landauer multiple meanings in lsalsa.colorado.edu/papers/draft.gorfein.ch.fin.4.pdf · landauer...
TRANSCRIPT

Landauer Multiple meanings in LSA
1
Single representations of multiple meanings in Latent Semantic Analysis
Thomas K Landauer
University of Colorado at Boulder
WW XX
YY ZZ
YY is kleeper than WW .
YY is kleeper than ZZ .
Is YY kleeper than XX?
Is "kleeper" ambiguous?
Latent Semantic Analysis (LSA) is a psychological model and computational simulation
intended to mimic and help explain the way that humans learn and represent the meaning of
words, text, and other knowledge. In this chapter I briefly describe the underlying theoretical and
computational machinery of LSA, review some of the surprising things it is able to do, and
discuss some of its limitations and possibilities for future development. I will concentrate on
what LSA has to say about multiple word meanings, where it succeeds and fails, and what is
needed to fix it.
For researchers and theorists concerned with word meanings and ambiguity, the most
important implication of the LSA theory is that it questions the idea that different senses of a
word have separate and discrete representations that are individually disambiguated. Instead, it
represents a word meaning as a single point in a very high dimensional semantic space. In LSA,
the acquisition of a word meaning is an irreversible mathematical melding of the meanings of all
the contexts in which it has been encountered. In comprehension, words are not disambiguated by
sense one at a time; their different effects in different contexts are merely determined by how they
combine. Thus, a word has a different "sense" every time it is used.

Landauer Multiple meanings in LSA
2
In LSA, the representation of a single word carries a very large number of independent
dimensions of meaning. Therefore, it can have quite different effects depending on whether its
various meaning components are consistent, inconsistent, or orthogonal, strong or weak relative
to the rest of the passage. Because the semantic space in which words and passages are
represented is extremely sparse, apparent ambiguity of one word in a passage does not necessarily
affect the meaning of a passage sufficiently to make the whole ambiguous
The conspicuous deficiency of LSA referred to above is that it ignores dynamic changes
in the meaning of a sentence that depend on the order of the words, that is, many of the semantic
effects of grammatical and syntactic factors. These obviously have much to do with sentential
ambiguity. It turns out, empirically, that LSA's account substantially narrows the necessary role
of such factors, but it is nevertheless often critically hampered by their absence. For example,
it does a poor job of distinguishing between the meaning effects of antonyms. Thus, LSA should
be considered a baseline model of the learning and representation of meaning, not a theory of the
entire human processes of language production and comprehension.
Mathematically, what allows LSA to work at all is the representation of passage meaning
as a simple linear sum of word meanings. Clearly this is only a first-order approximation. While
LSA has been found to model human meaning very much better than one would expect if that
assumption were often badly wrong, there are certainly higher order dynamic processes that
appear as syntactic effects on meanings.
The main purpose of this chapter is to describe how LSA represents multiple senses in a
single representation and explore the theoretical and empirical consequences this has for
understanding verbal ambiguity. For those unfamiliar with LSA, the relevant foundations of LSA
will be sketched and the psycholinguistic phenomena that is has successfully modeled listed.
Then its representation of multiple meanings will be illustrated and discussed.
The basis of Latent Semantic Analysis.

Landauer Multiple meanings in LSA
3
LSA uses a fully automatic mathematical/statistical technique to extract and infer
semantic relations between the meanings of words from their contextual usage in large collections
of natural discourse. The analysis yields a mathematically well-defined representation of a word
that can be thought of as a kind of average meaning. LSA is not a traditional natural language
processing or artificial intelligence program; it uses no humanly constructed ontologies,
dictionaries, knowledge bases, semantic networks, grammars, syntactic parsers, part-of-speech
taggers, or morphologies. It takes as input large quantities of raw text that it parses into words and
passages such as sentences and paragraphs using the same formatting conventions that human
readers see. Although LSA uses as input data the patterns of how words are used in ordinary
language, its analysis is much deeper than the simple frequency, word-word co-occurrence,
sequential probability modeling, or keyword counting and matching techniques that have
sometimes been assumed to be the only purely computational alternatives to traditional linguistic-
theory.
The theory and assumptions behind LSA. The problem of language learning for machine
or a human can be represented as follows. The meaning of a passage (psg) is some function of the
meaning of its words plus other linguistic and non-linguistic context. For example:
the meaning of "husband and wife"
= ƒ{m("husband") > m("and") > m("wife") , m (context)};
in general,
m(psgi) = f{m(wdi1) > m(wdi2)> ... >m(wdin) , m (contexti)}.
where “>” means followed by and “ , “ means combined with.
The language learner's problem is to solve an enormous system of such simultaneous
equations for the meanings of all the words in the language and thus also the meaning of any
passage. To make an approximate solution feasible, LSA makes three strong simplifying
assumptions: (1) concurrent extra-passage context and non-verbal contextual learning experience is

