knowledge and strategy-based computer player for texas ... · knowledge and strategy-based computer...
TRANSCRIPT

Knowledge and Strategy-based Computer Player for Texas Hold'em Poker
Ankur Chopra
Master of Science
School of Informatics
University of Edinburgh
2006

Abstract
The field of Imperfect Information Games has interested researchers for many years, yet the
field has failed to provide good competitive players to play some of the complex card games
at the master level. The game of Poker is observed in this project, along with providing two
Computer Poker Player solutions to the gaming problem, Anki – V1 and Anki – V2. These
players, along with a few generic ones, were created in this project using methods ranging
from Expert Systems to that of Simulation and Enumeration. Anki – V1 and Anki – V2 were
tested against a range of hard-coded computer players, and a variety of human players to reach
the conclusion that Anki – V2 displays behaviour at the intermediate level of human players.
Finally, many interesting conclusions regarding poker strategies and human heuristics are
observed and presented in this thesis.
ii

Acknowledgments
I would like to thank Dr. Jessica Chen-Burger for her overwhelming support and help
throughout the life-cycle of this project, and for the late nights she spent playing my Poker
Players. I would also like to thank Mr. Richard Carter for his insight into the workings of
some of the Poker players, and all the authors of the research quoted in my bibliography,
especially the creators of Gala, Loki, Poki and PsOpti.
I would also like to thank my parents, who have always been there to me, and inspire me
every step of the way. And finally, I would like to acknowledge the calming contribution of
my lab-fellows, without whom, completing this dissertation couldn't have been nearly this
much fun.
iii

Declaration
I declare that this thesis was composed by myself, that the work contained herein is my own
except where explicitly stated otherwise in the text, and that this work has not been submitted
for any other degree or professional qualification except as specified.
(Ankur Chopra)
iv

Table of Contents
Chapter 1 – Introduction............................................................................................................1
Chapter 2 – Literature Review...................................................................................................3
2.1 - Imperfect Information games.............................................................................4
2.2 - Poker history......................................................................................................4
2.3 - Gala....................................................................................................................5
2.4 - Loki....................................................................................................................7
2.5 - Poki....................................................................................................................9
2.6 - PsOpti...............................................................................................................11
Chapter 3 – Playing Poker.......................................................................................................14
3.1 – Basic rules and aim of tournament..................................................................14
3.2 - Sequence of each game (specific to Texas Hold'em).......................................15
3.3 - Betting Rounds.................................................................................................15
3.4 - Winning combinations......................................................................................16
3.5 - Basic player/strategy types...............................................................................17
3.6 - Advanced strategies and Poker complexity......................................................18
3.7 - Abstraction Techniques of 2-Person Bet-Limit Poker......................................19
Chapter 4 – Design and Methodology......................................................................................20
4.1 - Choice of Prolog...............................................................................................20
4.2 – General.............................................................................................................20
4.2.1 - Incorporation of Rules........................................................................................20
4.2.2 - Basic Two-Human-Player Poker........................................................................23
4.2.3 - General Strategic Behavior.................................................................................24
4.3 - Anki – V1.........................................................................................................25
4.3.1 - Strategy based player..........................................................................................25
4.3.2 - Overview of functioning and method.................................................................26
4.3.3 - Probability realisation of all possible starting hands...........................................28
4.3.4 - Grouping form of strategy..................................................................................30
4.3.5 - Similarities and differences from human beings.................................................31
v

4.4 - Anki – V2.........................................................................................................33
4.4.1 - A Randomised Rational Strategy Player.............................................................33
4.4.2 - Statistical Method vs. Random Generator .........................................................34
4.4.3 - Formulas and Evaluation....................................................................................35
4.4.3.1 - Pseudo games and Winning Potential.........................................................36
4.4.3.2 - Calculation of Probability Triples...............................................................37
4.4.3.3 – Betting Strategies, Randomised Numbers and Enumeration......................38
Chapter 5 – Testing and Evaluation.........................................................................................41
5.1 - System Test – White and Black Box Testing...................................................41
5.2 - Random -1 player's Evaluation........................................................................45
5.3 - Evaluation of Anki – V1..................................................................................46
5.3.1 - Anki – V1 vs. Computer players........................................................................46
5.3.2 - Anki – V1's Evaluation against Human Players.................................................50
5.4 - Evaluation of Anki - V2...................................................................................54
5.4.1 - Anki - V2 vs. Computer players.........................................................................55
5.4.2 - Anki – V2's Evaluation against vs. Human.........................................................58
5.5 - Anki – V1 vs. Anki – V2.................................................................................60
5.5.1 – Direct Anki Comparison....................................................................................60
5.5.2 – Anki Comparison in Human and Random Players.............................................61
5.6 - Anki and the Previous Research.......................................................................65
Chapter 6 – Conclusion and Future Work................................................................................68
6.1 - General conclusions.........................................................................................68
6.2 - Conclusions of Anki – V1 and Anki – V2.......................................................68
6.3 - Conclusions of Poker Game and Betting Strategies.........................................70
6.4 - Future Work.....................................................................................................71
6.4.1 – The Anki Poker Teaching Tool..........................................................................71
6.4.2 - Testing and Extensions to project.......................................................................72
6.4.3 - Resource based extensions to project.................................................................73
Bibliography............................................................................................................................75
Appendix A – Program Code...................................................................................................77
vi

Chapter 1 – Introduction
Poker has recently become one of the most popular games in the gaming community with many
online poker rooms and programs. Despite the high level of human interest in this game, the
computer programs and existing AI of this game are still in its infancy. A very interesting and
influential paper was written in this field in 1995 by Daphne Koller on Imperfect Information
Games[1]; and after more than a decade of research and advancements, the best of Poker
programs are still known to lose regularly to master level players.
The concept of Imperfect Information Games makes this field and project very significant. The
AI community has come leaps and bounds in creating world champion level players for Perfect
Information Games, e.g. chess, backgammon, etc. The approach of these games is very different
from Imperfect Information Games, as all players can view the entire state of the game or gaming
world at any point of time. This allows all the required information to be coded into the AI
player's game design. On the other hand, extensive work done on the Imperfect Information field
has only yielded either theoretical solutions or restricted Poker players. The statistically best
Poker player, PsOpti, is considered better than most human players, but is still below the master
level. PsOpti, also, only works with a restricted form of Texas Hold'em Poker, a variant of poker,
optimised for 2 players.
The reason why Imperfect Information Games are considered hard is because it requires players,
human and AI, to cope with uncertainty, taking risks and deploying strategies. Also in such
games, there is no concept of strict strategy, whereby a method could be found which would
always lead to the optimal result. To have a strict strategy in most Imperfect Information Games,
including poker, is considered suboptimal, as it provides additional information to the opponent.
Thus, in addition to playing well with good strategies, an aspect of randomness needs to be
incorporated into the player's strategy. It is sometimes beneficial to play a bad game, to encourage
the opponent to bet more in future games, and thus win more in the long run.
This project aimed to create Texas Hold'em Poker players in Prolog based on the concepts of
Knowledge Base and Strategy. This project offers a useful insight into the AI gaming community
through its exploration of Imperfect Information Games. Logic is one of the best languages to
1

represent a Knowledge Base, and thus Prolog has been chosen as the language for implementing
this project. There are a variety of computer Poker players that were created, including Random –
1, Random – 2, Anki – V1 and Anki – V2.
The players created in this project are tested against many pre-coded Strict Strategy computer
players, and also against various categories of Human Players, ranging from Beginner to
Advanced. A comparison to previous research has also been done, all of which is documented and
presented in the form of results and conclusions.
The next chapter, Chapter 2, presents the Literature Review on the subjects of Imperfect
Information Games and previous Computer Poker Player Solutions to the Poker gaming problem.
It also provides in-depth information about three of the best and well-documented players in the
field, i.e. Loki, Poki and PsOpti.
Chapter 3, Playing Poker, deals with the Poker game and Texas Hold'em in particular. The game,
its rules, sequence of play and winning or losing conditions are presented along with the basic and
complex strategies used by Human Players during the game. The abstraction techniques being
utilised in this program, i.e. Bet-Limit Two-Player Texas Hold'em Poker Player, is explained in
Section 3.7.
Chapter 4, Methodology, presents the design and structure of the system and computer players
created. The system architecture is represented along with the strategies and specifications of
Random – 1, Random – 2, Anki – V1 and Anki – V2.
The testing documentation, results and evaluation of Anki – V1 and Anki – V2 is presented in
Chapter 5, Testing and Evaluation. Both these players are compared against strict or random
strategy players explained in Chapter 4, against Human Players and also against each other. They
are finally compared to the previous research and Computer Poker Players created in the field.
The project is summed up in the final chapter, Chapter 6, Conclusions and Future Work.
2

Chapter 2 – Literature Review
Game theory has been a very prominent area of research since the 1940's. It has been utilised and
successfully applied to various other fields such as
“...inspection of nuclear facilities, models of biological evolution, the FCC auctions for radio and television bandwidth, and much more.” [1]
It has also helped accomplish big advances in the AI gaming community. AI player capabilities
have reached an extent whereby games such as Chess and Backgammon are no longer under
human dominance. Computer players compete against grandmasters in such games and win on a
very frequent basis. Other games with lesser strategical requirements can no longer even be won
by humans, when playing against a competent computer player.
It is, however, found that AI dominance exists only in one section of the gaming field. The games
mentioned above and others like it are called Perfect Information Games. These are games in
which the entire state of the game is visible to all players, or, all players of the game have equal
“Knowledge”. This complete knowledge of the game state allows brute-search algorithms to
compute scenarios and possible future moves. Success has been achieved in this field through
improvement in speed of searches, for example, Deep Blue searched over 250 million chess
positions a second to allow it to make the most optimal move.
The other section of the gaming field lies in Imperfect Information Games. Examples of these
are Bridge, Poker and RoShamBo (also known as Stone-Paper-Scissors). These are games that
only allow partial world knowledge to be available to players, and requires them to base decisions
on the same uncertainty. In the case of poker, or other similar card games, imperfect information
is created by the hidden cards that the opponent holds. Similarly, as your cards are hidden, your
opponent too has imperfect information.
“It is well-known in game theory that the notion of a strategy is necessarily different for games with imperfect information.” [1]
3

Perfect Information Games have a well-defined optimal move, i.e. there is always a move which is
at least as good as some other move. In addition to this, if the opponent gains knowledge of this
move, it would make no difference to the current play, as it is by definition, the optimal move.
This property is exploited by search algorithms to find that optimal move in the game tree.
2.1 - Imperfect Information games
“Although game-tree search works well in perfect-information games, there are problems in trying to use it for imperfect information games such as bridge (and poker). The lack of knowledge about the opponents' possible moves gives the game tree a very large branching factor, making the game tree search infeasible.” [4]
Imperfect Information Games are played with a constant knowledge-gap between players with
both having partial knowledge of the game state. Unlike Perfect Information Games, a
deterministic strategy cannot be utilised in these games as that would allow the opponent to have
an advantage of guessing the complete knowledge of the game. For this reason, optimal strategies
in Imperfect Information Games can be described as a random combination of strategies with
optimal evaluation of the partially known game state.
“Kuhn ([19]) has shown for a simplified poker game that the optimal strategy does, indeed, use randomization.” [1]
2.2 - Poker history
It is evident from the previous citation that people have been interested in computer poker players
for a very long time. Apart from Kuhn, illustrious mathematicians and economists have also
worked on theoretical and practical solutions for poker. This research field dates back to John von
Neumann and John Nash, who used simplified poker to illustrate fundamental principles
[16][17][18].
With such a long history of focus on Imperfect Information Games, especially Poker, it would be
expected that the current computer players at least be of commendable standard. However, this is
not the case. The most prolific players have all been created under the same umbrella of Darse
Billings' work. Also, the best full-game Poker players are intermediate quality at best. The
4

creators of these programs confess to this fact in [10][13]. Their latest player, PsOpti is shown to
perform well at the master level but only after a variety of changes to game-play, for example,
restricting the game to a two person play. Most games of poker can see between 8 to 10 players
playing a single game (full-game Poker).
There is now a need for Imperfect Information Game computer players to catch up with their
Perfect Information Game counterparts and offer a similar challenge to the human gaming
community. This is the purpose on the basis of which this project has been proposed and
evaluated.
Over the previous two decades, a variety of solutions have been offered to the computer Poker
player creation problem. These solutions can be sub-divided into the following four categories;
Theoretical, Expert Systems, Simulation and Enumeration and finally, Game-Theoretic.
These terms are further explained in detail below along with a case study of their most prominent
example.
2.3 - Gala
Gala was created by Daphne Koller and Avi Pfeffer, first documented in [1]. It offers a theoretical
solution to a restricted form of Poker. Once again, a two player system was evaluated, to which
Gala, a logic programming language, was applied.
Even though it was only a theoretical solution, Gala offered to write down the rules and
constraints of Poker play in pseudo code form for the first time. This allowed future programmers
such as Darse Billings and this project to gain insight into the sequential methods and workings of
computer Poker players. Darse Billings, one of the major contributors of modern computer Poker
players frequently refers to both [1] and [5], the works of Koller and Pfeffer.
Figure 1 shows a small portion of the code designed for the Poker player. Gala is;
“ ... a knowledge representation language that allows a clear and concise specification of imperfect information games.”[1]
5

In addition to the language, Gala also provided algorithms that prevented exponential growth of
the game-trees with Imperfect Information.
Figure 1. An abbreviated Gala description of Poker, from [1]
However, as the game-trees were still found to be proportional to the unknown states in the game,
the algorithm was found to be impractical for its application to full-scale poker. The authors
concluded,
“. . . we are nowhere close to being able to solve huge games such as full-scale poker, and it is unlikely that we will ever be able to do so” [1]
6

This statement of Koller and Pfeffer and been repeated many times in the various papers by Darse
Billings, e.g. [10].
2.4 - Loki
Loki was one of the first ever full-game computer poker players. It was developed by Darse
Billings et. al., and is documented in [11]. It was created in two stages. Both versions have an
expert knowledge and rule-based engine hard-coded into them, i.e. the experience of Darse
Billings as a master poker player facilitated the formation of a form of game tree. This game tree
consisted of scenarios and strategies suggested by the expert, and thus the game engine could
brute-search through these strategies to obtain a near-optimal or random solution.
The first version of the program relied solely on this expert knowledge to play against other
players. It can be argued if this was truly an AI player or just the code representation of a
particular master's player. Strategies were given priority rankings, and were randomly selected
using weights, this allowed them to be relatively random.
The first version, created on 1998, was shown to perform well solely against beginners, as even
with the expert system, certain situations resulted in near deterministic working. As discussed
earlier, any form of fixed strategy by an opponent can be used by the player to their advantage,
and this occurred with Loki when it played against more experienced players. Figure 2 shows the
basic Loki Architecture, and its functions.
7

Figure 2. Loki Architecture
The second version, updated in 1999, added more computing concepts into the player. It,
however, still kept the core expert engine,
“ Loki uses expert knowledge in four places:1. Pre-computed tables of expected income rates are used to evaluate its
hand before the pre-flop, and to assign initial weight probabilities for the various possible opponent hands.
2. The Opponent Modeler applies re-weighting rules to modify the opponent hand weights based on the previous weights, new cards on the board, opponent betting actions, and other contextual information.
3. The Hand Evaluator uses enumeration techniques to compute hand strength and hand potential for any hand based on the game state and the opponent model.
4. The Bettor uses a set of expert-defined rules and a hand assessment provided by the Hand Evaluator for each betting decision: fold, call/check or raise/bet.” [13]
In the above statement, there is a mention of 'hand strength' and 'hand potential'. Hand Strength is
the probability that the cards held by a player are the best possible cards in the game. On the other
8

hand, Hand Potential refers to the probability of the current cards becoming the best cards in the
game in the future. These two terms together form the basis of a Hand Evaluator.
There were major changes installed in the hand evaluator. Figure 3 shows the transformation of
Loki from one form to another, and its reduction of dependence on expert knowledge. Another
major update was the introduction of simulation to determine the best future action. This is
explained in detail under the next sub-heading of Poki, as the transformation from Loki – 2 to
Poki was almost immediate.
Figure 3. Transformation from Loki - 1 to Loki – 2
Loki offered some useful insight into the design of the player created in this project. The most
prominent of these was Bucketing, which was incorporated in Loki – 2 and is present in Anki -
V1. Bucketing is a method of abstraction, whereby, scenarios or game states are bunched together
in groups. These groups are based on the expected reaction of the player, for example, in poker,
hands of King-King and Ace-Ace can be grouped together as they are nearly as good as each
other. More poker glossary and information is available from Chapter 3.
Another important concept introduced in Loki - 2 was the usage of Triples to represent
probability values for fold, bet and raise. The definition of these terms can be found in Chapter 3,
but they are basically the options available to a player during the course of a Poker game betting
round. This concept has also been incorporated into Anki – V2.
9

2.5 - Poki
Poki, the step up from Loki, introduced the strategy of Simulation and Enumeration to the
computer poker players. It was created in 1999 – 2000, once again by Darse Billings et. al., [10].
Poki is also currently the best full-game Texas Hold'em Poker player, the variant of poker under
consideration in this project. Once again, more information is available in Chapter 3 regarding
Texas Hold'em.
“Poki supports a simulation-based betting strategy. It consists of playing out many likely scenarios, keeping track of how much each decision will win or lose. Every time it faces a decision, Poki invokes the Simulator to get an estimate of the expected value (EV) of each betting action. ... A single trial consists of playing out the hand from the current state of the game through to the end. Many trials produce a full information simulation.” [10]
Enumeration, on the other hand, refers to the updating of the current belief or partial information
state, with data received through interaction from the outside world. In the case of any card game,
this can be implemented in the form of increasing the apparent chance of good cards with the
opponent, if the opponent continues to bet excessive money during the game. This requires some
form of an opponent modeler, which tries to guess an opponent's hand or strategy through an
opponent's actions.
Figure 4 shows the architecture of Poki. It can be seen how it is very similar to that of Loki – 2 in
Figure 3. The most major upgrade that resulted in a different name was concerning the opponent
modeling.
10

Figure 4. Poki's Architecture
In spite of the above upgrades to the AI player, Poki was still found to be inadequate in certain
situations,
“The program’s weaknesses are easily exploited by strong players, especially in the 2-player game.” [2]
So, the Computer Poker Community managed to increase their level of play, but they were still
below par in comparison to good human players.
Anki – V2, the system developed in this thesis, also uses the concepts of Simulation and
Enumeration in addition with Triple Generator to decide on its actions during a betting round.
This is further explained in Chapter 4, Design and Methodology.
2.6 - PsOpti
PsOpti is the most recent player in the market, created once again by Darse Billings et. al. in 2003
[2]. It is a player based on game-theoretic strategies, using concepts of game theory. Ironically,
the approach is quite similar to Gala, but only at the most fundamental level. PsOpti is the first
game-theoretic AI player that was successfully tested against a master poker player, and was
usually found to compete at a better scale with the master, than any of the previous computer
players.
11

“A game-theoretic solution produces a sophisticated strategy that is well-balanced in all respects. It is also safe and "robust", because it is guaranteed to obtain the theoretical (optimal) value of the game against *any* other strategy.“ [1]
This value allows the player to play a pseudo-optimal game throughout its tournament. As it finds
the value against any game, this also holds true for randomised, aggressive and bluffing game-
play, all of which exist to a very high extent in master level poker play. Figure 5 shows PsOpti's
player against a master level player 'the count'. The unit of measure used here is 'small bets won',
which can basically be replaced in this case by 10s of dollars.
Figure 5. “the count's” performance against PsOpti
However, this player is severely restricted in its game play.
“... abstraction techniques are combined to represent the game of 2- player Hold’ em, having size O(1018), using closely related models each having size O(107) .” [2]
Some of these abstraction techniques remove the possibility of PsOpti being utilised in the full-
game field in its current state. For example, one of the abstractions removes one of the betting
rounds from the game of play, and another restricts the play to only a two-player game. A two-
player game can be viewed as a simplified version of a full-game, wherein upto ten people can be
playing at the same time.
12

