people.inf.elte.hu folia4... · web viewkerül végrehajtásra. ahhoz, hogy az adatbázis egy ilyen...
TRANSCRIPT

Adatbázis fogalmaadatok valamely célszerűen rendezett, szisztéma szerinti tárolásaAz informatika elterjedése előtt is számos adatbázis létezett pl.
●Vállalati személyzeti nyilvántartás●Könyvtári kartoték rendszerek
Az adatkezelő rendszerek kialakulása
• i.e. az írásbeliség kialakulásával jöttek létre az első „adatbázisok”• Kézi kartotékrendszer• Lyukkártya-köteges rendszer
Hollerith 1884. szeptember 23-án szabadalma, 1890-es népszámlálás• Elektromechanikus kartotékrendszer (1934)
• Az első szekvenciális fájlok az 1940-es évek végén• Nagyszámítógépi operációs rendszerek fájlkezelése (1959)• Adatbázis-kezelők
– Hierarchikus (1963)– Relációs (1970)– Objektum-orientált (1985)
• Táblázatkezelők (1980)• 4GL Objektum-orientált programnyelvek (1990)• On-Line Analytical Processing (OLAP) rendszerek (1997)

Az első ilyen architekturális szint a lokális adatbázisokezek a „legjobbak”,
egy gép, egy adatbázis, egy felhasználó
1980 körül, DOS alapokon (a DOS eleve nem adott lehetőséget több felhasználóra, több szálon futtatásra).Ilyen adatbázisok voltak a foxbase; dBase 3, 4, 5; clipper, ennek a továbbfejlesztett változata a Paradox 4, 5, 7; aminek stabilabb volt az adattábla–kezelése, de cserébe kaptunk egy sérülékeny indextáblát.Mindegyikre jellemző volt, hogy
egy adattábla – egy fájl;egy index –egy fájl;egy leíró tábla – egy fájl,check-feltételek egy táblához – egy fájl.
Ha volt egy adatbázisom 100 táblával, akkor egy könyvtárban néhány 100 darab fájl jött létre és ezeket kezelte egy adatbázis–kezelő motor.Fájl szinten dolgozott, bájtokat mozgatott és blokkokat kezelt.Mivel fájl szinten nyúlt hozzá, sérülékeny volt. Sok fájl volt, ezért sok sérülési lehetőség volt, sok törlési lehetőség volt már az operációs rendszer szintjén is.
MSAccess annyival modernebb, hogy az összes eszközt, adatot és leíró eszközt egy fájlban tárolja.(Nagyon sérülékeny tud lenni, ha nagyobb terheléssel akarjuk használni. Tanításra kiváló eszköz (ECDL, érettségi))A LibreOffice-nak is ott van a Base adatbázisa, az hasonló az Accessshez, ingyenes, ismerkedésre és tanulásra való.Ezeknek az adatbázis kezelőknek vannak korlátaik: egy forgalmi táblában folyamatosan növekszik a rekordok száma. Könnyedén elérheti a 100 000 mennyiséget. egyre többször jönnek elő hibák, elkezd lassulni a rendszer, indexsérülések jönnek elő, tehát a lokális, fájl-alapú rendszereknek a teljesítőképessége kb. 100 000-es nagyságrendű. Ha tudjuk ezt, és ha tudjuk, hogy milyen feladattal akarnak megbízni, akkor nincsen gond, hogy ezt használjuk. Ha Mariska néninek kell a virágboltjába csinálni egy adatbázist, amibe hetente beviszi, hogy kapott 10 szál tulipánt és 30 szál rózsát, meg eladott 9 szál tulipánt meg 34 szál rózsát és semmi mást nem visz be, arra kiváló az Access. Ne próbáljuk rábeszélni a Mariska nénire az Oracle-t.
File – server architektúraFejlődött a világ, van kábel, összekötjük a gépeket, akármennyit. Kifejlesztették a file – server architektúrát.Novell szerver fénykora, Windows szerver.„fájl-szerver”, már a nevében benne van, hogy dokumentumokat, fájlokat osszon meg, mint erőforrásokat.Az adatbázis file-okat berakták a szerver megosztott mappájába: Ekkor az operációs rendszer biztosítja azt, hogy ki érheti el, ki nem érheti el. Nem működött, mert nem volt írási joga a felhasználónak. Meg kellett a jogot adni hozzá, kiderült, hogy igazándiból akkor működik, hogyha admin jogot adunk abba a könyvtárba. Elkezdtük a lokális adatbázis fájlokat megosztani a hálózaton. Innen kezdődtek a problémák. A userek egyszerre akarták ugyanannak a táblának ugyanazt a rekordját módosítani. Előjött a konkurens hozzáférés problémája.Elkezdtük patkolni az adatbázis kezelőket, kitaláltunk egy programozói felületet. Meg tudták mondani, hogy zárolják az adattáblát, vagy az egész adatbázist. Enyém, senki másé. Dolgozok benne, ha végeztem, felszabadítom, és Te is hozzányúlhatsz. Ja, elfelejtettem, majd holnapután felszabadítom. Sok probléma forrása volt a nem megfelelően finom szemcsézettségű zárolás.Ráadásul ez nem a rendszer része volt, hanem a programozó vezérelte.A megbízhatóság sok kívánnivalót hagyott: a konzisztens adatbázis fogalom, ami még megvolt lokálisan, azt el is felejthetjük. Nem volt eszköz a konkurens hozzáférés kezelésére.Próbálkozások, hogy amikor az egyik felhasználó dolgozik vele, akkor lemásolja, a teljes adatbázist magának, abban dolgozott, kinaplózta a különbségeket, amiket ő csinált, és amikor visszatöltötte, csak különbségeket vitte a napló alapján föl. De ezt csak este lehetett, amikor más nem nyúlt az adatbázishoz.accessAdatok megosztása hálózati mappák használatával

Ez a legegyszerűbb lehetőség, és rendelkezik a legkisebb követelményekkel, de biztosítja a legkisebb funkciókat is. Ebben az eljárásban az adatbázis fájl egy megosztott hálózati meghajtón tárolódik, és az összes felhasználó közösen osztja meg az adatbázis fájlt. Néhány korlátozás magában foglalja a megbízhatóságot és a rendelkezésre állást, ha több egyidejű felhasználó megváltoztatja az adatokat, mivel az összes adatbázis objektum meg van osztva. Ez a technika csökkentheti a teljesítményt is, mivel az összes adatbázis objektum a hálózaton keresztül kerül elküldésre.Ez az opció akkor működik az Ön számára, ha csak néhány ember várhatóan egyszerre használja az adatbázist, és a felhasználóknak nem kell testreszabniuk az adatbázis tervezését.
Megjegyzés: Ez a módszer kevésbé biztonságos, mint az adatbázis megosztásának más módjai, mivel minden felhasználónak az adatbázis fájl teljes példánya van, ami növeli a jogosulatlan hozzáférés kockázatát. Másolja az adatbázist a megosztott mappába. Miután átmásolta a fájlt, győződjön meg róla, hogy a fájlattribútumok be vannak állítva, hogy engedélyezzék az olvasási / írási hozzáférést az adatbázis fájlhoz. A felhasználóknak olvasási / írási hozzáférést kell biztosítaniuk az adatbázis használatához.
Osztott adatbázis megosztásaAz adatbázishoz való megosztásakor átrendezi azt két fájlba - egy adatállományt tartalmazó háttér-adatbázisba, valamint egy olyan front-end adatbázisba, amely tartalmazza az összes többi adatbázis objektumot, például lekérdezéseket, űrlapokat és jelentéseket. Minden felhasználó együttműködik az adatokkal a front-end adatbázis helyi példányának használatával.Az adatbázis felosztásának előnyei Jobb teljesítmény. Csak az adatok oszlanak meg a hálózaton, nem az asztalok, lekérdezések, űrlapok, jelentések, makrók és modulok.
Kliens – szerver architektúraA szerver valamilyen szolgáltatást nyújt, a kliens meg ezt használja.Az a szerver, amelyik az adatbázis szolgáltatást nyújtja és az a kliens, aki az adatbázis szolgáltatást igénybe veszi.A kliens-szerver architektúrában a kliens program közvetlenül az SQL szervert éri el. Az SQL szerver által menedzselt adatbázisban tárolt eljárást hívja meg.Ami ezt tudja, az két nagy csoportra szedném szét.Fizetős szoftverek:Magyarországon az Oracle a legelismertebb „adatbázis–kezelő”, Romániában azt mondják, hogy igen, van Oracle, de az IBMDB2 az „adatbázis–kezelő”. Marketing, semmi más. Mivel fizetős (és nem is kicsit)..Ide sorolom az IBM DB2-t és a Sybase-t is. A fizetősök közé kell még sorolnom az InterBase-t.Tehát amikor Mariska néni kisboltjába írunk egy raktárkezelő programot és azt mondjuk neki, hogy figyelj Mariska néni, sütsz nekem két tálca süteményt, megcsinálom a programodat, de vegyél 15 millióért egy Oracle-t alá. Nem fogja kérni. Nagyon fontos, hogy az SQL szerver kiválasztásakor a feladat méretéhez legjobban illő verziót keressük meg.Az SQL szerverek árát jelentősen befolyásolja és emeli a hozzájuk adott kiegészítő szoftver és menedzser felület. Természetesen jelentős és sokszor nélkülözhetetlen a terméktámogatást is kapunk a pénzünkért.Tehát ezek fizetősek; a pénzért adnak szolgáltatást, supportot. Hogyha egy éles rendszert csinálunk egy nagy cégnek, akkor ez fontos.
Ingyenes szoftverek:MariaDB (MySQL)PostgreSQL.Firebird. Az Interbassel egyenértékű, vele 100%-ban kompatibilis SQL szerver.A Firebird kiválóan alkalmas egy kis, esetleg egy közepes vállalkozás adattárolási és nyilvántartási rendszerek kezelésére.Ahol komoly adatreplikáció van, ott már tényleg nem alkalmas. És ezeknek a rendszereknek, pl. a Firebird-nek megvan az az előnye, hogyha írtunk egy rendszert és szeretnénk eladni kis és középvállalkozásoknak, akkor ezek kiszolgálják. Ugyanúgy el tudjuk adni változtatások nélkül lokális rendszerben is, tehát amikor Mariska néni nyit egy virágboltot és mondja, hogy számláznia kell, vagy számlát kell kiállítani esetleg, mondjuk egy

héten ötöt, meg bevételezni kell egy héten kétszer, azt is kiválóan kiszolgálja. Nem kell neki 5 processzoros gép gigabájttal, hanem egy sima laptopon elmegy. A Firebird telepítőjének még menedzser - felülete sincsen, tehát hat vagy hét megabájttal megy, a tranzakció-kezelés kiváló benne, tárolt eljárások, triggerek, hatos verziótól már simán megvannak. Gyakorlatilag mindent tud; csak nem monumentálisban, hanem ilyen kicsi vagy közepes vállalkozás szinten.
Multi-TierTöbbrétegű architektúra. Egy SQL szerver és vannak a kliens programok. Egy köztes réteget ezek közé azzal a feltétellel, hogy ezt a réteget kereshetik meg a kéréssel a kliensek, és tőle várják a választ. És csak ez a réteg nyúlhat az SQL szerverhez, csak ez a réteg fordulhat az SQL rendszerhez kérdéssel.Itt van egy köztes réteg, úgy szokták hívni, hogy üzleti logika. Egy eljárás, függvény, metódus gyűjtemény, amit a kliensek hívogathatnak. A BL(Bussnis Logic Layer) felel azért, hogy az SQL rendszerrel kommunikáljanak. A BL-t nem lehet megkerülni. Onnan fejlődött ki jellemzően, hogy milyen kellemes az, ha egy programot nem kell telepíteni a kliensre, hanem azt mondja a kliens, hogy nekem úgy is van egy böngészőm, beírunk egy webcímet, és akkor majd úgy kommunikálok. A webhelyen meg fog jelenni valamilyen adat. Nyilván azért ez szélsőséges, mert nagyon sok olyan rendszert tudunk mondani, amit nem tud kiszolgálni egy böngésző. Ez komoly rendszereknél biztos, hogy kettő hardver eszköz, kettő szerver. Tehát az nem komoly rendszer, amikor azt mondják, hogy egy webszervert és egy adatbázis-szervert egy vasra tesznek. Ez nem rendszer adatbiztonság szempontjából. A biztonságos dolgok miatt szoktuk azt mondani, hogy az egyik vas egy adatbázis szerver, amit egy úgynevezett DMZ-ben helyezünk el (demilitarizált zóna) sok tűzfallal körbebástyázva, bezárva. Egyszerűen arról van szó, hogy ezek az adatok értékek; tehát egy cégnek ezek vesznek el vagy szivárognak ki, akkor óriási károkat okozhatnak.
adatbázis-kezelő rendszer (Database Management System, DBMS)Adatbázis-kezelő rendszernek nevezik az olyan programrendszereket, melynek feladata az adatbázishoz történő hozzáférések biztosítása és az adatbázis belső karbantartási feladatainak ellátása, azaz:• Adatbázisok létrehozása• Adatbázisok tartalmának definiálása• Adatok tárolása• Adatok lekérdezése• Adatok védelme• Adatok titkosítása• Hozzáférési jogok kezelése• Fizikai adatszerkezet szervezése
Adatbázis-kezelő (DBMS – Database Management System) rendszerrel szembeni elvárásaink:1. Lehessen új adatbázisokat létrehozni és azok sémáját (az adatok logikai struktúráját) egy nyelv utasításai segítségével megadni. Ezek a nyelv adatdefiníciós utasításai.2. Az adatokat nyelvi utasítások segítségével lekérdezhessük és módosíthassuk.Ezek a nyelv adatmanipulációs utasításai.3. Biztosítsa az adatok hosszú időn keresztül való tárolását. Védje az adatokat a meghibásodásokkal és az illetéktelen felhasználókkal szemben.4. Felügyelje több-felhasználós környezetben az egyidejű adathozzáféréseket.A felhasználók műveletei ne legyenek hatással más felhasználók műveleteire. Az egyidejű adathozzáférések ne okozzák az adatok hibássá vagy következetlenné válását (feleljenek meg bizonyos szabályoknak, megszorításoknak).

