elastic hbase on mesos - hbasecon 2015
TRANSCRIPT
Elastic HBase on Mesos
Cosmin Lehene Adobe
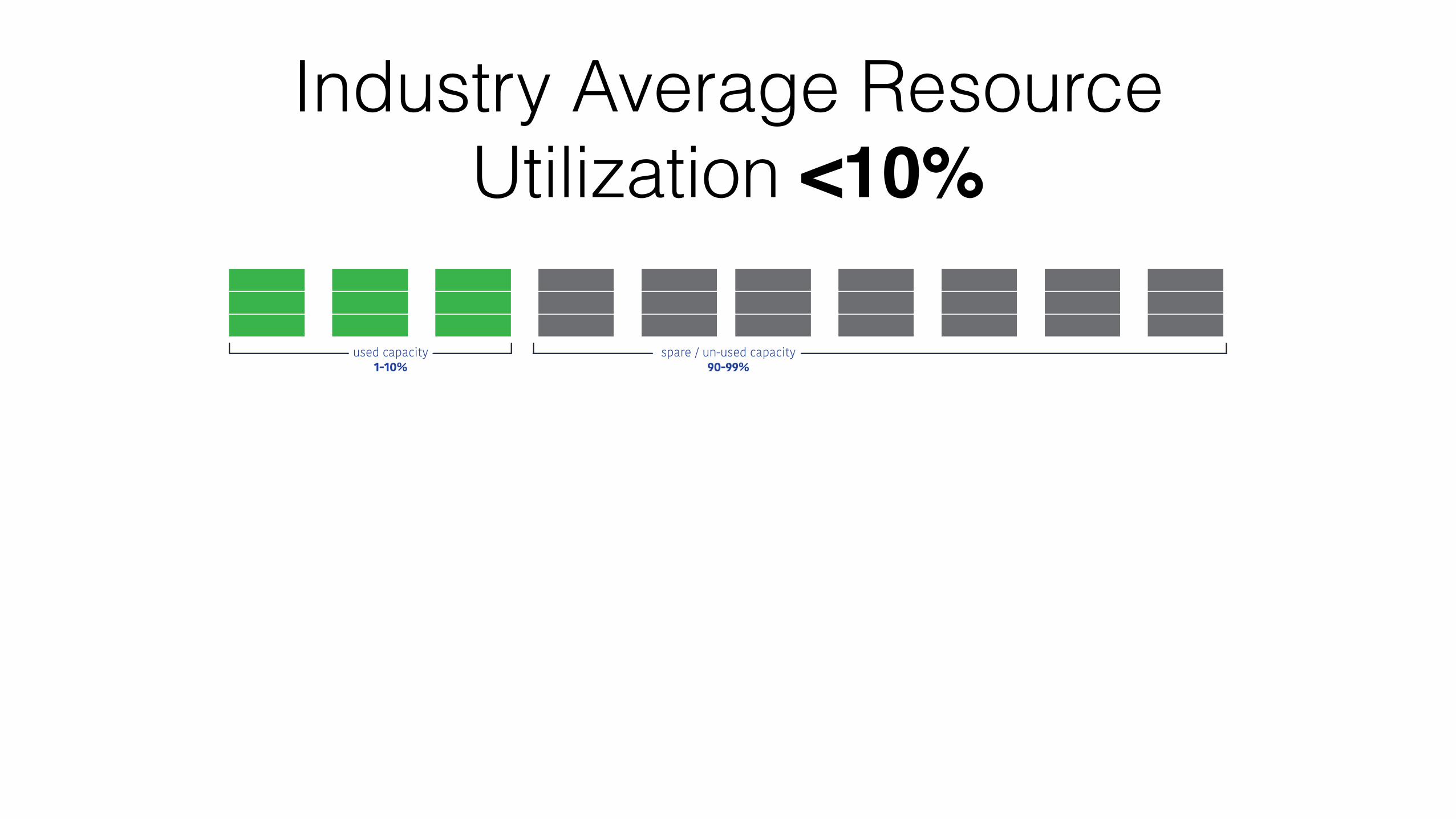
Industry Average Resource Utilization <10%
used capacity1-10%
spare / un-used capacity90-99%

