diplomski rad otkrivanje zakonitosti u podacima u obrazovnim organizacijama
TRANSCRIPT

UNIVERZITET U BEOGRADU
FAKULTET ORGANIZACIONIH NAUKA
DIPLOMSKI RADTema: Otkrivanje zakonitosti u podacima u obrazovnim
organizacijama
MENTOR: STUDENT:
Doc. dr Boris Delibašić Mladen Mijatović,
261/02
BEOGRAD, 2009

SADRŽAJ:
1. UVOD..........................................................................................3
2. NASTANAK I ISTORIJSKI RAZVOJ.........................................5
2.1. DEFINICIJA OZP-A..................................................................62.2. ZADACI I FAZE OZP-A.............................................................7
3. OZP U VISOKOŠKOLSKOM OBRAZOVANJU.......................11
3.1 OTKRIVANJE ZAKONITOSTI U PODACIMA – LOGIČAN ODGOVOR NA TURBULENTNO OKRUŽENJE...........................................................113.2 PRIMERI PRIMENE OZP-A U VISOKOŠKOLSKOM OBRAZOVANJU. 123.3 PRAVCI BUDUĆEG RAZVOJA OZP-A U VISOKOŠKOLSKOM OBRAZOVANJU.............................................................................28
4. OTKRIVANJE ZAKONITOSTI U PODACIMA I VIZUELIZACIJA PODATAKA..................................................................................41
4.1 ŠTA ČINI VIZUELIZACIJU BITNOM..............................................414.2 PRIMER STUDIJE U VISOKOŠKOLSKOM OBRAZOVANJU BAZIRANE NA NAPREDNIM ALATIMA PROSTORNE VIZUELIZACIJE......................42
5. ZAKLJUČCI I BUDUĆI RAD....................................................47
6. Literatura...................................................................................49
2

1. Uvod
Razum je, od postanka sveta, najveći i neprevaziđeni dar, koji je čovek
ikada dobio. Pomoću razuma čovek opstaje, postoji, stvara i razvija se.
Znanje pak ima svoje granice, ma koliko obimno i sveobuhvatno bilo.
Razumom čovek uvek teži da, do sledećeg koraka u saznavanju, objasni
neobjašnjeno i ispuni praznine u svom znanju. Koristeći, pre svega dokaze o
zakonima prirode koje mu pruža neposredno okruženje, čovek usvaja znanje i
stiče iskustvo. Godinama i vekovima su se razvijale discipline i nauke kojima
je čovek prelazio tu granicu razumnog i saznajnog.
Preko matematike, zatim statistike a kasnije, sa razvojem računarskih
mašina, putem mašinskog učenja, data warehouse-a1 i podrške odlučivanju,
OLAP-a2, kao i povećane mogućnosti procesiranja velike količine podataka
dolazi do razvoja otkrivanja zakonitosti u podacima (OZP)3, kao discpline i
oruđa pomoću kojeg iz skupa podataka dobijamo korisne informacije.
Nastanak i razvoj OZP-a traje dvadesetak godina. Počeci se vezuju za 1989.
godinu, kada je Gregory Piatetsky-Shapiro organizovao prvu konferenciju na
temu otkrivanja znanja u bazama podataka4, koje će kasnije prerasti u
otkrivanje zakonitosti u podacima. Devedesetih godina mnoge kompanije
počinju razvoj OZP alata i standarda, pa tako na tom polju rade IBM,
Lockheed, SGI, SPSS Inc. i drugi. Danas, to je jedna od oblasti primenjene
nauke koja ima višestruku primenu, za koju su razvijeni standardi na
svetskom nivou i čiji doprinos postaje nezamenljiv u mnogim institucijama i
poljima primene. Postoje dve stvari koje su uticale na pojavu OZP-a. S jedne
strane to su stalne, nepredvidive i brze promene u okruženju organizacije i
potreba da se na njih što kvalitetnije odgovori, a OZP predviđa buduće
trendove i kretanja, dozvoljavajući da se donose proaktivne odluke, bazirane
na znanju. Sa druge strane to je pojava moćnih informacionih tehnologija koje
omogućavaju obradu podataka jer se količina podataka čuvanih u
elektronskom obliku enormno povećava u današnje vreme. Količina podataka
1 Sistemi za čuvanje i obradu velikih količina podataka, dizajnirani da, prvenstveno, omoguće formiranje izveštaja i analiza nad podacima.2 OLAP (Online analytical processing) predstavlja pristup matričnog uređivanja baze podataka koji omogućuje korisniku uvid, navigaciju, obradu i analizu višedimenzionalnim upitima nad podacima.3 Naziv “otkrivanje zakonitosti u podacima” na engleskom jeziku glasi “data mining”.4 Otkrivanje znanja u bazama podataka ili na engleskom KDD – Knowledge Discovery in Databases.
3

se duplira svakih 20 meseci, dok se broj baza podataka povećava još većim
intezitetom. Prema istraživanjima Berkli univerziteta, iz 2002. godine, procena
je bila da količina podataka koji se generišu iznosi oko jedan milion terabajta
godišnje, od kojih je velika većina u elektronskom formatu. To je značilo da je
u naredne tri godine generisano više podataka nego u čitavoj ljudskoj istoriji
do tada.
Dosta je radova objavljeno na temu OZP-a, od onih koji se bave
teorijskim osnovama do radova koji obrađuju praktičnu primenu OZP-a u
raznim sferama društvenog delovanja. Ovaj rad pokušaće da predstavi stranu
praksu u primeni OZP-a u visokoškolskim ustanovama i da tako pruži uvid u
moguće pravce razvoja njegovih aplikacija za domaće potrebe.
U nastavku, u okviru drugog poglavlja biće dati osnovni podaci o OZP-
u kao i pregled faza i zadataka OZP-a. Treće poglavlje predstavlja primere
studija i istraživanja koja su uz pomoć OZP-a vršena na nekima od stranih
univerziteta. Cilj ovoga bio je da se odgovori na pitanja zašto je potrebno
koristiti OZP i kako on može pomoći visokoškolskim ustanovama. Takođe, u
trećem poglavlju, predstavljeno je korišćenje savremenih tehnologija u
obrazovanju i aplikacija OZP-a koje će pratiti taj tehnološki napredak i
iskorišćavati sve njegove mogućnosti. Četvrto poglavlje govori o veoma
bitnom aspektu OZP-a, o vizuelizaciji podataka. Zašto je vizuelizacija bitna i
kako se praktično može primeniti, pitanja su na koja je pokušano naći
odgovore u ovom delu rada. Na kraju, peto poglavlje će sumirati zaključke do
kojih se došlo i dati pravce budućeg rada i usavršavanja ove teme.
4

2. Nastanak i istorijski razvoj
OZP se razvijao kao direktna posledica dostupnosti velikih skladišta
podataka. Prikupljanje podataka u digitalnoj formi je već šezdesetih bilo u
toku, omogućavajući u budućnosti analizu tih podataka putem računara.
Pojava relacionih baza podataka u osamdesetim zajedno sa SQL (Structured
Query Language) jezicima dozvolila je dinamičku, na-zahtev, analizu.
Devedesetih dolazi do naglog porasta broja podataka koje je moguće
procesuirati. Data warehouse (skladišta podataka) počinju da se koriste za
čuvanje istih. OZP tako postaje odgovor na izazove sa kojima se suočavamo
u obradi ogromne količine podataka. Danas je OZP disciplina koja objedinjuje
statistiku, mašinsko učenje, podršku odlučivanju, data warehouse, paralelno
procesiranje, vizuelzaciju itd. kao što vidimo na slici 2.1.
Slika 2.1
Tehnike koje su uticale
na razvoj
OZP-a, preuzeto
iz [1]
Motiva za razvoj i upotrebu OZP-a ima dosta a neki od njih su
smanjenje troškova, povećanje prihoda, otkrivanje neuobičajenih obrazaca,
automatizacija teških zadataka, otkrivanje obmana, poboljšanje iskustva
korisnika ili kupaca, predviđanje budućih trendova itd.
5

Slika 2.2
Razvoj metoda za dobijanje
informacija iz baza
podataka, preuzeto iz
[2]
2.1. Definicija OZP-a
OZP u uskom smislu znači proces sortiranja velikog broja informacija i
biranja samo relevantnih. Verovatno da nema boljeg naziva za ovaj proces od
bukvalnog prevoda engleskog naziva „data mining“ na srpski - rudarenje po
podacima. Obično se koristi za poslovne informacije i finansijske analize, ali
sve češće i od strane naučnika za izdvajanje informacija iz velikog broja
podataka generisanih u modernim eksperimentalnim i metodama
posmatranja, a u novije vreme i u bioinformatici, genetici, medicini,
bezbednosti i obrazovanju. Jedinstvenu definiciju OZP-a nećemo dati nego
ćemo umesto toga navesti nekoliko definicija koje su danas u opticaju:
“OZP je proces selekcije, klasifikacije i istraživanja velike količine
podataka da bi se otkrila pravila i veze koja su prvobitno nepoznata, sa ciljem
da se pribave jasni i korisni rezultati za vlasnika baze podataka.“ [3]
“OZP je ekstrakcija prethodno nepoznatih i potencijalno korisnih
informacija iz podataka i nauka ekstrakcije korisnih informacija iz velikog broja
podataka i baza podataka.” [4]
6

“OZP je proces pronalaženja paterna i veza u podacima. U svom
jezgru, OZP sadrži razvoj modela, koji je tipična, kompaktna reprezentacija
paterna pronađenih u podacima i primena tog modela na nove podatke.
Model se primenjuje da bismo predvideli individualno ponašanje (klasifikacija i
regresija), ponašanje segmenta populacije (klastering), odredili veze unutar
populacije (asocijacija), kao i otkrivanje atributa koji imaju najveći uticaj na
ponašanje populacije.” [5]
“OZP je proces otkrivanja smislenih korelacija, paterna i trendova
prosejavanjem velike količine uskladištenih podataka uz korišćenje
tehnologija za prepoznavanje paterna, kao i statističkih i matematičkih
tehnika.” [6]
“OZP je skup tehnika za analizu podataka, čiji je cilj da u podacima
pronađe određene zavisnosti, veze i pravila vezana za podatke i iste
protumači u novi, viši nivo kvalitetne informacije.” [7]
2.2. Zadaci i faze OZP-a
Iz definicija možemo zaključiti da je OZP proces i da je kao takav
sastavljen iz niza faza. Poznavanje svake od njih, njihovo dobro razumevanje
i izvođenje kritično je za uspešnost procesa OZP-a. Međutim da bismo bili u
stanju da to uradimo moramo se prvo upoznati i sa zadacima OZP-a. Prema
[7] najčešći i najpoznatiji zadaci OZP-a su:
1. Redukcija – smanjivanje ili izostavljanje podataka koji nisu od
značaja za istraživanje;
2. Procena – procena vrednosti određene (egzogene) promenljive
na osnovu postojećih (endogenih) promenljivih;
3. Predviđanje – slična proceni ali se koriste složenije metode
modelovanja;
4. Klasifikacija – raspoređivanje elemenata u predodređene grupe
ili klase;
7

5. Klasterovanje – stvaranje kolekcija elemenata (klastera) koji su
međusobno slični i koji su različiti u odnosu na elemente iz
drugih klastera i,
6. Asocijacija - pronalaženje pravila u bazi podataka.
Sada, kada smo saznali zadatke, možemo odrediti i koje su to faze
OZP procesa kroz koje je potrebno proći da bi smo što bolje i brže došli do
validnih, korisnih i željenih izlaznih rezultata.
U cilju standardizacije primene OZP-a od 1996. do 1998. je od strane
najuticajnijih firmi iz ove oblasti (SPSS Inc, NCR, DaimlerChrysler AG i
OHRA) stvaran CRISP-DM (Cross-Industry Standard Process for Data
Mining) kao jedinstven proces vođenja OZP-a [8]. Na slici 2.3 vidimo da se
proces sastoji iz šest faza.
Slika 2.3
Faze CRISP-
DM, preuzeto iz
[8]
Faza razumevanja poslovnog procesa (Buisness understanding phase)
se fokusira na dobro razumevanje ciljeva projekta, formulaciju ciljeva i
ograničenja u formi pogodnoj za OZP i pripremu strategije.
Faza razumevanja podataka (Data understanding phase) počinje sa
inicijalnim prikupljanjem podataka, identifikacijom problema vezanih za kvalitet
podataka, otkrivanjem prvih veza i interesantnih podskupa u podacima za
formiranje hipoteza koje se odnose na skrivene informacije.
8