Az adatkezelő rendszerekkel szembeni elvárásokAz adatbázis-kezelő rendszer több programból álló szoftvertermék, melynek biztosítania kell:
- egy megfelelő módon leírt adatfeldolgozás végrehajtását (adatbázis létrehozása, módosítása, törlése),- az adatbázis következetességét (csak valós adatokat tároljunk),- az adatok közti komplex kapcsolatok kezelését és ábrázolását,- az adatbázis valamennyi adatának elérését,- egyszerű használatot,- az adatok közötti komplex kapcsolatok ábrázolását,
1. Redundancia-mentesség (Non-Redundancy): az adatok nem ismétlődhetnek, csak egyszer tároljuk el őket, a fajlagos helyfogyasztást minimalizálva
- a redundancia-mentességet és annak ellenőrzését,2. Hatékonyság (Efficiency): gyors visszakeresés és adatmódosítás3. Rugalmasság (Flexibility): nem fix hosszúságú, bonyolult adatszerkezetek tárolásának képessége4. Programozhatóság (Programmability): az adatszerkezetek és a feldolgozó eljárások egyszerű módosítása5. Adatfüggetlenség (Data Independence): az adatok, és az adatszerkezet hardvertől, szoftvertől való
függetlensége 6. Metaadatok elekülönülése (Separation of MetaData): az adatok szerkezeti leírását és feldolgozási
eljárásaikat az adatoktól elkülöníthető módon kell tárolni7. Adatintegritás (Data Integrity): a tárolt adatoknak folyamatos módosítások közepette is eleget kell tennie
bizonyos szabályoknak- a redundancia-mentességet és annak ellenőrzését,- az adatok integritását, hogy lehetőleg a hozzáférésre jogosultak se ronthassák el az adatbázist,
- az adatok védelmét, titkosítását8. Adatbiztonság (Data Safety): adatok védelme a hardver- és szoftverhibák ellen
- a helyreállíthatóságot, hogy bármilyen hiba esetén az eredeti állapotot vissza lehessen állítani,
9. Adatvédelem (Data Security): az adatokat csak az arra jogosult felhasználók kezelhessék- a hozzáférési jogok kezelését,- az adatok védelmét, nehogy illetéktelenek hozzáférhessenek,
10. Osztott adathozzáférés (Shared Data Access): ugyanazokkal az adatokkal több felhasználó is dolgozhasson egyidejűleg.- több felhasználós rendszerekben az egyidejű hozzáférést,- osztott adatbázisokban az adatok szétosztását, megtalálását, valamint- az adatforgalom optimalizálását.- különféle felhasználói igények hatékony kielégítését,- osztott adatbázisnál az adatok fizikai szétosztását, logikai összevonását és a
duplikátumok konzisztenciáját.Az adatok definiálása különüljön el az adatkezeléstől, (ADATKATALÓGUS –ban történik)Az adatkatalógus maga is az AB része, az adatokkal azonos módon történjen a feldolgozása Az adatdefiníciónak, az adatkezelésnek és az adatbiztonságnak legyen programozási nyelve.Ezen nyelvi eszközök adjanak módot más alkalmazások, programnyelvek számára a hozzáféréshez. (interfész elemek )
Mi is az a CODASYL bizottság?A rövidítés a Conference on Data Systems Languages szavakat takarja. Ez egy amerikai szervezet, amelyet 1957-ben hozott létre az Amerikai Egyesült Államok Védelmi Minisztériuma. Küldetése eredetileg programnyelvek fejlesztése volt. Ez a bizottság volt felelős a COBOL (a második legrégebbi magas szintű programozási nyelv, elsősorban nagygépeken futó üzleti alkalmazások számára alakították ki) kifejlesztéséért. A szervezet ma már nem létezik.
A CODASYL bizottság egyik albizottsága a DBTG (Data Base Task Group) megfogalmazott egy ajánlást az adatbázis-kezelő rendszerekkel szemben (1969). Lényegében sok új dolgot nem közöltek, inkább csak

összeszedték az üzleti életben és egyéb területeken már megfogalmazódott követelményeket az adatbázisokkal szemben. Ezek a következők:
- Az adatbázis-kezelő rendszernek többféle hozzáférési módot kell támogatnia- csak irányított redundancia megengedett - támogassa a konkurens hozzáférési lehetőséget- támogassa az adatvédelmet (egyrészt egymás ellen: jogosultságok, másrészt külső hatások ellen: naplózás, archiválás)- támogasson legalább egy, de inkább több magas szintű programozási nyelvet (ez az ajánlásban pont a COBOL lett).- gépi hatékonyság emberi hatékonyság- almodell szemlélet: bizonyos felhasználók csak bizonyos részeket láthatnak az adatbázisból (pl.: a Neptunban a hallgatók csak a hallgatóknak szóló információkat).- adat-program függetlenség, azon belül is
- logikai: ne kelljen átírni a programot az adatbázis szerkezetének megváltozásakor.- fizikai: az adatok tárolási módja legyen független a felhasználótól. Nem kell azt feltétlenül tudnia az egyszerű mezei felhasználónak, hogy az adatok hol és milyen formában tárolódnak.
A CODASYL-ajánlás1969: Conference on Data Systems Languages1 összetett logikai adatszerkezetek2 irányított redundancia3 jogosultságkezelés4 konkurens hozzáférés5 többféle hozzáférés6 magas szintű nyelvek támogatása7almodell szemlélet (nézetek)8 emberi hatékonyság9 program-adat függetlenség10 logikai11 fizikai (átlátszóság, transzparencia)
Adatbázis-kezelők előnyei●Elfedi az adatok fizikai tárolási szerkezetét, a felhasználóknak, programoknak csak a logikai adatszerkezetet kell ismernie●Hatékony adatelérést biztosítanak●Adatintegritás ellenőrzése, jogosultságok kezelése●Konkurens adatelérés és adatvesztés elleni védelem (hardver hiba esetén is)●Lerövidíti a programfejlesztés idejét
Az adatbázis-kezelő rendszerek az alábbi lényeges előnyöket biztosítják a hagyományos nyilvántartó rendszerekkel szemben:
az adatok strukturált „szabványos” tárolása az adatok közötti komplex kapcsolatok ábrázolása egyszerű használat eltérő forrásokból származó adatok összekapcsolhatósága adatbevitel ellenőrzése, adateredet naplózása felhasználói programoktól való függetlenség fejlesztői nyelvektől való függetlenség felhasználói jogosultság, hozzáférés-kezelés konkurens hozzáférés erőforrásokhoz való konfigurálhatóság szabványos felhasználói, lekérdező felületek adatvédelem, titkosság redundancia mentes tárolás adatbázis-konzisztencia biztosítása

külső rendszerekkel való kapcsolattartás hibakezelés-, hibajavítás;
Az adatbázis-kezelő rendszerek hátrányai a hagyományos nyilvántartó rendszerekkel összehasonlítva az alábbiak:
az adatkezelés speciális szakértelmet kíván a megbízható rendszerek relatíve drágák a végfelhasználó a hagyományos bizonylatolástól eltérő adatkezelésre kényszerül a felhasználó új szervezet kialakítására kényszerül az adatokkal való visszaélés veszélye fokozottan jelentkezik az adatok könnyen megsérülnek, (megbízható adatkezelési, archiválási rendszer
szükséges)
Néhány elterjedtebb relációs relációs adatbázis-kezelő rendszer (RDBMS)Kereskedelmi szoftverek:
Oracle, MS SQL Server, DB2Korlátozott ingyenes változatok
MS SQL Server ExpressNyíltforrású szoftverek:
PostgreSQL, MySQL, MariaDB, SQLiteFizetős változatok
MySQL Server Enterprise
Néhány elterjedtebb NoSQL adatbázis-kezelő rendszer Apache Cassandra MongoDB Redis

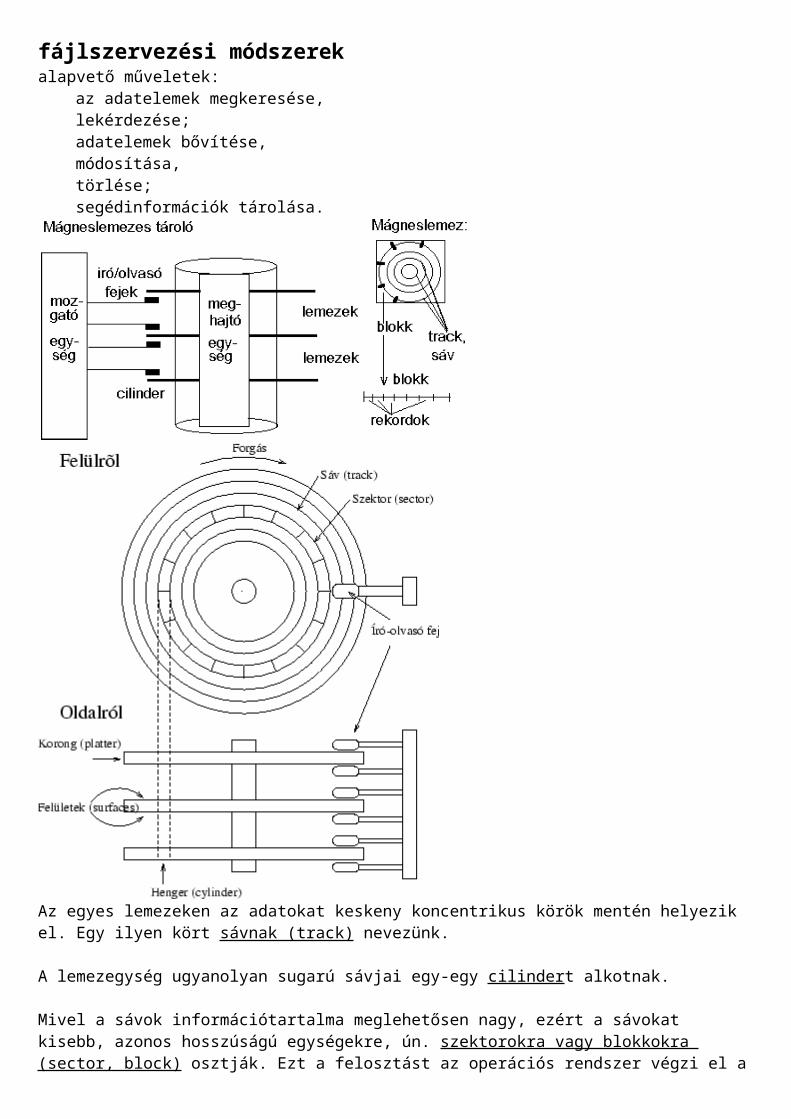
fájlszervezési módszerekalapvető műveletek:
az adatelemek megkeresése,lekérdezése;adatelemek bővítése,módosítása,törlése;segédinformációk tárolása.
Az egyes lemezeken az adatokat keskeny koncentrikus körök mentén helyezik el. Egy ilyen kört sávnak (track) nevezünk.
A lemezegység ugyanolyan sugarú sávjai egy-egy cilindert alkotnak.
Mivel a sávok információtartalma meglehetősen nagy, ezért a sávokat kisebb, azonos hosszúságú egységekre, ún. szektorokra vagy blokkokra (sector, block) osztják. Ezt a felosztást az operációs rendszer végzi el a lemez formázásakor. Egy blokk, amit lapnak(page) is neveznek, 512-4096 (a 2 n-dik hatványa, fix hosszú) byte információt hordozhat. [ 2 ]

