hdfs & mapreduce
TRANSCRIPT

Slide 1© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
HDFS and MapReduce

Slide 2© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Session Objectives
ᗍ Introduction to Big Data and Hadoop
ᗍ Understanding HDFS
ᗍ Introduction to MapReduce
ᗍ MapReduce Programming Tutorial
ᗍ BIG Data & Hadoop Course Syllabus
ᗍ Webinar by Skillspeed
Get Started with BIG Data & Hadoop

Slide 3© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Big Data and its Challenges
Get Started with BIG Data & Hadoop

Slide 4© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Big Data and its Challenges
Big data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications
Systems / Enterprises generate huge amount of data from Terabytes to and even Petabytes of information
It’s very difficult to manage such huge data……
Get Started with BIG Data & Hadoop

Slide 5© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Who Generates Big Data?
Have you ever wondered how Google, Facebook or LinkedIn manages to store and utilize the huge data?
Today, it is becoming a problem for all of us to manage such BIG DATA…. Get Started with BIG Data & Hadoop

Slide 6© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Hadoop can be used for easy processing of such huge Data…..
We will answer how?
Before that let’s understand what is Hadoop?Get Started with BIG Data & Hadoop

Slide 7© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Hadoop and its Characteristics
Apache Hadoop is a framework that allows the distributed processing of large data sets across clusters of commodity computers using a simple programming model
It is an Open-source Data Management technology with scale-out storage and distributed processing
Hadoop Characteristics
Flexible
Reliable
Economical
Scalable Get Started with BIG Data & Hadoop

Slide 8© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Hadoop Ecosystem
Flume Sqoop
Import Or Export
Unstructured or Semi-Structured data Structured Data
Apache Oozie (Workflow)
HDFS(Hadoop Distributed File System)
Pig LatinData Analysis
HiveDW System
MapReduce Framework HBase
OtherYARN
Frameworks (MPI,GIRAPH)
YARNCluster Resource Management
Get Started with BIG Data & Hadoop

Slide 9© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
HDFS
Get Started with BIG Data & Hadoop

Slide 10© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Hadoop Distributed File System (HDFS) – a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster
HDFS and its Components
The Hadoop distributed file system (HDFS) is a distributed, scalable, and portable file-system written in Java for the Hadoop framework
NameNode
ᗍ Storage side master of the systemᗍ It maintains, manages, and administers the data blocks present on the DataNodes
DataNodes
ᗍ Slave machines which provide the actual and redundant storageᗍ End points for client read and write operations
Get Started with BIG Data & Hadoop

Slide 11© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
HDFS Architecture
NameNode
Client
Rack 1 Client Rack 2
Metadata (Name, replicas,...): /home/foo/data, 3,…
Read DataNodes
Write
Replication
Blocks
Block ops
DataNodes
Metadata ops
Get Started with BIG Data & Hadoop

Slide 12© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
HDFS NameNode
Keeps Meta data in Main Memory
ᗍ The entire metadata is in main memoryᗍ FS meta-data is not loaded from hard disk
Metadata type
ᗍ Files in HDFSᗍ Data Blocks for each fileᗍ DataNodes for each blockᗍ File attributes, e.g. access time, replication factor, access control
Get Started with BIG Data & Hadoop

Slide 13© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Secondary NameNode
Secondary NameNode:
ᗍ In HDFS 1.0, not a hot standby for the NameNode
ᗍ By Default connects to NameNode every hour*
ᗍ Housekeeping, backup of NameNode metadata
ᗍ Saved metadata is used to bring up the secondary NameNode
NameNode
SecondaryNameNode
Metadata
I’’ll take metadata every hour and
will make it secure
Get Started with BIG Data & Hadoop

Slide 14© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Map Reduce
Get Started with BIG Data & Hadoop

