europython 2016 bquery lightning talk
TRANSCRIPT

Our open source project BQuery
High Performant Aggregation of Bcolz Compressed containers
Carst Vaartjes
Twitter: @cvaartjes

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
So you are a start up and you have…
• No money
• Lots of data
• A need for responsive reporting
21 July 20162

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
We ended up with a great solution
21 July 20163
But the road to get there was bumpy

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
And yes...
All business on the front,
All Python in the back
21 July 20164
LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
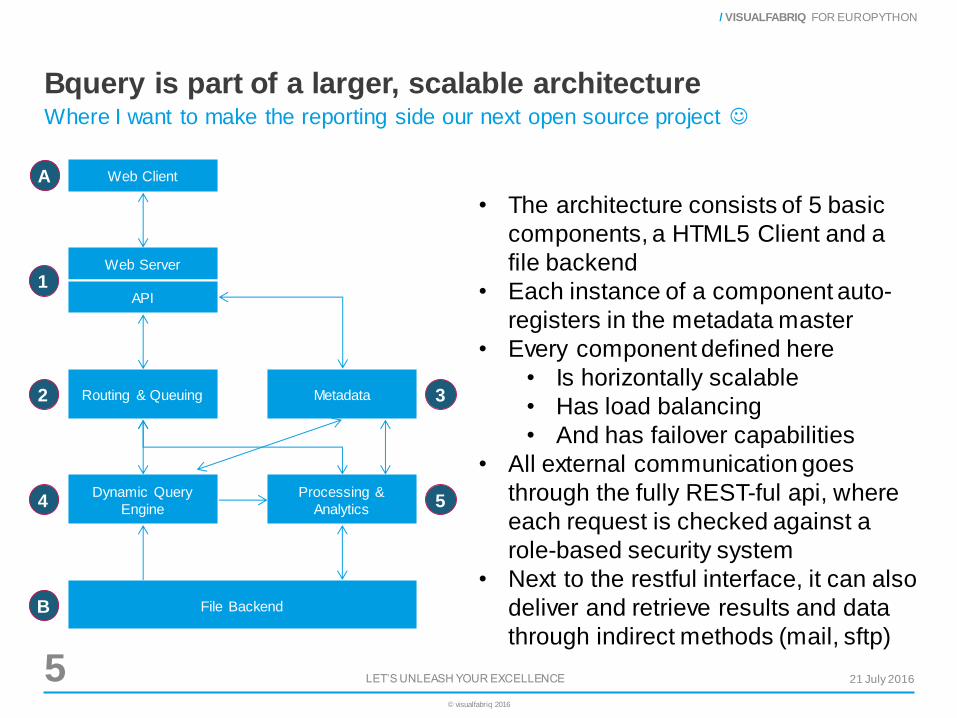
Bquery is part of a larger, scalable architecture
21 July 20165
Where I want to make the reporting side our next open source project
Web Server
API
Routing & Queuing Metadata
Dynamic Query
Engine
Processing &
Analytics
File Backend
• The architecture consists of 5 basic
components, a HTML5 Client and a
file backend
• Each instance of a component auto-
registers in the metadata master
• Every component defined here
• Is horizontally scalable
• Has load balancing
• And has failover capabilities
• All external communication goes
through the fully REST-ful api, where
each request is checked against a
role-based security system
• Next to the restful interface, it can also
deliver and retrieve results and data
through indirect methods (mail, sftp)
1
2
4
B
3
5
Web ClientA

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
We had to make Bquery, because it was hard to find something that suited our needs well
Relational DBs Do not scale well
Expensive (non-open source)
Hadoop Not really fast
Hard to administrate
Spark Hard to administrate
Cassandra Hard to administrate
MongoDB Not really fast for numerical data
processing
21 July 20166
LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
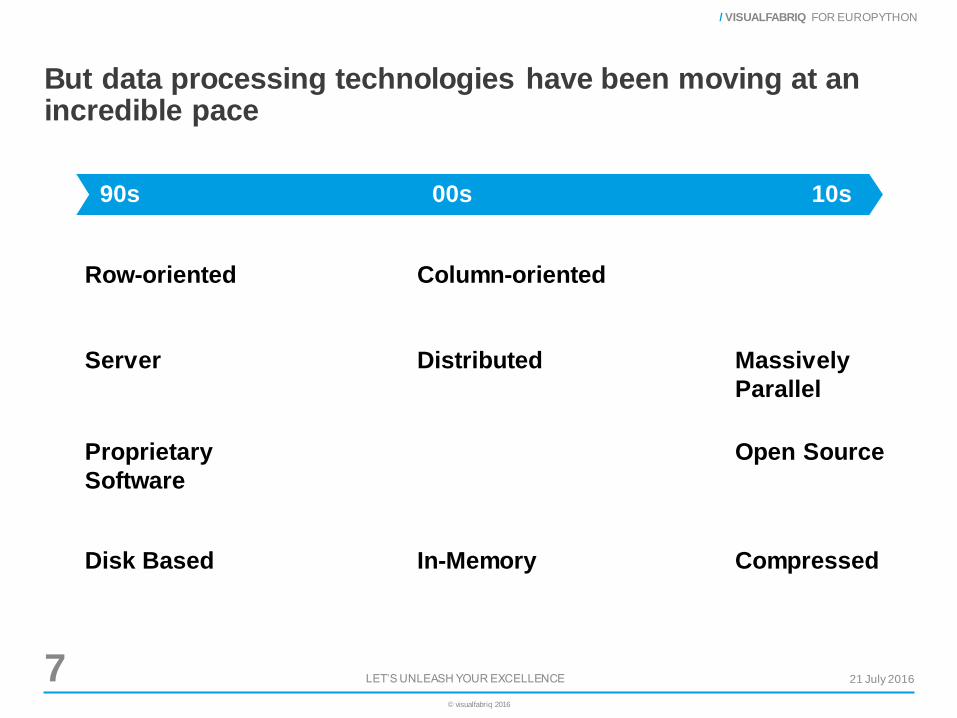
But data processing technologies have been moving at an incredible pace
21 July 20167
90s 10s00s
Row-oriented Column-oriented
Server Distributed Massively
Parallel
Proprietary
Software
Open Source
Disk Based In-Memory Compressed