Faza pripreme podataka (Data preparation phase) pokriva sve
aktivnosti vezane za formiranje konačnog seta podataka. Uključuje izbor
promenljivih i atributa koji će biti analizirani, transformaciju i čišćenje
podataka.
Faza modelovanja (Modeling phase) podrazumeva korišćenje raznih
tehnika modelovanja i podešavanje parametara modela. Obično postoji više
tehnika za isti problem i neke od njih imaju posebne zahteve po pitanju forme
podataka tako da ova faza nekada podrazumeva vraćanje na fazu pripreme
podataka.
Faza ocene (Evaluation phase) podrazumeva ocenu rezultata modela,
da li se primenom modela zaista rešavaju problemi definisani u prvoj fazi,
određuje se da li su sva bitna pitanja dovoljno razmotrena i na kraju se donosi
odluka da li će rezultati OZP-a biti korišćeni.
Faza primene rešenja (Deployment phase) je faza u kojoj se ostvaruje
korisna primena modela, jer formiranje samog modela nije i završetak rada,
modelom se dobija znanje koje dalje treba organizovati i prezentovati na
način na koji to krajnji korisnici razumeju i mogu da koriste. Ona se može
sastojati od prostog formiranja izveštaja do formiranja ponavljajućeg procesa
OZP-a. Tokom ove faze korisnik shvata svrhu primene modela.
9

Slika 2.4
Zadaci i izlazi faza
CRISP-DM
modela, preuzeto iz [8]
Na slici 2.4 boldovanim su dati zadaci svake od faza a italikom rezultati
istih.
10

3. OZP u visokoškolskom obrazovanju
OZP je disciplina koja će uskoro biti u vrhu prioriteta za istraživače i
administraciju univerziteta. Visokoškolsko obrazovanje će pronaći širu
upotrebu OZP-a nego što je ona u sferi biznisa, iz razloga što visokoškolsko
obrazovanje obuhvata tri oblasti koje OZP može značajno da unapredi i to su:
naučna istraživanja koja su vezana za stvaranje znanja, predavanja koja se
tiču prenošenja tog znanja i istraživanja vezana za donošenje odluka same
univerzitetske institucije. OZP u visokoškolskom obrazovanju se koristi pri
donošenju odluka vezanih za marketing, predviđanju vremena diplomiranja,
upisa godine, boljoj raspodeli resursa svih vrsta, unapređenju studijskih
programa, uvođenju novih smerova, predviđanju uspeha studenata itd. Ovo
su razlozi koji su otvorili jedno novo, uzbudljivo i široko područje primene
OZP-a. U ovom delu pokušaćemo predstaviti razloge koji čine OZP veoma
korisnim i atraktivnim pristupom u oblikovanju visokoškolskog obrazovanja,
upoznaćemo se sa nekim od radova iz ove oblasti i dati primere primene
drugih naprednih tehnologija sa OZP-om.
3.1 Otkrivanje zakonitosti u podacima – logičan odgovor na turbulentno
okruženje
Moderne visokoškolske ustanove funkcionišu u uslovima velike
ekspanzije u broju i raznolikosti fakulteta. Pojava privatnih fakulteta uvodi
nove igrače u sferu obrazovanja i prenosi čitavu delatnost i u polje
ekonomskog poslovanja. To znači da fakultet mora što efikasnije, efektivnije i
kvalitetnije stvarati svoj proizvod, uspešnog studenta. Pod time
podrazumevamo ceo jedan proces od povećanja broja upisnika na fakultet
putem ciljanog marketinga, preko osmišljanja i uvođenja što boljih studijskih
programa kojima će se student zadržati na istom i pomoći da se ti programi
što bolje usvoje, do ispitivanja raznih drugih aspekata studentskog ponašanja
kojima će se poboljšati njihov rad, motivisanost i količina usvojenog znanja.
Preduslov da se ovim problemima pristupi putem OZP-a je postojanje
odgovarajuće tehničke podrške.
11

Informacione tehnologije danas, u svom naglom razvoju, došle su do
tačke kada mogu da posluže kao odgovarajuća tehnička podrška procesiranju
velike količine podataka prikupljenih u fakultetskim bazama podataka o
studentima, nastavnim programima, predavačima, organizacionom i
menadžerskom osoblju i tako dalje. Ti podaci predstavljaju strateški resurs
fakulteta. Sada je znanje, koje će fakultetu pomoći da sve navedeno ostvari,
skriveno među tim podacima i moguće ga je izvući i generisati putem OZP-a.
3.2 Primeri primene OZP-a u visokoškolskom obrazovanju
Jing Luan (2001) [9] je u svojoj studiji pokušao da predvidi studente koji
će biti istrajni na studijama. Kao izlaz u svojoj studiji koristio je dve
promenljive: istrajni „P“, oni koji su upisali naredni semestar i neistrajni „NP“,
oni koji to nisu uradili. Svoje podatke podelio je na dva jednaka dela i tako
dobio trening skup podataka za validaciju rezultata i test skup podataka.
Zatim je trenirao modele sa nekoliko povezanih algoritama na tim skupovima
da identifikuje jedan ili dva modela koji su konstantno davali optimalna
predviđanja. Promenljive koje su korišćene su:
Demografske: godine, pol, nacionalnost, srednja škola, poštanski kod,
planirani fond časova rada;
Stručnost, osnovne veštine, spretnost;
Broj pohađanih kurseva po smeru i,
Broj ostvarenih poena i ocena po kursu.
Koristeći se SPSS softverom Clementine on je upotrebio Neuronske mreže
(Neural networks) i dva algoritma C5.0 i C&RT. Neuronska mreža rezultovala
je sa 61.3% tačnosti u predviđanju, takođe ni C5.0 ni C&RT nisu dali preko
65% tačnosti predviđanja tako da je bilo neophodno ispitati podatke.
Otkriveno je više karakteristika podataka koje su uticale na teškoće koje su se
pojavile, i to su bile činjenica da podaci sežu unazad više od pet godina i da
su se neki smerovi tada drugačije zvali i da su primenjivane različite
metodologije nastave kao i da studenti imaju malu lojalnost, to jest da mnogi
od njih istovremeno upisuju više koledža i prelaze sa jednog na drugi. Tada je
akcenat stavljen na predviđanje onih koji nisu istrajni jer je donešena odluka
da je bolje neke od istrajnih tretirati kao neistrajne kada se sprovodi ciljni
12

marketing nego obrnuto. Ovo je rezultiralo visokom stopom tačnosti
predviđanja i to:
Neuronska mreža 85.1% za NP (neistrajne) i 27.5% za P (istrajne).
C5.0 77.1 za NP i 45.5% za P.
C&RT 63.1% za NP i 57.2% za P.
Kao što se vidi, neuronska mreža je proizvela najbolji model ali nije proizvela
dalje informacije, ponašala se kao “crna kutija” i nikakva pravila zaključivanja
nisu otkrivena da bi se bolje shvatilo kako model radi. C5.0 je generisao i
model odlučivanja i set pravila zaključivanja. Bilo je 13 pravila za istrajne i 38
za neistrajne.
Tipično pravilo za istrajne je:
Ako je Broj pohađanih kurseva>7
i Probni status=Dobar
i Kurs primenjene umetnosti uzet=0
onda P(426, 0.743)
A za neistrajne:
Ako je Broj pohađanih kurseva>7
i Kurs osnovnih veština uzet<=1
i Probni status=Slab
i Kurs prve pomoći uzet<=0
i Istorija umetnosti>1
onda NP(104, 0.585)
Takođe veoma zanimljiv deo rada je i onaj koji objašnjava kada se koriste
nadgledani i nenadgledani algoritmi, gde se kaže da kada istraživač ima
veoma dobro znanje o domenu podataka i kada je siguran u izbor izlaznih
podataka treba koristiti nadgledane algoritme a kada to nije slučaj treba
koristiti nenadgledane algoritme. Tabela sa slike 3.2.1 daje kategorizaciju
OZP algoritama.
13

Slika 3.2.1
Kategorije OZP
algoritama preuzeto iz
[9]
Peter B. Wylie i John Samis [10] u studiji iz 2008. godine govore o
tome kako univerzitet može uštedeti u ciljnom marketingu. Zapadni univerziteti
prikupljaju priloge od diplomiranih studenata tako što šalju pisma koja
pozivaju na donaciju. Za tipičan univerzitet sa 25,000 studenata, broj
diplomaca može biti i desetostruko veći od broja upisanih. Većina univerziteta
šalje pisma redovno svim diplomiranim studentima, čak i kada oni ne
odgovore. Taj proces obično košta više od 100,000$ godišnje. Na slici 3.2.2
vidimo kolika dobit se može ostvariti ako bi koristili OZP da odredimo
diplomce kojima bi pisali i to uporedili sa rezultatima prostog pisanja svim
diplomiranim studentima.
Slika 3.2.2
Grafikon dobiti,
preuzeto iz [10]
14

Zakrivljena linija na grafikonu predstavlja optimalni nivo odgovora putem
donacija od strane diplomiranih studenata ukoliko se pisma šalju
predviđanjem potencijalnih diplomaca donatora putem OZP-a, dok je deblja
crna linija na grafiku rezultat koji je ostvaren kada su poslata pisma svim
diplomcima. U ovom slučaju, na grafiku se vidi da kada je dostignuto 30
procenata poslatih pisama populaciji predviđenoj OZP-om, 80 procenata njih
je odgovorilo donacijom.U istoj tački kada se šalju pisma celokupnoj populaciji
diplomaca stopa odgovora je samo 40 procenata, a dostiže 80 tek na 70
procenata kontaktiranih. Ako bi postavili da kontaktiranje jednog procentnog
poena populacije košta 2,500$ ušteda je (70%*2,500$)-
(30%*2,500$)=175,000$-75,000$=100,000$. Znači bez OZP-a potrošeno bi
bilo 100,000$ da bi dostigli 80% diplomaca koji odgovore na pismo putem
donacije. Luan [9] to naziva „One Percent Doctrine“(Pravilo jednog procenta),
jer na primer ako je prosečna donacija 100$, jedan procenat povećanja znači
25,000$ više na 25,000 diplomiranih studenata univerziteta. Da bi povećali
učinak slanja pisama i povećali donacije, a ujedno smanjili troškove autori su
sakupili podatke za 5 univerziteta i svakog od studenata predstavili određenim
brojem bodova koristeći standardne statističke tehnike. Nekada je broj bodova
bio baziran na samo nekoliko polja kao što su: postojanje ili nepostojanje
kućnog broja telefona u bazi podataka, postojanje ili nepostojanje e-mail
adrese u bazi, oznaka bračnog stanja, željena godina diplomiranja studenta.
Dok je u nekim slučajevima to bilo na osnovu 25 i više polja kao što su: broj
godišnjica mature na kojima su studenti bili, broj volonterskih aktivnosti posle
diplomiranja, da li je prisutno ime bračnog druga u bazi podataka, da li je
student član asocijacije diplomaca koji doniraju, poštanski kod da li postoji,
broj pogledanih e-mail poruka. Taj broj bodova po studentu nije odmah
korišćen da bi se izdvojili donatori, tako da je to pružilo priliku da se testira
njihova moć predviđanja jer broj bodova tako nije uticao na rezultate
doniranja. Zatim je urađeno sledeće:
Za svaku školu je izračunato kolike su donacije bile u periodu za koji je
rađeno bodovanje studenata (nekada je vremenski interval bio samo
par meseci, a nekada nekoliko godina).
Zabeleženo je da li je određeni student dao donaciju i kolika je ona bila.
15

