hadoop 2 - more than mapreduce
DESCRIPTION
This talk gives an introduction into Hadoop 2 and YARN. Then the changes for MapReduce 2 are explained. Finally Tez and Spark are explained and compared in detail. The talk has been held on the Parallel 2014 conference in Karlsruhe, Germany on 06.05.2014. Agenda: - Introduction to Hadoop 2 - MapReduce 2 - Tez, Hive & Stinger Initiative - SparkTRANSCRIPT

06.05.2014
2
Hadoop 2 - More than MapReduce!
uweseiler

06.05.2014
2 About me
Big Data Nerd
TravelpiratePhotography Enthusiast
Hadoop Trainer NoSQL Fan Boy

06.05.2014
2 About us
specializes on...
Big Data Nerds Agile Ninjas Continuous Delivery Gurus
Enterprise Java Specialists Performance Geeks
Join us!

06.05.2014
2 Agenda
• Introduction to Hadoop 2
• MapReduce 2
• Tez, Hive & Stinger Initiative
• Spark

06.05.2014
2 Agenda
• Introduction to Hadoop 2
• MapReduce 2
• Tez, Hive & Stinger Initiative
• Spark

06.05.2014
2
…there was MapReduce
In the beginning of Hadoop
• It could handle data sizes way beyond thoseof its competitors
• It was resilient in the face of failure
• It made it easy for users to bring their codeand algorithms to the data

06.05.2014
2
…but it was too low level
Hadoop 1 (2007)

06.05.2014
2
…but it was too rigid
Hadoop 1 (2007)
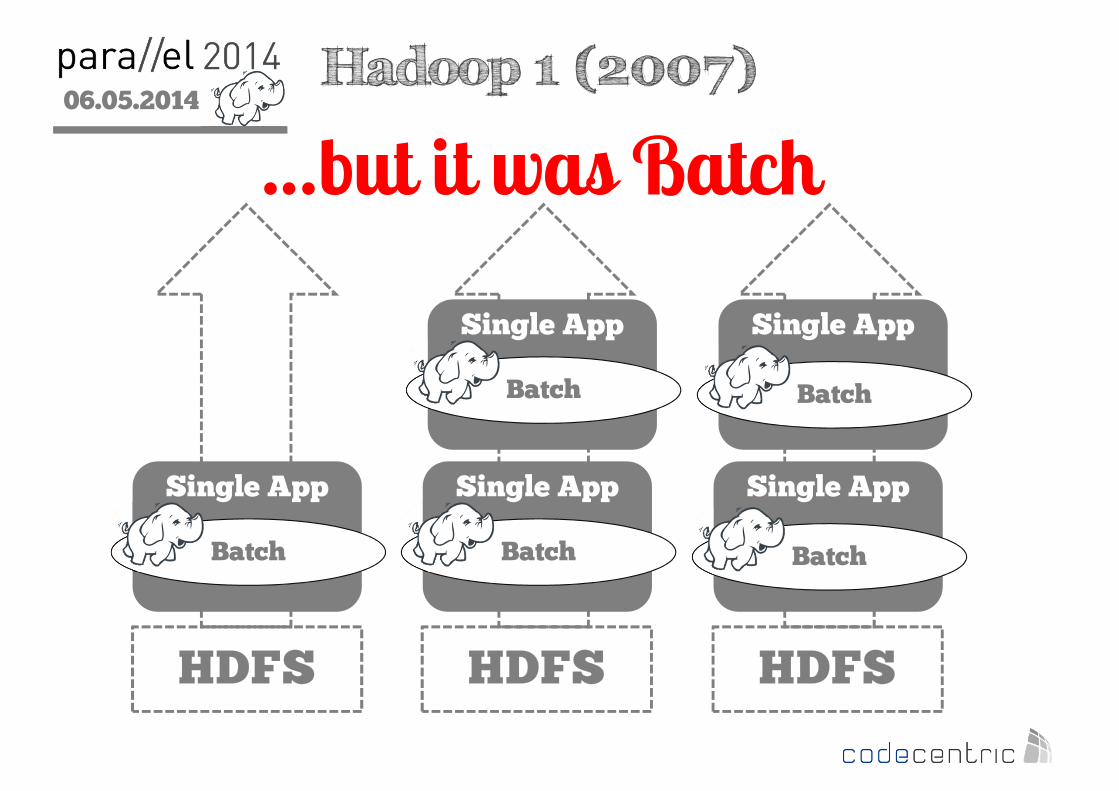
06.05.2014
2
HDFS
…but it was Batch
HDFS HDFS
Single App
Batch
Single App
Batch
Single App
Batch
Single App
Batch
Single App
Batch
Hadoop 1 (2007)

06.05.2014
2
…but it had limitations
Hadoop 1 (2007)
• Scalability
– Maximum cluster size ~ 4,500 nodes – Maximum concurrent tasks – 40,000– Coarse synchronization in JobTracker
• Availability
– Failure kills all queued and running jobs
• Hard partition of resources into map & reduce slots
– Low resource utilization
• Lacks support for alternate paradigms and services

06.05.2014
2
YARN to the rescue!
Hadoop 2 (2013)

06.05.2014
2 A brief history of Hadoop 2
• Originally conceived & architected by the team at Yahoo! – Arun Murthy created the original JIRA in 2008 and now is
the Hadoop 2 release manager
• The community has been working on Hadoop 2 for over 4 years
• Hadoop 2 based architecture running at scale at Yahoo! – Deployed on 35,000+ nodes for 6+ months
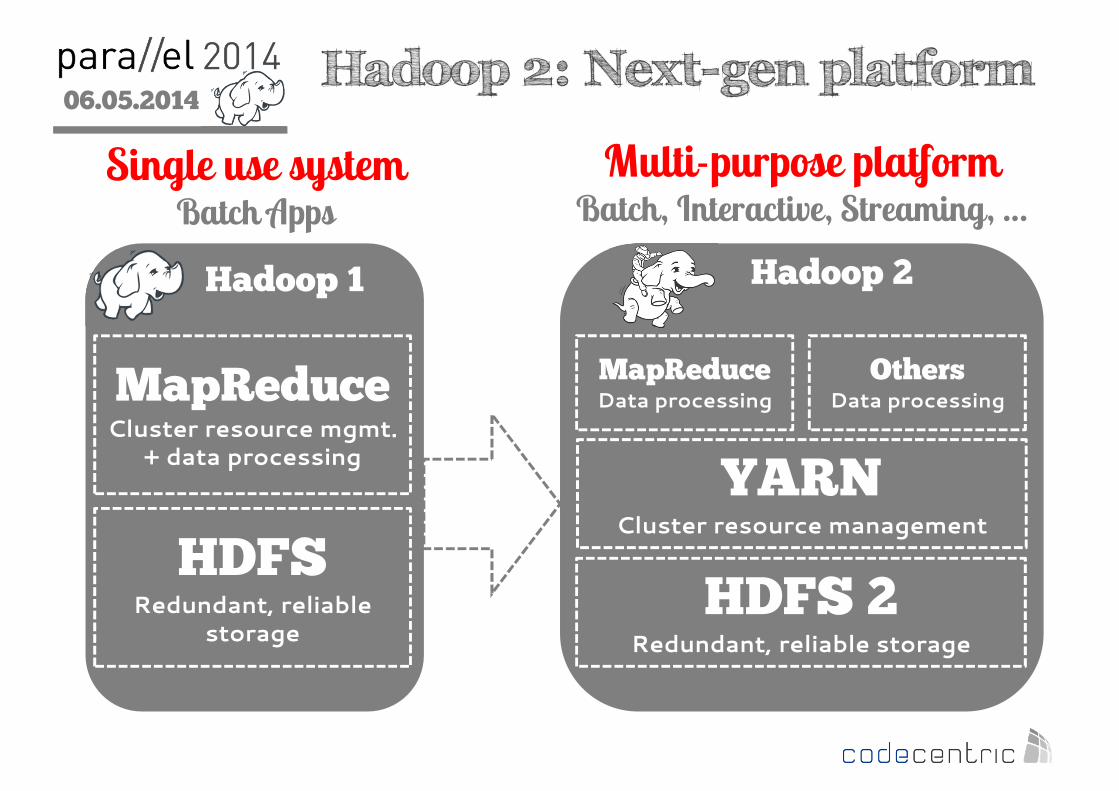
06.05.2014
2
Hadoop 1
HDFSRedundant, reliable
storage
Hadoop 2: Next-gen platform
MapReduceCluster resource mgmt.
+ data processing
Hadoop 2
HDFS 2Redundant, reliable storage
MapReduceData processing
Single use systemBatch Apps
Multi-purpose platformBatch, Interactive, Streaming, …
YARNCluster resource management
OthersData processing

06.05.2014
2 Taking Hadoop beyond batch
Applications run natively in Hadoop
HDFS 2Redundant, reliable storage
BatchMapReduce
Store all data in one placeInteract with data in multiple ways
YARNCluster resource management
InteractiveTez
OnlineHOYA
StreamingStorm, …
GraphGiraph
In-MemorySpark
OtherSearch, …