Cloud Resource Utilization ~60%
used capacity60%
spare / un-used capacity40%
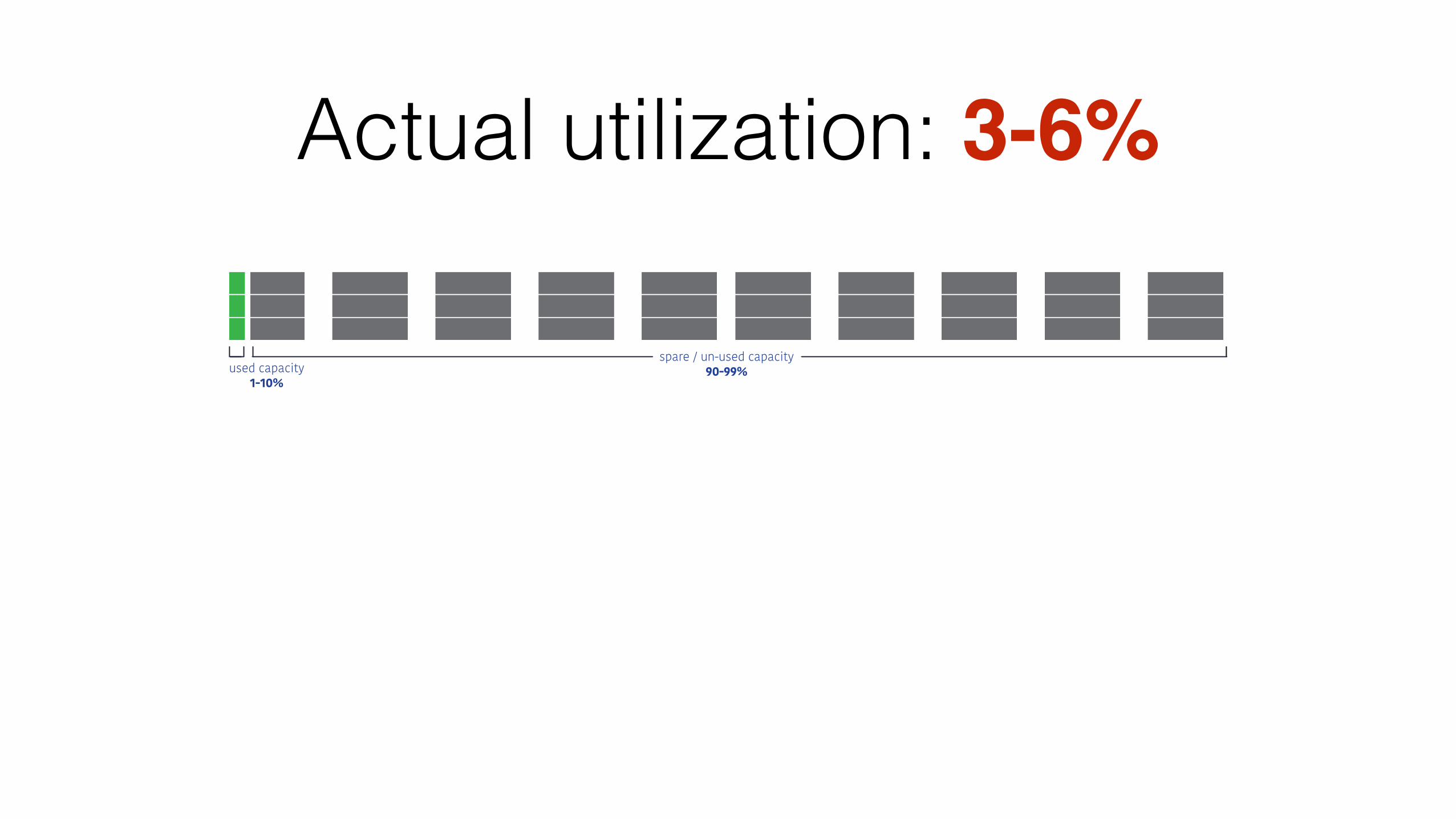
Actual utilization: 3-6%
used capacity1-10%
spare / un-used capacity90-99%