Landauer Multiple meanings in LSA
4
ignored, (2) only textually represented language that a simulated person might have experienced is
used as data, and (3) the function by which word meanings are combined is addition.
Thus, the meaning of "husband and wife" becomes
m ("husband and wife") = {m(husband)+ m(and) +m("wife")},
and, in general,
m(psgi) = {mwdi1+mwdi2 ...+ mwdin,}
The simulations to date are all of word-to-word, word-to-passage or passage to-passage
relations, and are thus totally within a semantic space learned exclusively from word-passage
relations. If direct perceptual and intentional experiences were necessary for the simulated human
functions, LSA's simulations would fail entirely. They do not. Of course, they would probably be
more accurate if the model could also take advantage of these sources. Moreover, around three-
fourths of the word meanings known to adults, and of those learned by students from around age
ten, are learned solely from reading (see Landauer and Dumais (1997), and there is no a priori
reason to believe that the mechanisms of learning from text and speech are fundamentally
different. How well text alone serves can best be determined by realistic simulations of human
understanding.
In LSA the representation of a word or passage is not a single number, but a vector, a set
of real-numbered coefficients on a large number, typically 300, orthogonal dimensions. Meanings
can also be representation geometrically, as a line or point in very high dimensional space. The
representation of a passage is then the vector sum of its component words. Fig.1 shows an
example. The word “and” has a very short vector that runs in a direction almost orthogonal to
“wife” and “husband” and thus has very little effect on the resultant parallelogram that gives a
point for the combined meaning.
To give an initial intuitive impression of how well LSA works, here are some examples
of its estimate of semantic similarity between pairs of words after learning from a corpus of the

Landauer Multiple meanings in LSA
5
same size and content as a typical first-year American college student’s lifetime reading. LSA’s
usual measure of semantic similarity is the cosine of the angle between meaning vectors for
words or passages in the semantic space. A cosine is a correlation-like measure that varies
between -1 and 1. On average, two randomly chosen words have cosines of about .02 ± .06. LSA
infers appropriate degrees of relations between synonyms (e. g. tiny-small cos = .54), antonyms
(left-right, .72), singulars and plural forms of nouns (house-houses, .54; child-children, .62) and
present and past tenses of verbs (talk-talked, .67; run-ran, .57) whether regular or irregular, and
various other related forms (think-thinking, .67; quick-quickly, .62; thankful-thankless, .22;
birdcage-bird, .13; birdcage-cage, .23, chocolate-candy, .62; money-coins, .62, and, N.B., well-
hole, .22, well-healthy, .29, but hole-healthy, .04).
Fig. 1 about here.
The rationale behind singular value decomposition, the mathematical heart of
LSA, is that it can solve sets of simultaneous linear equations that are ill conditioned or
“singular”. Two or more equations may not be independent, that is one or more of them can be
constructed by some linear combination of the others. There may not be enough equations to
solve for all of the variables. Two or more equations may imply different values for the same
variable. The psychological counterparts are obvious: a human language learner gets insufficient
experience for very large numbers of words and encounters many contexts of different meaning
that contain the same word.
Singular Value Decomposition (SVD) accomplishes several things in the face of such
difficulties. In the case of redundancy, it finds a smaller set of abstract variables to substitute for
the original, collapsing any two variables that always have the same implied value into one. It
partially overcomes incompleteness (not enough equations—that is, language experience—for the
number of variables) by deriving an approximate solution through a kind of transitive inference
procedure. It is can always derive some number of independent (not derivable by linear
combinations of others) variables such that every word is described by an equation containing

Landauer Multiple meanings in LSA
6
values for all the other. This representation relates every word to every other without establishing
an absolute value for any. A whole system of such relative values is extremely useful. A natural
language, for example, could be built only on relations, as has long been conjectured by some
philosophers and linguists. LSA explicitly models languages in this way.
By applying SVD to a language corpus, LSA deals with inconsistent contextual usages by
representing a word with values on more than one variable, usually on several hundred. Thus, in
the data from which LSA (and humans) infer meaning, each occurrence of a word in context
makes a unique contribution to its meaning. But its high-dimensional representation, LSA (and by
hypothesis, the humans it models), can capture all the independent aspects of a word's meaning in
a single mathematical entity.
For the linguistics and psychology of ambiguity, this is the most important point. In the
LSA model, the meaning of a word is just how it affects the meaning of a verbal contexts in
which it appears. Because every context is potentially different, there are an infinite number of
effects that any word can have. Thus, "sense" differences are continuous, not discrete. At a fine
enough level, a word has a different "sense" in every different passage in which it occurs. Except
for words that have been used so few times that each occasion can be enumerated, listing or
describing different senses in a dictionary is only an approximation, a way of partitioning the
various uses of the word into larger or smaller subsets. The variation in meanings may be small or
large, the tightness, amount of overlap, and average separation of clusters great or small,
but—according to LSA—the differences between one use and another is fundamentally
continuous.
If this characterization is correct, even if LSA's current formulation or solution method is
not, the idea of multiple separate and discrete meanings or senses is mistaken. It is replaced with
the idea that a word's meaning is a complex, that it combines into one representation many
different aspects. In mathematical terms, it is very high dimensional. Different meanings or
senses should not to be thought of as stored separately in memory at all, and experiments

Landauer Multiple meanings in LSA
7
designed to determine how people "access" or choose between different senses, or how they
disambiguate individual words before computing clause or sentence meaning, are misguided.
What should take their place is research on how word meanings combine with each other.
How LSA is applied. A large corpus of text, as similar as possible to the sources from
which the humans whose performance is to be simulated would have acquired the knowledge to
be simulated, is divided into meaningful passages, such as paragraphs, which are then represented
as equations. An approximate solution to the system of equations is found by the matrix algebraic
technique of Singular Value Decomposition. (For mathematical and computational details see
Berry, 1992, or Landauer and Dumais, 1997). After the analysis, each word in the corpus, and any
passage, is represented as a high (typically around 300) dimensional vector. This general, and
sometimes strongly non-monotonic optimal number of dimensions is important. Dimension
reduction constitutes an inductive step by which words are represented by values on a smaller set
of abstract features rather than their raw pattern of observed occurrences. The effect of the
dimension reduction is analogous to the extra information about geographical locations that is
gained by plotting multitudes of point-to-point distances on a three-dimensional globe. One
important result of this step is that words of similar meaning that rarely or never appear in the
same passage, such as different terms for the same thing, get appropriately represented by similar
vectors. In a typical LSA generated “semantic space”, less than 2% of the word-word pairs for
which similarities are estimated ever occurred in the same passage.
How well LSA works. LSA yields good simulation of human verbal meaning across a
wide spectrum of verbal phenomena and test applications: (1) correct query-document topic
similarity judgments, even when there are no literal words in common between query and
document (Dumais, 1994); (2) correct mimicking of human word-word semantic relation and
category membership judgments (Landauer, Foltz and Laham, 1998), (3) correct choices on
vocabulary, and—after training on a textbook—subject-matter multiple choice tests (Landauer,
Foltz and Laham, 1998), (4) accurate measurement of conceptual coherence of text and resulting

