Download - Big-Data Computing on the Cloud

Big-Data Computing on the Cloud an Algorithmic Perspective
Andrea PietracaprinaDept. of Information Engineering (DEI)
University of Padova, [email protected]
Supported in part by MIUR-PRIN Project Amanda: Algorithmics for MAssive and Networked DAta
Roma, May 20, 2016 Data Driven Innovation 1

OUTLINE
Roma, May 20, 2016 Data Driven Innovation 2
OUTLINE
From supercomputing to cloud computing
Paradigm shift
MapReduce
Big data algorithmics
Coresets
Decompositions of large networks
Conclusions

From Supercomputing to Cloud Computing
Roma, May 20, 2016 Data Driven Innovation 3
Supercomputing (‘70s – present)
Tianhe-2 (PRC)
Algorithm designfull knowledge and exploitation of
platform architecture
• Low productivity, high costs
• Grand Challenges
• Maximum performance (exascale in 2018?)
• Massively parallel systems

From Supercomputing to Cloud Computing
Roma, May 20, 2016 Data Driven Innovation 4
Cluster era (‘90s – present)
Algorithm designExploitation of architectural features
abstracted by few parameters
• Higher productivity and lower costs
• Wide range of commercial/scientific applications
• Good cost/performance tradeoffs
• Distributed systems (e.g., clusters, grids)
Network (bandwidth/latency)
From Supercomputing to Cloud Computing
Roma, May 20, 2016 Data Driven Innovation 5
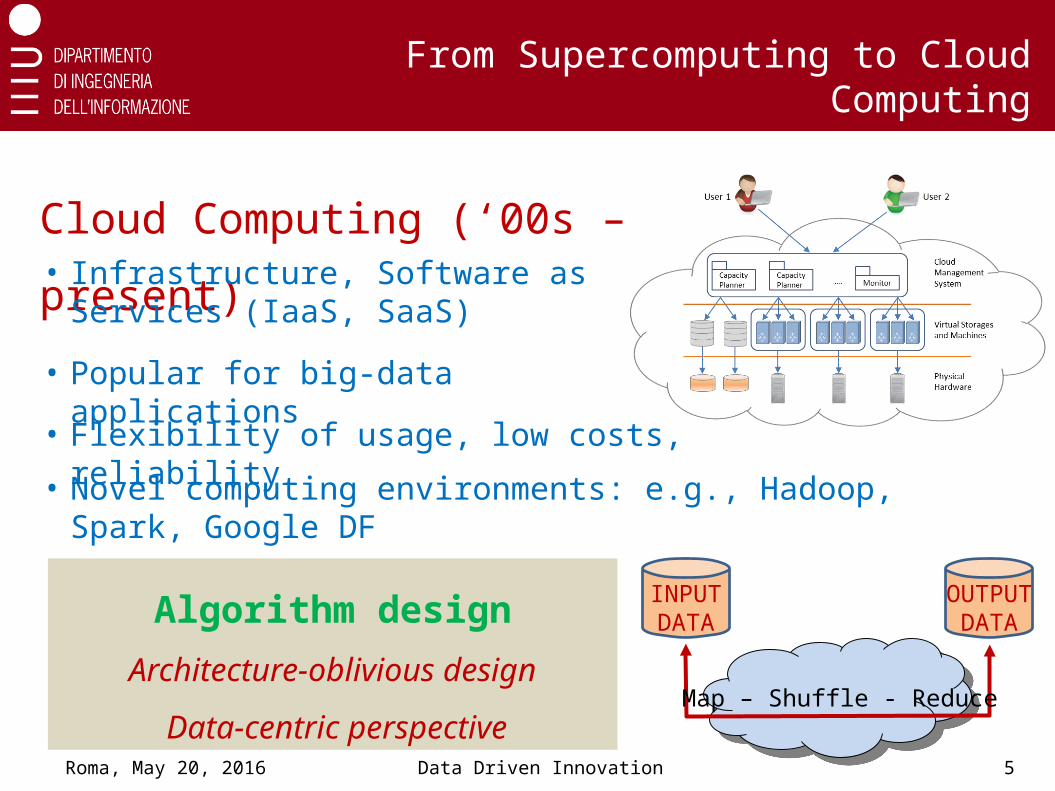
Cloud Computing (‘00s – present)
Algorithm designArchitecture-oblivious design
Data-centric perspective
• Novel computing environments: e.g., Hadoop, Spark, Google DF
• Popular for big-data applications
• Flexibility of usage, low costs, reliability
• Infrastructure, Software as Services (IaaS, SaaS)
INPUT DATA
OUTPUT DATA
Map – Shuffle - Reduce