Why
• peak load provisioning (can be 30X)
• resource imbalance (CPU vs. I/O vs. RAM bound)
• incorrect usage predictions
• all of the above (and others)

Typical HBase Deployment
• (mostly) static deployment footprint
• infrequent scaling out by adding more nodes
• scaling down uncommon
• OLTP, OLAP workloads as separate clusters
• < 32GB Heap (compressed OOPS, GC)

Wasted Resources

Idleness Costs
• idle servers draw > ~50% of the nominal power
• hardware deprecation accounts for ~40%
• public clouds idleness translates to 100% waste (charged by time not by resource use)

Workload segregation nulls economy of scale
benefits

• daily, weekly, seasonal variation (both up and down)
• load varies across workloads
• peaks are not synchronized
Load is not Constant

Opportunities
• datacenter as a single pool of shared resources
• resource oversubscription
• mixed workloads can scale elastically within pools
• shared extra capacity





Elastic HBase
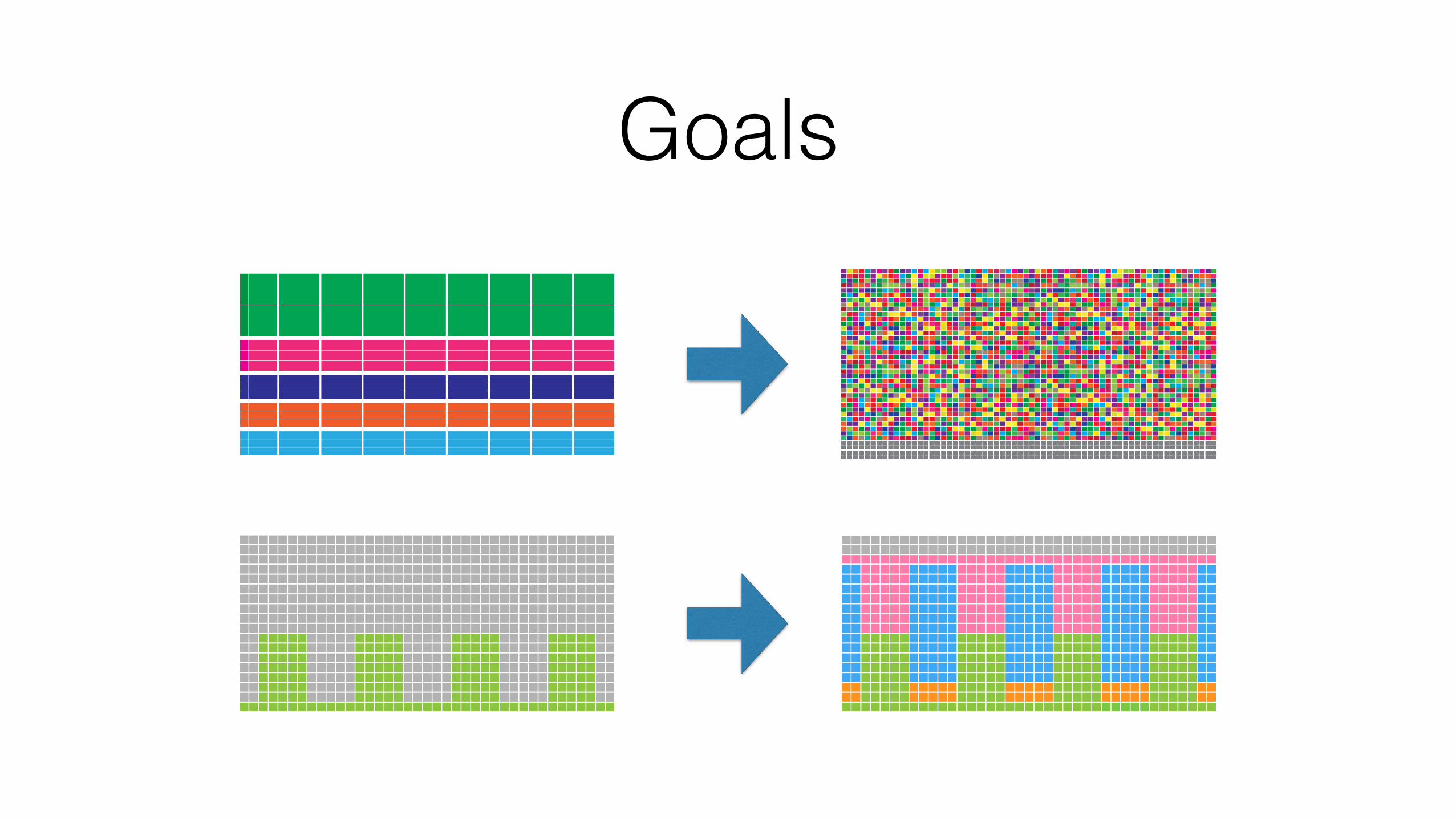
Goals

Cluster Management “Bill of Materials”
• single pool of resources
• multi-tenancy
• mixed short and long running tasks
• elasticity
• realtime scheduling
★Mesos
★Mesos
★Mesos (through frameworks)
★Marathon / Mesos
★Marathon / Mesos