This can still be seen as a great beginning, as all the abstractions are mostly computational
reductions, and such players can easily be scaled up once they have proven their might.
“The drawback is that this type of strategy is fixed -- it can't adapt to the style of a particular opponent. Although it will break even against any opponent, it might only win at a slow rate against a weak or predictable player.” [1]
Another manner of interpreting this statement is that the game-theoretic player evaluates its
current state and the state of the game, to try and obtain a near-optimal strategy. It has has no
opponent modeling and thus cannot take advantage of human inexperience or mistakes. Opponent
Modeling cannot be expressed in a similar manner as a game-theoretic approach; and thus the
creators of PsOpti are currently looking into a player which plays game-theoretic till it develops
enough knowledge about an opponent, so that it can switch to more sub-optimal strategies. These
are strategies, which do not necessarily give the best result against an optimal player, but are the
expertly determined best response to the manner in which the opponent is playing.
Many of the abstractions used in PsOpti's creation are also being used to create the program of
this project. This is because these abstractions offer a smaller set of constraints to satisfy, which is
a commodity in a time constrained project such as this. Also, PsOpti's creation shows how these
abstractions are mere computational releases of regulations, and offer a faster cycle of design,
prototyping and results which are still relevant to the full-game analysis.
The next chapter introduces the game of poker, Texas Hold'em, and its strategies and complexity.
13

Chapter 3 – Playing Poker
3.1 – Basic rules and aim of tournament
Poker is a game played with a normal deck of 52 cards. The cards are divided into four set of
thirteen cards, with each set have a distinctive symbol. These sets are called suits, and are named;
spades, clubs, diamonds and hearts. The first two suits are usually represented in black, and the
latter two in red. Each suit has cards from two till ten, followed by Jack, Queen, King and Ace, in
order of value.
The aim of a poker game is to obtain the best possible pattern with a 'hand' of 5 cards. 'Hand' has
two definitions in poker, it refers to the final set of cards available to a player to form his/her
pattern, and also the initial cards that are provided to each player and are hidden from the rest.
This project will use the word in both contexts, but the difference can be found through the use of
the words 'final hand' and 'initial hand'.
A game in Poker is defined as the entire sequence of play from receiving the initial hand, to the
point where some-one 'folds'; forfeits the current money in the pot, or a showdown determines
which of the players have the strongest final hands. A game starts with a couple of blinds, which
is small amount of money put into the game by two players without looking at individual initial
hands. This allows each game to be worth at least some amount of money, and encourages more
aggressive strategies by players. The game ends with the last remaining player, or the strongest
player taking all the money in the 'pot' after the various betting rounds.
A poker tournament consists of various players who start with equal money. As the games
proceed, any player who reaches the end of their monies is said to have been eliminated and
leaves the table. The last person left on the table with all the money is the winner of that
tournament.
Basic aim of poker can be described as “Win as much as you can, but when you about to lose,
lose as little as you can.” Quite clearly the statement portrays the need for evaluation and
deception.
14

3.2 - Sequence of each game (specific to Texas Hold'em)
“ ... the game of Texas Hold’em, the poker variation used to determine the world champion in the annual World Series of Poker. Hold’em is generally considered to be the most strategically complex poker variant that is widely played in casinos and card clubs. It is also convenient because it has particularly simple rules and logistics.” [10]
The popularity of Poker has already been discussed in Chapter 1, so the choice of Texas Hold'em
should be obvious, as it is seen as the most popular form of the game.
Texas Hold'em starts with all the players receiving a two-card initial hand. These cards are hidden
from all the players bar the one to whom they are dealt. With deception or future potential of
cards in mind, a betting round is held. The exact semantics of a betting round are explained in the
next sub-section. At the end of the betting round, three community cards are dealt face-up. In
computer play, this is represented by making the knowledge of the three cards available to both
players. These three cards are called the 'Flop'.
The Flop is followed by another round of betting, at the end of which another community card is
shown. This card is known as the 'Turn'. This is followed by another round of betting and then
another community card called the 'River' is revealed. The final betting round takes place
afterwards, and if more than one person remains till the end, the seven cards are checked for the
best hand of five. The winner takes all the money collected in the betting rounds of that game.
3.3 - Betting Rounds
The aim of the betting round is to collect equal money from all players before proceeding to the
next stage, be it the revealing of community cards or a showdown. The options available to a
player at any point in the round is fold and bet. Folding results in immediate forfeit of the money
in the pot. Bad as it may sound, it is usually better to fold a hand which you are quite certain
would not win, rather than lose money on it.
Betting puts in a 'bet amount' into the pot. In this project this bet-amount is fixed at 10 units of
money. There is another option available to the player, i.e. to check. Checking can be done when
15

there has been no money put down at the start of a betting round. So, at the start of any betting
round, the person with the first turn has the option to check, and after that the second person has
the option to check, bet or fold.
The final option available to a player is that of a raise. Raising puts 20 units of money into the pot
and is almost the opposite of checking, as it is allowed only when there has already been a bet on
the table. Also, raising is restricted to a maximum of three times per player.
Betting rounds can follow many patterns from the choices available above. For a two player game,
an example is both players checking, in which case neither player puts any money into the pot.
Another is that of both players betting, whereby both put in 10 units each. Certain complex
betting rounds can also occur, such as check, bet, raise, raise, bet. Here, the first player checked,
only to have the second player bet. The first player now has the option of betting, folding or
raising, and he chooses the latter most. The second player re-raises and finally the first player bets
to bring the contribution of both players at the end of the betting round to 30 units each.
A betting round terminates as soon as a person folds, in which case the game ends, or when a
person matches the opponent's contribution to the pot by checking or betting. Raising is usually
used to 'raise-the-stakes'.
3.4 - Winning combinations
The strength of a winning five-card hand is determined by the table shown in Figure 6. The top-
most 'Royal Flush' is considered the best hand in the game, whereas a 'High Card' is the worst.
When determining a winner at the showdown, the player with the pattern which is highest on the
table in Figure 6 wins.
16

Figure 6. Winning combinations in Texas Hold'em Poker
Certain circumstances require further evaluation to find the winner of a hand. In such a case, the
entire best-five hand is seen. For example, if by some strange luck, the community cards are the
four Jacks and an 8, then the best five-card hand for each player is going to be the four jacks, as
royal and straight flush and not possible, followed by the next highest card. It is this card that
determines the winner of the game. If Player 1 has King-Four, and Player 2 has Queen-Ten, then
the winner is Player 1, as his 'Four Jacks with King kicker' beat Player 2's 'Four Jacks with Queen
kicker'. As is the case with Four of a Kind, sometimes, the second or third kickers are seen to
determine the winner, but never beyond the best-five hand of a player.
Draws occur in poker usually when both player 'play-the-board', i.e. the best-five hand for both
players is actually the community cards. In this case, as the ranking of all the five cards is the
same for both players, the pot is split halfway between the two players.
3.5 - Basic player/strategy types
“There are several different ways to categorise the playing style of a particular player. When considering the ratio of raises to calls a player may be classified as aggressive, moderate or passive (conservative). Aggressive means that the player
17

frequently bets or raises rather than checking or calling (more than the norm), while passive means the opposite. Another simple set of categories is loose, moderate and tight. A tight player will play fewer hands than the norm, and tend to fold in marginal situations, while a loose player is the opposite. Players may be classified as differently for pre-flop and post-flop play” [3]
Pre-flop refers to the betting round held before the flop is revealed, whereas post-flop refers to the
rest of the game after the display of the flop. A differentiation is usually made between these
stages as the amount of information change is very great. Initially, each player has knowledge of 2
of the 4 cards that have been dealt, and after the flop, each player has knowledge of 5 of the 7
cards in play.
The different strategies mentioned above also result in a specific form of reaction from the
opponent. Games against aggressive or loose players would be worth a lot more, and at the same
time, raising by an aggressive player may not always mean that the player has a good hand. On
the contrary, raising by a tight or conservative player should be considered with greater concern.
Apart from these basic player types, there are also known to exist many complex strategies which
make the game of Poker both interesting and exceedingly hard.
3.6 - Advanced strategies and Poker complexity
“Poker is a complex game, with many different aspects, from mathematics and hidden information to human psychology and motivation. To master the game, a player must handle all of them at least adequately, and excel in most.” [10]
This is the task being handed to a computer player to successfully excel in the game of Poker.
Quite clearly, this is a huge task, and it probably would not be accomplished in the next few
years. Mostly this is due to the inability of computing players to have a gut instinct or the ability
to rapidly change one's strategy to combat another's. This topic is discussed further in Future
Work in Chapter 6.
Computing players have to deal with a lot of advanced strategies like check-raising, whereby a
false impression is imparted on the opponent by checking on a good hand to raise when the turn
comes back to the player. This would usually cause the opponent to at least respond with a bet,
18

and thereby allow the current Player to extract more money from the opponent. In addition to this,
a check-raise may be made only in order to scare an opponent, as it is a well-known aggressive
strategy.
The best player to date, i.e. PsOpti incorporates no opponent modeling.
“It is important to understand that a game-theoretic optimal player is, in principle, not designed to win. Its purpose is to not lose. An implicit assumption is that the opponent is also playing optimally, and nothing can be gained by observing the opponent for patterns or weaknesses.” [2]
It is in the face of these challenges that this project hopes to show a brave front and come up with
some important conclusions that may assist in furthering the field of AI poker players.
3.7 - Abstraction Techniques of 2-Person Bet-Limit Poker
The form of poker being considered for design and evaluation is that of two-player, bet-limit
Texas Hold'em Poker. These abstractions have been made as they allow a player to be built under
the required time constraints, and yet have conclusions which are applicable to full-scale poker
players.
Bet-limit poker is a form of poker whereby each bet is of a set limit, i.e. 10 money units in this
case. Texas Hold'em tournaments are usually held with no-limit poker, whereby a player can
dedicate his/her entire money on the first bet of the first game itself. Bet-limit poker provides both
a regulated and a beginner level of understanding, which can be matched by the scope of this
project.
19

Chapter 4 – Design and Methodology
4.1 - Choice of Prolog
The first decision taken for this thesis was regarding the choice of programming base. The
duration of time available or the project and the heuristics constraints required a language that
expressed a knowledge base and rule-based reasoning in a clear and concise manner, and yet had
to ability to produce a quick design-to-result cycle. For this reason, Logic Programming was
chosen to be the fundamental base upon which the program would be created.
This decision does result in a disadvantage to the computing power efficiency of the final result,
however, Prolog's ability to create programs and obtain prototypes and results much faster, makes
it an ideal choice for this thesis. Rewriting the program to allow interoperability through the usage
of platform-independent languages such as Java has been discussed in Chapter 6, Future Work
and Conclusion.
4.2 – General
4.2.1 - Incorporation of Rules
The primary design of the thesis program required a structure, this was provided through insight
into the Gala system. An in-depth knowledge of Poker rules was also discussed with the people
mentioned in the Acknowledgment section to finalise certain discrepancies in the system. Like all
popular games, Texas Hold'em has a variety of different rules, which are used by different
organisations in their tournaments. For example, the first step in any game is the small and big
blinds, whereby the first and second players put the money equivalent to half the betting amount
and the betting amount respectively without looking at their cards. This allows each game to be
worth at least some amount, and thereby more interesting.
This is a rule seen for major multi-player tournaments where the chance to be the first or the last
in a betting round circulates and thus allows every player to be at an advantage or disadvantage at
some point in the game. This does not hold true for two-player poker, as the significant pro-con
20

scenario of a tournament is lost in two-player poker. For example, every player that is required to
put in a big blind that player also gets to be the final player to bet in that betting round. Thus the
pros and cons seem to balance each other out, a system which would be redundant in a smaller
table of two-player poker. Also, the program designed for this project has very limited opponent
modeling, which makes the changing of sequence of play unnecessary as a player's strategy
doesn't effect the betting decision of the AI Player. For this reason, the blind system has been
replaced with an ante. An ante is a fixed amount of money contributed by each player at the start
of each game, due to the same reason as blinds. It is worth a bet amount, i.e. 10 units of money in
this case.
Figure 7 shows a clear view of the playing sequence of each game, in the form of cards and
Betting Rounds. The Start represents the submission of ante, this is followed by the individual
hands being allocated. The next step on the board is the revealing of the Flop, however, there is a
betting round, known as Pre-Betting Round that is played before the Flop is revealed. Similarly,
the Post-Flop and Post-Turn Betting Rounds sit between the Flop and Turn, and the Turn and the
River respectively. The tournament continues onto the Post-River Betting Round, which is also
called Final Betting Round sometimes. The final step, i.e. the Showdown represents the
calculation of the winner/s of the game and the distribution of finances to that/those players.
21
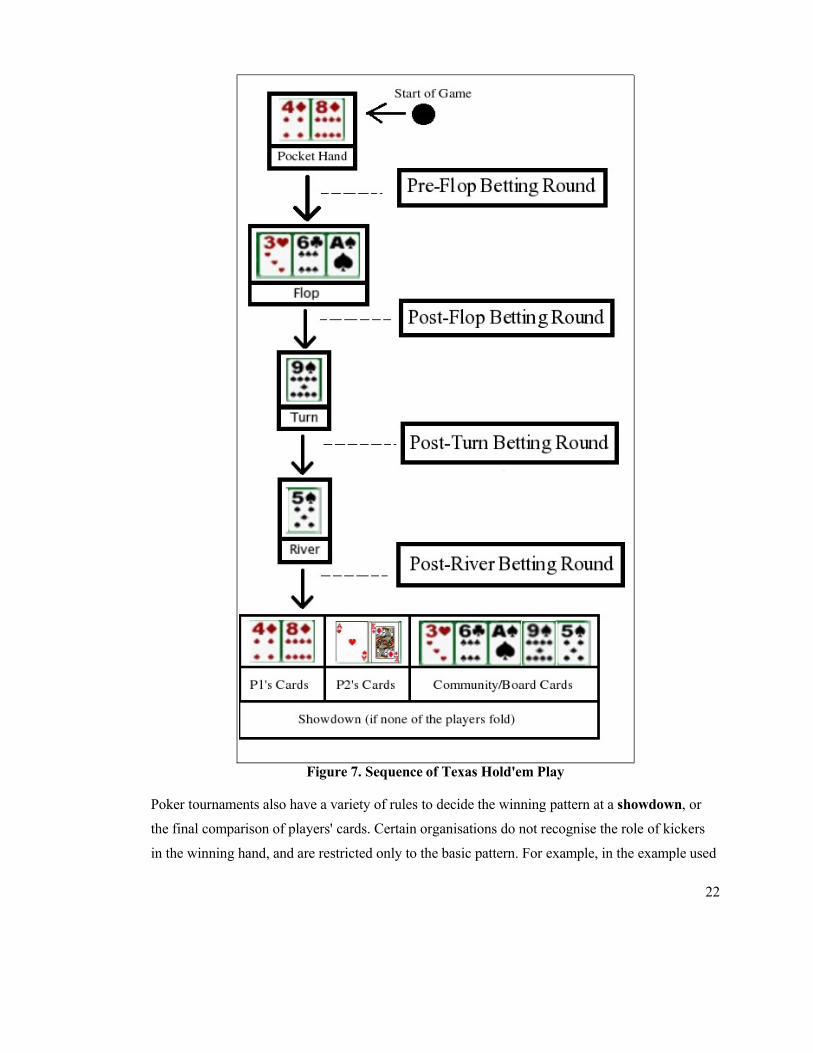
Figure 7. Sequence of Texas Hold'em Play
Poker tournaments also have a variety of rules to decide the winning pattern at a showdown, or
the final comparison of players' cards. Certain organisations do not recognise the role of kickers
in the winning hand, and are restricted only to the basic pattern. For example, in the example used
22

in Section 3.4 regarding the comparison of “Four Jacks with a King Kicker” and “Four Jacks with
a Queen Kicker”, the above mentioned organisations would regard the result to be a draw, as the
basic pattern is Four-of-a-Kind and both players have it in the form of Jacks. The kicker plays no
role in the decision.
The program created for this thesis follows the more generally accepted rule of recognising the
role of a kicker. This is due to both the rules' popularity and the extensive strategy management
required on the addition of this rule. The cards available to both players, i.e. community cards, can
sometimes lead to a very good hand by themselves. But even in such a case, this rule creates the
need for additional strategy, as kickers can be used to determine the outcome.
4.2.2 - Basic Two-Human-Player Poker
The next step after the creation of a framework like the one described in the above section, is the
formation of players. The most basic form of play was implemented first, i.e. Human vs. Human.
Clearly, this required no knowledge base or strategy on behalf of the computer in terms of game-
play. The primary purpose of a Human vs. Human player was to brute-force check the stability
and rules of the Poker framework.
A user-friendly Prolog interface was created for the users to allow multiple games to be played.
Section 3.3 discusses the various betting choices available to each player, most of them only
under certain circumstances. Choices of checking and raising were encoded along with their
necessary rules and restrictions. A recursive error checker was also added to return the game state
to its previous form in the case of an invalid entry from a human player.
Finally, at the end of each game, if no player has folded, the program displays the cards of both
players and specifies the winning pattern and player (showdown scenario). In the case of a player
folding, there is no showdown and the cards are scratched, i.e. none of the players get to see each
other's cards. This follows the working of real poker, whereby you can only see your opponent's
cards if you fight them all the way to the end, and they do the same.
23

4.2.3 - General Strategic Behavior
Basic player strategies have been discussed in Section 3.5, and the keywords such as aggressive,
conservative, tight and loose will be used very frequently in this thesis. These keywords are used
to describe the playing strategies of a poker player, and the basic aim of such a player is to
randomise these strategies as much as possible. Sticking to just one of the strategies can allow the
opponent to recognise it and respond accordingly. The first step towards finding a near-optimal
poker strategy is to create poker players which utilise these basic strategies strictly or randomly,
and then to compare their performances. The comparison is given in Chapter 5, Testing and
Evaluation, and the detail of the players created is provided below.
Most of the previous research in the field also points towards this form of project cycle, whereby
known bad or random players are created, and newer versions of the actual AI players are played
against these players to obtain performance data. [2]
The single most important decision in Poker can be stated as “knowing when to play your
hand”. The keywords associated with this feature are tight and loose, where tightness signifies
fewer hand plays and loose signifies a more liberal approach. Based on these keywords, two
players were created.
The first type of player randomly chose between acting loose and tight when it was it's turn to act.
This player was coined 'Random - 1'. In addition to having a randomised betting strategy, it also
had a randomised strategy to determine its aggressiveness. So, in theory, this Random - 1 was a
completely random player, which could fold, bet, check or raise at any time; the final two options
being restricted under the relevant circumstances.
The second type of player chose a randomised aggression but has a strictly loose policy. It played
every hand that it was dealt, randomly choosing how much money it wanted to bet on it. This
player is called 'Random - 2'. As the policy of the player forces it to be completely loose, it never
folds a hand, and bets and raises quite frequently. Thus, it is also seen as a more aggressive player
by humans.
24

A third type of player with a completely tight strategy was not required, as such a player would
always fold, or check, and would thus lose against any other player which chose to bet even once
during the whole game.
4.3 - Anki – V1
Anki – V1 is best introduced through its architectural diagram. Figure 8 shows the overview of
Anki – V1 along with all its functions and working. These are further explained in the later
subsections of this chapter.
Figure 8. Anki - V1's Architectural Overview
4.3.1 - Strategy based playerAfter the creation of the generic Random - 1 and Random - 2, the need for a more intelligent
player arose. The secret to a human-level intelligence player may lie in the strategies used by
human beings to decide their betting strategies.
Like it has been mentioned in the previous section, one of the most important decisions is
knowing when to play one's hand; this player tries to offer a solution to that problem. It evaluates
it's hand before every betting round using domain knowledge and uses that evaluation to come up
with a betting strategy.
25