06.05.2014
2 YARN: Design Goals
• Build a new abstraction layer by splitting up the two major functions of the JobTracker• Cluster resource management • Application life-cycle management
• Allow other processing paradigms• Flexible API for implementing YARN apps• MapReduce becomes YARN app
• Lots of different YARN apps
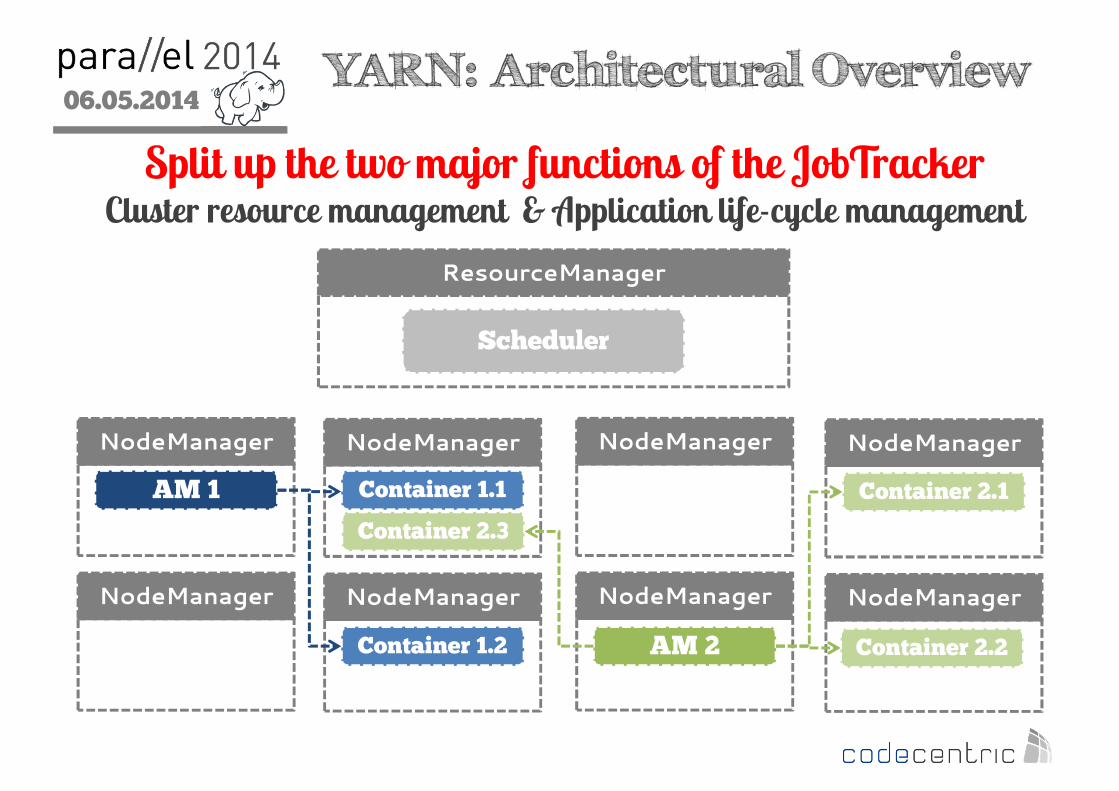
06.05.2014
2 YARN: Architectural Overview
Split up the two major functions of the JobTrackerCluster resource management & Application life-cycle management
ResourceManager
NodeManager NodeManager NodeManager NodeManager
NodeManager NodeManager NodeManager NodeManager
Scheduler
AM 1
Container 1.2
Container 1.1
AM 2
Container 2.1
Container 2.2
Container 2.3
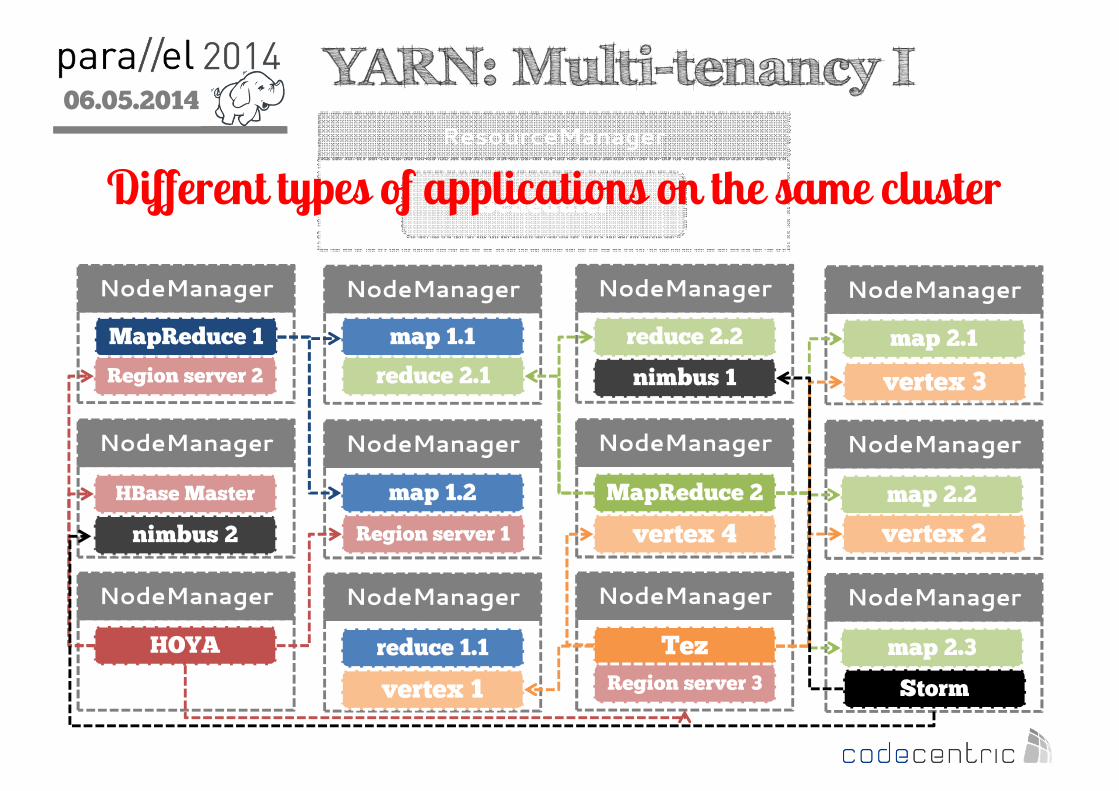
06.05.2014
2 YARN: Multi-tenancy IResourceManager
NodeManager NodeManager NodeManager NodeManager
NodeManager NodeManager NodeManager NodeManager
Scheduler
MapReduce 1
map 1.2
map 1.1
MapReduce 2
map 2.1
map 2.2
reduce 2.1
NodeManager NodeManager NodeManager NodeManager
reduce 1.1 Tez map 2.3
reduce 2.2
vertex 1
vertex 2
vertex 3
vertex 4
HOYA
HBase Master
Region server 1
Region server 2
Region server 3 Storm
nimbus 1
nimbus 2
Different types of applications on the same cluster
06.05.2014
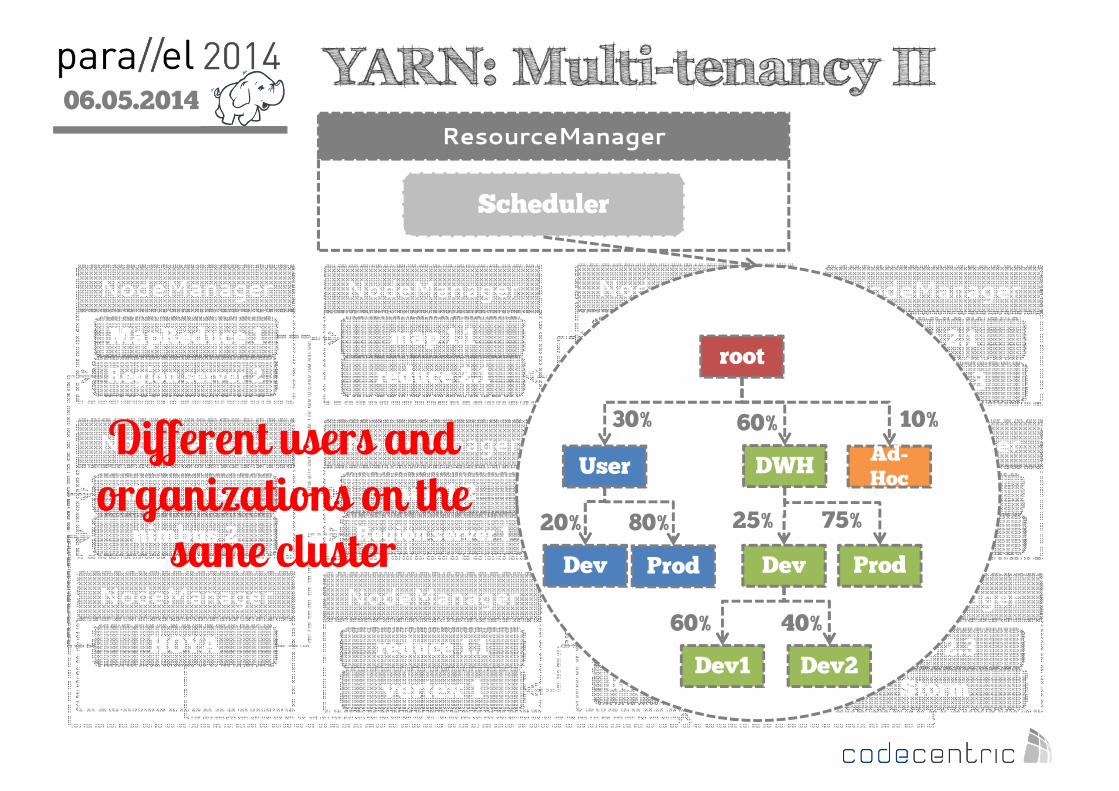
2 YARN: Multi-tenancy IIResourceManager
NodeManager NodeManager NodeManager NodeManager
NodeManager NodeManager NodeManager NodeManager
Scheduler
MapReduce 1
map 1.2
map 1.1
MapReduce 2
map 2.1
map 2.2
reduce 2.1
NodeManager NodeManager NodeManager NodeManager
reduce 1.1 Tez map 2.3
reduce 2.2
vertex 1
vertex 2
vertex 3
vertex 4
HOYA
HBase Master
Region server 1
Region server 2
Region server 3 Storm
nimbus 1
nimbus 2
DWHUserAd-Hoc
root
30% 60% 10%
Dev Prod
20% 80%
Dev Prod
Dev1 Dev2
25% 75%
60% 40%
Different users and organizations on the
same cluster