HBase “Bill of Materials”
• task portability
• statelessness
• auto discovery
• self contained binary
• resource isolation
✓ built-in (HDFS and ZK)
✓ built-in
★ docker
★ docker (through CGroups)
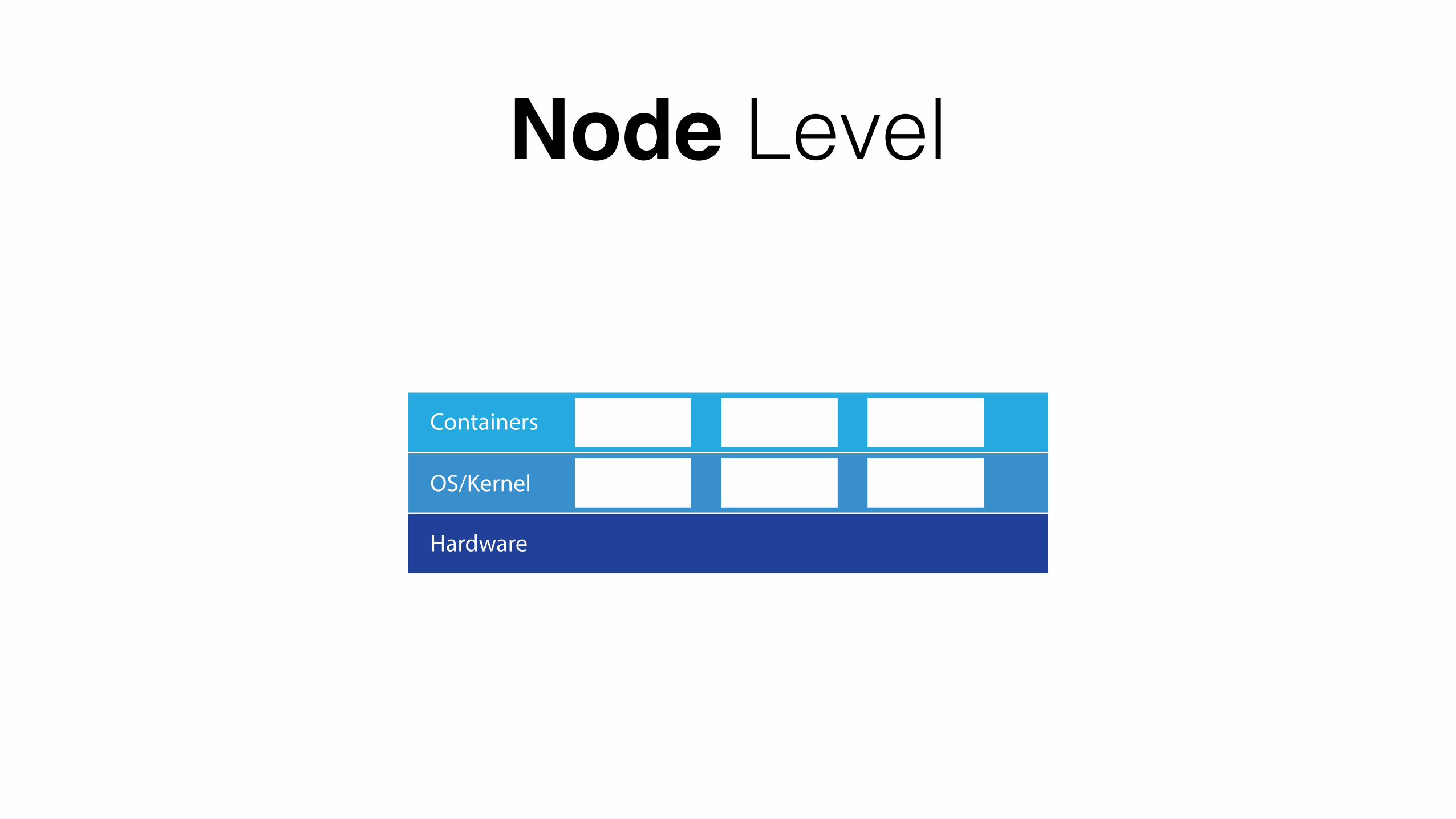
Node Level
Hardware