Landauer Multiple meanings in LSA
8
comprehensibility (Foltz, Kintsch and Landauer, 1993, 1998), (5) correct prediction of word-
word and passage-word priming of word recognition in psycholinguistic experiments (Landauer
and Dumais, 1997), (6) accurate prediction of expert human holistic ratings and matching of the
conceptual content of student essays and textbook sections (Landauer, Foltz and Laham, 1998),
(7) optimal matching of instructional texts to learner knowledge as displayed in essays (Wolfe et
al., 1998), (8) mimicking of synonym, antonym, singular-plural, past-present, and compound-
component word relations, (Landauer, Foltz and Laham, 1998), (9) representing word ambiguity
and polysemy—the possession of two or more distinct senses or meanings by the same word
(more later), (10)correct mimicking of semantic categorization of words by children and adults
(Landauer, Foltz and Laham, 1998), (11) providing significant improvement for language
modeling in automatic speech recognition (Jurafsky and Coccaro, 1998, Belagarda, 2000,
Hofmann, 1999), (12) matching textual personnel work histories to discursive job and task
descriptions (Laham, Bennett and Landauer, 2000), (13) estimating conceptual overlap among
large numbers of training courses by analysis of test contents (Laham , Bennett and Landauer,
2000s), (14) accurately simulating the phenomenal rate of growth of human vocabulary during K-
12 school years (Landauer and Dumais, 1995; Anglin, 1970,1993), and several other
psycholinguistic and psychological phenomena (Kintsch, 1999, 2001).
Multiple meanings of a word. To repeat, LSA deals with inconsistent contextual usages
by representing a word as an equation containing many independent variables; usually several
hundred. Therefore, a word in LSA could, in principle, have as many entirely unrelated meanings
as there are dimensions in its representational space. Because of the high-dimensionality of the
space, a word can be simultaneously close to to any number of other words, some of which may
be close to each-other while others may be relatively quite far apart. Therefore, a single LSA
representation of a word can, in the usual sense, be ambiguous. For example, it can represent two
entirely different meanings of "sage". We can see this in the cosines between the word sage and

Landauer Multiple meanings in LSA
9
the passage-length definitions of two of its senses in WordNet, as represented in a semantic space
based on a representative sample of the lifetime reading of a typical first year college student 1.i
sage"-- definition 1. cos = .23 "One as a profound philosopher distinguished for wisdom"
"sage"-- definition 2. cos = .21 "A perennial herb or shrub sometimes grown as an
ornamental… scarlet flowered salvia splendens"
def1--def2: cos = .06
The word "sage" is similar to both definitions, but the two definitions are not very similar to each
other.
Unfortunately there is no easy way to choose sets of examples of ambiguous words in a
representative or random manner. However, we can examine a variety of common and obvious
cases. For an intuitive baseline, synonyms randomly picked from a synonym dictionary have
average cosines of around .25.
First, to illustrate the kind of analyses and results to be exhibited, here are cosine
similarities of "lead" to related words from two sets of five words each, the two sets representing
two quite different senses.
1 In all of these examples, the measures of semantic relations in LSA were provided by facilities
available at http://LSA.colorado.edu. Measures were based on the general reading, adult level
semantic space, with 300 dimensions. The training corpus for space this was a ~12 million token,
~92 thousand type, ~66,000 sample collection of texts representative of the lifetime reading of a
single typical American college freshman collected by Touchstone Applied Science Associates
(TASA) as the basis of their Educator's Word Frequency Guide. Any researcher may use this
facility, but careful reading of background material and detailed instructions before so doing is
strongly advised, as there are non-obvious technical and conceptual issues that can determine the
meaning and validity of obtained results.

Landauer Multiple meanings in LSA
10
lead
metal .34
zinc .46
tin .35
solder .26
pipe .25
mean .33
follow .36
pull .12
direct .26
guide .17
harness .19
mean .22
Within the two sets above, the “metal” and “guide”-like words have intra-set average cosines .48
and .18, respectively, whereas pairs of words taken from different sets, have average cosines of
.06.
In the remaining examples, I present three exhibits for each homographic word. (1) Its
relation to four other selected words, two related to one and two to another of its relatively
unrelated senses. To show the pattern, this starts with "lead". (2) Examples illustrating how the
LSA representation of a word can be close to two dictionary style definitions of two quite
different senses. The definitions were taken from the online version of WordNet (Fellbaum,
1998), edited to remove words with the same lemma as the homographic word as well as some
superfluous function words. (3) Summary statistics on the cosine similarity of the word to the

