experience inclusion in iterative learning controllers: fuzzy model based approaches
TRANSCRIPT

ARTICLE IN PRESS
0952-1976/$ - se
doi:10.1016/j.en
�CorrespondE-mail addr
Engineering Applications of Artificial Intelligence 21 (2008) 578–590
www.elsevier.com/locate/engappai
Brief paper
Experience inclusion in iterative learning controllers:Fuzzy model based approaches
S. Gopinath�, I.N. Kar, R.K.P. Bhatt
Department of Electrical Engineering, IIT Delhi, New Delhi 110 016, India
Received 25 February 2006; received in revised form 4 April 2007; accepted 15 May 2007
Available online 16 July 2007
Abstract
Iterative learning control (ILC) is a new domain in control system that motivates, whether mechanical robots can learn a prescribed
ideal motion by themselves using information represented by the measured data gathered in the previous practice. For each new desired
trajectory task, the conventional ILC methods have to start its learning with zero initial input assumption. Instead of such zero initial
input assumption, in this paper, the idea of using the past trajectory tracking experiences on the initial input selection for tracking new
trajectory-tracking tasks have been highlighted. Certain methods of experience inclusion in iterative learning controllers (ILC) are
proposed. Approximate fuzzy data model (AFDM) and type-1 fuzzy logic system (FLS) techniques have been adopted for the process of
initial input selection. Performance of the proposed fuzzy rule based model-based ILC approaches on initial error reduction and in error
convergence issues are proved. Numerical experimentation on a two-link manipulator model with the inclusion of actuator dynamics
verifies the performance of the proposed fuzzy model-based ILC approaches. Comparison with existing local learning technique on the
selection of initial input for ILC algorithm proves the efficacy of the proposed AFDM and type-1 FLS-based methods.
r 2007 Elsevier Ltd. All rights reserved.
Keywords: Learning control; Intelligence; Robot control; Fuzzy curves; Back propagation
1. Introduction
Iterative learning control (ILC) has become the activeresearch area for the past two decades and great effortshave been put in the development of different learningcontrollers. ILC can be considered for improving thetransient response and tracking performance of processes,machines, equipments or systems that execute the sametrajectory, motion or operation in a repetitive manner(Arimoto, 1996). Industrial robotic operations, chemicalprocesses are such situations where ILC can be used toimprove the performance. The approach is motivated bythe observation that if the system controller is fixed and ifthe system’s operating conditions are the same each time itexecutes, then any errors in the output response will berepeated during each operation. These errors can berecorded during system operation and can be used to
e front matter r 2007 Elsevier Ltd. All rights reserved.
gappai.2007.05.008
ing author. Tel.: +9111 26591093; fax: +91 11 26581606.
esses: [email protected] (S. Gopinath),
n (I.N. Kar), [email protected] (R.K.P. Bhatt).
compute modifications to the input signal that will beapplied to the system during the next operation, or trial. InILC, refinements are made to the input signal after eachtrial until the desired performance level is reached.Fig. 1 illustrates the basic configuration of ILC, where
uk(t) the input signal during the kth iteration applied to thesystem produces the output trajectory yk(t) and yd(t)denotes the desired trajectory, which the system shouldtrack. These signals are stored in the memory until thecurrent (kth) iteration is over, at which time they areprocessed offline by the ILC algorithm. The learningcontroller compares yd(t) and yk(t) and adds an updateterm with uk(t) to produce uk+1(t), the refined input signalgiven to the system for the (k+1)th iteration. The abovesignals/trajectories are functions of time defined on a finiteinterval tA[0,T] and updates occur sequentially in timeupto the required error goal is reached. D-type ILCalgorithm was introduced by Arimoto et al. (1984) , as afirst work on ILC is of the form ukþ1ðtÞ ¼ ukðtÞ þ G_ekðtÞ,where the derivative of the tracking error is defined as_ekðtÞ ¼ _ydðtÞ � _ykðtÞ with a suitable learning gain G. Bondi

ARTICLE IN PRESS
uk
SYSTEM
LEARNING
CONTROLLER
Memory
yk
yk
yd
uk+1
MemoryMemory
uk
Fig. 1. Basic iterative learning control configuration.
S. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 579
et al. (1988) set the learning controller with a sufficientlinear feedback, which is shown to ensure the trackingperformance. Further research on ILC led to the develop-ment of new algorithms and their implementation issueswith the existing conventional feedback controllers (Atke-son and McIntyre, 1986; Kuc et al., 1991; Jang et al., 1995).The capability of ILC for varying environments andmodeling errors has been explained in Moore (1998). Asan extension to the first-order systems, higher-order ILCfor a class of nonlinear dynamic systems was reported inBien and Huh (1989). It uses more historical data to get thebetter output tracking performance. Stability analysis oflearning control scheme with disturbances and uncertaininitial condition were discussed by Heinzinger et al. (1992).Some of the nonlinear robust, adaptive and model basedILC algorithms are also addressed by Xu and Tan (2003),Tayebi (2004) and Bukkems et al. (2005). Applications ofILC algorithms are applied for the robot including itsactuator dynamics and for direct drive robots are explainedin (Gopinath and Kar, 2004; Bukkems et al., 2005). Thedetailed survey of research progress in ILC area can befound in (Bristow et al., 2006).