Slide 15© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Map Reduce – Scenario
Let us consider a real life scenario to understand the importance of “Map Reduce” in Hadoop
Suppose, you are the handling a project which has x tasks and takes 100 hours
for one resource to complete
1 x 100 = 100 hours
100/10(resources) = 10 hours
Get Started with BIG Data & Hadoop
Slide 16© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
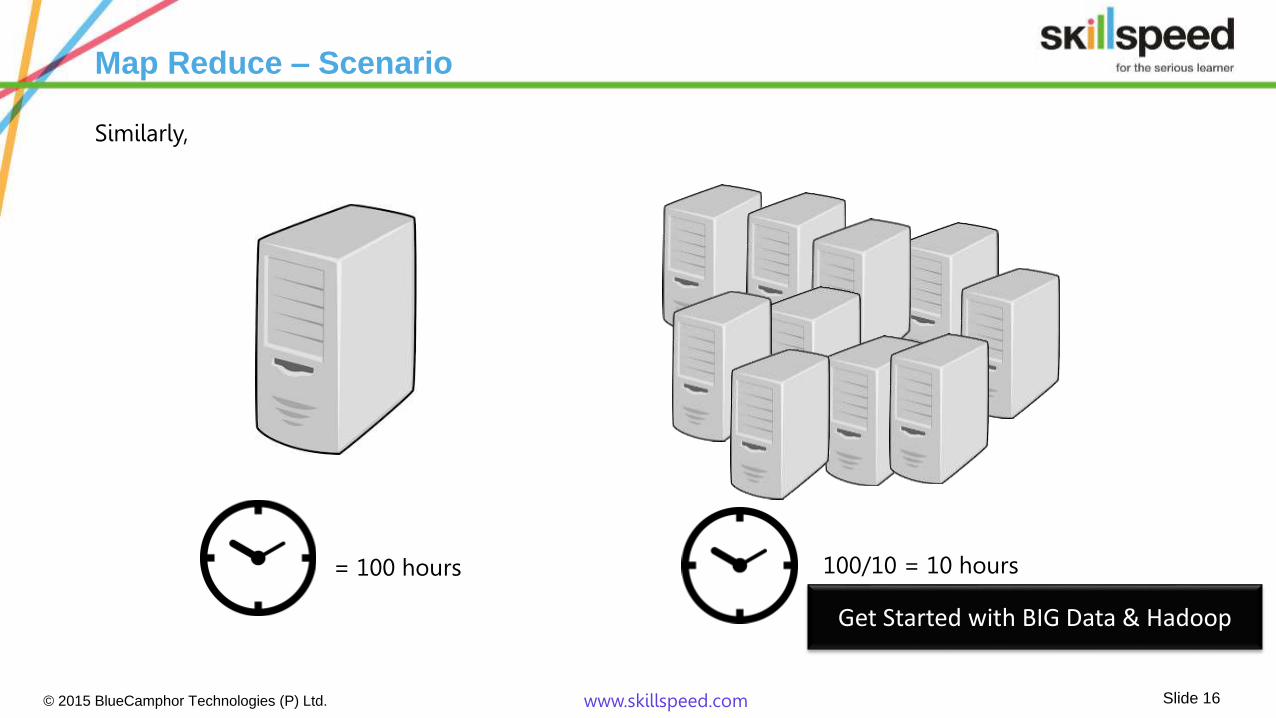
Similarly,
= 100 hours 100/10 = 10 hours
Map Reduce – Scenario
Get Started with BIG Data & Hadoop

Slide 17© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
More Scenarios on Map-Reduce
Problem Statement:
Find maximum stock market levels recorded in a span of 5 years
Problem Statement:
De-identify personal identifier information
Get Started with BIG Data & Hadoop

Slide 18© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Traditional Solution
matchesSplit Data
VeryBig
Data
Allmatches
grep
grep
grep
cat
grep
:
matches
matches
matches
Split Data
Split Data
Split Data
Get Started with BIG Data & Hadoop

Slide 19© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
MapReduce Solution
VeryBig
Input
Split Data
Allmatches
:
Split Data
Split Data
Split Data
MAP
REDUCE
MapReduce Framework
Get Started with BIG Data & Hadoop

Slide 20© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
MapReduce Advantages
Two biggest advantages:
ᗍ Takes processing to the dataᗍ Allows processing data in parallel
a b
c
Map Task
HDFS BlockData Center
Rack
Node
Get Started with BIG Data & Hadoop

Slide 21© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
MapReduce Flow
1. Input data is present in data nodes
2. Map tasks = Input Splits
3. Mappers produce intermediate data
4. Data exchanged among nodes in “shuffling”
5. All data of same key goes to same reducer
6. Reducer output stored at output location
Node 1
INPUT DATA
Map
Node 2
Map
Node 1
Reduce
Node 1
Reduce
Get Started with BIG Data & Hadoop

Slide 22© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
What is Expected?
In this section, we will discuss the questions on HDFS and MapReduce that is asked during the interview
This will help you analyze the importance of the topics under study!
Get Started with BIG Data & Hadoop

Slide 23© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
What is the use of Namenode in HDFS?
What is DataNode in HDFS?
What is Job Tracker in HDFS?
What is MapReduce?
How does an Hadoop application look like on their basic components?
And many more…………….
The Top 5 Interview Questions
Get Started with BIG Data & Hadoop

Slide 24© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Job Trends – Hadoop
Get Started with BIG Data & Hadoop