Za svaki bodovni nivo izračunato je koji procenat diplomaca sa tog
nivoa je dao donaciju kao i prosečna visina donacije za taj nivo.
Za svaku od pet visokoškolskih institucija su konvertovani bodovi tako da se
dobije skala od 1 do 20 gde je svaki bodovni nivo predstavljao oko 5
procenata od uzorka za tu instituciju i zatim su na graficima predstavljeni
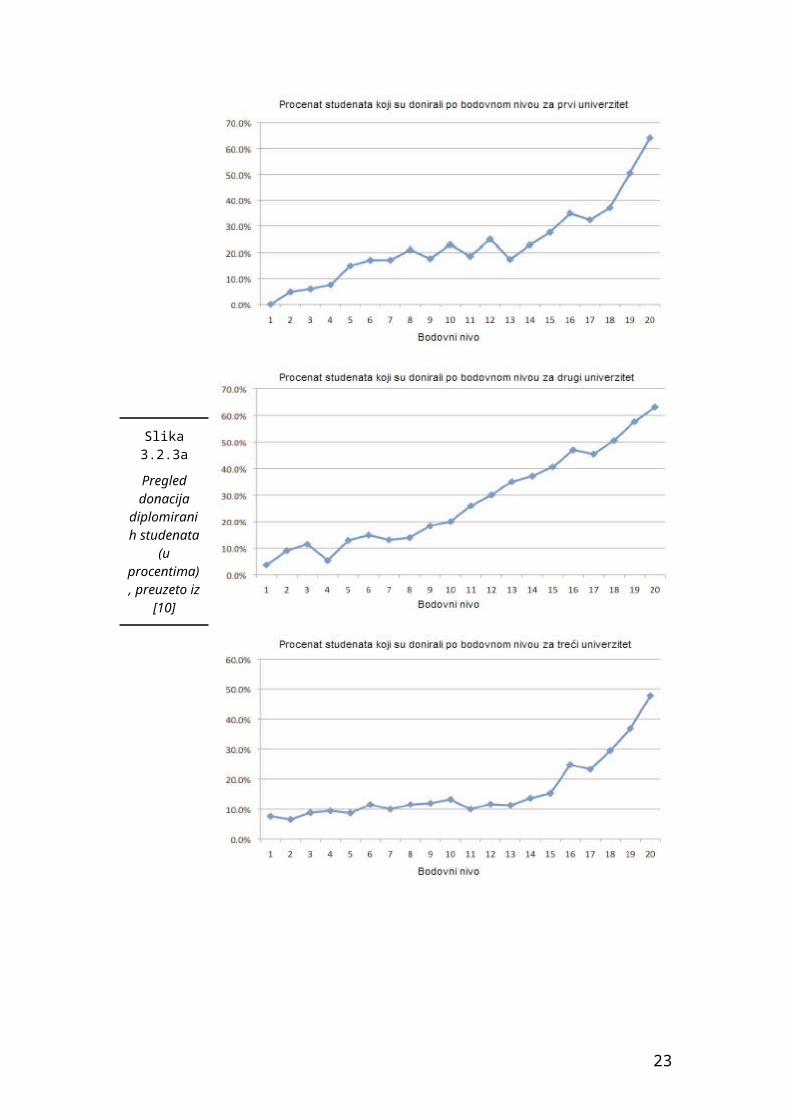
procenti donatora za svaki bodovni nivo. Na slikama 3.2.3a i 3.2.3b vidimo te
grafike za svaku od 5 visokoškolskih institucija.
16

Slika 3.2.3a
Pregled donacija
diplomiranih studenata (u procentima), preuzeto iz
[10]
17

Slika 3.2.3b
Pregled donacija
diplomiranih studenata (u procentima), preuzeto iz
[10]
Vidimo da kako raste broj bodova raste i procenat diplomiranih studenata iz
tih kategorija koji doniraju. Takođe na svim, sem četvrtog univerziteta, vidi se
ogromna razlika u doniranju studenata iz prvih pet, najnižih, bodovnih nivoa i
poslednjih pet, najviših. Tako najviši procenat za bodovne nivoe 1-5 iznosi
14.9% dok najniži za nivoe 16-20 iznosi 24.8%. Jedino četvrti univerzitet ima
relativno ujednačen rast donacija i visok procenat u nižim bodovnim nivoima.
Nema sumnje da je bodovanje u ovoj studiji uspelo jer su njime sa velikom
preciznošću predviđeni oni diplomci koji više doniraju, tako da ukoliko
univerziteti budu koristili ovo bodovanje pri slanju pisama ili poziva na
donaciju, moći će da fokusiraju svoje napore i resurse na diplomirane
studente u višim bodovnim nivoima. Tako će uštedeti novac i dobiti veći odziv
donacija, drugim rečima povećaće povrat investicija.
18

J. F. Superbay, J.-P. Vandamme i N. Meskens u svojoj studiji [11] iz
2006. godine pokušali su da daju odgovor na to kako predvideti studente koji
neće proći prvu godinu studija. Istraživanje je rađeno na tri Belgijska
univerziteta, na uzorku od 533 studenta. Posle analize rezultata studenata
prve godine otkriveno je da oko 60% njih padne godinu ili napusti studije.
Glavni cilj je bio da se klasifikuju studenti u tri grupe:
Nisko rizični studenti, sa velikom verovatnoćom uspeha;
Srednje rizični studenti, koji mogu uspeti ukoliko se preduzmu mere
od strane univerziteta i,
Visoko rizični studenti, koji imaju veliku verovatnoću da padnu godinu
ili napuste studije.
Kreirana je baza podataka u kojoj je svaki student opisan preko određenog
broja kriterijuma kao što su godine, nivo obrazovanja roditelja, mišljenje
studenta o univerzitetu itd. Svaki student je opisan sa 375 promenljivih od
kojih su neke dobijene putem zatvorenih upitnika poslatih studentima.
Pokušano je na osnovu ovih promenljivih da se predvidi varijabla vezana za
uspeh studenta, da se to učini što je pre moguće u školskoj godini i da se
obezbeđivanjem optimalne distribucije nastavnih resursa ograniči neuspeh
studenata. Promenljive su podeljene u 3 grupe. Prva grupa su bile one koje
se odnose na prošlost studenta (njegov identitet, socio-ekonomski status,
porodica, prethodno školovanje itd.). Druga grupa su bili faktori koji opisuju
ponašanje studenta na studijama (učestvovanje u dopunskim aktivnostima,
odlazak na konsultacije itd). Treća grupa je obuhvatala studentska shvatanja i
stavove (način na koji shvata akademske studije, profesore, kurseve itd.). Na
slici 3.2.4 vidimo vezu između proseka ocena studenta u januaru upoređene
sa uspehom na kraju godine. Lako se može primetiti razlika između dve
potpuno suprotne grupe studenata, one u kojoj su studenti čija je ukupna
ocena ispod 45% od ukupno moguće u januaru, koji su svi pali na kraju
godine (uz izuzetak dva studenta) i druge u kojoj su studenti ostvarili preko
70% od ukupne ocene u januaru, i svi su završili godinu.
19

Slika 3.2.4
Uspeh studenat
a u januaru i na kraju godine,
preuzeto iz [11]
Sledeće što je urađeno je da je konstruisana promenjliva koja će biti izlaz i
koja će opisivati zonu u kojoj se student nalazi (visok, srednji ili nizak rizik).
Sada ćemo nabrojati neke od objašnjavajućih promenljivih i njihove
korelacione koeficijente (dati u zagradama).
Iz prve grupe, faktori koji dosta utiču na uspeh, su: prosek poslednje
godine školovanja (0.337), broj časova matematike u poslednjoj godini
srednje škole (0.313), nemogućnost samostalnog finansiranja studija
(0.162), nisu pohađali kurseve ekonomije ili društvenih nauka u
srednjoj školi (0.157), nisu stariji od proseka na prvoj godini (0.157),
nepušači (0.177). Ostali faktori, kao što su pol, nivo obrazovanja
roditelja, zanimanje roditelja, broj braće ili sestara, razvedeni roditelji
itd. nisu bitno korelisani sa uspehom.
Iz druge grupe značajni su: broj časova predavanja koje pohađaju
(0.250), stalno izostajanje sa određenih predavanja (0.164), izostajanje
sa predavanja koje i većina studenata propušta (0.134), potpuno
razumevanje materije koja se izučava (0.165), neodustajanje od
gradiva koje studenta zaista zanima (0.159), shvatanje da je
neophodna izrada domaćih zadataka (0.143).
Treću grupu čine: mišljenje studenta o šansama za uspeh (0.326),
mišljenje da kurs nije previše težak (0.150), mišljenje da su loše
20

pripremljeni za studiranje (0.182), mišljenje da su napravili dobar izbor
pri upisu (0.182), dobra procena vremena potrebnog za učenje (0.159),
volja za radom u grupi pre nego samostalno (0.232).
Da bi predvideli uspeh i klasifikovali studente u jednu od tri predefinisane
kategorije koristili su stablo odlučivanja, neuronske mreže i linearnu
diskriminacionu analizu [1], [12].
Slika 3.2.5
Sumirani rezultati
klasifikacije studenata
nakon validacije nad
test delom podataka, preuzeto iz
[11]
Na slici 3.2.5 vidimo kako su pojedini algoritmi uspevali da predvide kojoj klasi
pripada određeni student. U prvoj tabeli slike 3.2.5 vidimo rezultate za stablo
odlučivanja i oni nisu posebno dobri: samo 48.65 procenta studenata prve
klase (Visok rizik) su tačno klasifikovani predviđanjem, samo 18.46 procenta
druge (Srednji rizik) i 60.34 procenta treće klase (Nizak rizik). Vidimo da je
stablo odlučivanja delimično dobro uradilo posao za dve granične klase ali je
za klasu Srednji rizik taj rezultat veoma loš (iako je to klasa koja obuhvata
najveći deo studentske populacije sa 40%, dok u klasi Visok rizik imamo 27%
i 33% u klasi Nizak rizik). Postignut je nivo ukupne tačne klasifikacije od samo
40.63%. Druga tabela slike 3.2.5 prikazuje rezultate neuronske mreže i ni oni
nisu naročito dobri ali su malo bolji od onih za stablo odlučivanja. Procenat
ukupne tačne klasifikacije dostiže 51.88%. Analizom podataka iz treće tabele
dolazi se do toga da je ukupna tačnost klasifikacije 57.35% a i pojedinačni
21