The advantage of ILC is that it does not require theknowledge about the system dynamics and learning startsas iteration progress. This results in large initial errors inthe early stage of iterations and very slow convergence oftracking error as the iteration number (k)-N. In theabove ILC algorithms (Arimoto et al., 1984; Bondi et al.,1988; Atkeson and McIntyre, 1986; Kuc et al., 1991; Janget al., 1995; Moore, 1998; Bien and Huh, 1989; Heinzingeret al., 1992; Gopinath and Kar, 2004; Xu and Tan, 2003;Tayebi, 2004; Bukkems et al., 2005; Bristow et al., 2006 ),the controller is designed with the assumption of zerolearning. i.e., the ILC has zero initial input ðu0ðtÞ ¼ 0; 8t 2½0;T �Þ to the system for each new desired trajectorytracking. The past data of old iterations, which will notbe used in future iterations, are discarded in the case ofsingle trajectory-tracking task. If the system has to trackthe multiple desired trajectories in different time spans withdifferent magnitudes for different purposes, then the ILCalgorithm will have relatively high error or poor initialiterations performance and will require more number ofiterations each time to reach the acceptable level of
performance. Preserving the knowledge of the previousdesired trajectory tracking would be more useful in suchsituations. In conventional methods, this knowledge will belost and for each new desired trajectory tracking, ILCalgorithm will start from zero learning. If the knowledge ofthe past desired trajectory tracking could be stored as adatabase of ‘experience’, it can be used for the selection ofthe initial input for the new trajectory-tracking tasks.Direct learning of desired control input for the trajectorieswith different time scales has been explained in Xu (1998).Initial control input selection and its importance over thespeed of error convergence for time domain-based ILCalgorithms have been suggested by Arif et al. (2001). Localweighted learning techniques suggested by Atkeson et al.(1997a), are used as the tool for finding the initial controlinputs from the experience database, which contains theprevious desired output trajectories and their correspond-ing inputs. It is possible to get a better convergence of thesystem’s output to the desired trajectory with, if the initialcontrol input can be selected properly and efficiently fromthe earlier experiences of tracking several trajectories.Thus, it leads from the ILC view point, the significantinitial input selection may lead to the great reduction in theinitial iteration errors and thus the convergence of the errorwith iteration could be significantly improved as comparedto learning controller with zero learning.Fuzzy logic is widely used in intelligent control to reason
about rules, which describe the relationship betweenimprecise, linguistic assessment of the system’s input andoutput states. These production rules are generally naturallanguage representation of expert’s knowledge and providean easily understood knowledge representation scheme.Fuzzy rule-based systems could also be used as a tool formodeling nonlinear systems from the viewpoint of uni-versal approximator of functions (Wang and Mendel, 1992;Kreinovich et al., 1998). In this paper, we are exploiting thefuzzy curves technique reported in (Lin and Cunningham,1995; Azeem et al., 2003), for determining the initialcontrol input of the ILC. We propose a new idea ofpreservation of the trajectory-tracking experience as anapproximate fuzzy data model (AFDM). The key idea ofthe proposed approach is to generate a rule base of IF-THEN fuzzy rules using the experience database of desiredsystem states and their corresponding optimal controlinputs. The initial input selection for the multipletrajectory-tracking tasks by the use of AFDM-defined rulebase technique, are explained in detail in the paper. Theproposed method of experience inclusion has been shownto be better on initial error reduction and convergenceissues in comparison with zero learning. These issues havebeen proved analytically and verified through simulations.A comparative study has also been performed on thelearning controller with experience inclusion using theAFDM and the locally weighted learning methods.This paper has been organized as follows. The problem
statement is presented in Sections 2 and 3 describes theissue of experience inclusion in learning controllers and the

ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590580
use of existing local learning technique. Proposed AFDM-based ILC approach, its rule base formation and initialinput selection issues are explained in Section 4. Thissection also contains the detailed mathematical justifica-tions on initial iteration error reduction and the errorconvergence issues. Section 5 presents the detailed numer-ical experimentation carried on a two-link robot manip-ulator system with the inclusion of its actuator dynamics,thus verifies the performance of the proposed AFDMapproach in comparison with local learning method.
2. Problem statement
Consider a nonlinear time-varying dynamic systemdescribed as
_xkðtÞ ¼ fðxkðtÞ; ukðtÞÞ,
ykðtÞ ¼ gðxkðtÞ; ukðtÞÞ, ð1Þ
where k corresponds to the kth iteration of the system,xk(t)ARnx1, uk(t)ARmx1 and yk(t)ARrx1 are the states,control input and output of the system, respectively, fortA[0,T ] and fð:Þ and gð:Þ are unknown nonlinear functions.Also. the function fð:Þ satisfies the Lipschitz condition
jjfðx1; u1; tÞ � fðx2; u1; tÞjjpLf ½jjx1ðtÞ � x2ðtÞjj
þ jju1 � u2jj�, ð2Þ
where 0oLfoN is an unknown Lipschitz constant. Let thedesired trajectory be yd(t) is continuously differentiable onthe finite time interval tA[0,T], such that for bounded desiredtrajectory yd(t), there exists a unique bounded input ud(t) fortA[0, T], for which system has unique bounded states xd(t)and yd(t) ¼ g(xd(t), ud(t), t) for tA[0,T]. The trajectory-tracking problem can be stated as follows: for a desiredtrajectory yd(t), find a sequence of piecewise continuouscontrol input u(t) such that the system’s output y(t)converges to yd(t). For practical systems, only boundedconvergence is expected. In the context of ILC, this trackingproblem is solved by modifying the control input uk(t) ineach iteration k such that the control input uk(t) converges tothe desired control input ud(t). In search of this desiredcontrol input ud(t), instead of zero initial input assumption aswe do in conventional ILC algorithms, this paper addressesthe issues related to the selection of appropriate initial inputsfor the multiple trajectory tasks. In this paper, the followingnorm definitions are used for a function f(t) are stated as
jjf ðtÞjjs ¼ supt2½0;T �
e�stjjf ðtÞjj, (3)
jjf ðtÞjj1 ¼ supt2½0;T �
jjf ðtÞjj. (4)
3. Experience inclusion techniques in ILC
Incorporation of the experience in ILC algorithms makethe learning controllers more intelligent, which are able to
handle the multiple trajectory tasks with less initialtracking errors and quick convergence with iterations.This section briefs the existing locally weighted learningtechnique for experience inclusion and the initial inputselection issues.
3.1. Locally weighted learning approach-brief overview
Local learning is one of the memory-based techniquesthat, once a query is received, extract a predictioninterpolating the neighboring points of the query locally,which are considered relevant according to some distancemeasure (Azeem et al., 2003; Atkeson et al., 1997b;Bontempi et al., 1999). Thus, local learning methodinvolves storing the training data in memory and findingrelevant data in the database by using kernel functions toanswer a particular query. In the tracking problem of robotsystem, the main objective is to find the desired controlinput such that the robot output y(t) tracks the desiredtrajectory yd(t). The desired control input corresponds tothe desired output yd(t) and the desired states xd(t) can becomputed as
udðtÞ ¼ g�1ðxdðtÞ; ydðtÞÞ ¼ ZðxdðtÞ; ydðtÞÞ. (5)
In the above Eq. (5) , the function Zð:Þ represents thenonlinear complex inverse model of the system. Thisinverse model can be represented by a database ofexperiences, which consists of the information correspond-ing to the desired system states such as position, velocityof the robot links and the corresponding desired torqueinput for robot links. The experience database is repre-sented as [X, U], where X represents the state vector ofposition and velocity information and U represents thecorresponding control input vector. Let us consider aquery vector Q consists of new desired trajectory informa-tion. According to the locally weighted learning, a locallinear model can be formed using the query point withthe use of Euclidean distance of the k-nearest neighbordata points (Seidl and Kriegel, 1998) from the querypoint. Weights are assigned for these data points accordingto their distance from the query point. More weightage forthe nearer points and less for the far away points areassigned. Kernel functions (Atkeson et al., 1997a) areutilized for weighting the k-nearest data points. Initialiteration input for the new desired trajectory can becomputed from the local linear model either by locallyweighted regression (Arif et al., 2001) or by the weightedaverage local models (Atkeson et al., 1997a). In the latermethod the local linear models, weighted average thecontrol signals (uj) of past desired trajectories as stored inthe database. These points are searched from the databaseby the k-nearest neighbor search and given weights by thekernel functions. Let wj be the weights for each k-nearestdata points to the query. Thus for a query vector Q, thepredicted value of the control input vector u0(t) could befound by the following weighted average of the linear local

ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 581
models as:
u0ðtÞ ¼
Pkj¼1wjujPk
j¼1wj
8t 2 ½0;T �, (6)
where uj represents the k-nearest control input points fromthe database, which corresponds to the query vector Q.This predicted control input (u0(t)) can be used as the initialcontrol input for the learning controllers instead of zerolearning assumption in the case of multiple trajectory tasks.
