hierarchical solutions in reinforcement learning using graph algorithms project presentation control...
TRANSCRIPT

Hierarchical Solutions in Hierarchical Solutions in Reinforcement Learning Reinforcement Learning using Graph Algorithmsusing Graph Algorithms
Project PresentationProject Presentation
Control and Robotics Control and Robotics LaboratoryLaboratoryElectrical Engineering FacultyElectrical Engineering FacultyTechnionTechnion
ByBen Ezair & Uri WienerBen Ezair & Uri WienerInstructor: Mr. Ishai MenacheInstructor: Mr. Ishai Menache
Winter 2004Winter 2004/5/5

Agenda
•Motivation
•Background
•Description of the algorithms
•The domains & experimental results
•Conclusions
•Future work

Motivation
• Many problems can be modeled as MDP’s(Markov Decision Processes).
• Reinforcement learning algorithms were designed in order to solve MDPs, when the environment model is unknown.
• Q-learning is a popular algorithm within the Reinforcement Learning paradigm, guaranteed to asymptotically converge.
•Yet, due to an enormous state-space, Q-learning performs poorly in many real-life tasks.
• We will present ways to enhance the standard Q-learning algorithm using an hierarchical, graph-based approach.

Reinforcement Learning
agentenvironment
reinforcement
action
State
• The Reinforcement learning framework: The agent explores the environment; the agent perceives its current state and takes actions.
• The environment, in return, provides a reward (which can be positive or negative).

Q-learning
•The Q-learning algorithm works by estimating the values - Q(s,a).
•These values try to predict the payoffs that may be obtained by taking action a from state s. Q-values are estimated on the basis of experience as follows:
1. From the current state s, select an action a. This will cause a receipt of an immediate payoff r, and arrival at a next state s'.
2. Update Q(s,a) based upon this experience as follows:
Learning rate: (0,1]
Discount factor: [0,1]
Next state
3. Go to 1.
Where:

ε-greedy policy
Explore policy
•The least explored action in current state is chosen.
Exploit policy
•The action with the highest Qvalue is chosen.
•With probability of 0 < ε < 1, use explore policy,otherwise use exploit policy.
•Throughout our experiments a ε value of 0.3 was used.
Description of policies

• 'Options‘, also known as “Macro-actions”, are sets of actions defined for multiple states in the state-space. They are designed to bring the agent to a certain state (or set of states).
The use of options
For example:

Clustering algorithm
•The algorithm aims at maximizing:
The K-cluster algorithm
Where:• g() is a function that defines how well the two clusters are separated,• f() is a function that defines the quality of a cluster.

•The function g may also account for Qvalue differences between the two clusters, making it more likely that clusters with similar Qvalue will be merged:
The K-cluster algorithm - continued
For example:

•This approximation dramatically reduces the complexity of the clustering process allowing us to deal with larger state-spaces.
•We chose an approximation method in which we attempt to maximize the clustering score by removing its smallest element in each step.
The K-cluster algorithm - continued

•Performed by running a max-flow/min-cut algorithm using a graph derived from the state space.
Cut algorithm
•The algorithm examines the quality of the bottlenecks found according to a quality factor defined as:
•If this quality factor exceeds a predetermined value, then options are set to reach the bottlenecks. Otherwise, no options are set and the cut algorithm should be run again later.

Cut algorithm - continued
•Once the first cut is made successfully, we recursively call the cut algorithm separately for all states on either side of the bottlenecks.
Example of a conversion of a maze into a graph:(both possible bottlenecks are highlighted)

Software implementationBlock diagram of the software implementation we used:

Six-pass maze:
Maze environments
Step reward: 0Bump wall reward: 0Noise: 10% chance
for random action
Algorithm dependent parameters:
Kcluster:Steps before calling algorithm: 3256Clusters: 5 for Ni 10, 6 for Ni 0Ni: 10, 0
Qcut:
Steps before calling algorithm: 2000Quality factor: 1000

