draw: deep recurrent attentive writer
TRANSCRIPT

DRAW
PresentedbyMarkChang
1

OriginalPaper
• Title:– DRAW:ARecurrentNeuralNetworkForImageGeneraEon
• Authors:– KarolGregor,IvoDanihelka,AlexGraves,DaniloJimenezRezendeandDaanWierstra
• OrganizaEon:– GoogleDeepMind
• URL:– hNps://arxiv.org/pdf/1502.04623v2.pdf
2

Outline
• ImageGeneraEon– DiscriminaEveModel– GeneraEveModel– WhatisDRAW?
• BackgroundKnowledge– NeuralNetworks– Autoencoder– VariaEonalAutoencoder– RecurrentNeuralNetworks– LongShort-termMemory
• DRAW– NetworkArchitecture– SelecEveANenEonModel– TrainingDRAW– GeneraEngNewImages– Experiments
3

ImageGeneraEon
• DiscriminaEveModel• GeneraEveModel• WhatisDRAW?
4

DiscriminaEveModel
model trainingdata Theyare5.
Theyare7.
Thisis7.
tesEngdata
a_ertraining
Isthis5or7?
5

DiscriminaEveModel
lowdimensionalspace
highdimensionalspace
discriminaEvemodel
featureextracEon
otherexample
6

GeneraEveModel
model trainingdata Theyare5.
Theyare7.
Drawa7,please.
a_ertraining
7

GeneraEveModel
lowdimensionalspace
highdimensionalspace
GeneraEvemodel
generatenew
example otherexample
8

WhatisDRAW?
• GeneraEveModelforImageGeneraEon:– DeepConvoluEonalGeneraEveAdversarialNetworks(DCGAN)
– PixelRecurrentNeuralNetworks(PixelRNN)– DeepRecurrentANenEveWriter(DRAW)
9

WhatisDRAW?
Youcan’tcaptureallthedetailsatonce.
image
reconstructtheimage
feeditintothemodel
model
10

WhatisDRAW?
reconstructtheimage“stepbystep”
DeepRecurrentANenEveWriter(DRAW)
aNenEon
reconstructtheimage
resultmodel
11

BackgroundKnowledge
• NeuralNetworks• Autoencoder
• VariaEonalAutoencoder• RecurrentNeuralNetworks• LongShort-termMemory
12

BackgroundKnowledge
13
Autoencoder
VariaEonalAutoencoder
RecurrentNeuralNetworks
LongShort-termMemory
NeuralNetworks
generatenewexample
lowdimensionalspace
highdimensionalspace
reconstructtheimage“stepbystep”
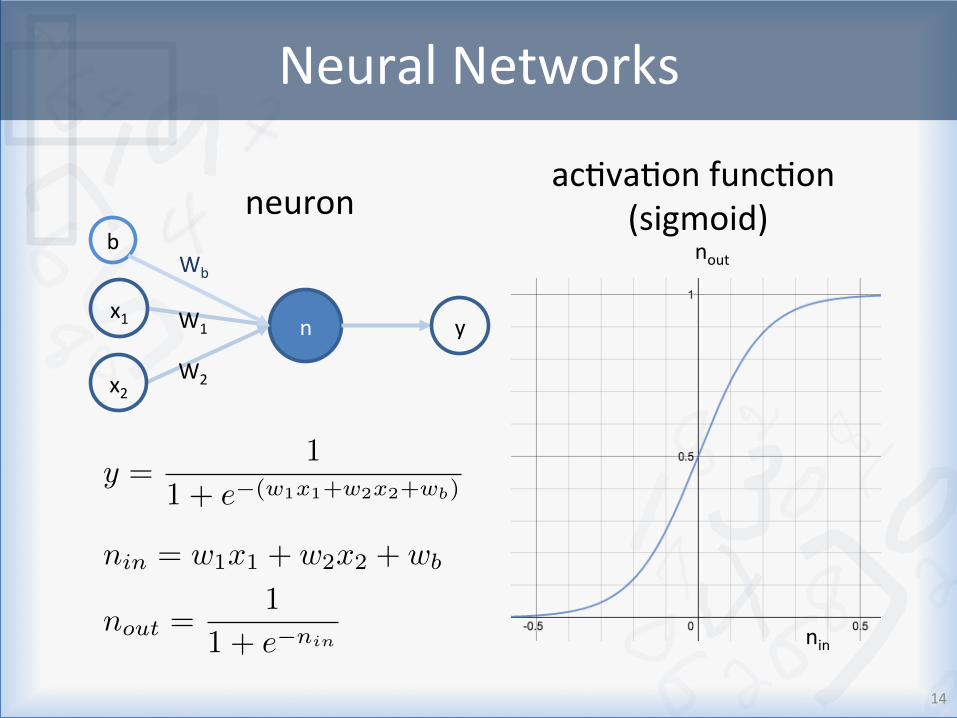
NeuralNetworks
n W1
W2
x1
x2
b Wb
y
n
in
= w1x1 + w2x2 + w
b
n
out
=1
1 + e
�nin nin
nout
y =1
1 + e�(w1x1+w2x2+wb)
neuronacEvaEonfuncEon
(sigmoid)
14