nivoi za svaku od klasa su najviši od sve tri korišćene metode. Zaključci ove
studije su bili da nivo tačnosti predviđanja koji je postignut pri validaciji
metoda nije naročit, ali da je za petinu promenljivih korišćenih u studiji
pokazano da imaju značajan uticaj na akademski uspeh. Ipak čini se da
diskriminaciona analiza, a u nešto manjoj meri i neuronske mreže, mogu
dovesti do interesantnih zaključaka, a takođe treba i povećati veličinu uzorka
u narednim ispitivanjima.
Emily H. Thomas i Nora Galambos pokušale su u svom radu [13] da
putem OZP-a daju odgovore na pitanje šta čini studente zadovoljnim, koristeći
pri tom regresionu analizu i stablo odlučivanja [12]. Ako studente smatramo
kao potrošače visokoškolskog obrazovanja, njihovo zadovoljstvo je važno za
uspeh institucije, i iz razloga što efikasne institucije treba da imaju zadovoljne
mušterije kao i iz razloga što zadovoljstvo podstiče dolazak novih mušterija.
Veličina uzorka u ovom istraživanju je bila 1698 studenata. Prikaz
studentskog mišljenja sakupio je podatke o velikom broju studentskih
karakteristika, iskustava i planova. Na primer, 44 promenljive su merile
zadovoljstvo karakteristikama univerziteta, klimatskim uslovima studentskog
doma i okolinom, kao što su: vaš osećaj pripadnosti univerzitetu, dostupnost
profesora za konsultacije i rasna tolerancija. Dok je 35 promenljivih merilo
zadovoljstvo uslugama i kapacitetima unutar studentskog doma kao što su:
biblioteka ili društvene aktivnosti fakulteta. Ovaj prikaz je uključivao i četiri
pitanja koja su pokazivala ukupno zadovoljstvo iskustvom na fakultetu:
Nagovestite vaš nivo zadovoljstva ovim fakultetom u celosti.
Ako biste mogli da ponovo upišete fakultet da li biste izabrali isti?
Koji je vaš ukupni utisak o kvalitetu obrazovanja na ovom fakultetu?
Verovatno je da ću se prebaciti na drugi fakultet ove jeseni.
Slika 3.2.6 nam pokazuje korelaciju [14] između ovih faktora.
22
Slika 3.2.6
Korelacija faktora opšteg
zadovoljstva fakultetom, preuzeto iz
[13]
Tri faktora su prilično povezani, dok verovatnoća prelaska na drugi fakultet
pokazuje slabu korelaciju sa zadovoljstvom. Da bismo razumeli zašto su
studenti različito odgovarali na pitanja o opštem zadovoljstvu fakultetom
moramo znati koja specifična iskustva prikazuju njihovi odgovori. Znajući to i
fakulteti mogu drugačije organizovati svoje prioritete da bi poboljšali
zadovoljstvo studenata. Regresiona analiza [12] je jedan od način za
identifikaciju veoma važnih uticaja, dok stablo odlučivanja nudi bogatije
objašnjenje. U model regresione analize uključeno je 17 promenljivih.
Promenljive vezane za zadovoljstvo kvalitetom obrazovanja su naročito
upečatljive. Nijedan od pokazatelja društvene integracije se ne pojavljuje
među promenljivim vezanim za zadovoljstvo kvalitetom obrazovanja, budući
da su te promenljive najvažniji pokazatelji druga dva faktora opšteg
zadovoljstva fakultetom. Verovatnoća da bi ponovo izabrali ovaj fakultet je
veoma jako uslovljena time da li je to bio njihov prvi, drugi, treći izbor.
Zadovoljstvo fakultetom u celosti jako je uslovljeno informacijama koje su
studenti prikupili pre samog upisa na fakultet, verovatno kao pokazatelj toga
koliko su ispunjena njihova očekivanja. Sa druge strane, promenljive koje su
pokazatelji mogućeg prelaska na drugi fakultet su potpuno različite od onih
vezanih za prethodna tri faktora. Te promenljive vezane su za željenu karijeru,
odsustvo određenih fakultetskih smerova i programa koje bi studenti želeli itd.
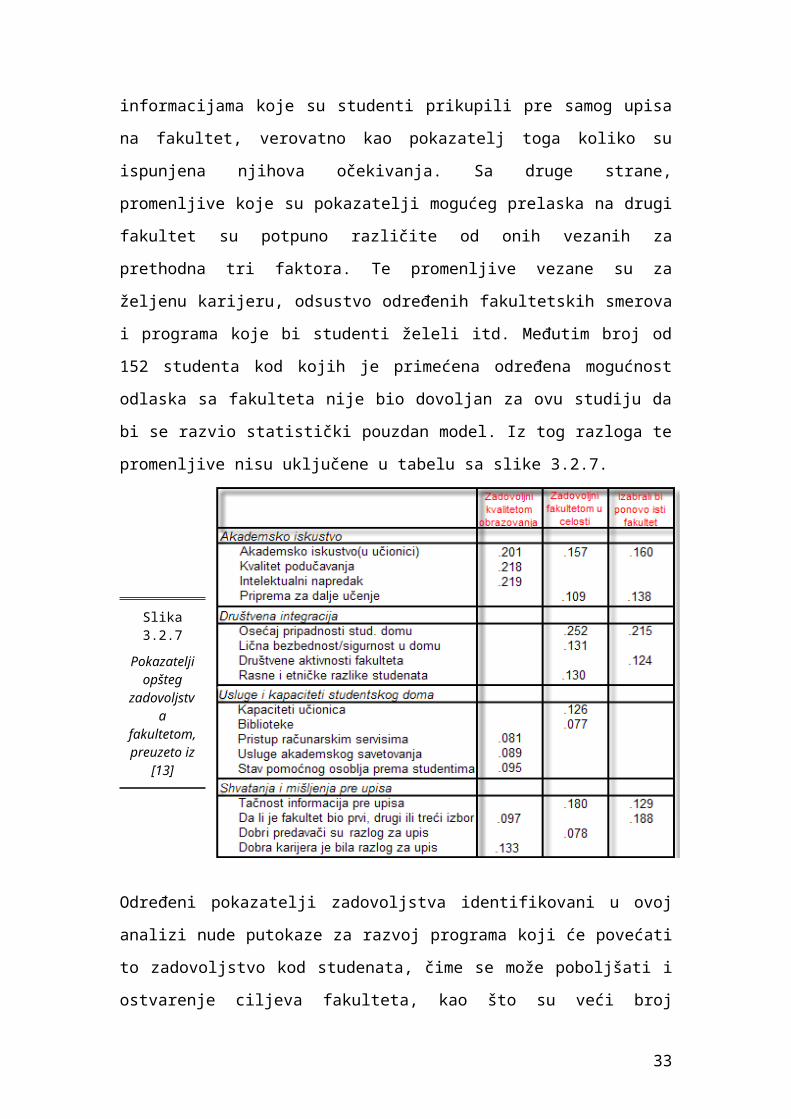
Međutim broj od 152 studenta kod kojih je primećena određena mogućnost
odlaska sa fakulteta nije bio dovoljan za ovu studiju da bi se razvio statistički
23

pouzdan model. Iz tog razloga te promenljive nisu uključene u tabelu sa slike
3.2.7.
Slika 3.2.7
Pokazatelji opšteg
zadovoljstva
fakultetom, preuzeto iz
[13]
Određeni pokazatelji zadovoljstva identifikovani u ovoj analizi nude putokaze
za razvoj programa koji će povećati to zadovoljstvo kod studenata, čime se
može poboljšati i ostvarenje ciljeva fakulteta, kao što su veći broj studenata,
njihov bolji uspeh, bolji studijski programi itd.
Regresiona analiza je identifikovala uticajne promenljive koje su najviše
povezane sa faktorima zadovoljstva dok će, nasuprot tome, stablo odlučivanja
identifikovati važne elemente studentskog iskustva koji najviše prave razliku
između zadovoljnih i nezadovoljnih. Tako, na primer, iskustvo koje najviše
razdvaja studente koji su zadovoljni kvalitetom obrazovanja od onih koji to
nisu je opažanje intelektualnog napretka. Tabela na slici 3.2.8 pokazuje
frekvenciju distribucije za prvi list stabla odlučivanja. Vidimo da je 70%
studenata odgovorilo da je kvalitet obrazovanja bio odličan (18%) ili dobar
(52%).
24

Slika 3.2.8
Veza zadovoljstva kvalitetom
obrazovanja i zapažanja
intelektualnog napretka,
preuzeto iz [13]
Međutim raspodela odgovora oko kvaliteta obrazovanja je bila veoma različita
za studente koji su prijavili visok intelektualni napredak od onih koji su prijavili
nizak. Na primer, 19% studenata su zapazili veoma velik intelektualni
napredak i ti studenti su bili veoma zadovoljni kvalitetom obrazovanja: čak
91% njih smatra da je kvalitet obrazovanja odličan (46%) ili dobar (45%). Dok
nasuprot tome, studenti koji su zapazili nizak ili nikakav intelektualni napredak
su sa samo 30% ocenili odličnim ili dobrim kvalitet obrazovanja. Algoritam
stabla odlučivanja je otkrio da nema značajnih razlika između studenata sa
niskim ili nikakvim intelektualnim napretkom pa su te dve kategorije grupisane
u jednu.
Tabela sa slike 3.2.9 pokazuje promenljive koje određuju zadovoljstvo
kvalitetom obrazovanja studenata koji su imali veoma velik intelektualni
napredak. Procenti prikazani u svakom od polja pokazuju koji deo studenata
iz te grupe je ocenio kvalitet obrazovanja kao odličan ili dobar. Tako, na
primer, među 119 studenata koji su prijavili veoma velik intelektualni napredak
i koji su takođe veoma zadovoljni kvalitetom podučavanja, njih 97% misli da je
kvalitet obrazovanja dobar ili odličan. Daljim pomeranjem kroz stablo vidimo
da je čak 100% studenata, koji su konstantno intelektualno podsticani, ocenilo
kvalitet obrazovanja kao dobar ili odličan.
25

Slika 3.2.9
Zadovoljstvo kvalitetom
obrazovanja: Studenti sa
veoma velikim intelektualnim
napretkom, preuzeto iz [13]
Nisu otkrivene nikakve značajne veze među studentima koji su manje
zadovoljni kvalitetom podučavanja, tako da ti listovi nisu imali dalja
grananja.Na slici 3.2.10 je predstavljen deo stabla odlučivanja koji pokazuje
grananja za studente koji su prijavili veliki intelektualni napredak (41% uzorka)
a na slici 3.2.11 za studente koji su prijavili nizak ili srednji intelektualni
napredak (40% uzorka).
Slika 3.2.10
Zadovoljstvo kvalitetom
obrazovanja: Studenti sa
velikim intelektualnim
napretkom, preuzeto iz
[13]
26

Slika 3.2.11
Zadovoljstvo kvalitetom
obrazovanja: Studenti sa
niskim i srednjim
intelektualnim napretkom, preuzeto iz
[13]
Sa prethodne tri slike možemo da vidimo kako različita iskustva utiču na
zadovoljstvo studenata sa različitim percepcijama intelektualnog napretka.
Vidi se da pokazatelji društvene integracije kao što je “briga za vas kao
osobu” i “osećaj pripadnosti” su mnogo važniji studentima koji su manje
akademski aktivni. Intelektualni napredak, kvalitet podučavanja i zadovoljstvo
akademskim iskustvom su promenljive koje imaju jak uticaj u regresionom
modelu i one se takođe pojavljuju i kod stabla odlučivanja kao veoma važne.
Međutim, stablo odlučivanja otkriva nove sekundarne promenljive:
intelektualnu podstaknutost za studente sa najvišim intelektualnim napretkom,
brigu o osobi i korisnost kursa za studente sa velikim intelektualnim
napretkom, veličinu nastavne grupe i osećaj pripadnosti za one sa niskim
intelektualnim napretkom.
Regresiona analiza je identifikovala veoma značajne pokazatelje za
populaciju kao celinu, dok je jedna od prednosti stabla odlučivanja njegova
mogućnost da identifikuje grupe promenljivih koje najviše utiču na podgrupe
uzorka a ne na uzorak kao celinu. Zaključci studije bili su sledeći:
Studentsko zadovoljstvo fakultetom u celosti, kvalitetom obrazovanja i
verovatnoća ponovnog izbora istog fakulteta su uslovljeni različitim
aspektima fakultetskog iskustva.
Zadovoljstvo je jako povezano sa studentskom reakcijom na
predavače.
Akademsko iskustvo i intelektualni napredak su veoma bitne
promenljive mada i osećaj pripadnosti fakultetu značajno doprinosi
ukupnom zadovoljstvu.
27