06.05.2014
2 YARN Apps: Overview
• MapReduce 2 Batch
• Tez DAG Processing
• Spark In-Memory
• Storm Stream Processing
• Samza Stream Processing
• Apache S4 Stream Processing
• HOYA HBase on YARN
• Apache Giraph Graph Processing
• Apache Hama Bulk Synchronous Parallel
• Elastic Search Scalable Search

06.05.2014
2 Agenda
• Introduction to Hadoop 2
• MapReduce 2
• Tez, Hive & Stinger Initiative
• Spark

06.05.2014
2 MapReduce 2: In a nutshell
• MapReduce is now a YARN app• No more map and reduce slots, it’s containers now
• No more JobTracker, it’s YarnAppmaster library now
• Multiple versions of MapReduce • The older mapredAPIs work without modification or recompilation
• The newer mapreduceAPIs may need to be recompiled
• Still has one master server component: the Job History Server • The Job History Server stores the execution of jobs
• Used to audit prior execution of jobs
• Will also be used by YARN framework to store charge backs at that level
• Better cluster utilization
• Increased scalability & availability

06.05.2014
2 MapReduce 2: Shuffle
• Faster Shuffle • Better embedded server: Netty
• Encrypted Shuffle • Secure the shuffle phase as data moves across the cluster
• Requires 2 way HTTPS, certificates on both sides
• Causes significant CPU overhead, reserve 1 core for this work
• Certificates stored on each node (provision with the cluster), refreshed every 10 secs
• Pluggable Shuffle Sort • Shuffle is the first phase in MapReduce that is guaranteed to not be data-local
• Pluggable Shuffle/Sort allows application developers or hardware developers to intercept the network-heavy workload and optimize it
• Typical implementations have hardware components like fast networks and software components like sorting algorithms
• API will change with future versions of Hadoop

06.05.2014
2 MapReduce 2: Performance
• Key Optimizations • No hard segmentation of resource into map and reduce slots
• YARN scheduler is more efficient
• MR2 framework has become more efficient than MR1: shuffle phase in MRv2 is more performant with the usage of Netty.
• 40.000+ nodes running YARN across over 365 PB of data.
• About 400.000 jobs per day for about 10 million hours of compute time.
• Estimated 60% – 150% improvement on node usage per day
• Got rid of a whole 10,000 node datacenter because of their increased utilization.

06.05.2014
2 Agenda
• Introduction to Hadoop 2
• MapReduce 2
• Tez, Hive & Stinger Initiative
• Spark