4. Approximate fuzzy data model (AFDM) approach
This section presents the AFDM methodology used inthe proposed method of experience inclusion. It providessignificant initial input for the ILC, necessary for themultiple trajectory tasks. The trajectory tracking informa-tion such as position, velocity and the correspondingtorque inputs are utilized to derive a rule base for AFDM.Thus, the past trajectory tracking experience are utilized toderive an AFDM consisting of a rule base as an alternativeto local linear models as in locally weighted learningapproach.
4.1. Rule base for AFDM
The proposed fuzzy model-based ILC approach is shownin Fig. 2. In consideration of the tracking problem ofrobot, let the experience data set be (Xj, Uj), where Xj is thestate trajectory vector containing 2n elements such as theposition ðx
j1iÞ, velocity ðx
j2iÞ information and Uj denotes
the corresponding control input vector with n elements.Here, j ¼ 1,2,y,m is an index representing the number ofdesired trajectories experienced by the ILC.
Elements n depends on the total time duration of thedesired trajectory (T) and the sampling interval (Dt) andcan be computed as n ¼ T/Dt. Suppose the learningcontroller has to track a new desired trajectory ðX new
d Þ. It
u0 (t)
Fuzzy model
d
newX
ek
(t)
ILC Learning
Algorithm
Memory
Fuzzifier
Defuzzifier
Fig. 2. Fuzzy model based ite
consists of position ðqiÞ and velocity ð _qiÞ information,which are denoted by a query vector Q ¼ ½q1; q2; . . . ; qn;_q1; _q2; . . . ; _qn�. In the rule base of AFDM, we require todefine each rule for each vector pair (Xj, Uj) of thefollowing form:
Rulej
i : IF x1i is mj
i ðx1i; xj1iÞ
AND x2i is mj
i ðx2i; xj2iÞ THEN ux1i ;x2i
i is uj
i
ðfor i ¼ 1; 2; . . . ; n and j ¼ 1; 2; . . . ;mÞ. ð7Þ
Here ux1i ;x2i
i is the ith input element corresponding to theinput elements (x1i, x2i) and u
ji is a crisp value of input
vector Uj. Also, m ji ðx1i; x
j1iÞ and m j
i ðx2i; xj2iÞ are the Gaussian
membership functions defined by
m ji x1i; x
j1i
� �¼ exp �
x1i � xj1i
b
!20@
1A;
m ji x2i; x
j2i
� �¼ exp �
x2i � xj2i
b
!20@
1A. ð8Þ
From Eq. (8), it is clear that when x1i ¼ xj1i and x2i ¼ x
j2i,
the corresponding membership function values,m j
i ðx1i; xj1iÞ ¼ m j
i ðx2i; xj2iÞ ¼ 1:0.
4.2. Selection of initial control input by AFDM approach
AFDM technique is basically used to evaluate therelative significance of an input candidate. An approximateinverse model of the nonlinear system as given in Eq. (5)can be learnt by the AFDM using the IF-THEN rules.Each time when a new trajectory has to be tracked, anapproximate desired control input ~udðtÞ will be generatedby the AFDM, which then be corrected by the learningcontroller in a way that the control input ukðtÞ converges tothe desired control input udðtÞ as iteration progress. Hence,the fuzzy data model provides more significant andappropriate prediction of control input required to trackthe new desired trajectory. Thus, the convergence of
uk (t) X
k (t)
Plant
IF-THENRule Base
rative learning controller.

ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590582
learning controller will be improved as compared to that ofzero initial input learning for acceptable bounded errors.The significant initial input u0ðtÞ corresponding to newdesired trajectory task has been computed from thedefuzzifier of the AFDM as shown in Fig. 2. The centroiddefuzzification formula for the output of AFDM definedby rules as in Eq. (7) is given by
u0 ið Þ ¼
Pmj¼1
m ji qi; x
j1i
� �^ m j
i _qi;xj2i
� �� �u
qi ; _qi
i
Pmj¼1
m ji qi;x
j1i
� �^ m j
i _qi; xj1i
� �� � ; for i ¼ 1; 2; . . . ; n,
(9)
where 4 is the minimum operator. Thus, Eq. (9) provesthat AFDM is a special case of generalized fuzzy model(GFM) (Kreinovich et al., 1998; Lin and Cunningham,1995). The defuzzified output of AFDM is called as fuzzycurve (Lin and Cunningham, 1995), which is used as theinitial input ðu0ðtÞÞ for the ILC algorithm. This methodgives more proper and efficient initial control input signalof the learning controller to the system. This leads to thegreater reduction in initial errors with reduced number ofiterations, which is required to reach acceptable error levelfor tracking new desired trajectories as compared to zerolearning as well as with locally weighted learning-basedILC approaches.
Remarks (1). In AFDM based approach, the total numberof rules is equal to mn, where n represents the number ofsampling points and m represents the number of experiencetrajectories. For each new experience trajectory, a new setof rules will be added into the rule base of AFDM. As thenumber of trajectories in the experience set increases, thenumber of rules will increase significantly. The size ofthe rule base can be reduced by the following ways:
�
use of type-1 FLS approach (Mendel, 2001), � use of clustering methods (Azeem et al., 2003) andjudicious selection of trajectories for experience set and
� defining the trajectory-tracking problem in frequencydomain (Gopinath et al., 2005), so that the numberof points to represent each trajectory is reducedsignificantly.
4.3. Type-1 fuzzy logic system approach
To overcome the difficulty of choosing one rule persample point, a type-1 FLS approach is defined in place theAFDM approach. In this paper, multiple-input–single-output (MISO) FLSs are considered, because a multiple-output system can always be separated into a collection ofsingle-output systems. A MISO–FLS can be seen as afunction f : U � <n ! V � <, where U is the input space,V is the output space. The fuzzifier is a mapping from theobserved crisp input space U � <n to the fuzzy sets definedin U, where a fuzzy set defined in U is characterized by amembership function mF : U ! ½0; 1� and is labeled by a
linguistic term F such as ‘‘small’’, ‘‘medium’’, ‘‘large’’,‘‘very large’’, etc. The fuzzy rule base is a set of linguisticrules in the form of ‘‘IF a set of conditions are satisfied,THEN a set of consequences are inferred’’. The positionand velocity information of the experience trajectories areconsidered as the inputs and the corresponding controlinput signal as the output. Thus for a two-input and single-output type-1 FLS, the fuzzy rule base may consist of thefollowing M rules:
Rulel : IF x1 is Al1 AND x2 is Al
2 THEN u is Bl
l ¼ 1; 2; . . . ;M, ð10Þ
where x1 and x2 are the input variables and u is the outputvariable of the fuzzy system. Al
1; Al2 and Bl are the
linguistic terms characterized by the fuzzy membershipfunctions mAl
1ðx1Þ; mAl
2ðx2Þ and mBl ðuÞ respectively. In type-1
FLS approach, the number of rules (M) depends on thenumber of linguistic terms defined to label the experiencedatabase, instead of number of data points as the case inAFDM. The fuzzy inference engine is a decision-makinglogic, which employs fuzzy rules from the fuzzy rule base todetermine the fuzzy outputs of a type-1 fuzzy systemcorresponding to the fuzzified inputs. The defuzzifierperforms a mapping from the fuzzy sets in the outputspace V to the crisp points in V. The following definition isused for the computation of initial iteration input (u0(t)) forthe ILC corresponding to a query Q.