A központi memória és a lemezegység közötti információátvitel egysége a blokk!
A blokk hardvercíme a lemezfelület, a sávszám és a blokkszám kombinációja. Olvasási művelet során a kívánt blokk a megfelelő pufferba kerül, íráskor pedig a puffer tartalma kerül a blokkba.
A rekordcím meghatározása: fizikai cím alapján vagy blokkcím és az offset alapján.Az adatelérés folyamata több lépésből áll:1. fejmozgatás: a megfelelő cilinderre állnak a fejek (lassú),2. fejkiválasztás: a keresett lemezfelülethez tartozó fej (gyors),3. forgási idő: a keresett rekord a fejhez kerül (közepes),4. adatátvitel: elektronikus (a leggyorsabb művelet)
Az 1. és 3. lépés a leghosszabb idejű művelet. Amennyiben logikailag valamely mező szerint növekvő vagy csökkenő sorrendben következő rekordok fizikailag különböző cilinderen vannak, vagy ugyanazon cilinderen belül más-más, de nem egymás után következő blokkban helyezkednek el, a hozzáférés ideje jelentősen megnőhet. Az adatbázis-kezelő rendszerek általában lehetővé teszik a rekordok fizikai rendezettségét is. [2]
A leggyakoribb művelet a lekérdezés, célszerű ezért olyan fizikai tárolási struktúrát választani, amely a hatékony lekérdezést segíti.
- Adathordozói szint. A hatékonyságnövelési lehetőségek keresését már az adathordozó szintjén el kell kezdeni, hiszen az adatelem beolvasása a címének ismeretében három fő lépésből áll, melyek különböző időszükséglet rendelhető:
fejmozgatás (a fejet a lemez megfelelő sávjára, cilinderére kell mozgatni),fejkiválasztás (lemezcsomag esetén a megfelelő lemez kijelölése),forgatás (az adott sávon belül a megfelelő szektor, blokk mozgatása a fej alá).
E három elemből a fejmozgatás igényli a legtöbb időt, de ez lényegesen függ attól, hogy hol helyezkedik a sáv, mi volt az előzőleg felkeresett sáv.Minden sávváltás időszükséglettel jár, mégpedig minél nagyobb volt a távolság, annál több idő szükséges. Ebből két fontos megállapítás is vonható le:
az egymásután, együtt olvasott adatokat célszerű ugyanazon, vagy szomszédos sávokra elhelyezni,egy adatelemnek, más programok véletlenszerű sávpozícióit feltételezve, az optimális elhelyezkedése a középső sávokban található.
File-szervezési módok• heap - szabad elhelyezés• szekvenciális
– fizikai és logikai szekvenciális• indexelt avagy direkt
– determinisztikus• egymáshoz rendelés: keresési kulcs - fizikai cím• algoritmussal: keresési kulcsból fizikai cím• indexelt szekvenciális: ISAM, VSAM, C_ISAM,B+ tree, R tree
– random• cluster szervezés (kapcsolat-file-ok)
Keresési megoldások, visszaolvasásAz a lehetőség, ahogyan a háttértárolón őrzött adatrekordokat feldolgozáshoz visszanyerhetjük.Megoldások:– fizikai cím ismerete nélküli keresés– a rekord fizikai címe szerinti keresés– keresés pointerláncokon keresztül

– keresés indextáblákkal
- Fizikai fájlszerkezet.A következő lépcsőfok a megfelelő fájlszervezés kiválasztása.A fájlokon belül az adatok blokkokban tárolódnak, ahol egy blokk egy adatátviteli egységnek fogható fel, azaz egy írás vagy olvasás művelete minimum egy blokk adatmennyiséget mozgat az adathordozó és a központi egység között. A fájlhoz tartozó és egymás után következő blokkok nyilvántartására is több különböző módszer létezik: a blokkok láncolása (minden blokkban van egy mutató a következő blokkra; az első blokk címének ismeretében sorban felkereshető az összes többi blokk); blokk címlista (minden fájlhoz létezik egy lista, amely a hozzá tartozó blokkok címeit tartalmazza; ez a lista lehet egyszerű, összefüggő, de lehet bonyolultabb felépítésű is).
- Logikai fájlszerkezet.A blokkok a fájlok fizikai szerkezetét mutatják, de emellett a fájl egy belső logikai struktúrával is rendelkezik. A logikai fájlszerkezet lehet stream jellegű vagy rekord jellegű. A stream fájltípusnál a fájl egy belső struktúra nélküli byte vagy karakter sorozatból áll. A karaktersorozatot a felhasználó program értelmezi saját igénye szerint. Ugyanazt a fájlt a különböző programok másképp értelmezhetik. A rekord jellegű típusnál feltesszük, hogy a fájl felbontható logikai részelemekre, úgynevezett rekordokra. A rekord egy logikailag összetartozó adatelemek, mezők összessége. A rekord és a blokk viszonya alapján beszélhetünk spanned rekordokról, ha egy rekord több blokkra is kiterjedhet, és unspanned rekordokról, ha egy rekord csak egy blokkhoz tartozhat. A rekord jellegű állományokban a rekordok lehetnek fix hosszúságúak, vagy változó hosszúságúak.
- Adatelemek elérése.stream (belső struktúra nélküli) fájlkezelés adatelemek gyors elérésére nem megfelelő, Ebben az esetben csak a fájl soros átolvasásával találhatjuk meg a keresett elemet, ami azt jelenti, hogy egy elem meg találásához átlagosan a fájl felét át kell olvasni.rekordjellegű megközelítés esetében is megvalósítható ez a számunkra nem előnyös felépítés, ugyanis a rekordjellegű fájl szerkezeteknek az alábbi típusai ismertek: soros elérés, szekvenciális elérés, indexelt elérés, random és hashing elérés.
A fájlszerkezetek, vagyis az alkalmazott adatállományok típusai :Soros fájlszerkezet:
A legegyszerűbb, de feldolgozás szempontjából legmunkaigényesebb szerkezet.A rekordok a fájlban tetszőleges sorrendben (például a felvitel sorrendjében) helyezkednek el, azaz nincs kapcsolat a rekord kulcsértéke és a rekord fájlon belüli pozíciója között.A soros fájlban a rekordok minden rendezettség nélkül, a felvitelük sorrendjében kerülnek eltárolásra.Az új rekord, a már létező rekord sorozat végére, utánírással vihető fel.A törlés, módosítás csakis újraszervezéssel, vagyis a módosított tartalmú fájl felírásával és a módosítás előtti fájl megszüntetésével, törlésével hajtható végre. A visszakeresés pedig a fájl tartalmának végigolvasásával lehetséges, amely mindaddig tart, amíg meg nem találjuk a keresett rekordot illetve az állomány végére nem jutunk.
- Soros elérés. Egy adott kulcsértékű rekord bárhol elhelyezkedhet a fájlban, kereséskor a fájl minden rekordját át kell nézni egymás után a fájl elejétől kezdve, amíg meg nem találjuk a keresett rekordot.Ez átlagosan a fájlban tárolt rekordok felének átnézését igényli, ezért az egyedi keresések szempontjából nem tekinthető hatékony módszernek. Amennyiben minden fájlhozzáférésnél szükség van az összes rekordra, akkor ez a fájlszervezés lesz a leghatékonyabb.

Szekvenciális fájlszerkezet:A fájl rekordjai itt is sorosan érhetők el, de a rekordok sorrendje valamilyen felhasználói igény szerint már rendezettek.A kereséskor egy közvetlen elérésű adattárolón (merevlemez) gyorsabb elérési módszerek is alkalmazhatók, mint a rekordok végigolvasása, főleg több rekord egyidejű feldolgozása esetén. A törlés, módosítás mellett az új rekord felvitele is a fájl újraszervezését igényli, mert a rendezettség fenntartása érdekében (nem lehet két rekord közé beszúrni).
A rekordok a fájlban a kulcsértékeik alapján sorba rendezve helyezkednek el (pontosabban a rekordok a fájlban a kulcsértékeik növekvő, vagy csökkenő sorrendjében érhetők el).A szekvencia előnye, hogy nem szükséges a teljes fájlt végignézni adott kulcsértékű rekord keresésekor, mivel a sorrendbe rendezés miatt egy adott kulcstól jobbra csak tőle nagyobb (növekvő rendezést feltételezve) kulcsértékű elemek helyezkedhetnek el. Ez a sorrendbe rendezés megvalósítható fizikai szekvenciával vagy logikai, láncolt szekvenciával.
A fizikai szekvenciánál a rekordok fizikai helye megfelel a sorrendben elfoglalt helyének. Ezáltal gyors lesz az egymást követő rekordok elérése, de egy új rekord beszúrása esetén át kell rendezni a rekordokat a fájlon belül. Gyakran változó fájl esetén nem javasolt ez a módszer.
A logikai szekvencia esetén a rekordok a bevitelük sorrendjében helyezkednek el fizikailag a fájlban, és a sorrendbe rendezettséget mutatók segítségével valósítják meg, azaz minden rekord tartalmaz egy mutatót a sorrendben őt követő rekordra.Így beszúráskor csak a mutatókat kell átrendezni, a rekordok fizikai pozíciója ugyanaz marad. Mivel mind a két esetben továbbra is a fájl elejéről kiindulva, az egymást követő elemek ellenőrzésével lehet keresni, ez a módszer sem hatékony.
Direkt (vagy közvetlen) hozzáférésű fájlszerkezet:Jellemzője, hogy a rekordok és tárolási helyük fizikai vagy relatív (egymáshoz viszonyított) címei között rögzített, közvetlen kapcsolat van. A cím vagy sorszám rekordhoz rendelése a feldolgozó program feladata, amely a felhasználó rekord elérési igényeit tükrözik. A gyors feldolgozási igények olyan feladatokra terjedhetnek ki, mint az 1. vagy utolsó vagy n. rekordra ugrás, minden 5. rekord feldolgozása, stb. A rekordok feldolgozhatók a címük sorrendjében és a háttértáron történő fizikai tárolásuk sorrendjében (mint egy soros állománynál). A törlés speciális jelenséget okoz, az úgynevezett álrekordot, ami nem más, mint a fizikai sorban benne levő, de tartalmát "vesztett" rekord. (lásd a logikai törlést) A hely és a helyhez tartozó cím meg van de nincs értékes adat benne. Az álrekordok törlése az állomány átszervezésével a fizikai törléssel történhet.Az új rekord felvitele az ilyen álrekordok helyére történhet, vagy utánírással.
Indexelt szekvenciális fájlszerkezet:Egy direkt elérésű alapfájlból és egy vagy több úgynevezett indextáblából áll. Az indextábla önmaga is egy állomány, amely két fontos adatot tartalmaz. Az egyik azon mező vagy mezők csoportja, amely(ek) szerint indexelni kívánjuk az alapállományt, a másik pedig az alapfájl rekordjainak cím adata. Az indexelés nem más, mint az adott mező(k) szerinti rendezettségi sorrend.A visszakeres az indextábla alapján, a valódi műveletvégzés az indexfájlban tárolt cím segítségével gyorsan megtalált alapfájlon történik meg.A törlés és új rekord felvitel természetesen az index táblák újraszervezését is jelentik.
- Indexelt struktúra.A keresés meggyorsítható, ha nem kell minden, a keresett rekordot megelőző rekordot fizikailag is átolvasni. Valójában a keresett rekordot megelőző rekordokból csak azok kulcsértékei fontosak számunkra, a rekord többi mezője lényegtelen. Mivel rendszerint a kulcsmező nagysága csak egy töredéke a teljes rekord méretének, ezért ezeket a redukált adatokat sokkal gyorsabban át lehetne olvasni, sőt egy minőségi javulást hozna, ha az átolvasandó sor elhelyezhető lenne a memóriában, ugyanis ekkor az egymás utáni elem beolvasások helyett egy sokkal gyorsabb keresési módszer, a bináris keresés is alkalmazható lenne. Mindennek megvalósítása az index szerkezet, mely egy külön listában tartalmazza a rekordok kulcsait és az elérésükhöz szükséges mutatókat. A legegyszerűbb indexszerkezet egy indexlista, mely az összes rekord kulcsát tartalmazza egy listában, ahol a kulcsértékek rendezetten helyezkednek el.