06.05.2014
2 Apache Tez: In a nutshell
• Distributed execution framework that works on computations represented as directed acyclic graphs (DAG)
• Tez is Hindi for “speed”
• Naturally maps to execution plans produced by query optimizers
• Highly customizable to meet a broad spectrum of use cases and to enable dynamic performance optimizations at runtime
• Built on top of YARN
06.05.2014
2
Hadoop 1
HDFSRedundant, reliable storage
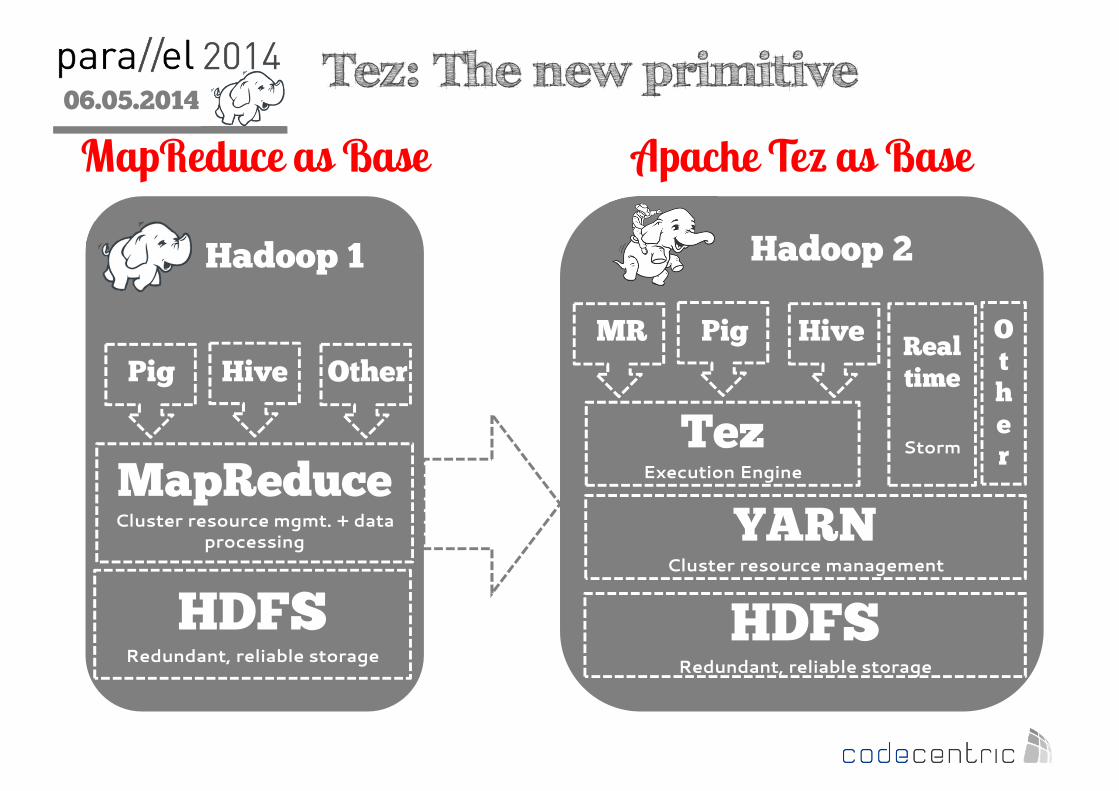
Tez: The new primitive
MapReduceCluster resource mgmt. + data
processing
Hadoop 2
MapReduce as Base Apache Tez as Base
Pig Hive Other
HDFSRedundant, reliable storage
YARNCluster resource management
TezExecution Engine
MR Pig HiveRealtime
Storm
Other
06.05.2014
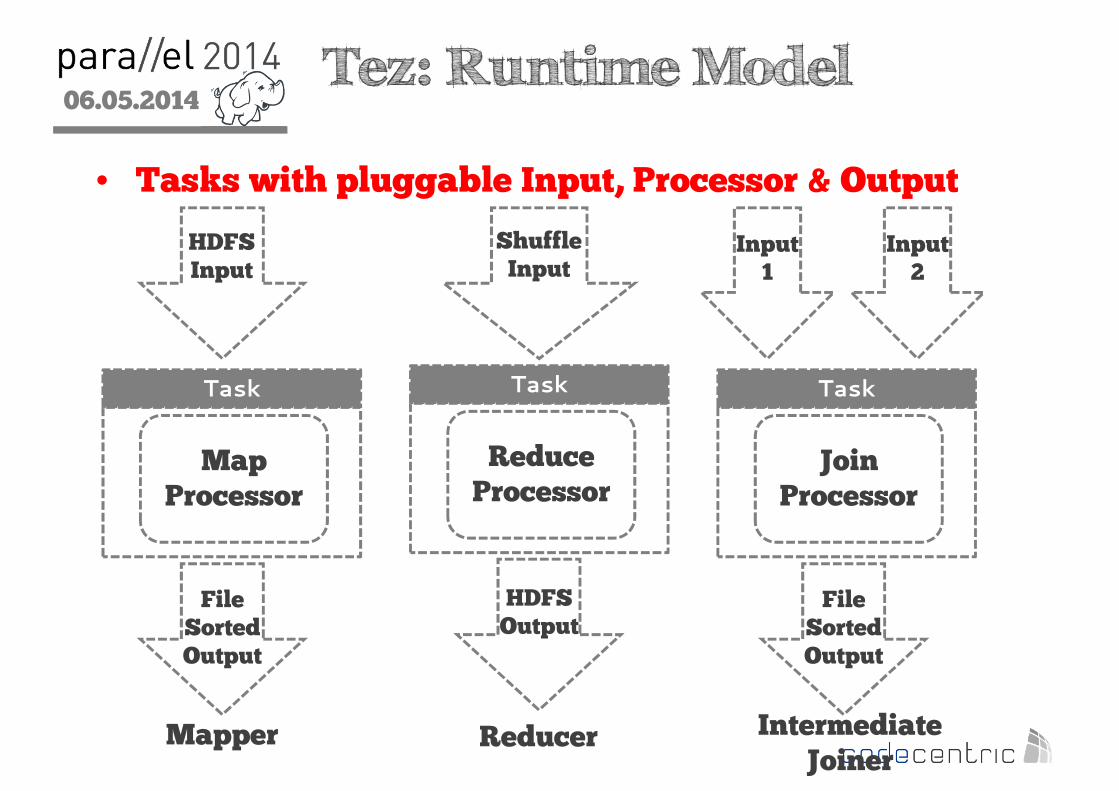
2 Tez: Runtime Model
• Tasks with pluggable Input, Processor & Output
Task
HDFSInput
MapProcessor
FileSortedOutput
Mapper
Task
ReduceProcessor
Reducer
ShuffleInput
HDFSOutput
Task
Input1
JoinProcessor
FileSortedOutput
Intermediate Joiner
Input2
06.05.2014
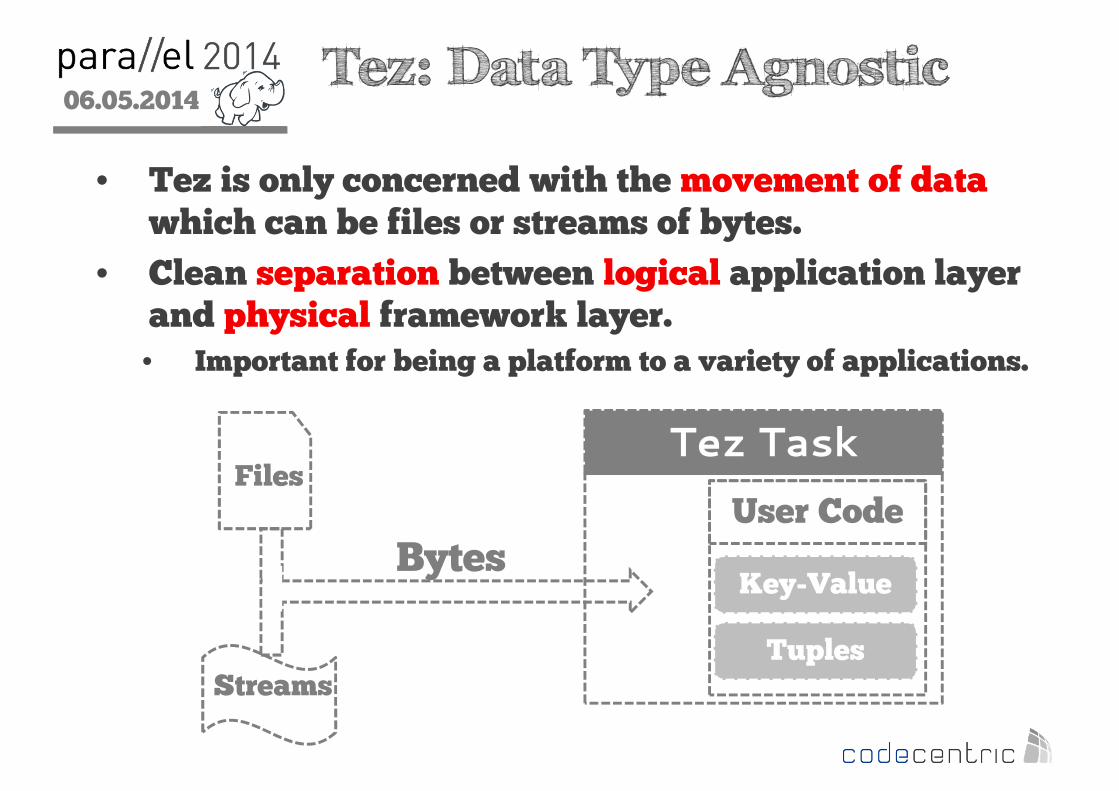
2 Tez: Data Type Agnostic
• Tez is only concerned with the movement of data which can be files or streams of bytes.
• Clean separation between logical application layer and physical framework layer. • Important for being a platform to a variety of applications.
Files
Streams
Tez Task
User Code
Key-Value
Tuples
Bytes
06.05.2014
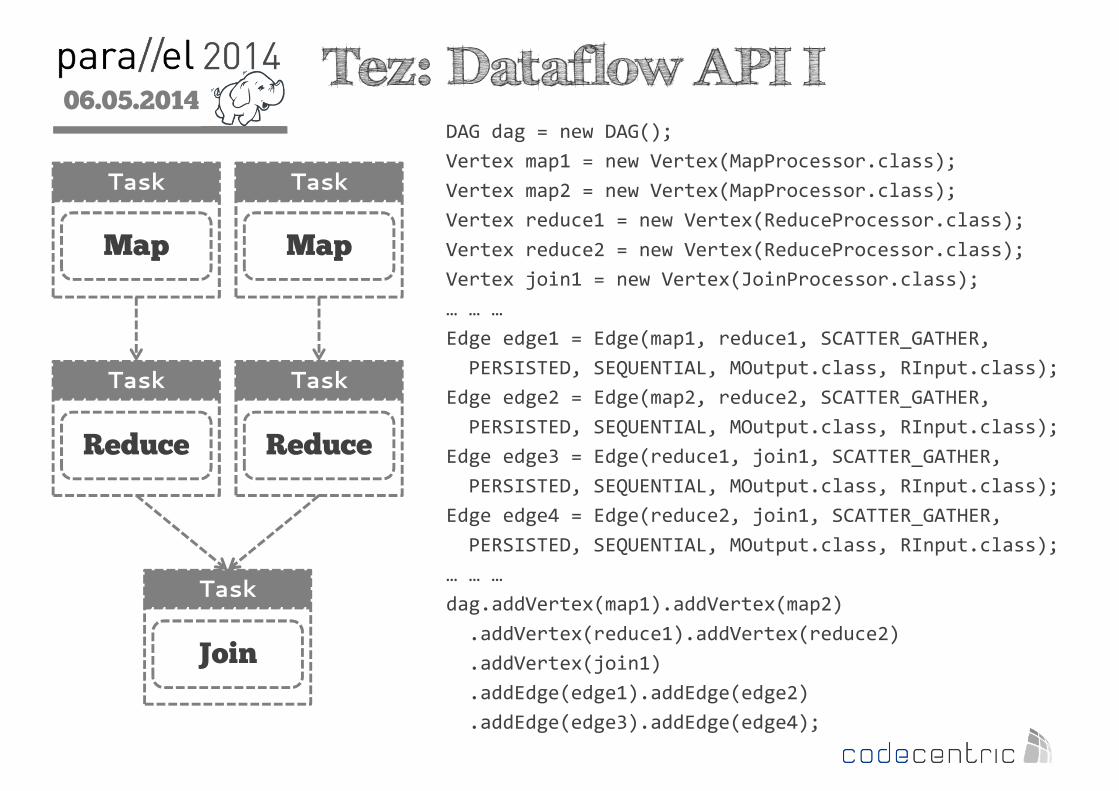
2 Tez: Dataflow API I
Task
Map
Task
Map
Task
Reduce
Task
Reduce
Task
Join
DAG dag = new DAG();
Vertex map1 = new Vertex(MapProcessor.class);
Vertex map2 = new Vertex(MapProcessor.class);
Vertex reduce1 = new Vertex(ReduceProcessor.class);
Vertex reduce2 = new Vertex(ReduceProcessor.class);
Vertex join1 = new Vertex(JoinProcessor.class);
… … …
Edge edge1 = Edge(map1, reduce1, SCATTER_GATHER,
PERSISTED, SEQUENTIAL, MOutput.class, RInput.class);
Edge edge2 = Edge(map2, reduce2, SCATTER_GATHER,
PERSISTED, SEQUENTIAL, MOutput.class, RInput.class);
Edge edge3 = Edge(reduce1, join1, SCATTER_GATHER,
PERSISTED, SEQUENTIAL, MOutput.class, RInput.class);
Edge edge4 = Edge(reduce2, join1, SCATTER_GATHER,
PERSISTED, SEQUENTIAL, MOutput.class, RInput.class);
… … …
dag.addVertex(map1).addVertex(map2)
.addVertex(reduce1).addVertex(reduce2)
.addVertex(join1)
.addEdge(edge1).addEdge(edge2)
.addEdge(edge3).addEdge(edge4);

06.05.2014
2 Tez: Dataflow API II
Data movement - Defines routing of data between tasks
Task
Task
Task
Task
Task
Task Task
Task
Task
Task
Task
• One-To-One: Data from producer task x routes to consumer task y
• Broadcast: Data from a producer task routes to all consumer tasks.
• Scatter-Gather: Producer tasks scatter data into shards and consumer tasks gather the data.

