improving iris recognition performance using … improving iris recognition performance using...
TRANSCRIPT

1
Improving Iris Recognition Performance using
Segmentation, Quality Enhancement, Match Score
Fusion and IndexingMayank Vatsa, Richa Singh, and Afzel Noore
Abstract—This paper proposes algorithms for iris segmenta-tion, quality enhancement, match score fusion, and indexing to
improve both the accuracy and speed of iris recognition. A curve
evolution approach is proposed to effectively segment a non-idealiris image using the modified Mumford-Shah functional. Different
enhancement algorithms are concurrently applied on the seg-mented iris image to produce multiple enhanced versions of iris
image. A SVM based learning algorithm selects locally enhancedregions from each globally enhanced image and combines these
good quality regions to create a single high quality iris image.Two distinct features are extracted from the high quality iris
image. The global textural feature is extracted using 1D log polarGabor transform and the local topological feature is extracted
using Euler numbers. An intelligent fusion algorithm combinesthe textural and topological matching scores to further improve
the iris recognition performance and reduce the false rejectionrate, while an indexing algorithm enables fast and accurate iris
identification. The verification and identification performance ofthe proposed algorithms are validated and compared with other
algorithms using CASIA Version 3, ICE 2005, and UBIRIS irisdatabases.
Index Terms—Iris Recognition, Mumford-Shah Curve Evolu-
tion, Quality Enhancement, Information Fusion, Support VectorMachine, Iris Indexing.
I. INTRODUCTION
CURRENT iris recognition systems claim to perform
with very high accuracy. However, these iris images are
captured in a controlled environment to ensure high quality.
Daugman proposed an iris recognition system representing iris
as a mathematical function [1]-[4]. Wildes [5], Boles [6], and
several other researchers proposed different recognition algo-
rithms [7]-[32]. With a sophisticated iris capture setup, users
are required to look into the camera from a fixed distance and
the image is captured. Iris images captured in an uncontrolled
environment produce non-ideal iris images with varying image
quality. If the eyes are not opened properly, certain regions of
the iris cannot be captured due to occlusion which further
affects the process of segmentation and consequently the
recognition performance. Images may also suffer from motion
blur, camera diffusion, presence of eyelids and eyelashes, head
rotation, gaze direction, camera angle, reflections, contrast,
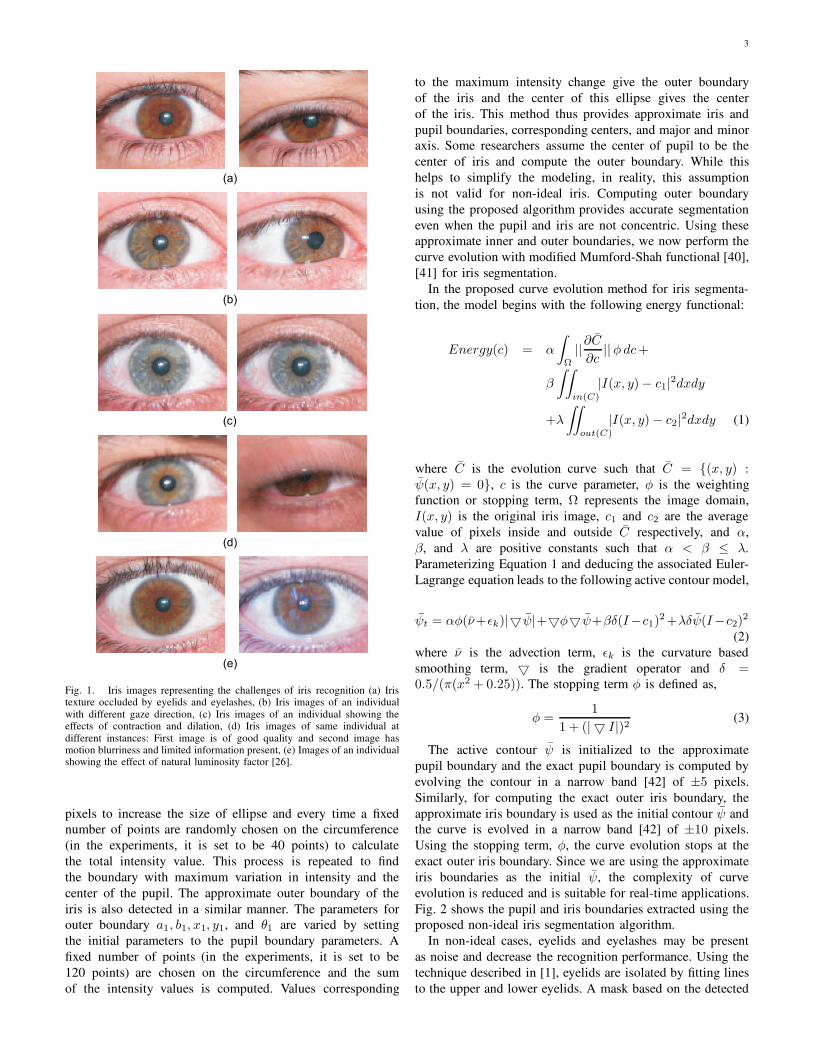
luminosity, and problems due to contraction and dilation. Fig.
1 from the UBIRIS database [26], [27] shows images with
some of the above mentioned problems. These artifacts in iris
M. Vatsa, R. Singh, A. Noore are with Lane Department of ComputerScience and Electrical Engineering, West Virginia University, Morgantown,
WV, USA mayankv, richas, [email protected].
images increase the false rejection rate (FRR) thus decreasing
the performance of recognition system. Experimental results
from the Iris Challenge Evaluation (ICE) 2005 and ICE 2006
[30], [31] also show that most of the recognition algorithms
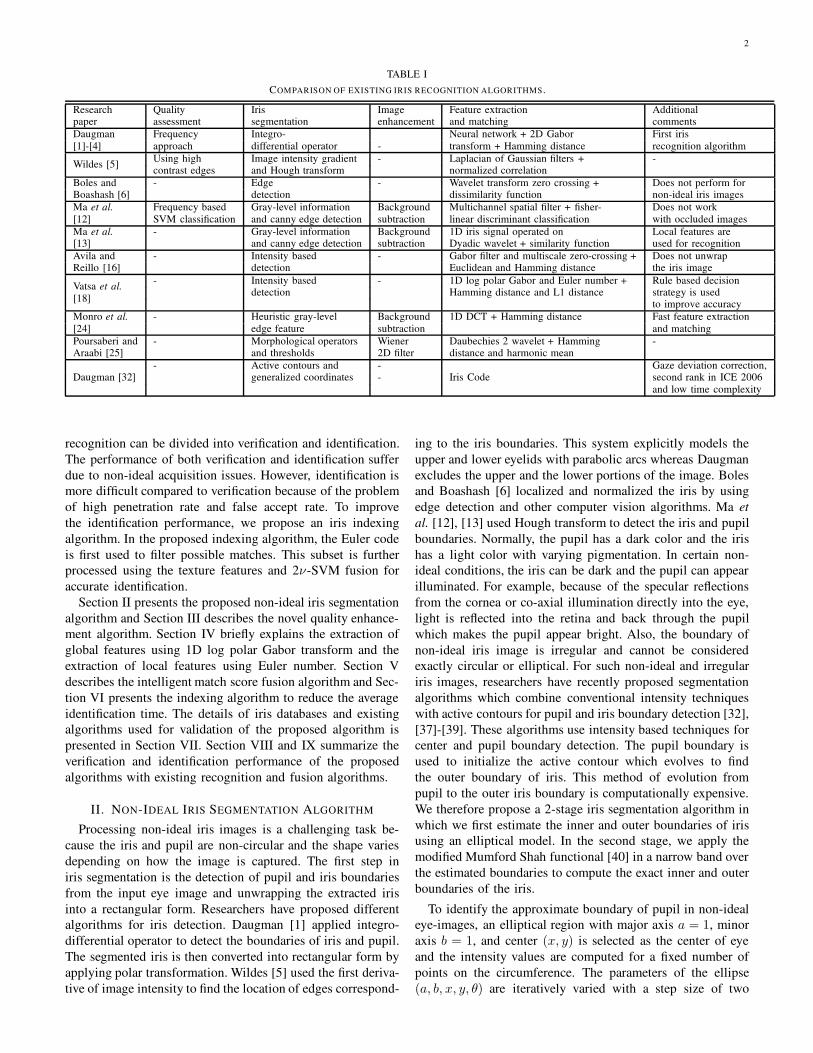
have high FRR. Table I compares existing iris recognition
algorithms with respect to image quality, segmentation, en-
hancement, feature extraction, and matching techniques. A
detailed literature survey of iris recognition algorithms can
be found in [28].
This research effort focuses on reducing the false rejection
by accurate iris detection, quality enhancement, fusion of
textural and topological iris features, and iris indexing. For
iris detection, some researchers assume that iris is circular or
elliptical. In non-ideal images such as off-angle iris images,
motion blur and noisy images, this assumption is not valid
because the iris appears to be non-circular and non-elliptical.
In this research, we propose a two-level hierarchical iris
segmentation algorithm to accurately and efficiently detect iris
boundaries from non-ideal iris images. The first level of iris
segmentation algorithm uses intensity thresholding to detect
approximate elliptical boundary and the second level applies
Mumford Shah functional to obtain the accurate iris boundary.
