fine-grained prediction of syntactic typology: discovering...
TRANSCRIPT

Fine-Grained Prediction of Syntactic Typology:Discovering Latent Structure with Supervised Learning
Dingquan Wang and Jason EisnerDepartment of Computer Science, Johns Hopkins University
{wdd,eisner}@jhu.edu
Abstract
We show how to predict the basic word-orderfacts of a novel language given only a cor-pus of part-of-speech (POS) sequences. Wepredict how often direct objects follow theirverbs, how often adjectives follow their nouns,and in general the directionalities of all depen-dency relations. Such typological propertiescould be helpful in grammar induction. Whilesuch a problem is usually regarded as unsu-pervised learning, our innovation is to treat itas supervised learning, using a large collec-tion of realistic synthetic languages as train-ing data. The supervised learner must identifysurface features of a language’s POS sequence(hand-engineered or neural features) that cor-relate with the language’s deeper structure (la-tent trees). In the experiment, we show: 1)Given a small set of real languages, it helps toadd many synthetic languages to the trainingdata. 2) Our system is robust even when thePOS sequences include noise. 3) Our systemon this task outperforms a grammar inductionbaseline by a large margin.
1 Introduction
Descriptive linguists often characterize a humanlanguage by its typological properties. For instance,English is an SVO-type language because its basicclause order is Subject-Verb-Object (SVO), andalso a prepositional-type language because itsadpositions normally precede the noun. Identifyingbasic word order must happen early in the acqui-sition of syntax, and presumably guides the initialinterpretation of sentences and the acquisition of afiner-grained grammar. In this paper, we proposea method for doing this. While we focus on wordorder, one could try similar methods for other typo-logical classifications (syntactic, morphological, orphonological).
The problem is challenging because the lan-guage’s true word order statistics are computed fromsyntax trees, whereas our method has access onlyto a POS-tagged corpus. Based on these POS se-quences alone, we predict the directionality of eachtype of dependency relation. We define the direc-tionality to be a real number in [0, 1]: the fractionof tokens of this relation that are “right-directed,” inthe sense that the child (modifier) falls to the rightof its parent (head). For example, the dobj relationpoints from a verb to its direct object (if any), so a di-rectionality of 0.9—meaning that 90% of dobj de-pendencies are right-directed—indicates a dominantverb-object order. (See Table 1 for more such exam-ples.) Our system is trained to predict the relativefrequency of rightward dependencies for each of 57dependency types from the Universal Dependenciesproject (UD). We assume that all languages draw onthe same set of POS tags and dependency relationsthat is proposed by the UD project (see §3), so thatour predictor works across languages.
Why do this? Liu (2010) has argued for usingthese directionality numbers in [0, 1] as fine-grainedand robust typological descriptors. We believe thatthese directionalities could also be used to help de-fine an initializer, prior, or regularizer for tasks likegrammar induction or syntax-based machine trans-lation. Finally, the vector of directionalities—orthe feature vector that our method extracts in or-der to predict the directionalities—can be regardedas a language embedding computed from the POS-tagged corpus. This language embedding may beuseful as an input to multilingual NLP systems, suchas the cross-linguistic neural dependency parser ofAmmar et al. (2016). In fact, some multilingual NLPsystems already condition on typological propertieslooked up in the World Atlas of Language Struc-tures, or WALS (Dryer and Haspelmath, 2013), as
147
Transactions of the Association for Computational Linguistics, vol. 5, pp. 147–161, 2017. Action Editor: Mark Steedman.Submission batch: 11/2016; Revision batch: 2/2017; Published 6/2017.
c©2017 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.

Typology Example
Verb-Object(English) She gave me a raise
dobj
Object-Verb(Hindi) She me a raise gave
vah mujhe ek uthaane diya
dobj
Prepositional(English) She is in a car
case
Postpositional(Hindi)
She a car in isvah ek kaar mein hai
case
Adjective-Noun(English) This is a red car
amod
Noun-Adjective(French)
This is a car redCeci est une voiture rouge
amod
Table 1: Three typological properties in the World Atlas of Lan-guage Structures (Dryer and Haspelmath, 2013), and how theyaffect the directionality of Universal Dependencies relations.
we review in §8. However, WALS does not list allproperties of all languages, and may be somewhatinconsistent since it collects work by many linguists.Our system provides an automatic alternative as wellas a methodology for generalizing to new properties.
More broadly, we are motivated by the chal-lenge of determining the structure of a languagefrom its superficial features. Principles & Parame-ters theory (Chomsky, 1981; Chomsky and Lasnik,1993) famously—if controversially—hypothesizedthat human babies are born with an evolutionarilytuned system that is specifically adapted to naturallanguage, which can predict typological properties(“parameters”) by spotting telltale configurations inpurely linguistic input. Here we investigate whethersuch a system can be tuned by gradient descent. It isat least plausible that useful superficial features doexist: e.g., if nouns often precede verbs but rarelyfollow verbs, then the language may be verb-final.
2 Approach
We depart from the traditional approach to latentstructure discovery, namely unsupervised learning.Unsupervised syntax learners in NLP tend to berather inaccurate—partly because they are failing tomaximize an objective that has many local optima,and partly because that objective does not captureall the factors that linguists consider when assigning
syntactic structure. Our remedy in this paper is a su-pervised approach. We simply imitate how linguistshave analyzed other languages. This supervised ob-jective goes beyond the log-likelihood of a PCFG-like model given the corpus, because linguists do notmerely try to predict the surface corpus. Their de-pendency annotations may reflect a cross-linguistictheory that considers semantic interpretability andequivalence, rare but informative phenomena, con-sistency across languages, a prior across languages,and linguistic conventions (including the choice oflatent labels such as dobj). Our learner does notconsider these factors explicitly, but we hope it willidentify correlates (e.g., using deep learning) thatcan make similar predictions. Being supervised, ourobjective should also suffer less from local optima.Indeed, we could even set up our problem with aconvex objective, such as (kernel) logistic regres-sion, to predict each directionality separately.
Why hasn’t this been done before? Our set-ting presents unusually sparse data for supervisedlearning, since each training example is an en-tire language. The world presumably does notoffer enough natural languages—particularly withmachine-readable corpora—to train a good classi-fier to detect, say, Object-Verb-Subject (OVS) lan-guages, especially given the class imbalance prob-lem that OVS languages are empirically rare, andthe non-IID problem that the available OVS lan-guages may be evolutionarily related.1 We miti-gate this issue by training on the Galactic Depen-dencies treebanks (Wang and Eisner, 2016), a col-lection of more than 50,000 human-like syntheticlanguages. The treebank of each synthetic languageis generated by stochastically permuting the sub-trees in a given real treebank to match the word or-der of other real languages. Thus, we have manysynthetic languages that are Object-Verb like Hindibut also Noun-Adjective like French. We know thetrue directionality of each synthetic language and wewould like our classifier to predict that directional-ity, just as it would for a real language. We will showthat our system’s accuracy benefits from fleshing outthe training set in this way, which can be seen as aform of regularization.
1Properties shared within an OVS language family may ap-pear to be consistently predictive of OVS, but are actually con-founds that will not generalize to other families in test data.
148

A possible criticism of our work is that obtainingthe input POS sequences requires human annotators,and perhaps these annotators could have answeredthe typological classification questions as well. In-deed, this criticism also applies to most work ongrammar induction. We will show that our systemis at least robust to noise in the input POS sequences(§7.4). In the future, we hope to devise similar meth-ods that operate on raw word sequences.
3 Data
We use two datasets in our experiment:
UD: Universal Dependencies version 1.2 (et al.,2015) A collection of dependency treebanks for 37languages, annotated in a consistent style with POStags and dependency relations.
GD: Galactic Dependencies version 1.0 (Wangand Eisner, 2016) A collection of projective de-pendency treebanks for 53,428 synthetic languages,using the same format as UD. The treebank ofeach synthetic language is generated from the UDtreebank of some real language by stochasticallypermuting the dependents of all nouns and/or verbsto match the dependent orders of other real UD lan-guages. Using this “mix-and-match” procedure, theGD collection fills in gaps in the UD collection—which covers only a few possible human languages.
4 Task Formulation
We now formalize the setup of the fine-grained typo-logical prediction task. LetR be the set of universalrelation types, with N = |R|. We use r→ to denote arightward dependency token with label r ∈ R.
