cues to emotion: anger and frustration julia hirschberg coms 4995/6998 thanks to sue yuen and yves...
Post on 21-Dec-2015
220 views
TRANSCRIPT

Cues to Emotion: Anger and Frustration
Julia Hirschberg
COMS 4995/6998
Thanks to Sue Yuen and Yves Scherer
:Real-life Emotions Detection with Lexical and
Paralinguistic Cues on Human-Human Call CenterDialogs (Devillers & Vidrascu ’06)
• Domain: Medical emergencies
• Motive: Study real-life speech in highly emotional situations
• Emotions studied: Anger, Fear, Relief, Sadness (but finer-grained annotation)
• Corpus: 680 dialogs, 2258 speaker turns
• Training-test split: 72% - 28%
• Machine Learning method: Log-likelihood ratio (linguistic), SVM (paralinguistic)

Features
• Lexical features / Linguistic cues: Unigrams of user utterances, stemmed
• Prosodic features / Paralinguistic cues:
– Loudness (energy)
– Pitch contour (F0)
– Speaking rate
– Voice quality (jitter, ...)
– Disfluency (pauses)
– Non-linguistic events (mouth noise, crying, …)
– Normalized by speaker

Motivation
• “The context of emergency gives a larger palette of
• complex and mixed emotions.”
• Emotions in emergency situations are more extreme, and are “really felt in a natural way.”
• Debate on acted vs. real emotions
• Ethical concerns?

Corpus
• 688 dialogs, avg 48 turns per dialog• Annotation:
– Decisions of 2 annotators are combined in a soft vector:– Emotion mixtures– 8 coarse-level emotions, 21 fine-grained emotions– Inter-annotator agreement for client turns: 0.57 (moderate)– Consistency checks:
• Self-reannotation procedure (85% similarity)• Perception test (no details given)
• Restrict corpus to caller utterances -- 2258 utterances from 680 speakers.

Annotation
• Utterances annotated with one of the following nonmixed emotions:
– Anger, Fear, Relief, Sadness
– Justification for this choice?

Lexical Cue Model
• Log-likelihood ratio: 4 unigram emotion models (1 for each emotion)– A general task-specific model– Interpolation coefficient to avoid data sparsity
problems– A coefficient of 0.75 gave the best results
• Stemming:– Cut inflectional suffixes (more important for rich
morphology languages like French)– Improves overall recognition rates by 12-13 points

Paralinguist (Prosodic) Cue Model
• 100 features, fed into SVM classifier:– F0 (pitch contour) and spectral features (formants)– Energy (loudness)– Voice quality (jitter, shimmer, ...)
• Jitter: varying pitch in the voice• Shimmer: varying loudness in the voice• NHR: Noise-to-harmonic ratio• HNR: Harmonic-to-noise ratio
– Speaking rate, silences, pauses, filled pauses– Mouth noise, laughter, crying, breathing
• Normalized by speaker (~24 user turns per dialog)
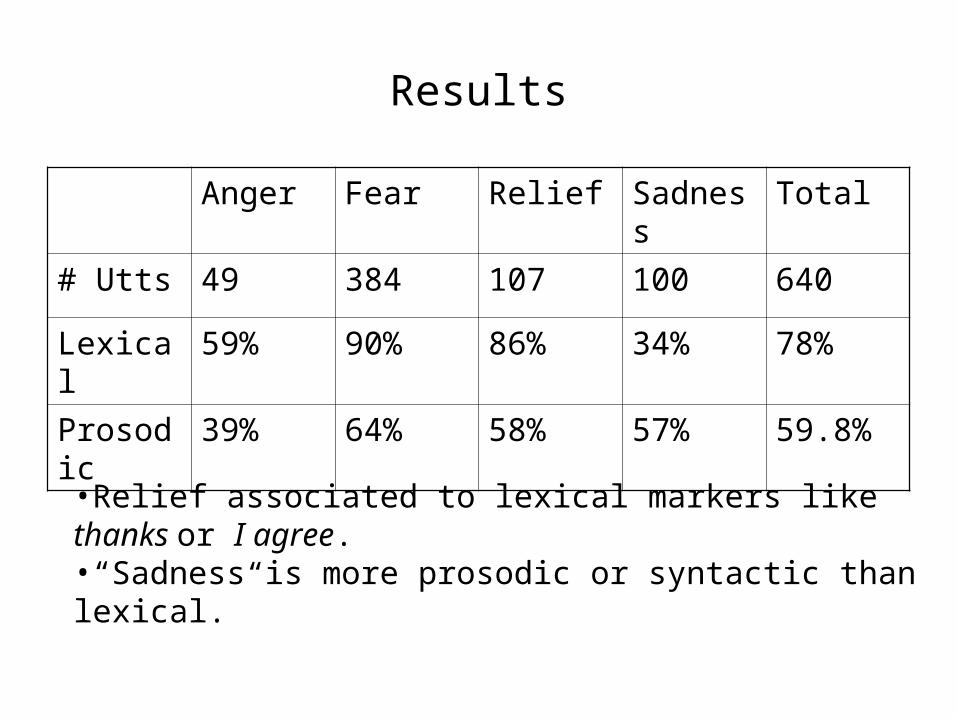
Results
Anger Fear Relief Sadness Total
# Utts 49 384 107 100 640
Lexical 59% 90% 86% 34% 78%
Prosodic 39% 64% 58% 57% 59.8%
•Relief associated to lexical markers like thanks or I agree.•“Sadness is more prosodic or syntactic than lexical.”

