csci-2500: computer organization intel x86 assembly language: welcome to the real world adopted from...
TRANSCRIPT

CSCI-2500:Computer Organization
Intel X86 Assembly Language: Welcome to the Real WorldAdopted from “Computer Systems” by Bryant and O’Hallaron

CSCI-2500 FALL 2012, x86 ISA
IA32 ProcessorsIA32 Processors Totally Dominate Computer Market AMD is x86_64 is ramping up to replace IA32 Evolutionary Design
Starting in 1978 with 8086 Added more features as time goes on Still support old features, although obsolete
Complex Instruction Set Computer (CISC) Many different instructions with many different formats
But, only small subset encountered with Linux programs
Hard to match performance of Reduced Instruction Set Computers (RISC)
But, Intel has done just that!

CSCI-2500 FALL 2012, x86 ISA
X86 Evolution: Programmer’s View
Name Date Transistors 8086 1978 29K
16-bit processor. Basis for IBM PC & DOS Limited to 1MB address space. DOS only gives you
640K 80286 1982 134K
Added elaborate, but not very useful, addressing scheme
Basis for IBM PC-AT and Windows 386 1985 275K
Extended to 32 bits. Added “flat addressing” Capable of running Unix Linux/gcc uses no instructions introduced in later
models

CSCI-2500 FALL 2012, x86 ISA
X86 Evolution: Programmer’s View
Name Date Transistors 486 1989 1.9M Pentium 1993 3.1M Pentium/MMX 1997 4.5M
Added special collection of instructions for operating on 64-bit vectors of 1, 2, or 4 byte integer data
PentiumPro 1995 6.5M Added conditional move instructions Big change in underlying microarchitecture

CSCI-2500 FALL 2012, x86 ISA
X86 Evolution: Programmer’s View
Name Date Transistors Pentium III 1999 8.2M
Added “streaming SIMD” instructions for operating on 128-bit vectors of 1, 2, or 4 byte integer or floating point data
Pentium 4 2001 42M Added 8-byte formats and 144 new instructions for streaming
SIMD mode Intel “Quad Core” 2006 ~580M
64 bit processor cores (x86_64 architecture) “Kentsfield” uses two dies in a single package where each die has
2 processors cores. Each die has a shared 4 MB L2 cache (8MB for whole package).
Intel “Nehalem” Family 2009 700+ Million transistors, 45 nm and 4 to 12MB per core Designs for 2 to 12 cores

CSCI-2500 FALL 2012, x86 ISA
X86 Evolution: Clones
Advanced Micro Devices (AMD) Historically
AMD has followed just behind Intel A little bit slower, a lot cheaper Now, a lot faster (except Core2 Duo) and cheaper. Better more scalable memory design (network as opposed to
bus)
Recently Recruited top circuit designers from Digital Equipment Corp. Exploited fact that Intel distracted by IA64 Now are close competitors to Intel (well maybe )
Developed own extension to 64 bits (x86_64) Became industry standard for x86 class systems

CSCI-2500 FALL 2012, x86 ISA
X86 Evolution: Clones
Transmeta Recent start-up
Employed of Linus Torvalds Linus has since left.
Radically different approach to implementation Translates x86 code into “Very Long Instruction Word” (VLIW) code
High degree of parallelism Shooting for low-power market Good idea, but marketplace did not adapt… Nolonger shipping hardware, trying to sell-off IP

CSCI-2500 FALL 2012, x86 ISA
New Species That Will Be Killed Off: IA64
Name Date Transistors Itanium 2001 10M
Extends to IA64, a 64-bit architecture Radically new instruction set designed for high
performance Will be able to run existing IA32 programs
On-board “x86 engine” Joint project with Hewlett-Packard
Itanium 2 2002 221M Big performance boost But still does not keep-up with current Kentsfield or AMD
Opteron processors Very costly

CSCI-2500 FALL 2012, x86 ISA
Whose Assembler?
Intel/Microsoft Differs from GAS Operands listed in opposite ordermov Dest, Src movl Src, Dest
Constants not preceded by ‘$’, Denote hex with ‘h’ at end100h $0x100
Operand size indicated by operands rather than operator suffixsub subl
Addressing format shows effective address computation[eax*4+100h] $0x100(,%eax,4)
lea eax,[ecx+ecx*2]sub esp,8cmp dword ptr [ebp-8],0mov eax,dword ptr [eax*4+100h]
leal (%ecx,%ecx,2),%eaxsubl $8,%espcmpl $0,-8(%ebp)movl $0x100(,%eax,4),%eax
Intel/Microsoft Format GAS/Gnu Format

CSCI-2500 FALL 2012, x86 ISA
Assembly Programmer’s View
Programmer-Visible State EIP Program Counter
Address of next instruction Register File
Heavily used program data Condition Codes
Store status information about most recent arithmetic operation
Used for conditional branching
EIP
Registers
CPU Memory
Object CodeProgram Data
OS Data
Addresses
Data
Instructions
Stack
ConditionCodes
Memory Byte addressable array Code, user data, (some)
OS data Stack used to support
procedures

CSCI-2500 FALL 2012, x86 ISA
text
text
binary
binary
Compiler (gcc -S)
Assembler (gcc or as)
Linker (gcc or ld)
C program (p1.c p2.c)
Asm program (p1.s p2.s)
Object program (p1.o p2.o)
Executable program (p)
Static libraries (.a)
Turning C into Object Code
Code in files p1.c p2.c Compile with command: gcc -O p1.c p2.c -o p
Use optimizations (-O) Put resulting binary in file p

CSCI-2500 FALL 2012, x86 ISA
Compiling Into AssemblyCompiling Into Assembly
C Code
int sum(int x, int y){ int t = x+y; return t;}
Generated Assembly_sum:pushl %ebpmovl %esp,%ebpmovl 12(%ebp),%eaxaddl 8(%ebp),%eaxmovl %ebp,%esppopl %ebpret
Obtain with command
gcc -O -S code.c
Produces file code.s

CSCI-2500 FALL 2012, x86 ISA
X86 Assembly Characteristics Minimal Data Types
“Integer” data of 1, 2, or 4 bytes Data values Addresses (untyped pointers)
Floating point data of 4, 8, or 10 bytes No aggregate types such as arrays or structures
Just contiguously allocated bytes in memory Primitive Operations
Perform arithmetic function on register or memory data Transfer data between memory and register
Load data from memory into register Store register data into memory
Transfer control Unconditional jumps to/from procedures Conditional branches

CSCI-2500 FALL 2012, x86 ISA
Code for sum0x401040 <sum>:
0x550x890xe50x8b0x450x0c0x030x450x080x890xec0x5d0xc3
Object Code Assembler
Translates .s into .o Binary encoding of each instruction Nearly-complete image of
executable code Missing linkages between code in
different files Linker
Resolves references between files Combines with static run-time
libraries E.g., code for malloc, printf
Some libraries are dynamically linked
Linking occurs when program begins execution
• Total of 13 bytes
• Each instruction 1, 2, or 3 bytes
• Starts at address 0x401040

CSCI-2500 FALL 2012, x86 ISA
X86 Machine Instruction Ex
C Code Add two signed integers
Assembly Add 2 4-byte integers
“Long” words in GCC parlance Same instruction whether
signed or unsigned Operands:
x: Register %eax
y: MemoryM[%ebp+8]
t: Register %eax
Return function value in %eax
Object Code 3-byte instruction Stored at address 0x401046
int t = x+y;
addl 8(%ebp),%eax
0x401046: 03 45 08
Similar to expression x += y

CSCI-2500 FALL 2012, x86 ISA
Disassembled00401040 <_sum>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 8b 45 0c mov 0xc(%ebp),%eax 6: 03 45 08 add 0x8(%ebp),%eax 9: 89 ec mov %ebp,%esp b: 5d pop %ebp c: c3 ret d: 8d 76 00 lea 0x0(%esi),%esi
Disassembling Object Code
Disassemblerobjdump -d p Useful tool for examining object code Analyzes bit pattern of series of instructions Produces approximate rendition of assembly code Can be run on either a.out (complete executable) or .o file

CSCI-2500 FALL 2012, x86 ISA
Disassembled
0x401040 <sum>: push %ebp0x401041 <sum+1>: mov %esp,%ebp0x401043 <sum+3>: mov 0xc(%ebp),%eax0x401046 <sum+6>: add 0x8(%ebp),%eax0x401049 <sum+9>: mov %ebp,%esp0x40104b <sum+11>: pop %ebp0x40104c <sum+12>: ret 0x40104d <sum+13>: lea 0x0(%esi),%esi
Alternate Disassembly
Within gdb Debuggergdb p
disassemble sum Disassemble procedurex/13b sum Examine the 13 bytes starting at sum
Object0x401040:
0x550x890xe50x8b0x450x0c0x030x450x080x890xec0x5d0xc3

CSCI-2500 FALL 2012, x86 ISA
What Can be Disassembled?
Anything that can be interpreted as executable code Disassembler examines bytes and reconstructs
assembly source
% objdump -d WINWORD.EXE
WINWORD.EXE: file format pei-i386
No symbols in "WINWORD.EXE".Disassembly of section .text:
30001000 <.text>:30001000: 55 push %ebp30001001: 8b ec mov %esp,%ebp30001003: 6a ff push $0xffffffff30001005: 68 90 10 00 30 push $0x300010903000100a: 68 91 dc 4c 30 push $0x304cdc91

CSCI-2500 FALL 2012, x86 ISA
Moving Data Moving Data
movl Source,Dest: Move 4-byte (“long”) word Lots of these in typical code
Operand Types Immediate: Constant integer data
Like C constant, but prefixed with ‘$’ E.g., $0x400, $-533 Encoded with 1, 2, or 4 bytes
Register: One of 8 integer registers But %esp and %ebp reserved for special use Others have special uses for particular instructions
Memory: 4 consecutive bytes of memory Various “address modes”
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp

CSCI-2500 FALL 2012, x86 ISA
movl Operand Combinations
Cannot do memory-memory transfers with single instruction
movl
Imm
Reg
Mem
Reg
Mem
Reg
Mem
Reg
Source Destination
movl $0x4,%eax
movl $-147,(%eax)
movl %eax,%edx
movl %eax,(%edx)
movl (%eax),%edx
C Analog
temp = 0x4;
*p = -147;
temp2 = temp1;
*p = temp;
temp = *p;

CSCI-2500 FALL 2012, x86 ISA
Simple Addressing Modes
Normal (R) Mem[Reg[R]] Register R specifies memory address
movl (%ecx),%eax
Displacement D(R) Mem[Reg[R]+D] Register R specifies start of memory region Constant displacement D specifies offset
movl 8(%ebp),%edx

CSCI-2500 FALL 2012, x86 ISA
void swap(int *xp, int *yp) { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
swap:pushl %ebpmovl %esp,%ebppushl %ebx
movl 12(%ebp),%ecxmovl 8(%ebp),%edxmovl (%ecx),%eaxmovl (%edx),%ebxmovl %eax,(%edx)movl %ebx,(%ecx)
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
Body
SetUp
Finish
Example using Swap

CSCI-2500 FALL 2012, x86 ISA
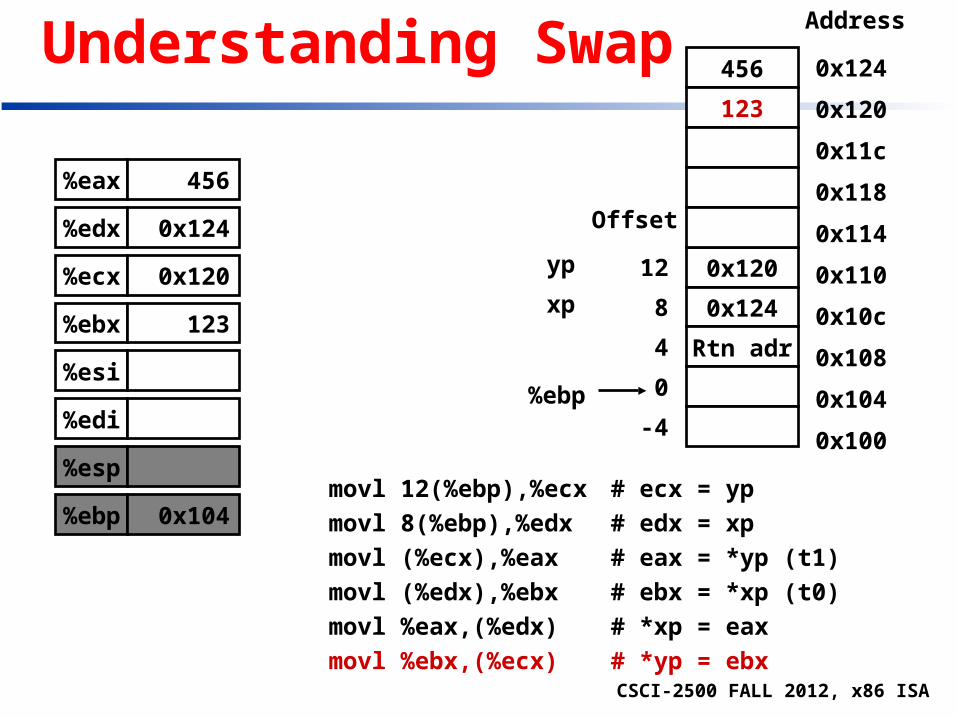
Understanding Swap
void swap(int *xp, int *yp) { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
Stack
Register Variable
%ecx yp
%edx xp
%eax t1
%ebx t0
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
•••
Old %ebx-4