Input for language L: A POS-tagged corpus u.(“u” stands for “unparsed.”)
Output for language L: Our system predictsp(→| r, L), the probability that a token in languageL of an r-labeled dependency will be right-oriented.It predicts this for each dependency relation typer ∈ R, such as r = dobj. Thus, the output is avector of predicted probabilities p ∈ [0, 1]N .
Training: We set the parameters of our systemusing a collection of training pairs (u,p∗), each ofwhich corresponds to some UD or GD training lan-guage L. Here p∗ denotes the true vector of proba-bilities as empirically estimated from L’s treebank.
Evaluation: Over pairs (u,p∗) that correspondto held-out real languages, we evaluate the expectedloss of the predictions p. We use ε-insensitive loss2
with ε = 0.1, so our evaluation metric is∑
r∈Rp∗(r | L) · lossε(p(→| r, L), p∗(→| r, L)) (1)
where
• lossε(p, p∗) ≡ max(|p− p∗| − ε, 0)
• p∗(→| r, L) = countL(r→)
countL(r) is the empirical esti-mate of p(→| r, L).• p(→| r, L) is the system’s prediction of p∗
The aggregate metric (1) is an expected loss that isweighted by p∗(r | L) = countL(r)∑
r′∈R countL(r′) , to empha-size relation types that are more frequent in L.
Why this loss function? We chose an L1-styleloss, rather than L2 loss or log-loss, so that the ag-gregate metric is not dominated by outliers. We tookε > 0 in order to forgive small errors: if some pre-dicted directionality is already “in the ballpark,” weprefer to focus on getting other predictions right,rather than fine-tuning this one. Our intuition is thaterrors < ε in p’s elements will not greatly harmdownstream tasks that analyze individual sentences,and might even be easy to correct by grammar rees-timation (e.g., EM) that uses p as a starting point.
In short, we have the intuition that if our pre-dicted p achieves small lossε on the frequent relationtypes, then p will be helpful for downstream tasks,although testing that intuition is beyond the scope ofthis paper. One could tune ε on a downstream task.
5 Simple “Expected Count” Baseline
Before launching into our full models, we warmup with a simple baseline heuristic called expectedcount (EC), which is reminiscent of Principles & Pa-rameters. The idea is that if ADJs tend to precedenearby NOUNs in the sentences of language L, thenamod probably tends to point leftward in L. Afterall, the training languages show that when ADJ andNOUN are nearby, they are usually linked by amod.
Fleshing this out, EC estimates directionalities as
p(→| r, L) =ecountL(
r→)
ecountL(r→) + ecountL(
r←)(2)
2Proposed by V. Vapnik for support vector regression.
149

where we estimate the expected r← and r→ counts by
ecountL(r→) =
∑
u∈u
∑
1≤i<j≤|u|j−i<w
p(r→| ui, uj) (3)
ecountL(r←) =
∑
u∈u
∑
1≤i<j≤|u|j−i<w
p(r←| ui, uj) (4)
Here u ranges over tag sequences (sentences) of u,and w is a window size that characterizes “nearby.”3
In other words, we ask: given that ui and uj arenearby tag tokens in the test corpus u, are they likelyto be linked? Formulas (3)–(4) count such a pair as a“soft vote” for r→ if such pairs tended to be linked byr→ in the treebanks of the training languages,4 and a
“soft vote” for r← if they tended to be linked by r←.Training: For any two tag types t, t′ in the univer-
sal POS tagset T , we simply use the training tree-banks to get empirical estimates of p(· | t, t′), taking
p(r→| t, t′) =
∑L sL · countL(t
r→ t′)∑L sL · countL(t, t′)
(5)
and similarly for p( r←| t, t′). This can be interpretedas the (unsmoothed) fraction of (t, t′) within a w-word window where t is the r-type parent of t′, com-puted by micro-averaging over languages. To geta fair average over languages, equation (5) down-weights the languages that have larger treebanks,yielding a weighted micro-average in which we de-fine the weight sL = 1/
∑t∈T ,t′∈T countL(t, t′).
As we report later in Table 5, even this simple su-pervised heuristic performs significantly better thanstate-of-the-art grammar induction systems. How-ever, it is not a trained heuristic: it has no free pa-rameters that we can tune to optimize our evaluationmetric. For example, it can pay too much attentionto tag pairs that are not discriminative. We thereforeproceed to build a trainable, feature-based system.
6 Proposed Model Architecture
To train our model, we will try to minimize the eval-uation objective (1) averaged over the training lan-
3In our experiment, we chose w = 8 by cross-validationover w = 2, 4, 8, 16,∞.
4Thus, the EC heuristic examines the correlation betweenrelations and tags in the training treebanks. But our methods inthe next section will follow the formalization of §4: they do notexamine a training treebank beyond its directionality vector p∗.
logistic
Figure 1: Basic predictive architecture from equations (6)–(7).bW and bV are suppressed for readability.
guages, plus a regularization term given in §6.4.5
6.1 Directionality predictions from scoresOur predicted directionality for relation r will be
p(→| r, L) = 1/(1 + exp(−s(u)r)) (6)
s(u) is a parametric function (see §6.2 below) thatmaps u to a score vector in RN . Relation typer should get positive or negative score accordingto whether it usually points right or left. The for-mula above converts each score to a directionality—a probability in (0, 1)—using a logistic transform.
6.2 Design of the scoring function s(u)
To score all dependency relation types given the cor-pus u, we use a feed-forward neural network withone hidden layer (Figure 1):
s(u) = V ψ(Wπ(u) + bW ) + bV (7)
π(u) extracts a d-dimensional feature vector fromthe corpus u (see §6.3 below). W is a h × d ma-trix that maps π(u) into a h-dimensional space andbW is a h-dimensional bias vector. ψ is an element-wise activation function. V is aN ×hmatrix whoserows can be regarded as learned embeddings of thedependency relation types. bV is a N -dimensionalbias vector that determines the default rightwardnessof each relation type. We give details in §7.5.
The hidden layer ψ(Wπ(u) + bW ) can be re-garded as a latent representation of the language’sword order properties, from which potentially cor-related predictions p are extracted.
5We gave all training languages the same weight. In prin-ciple, we could have downweighted the synthetic languages asout-of-domain, using cross-validation to tune the weighting.
150

6.3 Design of the featurization function π(u)
Our current feature vector π(u) considers only thePOS tag sequences for the sentences in the unparsedcorpus u. Each sentence is augmented with a specialboundary tag # at the start and end. We explore bothhand-engineered features and neural features.
Hand-engineered features. Recall that §5 consid-ered which tags appeared near one another in a givenorder. We now devise a slew of features to measuresuch co-occurrences in a variety of ways. By train-ing the weights of these many features, our systemwill discover which ones are actually predictive.
Let g(t | j) ∈ [0, 1] be some measure (to be de-fined shortly) of the prevalence of tag t near tokenj of corpus u. We can then measure the prevalenceof t, both overall and just near tokens of tag s:6
πt = meanj
g(t | j) (8)
πt|s = meanj:Tj=s
g(t | j) (9)
where Tj denotes the tag of token j. We now defineversions of these quantities for particular prevalencemeasures g.
Givenw > 0, let the right windowWj denote thesequence of tags Tj+1, . . . , Tj+w (padding this se-quence with additional # symbols if it runs past theend of j’s sentence). We define quantities πwt|s andπwt via (8)–(9), using a version of g(t | j) that mea-sures the fraction of tags in Wj that equal t. Also,for b ∈ {1, 2}, we define πw,bt|s and πw,bt using a ver-sion of g(t | j) that is 1 if Wj contains at least btokens of t, and 0 otherwise.
For each of these quantities, we also define acorresponding mirror-image quantity (denoted bynegating w > 0) by computing the same feature ona reversed version of the corpus.
We also define “truncated” versions of all quan-tities above, denoted by writing ˆ over the w. Inthese, we use a truncated window Wj , obtainedfrom Wj by removing any suffix that starts with #
6In practice, we do backoff smoothing of these means. Thisavoids subsequent division-by-0 errors if tag t or s has count 0in the corpus, and it regularizes πt|s/πt toward 1 if t or s is rare.Specifically, we augment the denominators by adding λ, whileaugmenting the numerator in (8) by adding λ ·meanj,t g(t | j)(unsmoothed) and the numerator in (9) by adding λ times thesmoothed πt from (8). λ > 0 is a hyperparameter (see §7.5).