nout
= 1
nout
= 0.5
nout
= 0(0,0)
x2
x1
Neuron
n
in
= w1x1 + w2x2 + w
b
n
out
=1
1 + e
�nin
n
in
= w1x1 + w2x2 + w
b
n
out
=1
1 + e
�nin
w1x1 + w2x2 + wb = 0
w1x1 + w2x2 + wb > 0
w1x1 + w2x2 + wb < 0
1
0
inputsignal outputsignal
15

ANDGate
x1 x2 y
0 0 0
0 1 0
1 0 0
1 1 1 (0,0)
(0,1) (1,1)
(1,0)
0
1
n 20 20
b-30
y x1
x2
y =1
1 + e�(20x1+20x2�30)
20x1 + 20x2 � 30 = 0
16

XORGate?
(0,0)
(0,1) (1,1)
(1,0)
0
0 1
x1 x2 y
0 0 0
0 1 1
1 0 1
1 1 0
17

XORGate
n
-20
20
b
-10
y
(0,0)
(0,1) (1,1)
(1,0)
0 1
(0,0)
(0,1) (1,1)
(1,0)
1 0
(0,0)
(0,1) (1,1)
(1,0) 0
0 1
n1 20 20
b-30
x1
x2
n2 20 20
b-10
x1
x2
x1 x2 n1 n2 y
0 0 0 0 0
0 1 0 1 1
1 0 0 1 1
1 1 1 1 0
18

NeuralNetworks
x
y
n11
n12
n21
n22 W12,y
W12,x
b
W11,y
W11,b W12,b
b
W11,x W21,11
W22,12
W21,12
W22,11
W21,b W22,b
z1
z2
InputLayer
HiddenLayer
OutputLayer
19

TrainingNeuralNetworks
75
Inputs: Outputs:
60%
40%
75 100%
Golden: y
p(y|x)x
J = �log(p(y|x))
w = w � ⌘
@log(p(y|x))@w
forwardpropagaEon
backwardpropagaEon
lossfuncEon
20

TrainingNeuralNetworks
w w
21
p(y|x) ⇡ 1
p(y|x) ⇡ 0
J = �log(p(y|x))

TrainingNeuralNetworks
LearningRate22
gradientdescent
w = w � ⌘
@log(p(y|x))@w
�@log(p(y|x))@w

TrainingNeuralNetworks
23
Goldenis1
Goldenis0
p(y|x)
y
y
w = w � ⌘
@log(p(y|x))@w
x

TrainingNeuralNetworks
24

BackwardPropagaEon
n2 n1 JCost
funcEon:
n2(out) n2(in) w21
25
@J
@w21=
@J
@n2(out)
@n2(out)
@n2(in)
@n2(in)
@w21
w21 w21 � ⌘@J
@w21
w21 w21 � ⌘@J
@n2(out)
@n2(out)
@n2(in)
@n2(in)
@w21

Autoencoder
input output
encode decode
x
h(x)
x̂ = g(h(x))
smallerhiddenlayer
samesize
26

Autoencoder
inputx
lowdimensional
spacehigh
dimensionalspace
h(x)encode
encode
decode
decode
outputx̂ = g(h(x))
27

VariaEonalInference
Intractabletocompute
observabledata:
x
latentspace:z
p(z|x) = p(z,x)
p(x)=
p(x|z)p(z)Rp(x|z)p(z)dz
p(x|z) canbeeasilycomputed.
28

VariaEonalAutoencoder
VariaEonalInference:1.Approximate by2.MinimizetheKLDivergence:
p(z|x) q(z)
DKL[q(z)||p(z|x)] =Z
q(z)logq(z)
p(z|x)dz
hNps://www.youtube.com/playlist?list=PLeeHDpwX2Kj55He_jfPojKrZf22HVjAZY
29