Six-pass maze experimental results
Maze environments - continued
Clusters & bottleneck:
K-cluster, Ni=10, 5 clusters K-cluster, Ni=0, 6 clusters
Q-cut bottlenecks
(averaged over 150 runs)

Six-pass maze experimental resultsMaze environments - continued
1st state Qvalue: Steps to goal
(averaged over 150 runs)

Big maze:
Maze environments - continued
Step reward: 0Bump wall reward: 0Noise: 10% chance
for random action
Algorithm dependent parameters:
Kcluster:Steps before calling algorithm: 42475Clusters: 5Ni: 10
Qcut:
Steps before calling algorithm: 20000Quality factor: 50000

Big maze experimental resultsMaze environments - continued
Clusters & bottleneck:
K-cluster, Ni=10, 5 clusters Q-cut bottlenecks
(averaged over 150 runs)

Big maze experimental resultsMaze environments - continued
1st state Qvalue: Steps to goal
(averaged over 150 runs)

Taxi environment
Step reward: 0Bump wall reward: 0Noise: 10% chance
for random action
Algorithm dependent parameters:
Kcluster:Steps before calling algorithm: 11000 Clusters: 20Ni: 10
Qcut:
Steps before calling algorithm: 10000 Quality factor: 200
R
Y B
G
Standard taxi problem as introduced by Dietterich (2000).
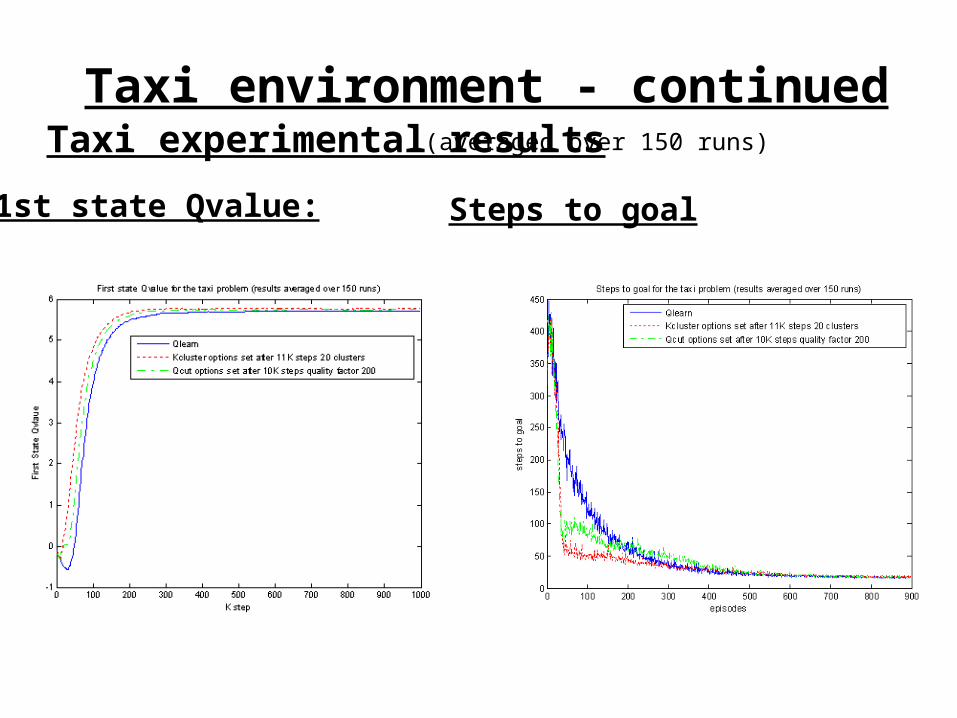
Taxi experimental resultsTaxi environment - continued
1st state Qvalue: Steps to goal
(averaged over 150 runs)

Taxi experimental results
Taxi environment - continued
Kcluster’s solution quality as function of the algorithm’s starting time:
(averaged over 150 runs)

Car-hill environment
Algorithm dependent parameters:
Kcluster:
Steps before calling algorithm: 100000 Clusters: 12Ni: 10
Qcut:
Steps before calling algorithm: 20000 Quality factor: 1 (much too low to give good results)
•The state-space is divided uniformly to a discrete 50x50 space.

