a challenge
• We can sample quickly, but
we would like an exact fast
sampling algorithm

Twitter: 3 categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
LEARNING MULTIFRACTAL
STRUCTURE IN LARGE
NETWORKS
Austin Benson ([email protected])
Carlos Riquelme
Sven Schmit
Institute for Computational and Mathematical Engineering, Stanford University
Purdue Machine Learning Seminar, Sept. 11 2014
KDD 2014