Paradigm Shift
Roma, May 20, 2016 Data Driven Innovation 6
Traditional Algorithmics
Big-Data Algorithmics
Best balance between computation, parallelism,
communication
Few scans of the whole input data
Machine-conscious design Machine-oblivious design
Noiseless, static input data Noisy, dynamic input data
Polynomial complexity (Sub-)Linear complexity
PARADIGM SHIFT
Roma, May 20, 2016 Data Driven Innovation 7
MAPREDUCE
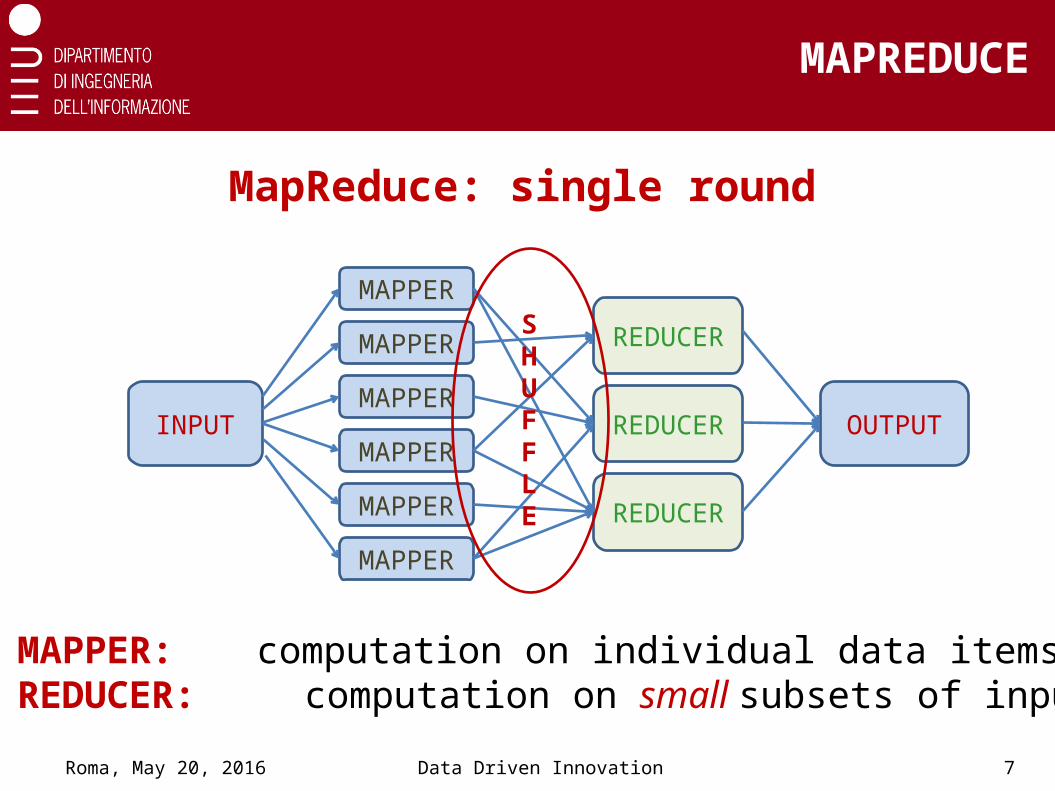
MapReduce: single round
INPUT
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
OUTPUT
REDUCER
REDUCER
REDUCER
SHUFFLE
MAPPER: computation on individual data itemsREDUCER: computation on small subsets of input

Roma, May 20, 2016 Data Driven Innovation 8
MAPREDUCE
MapReduce: multiround
Key Performance Indicators (input size N):
Memory requirements per reducer: << N #Rounds (i.e., #shuffles): 1,2 Aggregate space and communication N
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
OUTPUT
REDUCER
REDUCER
REDUCER
INPUT
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
REDUCER
REDUCER
REDUCER
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
MAPPER
REDUCER
REDUCER
REDUCER
ROUND 1 ROUND 2 ROUND r