06.05.2014
2 Tez: Dataflow API III
• Data source – Defines the lifetime of a task output• Persisted: Output will be available after the task exits.
Output may be lost later on.
• Persisted-Reliable: Output is reliably stored and will always be available
• Ephemeral: Output is available only while the producer task is running
• Scheduling – Defines when a consumer task is scheduled• Sequential: Consumer task may be scheduled after a
producer task completes.
• Concurrent: Consumer task must be co-scheduled with a producer task.
06.05.2014
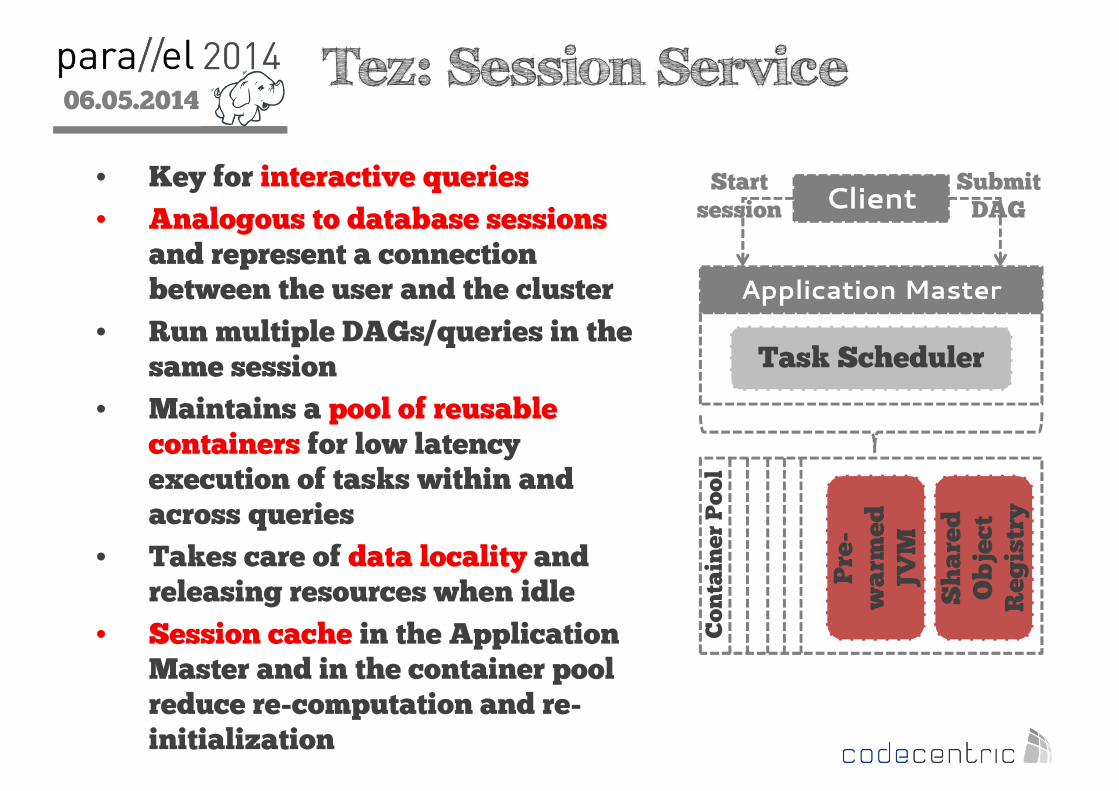
2 Tez: Session Service
• Key for interactive queries
• Analogous to database sessions and represent a connection between the user and the cluster
• Run multiple DAGs/queries in the same session
• Maintains a pool of reusable containers for low latency execution of tasks within and across queries
• Takes care of data locality and releasing resources when idle
• Session cache in the Application Master and in the container pool reduce re-computation and re-initialization
Application Master
Task Scheduler
Client
Shared
Object
Registry
Pre-
warmed
JVM
Container Pool
Startsession
SubmitDAG