OS/Kernel MesosSlaveDocker Salt
Minion
Containers KafkaBroker
HBaseHRS [APP]
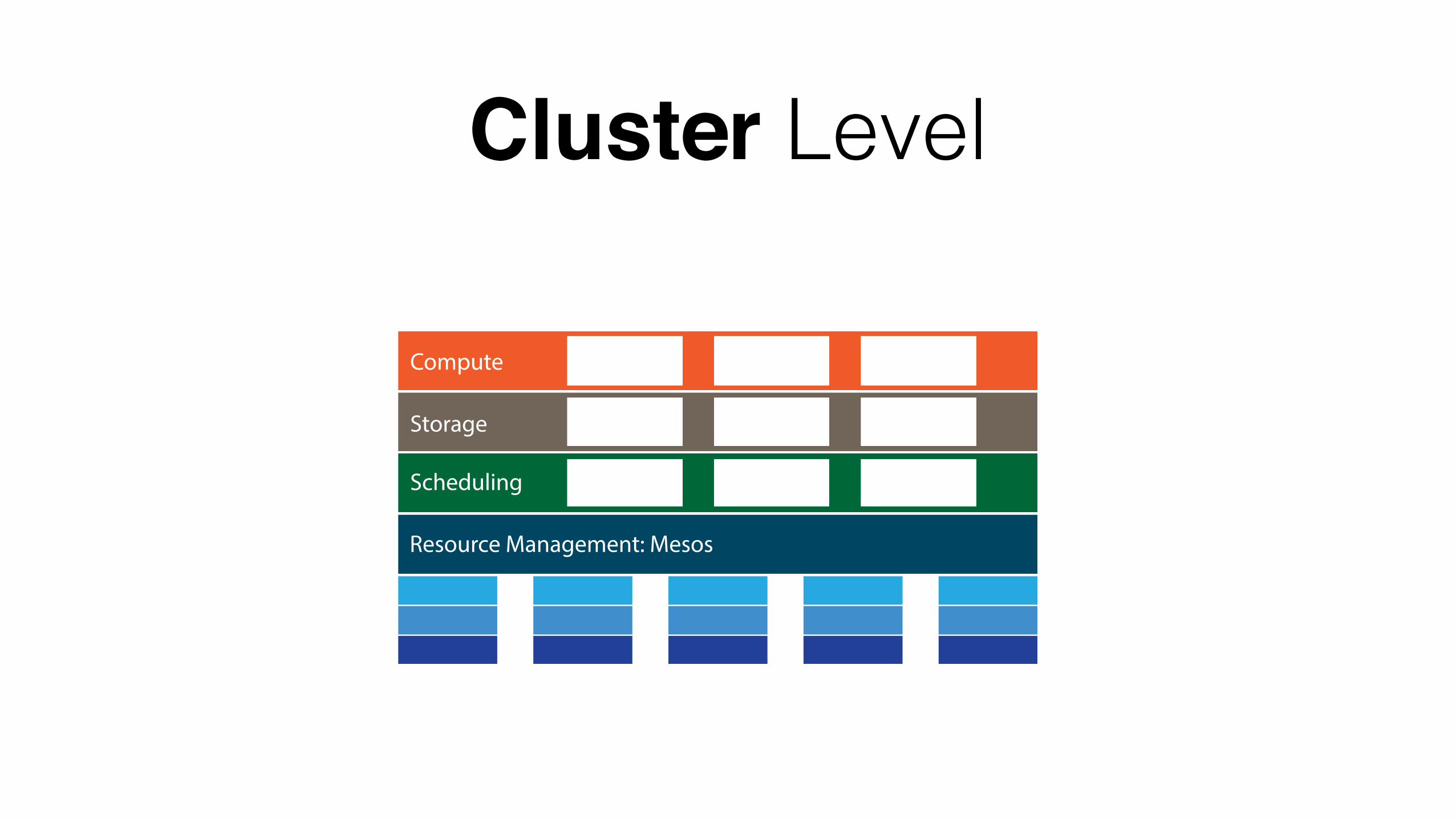
Resource Management: Mesos
Kubernetes Marathon AuroraScheduling
Storage HDFS Tachyon HBase
Compute MapReduce Storm Spark
Cluster Level

