finding the best mismatched detector for channel coding ... · finding the best mismatched detector...
TRANSCRIPT

Finding the best mismatched detector
Sean Meyn
Department of Electrical and Computer EngineeringUniversity of Illinois and the Coordinated Science Laboratory
Joint work with Emmanuel Abbe, Muriel Me’dard, and Lizhong Zheng Laboratory for Information and Decision Systems, MIT
Supported in part by Motorola RPS #32 and ITMANET DARPA RK 2006-07284
for channel coding and hypothesis testing
Outline
Introduction
Mismatched channel
Learning the best detector
Conclusions
η�
β∗(η�)
X memoryless Y channel
π0
PXY
IIntroduction
π0
PXY

Background: Mismatch Channel
YX
Optimal detector ML: Based on the empirical distributions,
where, F is the log-likelihood ratio (real-valued function of x, y)
is the empirical distribution of
i∗ = arg maxi
〈Γin, F 〉
Γin X , Y )( i
memoryless channel

Background: Mismatch Channel
YX
Optimal detector ML: Based on the empirical distributions,
where,
Question considered by Lapidoth 1994, Csiszar et. al. 1981, 1995:
What if the channel model is not known exactly ?
F is the log-likelihood ratio
is the empirical distribution of
i∗ = arg maxi
〈Γin, F 〉
Γin X , Y )( i
memoryless channel

Background: Robust Hypothesis Testing
Uncertainty classes defined by moment constraintsFor given false alarm exponent η, min-max optimal missed detection exponent
Meyn, Pandit, Veeravalli 200X
β∗ = infπ1∈P1
infµ∈Qη(P0)
D(µ π1 )
P0 P, 1
β∗
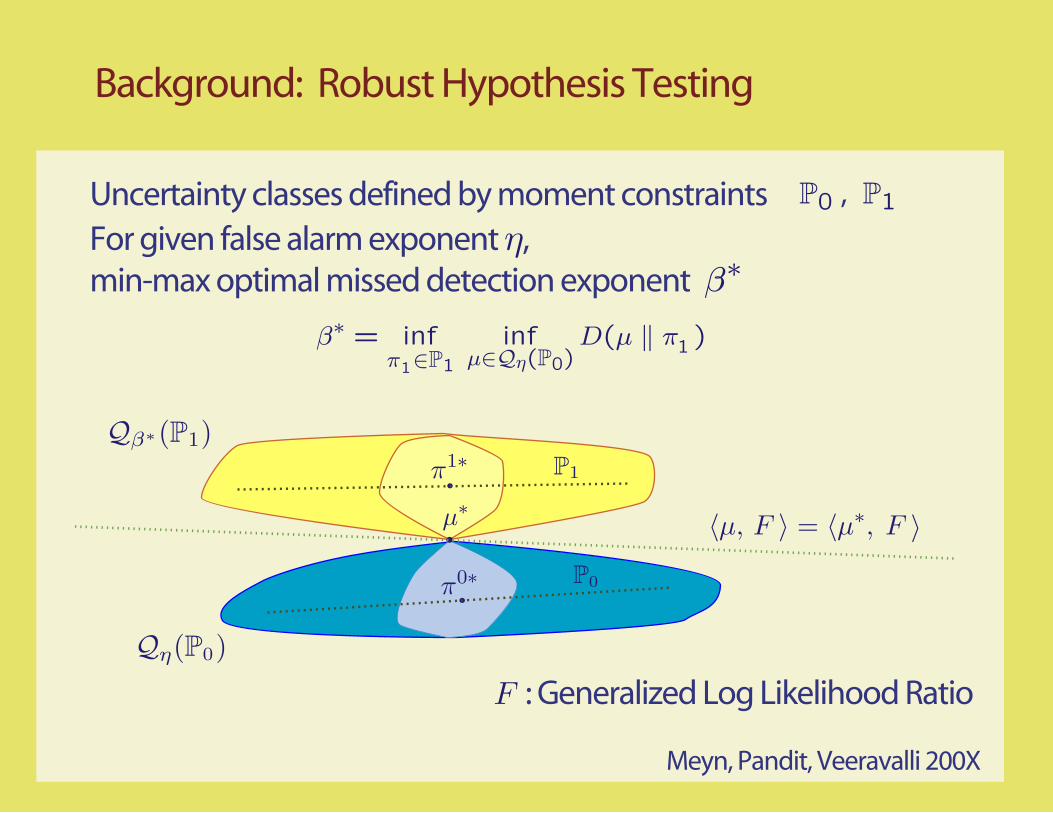
Background: Robust Hypothesis Testing
Uncertainty classes defined by moment constraintsFor given false alarm exponent η, min-max optimal missed detection exponent
F : Generalized Log Likelihood Ratio
Meyn, Pandit, Veeravalli 200X
β∗ = infπ1∈P1
infµ∈Qη(P0)
D(µ π1 )
P0 P, 1
Qβ∗(P1)P1
P0
Q (P0)η
µ, F F= µ∗,
π0∗
π1∗
µ∗
β∗

