interactive discovery in large data sets kiri l. wagstaff jet propulsion laboratory...
TRANSCRIPT

Interactive Discovery in Large Data SetsKiri L. WagstaffJet Propulsion [email protected]
October 11, 2012
Joint work with David R. Thompson (JPL), Nina Lanza (Los Alamos National Lab),Thomas G. Dietterich (Oregon State University), and Diana Blaney (JPL)
Guest lecture for CS 886, Applied Machine Learning
This work was carried out in part at the Jet Propulsion Laboratory, California Institute of Technology, © 2012. Government sponsorship acknowledged. It was also supported by the Defense Advanced
Research Projects Agency (DARPA) under Contract W911NF-11-C-0088. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author’s and do not
necessarily reflect the views of the DARPA, the Army Research Office, or the US government.

Interactive Discovery in Large Data Sets - CS 886
2
Interactive Discovery in Large Data Sets
Discovery◦What is interesting? Novel?◦Big NASA data sets
LSST: 28 TB/day SKA: 86 TB/day
Explanations◦AI: actions + reasons for them
Why “interactive”?◦No general definition of “interesting”
Large Synoptic Survey Telescope
(LSST)
Square Kilometre Array (SKA)

Interactive Discovery in Large Data Sets - CS 886
3
Spirit’s McMurdo Panorama, 1000 sols, October 2006 (NASA/JPL/Cornell)
22,348 x 5771 pixels = 386 MBWhat’s most interesting here?
Example: Mars Rover Panorama

Interactive Discovery in Large Data Sets - CS 886
4
Zooming in
Portion of Spirit’s McMurdo Panorama, 1000 sols, October 2006 (NASA/JPL/Cornell)

Interactive Discovery in Large Data Sets - CS 886
Zooming in
Portion of Spirit’s McMurdo Panorama, 1000 sols, October 2006 (NASA/JPL/Cornell)
Possible meteorit
e
Impact ejecta
Sand ripples
Exposed layers
Bright rocks
Dark rocks
5

Interactive Discovery in Large Data Sets - CS 886
6
Discovery
Exploration of large data sets
Desiderata◦Diverse sampling of data set
System
learns model
System
chooses
item
Unsupervised learning

What to select?Items that differ from those
previously seenPrincipal Components Model
◦Approximate model of data set variation
◦Keep only the top K vectors from U
Known items
[M. Scholz, 2006] Interactive Discovery in Large Data Sets - CS 886 7

What to select?Items that differ from those
previously seenPrincipal Components Model
◦Approximate model of data set variation
◦Keep only the top K vectors from U◦Select items in D that are
difficult to represent with model UReconstruction error
Reconstruction of x
Mean of X
For x in D Interactive Discovery in Large Data Sets - CS 886 8
Known items

Updating model U with new xRedo PCA from scratch:
expensiveIncrementally update U: fast!
◦U depends only on previous U and new x
◦[Ross et al., 2008]
Iterations
Data
Principal Components
X1 X2 X3 X4 X5
U1 U2 U3 U4 U5
Interactive Discovery in Large Data Sets - CS 886 9

DEMUD: Discovery through Eigenbasis Modeling of Uninteresting Data
Select most interesting x
in D
Update model U to include x
Compute score for all x in D using
U
Initial ranking of D by PCA-1
reconstruction error
Interactive Discovery in Large Data Sets - CS 886 10
Treat x as “no longer
interesting”

Interactive Discovery in Large Data Sets - CS 886
11
McMurdo selections1200 features: 100x100 RGB,
downsamp. 5xK=20
Selection #1

Interactive Discovery in Large Data Sets - CS 886
12
McMurdo selections1200 features: 100x100 RGB,
downsamp. 5xK=20
Selection #2

Interactive Discovery in Large Data Sets - CS 886
13
McMurdo selections1200 features: 100x100 RGB,
downsamp. 5xK=20
Selection #10

Interactive Discovery in Large Data Sets - CS 886
14
ExplanationsReconstruction residuals
Original Features Residuals
1
2
3
Dark: lower intensity than expectedBright: higher intensity than expected
Dark area at bottom has small residual learning happened!