Docker(and containers
in general)

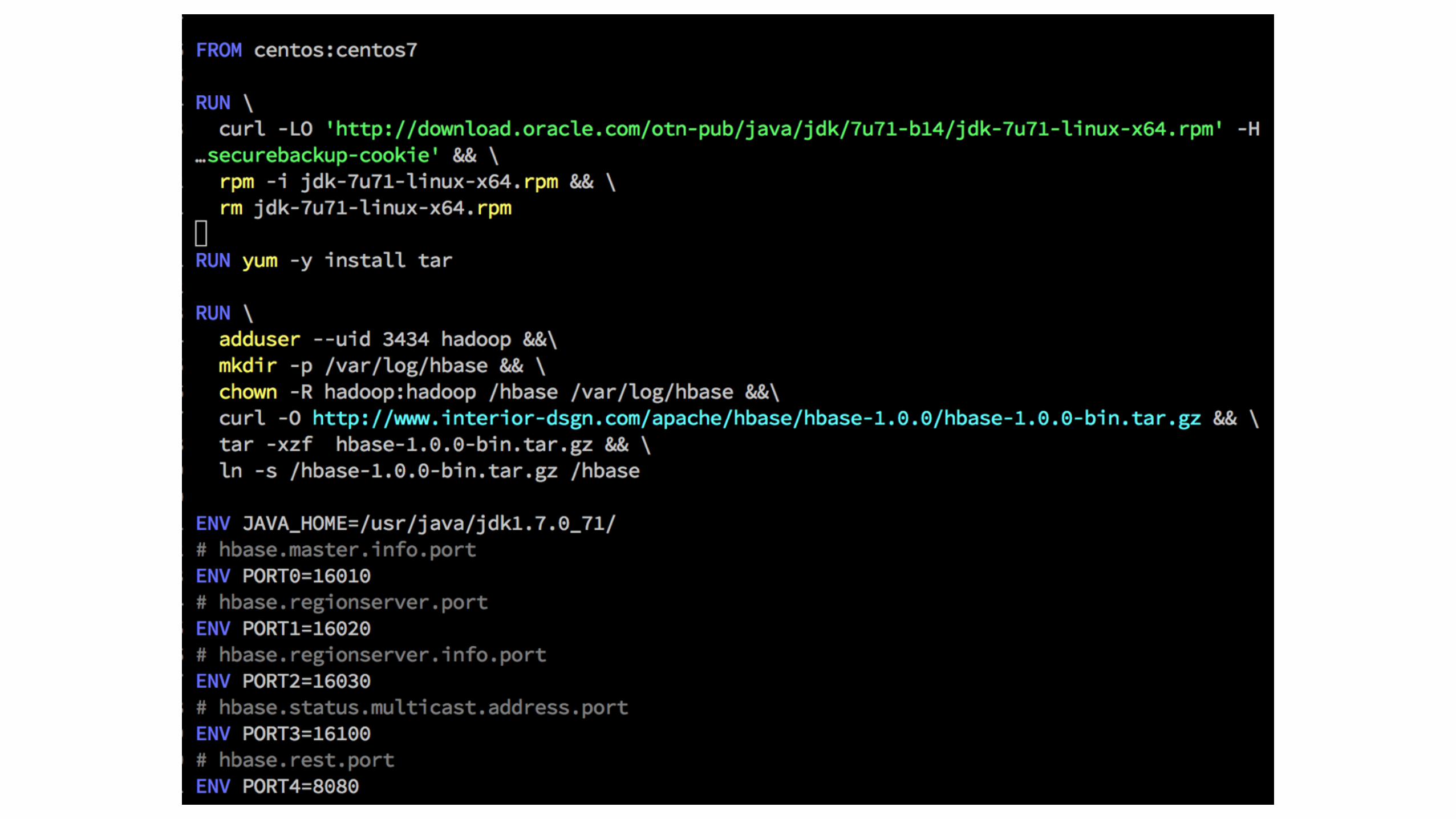
Why: Docker Containers• “static link” everything (including the OS)
• standard interface (resources, lifecycle, events)
• lightweight
• just another process
• no overhead, native performance
• fine-grained resources
• e.g. 0.5 cores, 32MB RAM, 32MB disk