Nagy fájlméreteknél az indexlista is olyan hosszú lehet, hogy már nem fér egyszerre a memóriába, a lista kezelhetővé tételére új megoldásokat kerestek.Ennek egyik módszere az index-szekvenciális fájlszerkezet, melyben a rekordok fizikailag is rendezetten helyezkednek el a fájlban, mint a szekvenciális állományoknál, így az indexlistának nem szükséges minden elemet tartalmaznia, csak bizonyos jelző rekordokat, mondjuk minden k-adik elemet. Így rekord keresését a fájlban a hozzá legközelebb eső, tőle kisebb kulcsértékű jelzőrekordtól kell csak kezdeni. Az állományban történő szekvenciális keresés sem tarthat sokáig, hiszen maximum k rekordot kell egymás után átnézni.A másik lehetséges, elterjedt módszer a többszintű, hierarchikus indexstruktúra bevezetése, melyben a felül elhelyezkedő listából nem közvetlenül a rekordokra, hanem újabb indexlistákra történik hivatkozás. A módszerrel minden rekordot közel azonos idő alatt érhetünk el, azaz az indexszerkezet kiegyensúlyozottnak mondható. Ez az indexelési módszer tekinthető az egyik leghatékonyabb módszernek. Az indexelés feladatát még annyi bonyolíthatja, hogy esetleg több mező szerint kívánunk indexelni, vagy éppen nem kulcs mező szerint kívánjuk az indexelést elvégezni a lekérdezések jellegét figyelembe véve. Ha egy mezőnél egy érték több rekordban is előfordul, akkor nem szokás minden ilyen értéket külön felvenni az indexlistába, hanem csak egyet, az első előfordulást, s a többi rekord ebből a rekordból kiinduló láncolt listán keresztül érhető el.
- Hashing.A rekord pozícióját közvetlenül a rekord kulcsértékéből határozzák meg, tehát csak egy blokkolvasásra van szükség a rekord eléréséhez. Sajnos azonban nem mindig igaz, hogy egy blokkolvasás elég, ez csak ideális esetben valósul meg. A hash elérési módszer alapelve, hogy a kulcs értékéből valamilyen egyszerűbb eljárással, a h() hash függvénnyel meghatároznak egy pozíciót. Numerikus kulcsok esetén a „h(x)=x mod n” egy szokásos hash függvény, ahol „x” a kulcs érték és „n” hash tábla rekeszeinek a darabszáma. A h(x) megadja, hogy mely rekeszbe tegyük le az x kulcsú elemet. Mivel a hatékony kezelhetőség végett a lehetséges pozíciók darabszáma lényegesen kisebb a lehetséges kulcs értékek darabszámánál, így szükségszerűen több kulcsérték is ugyanazon címre fog leképződni. Egy címhez rendelt tárterületet szokás bucket-nak is nevezni, mely lemez esetében rendszerint egy blokknak felel meg. Ha több rekord kerül egy címre, mint amennyi egy bucketban elfér, akkor lép fel a túlcsordulás jelensége, amikor is egy újabb blokkot, területet kell a címhez hozzákötni. Tehát egy címhez több különálló terület is tartozhat, melyeket láncolással kötnek össze. Ebben az esetben a rekord kereséséhez több blokkot is át kell nézni, amely lényegesen csökkenti a hash elérési módszer hatékonyságát. A túlcsordulás mellett a hash módszer másik hátránya, hogy csak nagyon körülményesen lehet vele megvalósítani a rekordok kulcs szerint rendezett listájának előállítását, hiszen a hash módszer az egymást követő rekordokat tetszőlegesen szétszórhatja a címtartományon a kiválasztott hash függvénytől függően. A jó hash függvény a túlcsordulást rekordok egyenletes elosztásával tudja kivédeni. Mivel a rekordokhoz rendelt címek eloszlása nagyban függ a kulcsértékek eloszlásától, a túlcsordulás soha sem védhető ki teljesen.
HASÍTOTT FÁJLOK (HASHED FILES)
Alapötlet: szervezzük a blokkokat 'bucket'-okba (bucket ~ vödör)!Hogyan? Hasító algoritmussal (Hashing Algorithm)!
H: V → B V: kulcsok halmaza; B: bucket-számok halmazaH: v → bH(v)=b v: egy adott kulcs; b:cím, egy bucket számaAz eljárás lényege, hogy a kulcsmezőből alkalmasan választott függvénnyel címet képezünk,amely cím a rekord blokkjának fizikai helyét jelenti. A leképezés nem egy-egyértékű, ezért kételtérő kulcshoz ugyanaz az egész szám tartozhat.A hashing néven elterjedt szervezési-hozzáférési módszer közvetlen hozzáférést biztosít,amennyiben a hashing-függvénnyel nyert címérték egyedi, vagyis nincs két olyan kulcsérték,amelyre a leképzés ugyanazt a címértéket adja.A hashnig eljárás egyik legegyszerűbb változata:

Adattétel beszúrása:
A hasítóérték a bucket táblában elfoglalt elsődleges pozíciót jelöli. Ha ez a pozíció már foglalt, akkor a rákövetkező pozíciókat nézi végig mindaddig, amíg egy szabad helyet nem talál (a táblát cirkulárisnak tekinti). Az adattételt a hozzá tartozó kulccsal együtt ezen a helyen szúrja be a táblába.
Adattétel táblázatbeli lokalizálása:
Kiszámítja a kulcshoz tartozó hasítóértéket, és az annak megfelelő pozícióban levő táblabejegyzést megvizsgálja. Ha az ott talált kulcs megegyezik a keresett tétel kulcsával, a tételt lokalizálta; ha nem, a rákövetkező pozíciókat mindaddig vizsgálja, amíg egy megfelelő kulccsal rendelkező bejegyzést nem talál, vagy üres pozícióhoz nem ér. Ez utóbbi eset azt jelenti, hogy az adott táblában nem létezik a keresett kulcs, mivel a behelyező eljárás biztosan elhelyezte volna az üres pozícióban.
A módszer működéséhez elengedhetetlenül szükséges, hogy lényegesen több pozíció legyen a táblában, mint ahány tételt el kívánnak helyezni. Feltéve, hogy a táblának legfeljebb 60% -a kitöltött, egy tétel táblabeli lokalizálása legfeljebb két pozíció megvizsgálásával végrehajtható.
Kifinomultabb technikák alkalmazásával oldható meg az ütközés problémája, amely akkor lép fel, ha a hasítóérték által kijelölt pozíció már foglalt. E technikákkal a tábla átnézését még hatékonyabban lehet végrehajtani. [3]
Ütközés (Collision):Ütközésről akkor beszélünk, amikor különböző kulcs-értékekhez ugyanazt a bucket-számot (címértéket) rendeljük.
Közvetlen láncolás (Direct Chaining) :Egyszeresen láncolt listát használ az ütközés feloldására.
HASÍTÓFÜGGVÉNYEK (HASHING FUNCTIONS)• Több hasítófüggvény is létezik.• A legáltalánosabban használt a moduló függvény.
Pl.: 11(mod 3)=2 ; H(v)=v(mod m) ;v: a kulcsnak megfelelő egész típusú szám; m: bucketek száma
Fontos követelmény, hogy a H függvénnyel meghatározott blokkok egyenletesen töltsék ki az m által meghatározott tárterületet (bucket táblát), azaz ne maradjanak üres vagy alig kitöltött helyek.
Ennél is fontosabb követelmény, hogy ne legyen két olyan v érték, amelyre ugyanazt a H értéket kapjuk, azaz teljesüljön: H(K1) ≠ H(K2) feltétel. Más szóval ne legyen ütközés (collision). [2]
Hasonlítsuk össze a lineáris és a bináris keresést egy hash fájlban:a) Lineáris keresés b) Bináris kereséssoros keresés a bucket-táblában bináris keresés a bucket táblában (mivel a bucketek növekvő sorba
rendezettek)soros keresés a bucketen belül soros keresés a bucketen belül (ha a blokkok rendezve vannak, akkor a

bináris keresés lehetséges a bucketen belül)
Hash függvény meghatározásának esetei:• Legjobb eset: minden bucketban pontosan egy blokk van.• Átlagos eset: a bucketekben több blokk van.• A gyakorlatban rendszerint amikor új rekordokkal bővül az adatbázis, akkor bizonyosbucketek egyre több és több blokkot fognak tartalmazni.A probléma leírásaLehetséges már az adatbázis-tervezés elején olyan hash függvényt meghatározni, hogy az adatbázis növekedése során a későbbiekben is viszonylag egyenletes legyen a bucket-tábla kitöltöttsége, és ne kelljen a hash függvényt újratervezni?
A probléma megoldásaA hash függvény tervezésekor a cél az, hogy a kulcsértékeket egyenletesen osszuk el a 0 és N-1 egész számok között, ahol N a bucket tábla mérete.
Egy lehetséges megközelítés:Az S sztring c1, ...,ck karakterei alapján határozzunk meg egy h pozitív egész számot.• a karakterenkénti konverziót az implementációs nyelvek használják• a sztring karaktereinek értékét kombináljuk
Hogyan határozzuk meg a sztringet reprezentáló egész számot ?Rossz módszer:• csak az első, a középső és az utolsó karaktert vegyük figyelembe az adott sztringben• a sztringben szereplő összes egész számot adjuk összeJobb módszer:• legyen h(0)=0; h(i)=Ah(i-1)+c(i), ahol 1 ≤ i ≥k. Legyen h=hk, ahol a sztring hossza k...
h meghatározása után konvertáljuk azt egy 0 és N-1 közötti egész számmá, például osszuk el N-nel, és vegyük a maradékot. [4]
Más típusú hasítófüggvény pl. az f(k) függvény, amely adott A konstans esetén a k kulcshoz az Ak szorzat alacsonyabb helyiértékű felének első bitjeit rendeli. [3]
Nézzünk egy példát konkrét hash-függvények alkalmazási korlátaira:Tegyük fel, hogy a következő 6 sztringre akarjuk alkalmazni a hash függvényt:alma, banán, citrom, dinnye, körte, meggy. Ekkor egy hatékony hash függvény lenne, ha a sztringek első betűjét vennénk figyelembe. De abban az esetben, ha ezt az aaa0001, aaa0010, aaa0011, aaa0100, aaa0101, aaa0110 sztringekre akarjuk alkalmazni, akkor a legrosszabb megoldást kapnánk eredményül, mivel mindegyik sztring egy bucketba kerülne.
Megjegyzés, véleményTehát az adatok várható értékétől, és eloszlásától függ a bucket tábla kitöltöttsége. A jövőbeni adatok eloszlását pedig csak becsülni tudjuk. Az adatok egyenletes eloszlása esetén lehetséges jó hash függvényt megadni, sztochasztikus eloszlás esetén pedig lehetetlen. A fenti példa rámutat arra, hogy nincs olyan hash függvény, amely minden alkalmazásban a legjobb eredményt adná.
Sajnos a legtöbb leképező algoritmus sem tesz eleget a bucket tábla egyenletes kitöltése és az ütközésmentesség követelményének. Legjobbnak mondható a következő maradékképző függvény, mert aránylag egyenletesen tölti ki a tárterületet (bucket-táblát) és kevés az ütközés is.
H(v)=v (mod m), aholv a kulcsnak megfelelő egész típusú szám,m pedig a tervezett bucketek számához legközelebb eső prímszám. [2]
Az ütközések kezelésére legmegfelelőbbek a dinamikus szerkezetek, mint pl. a láncolt lista, vagy faszerkezet.

A hash függvény néhány alkalmazási területe:
a) FordítóprogramokAz azonosítók véletlenszerűen jelennek meg a fordítóprogramokban, melyek száma programonként változó. A szimbólumtábla hasított fájl struktúrájú is lehet.Hasítófüggvénye az azonosító első karaktere (- ez meghatározza a bucketek számát).
b) Soundex kódolásEz a kódolási módszer hasított fájl struktúrát használ.
Pl. a következő angol kifejezések kiejtése azonos: waits, waites, whaits, whates. A magyar nyelvben a tulajdonneveknél előfordulhat a következő eset:a Desewfy, Dessewfy, Dezsőffy szavak kiejtése megegyezik.
A Soundex kódolásnál az egyforma kiejtésű nevekhez a hash függvény ugyanazt a bucketszámot rendeli.
Hashing algoritmusa:- a magánhangzókat nem vesszük figyelembe- átugrunk a h-n és az y-on- a többszörös hangzókat csak egyszer vesszük figyelembe- a lényeges mássalhangzókat meghatározzuk, és kódoljuk.
Pl. a waits, waites, whaits, whates szavak Soundex kódja: W78; ahol T=7; S=8;a Desewfy, Dessewfy, Dezsőffy szavak kódja pedig D56, ahol ‘zs’=5, ‘f’=6.
A Soundex-kódolás egy másik lehetséges alkalmazása:Információ visszakeresés- Keresés az Interneten (Yahoo, Altavista,...)- DIALOG, European Space Agency, CARL (CARL kb. 40 adatbázist menedzsel, több mint félmillió indexet használ ...; a DIALOG és az ESA nem nyújt ingyenes szolgáltatást..)

A Relációs adatbáziskezelés (Relational Database Management): E.F. Codd által 1970-ben kitalált módszer, amelynek lényege:
• A valóságos problémákban a személyekhez vagy tárgyakhoz általában nem fix hosszúságú adatszerkezetek tartoznak (pl. egyes szülőkhöz elérő számú gyerek adata tartozik, egyes könyvekhez eltérő számú kiadás adata tartozik),
• Ezek egy az egyben csak óriási helypazarlással lennének tárolhatók számítógépen gyorsan visszakereshető fix rekordhosszúságú táblázatokban
• Ezért Szétbontjuk (Decomposition) a valós adatszerkezeteket több, fix hosszúságú rekordszerkezetre, így néhány gyorsan elérhető, fix rekordhosszúságú adattáblában tárolhatjuk őket
• Hogy a szétbontás miatt ne vesszünk el információkat, a különböző táblákat Relációkkal (Relation) kapcsoljuk össze:
• Ezek a táblák egyes rekordjaira történő hivatkozások más táblák rekordjaiban, amelyek biztosítják, hogy az eredeti, nem fix hosszúságú adatszerkezetek visszakereshetők az adatbázisból.
• A relációk maguk is gyorsan visszakereshető fix hosszúságú szerkezetekben tárolhatók: az adattáblák külön mezőiben, vagy külön táblázatokban
A Relációs adatbáziskezelő (Relational Database Management System, RDBMS): olyan szoftver, amely lehetővé teszi:
1. Adattáblák és a köztük lévő relációk definiálását, 2. Adattáblák adatokkal való feltöltését:
• Manuális inputból elektronikus Űrlapokon (Form), • Más adatbázisból, • Távadat kapcsolatból hálózaton
3. Az adatok manipulációját SQL (Structured Query Language) nyelven:• Létrehozás,• Módosítás,• Számítások,• Törlés
4. Az összesített eredmények felhasználó számára történő megjelenítését Jelentésekkel (Report):• Alfanumerikusan,• Diagrammokkal• Audiovizuálisan
Az Struktúrált Lekérdező Nyelv (Structured Query Language, SQL): olyan programnyelv, amely:• A relációs adatbázis tábláinak létrehozását, módosítását, törlését teszi lehetővé• A relációs adatbázis-kezelésen alapul, 80-90%-ban szabványos az adatbázis-kezelők közt• Utasításkészlete leegyszerűsített egy procedurális programnyelvhez képest• Mert előre programozva tartalmazza a gyakran előforduló adatkezelési műveleteket.• Így csak a számítások célját kell megadni, az algoritmusukat automatikusan számítja ki• Egy rekord elérhetőségét függetleníti az adattáblában történő aktuális fizikai tárolási helyétől, ezzel
könnyebbé teszi a beszúrási és törlési műveleteket
Az adatbázisokat kezelő programozási nyelvek tagolódása:A korábbi megállapításokból következően, (lásd adatfüggetlenség, az adatvédelem fontossága, az elvárások 3. pontja) belátható, hogy az adatbázisok feldolgozása sok funkcióból, eljárásból tevődik össze. Ennek megfelelően az egyes funkciók megvalósítása érdekében különböző fejlesztő intézetek, különböző programrendszereket hoztak létre. Ezek a programrendszerek vagy lefedik az összes funkciót, vagy egy-egy részterület feladatait oldják meg. A fontos csak az, hogy ezek kompatibilisek legyenek egymással. Ezért nemzetközi konferenciákon közösen kialakított, szabványosítási megállapodásokkal biztosítják az "átjárhatóságot" a programrendszerek között. A szabványosítási törekvések eredményeként születtek az egyes részterületeket lefedő önálló programnyelvek.
Adatdefiníciós utasítások (Data Definition Language – DDL), amelyek objektumok létrehozására, módosítására, törlésére valók.