Car-hill experimental resultsCar-hill environment - continued
Clustering result:
(averaged over 150 runs)
Note that higher speeds are towards the bottom of the figure, and positions closer to the goal are towards the right of the figure.
Because of the transition-space magnitude of the problem, running the Q-cut algorithm with reasonable quality factor and initial conditions is not applicable.
Remark:

Car-hill experimental results
Car-hill environment - continued
1st state Qvalue: 1st state Qvalue standard deviation:
(averaged over 150 runs)

Description of the ODE(Open Dynamics Engine)
(taken from the Open Dynamics Engine user guide)
“The Open Dynamics Engine (ODE) is a free, industrial quality library for simulating articulated rigid body dynamics.
For example, it is good for simulating ground vehicles, legged creatures, and moving objects in VR environments.
It is fast, flexible and robust, and it has built-in collision detection. ODE is being developed by Russell Smith with help from several contributors".
More information on ODE: http://www.ode.org

Robot environments
• We experimented with 3 robot environments:
1. 2-link robot environment 2. 3-link dynamic robot environment3. 3-link static robot environment
• In all 3 environments, the robot must learn to stand up.
Environment screenshots:

• Standing is achieved when the agent brings the robot to a position in which the joints' angles and angular speeds, as well as the angle between the bottom link and the ground are less than 0.05*PI (0.05*PI/sec for the speeds).
• At that point, a discrete PD controller takes over and makes sure the robot keeps standing straight.
• Conversion between angles/angular speeds and discrete values uses a resolution of 0.1*PI radians (or radians per second).
• The agent controls the robot by giving the angular speed it wants each joint to have. An independent discrete proportional controller on each joint then tries to achieve this speed.
• An episode ends when the robot successfully stands up.
Robot environments - continued

Rewards
• The agent is rewarded when the angles and angular speeds fall below 0.1*PI (0.1*PI/sec for the speeds).
• If that is not the case than the agent is rewarded when it gets the one of the links to a certain height.
• The agent is negatively rewarded by a larger amount when it loses these mid-goals.
Robot environments - continued

2-link robot environment
•The 2-link robot has 3 links; the bottom link is so massive that it's essentially a stationary object.
•The problem starts with the bottom link already in an upright position and the two joints in some arbitrary angles.
•The bottom link lacks the power needed to lift the two top links and the agent has to use momentum generated by the upper link to stand up.
•The four state variables used for this environment are the angles and angular speeds of the two joints.
2-link600ks_593e_b.wmv
Video clip:
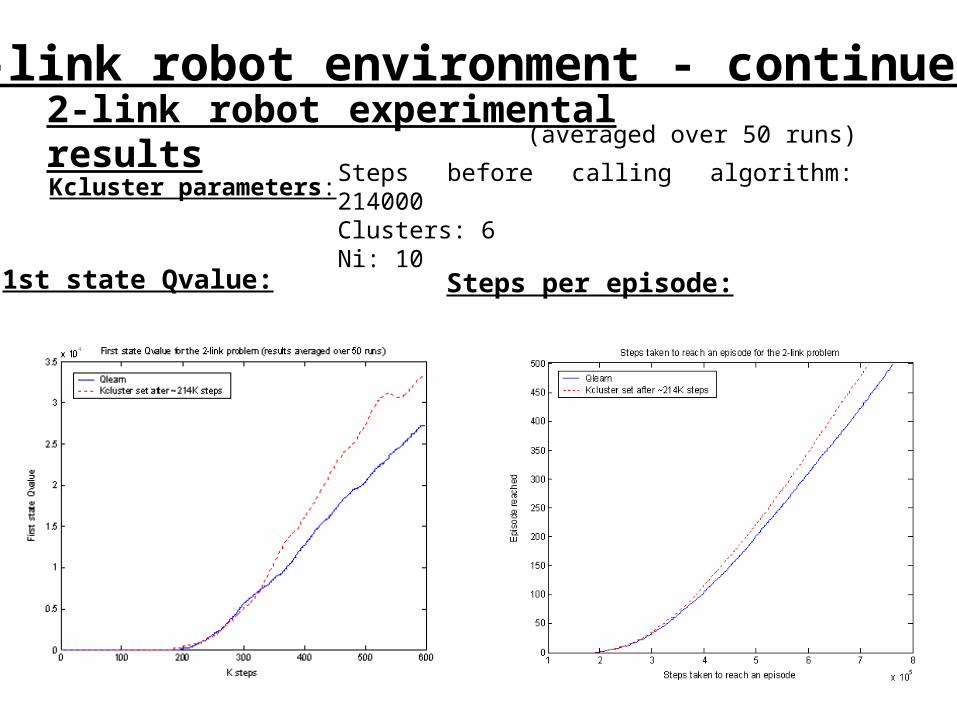
2-link robot experimental results
2-link robot environment - continued(averaged over 50 runs)
1st state Qvalue: Steps per episode:
Steps before calling algorithm: 214000 Clusters: 6Ni: 10
Kcluster parameters:

3-link dynamic robot environment
•The five state space variables are the angles and angular speeds of the two joints as well as the angle between the bottom link and the ground.
•The robot starts this problem lying down and must use leverage to get itself up.
• The upper joint is very weak, the agent has to use momentum generated by the bottom joint to bring the two upper links into position.
3link_5_variable_1k_episodes_323k_steps.wmv
Video clip:

3-link dynamic robot experimental results
3-link dynamic robot environment(averaged over 10 runs)
1st state Qvalue: Steps per episode:
Steps before calling algorithm: 50K, 14KClusters: 6Ni: 10
Kcluster parameters:
0 1 2 3 4 5 6 7
x 105
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
Steps taken
Epi
sode
rea
ched
Number of steps it took to reach an episode (averaged over ten runs), for the 3-link dynamic problem
QlearnKcluster set after ~14K steps, ni=10Kcluster set after 50K steps, ni=10
0 100 200 300 400 500 6000
2
4
6
8
10
12
14
16
18x 10
4 First state Qvalue for the dynamic problem results averaged over 10 runs
K steps
Firs
t sta
te Q
valu
e
QlearnKcluster set after 50K steps ni = 10Kcluster set after ~14K steps ni = 10

Wall-ball environment•This environment resembles air hokey.
•A bat positioned at the bottom of a rectangular area is able to move from side to side and is supposed to hit a ball, preventing it from falling to the bottom, trying to make it go through an opening at the top of the rectangular area.
•The bat and walls have an infinite mass compared to the ball so all impacts are completely elastic, the whole environment is also frictionless and without gravity.
•The agent is rewarded when the ball goes through the gap at the top, and is negatively rewarded when the ball falls through the bottom, or (larger negative reward) if the bat goes "out of bounds".
Environment screenshots:
Wb_ql_50ke.wmvVideo clip:

Conclusions
1. In the first part of the project we mostly dealt with domains that were almost tailored for the algorithms.
As expected, Qcut and Kcluster outperformed QL for the examined domains.
2. In the second part, we demonstrated the advantage of the hierarchical approach over standard Q-learning, even for domains which do not posses a clear hierarchical structure.
3. In domains that have small state-spaces, Qcut and Kcluster exhibited similar performance.
However, in domains with larger state-spaces with many state-transitions, Q-cut is not applicable, as its polynomial complexity of O(N^3) grows to unmanageable proportions.

Future work1. Use the framework we set up to simulate additional complex (dynamic)
environments.
2. Currently Qcut or Kcluster are only invoked once. Even if later changes are detected there will be no attempt to re-cut or re-cluster the state-space. It could be beneficial to perform successive cuts/clusters.
3. Qcut could be still used in large state-space domains, if an approximation of the min-cut-max-flow algorithm is used instead of the original algorithm.
4. Improve the quality factor which is used for the Kcluster algorithm.
Video clips:clip_long_run-1.wmv clip_long_run-2.wmv