Roma, May 20, 2016 Data Driven Innovation 9
Big Data Algorithmics
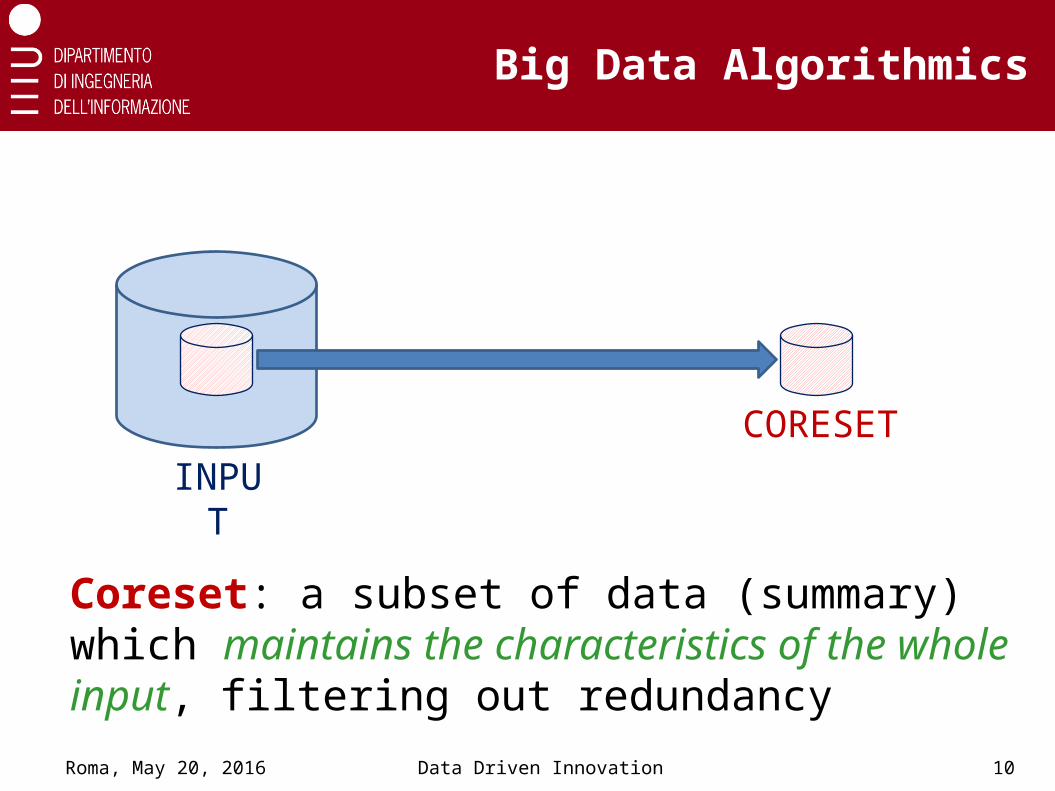
Coresets
Roma, May 20, 2016 Data Driven Innovation 10
Big Data Algorithmics
INPUTCORESET
Coreset: a subset of data (summary) which maintains the characteristics of the whole input, filtering out redundancy

Roma, May 20, 2016 Data Driven Innovation 11
Big Data Algorithmics
General 2-round MapReduce approach
Round 1: partition into small subsets and extraction of partial coresetsRound 2: perform analysis on aggregation of partial coresets
INPUT
AGGREGATE CORESET
PARTIAL CORESET
CHALLENGE: composability of coresets

Roma, May 20, 2016 Data Driven Innovation 12
Big Data Algorithmics
Example: diversity maximization

Roma, May 20, 2016 Data Driven Innovation 13
Big Data Algorithmics
Example: diversity maximization
Goal: find k most diverse data objectsApplications: Recommendation systems, search engines
Roma, May 20, 2016 Data Driven Innovation 14
Big Data Algorithmics
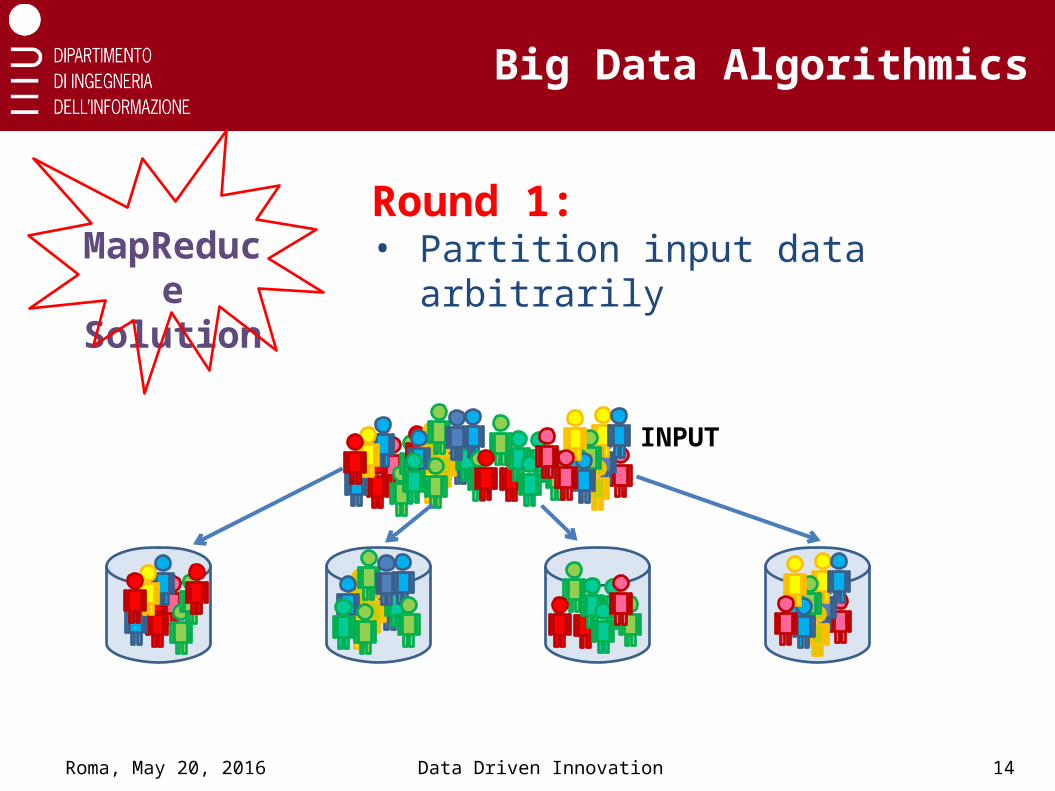
INPUT
MapReduce Solution
Round 1:• Partition input data arbitrarily