Adatmanipulációs utasítások (Data Manipulation Language – DML), amelyek rekordok felvitelére, módosítására és törlésére alkalmazhatók.
Adatkezelő utasítások (Data Query Language – DQL), amelyekkel a letárolt adatokat tudjuk visszakeresni.
Adatvezérlő utasítások (Data Control Language – DCL), amelyekkel az adatvédelmi és a tranzakció-kezelő műveletek végrehajthatóak.
1. Az Adatleíró nyelv ( Data Definition Language - DDL) adatstruktúrát definiáló utasításokA számítógéppel feldolgozott adatok tulajdonképpen a valós világ objektumainak valamilyen leképezése,
modellezése. Ez az adatmodell szolgál a felhasználó által igényelt információk alapjául. Első lépés tehát a rendszer létrehozása során a feldolgozásra alkalmas adatmodell kialakítása. Nevezzük még ezt a logikai modellt sémá -nak is. Egy integrált, osztottan alkalmazott adatbázis esetén az egyes felhasználók által „látott” adatszerkezet (modell) neve pedig alséma, amely a teljes adatbázisnak az adott felhasználói igény szerinti részhalmazát írja le.
Az adatmodell (séma) létrehozása során tartalmi és formai előírásokat rendelünk a tárolandó adatokhoz. Ennek megfogalmazására szolgál az Adatleíró nyelv, ami valójában nem más, mint program utasítások csoportja, amelyekkel definiáljuk az adatok nevét, adattípusát, méretét, formátumát, hozzáférhetőségét. Azt a "listát", amely a használt adatok jellemzőit tartalmazza, Adatszótár –nak nevezzük.
Megjegyzés: ilyen utasítások például a CREAT <objektum>, ALTER <objektum> (lásd SQL jegyzet)
2. Az Adatkezelő nyelv (Data Manipulation Language - DML) adatok aktualizálásaAz adatbázisok feldolgozása az úgynevezett adatbázis-kezelő műveletek sorozataként valósul meg. Ez azt
jelenti, hogy az adatbázis elemeket (állományokat, rekordokat, kapcsolat leíró elemeket, stb.) és az adatokat mozgatni, létrehozni, felvinni, keresni, módosítani, törölni, egyszóval manipulálni (kezelni) kell.
Az adatbázis-kezelő rendszerek erre a célra rendelkeznek saját parancskészlettel ( DML ), amelyet önállóan alkalmaznak a feldolgozás során, de lehetséges az is, hogy a DML beépül egy magas szintű programozási nyelvbe és annak utasításai között kerülnek meghívásra és végrehajtásra.
Megjegyzés: ilyen utasítások például az INSERT INTO …, UPDATE …, (lásd SQL jegyzet)
3. A Lekérdező nyelv ( Query Language - QL ) lekérdezésekAz adatbázisban tárolt adatok legfőbb értéke, hogy belőlük, meghatározott igények szerint adatok, végső soron
információk nyerhetők. A „meghatározott” adatnyerés leegyszerűsítve annyit jelent, hogy a teljes adathalmazból csak egy részhalmazra vagyunk kíváncsiak, és/vagy az adatokat valamilyen sorrendben szeretnénk látni, és/vagy olyan adatokat akarunk együtt látni, amelyek az adatbázisban nem tárolódnak együtt.
Az adatbázis-kezelő rendszerek erre a célra szintén rendelkeznek saját parancskészlettel ( QL ), amely olyan utasításokat foglal magában, amelyek ezeket az igényeket kielégítik. A lekérdező nyelv szintén beépülhet egy magas szintű programozási nyelvbe.
A lekérdezés kiemelt szerepét jellemzi, hogy ez a terület az, amelyet a szoftver gyártók megegyezése alapján standardizálni (szabványosítani) lehetett. Ez a szabványos lekérdező nyelv az SQL - Structured Query Language, azaz magyarul a Strukturált lekérdező nyelv.
Megjegyzés: ilyen utasítások például az SELECT …, WHERE …, GROUP BY … (lásd SQL jegyzet)
4. Az Adatvezérlő nyelv ( Data Control Language - DCL) vezérlés (jogosultságkezelés, tranzakciókezelés)Az adatbázis feldolgozása során sok és bonyolult művelet, idegen szóval tranzakció kerül végrehajtásra.
Ahhoz, hogy az adatbázis egy ilyen tranzakció után is „jó” maradjon, ne sérülhessenek benne adatok vagy adat kapcsolatok, folyamatosan ellenőrizni (kontrollálni) kell a műveletvégzéseket. Biztosnak kell lenni abban, hogy valóban végrehajtódott-e a kívánt művelet, minden szükséges művelet megtörtént-e és abban a sorrendben, ahogy kell, nem szakadt-e meg egy művelet lánc, stb. Ugyanakkor azzal a minimális biztonsággal is rendelkeznünk kell, hogy ha véletlenül nem jól kerültek

végrehajtásra a műveletek vagy a kezelő hibájából „véletlenül” egy nem kívánt művelet (például törlés) került végrehajtásra, az eredeti állapot visszaállítható legyen. De hasonló problémákat okozhatnak a géphibák vagy a program téves működése.
Még egy példa a tranzakció értelmezésére, amely egymással összefüggő műveletsort takar. A tranzakció elkezdődik (BEGIN) amikor valaki a bankbetét ablakánál megjelenik és közli, hogy pénzt kíván elhelyezni a számláján. Következik a QL utasítás, amellyel lekérdezik, hogy a személy létező ügyfél-e és azonosítható-e a bemutatott okmányok alapján. Ezután módosítják a számla adatát a betét összegével, amely egy DML utasítás. Mi van akkor, ha az ügyfél a pénztárnál jön rá, hogy otthon hagyta a pénzét? Minden eddigi műveletet törölni kell, pontosabban a műveletek hatását az adatbázisból. Szükség van tehát egy olyan utasításra, amellyel nyugtázni lehet a műveletek elvégzését a BEGIN –től (COMMIT) vagy érvénytelenít mindent (ROLLBACK). Ez után következhet csak az újabb „betét” tranzakció.
Megjegyzés: a BEGIN, COMMIT, ROLLBACK az adatvezérlő nyelv utasításai.Az Adatvédelmi utasítások Egy adatbázis, a benne tárolt adatok egyrészt anyagi értéket képviselnek, pontosabban a megsemmisülése vagy
illetéktelen kezekbe kerülése anyagi kárt okoz. Gondoljunk továbbá egy kórházi adatbázisra ahol emberek „életét jelentő” adatok tárolódnak. Bár nem beszélünk adatvédelmi nyelvről, de külön beszélni kell az adatvédelmi utasításokról. Itt csak a figyelem felkeltése a cél, de az SQL tárgyalása során részletesen foglakozunk vele.
Két alapvető célt valósítanak meg az adatvédelmi utasítások: hozzáférési jogokat definiálnak az adatbázishoz és annak elemeihez illetve a műveletvégzést szabályozzák. Például egy adatbázis bizonyos adatcsoportjához férhet csak hozzá az adott kezelő, illetve amihez hozzáfér azt is csak olvashatja és módosíthatja de már nem törölheti.
Adatbázis-kezelő nyelvek• DDL – adatdefiniáló nyelv (sémák, adatstruktúrák megadása)• DML – adatkezelő nyelv (beszúrás, törlés, módosítás)• QL – lekérdező nyelv
– Deklaratív (SQL, kalkulusok)– Procedurális (relációs algebra)
• PL/SQL – programozási szerkezetek + SQL• Programozási nyelvbe ágyazás (előfordító használata)• 4GL nyelvek (alkalmazások generálása)

Az SQL nyelvAz SQL alapjait az IBM-nél fektették le, még az 1970-es években. Elvi alapot a relációs adatmodell szolgáltatott, amit Edgar F. Codd híres 12 szabályával írt le először, 1970-ben.
A relációs modellE. F. Codd (IBM) 1970-ben publikált egy híres cikket: A Relational Model for Large Shared Data Banks (Nagy, osztott adatbankok egy relációs modellje), amely egy lekérdező nyelv fő kritériumait tartalmazta. Az adatbázisok az adatokat táblázatok formájában jelenítik meg. A modell matematikai alapjait a relációs algebra adja.
1974-ben Dr. Donald Chamberlin és munkatársai kifejlesztették a SEQUEL (Structured English QueryLangugage, strukturált angol lekérdezőnyelv) nyelvet, amely lehetővé tette a felhasználóinak, hogy világosan meghatározott, az angolhoz hasonló nyelvű mondatokkal kérdezzenek le adatokat egy relációs adatbázisbóL Dr. Chamberlin és csapata az új nyelvet először a SEQUEL-XRM nevű rnintaadatbázisban valósította meg.A SEQUEL-XRM sikere és a kezdeti visszajelzések arra bátorították Dr. Chamberlint és társait, hogy folytassák a kutatómunkát. 1976-77-ben teljesen áttervezték a SEQUEL-t, és az új változatot SEQUEV2-nek nevezték el. Később azonban a nevet jogi okokból SQL-re (Structured Query Language, strukturált lekérdezőnyelv) kellett változtatniuk (valaki más ugyanis már használta a SEQUEL betűszót). Sokan a mai napig úgy ejtik ki az SQL nevét, mint a sequel szót, bár a "hivatalos" (a legszélesebb körben elfogadott) kiejtés "es-kú-el" (illetve angolul "esz-kjú-el"). Az SQL több új szolgáltatást is kínált, például támogatta a többtáblás lekérdezéseket, valamint az adatok több felhasználó általi megosztott elérését.Az SQL megjelenése után nem sokkal az IBM egy új és még nagyratörőbb terv megvalósításába fogott: egy olyan adatbázis-prototípust igyekeztek megalkotni, amely még kézzelfoghatóbbá teszi a relációs modell alkalmasságát. Az új prototípust System R-nek nevezték el, és az SQL egy kiterjedt részhalmazára alapozták. Miután az előkészítő munka nagyja befejeződött, az IBM több belső hálózatára, illetve néhány kiválasztott ügyfelére telepítette a System R-t tesztelés és értékelés céljából, majd a tapasztalatok és a felhasználók visszajelzései alapján számos változtatást eszközölt a rendszeren és az SQL-en. Az IBM 1979-ben fejezte be a kísérletet, ami azzal a megállapítással zárult, hogy a relációs modell valóban alkalmas adatbázis-technológia, amelyben komoly üzleti lehetőségek vannak.
1977-ben a kaliforniai Menlo Park mérnökei megalapították a Relational Software, Inc. nevű céget, azzal a szándékkal, hogy egy új relációs adatbázisterméket készítsenek, amely az SQL-en alapul. A termék az Oracle nevet kapta. Az Oracle 1979-ben került a piacra, két évvel megelőzve az IBM első hasonló termékét, és így az első kereskedelmi forgalomban kapható relációs adatbázis-kezelő rendszerré (RDBMS, relational database management system) vált. Az Oracle egyik előnye az volt, hogy a Digital VAX illiniszámítógépein futott, nem pedig a költségesebb IBM-nagygépeken. A Relational Software azóta Oracle Corporationre változtatta a nevét, és a mai napig az egyik piacvezető az RDBMS-szoftvergyártók között.Mindeközben Michael Stonebraker, Eugene Wong és a kaliforniai Berkeley Egyetem számítógépes laboratóriumának más professzorai ugyancsak a relációs adatbázis-technológia terén végeztek kutatásokat. Az IBM csapatához hasonlóan kifejlesztettek egy relációsadatbázis-prototípust, amelynek a neve INGRES lett. Az INGRES-be beépítették a QUEL (Query Language) nevű adatbázis-kezelő nyelvet is, amely az SQL-lel összevetve strukturáltabb nyelv, de kevésbé támaszkodik a természetes (angol) nyelvű utasításokra. Az INGRES-t végül SQL alapú RDBMS rendszerré alakították át, arnikor