Slide 25© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Why SkillSpeed?
Course Curriculum
from Industry Experts
Instructor Led Live Virtual
Sessions
Lifetime access to Course
Content via LMS
100% Placement Assistance
24x7 Support
Get Started with BIG Data & Hadoop
Slide 26© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
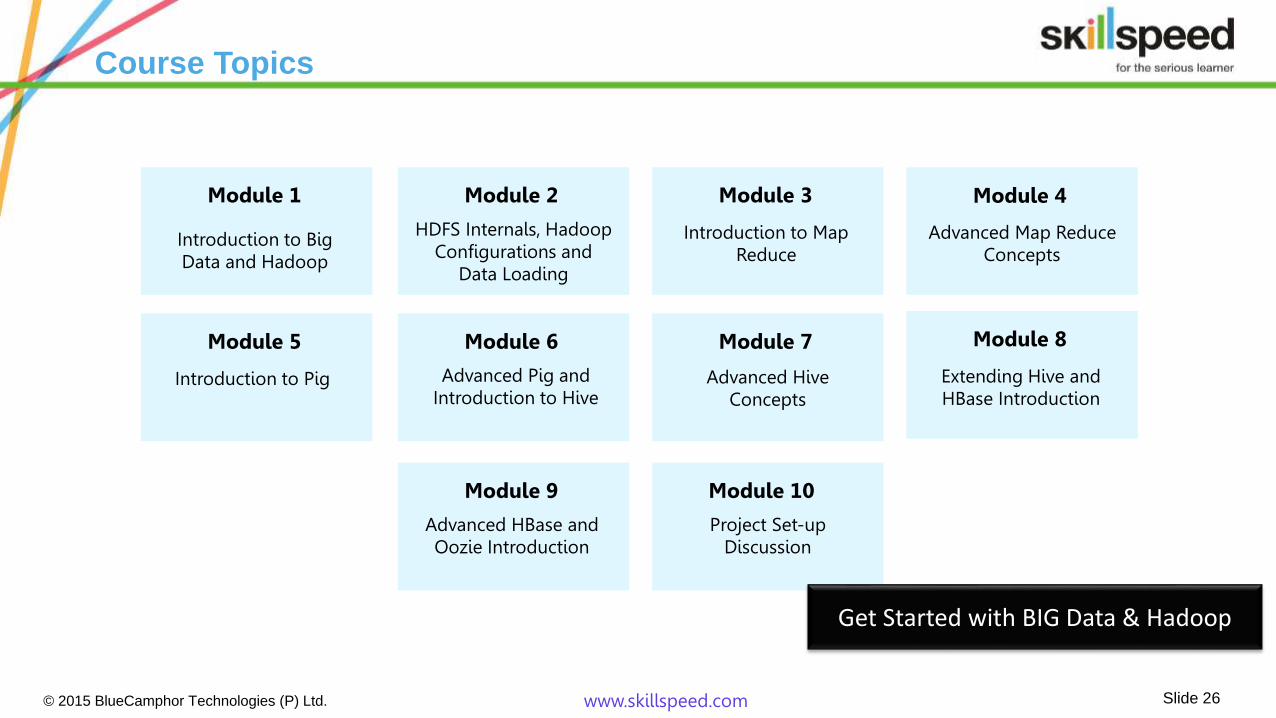
Course Topics
Module 1
Introduction to Big Data and Hadoop
Module 2
HDFS Internals, Hadoop Configurations and
Data Loading
Module 3
Introduction to Map Reduce
Module 4
Advanced Map Reduce Concepts
Module 5
Introduction to Pig
Module 6
Advanced Pig and Introduction to Hive
Module 7
Advanced Hive Concepts
Module 8
Extending Hive and HBase Introduction
Module 9
Advanced HBase and Oozie Introduction
Module 10
Project Set-up Discussion
Get Started with BIG Data & Hadoop

Slide 27© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Corporate Partners
Get Started with BIG Data & Hadoop

Slide 28© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Lines open 24/7
To know more about the course, Please contact:
IND +91-90660-20904 USA 1866-607-6547 (Toll Free)
Or reach us at
Contact Us
Get Started with BIG Data & Hadoop

Slide 29© 2015 BlueCamphor Technologies (P) Ltd. www.skillspeed.com
Image References
Google images – credit for google, Facebook and LinkedIn LOGO and Snapshots
http://iconizer.net/en/search/1/collection:Practika
http://findicons.com/icon/66444/user_group
http://www.virtualizor.com/tour
https://accounts.it.et.byu.edu/
http://www.clipartsfree.net/tag/server.html
http://www.gopixpic.com/16/time-clock-icon-png-download
http://blog.smartbear.com/requirements/how-to-interview-users-to-find-out-what-they-really-want/
http://www.lincs.fr/research/areas/big-data/
http://www.counsellingpages.co.uk/
http://langfordsconsultancy.com/langfords-training-support-package/
http://cbsepathshala.blogspot.in/2012/05/physics-class-x-chapter-electricity.html
http://mmatycoon.com/tycoontimes/tycoontimesstory.php?SID=1010