Goal: Robustness
Original motivation for the research on mismatched detectors
What is the impact on capacity given a poor model?How should codes be constructed to take into account uncertainty?
X memoryless Y channel
Goal: Complexity
Detection and capacity - easy. Its just mutual information!!
Linear detectors suggest relaxation techniques for multiuserand network settings

Goal: Adaptation
A new point of view!
How can a detector be tuned on-line in a dynamic environment?
This will depend on SNROther usersNetwork conditions ...
X memoryless Y channel
Estimates
Capacity

IIMismatched Channel
X memoryless Y channel

Mismatched Detector
A given function F (x,y) defines a surrogate ML detector:
Empirical distributions for ith codeword:
Reliably received rate (in general a lower bound):Generalized Mutual Information (Lapidoth, Csiszar)
Γin = n−1
n
t=1
δXit ,Yt
i∗ = arg maxi
Γin,F = arg max
i
n
t=1
F (Xit , Yt)

Mismatched Detector: Sanov’s Theorem
Sanov’s Theorem (in form of Chernoff’s Bound) gives
ILDP(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F,F 〉nf{ }
log Pe P pair-wise prob. of error)( e≤ −nILDP(PX ;F )

Mismatched Detector: Sanov’s Theorem
π0
Sanov’s Theorem (in form of Chernoff’s Bound) gives
ILDP(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F,F 〉nf{ }
log Pe P pair-wise prob. of error)( e≤ −nILDP(PX ;F )
) =
=
{ {Γ : D(ΓQβ0β0(π0 ) ≤π0
π0 PX ⊗ PY
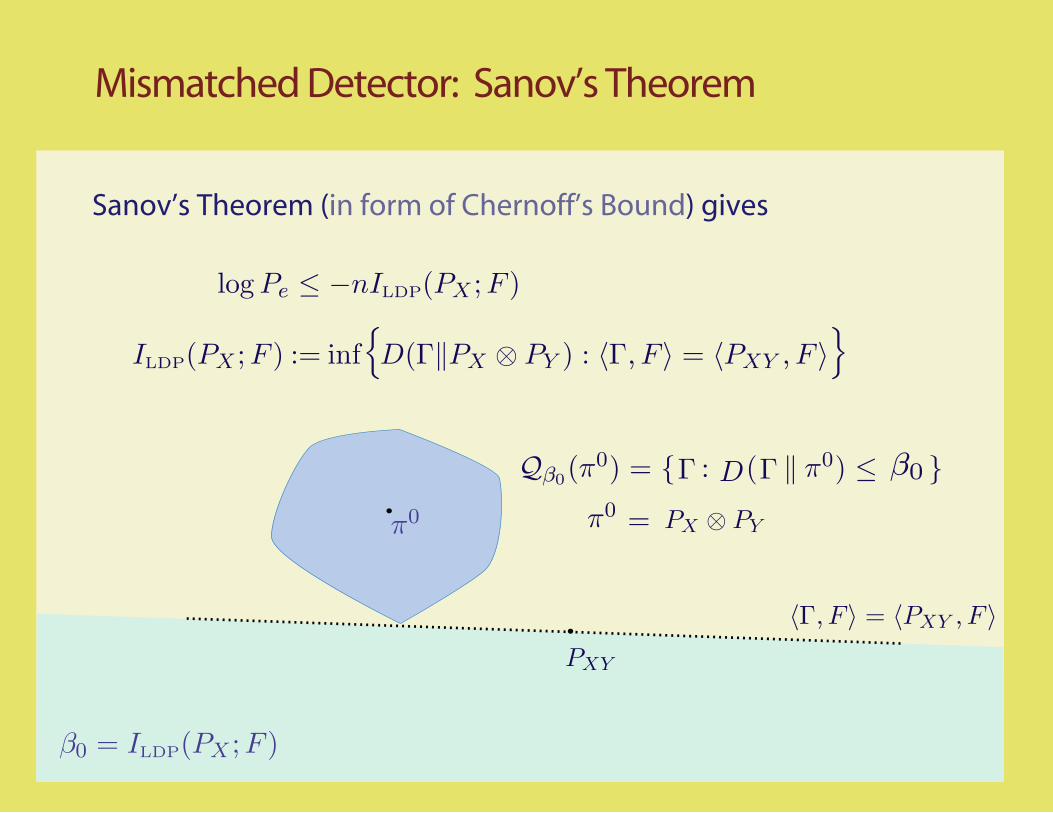
Mismatched Detector: Sanov’s Theorem
π0
Sanov’s Theorem (in form of Chernoff’s Bound) gives
ILDP(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F,F 〉nf{ }
log Pe ≤ −nILDP(PX ;F )
β0 = ILDP(PX ;F )
PXY
) =
=
{ {Γ : D(ΓQβ0β0(π0 ) ≤π0
π0 PX ⊗ PY
〈Γ 〉 = 〈PXY ,F,F 〉