nyilvánvalóvá vált, hogy az SQL lesz az adatbázis-kezelő nyelvek szabványa. 1980-ban a Berkeley-ről távozó néhány professzor megalapította a Relational Technology, Inc. céget, és 1981-ben bejelentették az INGRES első kereskedelmi változatának megjelentetését. A Relational Technology azóta számos átalakuláson esett keresztül, és ma a Computer Associates International, Inc. része.Az INGRES azonban még mindig az iparág egyik piacvezető adatbázisterméke.
Az ANSI 1986-ban, ANSI X3.135-1986 Database Language SQL néven szentesítette az X3H2 szabványtervezetét, amely végül SQV86 néven vált széles körben ismertté. Bár az X3H2 kisebb javításokat is eszközölt a szabványon, mielőtt azt az ANSI elfogadta volna, az SQV86 csupán a legkisebb közös részhalmazát határozta meg azoknak a követelményeknek, amelyeknek az adatbázisgyártóknak eleget kellett tenniük. Lényegében tehát csak hivatalos szintre emelte azokat az elemeket, amelyek a különböző SQL-nyelvjárásokban megegyeztek, és amelyeket a legtöbb adatbázisgyártó már megvalósított. Mindazonáltal az új szabvány végre konkrét alapot biztosított, ahonnan kiindulva a nyelvet és annak megvalósításait tovább lehetett fejleszteni.A Nemzetközi Szabványügyi Szervezet (ISO, International Organization for Standardization) a saját szabványtervezetét (ami pontosan megfelelt az ANSI SQV86-nak) 1987-ben hagyta jóvá nemzetközi szabványként, és ISO 9075-1987 Database Language SQL néven tette közzé. (Általában mindkét szabványra ma is csak SQV86-ként szaktak hivatkozni.)Az adatbázisgyártók nemzetközi közössége innen kezdve ugyanazokra a szabványokra építhetett, mint az Egyesült Államokban tevékenykedő társaik. Mindazonáltal annak ellenére, hogy az SQL hivatalos szabvánnyá vált, a nyelv még messze nem állt teljesen készen.
1976-ban az IBM-nél megszületett a SEQUEL adatbázisnyelv (E. F. Codd, P. Chen, C. Date), amit később SQL (Structured Query Language)-re rövidítettek, amely:• Szabványos adatszerkezet definiálási, adatkezelési és adatbiztonsági lehetőségeket biztosít.• A fizikai műveleteket rejtse el a lekérdezést, karbantartást (felvitel, módosítás, törlés) végző utasítások mögé.A relációs adatmodellben az egyedet egy táblázattal adjuk meg. A táblázat oszlopai az egyedre jellemző tulajdonságok, a sorai az egyed értékei (egyedtípus előfordulásai). A táblák közötti kapcsolatokat közös tulajdonságokkal, indexeken keresztül, valósítjuk meg.Az alábbi felsorolás néhány fontos fejlesztő céget és részben azonos nevű SQL terméküket tartalmazza:• IBM-1983: DB2• Oracle-1983: Oracle• Relational Co. - 1984: INFORMIX• Sybase Miután egyre több cég jelent meg• Ingres• Microsoft: SQL-Server
Időközben már néhány cég megszűnt, terméküket mások felvásárolták.
1976: SEQUEL (IBM)1981: ORACLE 2 (SQL alapú DBMS)

1983: IBM: DB2 (SQL alapú DBMS)
SQL szabványosítás saját fejlesztésű relációs adatbázis-kezelő rendszerrel, lassan elindult egy szabványosítási folyamat. Az első ANSI (1986), majd az ISO (1987) szabvány csak a nyelv alaputasításait tárgyalta.Az 1989-ben megjelent ISO: 9075:1989 szabvány már foglalkozik az előfordítókkal és az ún. dinamikus SQL utasításokkal is.A jelenlegi szoftverek, az 1992-ben bejelentett ISO: 9075:1992 szabvány elvárásainak megfelelően, bővített adattípusokkal, értékszabályokkal, kulcsdefiniálási lehetőségekkel, stb. dolgoznak. A szabványt az irodalom SQL2 néven említi.Az SQL3 szabvány 1998/99-re készült el. Kezeli az összetett, rekurzív adatszerkezeteket, megjelenik benne az objektumorientált adatbáziskezelés.Az ODMG (Object Database Management Group) szabványok (1993–2003) tartalmazzák az objektumorientált adatbázisokra vonatkozó elvárásokat, követelményeket.
A szabványt az ANSI (Amerikai Nemzeti Szabványügyi Intézet – American National Standards Institute) 1986-ban, az ISO (Nemzetközi Szabványügyi Szervezet – International Organization for Standardization) 1987-ben jegyezte be. Az SQL leírását az ISO 9075 szabvány rögzíti.[1] Az első változatot SQL86 néven is szokták emlegetni.
Az első kivételével mindegyik szabvány többszintű megvalósítást tesz lehetővé a gyártóknak (belépő szintű, közepes vagy teljes). Általában a későbbi szabványok belépő szintjei az előző szabvány teljes szintjeinek felelnek meg.
1986: szabvány SQL (ANSI)1992: SQL-92 szabvány (SQL2)1999: SQL:1999 szabvány (SQL3) (objektum-relációs)2003: SQL:2003 szabvány (XML)2006, 2008: további bővítések
Year Name Alias Comments 1986 SQL-86 SQL-87 First formalized by ANSI. 1989 SQL-89 FIPS 127-1 Minor revision that added integrity constraints, adopted as FIPS 127-1.
1992 SQL-92 SQL2, FIPS 127-2 Major revision (ISO 9075), Entry Level SQL-92 adopted as FIPS 127-2.
1999 SQL:1999 SQL3
Added regular expression matching, recursive queries (e.g. transitive closure), triggers, support for procedural and control-of-flow statements, non-scalar types (arrays), and some object-oriented features (e.g. structured types). Support for embedding SQL in Java (SQL/OLB) and vice versa (SQL/JRT).
2003 SQL:2003 Introduced XML-related features (SQL/XML), window functions, standardized sequences, and columns with auto-generated values (including identity-columns).
2006 SQL:2006
ISO/IEC 9075-14:2006 defines ways that SQL can be used with XML. It defines ways of importing and storing XML data in an SQL database, manipulating it within the database, and publishing both XML and conventional SQL-data in XML form. In addition, it lets applications integrate queries into their SQL code with XQuery, the XML Query Language published by the World Wide Web Consortium (W3C), to concurrently access ordinary SQL-data and XML documents.[34]
2008 SQL:2008 Legalizes ORDER BY outside cursor definitions. Adds INSTEAD OF triggers, TRUNCATE statement,[35] FETCH clause.
2011 SQL:2011 Adds temporal data (PERIOD FOR)[36] (more information at: Temporal database#History). Enhancements for window functions and FETCH clause.[37]
2016 SQL:2016 Adds row pattern matching, polymorphic table functions, JSON.

Általános jellemzőkAz SQL nyelv a relációs adatbázis-kezelők (RDBMS: Relational Batabase Management System) (pl. ORACLE, MS SQL Server, INGRES, INFORMIX, DB2, SYBASE, NOVELL XQL, PROGRESS, stb.) szabványos adatbázis nyelve.
Jellemzői:- Nem algoritmikus, deklaratív nyelv:
Parancsnyelv jellegű, azaz lényegében azt fogalmazhatjuk meg vele, hogy mit akarunk csinálni, a hogyant azaz a feladat megoldási algoritmusát nem kell a felhasználónak megadni. Nincsenek benne az algoritmikus nyelvekben megszokott utasítások (ciklusok, feltételes elágazások, stb.)
- Halmazorientált:Táblákat mint a sorok (rekordok) halmazát tekintjük. Az utasításban megfogalmazott feltételnek eleget tevő összes sor részt vesz a műveletben.
- Teljes adat - nyelv függetlenség: fizikai, és logikai szintenFizikai szinten: az adatok fizikai tárolási, hozzáférési, ábrázolási módjában bekövetkező változáskor nincs szükség a programok módosítására.Logikai szinten: a programokat nem befolyásolja az adatok logikai szerkezetének megváltozása: pl. sorok, oszlopok sorrendje, új oszlopok, indexek, tablespace-ek, stb.
- Szabványos:Illeszkedik az SQL szabványhoz: SQL89 (SQL1), SQL92 (SQL2), SQL99 (SQL3).Egy szabványnak kötelező, ajánlott, szabadon választott részei vannak.A szabványban van egy SQL utasításcsoport, amelyet minden SQL alapú szoftver implementációnak meg kell valósítani, de mindegyik implementáció plusz lehetőséget is nyújt a standard SQL-hez képest, azaz felülről kompatibilis a szabvánnyal.
Az SQL mondatokat pontosvesszővel zárjuk le
A parancsok szóközökkel, tabulátorokkal tagolhatók és több sorba írhatók
Szintaxis• Kisbetű és nagybetű egyenértékű• Utasítások sorfolytonosan, szóközökkel, tabulátorokkal tagolhatók és több sorba
írhatók• Utasítások lezárás: pontosvessző• Változó nincs, csak tábla- és oszlopnevek
Jelölés: [tábla . ] oszlop• Alias név: név AS másodnév• Szövegkonstans: 'szöveg'• Stringek konkatenációja: + vagy ||• Relációjelek: =, <=, >=, !=, <>• Logikai műveletek: AND, OR, NOT.• Háromértékű logika: TRUE, FALSE, NULL. (SQL-szabvány szerint UNKNOWN)
A B A OR B A AND B NOT ATrue True True True FalseTrue Unknown True Unknown FalseTrue False True False FalseUnknown True True Unknown UnknownUnknown Unknown Unknown Unknown UnknownUnknown False Unknown False Unknown

False True True False TrueFalse Unknown Unknown False TrueFalse False False False True
• x IS NULL (x=NULL értéke UNKNOWN)• x BETWEEN a AND b
a x bPélda: évszám BETWEEN 1950 AND 2000
• x LIKE mintaPélda: lakcím LIKE '%Vár u.%'
• x IN halmazPélda: város IN ('Szeged','Szolnok','Pécs')Példa: város IN (lekérdezés)
• x relációjel ALL halmazPélda: fizetés != ALL (81000, 136000, 118000)
• x relációjel ANY halmazPélda: fizetés < ANY (81000, 136000, 118000)
• EXISTS halmazPélda: EXISTS (lekérdezés)
NOT használata: például NOT INHárom értékű logika (3VL)
A kérelmek lefordítása SOL-reAmikor információkért folyamodunk az adatbázishoz, ezt általában kérdések vagy kérdésként is megfogalmazható utasítások formájában tesszük. Például ilyen utasításokat fogalmazhatunk meg:
"Mely városokhan laknak a vásárlóink?""Mutasd meg az alkalmazottak aktuális listáját és a telefonszámaikat!""Milyen órákat kínálunk jelenleg?""Add meg a tanári kar tagjainak a nevét és a dátumokat, amikor felvettük őket!"
Miután már tudjuk, mit akarunk kérdezni, a kérelmeket szabályszerű alakra fordíthatjukEzt az alábbi minta szerint tehetjük meg:Select <elem> from the <forrás>Érdemes azzal kezdenünk, hogy a felvetett kérdésben az olyan szavakat és kifejezéseket, mint az "Írd ki"', "Mutasd meg', "Melyek azok ...", "Kik azok ... " a "Select" (kiválaszt)szóra cseréljük. Következő lépésként keressük meg a főneveket a kérdésben, és döntsük el, hogy az adott főnév megfeleltethető-e a keresett elemnek vagy egy táblának, amelyben az elem tárolódik. Ha egy elemről van szó, akkor azt helyettesítsük be az <elem> helyére, ha egy tábla nevéről, akkor pedig a <forrás> helyére. Ha az első példakérdésünket lefordítjuk, valami ilyesmit kapunk:
Select city from the customers table (Válaszd ki a várost a vásárlók táblájából)
Miután a mondatot "szabályosabb" formára fordítottuk, át kell alakítanunk egy teljesen kész SELECT utasítássá, hogy megfeleljen az SQL nyelvtani szabályainak, amint az ábrán látható. Ehhez az első lépés az, hogy letisztázzuk a lefordított mondatot.Húzzuk ki azokat a szavakat, amelyek nem oszlopot vagy táblát megnevező főnevek, vagy nem tartoznak az SQL nyelvi elemei közé. Ezután a mondatunk így fog kinézni:
Select city from the customers table
SELECT City FROM Custorners

SELECT lekérdező utasításEgy vagy több tábla vagy nézettábla tartalmát kérdezhetjük le, de használhatjuk beépítve más SQL utasításban is (alselect). Legáltalánosabb formája a következő:
SELECT [DISTINCT] ... oszlopok kiválasztása (projekció)(6 7)
FROM ... táblanév(-ek) (Descartes szorzat)(1)
[WHERE ... ] sorok kiválasztása (szelekció)(2)
[CONNECT BY ... [START WITH ...]] hierarchia kezelés (3)[GROUP BY ... ] csoportosítás (4)
[HAVING ... ] csoportok közötti válogatás (5)[{UNION | UNION ALL | INTERSECT | MINUS} alselect]
halmazműveletek (8)[ORDER BY ... ] eredménysorok rendezése (9)
[FOR UPDATE OF …] kiválasztott sorok zárolása az(10)updatelés idejére