...
...f1
...
...
...
...
...f2
...soft-pooling
...
Figure 2: Extracting and pooling the neural features.
or with a copy of tag Tj (that is, s).7 As an example,
π8,2N|V asks how often a verb is followed by at least 2
nouns, within the next 8 words of the sentence andbefore the next verb. A high value of this is a plausi-ble indicator of a VSO-type or VOS-type language.
We include the following features for eachtag pair s, t and each w ∈ {1, 3, 8, 100,−1,−3,−8,−100, 1, 3, 8, ˆ100,−1,−3,−8,− ˆ100}:8
πwt , πwt|s, π
wt|s · πws , πwt|s//πwt , πwt //πwt|s, πwt|s//π−wt|s
where we define x//y = min(x/y, 1) to preventunbounded feature values, which can result in poorgeneralization. Notice that for w = 1, πwt|s is bigramconditional probability, πwt|s·πws is bigram joint prob-ability, the log of πwt|s/π
wt is bigram pointwise mu-
tual information, and πwt|s/π−wt|s measures how much
more prevalent t is to the right of s than to the left.By also allowing other values of w, we generalizethese features. Finally, our model also uses versionsof these features for each b ∈ 1, 2.
Neural features. As an alternative to the manu-ally designedπ function above, we consider a neuralapproach to detect predictive configurations in thesentences of u, potentially including complex long-distance configurations. Linguists working withPrinciples & Parameters theory have supposed that asingle telltale sentence—a trigger—may be enough
7In the “fraction of tags” features, g(t | j) is undefined ( 00
)when Wj is empty. We omit undefined values from the means.
8The reason we don’t include π−wt|s //π
wt|s is that it is in-
cluded when computing features for −w.
151

to determine a typological parameter, at least giventhe settings of other parameters (Gibson and Wexler,1994; Frank and Kapur, 1996).
We map each corpus sentence ui to a finite-dimensional real vector f i by using a gated recur-rent unit (GRU) network (Cho et al., 2014), a type ofrecurrent neural network that is a simplified variantof an LSTM network (Hochreiter and Schmidhuber,1997). The GRU reads the sequence of one-hot em-beddings of the tags in ui (including the boundarysymbols #). We omit the part of the GRU that com-putes an output sequence, simply taking f i to be thefinal hidden state vector. The parameters are trainedjointly with the rest of our typology prediction sys-tem, so the training procedure attempts to discoverpredictively useful configurations.
The various elements of f i attempt to detect vari-ous interesting configurations in sentence ui. Somemight be triggers (which call for max-pooling oversentences); others might provide softer evidence(which calls for mean-pooling). For generality,therefore, we define our feature vector π(u) by soft-pooling of the sentence vectors f i (Figure 2). Thetanh gate in the GRU implies fik ∈ (−1, 1) and wetransform this to the positive quantity f ′ik = fik+1
2 ∈(0, 1). Given an “inverse temperature” β, define9
πβk =
(mean
i(f ′ik)
β
)1/β
(10)
This πβk is a pooled version of f ′ik, ranging frommax-pooling as β → −∞ (i.e., does f ′ik fire stronglyon any sentence i?) to min-pooling as β → −∞. Itpasses through arithmetic mean at β = 1 (i.e., howstrongly does f ′ik fire on the average sentence i?), ge-ometric mean as β → 0 (this may be regarded as anarithmetic mean in log space), and harmonic meanat β = −1 (an arithmetic mean in reciprocal space).
Our final π is a concatenation of the πβ vectorsfor β ∈ {−4,−2,−1, 0, 1, 2, 4}. We chose these βvalues experimentally, using cross-validation.
Combined model. We also consider a model
s(u) = α sH(u) + (1− α) sN(u) (11)
where sH(u) is the score assigned by the hand-feature system, sN(u) is the score assigned by the
9For efficiency, we restrict the mean to i ≤ 1e4 (the first10,000 sentences).
neural-feature system, and α ∈ [0, 1] is a hyperpa-rameter to balance the two. sH(u) and sN(u) weretrained separately. At test time, we use (11) to com-bine them linearly before the logistic transform (6).This yields a weighted-product-of-experts model.
6.4 Training procedure
Length thresholding. By default, our feature vec-tor π(u) is extracted from those sentences in u withlength ≤ 40 tokens. In §7.3, however, we try con-catenating this feature vector with one that is ex-tracted in the same way from just sentences withlength ≤ 10. The intuition (Spitkovsky et al., 2010)is that the basic word order of the language can bemost easily discerned from short, simple sentences.
Initialization. We initialize the model of (6)–(7)so that the estimated directionality p(→| r, L), re-gardless of L, is initially a weighted mean of r’s di-rectionalities in the training languages, namely
pr ≡∑
L
wL(r) p∗(→| r, L) (12)
where wL(r) ≡ p∗(r|L)∑L′ p∗(r|L′) (13)
This is done by setting V = 0 and the bias (bV )r =log pr
1−pr , clipped to the range [−10, 10]. As a result,we make sensible initial predictions even for rare re-lations r, which allows us to converge reasonablyquickly even though we do not update the parame-ters for rare relations as often.
We initialize the recurrent connections in theGRU to random orthogonal matrices. All otherweight matrices in Figure 1 and the GRU use“Xavier initialization” (Glorot and Bengio, 2010).All other bias weight vectors are initialized to 0.
Regularization. We add an L2 regularizer to theobjective. When training the neural network, we usedropout as well. All hyperparameters (regularizationcoefficient, dropout rate, etc.) are tuned via cross-validation; see §7.5.
Optimization. We use different algorithms in dif-ferent feature settings. With scoring functions thatuse only hand features, we adjust the feature weightsby stochastic gradient descent (SGD). With scor-ing functions that include neural features, we useRMSProp (Tieleman and Hinton, 2012).
152

Train Testcs, es, fr, hi,de, it, la itt,no, ar, pt
en, nl, da, fi,got, grc, et,la proiel,grc proiel, bg
la, hr, ga, he, hu,fa, ta, cu, el, ro,sl, ja ktc, sv,fi ftb, id, eu, pl
Table 2: Data split of the 37 real languages, adapted from Wangand Eisner (2016). (Our “Train,” on which we do 5-fold cross-validation, contains both their “Train” and “Dev” languages.)
7 Experiments
7.1 Data splits
We hold out 17 UD languages for testing (Table 2).For training, we use the remaining 20 UD languagesand tune the hyperparameters with 5-fold cross-validation. That is, for each fold, we train the systemon 16 real languages and evaluate on the remaining4. When augmenting the 16 real languages with GDlanguages, we include only GD languages that aregenerated by “mixing-and-matching” those 16 lan-guages, which means that we add 16 × 17 × 17 =4624 synthetic languages.10
Each GD treebank u provides a standard split intotrain/dev/test portions. In this paper, we primarilyrestrict ourselves to the train portions (saving thegold trees from the dev and test portions to tune andevaluate some future grammar induction system thatconsults our typological predictions). For example,we write utrain for the POS-tagged sentences in the“train” portion, and p∗train for the empirical probabil-ities derived from their gold trees. We always trainthe model to predict p∗train from utrain on each train-ing language. To evaluate on a held-out languageduring cross-validation, we can measure how wellthe model predicts p∗train given utrain.11 For our fi-
10Why 16×17×17? As Wang and Eisner (2016, §5) explain,each GD treebank is obtained from the UD treebank of somesubstrate language S by stochastically permuting the depen-dents of verbs and nouns to respect typical orders in the super-strate languages RV and RN respectively. There are 16 choicesfor S. There are 17 choices for RV (respectively RN), includingRV = S (“self-permutation”) and RV = ∅ (“no permutation”).
11In actuality, we measured how well it predicts p∗dev given
udev. That was a slightly less sensible choice. It may haveharmed our choice of hyperparameters, since dev is smallerthan train and therefore p∗
dev tends to have greater sampling er-ror. Another concern is that our typology system, having beenspecifically tuned to predict p∗
dev, might provide an unrealisti-cally accurate estimate of p∗
dev to some future grammar induc-tion system that is being cross-validated against the same devset, harming that system’s choice of hyperparameters as well.