Definition. The output of a MISO type-1 FLS withsingleton fuzzifier, product t-norm, center of sets defuzzi-fier and Gaussian membership function can be written inthe form:
u q; _qð Þ ¼
PMl¼1
cl mAl1
qð ÞmAl2_qð Þ
� �PMl¼1
mAl1
qð ÞmAl2_qð Þ
� � , (11)
where Q ¼ ½q1; q2; . . . ; qn; _q1; _q2; . . . ; _qn� are the inputs forthe fuzzy system, cl is the centroid of consequent part (apoint in the output space V at which mB l ðuÞ achieves itsmaximum value) and mAl
1ðqÞ:mAl
2ð _qÞ are the Gaussian
membership functions, defined by
mAl1ðqÞ ¼ exp �
1
2
q�ml1
sl1
� �2" #
,
mAl2ð _qÞ ¼ exp �
1
2
_q�ml2
sl2
� �2" #
, ð12Þ
where ml1; ml
2 are the mean and sl1; s
l2 standard deviations
of fuzzy sets of lth rule, are real-valued parameters.
4.4. Designing type-1 FLS using back-propagation method
The Gaussian membership functions defined in Eq. (12),has to be provided with the mean and standard deviation

ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 583
parameters for each fuzzy set. Certainly, we will be havinga number of antecedent as well as consequent parameters,which has to be provided by us initially from theknowledge extracted from the initial experience database.In the back-propagation method, both antecedent andconsequent parameters are tuned using a steepest descentmethod. The defuzzified output of the FLS can beexpressed in Eq. (11). As mentioned above, with theexperience data set (X, U), where X is the state trajectoryvector contains the position ðx
ðiÞ1 Þ, velocity ðx
ðiÞ2 Þ informa-
tion, Uj denotes the corresponding control input vector.Here i ¼ 1,2,y,n denotes the number of samples intrajectory, control input vectors. For an input–outputexperience database as training pair [X(i), U(i)], we wish todesign the type-1 FLS such that the following errorfunction is minimized:
eðiÞ ¼ 12½uðiÞ �U ðiÞ�2 for i ¼ 1; 2; . . . ; n. (13)
It is evident from Eq (11) that control input vector u(.) iscompletely characterized by the design parameters such ascentroid (cl), mean ðml
kÞ and standard deviation ðslkÞ (for all
the rules l ¼ 1,y,M and k ¼ 1, 2). In the back-propaga-tion method both antecedent and consequent parametersare tuned using steepest descent method. In steepestdescent algorithm the following recursive relations areused to update all the design parameters of type-1 FLS,such that the error function defined in Eq. (13) isminimized. Let the recursive count be, p ¼ 0,1,y,
mlkðpþ 1Þ ¼ ml
kðpÞ � am½uðiÞ �U ðiÞ�½clðpÞ � uðiÞ�
�½xðiÞk �ml
kðpÞ�
ðslkðpÞÞ
2ðmAl
1ðxðiÞ1 Þ:mAl
2ðxðiÞ2 ÞÞ, ð14Þ
clðpþ 1Þ ¼ clðpÞ � ac½uðiÞ �U ðiÞ�
�ðmAl1ðxðiÞ1 Þ:mAl
2ðxðiÞ2 ÞÞ, ð15Þ
slkðpþ 1Þ ¼ sl
kðpÞ � as½uðiÞ �U ðiÞ�½clðpÞ � uðiÞ�
�½xðiÞk �ml
kðpÞ�2
ðslkðpÞÞ
3
" #
�ðmAl1ðxðiÞ1 Þ:mAl
2ðxðiÞ2 ÞÞ. ð16Þ
In the above equations, the initial values such as mlkð0Þ,
clð0Þ and slkð0Þ must be provided. Also the values of am, ac
and as must be chosen with some care.
4.5. Initial iteration error reduction and convergence issues
The convergence of the learning controller is stated bythe following condition (Arimoto et al., 1984; Arif et al.,2001):
jjekjjsprjjek�1jjs for ro1. (17)
To validate the effectiveness of experience inclusion theabove inequality condition can be rewritten as
jjekjjsprkjje0jjs for ro1. (18)
Eq. (18) implies that the error at kth iteration depends onthe parameter r, which controls the convergence rate andinitial error e0(t). The following lemma has been stated forthe selection of r.
Lemma. (Arimoto et al., 1984) For the nonlinear timevarying repetitive uncertain system given in Eq. (1), byusing the D-type ILC law incorporating the condition
r9 I r � CBGk k1o1 for 8t 2 ½0;T � (19)
the final tracking error will converge to zero as iterationk-N. &
The proposed fuzzy model based experience inclusionhas a special interest on the other parameter e0(t). Byselecting the significant initial control input u0(t) using theprevious tracking experiences from IF-THEN rule base offuzzy data model, the initial error e0(t) will be less andreduce the error more effectively as the iteration (k)progress. IF-THEN fuzzy rule base gives an inversemapping between the experience trajectory informationsuch as position and velocity with the correspondingcontrol input information due to their universal approx-imation property (Wang and Mendel, 1992; Kreinovichet al., 1998). The fuzzy model provides an approximation~f ðxÞ of a unknown nonlinear function f(x) uniformly onX � <n such that,
jjf ðxÞ � ~f ðxÞjjpd 8x 2 X , (20)
where d40, is a bound for the approximation error.The function f(x) is described by the trajectory and thecontrol input information dataset. AFDM or type-1 FLSfuzzy models approximate the function f(x) by using theIF-THEN fuzzy rules defined in Eqs. (7) and (10). In thecurrent context, the function to be approximated is givenby Eq. (5) where the function output is the desired controlinput and the domain of function is the specified desiredstate trajectory. Define the approximation error in theinitial control input obtained from the fuzzy data model asin Eqs. (9) and (11) can be stated as
Du0ðtÞ ¼ udðtÞ � u0ðtÞ
¼ ZðxdðtÞ; ydðtÞÞ � ~ZðxdðtÞ; ydðtÞÞ, ð21Þ
where ~Zð:Þ is the approximation of inverse mapping by thefuzzy model. Applying norm for above Eq. (21) we get
jjDu0ðtÞjj ¼ jjudðtÞ � u0ðtÞjj
¼ jjZðxdðtÞ; ydðtÞÞ � ~ZðxdðtÞ; ydðtÞÞjjpd. ð22Þ
Thus, the approximation error of the initial control inputu0(t) obtained from the fuzzy model is bounded. By givingthis initial input u0(t) to the system (1), the output error ofthe system will also be bounded such that
jje0ðtÞjj ¼ jjydðtÞ � y0ðtÞjjp�, (23)

ARTICLE IN PRESS
Fig. 3. 2-dof robot manipulator model.
Table 1
Manipulator link details
Parameter Value
Mass of link-1 3.0Kg
Mass of link-2 1.5Kg
Length of links 0.3m
Gravity (G) 9.8m s�2
Table 2
Actuator specifications
Parameters Values
Resistance R1 ¼ R2 ¼ 1.0OInductance L1 ¼ L2 ¼ 0.01H
Torque constant KT ¼ 1.0NmA�1
Turns ratio (N) 1
S. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590584
where e is small constant depending on d (sincejjDu0ðtÞjj ! 0) jje0ðtÞjj ! 0).