Neakademski aspekti fakulteta su bitniji studentima koji su manje
akademski angažovani.
Demografske karakteristike se nisu pojavile kao značajni pokazatelji.
Zadovoljstvo je i pod uticajem stavova o fakultetu pre upisa kao i onih
posle upisa.
Različita mišljenja o studentskom domu i njegovim servisima imaju
relativno mali uticaj.
Pojavljuje se važnost organizovanja programa koji povećavaju
društvenu integraciju novoupisanih studenata.
3.3 Pravci budućeg razvoja OZP-a u visokoškolskom obrazovanju
Razvoj čovečanstva utiče na sve pore ljudskog društva pa tako i na
visokoškolsko obrazovanje. Iako je primarna misija fakulteta - stvaranje,
očuvanje, integracija i prenošenje znanja - ostala nepromenjena, realizacija
svake od ovih uloga se drastično izmenila. U poslednje vreme, kao važne
teme, ističu se:
Važnost znanja kao ključnog faktora za bezbednost, napredak i
kvalitet života;
Globalna priroda društva;
Lakoća kojom informacione tehnologije omogućavaju brzu razmenu
informacija i,
Povećanje neformalne kolaboracije među pojedincima i ustanovama
koja zamenjuje formalne društvene strukture, među njima i fakultete.
Tako, pod uticajem informacione tehnologije, dolazimo do vremena kada se
fakulteti mogu posmatrati kao serveri znanja, koji pružaju usluge u domenu
znanja, u kojoj god formi one bile potrebne. Moguće je da će jednog dana biti
neophodno da zaposleni na fakultetu napuste svoje uloge predavača i
postanu dizajneri procesa učenja. Vekovima je intelektualni fokus fakulteta bio
njegova biblioteka, kolekcije pisanih radova koje su u sebi nosile znanja
civilizacije. Sada to znanje postoji u mnogim formama – kao tekst, grafika,
zvuk, algoritam ili virtualna simulacija – i distribuirano je širom sveta putem
mreža, dostupno gotovo svima. Danas se fakulteti sreću sa novim izazovima.
28

Kako raste potreba za visoko obrazovanim kadrovima, neke institucije
pomeraju fokus svoje delatnosti daleko od tradicionalnih geografskih oblasti
na kojima su delovale i ulaze u borbu za studente i resurse. Visokoškolsko
obrazovanje evoluira od labavo ujedinjenog sistema fakulteta i univerziteta
koji služe studentima lokalnih zajednica do industrije znanja u naglom razvoju.
I kako naše društvo postaje sve više zavisno od novih znanja, obrazovanih
ljudi i zaposlenih u obrazovanju, obrazovanje treba posmatrati kao jednu od
najaktivnijih i brzo rastućih industrija današnjeg vremena.
Prema podacima Republičkog zavoda za statistiku u Statističkom godišnjaku
Srbije za 2008. godinu u 2006/2007 školskoj godini u Srbiji je bilo 178
fakulteta i 94 više škole. Oni su organizovani unutar 14 univerziteta dok još 4
univerziteta čekaju na akreditaciju kod Republičke komisije za akreditaciju.
Postoji velika različitost u veličini, misiji, sastavu i izvorima finansiranja. U
godinama koje slede ne samo da ćemo biti svedoci pojave novih obrazovnih
ustanova, nego će doći i do toga da će neki fakulteti prestati sa radom, drugi
će se udružiti, a neki će sebi pripojiti druge. Jedno je sigurno, uspešni će
koristiti OZP.
A da bi to činili moraju se pronaći novi pravci primene OZP, koji će podržati
nove informacione tehnologije. U daljem tekstu videćemo neke od primera
primene OZP-a zajedno sa naprednim informacionim tehnologijama i time
pokazati još jednu snagu OZP-a, a to je njegova sposobnost da se prilagodi
novim uslovima i potrebama savremenog obrazovanja.
W. Hämäläinen, T.H. Laine i E. Sutinen u svom istraživanju „Data
mining in personalizing distance education courses“ [15] govore o potrebi
personalizovanja obrazovanja na daljinu koja proizilazi iz činjenice da je
potrebno nadzirati i pomagati svakom studentu posebno, nezavisno od
vremena, mesta i bilo kojih drugih ograničenja. To znači da obrazovanje na
daljinu treba da koristi OZP kako bi se mogao nadzirati proces učenja i kako
bi se mogao vršiti uticaj i promene na istom. OZP uključuje u ceo proces
ulogu eksperta, u ovom slučaju predavača, da tumači otkrića do kojih se dođe
analizom podataka sa kursa. ViSCoS (Virtual Studies of Computer Science)
program, koji je korišćen kao izvor podataka za ovo istraživanje, je program
obrazovanja na daljinu, prvobitno namenjen srednjoškolcima koji su
29

zainteresovani da obrazovanje nastave na fakultetima informacionih nauka.
Razlozi za uvođenje ovog programa 2000. godine na University of Joensuu,
Department of Computer Science, Finska, bili su sledeći:
Regrutovanje srednjoškolaca za upis na smer kompjuterskih nauka;
Stvaranje eksperimentalne platforme sa stvarnim predavačima kako
bi se ispitale mogućnosti novih tehnologija u obrazovanju i,
Privlačenje mladih ljudi izboru informacionih i komunikacionih
tehnologija kao njihove buduće karijere.
Važna uloga traženja studenata pomoću ViSCoS-a je da oni završe svoje
studije u očekivanom roku i na odgovarajući način. Međutim, kao i na svakom
programu obrazovanja na daljinu i svakom programerskom smeru, problem je
bio velik broj studenata koji odustaju. Čini se da bi bar jedan deo studenata
mogao biti zadržan, ukoliko bi se proces njihovog učenja pratio i analizirao i
time dobili podaci za ranu intervenciju. To podrazumeva model sposoban da
predvidi njihove buduće pokazatelje učinka pomoću podataka iz prethodnih
perioda vezanih za njihove uspehe, kao što su poeni sakupljeni na vežbama i
zadacima. Umesto biranja nekog ad hoc5 modela, glavni motiv ovog
istraživanja bio je konstruisanje modela na osnovu stvarnih podataka.
Autori su usvojili dualni princip deskriptivnog i predviđajućeg modelovanja koji
kombinuje paradigme OZP-a i mašinskog učenja. Ideja je bila da se u
deskriptivnoj fazi analiziraju podaci iz prethodne godine i traže veze i obrasci
kao što su korelaciona i asocijativna pravila. Ti rezultati bi bili vodič za izbor
odgovarajućeg modela i za određivanje stukture modela predviđanja. U fazi
predviđanja bi se podešavali parametri modela na osnovu ovih podataka.
Koristili su dva tipa modelovanja. Prvi je uključivao korelaciju i linearnu
regresiju a drugi asocijativna pravila i Bajesov model6.
5 Latinski pojam koji znači “za ovu svrhu” i podrazumeva rešenje za specifičan problem, koje se ne može generalizovati niti može biti prilagođeno za druge svrhe6 Thomas Bayes (1702.-1761.), Britanski matematičar i statističar.
30

Slika 3.3.1
Iterativni proces
deskriptivnog i predviđajućeg modelovanja
U konstruisanju modela korišćeni su podaci sa dva programerska kursa
(Prog1 i Prog2) koji se izučavaju putem ViSCoS programa obrazovanja na
daljinu. Podaci sadrže identifikacioni broj studenta, pol, poene na vežbama,
poene na ispitima, ukupne poene i ocene. Prikupljeni su tokom 2001/2002 i
2002/2003 školskih godina. Odabrani su sledeći atributi:
Slika 3.3.2
Atributi korišćeni u istraživanju,
preuzeto iz [15]
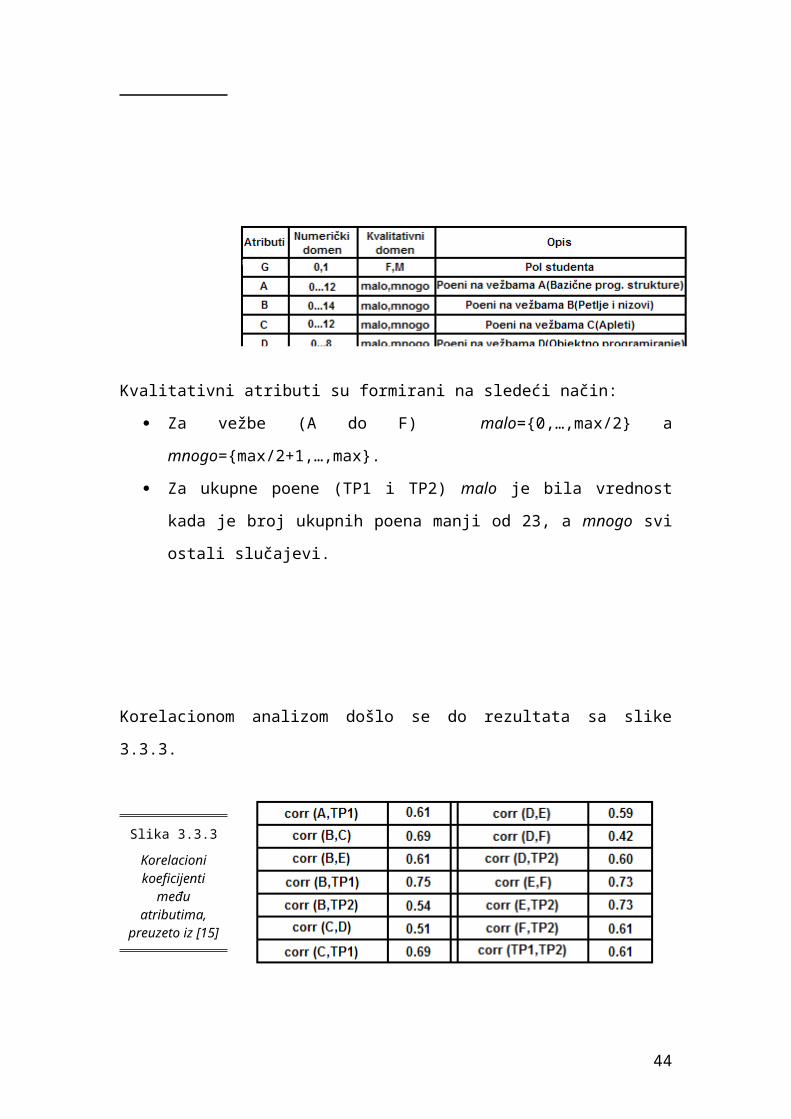
Kvalitativni atributi su formirani na sledeći način:
Za vežbe (A do F) malo={0,…,max/2} a mnogo={max/2+1,…,max}.
Za ukupne poene (TP1 i TP2) malo je bila vrednost kada je broj
ukupnih poena manji od 23, a mnogo svi ostali slučajevi.
31