The evaluation before each betting round is done by looking at the 'type of hand' that the player
has. 'Type of Hand' here refers to both the current hand strength and the future potential to have a
strong hand. This is done by grouping together similar 'types of hands'. There are check, bet and
raise 'buckets' or groups, and by matching the current hand to the grouping, the final betting
strategy is decided.
4.3.2 - Overview of functioning and method
“The most important method of abstraction for the computation of our pseudo-optimal strategies is called bucketing. This is an extension of the natural and intuitive concept that has been applied many times in previous research [22][23][14]. The set of all possible hands is partitioned into equivalence classes (called buckets or bins). A many-to-one mapping function determines which hands will be grouped together. Ideally, the hands should be grouped according to strategic similarity, meaning that they can all be played in a similar manner without much loss in EV (Expected Value).” [2]
Before the working of the code and player is understood, there is a need to express the method by
which the above mentioned buckets have been created. The most difficult time to correctly judge
a betting strategy is that of the pre-flop betting round. This is the time when the player has the
least percentage of information available to him/her, only 50%, as only two of four cards are
visible, compared to the end, where 7 of the 9 cards are known to the player.
However, playing strategies for initial hand can be determined as well. This can be done through
simulation and expert knowledge. [3] provides an extensive table for comparison of performance
of opening hands, however, it was designed specifically for Loki, and thus uses certain
unspecified changes and heuristics. A similar table specific to this project needed to be created,
with estimated performance values of opening hands. These performance values were used to
determine the bucket or group that the hand would be assigned in. More details regarding this
simulation is given in the next subsection, 4.3.3.
After having dealt with the pre-flop, the post-flop also needs some extensive strategies. Groups in
this case were decided on the basis of an optimistic hand potential. Optimistic here can be defined
has a fairly loose strategy that looks for patterns and hopes to complete them in the future. All the
26

possible winning patters such as sequences, flush or pairs are seen, along with their completeness
to finally determine the group of a particular state of a hand.
It is important to note that unlike the pre-flop hand, the post-flop works on patterns rather than
on actual cards. For example, simulation determines the playing value of each possible initial
hand, i.e. all 2,652 of them, yet, the post-flop hands are taken on the basis of pattern, instead of
individual values. A sequence of 3,4,5,6,7 would be treated in this system exactly the same as a
sequence of 4,5,6,7,8 as they both follow the same pattern. The sequences pattern, is divided into
low and high number sequences, and is not judged on the exact value of the cards. This is because
of the information explosion of the game state. For example, leading up to the final betting round,
a player could have 6.74 * 1011 combinations of cards available. This number is clearly too large to
allow individual analysis of each hand.
Aggressive strategies are commonplace among expert human players. This is one of the well
known strategies of master play, i.e. to intelligently utilise aggressive play to increase the doubt in
an opponent's mind about a player's luck or bluff. Always staying aggressive is obviously not
considered wise, as it discloses the player's strategy, but general aggressive behaviour is accepted
at the master level. This reasoning has lead to a tight aggressive showdown player.
The above categorisation requires more explanation. The tightness refers to its decision to only
play to the end if it feels it has at least some form of a pattern available to it, i.e. it does not play to
the end with a 'High Card'. The aggressive nature is apparent from Section 4.3.4 where the table
shows that anything above a pair is automatically put into the raising group, and is thus given the
maximum aggression.
Another important point to be mentioned is that the evaluation of the betting strategy for Anki –
V1 is done before each betting round, and the decision is maintained throughout that betting
round, irrespective of the strategy of the opponent.
It should also be clear from the above explanation that the Anki – V1 does not bluff, it works with
pure evaluation strategies, evaluated after each betting round. Overall it can be termed as a 'Tight
Aggressive Player'.
27

4.3.3 - Probability realisation of all possible starting hands
As it has been discussed before, the pre-flop strategy evaluator looks at all the possible hands to
determine their performance. Performance can be measured in many ways; Darse Billings uses
sb/hds, i.e. small bets won per hand. In a tournament game, the size of the smallest bet allowed
keeps increasing, and thus the winning is described by small bets won per hand, which is can be
constant over the tournament. If money per hand was considered, latter games would be given
undue additional weights due to their larger small bets. For the purposes of this project, a more
generic definition has been implemented. Performance is described as the probability of winning a
game with a particular hand.
An exhaustive method to determine the probability of winning is not possible, simply due to the
large game state that results O(1011). As a result, a combination of simulation and previously
defined optimistic hand potential is referenced to determine the various betting strategy groups.
Figure 9 shows a tabular form of the result of playing any particular starting hand. This table was
created by the author of this thesis, and the exact manner of its creation is explained below the
figure. There is a reduction in the number of observed possible hands when the need for specific
suits is abstracted. A hand can either be suited, i.e. both cards are of the same suit, or unsuited, i.e.
different suits. Either way, the exact suit is unimportant, a suited 'spade' is considered at par with a
suited 'diamond', and the same is true for all other combinations.
Figure 9. Probability of victory of initial hands
28
A K Q J T 9 8 7 6 5 4 3 2A 88.68 69.95 68.92 67 66.62 65.35 63.48 64.26 61.62 60.43 59.8 59.6 58.61K 66.15 81.88 63.25 62.57 62.49 61.17 57.81 57.09 55.86 56.02 54.54 53.43 53.1 Key : UnsuitedQ 66.5 61.59 80.92 60.36 58.46 57.54 55.16 53.88 53.52 53.73 52.26 50.27 50.3 SuitedJ 65.87 61.19 58.66 77.52 57.23 55.11 53.76 53.41 50.69 50.6 49.33 48.45 48.67 PairT 64.01 59.68 56.48 54.48 75 53.85 51.75 50.77 49.41 47.25 46.83 45.35 46.32 A – Ace9 62.3 57.34 53.97 53.57 51.23 71.88 51.16 50 46.75 45.72 43.92 43.67 42.66 K – King8 61.68 54.78 51.99 51.49 49.96 47.96 68.04 48.39 46.35 44.42 42.95 41.52 41.78 Q- Queen7 61.15 54.31 52.83 49.52 48.08 46.65 44.32 65.76 45.18 42.73 40.95 39.87 39.52 J – Jack6 60.6 54.18 50.25 48.77 45.09 45.7 44.23 42.77 63.33 43.08 41.46 39.7 37.9 T – 105 58.95 53.82 50.91 47.29 45.34 41.91 41.36 39.88 38.07 59.8 41.66 38.73 36.74 57.67 52.13 48.35 46.99 43.48 39.83 39.48 38.37 37.61 37.68 56.5 38.52 35.943 54.88 50.41 48.15 45.09 42.68 41.05 37.74 37.08 36.32 37.22 36.28 52.95 35.962 54.72 50.26 46.41 44.79 42.22 39.78 36.22 35.52 33.6 35.66 32.35 31.62 49.83

Each of the numbers given above is obtained in same manner:
1. The specified hand of the player is used along with a random hand for the opponent.
2. A random flop, turn and river are generated.
3. The final hands of both the player and opponent are compared to decide the victor.
4. Steps 1 – 3 are repeated for 5000 games.
5. Finally, the percentage of times that the player won is calculated, by dividing the victories
by total number of games, i.e. 5000 in this case.
The approach followed above is similar to the one used to create the table in [3], however, the use
of heuristics and strategies has been removed. This is because the calculation is used to find the
Winning Potential, and not the sb/hds value that Loki uses. This eases both the creation and use of
the data from the table.
The buckets or groups of the pre-flop strategies are decided on the basis of the numbers created in
Figure 9 and optimistic potential. The latter term forces any suited or sequenced player to be
played irrespective of the number that was actually received from the table above. For example,
even though a 2-3 unsuited only has a 31.62% chance of winning at the end, it is still played as a
bet, as it may result in a high winner in the form of a sequence.
The exact grouping of the pre-flop strategies is provided in Figure 10. The hands have been
explained in plain English, followed by Figure 11, which is a modified form of Figure 9, and
shows the grouping explicitly over the all the initial hands in the game.
Figure 10. Grouping of Pre-Flop Strategies
29
If possible Raise, otherwise Bet Bet If possible Check, otherwise FoldEverything Else
High Pair (i.e. 9-9 or higher) High Suited Seq (i.e. 9-10 suited or higher)
Any pair, suited or sequenced cardsHigh cards (i.e. both cards above 8)

Figure 11. A modified version of Figure 8 to show grouping of initial hands
It may seem from the Figure 11 that the majority of the hands are bet, with a comparatively
smaller set being checked or folded. However, this is not the case. Each example of a suited cell
in the table above can exist in four different forms, i.e. through the four suits of the game. On the
other hand, each non-suited cell, exists 12 times in the actual game, through all non-suited
combinations of the four suits.
4.3.4 - Grouping form of strategy
Figure 12 provides the rest of the betting strategies used to group hands in later stages of the
game. Post-Flop refers to the betting hand right after the Flop, and similarly with Post-Turn and
Post-River. Post-River is also the final betting round of the game.
Figure 12. Buckets of betting strategy at various stages
30
A K Q J 10 9 8 7 6 5 4 3 2A 88.68 69.95 68.92 67 66.62 65.35 63.48 64.26 61.62 60.43 59.8 59.6 58.61K 66.15 81.88 63.25 62.57 62.49 61.17 57.81 57.09 55.86 56.02 54.54 53.43 53.1 Key : RaiseQ 66.5 61.59 80.92 60.36 58.46 57.54 55.16 53.88 53.52 53.73 52.26 50.27 50.3 BetJ 65.87 61.19 58.66 77.52 57.23 55.11 53.76 53.41 50.69 50.6 49.33 48.45 48.67 CheckT 64.01 59.68 56.48 54.48 75 53.85 51.75 50.77 49.41 47.25 46.83 45.35 46.32 A – Ace9 62.3 57.34 53.97 53.57 51.23 71.88 51.16 50 46.75 45.72 43.92 43.67 42.66 K – King8 61.68 54.78 51.99 51.49 49.96 47.96 68.04 48.39 46.35 44.42 42.95 41.52 41.78 Q- Queen7 61.15 54.31 52.83 49.52 48.08 46.65 44.32 65.76 45.18 42.73 40.95 39.87 39.52 J – Jack6 60.6 54.18 50.25 48.77 45.09 45.7 44.23 42.77 63.33 43.08 41.46 39.7 37.9 T – 105 58.95 53.82 50.91 47.29 45.34 41.91 41.36 39.88 38.07 59.8 41.66 38.73 36.74 57.67 52.13 48.35 46.99 43.48 39.83 39.48 38.37 37.61 37.68 56.5 38.52 35.943 54.88 50.41 48.15 45.09 42.68 41.05 37.74 37.08 36.32 37.22 36.28 52.95 35.962 54.72 50.26 46.41 44.79 42.22 39.78 36.22 35.52 33.6 35.66 32.35 31.62 49.83
If possible Raise, else Bet Bet If possible Check, else Fold
Post – Flop Everything Else
Post-Turn Everything Else
Post – River Any winning pattern better than a low pair Low pair and High Cards Everything Else
Flush, or one card away from it Seq or 1 away from a High Seq (more than 9)
Three or Four of a kind, or Full House Two pair, with at least one of the no. in hand
High Pair (i.e. 10-10 or higher)
2 cards away from Flush or High SeqOne away from a Seq
All other pairsPairs in board with high cards in
Both cards higher than a 10
Three or Four of a kind, or Full HouseFlush, Seq, or High Pair
Two pair with both numbers in hand
One away from Flush or SeqPairs in Board, or just one in hand
High cards

As can be seen from the figure, the player continues with its optimistic policy, whereby any
chance of a flush or sequence is not abandoned. The headings of the columns of Figures 10 and 12
also show the exact strategies being utilised by the player. For example, it is not always possible
to raise in a situation, thus in that case, the player decides to bet, and similarly when the player is
unable to check, it folds.
4.3.5 - Similarities and differences from human beings
There are many similarities between the workings of Anki – V1 and that of a human being. One
of the major ones is that of Bucketing. Human players tend to form pre-defined groups in their
minds that allow them to act in face of familiar situations. For example, a player with K-Q suited
would probably behave similar to when given the cards J-Q suited.
There are only a maximum of three betting choices available to a player at any given time, and a
human player is required to play to the merit of the cards. Pre-Flop strategies are usually quite
strict with intermediate or beginner level players. Lower-level human players decide beforehand
about which kind of cards they would play with, and which ones they would usually fold. This
method is similar to one being utilised in Anki – V1.
Post-Flop bucketing resembles human play even more in Anki – V1, whereby the player works
by matching the best patterns that they can find. Human players also tend to look for flushes,
sequences, etc., before looking at the exact cards or suits available.
Apart from the expressed similarities, there are also a number of human features with which Anki
– V1 differs. Human players do not have the capability to create a probability table similar to the
one shown in Figure 9, instead, they rely on instinct and experience. Anki – V1 can benefit from
its higher computation power to allow such a table to tone it's betting strategies. A definite
advantage that humans hold over Anki – V1 is that of opponent modeling and the randomisation
of their strategies to some extent. This plays a great part in the final result of its Anki – V1's play
against humans, more of which is expressed in Chapter 5, Testing and Evaluation.
Anki – V1 plays a completely evaluated strategy game, and thus lacks the randomisation
discussed in Chapter 2, Literature Review. Thus, following from a hand evaluation, which is
31

handled very well in Anki – V1, the introduction of randomised betting strategy is required. This
leads to the creation of Anki – V2.
4.4 - Anki – V2
Figure 13. Anki - V2's Architectural Overview
Figure 13 shows the emphasis on the creation of a randomised betting strategy, along with the
ability to tone the randomisation through methods such as adjusting the Tightness Threshold, etc.
More on the player is discussed below.
4.4.1 - A Randomised Rational Strategy Player
Following the expert-rule based approach of Anki – V1, a player was required that
followed a more Simulation and Enumeration form of strategy build-up. It is obvious that
an AI player has higher computation power than that of a normal human player, thus the
computer needs to given the opportunity to utilise this power to better itself at Poker.
32

Simulation and Enumeration allows real-time strategy build up, and limited reaction to
opponent's responses in a game. This new player is called Anki – V2. It primarily uses the
concept of Probability Triples.
“ A probability triple is an ordered triple of values, PT = [f ,c ,r ], such that f + c + r = 1.0, representing the probability distribution that the next betting action in a given context is a fold (check), call (bet), or raise, respectively.” [13]
The probability triples allow the program to create a controlled randomised strategy over a betting
round, as compared to Anki – V1, which worked with a strict strategy over the whole round. Each
of the numbers in the Triple represent the individual probability of a certain action. A significant
difference between the quotation given above and the implementation in this project lies in the
range of the numbers used. Poki and Loki used a range between 0.0 – 1.0 to express the Triples,
whereas this thesis utilises all the real numbers between 0.0 and 100.0. It makes no major change
to the expressive power of the program, but allows a percentage output for each of the Triple
values.
4.4.2 - Statistical Method vs. Random Generator
The exact working of the Anki – V2 is explained in sequence below, this provides an overview of
the entire Figure 13 seen previously :
1. Like Anki – V1 for the initial hand, Anki – V2 also plays simulated games with
randomised values for the flop, turn, river and opponent hands. In the end, it receives a
winning percentage. The games played are called 'pseudo games' and the winning
percentage is called WP or Winning potential.
2. Using this WP, and some pre-defined formulas, the player creates a Probability Triple for
the next betting round.
3. During the course of the betting round, at every decision point, a random real number
between 0 and 100 is generated which is compared against the probabilities of the
Probability Triples, to decide on the betting action.
4. The randomised betting action is adjusted using the Tightness setting provided to prevent
'silly' decisions by the player.
33

5. At the end of the betting round, when the next set of community cards are shown, the
pseudo games are played again, by including information that is now available. For
example, if the flop and turn have been revealed, Steps 1 through 4 are repeated, but Step
1 only generates random rivers and opponent hands, and uses the flop and turn
information to get a more exact WP.
The exact formulas and values used to calculate all the data mentioned above is given in Section
4.4.3. However, it is important to understand the need for this simulation method against a more
mathematical statistical model.
One of the major drawbacks of simulation is that it is essentially a form of approximation. Experts
have documented and proven that luck or a strange coincidence of events can effect a hand's
performance to make it seem better or worse than its actual value [10]. This phenomenon can
show its effects for a couple of thousand hands at a time. For this reason, even though extensive
simulation can be considered to be a very good approximation, it is always exactly that, and can
unknowingly contain high levels of noise. The other option that can be considered is that of
statistics.
A statistical method to find the Winning Potential of a given hand would consist of finding all the
scenarios under which the current hand is stronger than an opponents'. This is clearly a more exact
method of hand evaluation. Also, there is definite possibilities of this method in the final betting
round, when the final state or pattern of a player is known. The amount of unknown information is
quite scarce, i.e. only the opponent's two-card hand. Thus an exact statistical model of hands
better than the players' can be generated.
This method however has a near exponential blow-out when the first betting round is considered.
The number of possibilities of future cards have been discussed earlier, i.e. 6.74 * 1011 possible
hands. To group these hands in terms of those which are better, equivalent or worse is clearly a
mammoth task, the kind for which there is neither computational power nor time. This is further
proven by the fact that no computer Poker player created till date has ever tried to obtain the exact
statistical evaluation of a game state.
34

Another major reason for the choice of simulation is that fact that it mimics human play. It offers
both optimistic or pessimistic viewpoints at times, quite like another human player. This allows a
more random strategy than what a strict statistical model would provide.
4.4.3 - Formulas and Evaluation
There are a variety of formulas and numbers that have been utilised in the formation of Anki –
V2. These features need further explanation, both for their function in the program and their
justification. The exact formation of the Probability Triple is also explained, and so is the working
of the betting action evaluator.
4.4.3.1 - Pseudo games and Winning Potential
Each pre-betting round evaluation begins with the simulation of 1000 pseudo games, at the end of
which the number of games that the player won, drew or lost are reported back. These numbers
are then used to determine a Winning Potential. The WP is then adjusted using enumeration,
which is explained in Section 4.4.3.3. And finally, the WP is converted into a Probability Triple.
Figure 14 shows a part of the program code which relates to this exact sequence of work, along
with a representation of the formula used to calculate WP from the data of pseudo games.
Figure 14. Sequence of evaluation of Winning Potential
The 'X' written in the final line of the Prolog code is the Probability Triple that is generated. The
method 'assign_str' is explained in Section 4.4.3.2.
The first justification is regarding the 1000 pseudo games being played. This is due to the time
constraints specified by Darse Billings that a player should not ponder over a decision for more
than two seconds. And with the provided computational power, 1000 pseudo games were found to
require 1 – 2 seconds of computation time. Higher computation power would allow more pseudo
games, and thus provide a better approximation, but under the current restrictions, this the best
that the game can offer.
35
play_pseudo_game(...),WP is ((W + (D / 2)) / (W + D + L)) * 100,WP1 is WP + N,assign_str(WP1, X), ...
Winning Potential=Win Draw
2WinDrawLose
×100

