Download - Building an Event Bus at Scale

Building an Event Bus at Scale
Senior Software Developer@jimriecken
Jim Riecken

• Senior developer on the Platform Team at Hootsuite• Building backend services + infrastructure• I <3 Scala
About me

A bit of history
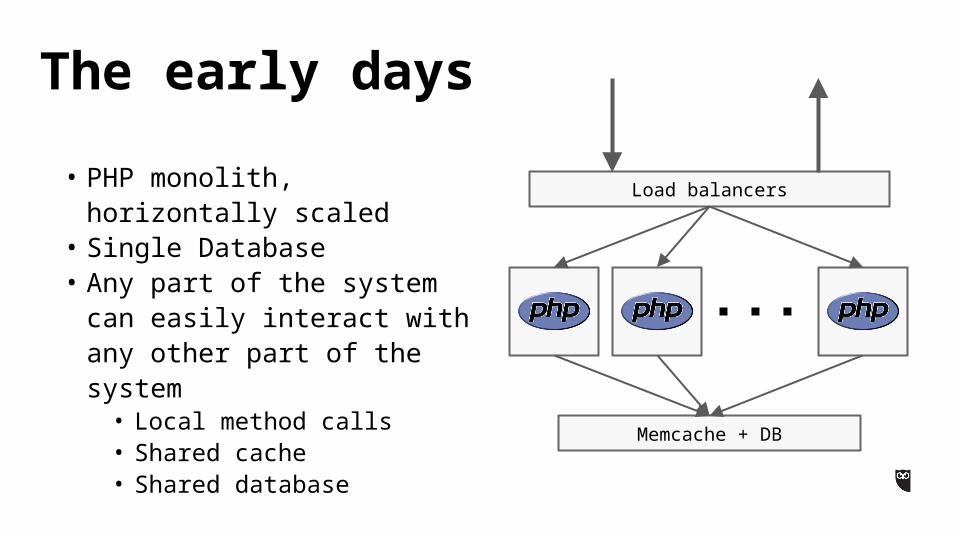
• PHP monolith, horizontally scaled
• Single Database• Any part of the system can
easily interact with any other part of the system
• Local method calls• Shared cache• Shared database
The early days
Load balancers
Memcache + DB

• Smaller PHP monolith• Lots of Scala microservices• Multiple databases• Distributed Systems
• Not local anymore• Latency• Failures, partial failures
Now

Dealing with Complexity
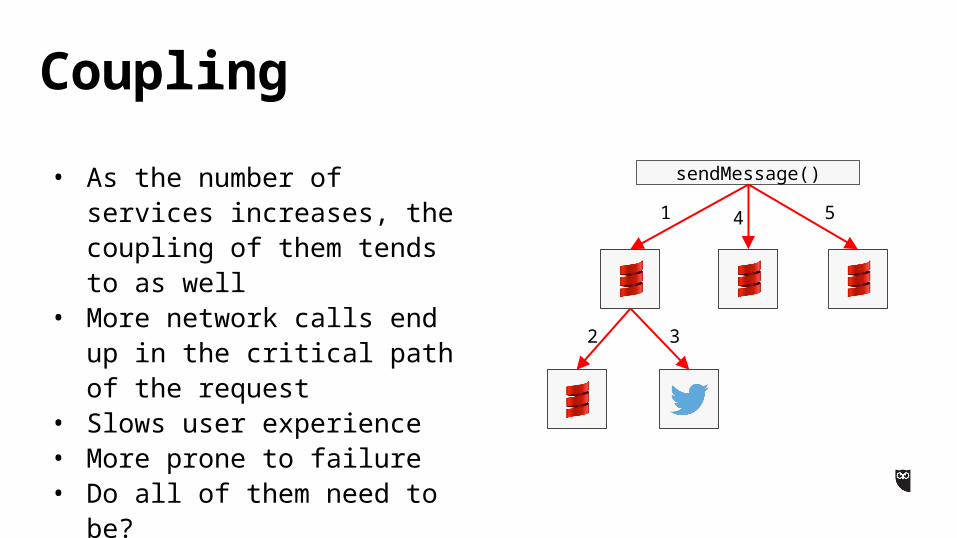
• As the number of services increases, the coupling of them tends to as well
• More network calls end up in the critical path of the request
• Slows user experience• More prone to failure• Do all of them need to be?
CouplingsendMessage()
1
2 3
4 5

Event Bus

• Decouple asynchronous consumption of data/events from the producer of that data.
• New consumers easily added• No longer in the critical path
of the request, and fewer potential points for failure
• Faster requests + happier users!
Event BussendMessage()
Event Bus
1
2 3
4

• High throughput• High availability• Durability• Handle fast producers + slow consumers• Multi-region/data center support• Must have Scala and PHP clients
Requirements

Which technology to choose?

• RabbitMQ (or some other flavour of AMQP)• ØMQ• Apache Kafka
Candidates

• ØMQ• Too low level, would have to build a lot on top of it
• RabbitMQ• Based on previous experience• Doesn’t recover well from crashes• Doesn’t perform well when messages are persisted to disk• Slow consumers can affect performance of the system
Why not ØMQ or RabbitMQ?