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp 0x104

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
0x120
0x104

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
0x124
0x120
0x104

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
456
0x124
0x120
0x104

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
123
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
456
0x124
0x120
123
0x104

CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
456
456
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
456
0x124
0x120
123
0x104
CSCI-2500 FALL 2012, x86 ISA
Understanding Swap
movl 12(%ebp),%ecx # ecx = yp
movl 8(%ebp),%edx # edx = xp
movl (%ecx),%eax # eax = *yp (t1)
movl (%edx),%ebx # ebx = *xp (t0)
movl %eax,(%edx) # *xp = eax
movl %ebx,(%ecx) # *yp = ebx
0x120
0x124
Rtn adr
%ebp 0
4
8
12
Offset
-4
456
123
Address
0x124
0x120
0x11c
0x118
0x114
0x110
0x10c
0x108
0x104
0x100
yp
xp
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
456
0x124
0x120
123
0x104

CSCI-2500 FALL 2012, x86 ISA
Indexed Addressing Modes
Most General Form D(Rb,Ri,S) Mem[Reg[Rb]+S*Reg[Ri]+ D]
D: Constant “displacement” 1, 2, or 4 bytes Rb: Base register: Any of 8 integer registers Ri: Index register: Any, except for %esp
Unlikely you’d use %ebp, either S: Scale: 1, 2, 4, or 8
Special Cases (Rb,Ri) Mem[Reg[Rb]+Reg[Ri]] D(Rb,Ri) Mem[Reg[Rb]+Reg[Ri]+D] (Rb,Ri,S) Mem[Reg[Rb]+S*Reg[Ri]]

CSCI-2500 FALL 2012, x86 ISA
Address Computation Examples
%edx
%ecx
0xf000
0x100
Expression Computation Address
0x8(%edx) 0xf000 + 0x8 0xf008
(%edx,%ecx) 0xf000 + 0x100 0xf100
(%edx,%ecx,4) 0xf000 + 4*0x100 0xf400
0x80(,%edx,2) 2*0xf000 + 0x80 0x1e080

CSCI-2500 FALL 2012, x86 ISA
Address Computation Instruction
leal Src,Dest Src is address mode expression Set Dest to address denoted by expression
Uses Computing address without doing memory
reference E.g., translation of p = &x[i];
Computing arithmetic expressions of the form x + k*y
k = 1, 2, 4, or 8.

CSCI-2500 FALL 2012, x86 ISA
Some Arithmetic Operations
Format Computation Two Operand Instructionsaddl Src,Dest Dest = Dest + Srcsubl Src,Dest Dest = Dest - Srcimull Src,Dest Dest = Dest * Srcsall Src,Dest Dest = Dest << Src Also called shll
sarl Src,Dest Dest = Dest >> Src Arithmeticshrl Src,Dest Dest = Dest >> Src Logicalxorl Src,Dest Dest = Dest ^ Srcandl Src,Dest Dest = Dest & Srcorl Src,Dest Dest = Dest | Src

CSCI-2500 FALL 2012, x86 ISA
Some Arithmetic Operations
Format Computation One Operand Instructionsincl Dest Dest = Dest + 1decl Dest Dest = Dest - 1negl Dest Dest = - Destnotl Dest Dest = ~ Dest

CSCI-2500 FALL 2012, x86 ISA
Using leal for Arithmetic Expressions
int arith (int x, int y, int z){ int t1 = x+y; int t2 = z+t1; int t3 = x+4; int t4 = y * 48; int t5 = t3 + t4; int rval = t2 * t5; return rval;}
arith:pushl %ebpmovl %esp,%ebp
movl 8(%ebp),%eaxmovl 12(%ebp),%edxleal (%edx,%eax),%ecxleal (%edx,%edx,2),%edxsall $4,%edxaddl 16(%ebp),%ecxleal 4(%edx,%eax),%eaximull %ecx,%eax
movl %ebp,%esppopl %ebpret
Body
SetUp
Finish

CSCI-2500 FALL 2012, x86 ISA
Understanding arithint arith (int x, int y, int z){ int t1 = x+y; int t2 = z+t1; int t3 = x+4; int t4 = y * 48; int t5 = t3 + t4; int rval = t2 * t5; return rval;}
movl 8(%ebp),%eax # eax = xmovl 12(%ebp),%edx # edx = yleal (%edx,%eax),%ecx # ecx = x+y (t1)leal (%edx,%edx,2),%edx # edx = 3*ysall $4,%edx # edx = 48*y (t4)addl 16(%ebp),%ecx # ecx = z+t1 (t2)leal 4(%edx,%eax),%eax # eax = 4+t4+x (t5)imull %ecx,%eax # eax = t5*t2 (rval)
y
x
Rtn adr
Old %ebp %ebp 0
4
8
12
OffsetStack
•••
z16

CSCI-2500 FALL 2012, x86 ISA
Understanding arith
int arith (int x, int y, int z){ int t1 = x+y; int t2 = z+t1; int t3 = x+4; int t4 = y * 48; int t5 = t3 + t4; int rval = t2 * t5; return rval;}
# eax = xmovl 8(%ebp),%eax
# edx = ymovl 12(%ebp),%edx
# ecx = x+y (t1)leal (%edx,%eax),%ecx
# edx = 3*yleal (%edx,%edx,2),%edx
# edx = 48*y (t4)sall $4,%edx
# ecx = z+t1 (t2)addl 16(%ebp),%ecx
# eax = 4+t4+x (t5)leal 4(%edx,%eax),%eax
# eax = t5*t2 (rval)imull %ecx,%eax

CSCI-2500 FALL 2012, x86 ISA
Another Example
int logical(int x, int y){ int t1 = x^y; int t2 = t1 >> 17; int mask = (1<<13) - 7; int rval = t2 & mask; return rval;}
logical:pushl %ebpmovl %esp,%ebp
movl 8(%ebp),%eaxxorl 12(%ebp),%eaxsarl $17,%eaxandl $8185,%eax
movl %ebp,%esppopl %ebpret
Body
SetUp
Finish
movl 8(%ebp),%eax eax = xxorl 12(%ebp),%eax eax = x^y (t1)sarl $17,%eax eax = t1>>17 (t2)andl $8185,%eax eax = t2 & 8185
213 = 8192, 213 – 7 = 8185

CSCI-2500 FALL 2012, x86 ISA
CISC Properties Instruction can reference different operand types
Immediate, register, memory
Arithmetic operations can read/write memory
Memory reference can involve complex computation Rb + S*Ri + D Useful for arithmetic expressions, too
Instructions can have varying lengths IA32 instructions can range from 1 to 15 bytes
What is the common case here?? Very much unclear..
Definitely violates our MIPS design principles!!!

CSCI-2500 FALL 2012, x86 ISA
Summary: Abstract MachinesSummary: Abstract Machines
1) loops2) conditionals3) switch4) Proc. call5) Proc. return
Machine Models Data Control
1) char2) int, float3) double4) struct, array5) pointer
mem proc
C
Assembly1) byte2) 2-byte word3) 4-byte long word4) contiguous byte allocation5) address of initial byte
3) branch/jump4) call5) retmem regs alu
processorStack Cond.Codes

CSCI-2500 FALL 2012, x86 ISA
X86:Control FlowX86:Control Flow Topics
Condition Codes Setting Testing
Control Flow If-then-else Varieties of Loops Switch Statements

CSCI-2500 FALL 2012, x86 ISA
Condition Codes Single Bit Registers
CF Carry Flag SF Sign FlagZF Zero Flag OF Overflow Flag
Implicitly Set By Arithmetic Operationsaddl Src,DestC analog: t = a + b CF set if carry out from most significant bit
Used to detect unsigned overflow ZF set if t == 0 SF set if t < 0 OF set if two’s complement overflow
(a>0 && b>0 && t<0) || (a<0 && b<0 && t>=0) Not Set by leal instruction

CSCI-2500 FALL 2012, x86 ISA
Setting Condition Codes (cont.)
Explicit Setting by Compare Instructioncmpl Src2,Src1 cmpl b,a like computing a-b without
setting destination CF set if carry out from most significant bit
Used for unsigned comparisons ZF set if a == b SF set if (a-b) < 0 OF set if two’s complement overflow
(a>0 && b<0 && (a-b)<0) || (a<0 && b>0 && (a-b)>0)

CSCI-2500 FALL 2012, x86 ISA
Setting Condition Codes (cont.)
Explicit Setting by Test instructiontestl Src2,Src1 Sets condition codes based on value of
Src1 & Src2 Useful to have one of the operands be a
mask testl b,a like computing a&b without
setting destination ZF set when a&b == 0 SF set when a&b < 0

CSCI-2500 FALL 2012, x86 ISA
Reading Condition Codes
SetX Condition Descriptionsete ZF Equal / Zero
setne ~ZF Not Equal / Not Zero
sets SF Negative
setns ~SF Nonnegative
setg ~(SF^OF)&~ZF Greater (Signed)
setge ~(SF^OF) Greater or Equal (Signed)
setl (SF^OF) Less (Signed)
setle (SF^OF)|ZF Less or Equal (Signed)
seta ~CF&~ZF Above (unsigned)
setb CF Below (unsigned)
SetX Instructions Set single byte based on combinations of
condition codes

CSCI-2500 FALL 2012, x86 ISA
Reading Condition Codes (Cont.)
SetX Instructions Set single byte based on combinations
of condition codes One of 8 addressable byte registers
Embedded within first 4 integer registers
Does not alter remaining 3 bytes Typically use movzbl to finish job
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
%al%ah
%dl%dh
%cl%ch
%bl%bh
int gt (int x, int y){ return x > y;}
movl 12(%ebp),%eax # eax = ycmpl %eax,8(%ebp) # Compare x : ysetg %al # al = x > ymovzbl %al,%eax # Zero rest of %eax
Note inverted ordering!
Body

CSCI-2500 FALL 2012, x86 ISA
Jumping
jX Condition Descriptionjmp 1 Unconditional
je ZF Equal / Zero
jne ~ZF Not Equal / Not Zero
js SF Negative
jns ~SF Nonnegative
jg ~(SF^OF)&~ZF Greater (Signed)
jge ~(SF^OF) Greater or Equal (Signed)
jl (SF^OF) Less (Signed)
jle (SF^OF)|ZF Less or Equal (Signed)
ja ~CF&~ZF Above (unsigned)
jb CF Below (unsigned)
jX Instructions Jump to different part of code depending on condition
codes
CSCI-2500 FALL 2012, x86 ISA
Conditional Branch Example
int max(int x, int y){ if (x > y) return x; else return y;}
_max:pushl %ebpmovl %esp,%ebp
movl 8(%ebp),%edxmovl 12(%ebp),%eaxcmpl %eax,%edxjle L9movl %edx,%eax
L9:
movl %ebp,%esppopl %ebpret
Body
SetUp
Finish

CSCI-2500 FALL 2012, x86 ISA
Conditional Branch Example (Cont.)
movl 8(%ebp),%edx # edx = xmovl 12(%ebp),%eax # eax = ycmpl %eax,%edx # x : yjle L9 # if <= goto L9movl %edx,%eax # eax = x
L9: # Done:
int goto_max(int x, int y){ int rval = y; int ok = (x <= y); if (ok) goto done; rval = x;done: return rval;}
Skipped when x y
C allows “goto” as means of transferring control
Closer to machine-level programming style
Generally considered bad coding style