Another formula created by the author was the regarding the finding of the Winning Potential.
Previous papers explain Positive Potential as Winning probability over Total number of games.
Drawn games are not discussed, and definitely need to be addressed, especially in the case of a
smaller number of pseudo games such as this. The decision was taken to give half importance to
drawn games, as they offer half the return of a normal winning game.
4.4.3.2 - Calculation of Probability Triples
Winning Potential is converted to Probability triples using a method 'assign_str'. This method uses
the value of the Winning Potential to return percentage values for the next betting round. There
are three sub-sets that have been introduced in the method:
1. When the WP is less than or equal to 50 : The chances of raising are quite low. In
addition to this, at 0 WP, the chances of folding are maximum, with a low betting
potential. As the WP increases, so do the chances of betting.
2. When the WP is less than or equal to 75 : Chances of raising are higher, with betting
getting a major bonus, and checking reducing significantly.
3. When the WP is greater than 75 : Checking has a low probability, with the chance of
raising slowly increasing and betting reaching a moderate level.
Figure 15 shows the formulas used to portray the above three points. More explanation regarding
the numbers follows the figure.
Figure 15. Formulas used to calculate Probability Triples, given WinPot
The formulas arise by firstly looking at the most basic premises, i.e. the Probability Triples
required at the crucial points of 0, 50 and 100% probability. It is obvious that at no point should
the value of any of these be 0, as that would lead to a strict strategy, and would thus be
recognisable by humans. It was decided that the value of betting or raising should not fall below
36
Check Bet Raise
<= 50 10
<= 75 20> 75 15
90 – WinPot WinPot – 10105 – WinPot WinPot – 20
WinPot2
1080−WinPot2

10%, as this allows substantial bluffing power to the player even in the case of bad hands. As a
result, the probability triple for 0% WP becomes [80,10,10] in the form [Check, Bet, Raise].
Human players can be found to change their strategy rather dramatically with knowledge of the
current hand having more than 50% or 75% Winning Potential. This strategy change has been
dulled to a large extent in the program, to allow a more gradual change relating to the exact
Winning Potential.
The hand with an exact 50% WP can be seen to have the Triple [45, 45, 10], with a jump to [40,
40, 20] for a hand with a number just above 50 but tending to it. From this point on, the checking
power falls at a greater speed, while the betting power builds up.
The final change occurs at 75%WP, at which point the need for a greater raise probability is
introduced. Exact 75% WP has a Triple [15, 65, 20] and a WP just over 70, but tending to it, has a
Triple [15, 30, 55]. This may seem like a dramatic jump, but in practice it is quite mellow due to
the inability to raise in most situations. In these situations, the player simply bets, thereby
reducing the apparent jump in probability. This is discussed further in the next subsection.
4.4.3.3 – Betting Strategies, Randomised Numbers and Enumeration
This section deals with the happening inside a betting round. The Anki – V2 Player has a
Probability Triple available to it, guiding its future moves, however, these moves still need to be
monitored and executed.
“The choice (of betting action) can be made by generating a random number, allowing the program to vary its play, even in identical situations. This is analogous to a mixed strategy in game theory, but the probability triple implicitly contains contextual information resulting in better informed decisions which, on average, can outperform a game theoretic approach.” [13]
Figure 16 provides a Prolog code excerpt from the actual program that details the working of
Anki – V2's betting turn. The random number generated is a real number between 0 and 100. That
allows decimal type Triples to be treated correctly, and not rounded off to the nearest integer.
37

Figure 16. Anki – V2 Betting Rounds
The Strategy Selection shown in Figure 16 converts the random number into one of the betting
strategies. It is done in the following manner; if the random number is lesser than the probability
of a check, the result is Check. Otherwise, if the number is between the probabilities of check and
the sum of check and raise, then the result is a Raise. In all other cases, the result is a Bet. For
example, if we are given the Triple [40, 35, 25], random numbers generated between 1- 40 would
lead to Checks, 40 – 65 would lead to Raises and 65 – 100 would lead to Bets.
The Enumeration step involves looking at the previous action of the opponent and slightly
changing the odds to represent the game state more accurately.
“... we have specific information that can be used to bias the selection of (opponent's) cards. For example, a player who has been raising the stakes is more likely to have a strong hand than a player who has just called every bet.” [1]
Thus, both the actions of checking and raising by an opponent offer information regarding the
opponent's hand. It can generally be assumed that a raise results from a good hand, and a check
from a much worse one. Using this data, the Winning Potential can receive small tweaks to better
represent this information. It has been decided that upon each of the opponent's checks, the WP
would be incremented by 2, thus implying that the player now has a 2% greater chance of
winning, as the opponent seems to have a bad hand. Similarly, an opponent's raise decrements the
value of the WP by 2.
This enumerated value is usually transferred between the betting rounds, with the exception of the
pre-flop to post-flop change. In this case, the WP of hands are found to change so drastically
through the different flops possible that any notion of enumeration over this stage would be
redundant. Also, the value of 2 was chosen to allow a maximum of 10% change in the value
created by the Simulator. This is a value chosen by the author, and thus, further improvements can
38
random_float(...), % Random Number Generationchoose_rel_str(...), % Strategy selectionchange_win(...), % Enumeration Stepexact_str(...), % Strategy Refinementeval(...). % Strategy Implemented

be made to this value through expert external input. Only the experts of the field can truly shed
light on the importance of a person's raising and checking. For the sake of a controlled
experiment, it is not possible to keep this number too high, as that may result in radical changes to
strategy.
Finally, before the final action is played, the probabilistic random action is refined. This is done in
order to prevent the player from making 'silly' decisions, and also to implement some of the
betting rules. It is at this stage that a raise is converted to a bet, in case that there is no money on
the table, i.e. there have been no bets in the round, and hence the raise is invalid. More
importantly, it is also at this step that a restriction is forced upon the player to never fold a hand
with the Winning Potential higher than a particular percentage. If the action chosen is a check, and
the play requires either a bet or a fold, this refinement is used to decide on the correct betting
action.
The number chosen for this non-folding refinement in most of the experimentation is 60, i.e. Anki
– V2 never folds any hand in which it believes it has a higher than 60% chance of winning. This
number was chosen as initial experimentation found that it implemented a similar form of
tightness to the strategy as compared to Anki – V1, thereby leveling their playing field during
human testing. Experimentation with this number and Triple Creation Formulas are discussed in
the next chapter.
39

Chapter 5 – Testing and Evaluation
This chapter tests and evaluates both the system and all the computer players described in Chapter
4, Methodology. Firstly, there is a testing of the system design and architecture in the white box
method. This is followed by black box result checking of the system. Finally, all the players, i.e.
Random – 1, Random – 2, Anki – V1, and Anki – V2 are evaluated, with most emphasis on the
latter two. The results and evaluation is also compared to the previous research of Loki, Poki, etc.
discussed in Chapter 2, Literature Review.
5.1 - System Test – White and Black Box Testing
The first batch of experimentation and testing that needed to be performed on the program is
regarding its completeness and soundness. Its stability needed to be proven, to justify any results
obtained from it later on. The architecture of the program was put to brute-force worst-case
scenario tests to try and prove its soundness. These test were conducted on the Human vs. Human
specification, so that each step of the program could be monitored and observed.
The following tests were conducted and found to complete successfully :
1. The program started up without any errors and provided completely random opening
hands to both the players of the game. Also, absolutely no repetition or pattern in the
cards was found over a number of hand requests.
2. The program was found to provide the Human Player with all the necessary game state
information, including the cards he/she held, community cards and the financial state of
the game. All the information was found to be accurate. An example screen shot of the
program is provided in Figure 17.
3. The betting options were found to adhere to their respective constraints, along with
allowing the player to re-play the last move in case an erroneous choice was entered, e.g.
raising when it is not permitted.
4. The betting rounds were found to progress in the manner required, and ended upon equal
commitment of monies from both players, i.e. in the cases of two checks, two bets or a
raise followed by a bet.
40

5. Each of the player's actions such as betting or checking was displayed clearly, with no
information of the opponent available to a player.
6. Folding sets the game into a quick end mode, whereby all the community card displays
and betting rounds are bypassed to reach the end. The cards of each player are not
displayed on the board either.
7. Finally, the situation under which a player finishes his/her money is addressed. The
program was found to display the required community cards and hurry to the end of
showdown without any more betting requests.
Figure 17. Screen shot of normal gameplay in the Prolog window
Following the successful completion of the above mentioned tests, the winning pattern evaluator
also needed to be tested. Strict rules are available for this section of the program and their stability
and correct implementation needed to be proven. The winning pattern finder was put through a
series of extreme case scenarios along with regular tests to make sure it worked in the least
probable draw situations. For example, the evaluator was asked to find the winner in the case of
the Fourth Kicker for a High Card, i.e. the 5th card of the hand. At the same time, a draw result
41

was tested by providing the tester with identical hands that differed only on the 6th most important
card.
The following tests were completed on the winning pattern evaluator :
1. The correct winner was identified using the priority table explained in Section 3.4. For
example, Full House won over a Flush, etc.
2. In the case that the patterns on both players were found to match, the owner of the highest
ranking card of the pattern was chosen as the winner. For example, 'Three Jacks' won
over 'Three 8s'.
3. The comparison of hands with similar patterns was restricted to the correct number of
kickers. For example, there are 2 kickers in 'Three-of-a-Kind', but none in a Sequence.
4. In the case of the best 5-card hand of each player being the same, or of similar
importance, the result was announced as a Draw.
5. The correct amount of money was alloted to the players at the end of the pattern
evaluation, i.e. the winner got all the money in the pot, or the money was divided between
the players in the case of a draw.
6. All the information concerning the cards being played, the winning pattern type, the
winning player and the new financial state of the game is displayed. A screen shot of a
final result is provided in Figure 18.
42

Figure 18. Screen shot of a showdown (end-game scenario) with Winning Evaluator
As mentioned previously, the above methods were conducted on all of the patterns individually,
and were created with a specific purpose of checking the most computational and in-depth rule
scenarios of each of the winning patterns. All the cards were created by the author and then tested
individually, as each winning pattern needed to deal with a different formation of cards. Certain
tests revealed errors in the coding, in which case, the error was corrected, and the entire testing
cycle was repeated.
The above test carried out was more than 2000 hands in number, however, they were created
specially to check specific features or components of the program. There was a need to test the
program in its entirety. For this reason, the following four 'Strict' players were created; Always-
Checks1 (else Folds), Always-Checks2 (else Bets), Always-Bets and Always-Raises (else Bets).
These players were made to play 1000 games against each other, and the entire decision and game
state of each of the games was recorded. This transcript of the 6000 games was checked manually
by the author to confirm the stability and soundness of the program created. All the decisions
were found to be correct according to the Poker rules discussed in previous chapters. These
players continue to exist in the code given in Appendix A, but future testing was preferred on
players such as Random – 1 and Random – 2 as they provided more varied results.
43

5.2 - Random – 1 Player's Evaluation
As expressed earlier, the main phase of computer player testing began with the introduction of
Random – 1 and Random – 2, also called Random Player and Non-Folding Random Player
respectively. This sub-section explains the bad performance of Random – 1, and the reason why it
was not tested to as much depth as Random – 2. It also has certain implications on the workings
and required strategies of future computer players.
Random – 1 was found to play appallingly badly against both Random – 2 and Anki – V1, given
the same test conditions. All the games experiments were conducted to play 10,000 tournaments.
Under these conditions both Random – 2 and Anki – V1 were found to beat Random – 1 in all of
the 10,000 tournaments. This clearly shows the flawed strategy of the player.
This finding leads to our first major conclusion of the thesis, i.e. randomisation is required over
strategies and meta-strategies, i.e. the decision to be aggressive, loose, etc. at any one time, that
influence individual betting actions. This is especially proven in the Random – 1 vs. Random –
2 experiments, where the high folding rate of Random – 1 forces it to bow out of the competition
too often and too early unnecessarily, and thereby loose tournaments quickly. Random – 1
performs slightly better against Anki – V1 because Anki – V1 assumes that Random – 1 is a
rational player, and thus if Random – 1 bets, and Anki – V1 has really bad cards, it chooses to
fold. But once again, the sheer volume of folding by Random - 1 leads to its eventual downfall.
Figure 19 provides more insight into the exact statistics of the two experiments.
44

Figure 19. Player Performance when playing against Random - 1
Random – V1 was found to play a total of 506,026 and 860,978 games against Random – 2 and
Anki – V1 respectively and was beaten by both opponent players in all the tournaments. The
game - winning percentages of the latter players is also shown in Figure 19.
Through the results obtained above, the Random – 1 player was abandoned. Future testing is
conducted through self-play or through play against Random – 2, with the only occasional
comparison to Random – 1.
5.3 - Evaluation of Anki – V1
The evaluation of Anki – V1 is done in the form of two broad categories; playing against pre-
programmed players for evolutionary and basic results, and playing against humans for more
advanced results and final evaluation. Each of the category of tests are presented in the
subsections below in more detail.
5.3.1 - Anki – V1 vs. Computer players
The first test that Anki – V1 faced was with the Random – 2 player. The Random - 2 player's
strategy, however static or randomised, was found to be very aggressive and quite close to the
45
Random – 2 Anki – V10
10
20
30
40
50
60
70
80
90
100% Tournaments Won
% Games Won
Player
Perc
enta
ge
of
Vic
tory

strategy that an expert would recommend for master play. The static aspect of this player is not a
disadvantage to it either, as the opponent, Anki – V1, does not have opponent modeling.
In addition to testing the performance of Anki – V1 against the pre-defined computer player, it is
also imperative that Anki – V1 prove its increase in its performance as it develops. Anki – V1 is
created from four different betting strategy/evaluation components; pre-flop evaluation, post-flop
evaluation, post-turn evaluation and final evaluation (post-river). It needs to be shown that the
introduction of each one of these components adds value to the player as a whole.
For the purpose of these experiments, the Anki – V1 with only pre-flop evaluation was coined as
Start-Eval Anki. The next upgrade with both pre-flop and post-flop evaluations is called Flop-
Eval Anki. The addition of post-turn evaluation leads to Turn-Eval Anki and finally, all four
evaluations come together to be called Final-Eval Anki. Each experiment between the players
consisted of 10,000 tournaments. This was done so, in lieu of the fact that previous research has
shown that up to a couple of thousands of games can be affected by good or bad luck of a player
[10]. Thus, to make the statistical result more accurate, and assuming at least 100 hands per
tournament, 10,000 tournaments provide us with a million games. This gives us an unbiased result
that is free from the luck factor. All the results were checked to confirm that more than a million
games had at least been played, and this was found to be true.
Figure 21 shows the performance of improving Anki – V1 against Random – 2. As can be seen,
each improvement is found to benefit the performance.
46

Figure 21. Anki – V1's performance against Random – 2 Player improves as more heuristics are added in average of 2.8 million games for each evaluation
The figure above is seen to have an extraordinary quality, in that, from Start-Eval Anki to Flop-
Eval Anki, there is a major change in improvement. Also, there is noticeable but not major
improvement between the last three players. Both these observations can be explained through the
concept of game state information. In the first case, the evaluator has 50% (2 of the 4 cards)
information available to it. The decision based on this information is thus seriously flawed, which
leads to the folding of good potential hands and protection of bad final hands in the Start-Eval
Anki Player. In comparison to this, the information jump is very substantial in the next round,
from 50% to 71.4%, as 5 of the 7 cards are now visible to the player. This allows the player to
progress more intelligently.
Partial, but small Information Gain is also responsible for the slow growth in the latter three forms
of Anki - V1. The percentages of information available to Flop-Eval, Turn-Eval and Final-Eval
Anki are 71.4%, 75% and 77.8% respectively, all of which are not much of an increase. As three
players discussed above do not improve their knowledge of the world by a large percentage, their
relative intelligence improves only a little (just one more card each time).
47
Start-Eval Anki
Flop-Eval Anki
Turn-Eval Anki
Final-Eval Anki
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
Anki - V1 Player with accumulated heuristics
No. of
Tourn
amen
ts W
on

Apart from the tournament victory of Anki – V1, the various players also need to be measured for
their profitability and their efficiency. Figure 21 shows the increase in earnings of the players,
whereas Figure 22 shows the relative increase in game winnings.
Figure 21. Profitability of Anki – V1 Players increases, as it adds heuristics to its play.
Figure 21 shows the increase in the profits of the various players. For example, whereas Start-
Eval Anki is found to lose 2.52 units of money with every game, Final-Eval wins 9.21 units on
average for every game that is played. This shows the increasing intelligence and playing ability
of each player.
Figure 22 sums up the Anki – V1's performance against the random player's by showing the
comparison between the winnings of tournaments and games. Unlike the victory of tournaments,
which describes a players performance, the lesser the number of games won, while improving
tournament play, the better the player. This is because the player simultaneously improves both
tournament play and overall profitability. It knows better of when and which hands it should play.
48
Start-Eval Anki
Flop-Eval Anki
Turn-Eval Anki
Final-Eval Anki
-3
-2
-1
0
1
2
3
4
5
6
7
8
9
10
Anki - V1 Player
Mon
ey w
on p
er g
ame
play
ed

Figure 22. Tournaments and Games won by Anki – V1 playing against Random – 2 show that the efficiency of the player is improving.
Figure 22 shows how the increase in the number of tournament wins doesn't seem to affect the
percentage of games being played and won by the player Anki - V1, i.e. the percentage of games
won remains constant. This is a positive sign for the latter versions of Anki – V1, as it shows
that the players are becoming more efficient in winning tournaments. Their improvement is
proven by the increase in tournament wins, and their intelligence by the stability of percentage of
game victories.
5.3.2 - Anki – V1's Evaluation against Human Players
Anki – V1 was played against three forms of players; beginners, intermediate and advanced.
Beginners are newcomers to the game, these are people who have never played poker before. One
of the subscribed aims of this project is also to investigate the formation of a Poker player that
teaches beginners, and for the same reason, it also needs to be able to play well against them.
Intermediate Players are either infrequent players of Poker, with detailed knowledge of the game
or beginner players with knowledge of the functioning of the program. Due to resource and time
49
Start-Eval Anki
Flop-Eval Anki
Turn-Eval Anki
Final-Eval Anki
0
10
20
30
40
50
60
70
80
90
100
% Tournaments Won
% Games Won
Anki - V1 Player
Perc
enta
ge
of
Vic
tory

constraints of the project, the test base for the project was restricted to a close community, and
thus certain members of the community had additional information available to them, which
helped them develop a strategy against Anki – V1. For this reason, they have been considered in
the category above the absolute class.
Finally, advanced players are either people with frequent exposure to the game in tournament play
(with real money online or in the cash form), or intermediate players with knowledge of the
player's capabilities. Once again, due to the given constraints, the experiments were held to a
lower capacity than ideal. However, at least three individuals were gathered from each of the
prescribed categories and were asked to play till they either won or lost a tournament.
The final result data from all the tournaments was gathered, and sorted once again according to
the categories in which the human players had been divided. Figure 23 provides a brief outlook of
Anki – V1's performance against the human players. Each point on the line of a performance
curve is the cumulative average of Anki – V1's money at that point of time, hereby measured in
number of games. Also, the important points in the game are provided with their game number.
Figure 23. Anki – V1's performance against human players
It can be seen from the figure above that Anki – V1 succeeds in its primary objective of beating
the beginner player, i.e. the tournament ends with Anki – V1 having all of the 2000 money on the
50

table. The beginners involved in the testing found the player to be quite informative and user
friendly, however, they did sometimes require assistance in trying to understand the winning
situations with kickers, etc.
Intermediate players finished better off against Anki – V1, but only after a good struggle. It can
be seen from the graph that Anki - V1 managed to get an upper hand very early in the game, while
the human players tried to control their losses. About halfway in the graph (marked at game 560),
it can be seen how Anki – V1 loses a lot money, this was mostly attributed to two of the players
having a couple of very big games that went their way around that time frame. This lucky break
allowed the human players to move close to winning, however, by looking at the graph, it took a
bit of commitment to finish off Anki – V1. This can also seen by the fact that it took an average of
1308 hands for Intermediate Human Players to finally beat the Anki – V1 Player. The general
feedback from intermediate players was positive, whereby they felt that the player had a lot to
offer if it incorporated a looser or more aggressive form of betting strategy.
The general strategy of the Human Intermediate Players became 'bet-first'. They utilised an
exceedingly loose strategy, as it lead to Anki – V1 folding on most accounts. Similarly, closer to
the end, the players commented on how they were beginning to trust the tightness of Anki – V1,
i.e. they folded when they saw Anki – V1 fighting hard for its cards. This was an expected result
from the intermediate bench, as Anki – V1 definitely had the short-comings of being partially
predictable.
It is also clear from Figure 23 of how Anki – V1 succumbed to the aggressive and loose
behaviour of the Advanced Players. Yet, it is against these players that the Anki – V1 can show its
best traits. Anki – V1's relatively quick defeat was expected at the hands of the Advanced players,
due to its failure to cause doubts in the opponent's mind. The advanced players began to trust the
computer's tightness strategy from the beginning and used this to their advantage. Apart from all
these well-understood problems, Anki – V1 still needed to prove its worth in at least one of the
department for which it was created, i.e. quality of evaluation of playing hands.
The best quality of human hand evaluation is obviously available from the advanced players. And
it is quite clear that by bluffing and aggressive play Anki – V1 can be beaten without the need for
51