Roma, May 20, 2016 Data Driven Innovation 15
Big Data Algorithmics: coresets
MapReduce Solution
Round 1:• Partition input data arbitrarily• In each subset:
k’-clustering based on similarity (k’>k) pick one representative per cluster
( partial coreset)
subset of partition k’-clustering partial coreset
N.B. For enhanced accuracy, it is crucial to fix k’>k

Roma, May 20, 2016 Data Driven Innovation 16
Big Data Algorithmics: coresets
MapReduce Solution
Round 2:• Aggregate partial coresets• Compute output on aggregate coreset
partial coresets
aggregate coresetOUTPUT

Roma, May 20, 2016 Data Driven Innovation 17
Big Data Algorithmics
Round 1
Round 2
INPUT
PARTIAL CORESET
AGGREGATE CORESET
OUTPUT

Roma, May 20, 2016 Data Driven Innovation 18
Big Data Algorithmics
Experiments:
• N=64000 data objects
• Seek k=64 most diverse ones
• Final coreset size: [21024] k∙
• Measure: accuracy of solution
• 4 diversity measures
N.B. Same approach can be used in a streaming setting

Roma, May 20, 2016 Data Driven Innovation 19
Big Data Algorithmics
Decompositions of Large Networks

Roma, May 20, 2016 Data Driven Innovation 20
Big Data Algorithmics
Analysis of large networks in MapReduce must avoid:

Roma, May 20, 2016 Data Driven Innovation 21
Big Data Algorithmics
• Long traversals• Superlinear complexities
Known exact algorithms often do not meet these criteria
Analysis of large networks in MapReduce must avoid:

Roma, May 20, 2016 Data Driven Innovation 22
Big Data Algorithmics
• Long traversals• Superlinear complexities
Known exact algorithms often do not meet these criteria
Analysis of large networks in MapReduce must avoid:
Network decomposition can provide concise summary of network characteristics

Roma, May 20, 2016 Data Driven Innovation 23
Big Data Algorithmics
Example : network diameter
Goal: determine max distanceApplications: social networks, internet/web, linguistics, biology
B
A