Two Stream Emotion Recognition for Call Center Monitoring (Gupta & Rajput ’07)
• Goal: Help supervisors evaluate agents at call centers• Method: Develop two stream technique to detect strong
emotion • Previous Work:
– Fernandez categorized affect into four main components: intonation, loudness, rhythm, and voice quality
– Yang studied feature selection methods in text categorization and suggested that information gain should be used
– Petrushin and Yacoub examined agitation and calm states in people-machine interaction
Two-Stream Recognition
Acoustic StreamExtracted features based on pitch and energy•Trained on 900 calls, ~60hrs of speech•Vocabulary system of more than 10 000 words•TF-IDF scheme = Term Frequency – Inverse Document Frequency
Semantic Stream•Performed speech-to-text conversion•Text classification algorithms identified phrases such as “pleasure,” “thanks,” “useless,” & “disgusting.”

Implementation
• Method: – Two streams analyzed separately:
• speech utterance/acoustic features • spoken text/semantics/speech recognition of conversation
– Confidence levels of two streams combined – Examined 3 emotions
• Neutral• Hot-anger• Happy
• Tested two data sets: – LDC data– 20 real-world call-center calls

Two Stream - Conclusion
•Table 2 suggested that two-stream analysis is more accurate than acoustic or semantic alone•LDC data recognition significantly higher than real-world data•Neutral emotions had less accuracy•Combination of two-stream processing showed improvement (~20%) in identification of “happy” and “anger” emotions•Low acoustic stream accuracy may be attributed to length of sentences in real-world data. Normal people do not exhibit different emotions significantly in long sentences

Questions
• Gupta&Rajput analyzed 3 emotions (happy, neutral, hot-anger): Why break it down into these categories? Implications? Can this technique be applied to a wider range of emotions? For other applications?
• Speech to text may not translate the complete conversation. Would further examination greatly improve results? What are the pros and cons?
• Pitch range was from 50-400Hz. Research may not be applicable outside this range. Do you think it necessary to examine other frequencies?
• In this paper, TF-IDF (Term Frequency – Inverse Document Frequency) technique is used to classify utterances. Accuracy for acoustics only is about 55%. Previous research suggest that alternative techniques may be better. Would implementation better results? What are the pros and cons of using the TF-IDF technique?

Voice Quality and f0 Cues for Affect Expression: Implications for Synthesis
• Previous work: – 1995; Mozziconacci suggested that VQ combined with
f0 combined could create affect– 2002; Gobl suggested synthesized stimuli with VQ can
add affective coloring. Study suggested that “VQ + f0” stimuli is more affective than “f0 only”
– 2003; Gobl tested VQ with large f0 range. Did not examine contribution of affect-related f0 contours
• Objective: To examine affects of VQ and f0 on affect expression