extensive evaluation knowledge. However, the comparison between Human and Anki – V1's
evaluators needs to be done to prove its competence.
In the final result file generated through human play, it was noted that the majority of AI losses
were due to folding early on in the game. This resulted in the loss of 10 or 20 units of money each
time, but were so frequent that it led to Anki – V1's downfall. Thus to properly estimate the power
of Anki – V1's evaluator these smaller values need to be slowly removed. Figure 24 provides two
indexes to measure Anki – V1's true capabilities. The indexes are grouped by 'Bet Placed By Anki
- V1', this is the 'at least amount' committed by Anki – V1 in the game. Thus a game with 20+ of
Bet Placed By Anki - V1 removes the games in which Anki – V1 or the human player folded right
after a person bet in the first round of betting, i.e. all the games with the value of just 10.
Figure 24. Anki – V1 evaluation against advanced human players using a couple of indexes explained in text. Once again, the improvement is visible.
The first index that can be seen slowly rising is Relative Performance Index. It is calculated by the
formula given in Figure 25. As expected, this value is above 1 for Anki – V1 from the start, this is
because Anki – V1 only plays games it believes it will win, thus the result per won games for
Anki – V1 will be higher than that of an opponent, who play aggressive to just win 10 units most
52
10+ 20+ 30+ 40+-12.5
-10
-7.5
-5
-2.5
0
2.5
5
7.5
10
12.5
15
Relative Performance Index
Money acquired per winning game
Bet Placed by Anki - V1

of the time. The Relative Performance Index can also be seen to increase in the graph and thus
proves Anki – V1's growing dominance in the higher valued games. This shows that Anki – V1
wins larger games more often than advanced players.
Relative Performance Index =Anki V1's Performance IndexOpponent's Performance Index
Performance Index=Money won from game typeGames won in game type
Figure 25. Formulas used to calculate Relative Performance Index
The second index is concerning the Money acquired per Winning Game. This is calculated by the
formula given in Figure 26. As expected, this value starts off in the negative, this is due to the
high majority of 10 valued games that Anki – V1 loses, which also ultimately costs Anki – V1 the
tournament. However, Anki – V1's true brilliance is shown when the 10 valued games are
removed. Instantly, the value jumps from 12.44 money being lost in between each victory by
Anki – V1 to 9.88 money being won with every game. In addition to the increase, Anki – V1 can
be seen to perform even better as the values of games increase, and more money is at stake.
Money Acquired per winning game =
Money Anki V1 won from game types−Money Opponent won from game typesGames Anki won in game type
Figure 26. Formula used to calculate Money acquired per winning game
5.4 - Evaluation of Anki - V2
Like the evaluation of Anki – V1, Anki – V2 was also played against both computer and human
players. Due to the time constraints, Anki – V2 was played with the strict constraints of Tightness
and Aggressiveness expressed in Chapter 4, Methodology, against Human players. The strict
constraints and a few slightly modified versions were played against the pre-designed AI Players
to further understand the workings of strategy and evaluation in a successful Poker Player. More
53

on the actual experiments and their results is given in the subsections below, with certain aspects
of the research expressed in Chapter 6, Conclusions and Future Work.
5.4.1 - Anki – V2 vs. Computer players
Tests for Anki – V2 start from the easiest, i.e. the Completely Random Player. Anki – V1 has set
the bar for most of the test results of Anki – V2, and thus Anki – V2 would be expected to win all
the tournaments against this player, like Anki – V1.
The amount of result data, however, is more restricted in this case. Anki – V1 could play 10,000
tournaments in an hour and was thus given the ideal figure of 10,000 tournaments. On the other
hand, Anki – V2 takes 1 – 2 seconds for each evaluation that it creates. This introduces a massive
time lag into the system, and faced with the time constraints of the project, it is unreasonable to
play 10,000 tournaments. Instead, the figure has been reduced to 100 tournaments. This figure
may seem very small, but it is the best compromised size that can be considered. 100 tournaments
take about a day to finish evaluation, and provide an average of 25,000 games, which is more than
twenty times the recommended amount required to get rid of the luck factor [10].
Figure 27 shows a graphical representation of the Anki – V2 vs. Completely Random Player
tournaments. As it can be seen, Anki – V2 passes the first test and easily wins all its tournaments
against Random – 1.
54

Figure 27. Anki – V2's performance against Completely Random Player
The next test for Anki – V2 comes from Random – 2, or the Non-Folding Random Player. This
should be a true test for Anki – V2 as Anki – V2 is a quite a moderate player in terms of
tightness, and tends to fluctuate quite highly between its perception of tightness and looseness.
This is mostly due to the incorporation of the Simulation engine and allowing some deliberate
randomness to creep into the system.
Figure 28 shows the result of the first test conducted between Anki – V2 and Random – 2. As can
be seen, it was a complete failure. This was mostly seen due to Anki – V2's inability to continue a
strategy. It is found to abandon reasonably good cards in which it has invested a lot of money just
because their their chance of winning falls below the specified threshold. Unlike Anki – V1, Anki
– V2 saw a lot of hands folded in the latter stages of the game, after they had already been deemed
play worthy. Betting round memory was found to be inadequate and the need for game memory
was recognised.
55
0
10
20
30
40
50
60
70
80
90
100
% Tournaments Won% Games Won
Anki - V2's Performance
% V
icto
ry

Figure 28. Original Anki – V2's failure against Random – 2
Anki – V2 still comes out superior to Anki – V1 and Random – 2, through the capabilities
incorporated into the Player to make it more like a learning human being. A human being can
change his/her strategy based on the opponent, and if this power is imparted onto the Player, then
the player would only need expert knowledge. Anki – V2 has the ability to change its strategy by
simply changing a couple of numbers in the program, a task that the Player would hopefully do by
itself in much later versions.
A human being can see the operation of Random – 2, and quite clearly, the current strategy
operated by Anki – V2 is not sufficient to battle it. Random – 2 is very loose and aggressive, and
thus requires a loose evaluating player to beat it as well. On one hand, where Anki – V1 was
willing to battle to the showdown with a simple pair, Anki – V2 is too tight, and can sometimes
even fold a low Flush. Quite clearly, this is not acceptable.
A change needed to be made in the Tightness setting of the Player, this is the number that was
pre-defined in the player using the Winning Potential of the Player's hand. Chapter 4,
Methodology, described how the setting of 60 was chosen to limit Anki – V2's 'silly' actions, i.e.
to prevent it from folding anything that is too good by mistake. To make the player more loose,
this number needed to be lowered. Figure 29 shows the results of the experiments done from
doing exactly this.
56
0
2.5
5
7.5
10
12.5
15
17.5
20
22.5
25
27.5
% Tournaments Won
% Games Won
Anki - V2
% V
icto
ry

Figure 29. Increasing Performance of Anki – V2 as the Looseness of the player is increased
or Winning Potential Threshold is lowered.
The above figure gives the desired result, and thus through a specific and experimental
mechanism, it can be seen that Anki – V2 can easily beat Random – 2 provided it is supplied with
the right modifications. It is this ability of Anki – V2 to be able to easily change its strategy that it
will be of further use to the development of future versions, more of which has been discussed in
Chapter 6, Conclusions and Future Work. Section 5.5 also compares the results received above to
those of Anki – V1. Time constraints on the project prevented future experimentation to obtain
values for the Tightness settings to be 20 and 10. However, it is expected that Anki - V2 would
suffer from such low settings, as it would make it almost equivalent to the Non – Folding Random
Player itself, and thus level the playing field.
5.4.2 - Anki – V2's Evaluation against vs. Human
Once again, the experiments on the program were conducted on the three broad categories of
humans labeled as Beginner, Intermediate and Advanced. The complex and randomised strategy
base of Anki – V2 removed the possibility of anyone understanding the player beforehand, thus
the category upgrade that certain people had received in the Anki – V1's experiments is now no
57
70 60 50 40 300
10
20
30
40
50
60
70
80
90
100
Loose and Tight Anki - V2
% Tournaments Won
% Games Won
Winning Potential Threshold (Looseness of Betting Strategy)
% V
icto
ry

longer necessary. There is however another issue at hand, those beginners who participate in both
Anki – V1 and Anki – V2 experiments, bring with them knowledge and strategy to deal with the
poker player. Also, as this strategy closely resembles that of Random – 2, and the original Anki –
V2's incompetence has been seen against it, these Human Players were considered Intermediate.
In addition to the above information, it is also imperative to understand that due to time and
resource constraints of this project, there was only limited users and time available for a single
batch of experiments. Thus, the original value of 60 for Tightness was retained and so was all the
values of Aggressive and Conservative behaviour. Figures 30 and 31 show the results of the
experiments conducted with Human Players. Figure 30 allows a closer look at Beginner and
Advanced Players, which are not to clear in Figure 31. Also, once again, there were at least 3
persons present per playing group.
Figure 30. Anki – V2's Performance playing against Beginner and Advanced Humans
58

Figure 31. Anki – V2's Performance playing against Human Players
Overall, Anki – V2 was found to perform satisfactorily. Its exact comparison to Anki – V1 is
given in the section below. There was a lot of positive feedback from the Human players,
especially from the Advanced Players who seemed to find the player quite good.
In comparison to the Beginner players, Anki – V2 was found to be quite superior, however, two
of the three beginners commented on the player's good luck at the time. Even if the true
performance of Anki – V2 is actually lower at the current setting, it can be expected that through
strategy modification and experimentation, a player can be created that is more suited to fight
beginners.
The players lost, as expected, to the Advanced Players, once again, not putting up too much of a
fight. Once again, due to time constraints, modified versions of the player which were more loose
and aggressive were not tried, but would have offered some insight into the playing capabilities of
the master level players, and then try to imitate them.
The intermediate players took a long time to understand the working of Anki – V2 (upto 1686
games), but were once again able to exploit the Tightness in pre-flop and the inability to stick to a
strategy for the whole game. Anki – V2 was found to fold a lot of the times after the turn or the
river because the probability of winning dropped, and it chose a 'bad' random number. This flaw
59

encouraged the Humans to be even more aggressive and loose, allowing them to once again
imitate the Random – 2 Player.
5.5 - Anki – V1 vs. Anki – V2
The most important results also lie in the comparison between the two players Anki – V1 and
Anki – V2. This comparison is two-fold, firstly, there is the direct play, in which the two Players
Anki – V1 and Anki – V2 play against each other. Secondly, the players are compared on their
performances against the Human and Random – 2 Players.
5.5.1 – Direct Anki Comparison
The two players faced each other in a direct competition similar to experiments performed on
them with Random – 2, i.e. 100 tournaments. Figure 32 shows the result of the first series of
experiments, playing Anki – V1 against the original Anki – V2.
Figure 32. Original Anki – V2's playing against Anki – V1
It is visible from the figure that Anki – V2 acted at par with Anki – V1, so there is no apparent
increase in performance. However, similar to Anki – V2's fight against Random – 2, the most
60
0
5
10
15
20
25
30
35
40
45
50
55
60
% Tournaments Won
%Games Won
Anki - V2's Performance
% V
icto
ry

powerful tool that Anki – V2 possesses is the power to adapt or change strategies to fight its
opponent. Anki – V1 offers a high tightness scale, where it only plays the games that it is sure it
would do well in. Thus, the ideal strategy against such a player is either to play according to the
opponent's play, i.e. use opponent modeling, or increase the aggressiveness and thereby bet more
than often. The latter scenario would allow the player to maintain its tightness strategy and yet
behave more appropriately against the opponent. Figure 33 shows the Anki – 2's changing
performance with the change in betting aggressiveness.
Figure 33. Changing Anki – V2 to fight Anki – V1, and succeeding
It is clear once again from Figure 33 that the abilities of Anki – V2 gives it clear superiority over
Anki – V1. Conservativeness is introduced into the player by changing the base values of the
probability triple formation, making it more likely to check and bet more than raising. Similarly,
aggressiveness is incorporated by reducing the chances of checking.
5.5.2 – Anki Comparison in Human and Random PlayersThe first comparison lay in the performance of the players against the Random – 2 or Non-
Folding Random Player. It is clear that the Original Anki – V2 fails in comparison, as it even fails
to win a single tournament against Random – 2. But it is best to compare the top performer of
Anki – V1, i.e. the final Player, against the best performance of Anki – V2, with a 30 Tightness
Index as discussed in the section 5.4.1. Figure 34 shows this comparison.
61
Conservative Anki
Original Anki Aggressive Anki
0
10
20
30
40
50
60
70
80
% Tournaments Won%Games Won
Anki - V2 Players' Performance
% V
icto
ry

Figure 34. Comparison of Anki – V1's and Anki – V2's performance against Random – 2
It is clear from the above figure that Anki – V2 outperforms Anki – V1, though both of them put
in an excellent performance of beating the Random – V2 Player, more than 90% of the time in all
cases.
The next comparison lies in the players' play against Beginner Human Players. Figure 35 below
shows the two curves represented in the Figures 23 and 31, so that their contrast is more visible.
Figure 35. Comparison of Anki – V1 and Anki – V2 against Beginner Humans
62
% Tournaments Won
% Games Won
0
10
20
30
40
50
60
70
80
90
100
Anki – V1Anki – V2
Performance Index%
Vic
tory

As it is clear from the figure above, Anki – V2 beats the human players slightly faster than Anki –
V1, and all this with the settings of the Original Anki – V2 engine. A more adaptive or
experimentally enhanced Anki – V2 Player could easily outdo Beginner Players, thereby proving
its dominance.
Figure 36 shows the Intermediate Human Player comparison for Anki – V1 and Anki – V2. Both
Players were found to lose in the long run, but the major comparison lies in the delay of loss. The
longer the computer player lasts, the more chance it has to recover or understand the opponent.
Figure 36. Comparison of Anki – V1 and Anki – V2 against Intermediate Humans
It is clear from the figure that Anki – V2 takes longer to lose against the Intermediate people.
Thus, Anki – V2 proves its improvement over Anki – V1, even without the necessary adaption to
Human competition.
Finally, the comparison lies in the play against Advanced Players. Figure 37 shows this
comparison.
63

Figure 37. Comparison of Anki – V1 and Anki – V2 against Advanced Humans
It is in this figure that we see some disappointing results, as Anki – V2 loses faster than Anki –
V1. However, once again, further experiments with a more aggressive and intelligently tight
versions of Anki – V2 will offer a better insight into the true power of Anki – V2, as it will win
more and in a more efficient manner. Also, apart from the numerical results, all the advanced
players who had played Anki – V1 as well, commented on the uncertainty of Anki – V2. One of
the Advanced Player had the following insight to offer;
“Anki – V2 has clearly introduced randomisation; this is forcing me to concentrate harder and play a smarter game. I am less likely to blindly bet pre-flop, am forced to fold later in the game and don't understand the player's hand till after the turn. Anki – V1 offered the same card information at every betting round (which Anki – V2 doesn't).” [24]
The advanced players were surprised to find that they had beaten Anki – V2 faster than Anki –
V1. They commented on how they found Anki – V2 a much harder player, and thought that the
only reason for a faster tournament was that each game became worth a lot more due to Anki –
V2's randomised betting strategy even in the face of bad hands. It is also for this reason that the
players treated Anki – V2 with more respect as it fought harder than Anki – V1.
5.6 - Anki and the Previous ResearchSome of the results that were observed in the sections given above are consistent with many of the
64

observations received from the result sets of Loki, Poki and PsOpti. This proves the consistency
of the program and the results. Most of the similarities lay in the patterns observed playing against
both Intermediate and Advanced Players.
Figure 5 from Chapter 2, Literature Review is represented again below in the form of Figure 38.
The figure will be discussed in detail, taking comments made about it from [2], and comparing it
to the results obtained in the evaluation of Anki – V1 and Anki – V2 against all categories of
Human Players. The play in Figure 38 corresponds to PsOpti, the best two-person Poker player
available, against a Master level player known as 'the count'.
Figure 38. “The count”'s (Human Player's) performance against PsOpti, same as Figure 5.
Starting from the left-most point on the graph above, it can be seen that PsOpti won the first
couple of hands. This is the learning period, during which human opponents try to understand
each other and take a few risks just to see the opponent's reactions. PsOpti does not incorporate
any opponent modeling, similar to both the Anki versions created in this project, and thus starts to
play its near-optimal strategies from the beginning, oblivious to the workings of its opponent.
Exactly the same behaviour can also be seen in Anki – V1's play against all beginner, intermediate
and advanced players. This can be confirmed from Figures 35, 36 and 37 by observing the play of
Anki – V1. Anki – V2 has the opposite result, but this is due to player experience against Anki –
V1, this is also discussed later in this section.
65

'Luck plays a huge factor in poker'; this is a statement that has been repeated many times in both
this thesis and in many previous research papers. This can be seen in Figure 38, at both the sharp
drops, at around 2500 and 5500 hands played. These are the sharpest drops in the graph, and have
been accredited to luck in [3]. Similar trends can also be seen in Figure 36, in the plays of both
Anki – V1 and Anki – V2 against Intermediate Human Players. These games against the
Intermediate Players are long enough for certain luck factors to show themselves, and they do. It
can also be noted that these luck factors introduce the steepest curves seen in any of the analysis.
Thus, the factor of luck cannot be denied in Poker play.
Another observation made in both PsOpti and the versions of Anki is that of the 'Blink Factor', or
the fact that humans get tired, but machines never do. The first fall of 'the count' at around 2500
hands was due to luck, but he continued to perform badly, and he stopped after a while saying that
he was tired and wanted to retire for the day. He came the next day and started to recover. Once
again, the Anki analysis that best shows this result is the long tournaments Anki – V2 played
against Intermediate Human Players. At least half of the Intermediate players complained of
fatigue at this point in the game, and commented on how they 'took a short break to gather their
senses' before continuing once again. This 'Blink factor' is something a future version of Anki
could be taught to exploit, as Human players' ability seem to take a serious fall during this time.
Lastly, an aspect of memory that needs to be developed that human beings already utilise in their
strategies is that of 'remembering the best strategy to compete against an opponent'. Both PsOpti
and the versions of Anki do not try to remember the strategies that helped it win against the
opponent, and this makes a difference to the output. After the 'Blink Factor' experienced by 'the
count', he bounces back after around 3800 hands. This is because, even after a day's break, he
remembers the strategies he had played earlier to good effect, and utilises these strategies once
again to increase his performance. This phenomenon can be seen in Figures 36 and 37 for Anki –
V2 plays against Intermediate and Advanced players. Anki – V1 was seen to perform well right at
the start, as was noted at the start of this discussion, but Anki – V2 starts of quite poorly. This is
simply because the Human Players attack Anki – V2 similar to the strategy they learned playing
against Anki – V1, and even though Anki – V2 is a better player, that strategy is found to work
well against it as well.
66