EncoderNetworks
DecoderNetworks
VariaEonalAutoencoder
p✓(x|z)
✏ ⇠ N (0, I)
x
z = µ+ �✏z
inputx̂
output
µ �
SamplingnormaldistribuEonN (µ,�)
g�(µ,�|x)
30

VariaEonalAutoencoder
encode
lowdimensionalspace
encode
decode
decode
decode
x
µ,�
z = µ+ �✏✏ ⇠ N (0, I)
z
x̂
normaldistribuEon
Sampling
input
output
N (µ,�)
highdimensional
space31

RecurrentNeuralNetwork
Thisisacat. Thisisacat.
ThisisaThis Thisis
modelwithmemory
Thisisacat.
32

RecurrentNeuralNetwork
n
in,t
= w
c
x
t
+ w
p
n
out,t�1 + w
b
n
out,t
=1
1 + e
�nin,t
Theoutputisfeedbackintotheinput.
n Wc
b Wb
xt
yt nout,t nin,t
Wp
33

RecurrentNeuralNetwork
This
is n(n(This),is)
n(This)
a n(n(n(This),is),a)
n Wc
b Wb
xt yt nout,t nin,t
Wp
n Wc
b Wb
xt yt nout,t nin,t
Wp
n Wc
b Wb
xt yt nout,t nin,t
Wp
34

Theblackdogischasingthewhitecat.
RecurrentNeuralNetwork
QuesEon:whatisthecolorofthedogchasingthecat?
Thememoryislimited,soitcan’tremembereverything.
35
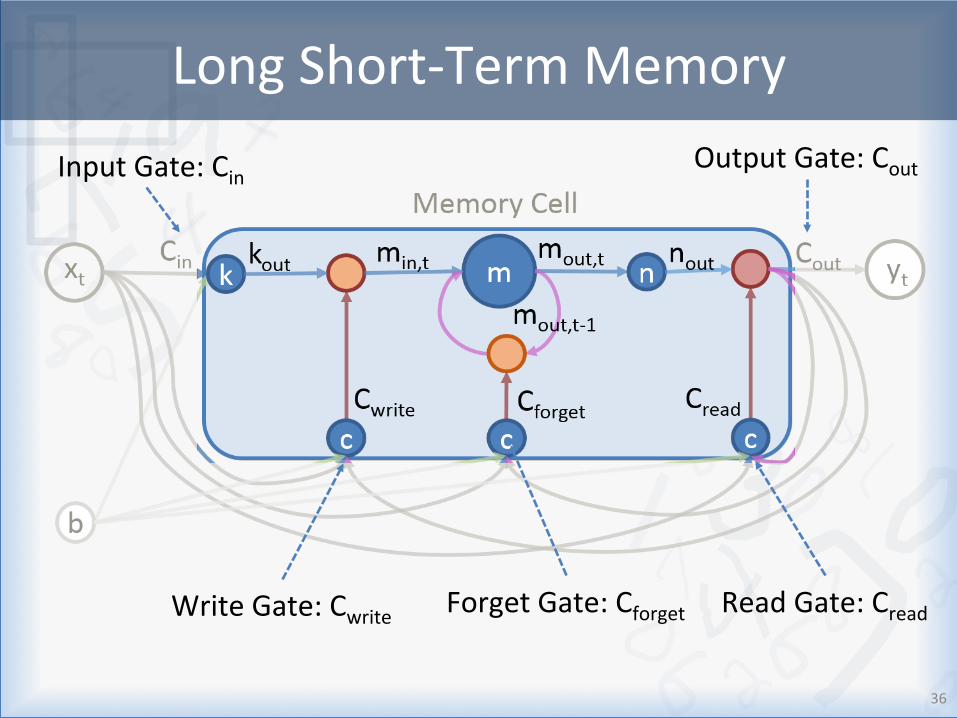
LongShort-TermMemory
InputGate:Cin
ReadGate:Cread ForgetGate:Cforget WriteGate:Cwrite
OutputGate:Cout
36
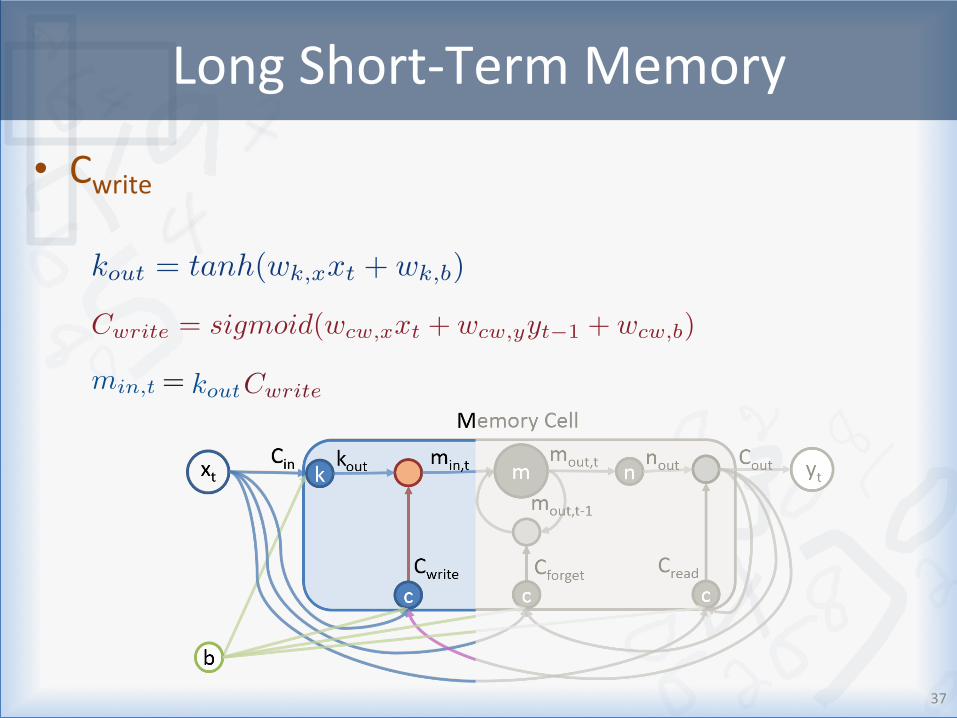
LongShort-TermMemory
• Cwrite
C
write
= sigmoid(wcw,x
x
t
+ w
cw,y
y
t�1 + w
cw,b
)
min,t = kout
Cwrite
k
out
= tanh(wk,x
x
t
+ w
k,b
)
37