Architecture ε-insensitive lossScoring Depth UD +GD
EC - 0.104 0.099sH 0 0.057 0.037*sH 1 0.050 0.036*sH 3 0.060 0.048sN 1 0.062 0.048
α sH + (1− α) sN 1 0.050 0.032*
Table 3: Average expected loss over 20 UD languages, com-puted by 5-fold cross-validation. The first column indicateswhether we score using hand-engineered features (sH), neuralfeatures (sN), or a combination (see end of §6.3). As a baseline,the first line evaluates the EC (expected count) heuristic from§5. Within each column, we boldface the best (smallest) re-sult as well as all results that are not significantly worse (pairedpermutation test by language, p < 0.05). A starred result issignificantly better than the other model in the same row.
nal test, we evaluate on the 17 test languages usinga model trained on all training languages (20 tree-banks for UD, plus 20 × 21 × 21 = 8840 whenadding GD) with the chosen hyperparameters. Toevaluate on a test language, we again measure howwell the model predicts p∗train from utrain.
7.2 Comparison of architectures
Table 3 shows the cross-validation losses (equa-tion (1)) that are achieved by different scoring ar-chitectures. We compare the results when the modelis trained on real languages (the “UD” column) ver-sus on real languages plus synthetic languages (the“+GD” column).
The sH models here use a subset of the hand-engineered features, selected by the experiments in§7.3 below and corresponding to Table 4 line 8.
Although Figure 1 and equation (7) presented an“depth-1” scoring network with one hidden layer,Table 3 also evaluates “depth-d” architectures with dhidden layers. The depth-0 architecture simply pre-dicts each directionality separately using logistic re-gression (although our training objective is not theusual convex log-likelihood objective).
Some architectures are better than others. Wenote that the hand-engineered features outperformthe neural features—though not significantly, sincethey make complementary errors—and that com-bining them is best. However, the biggest benefitcomes from augmenting the training data with GDlanguages; this consistently helps more than chang-ing the architecture.
153

ID Features Length Loss (+GD)0 ∅ — 0.0761 conditional 40 0.0582 joint 40 0.0573 PMI 40 0.0394 asymmetry 40 0.0415 rows 3+4 40 0.0386 row 5+b 40 0.0377 row 5+t 40 0.0378* row 5+b+t 40 0.0369 row 8 10 0.04310 row 8 10+40 0.036
Table 4: Cross-validation losses with different subsets of hand-engineered features from §6.3. “∅” is a baseline with no fea-tures (bias feature only), so it makes the same prediction for alllanguages. “conditional” = πw
t|s features, “joint” = πwt|s ·πw
s fea-tures, “PMI” = πw
t|s//πwt and πw
t //πwt|s features, “asymmetry”
= πwt|s//π
−wt|s features, “b” are the features superscripted by b,
and “t” are the features with truncated window. “+” means con-catenation.The “Length” field refers to length thresholding (see§6.4). The system in the starred row is the one that we selectedfor row 2 of Table 3.
7.3 Contribution of different feature classes
To understand the contribution of different hand-engineered features, we performed forward selec-tion tests on the depth-1 system, including onlysome of the features. In all cases, we trained inthe “+GD” condition. The results are shown in Ta-ble 4. Any class of features is substantially betterthan baseline, but we observe that most of the totalbenefit can be obtained with just PMI or asymme-try features. Those features indicate, for example,whether a verb tends to attract nouns to its right orleft. We did not see a gain from length thresholding.
7.4 Robustness to noisy input
We also tested our directionality prediction systemon noisy input (without retraining it on noisy input).Specifically, we tested the depth-1 sH system. Thistime, when evaluating on the dev split of a held-outlanguage, we provided a noisy version of that inputcorpus that had been retagged by an automatic POStagger (Nguyen et al., 2014), which was trained onjust 100 gold-tagged sentences from the train splitof that language. The average tagging accuracy overthe 20 languages was only 77.26%. Nonetheless, the“UD”-trained and “+GD”-trained systems got re-spective losses of 0.052 and 0.041—nearly as goodas in Table 3, which used gold POS tags.
MS13 N10 EC ∅ UD +GDloss 0.166 0.139 0.098 0.083 0.080 0.039
Table 5: Cross-validation average expected loss of the twogrammar induction methods, MS13 (Marecek and Straka, 2013)and N10 (Naseem et al., 2010), compared to the EC heuristic of§5 and our architecture of §6 (the version from the last line ofTable 3). In these experiments, the dependency relation typesare ordered POS pairs. N10 harnesses prior linguistic knowl-edge, but its improvement upon MS13 is not statistically signif-icant. Both grammar induction systems are significantly worsethan the rest of the systems, including even our two baselinesystems, namely EC (the “expected count” heuristic from §5)and ∅ (the no-feature baseline system from Table 4 line 0). LikeN10, these baselines make use of some cross-linguistic knowl-edge, which they extract in different ways from the training tree-banks. Among our own 4 systems, EC is significantly worsethan all others, and +GD is significantly better than all others.(Note: When training the baselines, we found that includingthe +GD languages—a bias-variance tradeoff— harmed EC buthelped ∅. The table reports the better result in each case.)
7.5 Hyperparameter settingsFor each result in Tables 3–4, the hyperparameterswere chosen by grid search on the cross-validationobjective (and the table reports the best result). Forthe remaining experiments, we select the depth-1combined models (11) for both “UD” and “+GD,”as they are the best models according to Table 3.
The hyperparameters for the selected models areas follows: When training with “UD,” we tookα = 1 (which ignores sN), with hidden layer sizeh = 256, ψ = sigmoid, L2 coeff = 0 (no L2regularization), and dropout = 0.2. When trainingwith “+GD,” we took α = 0.7, with different hy-perparameters for the two interpolated models: sHuses h = 128, ψ = sigmoid, L2 coeff = 0, anddropout = 0.4, while sN uses h = 128, emb size =128, rnn size = 32, ψ = relu, L2 coeff = 0, anddropout = 0.2. For both “UD” and “+GD”, we useλ = 1 for the smoothing in footnote 6.
7.6 Comparison with grammar inductionGrammar induction is an alternative way to predictword order typology. Given a corpus of a language,we can first use grammar induction to parse it intodependency trees, and then estimate the directional-ity of each dependency relation type based on these(approximate) trees.
However, what are the dependency relation types?Current grammar induction systems produce unla-beled dependency edges. Rather than try to obtain
154
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16
Average Proportion
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
ε-In
sen
siti
ve L
oss
cc
det
emph
ccomp
prt
remnant
nsubjpasscsubj
conj
foreign
vocative
neg
discourse
mark case
auxpass
mwe
advcl
aux
amodreflex
parataxis
advmodnsubj
nummod
reparandum
punct
relcl
tmod
compound
csubjpass
poss
goeswith
xcomp
cop
name
dep
appos
list
nmoddobj
iobj
expl
predetpreconj
acl
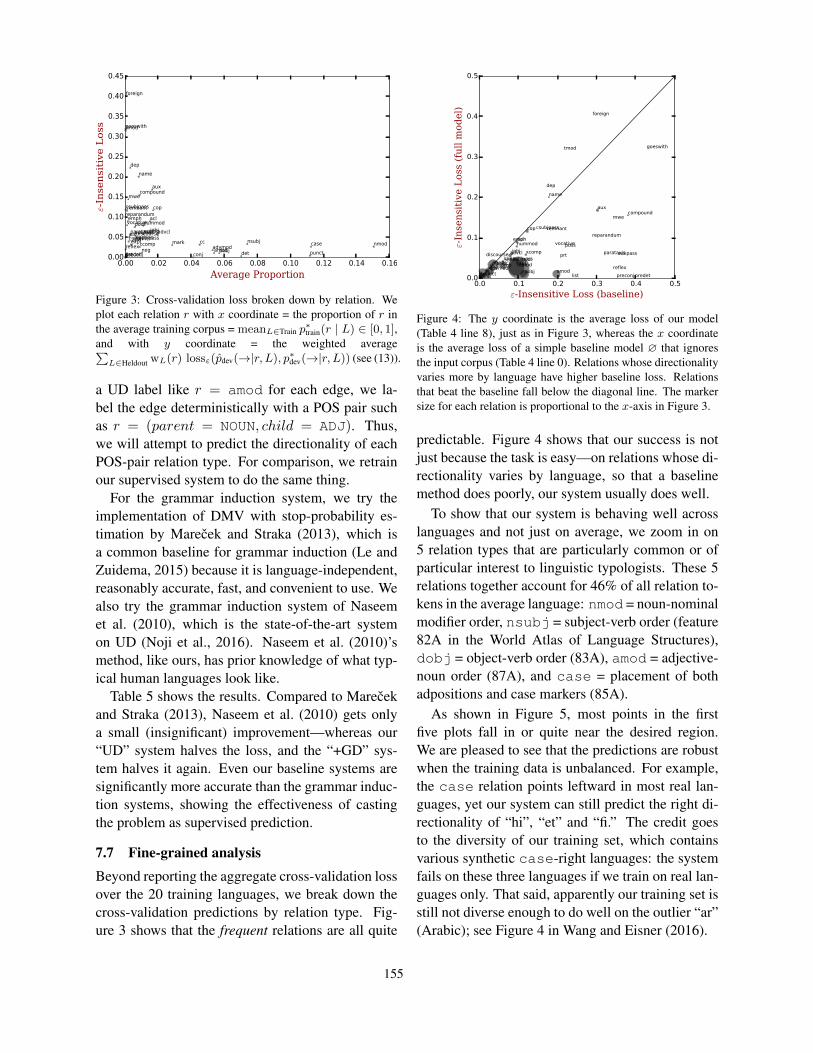
Figure 3: Cross-validation loss broken down by relation. Weplot each relation r with x coordinate = the proportion of r inthe average training corpus = meanL∈Train p
∗train(r | L) ∈ [0, 1],
and with y coordinate = the weighted average∑L∈Heldout wL(r) lossε(pdev(→|r, L), p∗dev(→|r, L)) (see (13)).