Korelacionom analizom došlo se do rezultata sa slike 3.3.3.
Slika 3.3.3
Korelacioni koeficijenti
među atributima,
preuzeto iz [15]
Vidimo da poeni u vežbama B (Petlje i nizovi) imaju snažan uticaj na ukupan
broj poena, posebno na kursu Prog1. Dok na primer broj poena u vežbama A
(Bazične programske strukture) ima slab uticaj, verovatno iz razloga jer se
radi o najlakšim vežbama i gotovo svi studenti ih prolaze. Takođe se vidi da
vežbe E (Grafičke aplikacije) imaju veoma jak uticaj na broj poena na kursu
Prog2, što govori da rezultati studenata na sredini kursa mogu veoma pomoći
u predviđanju krajnjeg rezultata. Pol studenata nije imao značajnijeg uticaja
pa je isključen iz ove tabele (npr. njegova korelacija sa TP1/TP2 bila je 0.16).
U nastavku, na osnovu rezultata korelacione analize, je korišćena linearna
regresija za predviđanje, tj. korišćen je model višestruke linearne regresije
[16] u kojoj promenljiva koja se predviđa može zavisiti od više faktora. Na slici
3.3.4 vidimo konstruisane modele, gde nam naziv modela govori koje su
promenljive korišćene za predviđanje finalnih rezultata FR1 i FR2 (pri tom je
važilo pravilo da ako je TP>15 onda je FR=1), kao i validacione pokazatelje
modela. Kolone „Položili“ odnosno „Pali“ nam govore koliko je precizna bila
klasifikacija studenata u jedan od ta dva klastera.
Slika 3.3.4
Rezultati regresione
analize, preuzeto iz [15]
32
Vidimo da model koji uključuje samo vežbe B daje dobre rezultate predviđanja
(0.820 je tačnost za one koji će položiti i 0.560 za one koji će pasti), dok
modeli koji koriste rezultate iz vežbi E daju izuzetno dobre rezultate, kako kod
predviđanja onih koji će položiti tako i onih koji će pasti. Takođe na osnovu
poslednje dve kolone tabele izvlači se zaključak da je uticaj rezultata u
vežbama F minimalan, jer poslednja dva modela daju iste rezultate
predviđanja iako jedan od njih uključuje vežbe F a drugi ne.
Dalje u radu Hämäläinen, Laine i Sutinen koriste asocijativna pravila kao
dobar način da se ispitaju nelinearne zavisnosti među atributima. Poverenje
pravila „cf“ govori nam koliko je snažno pravilo, dok nam frekvencija ili podrška
„fr“ govori kolika je pokrivenost pravila. Na primer, asocijativno pravilo „B =
mnogo, E = mnogo, F = mnogo => FR2 = 1“ sa poverenjem c f = 0.956 i
frekvencijom fr = 0.516 govori da oko 96% studenata koji su imali „mnogo“
poena u vežbama B, E i F su prošli kurs Prog2. Takođe, frekvencija nam
govori da pravilo pokriva skoro 52% studenata. Na slici 3.3.5 su data neka od
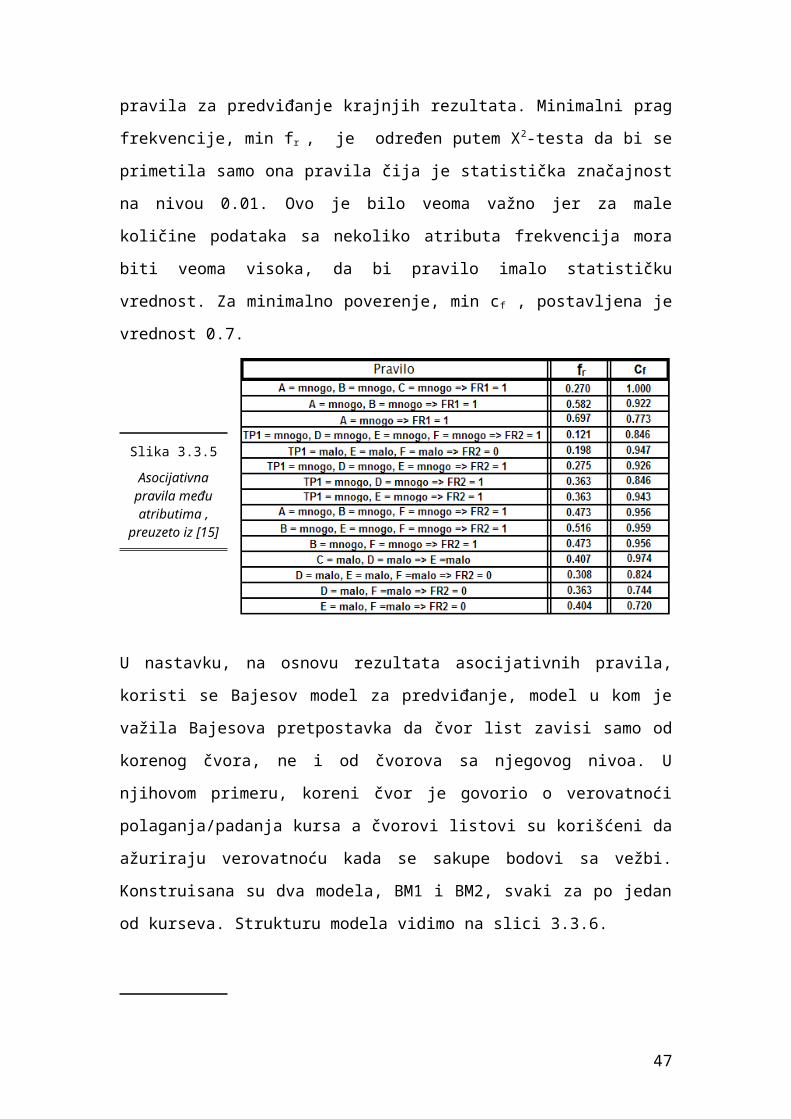
pravila za predviđanje krajnjih rezultata. Minimalni prag frekvencije, min fr , je
određen putem X2-testa da bi se primetila samo ona pravila čija je statistička
značajnost na nivou 0.01. Ovo je bilo veoma važno jer za male količine
podataka sa nekoliko atributa frekvencija mora biti veoma visoka, da bi pravilo
imalo statističku vrednost. Za minimalno poverenje, min cf , postavljena je
vrednost 0.7.
Slika 3.3.5
Asocijativna pravila među atributima ,
preuzeto iz [15]
U nastavku, na osnovu rezultata asocijativnih pravila, koristi se Bajesov model
za predviđanje, model u kom je važila Bajesova pretpostavka da čvor list
33

zavisi samo od korenog čvora, ne i od čvorova sa njegovog nivoa. U njihovom
primeru, koreni čvor je govorio o verovatnoći polaganja/padanja kursa a
čvorovi listovi su korišćeni da ažuriraju verovatnoću kada se sakupe bodovi sa
vežbi. Konstruisana su dva modela, BM1 i BM2, svaki za po jedan od
kurseva. Strukturu modela vidimo na slici 3.3.6.
Slika 3.3.6
Struktura Bajesovih modela za
kurseve Prog1(BM1
slika a) i Prog2 (BM2 slika b) , preuzeto iz [15]
U modelu BM1 prvobitna verovatnoća prolaska kursa je postavljena na 0.5.
Uslovne verovatnoće su izračunate iz podataka pomoću formule :
(1)
i vidimo ih na slici 3.3.7.
Slika 3.3.7
Verovatnoće za Bajesove
model BM1 (slika a) i BM2
(slika b) , preuzeto iz [15]
Kada se kurs nastavio, prvenstvene verovatnoće su dopunjene novim
podacima (broju poena u vežbama A, B, C, D, E i F) pomoću Bajesovog
pravila [16], [17] i [18] :
(2)
34

Predviđanja pomoću Bajesovog modela data su na slici 3.3.8. Na početku
kursa Prog1 skoro svi studenti rade dosta vežbi i stoga se predviđa da će
položiti kurs. Međutim kada su poznati poeni sa vežbi B, predviđanja su već
veoma precizna, kako za one koji su položili tako i za one koji su pali. Poeni
sa vežbi C ne poboljšavaju rezultate predviđanja mnogo jer je samo par
studenata radilo dosta ovih vežbi. Što se tiče kursa Prog2, rezultati se mogu
predvideti odmah jer je poznat ishod kursa Prog1. Predviđanja se znatno
poboljšavaju kada su poznati rezultati sa vežbi D i E. Rezultati sa vežbi F
dovode do jednog fenomena: tačnost predviđanja opada iako imamo više
podataka. Do toga dolazi jer su vežbe E i F u snažnoj korelaciji tako da dolazi
do kršenja Bajesove pretpostavke.
Slika 3.3.8
Rezultati Bajesovih modela,
preuzeto iz [15]
Ohrabrujući rezultati ove studije su ti da je bilo moguće predvideti uspeh na
kursevima za više od 80% studenata, dok je kurs još bio u toku. Model
zasnovan na korelacijama i linearnoj regresiji je davao pesimističnija
predviđanja, tj. bolje je predviđao padanje kursa nego polaganje, dok je model
zasnovan na asocijativnim pravilima i Bajesovom modelu bio optimističniji.
Oba deskriptivna modela (korelacije i asocijacije) su otkrila statistički značajne
zavisnosti koje su kasnije mogle biti korišćene da se konstruišu modeli
predviđanja.Studija je pokušala da odgovori na probleme predviđanja
studenata koji će odustati ali isto tako može biti korišćena da predvidi
nadarene studente. Takođe njome se mogu uočiti razlike između studenata
koji odustanu i onih koji padnu na ispitu jer postoji mogućnost da te dve grupe
studenata zahtevaju različitu vrstu pomoći. Rezultati studije su pokazali
primenljivost OZP-a kako za studente, jer mogu razviti sposobnosti da
posmatraju, analiziraju i poboljšaju svoje učenje, tako i za predavače da bolje
razumeju i prate kurseve i studente na njima. Tako OZP može pomoći da se
35

proces visokoškolskog obrazovanja pomeri ka polu-automatizovanom
procesu.
Logično da se sa sve većim brojem kurseva i studija koje se odvijaju
putem interneta pojavljuje i problem varanja pri rešavanju zadataka i ispita.
Studija „Detecting cheats in online student assessments using Data Mining“
[19], urađena od strane grupe autora sa Južnoameričkih fakulteta, je pokušaj
da se pomoću OZP-a detektuje to varanje. Nove tehnologije sa sobom nose i
negativni predznak, u smislu da dozvoljavaju nalaženje novih načina varanja,
a to više nisu „prepisivanje od studenta pored“ ili „korišćenje nedozvoljenih
skripti“, nego mnogo kompleksniji načini varanja putem internet mreže. Studija
[19] pokušava da putem praćenja ponašanja studenata, u toku izrade
zadataka putem interneta, dođe do obrazaca ponašanja onih koji varaju. Prvo
je urađena analiza studentskih ličnosti, zatim je praćeno njihovo ponašanje
tokom stresnih situacija izrade zadataka kao i načini na koje studenti varaju
da bi za sebe obezbedili bolje ocene. Promenljive vezane za studenta koje su
analizirane su : prosek ocena, godine, semestar, status studenta (budžet,
samofinansiranje), smer, lične osobine, društvene aktivnosti, pretnje kaznama
itd. Ostale promenljive bile su vezane za profesore kao npr. da li su i koliko
uključeni u proces ispitivanja putem mreže; za ispite kao npr. da li su
zbunjujući, da li su odgovarajuće težine, kao i u kom su obliku dati (otvorena
pitanja, zatvorena pitanja, kviz testovi); i za tehničke detalje a to su IP adrese
sa kojih se pristupa mreži, datum i vreme pristupa, korisnička identifikacija itd.
Podaci su pribavljani putem nadzora aktivnosti na mreži i putem mrežnog
sistema testiranja. Softver koji je korišćen pri obradi podataka je Weka
(Waikato Environment for Knowledge Analysis), razvijen na University of
Waikato, Novi Zeland. Kada je decembra 2005. godine sprovedeno prvo
mrežno testiranje i kad su podaci obrađeni putem OZP-a, nisu pronađeni
nikakvi sumnjivi obrasci ponašanja koji bi ukazali na studente koji su varali.
Dva faktora su uticala na to:
Sredina u kojoj se odvijalo testiranje je bila dosta kontrolisana. To su
bile učionice u kojima su bili prisutni profesori i svi računari su bili u
okviru jedne lokalne mreže i,
36

Mala količina podataka za ispitivanje. Broj studenata koji su podvrgnuti
ovom ispitivanju je bio 97. OZP zahteva više podataka kako bi rezultati
bili pouzdani.
Međutim, ovaj rad je pokazao da OZP može biti alat za rešavanje problema
detekcije varanja kod studenata, te da se može uspešno koristiti u te svrhe.
Informacije dobijene iz takvih analiza mogu biti korišćene da se poboljša
okruženje u kom se testiranje izvodi kao i da se na studente raznim
sredstvima utiče da do varanja ne dođe.
Kako je sve češća pojava da institucije visokoškolskog obrazovanja
uspostavljaju i predavanja i učenja putem mreže, tako se razvijaju i posebni
servisi koji omogućavaju te usluge. Grupa autora u studiji [20] namenjenoj
predviđanju uspeha studenata koristi jedan od tih naprednih servisa. Radi se
o mrežnom sistemu LON-CAPA (Learning Online Network with Computer-
Assisted Personalized Approach) razvijenom na Michigan State University,
SAD, koji služi kao mrežni obrazovni sistem. Dve baze podataka su razvijene
za ovaj sistem. Prva je sadržala obrazovne resurse, kao što su web stranice,
vežbe, simulacije, zadaci, testovi i ispiti. Druga je sadržala podatke o
studentima koji su korisnici sistema. U ovoj studiji primenjen je OZP na baze
podataka sistema LON-CAPA da bi se došlo do odgovora na sledeća pitanja:
Mogu li se klasifikovati studenti? To jest, da li postoje grupe studenata
koji koriste ovaj sistem na sličan način, i ako postoje da li se za svakog
studenta može predvideti kojoj klasi pripada. Ovim informacijama se
može pomoći studentima da koriste resurse na bolji način.
Mogu li se klasifikovati problemi na koje studenti nailaze? Tako bismo
pokazali kako različite vrste problema utiču na uspeh studenata i
omogućilo bi se predavačima da razviju efikasnije i efektivnije zadatke.
Autori su se nadali da će pronaći slične obrasce korišćenja sistema i da će biti
u mogućnosti da predvide najbolje načine za dalje odvijanje nastave na
osnovu dosadašnjeg korišćenja. Kao test podaci korišćeni su podaci o 227
studenata sa kursa fizike, koji je održan na MSU u proleće 2002. godine. Ovaj
kurs je uključivao 12 domaćih zadataka sa ukupno 184 pitanja, koji su svi
rešavani putem mrežnog sistema LON-CAPA. Distribucija završnih ocena na
kraju kursa je data na slici 3.3.9.
37

