dvm: a big virtual machine for cloud computing
TRANSCRIPT

DVM: A Big Virtual Machine for Cloud ComputingZhiqiang Ma, Zhonghua Sheng, and Lin Gu, Member, IEEE
Abstract—As cloud-based computation grows to be an increasingly important paradigm, providing a general computational interface tosupport datacenter-scale programming has become an imperative research agenda. Many cloud systems use existing virtual machinemonitor (VMM) technologies, such as Xen, VMware, and Windows Hypervisor, to multiplex a physical host into multiple virtual hosts andisolate computation on the shared cluster platform. However, traditional multiplexing VMMs do not scale beyond one single physical host,and it alone cannot provide the programming interface and cluster-wide computation that a datacenter system requires. We design anew instruction set architecture, DISA, to unify myriads of compute nodes to form a big virtual machine called DVM and presentprogrammers the viewof a single computer,where thousandsof tasks run concurrently in a large, unified, and snapshottedmemory space.The DVM provides a simple yet scalable programming model and mitigates the scalability bottleneck of traditional distributed sharedmemory systems. Along with an efficient execution engine, the capacity of a DVM can scale up to support large clusters. We haveimplemented and tested DVM on four platforms, and our evaluation shows that DVM has excellent performance and scalability. On onephysical host, the system overhead of DVM is comparable to that of traditional VMMs. On 16 physical hosts, the DVM runs 10 times fasterthanMapReduce/Hadoop andX10. On 160 compute nodes in the TH-1/GZ supercomputer, the DVMdelivers a speedup over thecomputationon10computenodes.The implementationofDVMalsoallows it to runabove traditionalVMMs,andweverify thatDVMshowslinear speedup on a parallelizable workload on 256 large EC2 instances.
Index Terms—Distributed systems, concurrent programming, datacenter, virtualization, cloud computing
1 INTRODUCTION
VIRTUALIZATION is a fundamental component in cloud tech-nology. Particularly, ISA-level virtual machine monitors
(VMM) are used by major cloud providers for packagingresources, enforcing isolation [1], [2], and providing under-lying support for higher-level language constructs [3].However, the traditional VMMs are typically designed tomultiplex a single physical host to be several virtual machineinstances [4]-[6]. Thoughmanagement or single system image(SSI) services can coordinatemultiple physical or virtual hosts[6]-[8], they fall short of providing the functionality andabstraction that allow users to develop and execute programsas if the underlyingplatformwere a single big “computer” [9].Extending traditional ISA abstractions beyond a single ma-chine has only met limited success. For example, vNUMAextends the IA-64 instruction set to a cluster of machines [10],but finds it necessary to simplify the memory semantics andencounters difficulty in scaling to very large clusters.
On the other hand, exposing the distributed detail of theplatform to the application layer leads to increased complexi-ty in programming, decreased performance, and, sometimes,loss of generality. In recent years, application frameworks[11], [12] and productivity-oriented parallel programminglanguages [13]-[16] have been widely used in cluster-widecomputation. MapReduce and its open-source variant, Ha-doop, are perhaps the most widely-used framework in this
category [17]. Without completely hiding the distributedhardware,MapReduce requires programmers to partition theprogram state so that each map and reduce task can beexecuted on one individual host, and enforces a specificcontrol flow and dependence relation to ensure correctnessand reliability. This leads to a restricted programming modelwhich is efficient for “embarrassingly parallel” programs,where data can be partitioned with minimum dependenceand thus the processing is easily parallelizable, but makes itdifficult to support sophisticated application logic [17]-[20].The language-level solutions, such as X10 [14], Chapel [21]and Fortress [13], are more general and give programmersbetter control over the program logic flows, parallelizationand synchronization, but the static locality, programmer-specified synchronization, and the linguistic artifacts influ-ence such solutions to perform well with one set of programsbut fail to deliver performance, functionality, or ease-of-programming with another. It remains an open problem todesign an effective system architecture and programmingabstraction to support general, flexible, and concurrent appli-cation workloads with sophisticated processing.
Considering that ISAs indeed provide a clearly definedinterface between hardware and software and allow bothlayers to evolve and diversify, we believe it is effective tounify the computers in a datacenter at the instruction level,and present programmers the view of a big virtual machinethat can potentially scale to the entire datacenter. The key is toovercome the scalability bottleneck in traditional instructionsets and memory systems. Hence, instead of porting anexisting ISA, we design a new ISA, Datacenter Instruction SetArchitecture (DISA), for cluster-scale computation. Throughits instruction set, memory model and parallelization mecha-nism, the DISA architecture presents the programmers anabstraction of a large-scale virtual machine, called the DISA
• The authors are with the Department of Computer Science and Engineering,The Hong Kong University of Science and Technology, Hong Kong.E-mail: {zma, szh, lingu}@cse.ust.hk.
Manuscript received 25Oct. 2012; revised 31Mar. 2013; accepted 24Apr. 2013.Date of publication 28 Apr. 2013; date of current version 07 Aug. 2014.Recommended for acceptance by S. Ranka.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference the Digital Object Identifier below.Digital Object Identifier no. 10.1109/TC.2013.102
IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014 2245
0018-9340 © 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

VirtualMachine (DVM),which runs on a plurality of physicalhosts inside a datacenter. It defines an interface between theDVM and the software running above it, and ensures that aprogram can execute on any collection of computers thatimplement DISA.
Different from existing VMMs (e.g., VMware [6], Xen [4],vNUMA [10]) on traditional architectures (e.g., x86), DVMand DISA make design choices on the instruction set, execu-tion engine, memory semantics and dependence resolution tofacilitate scalable computation in a dynamic environmentwith many loosely coupled physical or virtual hosts. Thereare certainly many technical challenges in creating an ISAscalable to a union of thousands of computers, and backwardcompatibility used to constrain the adoption of new ISAs.Fortunately, the cloud computing paradigm presents oppor-tunities for innovations at this basic system level—first, adatacenter is often a controlled environmentwhere the ownercan autonomously decide internal technical specifications;second, major cloud-based programming interfaces (e.g.,RESTful APIs, RPC, streaming) require minimum instruc-tion-level compatibility; finally, there is only a manageableset of “legacy code”.
As an approach to supporting computing in datacenters,the design of DVM has the following goals.
General. DVM should support the design and executionof general programs in datacenters.Efficient. DVM should be efficient and deliver highperformance.Scalable.DVM should be scalable to run on a plurality ofhosts, execute a large number of tasks, and handle largedatasets.Portable. DVM should be portable across different clus-ters with different hardware configurations, networks,etc.Simple. It should be easy to program the DVM; DISAshould be simple to implement.
With the design goals stated, we revisit the approach andrationale of unifying the computers in a datacenter at the ISAlayer. The programming framework, language, and systemcall/API are also possible abstraction levels for large-scalecomputation. However, as aforementioned, the frameworksand languages have their limitations and constraints. Theyfall short of providing the required generality and efficiency.Using system calls/APIs to invoke distributed system ser-vices can be efficient and reasonably portable. However, anabstraction on this level creates dichotomized programmingdomains and requires the programmers to explicitly handlethe complexity of organizing the program logic aroundthe system calls/APIs and filling any semantic gap, whichfails to provide the illusion of a “single big machine” to theprogrammers and leads to a far less general and easy-to-program approach than what we aim to design. The existingISAs, designed for a single computer with up to a moderatenumber of cores, can hardly provide the scalability requiredby the “machine” that scales potentially to the datacentersize. On the other hand, the design of the DVM is motivatedby the necessity of developing a next-generation datacentercomputing technology that overcomes several importantlimitations in current solutions. The DVM should providethe basic program execution and parallelization substrate inthis technology, and should meet all the goals on generality,
efficiency, scalability, portability and ease-of-programming (withcompilers’ help). This leads us to choose the ISA layer toconstruct a unified computational abstraction of the data-center platform. To break the scalability bottleneck in tradi-tional ISAs and retain the advantages of generality andefficiency, we design the new ISA, DISA, and build the DVMon this architecture.
We implement and evaluate DVM on several platforms.The evaluation results (refer to Section 4) show that theperformance of the programs benefit much from the ISA-levelabstraction—DVM can be more than 10 times faster thanHadoop and X10 on certain workloads with moderatelyiterative logic, and scale up with near-linear speedup to atleast 256 compute nodes on parallelizable workloads.
The structure of this paper is as follows. We give anoverview of DVM in Section 2. Section 3 presents the designsof DISA, memory space and parallelization mechanisms.Section 4 describes the implementation and the evaluationresults.We discuss relatedwork in Section 5 and conclude thepaper in Section 6.
2 SYSTEM OVERVIEW
The architecture of DVM is illustrated in Fig. 1. Many DVMscan run in one physical host as the traditional VMMs tomultiplex the resources of the host, and a DVM can run ontop of multiple or many physical hosts to form a big virtualmachine in a datacenter.