a UD label like r = amod for each edge, we la-bel the edge deterministically with a POS pair suchas r = (parent = NOUN, child = ADJ). Thus,we will attempt to predict the directionality of eachPOS-pair relation type. For comparison, we retrainour supervised system to do the same thing.
For the grammar induction system, we try theimplementation of DMV with stop-probability es-timation by Marecek and Straka (2013), which isa common baseline for grammar induction (Le andZuidema, 2015) because it is language-independent,reasonably accurate, fast, and convenient to use. Wealso try the grammar induction system of Naseemet al. (2010), which is the state-of-the-art systemon UD (Noji et al., 2016). Naseem et al. (2010)’smethod, like ours, has prior knowledge of what typ-ical human languages look like.
Table 5 shows the results. Compared to Marecekand Straka (2013), Naseem et al. (2010) gets onlya small (insignificant) improvement—whereas our“UD” system halves the loss, and the “+GD” sys-tem halves it again. Even our baseline systems aresignificantly more accurate than the grammar induc-tion systems, showing the effectiveness of castingthe problem as supervised prediction.
7.7 Fine-grained analysisBeyond reporting the aggregate cross-validation lossover the 20 training languages, we break down thecross-validation predictions by relation type. Fig-ure 3 shows that the frequent relations are all quite
0.0 0.1 0.2 0.3 0.4 0.5
ε-Insensitive Loss (baseline)
0.0
0.1
0.2
0.3
0.4
0.5
ε-In
sen
siti
ve L
oss
(fu
ll m
od
el)
cc
det
emph
ccomp
prt
remnant
nsubjpasscsubj
conj
foreign
vocative
neg
discourse
mark case
auxpass
mwe
advcl
aux
amodreflex
parataxis
advmodnsubj
nummod
reparandum
punct
relcl
tmod
compound
csubjpass
poss
goeswith
xcomp
cop
name
dep
appos
list
nmoddobj
iobj
expl
predetpreconj
acl
Figure 4: The y coordinate is the average loss of our model(Table 4 line 8), just as in Figure 3, whereas the x coordinateis the average loss of a simple baseline model ∅ that ignoresthe input corpus (Table 4 line 0). Relations whose directionalityvaries more by language have higher baseline loss. Relationsthat beat the baseline fall below the diagonal line. The markersize for each relation is proportional to the x-axis in Figure 3.
predictable. Figure 4 shows that our success is notjust because the task is easy—on relations whose di-rectionality varies by language, so that a baselinemethod does poorly, our system usually does well.
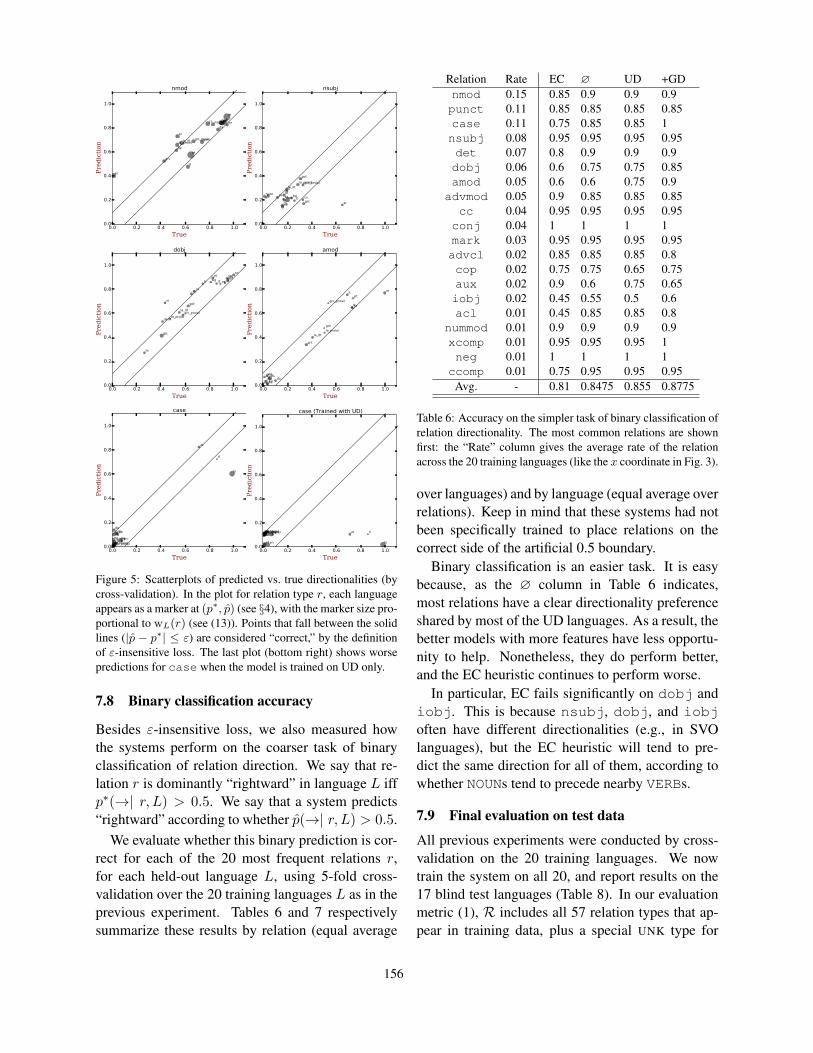
To show that our system is behaving well acrosslanguages and not just on average, we zoom in on5 relation types that are particularly common or ofparticular interest to linguistic typologists. These 5relations together account for 46% of all relation to-kens in the average language: nmod = noun-nominalmodifier order, nsubj = subject-verb order (feature82A in the World Atlas of Language Structures),dobj = object-verb order (83A), amod = adjective-noun order (87A), and case = placement of bothadpositions and case markers (85A).
As shown in Figure 5, most points in the firstfive plots fall in or quite near the desired region.We are pleased to see that the predictions are robustwhen the training data is unbalanced. For example,the case relation points leftward in most real lan-guages, yet our system can still predict the right di-rectionality of “hi”, “et” and “fi.” The credit goesto the diversity of our training set, which containsvarious synthetic case-right languages: the systemfails on these three languages if we train on real lan-guages only. That said, apparently our training set isstill not diverse enough to do well on the outlier “ar”(Arabic); see Figure 4 in Wang and Eisner (2016).