LongShort-TermMemory
• Cforget
C
forget
= sigmoid(wcf,x
x
t
+ w
cf,y
y
t
+ w
cf,b
)
mout,t = min,t +C
forget
mout,t�1
38

LongShort-TermMemory
• Cread
C
read
= sigmoid(wcr,x
x
t
+ w
cr,y
y
t�1 + w
cr,b
)
Cout
nout
= Cread
nout
= tanh(mout,t
)
39

Theblackdogischasingthewhitecat.
LongShort-TermMemory
QuesEon:whatisthecolorofthedogchasingthecat?
ItkeepsthemostimportantinformaEoninitsmemory.
blackdogchasingcat
40

DRAW
• NetworkArchitecture• SelecEveANenEonModel
• TrainingDRAW• GeneraEngNewImages
• Experiments
41

NetworkArchitecture
zt ⇠ Q(Zt|henct )
henct = RNNenc(henc
t�1, [rt, hdect�1])
hdect = RNNdec(hdec
t�1, zt)
ct = ct�1 + write(hdect )
rt = read(x, x̂t, hdect�1)
RNNdec
x
henct
zt
ct�1 ct
hdect�1
RNNenc
x̂t
RNNdec
RNNenc
henct�1
inputimage
sampling
canvas
hdect
x̂t = x� sigmoid(ct�1)
42

NetworkArchitecturex
hdect
henct
zt
ct�1 ct
hdect�1
RNNenc
x̂t
RNNdec
RNNenc
henct�1
x
zt+1
henct+1
hdect+1
ct+1
x̂t+1
RNNenc
RNNdec
cT
sigmoid
RNNdec
P (x|z1:T )
outputimage
inputimage
canvas
43

X
A
B
Y
N = 3
SelecEveANenEonModel
(gX , gY )
centreofthegrid
centreofthefilter1,2(µ1
X , µ2Y )
µiX = gX + (i�N/2� 0.5)�
µjY = gY + (i�N/2� 0.5)�
�
µ1X = gX + (1� 1.5� 0.5)�
= gX � �
µ2Y = gY + (2� 1.5� 0.5)�
= gY
N×NgridofGaussianfiltersdistancebetweenthefilters
44

SelecEveANenEonModel
(gX , gY )X
A
B
Y
(µ1X , µ2
Y )
N = 3
�
(g̃X , g̃Y , log�2, log˜�, log�) = W (hdec
)
gX =A+ 1
2(g̃X + 1)
gY =B + 1
2(g̃Y + 1)
� =max(A,B)� 1
N � 1�̃
parametersaredeterminedbyhdec
�
varianceoftheGaussianfilters
45