We next describe a novel Support Vector Machine (SVM)
based iris quality enhancement algorithm [29]. The SVM
quality enhancement algorithm identifies good quality regions
from different globally enhanced iris images and combines
them to generate a single high quality feature-rich iris image.
Textural and topological features [17], [18] are then extracted
from the quality enhanced image for matching. Most of the iris
recognition algorithms extract features that provide only global
information or local information of iris patterns. In this paper,
the feature extraction algorithm extracts both global texture
features and local topological features. The texture features
are extracted using 1D log polar Gabor transform which
is invariant to rotation and translation, and the topological
features are extracted using Euler number which is invariant
under translation, rotation, scaling, and polar transformation.
The state-of-art iris recognition algorithms have a very
low false acceptance rate but reducing the number of false
rejection is still a major challenge. In multibiometric literature
[33], [34], [35], [36], it has been suggested that fusion of
information extracted from different classifiers provides better
performance compared to single classifiers. In this paper,
we propose using 2ν-SVM to develop a fusion algorithm
that combines the match scores obtained by matching texture
and topological features for improved performance. Further,
2
TABLE I
COMPARISON OF EXISTING IRIS RECOGNITION ALGORITHMS.
Research Quality Iris Image Feature extraction Additionalpaper assessment segmentation enhancement and matching comments
Daugman
[1]-[4]
Frequency Integro- Neural network + 2D Gabor First iris
approach differential operator - transform + Hamming distance recognition algorithm
Wildes [5]Using high Image intensity gradient - Laplacian of Gaussian filters + -contrast edges and Hough transform normalized correlation
Boles and - Edge - Wavelet transform zero crossing + Does not perform forBoashash [6] detection dissimilarity function non-ideal iris images
Ma et al.
[12]
Frequency based Gray-level information Background Multichannel spatial filter + fisher- Does not work
SVM classification and canny edge detection subtraction linear discriminant classification with occluded images
Ma et al.
[13]- Gray-level information Background 1D iris signal operated on Local features are
and canny edge detection subtraction Dyadic wavelet + similarity function used for recognition
Avila andReillo [16]
- Intensity based - Gabor filter and multiscale zero-crossing + Does not unwrapdetection Euclidean and Hamming distance the iris image
Vatsa et al.
[18]
- Intensity based - 1D log polar Gabor and Euler number + Rule based decisiondetection Hamming distance and L1 distance strategy is used
to improve accuracy
Monro et al.
[24]
- Heuristic gray-level Background 1D DCT + Hamming distance Fast feature extraction
edge feature subtraction and matching
Poursaberi and - Morphological operators Wiener Daubechies 2 wavelet + Hamming -Araabi [25] and thresholds 2D filter distance and harmonic mean
- Active contours and - Gaze deviation correction,Daugman [32] generalized coordinates - Iris Code second rank in ICE 2006
and low time complexity
recognition can be divided into verification and identification.
The performance of both verification and identification suffer
due to non-ideal acquisition issues. However, identification is
more difficult compared to verification because of the problem
of high penetration rate and false accept rate. To improve
the identification performance, we propose an iris indexing
algorithm. In the proposed indexing algorithm, the Euler code
is first used to filter possible matches. This subset is further
processed using the texture features and 2ν-SVM fusion for
accurate identification.
Section II presents the proposed non-ideal iris segmentation
algorithm and Section III describes the novel quality enhance-
ment algorithm. Section IV briefly explains the extraction of
global features using 1D log polar Gabor transform and the
extraction of local features using Euler number. Section V
describes the intelligent match score fusion algorithm and Sec-
tion VI presents the indexing algorithm to reduce the average
identification time. The details of iris databases and existing
algorithms used for validation of the proposed algorithm is
presented in Section VII. Section VIII and IX summarize the
verification and identification performance of the proposed
algorithms with existing recognition and fusion algorithms.
II. NON-IDEAL IRIS SEGMENTATION ALGORITHM
Processing non-ideal iris images is a challenging task be-
cause the iris and pupil are non-circular and the shape varies
depending on how the image is captured. The first step in
iris segmentation is the detection of pupil and iris boundaries
from the input eye image and unwrapping the extracted iris
into a rectangular form. Researchers have proposed different
algorithms for iris detection. Daugman [1] applied integro-
differential operator to detect the boundaries of iris and pupil.
The segmented iris is then converted into rectangular form by
applying polar transformation. Wildes [5] used the first deriva-
tive of image intensity to find the location of edges correspond-
ing to the iris boundaries. This system explicitly models the
upper and lower eyelids with parabolic arcs whereas Daugman
excludes the upper and the lower portions of the image. Boles
and Boashash [6] localized and normalized the iris by using
edge detection and other computer vision algorithms. Ma et
al. [12], [13] used Hough transform to detect the iris and pupil
boundaries. Normally, the pupil has a dark color and the iris
has a light color with varying pigmentation. In certain non-
ideal conditions, the iris can be dark and the pupil can appear
illuminated. For example, because of the specular reflections
from the cornea or co-axial illumination directly into the eye,
light is reflected into the retina and back through the pupil
which makes the pupil appear bright. Also, the boundary of
non-ideal iris image is irregular and cannot be considered
exactly circular or elliptical. For such non-ideal and irregular
iris images, researchers have recently proposed segmentation
algorithms which combine conventional intensity techniques
with active contours for pupil and iris boundary detection [32],
[37]-[39]. These algorithms use intensity based techniques for
center and pupil boundary detection. The pupil boundary is
used to initialize the active contour which evolves to find
the outer boundary of iris. This method of evolution from
pupil to the outer iris boundary is computationally expensive.
We therefore propose a 2-stage iris segmentation algorithm in
which we first estimate the inner and outer boundaries of iris
using an elliptical model. In the second stage, we apply the
modified Mumford Shah functional [40] in a narrow band over
the estimated boundaries to compute the exact inner and outer
boundaries of the iris.
To identify the approximate boundary of pupil in non-ideal
eye-images, an elliptical region with major axis a = 1, minor
axis b = 1, and center (x, y) is selected as the center of eye
and the intensity values are computed for a fixed number of
points on the circumference. The parameters of the ellipse
(a, b, x, y, θ) are iteratively varied with a step size of two
3
(a)
(b)
(c)
(d)
(e)
Fig. 1. Iris images representing the challenges of iris recognition (a) Iristexture occluded by eyelids and eyelashes, (b) Iris images of an individual
with different gaze direction, (c) Iris images of an individual showing theeffects of contraction and dilation, (d) Iris images of same individual at
different instances: First image is of good quality and second image hasmotion blurriness and limited information present, (e) Images of an individualshowing the effect of natural luminosity factor [26].
pixels to increase the size of ellipse and every time a fixed
number of points are randomly chosen on the circumference
(in the experiments, it is set to be 40 points) to calculate
the total intensity value. This process is repeated to find
the boundary with maximum variation in intensity and the
center of the pupil. The approximate outer boundary of the
iris is also detected in a similar manner. The parameters for
outer boundary a1, b1, x1, y1, and θ1 are varied by setting
the initial parameters to the pupil boundary parameters. A
fixed number of points (in the experiments, it is set to be
120 points) are chosen on the circumference and the sum
of the intensity values is computed. Values corresponding
to the maximum intensity change give the outer boundary
of the iris and the center of this ellipse gives the center
of the iris. This method thus provides approximate iris and
pupil boundaries, corresponding centers, and major and minor
axis. Some researchers assume the center of pupil to be the
center of iris and compute the outer boundary. While this
helps to simplify the modeling, in reality, this assumption
is not valid for non-ideal iris. Computing outer boundary
using the proposed algorithm provides accurate segmentation
even when the pupil and iris are not concentric. Using these
approximate inner and outer boundaries, we now perform the
curve evolution with modified Mumford-Shah functional [40],
[41] for iris segmentation.
In the proposed curve evolution method for iris segmenta-
tion, the model begins with the following energy functional:
Energy(c) = α
∫
Ω
||∂C
∂c|| φ dc+
β
∫∫
in(C)
|I(x, y) − c1|2dxdy
+λ
∫∫
out(C)
|I(x, y) − c2|2dxdy (1)
where C is the evolution curve such that C = (x, y) :ψ(x, y) = 0, c is the curve parameter, φ is the weighting
function or stopping term, Ω represents the image domain,
I(x, y) is the original iris image, c1 and c2 are the average
value of pixels inside and outside C respectively, and α,
β, and λ are positive constants such that α < β ≤ λ.
Parameterizing Equation 1 and deducing the associated Euler-
Lagrange equation leads to the following active contour model,
ψt = αφ(ν+εk)|5 ψ|+5φ5 ψ+βδ(I−c1)2 +λδψ(I−c2)
2
(2)
where ν is the advection term, εk is the curvature based
smoothing term, 5 is the gradient operator and δ =0.5/(π(x2 + 0.25)). The stopping term φ is defined as,
φ =1
1 + (| 5 I|)2(3)
The active contour ψ is initialized to the approximate
pupil boundary and the exact pupil boundary is computed by
evolving the contour in a narrow band [42] of ±5 pixels.
Similarly, for computing the exact outer iris boundary, the
approximate iris boundary is used as the initial contour ψ and
the curve is evolved in a narrow band [42] of ±10 pixels.
Using the stopping term, φ, the curve evolution stops at the
exact outer iris boundary. Since we are using the approximate
iris boundaries as the initial ψ, the complexity of curve
evolution is reduced and is suitable for real-time applications.