06.05.2014
2 Tez: Performance I
Performance gains over MapReduce• Eliminate I/O synchronization barrier between successive computations.
• Eliminate job launch overhead of workflow jobs.
• Eliminate extra stage of map reads in every workflow job.
• Eliminate queue and resource contention suffered by workflow jobs that are started after a predecessor job completes.
MapReduce Tez
06.05.2014
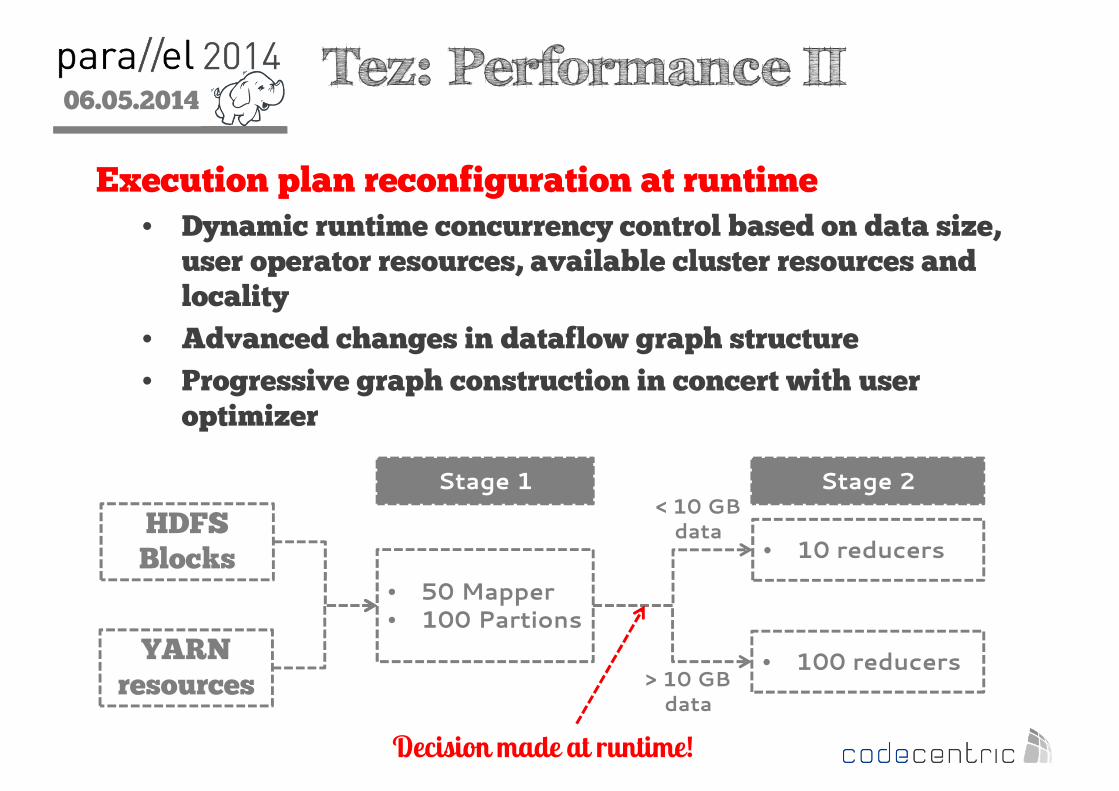
2 Tez: Performance II
Execution plan reconfiguration at runtime• Dynamic runtime concurrency control based on data size, user operator resources, available cluster resources and locality
• Advanced changes in dataflow graph structure
• Progressive graph construction in concert with user optimizer
• 50 Mapper• 100 Partions
Stage 1
HDFS Blocks
YARN resources
• 10 reducers
Stage 2
• 100 reducers
< 10 GBdata
> 10 GBdata
Decision made at runtime!
06.05.2014
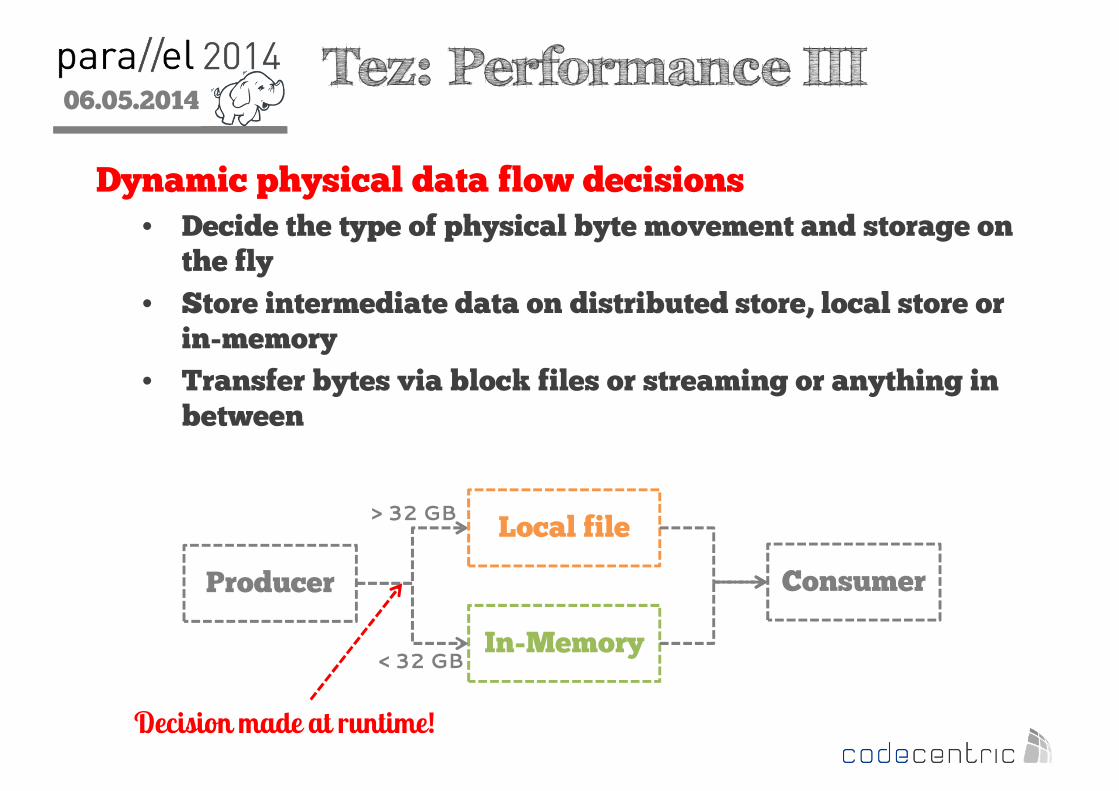
2 Tez: Performance III
Dynamic physical data flow decisions• Decide the type of physical byte movement and storage on the fly
• Store intermediate data on distributed store, local store or in-memory
• Transfer bytes via block files or streaming or anything in between
Producer Consumer
Local file
In-Memory
Decision made at runtime!
< 32 GB
> 32 GB
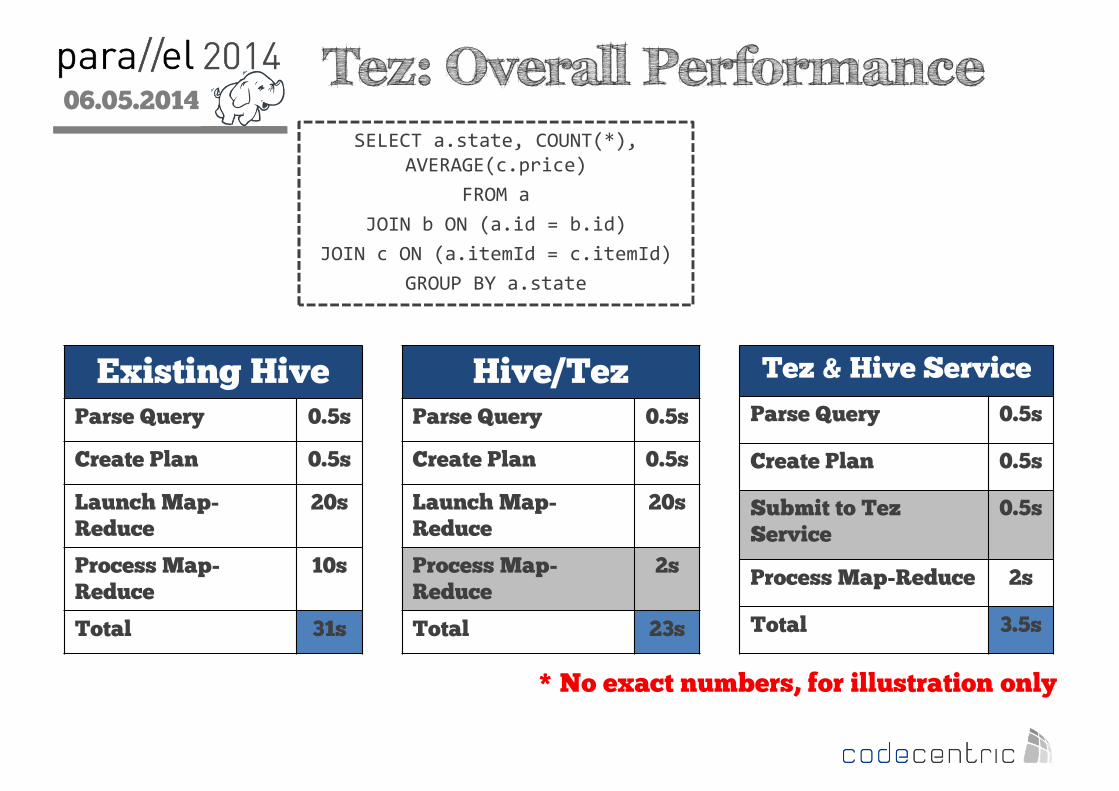
06.05.2014
2 Tez: Overall PerformanceSELECT a.state, COUNT(*),
AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
Existing HiveParse Query 0.5s
Create Plan 0.5s
Launch Map-Reduce
20s
Process Map-Reduce
10s
Total 31s
Hive/TezParse Query 0.5s
Create Plan 0.5s
Launch Map-Reduce
20s
Process Map-Reduce
2s
Total 23s
Tez & Hive Service
Parse Query 0.5s
Create Plan 0.5s
Submit to Tez Service
0.5s
Process Map-Reduce 2s
Total 3.5s
* No exact numbers, for illustration only
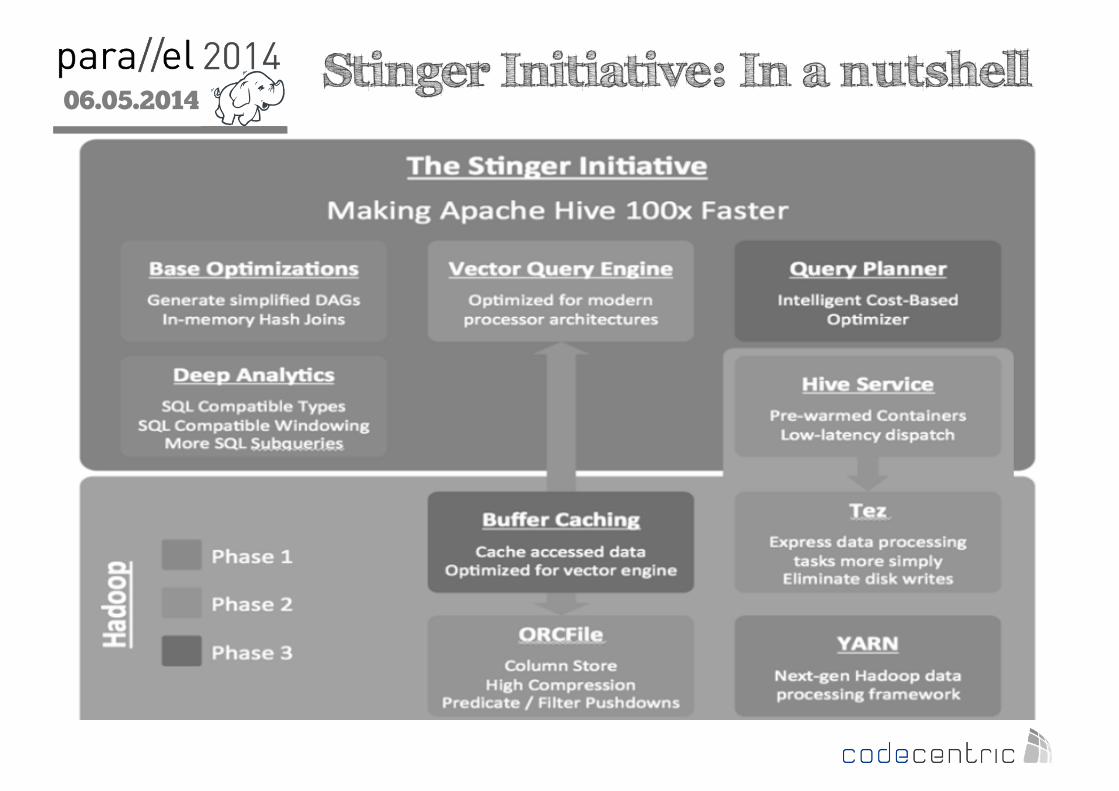
06.05.2014
2 Stinger Initiative: In a nutshell
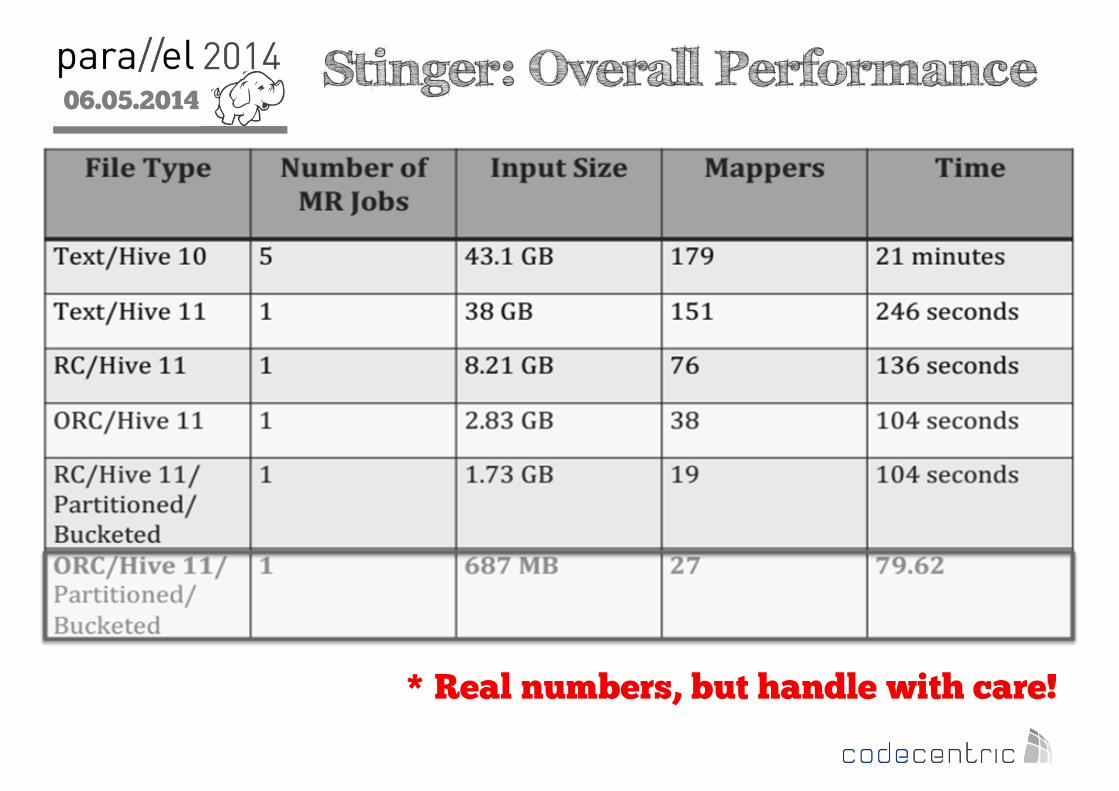
06.05.2014
2 Stinger: Overall Performance
* Real numbers, but handle with care!