2.1 System OrganizationWe abstract a group of computational resources includingprocessor cores and memory to be an available resource con-tainer (ARC). In the simplest form, an ARC is a physicalcomputer. However, it can also materialize as a traditionalvirtual machine or other container structure, given the con-tainer provides an appropriate programming interface andadequate isolation level. Although one ARC is exclusivelyassigned to one DVM during one period of time, the ARCs inone physical host may belong to one or more DVMs and oneDVM’s capacity can be dynamically changed by adding orremoving ARCs. Hence, the capacity of a DVM is flexible andscalable—a DVM can share a single physical host with otherDVMs, or include many physical hosts as its ARCs.
A DVM accommodates a set of tasks running in a unifiedaddress space. Although DVMs may have different capacityand the size of a DVM can grow very large depending on theavailable resources, the DVMs provide the same architectural
Fig. 1. Organization of 2 DVMs on 3 physical hosts.
2246 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014

abstraction of a “single computer” to programs through theDISA.
The programs in DVMs are in DISA instructions and aprogram running inside aDVM instantiates to be a number oftasks called runners executing on many processor cores inmany ARCs. Inside an ARC, many runners, each residing inone runner compartment (RComp), can execute in parallel. TheRComp is a semi-persistent facility that provides varioussystem functions to runners and a meta-scheduler (discussedlater) to facilitate andmanage runners’ execution. Specifically,the RComp a) accepts the meta-scheduler’s commands toprepare and extend runners’ program state and start runners,b) helps the memory subsystem handle runners’ memoryaccesses, c) facilitates the execution of instructions such asnewr (see Table 1), d) sends scheduling-related requests to themeta-scheduler, and e) provides I/O services. As these func-tions are tightly correlatedwith other subsystems ofDVM,weintroducepertinentdetailsof theRCompdesignalongwiththetreatiseof theothersystemcomponents inSection3.Suffice itatpresent to know that one RComp contains at most one runnerat a specific time, and it becomes available for accommodatinganother runner after the current incumbent runner exits.
The DVM contains an internal meta-scheduler (scheduler)to schedule runners executing in RComps. The scheduler is adistributed service running on all constituent hosts of a DVM,with one scheduler master providing coordination and seri-alization functions.
2.2 Programming in DISAWe use one example to illustrate how to write a simpleprogram on a DVM using DISA. Details of the DISA archi-tecture will be introduced in Section 3, and a more complexexample is introduced in [22].
The following DISA code performs a sum operation oftwo 64-bit integers by a sum runner runner. The startingaddress of the memory range storing the two integers is in0x300001000, and 0x300001008 contains the address wherethe results should be stored. The text after “;” in a line is acomment, and the runner’s name is in italic.
1
2 add 0x300001000 : q, 8 0x300001000 , 0x300001008
3 ; :q indicates 64-b data
4 mov: z $1:q, 8 0x300001008 : q ; set exit code
5 exit: c ; exit and commit
The code above adds two 64-bit integers with all operandsstored in memory. Fig. 2 shows the execution of the sum
operation. Suppose the memory location 0x300001000 and0x300001008 store values 0x800000000 and 0x900000000,respectively. The add instruction at line 2 obtains the oper-ands at 0x800000000 and 0x800000008, computes the sum,and stores the sum in 0x900000000. The mov: z instruction atline 4 sets the exit code for the runner with zero-extension ataddress 8 0x300001008 (0x900000008 after dereferencing).Finally, the exit: c instruction at line 5 makes the runner exitand commit its changes to the memory. After being commit-ted, the changes become visible to other runners.
The example illustrates several important design choices ofDISA.First, itusesmemoryaddressing,notcombinedregister-memory addressing, for all operands. With an emphasis oninstruction orthogonality,DISAallows an instruction to freelychoose memory addressing modes to reference the operands.Second,DISAprovidesalow-levelabstractionwhichisclosetohardware and the semantics of most of the instructions arecommon in other widely used ISAs. With this design, DISAretains traditional ISAs’ advantages, such as generality andefficiency, and it is easy to map DISA to hardware or anothercommon ISAat lowcost. Finally, the commit operation,whichmakes a runner’s changes to the memory visible to otherrunners, occurs at the end of a runner’s execution. This ar-rangement enforces a clearly defined runner lifecycle and itssemantics concerning the program state of the DVM.
3 DESIGN
We design DISA as a new ISA targeting a large-scale virtualmachine running on a plurality of networked hosts and build
TABLE 1DISA Instructions
specifies an operand in memory; specifies an operand in memory or an immediate operand.
Fig. 2. Execution of an add instruction.
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2247

the DVM above this architectural abstraction. In this section,we first introduce the design of DISA’s instructions, and thenpresent DISA’s memory model in Section 3.2 and the paralle-lization mechanism in Section 3.3.
3.1 DISAGiven the system goals of the DVM design as listed inSection 1, the goals of the DISA design are as follows.
DISA should support a memory model and paralleliza-tion mechanism scalable to a large number of hosts.DISA programs should efficiently execute on commoncomputing hardware used in datacenters, which areusually made of commodity components. Certain hard-ware may provide native support to DISA in the future,although we emulate DISA instructions on the x86-64architecture in our current implementation.DISA instructions should be able to express generalapplication logic efficiently.DISA should be a simple instruction set with a smallnumber of instructions so that it is easy to implement andport.DISA should be Turing-complete.
In summary, DISA should be scalable, efficient, general,simple, and Turing-complete. To ensure programmability,simplicity and efficiency, DISA, as shown in Table 1, includesa selected group of frequently used instructions. In addition,the newr and exit instructions facilitate construction of con-current programswithmany executionflows.Our priorworkshows the Turing completeness by using DISA to emulate aTuring-complete subleq machine [22].
A DISA instruction may use options to indicate specificoperation semantics, such as the options :z and :c in thesum runner example in Section 2.2, and the operands canreference immediate values or memory contents using direct,indirect or displacement addressing modes. Although notexplicitly providing registers, the unified operand represen-tation permits register-based optimization because thememory model allows some memory ranges in DR (Direct-addressing Region, discussed in Section 3.2), which can only bereferenced with direct addressing, to be affiliated with regis-ters. We name these ranges Register-Affiliated Memory Rangesor RAMR for short.
Fig. 3a shows the RAMR to physical register mapping inour implementation on x86-64. DISA currently supports 8registers named RAMR 0 to 7. The programmers or compilerscanuse theseRAMRs to storemost frequently accesseddata in
the program to improve the performance. In our evaluationdiscussed in Section 4, we show that using RAMRs can speedup the loop microbenchmark by more than 5 times.
At first glance the RAMR design seems to make DISA lessportable. However, the programs using RAMRs need not tobe changed for DVMs on different platforms. On a platformthat has fewer physical registers in the processors than theRAMRs, the RAMRs simply revert to direct-addressed mem-ory ranges. Hence, a DVM can speed up the programs withphysical registers as much as possible while ensuring theportability and correctness.
3.2 Unified Memory SpaceTo facilitate the illusion of programming on a single comput-er, DISA provides a large, flat, and unified memory spacewhere all runners in a DVM reside. The memory layout isshown in Fig. 3b. Thememory space of a DVM is divided intotwo regions–the private region (PR) and the shared region (SR).The starting address of the SR is the region boundary (RB)which is just after the address of PR’s last byte. InsidePR, thereis a special region, direct-addressing region (DR), in whichmemory ranges can only be referenced in the direct addres-sing mode. The DR allows the program to access systemresources, such as RAMR (discussed in Section 3.1) andI/O channels (to be discussed in Section 3.4), with the unifiedoperand representation using memory addressing.
A write in an individual runner’s PR does not affect thecontent stored at the same address in other runners’ PRs. Incontrast, the SR is shared among all the runners in the sensethat a value written by one runner can be visible to anotherrunner in the same DVM, with DISA’s memory consistencymodel controlling when values become visible. A runner canuse the PR to store temporary or buffered data because of itsvery small overhead, and use the SR to store the mainapplication data which may be shared among runners. Inour implementation on the x86-64 platform, we set RB to0x400000000 and an application can use a 46-bit memoryaddress space. Therefore, programs can potentially storearound 64TB data in the SR and each runner can store severalgigabytes of data in its PR, which is sufficient for most of theapplications in datacenters.
3.2.1 Snapshot-Based ConsistencyThe consistency model of a shared memory system specifieshow the system appears to programmers, placing restrictionson the values that can be returned by a read, and is critical for
Fig. 3. Organization of the memory space and RAMRs. (a) Mapping of RAMRs to physical registers in x86-64; (b) Organization of the memory space.