Fig. 2 shows the pupil and iris boundaries extracted using the
proposed non-ideal iris segmentation algorithm.
In non-ideal cases, eyelids and eyelashes may be present
as noise and decrease the recognition performance. Using the
technique described in [1], eyelids are isolated by fitting lines
to the upper and lower eyelids. A mask based on the detected

4
Fig. 2. Iris detection using the proposed non-ideal iris segmentation algorithm.
eyelids and eyelashes is then used to extract the iris without
noise. Image processing of iris is computationally intensive
as the area of interest is of donut shape and grabbing the
pixels in this region requires repeated rectangular to polar
conversion. To simplify this, the detected iris is unwrapped
into a rectangular region by converting into polar coordinates.
Let I(x, y) be the segmented iris image and I(r, θ) be the
polar representation obtained using Equations 4 and 5.
r =√
(x− xc)2 + (y − yc)2 0 ≤ r ≤ rmax (4)
θ = tan−1
(
y − yc
x− xc
)
(5)
r and θ are defined with respect to the center coordinates,
(xc, yc). The center coordinates obtained during approximate
elliptical iris boundary fitting are used as the center point for
cartesian to polar transformation. The transformed polar iris
image is further used for enhancement, feature extraction, and
matching.
III. GENERATION OF SINGLE HIGH QUALITY IRIS IMAGE
USING ν -SUPPORT VECTOR MACHINE
For iris image enhancement, researchers consecutively apply
selected enhancement algorithms such as deblurring, denois-
ing, entropy correction, and background subtraction, and use
the final enhanced image for further processing. Huang et
al. [43] used super-resolution and Markov network for iris
image quality enhancement but their method does not perform
well with unregistered iris images. Ma et al. [12] proposed
background subtraction based iris enhancement that filters the
high frequency noise. Poursaberi and Araabi [25] proposed the
use of low pass Wiener 2D filter for iris image enhancement.
However, these filtering techniques are not effective in mit-
igating the effects of blur, out of focus, and entropy based
irregularities. Another challenge with existing enhancement
techniques is that they enhance the low quality regions present
in the image but are likely to deteriorate the good quality
regions and alter the features of the iris image. A non-ideal
iris image containing multiple irregularities may require the
application of specific algorithms to local regions that need
enhancement. However, identifying and isolating these local
regions in an iris image can be tedious, time consuming, and
not pragmatic. In this paper, we address the problem by con-
currently applying a set of selected enhancement algorithms
globally to the original iris image [29]. Thus each resulting
image contains enhanced local regions. These enhanced local
regions are identified from each of the transformed images
using support vector machine [44] based learning algorithm
and then synergistically combined to generate a single high
quality iris image.
Let I be the original iris image. For every iris image in the
training database, a set of transformed images is generated by
applying standard enhancement algorithms for noise removal,
defocus, motion blur removal, histogram equalization, entropy
equalization, homomorphic filtering, and background subtrac-
tion. The set of enhancement functions is expressed as,
I1 = fnoise(I)
I2 = fblur(I)
I3 = ffocus(I)
I4 = fhistogram(I) (6)
I5 = fentropy(I)
I6 = ffilter(I)
I7 = fbackground(I)
where fnoise is the algorithm for noise removal, fblur is
the algorithm for blur removal, ffocus is the algorithm for
adjusting the focus of the image, fhistogram is the histogram
equalization function, fentropy is the entropy filter, ffilter
is the homomorphic filter for contrast enhancement, and
fbackground is the background subtraction process. I1, I2,
I3, I4, I5, I6, and I7 are the resulting globally enhanced
images obtained when the above enhancement operations are
applied to the original iris image I. Applying several global
enhancement algorithms does not uniformly enhance all the
regions of the iris image. A learning algorithm is proposed
to train and classify the pixel quality from corresponding
locations of the globally enhanced iris images. This knowledge
is used by the algorithm to identify the good quality regions
from each of the transformed and original iris images, and
combined to form a single high quality iris image. The learning
algorithm uses ν-SVM [45] which is expressed as,

5
f(x) = sgn
(
m∑
i=1
αiyik(x, xi) + b
)
m∑
i=1
αiyi = 0 (7)
m∑
i=1
αi ≥ ν
where ν ε [0, 1], xi is the input to ν-SVM, yi is the
corresponding label, m is the number of tuples, αi is the dual
variable, and k is the RBF kernel. Further, a fast implementa-
tion of ν-SVM [46] is used to decrease the time complexity.
Training involves classifying the local regions of the input
and global enhanced iris image as good or bad. Any quality
assessment algorithm can be used for this task. However, in
this research we have used the redundant discrete wavelet
transformation based quality assessment algorithm described
in [47]. To minimize the possibility of errors due to the quality
assessment algorithm, we also verify the labels manually and
correct them in case of errors. The labeled training data is then
used to train the ν-SVM. The training algorithm is described
as follows:
• The training iris images are decomposed to l levels using
Discrete Wavelet Transform. The 3l detail subbands of
each image contain the edge features and thus these bands
are used for training.
• The subbands are divided into windows of size 3×3 and
the activity level of each window is computed.
• The ν-SVM is trained using labeled iris images to deter-
mine the quality of every wavelet coefficient. The activity
levels computed in the previous step are used as input to
the ν-SVM.
• The output of training algorithm is ν-SVM with a separat-
ing hyperplane. The trained ν-SVM labels the coefficient
G or 1 if it is good and B or 0 if the coefficient is bad.
Next the trained ν-SVM is used to classify the pixels from
input image and to generate a new feature-rich high quality iris
image. The classification algorithm is described as follows:
• The original iris image and the corresponding globally
enhanced iris images generated using Equation 6 are
decomposed to l DWT levels.
• The ν-SVM classifier is then used to classify the co-
efficients of the input bands as good or bad. A decision
matrix, Decision, is generated to store the quality of each
coefficient in terms of G and B. At any position (i, j), if
the SVM output O(i, j) is positive then that coefficient
is labeled as G, otherwise it is labeled as B.
Decision(i, j) =
G if O(i, j) ≥ 0B if O(i, j) < 0
(8)
• The above operation is performed on all eight images
including the original iris image and a decision matrix
corresponding to every image is generated.
• For each of the eight decision matrices, the average
of all coefficients with label G is computed and the
coefficients having label B are discarded. In this man-
ner, one fused approximation band and 3l fused detail
subbands are generated. Individual processing of every
coefficient ensures that the irregularities present locally
in the image are removed. Further, the selection of good
quality coefficients and removal of all bad coefficients
addresses multiple irregularities present in one region.
• Inverse DWT is applied on the fused approximation and
detail subbands to generate a single feature-rich high
quality iris image.
In this manner, the quality enhancement algorithm enhances
the quality of the input iris image and a feature-rich image is
obtained for feature extraction and matching. Fig. 3 shows an
example of the original iris image, different globally enhanced
images, and the combined image generated using the proposed
iris image quality enhancement algorithm.
IV. IRIS TEXTURE AND TOPOLOGICAL FEATURE
EXTRACTION AND MATCHING ALGORITHMS
Researchers have proposed several feature extraction al-
gorithms to extract unique and invariant features from iris
image. These algorithms use either texture or appearance
based features. The first algorithm was proposed by Daugman
[1] which used 2D Gabor for feature extraction. Wildes [5]
applied isotropic band-pass decomposition derived from the
application of Laplacian of Gaussian filters to the iris image.
It was followed by several different research papers such as,
Ma et al. [12], [13] in which multichannel even-symmetric
Gabor wavelet and the multichannel spatial filters were used to
extract textural information from iris patterns. The usefulness
of the iris features depends on the properties of basis function
and the feature encoding process.
In this paper, the iris recognition algorithm uses both global
and local properties of an iris image. 1D log polar Gabor
transform [48] based texture feature [17], [18] provides the
global properties which are invariant to scaling, shift, rotation,
illumination, and contrast. Topological features [17], [18]
extracted using Euler number [49] provide local information
of iris patterns and are invariant to rotation, translation, and
scaling of the image. The following two subsections briefly
describe the textural and topological feature extraction algo-
rithm.
1) Texture Feature Extraction using 1D Log Polar Ga-
bor Wavelet: The texture feature extraction algorithm [17],
[18] uses 1D log polar Gabor transform [48]. Like Gabor
transform [50], log polar Gabor transform is also based on
polar coordinates but unlike the frequency dependence on a
linear graduation, the dependency is realized by a logarithmic
frequency scale [50], [51]. Therefore, the functional form of
1D log polar Gabor transform is given by:
Gr0θ0(θ) = exp
[
−2π2σ2
[
ln( r−r0
f )2
τ2 +2ln(f0sin(θ−θ0))2
]]
(9)
where (r, θ) are the polar coordinates, r0 and θ0 are the initial
values, f is the center frequency of the filter and f0 is the
parameter that controls the bandwidth of the filter. σ and τare defined as follows:

6
Fig. 3. Original iris image, seven globally enhanced images and the SVM enhanced iris image.