Voice Quality and f0 Cues for Affect Expression: Implications for Synthesis
• 3 series of stimuli of Sweden utterance – “ja adjo”:– Stimuli exemplifying VQ– Stimuli with modal voice quality with different affect-related f0 contours– Stimuli combining both
• Tested parameters exemplifying 5 voice quality (VQ):– Modal voice– Breathy voice– Whispery voice– Lax-creaky voice– Tense voice
• 15 synthesized stimuli test samples (see Table 1)
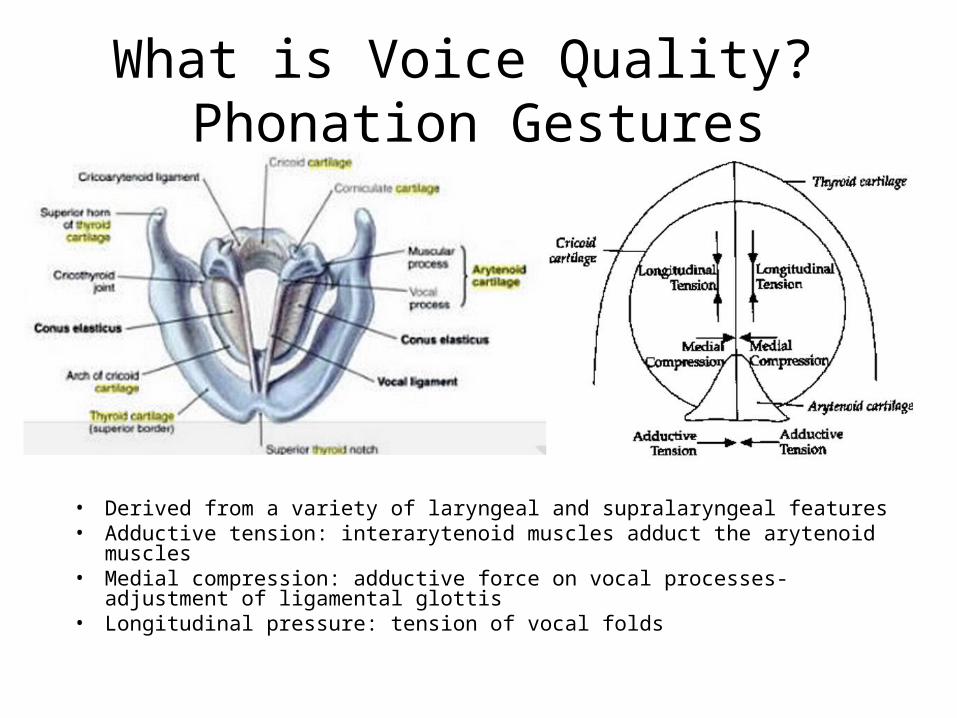
What is Voice Quality? Phonation Gestures
• Derived from a variety of laryngeal and supralaryngeal features• Adductive tension: interarytenoid muscles adduct the arytenoid muscles• Medial compression: adductive force on vocal processes- adjustment of
ligamental glottis• Longitudinal pressure: tension of vocal folds
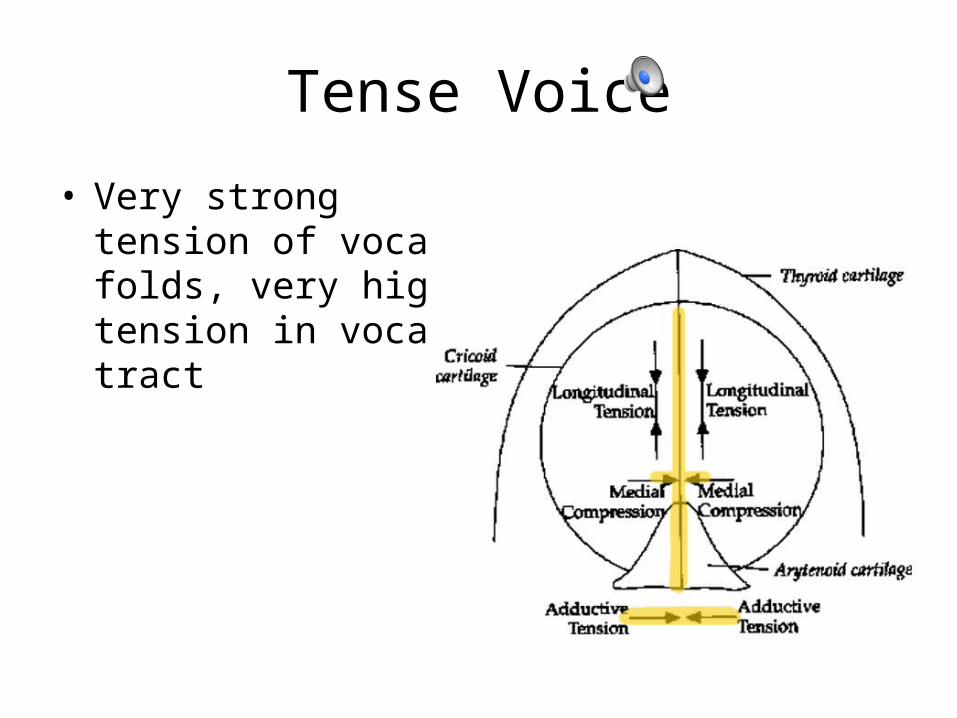
Tense Voice
• Very strong tension of vocal folds, very high tension in vocal tract