Landauer Multiple meanings in LSA
11
texts of all its senses defined in WordNet. Unfortunately, the mean and standard deviation of
cosines for random pairs of this kind cannot be calculated because we cannot specify the
population of passages.
Landauer Multiple meanings in LSA
12
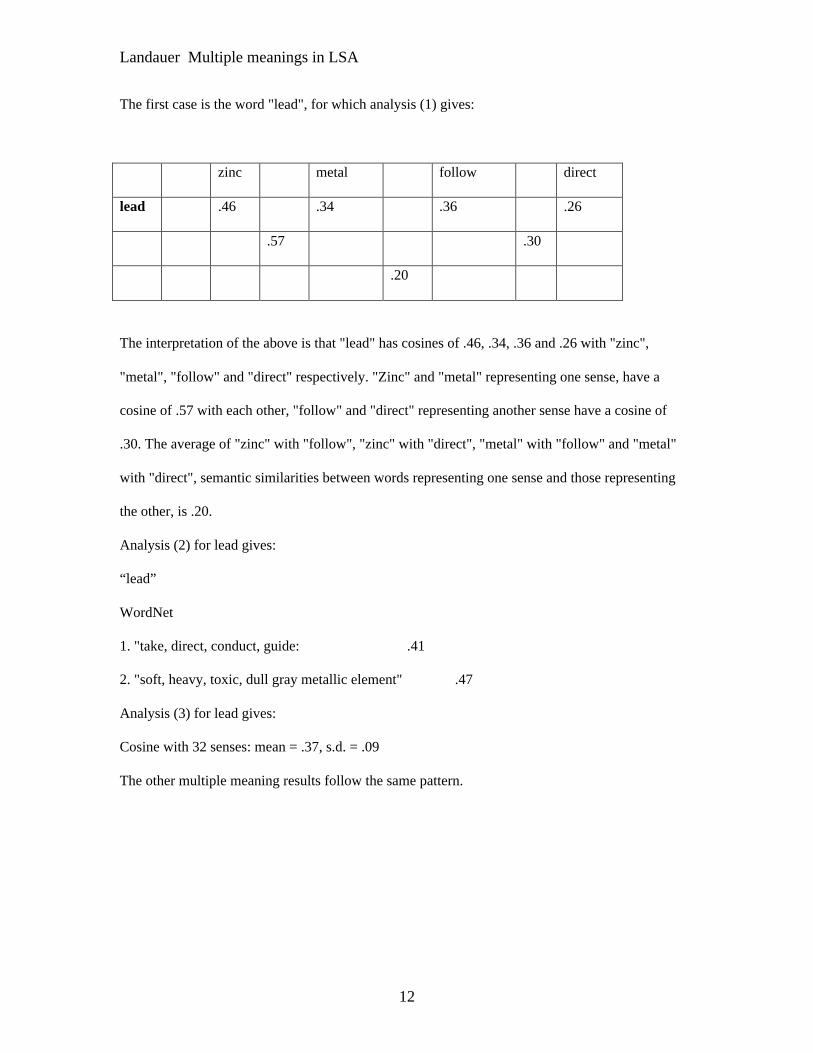
The first case is the word "lead", for which analysis (1) gives:
zinc metal follow direct
lead .46 .34 .36 .26
.57 .30
.20
The interpretation of the above is that "lead" has cosines of .46, .34, .36 and .26 with "zinc",
"metal", "follow" and "direct" respectively. "Zinc" and "metal" representing one sense, have a
cosine of .57 with each other, "follow" and "direct" representing another sense have a cosine of
.30. The average of "zinc" with "follow", "zinc" with "direct", "metal" with "follow" and "metal"
with "direct", semantic similarities between words representing one sense and those representing
the other, is .20.
Analysis (2) for lead gives:
“lead”
WordNet
1. "take, direct, conduct, guide: .41
2. "soft, heavy, toxic, dull gray metallic element" .47
Analysis (3) for lead gives:
Cosine with 32 senses: mean = .37, s.d. = .09
The other multiple meaning results follow the same pattern.

Landauer Multiple meanings in LSA
13
Fly:
insect mosquito soar pilot
fly .26 .34 .54 .58
.61 .27
.09
WordNet
1. "travel through the air" .34
2. "two-winged insect" .36
Cosine with 21 senses: mean = .27, s.d. =.12
--------------------------------------------------------------------------------------
Run:
stride sprint operate manage
run .45 .47 .24 .28
.47 .31
.08
WordNet:
1. "a row of unravelled stitches" .30
2. "move fast by using feet, with one foot off
the ground at any given time" .50
Cosine with 52 senses: mean = .35, s.d. =.05
--------------------------------------------------------------------------------------
Bank:
money saving river levee

Landauer Multiple meanings in LSA
14
bank .33 .30 .17 .14
.52 .57
.04
WordNet
1. "sloping land beside a river".15
2. "deposit, put in an account" .57
Cosine with 16 senses: mean = .21, s.d. =.07
----------------------------------------------------------------------------------------
Swallow:
bird sparrow gulp chew
swallow .23 .18 .31 .75
.32 .24
.07
WordNet
1. "the process of taking food into the body through the mouth by eating" .57
2. "small long-winged songbird noted for swift graceful flight and the regularity of its migrations"
.30
Cosine with 11 senses: mean = .32, s.d. =.04
In each of these and several other cases examined: (1) the homographic word is
significantly (> 1.7 s.d. above chance) related to each of two members of two sets of words of
different senses, and the two words in one set are less well related on average to the two words in
the other set, usually significantly so; (2) in every case, the homographic word is significantly
related to definitions of two quite different senses; and (3) in every case, the average cosine