Mismatched Detector: Generalized Mutual Information
Generalized Mutual Information - introduces typicality constraint,
IGMI(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F ,,F 〉nf{
log Pe ≤ −nIGMI(PX ;F )}
Γ2 = PY

Mismatched Detector: Generalized Mutual Information
Generalized Mutual Information
IGMI(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F ,,F 〉nf{
log Pe ≤ −nIGMI(PX ;F )}
Γ2 = PY
Derivation of GMI bound using Sanov:

Mismatched Detector: Generalized Mutual Information
Generalized Mutual Information
IGMI(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F ,,F 〉nf{
log Pe ≤ −nIGMI(PX ;F )}
Γ2 = PY
Derivation of GMI bound using Sanov: For any function G(y),
log Pe ≤ −nILDP(PX ;F G any G(y))
i∗ = arg maxi
〈Γin, F + G〉 = arg max
i
{ n∑t=1
[F (Xit ,Yt) + G
+
(Yt)]}

Mismatched Detector: Generalized Mutual Information
Generalized Mutual Information
G : Lagrange multiplier for equality constraint
IGMI(PX ;F ) := i D(Γ‖PX ⊗ PY ) : 〈Γ 〉 = 〈PXY ,F ,,F 〉nf{
log Pe ≤ −nIGMI(PX ;F )}
Γ2 = PY
Γ2 = PY
supG(y)
ILDP(PX ;F + G) = IGMI(PX ;F )
log Pe ≤ −nILDP(PX ;F G ) +
*
any G(y)

IIILearning the Best Detector
η�
β∗(η�)

Learning the Best Test
MaximizeMM capacity:
Given a parameterized class of detectors,
What is the best value of α?
J(α) := ILDP(PX ;Fα)
{Fα = αiψi : α ∈ Rd}

Learning the Best Test
Derivatives:
MaximizeMM capacity: J(α) := ILDP(PX ;Fα)
∇J = ψ Γα,ψ
∇2J = Γα,ψψT Γα,ψ Γα,ψ T
where for any set A ∈ B(X × Y),
Γα(A) :=PX ⊗ PY , eFαIA
PX ⊗ PY , eFα