Slika 3.3.9
Disribucija završnih ocena na kursu fizike
u okviru sistema LON-
CAPA, preuzeto iz [20]
Studenti se mogu grupisati na osnovu njihove završne ocene na više načina,
a u studiji su izabrana 3 sledeća:
Prema ocenama sa slike 3.3.9 u 9 klasa;
U 3 klase se studenti mogu grupisati na način da: „visoka“ klasa
predstavlja one sa ocenom od 3.5 do 4, „srednja“ one sa ocenom od 2
do 3.5 i „niska“ klasa sa studentima koji imaju ocenu manju od 2 i,
Takođe se mogu klasifikovati i u dve klase: „prošli“ gde su studenti sa
ocenom preko 2 i „pali“ gde su ocene manje ili jednake 2.
Glavni korak u klasifikaciji studenata i predviđanju njihovog učinka predstavlja
odabir promenljivih koje će se za tu klasifikaciju koristiti. Promenljive, vezane
za studente, koje su oni koristili su: ukupan broj tačnih odgovora, uspeh
rešavanja problema iz prvog pokušaja, ukupan broj pokušaja da se završi
domaći, vreme koje je utrošeno da se problem reši, uzimanje učešća u
grupnom radu u odnosu na one koji su radili samostalno, čitanje pomoćnih
materijala pre nego se pokuša izrada domaćeg, broj odustajanja od problema
u odnosu na broj studenata koji su pokušavali da urade domaći do samog
isteka vremenskog roka, vreme prvog pristupa sistemu (da li je bilo na
početku zadatka, sredinom nedelje ili u poslednjim trenucima). Za klasifikaciju
je korišćeno 6 različitih vrsta klasifikatora i to: Kvadratni Bajesov klasifikator
(Quadratic Bayesian classifier), 1-najbliži sused (1-NN) [16], k-najbliži sused
(k-NN) [16], Parzenov prozor [21], višeslojno filtriranje (MLP - multilayer
perceptron) i stablo odlučivanja. U okviru klasifikatora baziranih na stablu
odlučivanja korišćeni su: C5.0, CART, QUEST i CRUISE. Takođe je kasnije
urađena i kombinacija više klasifikatora (CMC – Combination of Multiple
Classifiers) da bi se poboljšali rezultati. Korišćen je i genetički algoritam (GA)
38

[16], [22] kako bi se optimizovale performanse pronalaženja obrazaca.
Postoje dva načina korišćenja GA od kojih jedan podrazumeva direktnu
primenu GA kao klasifikatora dok drugi koristi GA kao alat za optimizaciju
parametara drugih klasifikatora. U ovoj studiji je primenjen pristup u kom se
pomoću GA pokušava optimizovati kombinacija klasifikatora. Cilj je da se
predvide završne ocene studenata pomoću praćenja promenljivih vezanih za
studente. Rezultati klasifikacije, bez upotrebe GA, se mogu videti na slici
3.3.10. U slučaju dve klase najbolji rezultat je dao k-NN klasifikator, sa
tačnošću od 82.3%, dok kada su u pitanju tri klase ili devet klasa CART daje
najbolje rezultate. Međutim najbolje rezultate, u sva tri slučaja, je dala
kombinacija više klasifikatora ili CMC u koju su uključeni Kvadratni Bajesov
klasifikator, 1-NN, k-NN, Parzenov prozor i MLP.
Slika 3.3.10
Upoređivanje rezultata
klasifikacije bez GA, preuzeto iz
[20]
Sledila je optimizacija CMC putem GA, s tim što je iz kombinacije klasifikatora
izuzet MLP da bi se skratilo vreme izvršenja procesa, jer je MLP zahtevao oko
dva minuta vremena za izvršenje a ostala četiri klasifikatora (Kvadratni
Bajesov klasifikator, 1-NN, k-NN, Parzenov prozor) su zajedno trajala tri
sekunde.
Na slici 3.3.11 vidimo upoređenje rezultata klasifikacije putem CMC-a bez
optimizacije i sa njom.
39

Slika 3.3.11
Rezultati CMC bez
optimizacije putem GA i sa njom, preuzeto
iz [20]
Na kraju je ispitana važnost svake od promenljivih i došlo se do rezultata da
su „ukupni broj tačnih odgovora“, „dobijanje tačnog odgovora sa više od deset
pokušaja“ i „ukupan broj pokušaja“ najvažnije promenljive za klasifikaciju sa
stepenom uticaja većim od 0.9. Kao rezultat, dobijajući informacije putem
ovog istraživanja, predavači će biti u mogućnosti da rano identifikuju studente
kod kojih postoji rizik od slabih rezultata i moći će da pruže savete i pomoć na
vreme. Uspešna optimizacija klasifikacije studenata u sva tri slučaja pokazuje
prednosti korišćenja podataka sistema LON-CAPA za predviđanje konačne
ocene na osnovu promenljivih vezanih za studente i njihov rad na zadacima.
Takođe, ovakvim studijama mogu se otkriti i različiti načini i pristupi studenata
u rešavanju problema iz drugačijih oblasti (matematika, programiranje,
društvene nauke) i uočiti neke karakteristike za svaku od tih oblasti i time
shvatiti specifičnost svakog procesa pojedinačno. Kako je sve više ovakvih
kurseva i podataka dobijenih iz njih, povećavaće se i tačnost rezultata
dobijenih OZP-om.
4. Otkrivanje zakonitosti u podacima i vizuelizacija podataka
4.1 Šta čini vizuelizaciju bitnom
40

Kao veoma važan aspekt OZP javlja se činjenica da je dobijene
rezultate potrebno dobro prezentovati. Pronaći vredne informacije u podacima
je veoma težak zadatak. Moguće je sagledati samo male delove podataka,
kao što je to, na primer, slučaj sa tekstulanim vidom prezentovanja podataka
koji je težak za pregled i ograničen za prikazivanje, te kao takav čini samo
malu kap u okeanu kada imamo posla sa velikim bazama podataka. Da bi
OZP bio efikasan potrebno je da uključuje ljude u proces istraživanja
podataka i da kombinuje njihovu kreativnost, fleksibilnost i znanja sa
ogromnim skladištenim kapacitetima i proračunskim prednostima modernih
računara. Osnovna ideja vizuelizacije je da podaci budu predstavljeni u nekoj
od vizuelnih formi dozvoljavajući čoveku da dobije uvid, izvlači zaključke i
ostvari direktnu interakciju sa podacima. Prednosti koje vizuelizacija donosi
su:
Lako se obrađuju nehomogeni podaci.
Intuitivna je i ne zahteva razumevanje kompleksnih matematičkih i
statističkih algoritama i parametara.
Tehnike kojima se vizuelizacija ostvaruje mogu biti klasifikovane na sledeći
način [23] :
2D i 3D dijagrami,
Geometrijski transformisani dijagrami,
Dijagrami bazirani na sličicama,
Tačkasti dijagrami gustine i,
Napredni alati prostorne vizuelizacije.
4.2 Primer studije u visokoškolskom obrazovanju bazirane na naprednim
alatima prostorne vizuelizacije
41

U novije vreme OZP se kombinuje sa savremenim alatima vizuelizacije
podataka. Kao primer takvog istraživanja imamo studiju H. Tang-a i S.
McDonald-a [24] u kojoj se OZP integriše sa Geografskim Informacionim
Sistemom (GIS). Studija je sprovedena na Charles Sturt University u Australiji,
tačnije u regionima Viktorija (VIC)7 i Novi Južni Vels (NSW)7. Radjena je da bi
se istražila nova potencijalna tržišta za upis studenata i time maksimizovali
marketinški resursi fakulteta. Odabran je jedan od kurseva fakulteta koji
omogućava sticanje diplome u primenjenoj nauci i koji je jedinstven na tom
polju. Razlog da se odabere taj kurs bio je velika fleksibilnost upisnog
program koji je nudio studiranje na daljinu, kao i redovne i vanredne studije,
kao i činjenica da se u skorije vreme broj studenata na smeru smanjivao.
Tehnika koja je ovde korišćena je prostorni OZP koji svojim metodama
omogućava da se shvate prostorni podaci, otkriju veze među prostornim i
drugim promenljivim, uoče veze prostorne rasprostranjenosti određenog
fenomena i predvide budući trendovi tih veza. GIS omogućava da se takvi
podaci skladište, obrađuju, analiziraju i vizuelizuju. Takva upotreba GIS-a
uključuje mape rasprostranjenosti, mape prostorne klasifikacije volumetrijskih
podataka itd. Dostupnost funkcija kao što su upiti i selekcije, klasifikacija,
preklapanje mapa, mrežna analiza i kreiranje mapa, čine GIS veoma korisnim
alatom. Vizuelizacija pomoću GIS-a daje korisniku mogućnost da uvidi greške
u podacima i pomaže u vizuelnoj analizi i otkrivanju distribucije određenih
karakteristika i obrazaca ponavljanja. Studija je ciljala na pronalaženje veza
na nižim nivoima apstrakcije između upisa studenata i njihovih karakteristika,
kao, na primer, udaljenost studenta od železničke stanice manja 5km umesto
udaljenosti od 20km. Niži nivoi apstrakcije mogu otkriti specifičnije veze i to
daje korisnije i bolje informacije. Da bi efikasno pronašli veze na nižim nivoima
potrebno je postaviti visok minimum poverenja za pravilo na višim nivoima
apstrakcije i progresivno ga redukovati dok nastavljamo ka nižim nivoima.
Tako možemo izbaciti samo one promenljive koje nam nisu zanimljive na
pojedinim nivoima i ne dozvoliti da nam promaknu korisne informacije. Ovaj
proces će identifikovati veze između upisa studenata i njihovih prostornih i
demografskih karakteristika na definisanom najnižem nivou apstakcije za
7 Savezne države u okviru Australije
42