155
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0P
red
icti
on
no
grc_proiel
ar
da
pt
et
cs
grc
it
got
de
la_proiel
frbg
fi
la_itt
es
nl
hi
en
nmod
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0
Pre
dic
tion
no
grc_proiel
arda
ptet cs
grcit
got
de
la_proiel
fr bg
fila_itt
esnlhi en
nsubj
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0
Pre
dic
tion
no
grc_proiel
arda
pt
et
cs
grc
it
got
dela_proiel
fr bg
fi
la_itt
es
nl
hi
en
dobj
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0
Pre
dic
tion
no
grc_proiel
ar
da
pt
et
cs
grc
it
got
de
la_proiel
fr
bgfi
la_itt
es
nl
hien
amod
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0
Pre
dic
tion
no
grc_proielar
da
pt
et
csgrc
itgot
de
la_proielfr
bg
fi
la_ittes
nl
hi
en
case
0.0 0.2 0.4 0.6 0.8 1.0
True
0.0
0.2
0.4
0.6
0.8
1.0
Pre
dic
tion
nogrc_proielar dapt etcs grcitgotdela_proielfr bg fila_itt
esnl hien
case (Trained with UD)
Figure 5: Scatterplots of predicted vs. true directionalities (bycross-validation). In the plot for relation type r, each languageappears as a marker at (p∗, p) (see §4), with the marker size pro-portional to wL(r) (see (13)). Points that fall between the solidlines (|p − p∗| ≤ ε) are considered “correct,” by the definitionof ε-insensitive loss. The last plot (bottom right) shows worsepredictions for case when the model is trained on UD only.
7.8 Binary classification accuracy
Besides ε-insensitive loss, we also measured howthe systems perform on the coarser task of binaryclassification of relation direction. We say that re-lation r is dominantly “rightward” in language L iffp∗(→| r, L) > 0.5. We say that a system predicts“rightward” according to whether p(→| r, L) > 0.5.
We evaluate whether this binary prediction is cor-rect for each of the 20 most frequent relations r,for each held-out language L, using 5-fold cross-validation over the 20 training languages L as in theprevious experiment. Tables 6 and 7 respectivelysummarize these results by relation (equal average
Relation Rate EC ∅ UD +GDnmod 0.15 0.85 0.9 0.9 0.9punct 0.11 0.85 0.85 0.85 0.85case 0.11 0.75 0.85 0.85 1nsubj 0.08 0.95 0.95 0.95 0.95det 0.07 0.8 0.9 0.9 0.9dobj 0.06 0.6 0.75 0.75 0.85amod 0.05 0.6 0.6 0.75 0.9advmod 0.05 0.9 0.85 0.85 0.85cc 0.04 0.95 0.95 0.95 0.95
conj 0.04 1 1 1 1mark 0.03 0.95 0.95 0.95 0.95advcl 0.02 0.85 0.85 0.85 0.8cop 0.02 0.75 0.75 0.65 0.75aux 0.02 0.9 0.6 0.75 0.65iobj 0.02 0.45 0.55 0.5 0.6acl 0.01 0.45 0.85 0.85 0.8
nummod 0.01 0.9 0.9 0.9 0.9xcomp 0.01 0.95 0.95 0.95 1neg 0.01 1 1 1 1ccomp 0.01 0.75 0.95 0.95 0.95
Avg. - 0.81 0.8475 0.855 0.8775
Table 6: Accuracy on the simpler task of binary classification ofrelation directionality. The most common relations are shownfirst: the “Rate” column gives the average rate of the relationacross the 20 training languages (like the x coordinate in Fig. 3).
over languages) and by language (equal average overrelations). Keep in mind that these systems had notbeen specifically trained to place relations on thecorrect side of the artificial 0.5 boundary.
Binary classification is an easier task. It is easybecause, as the ∅ column in Table 6 indicates,most relations have a clear directionality preferenceshared by most of the UD languages. As a result, thebetter models with more features have less opportu-nity to help. Nonetheless, they do perform better,and the EC heuristic continues to perform worse.
In particular, EC fails significantly on dobj andiobj. This is because nsubj, dobj, and iobjoften have different directionalities (e.g., in SVOlanguages), but the EC heuristic will tend to pre-dict the same direction for all of them, according towhether NOUNs tend to precede nearby VERBs.
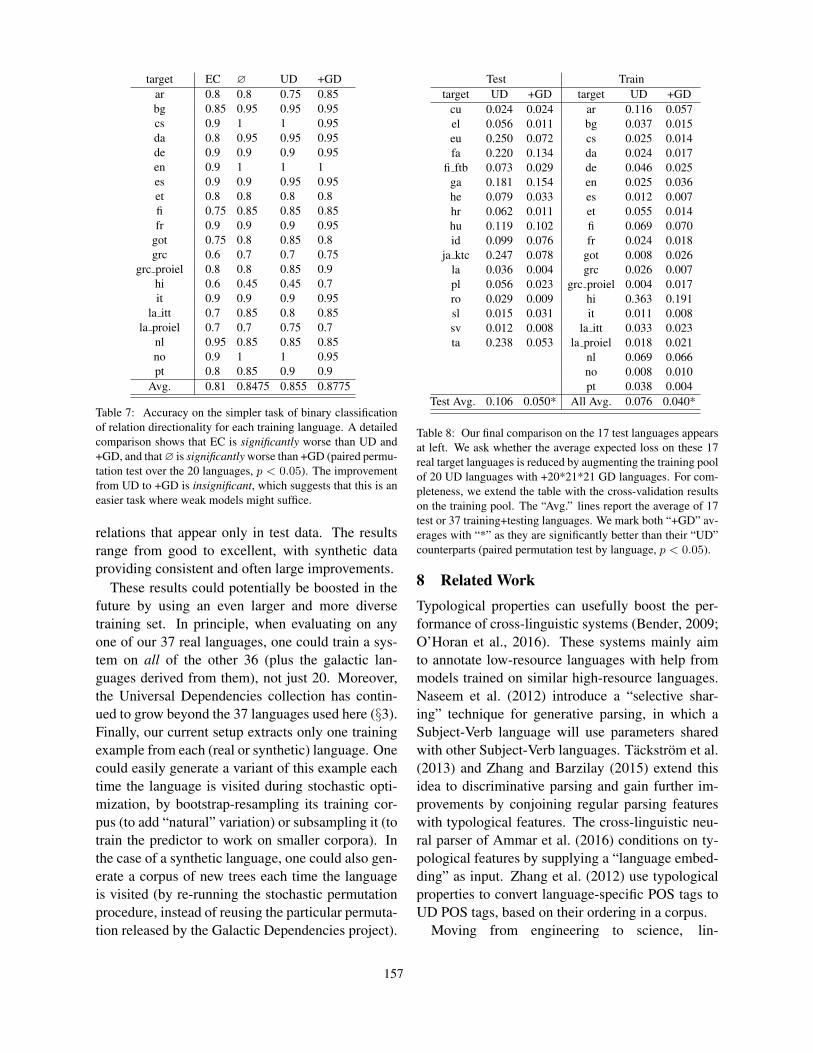
7.9 Final evaluation on test data
All previous experiments were conducted by cross-validation on the 20 training languages. We nowtrain the system on all 20, and report results on the17 blind test languages (Table 8). In our evaluationmetric (1), R includes all 57 relation types that ap-pear in training data, plus a special UNK type for
156
target EC ∅ UD +GDar 0.8 0.8 0.75 0.85bg 0.85 0.95 0.95 0.95cs 0.9 1 1 0.95da 0.8 0.95 0.95 0.95de 0.9 0.9 0.9 0.95en 0.9 1 1 1es 0.9 0.9 0.95 0.95et 0.8 0.8 0.8 0.8fi 0.75 0.85 0.85 0.85fr 0.9 0.9 0.9 0.95
got 0.75 0.8 0.85 0.8grc 0.6 0.7 0.7 0.75
grc proiel 0.8 0.8 0.85 0.9hi 0.6 0.45 0.45 0.7it 0.9 0.9 0.9 0.95
la itt 0.7 0.85 0.8 0.85la proiel 0.7 0.7 0.75 0.7
nl 0.95 0.85 0.85 0.85no 0.9 1 1 0.95pt 0.8 0.85 0.9 0.9
Avg. 0.81 0.8475 0.855 0.8775
Table 7: Accuracy on the simpler task of binary classificationof relation directionality for each training language. A detailedcomparison shows that EC is significantly worse than UD and+GD, and that ∅ is significantly worse than +GD (paired permu-tation test over the 20 languages, p < 0.05). The improvementfrom UD to +GD is insignificant, which suggests that this is aneasier task where weak models might suffice.
relations that appear only in test data. The resultsrange from good to excellent, with synthetic dataproviding consistent and often large improvements.