2248 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014

the system’s performance [23]. In DISA, a runner’s memoryoperations have a transaction-like semantics and completes asan atomic unit. We use the snapshot-based memory consis-tency model, in which every runner sees a consistent view ofthe memory space of a specific instantiation time, and thesystem imposes a sequential ordering of runners’ commits.DISA’s consistency model allows a runner to read data in itssnapshot and proceed to commit successfully without beingdisrupted by concurrent updates and commits from anotherrunner, providing the same properties as standard snapshotisolation [24], which is adopted bymany relational databases.
DISA’s snapshot-based consistency model relaxes the read/write order on different snapshots. In DISA, a snapshot is a setof memory ranges instantiated with the memory state at aparticular point in time. A memory range is a sequence ofconsecutive bytes starting from a memory address. After asnapshot is created for a runner, later updates to the associat-ed memory ranges by other runners do not affect the state ofthe snapshot. Hence, when reading data from an address in asnapshot, a runner always receives the value the runner itselfhas written most recently or the value stored at the address atthe time the snapshot is created. DISA permits concurrentaccesses optimistically, and detects write conflicts automati-cally. With this consistency model, it is possible to implementatomicwrites of a group of data, which are commonly used intransactional processing and other reliable systems requiringACID properties. This model indeed introduces slight con-straints on the organization of programs: only one of manyrunners that concurrently write to the same location cancommit successfully and the other runners need to give upor retry. However, it assures programs written this way aremuch easier to understand and reason about their correctness,as well as improves the system’s scalability.
3.2.2 Managing Snapshot MetadataThe consistency model of DISA provides programs a clearly-defined memory semantics and enables scalable parallel pro-cessing.However, it is challenging to efficientlymanage a largenumber of snapshots in the memory space. The snapshot’ssemantics, which ensures that any later changes of thememory content should not affect the existing snapshots,requires that the memory subsystemmaintain more than oneversion of the memory content. To efficiently support thesnapshot management, the memory subsystem organizes theSR as a sequence of fixed-size pages and each page has twoversions—a current version and a non-current version. Thecurrent version is the last committed version, and a snapshotconsists of a number of pages of their current versions at thetime the snapshot is created. Thenon-current versionof apageis not included in newly created snapshots. A page’s previousversion before the current one, which may be still used bysome runners, can be trackedwith the non-current version bythe memory subsystem.
With the two-version design, the memory subsystem needto onlymaintain a small amount ofmetadata for the pages, andcanefficientlyhandle a largenumber of snapshots.Meanwhile,the current and non-current version design is friendly to theread-only sharing of data—many runners can read shareddatawith snapshot isolation and complete their execution giventhey write to disjoint locations. The two-version design indeed
implies a slight limitation that some runners may need to waitfor available page versions. Typically, there are many runnersschedulable in a DVM and the waits usually occur to a smallfraction of them. Hence, the limitation does not lead to notice-able performance penalty in practice. On the other hand, thisdesign enables the system to scale, efficiently managing manyconcurrent snapshots.
To assist the runners in using the shared and snapshottedSR in the unified memory space, components of the DVMcooperate to manage the snapshots and facilitate the memoryaccesses. The scheduler manages the snapshots and coordi-nates runners to execute on RComps taking locality intoconsideration. The memory subsystem serializes the commit-ting of the memory ranges only when runners exit. TheRComps facilitate the memory subsystem to handle the run-ners’ memory accesses by leveraging the virtual memoryhardware to catch and handle the page fault when a runneraccesses a page for the first time, following well-knownpractices [25], [26]. When handling a page fault, the memorysubsystem first looks up the page in the runner’s snapshot toobtain the version and location information of the page andprevent the runner from accessing memory outside its snap-shot. The memory subsystemmakes a copy of the page if it ison the local node to protect that version which is potentiallyincluded in other runners’ snapshots, or fetches the page fromthe remote node through the network.
3.3 Parallelization and SchedulingWe design DVM’s parallelization mechanism so that it iseasier to develop not only “embarrassingly parallel” pro-grams, but also more sophisticated applications, and theprograms can efficiently execute in a datacenter environment.The goal is to provide a scalable, concurrent and easy-to-program task execution mechanism with automatic depen-dence resolution. To achieve the goal, we design amany-runner parallelization mechanism for large-scale par-allel computation, a scheduler to manage the runners, andwatchers to express and resolve task dependences.
3.3.1 RunnerRunners are the abstraction of the programflows in aDVM.Arunner is created by its parent runner and terminates after itexits or aborts. Fig. 4 summarizes the state transitions in arunner’s life cycle. The parent runner creates a new runner byexecuting the newr instruction. A “created” runner moves tothe “schedulable” state after the parent runner exits andcommits successfully. The runner moves to the “running”state after being scheduled and to the “finished” state after itexits or aborts. The “watching” state applies only to a class ofspecial runners called “watchers” which are introduced inSection 3.3.4.
Each runner uses a range of memory as its stack range(stack for short), changes to which are discarded after therunner exits, and multiple ranges of memory as its heapranges. Because runners are started by the scheduler, thescheduler needs to know certain control information aboutthe runner, such as the location of code and the runner’s stackand heap ranges. DVM uses a Runner Control Block (RCB) tostore such control information. Fig. 5 shows the content of arunner’s RCB as well as the runner’s initial stack. The RCB
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2249

contains the stack base address and stack size .specifies the address of the first instruction from which therunner starts to execute. The and
fields stores the locations and the number of the heapranges, respectively. The and
fields are used by the watcher mechanism discussedlater.
Every runner resides in one RComp. Providing systemfunctions related to the management and operations of run-ners, the RComp reduces the overhead of dispatching andstarting a runner. RComps interact with other parts of theDVM system, and hide the complexity of the system so thatthe runners can focus on expressing the application logic onthe abstraction provided by DISA. Because RComps arereused, a large portion of the runner startup overhead, suchas loading modules and setting up memory mapping, isincurred only once in the lifetime of a DVM. To start a runner,the RComp only needs to notify thememory subsystem to setup the runner’s snapshot, and the supporting mechanisms,such as the network connections, can be reused. Hence,RComps make it efficient to start runners in a DVM. Section4 quantitatively studies the overhead of creating and startingrunners.
3.3.2 SchedulingIn a complex program, myriads of runners may be createddynamically and exit the system after completing their com-putation. RComps, on the other hand, represent a semi-persistent facility to support runners’ execution. Hence, there
can be more runners than RComps in a DVM, and thescheduler assigns runners to RComps, as well as managesand coordinates the runners throughout their life cycles.Specifically, the scheduler is responsible for deciding whenrunners should start execution, assigning runners toRComps,preparing runners’ memory snapshots, handling runners’requests to create new runners and managing the runnersthat the DVM does not have resources (RComps) to executecurrently. As the child runners created by a parent runner arenot schedulable until the parent runner exits and commitssuccessfully, the scheduler also maintains the “premature”runners (the runners in the “created” state) in the DVM. Inaddition, the scheduler implements the DVM’s watchermechanism (to be discussed in Section 3.3.4).
The scheduler of DVM is a distributed service consisting oftwoparts: the schedulermaster (themaster) and the scheduleragent (the agent). There is a singlemaster in aDVM, and thereare many agents residing in RComps. The master and theagents communicate with each other through the datacenternetwork. The master makes high-level scheduling decisions,such as dispatching runners for execution and assigning themto RComps, and commands the agents to handle the remain-ing runner management work, such as preparing and updat-ing runners’ snapshots. In the other direction, an RComp cansend scheduling-related requests to its associated agent andthe agent may ask the master for coordination if it is needed.
The scheduler dispatches multiple runners from its poolof schedulable runners according to the schedulingpolicy, which takes locality along with other factors into
Fig. 4. State transition of the runner and watcher.
Fig. 5. Runner ’s initial stack and RCB.
2250 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014

consideration, to an RComp when it is free (no runner isrunning in it), creating amemory snapshot for the runner andnotifying the RComp to execute the runner. A runner maycreate asmanychild runners as the entireDVM(ordatacenter)canhandle.When a runner requests to create new runners, thescheduler constructs RCBs for the child runners, and extendsthe parent runner’s memory snapshot so that the parent canconstruct and access the child runners’ stacks.After the parentexits and commits successfully, the scheduler adds the childrunners to the runner pool and marks them as schedulable.
Although there is only one scheduler master in a DVM, ithas not been found that the single master constrains theDVM’s scalability. As aforementioned, the master is onlyresponsible for high-level decisions and occasional coordina-tion and arbitration, and is, consequently, very lightweight.Most of thework is handled inparallel by the scheduler agentsin the RComps. Hence, the scheduler does not constitute abottleneck in theDVMinpractice. Several large-scale systems,such as MapReduce [11], GFS [27], and Dryad [12], follow asimilar single-master design pattern.