σ =1
πln(r0)sin(π/θ0)
√
ln2
2(10)
τ =2ln(r0)sin(π/θ0)
ln2
√
ln2
2(11)
Gabor transform is symmetric with respect to the principal
axis. During encoding, Gabor function over-represents the
low frequency components and under-represents the high
frequency components [48], [50], [51]. In contrast, log polar
Gabor transform shows maximum translation from center of
gravity in the direction of lower frequency and flattening of the
high frequency part. The most important feature of this filter
is invariance to rotation and scaling. Also, log polar Gabor
functions have extended tails and encode natural images more
efficiently than Gabor functions.
To generate an iris template from 1D log polar Gabor
transform, the 2D unwrapped iris pattern is decomposed into a
number of 1D signals where each row corresponds to a circular
ring on the iris region. For encoding, angular direction is used
rather than radial direction because maximum independence
occurs along this direction. 1D signals are convolved with 1D
log polar Gabor transform in frequency domain. The values of
the convolved iris image are complex in nature. Using these
real and imaginary values, the phase information is extracted
and encoded in a binary pattern. If the convolved iris image
is Ig(r, θ), then the phase feature P (r, θ) is computed using
Equation 12.
P (r, θ) = tan−1
(
Im Ig(r, θ)
Re Ig(r, θ)
)
(12)
Ip(r, θ) =
[1, 1] if 00 < P (r, θ) ≤ 900
[0, 1] if 900 < P (r, θ) ≤ 1800
[0, 0] if 1800 < P (r, θ) ≤ 2700
[1, 0] if 2700 < P (r, θ) ≤ 3600
(13)
Phase features are quantized using the phase quantization
process represented in Equation 13 where Ip(r, θ) is the
resulting binary iris template of 4096 bits. Fig. 4 shows the
iris template generated using this algorithm.
Fig. 4. Binary iris templates generated using 1D log polar Gabor transform.
(a) and (b) are iris templates of the same individual at two different instances.
To verify a person’s identity, the query iris template is
matched with the stored templates. For matching the textural
iris templates, we use Hamming distance [1]. The match score,
MStexture, for any two texture-based masked iris templates,
Ai and Bi, is computed using Hamming distance measure
given by Equation 14.
MStexture =1
N
N∑
i=1
Ai ⊕Bi (14)
where N is the number of bits represented by each template
and ⊕ is the XOR operator. For handling rotation, the tem-
plates are shifted left and right bitwise and the match scores
are calculated for every successive shift [1]. The smallest
value is used as the final match score, MStexture. The bitwise

7
shifting in the horizontal direction corresponds to rotation of
the original iris region at an angle defined by the angular
resolution. This also takes into account the misalignments
in the normalized iris pattern which are caused due to the
rotational differences during imaging.
2) Topological Feature Extraction using Euler Number:
Convolution with 1D log polar Gabor transform extracts the
global textural characteristics of the iris image. To further
improve the performance, local features represented by the
topology of iris image are extracted using Euler numbers [18],
[49]. For a binary image, Euler number is defined as the
difference between the number of connected components and
the number of holes. Euler numbers are invariant to rotation,
translation, scaling, and polar transformation of the image
[18]. Each pixel of the unwrapped iris can be represented
as an 8-bit binary vector b7, b6, b5, b4, b3, b2, b1, b0. These
bits form eight planes with binary values. As shown in Fig. 5,
four planes formed from the four most significant bits (MSB)
represent the structural information of iris, and the remaining
four planes represent the brightness information [49]. The
brightness information is random in nature and is not useful
for comparing the structural topology of two iris images.
Fig. 5. Binary images corresponding to eight bit planes of the masked polar
image.
For comparing two iris images using Euler code, a common
mask is generated for both the iris images to be matched.
The common mask is generated by performing a bitwise-OR
operation of the individual masks of the two iris images and
is then applied to both the polar iris images. For each of the
two iris images with common mask, a 4-tuple Euler code is
generated which represents the Euler number of the image
corresponding to the four MSB planes. Table II shows the
Euler Codes of a person at three different instances.
We use Mahalanobis distance to match the two Euler codes.
Mahalanobis distance between two vectors is defined as,
D(x, y) =
√
(x− y)t S−1 (x− y) (15)
where, x and y are the two Euler codes to be matched and
S is the positive definite covariance matrix of x and y. If
TABLE II
EULER CODE OF AN INDIVIDUAL AT THREE DIFFERENT INSTANCES.
Euler codeMSB1 MSB2 MSB3 MSB4
Image 1 90 -73 127 -347
Image 2 89 -67 118 -355
Image 3 91 -82 135 -343
the Euler code has large variance, it increases the false reject
rate. Mahalanobis distance ensures that the features having
high variance do not contribute to the distance. Applying
Mahalanobis distance measure for comparison thus avoids the
increase in false reject rate. The topology based match score
is computed as,
MStopology =D(x, y)
log10max(D)(16)
where, max(D) is the maximum possible value of Maha-
lanobis distance between two Euler codes. The match score of
Euler codes is the normalized Mahalanobis distance between
two Euler codes.
V. FUSION OF TEXTURE AND TOPOLOGICAL MATCHING
SCORES
Iris recognition algorithms have succeeded in achieving
a low false acceptance rate but reducing the rejection rate
remains a major challenge. To make iris recognition algorithms
more practical and adaptable to diverse applications, the false
rejection rate needs to be reduced significantly. In [33], [35],
[36], [52], it has been suggested that the fusion of match scores
from two or more classifiers provides better performance
compared to a single classifier. In general, match score fusion
is performed using sum rule, product rule, or other statistical
rules. Recently in [35], a kernel based match score fusion
algorithm has been proposed to fuse the match scores of
fingerprint and signature. In this section, we propose using
2ν-SVM [53] to fuse the information obtained by matching
the textural and the topological features of iris image that
are described in Section IV. The proposed fusion algorithm
reduces the false rejection rate while maintaining a low false
acceptance rate.
Let the training set be Z = (xi, yi) where i = 1, ..., N .
N is the number of multimodal scores used for training and
yi ∈ (1,−1), where 1 represents the genuine class and -
1 represents the impostor class. SVM is trained using these
labeled training data. The mapping function ϕ(·) is used to
map the training data into a higher dimensional feature space
such that Z → ϕ(Z). The optimal hyperplane which separates
the higher dimensional feature space into two different classes
in the higher dimensional feature space can be obtained using
2ν-SVM [53].
We have xi, yi as the set of N multimodal scores with
xi ε <d. Here, xi is the ith score that belongs to the binary
class yi . The objective of training 2ν-SVM is to find the
hyperplane that separates two classes with the widest margins,
i.e.,

8
wϕ(x) + b = 0 (17)
subject to,
yi (wϕ(x) + b) ≥ (ρ− ψi), ξi ≥ 0 (18)
to minimize,
1
2‖w‖2 −
∑
i
Ci(νρ− ξi) (19)
where ρ is the position of margin and ν is the error parameter.
ϕ(x) is the mapping function used to map the data space to
the feature space and provide generalization for the decision
function that may not be a linear function of the training data.
Ci(νρ−ξi) is the cost of errors, w is the normal vector, b is the
bias, and ξi is the slack variable for classification errors. ν can
be calculated using ν+ and ν−, which are the error parameters
for training the positive and negative classes respectively.
ν =2ν+ ν−ν+ + ν−
, 0 < ν+ < 1 and 0 < ν− < 1 (20)
Error penalty Ci is calculated as,
C =
C+, if yi = +1C−, if yi = −1
(21)
where,
C+ =
[
n+
(
1 +ν+
ν−
)]−1
(22)
C− =
[
n−
(
1 +ν−ν+
)]−1
(23)
and n+ and n− are the number of training points for the
positive and negative classes respectively. 2ν-SVM training
can be formulated as,
max(αi)
−1
2
∑
i,j
αi αj yi yj K(xi, xj)
(24)
where,0 ≤ αi ≤ Ci
∑
i αiyi = 0
∑
i αi ≥ ν
(25)
i, j ε 1, ..., N and kernel function is
K (xi, xj) = ϕ(xi)ϕ(xj) (26)
Kernel function K(xi, xj) is chosen as the radial basis func-
tion. The 2ν-SVM is initialized and optimized using iterative
decomposition training [53], which leads to reduced complex-
ity.
In the testing phase, fused score ft of a multimodal test
pattern xt is defined as,
ft = f (xt) = wϕ (xt) + b (27)
The solution of this equation is the signed distance of xt
from the separating hyperplane given by 2ν-SVM. Finally, an
accept or reject decision is made on the test pattern xt using
a threshold X:
Result(xt) =
accept, if output of SV M ≥ Xreject, if otherwise
(28)
Fig. 6 presents the steps involved in the proposed 2ν-SVM
learning algorithm which fuses the texture and topological
match scores for improved classification.
VI. IRIS IDENTIFICATION USING EULER CODE INDEXING
Iris recognition can be used for verification (1:1 matching)
as well as identification (1:N matching). Apart from the irreg-
ularities due to non-ideal acquisition, iris identification suffers
from high system penetration and false accept cases. For
identification, a probe iris image is matched with all the gallery
images and the best match is rank #1 match. Due to the poor
quality and non-ideal acquisition, rank 1 match may not be the
correct match and lead to false acceptance. The computational
time for performing iris identification on large databases is
another challenge [31]. For example, identifying an individual
from a database of 50 million users requires an average of
25 million comparisons. On such databases, applying distance
based iris code matching or the proposed SVM fusion will take
significant amount of time. Parallel processing and improved
hardware can reduce the computational time at the expense of
operational cost.