Landauer Multiple meanings in LSA
15
between the homographic word and definitions for all its senses as given in WordNet is
substantial. The rationale for presenting both analysis (2) and (3) is that many of the WordNet
senses for a given homographic word are quite similar, so (3) does not necessarily show that LSA
captures more than one sense, while (2) demonstrates this phenomenon, but, being based on a
selected example, does not necessarily show that the LSA representation captures senses well on
average, while (3) does so (although, to repeat, there is no good way to find a chance level for a
traditional significance test.)
The effect of ambiguous words on passage meaning. Because a single word may
represent many different meanings, it should be obvious that adding an ambiguous word to a
passage could potentially make the LSA representation of the passage ambiguous as well. For
example, "He was impressed with the size of the ..." becomes an ambiguous sentence with the
addition of "bank" in LSA, just as it does in English. And as we will see later, and as discussed by
Kintsch (2001), in some sentences, such as "the hunter shot the elk", where one important aspect
the overall sentence meaning—who shot whom—depends on a predication relation conveyed by
word order, the standard LSA representation does not properly resolve the passage ambiguity.
(However, note that such a set of words is essentially unambiguous in conveying the major
meaning—as compared to almost every other sentence ever uttered—that a shooting occurred
involving a deer and a hunter, no matter what order the words are given in. And, moreover, world
knowledge—which LSA has, but which there is as yet no automatic process for applying to
disambiguation—will very often resolve the apparent ambiguity.)
Nevertheless, there are several ways in which the same word can lend different meanings
to different utterances without producing significant ambiguity or confusion. That is, one of two
or more meanings of a word may change an utterance in a useful way, while others also change it
but in ways that don't matter for communicating desired information. That is because it is the
direction of a passage vector (the vector sum of its components) relative to other possible
passages that defines its qualitative meaning.

Landauer Multiple meanings in LSA
16
A geographical landmark analogy may help. To go to west on Interstate highway 80 from
Omaha you take the direction labeled "Denver". To go to east from Salt Lake City you also take
the direction labeled "Denver". Thus the same word, "Denver" conveys the meaning "east" or
"west" depending on its context. And the fact that Denver is also slightly South of both Omaha
and Salt Lake City will not cause you to mistakenly take I 29 or I15 north or south instead.
Nonetheless in another pair of contexts, this time purely verbal, "Take I25 in the Denver direction
from Colorado Springs", and "Take I25 in the Denver direction from Cheyenne", "Denver" brings
the meanings north and south to the passage without causing any ambiguities about east and west.
The neologism, "kleeper" that opened this chapter displays this potential multiple-effect
property of a word.
WW XX
YY ZZ
YY is kleeper than WW .
YY is kleeper than ZZ .
Is YY kleeper than XX?
In LSA "kleeper" would be represented singly as a word that distinguishes left from right, or up
from down, and / from \ , and in sentences where only one such difference is at issue, the
extraneous (ambiguous) meanings are irrelevant to the communication. Moreover, if I were to say
"Place AA and BB so that AA is kleeper than BB", you could make several different conforming
diagrams, in this way expressing "kleeper"'s ambiguity. Thus a word can sometimes be
ambiguous, and sometimes not, depending on its context.
Some other meanings of "Denver", e.g. that it is a large city, are even less important
because they are orthogonal to the message and unlikely to cause it to be misunderstood in any
important way. Still other meanings of "Denver", e.g. that it is near the Rocky Mountains, are
highly redundant within the context and also lead to no confusion. What “Denver” contributes to