Together with the design of the scheduler, the design ofother components of DVM optimize the workflow to ensurescalability. The snapshot-based memory model of DISA en-ables massive runner-level parallelism by invoking schedul-ing and coordination only when a runner starts and commits.The ISA-level lightweight task creation through the newr
instruction enables programs to create tasks at low cost. Thetwo-versiondesignmakes themetadatamanagement fast andefficient so that the memory subsystem can scale to handlemany snapshots. These designs ensure that DVM scales wellas the processor count and the data size increase. In Section 4,we examine DVM’s scalability.
3.3.3 Many-Runner Parallel ExecutionThe DVM should be able to accommodate a large number ofrunners and execute them in parallel to exploit the aggregatecomputing capacity ofmanyphysical hosts. This requires thatthe parallelization mechanism of DVM provide scalable, con-current and efficient task execution and a flexible program-ming model to support many-runner creation and execution.
DVM uses the shared-memory model to simplify the pro-gram development.While a runner maywrite multiplemem-ory ranges in the SR during its execution, the runner may notwant to apply some changes, such as the temporary data, tothe global memory space. DISA’s memory subsystem enablesprogrammers to control the behaviors of memory ranges sothat it can support common cases of memory usage. A runnermainly obtains its input from its initial state comprising itsstack ranges constructedby its parent runner andheap ranges,and canalso readdata from I/Ochannels during its execution.The runner’s output is written into its heap ranges and I/Ochannels if it is needed.Upon completion, a runner can specifywhether it wants to commit or abort its changes to the heapranges. The changes to a runner’s stack are always discardedupon completion of the runner. We call this memory usagescheme the SIHO (Stack-In-Heap-Out) model.
To support many-runner parallel execution on the ISAlevel, the runner creation and dispatching mechanism mustbe highly efficient. We design an instruction-level runnercreation mechanism. To create a new runner and prepare it
for execution, the programonly needs to specify the and theheap ranges for the new runner, issue a “newr” instruction,and instantiate the stack.
We use an example to show how a runner creates a newrunner and how the DVM handles the runner creation. Whena runner, , creates a new runner, , executes theinstruction “newr” with addresses of ’s stack range, heapranges and , as operands. , the RComp inwhich
runs, sends ’s control information specified by theseoperands to the scheduler. As maywrite the input data into
’s stack and a memory range can be used by only afterhas the range’s snapshot, the scheduler creates a
snapshot of ’s stack and merges the snapshot into ’scurrent one.After thememory range for ’s stack is ready,writes the initial application data into ’s stack. The sched-uler constructs and records ’s RCB along with the RCBs ofthe other runners created by .
When exits and commits, the scheduler starts the newlycreated runners by , including , according to the recordedRCBs. Using as an example, the runner start-up procedureis as follows.
1) The scheduler chooses for2) The scheduler creates snapshot of ’s stack range and
heap ranges according to3) The scheduler sends and to and
commands to start4) sets ’s local context according to5) starts to execute from
3.3.4 Task DependencyTask dependency control is a key issue in concurrent programexecution. Related to this, synchronization is often used toensure the correct order of the operations, avoid race condi-tions, and, with execution order constrained, guarantee thatthe concurrent execution does not violate dependence rela-tions. The existing approaches have their limitations andconstraints: the synchronization mechanisms are not naturalor efficient to represent dependence [28], [29]; MapReduceemploys a restricted programming model and makes it diffi-cult to express sophisticated application logic [18]-[20]; DAG-based frameworks, such as Dryad [12], incur non-trivialburden in programming, and automatic DAG generation hasonly been implemented for certain high-level languages [16].
As an important goal in the DVM design, the DISA archi-tecture should provide a task dependency representation andresolution mechanism with which task-level dependence canbe naturally expressed, concurrent tasks can proceed withoutusing synchronization mechanisms such as locks [30], andsophisticated computation logic can be processed effectivelywith dynamically scheduled parallelism. Departing from ex-isting solutions, we design a watcher mechanism in the DISAarchitecture to provide a flexible way of declaring depen-dence and enable the construction of sophisticated applica-tion logic. We refer the readers to [22] for the discussion oftechnical details of the watcher mechanism.
3.4 I/O, Signals and System ServicesFor simplicity and flexibility, DISA adopts the memorymapped I/O for DVM to operate on I/O channels by acces-sing memory ranges in DR.
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2251

For example, we map the 1-byte memory range at0x100000200 to the standard input (STDIN) and the rangeat0x100000208 to the standardoutput (STDOUT). The runnercan input from STDIN by reading the address 0x100000200and output to STDOUT by writing to the address0x100000208. The DVM translates the memory accesses tothese addresses to requests to the RComp for I/O operations.For example, one runner can read one byte from STDIN andwrite the value to STDOUT by the following instructions.
mov:z 0x100000200:b, 0x300001000:b # read one byte from STDIN
mov:z 0x300001000:b, 0x100000208:b # write the byte to STDOUT
This design does not require additional instructions—allDISA’s memory access instructions can also be used for I/O.We canuse thismechanism to supportmanykinds and a largenumber of I/O channels which may be distributed in manyRComps.
In a DVM, many system events may occur. We design asignal mechanism to enable runners to catch the informationof events of interest in the system. Signals are notifications ofthese events. The signal mechanism is built on the watchermechanism and the system services (to be discussed below).The signals are represented as changes to specific memoryranges, and runners (watchers) can “watch” these memoryranges to get notified.
To support system functions, such as the I/O and signalmechanisms, several distributed system services cooperatewith the scheduler and RComps in DVM. For example, theI/O services on RComps manage I/O channels, and the“system state” service broadcasts “system idle” signals. Ontop of the compact and efficient core parts of the DVM asdescribed, it is easy to implement various system services toprovide a rich set of functions.
3.5 Programming on DVMBeing Turing-complete, DISA instructions are capableof expressing any computational logic. They can alsoemulate the semantics of instructions in other ISAs.Additionally, we design DISA as an extensible instructionset so that more instructions can be added to DISA if itis sufficiently beneficial to do so. More importantly, theparallelization and dependency control mechanisms alongwith the snapshot-based memory model provide a conve-nient and efficient way to design concurrent programs in the“lock-free” style [31].
We use an example to show how to naturally express taskdependence and avoid race conditions using watchers. Usingthe newr instruction, we can easily create 2 sum runner run-ners introduced in Section 2 to calculate sums in parallel. Inthis example, we design a new runner to add the 2 sumstogether. The new runner, implemented as a watchershown in the following code, “watches” the output of the 2sum runner runners.
1 :
2 ; read the heap addresses of the depended runners and
3 ; the address to store the result from the stack and store
4 ; them in 0x300001000 0x300001008 and 0x300001010 omitted
5 ; check whether the depended data are ready
6 br:e $0:uq 8 0x300001000 , create self
7 br:e $0:uq, 8 0x300001008 , create self
8 ; sum the two integers as the
9 add 0x300001000 :uq, 0x300001008 , 0x300001010
10 mov:z $1:q, 8 0x300001010 :q ; exit code
11 exit:c
12 create self:
13 ;create with the same control information
omitted
14 exit:c
The sum watcher is activated when either of thesum runners commits and can check their exit codes to deter-minewhether both operands for the sum operation are ready.The watcher creates itself again to continue “watching” thedata it depends on if either of the two depended runners hasnot exited and committed. As shown in this example, pro-grammers only need to create the watchers, and the depen-dences are automatically resolved by the scheduler andwatcher-related mechanisms in the DVM.
Although we show the examples in DISA in this paper,compilers can certainly be involved in theprogramming in theDVM environment and transform programs written in high-level languages into DISA code. With a sufficiently sophisti-cated compiler, it is also possible to port traditional softwareto DVM by recompiling them. Providing a compiler andruntime support for a high-level language on DVM is onepiece of our ongoing work.
Although one program instantiated as many runners runsin aDVMat a specific time,manyDVMs can run concurrentlyin one cluster by isolating the computing resources to ARCs.In theCCMRresearch testbed (introduced in Section 4),we setup multiple DVMs on the same cluster and many users candevelop and run their programs in a time-sharing manner.
4 IMPLEMENTATION AND EVALUATION
We have implemented DVM and DISA on x86-64 hardware.The implementation of the DISA andDVMcomprises around11,510 lines of C and assembly code. On each host, the DVMruns in conjunction with a local Linux OS as the base systemwhichmanages local hardware resources includingCPUsandlocal file systems.
We emulate DISA instructions on x86-64 machines in ourcurrent implementation by using binary translation to gener-ate x86-64 code on the fly during the execution of a DISAprogram. We have implemented and run DVM on multipleplatforms as listed below.