Other techniques which can be used to speedup the iden-
tification process are classification and indexing. Yu et al.
[19] proposed a coarse iris classification technique using
fractals which classifies iris images into four categories. The
classification technique improves the performance in terms
of computational time but compromises the identification
accuracy. Mukherjee [54] proposed an iris indexing algorithm
in which block based statistics is used for iris indexing. Single
pixel difference histogram used in the indexing algorithm
yields good performance on a subset of CASIA version 3.0
database. However, the indexing algorithm is not evaluated for
non-ideal poor quality iris images.
In this paper, we propose feature based iris indexing al-
gorithm for reducing the computational time required for iris
identification without compromising the identification accu-
racy. The proposed indexing algorithm is a two step process
where the Euler code is first used to generate a small subset of
possible matches. The 2ν-SVM match score fusion algorithm
is then used to find the best matches from the list of possible
matches. The proposed indexing algorithm is divided into two
parts: (1) feature extraction and database enrollment in which
features are extracted from the gallery images and indexed
using Euler code and (2) probe image identification in which
features from the probe image are extracted and matched.
A. Feature Extraction and Database Enrollment
Compared to the feature extraction and matching algorithm
described in Section IV, we use a slightly different strat-
egy for feature extraction. For verification, we use common

9
Fig. 6. Steps involved in the proposed 2ν-SVM match score fusion algorithm.
masks from gallery and probe images to hide the eyelids
and eyelashes. However, in indexing, we do not follow the
same method because generating common mask for every set
of probe and gallery images will increase the computational
cost. Using the iris center coordinates, the X and Y axis are
drawn and the iris is divided into four regions. Researchers
have shown that regions A and B in Fig. 7 contain minimum
occlusion due to eyelids and eyelashes, and hence are the most
useful for iris recognition [4], [9], [22]. Therefore for indexing
we use regions A and B to extract features. The extracted
features are stored in the database and Euler code is used as
the indexing parameter.
A B
A B
A B
A B
Fig. 7. Iris image divided into four parts. Regions A and B are used in theproposed iris indexing algorithm.
B. Probe Image Identification
Similar to the database enrollment process, features are
extracted from the probe iris image and Euler code is used
to find the possible matches. For matching two iris indexing
parameters (Euler codes), E1(i) and E2(i) (i = 1, 2, 3, 4),
we apply a thresholding scheme. Indexing parameters are
said to be matched if |E1(i) − E2(i)| ≤ T where T is the
geometric tolerance constant. Indexing score S is computed
using Equations 29 and 30.
s(i) =
1 if |E1(i) − E2(i)| ≤ T0 otherwise
(29)
S =1
4
4∑
i=1
s(i) (30)
where, |s| = 4 is the intermediate score vector that provides
the number of matched Euler values. We extend this scheme
for iris identification by matching the indexing parameter of
the probe image with the gallery images. Let n be the total
number of gallery images and Sn represent the indexing scores
corresponding to the n comparisons. The indexing scores, Sn,
are sorted in descending order and the top M match scores
are selected as possible matches.
For every probe image, the Euler code based indexing
scheme yields a small subset of top M matches from the
gallery where M << n (for instance, M = 20 and n =2000). To further improve the identification accuracy, we apply
the proposed 2ν-SVM match score fusion. We then use the
algorithms described in Sections IV and V to match the
textural and topological features of the probe image with top
M matched images from the gallery and compute the fused
match score for each of the M gallery images. Finally, these
M fused match scores are again sorted and a new ranking is
obtained to determine the identity.
VII. DATABASES AND ALGORITHMS USED FOR
PERFORMANCE EVALUATION AND COMPARISON
In this section, we describe the iris databases and algo-
rithms used for evaluating the performance of the proposed
algorithms.
A. Databases used for Validation
To evaluate the performance of the proposed algorithms, we
selected three iris databases namely ICE 2005 [30], [31], CA-
SIA Version 3 [55], and UBIRIS [26], [27]. These databases
are chosen for validation because the iris images embody
irregularities captured with different instruments and device
characteristics under varying conditions. The databases also
contain iris images from different ethnicity and facilitates a
comprehensive performance evaluation of the proposed algo-
rithms.
• ICE 2005 database [30], [31] used in recent Iris Challenge
Evaluation contains iris images from 244 iris classes. The
total number of images present in the database is 2,953.
• CASIA Version 3 database [55] contains 22,051 iris
images pertaining to more than 1,600 classes. The images

10
have been captured using different imaging setup. The
quality of images present in the database also varies
from high quality images with extremely clear iris texture
details to images with nonlinear deformation due to vari-
ations in visible illumination. Unlike the CASIA Version
1 where artificially manipulated images were present, the
CASIA Version 3 contains original unmasked images.
• UBIRIS database [26], [27] is composed of 1,877 images
from 241 classes captured in two different sessions. The
images in the first session are of good quality whereas the
images captured in the second session have irregularities
in reflection, contrast, natural luminosity and focus.
B. Existing Algorithms used for Validation
To evaluate the effect of the proposed quality enhance-
ment algorithm on different feature extraction and matching
techniques, we implemented Daugman’s integro-differential
operator and neural network architecture based 2D Gabor
transform described in [1]-[4]. We also used the Masek’s
iris recognition algorithm obtained from [11]. Further, the
performance of the proposed 2ν-SVM fusion algorithm is
compared with Sum rule [33], [34], Min/Max rule [33], [34],
and kernel based fusion rule [35].
VIII. PERFORMANCE EVALUATION AND VALIDATION FOR
IRIS VERIFICATION
In this section, we evaluate the performance of the proposed
segmentation, enhancement, feature extraction, and fusion al-
gorithms for iris verification. The performance of the proposed
algorithms is validated using the databases and algorithms
described in Section VII. For validation, we divided the
databases into three parts: training dataset, gallery dataset, and
probe dataset. Training dataset consist of manually labeled one
good quality and one bad quality image per class. This dataset
is used to train the ν-SVM for quality enhancement and 2ν-
SVM for fusion. After training, the good quality image in the
training dataset is used as the gallery dataset and the remaining
images are used as the probe dataset. The bad quality image
of the training dataset is not used for either gallery or probe
dataset.
For iris segmentation, we performed extensive experiments
to compute a common set of curve evolution parameters that
can be applied to detect exact boundaries of iris and pupil
from all the databases. The values of different parameters
for segmentation with narrow band curve evolution are α =0.2, β = 0.4, λ = 0.4, advection term ν = 0.72, and
curvature term εk = 0.001. These values provide accurate
segmentation results for all three databases. Fig. 8 shows
sample results demonstrating the effectiveness of the proposed
iris segmentation algorithm on all the databases with different
characteristics. The inner yellow curve represents the pupil
boundary and the outer red curve represents the iris boundary.
Fig. 8 also shows that the proposed segmentation algorithm is
not affected by different types of specular reflections present
in the pupil region.
Using the proposed iris segmentation and quality enhance-
ment algorithms, we then evaluated the verification perfor-
mance with the textural and topological features. The match
CASIA Version 3 Database
UBIRIS Database
ICE 2005 Database
Fig. 8. Results of the proposed iris segmentation algorithm.
scores obtained from texture and topological features were
fused using 2ν-SVM to further evaluate the proposed fusion
algorithm. Figs. 9-11 show the ROC plots for iris recogni-
tion using the textural feature extraction, topological feature
extraction, and 2ν-SVM match score fusion algorithms.
Fig. 9 shows the ROC plot for the ICE 2005 database
[30] and Fig. 10 shows the results for the CASIA Version 3
database [55]. The ROC plots show that the proposed 2ν-SVM
match score fusion performs the best followed by the textural
and topological features based verification. The false rejection
rate of individual features is high but the fusion algorithm
reduces it significantly and provides the FRR of 0.74% at
0.0001% false accept rate (FAR) on the ICE 2005 database and
0.38% on the CASIA Version 3 database. The results on the
ICE 2005 database also show that the verification performance
of the proposed fusion algorithm is comparable to the three
best algorithms in the Iris Challenge Evaluation 2005 [31].
The same set of experiments is performed using the UBIRIS
database [26]. The images in this database contain irregular-
ities due to motion blur, off angle, gaze direction, diffusion,
and other real world problems that enable us to evaluate the
robustness of the proposed algorithms on non-ideal iris images.