Roma, May 20, 2016 Data Driven Innovation 24
Big Data Algorithmics
MapReduce Solution
• Cluster the network into few regions with small radius R, around random nodes
• R rounds
R
Roma, May 20, 2016 Data Driven Innovation 25
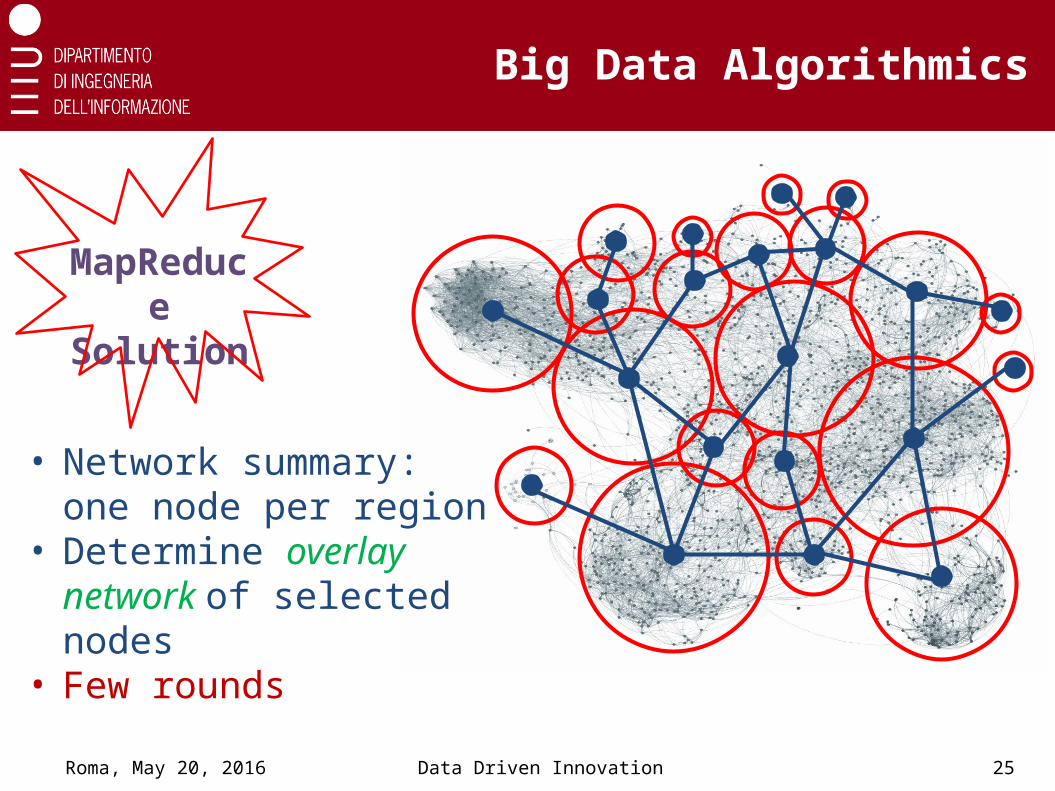
Big Data Algorithmics
MapReduce Solution
• Network summary: one node per region
• Determine overlay network of selected nodes
• Few rounds
Roma, May 20, 2016 Data Driven Innovation 26
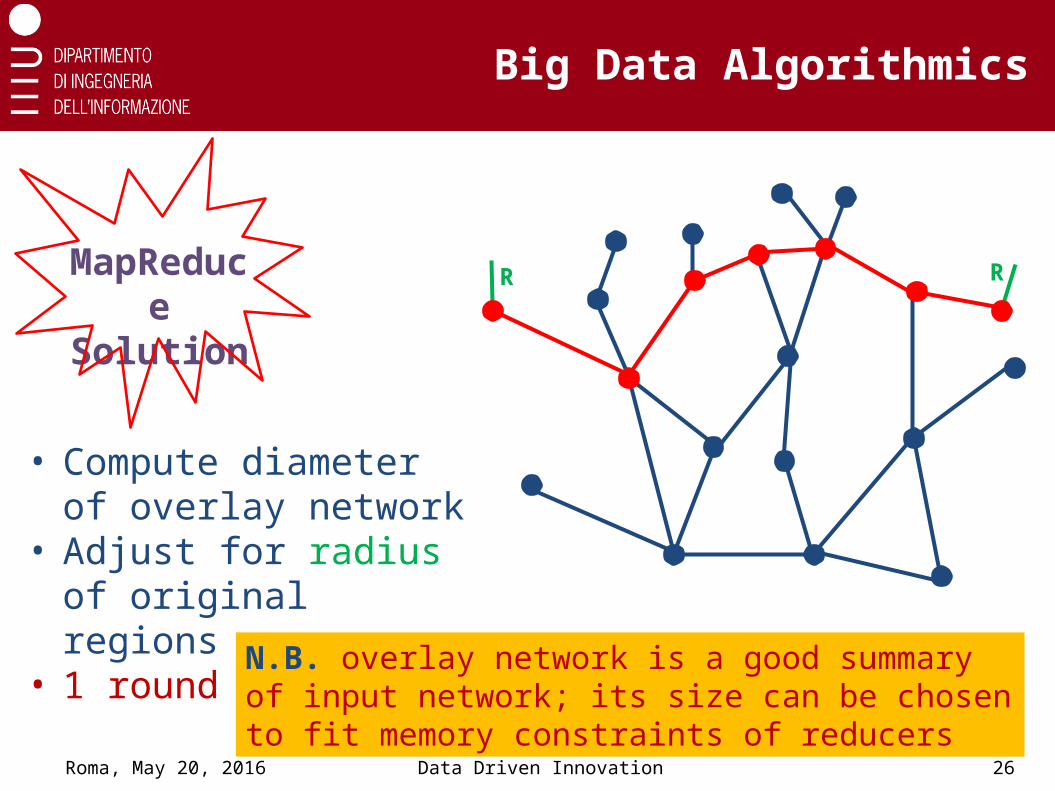
Big Data Algorithmics
MapReduce Solution
• Compute diameter of overlay network
• Adjust for radius of original regions
• 1 round
R R
N.B. overlay network is a good summary of input network; its size can be chosen to fit memory constraints of reducers