The CCMR research testbed. As shown in Fig. 6a, theCCMR testbed is constructed for cloud computing re-search. It is composed of 50 servers with Intel Quad-CoreXeon processors. The servers are connected by 10Gbpsand 1Gbps networks. We use 16 nodes connected by the10Gbps network for the microbenchmarks and compari-son experiments, andup to 50 nodes for experimentswithlarge datasets.The Amazon Elastic Compute Cloud (EC2). To examineDVM’s portability and scalability on public IaaS plat-forms, we conduct part of the experiments on AmazonEC2 instances of the m1.large type in the us-east-1a zone.
2252 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014

The TH-1/GZ supercomputer. To examine howDVM performs in a high-performance computing (HPC)environment, we conduct some experiments on theTH-1/GZ supercomputer (Fig. 6b) which follows thesame architecture of Tianhe-1A [32] ranked currentlynumber 5 in the TOP500 list [33].
The implementations on EC2 and TH-1/GZ also show theportability of DISA in virtualized, heterogeneous and HPCenvironments. In addition to these 3 platforms, we also im-plemented and evaluated DVM on an industrial testbed [22].Although the four platforms have quite different underlyinghardware configurations and different Linux kernels, itproves to be straightforward to port DISA to all platformsby adding logic to match specific kernel data structures.Application programs run unchanged at all on four platformswithout recompilation.
4.1 Workloads and MethodologyWe measure DVM’s mechanisms with microbenchmarks,compare DVM’s performance with Hadoop and X10’s, andinspect its scalability. We choose Hadoop and X10 for com-parison because they are representatives of two mainstreamapproaches to datacenter computing and their implementa-tions are relativelymature and optimized.Hadoop representsa class of MapReduce-style programming frameworks suchas Phoenix [19], Mars [34], CGL-MapReduce [18] andMapReduce online [35], and has been used extensively bymany organizations [36]. X10 represents a class of language-level solutions, including Chapel [21] and Fortress [13], tar-geting “non-uniform cluster computing” environments [14].
We use several workloads to evaluate DVM’s efficiencyand scalability. We first design the prime-checker which uses1000 runners to check the primality of 1,000,000 numbers. Asthe prime-checker is highly parallelizable, we use this arith-metic application to evaluate the scalability ofDVMasweaddmore compute nodes—whether DVM can achieve near-linearspeedup. To check DVM’s performance on widely used andmore complex algorithms, we implement the -means cluster-ing algorithm [37]. The -means program iteratively clusters alarge number of 4-dimensional data points into 1000 groups.This reflects known problem configurations in related work[38]-[40]. We run -means on DVM by scaling the number ofcompute nodes and the size of datasets to evaluate DVM’sscalability, and compare toHadoop andX10. Formore detailsof the implementation of the prime-checker and -meansprograms, we refer the readers to [22]. Additionally, to exam-ine how DVM scales as the overall memory usage grows, we
implement and run teragen which produces the TearSort [41]input datasets of various sizes.
For each technical solution in comparison, we apply thehighest performance setting among the standard configura-tions. For example, X10 programs are pre-compiled to nativeexecutable programs, and we write the x86-64-basedmicrobenchmark programs in comparison in the assemblylanguage. Note that the platforms have different perfor-mance characteristics. To make the comparison fair, weindicate the platform, use the same compute nodes andnetwork topology and configuration to run comparativeexperiments, and repeat the experiments to make sure resultsare consistent.
4.2 MicrobenchmarksWe runmicrobenchmarks to measure the virtualization over-head of DVMand compare the results with traditional virtualmachine monitors. We also measure the overhead and effi-ciency of creating runners, executing runners and memoryfetching. In addition,wemeasure the performance gains fromregister-based optimization.
4.2.1 Virtualization OverheadWedesignmicrobenchmarks tomeasure the overheadofCPUandmemoryvirtualization inDVM.To assess the overhead ofCPU virtualization, we measure the arithmetic and logicoperation performance by a microbenchmark program thatexecutes add operations. Memory is another importantsubsystem in the DVM, and we shall verify that the distribut-ed memory subsystem does not incur dramatic overhead onone machine. We measure the memory operation perfor-mance with another microbenchmark program that writes
64-bit integers (4 GB in total) to the memory for 256 timesand then read them for 256 times.
We implement the microbenchmarks in x86-64 assemblyand DISA, and execute the programs in Xen, VMware Player,native Linux, and a DVM on the same physical host. Toachieve the best performance, the x86-64 assembly implemen-tations heavily use registers. In theDVM, the binary translatortranslates DISA instructions into x86-64 instructions duringthe execution.
Table 2 shows the results of the microbenchmarks. Fromthe results, we can see that the virtualization overhead forarithmetic, logic and memory operation of DVM is 0.1–15%over native execution on the physical host, which is compa-rable to traditional VMMs. In particular, DVM exhibits evenhigher performance than VMware on one physical host. Forthe memory microbenchmark, the time on DVM includes7.47 seconds for creating and committing the memory snap-shot for the runner.
Fig. 6. The CCMR and TH-1/GZ supercomputer.
TABLE 2Microbenchmark Results
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2253

4.2.2 Runner OverheadTask creation, scheduling, and termination are important andfrequent operations in a task execution engine. To examineDVM’s performance in this aspect, we measure the overheadof creating and executing a runner. We use one parent runnerto create 1000 new empty runners and execute these runners.To measure the overhead accurately, we force the taskingoperation to be serial by conducting the experiment using oneRComp on one compute node so that we can obtain thecompletion time of each operation.
Table 3 shows the overhead of creating and executing arunner and the time used in each step. The results show thatthe overhead of creating and executing a runner in a DVM isonly several milliseconds. The small overhead enables DVMto handle thousands of runners efficiently, and gives pro-grammers the flexibility to use a large number of runners asthey want.
4.2.3 Memory FetchingWe measure the efficiency of the memory operations acrossmultiple physical hosts by a writer-reader microbenchmark.The writer-reader microbenchmark program consists of tworunners—one, the writer, writes 64-bit integers (8 GB intotal) into the SR, and the other one, the reader, reads theseintegers from the SR. We run the writer-reader program onDVMs that consist of one or two RComps residing on one ortwo nodes respectively to check the performance of memoryfetching from the local node and the remote node through thenetwork.
Table 4 shows the results of the writer-reader microbe-nchmark. In the 1-RCompexperiment, it takes 6.85 seconds onCCMR and 5.63 seconds on TH-1/GZ for the reader to readthe data. Although providing the advanced snapshot seman-tics and keeping two versions of the pages as discussed inSection 3.2, DVM exhibits the page fault handling through-puts of and page faults handled persecond on CCMR and TH-1/GZ respectively. The additional
execution time in 2-RComp experiments is spent on the datatransmission through the network. Applying copy-on-writemay potentially further improve the performance, which isone direction of our future work.
4.2.4 Register-Based OptimizationTomeasure howmuch performance improvement a programcan achieve by using RAMRs, we develop a loop microbe-nchmark since loops are very common in programs. The loopmicrobenchmark sums 64-bit integers initerations. We implement the loop microbenchmark in DISAwith and without putting the iterator and accumulator inRAMRs. We also implement and optimize it in assemblyusing physical registers on Linux for comparison.
Table 5 shows the execution time of loop on bothDVMandnative Linux on the same compute node. From the results, wecan see that, after using RAMRs, loop uses only 18.5% of thetime of the other implementation not using RAMRs on bothCCMR and TH-1/GZ. The results also show that loop onDVM using RAMRs produces very close performance as themanually optimized one using physical registers on Linux onboth CCMR and TH-1/GZ. This indicates that the binarytranslator can generate high-quality native code and alsoverifies the low virtualization overhead of DVM.
4.3 Performance ComparisonWe run the performance evaluation programs with the samedataset on different numbers of compute nodes on the CCMRtestbed to compare DVM’s performance and scalability withX10 and Hadoop’s.
Table 6 shows the time of prime-checker on Hadoop andDVM. We scale the number of compute nodes to 16 physicalhosts. The results show that both Hadoop and DVM scalelinearly as prime-check is easy to parallelize. For simpleALU-intensiveworkloads, bothDVMandHadoop are efficient, butDVM provides slightly higher performance in spite of itsadvanced instruction set features and memory model.
Fig. 7a presents the execution time of -means on Hadoop,X10 and DVM with 1 and 16 compute nodes. The executiontime on Hadoop and X10 is 11 times more than that on DVMon 1 compute node. As shown in this evaluation, DVMquickly exhibits superiority in efficiency as the complexityof application grows. The results on 16 compute nodes showthat DVM is at least 13 times faster than Hadoop.