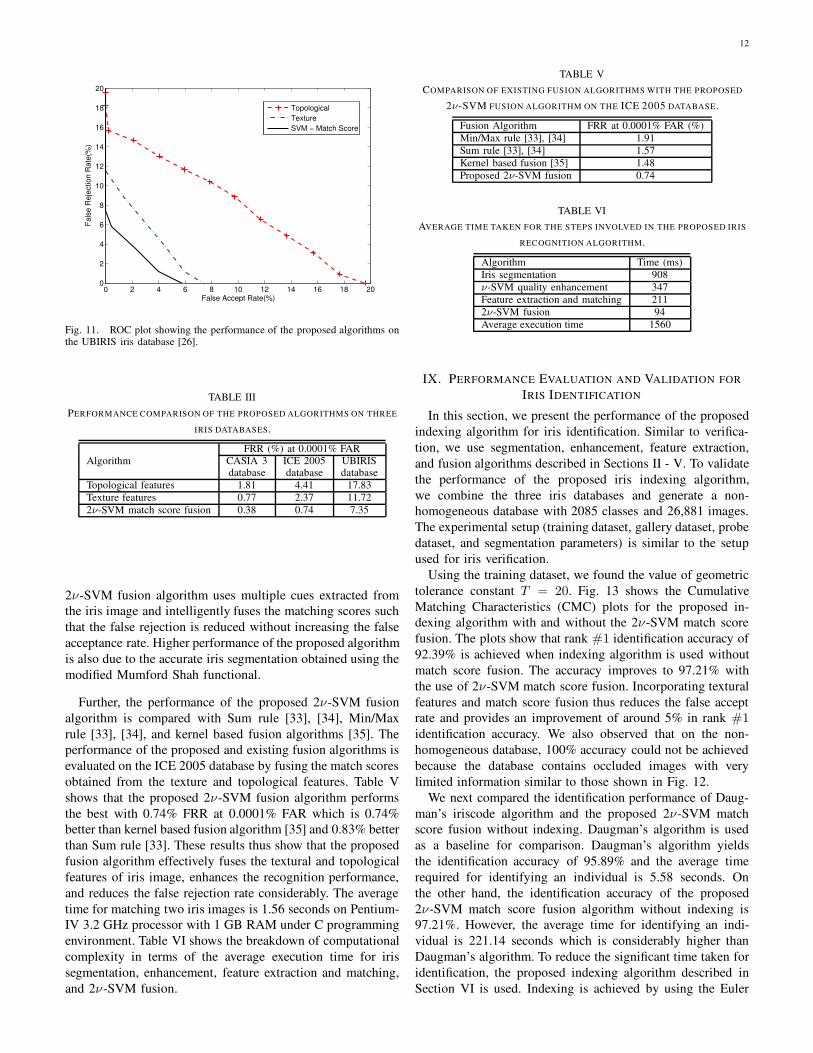
Fig. 11 shows the ROC plot obtained using the UBIRIS
database. In this experiment, the best performance of 7.35%
FRR at 0.0001% FAR is achieved using the 2ν-SVM match
score fusion algorithm. The high rate of false rejection is due
to cases where the iris is partially visible. Examples of such
cases are shown in Fig. 12.
The experimental results on all three databases are summa-
rized in Table III. In this table, it can be seen that the proposed
fusion algorithm significantly reduces the false rejection rate.

11
Fig. 12. Sample iris images from the UBIRIS database [26] on which the proposed algorithms fail to perform.
TABLE IV
EFFECT OF THE PROPOSED IRIS IMAGE QUALITY ENHANCEMENT ALGORITHM AND PERFORMANCE COMPARISON OF IRIS RECOGNITION ALGORITHMS.
False rejection rate (%) at 0.0001% false accept rate with different enhancement algorithms
Daugman’s implementation [1], [4] Masek’s algorithm [11] Proposed 2ν-SVM fusion algorithmDatabase None Wiener Background Proposed None Wiener Background Proposed None Wiener Background Proposed
filter subtraction SVM filter subtraction SVM filter subtraction SVM
CASIA 3 4.87 3.19 3.14 2.37 16.64 15.91 15.18 11.80 1.61 1.29 1.24 0.38
ICE 2005 2.11 1.81 1.73 0.98 12.34 11.88 11.73 9.62 1.99 1.64 1.63 0.74
UBIRIS 12.96 12.10 12.09 8.71 18.85 17.09 16.99 14.11 9.13 8.82 8.79 7.35
0 0.001 0.002 0.003 0.0040
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
False Accept Rate(%)
Fa
lse
Re
jectio
n R
ate
(%)
Topological
Texture
SVM − Match Score
Fig. 9. ROC plot showing the performance of the proposed algorithms onthe ICE 2005 database [30].
However, the rejection rate cannot be reduced if a closed eye
image or an eye image with limited information is present for
matching.
We next evaluated the effectiveness of the proposed iris
image quality enhancement algorithm and compared with
existing enhancement algorithms namely Wiener filtering [25]
and background subtraction [12]. Table IV shows the results
for the proposed and existing verification algorithms when the
original iris image is used and when the quality enhanced im-
ages are used. For the ICE 2005 database, this table shows that
without enhancement, the proposed 2ν-SVM fusion algorithm
gives 1.99% FRR at 0.0001% FAR. The performance improves
by 1.25% when the proposed iris image quality enhancement
algorithm is used. We also found that the proposed SVM
image quality enhancement algorithm outperforms existing
0 0.001 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 0.0180
0.25
0.50
0.75
1.00
1.25
1.50
1.75
2.00
False Accept Rate(%)
Fa
lse
Re
jectio
n R
ate
(%)
Topological
Texture
SVM − Match Score
Fig. 10. ROC plot showing the performance of the proposed algorithms onthe CASIA Version 3 database [55].
enhancement algorithms by at least 0.89%. Similar results are
obtained for other two iris image databases. SVM iris image
quality enhancement algorithm also improves the performance
of existing iris recognition algorithms. SVM enhancement
algorithm performs better because SVM locally removes the
irregularities such as blur and noise, and enhances the intensity
of the iris image whereas Wiener filter only removes the
noise and background subtraction algorithm only highlights
the features by improving the image intensity.
We further compared the performance of the proposed 2ν-
SVM fusion algorithm with Daugman’s iris detection and
recognition algorithms [1]-[4] and Masek’s implementation of
iris recognition [11]. The results in Table IV show that the
proposed 2ν-SVM fusion yields better performance compared
to the Daugman’s and Masek’s implementation because the
12
0 2 4 6 8 10 12 14 16 18 200
2
4
6
8
10
12
14
16
18
20
False Accept Rate(%)
Fa
lse
Re
jectio
n R
ate
(%)
Topological
Texture
SVM − Match Score
Fig. 11. ROC plot showing the performance of the proposed algorithms onthe UBIRIS iris database [26].
TABLE III
PERFORMANCE COMPARISON OF THE PROPOSED ALGORITHMS ON THREE
IRIS DATABASES.
FRR (%) at 0.0001% FAR
Algorithm CASIA 3 ICE 2005 UBIRISdatabase database database
Topological features 1.81 4.41 17.83
Texture features 0.77 2.37 11.72
2ν-SVM match score fusion 0.38 0.74 7.35
2ν-SVM fusion algorithm uses multiple cues extracted from
the iris image and intelligently fuses the matching scores such
that the false rejection is reduced without increasing the false
acceptance rate. Higher performance of the proposed algorithm
is also due to the accurate iris segmentation obtained using the
modified Mumford Shah functional.
Further, the performance of the proposed 2ν-SVM fusion
algorithm is compared with Sum rule [33], [34], Min/Max
rule [33], [34], and kernel based fusion algorithms [35]. The
performance of the proposed and existing fusion algorithms is
evaluated on the ICE 2005 database by fusing the match scores
obtained from the texture and topological features. Table V
shows that the proposed 2ν-SVM fusion algorithm performs
the best with 0.74% FRR at 0.0001% FAR which is 0.74%
better than kernel based fusion algorithm [35] and 0.83% better
than Sum rule [33]. These results thus show that the proposed
fusion algorithm effectively fuses the textural and topological
features of iris image, enhances the recognition performance,
and reduces the false rejection rate considerably. The average
time for matching two iris images is 1.56 seconds on Pentium-
IV 3.2 GHz processor with 1 GB RAM under C programming
environment. Table VI shows the breakdown of computational
complexity in terms of the average execution time for iris
segmentation, enhancement, feature extraction and matching,
and 2ν-SVM fusion.
TABLE V
COMPARISON OF EXISTING FUSION ALGORITHMS WITH THE PROPOSED
2ν-SVM FUSION ALGORITHM ON THE ICE 2005 DATABASE.
Fusion Algorithm FRR at 0.0001% FAR (%)
Min/Max rule [33], [34] 1.91
Sum rule [33], [34] 1.57
Kernel based fusion [35] 1.48
Proposed 2ν-SVM fusion 0.74
TABLE VI
AVERAGE TIME TAKEN FOR THE STEPS INVOLVED IN THE PROPOSED IRIS
RECOGNITION ALGORITHM.
Algorithm Time (ms)
Iris segmentation 908
ν-SVM quality enhancement 347
Feature extraction and matching 211
2ν-SVM fusion 94
Average execution time 1560
IX. PERFORMANCE EVALUATION AND VALIDATION FOR
IRIS IDENTIFICATION
In this section, we present the performance of the proposed
indexing algorithm for iris identification. Similar to verifica-
tion, we use segmentation, enhancement, feature extraction,
and fusion algorithms described in Sections II - V. To validate
the performance of the proposed iris indexing algorithm,
we combine the three iris databases and generate a non-
homogeneous database with 2085 classes and 26,881 images.
The experimental setup (training dataset, gallery dataset, probe
dataset, and segmentation parameters) is similar to the setup
used for iris verification.
Using the training dataset, we found the value of geometric
tolerance constant T = 20. Fig. 13 shows the Cumulative
Matching Characteristics (CMC) plots for the proposed in-
dexing algorithm with and without the 2ν-SVM match score
fusion. The plots show that rank #1 identification accuracy of
92.39% is achieved when indexing algorithm is used without
match score fusion. The accuracy improves to 97.21% with
the use of 2ν-SVM match score fusion. Incorporating textural
features and match score fusion thus reduces the false accept
rate and provides an improvement of around 5% in rank #1identification accuracy. We also observed that on the non-
homogeneous database, 100% accuracy could not be achieved
because the database contains occluded images with very
limited information similar to those shown in Fig. 12.