These results could potentially be boosted in thefuture by using an even larger and more diversetraining set. In principle, when evaluating on anyone of our 37 real languages, one could train a sys-tem on all of the other 36 (plus the galactic lan-guages derived from them), not just 20. Moreover,the Universal Dependencies collection has contin-ued to grow beyond the 37 languages used here (§3).Finally, our current setup extracts only one trainingexample from each (real or synthetic) language. Onecould easily generate a variant of this example eachtime the language is visited during stochastic opti-mization, by bootstrap-resampling its training cor-pus (to add “natural” variation) or subsampling it (totrain the predictor to work on smaller corpora). Inthe case of a synthetic language, one could also gen-erate a corpus of new trees each time the languageis visited (by re-running the stochastic permutationprocedure, instead of reusing the particular permuta-tion released by the Galactic Dependencies project).
Test Traintarget UD +GD target UD +GD
cu 0.024 0.024 ar 0.116 0.057el 0.056 0.011 bg 0.037 0.015eu 0.250 0.072 cs 0.025 0.014fa 0.220 0.134 da 0.024 0.017
fi ftb 0.073 0.029 de 0.046 0.025ga 0.181 0.154 en 0.025 0.036he 0.079 0.033 es 0.012 0.007hr 0.062 0.011 et 0.055 0.014hu 0.119 0.102 fi 0.069 0.070id 0.099 0.076 fr 0.024 0.018
ja ktc 0.247 0.078 got 0.008 0.026la 0.036 0.004 grc 0.026 0.007pl 0.056 0.023 grc proiel 0.004 0.017ro 0.029 0.009 hi 0.363 0.191sl 0.015 0.031 it 0.011 0.008sv 0.012 0.008 la itt 0.033 0.023ta 0.238 0.053 la proiel 0.018 0.021
nl 0.069 0.066no 0.008 0.010pt 0.038 0.004
Test Avg. 0.106 0.050* All Avg. 0.076 0.040*
Table 8: Our final comparison on the 17 test languages appearsat left. We ask whether the average expected loss on these 17real target languages is reduced by augmenting the training poolof 20 UD languages with +20*21*21 GD languages. For com-pleteness, we extend the table with the cross-validation resultson the training pool. The “Avg.” lines report the average of 17test or 37 training+testing languages. We mark both “+GD” av-erages with “*” as they are significantly better than their “UD”counterparts (paired permutation test by language, p < 0.05).
8 Related WorkTypological properties can usefully boost the per-formance of cross-linguistic systems (Bender, 2009;O’Horan et al., 2016). These systems mainly aimto annotate low-resource languages with help frommodels trained on similar high-resource languages.Naseem et al. (2012) introduce a “selective shar-ing” technique for generative parsing, in which aSubject-Verb language will use parameters sharedwith other Subject-Verb languages. Tackstrom et al.(2013) and Zhang and Barzilay (2015) extend thisidea to discriminative parsing and gain further im-provements by conjoining regular parsing featureswith typological features. The cross-linguistic neu-ral parser of Ammar et al. (2016) conditions on ty-pological features by supplying a “language embed-ding” as input. Zhang et al. (2012) use typologicalproperties to convert language-specific POS tags toUD POS tags, based on their ordering in a corpus.
Moving from engineering to science, lin-
157

guists seek typological universals of human lan-guage (Greenberg, 1963; Croft, 2002; Song, 2014;Hawkins, 2014), e.g., “languages with domi-nant Verb-Subject-Object order are always preposi-tional.” Dryer and Haspelmath (2013) characterize2679 world languages with 192 typological proper-ties. Their WALS database can supply features toNLP systems (see previous paragraph) or gold stan-dard labels for typological classifiers. Daume III andCampbell (2007) take WALS as input and proposea Bayesian approach to discover new universals.Georgi et al. (2010) impute missing properties of alanguage, not by using universals, but by backingoff to the language’s typological cluster. Murawaki(2015) use WALS to help recover the evolutionarytree of human languages; Daume III (2009) consid-ers the geographic distribution of WALS properties.
Attempts at automatic typological classificationare relatively recent. Lewis and Xia (2008) pre-dict typological properties from induced trees, butguess those trees from aligned bitexts, not by mono-lingual grammar induction as in §7.6. Liu (2010)and Futrell et al. (2015) show that the directional-ity of (gold) dependencies is indicative of “basic”word order and freeness of word order. Those paperspredict typological properties from trees that are au-tomatically (noisily) annotated or manually (expen-sively) annotated. An alternative is to predict the ty-pology directly from raw or POS-tagged text, as wedo. Saha Roy et al. (2014) first explored this idea,building a system that correctly predicts adpositiontypology on 19/23 languages with only word co-occurrence statistics. Zhang et al. (2016) evaluatesemi-supervised POS tagging by asking whether theinduced tag sequences can predict typological prop-erties. Their prediction approach is supervised likeours, although developed separately and trained ondifferent data. They more simply predict 6 binary-valued WALS properties, using 6 independent bi-nary classifiers based on POS bigram and trigrams.
Our task is rather close to grammar induction,which likewise predicts a set of real numbers giv-ing the relative probabilities of competing syntacticconfigurations. Most previous work on grammar in-duction begins with maximum likelihood estimationof some generative model—such as a PCFG (Lariand Young, 1990; Carroll and Charniak, 1992) ordependency grammar (Klein and Manning, 2004)—
though it may add linguistically-informed inductivebias (Ganchev et al., 2010; Naseem et al., 2010).Most such methods use local search and must wres-tle with local optima (Spitkovsky et al., 2013). Fine-grained typological classification might supplementthis approach, by cutting through the initial com-binatorial challenge of establishing the basic word-order properties of the language. In this paper weonly quantify the directionality of each relation type,ignoring how tokens of these relations interact lo-cally to give coherent parse trees. Grammar induc-tion methods like EM could naturally consider thoselocal interactions for a more refined analysis, whenguided by our predicted global directionalities.
9 Conclusions and Future WorkWe introduced a typological classification task,which attempts to extract quantitative knowledgeabout a language’s syntactic structure from its sur-face forms (POS tag sequences). We applied super-vised learning to this apparently unsupervised prob-lem. As far as we know, we are the first to utilizesynthetic languages to train a learner for real lan-guages: this move yielded substantial benefits.12
Figure 5 shows that we rank held-out languagesrather accurately along a spectrum of directionality,for several common dependency relations. Table 8shows that if we jointly predict the directionalitiesof all the relations in a new language, most of thosenumbers will be quite close to the truth (low aggre-gate error, weighted by relation frequency). Thisholds promise for aiding grammar induction.
Our trained model is robust when applied to noisyPOS tag sequences. In the future, however, wewould like to make similar predictions from rawword sequences. That will require features that ab-stract away from the language-specific vocabulary.Although recurrent neural networks in the presentpaper did not show a clear advantage over hand-engineered features, they might be useful when usedwith word embeddings.
Finally, we are interested in downstream uses.Several NLP tasks have benefited from typologi-cal features (§8). By using end-to-end training, ourmethods could be tuned to extract features (existingor novel) that are particularly useful for some task.
12Although Wang and Eisner (2016) review uses of synthetictraining data elsewhere in machine learning.
158

Acknowledgements This work was funded by theU.S. National Science Foundation under Grant No.1423276. We are grateful to the state of Marylandfor providing indispensable computing resources viathe Maryland Advanced Research Computing Cen-ter (MARCC). We thank the Argo lab members foruseful discussions. Finally, we thank TACL actioneditor Mark Steedman and the anonymous review-ers for high-quality suggestions, including the ECbaseline and the binary classification evaluation.
References
Waleed Ammar, George Mulcaire, Miguel Balles-teros, Chris Dyer, and Noah Smith. Many lan-guages, one parser. Transactions of the Associ-ation of Computational Linguistics, 4:431–444,2016.
Emily M. Bender. Linguistically naıve != languageindependent: Why NLP needs linguistic typol-ogy. In Proceedings of the EACL 2009 Workshopon the Interaction between Linguistics and Com-putational Linguistics: Virtuous, Vicious or Vacu-ous?, pages 26–32, 2009.
Glenn Carroll and Eugene Charniak. Two experi-ments on learning probabilistic dependency gram-mars from corpora. In Working Notes of the AAAIWorkshop on Statistically-Based NLP Techniques,pages 1–13, 1992.
Kyunghyun Cho, Bart van Merrienboer, DzmitryBahdanau, and Yoshua Bengio. On the propertiesof neural machine translation: Encoder-decoderapproaches. In Proceedings of Eighth Workshopon Syntax, Semantics and Structure in StatisticalTranslation, pages 103–111, 2014.