The final discussion concerning memory can be seen as a form of opponent modeling, but it is
not. Opponent modeling requires extensive calculation of the opponent's behaviour, and using
expert systems to decide a battling strategies. Memory is simpler, and only needs to increase the
probability of playing of strategies that consistently lead to positive results.
Finally, the most relevant observation that can be made from the play of PsOpti against 'the count'
and that of Anki – V2 against Intermediate Human Players is that the similarities between them
are uncanny. Both play against master and intermediate level players respectively and result in
very similar results. PsOpti claims to be a sub-master level player, whereby it can play two-player
tournaments against most humans and win; losing only in the case of master level players.
Similarly, Anki – V2 can make a claim to be at least a sub-intermediate level player. Its
dominance against beginners has already been proven, and if anything, the performance of Anki –
V2 can be expected in increase with a different Aggressive and Tightness strategy against
Intermediate-level Human Players.
This feature also gives both Anki – V1 and Anki – V2 the ability to be excellent learning tools, as
they offer a form of Level 1 and Level 2 of Playing Capabilities to teach a Human Player the
strategies and manner of playing Poker. More on the subject is discussed in the Chapter 6,
Conclusions and Future Work.
67

Chapter 6 – Conclusion and Future Work
6.1 - General conclusions
Four computer players, i.e. Random – 1, Random -2, Anki – V1 and Anki – V2, along with initial
strict strategy players such as Always-Checks1, Always-Checks2, Always-Bets and Always-
Raises were created by the author of this thesis.
The project succeeded in its goal to make Knowledge and Strategy based Texas-Hold'em Poker
Players in Prolog. The players created, Anki – V1 and Anki – V2, were of good quality and
provided many positive results. They were created using different approaches, which were well
documented, and have been presented in this thesis. The documentation also verifies the stability
and soundness of the program, which allows the results to be considered reliable. Through these
results, the quality of Anki – V1 and Anki – V2 can be justified to be good, as they both appear to
be sub-intermediate level, with the possibility of Anki – V2 excelling given the correct settings.
Both Anki – V1 and Anki – V2 were evaluated against Random – 1, a completely random player;
Random – 2, a non-folding random player; and three categories of Human Players, Beginner,
Intermediate and Advanced.
The project followed a life-cycle shown in Figure 39. The author's previous knowledge and
extensive reading provided a basis for Human Heuristics. These heuristics were formulated into
Computer/Machine Heuristics. Experimentation led to many lessons being learned and being re-
iterated to improve the Human Heuristics, which lead to further formulation of Computer
Heuristics.
Figure 39. Life-cycle of the Project leading to a better formulation of Human Heuristics
68

6.2 - Conclusions of Anki – V1 and Anki – V2
Anki – V1 used a Knowledge Base and Rule-Based Hand Evaluation technique to convert each
hand into a form of pattern. These patterns were grouped together using a technique known as
Bucketing, which was found to be very effective, and similar to the manner in which the human
brain treats its poker hands. These buckets were assigned scores based on their potential to form
winning hands, and further, these scores were converted into strategies which changed over the
game but remained strict over a betting round.
Anki – V1 played very well against Beginner Human Players and won all its tournaments. It
fought hard against the Intermediate Human Players, but lost eventually, and finally, lost
comprehensively against Advanced Player. The main reason behind its defeat was found to be the
predictable tight strategy that it followed, more on which is discussed in Section 6.3.
Anki – V2 offered a Simulation and Enumeration based approach to the two-player Poker Playing
scenario. It calculated its Winning Potential by playing simulated games with its current hand and
other available knowledge. This Winning Potential was converted into Probability Triples through
formulas that control the player's Aggressive and Conservative behaviours. These probability
triples remained static over a betting round, but were used to create a controlled randomised
betting action every time the player is faced with a decision. The decisions were slightly altered
through the Winning Potential Threshold that controlled the player's Tightness and Looseness
behaviours. Finally, the player recorded the opponent's actions in the game, and used enumeration
to make small changes to the Winning Potential to reflect it more accurately.
Anki – V2 was found to perform even better in most respect than Anki – V1 through its ability to
tweak the Aggressiveness and Tightness of its strategies. This was apparent when it played
against Random – 2 and Anki – V1 in tournament play as discussed in Section 5.5. Anki – V2
beats all the Beginner Human Players, slightly better than Anki – V1. It also loses against
Intermediate players but after a longer struggle than Anki – V1. This is mostly due to its
randomised betting action strategies that make it harder to figure out. Finally, Anki – V2 loses
against Advanced Players very hurriedly, and worse than Anki – V1. This is seen due to its
moderate bluffing strategy that changes in between betting rounds. Once again, this is discussed
further in Section 6.3. Anki – V2 can be expected to play even better and defeat Intermediate
69

Players if enough experiments are carried out with humans to tune its Aggressive and Tightness
Behaviours against those of the Intermediate Human Players.
Comparison of results obtained from PsOpti's play against the master level human player, 'the
count', and that of Anki – V2 against Intermediate Level Human Players revealed that Anki – V2
was at least just below Intermediate Level in its play. This coupled with the fact that Anki – V2
can further be tweaked in its strategies to play Intermediate Level Players even better, means that
it can possibly claim to be Intermediate Level with the right adjustments.
6.3 - Conclusions of Poker Game and Betting Strategies
The creation and evaluation of Poker Players Anki – V1 and Anki – V2 have revealed a lot of
interesting results and conclusions relating to human strategies. As discussed earlier, one category
of strategies is concerning the relative number of hands played, which is described by Tight,
Moderate or Loose. Anki – V1 was found to be very tight, as it only played the hands it had a
very good chance of winning in, and Anki – V2 was found to range from tight to moderate
depending on its randomised betting strategy.
The second category of discussing player strategies is concerning the amount bet per game. Both
Anki – V1 and Anki – V2 were very aggressive. This was a good choice as both players showed
good winnings in the games that they were confident of winning, and thus the aggressive attitude
managed to take more money than usual away from the Human Players they played against.
The extremely tight strategy of Anki – V1 was defeated by loose strategies of Human Players.
Beginners lost their games due to bad plays, and never sticking to a strategy. They also folded
early in the game without trying to figure out the hand that Anki – V1 may have. Thus, a tight
strategy against a very tight intelligent player does not work. Both advanced and intermediate
human players eventually defeated Anki - V1 by adopting loose strategies and trusting the player.
Thus, a predictably tight player can be defeated by a reactive loose player. The human players
had to be reactive loose players, i.e. react to the strategy of Anki – V1 and fold when Anki – V1
raises multiple times. The need for the reactive aspect can be proven by looking at the play of
Anki – V1 against Random – 2. Random – 2 was a very loose player and it lost against Anki – V1
to the extent of 93% of the tournaments. It can thus be concluded that a tight aggressive player
70

will beat a very loose player. The aggressiveness can be shown through the reasoning that a tight
player needs to make up for the money lost in folding numerous games through winning large
amounts in the games that it plays to the end.
Anki – V2 offered a much better test-bed for strategy manipulation as its aggressive and tightness
strategies could be tweaked to give the desired combinatorial strategy. Anki – V2's victory against
Beginners was for the same reason as that of Anki – V1, but its longer struggle against
Intermediate Human Players arose from its unpredictability and randomised betting strategy
which forced the human players to observe the player for longer to figure out a strategy to defeat
it. Thus, a controlled randomised strategy is a much better option against human players, as
it adds confusion to a human player's mind. Anki – V2's quick defeat against Advanced players
was also one of the project's biggest lessons. Even though it is known that Anki – V2 could be
tweaked to perform better against that category of human players, the conclusion received from
the experiment was that betting strategies need to be remembered over betting rounds. This is
true as most of the Advanced Players commented on Anki – V2's excellent unpredictability, but
poor choice to fold a bluffed hand after committing lots of money to the pot.
Anki – V2 also lost horribly against Random – 2 player, this was because an unsure moderate
(tightness index) player will loose to a completely loose player. However, when the moderate
player is converted into an intelligent loose player, it can perform wonders, as the intelligent
loose player was found to beat the completely loose player in over 98% of the tournaments
played. By intelligently loose, it refers to the fact that Anki – V2 chose to fold the worst of its
hands.
Finally, the last conclusion was obtained through the play of Anki – V1 against Anki – V2. They
were both created equal, and they performed as such. But as usual, Anki – V2's adaptive
capabilities allowed it to gain an upper hand through modifications. In the case of equal
tightness, the more aggressive player is found to win. This was proven through the
experimentation of making Anki – V2 more aggressive.
71

6.4 - Future Work
6.4.1 – The Anki Poker Teaching ToolThe quality of Anki – V1 and Anki – V2 allow these players to be excellent tools for teaching
beginner and intermediate players simple strategies of tightness and aggressiveness. These players
have already been fully coded, with the Prolog code provided in Appendix A, and thus only need
small additions to form teaching support. Both players have also proven their stability through
both documentation and extensive play against computer and human players.
Anki – V1 plays against beginner players really well, and offers a great future as a teaching tool
of poker to new human poker players. This is because it plays just above their level, and is based
completely on rules and strict strategy. Each action of Anki – V1 is justified through the hand
strength or the hand potential, and it can use this information to suggest possible moves and
provide support to beginner level human players. Human players at this level were found to have
most trouble understanding the concepts of poker, and getting to grasp with the winning patterns
and simple loose and tight strategies. All of these aspects can be expressed through an Anki – V1
based help engine.
Anki – V2 offers a slightly higher level teaching tool, as it encompasses not just tightness and
looseness but also aggressive and conservative strategies. On top of that, it is also fully
customisable, which allows a person to set the playing strength of Anki – V2. Moreover, the
complete control over Anki – V2's strategy, allows people learning poker to learn to play against
Aggressive, Conservative, Tight, Loose and Moderate players all using the same program. This
way, users can experience play against particular strategies, and learn to play better. The strategy
maker itself can be randomised, to give the user an Intermediate – level playing platform. Once
again, like Anki – V1, coding of the actual methods has already been done. Anki – V2's learning
tool can also provide help to its users, by giving them a good estimate of the winning probability
of their current hand, thereby allowing them to learn the value of any kind of hand.
72

6.4.2 - Testing and Extensions to project
The previous section discussed one of the possible applications of Anki – V1 and Anki – V2.
There are also certain additions that can to be made to the project, to both improve and realise its
full potential. Most of these additions involve human testing with the various settings of Anki –
V2. There is very few code addition to be done, but the inputs of experts to help provide better
enumeration is explored further in Section 6.4.3.
Anki – V1 has a static hand evaluation technique, and thus all of its groups and scoring system
was put to a complete test when it was played against both pre-coded players and Human players.
The extension that can be considered for this player involves the increase in scoring categories for
buckets and additional strategies. The current buckets are based on the patterns that were
observed in the Anki – V1's hand. The scoring system only involves numbers 0 to 4, in which 0
signifies the strategy of 'check else fold', 1 – 2 allocates betting, 3 allocates raising and 4 signifies
an excellent finished pattern which does not need to be re-evaluated. The scoring system can be
extended to provide support for additional strategies, some of which are present in Poki [10], like
'check else bet', 'bet if opponent checks, else check', etc.
Anki – V2, being the second player that was created, did not get the full extensive testing it
deserved to show its abilities against human players. It showed how by changing its internal
strategies, it could perform much better against static strategy players. Using the same reasoning,
and an automated strategy modifier, it can force it's opponents to frequently change their strategy
against this Anki – V2 as well, thereby increasing its performance. Also, this would allow a much
more extensive set of conclusions similar to the kind that were documented in Section 6.3.
6.4.3 - Resource based extensions to project
One of the major aspects missing from this project was that of expert systems. All previous
players such as Loki, Poki and PsOpti had the expert input available from a master level player,
i.e. Darse Billings. The author of this project started from being an Intermediate Human Player
and can now be considered Advanced at best. Darse Billings justifies a lot of his heuristics and
expert systems of Loki through past experiences [13], which are not expressed in the research to
the extensive detail as is required for the coding of a similar Poker Player. Thus, the availability of
73

input from a high-level Poker Player can offer a lot to the expert systems of Anki – V1 and the
strategy formation of Anki – V2. The final help of an expert lies in the enumeration strategy of
Anki – V2, which can only be confirmed by master level players due to the strategy's complexity
and presence in mostly master-level tournaments.
Anki – V1 and Anki – V2 both also estimate the Winning Potential through bucketing and
simulation respectively. Higher computation power and an time efficient platform can help
overcome the exponential blow up of the exact statistical method of Winning Potential calculation.
This can help future computer players to have more exact strategies and assign near-optimal
values to it's hands at any point in the game.
Another possible extension to the program can be its migration to a platform-independent
language such as Java, or to incorporate a Java interface to the already existing Prolog code. This
would allow the users of the program to test it at their convenience, and provides the possibility of
publishing it online.
Anki – V1 and Anki – V2 are very good players in their own respect, but they form even a better
foundation for the future to understand human behaviour and replicate it in the Poker Playing
community. As the results from this project show, the day when Imperfect Information Games
compete well with Master level players in full size tournaments is definitely close at hand.
74

Bibliography
1. D. Koller, A. Pfeffer; Generating and Solving Imperfect Information Games. IJCAI 1995: 1185-1193.
2. D. Billings, N. Burch, A. Davidson, R. Holte, J. Schaeffer, T. Schauenberg, D. Szafron; Approximating Game-Theoretic Optimal Strategies for Full-scale Poker. IJCAI 2003: 661-668.
3. D. Papp; Dealing with imperfect information in poker. Master's thesis, Department of Computing Science, University of Alberta, 1998.
4. S. J. J. Smith and D. S. Nau; Strategic planning for imperfect-information games. In Working Notes of the AAAI Fall Symposium on Games: Planning and Learning, 1993.
5. D. Koller, A. Pfeffer; Representations and Solutions for Game-Theoretic Problems. Artif. Intell. 94(1-2): 167-215 (1997).
6. S. A. Gordon; A comparison between probabilistic search and weighted heuristics in a game with incomplete information, in: AAAI Fall 1993.
7. J. R. S. Blair, D. Mutchler and C. Liu; Games with imperfect information. In Proceedings of the AAAI Fall Symposium on Games: Planning and Learning, 59— 67 (1993).
8. D. Koller, N. Megiddo, B. von Stengel; Fast algorithms for finding randomized strategies in game trees. STOC 1994: 750-759 (1994).
9. M. van Lent and D. Mutchler; A pruning algorithm for imperfect information games. In Proceedings of the AAAI Fall Symposium on Games: Planning and Learning (1993).
10. D. Billings, A. Davidson, J. Schaeffer, D. Szafron: The challenge of poker. Artif. Intell. 134(1-2): 201-240 (2002).
11. J. Schaeffer, D. Billings, L. Pea, D. Szafron; Learning to Play Strong Poker. In proceedings of the Sixteenth International Conference on Machine Learning (ICML-99), J. Stefan Institute, Slovenia (Invited Paper), 1999.
12. J. Cassidy; The Last Round of Betting in Poker, The American Mathematical Monthly, Vol. 105, No. 9. (Nov., 1998), pp. 825-831.
13. D. Billings, L. P. Castillo, J. Schaeffer, D. Szafron; Using Probabilistic Knowledge and Simulation to Play Poker. AAAI/IAAI 1999: 697-703.
14. J. Shi, M. L. Littman; Abstraction Methods for Game Theoretic Poker. Computers and Games 2000: 333-345.
15. A. Junghanns, J. Schaeffer; Search Versus Knowledge in Game-Playing Programs Revisited. IJCAI (1) 1997: 692-697.
16. J. F. Nash; Non-cooperative games, Ann. Math. 54 (1951) 286–295.
17. J. F. Nash, L. S. Shapley; A simple three-person poker game, Contributions to the Theory of Games 1 (1950) 105–116.
18. J. von Neumann, O. Morgenstern; The Theory of Games and Economic Behavior, 2nd
75

Edition, Princeton University Press, NJ, 1947.
19. H.W. Kuhn; A simplified two-person poker, Contributions to the Theory of Games 1 (1950) 97–103.
20. N. Findler; Studies in machine cognition using the game of poker. Communications of the ACM 20(4):230-245 (1977).
21. C. Cheng; Recognizing poker hands with genetic programming and restricted iteration. Genetic Algorithms and Genetic programming at Stanford, J. Koza (editor), Stanford, California (1997).
22. D. Sklansky and M. Malmuth; Texas Hold’em for the Advanced Player, Two Plus Two Publishing, 2nd edition, 1994.
23. K. Takusagawa; Nash equilibrium of Texas Hold’em poker, Undergraduate thesis, Computer Science, Stanford University, 2000.
24. Personal correspondence with Human Players
76

Appendix A – Program Code
% This program is the one that was used to test Human Play against Anki – V2. It still contains all the %different players such as Anki – V1, Random – 1, etc. within it.
:- use_module(library(system)).% 1 - 13 for Ace, 2, 3, ... Jack, Queen and King% 1 - 4 for Clubs, Diamonds, Hearts and Spades.
% Strategy 1 - Always bets.% Strategy 2 - Always raises when possible, otherwise bets.% Strategy 3 - Random choice including folding.% Strategy 4 - Random choice without folding.% Strategy 5 - Uses initial eval to decide fold(check) or bet.% Strategy 6 - Uses initial eval to decide fold(check) or raise.% Strategy 7 - Uses initial eval to decide fold(check) or bet or raise.% Strategy 8 - Uses initial eval to decide Strategy 3 or 4.%
:- dynamic seed/1.
seed(124353425).
:- nl, nl, write('************ Welcome to Texas Hold Them ***************'), nl, write('* Each card is represented in a tuple *'), nl, write('* (Card-number,Card-suit) as denoted below: *'), nl, write('* *'), nl, write('* 1 - 13 for Ace, 2, 3, ... Jack, Queen and King; *'), nl, write('* 1 - 4 for Clubs, Diamonds, Hearts and Spades. *'), nl, write('*******************************************************'), nl, write('Please give seed : '),
read(X),retract(seed(_)),assert(seed(X)),nl, write('*******************************************************'), nl,
write('Please write play. to start game!'), nl, write('*******************************************************'), nl.
% rand(R) generates random real number R in the range [0,1)rand(R) :- retract(seed(S)), N is (S * 314159262 + 453816693) mod 2147483647, assert(seed(N)), R is N / 2147483647.0 .
% ramdom(R,M) generates random integer R in the range 0..M-1random(R,M) :- rand(RR),
77