SelecEveANenEonModel
FY [i, b] =1
ZYexp(� (b� µi
Y )2
2�2)
horizontalandverEcalfilterbankmatrices
FX [i, a] =1
ZXexp(� (a� µi
X)
2
2�2)
A
B
FXFX [1, :]
FX [2, :]
FX [3, :]
horizontalfilterbankmatrix
verEcalfilterbankmatrix
FTY
FY [1, :]T FY [2, :]
T FY [3, :]T
46

SelecEveANenEonModel
read(x, x̂t, hdect�1) = �[FY xF
TX , FY x̂tF
TX ]
N
N
intensity horizontalfilterbankmatrix
verEcalfilterbankmatrix
FY FTXx
N
A
B
FY xFTX
47

SelecEveANenEonModel
(g̃0X , g̃0Y , log�02, log˜�0, log�0, wt) = W (hdec
)
write(hdect ) =
1
�̂F 0TY wtF
0X
F 0TY F 0
X
AB
wt
A
B
F 0TY wtF
0X
48

TrainingDRAW
reconstrucEonloss
BernoullidistribuEonD(x|c
T
) = P (x|z1:T )x(1� P (x|z1:T ))1�x
Lx
= �logD(x|cT
)
= �⇣xlogP (x|z1:T ) + (1� x)log
�1� P (x|z1:T )
�⌘
P (x|z1:T )
pixelatposiEoni,j
xi,j = P (x|z1:T )i,j) �logD(x|cT )i,j = 0
P (x|z1:T )i,j
xi,j
x
xi,j 6= P (x|z1:T )i,j) �logD(x|cT )i,j = 1
49

TrainingDRAW
Lz =TX
t=1
KL⇣Q(Zt|henc
t )||P (Zt)⌘
latentloss(regularizaEon)
Q(Zt|henct ) = N (Zt|µt,�t)
P (Zt) = N (Zt|0, 1)
Lz=
1
2
⇣ TX
t=1
µ2t + �2
t � log�2t
⌘� T
2
prior
henct
RNNenc
Q(Zt|henct )
W (henct )
µt,�t
P (Zt)
Qshouldbeassimpleaspossible
50

TrainingDRAW
L = Lx + Lz
totalloss=reconstrucEonloss+latentloss
w w � ⌘@L@w
gradientdescent
51
reconstrucEonandxshouldbeassimilaraspossible.
zshouldbeassimpleaspossible.

GeneraEngNewImages
z̃t ⇠ P (Zt)
h̃dect = RNNdec(h̃dec
t�1, z̃t)
c̃t = c̃t�1 + write(h̃dect )
x̃ ⇠ D(X|c̃T )
RNNdecRNNdec
canvas
D
z̃t
h̃dect
c̃t
c̃T
c̃t�1
h̃dect�1
52

Experiments
MNIST
hNps://www.youtube.com/watch?v=Zt-7MI9eKEo
generateddata trainingdata
53

Experiments
SVHN
hNps://www.youtube.com/watch?v=Zt-7MI9eKEo
generateddata trainingdata
54

Experiments
CIFAR
hNps://www.youtube.com/watch?v=Zt-7MI9eKEo
generateddata trainingdata
55

FurtherReading• NeuralNetworkBackPropagaEon:– hNp://cpmarkchang.logdown.com/posts/277349-neural-network-backward-propagaEon
• VariaEonalAutoencoder:– hNps://arxiv.org/abs/1312.6114– hNps://www.youtube.com/playlist?list=PLeeHDpwX2Kj55He_jfPojKrZf22HVjAZY
• DRAW– hNps://arxiv.org/pdf/1502.04623v2.pdf
• DCGAN– hNps://arxiv.org/abs/1511.06434
56

SourceCode
• hNps://github.com/ericjang/draw
57

AbouttheSpeaker
• Email:ckmarkohatgmaildotcom• Blog:hNp://cpmarkchang.logdown.com• Github:hNps://github.com/ckmarkoh
MarkChang
• Facebook:hNps://www.facebook.com/ckmarkoh.chang• Slideshare:hNp://www.slideshare.net/ckmarkohchang• Linkedin:hNps://www.linkedin.com/pub/mark-chang/85/25b/847• Youtube:
hNps://www.youtube.com/channel/UCckNPGDL21aznRhl3EijRQw
58