From .tgz/rpm + Puppet to Docker
• goal: optimize for Mesos (not standalone)
• cluster, host agnostic (portability)
• env config injected through Marathon
• self contained:
• OS-base + JDK + HBase
• centos-7 + java-1.8u40 + hbase-1.0

Marathon

Marathon “runs” Applications on Mesos
• REST API to start / stop / scale apps
• maintains desired state (e.g. # instances)
• kills / restarts unhealthy containers
• reacts to node failures
• constraints (e.g. locality)

Marathon Manifest• env information:
• ZK, HDFS URIs
• container resources
• CPU, RAM
• cluster resources
• # container instances
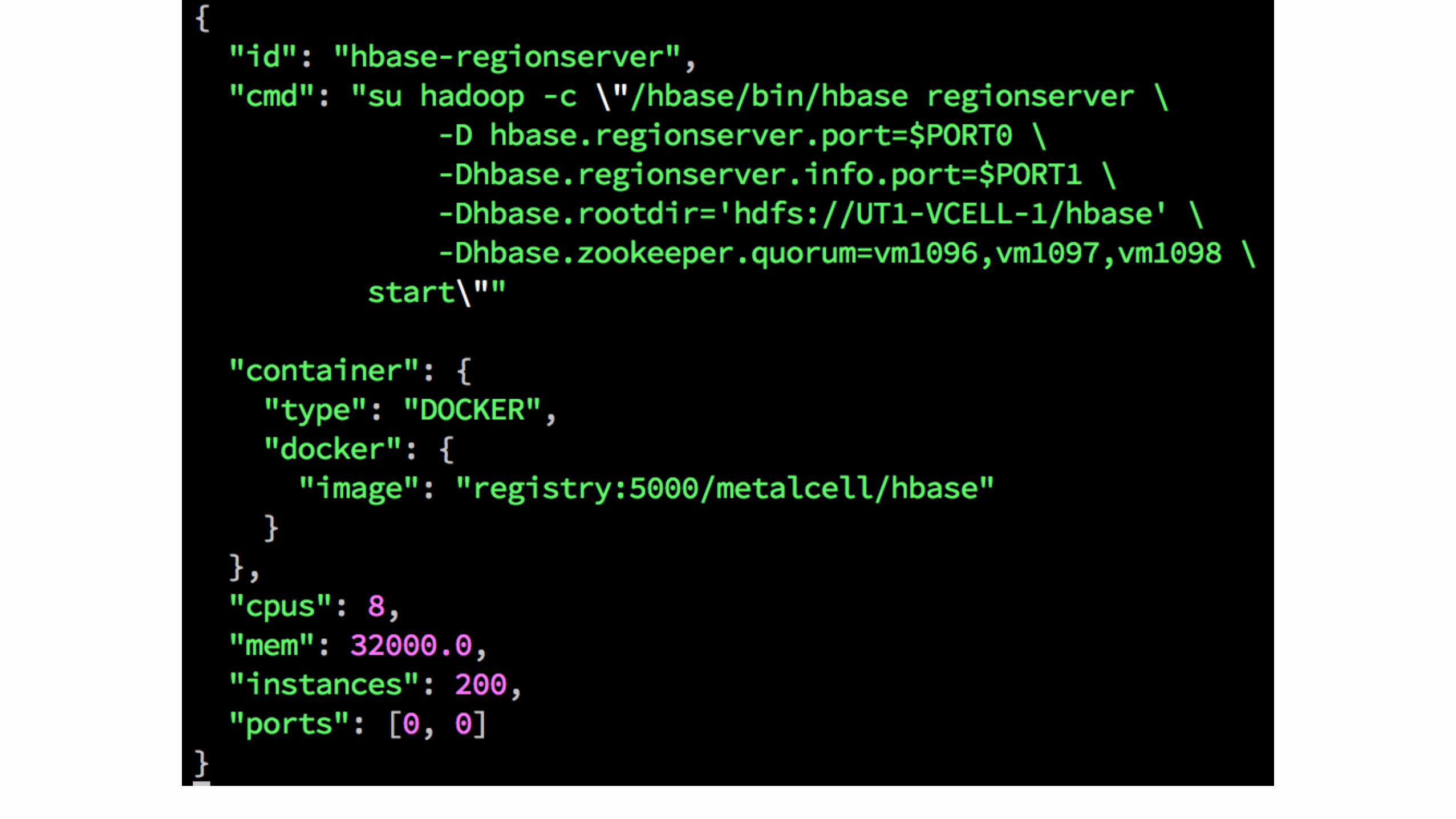

Marathon “deployment”
• REST call
• Marathon (and Mesos) handle the actual deployment automatically

Benefits

Easy
• no code needed
• trivial docker container
• could be released with HBase
• straight forward Marathon manifest

Efficiency
• improved resource utilization
• mixed workloads
• elasticity

Elasticity
• scale up / down based on load
• traffic spikes, compactions, etc.
• yield unused resources

Smaller, Better?
• multiple RS per node
• use all RAM without losing compressed OOPS
• smaller failure domain
• smaller heaps
• less GC-induced latency jitter

Simplified Tuning• standard container sizes
• decoupled from physical hosts
• portable
• same tuning everywhere
• invariants based on resource ratios