R is integer(M * RR).
random_float(R,M) :- rand(RR), R is (M * RR). play:-
open('ac_poker_result.pl', append, Stream),play_poker(X, (0,0,0,0,0,0,0), Stream),(X = 0 -> true ; play(X, Stream)),nl, write('*******************************************************'), nl,
write('Please write play. again to play more games.'), nl,write('*******************************************************'), nl,
close(Stream).
play(X, Stream):-play_poker(Y, X, Stream),(Y = 0 -> true ; play(Y, Stream)).
play_poker(X, N1, Stream):- initialise_game(A),set_players(A, B, C, 1000.0, 1000.0),play_game(A, B, C, X, 0, N1, Stream), !.
play_poker(X, Y, Z, 'n', N, N1, Stream):-end_game_check(Y, Z, X, N, N1, Stream), !.
play_poker(X, Y, Z, 'y', N, N1, Stream):-initialise_game(A),set_players(A, B, C, Y, Z),play_game(A, B, C, X, N, N1, Stream), !.
play_poker(X, Y, Z, _, N, N1, Stream):-nl, write('Kindly choose from the given options of y or n!'),nl, write('Do you wish to play another game? '),read(A),play_poker(X, Y, Z, A, N, N1, Stream).
initialise_game(X) :- game_hand(X).
game_hand(X):- run_rand(X, [], 4), !.
set_players(A, B, C, D, E) :-A = [M,N|P],B = (1, [M,N], D),C = (2, P, E).
end_game_check(B1, C1, X, N, (_, _, _, _, N6, N7, N9), Stream) :-nl, write('*******************************************************'), nl,
write('The tournament has ended. Player 1 has '), write(B1), write(' money, and Player 2 has '), write(C1), write('.'), nl, nl(Stream), write(Stream, 'The game has ended. Player 1 has '), write(Stream, B1),
78

write(Stream, ' money, and Player 2 has '), write(Stream, C1), write(Stream, '.'), nl(Stream), X = 0,(B1> C1 -> write('Player 1 wins the tournament!') ; write('Player 2 wins the tournament!')), write('There were '), write(N), write(' games played.'), nl, write('Player 1 won '), write(N6),nl, write('Player 2 won '), write(N7),nl, write('Drawn games were '), write(N9), write(Stream, 'There were '), write(Stream, N), write(Stream, ' games played.'), nl(Stream), write(Stream, 'Player 1 won '), write(Stream, N6),nl(Stream), write(Stream, 'Player 2 won '), write(Stream, N7),nl(Stream), write(Stream, 'Drawn games were '), write(Stream, N9),!.
play_game(_, (_,_,0.0), (_,_,C1), X, N, (N1, N2, N3, T, N6, N7, N9), Stream) :-T1 is T + N,N4 is N3 + 1, N5 is N1 + 1,nl, write('*******************************************************'), nl,
write('The tournament has ended. Player 1 has 0 money, and Player 2 has '),write(C1), write('.'),nl, write('Player 2 wins the tournament! '), write('There were '), write(N), write(' games played.'), !,(N5 > 0 -> X = 0, write(N5), write(' tounaments played.'),nl, write('Total games played: '), write(T1),nl, write('Player 1 won '), write(N2), write(' and '), write(N6),nl, write('Player 2 won '), write(N4), write(' and '), write(N7),nl, write('Drawn games were '), write(N9),nl(Stream), write(Stream, 'Total games played: '), write(Stream, T1),nl(Stream), write(Stream, 'Player 1 won '), write(Stream, N6),nl(Stream), write(Stream, 'Player 2 won '), write(Stream, N7),nl(Stream), write(Stream, 'Drawn games were '), write(Stream, N9);X = (N5, N2, N4, T1, N6, N7, N9)).
play_game(_, (_,_,5.0), (_,_,C1), X, N, (N1, N2, N3, T, N6, N7, N9), Stream) :-T1 is T + N,N4 is N3 + 1, N5 is N1 + 1,nl, write('*******************************************************'), nl,
write('The tournament has ended. Player 1 has 5 money, and Player 2 has '),write(C1), write('.'),nl, write('Player 2 wins the tournament! '), write('There were '), write(N), write(' games played.'), !,(N5 > 0 -> X = 0, write(N5), write(' tounaments played.'),nl, write('Total games played: '), write(T1),nl, write('Player 1 won '), write(N2), write(' and '), write(N6),nl, write('Player 2 won '), write(N4), write(' and '), write(N7),nl, write('Drawn games were '), write(N9), nl(Stream), write(Stream, 'Total games played: '), write(Stream, T1),nl(Stream), write(Stream, 'Player 1 won '), write(Stream, N6),nl(Stream), write(Stream, 'Player 2 won '), write(Stream, N7),nl(Stream), write(Stream, 'Drawn games were '), write(Stream, N9);X = (N5, N2, N4, T1, N6, N7, N9)).
play_game(_, (_,_,B1), (_,_,0.0), X, N, (N1, N2, N3, T, N6, N7, N9), Stream) :-
79

T1 is T + N,N4 is N2 + 1, N5 is N1 + 1,nl, write('*******************************************************'), nl,
write('The tournament has ended. Player 2 has 0 money, and Player 1 has '),write(B1), write('.'),nl, write('Player 1 wins the tournament! '), write('There were '), write(N), write(' games played.'), !,(N5 > 0 -> X = 0, write(N5), write(' tounaments played.'),nl, write('Total games played: '), write(T1),nl, write('Player 1 won '), write(N4), write(' and '), write(N6),nl, write('Player 2 won '), write(N3), write(' and '), write(N7),nl, write('Drawn games were '), write(N9), nl(Stream), write(Stream, 'Total games played: '), write(Stream, T1),nl(Stream), write(Stream, 'Player 1 won '), write(Stream, N6),nl(Stream), write(Stream, 'Player 2 won '), write(Stream, N7),nl(Stream), write(Stream, 'Drawn games were '), write(Stream, N9);X = (N5, N4, N3, T1, N6, N7, N9)).
play_game(_, (_,_,B1), (_,_,5.0), X, N, (N1, N2, N3, T, N6, N7, N9), Stream) :-T1 is T + N,N4 is N2 + 1, N5 is N1 + 1,nl, write('*******************************************************'), nl,
write('The tournament has ended. Player 2 has 5 money, and Player 1 has '),write(B1), write('.'),nl, write('Player 1 wins the tournament! '), write('There were '), write(N), write(' games played.'), !,(N5 > 0 -> X = 0, write(N5), write(' tounaments played.'),nl, write('Total games played.'), write(T1),nl, write('Player 1 won '), write(N4), write(' and '), write(N6),nl, write('Player 2 won '), write(N3), write(' and '), write(N7),nl, write('Drawn games were '), write(N9), nl(Stream), write(Stream, 'Total games played.'), write(Stream, T1),nl(Stream), write(Stream, 'Player 1 won '), write(Stream, N6),nl(Stream), write(Stream, 'Player 2 won '), write(Stream, N7),nl(Stream), write(Stream, 'Drawn games were '), write(Stream, N9);X = (N5, N4, N3, T1, N6, N7, N9)).
play_game(A, (1,B,B0), (2,C,C0), X, N, N2, Stream) :- N1 is N + 1,B1 is B0 - 10,C1 is C0 - 10,nl, write('*******************************************************'), nl,
write('Your hand (personal 2 cards) is : '), write(B), nl, write('*******************************************************'), nl, nl(Stream), write(Stream, 'Player 1 has cards : '), write(Stream, B),
nl(Stream), write(Stream, 'Player 2 has cards : '), write(Stream, C),
% First round evaluation and betting.
eval_start_good(C, Good1),
80

write(Stream, Good1),%eval_start(C, E),%better(E, _), !,betting_round(1, B, C, [], B1, C1, 20.0, B2, C2, R1, 'c', P, 0, 0, Good1, Stream, 0, _),
% Second Round evaluation and betting.
get_flop(A, Y, T1, P, Stream),eval_flop_good(C, Y, Good2, T1), write(Stream, Good2),append(C, Y, Cf),ace_it(Cf, Cf1),q_sort(Cf1, [], Cf2),%setof(E2, eval_flop(C, Cf2, 2, E2), E3),%get_best_str(E3, E4),%better(E4, E5), !,betting_round(1, B, C, Y, B2, C2, R1, B3, C3, R2, P, P1, 0, 0, Good2, Stream, 0, Chan),write(Stream, Chan),
% Third round evaluation and betting.
get_turn(T1, D, T2, P1, Stream),eval_turn_good(C, Y, [D], Good3, T2, Chan), write(Stream, Good3),append([D], Y, F),insert_card(D, Cf2, Ct), !,%setof(E6, eval_turn(C, Ct, 2, E6), E7),%get_best_str(E7, E8),%better(E8, E9), !,betting_round(1, B, C, F, B3, C3, R2, B4, C4, R3, P1, P2, 0, 0, Good3, Stream, Chan, Chan1),write(Stream, Chan1),
% Final round of betting
get_river(T2, G, P2, Stream),eval_river_good(C, Y, [D], [G], Good4, Chan1), write(Stream, Good4),append([G], F, H),insert_card(G, Ct, Cr), !,%setof(E10, eval_river(C, Cr, 2, E10), E11),%get_best_str(E11, E12),%better(E12, E13), !,betting_round(1, B, C, H, B4, C4, R3, B5, C5, R4, P2, P3, 0, 0, Good4, Stream, 0, _),
% Final evaluation - Complete!
final_eval(B, C, H, Cr, B5, C5, R4, B6, C6, P3, P4, Stream),game_add(P4, N2, (N3,N4,N5,N6,N7,N8,N9)),nl, write('*******************************************************'), nl,
(P4 = 3 -> write('It is a draw!'), write(Stream, 'It is a draw!'); write('Player '), write(P4), write(' has won!'),write(Stream, 'Player '), write(Stream, P4), write(Stream, ' has won!')),nl, write('Player 1 now has '), write(B6), write(' money.'),nl, write('Player 2 now has '), write(C6), write(' money.'), nl,
81

write('*******************************************************'), nl, nl(Stream), write(Stream, ' ; ; ; '), write(Stream, N1), write(Stream, ' ; '), write(Stream, N7), write(Stream, ' ; '), write(Stream, N8), write(Stream, ' ; '), write(Stream, N9), write(Stream, ' ; '), write(Stream, B6), write(Stream, ' ; '), write(Stream, C6), nl, nl, nl, write('Do you wish to play another hand? Type y for yes and n for no : '),
read(X1),play_poker(X, B6, C6, X1, N1, (N3,N4,N5,N6,N7,N8,N9), Stream).
insert_card([], Ct, Ct).insert_card((1,S), X, [(14,S)|T]):-
append(X, [(1,S)], T).insert_card((A,S), [], [(A,S)]).insert_card((A,S), [(A1,S1)|T], [(A,S),(A1,S1)|T]):-
A > A1.insert_card(X, [H|T], [H|T1]):-
insert_card(X, T, T1).
betting_round(A, _, _, _, B1, C1, R1, B1, C1, R1, 'f', A, _, _, _, _, _, 0).betting_round(_, _, _, _, B1, C1, R1, B1, C1, R1, 1, 1, _, _, _, _, _, 0).betting_round(_, _, _, _, B1, C1, R1, B1, C1, R1, 2, 2, _, _, _, _, _, 0).betting_round(_, _, _, _, B1, C1, R1, B1, C1, R1, 'm', 'm', _, _, _, _, _, 0).betting_round(A, _, _, _, 0.0, C1, R1, 0.0, C1, R1, _, 'm', _, _, _, Stream, _, 0):-
nl, write('Player '), write(A), write(' has finished his/her money'),nl(Stream), write(Stream, 'Player '), write(Stream, A), write(Stream, ' has finished his/her money').
%betting_round(A, _, _, _, B1, 0.0, R1, B1, 0.0, R1, _, 'm', _, _, _, _):-% change_over(A, 'm', B),% nl, write('Player '), write(B), write(' has finished his/her money').betting_round(A, _, _, _, 5.0, C1, R1, 5.0, C1, R1, _, 'm', _, _, _, Stream, _, 0):-
nl, write('Player '), write(A), write(' has insufficient money'),nl(Stream), write(Stream, 'Player '), write(Stream, A), write(Stream, ' has insufficient money').
%betting_round(A, _, _, _, B1, 5.0, R1, B1, 5.0, R1, _, 'm', _, _, _, _):-% change_over(A, 'm', B),% nl, write('Player '), write(B), write(' has insufficient money').betting_round(_, _, _, _, B1, C1, R1, B1, C1, R1, 'b2', 'c', _, _, _, _, C, C).betting_round(_, _, _, _, B1, C1, R1, B1, C1, R1, 'c3', 'c', _, _, _, _, C, C).betting_round(1, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, E, Stream, Chan, Chan1):-
nl, nl, nl, write('*******************************************************'), nl, write('Player 1'), nl,
nl, write('The current state of the poker game is as follows :'),nl, write('Your cards are '), write(B), write('.'),nl, write('The cards on the table are '), write(D), write('.'),nl, write('Your money is '), write(B1), write('.'),nl, write('Your opponent has '), write(C1), write(' money.'),nl, write('The money currently in the pot is '), write(R1), write('.'), nl,(M > 0 -> write('You need to bet a minimum of '), write(M), write(' to continue.'); true),nl, write('Please choose one of the following options for betting,'),nl, write('f - fold, b - bet'),((M > 0, N < 6, B1 >= 20, C1 >= 10) -> write(', r - raise') ; write('')),(M = 0 -> write(', c - check : ') ; write(' : ')),read(X),eval(X, B1, C1, R1, B3, R3, M, M1, 1, N, X1, Stream),!,change_over(1, X1, A1),change_over(P, X1, P2),
82

change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, E, Stream, Chan,
Chan1).
%Always raises, but in other situations, bets from belowbetting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, 2, Stream, Chan, Chan1):-
M > 0, N < 6, B1 >= 20, C1 >= 10,eval('r', B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,change_over(2, X1, A1),change_over(P, X1, P2),change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, 2, Stream, Chan,
Chan1).
%Always checks otherwise bets or folds from belowbetting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, 0, Stream, Chan, Chan1):-
M = 0,eval('c', B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,change_over(2, X1, A1),change_over(P, X1, P2),change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, 0, Stream, Chan,
Chan1).
betting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, 0, Stream, Chan, Chan1):-eval('f', B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,change_over(2, X1, A1),change_over(P, X1, P2),change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, 0, Stream, Chan,
Chan1).
%Strategy playerbetting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, (E1, E2, E3, Win), Stream, Chan, Chan1):-
random_float(E4, 100),write(Stream, E4),choose_rel_str(E4, E1, E2, E3, S1), !,change_win(Win, Win1, P, Chan, Chan2),exact_str(S1, Win1, S2, M, N, B1, C1), !,eval(S2, B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,change_over(2, X1, A1),change_over(P, X1, P2),change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, (E1,E2,E3,Win1),
Stream, Chan2, Chan1).
%Always betsbetting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, E, Stream, Chan, Chan1):-
eval('b', B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,
83

change_over(2, X1, A1),change_over(P, X1, P2),change_over_num(N, X1, N1),next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, E, Stream, Chan,
Chan1).
%Random strategy chooser with folding%betting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, E, Stream, Chan, Chan1):-% (M = 0 -> Y1 is 1 ; Y1 is 2),% ((M > 0, N < 6, B1 >= 20, C1 >= 10) -> Y2 is 5 ; Y2 is 4),% ret_rand(Y1, Y2, X),% eval(X, B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,% change_over(2, X1, A1),% change_over(P, X1, P2),% change_over_num(N, X1, N1),% next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, E, Stream, Chan, Chan1).
%Random strategy chooser without folding%betting_round(2, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, E, Stream, Chan, Chan1):-% (M = 0 -> Y1 is 5 ; Y1 is 6),% ((M > 0, N < 6, B1 >= 20, C1 >= 10) -> Y2 is 8 ; Y2 is 7),% ret_rand(Y1, Y2, X),% eval(X, B1, C1, R1, B3, R3, M, M1, 2, N, X1, Stream),!,% change_over(2, X1, A1),% change_over(P, X1, P2),% change_over_num(N, X1, N1),% next_betting_round(A1, B, C, D, B3, C1, R3, B2, C2, R2, P2, P1, N1, M1, X1, E, Stream, Chan, Chan1).
next_betting_round(A, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, 's', E, Stream, Chan, Chan1):-betting_round(A, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, E, Stream, Chan, Chan1), !.
next_betting_round(A, B, C, D, B1, C1, R1, B2, C2, R2, P, P1, N, M, _, E, Stream, Chan, Chan1):-betting_round(A, C, B, D, C1, B1, R1, C2, B2, R2, P, P1, N, M, E, Stream, Chan, Chan1).
choose_rel_str(X, C, _, _, 'c'):-X =< C.
choose_rel_str(X, C, _, R, 'r'):-C1 is C + R,X =< C1.
choose_rel_str(_, _, _, _, 'b').
exact_str('b', _, 'b', _, _, _, _).exact_str('r', _, 'r', M, N, B1, C1):-
M > 0, N < 6, B1 >= 20, C1 >= 10.
exact_str('r', _, 'b', _, _, _, _).exact_str('c', _, 'c', M, _, _, _):-
M = 0.
84

exact_str('c', Win, 'f', M, _, _, _):-M > 0,Win < 60.
exact_str('c', _, 'b', _, _, _, _).
change_win(Win, Win1, 'r', Chan, Chan1):-Win1 is Win - 2,Chan1 is Chan - 2.
change_win(Win, Win1, 'c2', Chan, Chan1):-Win1 is Win + 2,Chan1 is Chan + 2.
change_win(Win, Win, _, Chan, Chan).
better(0, 0).%For the random strategies%better(_,1).better(E, 1):-
E > 0,E < 3.
better(E, 2):-E > 2,E < 5.
get_best_str([4|_], 4).get_best_str([H], H).get_best_str([H|T], E):-
get_best_str(T, E1),(H > E1 -> E = H ; E = E1).
get_flop(_, _, [], 1, _).get_flop(_, _, [], 2, _).get_flop(X, Y, Z, _, Stream) :-
run_rand([A,B,C|X], X, 3), Y = [A,B,C], nl, nl, write('*******************************************************'), nl,
write('The flop (first three of five community cards) is : '),write(Y), nl,write('*******************************************************'), nl,
nl(Stream), nl(Stream), write(Stream, 'The flop is : '),write(Stream, Y),append(X,Y,Z).
get_turn(_, _, [], 1, _). get_turn(_, _, [], 2, _). get_turn(Z, D, E, _, Stream) :-
run_rand([D|Z], Z, 1),nl, nl, write('*******************************************************'), nl,
write('The turn (fourth of five community cards) is : '),write(D), nl, write('*******************************************************'), nl,
nl(Stream), nl(Stream), write(Stream, 'The turn is : '),
85

write(Stream, D),E = [D|Z].
get_river(_, [], 1, _). get_river(_, [], 2, _). get_river(Z, D, _, Stream) :-
run_rand([D|Z], Z, 1),nl, nl, write('*******************************************************'), nl,
write('The river (final community card) is : '),write(D), nl,write('*******************************************************'), nl,
nl(Stream), nl(Stream), write(Stream, 'The river is : '),write(Stream, D).
eval('c', B1, _, R1, B1, R1, M, 0, A, _, 'c', Stream):-M = 0,nl, nl, write('Player '), write(A), write(' has checked.'),nl(Stream), write(Stream, 'Player '), write(Stream, A), write(Stream, ' has checked.').
eval('c', B1, _, R1, B1, R1, M, M, _, _, 's', _):-nl, nl, write('Did I say that you could check? Did I? Huh? Huh? Go up and check...'),nl, write('I did not, did I? So, please answer correctly.').
eval('b', B1, _, R1, B2, R2, _, 10, A, _, 'b', Stream):-B2 is B1 - 10,R2 is R1 + 10,nl, nl, write('Player '), write(A), write(' has bet.'),nl(Stream), write(Stream, 'Player '), write(Stream, A), write(Stream, ' has bet.').
eval('r', B1, C1, R1, B2, R2, M, 10, A, N, 'r', Stream):- M > 0,N < 6,B1 >= 20,C1 >= 10,B2 is B1 - 20,R2 is R1 + 20,nl, nl, write('Player '), write(A), write(' has raised.'),nl(Stream), write(Stream, 'Player '), write(Stream, A), write(Stream, ' has raised.').
eval('r', B1, _, R1, B1, R1, M, M, _, _, 's', _):-nl, nl, write('Did I say that you could raise? Did I? Huh? Huh? Go up and check...'),nl, write('I did not, did I? So, please answer correctly.').
eval('f', B1, _, R1, B1, R1, _, _, A, _, 'f', Stream):-write('Player '), write(A), write(' has folded!'),write(Stream, 'Player '), write(Stream, A), write(Stream, ' has folded!').
eval(_, B1, _, R1, B1, R1, M, M, _, _, 's', _):-nl, nl, write('Did I say that you could write that? Did I? Huh? Huh? Go up and check...'),nl, write('I did not, did I? So, please answer correctly.').
change_over(1, 's', 1).change_over(1, _, 2).change_over(2, 's', 2).change_over(2, _, 1).change_over(P, 's', P).change_over('c', 'c', 'c2').change_over('c2', 'c', 'c3').
86

change_over('b', 'b', 'b2').change_over('c', 'b', 'b').change_over('c2', 'b', 'b').change_over('r', 'b', 'b2').change_over(_, 'r', 'r').change_over(_, 'f', 'f').
change_over_num(N, 's', N).change_over_num(N, _, N1):-
N1 is N + 1.
final_eval(_, _, _, _, B1, C1, R, B2, C1, 1, 1, _):-B2 is B1 + R.
final_eval(_, _, _, _, B1, C1, R, B1, C2, 2, 2, _):-C2 is C1 + R.
final_eval(_, _, _, _, B1, C1, R, B2, C2, 3, 3, _):-R1 is R / 2,C2 is C1 + R1,B2 is B1 + R1.
final_eval(B, C, D, C3, B1, C1, R, B2, C2, _, X, Stream):-nl, nl, nl, write('*******************************************************'), nl,
write('Player 1 has the following cards : '), write(B),nl, write('Player 2 has the following cards : '), write(C),nl, write('The following cards are on the table : '), write(D),nl, nl,nl(Stream), nl(Stream), write(Stream, 'Player 1 has the following cards : '), write(Stream, B),nl(Stream), write(Stream, 'Player 2 has the following cards : '), write(Stream, C),nl(Stream), write(Stream, 'The following cards are on the table : '), write(Stream, D),nl(Stream), append(B, D, B3),ace_it(B3, B4),q_sort(B4, [], B5),winner_eval(B5, C3, X, Win), final_eval(_, _, _, _, B1, C1, R, B2, C2, X, X, _), !,write('*******************************************************'), nl,
write(Win), write(Stream, Win).
winner_eval(B, C, X, 'Royal Flush'):-royal_flush(B, 0, A1, 0, 1, Y), royal_flush(C, A1, A2, 0, 2, Z),(A2 = 0 -> fail ; true),(A2 = 3 -> kick_eval(Y, Z, X, [4,_,_]) ; X is A2).
winner_eval(B, C, X, '4 of a kind'):-multiple_kind(B, 0, A1, 1, Y, 0, 3, 15),multiple_kind(C, A1, A2, 2, Z, 0, 3, 15),(A2 = 0 -> fail ; true),(A2 = 3 -> kick_eval(Y, Z, X1, [4,_,_]) ; X1 is A2),
87