Thus Eq. (18) becomes
jjekjjsprk�. (24)
For ro1, the error in kth iteration will decrease to zeroas iterations k-N. A proposition has been stated to showthe contribution of experience inclusion in ILC. The initialiteration error in zero learning of the learning controller isdenoted by eZ
0 ðtÞ and the same from the fuzzy model basedlearning controller by e0(t).
Proposition. For a new desired trajectory yd(t), the initialiteration error of the learning controller with the fuzzy datamodel-based experience inclusion will be less in comparisonwith the learning controller with zero learning, i.e.,jje0ðtÞjj5jje
Z0 ðtÞjj if the condition �ojjydðtÞjj is satisfied,
where e is a small positive constant.
Proof. Learning controller with zero initial input, uZ0 ðtÞ ¼
0; 8t 2 ½0;T � will lead to the zero output yZ0 ðtÞ ¼ 0 of the
system. This will leads to the initial iteration error, whosenorm is defined as
jjeZ0 ðtÞjj ¼ jjydðtÞjj. (25)
The initial iteration error in experience inclusion basedlearning controllers can be found from Eqs. (22) and (23) isrepresented as
jje0ðtÞjj ¼ jjydðtÞ � y0ðtÞjjp�, (26)
where e is the small positive constant representing theapproximation error in the output.
By taking the ratio of the errors in Eqs. (25) and (26) weget
jje0ðtÞjj
jjeZ0 ðtÞjj
¼jjydðtÞ � y0ðtÞjj
jjydðtÞjjp
�
jjydðtÞjj. (27)
In Eq. (27), if the condition �ojjydðtÞjj holds, thenthe ratio of the initial iteration errors of ILC with andwithout experience inclusion can be represented by
jje0ðtÞjjojjeZ0 ðtÞjj. Usually, jjydðtÞjj is not small and hence,
jje0ðtÞjj5jjeZ0 ðtÞjj.
5. Numerical experimentation
This section demonstrates the effectiveness of theexperience inclusion in learning controllers based on theproposed method over local weighted learning and zerolearning-based ILCs. Implementation of fuzzy data model-based experience inclusion in ILC algorithms, thus theinitial error reduction and error convergence issues, for thetrajectory-tracking problem of industrial robot manipula-tor system are discussed in this section.
5.1. Physical plant
In this case study, a trajectory-tracking problem of a2-dof robot manipulator system is considered as shown inthe Fig. 3. Two DC motors are used as the actuators of twojoints. The robot manipulator and the actuator modelparameters are given in the Tables 1 and 2.All the above physical parameters of the robot model are
used for the simulation purpose. The knowledge of theseparameters is not needed for computation of control. Adigital computer simulation is performed, to show theperformance of the proposed fuzzy rule based modelingapproaches (AFDM, type-1 FLS)-based Gradient descentILC algorithms (Gopinath and Kar, 2004) for thetrajectory-tracking problem of the robot manipulator.Using the model parameters, we get the following Inertia,Coriolis/centripetal, Friction (Viscous, Coulomb) matricesand Gravity vector terms and the feedback controller gainterms which ensures stability are given as (Gopinath andKar, 2004)
MðqÞ ¼0:54þ 0:27 cos q2 0:135þ 0:135 cos q2
0:135þ 0:135 cos q2 0:135
" #;
ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 585
Cðq; _qÞ ¼�0:135 _q2 sin q2 �0:135ð _q1 þ _q2Þ sin q2
0:135 _q1 sin q2 0
" #;
GðqÞ ¼13:1625 cos q1 þ 4:3875 cos ðq1 þ q2Þ
4:3875 cosðq1 þ q2Þ
" #;
F ð _qÞ ¼ diagð 4 4 Þ � ð _qÞ þ 5sgnð _qÞ;
K ¼15 0
0 15
� �; L ¼
5 0
0 5
� �.
Simulations are performed with the sampling intervalDt ¼ 0.01 s and the learning gain (G) is selected as 0.2.For comparing the performance of the learning controllerwithout, with experience inclusion using AFDM approachand with existing locally weighted learning approach, aperformance index I is defined as
root mean square error ðRMSEÞ
¼ I ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi1
T
Ze2ðtÞdt
s�
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi1
n
Xn
i¼0
e2i
sfor n ¼ T=Dt, ð28Þ
where the tracking error e(t ) is defined as the differencebetween desired and actual angular displacements of therobot links. i.e., eðtÞ ¼ qdðtÞ � qðtÞ.
5.2. Formulation of fuzzy rule base from experience
database
As a first step, the learning controller has been given aset of initial desired trajectories as shown in Fig. 4. Startingwith zero learning assumption, the ILC has performedsufficient number of iterations in such a way that accept-able tracking performance of robot has been obtained.Desired angular displacement and velocity information(Xd) and corresponding desired input information (Ud) fortracking the initial desired trajectory are stored as a
Fig. 4. Initial experience trajectories.
database of initial experience. This initial experiencedatabase is used to form the fuzzy rule base for the fuzzymodel. IF-THEN fuzzy rules of the rule base areformulated as per Eq. (7) in AFDM-based approach orby Eq. (10) in type-1 FLS-based approach. In case ofAFDM-based approach, the total number of fuzzy rules isequals to the number of elements of i nitial experiencetrajectory defined as n ¼ T=Dt, where T is total timeduration of the trajectory. But in type-1 FLS approach, itrequires only n2 number of rules/link (n is the number offuzzy sets used to define the initial experience trajectory).In our simulation studies we choose n ¼ 6, leads to only62 ¼ 36 rules/link to define the experience trajectory.
5.3. Implementation and error reduction issues
To show the essential role of experience inclusion in ILCusing the proposed method, a new desired test trajectoriesT-1 for links 1, 2 are considered is shown in Fig. 5. Insteadof zero initial input assumption, fuzzy model-basedapproaches provide more significant initial input for thelearning controllers. A step-by-step procedure to computethe significant initial input is as follows:
Step (1): A query vector Q has been formed thatcontains the position and velocity information of the newdesired test trajectory T-1.
Step (2): The membership values corresponding to thequery vector elements are calculated with respect to theelements of experience database using Gaussian member-ship functions as defined in Eqs. (8) and (12).
Step (3): IF-THEN fuzzy rules formulated from initialexperience database, are used to find the control inputelements corresponding to query vector Q. The member-ship values obtained from step (2) are used as weights forthe control input elements obtained from fuzzy rules.
Step (4): Using these weighted control input elements asobtained from step (3) the defuzzifier of AFDM computesa significant initial input u0(t) as shown in Fig. 7, using thedefuzzification formulas as in Eqs. (9) and (11).
Fig. 5. Test trajectory T-1.