CSCI-2500 FALL 2012, x86 ISA
C Codeint fact_do (int x){ int result = 1; do { result *= x; x = x-1; } while (x > 1); return result;}
Goto Versionint fact_goto(int x){ int result = 1;loop: result *= x; x = x-1; if (x > 1) goto loop; return result;}
“Do-While” Loop Example
Use backward branch to continue looping Only take branch when “while” condition holds

CSCI-2500 FALL 2012, x86 ISA
Goto Versionint fact_goto (int x){ int result = 1;loop: result *= x; x = x-1; if (x > 1) goto loop; return result;}
“Do-While” Loop Compilation
Registers%edx x
%eax result
_fact_goto:pushl %ebp # Setupmovl %esp,%ebp # Setupmovl $1,%eax # eax = 1movl 8(%ebp),%edx # edx = x
L11:imull %edx,%eax # result *= xdecl %edx # x--cmpl $1,%edx # Compare x : 1jg L11 # if > goto loop
movl %ebp,%esp # Finishpopl %ebp # Finishret # Finish
Assembly

CSCI-2500 FALL 2012, x86 ISA
C Codedo Body while (Test);
Goto Versionloop: Body if (Test) goto loop
General “Do-While” Translation
Body can be any C statement Typically compound statement:
Test is expression returning integer= 0 interpreted as false 0 interpreted as true
{ Statement1; Statement2; … Statementn;}

CSCI-2500 FALL 2012, x86 ISA
C Codeint fact_while (int x){ int result = 1; while (x > 1) { result *= x; x = x-1; }; return result;}
First Goto Versionint fact_while_goto (int x){ int result = 1;loop: if (!(x > 1)) goto done; result *= x; x = x-1; goto loop;done: return result;}
“While” Loop Example #1
Must jump out of loop if test fails

CSCI-2500 FALL 2012, x86 ISA
C Codeint fact_while(int x){ int result = 1; while (x > 1) { result *= x; x = x-1; }; return result;}
Second Goto Versionint fact_while_goto2 (int x){ int result = 1; if (!(x > 1)) goto done; loop: result *= x; x = x-1; if (x > 1) goto loop;done: return result;}
Actual “While” Loop Translation
Uses same inner loop as do-while version
Guards loop entry with extra test

CSCI-2500 FALL 2012, x86 ISA
C Codewhile (Test) Body
Do-While Version
if (!Test) goto done; do Body while(Test);done:
General “While” Translation
Goto Version if (!Test) goto done;loop: Body if (Test) goto loop;done:

CSCI-2500 FALL 2012, x86 ISA
“For” Loop Example
Algorithm Exploit property that p = p0 + 2p1 + 4p2 + … 2n–1pn–1
Gives: xp = z0 · z1 2 · (z2 2) 2 · … · (…((zn –12) 2 )…) 2
zi = 1 when pi = 0
zi = x when pi = 1 Complexity O(log p)
/* Compute x raised to nonnegative power p */int ipwr_for(int x, unsigned p) {int result; for (result = 1; p != 0; p = p>>1) { if (p & 0x1) result *= x; x = x*x; } return result;}
n–1 timesExample
310 = 32 * 38
= 32 * ((32) 2) 2

CSCI-2500 FALL 2012, x86 ISA
ipwr Computation/* Compute x raised to nonnegative power p */int ipwr_for(int x, unsigned p) {int result; for (result = 1; p != 0; p = p>>1) { if (p & 0x1) result *= x; x = x*x; } return result;}
result x p1 3 101 9 59 81 29 6561 1
531441 43046721 0

CSCI-2500 FALL 2012, x86 ISA
“For” Loop Example“For” Loop Example
for (Init; Test; Update )
Body
int result; for (result = 1; p != 0; p = p>>1) { if (p & 0x1) result *= x; x = x*x; }
General Form
Initresult = 1
Testp != 0
Updatep = p >> 1
Body { if (p & 0x1) result *= x; x = x*x; }

CSCI-2500 FALL 2012, x86 ISA
“For” “While”“For” “While”
for (Init; Test; Update )
Body
Init;while (Test ) { Body Update ;}
Goto Version
Init; if (!Test) goto done;loop: Body Update ; if (Test) goto loop;done:
While VersionFor Version
Do-While Version
Init; if (!Test) goto done; do { Body Update ; } while (Test)done:

CSCI-2500 FALL 2012, x86 ISA
“For” Loop Compilation“For” Loop Compilation
Initresult = 1
Testp != 0
Updatep = p >> 1
Body { if (p & 0x1) result *= x; x = x*x; }
Goto Version
Init; if (!Test) goto done;loop: Body Update ; if (Test) goto loop;done:
result = 1; if (p == 0) goto done;loop: if (p & 0x1) result *= x; x = x*x; p = p >> 1; if (p != 0) goto loop;done:

CSCI-2500 FALL 2012, x86 ISA
Switch StatementsSwitch Statements Implementation Options
Series of conditionals Good if few cases Slow if many
Jump Table Lookup branch target Avoids conditionals Possible when cases
are small integer constants
GCC Picks one based on
case structure Bug in example code
No default given
typedef enum {ADD, MULT, MINUS, DIV, MOD, BAD} op_type;
char unparse_symbol(op_type op){ switch (op) { case ADD : return '+'; case MULT: return '*'; case MINUS: return '-'; case DIV: return '/'; case MOD: return '%'; case BAD: return '?'; }}

CSCI-2500 FALL 2012, x86 ISA
Jump Table Structure
Code Block0
Targ0:
Code Block1
Targ1:
Code Block2
Targ2:
Code Blockn–1
Targn-1:
•••
Targ0
Targ1
Targ2
Targn-1
•••
JTab:
target = JTab[op];goto *target;
switch(op) { case val_0: Block 0 case val_1: Block 1 • • • case val_n-1: Block n–1}
Switch Form
Approx. Translation
Jump Table Jump Targets

CSCI-2500 FALL 2012, x86 ISA
Switch Statement ExampleSwitch Statement Example Branching Possibilities
Setup:
unparse_symbol:pushl %ebp # Setupmovl %esp,%ebp # Setupmovl 8(%ebp),%eax # eax = opcmpl $5,%eax # Compare op : 5
ja .L49 # If > goto donejmp *.L57(,%eax,4) # goto Table[op]
Enumerated ValuesADD 0MULT 1MINUS 2DIV 3MOD 4BAD 5
typedef enum {ADD, MULT, MINUS, DIV, MOD, BAD} op_type;
char unparse_symbol(op_type op){ switch (op) { • • • }}

CSCI-2500 FALL 2012, x86 ISA
Assembly Setup Explanation
Symbolic Labels Labels of form .LXX translated into addresses by
assembler Table Structure
Each target requires 4 bytes Base address at .L57
Jumpingjmp .L49 Jump target is denoted by label .L49jmp *.L57(,%eax,4) Start of jump table denoted by label .L57 Register %eax holds op Must scale by factor of 4 to get offset into table Fetch target from effective Address .L57 + op*4

CSCI-2500 FALL 2012, x86 ISA
Jump TableJump Table
Enumerated ValuesADD 0MULT 1MINUS 2DIV 3MOD 4BAD 5
.section .rodata .align 4.L57:.long .L51 #Op = 0.long .L52 #Op = 1.long .L53 #Op = 2.long .L54 #Op = 3.long .L55 #Op = 4.long .L56 #Op = 5
Table Contents .L51:movl $43,%eax # ’+’jmp .L49
.L52:movl $42,%eax # ’*’jmp .L49
.L53:movl $45,%eax # ’-’jmp .L49
.L54:movl $47,%eax # ’/’jmp .L49
.L55:movl $37,%eax # ’%’jmp .L49
.L56:movl $63,%eax # ’?’# Fall Through to .L49
Targets & Completion

CSCI-2500 FALL 2012, x86 ISA
Switch Statement Completion
Puzzle What value returned when op is invalid?
Answer Register %eax set to op at beginning of
procedure This becomes the returned value
Advantage of Jump Table Can do k-way branch in O(1) operations
.L49: # Done:movl %ebp,%esp # Finishpopl %ebp # Finishret # Finish

CSCI-2500 FALL 2012, x86 ISA
Object Code
Setup Label .L49 becomes address 0x804875c Label .L57 becomes address 0x8048bc0
08048718 <unparse_symbol>: 8048718:55 pushl %ebp 8048719:89 e5 movl %esp,%ebp 804871b:8b 45 08 movl 0x8(%ebp),%eax 804871e:83 f8 05 cmpl $0x5,%eax 8048721:77 39 ja 804875c <unparse_symbol+0x44> 8048723:ff 24 85 c0 8b jmp *0x8048bc0(,%eax,4)

CSCI-2500 FALL 2012, x86 ISA
Object Code (cont.)
Jump Table Doesn’t show up in disassembled code Can inspect using GDBgdb code-examples
(gdb) x/6xw 0x8048bc0 Examine 6 hexadecimal format “words” (4-bytes each) Use command “help x” to get format documentation
0x8048bc0 <_fini+32>:
0x08048730
0x08048737
0x08048740
0x08048747
0x08048750
0x08048757

CSCI-2500 FALL 2012, x86 ISA
Extracting Jump Table from Binary
Jump Table Stored in Read Only Data Segment (.rodata) Various fixed values needed by your code
Can examine with objdumpobjdump code-examples –s –-section=.rodata Show everything in indicated segment.
Hard to read Jump table entries shown with reversed byte ordering
E.g., 30870408 really means 0x08048730
Contents of section .rodata: 8048bc0 30870408 37870408 40870408 47870408 [email protected]... 8048bd0 50870408 57870408 46616374 28256429 P...W...Fact(%d) 8048be0 203d2025 6c640a00 43686172 203d2025 = %ld..Char = % …
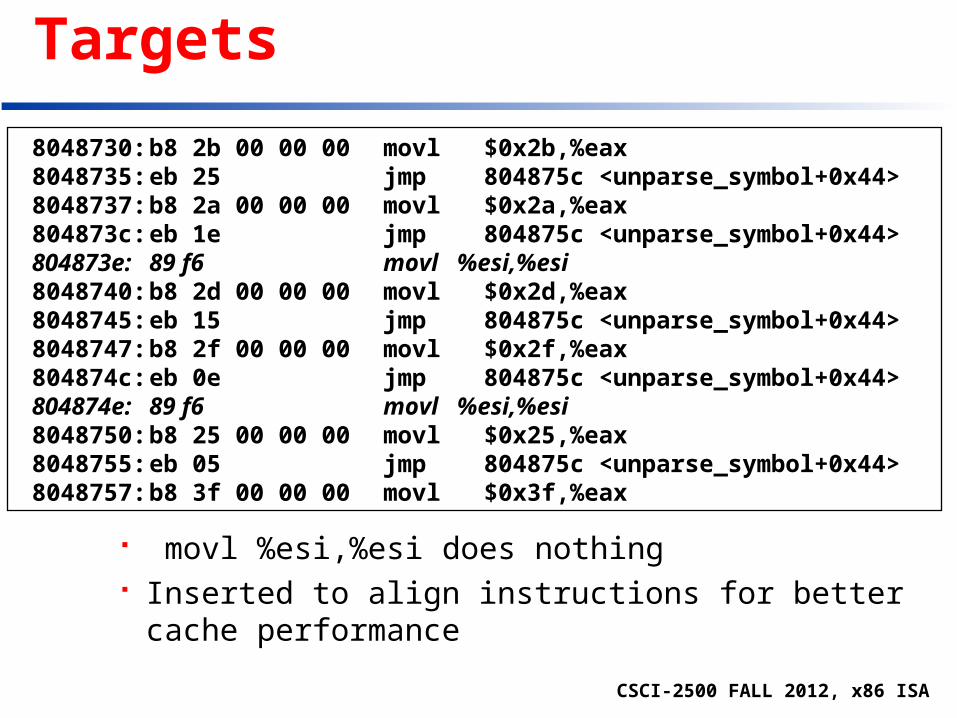
CSCI-2500 FALL 2012, x86 ISA
Disassembled Targets
movl %esi,%esi does nothing Inserted to align instructions for better cache
performance
8048730:b8 2b 00 00 00 movl $0x2b,%eax 8048735:eb 25 jmp 804875c <unparse_symbol+0x44> 8048737:b8 2a 00 00 00 movl $0x2a,%eax 804873c:eb 1e jmp 804875c <unparse_symbol+0x44> 804873e:89 f6 movl %esi,%esi 8048740:b8 2d 00 00 00 movl $0x2d,%eax 8048745:eb 15 jmp 804875c <unparse_symbol+0x44> 8048747:b8 2f 00 00 00 movl $0x2f,%eax 804874c:eb 0e jmp 804875c <unparse_symbol+0x44> 804874e:89 f6 movl %esi,%esi 8048750:b8 25 00 00 00 movl $0x25,%eax 8048755:eb 05 jmp 804875c <unparse_symbol+0x44> 8048757:b8 3f 00 00 00 movl $0x3f,%eax

