gpu for game computing - home -...
TRANSCRIPT

GPU for Game Computing
Avi Bleiweiss

GPU transitionCISC to RISC
Dynamic architectureCompute, bandwidth
Data parallelOften algorithm redesign
Game computingSimulation, AI, Audio

GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary
FYSI, physics simulation case study

GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary
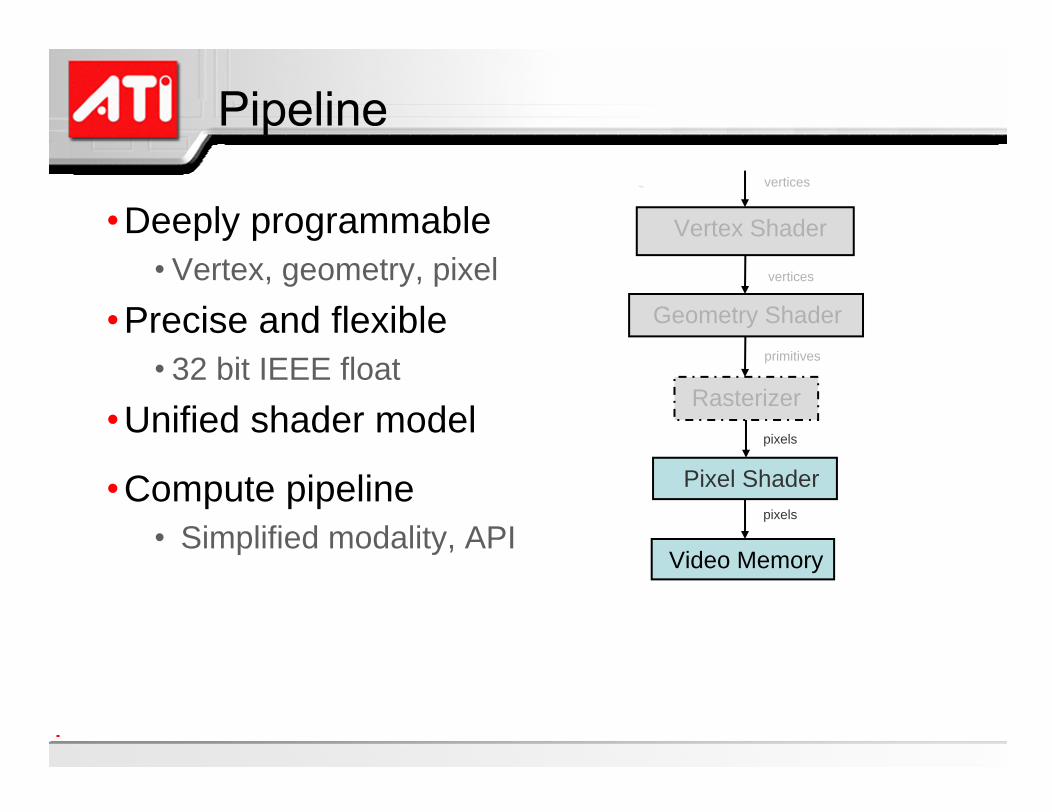
Deeply programmableVertex, geometry, pixel
Precise and flexible32 bit IEEE float
Unified shader model
Compute pipelineSimplified modality, API
Vertex Shader
Geometry Shader
Pixel Shader
Rasterizer
vertices
vertices
primitives
pixels
pixels
Video Memory

Raw compute power48 pixel engines, eachExecutes 4 float mad per cycle@650 MHz -> 250 GFlops
Shader model 3.0Dynamic branching
Shader model 4.0Integer arithmetic

Memory256 bits wide, double edge@775 MHz -> 50 GBytes/sec0.5 GByte video memory
I/O, PCI Express x164 GBytes/secMulti-GPU shared resources
Relatively small caches

Grid formationALU heavy architecture
Stream data memory system
Many in flight threadsHide memory latency
No static data
No read-modify-write buffers

ScatterIndirect memory write (data[i] = x)Populate data structures Usually performed on CPU
GatherIndirect memory read (x = data[i])Access of data structuresMaps onto texture fetch