Landauer Multiple meanings in LSA
17
the passage meaning depends on its relation to the rest: it does not need to be analyzed into
separate meanings first.
In the very sparsely populated, very high dimensional semantic spaces implied by LSA
analyses, moving a passage a small amount in either a nearly orthogonal or nearly collinear
direction is very unlikely to alter its relative meaning significantly, that is make the passage more
confusable with any other that is likely to occur.
Here are some examples of the effects a single word can have or not have in a passage.
Keep in mind that these are far from random examples. They are instead intentionally constructed
or chosen passages that serve as existence proofs of phenomena that can occur in LSA
representations. We start with two pairs of short phrases containing the word "lead" used in two
of its very different senses. In the first pair we see what happens when we substitute a relatively
unambiguous synonym of one of its meanings, the meaning related to mass. Doing so makes very
little difference in the LSA representation of the phrase, or of the relation of the phrase to one in
which an antonym of only one of the meanings of "lead" is substituted. The same pattern occurs
in the second pair, where the two phrases use a different meaning of "lead", the one having to do
with interpersonal behavior, and instead of a substituting an antonym , we substitute a word with
semantics totally unrelated to the mass meaning. Across the two pairs we see at most only the
slightest distortion of the meaning of the phrase by substituting a word one of whose meanings is
consistent and another strongly inconsistent. (By examining two cases where different senses of
"lead" are involved we avoid the possibility that one meaning is so dominant that no other has
any effect.)
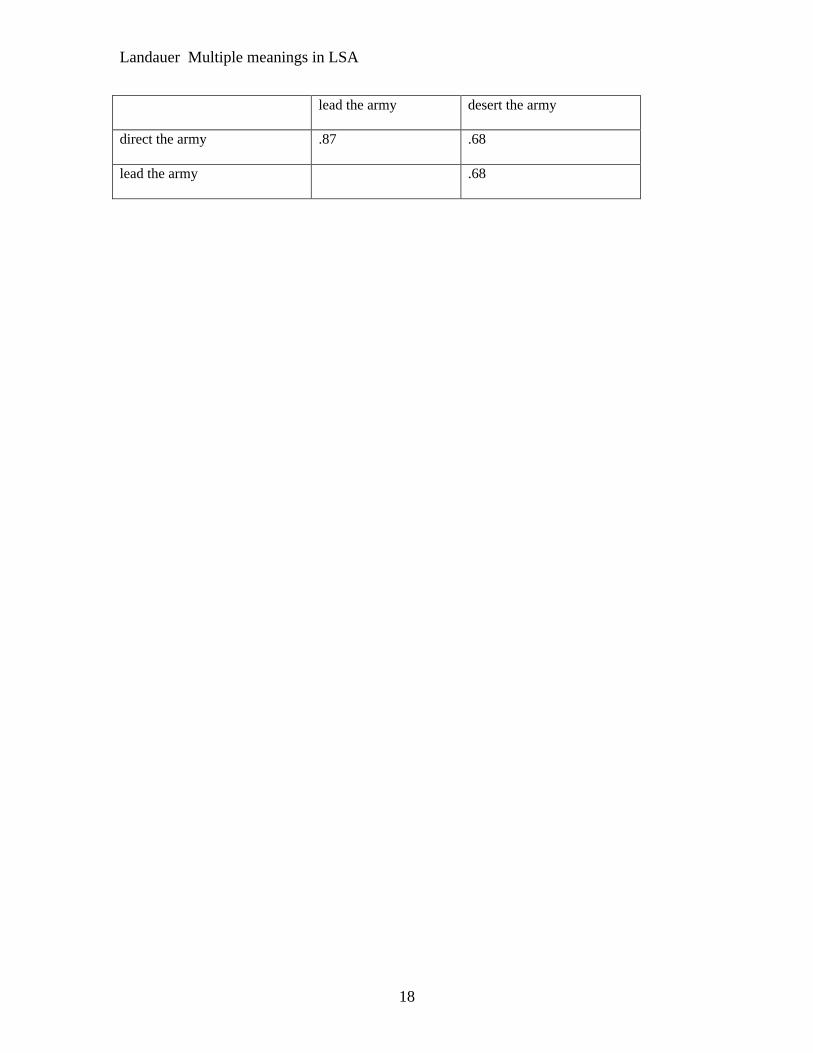
a lead weight a light weight
a heavy weight .92 .61
a lead weight .57
Landauer Multiple meanings in LSA
18
lead the army desert the army
direct the army .87 .68
lead the army .68

Landauer Multiple meanings in LSA
19
In the next example, we show the effect of leaving out or putting in a single highly
ambiguous word, "swallow", in a full sentence that is highly consistent with one or the other of
two meanings, one related to eating, the other naming a species of bird. The sentences are
definitions of "swallow" adapted from WordNet.
chew, gulp bird, sparrow swallow
To ... is the process of taking food into the body
through the mouth by eating.
.38 .14 .57
To swallow is the process of taking food into the
body through the mouth by eating.
.39 .15 .59
A ... is a small long-winged songbird noted for
swift graceful flight and the regularity of its
migrations.
.20 .30 .30
A swallow is a small long-winged songbird noted
for swift graceful flight and the regularity of its
migrations.
.24 .30 .39
Because the word "swallow" is so consistent with either definition, leaving it out of the definition
has almost no effect on the relation of the definition to the two words of related meaning, .38 vs.
.39, .30 vs. ,30. The ambiguous sense has some effect on the relation of the definition to the two
words of unrelated meaning, but affects the non-dominant bird-species meaning. Similarly,
including "swallow" itself in the definition makes the definition more like the word itself to a
greater degree for the non-dominant meaning. Dominance in LSA would presumably be reflected
in greater vector length along dimensions that determine one meaning rather than the other.
However, I have not tried to analyze examples in a way that would demonstrate that.