Roma, May 20, 2016 Data Driven Innovation 27
Big Data Algorithmics
Experiments: 16-node cluster, 10Gbit Ethernet, Apache Spark
Network No. Nodes
No. Links
Time (s) Rounds
Error
Roads-USA
24M 29M 158 74 26%
Twitter 42M 1.5G 236 5 19%
Artificial 500M 8G 6000 5 30%
benchmarks
scalability
(10K nodes in overlay network)

Roma, May 20, 2016 Data Driven Innovation 28
Big Data Algorithmics
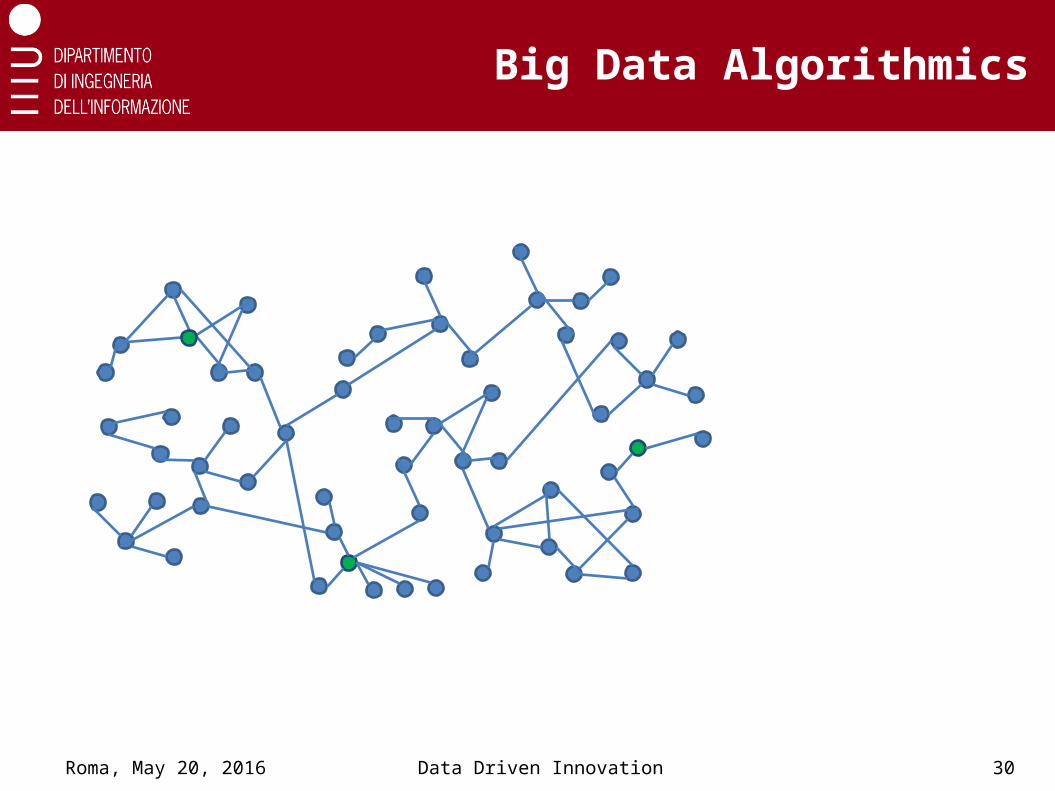
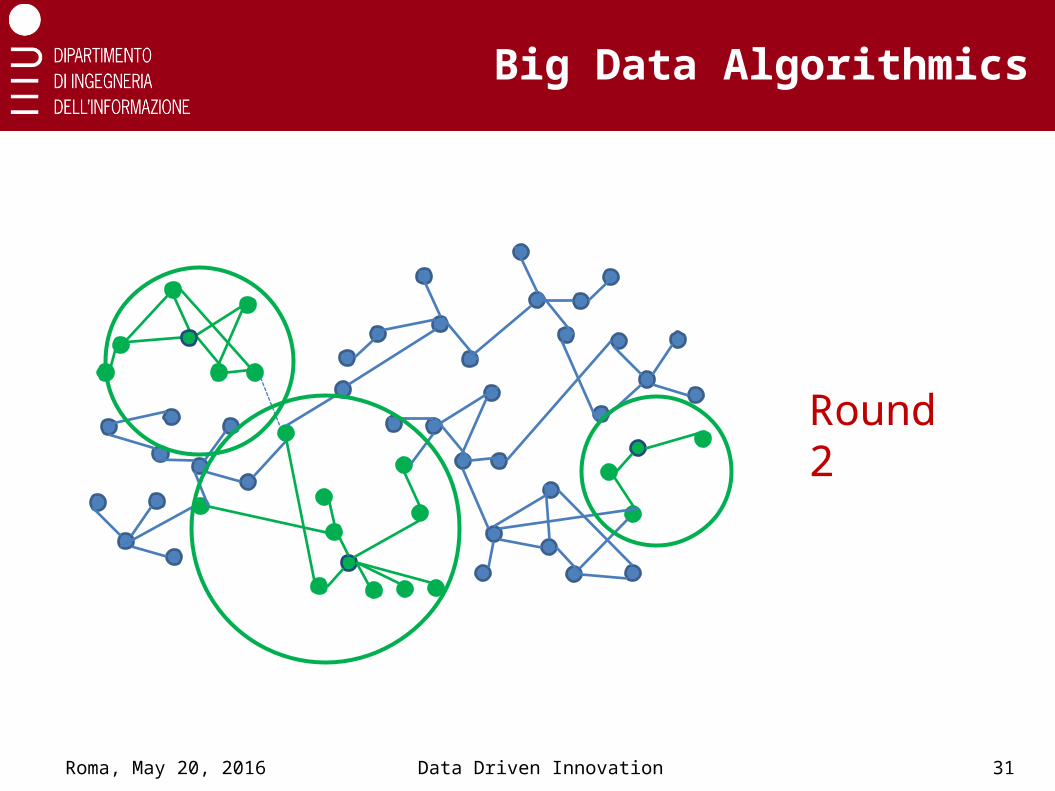
Efficient network partitioning
• Progressive node sampling
• Local cluster growth from sampled nodes
• #rounds = #cluster growing steps