Learning the Best Test
Derivatives:
MaximizeMM capacity:
Newton Raphson based on channel model, or
Stochastic Newton Raphson based on measurements alone!
J(α) := ILDP(PX ;Fα)
∇J = ψ Γα,ψ
∇2J = Γα,ψψT Γα,ψ Γα,ψ T
where for any set A ∈ B(X × Y),
Γα(A) :=PX ⊗ PY , eFαIA
PX ⊗ PY , eFα
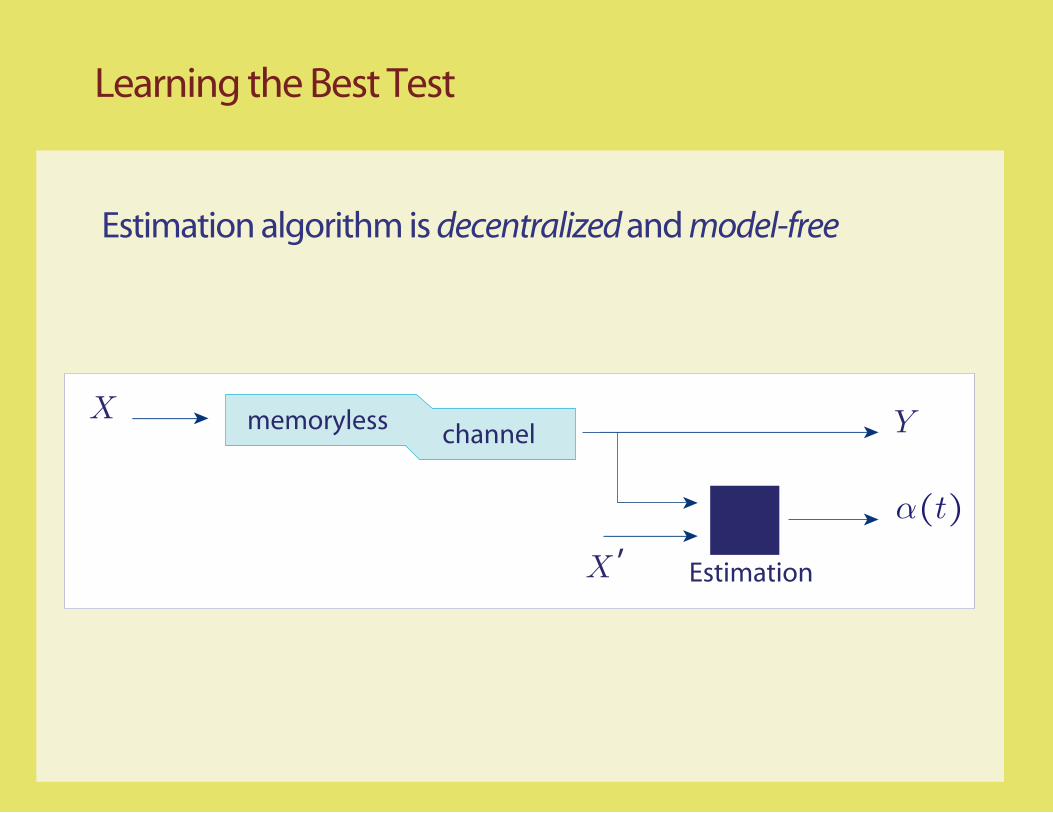
X memoryless Y channel
Estimation
Learning the Best Test
Estimation algorithm is decentralized and model-free
X
α(t)
’

AWGN Channel
Y = X + N
Estimates
Capacity
iterations0 2000 4000 6000 8000 100000.0
0.2
0.4
0.6
0.8
1.0
Basis:
SNR = 2
ψ = (x2, y2,xy)T