TABLE 3Time for Creating and Executing a Runner
TABLE 4Execution Time of the Reader Runner
TABLE 5Execution Time of Loop
TABLE 6Execution Time of Prime-Checker on HADOOP and DVM
2254 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014
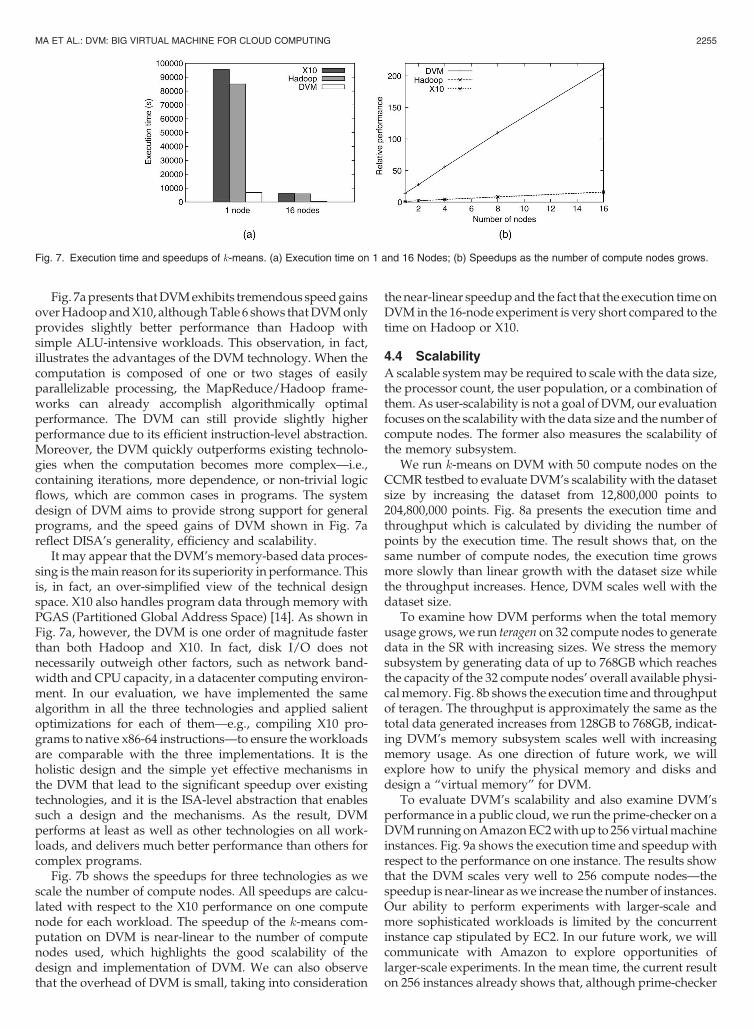
Fig. 7apresents thatDVMexhibits tremendous speedgainsoverHadoopandX10, althoughTable 6 shows thatDVMonlyprovides slightly better performance than Hadoop withsimple ALU-intensive workloads. This observation, in fact,illustrates the advantages of the DVM technology. When thecomputation is composed of one or two stages of easilyparallelizable processing, the MapReduce/Hadoop frame-works can already accomplish algorithmically optimalperformance. The DVM can still provide slightly higherperformance due to its efficient instruction-level abstraction.Moreover, the DVM quickly outperforms existing technolo-gies when the computation becomes more complex—i.e.,containing iterations, more dependence, or non-trivial logicflows, which are common cases in programs. The systemdesign of DVM aims to provide strong support for generalprograms, and the speed gains of DVM shown in Fig. 7areflect DISA’s generality, efficiency and scalability.
It may appear that the DVM’s memory-based data proces-sing is themain reason for its superiority in performance. Thisis, in fact, an over-simplified view of the technical designspace. X10 also handles program data through memory withPGAS (Partitioned Global Address Space) [14]. As shown inFig. 7a, however, the DVM is one order of magnitude fasterthan both Hadoop and X10. In fact, disk I/O does notnecessarily outweigh other factors, such as network band-width and CPU capacity, in a datacenter computing environ-ment. In our evaluation, we have implemented the samealgorithm in all the three technologies and applied salientoptimizations for each of them—e.g., compiling X10 pro-grams to native x86-64 instructions—to ensure the workloadsare comparable with the three implementations. It is theholistic design and the simple yet effective mechanisms inthe DVM that lead to the significant speedup over existingtechnologies, and it is the ISA-level abstraction that enablessuch a design and the mechanisms. As the result, DVMperforms at least as well as other technologies on all work-loads, and delivers much better performance than others forcomplex programs.
Fig. 7b shows the speedups for three technologies as wescale the number of compute nodes. All speedups are calcu-lated with respect to the X10 performance on one computenode for each workload. The speedup of the -means com-putation on DVM is near-linear to the number of computenodes used, which highlights the good scalability of thedesign and implementation of DVM. We can also observethat the overhead of DVM is small, taking into consideration
the near-linear speedup and the fact that the execution time onDVM in the 16-node experiment is very short compared to thetime on Hadoop or X10.
4.4 ScalabilityA scalable systemmay be required to scale with the data size,the processor count, the user population, or a combination ofthem. As user-scalability is not a goal of DVM, our evaluationfocuses on the scalabilitywith the data size and the number ofcompute nodes. The former also measures the scalability ofthe memory subsystem.
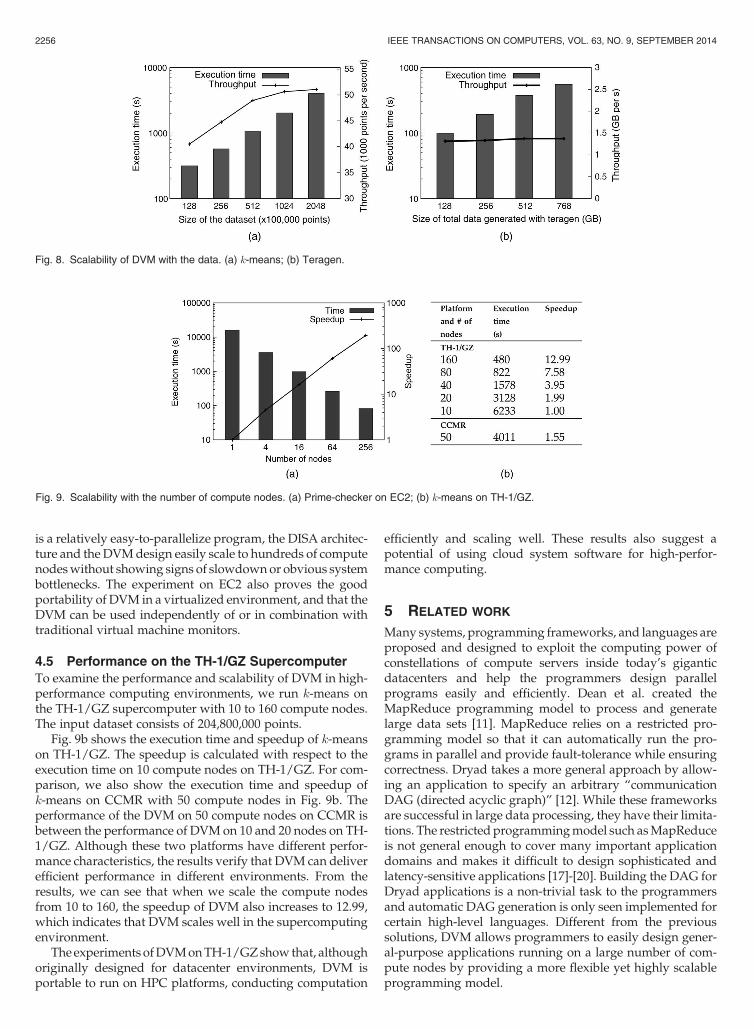
We run -means on DVM with 50 compute nodes on theCCMR testbed to evaluate DVM’s scalability with the datasetsize by increasing the dataset from 12,800,000 points to204,800,000 points. Fig. 8a presents the execution time andthroughput which is calculated by dividing the number ofpoints by the execution time. The result shows that, on thesame number of compute nodes, the execution time growsmore slowly than linear growth with the dataset size whilethe throughput increases. Hence, DVM scales well with thedataset size.
To examine how DVM performs when the total memoryusage grows, we run teragen on 32 compute nodes to generatedata in the SR with increasing sizes. We stress the memorysubsystem by generating data of up to 768GB which reachesthe capacity of the 32 compute nodes’ overall available physi-calmemory. Fig. 8b shows the execution time and throughputof teragen. The throughput is approximately the same as thetotal data generated increases from 128GB to 768GB, indicat-ing DVM’s memory subsystem scales well with increasingmemory usage. As one direction of future work, we willexplore how to unify the physical memory and disks anddesign a “virtual memory” for DVM.