Roma, May 20, 2016 Data Driven Innovation 29
Big Data Algorithmics
Example
Roma, May 20, 2016 Data Driven Innovation 30
Big Data Algorithmics
Roma, May 20, 2016 Data Driven Innovation 31
Big Data Algorithmics
Round 2

Roma, May 20, 2016 Data Driven Innovation 32
Big Data Algorithmics
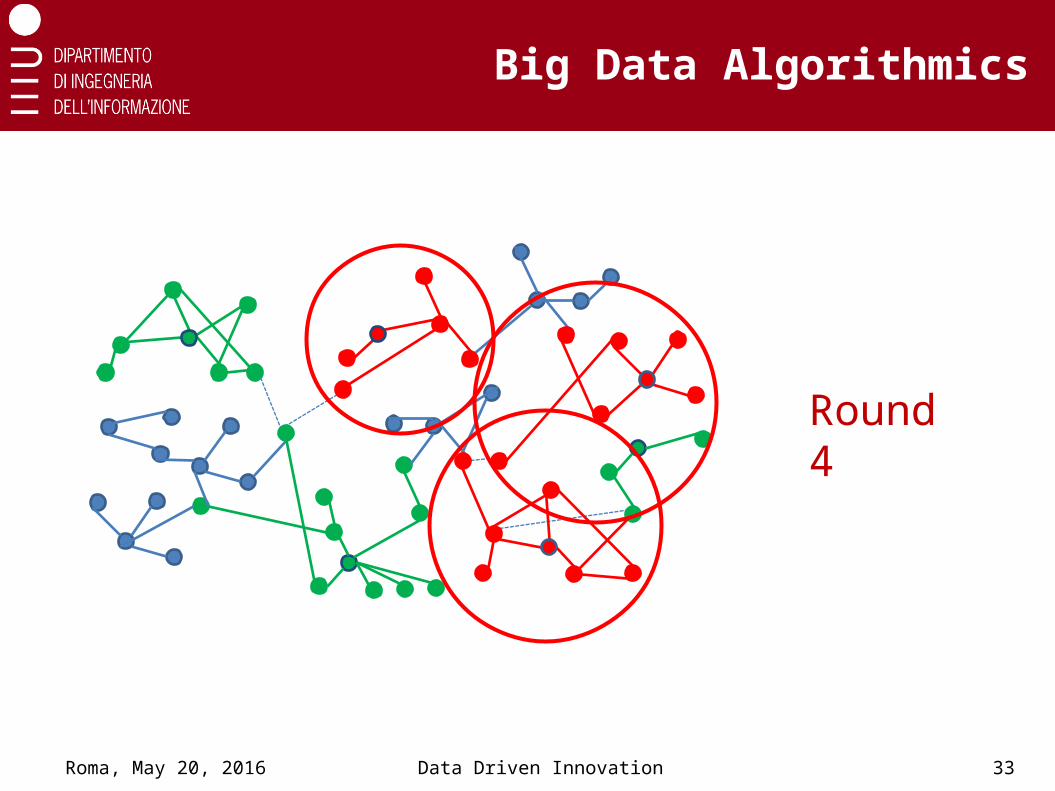
Roma, May 20, 2016 Data Driven Innovation 33
Big Data Algorithmics
Round 4