Mismatched Neyman Pearson Hypothesis Testing
X
False Alarm Error Exponent
Missed Detection Error Exponent
1 uniform on [0, 1], X0 =5√
X1
η
β∗(η)
η β∗(η)
Parameterized class of detectors,
Numerical experiment:
Stochastic Newton-Raphson to find [ , ] pairs
{Fα = αiψi : α ∈ Rd}
ψ(x) = [x,log(x)/10]T Optimal detector
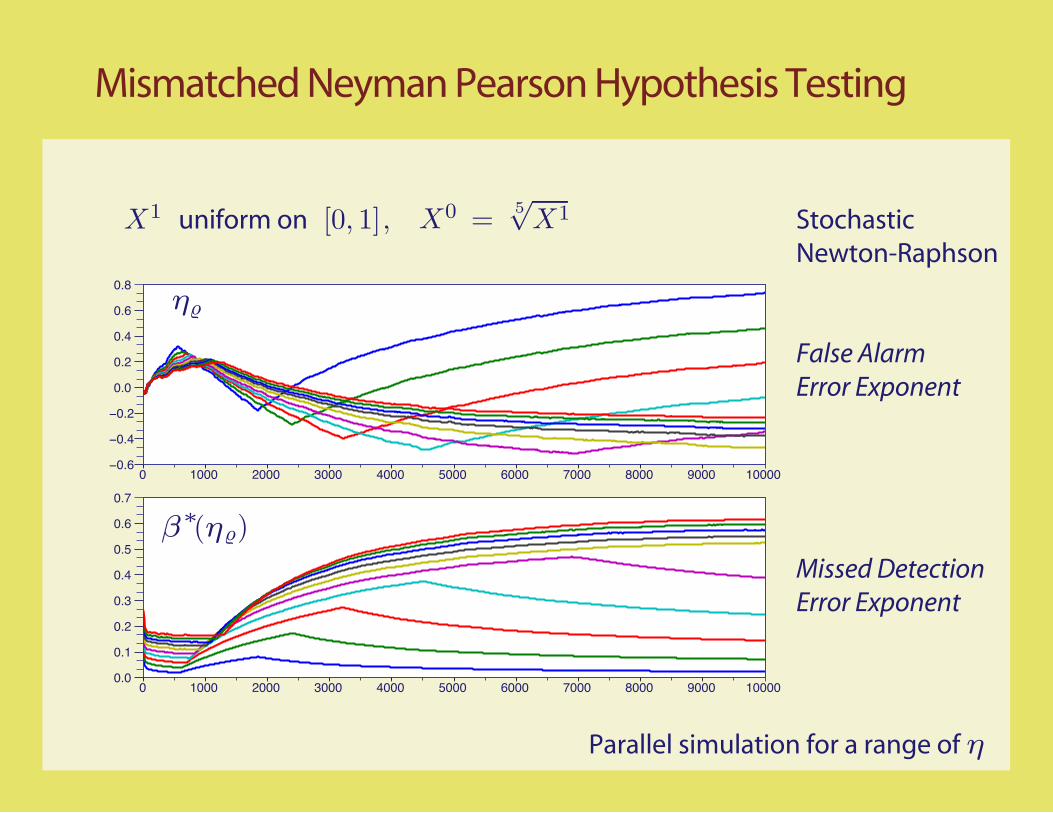
Mismatched Neyman Pearson Hypothesis Testing
X
Parallel simulation for a range of η
1 uniform on Stochastic Newton-Raphson
False AlarmError Exponent
Missed DetectionError Exponent
[0, 1], X0 =5√
X1
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000−0.6
−0.4
−0.2
0.0
0.2
0.4
0.6
0.8
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
η�
β∗(η�)
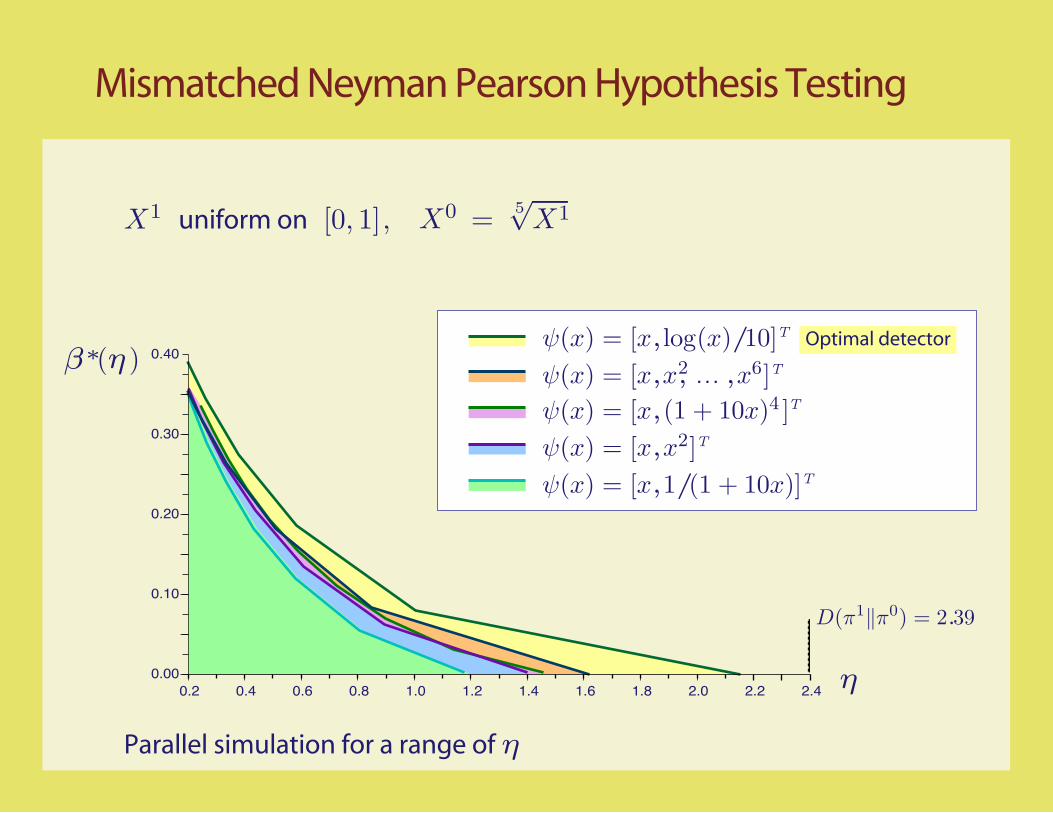
Mismatched Neyman Pearson Hypothesis Testing
Optimal detectorψ(x) = [x,log(x)/10]T
Tψ(x) = [x, 4
ψ(x) = [x,x2]T
ψ(x) = [x,x, ,...2 x6]T
ψ(x) = [x,1/(1 + 10x)]
(1 + 10x) ]
T
(η )
0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.20.00
0.10
0.20
0.30
0.40
D(π1‖π0) = 2.39
2.4
X
Parallel simulation for a range of η
1 uniform on [0, 1], X0 =5√
X1
β∗
η