Landauer Multiple meanings in LSA
20
Landauer Multiple meanings in LSA
21
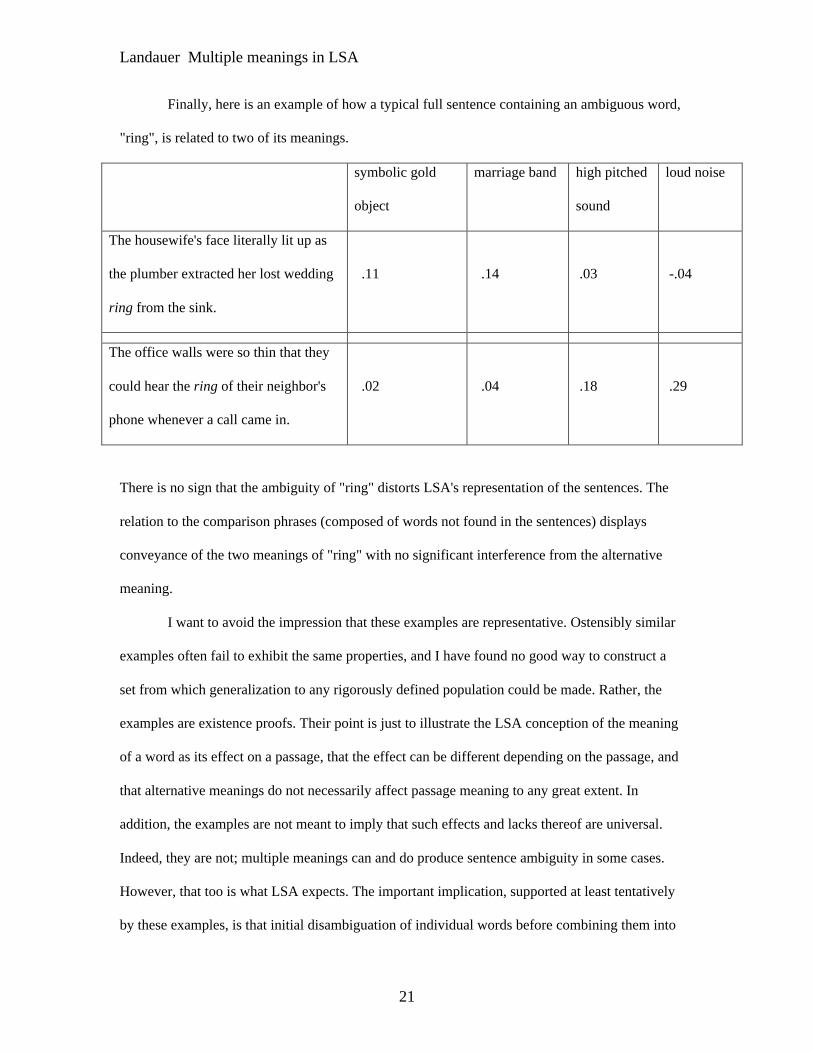
Finally, here is an example of how a typical full sentence containing an ambiguous word,
"ring", is related to two of its meanings.
symbolic gold
object
marriage band high pitched
sound
loud noise
The housewife's face literally lit up as
the plumber extracted her lost wedding
ring from the sink.
.11 .14 .03 -.04
The office walls were so thin that they
could hear the ring of their neighbor's
phone whenever a call came in.
.02 .04 .18 .29
There is no sign that the ambiguity of "ring" distorts LSA's representation of the sentences. The
relation to the comparison phrases (composed of words not found in the sentences) displays
conveyance of the two meanings of "ring" with no significant interference from the alternative
meaning.
I want to avoid the impression that these examples are representative. Ostensibly similar
examples often fail to exhibit the same properties, and I have found no good way to construct a
set from which generalization to any rigorously defined population could be made. Rather, the
examples are existence proofs. Their point is just to illustrate the LSA conception of the meaning
of a word as its effect on a passage, that the effect can be different depending on the passage, and
that alternative meanings do not necessarily affect passage meaning to any great extent. In
addition, the examples are not meant to imply that such effects and lacks thereof are universal.
Indeed, they are not; multiple meanings can and do produce sentence ambiguity in some cases.
However, that too is what LSA expects. The important implication, supported at least tentatively
by these examples, is that initial disambiguation of individual words before combining them into

Landauer Multiple meanings in LSA
22
passage meanings may not be needed to explain the affects of multiple meanings of words. LSA
does no such word-by-word disambiguation. However, obviously, much more work would be
necessary to determine just when the LSA process is sufficient and when it fails. I am sure, for
example, that there will be cases of failure in instances where word order based syntactic or
grammatical factors modify the meaning of an ambiguous word.
The overall argument of this section is that in most multiword passages the average
meaning of words may be enough to capture almost all of what is going on without the unrelated
meaning components of individual words causing enough difference to turn the total passage
meaning itself ambiguous. This helps to explain how the close simulations of human judgments
and behaviors with respect to passage meaning have been accomplished by the technique.
Failure of standard LSA to account for syntactically governed ambiguity. Obviously,
of course, ambiguous sentences—and, more rarely, ambiguous paragraphs—do occur, and much
use has been made of their explanation and implications in linguistics and psycholinguistics.
Thus, the fact that the vector representation of a word meaning may contain more than one
meaning is still both a matter of concern and an opportunity. The concern is exactly when and
how an ambiguous word settles into a definite meaning when alone, or has its appropriate effect
and not another, in a sentence or passage. The opportunity is that when a word representation
contains more than one sense or meaning, a mathematically precise way of explaining how word
meanings combine to form new meanings may be possible. In LSA representations, a passage is a
sum or average of the meanings of all the words in it, without modification of word meanings
themselves depending on the company they are currently keeping, and without assuming that
each sense is represented as a separate entity. The LSA representation allows a word to have a
quantitatively different effect in every utterance in which it takes part (just as it was embedded in
a different context each time it was encountered during learning). This makes it equivalent to
allowing every word to have an unlimited number of subtly different senses, a property that
common intuition and the differences between dictionaries seems to bear out, but avoids the

Landauer Multiple meanings in LSA
23
probably hopeless, and, I believe, fundamentally mistaken (although approximations are
practically useful) effort to exhaustively catalogue or separately model their mental
representations.
On the other hand, it is clear that combining words into a sentence, or placing them in a
particular order in a sentence, often generates different meanings, as for example in metaphorical
expressions, predications of the meaning of word A on word B rather than C, modifying word D,
not E, by the placement of word F, and so forth. "The red hen pecked the white rooster", vs. "The
red rooster pecked the white hen." No matter what kind of a representation one posits for the
meaning of a word, it would be necessary to have some mechanism by which these dynamic
changes can occur. The vector representation of LSA turns out to offer at least one such
explanation. The heart of the explanation is that all of the meanings of a word need not
necessarily be brought into play at once. Kintsch (1999, 2001) give clear examples of one way in
which this might be accomplished. In Kintsch’s model, a word does not enter into a passage
meaning simply as its vector. Rather it enters by producing an activation of neighboring words,
the closer, the more activated. The effect that these activated neighbors have on the meaning of
the passage in turn depends on what other words are present and on their relation to those
neighbors. In the result, it is a local selection on the possible combinations of the various meaning
dimensions of all the words that is used.
Kintsch’s model takes a big step towards showing us how LSA representations, or any
representations at all for that matter, can be dynamically combined through a computationally
specifiable process to produce correct emergent passage meanings. It does not yet avoid human
intervention, because to date Kintsch has had to tell the model which is the predicate and which
the argument.
How are we to attack this serious incompleteness in LSA in the mechanistic spirit we
desire? It seems likely that some of the dynamic effects are nonlinear, not simple arithmetic
averaging. This would mean that something different from simple addition needs to be embedded