To evaluate DVM’s scalability and also examine DVM’sperformance in a public cloud, we run the prime-checker on aDVMrunningonAmazonEC2withup to 256 virtualmachineinstances. Fig. 9a shows the execution time and speedup withrespect to the performance on one instance. The results showthat the DVM scales very well to 256 compute nodes—thespeedup is near-linear aswe increase the number of instances.Our ability to perform experiments with larger-scale andmore sophisticated workloads is limited by the concurrentinstance cap stipulated by EC2. In our future work, we willcommunicate with Amazon to explore opportunities oflarger-scale experiments. In the mean time, the current resulton 256 instances already shows that, although prime-checker
Fig. 7. Execution time and speedups of -means. (a) Execution time on 1 and 16 Nodes; (b) Speedups as the number of compute nodes grows.
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2255
is a relatively easy-to-parallelize program, the DISA architec-ture and the DVMdesign easily scale to hundreds of computenodeswithout showing signs of slowdownor obvious systembottlenecks. The experiment on EC2 also proves the goodportability of DVM in a virtualized environment, and that theDVM can be used independently of or in combination withtraditional virtual machine monitors.
4.5 Performance on the TH-1/GZ SupercomputerTo examine the performance and scalability of DVM in high-performance computing environments, we run -means onthe TH-1/GZ supercomputer with 10 to 160 compute nodes.The input dataset consists of 204,800,000 points.
Fig. 9b shows the execution time and speedup of -meanson TH-1/GZ. The speedup is calculated with respect to theexecution time on 10 compute nodes on TH-1/GZ. For com-parison, we also show the execution time and speedup of-means on CCMR with 50 compute nodes in Fig. 9b. The
performance of the DVM on 50 compute nodes on CCMR isbetween the performance of DVM on 10 and 20 nodes on TH-1/GZ. Although these two platforms have different perfor-mance characteristics, the results verify that DVM can deliverefficient performance in different environments. From theresults, we can see that when we scale the compute nodesfrom 10 to 160, the speedup of DVM also increases to 12.99,which indicates that DVM scales well in the supercomputingenvironment.
The experiments ofDVMonTH-1/GZshow that, althoughoriginally designed for datacenter environments, DVM isportable to run on HPC platforms, conducting computation
efficiently and scaling well. These results also suggest apotential of using cloud system software for high-perfor-mance computing.
5 RELATED WORK
Many systems, programming frameworks, and languages areproposed and designed to exploit the computing power ofconstellations of compute servers inside today’s giganticdatacenters and help the programmers design parallelprograms easily and efficiently. Dean et al. created theMapReduce programming model to process and generatelarge data sets [11]. MapReduce relies on a restricted pro-gramming model so that it can automatically run the pro-grams in parallel and provide fault-tolerance while ensuringcorrectness. Dryad takes a more general approach by allow-ing an application to specify an arbitrary “communicationDAG (directed acyclic graph)” [12]. While these frameworksare successful in large data processing, they have their limita-tions. The restricted programmingmodel such asMapReduceis not general enough to cover many important applicationdomains and makes it difficult to design sophisticated andlatency-sensitive applications [17]-[20]. Building the DAG forDryad applications is a non-trivial task to the programmersand automatic DAG generation is only seen implemented forcertain high-level languages. Different from the previoussolutions, DVM allows programmers to easily design gener-al-purpose applications running on a large number of com-pute nodes by providing a more flexible yet highly scalableprogramming model.
Fig. 8. Scalability of DVM with the data. (a) -means; (b) Teragen.
Fig. 9. Scalability with the number of compute nodes. (a) Prime-checker on EC2; (b) -means on TH-1/GZ.
2256 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014

As another approach, new languages may help program-mers write clearer, more compact and more expressiveprograms on a cluster. High-level languages, such as Sawzalland DryadLINQ, which are implemented on top of program-ming frameworks (MapReduce and Dryad), make the data-processing programs easier to design [15], [16]. However,these languages also suffer from the limitation of the under-lying application frameworks. Charles et al. design X10 towrite parallel programs in non-uniform cluster computingsystem, taking both performance and productivity as its goals[14]. The language-level approach gives the programmersmore precise control of the semantics of parallelization andsynchronization. DVM provides a lower-level abstraction byintroducing a new ISA—DISA. On top of DISA, we mayimplement various programming languages easily usingDVM’s parallelization and concurrency control mechanismalong with the shared memory model.
Different from the frameworks and languages that makethe data communication transparent to programmers, mes-sage passing-based technologies [42] require that the pro-grammer handle the communication explicitly [43]. This cansimplify the system design and improve scalability, but oftenimposes extra burden on programmers. In contrast, the dis-tributed shared memory (DSM) keeps the data transmissionamong computers transparent toprogrammers [44]. TheDSMsystems, such as Ivy [26] and Treadmark [25], combine theadvantages of “shared-memory systems” and “distributed-memory systems” to provide a simple programming modelby hiding the communication mechanisms [44], but incur acost in maintaining memory coherence across multiple com-puters. In order to reduce overhead and enhance scalability,DVM provides snapshotted memory, and the memory con-sistency model of DISA permits concurrent accessesoptimistically.
In contrast to the traditional ways of providing DSM inmiddleware which provide a limited illusion of sharedmemory, vNUMA uses virtualization technology to buildshared-memory multiprocessor (SMM) system and providesa single system image (SSI) on top of workstations connectedthrough anEthernet network that provides “causally-ordereddelivery” [10]. This also differs from widely used virtualiza-tion systems, such as Xen and VMware on the x86 ISA, whichdivide the resources of a single physical host into multiplevirtual machines [4], [6]. Both vNUMA and the emerging“inverse virtualization” [45] aim to merge a number of com-pute nodes to be one largermachine. Different from vNUMA,which is designed to be used on small clusters [10], DVMvirtualizes a large number of nodes in large clusters at the ISAlevel and allows programs to scale up to many logic flows.
6 CONCLUSION
Cloud computing is an emerging and important computingparadigm backed by datacenters. However, developing ap-plications running in datacenters is challenging. We designand implement DVM—a big virtual machine that is general,efficient, scalable, portable and easy-to-program—as an ap-proach to developing a next-generation computing technolo-gy for cloud computing. Giving programmers an illusion of a“big machine”, we design the DISA as the programminginterface and abstraction of DVM. We evaluate DVM on
research and public clusters, and show that DVM is one orderof magnitude faster than Hadoop and X10 for moderatelycomplex applications, and can scale to hundreds ofcomputers.
ACKNOWLEDGMENTS
This work was supported in part by the HKUST researchgrants REC09/10.EG06, DAG11EG04G and SJTU grant2011GZKF030902. The authors thank the Amazon AWS re-search grant and the Guangzhou Supercomputing Center forthe support in the EC2 and TH-1/GZ based evaluation.
REFERENCES
[1] Amazon Elastic Compute Cloud–EC2, http://aws.amazon.com/ec2/, 8 Oct. 2012.
[2] Rackspace, http://www.rackspace.com/, 8 Oct. 2012.[3] Windows Azure, http://www.windowsazure.com/, 8 Oct. 2012.[4] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho,
R. Neugebauer, I. Pratt, and A. Warfield, “Xen and the Art ofVirtualization,” Proc. Symp. Operating Systems Principles (SOSP’03),pp. 164-177, 2003.
[5] A. Kivity, Y. Kamay, D. Laor, U. Lublin, and A. Liguori, “KVM:The Linux Virtual Machine Monitor,” Proc. Linux Symp., vol. 1,pp. 225-230, 2007.
[6] C.A. Waldspurger, “Memory Resource Management in VMwareESX Server,” SIGOPSOperating Systems Rev., vol. 36, no. SI, pp. 181-194, 2002.
[7] R. Buyya, T. Cortes, and H. Jin, “Single System Image,” Int’l J. HighPerformance Computing Applications, vol. 15, no. 2, p. 124, 2001.
[8] D. Nurmi, R. Wolski, C. Grzegorczyk, G. Obertelli, S. Soman,L. Youseff, and D. Zagorodnov, “The Eucalyptus Open-SourceCloud-Computing System,” Proc. 9th IEEE/ACM Int’l Symp. ClusterComputing and the Grid, pp. 124-131, 2009.
[9] L. Barroso and U. Hölzle, “The Datacenter as a Computer: AnIntroduction to theDesign ofWarehouse-ScaleMachines,” SynthesisLectures on Computer Architecture, vol. 4, no. 1, pp. 1-108, 2009.
[10] M. Chapman and G. Heiser, “vNUMA: A Virtual Shared-MemoryMultiprocessor,” Proc. USENIX Ann. Technical Conf. (ATC’09),pp. 15-28, 2009.
[11] J. Dean and S. Ghemawat, “MapReduce: SimplifiedData Processingon Large Clusters,” Proc. 6th Symp. Operating Systems Design andImplementation (OSDI’04), pp. 137-150, 2004.
[12] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly, “Dryad:Distributed Data-Parallel Programs from Sequential BuildingBlocks,” Proc. EuroSys Conf. (EuroSys’07), pp. 59-72, 2007.