06.05.2014
2 Tez: Getting started
• Stinger Phase 3 has been delivered with Hive 0.13• Incorporated in Hortonworks Data Platform (HDP) 2.1
• Can also be integrated into CHD and MapR
• Switch the execution engine (using the Hive Shell)
set hive.execution.engine=tez;
• Query with HiveQL as usual, check the log output andcompare the execution times
• Get comfortable with all the other goodies of Stinger Phase 3
• Run the same query multiple times to make usage of Tez Service
• Make usage of vectorization (only with ORC format):
create table data_orc stored as orc as select * from data;
set hive.vectorized.execution.enabled;
explain select * from data_orc;

06.05.2014
2 Agenda
• Introduction to Hadoop 2
• MapReduce 2
• Tez, Hive & Stinger Initiative
• Spark

06.05.2014
2 Spark: In a nutshell
• A fast and general engine for large-scale data processing and analytics
• Advanced DAG execution engine with support for data locality and in-memorycomputing
• Spark is a top-level Apache project– http://spark.apache.org
• Spark can be run on top of YARN and canread any existing HDFS data– http://spark.apache.org/docs/0.9.1/running-on-yarn.html
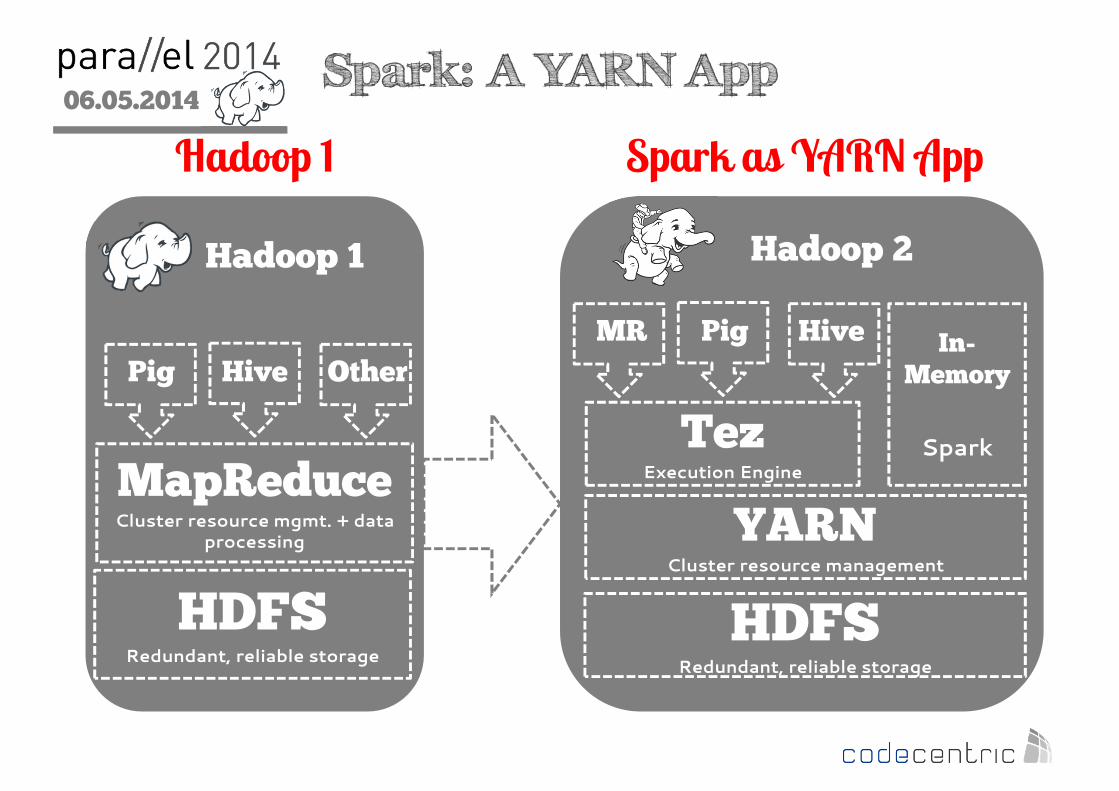
06.05.2014
2
Hadoop 1
HDFSRedundant, reliable storage
Spark: A YARN App
MapReduceCluster resource mgmt. + data
processing
Hadoop 2
Hadoop 1 Spark as YARN App
Pig Hive Other
HDFSRedundant, reliable storage
YARNCluster resource management
TezExecution Engine
MR Pig Hive In-Memory
Spark

06.05.2014
2
HDFSRedundant, reliable storage
Spark: Ecosystem
MapReduceCluster resource mgmt. + data
processing
BlinkDB
Spark Core Engine(MapReduce / Tez)
SharkSQL
(Hive)
Spark Streaming
Streaming(Storm)
MLLibMachine Learning(Mahout)
SparkRR on Spark
GraphXGraph
Computation(Giraph)

06.05.2014
2 Spark: Runtime Model
• Resilient Distributed Datasets (RDD)
• Read-only partitioned collection of records• Optionally cached in memory across cluster
• Conceptually, RDDs can be roughly viewed as partitioned, locality aware distributed vectors
• An RDD…– either points to a direct data source
– or applies some transformation to its parent RDD(s) to generate new data elements
– Computation can be represented by lazy evaluated lineage DAGs composed by connected RDDs
RDDA11A12
A13

06.05.2014
2 Spark: RDD Persistence
• One of the most important capabilities in Spark is caching a dataset in-memory across operations
Storage Level Meaning
MEMORY_ONLY Store RDD as deserialized Java objects in the JVM. If the RDD does not
fit in memory, some partitions will not be cached and will be
recomputed on the fly each time they're needed. This is the default
level.
MEMORY_AND_DISK Store RDD as deserialized Java objects in the JVM. If the RDD does not
fit in memory, store the partitions that don't fit on disk, and read
them from there when they're needed.
MEMORY_ONLY_SER Store RDD as serialized Java objects (one byte array per partition).
This is generally more space-efficient than deserialized objects,
especially when using a fast serializer, but more CPU-intensive to
read.
MEMORY_AND_DISK_SER Similar to MEMORY_ONLY_SER, but spill partitions that don't fit in
memory to disk instead of recomputing them on the fly each time they're
needed.
DISK_ONLY Store the RDD partitions only on disk.
MEMORY_ONLY_2,
MEMORY_AND_DISK_2,
… … …
Same as the levels above, but replicate each partition on two cluster
nodes.

06.05.2014
2 Spark: RDD Operations
• Transformations - Create new datasets from existing ones
• map(func)
• filter(func)
• sample(withReplacement,fraction, seed)
• union(otherDataset)
• distinct([numTasks]))
• groupByKey([numTasks])
• … … …
• Actions - Return a value to the client after running a computation on the dataset
• reduce(func)
• count()
• first()
• foreach(func)
• saveAsTextFile(path)
• … … …
06.05.2014
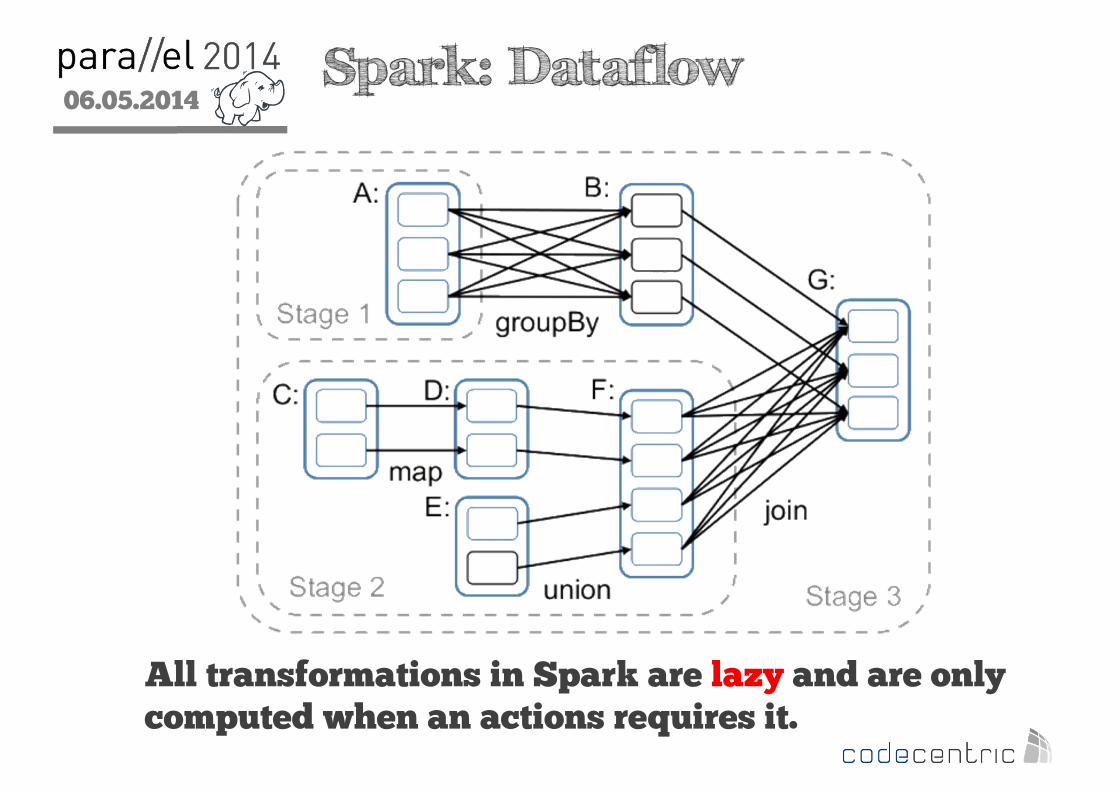
2 Spark: Dataflow
All transformations in Spark are lazy and are only computed when an actions requires it.