CSCI-2500 FALL 2012, x86 ISA
Matching Disassembled Targets
8048730:b8 2b 00 00 00 movl 8048735:eb 25 jmp 8048737:b8 2a 00 00 00 movl 804873c:eb 1e jmp 804873e:89 f6 movl 8048740:b8 2d 00 00 00 movl 8048745:eb 15 jmp 8048747:b8 2f 00 00 00 movl 804874c:eb 0e jmp 804874e:89 f6 movl 8048750:b8 25 00 00 00 movl 8048755:eb 05 jmp 8048757:b8 3f 00 00 00 movl
Entry
0x08048730
0x08048737
0x08048740
0x08048747
0x08048750
0x08048757

CSCI-2500 FALL 2012, x86 ISA
Sparse Switch Example Not practical to
use jump table Would require
1000 entries Obvious
translation into if-then-else would have max. of 9 tests
/* Return x/111 if x is multiple && <= 999. -1 otherwise */int div111(int x){ switch(x) { case 0: return 0; case 111: return 1; case 222: return 2; case 333: return 3; case 444: return 4; case 555: return 5; case 666: return 6; case 777: return 7; case 888: return 8; case 999: return 9; default: return -1; }}

CSCI-2500 FALL 2012, x86 ISA
Sparse Switch Code Compares x to possible
case values Jumps different places
depending on outcomes
movl 8(%ebp),%eax # get xcmpl $444,%eax # x:444je L8jg L16cmpl $111,%eax # x:111je L5jg L17testl %eax,%eax # x:0je L4jmp L14
. . .
. . .L5:
movl $1,%eaxjmp L19
L6:movl $2,%eaxjmp L19
L7:movl $3,%eaxjmp L19
L8:movl $4,%eaxjmp L19. . .

CSCI-2500 FALL 2012, x86 ISA
-1
-1 -1-1
Sparse Switch Code Structure
Organizes cases as binary tree Logarithmic performance
444
111 777
0 222 555 888
333 666 9990
1
4
7
5 8
9
2
3 6
<
=
>=
< >=
< >=
< >=
= = =
= =

CSCI-2500 FALL 2012, x86 ISA
Summarizing
C Control if-then-else do-while while switch
Assembler Control jump Conditional jump
Compiler Must generate
assembly code to implement more complex control
Standard Techniques All loops converted to do-while
form Large switch statements use
jump tables Conditions in CISC
CISC machines generally have condition code registers
Conditions in RISC Use general registers to store
condition information Special comparison
instructions E.g., on Alpha:
cmple $16,1,$1 Sets register $1 to 1 when
Register $16 <= 1

CSCI-2500 FALL 2012, x86 ISA
X86: ProceduresX86: Procedures Topics
IA32 stack discipline
Register saving conventions
Creating pointers to local variables
CSCI-2500Computer Organization

CSCI-2500 FALL 2012, x86 ISA
IA32 Stack Region of memory
managed with stack discipline
Grows toward lower addresses
Register %esp indicates lowest stack address
address of top element
StackPointer%esp
Stack GrowsDown
IncreasingAddresses
Stack “Top”
Stack “Bottom”
CSCI-2500 FALL 2012, x86 ISA
IA32 Stack Pushing Pushing
pushl Src Fetch operand at
Src Decrement %esp by
4 Write operand at
address given by %esp
Stack GrowsDown
IncreasingAddresses
Stack “Top”
Stack “Bottom”
StackPointer%esp
-4

CSCI-2500 FALL 2012, x86 ISA
IA32 Stack Popping
Popping popl Dest Read operand at
address given by %esp
Increment %esp by 4
Write to Dest
StackPointer%esp
Stack GrowsDown
IncreasingAddresses
Stack “Top”
Stack “Bottom”
+4

CSCI-2500 FALL 2012, x86 ISA
%esp
%eax
%edx
%esp
%eax
%edx
%esp
%eax
%edx
0x104
555
0x108
0x108
0x10c
0x110
0x104
555
213
213
123
Stack Operation Examples
0x108
0x10c
0x110
555
213
123
0x108 0x104
pushl %eax
0x108
0x10c
0x110
213
123
0x104
213
popl %edx
0x108
213

CSCI-2500 FALL 2012, x86 ISA
Procedure Control FlowProcedure Control Flow
Use stack to support procedure call and return Procedure call:
call label: Push return address on stack; Jump to label Return address value
Address of instruction beyond call Example from disassembly 804854e: e8 3d 06 00 00 call 8048b90 <main>
8048553: 50 pushl %eax Return address = 0x8048553
Procedure return: ret Pop address from stack; Jump to address

CSCI-2500 FALL 2012, x86 ISA
%esp
%eip
%esp
%eip 0x804854e
0x108
0x108
0x10c
0x110
0x104
0x804854e
0x8048553
123
Procedure Call Example
0x108
0x10c
0x110
123
0x108
call 8048b90
804854e: e8 3d 06 00 00 call 8048b90 <main>8048553: 50 pushl %eax
0x8048b90
0x104
%eip is program counter

CSCI-2500 FALL 2012, x86 ISA
%esp
%eip
0x104
%esp
%eip 0x80485910x8048591
0x1040x104
0x108
0x10c
0x110
0x8048553
123
Procedure Return Example
0x108
0x10c
0x110
123
ret
8048591: c3 ret
0x108
%eip is program counter
0x8048553
0x8048553

CSCI-2500 FALL 2012, x86 ISA
Stack-Based LanguagesStack-Based Languages
Languages that Support Recursion e.g., C, Pascal, Java Code must be “Reentrant”
Multiple simultaneous instantiations of single procedure
Need some place to store state of each instantiation Arguments Local variables Return pointer
Stack Discipline State for given procedure needed for limited time
From when called to when return Callee returns before caller does
Stack Allocated in Frames state for single procedure instantiation

CSCI-2500 FALL 2012, x86 ISA
Call Chain ExampleCall Chain Example Code Structureyoo(…){
••who();••
}
who(…){
• • •amI();• • •amI();• • •
}
amI(…){
••amI();••
}
yoo
who
amI
amI
amI
Call Chain
Procedure amI recursive
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
proc
FramePointer%ebp
Stack“Top”
Stack Frames
Contents Local variables Return information Temporary space
Management Space allocated when enter
procedure “Set-up” code
Deallocated when return “Finish” code
Pointers Stack pointer %esp indicates
stack top Frame pointer %ebp indicates
start of current frame
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
•••
FramePointer%ebp
Stack Operation
yoo
Call Chainyoo(…){
••who();••
}

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
•••
FramePointer%ebp
Stack Operation
yoo
who
Call Chainwho(…){
• • •amI();• • •amI();• • •
}

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
amI
Call ChainamI(…){
••amI();••
}

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
amI
Call ChainamI(…){
••amI();••
}
amIamI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
amI
Call ChainamI(…){
••amI();••
}
amIamI
amI
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
amI
Call ChainamI(…){
••amI();••
}
amIamI
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
amI
Call ChainamI(…){
••amI();••
}
amI
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
•••
FramePointer%ebp
Stack Operation
yoo
who
Call Chainwho(…){
• • •amI();• • •amI();• • •
} amI
amI
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
amI
•••
FramePointer%ebp
Stack Operation
yoo
who
Call ChainamI(…){
••••
}amI
amI
amI
amI

CSCI-2500 FALL 2012, x86 ISA
StackPointer%esp
yoo
who
•••
FramePointer%ebp
Stack Operation
yoo
who
Call Chainwho(…){
• • •amI();• • •amI();• • •
} amI
amI
amI
amI

CSCI-2500 FALL 2012, x86 ISA
yoo(…){
••who();••
}
StackPointer%esp
yoo
•••
FramePointer%ebp
Stack Operation
yoo
who
Call Chain
amI
amI
amI
amI

CSCI-2500 FALL 2012, x86 ISA
IA32/Linux Stack FrameIA32/Linux Stack Frame Current Stack Frame (“Top” to
Bottom) Parameters for function
about to call “Argument build”
Local variables If can’t keep in registers
Saved register context Old frame pointer
Caller Stack Frame Return address
Pushed by call instruction
Arguments for this callStack Pointer(%esp)
Frame Pointer(%ebp)
Return Addr
SavedRegisters
+Local
Variables
ArgumentBuild
Old %ebp
Arguments
CallerFrame

CSCI-2500 FALL 2012, x86 ISA
Revisiting swap
void swap(int *xp, int *yp) { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
int zip1 = 15213;int zip2 = 91125;
void call_swap(){ swap(&zip1, &zip2);}
call_swap:• • •pushl $zip2 # Global Varpushl $zip1 # Global Varcall swap• • •
&zip2
&zip1
Rtn adr %esp
ResultingStack
•••
Calling swap from call_swap

CSCI-2500 FALL 2012, x86 ISA
Revisiting swap
void swap(int *xp, int *yp) { int t0 = *xp; int t1 = *yp; *xp = t1; *yp = t0;}
swap:pushl %ebpmovl %esp,%ebppushl %ebx
movl 12(%ebp),%ecxmovl 8(%ebp),%edxmovl (%ecx),%eaxmovl (%edx),%ebxmovl %eax,(%edx)movl %ebx,(%ecx)
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
Body
SetUp
Finish

CSCI-2500 FALL 2012, x86 ISA
swap Setup #1
swap:pushl %ebpmovl %esp,%ebppushl %ebx
ResultingStack
&zip2
&zip1
Rtn adr %esp
EnteringStack
•••
%ebp
yp
xp
Rtn adr
Old %ebp
%ebp•••
%esp

CSCI-2500 FALL 2012, x86 ISA
swap Setup #2
swap:pushl %ebpmovl %esp,%ebppushl %ebx
yp
xp
Rtn adr
Old %ebp %ebp
ResultingStack
•••
&zip2
&zip1
Rtn adr %esp
EnteringStack
•••
%ebp
%esp

CSCI-2500 FALL 2012, x86 ISA
swap Setup #3
swap:pushl %ebpmovl %esp,%ebppushl %ebx
yp
xp
Rtn adr
Old %ebp %ebp
ResultingStack
•••
&zip2
&zip1
Rtn adr %esp
EnteringStack
•••
%ebp
Old %ebx %esp

CSCI-2500 FALL 2012, x86 ISA
Effect of swap Setup
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset(relative to %ebp)
ResultingStack
•••
&zip2
&zip1
Rtn adr %esp
EnteringStack
•••
%ebp
Old %ebx %esp
movl 12(%ebp),%ecx # get ypmovl 8(%ebp),%edx # get xp. . .
Body

CSCI-2500 FALL 2012, x86 ISA
swap Finish #1
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
swap’sStack
•••
Old %ebx %esp-4
Observation Saved & restored register %ebx
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
•••
Old %ebx %esp-4

CSCI-2500 FALL 2012, x86 ISA
swap Finish #2
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
swap’sStack
•••
Old %ebx %esp-4
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
swap’sStack
•••
%esp

CSCI-2500 FALL 2012, x86 ISA
swap Finish #3
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
yp
xp
Rtn adr
%ebp
4
8
12
Offset
swap’sStack
•••
yp
xp
Rtn adr
Old %ebp %ebp 0
4
8
12
Offset
swap’sStack
•••
%esp
%esp

CSCI-2500 FALL 2012, x86 ISA
swap Finish #4
movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
&zip2
&zip1 %esp
ExitingStack
•••
%ebp
Observation Saved & restored register %ebx Didn’t do so for %eax, %ecx, or %edx
yp
xp
Rtn adr
%ebp
4
8
12
Offset
swap’sStack
•••
%esp

CSCI-2500 FALL 2012, x86 ISA
Register Saving ConventionsRegister Saving Conventions When procedure yoo calls who:
yoo is the caller, who is the callee Can Register be Used for Temporary Storage?
Contents of register %edx overwritten by who
yoo:• • •movl $15213, %edxcall whoaddl %edx, %eax• • •ret
who:• • •movl 8(%ebp), %edxaddl $91125, %edx• • •ret