IVConclusions

Conclusions
Geometry based on Sanov’s Theorem combinedwith Stochastic Approximation provides powerful computational tools

Conclusions
Geometry based on Sanov’s Theorem combinedwith Stochastic Approximation provides powerful computational tools
Future work:
Optimizing the input distribution
Application to MIMO will simultaneously resolve coding and resource allocation. Extensions to network coding possible?
Simulation algorithm exhibits high variance. Application of importance sampling? Revisit robust approach?

References
[7] I. Csiszar and P. Narayan. Channel capacity for a given decoding metric. IEEE Trans.Inform. Theory, 41(1):35–43, 1995.
[12] G. Kaplan, A. Lapidoth, S. Shamai, and N. Merhav. On information rates for mis-matched decoders. IEEE Trans. Inform. Theory, 40(6):1953–1967, 1994.
[14] C. Pandit and S. P. Meyn. Worst-case large-deviations with application to queueingand information theory. Stoch. Proc. Applns., 116(5):724–756, May 2006.
[15] O. Zeitouni and M. Gutman. On universal hypotheses testing via large deviations.IEEE Trans. Inform. Theory, 37(2):285–290, 1991.
[1] E. Abbe, M. Medard, S. Meyn, and L. Zheng. Geometry of mismatched decoders.Submitted to IEEE International Symposium on Information Theory, 2007.
[3] S. Borade and L. Zheng. I-projection and the geometry of error exponents. In Proceed-ings of the Forty-Fourth Annual Allerton Conference on Communication, Control, andComputing, Sept 27-29, 2006, UIUC, Illinois, USA, 2006.
[4] I. Csiszar. The method of types. IEEE Trans. Inform. Theory, 44(6):2505–2523, 1998.Information theory: 1948–1998.