Az utasításrészek megadási sorrendje kötött. A kiértékelést a ()-ben megadott sorrendben célszerű követni. Az utasítás általános alakja elég bonyolult, így csak fokozatosan adjuk meg a részletesebb szintaktikáját.
Egyszerű lekérdezésekSELECT [ ALL | DISTINCT ] { [ táblanév.]* | o_kifejezés [ [AS] o_aliasnév] } ,...FROM táblanév [t_aliasnév ] ,...;ALL - alapértelmezés: az összes sort visszaadja.DISTINCT - csak az egymástól különböző sorokat adja visszao_aliasnév - a lekérdezés eredményében nem az oszlop v. kifejezés valódi neve, hanem az o_aliasnév jelenik meg.t_aliasnév - a táblanév rövidítésére használható az utasításban.Az o_aliasnév és a t_aliasnév csak az adott utasításban érvényes.o_kifejezés - legegyszerűbb esetben ez egy oszlop neve, de állhat itt oszlopnevek, konstansok és függvényhívások összekapcsolva aritmetikai operátorokkal (*, /, +, -) vagy konkatenáló karakteres operátorral ( || ), zárójelezés is megengedett.konstans: adattípusa lehet: karakteres, numerikus, dátum:Pl.: 'Karaktersor', 1234.56, 25E-3, '21-MAJ-74' vagy '74-MÁJ-21'Karakteres típus megkülönbözteti a kis- és nagybetűt.Dátum konstans függ az alapértelmezett dátum formátumtól és nyelvtől:Pl. 'DD-MON-YY' vagy 'YY-MON-DD' vagy 'RR-MON-DD'Ez a dokumentum többnyire az angol nyelvet és dátumformátumot használja! Az aktuális beállítások megtekinthetők:SELECT * FROM v$nls_parameters;függvények: később ismertetjük.oszlopnév: [táblanév.]oszlopnévMinősített név kell, ha egy oszlopnév az utasítás több táblájában is előfordul. Az oszlopnév helyén álló * a tábla összes oszlopát jelenti.
Sorok kiválasztása, lekérdezés keresési feltétellelSELECT ...FROM ...WHERE feltétel…;Csak a feltételnek eleget tevő (feltétel logikai értéke igaz) sorok vesznek részt a további műveletekben. Mindegyik alaptípus szerepelhet a feltételt alkotó összehasonlító műveletekben.Egyszerű feltételek tipikus formái:o_kifejezés relációs_operátor {o_kifejezés | (egy_értéket_adó_alselect)}relációs_operátorok (théta operátorok): =, !=, <>, <, >, <=, >=o_kifejezés [NOT] BETWEEN kif1 AND kif2kif1 és kif2 közé esés (zárt intervallum)(kif1 <= o_kifejezés <= kif2)o_kifejezés [NOT] LIKE 'karakterminta'illeszkedik-e a megadott karaktermintára. Dzsóker karakterek:% tetszőleges hosszú karaktersorrailleszkedés az adott pozíciótól,_ tetszőleges karakterre illeszkedés az adott pozícióbano_kifejezés IS [NOT] NULLNULL értékkel való egyezés vizsgálata(o_kifejezés=NULL helytelen, mindig NULL lesz az eredmény)"Halmazos" feltételek tipikus formái:"Halmaz" lehet:(kifejezés lista)(alselect) -- több oszlopot és sort is visszaadhat

o_kifejezés [NOT] IN (halmaz)a megadott halmazban szerepel-e?o_kifejezés relációs_operátor {ANY|SOME} (halmaz)teljesül-e a reláció a halmaz valamely (legalább egy) elemére?(megj: =ANY azonos az IN relációval, ANY és SOME azonos )o_kifejezés relációs_operátor ALL (halmaz)teljesül-e a reláció a halmaz minden egyes (összes) elemére?(megj: <>ALL azonos a NOT IN relációval )(o_kifejezés_lista) előbbi_műveletek_egyike (halmaz)relációs operátor itt csak =, <> lehet[NOT] EXISTS (alselect)az alselect visszaad-e legalább egy sort?
A műveletek precedenciája (kiértékelés sorrendje):Megadjuk az operátor csoportokat a precedenciájuk csökkenő sorrendjében, ettől zárójelezéssel lehet eltérni. Azonos precedenciájú műveletek esetén a balról-jobbra szabály érvényes.1. Aritmetikai operátorok ( *, /, +, - ) (közöttük a sorrend és a kötési irány a szokásos)2. Karakteres operátor ( || )3. Összehasonlító operátorok ( =, !=, <>, <, >, <=, >=,[NOT] IN, ANY, ALL, [NOT] BETWEEN, [NOT] EXISTS, [NOT] LIKE, IS [NOT] NULL ) (precedenciájuk azonos)4. Logikai operátorok ( NOT, AND, OR ) (közöttük a sorrend és a kötési irány szokásos)
Halmazműveletek selectek között:Két kompatíbilis lekérdezés (eredménytábla oszlopainak száma egyezik és típus szerint is rendrekompatibilisek) halmazműveletekkel kapcsolható össze:UNION - Egyesítés eredménye: legalább az egyik táblában előforduló sorok, sorduplikáció nincs.UNION ALL - Egyesítés eredménye: a táblákban előforduló sorok, sor duplikációtmegenged.INTERSECT - Metszet eredménye: mindkét táblában előforduló közös sorok.MINUS - Kivonás eredménye: az első táblából elhagyjuk a második táblábanelőforduló sorokat.
Származtatott adatok, SQL sor-függvényekSzármaztatott adatok azok, amelyeket a tábla adatbázisban tárolt adataiból lehet kiszámítanikifejezések segítségével. Ezeket oszlopkifejezésnek is szokás nevezni és az SQL utasításokbantöbb helyen megengedett a használatuk.Az oszlopkifejezés oszlopnevek, konstansok és függvényhívások összekapcsolva aritmetikaioperátorokkal (*, /, +, -) vagy konkatenáló karakteres operátorral ( || ), zárójelezés ismegengedett.A függvények részletes leírása megtalálható a referencia kézikönyvekben. A legtöbb függvény aNULL értékekkel nem tud számolni, NULL lesz a függvény értéke. A NULL érték kezelésére azNVL függvény alkalmazható, amelyet már korábban ismertettünk. A függvényhívásokegymásba ágyazhatók.Típusai:Sor-függvények (Row Functions): soronként egy eredményt adnak vissza.Csoport-függvények (Aggregate Functions): a sorok egy csoportjára egy értéket adnak vissza.

(ezeket egy külön fejezetben ismertetjük).A sor függvények többsége a legtöbb programozási nyelvben megtalálható. Ezek minden sorrakülön kiértékelődnek, függetlenül a többi sortól és soronként egy eredményt adnak vissza.Egy egyszerű sor függvény kipróbálásához a DUAL rendszertáblát használhatjuk, amelynek egysora és egy oszlopa van:SELECT FV_NÉV(arg1, …),… FROM DUALAritmetikai függvények: ABS, POWER, SQRT, SIGN, ROUND, TRUNC, MOD, FLOOR,CEIL, SIN, COS, TAN, stb.Karakteres függvények: LOWER, UPPER, INITCAP, LENGTH, SUBSTR, LPAD, RPAD,LTRIM, RTRIM, CHR, ASCII, stb.Pl.: SELECT * FROM alkalmazottDátum függvények: SYSDATE, ADD_MONTHS, MONTHS_BETWEEN, LAST_DAY,TRUNC, ROUND, stb.A teljes dátum és idő tárolásra kerül az adatbázisban speciális belső formában:évszázad, év, hónap, nap, óra, perc, másodpercA standard dátum megadási formátum és nyelv beállítható. Az adatszótárból lekérdezhetők azaktuális beállítások: SELECT * FROM v$nls_parameters;'DD-MON-YY' pl.: '03-MAR-94' angol nyelven'YY-MON-DD' pl.: '94-MÁR-03' magyar nyelvenAdatfelvitelnél az ilyen formában megadott dátumok tárolásához az évszázadot az aktuálisévszázadnak, az időpontot pedig éjfélnek veszi.YY helyett RR is alkalmazható: 'DD-MON-RR', 'RR-MON-DD', ebben az esetben az évszázadképzése a következő:A 2 számjeggyel megadott év:00-49 50-99Az aktuális év utolsó 2 számjegye: 00-49Aktuális évszázad Előző évszázad50-99 Következő évszázad Aktuális évszázadMűveletek: dátumok kivonása -- eredmény napokban,dátumhoz nap hozzáadása, kivonása -- eredmény dátum,dátumok összehasonlítása.Implicit adatkonverzió: a rendszer ha tudja, akkor szükség esetén automatikusan átalakítja azegyik típusú adatot egy másik típusra:SELECT a_nev, belepes, t_kod, fizetes+'10'FROM alkalmazottWHERE belepes>'80-jan-01' OR t_kod>40;TO_CHAR(dátum_kif, 'formátum'), TO_CHAR(szám_kif, ' formátum '),TO_DATE('dátum_kar', ' formátum '), TO_NUMBER('szám_kar', ' formátum ')Szám formátumban használható elemek: 9 (szám) 0 (zérus). (tizedespont) , (ezredes elválasztók) megjelenítésére, kezelésére, stb.SELECT a_nev, TO_CHAR(fizetes, '099,999.99')FROM alkalmazott;SELECT TO_CHAR(TO_NUMBER('123,456', '999,999'), '999999.00') FROM DUAL;Dátum formátumban használható elemek:Century, Year, Month, Day, Hour, MInute, Second, Week, Quarter, stb.

Az angol szavak kezdőbetűjét használjuk a dátumelemek számokkal való leírásánakmegformázásához. Egyes dátumelemek (Year, Month, Day ) teljes kiírását vagy annak 3 betűsrövidítését (MON, DY) is kérhetjük, valamint a kis- vagy nagybetűs írásmód is jelölhető.Csoportok képzése, SQL csoport-függvényekA kiválasztott sorok csoportosítására, csoportokon műveletek végzésére és a csoportok közöttiválogatásra alkalmazható.SELECT ...FROM ......GROUP BY o_kifejezés ,...[HAVING csoportkiválasztási_feltétel]…;A GROUP BY után megadott oszlopkifejezések (legtöbbször ez egy vagy több oszlopnév)határozza meg azt, hogy a sorok csoportosítása mely oszlop(ok) értéke szerint történjen. AHAVING részben adható meg a csoportok közüli válogatás feltétele.A létrejövő csoportokra különféle beépített, úgynevezett csoportfüggvények használhatók:AVG( ), MIN( ), MAX( ), COUNT( ), SUM( ), stb.Alakja: FV_NÉV ( [ DISTINCT | ALL ] o_kifejezés)COUNT ( { * | [ DISTINCT | ALL] o_kifejezés} )A csoportfüggvények a számolásnál ignorálják (kihagyják) a NULL értéket, kivéve aCOUNT(*).Ha nincs GROUP BY egy SELECT-ben, akkor egyetlen csoportot képez a teljes eredmény:

gyak- Adjuk meg osztályonként az osztály nevét és az ott dolgozók számát a dolgozók száma szerint növekvő sorrendben.- Adjuk meg azoknak az osztályoknak a nevét, ahol az átlagfizetés nagyobb mint 2000.- Adjuk meg azoknak a foglalkozásoknak a nevét, amelyek a 10-es és 20-as osztályon is előfordulnak. Ismétlődések ne legyenek a végeredményben.- Mekkora a minimális és a maximális fizetés a dolgozók között?- Kinek a legkisebb a fizetése?- Kinek a legnagyobb a fizetése?- Mennyi a dolgozók összfizetése?- Mennyi a 20-as osztályon az átlagfizetés?- Adjuk meg, hogy hány különböző foglalkozás fordul elő a dolgozók között! - Kik azok a dolgozók, és milyen munkakörben dolgoznak, akiknek a legnagyobb a fizetésük? - Adjuk meg osztályonként az átlagfizetést!- Adjuk meg osztályonként a telephelyet és az átlagfizetést! - Adjuk meg az osztályonkénti legmagasabb átlagfizetést! - Adjuk meg azokra az osztályokra az átlagfizetést, ahol ez nagyobb mint 2000.- Adjuk meg azokra az osztályokra az átlagfizetést, ahol legalább hárman dolgoznak!- Melyek azok az osztályok, ahol legalább hárman dolgoznak? - Adjuk meg osztályonként a minimális fizetést, de csak azokat az osztályokét, ahol a minimális fizetés nagyobb, mint a 30-as osztályon dolgozók minimális fizetése.- Adjuk meg osztályonként az ott dolgozó hivatalnokok (FOGLALKOZAS='CLERK') átlagfizetését, de csak azokon az osztályokon, ahol legalább két hivatalnok dolgozik! - Adjuk meg, hogy mely dolgozók fizetése jobb, mint a saját osztályán (ahol dolgozik) dolgozók átlagfizetése! - Adjuk meg, hogy mely dolgozók átlagjövedelme jobb, mint a saját osztályának az átlagjövedelme, ahol a jövedelem a fizetés és jutalék összege, ahol nincs jutalék megadva, ott a 0 helyettesítő értékkel számoljunk (NVL függvény alkalmazása). - Adjuk meg, hogy az egyes osztályokon hány ember dolgozik (azt is, ahol 0=senki).- Adjuk meg osztályonként a dolgozók összfizetését az osztály nevét megjelenítve ONEV, SUM(FIZETES) formában, és azok az osztályok is jelenjenek meg ahol nem dolgozik senki, ott az összfizetés 0 legyen. Valamint ha van olyan dolgozó, akinek nincs megadva, hogy mely osztályon dolgozik, azokat a dolgozókat egy 'FIKTIV' nevű osztályon gyűjtsük össze. Minden osztályt a nevével plusz ezt a 'FIKTIV' osztályt is jelenítsük meg az itt dolgozók összfizetésével együtt.
-------------------------------------DOLGOZO (dkod, dnev, foglalkozas, fonoke, belepes, fizetes, jutalek, oazon)OSZTALY (oazon, onev, telephely)Fiz_kategoria (kategoria, also, felso)-------------------------------------
Lekérdezések (Kiterjesztett rel. alg. + SQL)------------
-- Mekkora a maximális fizetés a dolgozók között?SELECT max(fizetes) FROM dolgozo;
-- Mennyi a dolgozók összes fizetése?SELECT sum(fizetes) FROM dolgozo;