[13] E. Allen et al., The Fortress Language Specification, https://labs.oracle.com/projects/plrg/fortress.pdf, 8 Oct. 2012.
[14] P. Charles, C. Grothoff, V. Saraswat, C. Donawa, A. Kielstra,K. Ebcioglu, C. Von Praun, andV. Sarkar, “X10: AnObject-OrientedApproach to Non-Uniform Cluster Computing,” ACM SIGPLANNotices, vol. 40, no. 10, pp. 519-538, 2005.
[15] R. Pike, S. Dorward, R. Griesemer, and S. Quinlan, “Interpreting theData: Parallel Analysis with Sawzall,” Scientific Programming,vol. 13, no. 4, pp. 277-298, 2005.
[16] Y. Yu, M. Isard, D. Fetterly, M. Budiu, Ú. Erlingsson, P.K. Gunda,and J. Currey, “DryadLINQ: A System for General-Purpose Distrib-utedData-Parallel ComputingUsing aHigh-Level Language,”Proc.Operating Systems Design and Implementation (OSDI’08), pp. 1-14,2008.
[17] Z. Ma and L. Gu, “The Limitation of MapReduce: A Probing Caseand a Lightweight Solution,” Proc. 1st Int’l Conf. Cloud Computing,GRIDs, and Virtualization, pp. 68-73, 2010.
[18] J. Ekanayake, S. Pallickara, and G. Fox, “MapReduce for DataIntensive Scientific Analysis,” Proc. 4th IEEE Int’l Conf. eScience,pp. 277-284, 2008.
[19] C. Ranger, R. Raghuraman, A. Penmetsa, G. Bradski, andC. Kozyrakis, “Evaluating MapReduce for Multi-Core and Multi-processor Systems,”Proc. 13th Int’l Symp.High PerformanceComputerArchitecture, pp. 13-24, 2007.
[20] H.-C. Yang, A. Dasdan, R.-L. Hsiao, andD.S. Parker, “Map-Reduce-Merge: Simplified Relational Data Processing on Large Clusters,”Proc. Int’l Conf. Management of Data (SIGMOD’07), pp. 1029-1040,2007.
MA ET AL.: DVM: BIG VIRTUAL MACHINE FOR CLOUD COMPUTING 2257

[21] B. Chamberlain, D. Callahan, and H. Zima, “Parallel Programma-bility and the Chapel Language,” Int’l J. High Performance ComputingApplications, vol. 21, no. 3, p. 291, 2007.
[22] Z. Ma, Z. Sheng, L. Gu, L. Wen, and G. Zhang, “DVM: Towards aDatacenter-Scale Virtual Machine,” Proc. 8th Ann. Int’l Conf. VirtualExecution Environments, pp. 39-50, 2012.
[23] S.V. Adve and K. Gharachorloo, “Shared Memory ConsistencyModels: A Tutorial,” Computer, vol. 29, no. 12, pp. 66-76, Aug. 1996.
[24] H. Berenson, P. Bernstein, J. Gray, J.Melton, E. O'Neil, and P.O'Neil,“ACritique of ANSI SQL Isolation Levels,” Proc. Int’l Conf. Manage-ment of Data (SIGMOD’95), pp. 1-10, 1995.
[25] P. Keleher, A. Cox, S. Dwarkadas, andW. Treadmarks, “DistributedShared Memory on Standard Workstations and OperatingSystems,” Proc. 1994 Winter USENIX Conf., pp. 115-131, 1994.
[26] K. Li and P. Hudak, “MemoryCoherence in SharedVirtualMemorySystems,” ACM Trans. Computer Systems, vol. 7, no. 4, pp. 321-359,1989.
[27] S. Ghemawat, H. Gobioff, and S.-T. Leung, “The Google FileSystem,” Proc. Symp. Operating Systems Principles (SOSP’03),pp. 29-43, 2003.
[28] C. Tseng, “CompilerOptimizations for EliminatingBarrier Synchro-nization,” ACM SIGPLAN Notices, vol. 30, no. 8, pp. 144-155, 1995.
[29] D.-K. Chen, H.-M. Su, and P.-C. Yew, “The Impact of Synchroniza-tion andGranularity onParallel Systems,”Proc. 17thAnn. Int’l Symp.Computer Architecture, pp. 239-248, 1990.
[30] K. Birman, G. hockler, and R. van Renesse, “Toward a CloudComputing Research Agenda,” SIGACT News, vol. 40, no. 2,pp. 68-80, 2009.
[31] M. Herlihy and J.E.B. Moss, “Transactional Memory: ArchitecturalSupport for Lock-Free Data Structures,” Proc. 20th Ann. Int’l Symp.Computer Architecture, pp. 289-300, 1993.
[32] X. Yang, X. Liao, K. Lu, Q. Hu, J. Song, and J. Su, “The TianHe-1ASupercomputer: ItsHardwareandSoftware,” J. Computer Science andTechnology, vol. 26, no. 3, pp. 344-351, 2011.
[33] TOP500 Supercomputer Sites, TOP500 List, http://www.top500.org/list/2012/06/100, 8 Oct. 2012.
[34] B. He, W. Fang, Q. Luo, N. Govindaraju, and T. Wang, “Mars: AMapreduce Framework on Graphics Processors,” Proc. 17th Int’lConf. Parallel Architectures and Compilation Techniques, pp. 260-269,2008.
[35] T. Condie,N.Conway, P.Alvaro, J.Hellerstein,K. Elmeleegy, andR.Sears, “MapReduce Online,” Proc. 7th USENIX Conf. NetworkedSystems Design and Implementation, pp. 21-21, 2010.
[36] Apache Hadoop, PoweredBy, http://wiki.apache.org/hadoop/PoweredBy, 8 Oct. 2012.
[37] J. MacQueen, “Some Methods for Classification and Analysis ofMultivariate Observations,” Proc. 5th Berkeley Symp. Math. Statisticsand Probability, vol. 1, pp. 281-297, 1967.
[38] H. Jégou,M.Douze, andC. Schmid, “ImprovingBag-of-Features forLarge Scale Image Search,” Int’l J. Computer Vision, vol. 87, no. 3,pp. 316-336, 2010.
[39] D. Lee, S. Baek, and K. Sung, “Modified k-means Algorithm forVectorQuantizerDesign,” IEEESignal ProcessingLetters, vol. 4, no. 1,pp. 2-4, 1997.
[40] R. Zhang and A. Rudnicky, “A Large Scale Clustering Schemefor Kernel k-Means,” Proc. 16th Int’l Conf. Pattern Recognition,pp. 289-292, 2002.
[41] Sort Benchmark, http://sortbenchmark.org/, 8 Oct. 2012.[42] Message Passing Interface Forum, MPI: A Message-Passing Interface
Standard, http://www.mpi-forum.org/docs/mpi-2.2/mpi22-report.pdf, 8 Oct. 2012.
[43] H. Lu, S. Dwarkadas, A. Cox, and W. Zwaenepoel, “MessagePassing Versus Distributed Shared Memory on Networks of Work-stations,” Proc. IEEE/ACM Supercomputing 95 Conf., p. 37, 1995.
[44] B. Nitzberg and V. Lo, “Distributed Shared Memory: A Survey ofIssues and Algorithms,” Computer, vol. 24, no. 8, pp. 52-60, 1991.
[45] B. Hedlund, Inverse Virtualization for Internet Scale Applications,http://bradhedlund.com/2011/03/16/inverse-virtualization-for-internet-scale-applications/, 8 Oct. 2012.
ZhiqiangMa received theBSdegree fromFudanUniversity, Shanghai, China in 2009. He is cur-rently a postgraduate student working toward thePhD degree in computer science and engineeringin the Department of Computer Science andEngineering at the Hong Kong University ofScience and Technology (HKUST), Hong Kong.His current research focuses on large-scale dis-tributed computing, data processing, and storagesystems for cloud computing.
Zhonghua Sheng received the BS degree fromHarbin Engineering University, Harbin, China, theMS degree from Harbin Institute of Technology,and the MPhil degree from the Hong Kong Uni-versity of Science and Technology (HKUST),Hong Kong in 2012. He conducted research onlarge-scale parallel computing and storage sys-tems for cloud computing during his study atHKUST.
Lin Gu received the BS degree from Fudan Uni-versity, Shanghai, China, the MS degree fromPeking University, Beijing, China, and the PhDdegree in computer science from the Universityof Virginia. He is an assistant professor in theDepartment of Computer Science and Engineer-ing at the Hong Kong University of Science andTechnology (HKUST), Honk Kong. His researchinterest includes cloud computing, operating sys-tems, computer networks, and wireless sensornetworks.
▽ For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
2258 IEEE TRANSACTIONS ON COMPUTERS, VOL. 63, NO. 9, SEPTEMBER 2014