Whispery Voice• Very low adductive
tension• Medial compression
moderately high• Longitudinal tension
moderately high• Little or no vocal fold
vibration• Turbulence
generated by friction of air in and above larynx

Creaky Voice • Vocal fold vibration at low
frequency, irregular• Low tension (only
ligamental part of glottis vibrates)
• The vocal folds strongly adducted
• Longitudinal tension weak
• Moderately high medial compression
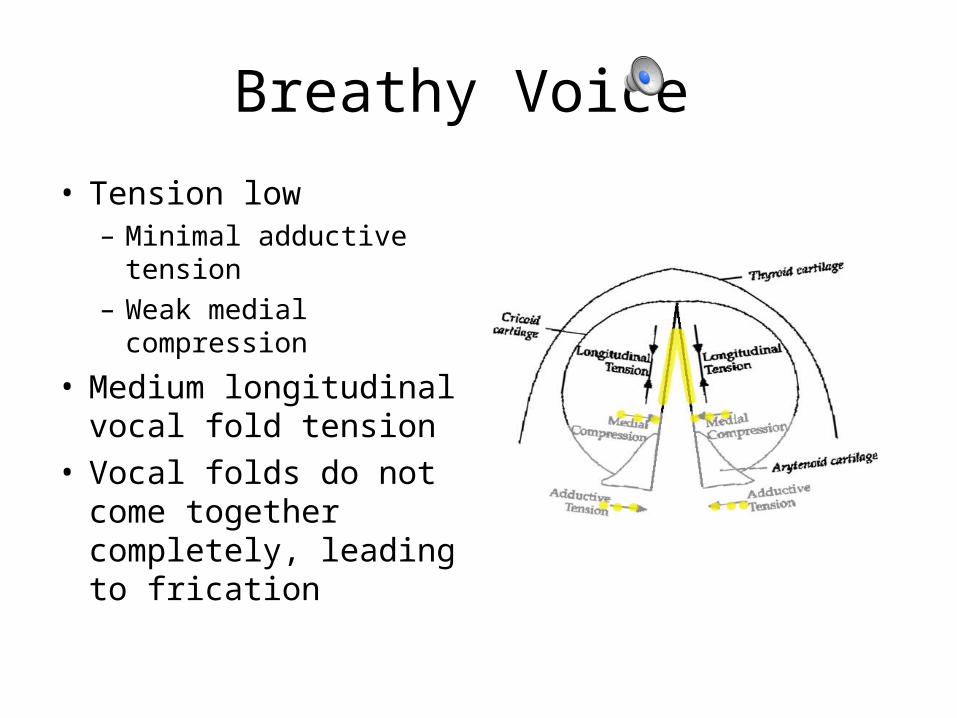
Breathy Voice
• Tension low– Minimal adductive
tension– Weak medial
compression
• Medium longitudinal vocal fold tension
• Vocal folds do not come together completely, leading to frication

Modal Voice
• “Neutral” mode
• Muscular adjustments moderate
• Vibration of vocal folds periodic, full closing of glottis, no audible friction
• Frequency of vibration and loudness in low to mid range for conversational speech

Voice Quality and f0 Cues for Affect Expression: Implications for Synthesis
• Six sub-tests with 20 native speakers of Hiberno-English.• Rated on 12 different affective attributes:
– Sad – happy– Intimate – formal– Relaxed – stressed– Bored – interested– Apologetic – indignant– Fearless – scared
• Participants asked to mark their response on scale
Intimate Formal
No affective load

Voice Quality and f0 Test: Conclusion
• Categorized results into 4 groups. No simple one-to-one mapping between quality and affect
• “Happy” was most difficult to synthesis
• Suggested that, in addition to f0 ,VQ should be used to synthesis affectively colored speech. VQ appears to be crucial for expressive synthesis

Voice Quality and f0 Test: Discussion
• If the scale is on a 1-7, then 3.5 should be “neutral”; however, most ratings are less than 2. Do the conclusions (see Fig 2) seem strong?
• In terms of VQ and f0, the groupings in Fig 2 seem to suggest that certain affects are closely related. What are the implications of this? For example, are happy and indignant affects closer than relaxed or formal? Do you agree?
• Do you consider an intimate voice more “breathy” or “whispery?” Does your intuition agree with the paper?
• Yanushevskaya found that the VQ accounts for the highest affect ratings overall. How to compare range of voice quality with frequency? Do you think they are comparable? Is there a different way to describe these qualities?

Questions?