• Simple - conceptually it’s just a log• High performance - in use at large organizations (e.g. LinkedIn, Etsy,
Netflix)• Can scale up to millions of messages per second / terabytes of data per
day• Highly available - designed to be fault tolerant• High durability - messages are replicated across cluster• Handles slow consumers
• Pull model, not push• Configurable message retention
• Can work with multiple regions/data centers• Written in Scala!
Why Kafka?

What is

• Distributed, partitioned, replicated commit log service
• Producers publish messages to Topics
• Consumers pull + process the feed of published messages
• Runs as a cluster of Brokers• Requires ZooKeeper for
coordination/leader election
KafkaP P P
C C C
ZKBrokersw/ Topics
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |

• Split into Partitions (which are stored in log files)• Each partition is an ordered, immutable sequence of
messages that is only appended to• Partitions are distributed and replicated across the cluster
of Brokers• Data is kept for a configurable retention period after which
it is either discarded or compacted• Consumers keep track of their offset in the logs
Topics

• Push messages to partitions of topics• Can send to
• A random/round-robined partition• A specific partition• A partition based on a hash constructed from a key
• Maintain per-key order• Messages and Keys are just Array[Byte]
• Responsible for your own serialization
Producers

• Pull messages from partitions of topics• Can either
• Manually manage offsets (“simple consumer”)• Have offsets/partition assignment automatically managed (“high
level consumer”)• Consumer Groups
• Offsets stored in ZooKeeper (or Kafka itself)• Partitions are distributed among consumers
• # Consumers > # Partitions => Some consume nothing• # Partitions > # Consumers => Some consume several partitions
Consumers

How we set up Kafka

• Each cluster consists of a set of Kafka brokers and a ZooKeeper quorum
• At least 3 brokers• At least 3 ZK nodes (preferably
more)• Brokers have large disks• Standard topic retention -
overridden per topic as necessary• Topics are managed via Jenkins
jobs
ClustersZK ZK
ZK
B B
B

• MirrorMaker• Tool for consuming topics
from one cluster + producing to another
• Aggregate + Local clusters• Producers produce to local
cluster• Consumers consume from
local + aggregate• MirrorMaker consumes
from local + produces to aggregate
Multi-Region
ZK
Local
Aggregate
MirrorMaker
ZK
Local
Aggregate
MirrorMaker
Region 1 Region 2
PP
C C

Producing + Consuming

• Wrote a thin Scala wrapper around the Kafka “New” Producer Java API
• Effectively send(topic, message, [key])• Use minimum “in-sync replicas” setting for Topics
• We set it to ceil(N/2 + 1) where N is the size of the cluster• Wait for acks from partition replicas before committing to
leader
Producing

• To produce from our PHP components, we use a Scala proxy service with a REST API
• We also produce directly from MySQL by using Tungsten Replicator and a filter that converts binlog changes to event bus messages and produces them
Producing
Kafka
TR

• Wrote a thin Scala wrapper on top of the High-Level Kafka Consumer Java API
• Abstracts consuming from Local + Aggregate clusters• Register consumer function for a topic• Offsets auto-committed to ZooKeeper
• Consumer group for each logical consumer• Sometimes have more consumers than partitions (fault
tolerance)• Also have consumption mechanism for PHP/Python
Consuming

Message Format

• Need to be able to serialize/deserialize messages in an efficient, language agnostic way that tolerates evolution in message data
• Options• JSON
• Plain text, everything understands it, easy to add/change fields• Expensive to parse, large size, still have convert parsed JSON into
domain objects• Protocol Buffers (protobuf)
• Binary, language-specific impls generated from an IDL• Fast to parse, small size, generated code, easy to make
backwards/forwards compatible changes
Data -> Array[Byte] -> Data

• All of the messages we publish/consume from Kafka are serialized protobufs
• We use ScalaPB (https://github.com/trueaccord/ScalaPB)• Built on top of Google’s Java protobuf library• Generates scala case class definitions from .proto
• Use only “optional” fields• Helps forwards/backwards compatibility of messages• Can add/remove fields without breaking
Protobuf

• You have to know the type of the serialized protobuf data before you can deserialize it
• Potential solutions• Only publish one type of message per topic• Prepend a non-protobuf type tag in the payload• The previous, but with protobufs inside protobufs
Small problem

• Protobuf that contains a list• UUID string• Payload bytes (serialized
protobuf)• Benefits
• Multiple objects per logical event• Evolution of data in a topic• Automatic serialization and
deserialization (maintain a mapping of UUID-to-Type in each language)
Message wrapper
UUID
Serialized protobuf payload bytes

• We use Kafka as a high-performance, highly-available asynchronous event bus to decouple our services and reduce complexity.
• Kafka is awesome - it just works!• We use Protocol Buffers for an efficient message format that
is easy to use and evolve.• Scala support for Kafka + Protobuf is great!
Wrapping up

Thank you!Questions?
Senior Software Developer@jimriecken
Jim Riecken