Roma, May 20, 2016 Data Driven Innovation 34
Big Data Algorithmics
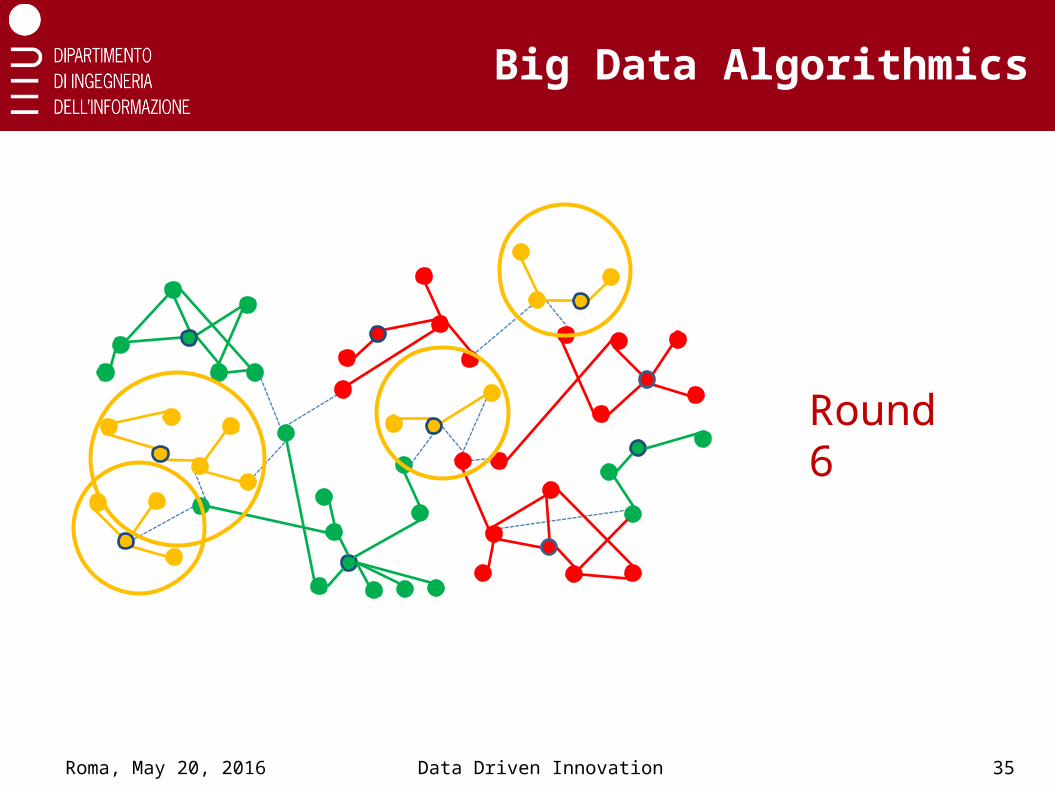
Roma, May 20, 2016 Data Driven Innovation 35
Big Data Algorithmics
Round 6

Roma, May 20, 2016 Data Driven Innovation 36
Big Data Algorithmics
Coping with uncertainty
Links exist with certain probabilities
Applications: biology, social network analysis
• Network partitioning strategy suitable for this scenario• cluster = region connected with high probability

Roma, May 20, 2016 Data Driven Innovation 37
Big Data Algorithmics
• PPI viewed as uncertain network
• Hp: protein complex region with high connection probability
• Traditional general partitioning approaches slowed down by uncertainty
Example: identification of protein complexes from Protein-Protein Interaction (PPI) networks
Experiments show effectiveness of approach

Roma, May 20, 2016 Data Driven Innovation 38
Conclusions
CONCLUSIONS
• Design of big data algorithms (on clouds) entails paradigm shift Data centric view Handling size through summarization Give up exact solution Cope with noisy/unreliable data

Roma, May 20, 2016 Data Driven Innovation 39
References
References
M. Ceccarello, A.P., G. Pucci, E. Upfal: Space and Time Efficient Parallel Graph Decomposition, Clustering, and Diameter Approximation. ACM SPAA 2015
M. Ceccarello, A.P., G. Pucci, E. Upfal : A Practical Parallel Algorithm for Diameter Approximation of Massive Weighted Graphs. IEEE IPDPS 2016
M. Ceccarello, A.P., G. Pucci, E. Upfal : MapReduce and Streaming Algorithms for DiversityMaximization in Metric Spaces of Bounded Doubling Dimension. ArXiv 1605.05590 , 2016
M. Ceccarello, C. Fantozzi, A.P., G. Pucci, F. Vandin: Clustering in uncertain graphs. Work in progress. 2016

Roma, May 20, 2016 Data Driven Innovation 40
Conclusions
THANK YOU!