CSCI-2500 FALL 2012, x86 ISA
Register Saving ConventionsRegister Saving Conventions When procedure yoo calls who:
yoo is the caller, who is the callee Can Register be Used for Temporary
Storage? Conventions
“Caller Save” Caller saves temporary in its frame before calling
“Callee Save” Callee saves temporary in its frame before using

CSCI-2500 FALL 2012, x86 ISA
IA32/Linux Register Usage
Integer Registers Two have special uses
%ebp, %esp Three managed as callee-
save%ebx, %esi, %edi Old values saved on
stack prior to using Three managed as caller-
save%eax, %edx, %ecx Do what you please,
but expect any callee to do so, as well
Register %eax also stores returned value
%eax
%edx
%ecx
%ebx
%esi
%edi
%esp
%ebp
Caller-SaveTemporaries
Callee-SaveTemporaries
Special

CSCI-2500 FALL 2012, x86 ISA
int rfact(int x){ int rval; if (x <= 1) return 1; rval = rfact(x-1); return rval * x;}
.globl rfact.type
rfact,@functionrfact:
pushl %ebpmovl %esp,%ebppushl %ebxmovl 8(%ebp),%ebxcmpl $1,%ebxjle .L78leal -1(%ebx),%eaxpushl %eaxcall rfactimull %ebx,%eaxjmp .L79.align 4
.L78:movl $1,%eax
.L79:movl -4(%ebp),%ebxmovl %ebp,%esppopl %ebpret
Recursive FactorialRecursive Factorial
Registers %eax used without first
saving %ebx used, but save at
beginning & restore at end

CSCI-2500 FALL 2012, x86 ISA
rfact:pushl %ebpmovl %esp,%ebppushl %ebx
rfact:pushl %ebpmovl %esp,%ebppushl %ebx
Rfact Stack Setup
Entering Stack
x
Rtn adr 4
8
Caller
%ebp 0
%espOld %ebx-4 Callee
x
Rtn adr
Caller
%esp
%ebppre %ebp
pre %ebx
pre %ebp
pre %ebx
Old %ebp
rfact:pushl %ebpmovl %esp,%ebppushl %ebx

CSCI-2500 FALL 2012, x86 ISA
Rfact Body
Registers%ebx Stored value of x%eax
Temporary value of x-1 Returned value from rfact(x-1)
Returned value from this call
movl 8(%ebp),%ebx # ebx = xcmpl $1,%ebx # Compare x : 1jle .L78 # If <= goto Termleal -1(%ebx),%eax # eax = x-1pushl %eax # Push x-1call rfact # rfact(x-1)imull %ebx,%eax # rval * xjmp .L79 # Goto done
.L78: # Term:movl $1,%eax # return val = 1
.L79: # Done:
int rfact(int x){ int rval; if (x <= 1) return 1; rval = rfact(x-1) ; return rval * x;}
Recursion

CSCI-2500 FALL 2012, x86 ISA
Rfact Recursion
x
Rtn adr
Old %ebp %ebp
Old %ebx
pushl %eax
%espx-1
x-1%eax x%ebx
x
Rtn adr
Old %ebp %ebp
Old %ebx %esp
%eax
x%ebx
x-1
leal -1(%ebx),%eax
x
Rtn adr
Old %ebp %ebp
Old %ebx
x-1
x-1%eax
x%ebx
%espRtn adr
call rfact

CSCI-2500 FALL 2012, x86 ISA
(x-1)!
Rfact Result
x
Rtn adr
Old %ebp %ebp
Old %ebx
%espx-1
imull %ebx,%eax
x!%eax
x%ebx
x
Rtn adr
Old %ebp %ebp
Old %ebx
%espx-1
(x-1)!%eax
x%ebx
Return from Call
(x-1)!
Assume that rfact(x-1) returns (x-1)! in register %eax

CSCI-2500 FALL 2012, x86 ISA
Pointer Code
void s_helper (int x, int *accum){ if (x <= 1) return; else { int z = *accum * x; *accum = z; s_helper (x-1,accum); }}
int sfact(int x){ int val = 1; s_helper(x, &val); return val;}
Top-Level CallRecursive Procedure
Pass pointer to update location

CSCI-2500 FALL 2012, x86 ISA
Temp.Space
%esp
Creating & Initializing Pointer
int sfact(int x){ int val = 1; s_helper(x, &val); return val;}
_sfact:pushl %ebp # Save %ebpmovl %esp,%ebp # Set %ebpsubl $16,%esp # Add 16 bytes movl 8(%ebp),%edx # edx = xmovl $1,-4(%ebp) # val = 1
Using Stack for Local Variable Variable val must be
stored on stack Need to create pointer
to it Compute pointer as -4(%ebp)
Push on stack as second argument
Initial part of sfact
x
Rtn adr
Old %ebp %ebp 0
4
8
-4 val = 1
Unused-12
-8
-16
_sfact:pushl %ebp # Save %ebpmovl %esp,%ebp # Set %ebpsubl $16,%esp # Add 16 bytes movl 8(%ebp),%edx # edx = xmovl $1,-4(%ebp) # val = 1
_sfact:pushl %ebp # Save %ebpmovl %esp,%ebp # Set %ebpsubl $16,%esp # Add 16 bytes movl 8(%ebp),%edx # edx = xmovl $1,-4(%ebp) # val = 1
_sfact:pushl %ebp # Save %ebpmovl %esp,%ebp # Set %ebpsubl $16,%esp # Add 16 bytes movl 8(%ebp),%edx # edx = xmovl $1,-4(%ebp) # val = 1

CSCI-2500 FALL 2012, x86 ISA
Passing Pointer
int sfact(int x){ int val = 1; s_helper(x, &val); return val;}
leal -4(%ebp),%eax # Compute &valpushl %eax # Push on stackpushl %edx # Push xcall s_helper # callmovl -4(%ebp),%eax # Return val• • • # Finish
Calling s_helper from sfact
x
Rtn adr
Old %ebp %ebp 0
4
8
val = 1 -4
Unused-12
-8
-16
%espx
&val
Stack at time of call
leal -4(%ebp),%eax # Compute &valpushl %eax # Push on stackpushl %edx # Push xcall s_helper # callmovl -4(%ebp),%eax # Return val• • • # Finish
leal -4(%ebp),%eax # Compute &valpushl %eax # Push on stackpushl %edx # Push xcall s_helper # callmovl -4(%ebp),%eax # Return val• • • # Finish
val =x!

CSCI-2500 FALL 2012, x86 ISA
Using Pointer
• • •movl %ecx,%eax # z = ximull (%edx),%eax # z *= *accummovl %eax,(%edx) # *accum = z• • •
void s_helper (int x, int *accum){ • • • int z = *accum * x; *accum = z; • • •}
Register %ecx holds x Register %edx holds pointer to accum
Use access (%edx) to reference memory
%edxaccum
x
x%eax
%ecx
accum*x
accum*x

CSCI-2500 FALL 2012, x86 ISA
Summary The Stack Makes Recursion Work
Private storage for each instance of procedure call Instantiations don’t clobber each other Addressing of locals + arguments can be relative to
stack positions Can be managed by stack discipline
Procedures return in inverse order of calls IA32 Procedures Combination of Instructions + Conventions
Call / Ret instructions Register usage conventions
Caller / Callee save %ebp and %esp
Stack frame organization conventions

CSCI-2500 FALL 2012, x86 ISA
X86: Structured DataX86: Structured Data
Topics Arrays Structs Unions
CSCI-2500Computer Organization

CSCI-2500 FALL 2012, x86 ISA
Basic Data TypesBasic Data Types Integral
Stored & operated on in general registers Signed vs. unsigned depends on instructions used
Intel GAS Bytes Cbyte b 1 [unsigned] charword w 2 [unsigned] shortdouble word l 4 [unsigned] int
Floating Point Stored & operated on in floating point registers
Intel GAS Bytes CSingle s 4 float
Double l 8 double
Extended t 10/12 long double

CSCI-2500 FALL 2012, x86 ISA
Array Allocation Basic Principle
T A[L]; Array of data type T and length L Contiguously allocated region of L * sizeof(T) bytes
char string[12];
x x + 12int val[5];
x x + 4 x + 8 x + 12 x + 16 x + 20double a[4];
x + 32x + 24x x + 8 x + 16
char *p[3];
x x + 4 x + 8

CSCI-2500 FALL 2012, x86 ISA
Array Access Basic Principle
T A[L]; Array of data type T and length L Identifier A can be used as a pointer to array element 0
Reference Type Value
val[4] int 3
val int * x
val+1 int * x + 4
&val[2] int * x + 8
val[5] int ??
*(val+1) int 5
val + i int * x + 4 i
1 5 2 1 3int val[5];
x x + 4 x + 8 x + 12 x + 16 x + 20

CSCI-2500 FALL 2012, x86 ISA
Array Example
Notes Declaration “zip_dig cmu” equivalent to “int cmu[5]” Example arrays were allocated in successive 20 byte blocks
Not guaranteed to happen in general
typedef int zip_dig[5];
zip_dig cmu = { 1, 5, 2, 1, 3 };zip_dig mit = { 0, 2, 1, 3, 9 };zip_dig ucb = { 9, 4, 7, 2, 0 };
zip_dig cmu; 1 5 2 1 3
16 20 24 28 32 36zip_dig mit; 0 2 1 3 9
36 40 44 48 52 56zip_dig ucb; 9 4 7 2 0
56 60 64 68 72 76

CSCI-2500 FALL 2012, x86 ISA
Array Accessing Example
Memory Reference Code
int get_digit (zip_dig z, int dig){ return z[dig];}
# %edx = z # %eax = dig
movl (%edx,%eax,4),%eax # z[dig]
Computation Register %edx contains
starting address of array Register %eax contains array
index Desired digit at 4*%eax + %edx
Use memory reference (%edx,%eax,4)

CSCI-2500 FALL 2012, x86 ISA
Referencing Examples
Code Does Not Do Any Bounds Checking! Reference Address Value Guaranteed?
mit[3] 36 + 4* 3 = 48 3
mit[5] 36 + 4* 5 = 56 9
mit[-1] 36 + 4*-1 = 32 3
cmu[15] 16 + 4*15 = 76 ?? Out of range behavior implementation-dependent
No guaranteed relative allocation of different arrays
zip_dig cmu; 1 5 2 1 3
16 20 24 28 32 36zip_dig mit; 0 2 1 3 9
36 40 44 48 52 56zip_dig ucb; 9 4 7 2 0
56 60 64 68 72 76
YesYes
NoNo
NoNo
NoNo

CSCI-2500 FALL 2012, x86 ISA
int zd2int(zip_dig z){ int i; int zi = 0; for (i = 0; i < 5; i++) { zi = 10 * zi + z[i]; } return zi;}
Array Loop Example
Original Source
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}
Transformed Version As generated by GCC Eliminate loop variable i Convert array code to
pointer code Express in do-while form
No need to test at entrance

CSCI-2500 FALL 2012, x86 ISA
# %ecx = zxorl %eax,%eax # zi = 0leal 16(%ecx),%ebx # zend = z+4
.L59:leal (%eax,%eax,4),%edx # 5*zimovl (%ecx),%eax # *zaddl $4,%ecx # z++leal (%eax,%edx,2),%eax # zi = *z + 2*(5*zi)cmpl %ebx,%ecx # z : zendjle .L59 # if <= goto loop
Array Loop Implementation
Registers%ecx z%eax zi%ebx zend
Computations 10*zi + *z implemented
as *z + 2*(zi+4*zi) z++ increments by 4
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}
# %ecx = zxorl %eax,%eax # zi = 0leal 16(%ecx),%ebx # zend = z+4
.L59:leal (%eax,%eax,4),%edx # 5*zimovl (%ecx),%eax # *zaddl $4,%ecx # z++leal (%eax,%edx,2),%eax # zi = *z + 2*(5*zi)cmpl %ebx,%ecx # z : zendjle .L59 # if <= goto loop
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}
# %ecx = zxorl %eax,%eax # zi = 0leal 16(%ecx),%ebx # zend = z+4
.L59:leal (%eax,%eax,4),%edx # 5*zimovl (%ecx),%eax # *zaddl $4,%ecx # z++leal (%eax,%edx,2),%eax # zi = *z + 2*(5*zi)cmpl %ebx,%ecx # z : zendjle .L59 # if <= goto loop
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}
# %ecx = zxorl %eax,%eax # zi = 0leal 16(%ecx),%ebx # zend = z+4
.L59:leal (%eax,%eax,4),%edx # 5*zimovl (%ecx),%eax # *zaddl $4,%ecx # z++leal (%eax,%edx,2),%eax # zi = *z + 2*(5*zi)cmpl %ebx,%ecx # z : zendjle .L59 # if <= goto loop
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}
# %ecx = zxorl %eax,%eax # zi = 0leal 16(%ecx),%ebx # zend = z+4
.L59:leal (%eax,%eax,4),%edx # 5*zimovl (%ecx),%eax # *zaddl $4,%ecx # z++leal (%eax,%edx,2),%eax # zi = *z + 2*(5*zi)cmpl %ebx,%ecx # z : zendjle .L59 # if <= goto loop
int zd2int(zip_dig z){ int zi = 0; int *zend = z + 4; do { zi = 10 * zi + *z; z++; } while(z <= zend); return zi;}