• # threads to # cores to RAM to Bandwidth

Collocated Clusters
• multiple versions
• e.g 0.94, 0.98, 1.0
• simplifies multi-tenancy aspects
• e.g. cluster-per-table resource isolation

NEXT

Improvements
• drain regions before suspending
• schedule for data locality
• collocate Region Servers and HFiles blocks
• DN short-circuit through shared volumes

HBase Ergonomics
• auto-tune to available resources
• JVM heap
• number of threads, etc.

Disaggregating HBase
• HBase is an consistent, highly available, distributed cache on top of HFiles in HDFS
• most *real* resource-wise, multi-tenant concerns revolve around a (single) table
• each table could have it’s own cluster (minus some security groups concerns)

HMaster as a Scheduler?
• could fully manage HRS lifecycle (start/stop)
• in conjunction to region allocation
• considerations:
• Marathon is a generic long-running app scheduler
• extend scheduling capabilities instead of “reinventing” it?

FIN

Resources
• The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines, Second edition - http://www.morganclaypool.com/doi/abs/10.2200/S00516ED2V01Y201306CAC024
• Omega: flexible, scalable schedulers for large compute clusters - http://research.google.com/pubs/pub41684.html
• Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center - https://www.cs.berkeley.edu/~alig/papers/mesos.pdf
• https://github.com/mesosphere/marathon
