
Learning set of rules

2Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Content
➔ Introduction Sequential Covering Algorithms Learning Rule Sets: Summary Learning First-Order Rule Learning Sets of First-Order Rules: FOIL Summary

3Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Introduction
If-Then Rules Are very expressive Easy to understand
Rules with variables: Horn-clauses Set of Horn-clauses build up a PROLOG program Learning of Horn-clauses: Inductive Logic Programming (ILP)
Example first-order rule set for the target concept Ancestor
IF Parent (x,y) THEN Ancestor (x,y)IF Parent(x,z) Ancestor(z,y) THEN Ancestor(x,y)

4Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Introduction 2 GOAL: Learning a target function as a set of IF-THEN rules BEFORE: Learning with decision trees
Learning the decision tree Translate the tree into a set of IF-THEN rules (for each leaf one rule)
OTHER POSSIBILITY: Learning with genetic algorithms Each set of rule is coded as a bitvector Several genetic operators are used on the hypothesis space
TODAY AND HERE: First: Learning rules in propositional form Second: Learning rules in first-order form (Horn clauses which include
variables) Sequential search for rules, one after the other

5Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Content
Introduction➔ Sequential Covering Algorithms
General to Specific Beam Search Variations
Learning Rule Sets: Summary Learning First-Order Rule Learning Sets of First-Order Rules: FOIL Summary

6Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Sequential Covering Algorithms
Goal of such an algorithm:Learning a disjunct set of rules, which defines a preferably good classification of the training data
Principle: Learning rule sets based on the strategy of learning one rule, removing the examples it covers, then iterating this process.
Requirement for the Learn-One-Rule method: As Input it accepts a set of positive and negative training examples As Output it delivers a single rule that covers many of the positive
examples and maybe a few of the negative examples Required: The output rule has a high accuracy but not necessarily a
high coverage

7Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Sequential Covering Algorithms 2 Procedure:
Learning set of rules invokes the Learn-One-Rule method on all of the available training examples
Remove every positive example covered by the rule Eventually short the final set of the rules: more accurate rules can be
considered first Greedy search: It is not guaranteed to find the smallest or best set
of rules that covers the training example.

8Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Sequential Covering Algorithms 3SequentialCovering( target_attribute, attributes, examples, threshold )
learned_rules { }
rule LearnOneRule( target_attribute, attributes, examples )
while (Performance( rule, examples ) > threshold ) do
learned_rules learned_rules + rule
examples examples - { examples correctly classified by rule }
rule LearnOneRule( target_attribute, attributes, examples )
learned_rules sort learned_rules according to Performance over examples
return learned_rules

9Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
General to Specific Beam Search Specialising search
Organises a hypothesis space search in general the same fashion as the ID3, but follows only the most promising branch of the tree at each step
Begin with the most general rule (no/empty precondition) Follow the most promising branch:
Greedily adding the attribute test that most improves the measured performance of the rule over the training example
Greedy depth-first search with no backtracking Danger of sub-optimal choice Reduce the risk: Beam Search (CN2-algorithm)
Algorithm maintains the list of the k best candidatesIn each search step, descendants are generated for each of these k-best candidatesThe resulting set is then reduced to the k most promising members
10Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
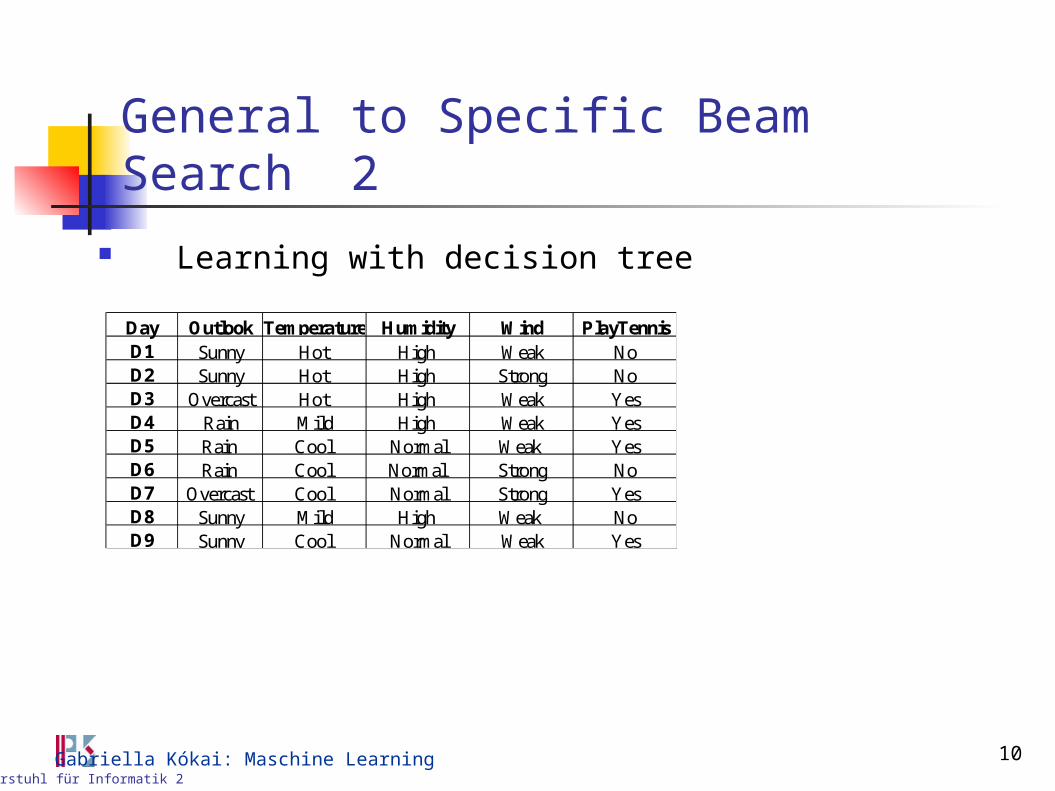
General to Specific Beam Search 2
Learning with decision tree
Day Outlook Temperature Humidity Wind PlayTennisD1 Sunny Hot High Weak NoD2 Sunny Hot High Strong NoD3 Overcast Hot High Weak YesD4 Rain Mild High Weak YesD5 Rain Cool Normal Weak YesD6 Rain Cool Normal Strong NoD7 Overcast Cool Normal Strong YesD8 Sunny Mild High Weak NoD9 Sunny Cool Normal Weak Yes

11Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
General to Specific Beam Search 3

12Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
General to Specific Beam Search 4
LearnOneRule( target_attribute, attributes, examples, k )Initialise best_hypothesis to the most general hypothesis ØInitialise candidate_hypotheses to the set { best_hypothesis }
while ( candidate_hypothesis is not empty ) do 1. Generate the next more-specific candidate_hypothesis 2. Update best_hypothesis 3. Update candidate_hypothesisreturn a rule of the form „IF best_hypothesis THEN prediction“ where prediction is the most frequent value of target_attribute among those examples that match best_hypothesis.
Performance( h, examples, target_attribute )h_examples the subset of examples that match hreturn -Entropy( h_examples ), where Entropy is with respect to target_attribute
The CN2-Algorithm

13Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
General to Specific Beam Search 5 Generate the next more specific candidate_hypothesis
' Update best_hypothesis
all_constraints set of all constraints (a = v), where a attributes and v is a value of a occuring in the current set of examplesnew_candidate_hypothesis for each h in candidate_hypotheses, for each c in all_constraints create a specialisation of h by adding the constraint c Remove from new_candidate_hypothesis any hypotheses which are duplicate, inconsistent or not maximally specific
for all h in new_candidate_hypothesis do if statistically significant when tested on examples Performance( h, examples, target_attribute ) > Performance( best_hypothesis, examples, target_attribute ) ) then best_hypothesis h

14Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
General to Specific Beam Search 6
Update the candidate-hypothesis
' Performance function guides the search in the Learn-One -RuleO s: the current set of training examples
O c: the number of possible values of the target attribute
O : part of the examples, which are classified with the ith. value
candidate_hypothesis the k best members of new_candidate_hypothesis, according to Performance function
c
i 2 ii=1
Entropy s = p log p
pi

15Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Example for CN2-AlgorithmLearnOneRule(EnjoySport, {Sky, AirTemp, Humidity, Wind, Water, Forecast, EnjoySport}, examples, 2)
best_hypothesis = Øcandidate_hypotheses = {Ø}all_constraints = {Sky=Sunny, Sky=Rainy, AirTemp=Warm, AirTemp=Cold, Humidity=Normal, Humidity=High, Wind=Strong, Water=Warm, Water=Cool, Forecast=Same, Forecast=Change}Performance = nc / nn = Number of examples, covered by the rulenc = Number of examples covered by the rule and classification is correct
Example Sky AirTemp Humidity Wind Water Forecast EnjoySport (target attribute)
1 Sunny Warm Normal Strong Warm Same Yes
2 Sunny Warm High Strong Warm Same Yes
3 Rainy Cold High Strong Warm Change No
4 Sunny Warm High Strong Cool Change Yes

16Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Example for CN2-Algorithm (2)Pass 1Remove delivers no result
Hypothese Performance candidate_hypothesis best_hypothesis
Sky=Sunny 1 x x
Sky=Rainy 0
AirTemp=Warm 1 x
AirTemp=Cold 0
Humidity=High 0.66
Humidity=Normal 1
Wind=Strong 0.75
Water=Warm 0.66
Water=Cool 1
Forecast=Same 1 candidate_hypotheses = {Sky=Sunny, AirTemp=Warm}
best_hypothesis ist Sky=Sunny

17Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Example for CN2-Algorithm (3)Pass 2Remove (duplicate, inconsistent, not maximally specific)
Hypothese Performance candidate_hyp best_hyp
Sky=Sunny AND Sky=Sunny not maximally specific
Sky=Sunny AND Sky=Rainy inconsistent
Sky=Sunny AND AirTemp=Warm 1 x
Sky=Sunny AND AirTemp=Cold undef. (n = 0)
Sky=Sunny AND Humidity=High 1 x
Sky=Sunny AND Humidity=Normal 1
Sky=Sunny AND Wind=Strong 1
Sky=Sunny AND Water=Warm 1
Sky=Sunny AND Water=Cool 1
Sky=Sunny AND Forecast=Same 1
Sky=Sunny AND Forecast=Change 0.5
AirTemp=Warm AND Sky=Sunny Duplicate (s.h. Hyp. 3)
AirTemp=Warm AND Sky=Rainy undef. (n = 0)
AirTemp=Warm AND AirTemp=Warm not maximally specific
AirTemp=Warm AND AirTemp=Cold inconsistent
AirTemp=Warm AND Humidity=High 1
AirTemp=Warm AND Humidity=Normal 1
AirTemp=Warm AND Wind=Strong 1
AirTemp=Warm AND Water=Warm 1
AirTemp=Warm AND Water=Cool 1
AirTemp=Warm AND Forecast=Same 1
AirTemp=Warm AND Forecast=Change 0.5
candidate_hypotheses = {Sky=Sunny AND AirTemp=Warm, Sky=Sunny AND Humidity=High}best_hypothesis remains Sky=Sunny

18Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Content
Introduction Sequential Covering Algorithms➔ Learning Rule Sets: Summary Learning First-Order Rule Learning Sets of First-Order Rules:FOIL Summary

19Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Rule Sets: Summary Key dimension in the design of the rule learning algorithm
Here sequential covering: learn one rule, remove the positive examples covered, iterate on the remaining examples
ID3 simultaneous covering Which one should be prefered?
Key difference: choice at the most primitive step in the searchID3: chooses among attributes by comparing the partitions of the data they generatedCN2: chooses among attribute-value pairs by comparing the subsets of data they cover
Number of choices: learn n rules each containing k attribute-value tests in their preconditionCN2: n*k primitive search stepsID3: fewer independent search steps
If the data is plentiful, then it may support the larger number of independent decisons If the data is scarce, the sharing of decisions regarding preconditions of different rules may
be more effective

20Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Rule Sets: Summary 2 CN2: general-to-specific (cf. Find-S specific-to-general)
Advantage: there is a single maximally general hypothesis from which to begin the search <=> there are many specific ones
GOLEM: choosing several positive examples at random to initialise and to guide the search. The best hypothesis obtained through multiple random choices is the selected one
CN2: generate then test Find-S, CN2, AQ and Cigol are example-driven Advantage: each choice in the search is based on the hypothesis
performance over many examples How are the rules post-pruned?

21Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Content Introduction Sequential Covering Algorithms Learning Rule Sets: Summary➔ Learning First-Order Rule
First-Order Horn Clauses Terminology
Learning Sets of First-Order Rules: FOIL Summary

22Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning First-Order Rule
Previous: Algorithms for learning sets of propositional rules Now: Extension of these algorithms for learning first-order rules In particular: inductive logic programming (ILP):
Learning of first-order rules or theories Use PROLOG: general purpose Turing-equivalent programming
language in which programs are expressed as collection of Horn clauses.

23Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
First-Order Horn Clauses
Advantage of the representation: learning Daughter(x,y)
Result of C4.5 or CN2
Result ILP
Problem: Propositional representations offer no general way to describe the essential relation among the values of the attributes
In first-order Horn clauses variables that do not occur in the postcondition may occur in the precondition
Possible: Use the same predicates in the rule postconditions and preconditions (recursive rules)
1 1 1 1 1
2 2 2 2 2 1,2
Name = Sharon,Mother = Louse,Father = Bob,Male = False,Female = True,
Name = Bob,Mother = Nora,Father = Victor,Male = True,Female = FalseDaughter = true
2 2 2 2 2Name = Bob,Mother = Nora,Father = Victor,Male = True,Female = False
IF Father x, y Female y THENDaughter y, x
IFFather y, z Mother z, x Female y THENGrandDaughter x, y

24Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Terminology Every well formed expression is composed of constants, variables,
predicates and functions A term is any constant, any variable, or any function applied to any term Literal is any predicate (or its negation) applied to any set of terms A ground literal is a literal that does not contain any variables A negative literal is a literal containing a negated predicate A positive literal is a literal with no negative sign A clause is any disjunction of literals: whose variables are
universally quantifed A Horn clause is an expression of the form
where are positive literals. H is called the head, postcondicions or consequent of the Horn clause. The conjunction of the literal is called the body precondition or ancendents of the Horn clause
1 nM .... M
1 nL .... L 1, nH,L ...,L
1 nH L .... L

25Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Terminology 2 For any literals A and B, the expression is equivalent to
, and the expression is equivalent to=> a Horn clause can equivalently be written as
A substitution is any function that replaces variables by terms. For example, the substitution replaces the variable x by the term 3 and replaces the variable y by the term z. Given a substitution and a literal L => denotes the result of applying the substitution to L.
An unifying substitution for two literals and is any substitution such that
1 nH ¬L ... ¬L
x / 3,y / z
¬ A BA B ¬A ¬B
θ
θL
1L 2Lθ 1 2L θ = L θ
A B
θ

26Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Content
Introduction Sequential Covering Algorithms Learning Rule Sets: Summary Learning First-Order Rule➔ Learning Sets of First-Order Rules:FOIL
Generating Candidate Specialisation in FOIL Guiding Search in FOIL Learning Recursive Rule Sets Summary of FOIL
Summary

27Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Sets of First-Order Rules:FOIL
FOIL( target_predicate, predicates, examples )
pos those examples, for which target_predicate is true
Neg those examples, for which target_predicate is false
learned_rules { }
while ( pos ) do /* learn a new rule */ new_rule the rule that predicts target_predicate with no preconditions new_rule_neg neg while ( new_rule_neg ) do /* Add a new literal to specialize new_rule */ candidate_literals generate candidate new literals for new_rule, based on predicates best_literal argmaxL candidate_literals FoilGain( L, new_rule ) add best_literal to preconditions of new_rule new_rule_neg subset of new_rule_neg that satisfies new_rule‘s preconditions learned_rules learned_rules + new_rule pos pos - { members of pos covered by new_rule }
return learned_rules

28Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Sets of First-Order Rules:FOIL 2
External loop : „Specific-to-General“ Generalise the set of rules:
Add a new rule to the existing hypothesis Each new rule „generalises“ the actual hypothesis to increase the
number of the positive classified instances Start with the special precondition, in which there is not any positive
target concept

29Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Sets of First-Order Rules:FOIL 3
FOIL( target_predicate, predicates, examples )
pos those examples, for which target_predicate is true
neg those examples, for which target_predicate is false
learned_rules { }
while ( pos ) do /* learn a new rule */ new_rule the rule that predict target_predicate with no preconditions new_rule_neg neg while ( new_rule_neg ) do /* Add a new literal to specialize new_rule */ candidate_literals generate candidate new literals for new_rule, based on predicates best_literal argmax L candidate_literals FoilGain( L, new_rule ) add best_literal to preconditions of new_rule new_rule_neg subset of new_rule_neg that satisfies new_rule's preconditions learned_rules learned_rules + new_rule pos pos - { members of pos covered by new_rule }
return learned_rules

30Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Sets of First-Order Rules:FOIL 4
Internal loop : „General-to-specific“ Specialization of the current rule
Generation of new literals Current rule: P( x1, x2, ..., xk ) L ... Ln
Treatment of new literales in the following form: • Q( v1, ..., vr ), where Q is a predicate name occuring in Predicates (Q
predicates) and where the vi are either new variables or variables already present in the rule
• At least one of the vi in the created literal must already exist as a variable in the rule.
Equal( xj, xk ), where xj and xk variables already present in the rule
• The negation of either of the above forms of literals
n+1L

31Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Learning Sets of First-Order Rules:FOIL 5
Example: predict GrandDaughter(x,y) other predicates: Father and Female
FOIL begins with the most general rule GrandDaughter(x,y) Specialisation: the following literals are generated as candidates:
Equal(x,y), Female(x), Female(y), Father(x,y), Father(y,x), Father(x,z),Father(z,x), Father(y,z), Father(z,y) + the negation of each of these literals
Suppose FOIL to select greedily Father(y,z): GrandDaughter(x,y) Father(y,z)
Generating the candidate literals to further specialise the rule:all in the previous step generated literals + Female(z), Equal(z,x), Equal(z,y), Father(z,w) Father(w,z) + their negation
Suppose FOIL to select greedily at this point Father(z,x) and on the next iteration Female(x)GrandDaughter(x,y) Father(y,z) Father(z,x) Female(x)

32Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Guiding the Search in FOIL
Select the most promising literal: FOIL considers the performance of the rule over the training data Consider all possible bindings of each variable in the current rule for
each literal As new literals are added to the rule the set of bindings will change If a literal is added that introduces a new variable then the bindings
for the rule will grow in length If the new variable can be bound to different constants, then the
number of bindings fitting the extended rule can be greater than the number associated with the original rule
The association function of FOIL (FOILGain) that estimates the utility of adding a new literal to the rule is based on the number of positive and negative bindings before and after adding the new literal

33Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Guiding the Search in FOIL 2
FoilGain✗ Consider some rule R and a candidate literal L that might be added to
the body of R (R') .✗ Prove for each literal and for all bindings the information gain✗ High value - high information gain
p0: the number of positive bindings of R
p1: the number of positive bindings of R'
n0: the number of negative bindings of R
n1: the number of negative bindings of R' t: the number of positive bindings of rule R that are still covered after adding
literal L to R
012 2
1 1 0 0
ppFOILGain L,R t log log
p + n p + n

34Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Summary of FOIL Extend CN2 to handle learning first-order rules similar to Horn
clauses During the learning process FOIL performs a general-to-specific
search at each step adding a single new literal to the rule precondition At each step FOILGain is used to select one of the candidate literals If new literals are allowed to refer to the target predicate, then FOIL
can, in principle learn sets of recursive rules Handling noisy data the search is continued until some trade-off
occurs between rule accuracy, coverage and complexity FOIL uses a minimum description length approach to limit the growth
of rules: by adding new literals only if their description length is shorter than the description length of the training data they explain.

35Lehrstuhl für Informatik 2
Gabriella Kókai: Maschine Learning
Summary Sequential covering learns a disjunctive set of rules by first
learning a single accurate rule then removing the positive examples covered by this rule and iterating the process over the remaining training examples
Variety of methods, vary in the search strategy CN2: general-to-specific beam search, generating and testing
progressively more specific rules until a sufficiently accurate rule is found
Set of first-order rules provides a highly expressive representation FOIL