svaku od promenljivih. Tako će biti identifikovane potencijalne oblasti
studentskog tržišta i to će biti oblasti gde su sva značajna pravila prisutna.
Postoji velika količina podataka vezana za upis studenata. Podaci koji su
korisni za ovu studiju su upisni podaci studenata, podaci o popisu
stanovništva, mreža puteva i mnogi drugi. Sledeće baze podataka su
korišćene u studiji:
Upisni podaci studenata na Charles Sturt University (CSU) za godine
1999., 2000. i 2001. godinu (sa informacijama kao što su datum
rođenja, mesto stanovanja, zemlja rođenja, prethodno obrazovanje
itd.),
Podaci o popisu stanovništva iz 1996. godine,
Prostorni podaci (lokacija autoputeva, glavnih puteva i drugih klasa
putne mreže i lokacija železničkih stanica),
Lokacije drugih univerziteta i,
Statistički izveštaji i analize smerova urađene od strane samog
fakulteta za 1999. i 2000. godinu.
Promenljive koje su izabrane u ovoj studiji trebale su da prouče vezu između
upisa studenata i njihove mogućnosti putovanja, njihovog etničkog porekla i
njihovog socio-ekonomskog statusa. Slika 4.2.1 prikazuje metod korišćen da
se klasifikuju bitni atributi, baziran na različitim nivoima apstrakcije i različitom
pragu vrednosti. Za svaku promenljivu proces se ponavlja a broj ponavljanja
zavisi od minimalnog praga poverenja definisanog od strane korisnika i
stepena asocijativnih veza otkrivenih među podacima. Svako dalje
ponavljanje obezbeđuje specifičnije informacije.
43
Slika 4.2.1
Generalizacija i klasifikacija bitnih detalja podataka na
različitim nivoima,
preuzeto iz [24]
Primer proste mere dostupnosti javnih i privatnih sredstava prevoza biće
udaljenost studenata do železničkih stanica, autoputeva i udaljenost do
fakulteta i studentskog doma kroz mrežu puteva. Gotovo 100% studenata živi
u manje od 50 km udaljenosti od stanice ili autoputa, a analize studije su
klasifikovale udaljenost na različite nivoe (na primer, 10 km ili 5 km) i ispitale
njihov uticaj na upis studenata. Slika 4.2.2 prikazuje rezultate različitih nivoa
klasifikacije za udaljenost od autoputa. Isti proces može biti izveden i za druge
faktore dostupnosti sredstava prevoza (kao što je udaljenost od železničke
stanice), stoga unakrsna klasifikacija različitih promenljivih vezanih za prevoz
studenata može biti kombinovana da bi se ispitala njihova veza sa upisom
studenata. Studija je pokazala da većina studenata ima lak pristup prevoznim
sredstvima (udaljenost od stanice ili autoputa od 5 km je bila u preko 75%
slučajeva).
Slika 4.2.2
Udaljenost studenata od
autoputa, preuzeto iz
[24]
Preko 80% studenata živi na manje od 10 km udaljenosti od autoputa (viši
nivo apstrakcije; na slici 4.2.2 A) i preko 75% studenata živi na manje od 5 km
udaljenosti (niži nivo apstrakcije; na slici 4.2.2 B). Udaljenost kroz mrežu
44

puteva (najkraći put) do fakulteta i studentskog doma imao je uticaja na upis,
ali je on bio manji nego što je očekivano.
Promenljive koje su izabrane kod socio-ekonomskog statusa studenata bile
su prosečna nedeljna primanja porodice i obrazovni nivo. Preko 90%
studenata došlo je iz oblasti gde je prosek obrazovnog nivoa bio u kategoriji
‘srednji’ – sa velikom većinom ljudi koji su završili dvogodišnje visoko
školovanje ili neku od viših škola. Upisani studenti su takođe imali jaku vezu
sa prosečnim nedeljnim dohotkom porodice. Gotovo 90% njih dolazilo je iz
porodica sa srednjim dohotkom (između 500-999$).
Tako je identifikovana grupa karakteristika koje su jako povezane sa upisom
studenata. Kada su oblasti, gde te karakteristike postoje, ucrtane i na mapu
naneti preseci svih datih karakteristika, dobijeno je potencijalno tržište za
narednu godinu. Slika 4.2.3 ilustruje potencijalne marketinške oblasti za 2000.
godinu koristeći podatke sa upisa studenata iz 1999. godine.
Slika 4.2.3
Marketinške oblasti za
upis studenata na
CSU, preuzeto iz
[24]
Istorijski podaci mogu biti korišćeni da se proveri stabilnost predviđenih
rezultata kao i primenjene metodologije, te da se vrše određene ispravke
modela. Kada su upoređene stvarne lokacije studenata koji su upisali CSU
2000. godine sa onim predviđenim studijom na osnovu podataka upisa za
1999. došlo se do rezultata da je 50% studenata bilo iz oblasti koje su
predviđene i u studiji. Stvarni rezultati upisa za 2001. godinu poklapali su se
sa onim iz predviđanja putem podataka iz prethodne godine sa preko 56%.
Na slici 4.2.4 imamo stvarne podatke upisa studenata upoređene sa
predviđenim potencijalnim marketinškim oblastima definisanim pomoću
45

podataka iz prethodne godine. Može se reći da su predviđanja blizu realnosti i
da daju prilično tačne nagoveštaje izvora budućih studenata. Tako je ova
metodologija dokazala da je u stanju da predvidi značajan broj upisanih
studenata.
Slika 4.2.4
Stvarni podaci u
odnosu na potencijalna
tržišta definisana na
osnovu podataka za prethodnu
godinu
A-2000. god.
B-2001. god. ,
preuzeto iz [24]
Dalje je otkriveno da oko 50% studenata ne dolazi iz oblasti koje su imale
upisane studente u prethodnoj godini, iako su te oblasti i dalje predviđene kao
potencijalna tržišta. To dokazuje da je izvor studenata dinamička kategorija ali
da ipak može biti predviđen, a takođe može se i istraživati njegova dinamička
priroda i predvideti budući trendovi.
Tako ova studija može biti korišćena da se:
Otkriju veze među promenljivim na različitim nivoima apstrakcije,
Definišu potencijalna tržišta novih studenata i,
Predvide budući trendovi upisa.
5. Zaključci i budući rad
Da li smo sada bliže odgovoru na pitanje: Da li OZP zaista funckioniše
u visokoškolskom obrazovanju? Nadamo se da je tako i da je odgovor na to
46
pitanje potvrdan. U radu su predstavljena neka od istraživanja primene OZP-a
u obrazovanju. Fokus tih istraživanja je dosta varirao, od onih koja su
usmerena na zadovoljstvo studenata do pokušaja da se putem OZP-a gradi
nastavni plan i program. To dokazuje koliko je OZP univerzalan pristup
rešavanju problema i koliko je širok domen njegove primene. Neka od ovih
istraživanja primenljiva su i u domaćim obrazovnim institucijama. Uslov za
njihovo sprovođenje je postojanje što obuhvatnijih baza podataka, kao i
poznavanje metoda, tehnika i alata OZP-a. Još jedan veoma bitan faktor za
uspešnost OZP-a je proces modelovanja, jer slaba je korist od izvrsne baze
podataka ili najsavremenijeg softvera i hardvera ako se konstruiše
neodgovarajući model. George E. P. Box8 je rekao: „Svi modeli su netačni, ali
neki su korisni“, i baš povećanje te korisnosti jeste naš zadatak pri
modelovanju.
U radu su predstavljeni i neki veoma korisni i napredni sistemi,
primenjeni u inostranoj obrazovnoj praksi, koje bi bilo korisno pokušati
implementirati i kod nas. Tu prvenstveno mislimo na ViSCoS i LON-CAPA,
čija bi primena otvorila nove mogućnosti i domaćim obrazovnim institucijama.
Ovaj rad napisan je da bi se predstavile sve mogućnosti i koristi koje se
mogu dobiti primenom OZP-a, međutim da bi se do njih došlo potrebno je
poboljšanja hardvera i softvera ali i ljudskih resursa neophodnih da bi se
promene dogodile. William Mitchell, sa MIT univeziteta, kaže da su
„informacioni ekosistemi divlja područja koja proizvode neprekidne mutacije i
brzo eliminišu one koji nisu u mogućnosti da se adaptiraju i takmiče. Pravi
izazov nije tehnologija, nego osmišljanje i stvaranje digitalnog okruženja za
one vrste života i zajednica kojima težimo“[25]. Tako da je veoma važno da se
ispitivanja ove i drugih novih tehnologija što pre sprovode, da ne bismo došli u
situaciju da odlučujemo kako da koristimo OZP a da pritom ne razumemo
posledice naših odluka. Cilj ovog rada bi bio ostvaren ukoliko bi on
predstavljao začetak takvih istraživanja u našoj zemlji.
Budući rad i dalja istraživanja na ovu temu sprovela bi se u pravcu
ulaženja u teorijske osnove pomenutih metoda, tehnika i algoritama, kako bi
se oni što bolje objasnili i shvatila suština jer ovde primenjen prikaz daje ulaze
i izlaze iz sistema i modela dok je način rada tih sistema i modela nepoznat,
8 George Edward Pelham Box (1919- ), jedan od najpoznatijih i najuticajnijih statističara dvadesetog veka.
47

što je poznato kao fenomen „crne kutije“. Takođe planiralo bi se i sprovođenje
praktične studije primene OZP-a na nekom od domaćih fakulteta sa
korišćenjem ovde opisane CRISP-DM metodologije kao i nekih od pomenutih
algoritama i alata.
6. Literatura
[1] Brazilian Journal of Oceanography, vol. 56, No. 1, januar/march 2008,
http://www.scielo.br, pristupljeno decembra 2008.
48

[2] ICS, http://www.thebiexperts.com/offerings/consultancy/data_mining.html,
pristupljeno decembra 2008.
[3] Paolo Giudici : "Applied Data Mining : Statistical Methods for Business and
Industry" John Wiley & Sons Inc, 2003.
[4] W. Frawley, G. Piatetsky-Shapiro and C. Matheus : “Knowledge Discovery
in Databases: An Overview” , AI Magazine, 1992.
[5] Mark F. Hornick, Erik Marcade and Sunil Venkayala : “Java Data Mining:
Strategy, Standard, and Practice”, Morgan Kaufmann Publishers, 2007.
[6] Gartner Group, http://www.gartner.com/Glossary , pristupljeno novembra
2008.
[7] Darko Krulj, Milija Suknović, Milutin Čupić i Milan Martić : “Primena
algoritama data mining-a u poslovnom odlučivanju”
[8] Pete Chapman, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas
Reinartz, Colin Shearer and Rudiger Wirth : “CRISP-DM 1.0 Step-by-step
data mining guide”, SPSS Inc., 2000.
[9] Jing Luan : “Data Mining as Driven by Knowledge Management in Higher
Education”, SPSS Public Conference, UCSF, 2001.
[10] Peter B. Wylie and John Samis : “Does Data Mining Really Work for
Higher Education Fundraising”, CASE Books, 2008.
[11] J. F. Superbay, J.-P. Vandamme and N. Meskens : “Determination of
factors influencing the achievement of the first-year university students using
data mining methods“, 2006.
49

[12] Mehmed Kantardžić : “Data Mining: Concepts, Models, Methods and
Algorithms”, John Wiley & Sons Inc, 2003.
[13] Emily H. Thomas and Nora Galambos : „Research in Higher Education :
What Satisfies Students? Mining Student-Opinion Data with Regression and
Decision Tree Analysis“, Human Sciences Press Inc., maj 2004.
[14] Bruce Thompson : “Correlation analysis: uses and interpretation”, Sage,
1984.
[15] W. Hämäläinen, T.H. Laine and E. Sutinen : „Data mining in personalizing
distance education courses“, Witpress, 2004.
[16] J. Han and M. Kamber : “Data Mining: Concepts and Techniques”,
Morgan Kaufmann Publishers, 2000.
[17] J. K. Ghosh, M. Delampady and T. Samanta : “An Introduction to
Bayesian Analysis: Theory and Methods”, Springer, 2006.
[18] A. Gelman, J. B. Carlin, H. S. Stern and D. B. Rubin : “Bayesian Data
Analysis”, CRC Press, 2004.
[19] José-Alberto Hernández, Alberto Ochoa, Jaime Muñoz and Genadiy
Burlak : „Detecting cheats in online student assessments using Data Mining“,
Proceedings for 2006 International Conference on Data Mining, DMIN’06, 26.-
29. jun 2006., Las Vegas, USA.
[20] B.M. Bidgoli, Deborah A. Kashy, Gerd Kortemeyer and William F. Punch :
„Predicting student performance : An application of Data Mining methods with
the educational web-based system LON-CAPA“, 33rd Frontiers in Education
Conference, 5.-8. novembar 2003., Volume 1, pages 13-18.
[21] J. P. Marques de Sa : “Pattern Recognition”, Springer, 2001.
50

[22] Daniel T. Larose : “Data mining – Methods and Models”, John Wiley &
Sons, 2006., strane 240.-265.
[23] Daniel A. Keim : “Information Visualization and Visual Data Mining”, IEEE
Transactions On Visualization And Computer Graphics, Vol. 8, No. 1, januar-
mart 2002
[24] Hong Tang and Simon McDonald : “Integrating GIS and spatial data
mining technique for target marketing of university courses”, Symposium on
Geospatial Theory, Processing and Applications, Ottawa 2002.
[25] William Mitchell: “City of Bits”, M.I.T. Press, Cambridge, 1995.
51