Interactive Discovery in Large Data Sets - CS 886
15
Interactive Discovery
Guided exploration of large data sets
Desiderata◦Quickly find items of interest, even if
rare◦Don’t miss anything!
User reviews item
System
chooses
item
Semi-supervised learning

Interactive DEMUD
Select most interesting x in
D
Query user on x• Interesting or
uninteresting?
If uninteresting, update model
U
Compute score for all x in D using
U
Initial ranking of D by PCA-1
reconstruction error
Interactive Discovery in Large Data Sets - CS 886 16

Alternatives: 1SVM-intTrain a one-class SVM to model
the interesting classSelect most interesting item
Smooth
Varied
Interactive Discovery in Large Data Sets - CS 886 17Dark
Light

Alternatives: 1SVM-unintTrain a one-class SVM to model
the uninteresting classSelect least uninteresting item
Smooth
Varied
Interactive Discovery in Large Data Sets - CS 886 18Dark
Light

Alternatives: 2SVM-bothTrain a two-class SVM to model
both classesSelect most interesting item
Smooth
Varied
Interactive Discovery in Large Data Sets - CS 886 19Dark
Light

Alternatives: 2SVM-activeTrain a two-class SVM to model
both classesSelect most ambiguous item
Smooth
Varied
Interactive Discovery in Large Data Sets - CS 886 20Dark
Light

Premature Specialization
Interactive Discovery in Large Data Sets - CS 886 21
(A possible danger of training on positives in a
discovery setting)

Alternatives: Static BaselineSelect by PCA-K ordering
◦Same initial model as DEMUDNo feedback
Interactive Discovery in Large Data Sets - CS 886 22

Faces Data Set40 people, 10 poses eachHigh dimensionality: 10,304Goal: Discover 3 women
◦Data set is mostly men◦Challenge: disjunction
Data from AT&T Laboratories CambridgeInteractive Discovery in Large Data Sets -
CS 886 23

Faces: Three Women Discovery
Premature specialization
Delayed start
Perfect
Random
Interactive Discovery in Large Data Sets - CS 886 24

Exploration Rate
Algorithm Queries
DEMUD 43
1SVM-unint 50
1SVM-int 164
2SVM-both 124
2SVM-active 124
Static baseline 223
Number of queries to find one image of each woman
Interactive Discovery in Large Data Sets - CS 886 25

Rare Class Discovery
6 classes, d=7, n=336, K=4 6 classes, d=9, n=214, K=4
DEMUDDEMUD
Interactive Discovery in Large Data Sets - CS 886 26
Figures from [He and Carbonell, 09]

Random subset of CRISM data
CRISM: Magnesite Discovery Magnesite (MgCO3): possible groundwater deposit CRISM data: 0.364 to 3.92 μm, 197 bands Only 17 of 15,400 items match
Data from Mars Reconnaissance Orbiter/CRISM
MgCO3
Interactive Discovery in Large Data Sets - CS 886 27
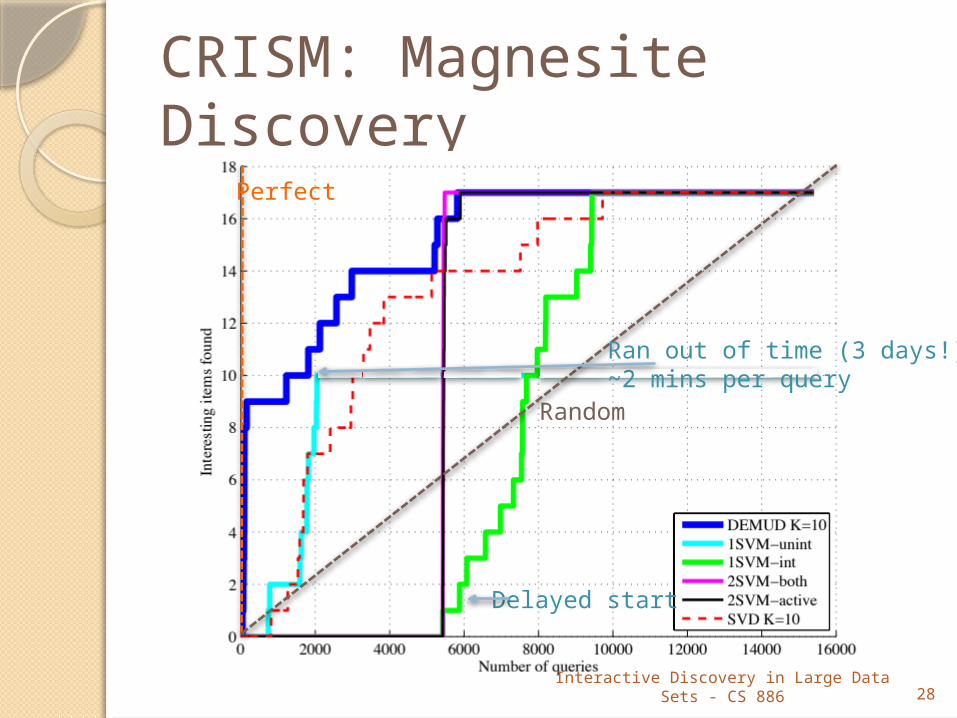
CRISM: Magnesite Discovery
Delayed start
Perfect
Random
Ran out of time (3 days!)~2 mins per query
Interactive Discovery in Large Data Sets - CS 886 28