CSCI-2500 FALL 2012, x86 ISA
Nested Array Example
Declaration “zip_dig pgh[4]” equivalent to “int pgh[4][5]” Variable pgh denotes array of 4 elements
Allocated contiguously Each element is an array of 5 int’s
Allocated contiguously
“Row-Major” ordering of all elements guaranteed
#define PCOUNT 4zip_dig pgh[PCOUNT] = {{1, 5, 2, 0, 6}, {1, 5, 2, 1, 3 }, {1, 5, 2, 1, 7 }, {1, 5, 2, 2, 1 }};
zip_digpgh[4];
76 96 116 136 156
1 5 2 0 6 1 5 2 1 3 1 5 2 1 7 1 5 2 2 1

CSCI-2500 FALL 2012, x86 ISA
Nested Array Allocation Declaration
T A[R][C]; Array of data type T R rows, C columns Type T element requires K
bytes Array Size
R * C * K bytes Arrangement
Row-Major Ordering
A[0][0] A[0][C-1]
A[R-1][0]
• • •
• • •A[R-1][C-1]
•••
•••
int A[R][C];
A[0][0]
A[0]
[C-1]• • •
A[1][0]
A[1][C-1]
• • •A
[R-1][0]
A[R-1][C-1]
• • •• • •
4*R*C Bytes

CSCI-2500 FALL 2012, x86 ISA
• • •
Nested Array Row Access
Row Vectors A[i] is array of C elements Each element of type T Starting address A + i * C * K
A[i][0]
A[i]
[C-1]• • •
A[i]
A[R-1][0]
A[R-1][C-1]
• • •
A[R-1]
• • •
A
A[0][0]
A[0]
[C-1]• • •
A[0]
int A[R][C];
A+i*C*4 A+(R-1)*C*4

CSCI-2500 FALL 2012, x86 ISA
Nested Array Row Access Code
Row Vector pgh[index] is array of 5 int’s Starting address pgh+20*index
Code Computes and returns address Compute as pgh + 4*(index+4*index)
int *get_pgh_zip(int index){ return pgh[index];}
# %eax = indexleal (%eax,%eax,4),%eax # 5 * indexleal pgh(,%eax,4),%eax # pgh + (20 * index)

CSCI-2500 FALL 2012, x86 ISA
• • •
Nested Array Element Access
Array Elements A[i][j] is element of type T Address A + (i * C + j) * K
• • •A
[i][j]
A[i][j]
• • •
A[i]
A[R-1][0]
A[R-1][C-1]
• • •
A[R-1]
• • •
A
A[0][0]
A[0]
[C-1]• • •
A[0]
int A[R][C];
A+i*C*4 A+(R-1)*C*4
A+(i*C+j)*4

CSCI-2500 FALL 2012, x86 ISA
Nested Array Element Access Code
Array Elements pgh[index][dig] is int Address:
pgh + 20*index + 4*dig Code
Computes addresspgh + 4*dig + 4*(index+4*index)
movl performs memory reference
int get_pgh_digit (int index, int dig){ return pgh[index][dig];}
# %ecx = dig# %eax = indexleal 0(,%ecx,4),%edx # 4*digleal (%eax,%eax,4),%eax # 5*indexmovl pgh(%edx,%eax,4),%eax # *(pgh + 4*dig + 20*index)

CSCI-2500 FALL 2012, x86 ISA
Strange Referencing Examples
Reference Address Value Guaranteed?pgh[3][3] 76+20*3+4*3 = 148 2
pgh[2][5] 76+20*2+4*5 = 136 1
pgh[2][-1] 76+20*2+4*-1 = 112 3
pgh[4][-1] 76+20*4+4*-1 = 152 1
pgh[0][19] 76+20*0+4*19 = 152 1
pgh[0][-1] 76+20*0+4*-1 = 72 ?? Code does not do any bounds checking Ordering of elements within array guaranteed
zip_digpgh[4];
76 96 116 136 156
1 5 2 0 6 1 5 2 1 3 1 5 2 1 7 1 5 2 2 1
YesYes
YesYes
YesYes
YesYes
YesYes
NoNo

CSCI-2500 FALL 2012, x86 ISA
Multi-Level Array Example
Variable univ denotes array of 3 elements
Each element is a pointer
4 bytes Each pointer points
to array of int’s
zip_dig cmu = { 1, 5, 2, 1, 3 };zip_dig mit = { 0, 2, 1, 3, 9 };zip_dig ucb = { 9, 4, 7, 2, 0 };
#define UCOUNT 3int *univ[UCOUNT] = {mit, cmu, ucb};
36160
16
56
164
168
univ
cmu1 5 2 1 3
16 20 24 28 32 36mit
0 2 1 3 9
36 40 44 48 52 56ucb9 4 7 2 0
56 60 64 68 72 76

CSCI-2500 FALL 2012, x86 ISA
Element Access in Multi-Level Array
Computation Element access Mem[Mem[univ+4*index]+4*dig]
Must do two memory reads First get pointer to row array Then access element within
array
# %ecx = index# %eax = digleal 0(,%ecx,4),%edx # 4*indexmovl univ(%edx),%edx # Mem[univ+4*index]movl (%edx,%eax,4),%eax # Mem[...+4*dig]
int get_univ_digit (int index, int dig){ return univ[index][dig];}

CSCI-2500 FALL 2012, x86 ISA
Array Element Accesses Similar C references
Nested Array
Element atMem[pgh+20*index+4*dig]
Different address computation
Multi-Level Array
Element atMem[Mem[univ+4*index]+4*dig]
int get_pgh_digit (int index, int dig){ return pgh[index][dig];}
int get_univ_digit (int index, int dig){ return univ[index][dig];}
36160
16
56
164
168
univ
cmu1 5 2 1 3
16 20 24 28 32 36mit
0 2 1 3 9
36 40 44 48 52 56ucb9 4 7 2 0
56 60 64 68 72 76
36160
16
56
164
168
univ
36160
16
56
164
168
univ
cmu1 5 2 1 3
16 20 24 28 32 36
1 5 2 1 31 5 2 1 3
16 20 24 28 32 36mit
0 2 1 3 9
36 40 44 48 52 56
0 2 1 3 90 2 1 3 9
36 40 44 48 52 56ucb9 4 7 2 0
56 60 64 68 72 76
9 4 7 2 09 4 7 2 0
56 60 64 68 72 76
76 96 116 136 156
1 5 2 0 6 1 5 2 1 3 1 5 2 1 7 1 5 2 2 1
76 96 116 136 156
1 5 2 0 6 1 5 2 1 3 1 5 2 1 7 1 5 2 2 11 5 2 0 61 5 2 0 6 1 5 2 1 31 5 2 1 3 1 5 2 1 71 5 2 1 7 1 5 2 2 11 5 2 2 1

CSCI-2500 FALL 2012, x86 ISA
Strange Referencing Examples
Reference Address Value Guaranteed?univ[2][3] 56+4*3 = 68 2
univ[1][5] 16+4*5 = 36 0
univ[2][-1] 56+4*-1 = 52 9
univ[3][-1] ????
univ[1][12] 16+4*12 = 64 7 Code does not do any bounds checking Ordering of elements in different arrays not guaranteed
36160
16
56
164
168
univ
cmu1 5 2 1 3
16 20 24 28 32 36mit
0 2 1 3 9
36 40 44 48 52 56ucb9 4 7 2 0
56 60 64 68 72 76
YesYes
NoNo
NoNo
NoNo
NoNo

CSCI-2500 FALL 2012, x86 ISA
Using Nested Arrays
Strengths C compiler handles
doubly subscripted arrays
Generates very efficient code
Avoids multiply in index computation
Limitation Only works if have fixed
array size
#define N 16typedef int fix_matrix[N][N];
/* Compute element i,k of fixed matrix product */int fix_prod_ele(fix_matrix a, fix_matrix b, int i, int k){ int j; int result = 0; for (j = 0; j < N; j++) result += a[i][j]*b[j][k]; return result;}
A
(i,*)
B
(*,k)
Column-wise
Row-wise

CSCI-2500 FALL 2012, x86 ISA
Dynamic Nested Arrays
Strength Can create matrix of
arbitrary size Programming
Must do index computation explicitly
Performance Accessing single element
costly Must do multiplication
int * new_var_matrix(int n){ return (int *) calloc(sizeof(int), n*n);}
int var_ele (int *a, int i, int j, int n){ return a[i*n+j];}
movl 12(%ebp),%eax # imovl 8(%ebp),%edx # aimull 20(%ebp),%eax # n*iaddl 16(%ebp),%eax # n*i+jmovl (%edx,%eax,4),%eax # Mem[a+4*(i*n+j)]

CSCI-2500 FALL 2012, x86 ISA
Dynamic Array Multiplication
Without Optimizations Multiplies
2 for subscripts 1 for data
Adds 4 for array indexing 1 for loop index 1 for data
/* Compute element i,k of variable matrix product */int var_prod_ele (int *a, int *b, int i, int k, int n){ int j; int result = 0; for (j = 0; j < n; j++) result += a[i*n+j] * b[j*n+k]; return result;}
A
(i,*)
B
(*,k)
Column-wise
Row-wise

CSCI-2500 FALL 2012, x86 ISA
Optimizing Dynamic Array Mult. Optimizations
Performed when set optimization level to -O2
Code Motion Expression i*n can be
computed outside loop Strength Reduction
Incrementing j has effect of incrementing j*n+k by n
Performance Compiler can optimize
regular access patterns
{ int j; int result = 0; for (j = 0; j < n; j++) result += a[i*n+j] * b[j*n+k]; return result;}
{ int j; int result = 0; int iTn = i*n; int jTnPk = k; for (j = 0; j < n; j++) { result += a[iTn+j] * b[jTnPk]; jTnPk += n; } return result;}

CSCI-2500 FALL 2012, x86 ISA
struct rec { int i; int a[3]; int *p;};
Assembly
# %eax = val# %edx = rmovl %eax,(%edx) # Mem[r] = val
void set_i(struct rec *r, int val){ r->i = val;}
Structures Concept
Contiguously-allocated region of memory Refer to members within structure by names Members may be of different types
Accessing Structure Member
Memory Layout
i a p
0 4 16 20

CSCI-2500 FALL 2012, x86 ISA
struct rec { int i; int a[3]; int *p;};
# %ecx = idx# %edx = rleal 0(,%ecx,4),%eax # 4*idxleal 4(%eax,%edx),%eax # r+4*idx+4
int *find_a (struct rec *r, int idx){ return( &(r->a[idx]));}
Generating Pointer to Struct. Member
Generating Pointer to Array Element
Offset of each structure member determined at compile time
i a p
0 4 16
r + 4 + 4*idx
r
CSCI-2500 FALL 2012, x86 ISA
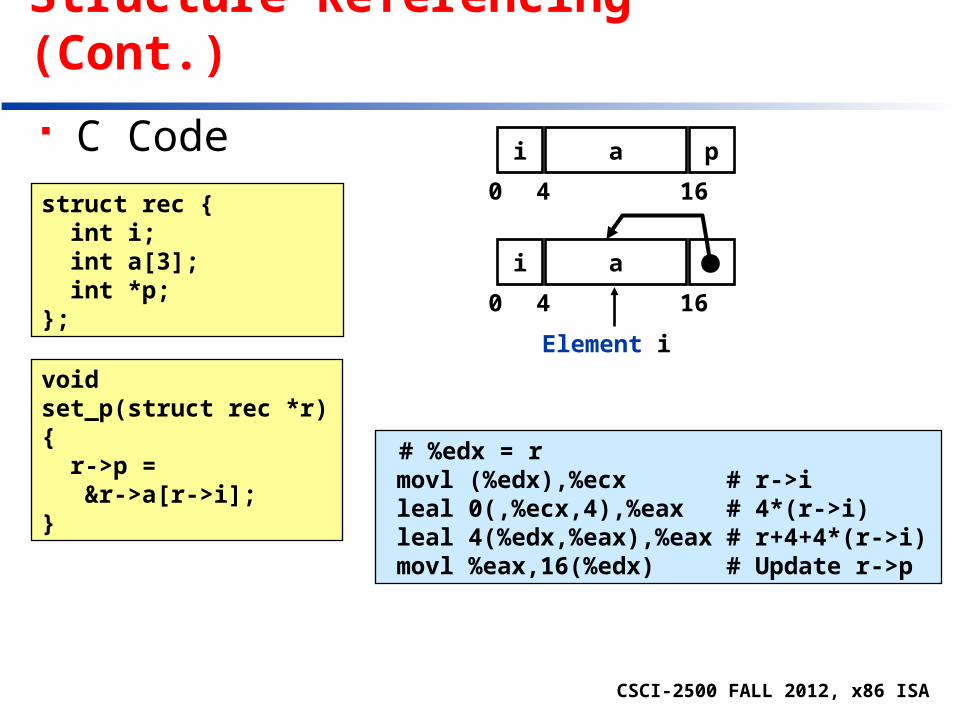
struct rec { int i; int a[3]; int *p;};
# %edx = rmovl (%edx),%ecx # r->ileal 0(,%ecx,4),%eax # 4*(r->i)leal 4(%edx,%eax),%eax # r+4+4*(r->i)movl %eax,16(%edx) # Update r->p
void set_p(struct rec *r){ r->p = &r->a[r->i];}
Structure Referencing (Cont.)
C Code
i a
0 4 16
Element i
i a p
0 4 16