Noam Chomsky. Lectures on Government and Bind-ing: The Pisa Lectures. Holland: Foris Publica-tions, 1981.
Noam Chomsky and Howard Lasnik. The theory ofprinciples and parameters. In Syntax: An Inter-national Handbook of Contemporary Research,Joachim Jacobs, Arnim von Stechow, WolfgangSternefeld, and Theo Vennemann, editors. Berlin:de Gruyter, 1993.
William Croft. Typology and Universals. CambridgeUniversity Press, 2002.
Hal Daume III. Non-parametric Bayesian areal lin-guistics. In Proceedings of Human LanguageTechnologies: The 2009 Annual Conference of theNorth American Chapter of the Association forComputational Linguistics, pages 593–601, 2009.
Hal Daume III and Lyle Campbell. A Bayesianmodel for discovering typological implications.In Proceedings of the 45th Annual Meeting of theAssociation of Computational Linguistics, pages65–72, 2007.
Matthew S. Dryer and Martin Haspelmath, editors.The World Atlas of Language Structures Online.Max Planck Institute for Evolutionary Anthropol-ogy, Leipzig, 2013. http://wals.info/.
Joakim Nivre, et al. Universal Dependencies 1.2.LINDAT/CLARIN digital library at the Instituteof Formal and Applied Linguistics, Charles Uni-versity in Prague. Data available at http://universaldependencies.org, 2015.
Robert Frank and Shyam Kapur. On the use of trig-gers in parameter setting. Linguistic Inquiry, 27:623–660, 1996.
Richard Futrell, Kyle Mahowald, and Edward Gib-son. Quantifying word order freedom in depen-dency corpora. In Proceedings of the Third Inter-national Conference on Dependency Linguistics,pages 91–100, 2015.
Kuzman Ganchev, Joao Graca, Jennifer Gillenwater,and Ben Taskar. Posterior regularization for struc-tured latent variable models. Journal of MachineLearning Research, 11:2001–2049, 2010.
Ryan Georgi, Fei Xia, and William Lewis. Com-paring language similarity across genetic andtypologically-based groupings. In Proceedings ofthe 23rd International Conference on Computa-tional Linguistics, pages 385–393, 2010.
Edward Gibson and Kenneth Wexler. Triggers. Lin-guistic Inquiry, 25(3):407–454, 1994.
Xavier Glorot and Yoshua Bengio. Understandingthe difficulty of training deep feedforward neu-ral networks. In Proceedings of the InternationalConference on Artificial Intelligence and Statis-tics, 2010.
Joseph H. Greenberg. Some universals of grammarwith particular reference to the order of mean-
159

ingful elements. In Universals of Language,Joseph H. Greenberg, editor, pages 73–113. MITPress, 1963.
John A. Hawkins. Word Order Universals. Elsevier,2014.
Sepp Hochreiter and Jurgen Schmidhuber. Longshort-term memory. Neural Computation, 9(8):1735–1780, 1997.
Dan Klein and Christopher Manning. Corpus-basedinduction of syntactic structure: Models of depen-dency and constituency. In Proceedings of the42nd Annual Meeting of the Association for Com-putational Linguistics, pages 478–485, 2004.
Karim Lari and Steve J. Young. The estimationof stochastic context-free grammars using theInside-Outside algorithm. Computer Speech andLanguage, 4(1):35–56, 1990.
Phong Le and Willem Zuidema. Unsupervised de-pendency parsing: Let’s use supervised parsers.In Proceedings of the 2015 Conference of theNorth American Chapter of the Association forComputational Linguistics: Human LanguageTechnologies, pages 651–661, 2015.
William D. Lewis and Fei Xia. Automatically iden-tifying computationally relevant typological fea-tures. In Proceedings of the Third InternationalJoint Conference on Natural Language Process-ing: Volume-II, 2008.
Haitao Liu. Dependency direction as a means ofword-order typology: A method based on de-pendency treebanks. Lingua, 120(6):1567–1578,2010.
David Marecek and Milan Straka. Stop-probabilityestimates computed on a large corpus improve un-supervised dependency parsing. In Proceedingsof the 51st Annual Meeting of the Association forComputational Linguistics (Volume 1: Long Pa-pers), pages 281–290, 2013.
Yugo Murawaki. Continuous space representationsof linguistic typology and their application to phy-logenetic inference. In Proceedings of the 2015Conference of the North American Chapter ofthe Association for Computational Linguistics:Human Language Technologies, pages 324–334,2015.
Tahira Naseem, Harr Chen, Regina Barzilay, andMark Johnson. Using universal linguistic knowl-edge to guide grammar induction. In Proceedingsof the 2010 Conference on Empirical Methods inNatural Language Processing, pages 1234–1244,2010.
Tahira Naseem, Regina Barzilay, and Amir Glober-son. Selective sharing for multilingual depen-dency parsing. In Proceedings of the 50th An-nual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers), pages629–637, 2012.
Dat Quoc Nguyen, Dai Quoc Nguyen, Dang DucPham, and Son Bao Pham. RDRPOSTagger: Aripple down rules-based part-of-speech tagger. InProceedings of the Demonstrations at the 14thConference of the European Chapter of the Asso-ciation for Computational Linguistics, pages 17–20, 2014.
Hiroshi Noji, Yusuke Miyao, and Mark Johnson.Using left-corner parsing to encode universalstructural constraints in grammar induction. InProceedings of the 2016 Conference on EmpiricalMethods in Natural Language Processing, pages33–43, 2016.
Helen O’Horan, Yevgeni Berzak, Ivan Vulic, RoiReichart, and Anna Korhonen. Survey on theuse of typological information in natural languageprocessing. In Proceedings of the 26th Interna-tional Conference on Computational Linguistics:Technical Papers, pages 1297–1308, 2016.
Rishiraj Saha Roy, Rahul Katare, Niloy Ganguly,and Monojit Choudhury. Automatic discoveryof adposition typology. In Proceedings of the25th International Conference on ComputationalLinguistics: Technical Papers, pages 1037–1046,2014.
Jae Jung Song. Linguistic Typology: Morphologyand Syntax. Routledge, 2014.
Valentin I. Spitkovsky, Hiyan Alshawi, and DanielJurafsky. From baby steps to leapfrog: How “lessis more” in unsupervised dependency parsing. InHuman Language Technologies: The 2010 An-nual Conference of the North American Chapterof the Association for Computational Linguistics,pages 751–759, 2010.
160

Valentin I. Spitkovsky, Hiyan Alshawi, and DanielJurafsky. Breaking out of local optima withcount transforms and model recombination: Astudy in grammar induction. In Proceedings ofthe 2013 Conference on Empirical Methods inNatural Language Processing, pages 1983–1995,2013.
Oscar Tackstrom, Ryan McDonald, and JoakimNivre. Target language adaptation of discrimina-tive transfer parsers. In Proceedings of the 2013Conference of the North American Chapter of theAssociation for Computational Linguistics: Hu-man Language Technologies, pages 1061–1071,2013.
Tijmen Tieleman and Geoffrey Hinton. Lecture6.5—RmsProp: Divide the gradient by a runningaverage of its recent magnitude. COURSERA:Neural Networks for Machine Learning, 2012.
Dingquan Wang and Jason Eisner. The Galac-tic Dependencies treebanks: Getting more databy synthesizing new languages. Transactions ofthe Association of Computational Linguistics, 4:491–505, 2016. Data available at https://github.com/gdtreebank/gdtreebank.
Yuan Zhang and Regina Barzilay. Hierarchical low-rank tensors for multilingual transfer parsing. InProceedings of the 2015 Conference on EmpiricalMethods in Natural Language Processing, pages1857–1867, 2015.
Yuan Zhang, Roi Reichart, Regina Barzilay, andAmir Globerson. Learning to map into a uni-versal POS tagset. In Proceedings of the 2012Joint Conference on Empirical Methods in Nat-ural Language Processing and ComputationalNatural Language Learning, pages 1368–1378,2012.
Yuan Zhang, David Gaddy, Regina Barzilay, andTommi Jaakkola. Ten pairs to tag—multilingualPOS tagging via coarse mapping between embed-dings. In Proceedings of the 2016 Conference ofthe North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies, pages 1307–1317, 2016.
161

162