ChemCam: CarbonatesChemCam: LIBS instrument on
MSLData set: 60 lab samples
+ 40 carbonates◦6143 features (bands)◦K (8) chosen to
capture 90% variance
Interactive Discovery in Large Data Sets - CS 886 29
Regular PCA
DEMUD
Colored items are carbonates; white are non-carbonates
1SVM-int
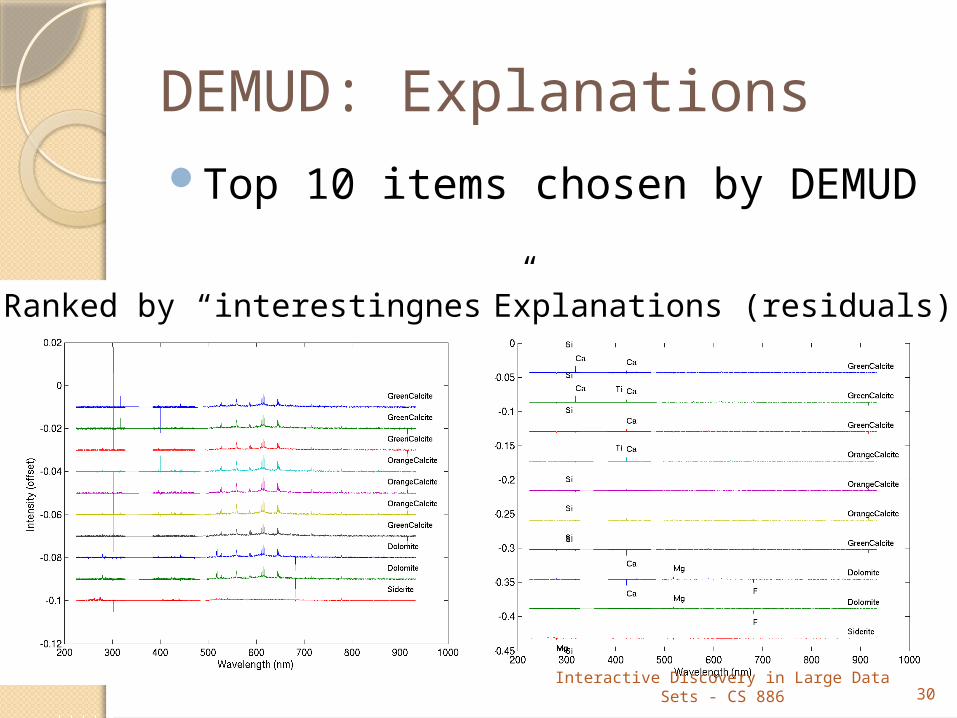
DEMUD: ExplanationsTop 10 items chosen by DEMUD
Ranked by “interestingness” Explanations (residuals)
Interactive Discovery in Large Data Sets - CS 886 30

Interactive Discovery in Large Data Sets - CS 886
31
Other ApplicationsText
◦Long Wavelength Array system log files
◦Detect anomalous system behavior
Onboard prioritization◦Imaging spectrometers
Hyperion on EO-1: 256x6000x242
◦Assign priorities for input to onboard compression: ROI-ICER

Interactive Discovery in Large Data Sets - CS 886
32
SummaryDiscovery
◦PCA-based model + reconstruction error
Explanations◦Why was it chosen?
Interactive discovery◦Model the uninteresting to avoid it
Next challenge: evolving class of interest Thank you!
Contact: [email protected]