Input, multiple arraysDifferent resolutions
Grid computationNo inter-cell dependencies
KernelsApplied to each grid elementHigh arithmetic intensity
Output, multiple arraysMust have same resolution

Porting to GPU non-trivialSignificant speedup payoff
Efficient data structuresIn video memory, sliver
GPU for computing cheapNone of display, texture filtering
Multi-GPU Load partition, shared resources
0 1 2
3 4 5
6
3x3 Grid
7 active elements
2 sliver elements

No double precision floatSingle float good enough
No pixel scatterSelf-modifying location expensive
Dedicated branch unitsBoth sides executed
Grid outputs limited4/8 in DirectX 9/10, respectively

GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary

Complex, non-intuitivefor general computation
Quest for RISC APIReduced interface set core
Full screen quad
RISC API for renderingRay tracing

Hide graphics APIUnderlying DirectX 9 & 10
Evolving hardware seamless
ScalableMulti GPU support
Automatic multi passingOvercome GPU limitations

Opaque device pointer(s)Single, multi-GPU
Interface objects
Object actionsCreate, assign, remove
ShaderKernel
Target (2D/3D)Scratch
Texture (2D/3D)Resource
GPU ObjectAbstract Object

Data typesScalars, vectors, matrices
Load, storeResource, scratch, respectively
Kernel parametersOne time compile overhead
Compute invocationAcross grid cells
Debug, scratch dump

A single formatFor both resource, scratch
Four float components
Three component vectorAlpha channel for control
Three/four squared matrixThree dimensional array
X Y Z C
00 01 02
10 11 12
20 21 22
vector
matrix
slice #0
slice #1
slice #2

IterativeRecirculate scratches
Parallel setup pathsResources, kernels
Implicit correlationScratches, kernel
Multi pass computeSingle kernel execution
Results CPU access
Assign
Unbind
Bind
Compute
Remove
scratchesresources kernels
results
Create
Remove
Create

Grid parallel traversalTiled pattern, ownership
Point sampled grid cellsVPOS for cell index
Relative resource address Multi resolution resources
Dependent data accessMulti pass reduction
0 1 2
3 4 5
6 70 1
3 4
0 1 2 3
resources
0 1
2 3
scratches
2
5
6 7
0 1
3 4
2
5
6 70 1 2 3
0 1 2 3
3D (4x1x3)
2D (2x2)
2D (3x3)
2D (3x3)
2D (3x3)

Compute bound process
Asymmetric processing
Computation distributionSimple grid subdivision
Synchronization overheadPCI Express contention
Shared resources

GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary

Game engineSimulation, visual rendering
Physics scope Rigid, deformable bodies
Physics platformsMulti core CPU, PPU, GPU
GPU assisted physicsGame play, effects
Physics
Rendering
scene description
display

Physics scene description formatFYSL, GPU oriented
Consistent I/O abstractionSimulation input and results
Stream APIAsynchronous, discrete simulation
GPU, CPU implementationPerformance analysis

Iterative physics pipelineSystem Setup, Solver, Collision
Physics to rendering interfacePosition, transform update
Compute Abstraction LayerOn top of DirectX API


Simulation controlType, time step
Actors, hierarchicalBounding volumes, meshesLinear, angular motion
Joints, motion constraintsSpring, distance
FeedbackPath decision