Landauer Multiple meanings in LSA
24
in the function by which a passage meaning is generated from its constituent words. There are
significant theoretical, mathematical, and computational difficulties in the way of doing this, and
we have not yet found a successful way. The ability of SVD to solve the huge system of
simultaneous equations posed by the language learning problem depends on the simplifications
that we listed above, among which the addition function is probably as important as any. One
possible escape from this dilemma would be to find other more complex elementary features,
such as multiword combinations, to include as terms in the additive equations.
An even more difficult problem may be representing the effect of the order of appearance
of words. Order has a large bearing on such syntactic issues as which word is the predicate,
especially in highly order depend languages such as English. Again, a new internal function for
the equations will be required. And again, we have not yet found a way to proceed. Among the
nonlinear combining and order phenomena that will need a mechanism are ones that generate
structured relations such as phrases and anaphora. Some sort of dynamical system approach, such
as ones recently explored in neural net language modeling (e.g. Tabor and Tannenhaus, 1999) is
one appealing possibility. Another approach would be the addition of ordered multiword
combinations.
Obviously, much remains to be done. However, I see no reason to despair. The fact that
people learn and use languages means that there are such functions, and also implies that there
must be a general way to infer the particular form of the function used in a particular language
from its observation and social practice. Some might claim that the project is futile because the
observed evidence is insufficient for any learning system to infer the functions. I think this
assumption is already well on its way to crumbling under the weight of evidence. A recent article
by Christiansen and Chater (1999a), for example has shown that a standard recurrent neural
network system can, with no direct human aid, produce recursive appearing embedded structures
that mimic rather nicely the corresponding performance that humans actually exhibit. Other
neural net experiments have chipped away at the anti-learning assumption as well, as reviewed by

Landauer Multiple meanings in LSA
25
Seidenberg (1997) and recently exemplified by Hinton (2000) in a multiplicative components
model that learns to produce long-distance word order relations, albeit in a toy environment. And,
of course, I think that the LSA results on word and passage meaning, along with the additions that
Kintsch proposes are quite encouraging.
However, I believe that the most important implication from what has been done so far is
just that the concept of independent storage of discrete multiple senses of words, the standard
framework for thinking about lexical ambiguity, needs reconsideration. The theory and results I
have reviewed suggest that it might be more fruitful to focus on mechanisms by which a single
meaning representation can be learned from and applied in multiple contexts.

Landauer Multiple meanings in LSA
26
References
Berry, M. W. (1992). Large scale singular value computations. International Journal of
Supercomputer Applications, 6(1), 13-49.
Christiansen, M. H. & Chater, N. (1999). Toward a connectionist model of recursion in
human linguistic performance. Cognitive Science, 23, 157-205.
Christiansen, M. H. & Chater, N. (1999b). Connectionist natural language processing:
The state of the art. Cognitive Science, 23, 417-437.
Collins, A. M. and Loftus, E. F. (1975), A spreading activation theory of semantic
processing. Psychological Review, 82, 407-428.
Fellbaum, C.(1998) (Ed.) WordNet: An electronic lexical database. Cambridge, MA.,
MIT Press.
Jurafsky, D. (1996) A probabilistic model of lexical and syntactic access and
disambiguation. Cognitive Science, 20, 137-194.
Kintsch, W. (1999) Metaphor comprehension: a computational theory. Psychonomic
bulletin and review, 7, 257-266.
Kintsch, W. (2001) Predication, Cognitive Science.
Landauer, T. K. & Dumais, S. T. (1997). A solution to Plato's problem: The Latent
Semantic Analysis theory of the acquisition, induction, and representation of knowledge.
Psychological Review, 104, 11-140
Landauer, T. K., Foltz, P. W. and Laham, D. (1998), An introduction to Latent Semantic
Analysis, Discourse Processes, 25, 259-284.
Landauer, T. K., Laham, D.,& Foltz, P. W. (1998), Learning human-like knowledge by
singular value decomposition: A progress report. In M. I. Jordon, M. J. Kearns & S. Solla (Eds),
Advances in Neural Information Processing Systems 10, (pp. 45-51). Cambridge: MIT Press.

Landauer Multiple meanings in LSA
27
Landauer, T. K. , Laham, D., Rehder, B, & Schreiner, M. E. (1997). How well can
passage meaning be derived without using word order? A comparison of Latent Semantic
Analysis and humans. In M. G. Shafto & P. Langley (Eds.), Proceedings of the 19th annual
meeting of the Cognitive Science Society (pp. 412-417). Mahwah, NJ: Erlbaum.
Lenat, D. B. (1995). CYC: A large-scale investment in knowledge infrastructure,
Communications of the ACM, 38, 32-38.
Schvaneveldt, R. W. (Ed.) (1990) Pathfinder networks: Theory and applications.
Norwood, NJ: Ablex.
Seidenberg, M. S. (1997) Language acquisition and use: Learning and applying
probabilistic constraints. Science, 275, 1599-1603.

Landauer Multiple meanings in LSA
28
"wife" "Husband
and wife"
"and"
"husband"
Figure 1.
i