CSCI-2500 FALL 2012, x86 ISA
Alignment Aligned Data
Primitive data type requires K bytes Address must be multiple of K Required on some machines; advised on IA32
treated differently by Linux and Windows! Motivation for Aligning Data
Memory accessed by (aligned) double or quad-words Inefficient to load or store datum that spans quad word
boundaries Virtual memory very tricky when datum spans 2 pages
Compiler Inserts gaps in structure to ensure correct alignment of fields

CSCI-2500 FALL 2012, x86 ISA
Specific Cases of Alignment Size of Primitive Data Type:
1 byte (e.g., char) no restrictions on address
2 bytes (e.g., short) lowest 1 bit of address must be 02
4 bytes (e.g., int, float, char *, etc.) lowest 2 bits of address must be 002
8 bytes (e.g., double) Windows (and most other OS’s & instruction sets):
lowest 3 bits of address must be 0002
Linux: lowest 2 bits of address must be 002
i.e., treated the same as a 4-byte primitive data type 12 bytes (long double)
Linux: lowest 2 bits of address must be 002
i.e., treated the same as a 4-byte primitive data type

CSCI-2500 FALL 2012, x86 ISA
struct S1 { char c; int i[2]; double v;} *p;
Satisfying Alignment with Structures
Offsets Within Structure Must satisfy element’s alignment
requirement Overall Structure Placement
Each structure has alignment requirement K
Largest alignment of any element Initial address & structure length must be
multiples of K Example (under Windows):
K = 8, due to double elementc i[0] i[1] v
p+0 p+4 p+8 p+16 p+24
Multiple of 4 Multiple of 8
Multiple of 8 Multiple of 8

CSCI-2500 FALL 2012, x86 ISA
Linux vs. Windows
Windows (including Cygwin): K = 8, due to double element
Linux: K = 4; double treated like a 4-byte data type
struct S1 { char c; int i[2]; double v;} *p;
c i[0] i[1] v
p+0 p+4 p+8 p+16 p+24
Multiple of 4 Multiple of 8Multiple of 8 Multiple of 8
c i[0] i[1]
p+0 p+4 p+8
Multiple of 4 Multiple of 4Multiple of 4
v
p+12 p+20
Multiple of 4

CSCI-2500 FALL 2012, x86 ISA
Overall Alignment Requirement
struct S2 { double x; int i[2]; char c;} *p;
struct S3 { float x[2]; int i[2]; char c;} *p;
p+0 p+12p+8 p+16 Windows: p+24Linux: p+20
ci[0] i[1]x
ci[0] i[1]
p+0 p+12p+8 p+16 p+20
x[0] x[1]
p+4
p must be multiple of: 8 for Windows4 for Linux
p must be multiple of 4 (in either OS)

CSCI-2500 FALL 2012, x86 ISA
Ordering Elements Within Structure
struct S4 { char c1; double v; char c2; int i;} *p;
struct S5 { double v; char c1; char c2; int i;} *p;
c1 iv
p+0 p+20p+8 p+16 p+24
c2
c1 iv
p+0 p+12p+8 p+16
c2
10 bytes wasted space in Windows
2 bytes wasted space

CSCI-2500 FALL 2012, x86 ISA
Arrays of StructuresArrays of Structures Principle
Allocated by repeating allocation for array type
In general, may nest arrays & structures to arbitrary depth
a[0]
a+0
a[1] a[2]
a+12 a+24 a+36
• • •
a+12 a+20a+16 a+24
struct S6 { short i; float v; short j;} a[10];
a[1].i a[1].ja[1].v

CSCI-2500 FALL 2012, x86 ISA
Accessing Element within ArrayAccessing Element within Array
Compute offset to start of structure Compute 12*i as 4*(i+2i)
Access element according to its offset within structure
Offset by 8 Assembler gives displacement as a + 8
Linker must set actual value
a[0]
a+0
a[i]
a+12i
• • • • • •
short get_j(int idx){ return a[idx].j;}
# %eax = idxleal (%eax,%eax,2),%eax # 3*idxmovswl a+8(,%eax,4),%eax
a+12i a+12i+8
struct S6 { short i; float v; short j;} a[10];
a[i].i a[i].ja[i].v

CSCI-2500 FALL 2012, x86 ISA
Satisfying Alignment within StructureSatisfying Alignment within Structure
Achieving Alignment Starting address of structure array must be
multiple of worst-case alignment for any element
a must be multiple of 4 Offset of element within structure must be
multiple of element’s alignment requirement v’s offset of 4 is a multiple of 4
Overall size of structure must be multiple of worst-case alignment for any element
Structure padded with unused space to be 12 bytes
struct S6 { short i; float v; short j;} a[10];
a[0]
a+0
a[i]
a+12i
• • • • • •
a+12i a+12i+4
a[1].i a[1].ja[1].v
Multiple of 4
Multiple of 4

CSCI-2500 FALL 2012, x86 ISA
Union AllocationUnion Allocation Principles
Overlay union elements Allocate according to largest element Can only use one field at a time
union U1 { char c; int i[2]; double v;} *up;
ci[0] i[1]
vup+0 up+4 up+8struct S1 {
char c; int i[2]; double v;} *sp;
c i[0] i[1] v
sp+0 sp+4 sp+8 sp+16 sp+24
(Windows alignment)

CSCI-2500 FALL 2012, x86 ISA
typedef union { float f; unsigned u;} bit_float_t;
float bit2float(unsigned u) { bit_float_t arg; arg.u = u; return arg.f;}u
f0 4
unsigned float2bit(float f) { bit_float_t arg; arg.f = f; return arg.u;}
Using Union to Access Bit Patterns
Get direct access to bit representation of float
bit2float generates float with given bit pattern
NOT the same as (float) u float2bit generates bit pattern
from float NOT the same as (unsigned) f

CSCI-2500 FALL 2012, x86 ISA
Byte OrderingByte Ordering Idea
Short/long/quad words stored in memory as 2/4/8 consecutive bytes
Which is most (least) significant? Can cause problems when exchanging binary data
between machines Big Endian
Most significant byte has lowest address PowerPC, Sparc
Little Endian Least significant byte has lowest address Intel x86, Alpha

CSCI-2500 FALL 2012, x86 ISA
Byte Ordering ExampleByte Ordering Example union { unsigned char c[8]; unsigned short s[4]; unsigned int i[2]; unsigned long l[1]; } dw;
c[3]
s[1]
i[0]
c[2]c[1]
s[0]
c[0] c[7]
s[3]
i[1]
c[6]c[5]
s[2]
c[4]
l[0]

CSCI-2500 FALL 2012, x86 ISA
Byte Ordering Example (Cont).Byte Ordering Example (Cont).int j;for (j = 0; j < 8; j++)dw.c[j] = 0xf0 + j;
printf("Characters 0-7 == [0x%x,0x%x,0x%x,0x%x,0x%x,0x%x,0x%x,0x%x]\n", dw.c[0], dw.c[1], dw.c[2], dw.c[3], dw.c[4], dw.c[5], dw.c[6], dw.c[7]);
printf("Shorts 0-3 == [0x%x,0x%x,0x%x,0x%x]\n", dw.s[0], dw.s[1], dw.s[2], dw.s[3]);
printf("Ints 0-1 == [0x%x,0x%x]\n", dw.i[0], dw.i[1]);
printf("Long 0 == [0x%lx]\n", dw.l[0]);

CSCI-2500 FALL 2012, x86 ISA
Byte Ordering on x86Byte Ordering on x86Little Endian
Characters 0-7 == [0xf0,0xf1,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7]Shorts 0-3 == [0xf1f0,0xf3f2,0xf5f4,0xf7f6]Ints 0-1 == [0xf3f2f1f0,0xf7f6f5f4]Long 0 == [f3f2f1f0]
Output on Pentium:
f0 f1 f2 f3 f4 f5 f6 f7c[3]
s[1]
i[0]
LSB MSB
c[2]c[1]
s[0]
c[0]
LSB MSB
LSB MSB
c[7]
s[3]
i[1]
LSB MSB
c[6]c[5]
s[2]
c[4]
LSB MSB
LSB MSB
l[0]
LSB MSB

CSCI-2500 FALL 2012, x86 ISA
Byte Ordering on SunByte Ordering on SunBig Endian
Characters 0-7 == [0xf0,0xf1,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7]Shorts 0-3 == [0xf0f1,0xf2f3,0xf4f5,0xf6f7]Ints 0-1 == [0xf0f1f2f3,0xf4f5f6f7]Long 0 == [0xf0f1f2f3]
Output on Sun:
c[3]
s[1]
i[0]
LSBMSB
c[2]c[1]
s[0]
c[0]
MSB LSB
LSB MSB
c[7]
s[3]
i[1]
LSB MSB
c[6]c[5]
s[2]
c[4]
MSB LSB
LSB MSB
f0 f1 f2 f3 f4 f5 f6 f7
l[0]
MSB LSB

CSCI-2500 FALL 2012, x86 ISA
Byte Ordering on AlphaByte Ordering on AlphaLittle Endian
Characters 0-7 == [0xf0,0xf1,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7]Shorts 0-3 == [0xf1f0,0xf3f2,0xf5f4,0xf7f6]Ints 0-1 == [0xf3f2f1f0,0xf7f6f5f4]Long 0 == [0xf7f6f5f4f3f2f1f0]
Output on Alpha:
c[3]
s[1]
i[0]
LSB MSB
c[2]c[1]
s[0]
c[0]
LSB MSB
LSB MSB
c[7]
s[3]
i[1]
LSB MSB
c[6]c[5]
s[2]
c[4]
LSB MSB
LSB MSB
f0 f1 f2 f3 f4 f5 f6 f7
l[0]
LSB MSB

CSCI-2500 FALL 2012, x86 ISA
Summary Arrays in C
Contiguous allocation of memory Pointer to first element No bounds checking
Compiler Optimizations Compiler often turns array code into pointer code (zd2int) Uses addressing modes to scale array indices Lots of tricks to improve array indexing in loops
Structures Allocate bytes in order declared Pad in middle and at end to satisfy alignment
Unions Overlay declarations Way to circumvent type system

CSCI-2500 FALL 2012, x86 ISA
X86:Miscellaneous TopicsX86:Miscellaneous Topics Topics
Linux Memory Layout
Understanding Pointers
Buffer Overflow
class09.ppt
CSCI-2500Computer Organization

CSCI-2500 FALL 2012, x86 ISA
Linux Memory Layout
Stack Runtime stack (8MB limit)
Heap Dynamically allocated storage When call malloc, calloc, new
DLLs Dynamically Linked Libraries Library routines (e.g., printf, malloc) Linked into object code when first
executed Data
Statically allocated data E.g., arrays & strings declared in code
Text Executable machine instructions Read-only
Upper 2 hex digits of address
Red Hatv. 6.2~1920MBmemorylimit
FF
BF
7F
3F
C0
80
40
00
Stack
DLLs
TextData
Heap
Heap
08