(X1 = 3 -> get_kicker(B, C, Y, X, 4) ; X is X1).winner_eval(B, C, X, 'Full House'):-
multiple_kind(B, 0, A1, 2, Y1, 0, 2, 15),(A1 = 0 -> A2 = 0 ; multiple_kind(B, A1, A2, 1, Y2, 0, 1, Y1)),multiple_kind(C, 0, C1, 2, Z1, 0, 2, 15),(C1 = 0 -> C2 = 0 ; multiple_kind(C, C1, C2, 1, Z2, 0, 1, Z1)),full_house_eval(A2, C2, A3), !,(A3 = 3 -> kick_eval(Y1, Z1, X1, [4,_,_]) ; X1 is A3),(X1 = 3 -> kick_eval(Y2, Z2, X, [4,_,_]) ; X is X1).
winner_eval(B, C, X, 'Flush'):-flusher(B, 0, A1, 1, Y, 3),flusher(C, A1, A2, 2, _, 3),(A2 = 0 -> fail ; true),(A2 = 3 -> flush_decide(Y, B, C, X, 0) ; X is A2).
winner_eval(B, C, X, 'Sequence'):-sequen(B, 0, A1, 0, 1, Y, 4),sequen(C, A1, A2, 0, 2, Z, 4),(A2 = 0 -> fail ; true),(A2 = 3 -> kick_eval(Y, Z, X, [4,_,_]) ; X is A2).
winner_eval(B, C, X, '3 of a kind'):-multiple_kind(B, 0, A1, 1, Y, 0, 2, 15),multiple_kind(C, A1, A2, 2, Z, 0, 2, 15),(A2 = 0 -> fail ; true),(A2 = 3 -> kick_eval(Y, Z, X1, [4,_,_]) ; X1 is A2),(X1 = 3 -> get_kicker(B, C, Y, X, 3) ; X is X1).
winner_eval(B, C, X, '2 pair'):-multiple_kind(B, 0, A1, 2, Y1, 0, 1, 15),(A1 = 0 -> A2 = 0 ; multiple_kind(B, A1, A2, 1, Y2, 0, 1, Y1)),multiple_kind(C, 0, C1, 2, Z1, 0, 1, 15),(C1 = 0 -> C2 = 0 ; multiple_kind(C, C1, C2, 1, Z2, 0, 1, Z1)),full_house_eval(A2, C2, A3), !,(A3 = 3 -> (greater(Y1, Y2, Y11, Y22), greater(Z1, Z2, Z11, Z22), kick_eval(Y11, Z11, X1,
[4,_,_])) ; X1 is A3),(X1 = 3 -> kick_eval(Y22, Z22, X2, [4,_,_]) ; X2 is X1),(X2 = 3 -> get_kicker(B, C, Y1, Y2, X, _) ; X is X2).
winner_eval(B, C, X, 'A pair'):-multiple_kind(B, 0, A1, 1, Y, 0, 1, 15),multiple_kind(C, A1, A2, 2, Z, 0, 1, 15),(A2 = 0 -> fail ; true),(A2 = 3 -> kick_eval(Y, Z, X1, [4,_,_]) ; X1 is A2),(X1 = 3 -> get_kicker(B, C, Y, X, 2) ; X is X1).
winner_eval(B, C, X, 'High Card'):-get_first(B, A1),get_first(C, A2),kick_eval(A1, A2, X1, [4, _, _]),(X1 = 3 -> get_kicker(B, C, A1, X, 1) ; X is X1).
royal_flush([], A, A, _, _, []).royal_flush([(H, _)|_], A, A1, 4, Y, H):-
88

A1 is A + Y.royal_flush([(H1, T1)|T], A, A1, C, Y, Z):-
H2 is H1 - 1,member((H2, T1), T),C1 is C + 1,royal_flush([(H2, T1)|T], A, A1, C1, Y, Z), !.
royal_flush([_|T], A, A1, _, Y, Z):-royal_flush(T, A, A1, 0, Y, Z), !.
multiple_kind([(H, _)|_], A, A1, Y, H, X, X, N):-\+ N = H,\+ H = 1,A1 is A + Y, !.
multiple_kind([_], A, A, _, [], _, _, _).multiple_kind([(H, _), (H, _)|T], A, A1, Y, Z, _, X, H):-
multiple_kind(T, A, A1, Y, Z, 0, X, H), !.multiple_kind([(H, _), (H, _)|T], A, A1, Y, Z, C, X, N):-
C1 is C + 1,multiple_kind([(H, _)|T], A, A1, Y, Z, C1, X, N), !.
multiple_kind([_|T], A, A1, Y, Z, _, X, N):-multiple_kind(T, A, A1, Y, Z, 0, X, N), !.
flusher([], A, A, _, [], _).flusher([(_, S)|T], A, A1, Y, Z, N):-
count_and_rem_s((_, S), T, T1, C),(C > N -> (A1 is A + Y,Z is S) ; (flusher(T1, A, A1, Y, Z, N))), !.
sequen([], A, A, _, _, [],_).sequen([(H, _)|_], A, A1, X, Y, H, X):-
A1 is A + Y.sequen([(H1, _)|T], A, A1, C, Y, Z, X):-
H2 is H1 - 1,member((H2, _), T),C1 is C + 1,sequen([(H2, _)|T], A, A1, C1, Y, Z, X), !.
sequen([_|T], A, A1, _, Y, Z, X):-sequen(T, A, A1, 0, Y, Z, X), !.
full_house_eval(3, 3, 3).full_house_eval(3, _, 1).full_house_eval(_, 3, 2).
flush_decide(Y, B, C, X, 4):-get_max_s(B, Y, A1),get_max_s(C, Y, A2),kick_eval(A1, A2, X, [4,_,_]), !.
flush_decide(Y, B, C, X, N):-get_max_s(B, Y, A1),
89

get_max_s(C, Y, A2),kick_eval(A1, A2, X, [Y, B, C, N]).
get_kicker(B, C, Y, X, 4):-count_and_rem_c((Y, _), B, B1, _),count_and_rem_c((Y, _), C, C1, _),get_first(B1, A1),get_first(C1, A2),kick_eval(A1, A2, X, [4,_,_]).
get_kicker(B, C, Y, X, N):-count_and_rem_c((Y, _), B, B1, _),count_and_rem_c((Y, _), C, C1, _),get_first(B1, A1),get_first(C1, A2),kick_eval(A1, A2, X, [N, B1, C1]).
get_kicker(B, C, Y1, Y2, X, _):-count_and_rem_c((Y1,_), B, B1, _),count_and_rem_c((Y1,_), C, C1, _),get_kicker(B1, C1, Y2, X, 4).
kick_eval(A1, A2, 1, _):-A1 > A2.
kick_eval(A1, A2, 2, _):-A2 > A1.
kick_eval(A1, A2, 3, [4,_,_]):-A1 = A2.
kick_eval(A1, A2, X, [N,B,C]):-A1 = A2,rem_one((A1,_), B, B1),rem_one((A1,_), C, C1),get_first(B1, A11),get_first(C1, A22),N1 is N + 1,kick_eval(A11, A22, X, [N1,B1,C1]).
kick_eval(A1, A2, X, [Y, B, C, N]):-A1 = A2,rem_one((A1,Y), B, B1),rem_one((A1,Y), C, C1),N1 is N + 1,flush_decide(Y, B1, C1, X, N1).
ret_rand(Y1, Y2, X):-Y3 is Y2 - Y1,random(Y4, Y3),Y is Y4 + Y1,ret_rand(Y, X).
ret_rand(1, 'c').ret_rand(2, 'f').ret_rand(3, 'b').ret_rand(4, 'r').ret_rand(5, 'c').ret_rand(6, 'b').ret_rand(7, 'r').
90

run_rand(X, X, 0).run_rand(H, X, N) :-
random(Y1, 13),Y is Y1 + 1,random(Z1, 4),Z is Z1 + 1,B is N - 1,(member((Y,Z),X) -> run_rand(H, X, N);
run_rand(H, [(Y,Z)|X], B)).
eval_start(X, A) :- paired(X, A), !.
eval_start(X, A) :- suited(X, A1), sequenced(X, A1, A), A > 0, !.
eval_start(X, A) :-high(X, A, 8).
suited([(_,A),(_,A)], 1).suited(_, 0).
paired([(A,_), (A,_)], X):-((A > 9 | A = 1) -> X is 3 ; X is 2).
sequenced([(A,_), (B,_)], X, X1) :-(B is A + 1 |B is A - 1 |A = 1, B = 13 |B = 1, A = 13),greater(A, B, _, B1),(B1 > 9 -> X1 is X + 2 ; X1 is X + 1).
sequenced(_, A, A).
high([(A, _), (B, _)], 1, N):-(A = 1 | A > N),(B = 1 | B > N).
high(_,0, _).
eval_flop(_, _, 4, 4).eval_flop(_, X, _, E):-
sequen(X, 1, 2, 0, 1, A, 2),E1 is 0,(A > 9 -> A1 = A ; A1 is A - 1),(member((A1,_),X) -> E2 is E1 + 2 ; E2 = E1),A2 is A1 - 1,(member((A2,_),X) -> E is E2 + 2 ; E = E2).
eval_flop(B, X, _, E):-eval_flusher(X, E1, 1, A),member((_,A), B),(E1 = 2 -> B = [(_,A),(_,A)], E is E1 ; E is E1).
91

eval_flop(_, X, _, E):-multiple_kind(X, 0, 2, 2, Y1, 0, A1, 15),multiple_kind(X, 0, 2, 2, _, 0, A2, Y1),A1 > 0,A1 < 3,A2 > 0,A2 < 3,E is 3.
eval_flop(B, X, _, E):-eval_multiple(X, E1, A),(member((A,_),B) -> E = E1 ; high(B, E, 9)).
eval_flop(B, _, _, 1):-high(B, 1, 10).
eval_flop(_, _, _, 0).
eval_turn(_, _, 4, 4).eval_turn(_, X, _, E):-
sequen(X, 1, 2, 0, 1, A, 2),E1 is 0,A1 is A - 1,(member((A1,_),X) -> E2 is E1 + 2 ; E2 = E1),A2 is A1 - 1,(member((A2,_),X) -> E is E2 + 2 ; E = E2).
eval_turn(B, X, _, E):-eval_flusher(X, E1, 2, A),(E1 = 3 -> E = 2 ; E = 4),member((_,A), B).
eval_turn(B, X, _, E):-multiple_kind(X, 0, 2, 2, Y1, 0, A1, 15),multiple_kind(X, 0, 2, 2, Y2, 0, A2, Y1),A1 > 0,A1 < 4,A2 > 0,A2 < 4,(member((Y1,_),B) -> E1 is 2 ; E1 is 0),(member((Y2,_),B) -> E is E1 + 2; E is E1).
eval_turn(B, X, _, E):-eval_multiple(X, E1, A),(member((A,_),B) -> E = E1 ; high(B, E, 10)).
eval_turn(B, _, _, 1):-high(B, 1, 10).
eval_turn(_, _, _, 0).
eval_river(_, _, 4, 4).eval_river(_, X, _, 4):-
sequen(X, 1, 2, 0, 1, _, 4).eval_river(B, X, _, 4):-
eval_flusher(X, _, 3, A),member((_,A), B).
eval_river(B, X, _, 4):-multiple_kind(X, 0, 2, 2, Y1, 0, A1, 15),
92

multiple_kind(X, 0, 2, 2, Y2, 0, A2, Y1),A1 > 0,A1 < 4,A2 > 0,A2 < 4,(member((Y1,_),B) | member((Y2,_),B)).
eval_river(B, X, _, E):-eval_multiple(X, E1, A),(member((A,_),B) -> E = E1 ; high(B, E, 10)).
eval_river(B, _, _, 1):-high(B, 1, 10).
eval_river(_, _, _, 0).
eval_flusher([_,_], 0, _, 0).eval_flusher([(_,S)|T], E, N, S1):-
count_and_rem_s((_,S), T, T1, A),(A > N -> E = A, S1 = S ; eval_flusher(T1, E, N, S1)).
eval_multiple([(A,_),(A,_),(A,_),(A,_)|_], 4, A).eval_multiple([(A,_),(A,_),(A,_)|_], 4, A).eval_multiple([(A,_),(A,_)|_], E, A):-
(A > 9 -> E is 3 ; E is 2).eval_multiple([_|T], E, A):-
eval_multiple(T, E, A).
eval_start_good(B, X):-good_eval(B, [], [], [], X, 0).
eval_flop_good(_, _, (0, 0, 0, 0), []).eval_flop_good(B, F, X, _):-
good_eval(B, F, [], [], X, 0).eval_turn_good(_, _, _, (0, 0, 0, 0), [], _).eval_turn_good(B, F, T, X, _, Chan):-
good_eval(B, F, T, [], X, Chan).eval_river_good(_, _, _, [[]], (0, 0, 0, 0), _).eval_river_good(B, F, T, R, X, Chan):-
good_eval(B, F, T, R, X, Chan).
good_eval(B, F, T, R, X, N):-play_pseudo_game(B, F, T, R, W, L, D, 0),Win is ((W + (D / 2)) / (W + D + L)) * 100,Win1 is Win + N,assign_str(Win1, X), !.
play_pseudo_game(_, _, _, _, 0, 0, 0, 1000).play_pseudo_game(B, F, T, R, W, L, D, N):-
N1 is N + 1,append(B, F, T, R, X),run_rand([C1, C2|X], X, 2),get_pseudo_flop(F, [C1, C2|X], F1, X1), !,get_pseudo_turn(T, X1, T1, X2), !,get_pseudo_river(R, X2, R1), !,
93

final_pseudo_eval(B, [C1, C2], F1, T1, R1, Y), !,play_pseudo_game(B, F, T, R, W1, L1, D1, N1),adder(W1, L1, D1, Y, W, L, D).
get_pseudo_flop([], X, [A, B, C], [A, B, C|X]):-run_rand([A, B, C|X], X, 3).
get_pseudo_flop(F, X, F, X).
get_pseudo_turn([], X, [T], [T|X]):-run_rand([T|X], X, 1).
get_pseudo_turn(T, X, T, X).
get_pseudo_river([], X, [R]):-run_rand([R|X], X, 1).
get_pseudo_river(R, _, R).
final_pseudo_eval(B, C, F, T, R, X):-append(B, F, T, R, B1),append(C, F, T, R, C1),ace_it(B1, B2),ace_it(C1, C2),q_sort(B2, [], B3),q_sort(C2, [], C3),winner_eval(B3, C3, X, _), !.
adder(W1, L1, D1, 1, W, L1, D1):-W is W1 + 1.
adder(W1, L1, D1, 2, W1, L, D1):-L is L1 + 1.
adder(W1, L1, D1, 3, W1, L1, D):-D is D1 + 1.
append(B, [], [], [], B).append(B, [M, N, O], [], [], [M, N, O|B]).append(B, [M, N, O], [P], [], [M, N, O, P|B]).append(B, [M, N, O], [P], [Q], [M, N, O, P, Q|B]).
assign_str(Win, (C, B, R, Win)):-Win =< 50,C is (80 - (Win / 2)),B is ((Win / 2) + 10),R is 10.
assign_str(Win, (C, B, R, Win)):-Win =< 75,C is (90 - Win),B is (Win - 10),R is 20.
assign_str(Win, (C, B, R, Win)):-Win > 75,C is 15,B is 105 - Win,R is Win - 20.
94

get_first([(H, _)|_], H).
get_last([(H, _)], H).get_last([_|T], X):-
get_last(T, X).
get_max([(H,_)], H).get_max([(H, _)|T], X):-
get_max(T, Z),(H > Z -> X is H ; X is Z).
get_max_s([(H,S)|_], S, H).get_max_s([_|T], S, X):-
get_max_s(T, S, X). count_and_rem_c(_, [], [], 0).count_and_rem_c((X, _), [(X, _)|T], T1, A):-
count_and_rem_c((X, _), T, T1, A1),A is A1 + 1, !.
count_and_rem_c(X, [H|T], [H|T1], A):-count_and_rem_c(X, T, T1, A), !.
count_and_rem_s(_, [], [], 0).count_and_rem_s(X, [(1, _)|T], T1, A):-
count_and_rem_s(X, T, T1, A).count_and_rem_s((_, X), [(_, X)|T], T1, A):-
count_and_rem_s((_, X), T, T1, A1),A is A1 + 1, !.
count_and_rem_s(X, [H|T], [H|T1], A):-count_and_rem_s(X, T, T1, A), !.
rem_one(H, [H|T], T).rem_one(H, [H1|T], [H1|X]) :-
rem_one(H, T, X).
ace_it([],[]).ace_it([(1,S)|T], [(1,S),(14,S)|T1]):-
ace_it(T, T1).ace_it([H|T], [H|T1]):-
ace_it(T, T1).
game_add(1, (A,B,C,D,N,E,F), (A,B,C,D,N1,E,F)):-N1 is N + 1.
game_add(2, (A,B,C,D,E,N,F), (A,B,C,D,E,N1,F)):-N1 is N + 1.
game_add(3, (A,B,C,D,E,F,N), (A,B,C,D,E,F,N1)):-N1 is N + 1.
q_sort([],Acc,Acc).q_sort([H|T],Acc,Sorted):-
pivoting(H,T,L1,L2),q_sort(L1,Acc,Sorted1),q_sort(L2,[H|Sorted1],Sorted).
pivoting(_,[],[],[]).
95

pivoting((H,S),[(X,S1)|T],[(X,S1)|L],G):-X=<H,pivoting((H,S),T,L,G).pivoting((H,S),[(X,S1)|T],L,[(X,S1)|G]):-X>H,pivoting((H,S),T,L,G).
greater(A, B, A, B):-A > B.
greater(A, B, B, A):-A < B.
member_rem(X, [X|T], T).member_rem(X, [H|T], [H|T1]) :-
member_rem(X, T, T1).
member(X, [X|_]).member(X, [_|T]) :-
member(X, T).
append([], X, X).append([H|T], X, [H|Y]):-
append(T, X, Y).
96