cs525 – in byzantium
DESCRIPTION
CS525 – In Byzantium. The Byzantine Generals Problem Leslie Lamport, Robert Shostak, and Marshall Pease ACM TOPLAS 1982. Presented by Keun Soo Yim March 19, 2009. Dr. Lamport Byzantine Clock Sync. Dist. Snapshot. Byzantine Generals Problem (BGP). A.C. 330. Goals - PowerPoint PPT PresentationTRANSCRIPT

CS525 – In Byzantium
Presented by Keun Soo Yim
March 19, 2009
The Byzantine Generals ProblemLeslie Lamport, Robert Shostak, and Marshall PeaseACM TOPLAS 1982
Dr. Lamport- Byzantine- Clock Sync.- Dist. Snapshot

Byzantine Generals Problem (BGP)
• Goals– Consensus (same plan) btw. loyal generals– A small number of traitors cannot cause the
loyals to adopt a bad plan– Do not have to identify the traitors
• N Generals• Some are traitors• Message passing
2
A.C. 330
100K
50K
40K
30K
10K 20K(commander)

BGP in Distributed Systems
• Goals– All correct nodes share the same global info.– Ensure that N corrupted nodes can not change the shared global
info., and maximize N– Identification of corrupted nodes would be needed
• What’s difference btw. BGP and consensus algo.?– Fail-stop vs. fail-silent violation. Design goal.
• N Computers• Some misbehave
• HW Fault, SW bug, Security attack, misconfiguration
• Message passing
3
A thousand years later…

Naïve Sol. & 3-General Impossibility
• Naïve solution– Each general sends its value, v(i), to all others– Majority vote using v(1), v(2), …, v(n)
• Is it true that no solutions with fewer than 3m+1 generals can cope with m traitors? If so, why?
4

3m-General Impossibility
– If there is a solution for 3m generals with m traitors, it can be reduced to a solution of 3-General problem
“3m+1<=n” “3m+1>n”
5

• n = 4, m = 1
• L1 and L2 both receive v,v,x. (Consensus)
• L1 and L2 obey C
• All lieutenants receive x,y,z
• Lieutenant can identify commander is a traitor
• What is communication complexity of this algorithm?
• Formal definition of OM(M)– Command broadcasts its value to all lieutenants– Each lieutenant acts as commander of OM(m-1)
Solution I – Oral Messages
6

• O(nm)
Communication Complexity
7
OM(m) triggers n-1 OM(m-1)OM(m-1) triggers n-2 OM(m-2)…OM(m-k) will be called by (n-1)…(n-k) times…OM(0)

Solution II – Signed Messages• Can we cope with any number of traitors? If so, how?
8
• Prevent traitors lie about the commander’s order• Message are signed by commander• The sign can be verified by all loyal lieutenants• When lieutenant receives no new messages,
and select majority as the desired action
• All loyals receive the same set of cmds eventually• If the commander is loyal, it works
• What if the commanderis not loyal?

Discussion Point
• Are the assumptions realistic?
• Reliable communication channel– Absence of a message can be detected.
(e.g., Timeouts or synchronized clocks )
• Failure of communication line cannot be distinguished from failure of nodes.– This is acceptable since we tolerate failures of m nodes.
• Can we determine the origin of message?Anyone can verify authenticity of signature?– Unforgeable signatures using asymmetric cryptograph.
9

PeerReview: Practical accountability for distributed systems
Andreas Haeberlen, Petr Kuznetsov, and Peter DruschelSOSP 2007
(Acknowledgement: Some of this presentation slide are borrowed from the original author’s one)

Practical Use Case of BGP
• Distributed file systems– Many small, latency-sensitive requests (tampering with files, lost
updates)
• Overlay multicast– Transfers large volume of data (tampering with content,
freeloading)
• P2P email– Complex, large, decentralized (Denial of service by misrouting)
Not only consensus but also identifying faulty nodes is important!

Providing accountability for distributed systems Stores all I/O events as a log Selected nodes are responsible for auditing
the log Assumptions:
System is modeled as deterministic state machines
State machines have reference implementations
Eventual communication Signe d message
PeerReview
12

Module B
Fault Detection• How to recognize
faults in a log?• Assumption
– Node can be modeled as a deterministic state machine
• To audit a node– Start from a snapshot in
the log– Replay inputs to a
trusted copy of the state machine
– Check outputs against the log
Module A
Module B
=?
LogNetwork
Input
Output
Sta
te m
achi
ne
if ≠
Module A
13

M
Communication Algorithrm• All nodes keep a log of
their inputs & outputs– Including all messages
• Each node has a set of witnesses, who audit its log periodically
• If the witnesses detect misbehavior, they– generate evidence– make the evidence avai-
lable to other nodes
• Other nodes check evi-dence, report fault
A's log
B's log
AA
BB
M
CCDD
EE
A's witnesses
M
14

Tamper-Proofing
A B
Message H
ash
chai
n
Send(X)
Recv(Y)
Send(Z)
Recv(M)
H0
H1
H2
H3
H4
B's log
ACK
What if a node modifies its log entries ?
Log entries form a hash chainInspired by secure histories
[Maniatis02]
Signed hash is included with every message
mi = (si, ti, ci) hi = H(hi-1||si||ti||H(ci))
Commitement protocol Sender and recevier
commit to its current state
Hash(log)
Hash(log)
15

Provable Guarantees
1) Completeness: Faults will be detected
2) Accuracy: Good nodes cannot be accused
If node commits a fault and has a correct witness,
then witness obtainsa proof of misbehavior (PoM), ora challenge that the faulty node cannot answer
If node is correctthere can never be a PoM, andit can answer any challenge
16