CSCI-2500 FALL 2012, x86 ISA
Linux Memory Allocation
LinkedBF
7F
3F
80
40
00
Stack
DLLs
TextData
08
Some Heap
BF
7F
3F
80
40
00
Stack
DLLs
TextData
Heap
08
MoreHeap
BF
7F
3F
80
40
00
Stack
DLLs
TextData
Heap
Heap
08
InitiallyBF
7F
3F
80
40
00
Stack
TextData
08

CSCI-2500 FALL 2012, x86 ISA
Text & Stack Example
(gdb) break main(gdb) run Breakpoint 1, 0x804856f in main ()(gdb) print $esp $3 = (void *) 0xbffffc78
Main Address 0x804856f should
be read 0x0804856f Stack
Address 0xbffffc78
InitiallyBF
7F
3F
80
40
00
Stack
TextData
08

CSCI-2500 FALL 2012, x86 ISA
Dynamic Linking Example(gdb) print malloc $1 = {<text variable, no debug info>} 0x8048454 <malloc>(gdb) run Program exited normally.(gdb) print malloc $2 = {void *(unsigned int)} 0x40006240 <malloc>
Initially Code in text segment that invokes
dynamic linker Address 0x8048454 should be read 0x08048454
Final Code in DLL region
LinkedBF
7F
3F
80
40
00
Stack
DLLs
TextData
08

CSCI-2500 FALL 2012, x86 ISA
Memory Allocation Example
char big_array[1<<24]; /* 16 MB */char huge_array[1<<28]; /* 256 MB */
int beyond;char *p1, *p2, *p3, *p4;
int useless() { return 0; }
int main(){ p1 = malloc(1 <<28); /* 256 MB */ p2 = malloc(1 << 8); /* 256 B */ p3 = malloc(1 <<28); /* 256 MB */ p4 = malloc(1 << 8); /* 256 B */ /* Some print statements ... */}

CSCI-2500 FALL 2012, x86 ISA
Example Addresses
$esp 0xbffffc78p3 0x500b5008p1 0x400b4008Final malloc 0x40006240p4 0x1904a640 p2 0x1904a538beyond 0x1904a524big_array 0x1804a520huge_array 0x0804a510main() 0x0804856fuseless() 0x08048560Initial malloc 0x08048454
BF
7F
3F
80
40
00
Stack
DLLs
TextData
Heap
Heap
08

CSCI-2500 FALL 2012, x86 ISA
C operators
Operators Associativity() [] -> . left to right! ~ ++ -- + - * & (type) sizeof right to left* / % left to right+ - left to right<< >> left to right< <= > >= left to right== != left to right& left to right^ left to right| left to right&& left to right|| left to right?: right to left= += -= *= /= %= &= ^= != <<= >>= right to left, left to right
Note: Unary +, -, and * have higher precedence than binary forms

CSCI-2500 FALL 2012, x86 ISA
C pointer declarations
int *p p is a pointer to int
int *p[13] p is an array[13] of pointer to int
int *(p[13]) p is an array[13] of pointer to int
int **p p is a pointer to a pointer to an int
int (*p)[13] p is a pointer to an array[13] of int
int *f() f is a function returning a pointer to int
int (*f)() f is a pointer to a function returning int
int (*(*f())[13])() f is a function returning ptr to an array[13] of pointers to functions returning int
int (*(*x[3])())[5] x is an array[3] of pointers to functions returning pointers to array[5] of ints

CSCI-2500 FALL 2012, x86 ISA
Internet Worm and IM War November, 1988
Internet Worm attacks thousands of Internet hosts. How did it happen?
July, 1999 Microsoft launches MSN Messenger (instant messaging system). Messenger clients can access popular AOL Instant Messaging
Service (AIM) servers
AIMserver
AIMclient
AIMclient
MSNclient
MSNserver

CSCI-2500 FALL 2012, x86 ISA
Internet Worm and IM War (cont.) August 1999
Mysteriously, Messenger clients can no longer access AIM servers.
Microsoft and AOL begin the IM war: AOL changes server to disallow Messenger clients Microsoft makes changes to clients to defeat AOL
changes. At least 13 such skirmishes.
How did it happen?
The Internet Worm and AOL/Microsoft War were both based on stack buffer overflow exploits!
many Unix functions do not check argument sizes. allows target buffers to overflow.

CSCI-2500 FALL 2012, x86 ISA
String Library Code Implementation of Unix function gets
No way to specify limit on number of characters to read
Similar problems with other Unix functions strcpy: Copies string of arbitrary length scanf, fscanf, sscanf, when given %s conversion specification
/* Get string from stdin */char *gets(char *dest){ int c = getc(); char *p = dest; while (c != EOF && c != '\n') { *p++ = c; c = getc(); } *p = '\0'; return dest;}

CSCI-2500 FALL 2012, x86 ISA
Vulnerable Buffer Code
int main(){ printf("Type a string:"); echo(); return 0;}
/* Echo Line */void echo(){ char buf[4]; /* Way too small! */ gets(buf); puts(buf);}

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Executions
unix>./bufdemoType a string:123123
unix>./bufdemoType a string:12345Segmentation Fault
unix>./bufdemoType a string:12345678Segmentation Fault

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Stack
echo:pushl %ebp # Save %ebp on stackmovl %esp,%ebpsubl $20,%esp # Allocate space on stackpushl %ebx # Save %ebxaddl $-12,%esp # Allocate space on stackleal -4(%ebp),%ebx # Compute buf as %ebp-4pushl %ebx # Push buf on stackcall gets # Call gets. . .
/* Echo Line */void echo(){ char buf[4]; /* Way too small! */ gets(buf); puts(buf);}
Return Address
Saved %ebp
[3][2][1][0] buf
%ebp
StackFrame
for main
StackFrame
for echo

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Stack Example
Before call to gets
unix> gdb bufdemo(gdb) break echoBreakpoint 1 at 0x8048583(gdb) runBreakpoint 1, 0x8048583 in echo ()(gdb) print /x *(unsigned *)$ebp$1 = 0xbffff8f8(gdb) print /x *((unsigned *)$ebp + 1)$3 = 0x804864d
8048648: call 804857c <echo> 804864d: mov 0xffffffe8(%ebp),%ebx # Return Point
Return Address
Saved %ebp
[3][2][1][0] buf
%ebp
StackFrame
for main
StackFrame
for echo
0xbffff8d8
Return Address
Saved %ebp
[3][2][1][0] buf
StackFrame
for main
StackFrame
for echo
bf ff f8 f8
08 04 86 4d
xx xx xx xx

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Example #1
Before Call to gets Input = “123”
No Problem
0xbffff8d8
Return Address
Saved %ebp
[3][2][1][0] buf
StackFrame
for main
StackFrame
for echo
bf ff f8 f8
08 04 86 4d
00 33 32 31
Return Address
Saved %ebp
[3][2][1][0] buf
%ebp
StackFrame
for main
StackFrame
for echo

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Stack Example #2
Input = “12345”
8048592: push %ebx 8048593: call 80483e4 <_init+0x50> # gets 8048598: mov 0xffffffe8(%ebp),%ebx 804859b: mov %ebp,%esp 804859d: pop %ebp # %ebp gets set to invalid value 804859e: ret
echo code:
0xbffff8d8
Return Address
Saved %ebp
[3][2][1][0] buf
StackFrame
for main
StackFrame
for echo
bf ff 00 35
08 04 86 4d
34 33 32 31
Return Address
Saved %ebp
[3][2][1][0] buf
%ebp
StackFrame
for main
StackFrame
for echo
Saved value of %ebp set to 0xbfff0035
Bad news when later attempt to restore %ebp

CSCI-2500 FALL 2012, x86 ISA
Buffer Overflow Stack Example #3
Input = “12345678”
Return Address
Saved %ebp
[3][2][1][0] buf
%ebp
StackFrame
for main
StackFrame
for echo
8048648: call 804857c <echo> 804864d: mov 0xffffffe8(%ebp),%ebx # Return Point
0xbffff8d8
Return Address
Saved %ebp
[3][2][1][0] buf
StackFrame
for main
StackFrame
for echo
38 37 36 35
08 04 86 00
34 33 32 31
Invalid address
No longer pointing to desired return point
%ebp and return address corrupted

CSCI-2500 FALL 2012, x86 ISA
Malicious Use of Buffer Overflow
Input string contains byte representation of executable code Overwrite return address with address of buffer When bar() executes ret, will jump to exploit code
void bar() { char buf[64]; gets(buf); ... }
void foo(){ bar(); ...}
Stack after call to gets()
B
returnaddress
A
foo stack frame
bar stack frame
B
exploitcode
pad
data written
bygets()

CSCI-2500 FALL 2012, x86 ISA
Exploits Based on Buffer Overflows
Buffer overflow bugs allow remote machines to execute arbitrary code on victim machines.
Internet worm Early versions of the finger server (fingerd)
used gets() to read the argument sent by the client:
Finger [email protected] Worm attacked fingerd server by sending
phony argument: finger “exploit-code padding new-return-address”
exploit code: executed a root shell on the victim machine with a direct TCP connection to the attacker.

CSCI-2500 FALL 2012, x86 ISA
Exploits Based on Buffer Overflows Buffer overflow bugs allow remote
machines to execute arbitrary code on victim machines.
IM War AOL exploited existing buffer overflow bug
in AIM clients exploit code: returned 4-byte signature
(the bytes at some location in the AIM client) to server.
When Microsoft changed code to match signature, AOL changed signature location.

CSCI-2500 FALL 2012, x86 ISA
Date: Wed, 11 Aug 1999 11:30:57 -0700 (PDT) From: Phil Bucking <[email protected]> Subject: AOL exploiting buffer overrun bug in their own software! To: [email protected]
Mr. Smith,
I am writing you because I have discovered something that I think you might find interesting because you are an Internet security expert with experience in this area. I have also tried to contact AOL but received no response.
I am a developer who has been working on a revolutionary new instant messaging client that should be released later this year. ... It appears that the AIM client has a buffer overrun bug. By itself this might not be the end of the world, as MS surely has had its share. But AOL is now *exploiting their own buffer overrun bug* to help in its efforts to block MS Instant Messenger. .... Since you have significant credibility with the press I hope that you can use this information to help inform people that behind AOL's friendly exterior they are nefariously compromising peoples' security.
Sincerely, Phil Bucking Founder, Bucking Consulting [email protected] It was later determined that this email
originated from within Microsoft!

CSCI-2500 FALL 2012, x86 ISA
Code Red Worm History
June 18, 2001. Microsoft announces buffer overflow vulnerability in IIS Internet server
July 19, 2001. over 250,000 machines infected by new virus in 9 hours
White house must change its IP address. Pentagon shut down public WWW servers for day
When We Set Up a Web Site Received strings of formGET /default.ida?NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN....NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN%u9090%u6858%ucbd3%u7801%u9090%u6858%ucbd3%u7801%u9090%u6858%ucbd3%u7801%u9090%u9090%u8190%u00c3%u0003%u8b00%u531b%u53ff%u0078%u0000%u00=a
HTTP/1.0" 400 325 "-" "-"

CSCI-2500 FALL 2012, x86 ISA
Code Red Exploit Code Starts 100 threads running Spread self
Generate random IP addresses & send attack string Between 1st & 19th of month
Attack www.whitehouse.gov Send 98,304 packets; sleep for 4-1/2 hours; repeat
Denial of service attack Between 21st & 27th of month
Deface server’s home page After waiting 2 hours

CSCI-2500 FALL 2012, x86 ISA
Code Red Effects Later Version Even More Malicious
Code Red II As of April, 2002, over 18,000 machines
infected Still spreading
Paved Way for NIMDA Variety of propagation methods One was to exploit vulnerabilities left
behind by Code Red II

CSCI-2500 FALL 2012, x86 ISA
Avoiding Overflow Vulnerability
Use Library Routines that Limit String Lengths fgets instead of gets strncpy instead of strcpy Don’t use scanf with %s conversion specification
Use fgets to read the string
/* Echo Line */void echo(){ char buf[4]; /* Way too small! */ fgets(buf, 4, stdin); puts(buf);}

CSCI-2500 FALL 2012, x86 ISA
Final Observations Memory Layout
OS/machine dependent (including kernel version) Basic partitioning: stack/data/text/heap/DLL found in
most machines Type Declarations in C
Notation obscure, but very systematic Working with Strange Code
Important to analyze nonstandard cases E.g., what happens when stack corrupted due to
buffer overflow Helps to step through with GDB