We next compared the identification performance of Daug-
man’s iriscode algorithm and the proposed 2ν-SVM match
score fusion without indexing. Daugman’s algorithm is used
as a baseline for comparison. Daugman’s algorithm yields
the identification accuracy of 95.89% and the average time
required for identifying an individual is 5.58 seconds. On
the other hand, the identification accuracy of the proposed
2ν-SVM match score fusion algorithm without indexing is
97.21%. However, the average time for identifying an indi-
vidual is 221.14 seconds which is considerably higher than
Daugman’s algorithm. To reduce the significant time taken for
identification, the proposed indexing algorithm described in
Section VI is used. Indexing is achieved by using the Euler

13
2 4 6 8 10 12 14 16 18 2090
91
92
93
94
95
96
97
98
99
100
Top M Matches (Rank)
Ide
ntifica
tio
n A
ccu
racy (
%)
Indexing without Match Score Fusion (Case 1)
Indexing with Match Score Fusion (Case 3)
Fig. 13. CMC plot showing the identification accuracies obtained by theproposed indexing algorithm.
code which is computed from the local topological features
of the iris image. The indexing algorithm identifies a small
subset of the most likely candidates that will yield a match.
Specifically, we analyze three scenarios. Case 1 determines
a match based on the local topological feature match score.
Case 2 is an extension that uses the subset of images identified
with the local features. However, the matching is based on
the global texture feature match score. Case 3 is a further
extension that fuses the match scores obtained from the local
and global features to perform identification. The identification
performance is determined by experimentally computing the
accuracy and the time taken for identification. The results are
summarized in Table VII for all three cases when indexing
is used with the proposed recognition algorithm. In all three
scenarios, the proposed algorithm considerably decreases the
identification time, thereby making it suitable for real-time
applications and the use with large databases.
In Case 1, since only the local Euler feature is used for
indexing, the identification time is the fastest (0.043 seconds);
however the accuracy is lower compared to Daugman’s al-
gorithm. The accuracy improved when both the global and
local features are used sequentially. Further, as shown in Table
VII, Case 3 yields the best performance in terms of accuracy
(97.21%) with an average identification time of less than 2
seconds.
X. CONCLUSION
In this paper we address the challenge of improving the
performance of iris verification and identification. The paper
presents an accurate non-ideal iris segmentation using the
modified Mumford-Shah functional. Depending on the type of
abnormalities likely to be encountered during image capture,
a set of global image enhancement algorithms is concurrently
applied to the iris image. While this enhances the low quality
regions, it also adds undesirable artifacts in the original high
quality regions of the iris image. Enhancing only selected
regions of the image is extremely difficult and not pragmatic.
This paper describes a novel learning algorithm that selects
enhanced regions from each globally enhanced image and
synergistically combines to form a single composite high
quality iris image. Furthermore, we extract global texture
features and local topological features from the iris image.
The corresponding match scores are fused using the proposed
2ν-SVM match score fusion algorithm to further improve the
performance. Iris recognition algorithms require significant
amount of time to perform identification. We have proposed
an iris indexing algorithm using local and global features
to reduce the identification time without compromising the
identification accuracy. The performance is evaluated using
three non-homogeneous databases with varying characteristics.
The proposed algorithms are also compared with existing
algorithms. It is shown that the cumulative effect of accurate
segmentation, high quality iris enhancement, and intelligent
fusion of match scores obtained using global and local features
reduces the false rejection rate for verification. Moreover, the
proposed indexing algorithm significantly reduces the compu-
tational time without affecting the identification accuracy.
ACKNOWLEDGMENT
The authors would like to thank Dr. Patrick Flynn, CASIA
(China), and U.B.I. (Portugal) for providing the iris databases
used in this research. Authors also acknowledge the reviewers
and editors for providing constructive and helpful comments.
REFERENCES
[1] J.G. Daugman, “High confidence visual recognition of persons by a test
of statistical independence,” IEEE Transactions on Pattern Analysis andMachine Intelligence, vol. 15, no. 11, pp. 1148-1161, 1993.
[2] J.G. Daugman, “The importance of being random: Statistical principles
of iris recognition,” Pattern Recognition, vol. 36, no. 2, pp. 279-291,2003.
[3] J.G. Daugman, “Uncertainty relation for resolution in space, spatial
frequency, and orientation optimized by two-dimensional visual corticalfilters,” Journal of the Optical Society of America A, vol. 2, no. 7, pp.1160-1169, 1985.
[4] J.G. Daugman, “Biometric personal identification system based on irisanalysis,” US Patent Number US5291560, 1994.
[5] R.P. Wildes, “Iris recognition: an emerging biometric technology,”Proceedings of the IEEE, vol. 85, no. 9, pp. 1348-1363, 1997.
[6] W.W. Boles and B. Boashash, “A human identification technique using
images of the iris and wavelet transform,” IEEE Transactions on SignalProcessing, vol. 46, no. 4, pp. 1185-1188, 1998.
[7] Y. Zhu, T. Tan, and Y. Wang, “Biometric personal identification based
on iris patterns,” Proceedings of the IEEE International Conference onPattern Recognition, pp. 2801-2804, 2000.
[8] C.L. Tisse, L. Martin, L. Torres, and M. Robert, “Iris recognition system
for person identification,” Proceedings of the Second InternationalWorkshop on Pattern Recognition in Information Systems, pp. 186-199,
2002.[9] C.L. Tisse, L. Torres, and R. Michel, “Person identification technique
using human iris recognition,” Proceedings of the 15th International
Conference on Vision Interface, pp. 294-299, 2002.[10] W.-S. Chen and S.-Y. Yuan, “A novel personal biometric authentica-
tion technique using human iris based on fractal dimension features,”
Proceedings of the International Conference on Acoustics, Speech andSignal Processing, vol. 3, pp. 201-204, 2003.
[11] L. Masek and P. Kovesi, “MATLAB source code for a biometric identi-
fication system based on iris patterns,” The School of Computer Scienceand Software Engineering, The University of Western Australia, 2003(http://www.csse.uwa.edu.au/ pk/studentprojects/libor/sourcecode.html).
[12] L. Ma, T. Tan, Y. Wang, and D. Zhang, “Personal identification basedon iris texture analysis,” IEEE Transactions on Pattern Analysis and
Machine Intelligence, vol. 25, no. 12, pp. 1519-1533, 2003.

14
TABLE VII
IRIS IDENTIFICATION PERFORMANCE WITH AND WITHOUT THE PROPOSED IRIS INDEXING ALGORITHM. ACCURACY IS REPORTED FOR RANK #1
IDENTIFICATION USING A DATABASE OF 2085 CLASSES WITH 26,881 IRIS IMAGES.
Algorithms Local feature Global feature Fusion Identification accuracy (%) Time (seconds)
Without indexing
DaugmanIriscode [2] - Texture - 95.89 5.58
(Baseline)Proposed2ν-SVM Euler code Texture 2ν-SVM 97.21 220.14
Fusion
With indexing
Proposedalgorithm Euler code - - 92.39 0.043Case 1
Proposedalgorithm Euler code Texture - 96.57 1.15
Case 2Proposedalgorithm Euler code Texture 2ν-SVM 97.21 1.82
Case 3
[13] L. Ma, T. Tan, Y. Wang, and D. Zhang, “Efficient iris recognitionby characterizing key local variations,” IEEE Transactions on Image
Processing, vol. 13, no. 6, pp. 739-750, 2004.
[14] B.R. Meena, M. Vatsa, R. Singh, and P. Gupta, “Iris based humanverification algorithms,” Proceedings of the International Conference onBiometric Authentication, pp. 458-466, 2004.
[15] M. Vatsa, R. Singh, and P. Gupta, “Comparison of iris recognitionalgorithms,” Proceedings of the International Conference on IntelligentSensing and Information Processing, pp. 354-358, 2004.
[16] C. Sanchez-Avila and R. Snchez-Reillo, “Two different approaches
for iris recognition using Gabor filters and multiscale zero-crossingrepresentation,” Pattern Recognition, vol. 38, no. 2, pp. 231-240, 2005.
[17] M. Vatsa, “Reducing false rejection rate in iris recognition by quality
enhancement and information fusion,” Master’s Thesis, West VirginiaUniversity, 2005.
[18] M. Vatsa, R. Singh, and A. Noore, “Reducing the false rejection rate
of iris recognition using textural and topological features,” InternationalJournal of Signal Processing, vol. 2, no. 1, pp. 66-72, 2005.
[19] L.Yu, D. Zhang, K.Wang, W.Yang, “Coarse iris classification using box-counting to estimate fractal dimensions,” Pattern Recognition, vol. 38,
pp. 1791-1798, 2005.
[20] B. Ganeshan, D. Theckedath, R. Young, and C. Chatwin, “Biometric irisrecognition system using a fast and robust iris localization and alignment
procedure,” Optics and Lasers in Engineering, vol. 44, no. 1, pp. 1-24,2006.
[21] N.D. Kalka, J. Zuo, V. Dorairaj, N.A. Schmid, and B. Cukic, “Imagequality assessment for iris biometric,” Proceedings of the SPIE Confer-
ence on Biometric Technology for Human Identification III, vol. 6202,pp. 61020D-1-62020D-11, 2006.