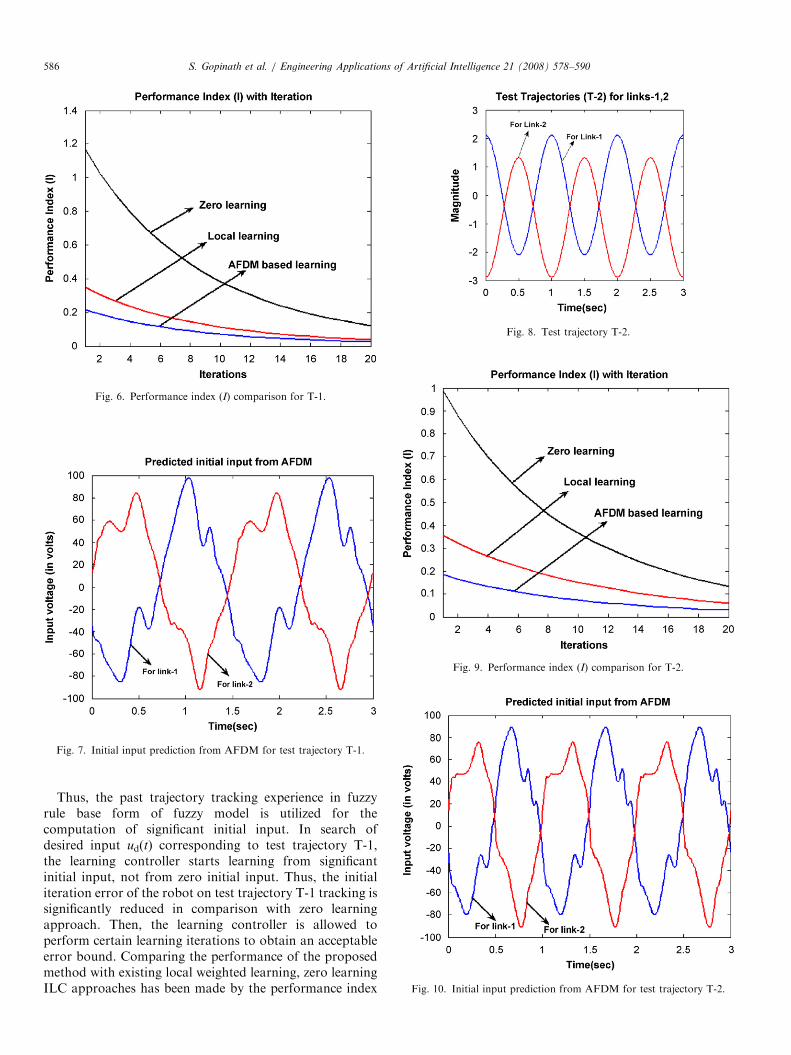
ARTICLE IN PRESS
Fig. 6. Performance index (I) comparison for T-1.
Fig. 7. Initial input prediction from AFDM for test trajectory T-1.
Fig. 8. Test trajectory T-2.
Fig. 9. Performance index (I) comparison for T-2.
Fig. 10. Initial input prediction from AFDM for test trajectory T-2.
S. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590586
Thus, the past trajectory tracking experience in fuzzyrule base form of fuzzy model is utilized for thecomputation of significant initial input. In search ofdesired input ud(t) corresponding to test trajectory T-1,the learning controller starts learning from significantinitial input, not from zero initial input. Thus, the initialiteration error of the robot on test trajectory T-1 tracking issignificantly reduced in comparison with zero learningapproach. Then, the learning controller is allowed toperform certain learning iterations to obtain an acceptableerror bound. Comparing the performance of the proposedmethod with existing local weighted learning, zero learningILC approaches has been made by the performance index
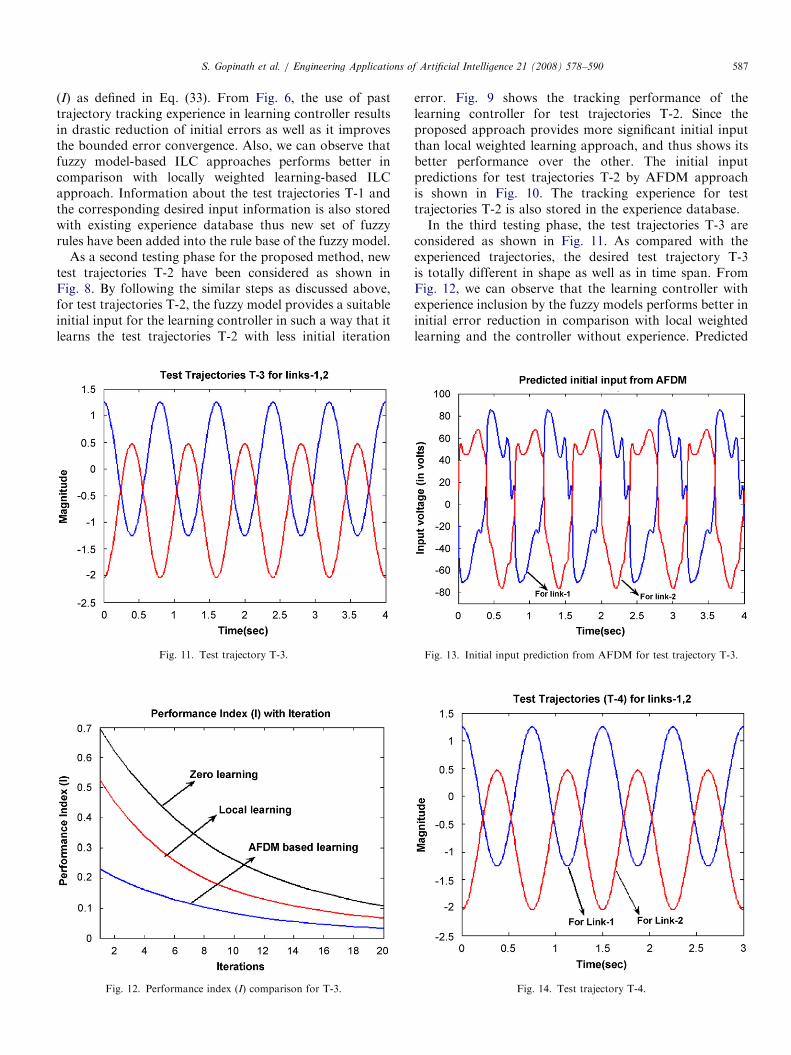
ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 587
(I) as defined in Eq. (33). From Fig. 6, the use of pasttrajectory tracking experience in learning controller resultsin drastic reduction of initial errors as well as it improvesthe bounded error convergence. Also, we can observe thatfuzzy model-based ILC approaches performs better incomparison with locally weighted learning-based ILCapproach. Information about the test trajectories T-1 andthe corresponding desired input information is also storedwith existing experience database thus new set of fuzzyrules have been added into the rule base of the fuzzy model.
As a second testing phase for the proposed method, newtest trajectories T-2 have been considered as shown inFig. 8. By following the similar steps as discussed above,for test trajectories T-2, the fuzzy model provides a suitableinitial input for the learning controller in such a way that itlearns the test trajectories T-2 with less initial iteration
Fig. 11. Test trajectory T-3.