06.05.2014
2 Spark: In-Memory Magic I
“In fact, one study* analyzed the accesspatterns in the Hive warehouses atFacebook and discovered that for the vastmajority (96%) of jobs, the entire inputscould fit into a fraction of the cluster’stotal memory.”
* G. Ananthanarayanan, A. Ghodsi, S. Shenker, and I. Stoica. Disk-locality
in datacenter computing considered irrelevant. In HotOS ’11, 2011.

06.05.2014
2 Spark: In-Memory Magic II
• Without cache• Elements are accessed in an iterator-based streaming
style
• One element a time, no bulk copy
• Space complexity is almost O(1) when there’s only narrow dependencies
• With cache• One block per RDD partition
• LRU cache eviction
• Locality aware
• Evicted blocks can be recomputed in parallel with the help of RDD lineage DAG

06.05.2014
2 Spark: Parallelism
Can be specified in a number of different ways
• RDD partition number• sc.textFile("input", minSplits = 10)
• sc.parallelize(1 to 10000, numSlices = 10)
• Mapper side parallelism• Usually inherited from parent RDD(s)
• Reducer side parallelism• rdd.reduceByKey(_ + _, numPartitions = 10)
• rdd.reduceByKey(partitioner = p, _ + _)
• “Zoom in/out”• rdd.repartition(numPartitions: Int)
• rdd.coalesce(numPartitions: Int, shuffle: Boolean)
06.05.2014
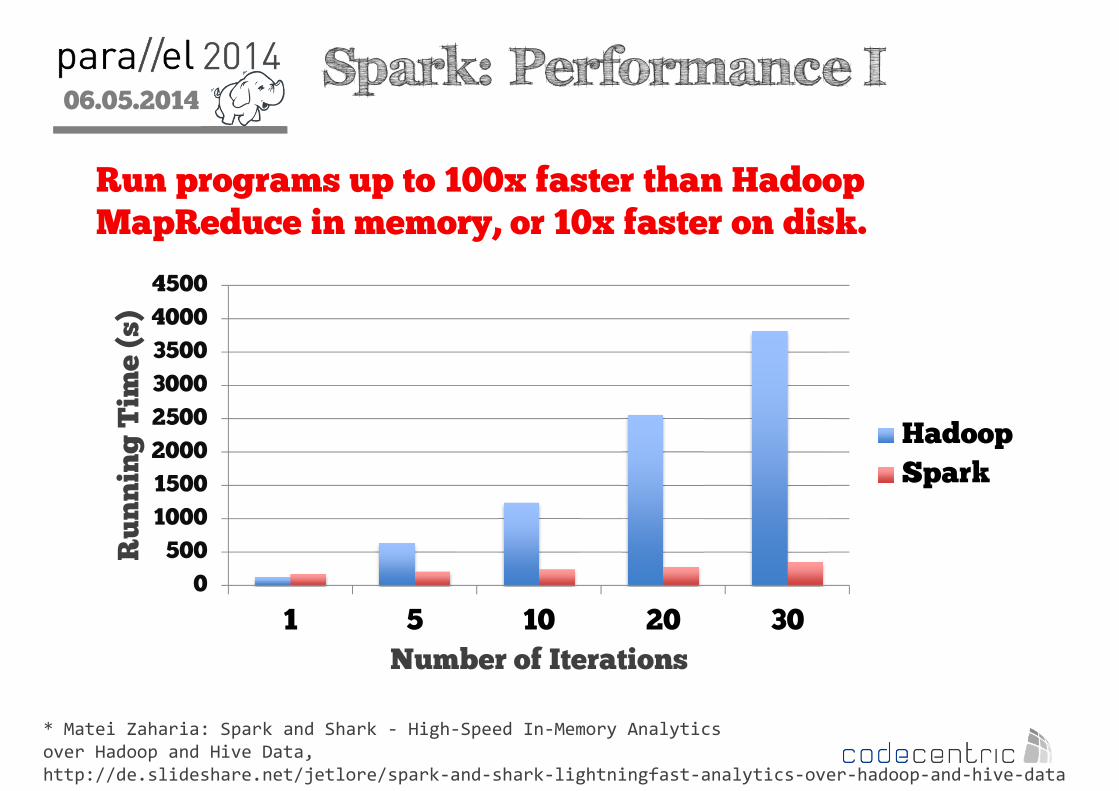
2 Spark: Performance I
* Matei Zaharia: Spark and Shark - High-Speed In-Memory Analytics
over Hadoop and Hive Data,
http://de.slideshare.net/jetlore/spark-and-shark-lightningfast-analytics-over-hadoop-and-hive-data
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
0
500
1000
1500
2000
2500
3000
3500
4000
4500
1 5 10 20 30
Running Time (s)
Number of Iterations
Hadoop
Spark
06.05.2014
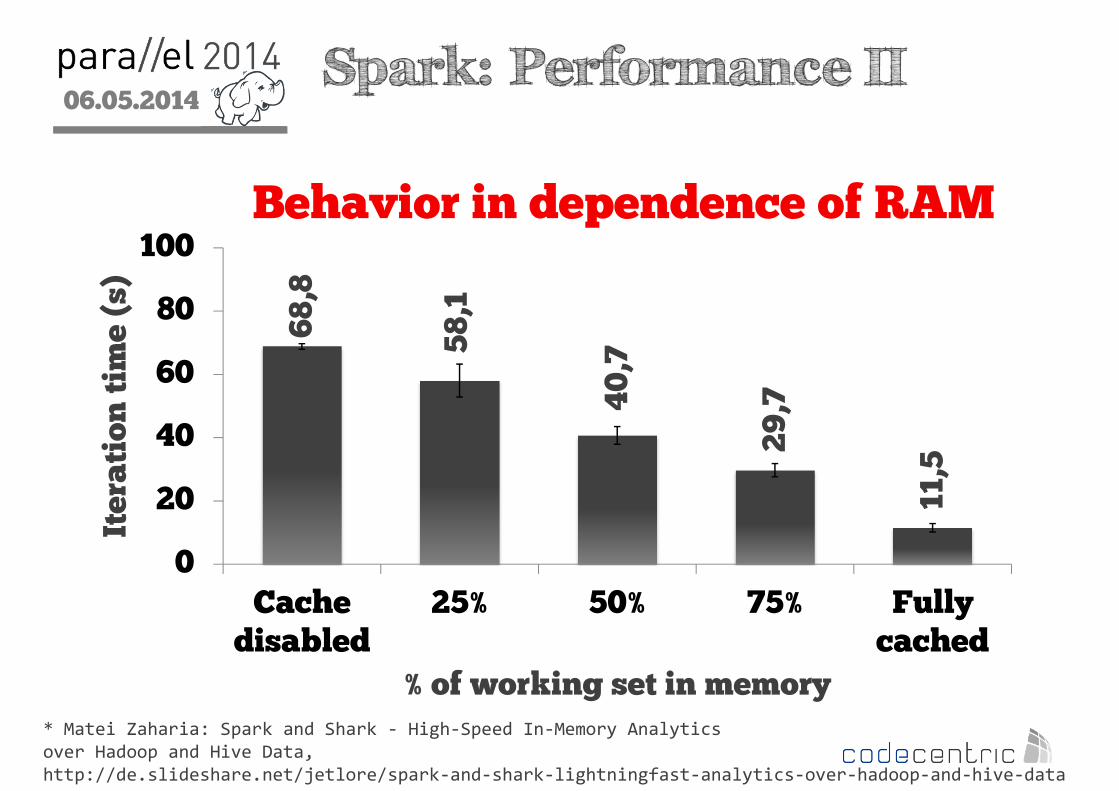
2 Spark: Performance II
68,8
58,1
40,7
29,7
11,5
0
20
40
60
80
100
Cachedisabled
25% 50% 75% Fullycached
Iteration time (s)
% of working set in memory
Behavior in dependence of RAM
* Matei Zaharia: Spark and Shark - High-Speed In-Memory Analytics
over Hadoop and Hive Data,
http://de.slideshare.net/jetlore/spark-and-shark-lightningfast-analytics-over-hadoop-and-hive-data

06.05.2014
2 Spark: Getting started
• Easiest to start with the standalone version• Can be integrated with CDH and HDP
• MapR recently integrated the whole stack
• Spark has Scala, Java and Perl API
• Start with the Quick Start Tourhttp://spark.apache.org/docs/latest/quick-start.html
• Make sure to check the ecosystem

06.05.2014
2
Hadoop 2: Summary
1. It’s about scale & performance
2. New programming models
3. MapReduce is here to stay
4. Tez vs. Spark: Fight!

06.05.2014
2 One more thing…
Let’s get started with Hadoop 2!

06.05.2014
2 Hortonworks Sandbox 2.1
http://hortonworks.com/products/hortonworks-sandbox

06.05.2014
2 Trainings
Developer Training
• 19. - 22.05.2014, Düsseldorf
• 30.06 - 03.07.2014, München
• 04. - 07.08.2014, Frankfurt
Admin Training
• 26. - 28.05.2014, Düsseldorf
• 07. - 09.07.2014, München
• 11. - 13.08.2014, Frankfurt
Details:
https://www.codecentric.de/schulungen-und-workshops/

06.05.2014
2 Thanks for listening