Communication Overhead
Baseline 1 2 3 4 5
100
80
60
40
20
0
Avg
traf
fic (
Kbp
s/no
de)
Number of witnesses
Baseline traffic
Signaturesand ACKs
Checking logs
17

Discussion Point• How would you determine the number of
witnesses in a practical system? How to select them?
• PeerReview is the first, practically applicable, faulty node detection technique. Then how can we make a consensus between correct nodes in a scalable manner?
18

Zyzzyva: Speculative
Byzantine Fault Tolerance
Ramakrishna Kotla, Lorenzo Alvisi, Mike Dahlin, Allen Clement and Edmund Wong
University of Texas at AustinSOSP 2007
Presented by Hui Xue, UIUC

MotivationByzantine Fault Tolerance
• Why we need BFT systems?
– Software systems : Valuable + Not reliable enough
• Amazon S3 crashed for hours in 2008
Reason: One corrupted bit
• Akami central nodes
– Hardware : Cheaper now
• Idea
– Use more hardware
Make software systems more reliable

Motivation for Zyzzyva

Assumptions (System Model)
• (Almost) asynchronous system• Multicast; unordered• Independent failures
– Replica: at most f any kind of faults– Network: unreliable – can delay, duplicate, corrupt or
drop messages
• Sufficiently strong cryptographic techniques• All public keys known by everyone• Need bounded msg delay in rare cases
(liveness)

Background:Practical Byzantine Fault TolerancePBFT: establish order before execution
Client
Primary
Replica
Replica
FaultyReplica
Pre-Prepare Prepare Commit Reply
Req, # n Req, # n?OK, Req,
# n!
What is the problem?
Before execution 4 network delays Many messages
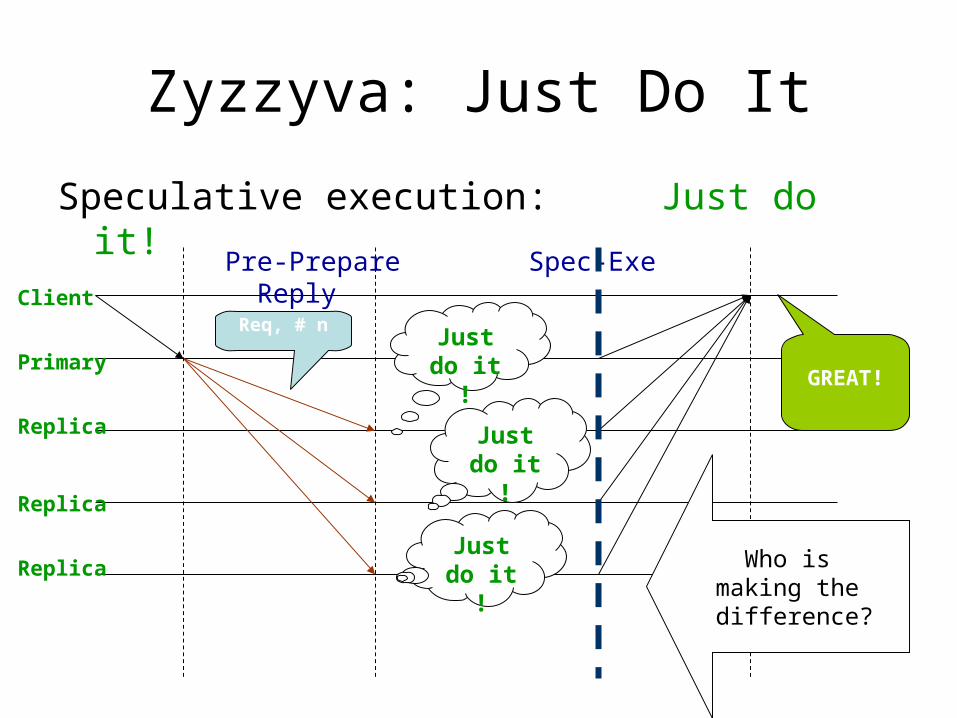
Zyzzyva: Just Do It
Speculative execution: Just do it!
Just do it !
Client
Primary
Replica
Replica
Replica
Pre-Prepare Spec-Exe Reply
Req, # n
GREAT!
Just do it !
Just do it !
Who is making the difference?

Client Can Correct Order CASE 1
Client’s
PowerClient
Primary
Replica
Replica
FaultyReplica
Pre-Prepare Spec-exe ReplyOrder
Correct
To This
state!
OrderCorrectNow!
Just do it !
Just do it !

Client Can Correct Order CASE 2
Client’s
PowerClient
Primary
Replica
Replica
FaultyReplica
Pre-Prepare Spec-exe Reply
Just do it !
Just do it !
Restart Req!

Client Can Correct Order CASE 3
Client’s
PowerClient
Primary
Replica
Replica
Replica
Pre-Prepare Spec-exe Reply
Just do it !
Just do it ! Change
Primary!

Design of Protocol
• Other Sub protocols:– Fill hole
Sequence # received: N+4
Sequence # expected: N+1 < N+4
(hole in between)
Send <FILL-HOLE> to
1. Primary
2. Slow primary, then all replicas

Optimizations
– Separating agreement from execution
– Batching requests
– Caching out of order requests
– Read only operations: 2f+1 consistent is enough
– Single full response

Performance: Throughput

Performance: Latency

Conclusion
• Clever Observation:– We can execute before the order is
established, hoping we are right.
• Pros– Practical, High throughput + low latency
• Cons– BFT suffer from deterministic bugs– Malicious behaviors may affect performance

Questions
• Why Zyzzyva is fast?
• What is the main difference between Zyzzyva and previous BFT papers?
• What does “zyzzyva” mean?
• Do you buy the idea of BFT at all?
• Name some examples of BFT in real applications.

Thank you!
• This is the end of Zyzzyva
– Questions?