Fig. 12. Performance index (I) comparison for T-3.
error. Fig. 9 shows the tracking performance of thelearning controller for test trajectories T-2. Since theproposed approach provides more significant initial inputthan local weighted learning approach, and thus shows itsbetter performance over the other. The initial inputpredictions for test trajectories T-2 by AFDM approachis shown in Fig. 10. The tracking experience for testtrajectories T-2 is also stored in the experience database.In the third testing phase, the test trajectories T-3 are
considered as shown in Fig. 11. As compared with theexperienced trajectories, the desired test trajectory T-3is totally different in shape as well as in time span. FromFig. 12, we can observe that the learning controller withexperience inclusion by the fuzzy models performs better ininitial error reduction in comparison with local weightedlearning and the controller without experience. Predicted
Fig. 13. Initial input prediction from AFDM for test trajectory T-3.
Fig. 14. Test trajectory T-4.
ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590588
initial inputs for the manipulator links correspond to thetest trajectories T-3 are shown in Fig. 13.
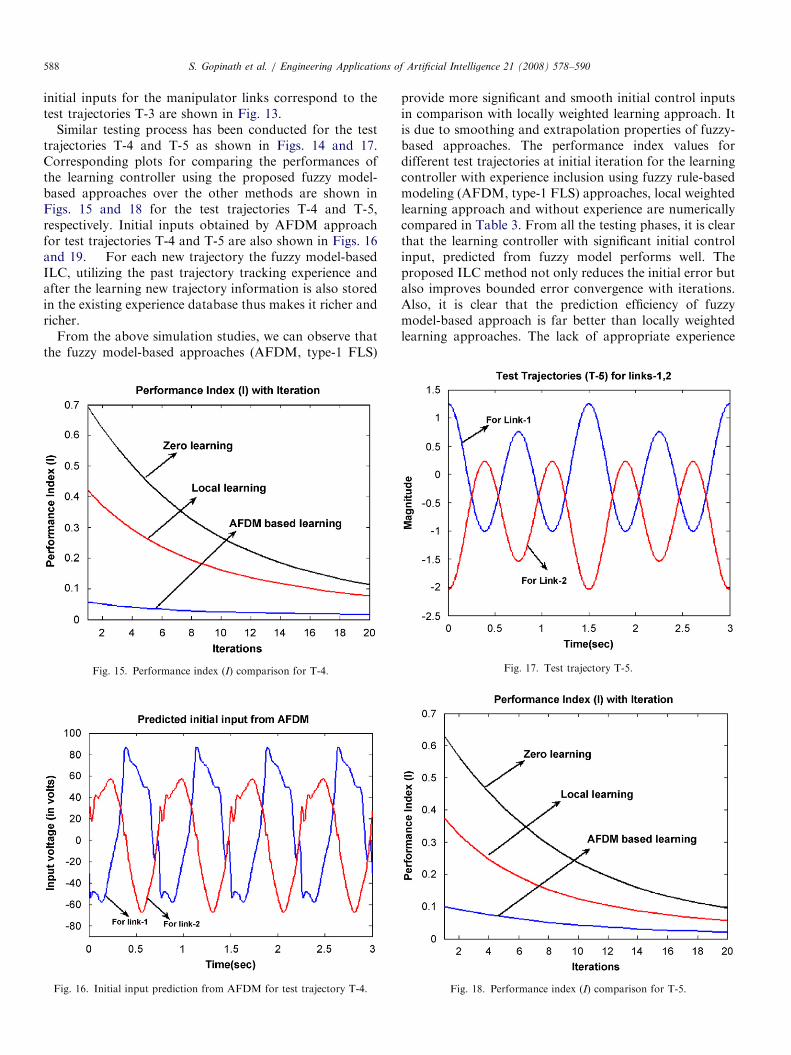
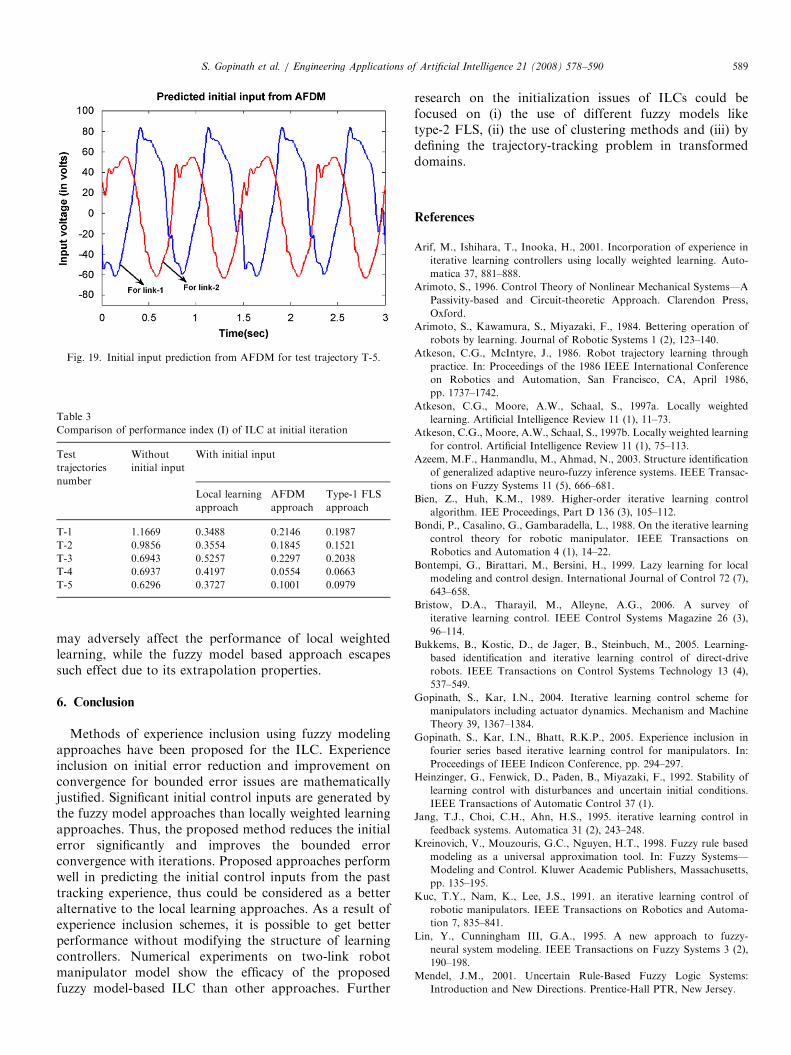
Similar testing process has been conducted for the testtrajectories T-4 and T-5 as shown in Figs. 14 and 17.Corresponding plots for comparing the performances ofthe learning controller using the proposed fuzzy model-based approaches over the other methods are shown inFigs. 15 and 18 for the test trajectories T-4 and T-5,respectively. Initial inputs obtained by AFDM approachfor test trajectories T-4 and T-5 are also shown in Figs. 16and 19. For each new trajectory the fuzzy model-basedILC, utilizing the past trajectory tracking experience andafter the learning new trajectory information is also storedin the existing experience database thus makes it richer andricher.
From the above simulation studies, we can observe thatthe fuzzy model-based approaches (AFDM, type-1 FLS)
Fig. 15. Performance index (I) comparison for T-4.