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
Enter Bcolz!
21 July 20168
Modules like Bcolz and WiredTiger realized how you can use compression to work around
Francesc Alted Valentin Haenel
We came there after using HDF5 (too slow) and Pandas (hot set issues, not
economical)
Bcolz on itself could save and read compressed data very fast, but we
still needed sql-like aggregations (sum, mean, etc)
LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
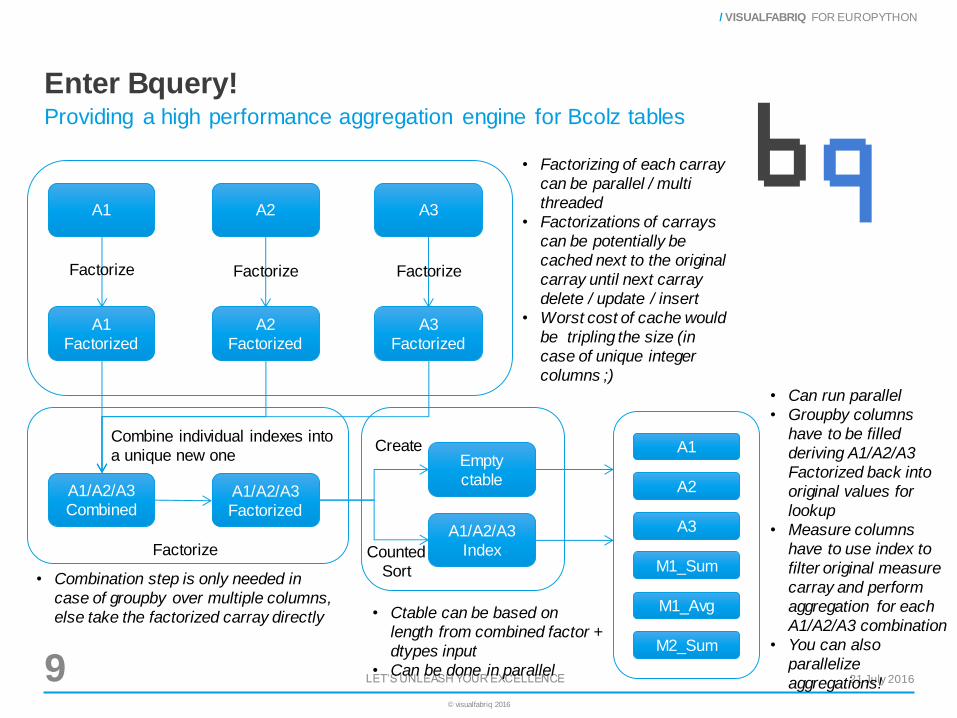
Enter Bquery!
21 July 20169
Providing a high performance aggregation engine for Bcolz tables
A1 A2 A3
A1
Factorized
A2
Factorized
A3
Factorized
A1/A2/A3
Combined
Factorize Factorize Factorize
Combine individual indexes into
a unique new one
• Factorizing of each carray
can be parallel / multi
threaded
• Factorizations of carrays
can be potentially be
cached next to the original
carray until next carray
delete / update / insert
• Worst cost of cache would
be tripling the size (in
case of unique integer
columns ;)
A1/A2/A3
Factorized
Factorize
• Combination step is only needed in
case of groupby over multiple columns,
else take the factorized carray directly
A1/A2/A3
Index
Empty
ctable
• Ctable can be based on
length from combined factor +
dtypes input
• Can be done in parallel
Counted
Sort
Create A1
A2
A3
M1_Sum
M1_Avg
M2_Sum
• Can run parallel
• Groupby columns
have to be filled
deriving A1/A2/A3
Factorized back into
original values for
lookup
• Measure columns
have to use index to
filter original measure
carray and perform
aggregation for each
A1/A2/A3 combination
• You can also
parallelize
aggregations!

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
Enter Bquery!
1.5-2.5x slower
No hot set issues
Greatly reduced memory usage
21 July 201610
Some bquery on-disk vs in-memory comparisons
Comparison Sources:
https://github.com/visualfabriq/bquery/blob/master/bquery/benchmarks/bench_groupby.ipynb
http://matthewrocklin.com/blog/work/2016/02/22/dask-distributed-part-2
https://github.com/visualfabriq/bquery/blob/master/bquery/benchmarks/taxi/Taxi%20Set.ipynb
PandasSame data set in-
memory
Single thread
5x slower
16x less processors
240x less memory usage
Dask8 Hadoop cluster with
8 processors per machine
30gb ram per machine
Vs quadcore laptop where
it uses 1gb ram temporary
https://github.com/visualfabriq/bquery

LET’S UNLEASH YOUR EXCELLENCE
/ VISUALFABRIQ FOR EUROPYTHON
© visualfabriq 2016
It’s in full production state
• Pip8 broke the pip install
• Memory and performance improvements
• Indexing
• Open sourcing the reporting engine (with the html5/d3.js front end + service
components)
• Move to ZeroMQ Docker containers
21 July 201611
Even though it’s version 0.11 but we still have a lot of stuff to do
https://github.com/visualfabriq/bquery
(Slides can be found on slideshare.net)