Actor definition Joints definition
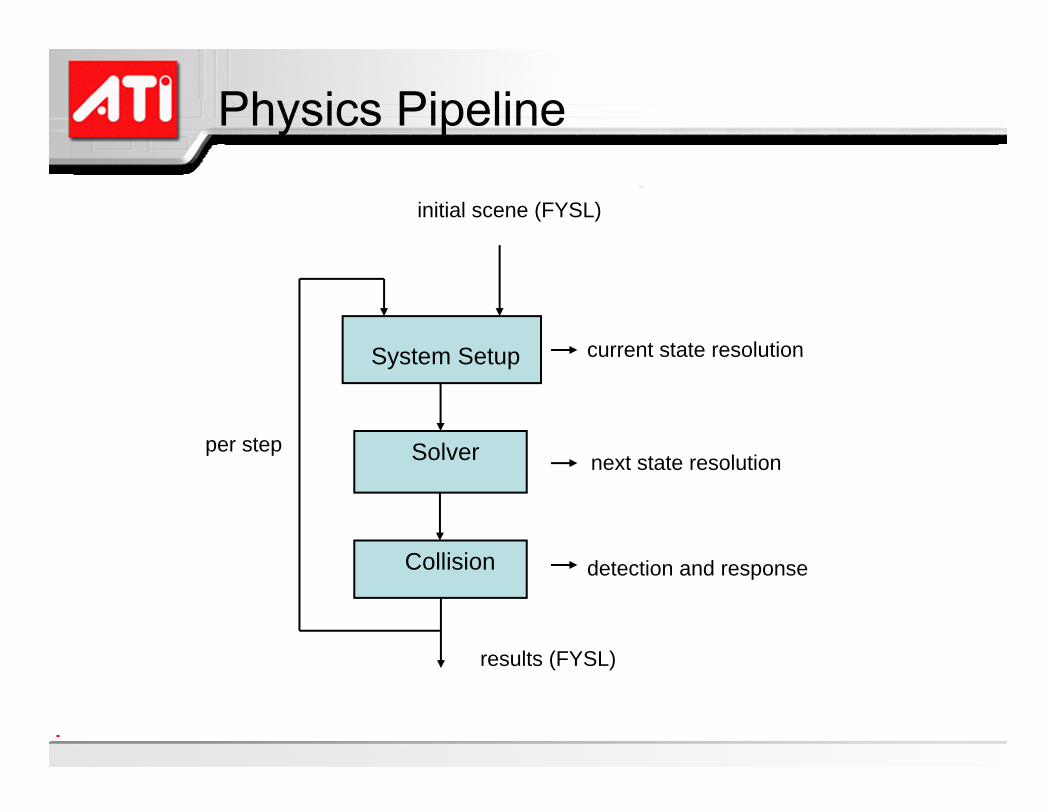
System Setup
Solver
Collision
results (FYSL)
initial scene (FYSL)
current state resolution
per stepnext state resolution
detection and response

Grid based simulationEuler method (x(t + dt) = x(t) + t * dx/dt;)
Geometry, property resourcesTexture array
Portable shading library
Resume from last stepResult caching
Adaptive time step


GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary

Object space representationPrecise, CPU equivalent
Geometry in video memoryMultiple arbitrary meshes
GPU texture addressability4K by 4K for 2D
Mesh representation1D vertex and index buffers
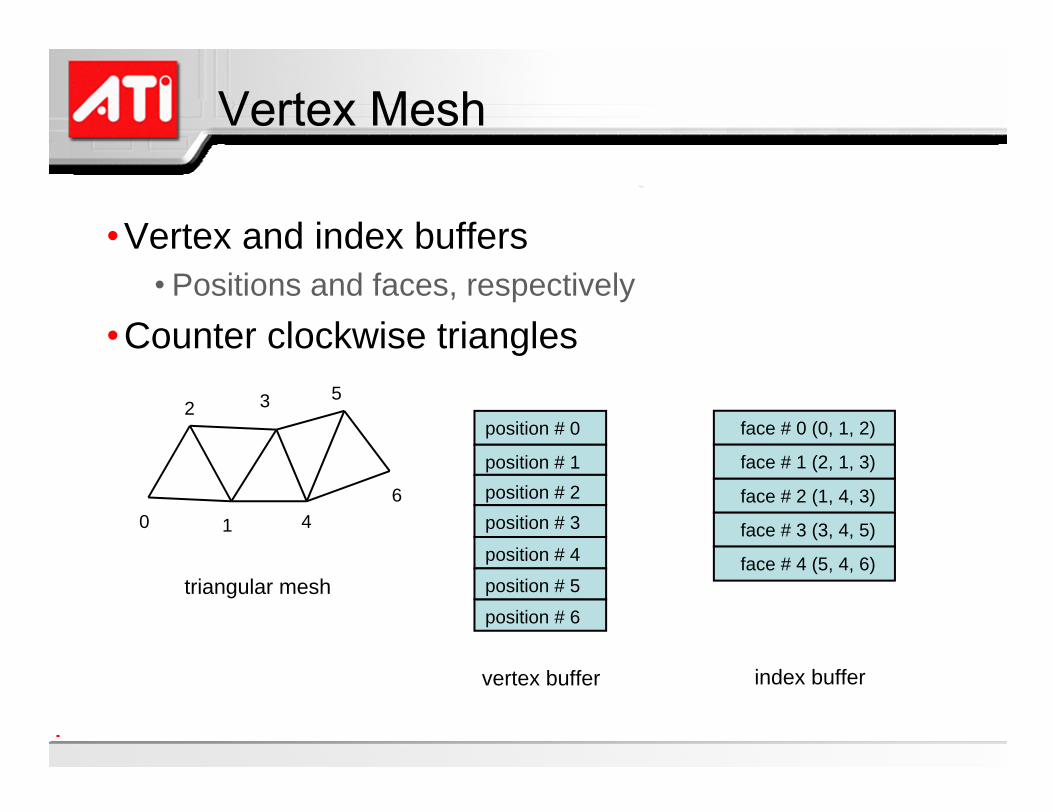
Vertex and index buffersPositions and faces, respectively
Counter clockwise triangles
vertex buffer
position # 0
position # 1
position # 2
position # 3
position # 4
face # 0 (0, 1, 2)
index buffer
0 1
2 3
4
5
6
position # 5
position # 6
triangular mesh
face # 1 (2, 1, 3)
face # 2 (1, 4, 3)
face # 3 (3, 4, 5)
face # 4 (5, 4, 6)