-- Mennyi a 20-as osztályon az összfizetes és az átlagfizetés? (Atlag, Össz)SELECT sum(fizetes), avg(fizetes) FROM dolgozo WHERE oazon=20;
-- Adjuk meg, hogy hány különböző foglalkozás fordul elő a dolgozók között. SELECT count(DISTINCT foglalkozas) FROM dolgozo;
-- Hány olyan dolgozó van, akinek a fizetése > 2000? SELECT count(*) FROM dolgozo WHERE fizetes > 2000;
-- Adjuk meg osztályonként az átlagfizetést (oazon, atl_fiz).SELECT oazon, round(avg(fizetes)) FROM dolgozo GROUP BY oazon;
-- Adjuk meg osztályonként a telephelyet és az átlagfizetést (oazon, telephely, atl_fiz).SELECT o.oazon, telephely, round(avg(fizetes)) FROM dolgozo d, osztaly oWHERE d.oazon=o.oazon GROUP BY o.oazon, telephely;-- más szintaxissal:SELECT oazon, telephely, round(avg(fizetes)) FROM dolgozo d NATURAL JOIN osztaly oGROUP BY oazon, telephely;
-- Adjuk meg, hogy az egyes osztályokon hány ember dolgozik.SELECT oazon, count(dkod) FROM dolgozo GROUP BY oazon;
-- Adjuk meg azokra az osztályokra az átlagfizetést, ahol ez nagyobb mint 2000.SELECT oazon, avg(fizetes) FROM dolgozo GROUP BY oazon HAVING avg(fizetes) > 2000;
-- Adjuk meg az átlagfizetést azokon az osztályokon, ahol legalább 4-en dolgoznak (oazon, avg_fiz)SELECT oazon, avg(fizetes) FROM dolgozo GROUP BY oazon HAVING count(dkod) >= 4;
-- Adjuk meg az átlagfizetést és telephelyet azokon az osztályokon, ahol legalább 4-en dolgoznak.SELECT o.oazon, telephely, avg(fizetes) FROM dolgozo d, osztaly oWHERE d.oazon=o.oazon GROUP BY o.oazon, telephely HAVING count(dkod) >= 4;
-- Adjuk meg azon osztályok nevét és telephelyét, ahol az átlagfizetés nagyobb mint 2000. (onev, telephely)SELECT onev, telephely FROM dolgozo d, osztaly oWHERE d.oazon=o.oazon GROUP BY onev, telephely HAVING avg(fizetes) >= 2000;
-- Adjuk meg azokat a fizetési kategóriákat, amelybe pontosan 3 dolgozó fizetése esik.SELECT kategoria FROM dolgozo, fiz_kategoriaWHERE fizetes BETWEEN also AND felsoGROUP BY kategoria HAVING count(*) = 3;-- más szintaxissalSELECT kategoria FROM dolgozo JOIN fiz_kategoria ON (fizetes BETWEEN also AND felso)GROUP BY kategoria HAVING count(*) = 3;
-- Adjuk meg azokat a fizetési kategóriákat, amelyekbe eső dolgozók mindannyian ugyanazon az osztályon dolgoznak.SELECT kategoria FROM dolgozo, fiz_kategoriaWHERE fizetes BETWEEN also AND felsoGROUP BY kategoria HAVING count(distinct oazon) = 1;
-- Adjuk meg azon osztályok nevét és telephelyét, amelyeknek van 1-es fizetési kategóriájú dolgozója.SELECT DISTINCT onev, telephely FROM dolgozo d, osztaly o, fiz_kategoria fWHERE o.oazon=d.oazon AND fizetes BETWEEN also AND felso AND kategoria = 1;
-- Adjuk meg azon osztályok nevét és telephelyét, amelyeknek legalább 2 fő 1-es fiz. kategóriájú dolgozója van.SELECT DISTINCT onev, telephely FROM dolgozo d, osztaly o, fiz_kategoria fWHERE o.oazon=d.oazon AND fizetes BETWEEN also AND felso AND kategoria = 1GROUP BY onev, telephely HAVING count(distinct dkod) > 1;

-- Készítsünk listát a páros és páratlan azonosítójú (dkod) dolgozók számáról. (paritás, szám)SELECT decode(mod(dkod, 2), 0, 'páros', 1, 'páratlan') paritas, count(dkod) szam FROM dolgozo GROUP BY mod(dkod, 2);
-- Listázzuk ki foglalkozásonként a dolgozók számát, átlagfizetését (kerekítve) numerikusan és grafikusan is.-- 200-anként jelenítsünk meg egy '#'-ot. (foglalkozás, szám, átlag, grafika)SELECT foglalkozas, count(dkod), round(avg(fizetes)), rpad('#', round(avg(fizetes)/200), '#') FROM dolgozo GROUP BY foglalkozas;
Lekérdezések (Kiterjesztett rel. alg. + SQL. Ahol beépített függvényre van szükség ott csak SQL)------------
-- Adjuk meg azon osztályok nevét és telephelyét, amelyeknek van 1-es fizetési kategóriájú dolgozója.SELECT onev, telephely from osztaly WHERE oazon IN (SELECT oazon FROM dolgozo, fiz_kategoria WHERE kategoria=1 AND fizetes BETWEEN also AND felso);
-- Adjuk meg azon osztályok nevét és telephelyét, amelyeknek nincs 1-es fizetési kategóriájú dolgozója.SELECT onev, telephely from osztaly WHERE oazon NOT IN (SELECT oazon FROM dolgozo, fiz_kategoria WHERE kategoria=1 AND fizetes BETWEEN also AND felso);
-- Adjuk meg azon osztályok nevét és telephelyét, amelyeknek két 1-es kategóriájú dolgozója van.SELECT onev, telephely from osztaly WHERE oazon IN (SELECT oazon FROM dolgozo, fiz_kategoria WHERE kategoria=1 AND fizetes BETWEEN also AND felso GROUP BY oazon HAVING COUNT(dnev)=2);
-- Adjuk meg azokat a foglalkozásokat, amelyek csak egyetlen osztályon fordulnak elő,-- és adjuk meg hozzájuk azt az osztályt is, ahol van ilyen foglalkozású dolgozó. (Foglalkozás, Onev)SELECT DISTINCT foglalkozas, onev FROM dolgozo NATURAL JOIN osztalyWHERE foglalkozas IN (SELECT foglalkozas FROM dolgozo GROUP BY foglalkozas HAVING count(DISTINCT oazon) = 1);
-- Adjuk meg azon dolgozók nevét, fizetését, jutalékát, adósávját és fizetendő adóját, akik-- nevében van T-betű. Adósávok 1000 alatt 0%, 1000 és 1999 között 20%, 2000 és 2999 között-- 30%, 3000 fölött 35%. Az adót a teljes jövedelemre (fizetes+jutalek) a megadott kulccsal kell fizetni.SELECT dnev, fizetes, jutalek, fizetes+NVL(jutalek,0) jov, DECODE(TRUNC((fizetes+NVL(jutalek,0))/1000, 0), 0, 0.00, 1, 0.20, 2, 0.30, 0.35) adosav, (fizetes+NVL(jutalek,0)) * DECODE(TRUNC((fizetes+NVL(jutalek,0))/1000, 0), 0, 0.00, 1, 0.20, 2, 0.30, 0.35) adoFROM dolgozo WHERE dnev like '%T%';
-- Adjuk meg osztályonként a legnagyobb fizetésu dolgozó(ka)t, és a fizetést (oazon, dnev, fizetes).SELECT dolgozo.oazon, dnev, fizetesFROM dolgozo, (SELECT oazon, MAX(fizetes) mf FROM dolgozo GROUP BY oazon) tWHERE dolgozo.oazon=t.oazon and dolgozo.fizetes=mf;
-- Adjuk meg, hogy kik szeretnek minden gyümölcsöt. -- (Adjuk meg a megoldást összesítő függvény használata nélkül, és összesítő függvénnyel is.)SELECT nev FROM szeretGROUP BY nev

HAVING count(gyumolcs) = (SELECT COUNT(DISTINCT gyumolcs) FROM szeret);
-- Adjuk meg azokat a fizetési kategóriákat, amelyekbe beleesik legalább 3 olyan dolgozónak-- a fizetése, akinek nincs beosztottja.SELECT kategoria FROM dolgozo, fiz_kategoria WHERE fizetes BETWEEN also AND felso AND dkod NOT IN (SELECT NVL(fonoke,0) FROM dolgozo)GROUP BY kategoria HAVING COUNT(dkod) >=3;
-- Adjuk meg a legrosszabbul kereső főnök fizetését, és fizetési kategóriáját. (Fizetés, Kategória)SELECT minf, kategoria FROM fiz_kategoria, (SELECT MIN(fizetes) minf FROM dolgozo WHERE dkod IN (SELECT fonoke FROM dolgozo)) tWHERE t.minf BETWEEN also AND felso;
-- Adjuk meg, hogy (kerekítve) hány hónapja dolgoznak a cégnél azok a dolgozók, akiknek a DALLAS-i-- telephelyű osztályon a legnagyobb a fizetésük. (Dnev, Hónapok)SELECT dnev, round(months_between(sysdate, belepes)) FROM dolgozoWHERE fizetes = (SELECT max(fizetes) FROM dolgozo natural join osztaly WHERE telephely='DALLAS');
-- Adjuk meg azokat a foglalkozásokat, amelyek csak egyetlen osztályon fordulnak elő,-- és adjuk meg hozzájuk azt az osztályt is, ahol van ilyen foglalkozású dolgozó. (Foglalkozás, Onev)SELECT DISTINCT foglalkozas, onev FROM dolgozo NATURAL JOIN osztalyWHERE foglalkozas IN (SELECT foglalkozas FROM dolgozo GROUP BY foglalkozas HAVING count(DISTINCT oazon) = 1);
-- Adjuk meg azoknak a dolgozóknak a nevét és fizetését, akik fizetése a 10-es és 20-as osztályok -- átlagfizetése közé esik. (Nem tudjuk, hogy melyik átlag a nagyobb!)SELECT dnev, fizetes FROM dolgozo WHERE fizetes BETWEEN (SELECT avg(fizetes) FROM dolgozo WHERE oazon=10) AND (SELECT avg(fizetes) FROM dolgozo WHERE oazon=20)OR fizetes BETWEEN (SELECT avg(fizetes) FROM dolgozo WHERE oazon=20) AND (SELECT avg(fizetes) FROM dolgozo WHERE oazon=10);
Példák:A,B+C->X(R) SELECT A, B+C AS X FROM R;(R) SELECT DISTINCT * FROM R;R S SELECT * FROM R UNION ALL SELECT * FROM S;R S SELECT * FROM R INTERSECT SELECT * FROM S; (halmaz!)R - S SELECT * FROM R MINUS SELECT * FROM S; (halmaz!)R ⨝ S SELECT * FROM R NATURAL JOIN S;R ⨝θ S SELECT * FROM R JOIN S ON (θ);R S SELECT * FROM R CROSS JOIN S; or SELECT * FROM R, S;A,SUM(B)(R) SELECT A, SUM(B) FROM R GROUP BY A;A,COUNT(B)( A,B R) SELECT A, COUNT(DISTINCT B) FROM R GROUP BY A;A, B+C(R) SELECT * FROM R ORDER BY A, B+C;
Egy bonyolultabb példa SQL-ben és kiterjesztett relációs algebrában:SELECT dname, AVG(sal) + 100 sal_plusFROM emp e, dept dWHERE e.deptno = d.deptnoGROUP BY dnameHAVING COUNT(empno) > 3ORDER BY dname;dname(dname,av+100->sal_plus(cnt>3(dname,AVG(sal)->av,COUNT(empno)->cnt(E.deptno=D.deptno(Emp x Dept)))))
Köv.héten: I.ZH

I.ZH témaköre: Lekérdezések relációs algebrában és SQL-benI.rész Papíros feladatok (Semmilyen segédeszköz nem használható!) (45 perc)Lekérdezések kifejezése (kiterjesztett) relációs algebrában és SQL SELECT-tel. -Tankönyv 2.4. fejezete: - Lekérdezések kifejezése relációs algebrában (lineáris jelöléssel v. kifejezésfával) - Tankönyv 6.1-6.3. fejezetei: - Lekérdezések kifejezése SQL SELECT-tel (egyszerű lekérdezések, több táblára vonatkozó lekérdezések, alkérdések használata, összekapcsolások, outer join is, valamint ismerni kell a relációs algebra és az SQL SELECT kapcsolatát, átírásokat)- Tankönyv 5.1-5.2. fejezetei: - Kiterjesztett műveletek a relációs algebrában (lineáris jelöléssel v. kifejezésfával) - Tankönyv 6.4. fejezete:- Lekérdezések kifejezése SQL SELECT-tel (minden záradékot ismerni kell, mint például GROUP BY és HAVING), aggregátorfüggvények, mint például MIN, MAX, SUM, COUNT és AVG lesznek a papíros feladatokban