[22] H. Proenca and L.A. Alexandre, “ Toward noncooperative iris recogni-
tion: a classification approach using multiple signatures,” IEEE Trans-actions on Pattern Analysis and Machine Intelligence, vol. 29, no. 4, pp.607-612, 2007.
[23] J. Thornton, M. Savvides, B.V.K. Vijaya Kumar, “A bayesian approach
to deformed pattern matching of iris images,” IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 29, no. 4, pp. 596-606,
2007.
[24] D.M. Monro, S. Rakshit, and D. Zhang, “DCT-based iris recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.29, no. 4, pp. 586-596, 2007.
[25] A. Poursaberi and B.N. Araabi, “Iris recognition for partially occludedimages: methodology and sensitivity analysis,” EURASIP Journal onAdvances in Signal Processing, vol. 2007, Article ID 36751, 12 pages,
2007.
[26] H. Proenca and L.A. Alexandre, “UBIRIS: a noisy iris image database,”Proceedings of the 13th International Conference on Image Analysis andProcessing, vol. 1, pp. 970-977, 2005.
[27] http://iris.di.ubi.pt/.
[28] K.W. Bowyer, K. Hollingsworth, and P.J. Flynn, “Image understandingfor iris biometrics: a survey,” Computer Vision and Image Understand-ing, doi:10.1016/j.cviu.2007.08.005, 2008 (To appear).
[29] R. Singh, M. Vatsa, and A. Noore, Improving verification accuracy by
synthesis of locally enhanced biometric images and deformable model,Signal Processing, vol. 87, no. 11, pp. 2746-2764, 2007.
[30] X. Liu, K.W. Bowyer, and P.J. Flynn, “Experiments with an improvediris segmentation algorithm,” Proceedings of the Fourth IEEE Workshop
on Automatic Identification Advanced Technologies, pp. 118-123, 2005.
[31] http://iris.nist.gov/ice/ICE Home.htm.
[32] J. Daugman, “New methods in iris recognition,” IEEE Transactions onSystems, Man and Cybernetics - B, vol. 37, no. 5, pp. 1168-1176, 2007.
[33] J. Kittler, M. Hatef, R.P. Duin, and J.G. Matas, “On combining classi-
fiers,” IEEE Transactions on Pattern Analysis and Machine Intelligence,vol. 20, no. 3, pp. 226-239, 1998.
[34] A. Ross and A.K. Jain, “Information fusion in biometrics,” PatternRecognition Letters, vol. 24, no. 13, pp. 2115-2125, 2003.
[35] J.F. Aguilar, J.O. Garcia, J.G. Rodriguez, and J. Bigun, “Kernel-basedmultimodal biometric verification using quality signals,” Proceedings ofthe SPIE Biometric Technology for Human Identification, vol. 5404, pp.
544-554, 2004.
[36] B. Duc, G. Maitre, S. Fischer, and J. Bigun, “Person authentication
by fusing face and speech information,” Proceedings of the FirstInternational Conference on Audio and Video based Biometric Person
authentication, pp. 311-318, 1997.
[37] A. Ross and S. Shah, “Segmenting non-ideal irises using geodesic active
contours,” Proceedings of Biometric Consortium Conference, 2006.
[38] E.M. Arvacheh and H.R. Tizhoosh, “Iris segmentation: detecting pupil,
limbus and eyelids,” Proceedings of the IEEE International Conferenceon Image Processing, pp. 2453-2456, 2006.
[39] X. Liu, “Optimizations in iris recognition,” Ph.D. Dissertation, Univer-sity of Notre Dame, 2006.
[40] A. Tsai, A. Yezzi, Jr., and A. Willsky, “Curve evolution implementationof the Mumford-Shah functional for image segmentation, denoising, in-
terpolation, and magnification,” IEEE Transactions on Image Processing,vol. 10, no. 8, pp. 1169-1186, 2001.
[41] T. Chan and L. Vese, “Active contours without edges,” IEEE Transac-tions on Image Processing, vol. 10, no. 2, pp. 266-277, 2001.
[42] R. Malladi, J. Sethian, and B. Vemuri, “Shape modeling with front prop-agation: a level set approach,” IEEE Transactions on Pattern Analysisand Machine Intelligence, vol. 17, no. 2, pp. 158-175, 1995.
[43] J.Z. Huang, L. Ma, T.N. Tan, and Y.H. Wang, “Learning-based en-hancement model of iris,” Proceedings of the British Machine Vision
Conference, pp. 153-162, 2003.
[44] V.N. Vapnik, The nature of statistical learning theory, 2nd Edition,Springer, 1999.
[45] P.-H. Chen, C.-J. Lin, and B. Schlkopf, “A tutorial on ν-support vectormachines,” Applied Stochastic Models in Business and Industry, vol. 21,pp. 111-136, 2005.
[46] C.C. Chang and C.J. Lin, “LIBSVM: a library forsupport vector machines,” 2001, Software available at
http://www.csie.ntu.edu.tw/∼cjlin/libsvm.
[47] R. Singh, M. Vatsa, and A. Noore, “SVM based adaptive biometric
image enhancement using quality assessment,” In B. Prasad and S.R.M.Prasanna (Eds), Speech, Audio, Image and Biomedical Signal Processing
using Neural Networks, Springer Verlag, Chapter 16, pp. 351-372, 2008.

15
[48] D.J. Field, “Relations between the statistics of natural images and the
response properties of cortical cells,” Journal of the Optical Society ofAmerica, vol. 4, pp. 2379-2394, 1987.
[49] A. Bishnu, B.B. Bhattacharya, M.K. Kundu, C.A. Murthy, and T.
Acharya, “Euler vector for search and retrieval of graytone images,”IEEE Transactions on Systems, Man and Cybernetics-B, vol. 35, no. 4,pp. 801-812, 2005.
[50] C. Palm and T.M. Lehmann, “Classification of color textures by Gaborfiltering,” Machine Graphics and Vision, vol. 11, no. 2/3, pp. 195-219,2002.
[51] D. J. Field, “What is the goal of sensory coding?” Neural Computation,vol. 6, pp. 559-601, 1994.
[52] Y. Wang, T. Tan, and A.K. Jain, “Combining face and iris biometrics foridentity verification,” Proceedings of the Fourth International Conferenceon Audio and Video Based Biometric Person Authentication, pp. 805-
813, 2003.[53] H.G. Chew, C.C. Lim, and R.E. Bogner, “An implementation of training
dual-nu support vector machines,” In L.Qi, K.L.Teo and X.Yang (Eds),
Optimization and Control with Applications, Kluwer, 2005.[54] R. Mukherjee, “Indexing techniques for fingerprint and iris databases,”
Master’s Thesis, West Virginia University, 2007.
[55] http://www.cbsr.ia.ac.cn/IrisDatabase/irisdatabase.php.
Mayank Vatsa is a graduate research assistant inthe Lane Department of Computer Science andElectrical Engineering at West Virginia University.
He is currently pursuing his Doctoral degree inComputer Science. He had been actively involvedin the development of a multimodal biometric sys-
tem which includes face, fingerprint, signature, andiris recognition at Indian Institute of TechnologyKanpur, India from July 2002 to July 2004. His
current areas of interest are pattern recognition,image processing, uncertainty principles, biometric
authentication, watermarking, and information fusion. Mayank has more than
65 publications in refereed journals, book chapters, and conferences. He hasreceived four best paper awards. He is a member of the IEEE, Computer
Society, and ACM. He is also a member of Phi Kappa Phi, Tau Beta Pi,Sigma Xi, Upsilon Pi Epsilon, and Eta Kappa Nu honor societies.
Richa Singh is a graduate research assistant in
the Lane Department of Computer Science andElectrical Engineering at West Virginia University.She is currently pursuing her Doctoral degree in
Computer Science. She had been actively involved inthe development of a multimodal biometric system
which includes face, fingerprint, signature, and irisrecognition at Indian Institute of Technology Kan-pur, India from July 2002 to July 2004. Her cur-
rent areas of interest are pattern recognition, imageprocessing, machine learning, granular computing,
biometric authentication, and data fusion. Richa has more than 65 publications
in refereed journals, book chapters, and conferences, and has received fourbest paper awards. She is a member of the IEEE, Computer Society, and ACM.She is also a member of Phi Kappa Phi, Tau Beta Pi, Upsilon Pi Epsilon, and
Eta Kappa Nu honor societies.
Afzel Noore received his Ph.D. in Electrical Engi-
neering from West Virginia University. He workedas a digital design engineer at Philips India. From1996 to 2003, Dr. Noore served as the Associate
Dean for Academic Affairs and Special Assistantto the Dean in the College of Engineering andMineral Resources at West Virginia University. He
is a Professor in the Lane Department of ComputerScience and Electrical Engineering. His researchinterests include computational intelligence, biomet-
rics, software reliability modeling, machine learning,hardware description languages, and quantum computing. His research has
been funded by NASA, NSF, Westinghouse, GE, Electric Power ResearchInstitute, the US Department of Energy, and the US Department of Justice.Dr. Noore has over 85 publications in refereed journals, book chapters, and
conferences. He has received four best paper awards. Dr. Noore is a member ofthe IEEE and serves in the editorial boards of Recent Patents on Engineeringand the Open Nanoscience Journal. He is a member of Phi Kappa Phi, Sigma
Xi, Eta Kappa Nu, and Tau Beta Pi honor societies.