Mesh as a resource2D video memory array
Three floats element{x,y,z} and {i0,i1,i2}
Arbitrary dimensionsPadded as necessary
Dependent textureFor each triangle access
0 1 2
3 4 5
6
vertex buffer (3x3)
0 1 2
3 4
index buffer (3x2)

Many mesh scene
16 textures constraint
A single super meshCoalesces multiple meshesVertex and index uber buffer
Index buffer offset
Boundary sub mesh id
b # 0 b # 1 b # n
b # 0 b # 1
b # 1
b # n
b # n
1D composite
2D composite

Low creation overhead
Sub mesh collisionTri-tri intersection, contact
Avoids self intersectionMulti pass compute
Intersect, response, integrate
Dependent texture accessFace to vertex fetch

GPU, processor array
Compute abstraction
Physics simulation
Mesh video mapping
Results, summary

GPU superior to CPUCollision detection, response
Understand compute behaviorGrid distributionFlow control, multi pass
Scalability across GPUsMore pipes, ALUs

Single CPU No dual core, no SSE2
System performancePhysics process, no rendering
Shape based benchmarksLinear motion
Absolute, normalized results

8655802 24 GeForce 7800
800650224GeForce 7900
775650316Radeon X1900
750625116Radeon X1800
70060034Radeon X1600
53334001(4)1Pentium 4
Memory (MHz)Core (MHz)ALUsPipesProcessor

7.5775367mesh update
30.138241300mesh-mesh
102
119
Ops
17.40587volume-volume
19
Texture
72
ALU
3.79impact
RatioShader Type

562768(0.0002)
197508(0.0001)
74793(0.0004)
101404(0.0004)
CPU
703(0.177)
187(0.171)
188(0.164)
203(0.231)
7800
482(0.259)
47(2.659)
110(1.136)
125(1.000)
tetrahedron128x128
247(0.129)
30(1.066)
16(2.000)
32(1.000)
mesh64x64(62471 tris)
201(0.154)
15(2.067)
15(2.067)
31(1.000)
sphere256x256
220(0.213)
15(3.133)
31(1.516)
47(1.000)
aabb256x256
7900X1900X1800X1600Benchmark
Compute draw calls (figures in msec)

CPU wins for small gridsExpected, setup overhead
GPU faster elsewhereUp to an order of magnitude
GPU ScalabilityFlow control might be stalling
GeForce 7800/7900 slower Across benchmarks

Unified shader architecture
Higher concurrency level64 pixel enginesFlexible mix of scalar/vector
DirectX 10Constant buffersTexture array, indexingNon-power-of-2 3D textures3D render target

GPU game computing Still a challenge
Parallel programmingMacro and micro level
Software productivityTools, tools, tools
Emerging CPU/GPU platformsAdaptive load balance

Thank You!
Questions?