Fig. 16. Initial input prediction from AFDM for test trajectory T-4.
provide more significant and smooth initial control inputsin comparison with locally weighted learning approach. Itis due to smoothing and extrapolation properties of fuzzy-based approaches. The performance index values fordifferent test trajectories at initial iteration for the learningcontroller with experience inclusion using fuzzy rule-basedmodeling (AFDM, type-1 FLS) approaches, local weightedlearning approach and without experience are numericallycompared in Table 3. From all the testing phases, it is clearthat the learning controller with significant initial controlinput, predicted from fuzzy model performs well. Theproposed ILC method not only reduces the initial error butalso improves bounded error convergence with iterations.Also, it is clear that the prediction efficiency of fuzzymodel-based approach is far better than locally weightedlearning approaches. The lack of appropriate experience
Fig. 17. Test trajectory T-5.
Fig. 18. Performance index (I) comparison for T-5.
ARTICLE IN PRESS
Table 3
Comparison of performance index (I) of ILC at initial iteration
Test
trajectories
number
Without
initial input
With initial input
Local learning
approach
AFDM
approach
Type-1 FLS
approach
T-1 1.1669 0.3488 0.2146 0.1987
T-2 0.9856 0.3554 0.1845 0.1521
T-3 0.6943 0.5257 0.2297 0.2038
T-4 0.6937 0.4197 0.0554 0.0663
T-5 0.6296 0.3727 0.1001 0.0979
Fig. 19. Initial input prediction from AFDM for test trajectory T-5.
S. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590 589
may adversely affect the performance of local weightedlearning, while the fuzzy model based approach escapessuch effect due to its extrapolation properties.
6. Conclusion
Methods of experience inclusion using fuzzy modelingapproaches have been proposed for the ILC. Experienceinclusion on initial error reduction and improvement onconvergence for bounded error issues are mathematicallyjustified. Significant initial control inputs are generated bythe fuzzy model approaches than locally weighted learningapproaches. Thus, the proposed method reduces the initialerror significantly and improves the bounded errorconvergence with iterations. Proposed approaches performwell in predicting the initial control inputs from the pasttracking experience, thus could be considered as a betteralternative to the local learning approaches. As a result ofexperience inclusion schemes, it is possible to get betterperformance without modifying the structure of learningcontrollers. Numerical experiments on two-link robotmanipulator model show the efficacy of the proposedfuzzy model-based ILC than other approaches. Further
research on the initialization issues of ILCs could befocused on (i) the use of different fuzzy models liketype-2 FLS, (ii) the use of clustering methods and (iii) bydefining the trajectory-tracking problem in transformeddomains.
References
Arif, M., Ishihara, T., Inooka, H., 2001. Incorporation of experience in
iterative learning controllers using locally weighted learning. Auto-
matica 37, 881–888.
Arimoto, S., 1996. Control Theory of Nonlinear Mechanical Systems—A
Passivity-based and Circuit-theoretic Approach. Clarendon Press,
Oxford.
Arimoto, S., Kawamura, S., Miyazaki, F., 1984. Bettering operation of
robots by learning. Journal of Robotic Systems 1 (2), 123–140.
Atkeson, C.G., McIntyre, J., 1986. Robot trajectory learning through
practice. In: Proceedings of the 1986 IEEE International Conference
on Robotics and Automation, San Francisco, CA, April 1986,
pp. 1737–1742.
Atkeson, C.G., Moore, A.W., Schaal, S., 1997a. Locally weighted
learning. Artificial Intelligence Review 11 (1), 11–73.
Atkeson, C.G., Moore, A.W., Schaal, S., 1997b. Locally weighted learning
for control. Artificial Intelligence Review 11 (1), 75–113.
Azeem, M.F., Hanmandlu, M., Ahmad, N., 2003. Structure identification
of generalized adaptive neuro-fuzzy inference systems. IEEE Transac-
tions on Fuzzy Systems 11 (5), 666–681.
Bien, Z., Huh, K.M., 1989. Higher-order iterative learning control
algorithm. IEE Proceedings, Part D 136 (3), 105–112.
Bondi, P., Casalino, G., Gambaradella, L., 1988. On the iterative learning
control theory for robotic manipulator. IEEE Transactions on
Robotics and Automation 4 (1), 14–22.
Bontempi, G., Birattari, M., Bersini, H., 1999. Lazy learning for local
modeling and control design. International Journal of Control 72 (7),
643–658.
Bristow, D.A., Tharayil, M., Alleyne, A.G., 2006. A survey of
iterative learning control. IEEE Control Systems Magazine 26 (3),
96–114.
Bukkems, B., Kostic, D., de Jager, B., Steinbuch, M., 2005. Learning-
based identification and iterative learning control of direct-drive
robots. IEEE Transactions on Control Systems Technology 13 (4),
537–549.
Gopinath, S., Kar, I.N., 2004. Iterative learning control scheme for
manipulators including actuator dynamics. Mechanism and Machine
Theory 39, 1367–1384.
Gopinath, S., Kar, I.N., Bhatt, R.K.P., 2005. Experience inclusion in
fourier series based iterative learning control for manipulators. In:
Proceedings of IEEE Indicon Conference, pp. 294–297.
Heinzinger, G., Fenwick, D., Paden, B., Miyazaki, F., 1992. Stability of
learning control with disturbances and uncertain initial conditions.
IEEE Transactions of Automatic Control 37 (1).
Jang, T.J., Choi, C.H., Ahn, H.S., 1995. iterative learning control in
feedback systems. Automatica 31 (2), 243–248.
Kreinovich, V., Mouzouris, G.C., Nguyen, H.T., 1998. Fuzzy rule based
modeling as a universal approximation tool. In: Fuzzy Systems—
Modeling and Control. Kluwer Academic Publishers, Massachusetts,
pp. 135–195.
Kuc, T.Y., Nam, K., Lee, J.S., 1991. an iterative learning control of
robotic manipulators. IEEE Transactions on Robotics and Automa-
tion 7, 835–841.
Lin, Y., Cunningham III, G.A., 1995. A new approach to fuzzy-
neural system modeling. IEEE Transactions on Fuzzy Systems 3 (2),
190–198.
Mendel, J.M., 2001. Uncertain Rule-Based Fuzzy Logic Systems:
Introduction and New Directions. Prentice-Hall PTR, New Jersey.

ARTICLE IN PRESSS. Gopinath et al. / Engineering Applications of Artificial Intelligence 21 (2008) 578–590590
Moore, K.L., 1998. Iterative learning control-an expository overview.
Applied and Computational Controls, Signal Processing and Circuits
1, 425–488.
Seidl, T., Kriegel, H., 1998. Optimal multi-step k-nearest neighbor search.
In: Proceedings of ACM SIGMOD International Conference on
Management of Data, USA.
Tayebi, A., 2004. Adaptive iterative learning control for robot manip-
ulators. Automatica 40, 1195–1203.
Wang, L., Mendel, J.M., 1992. Generating fuzzy rules by learning from
examples. IEEE Transactions on Systems, Man, and Cybernetics 22
(6), 1414–1427.
Xu, J.X., 1998. Direct learning of control efforts for trajectories with different
time scales. IEEE Transactions of Automatic Control 43 (7), 1027–1030.
Xu, J.X., Tan, Y., 2003. Linear and nonlinear iterative learning control.
Series of Lecture Notes in Control and Information Sciences, vol. 291.
Springer, Berlin, Germany.