cognitive control of real-time event-driven systems
TRANSCRIPT

COGNITIVE SCIENCE 8, 221-254 (1984)
Cognitive Control of Real-Time Event-
Driven Systems*
YUICHIRO ANZAI Faculty of Science and Technology
Keio University
The paper discusses the development of cognitive skills in control of real-
time, event-driven systems with long time lag. Using simulators of ship steer-
ing, and based on thinking-aloud protocol experiments, it is shown that un-
skilled persons may devote most of the initial period of learning control skills
to understanding the causal behavior of the human-machine interface. Ex-
perts employ goal-oriented strategies, planning from a relatively global view-
point. A possible explonation for the development of cognitive strategies is
presented to account for the gathering of information about the control inter-
face, the acquisition of various kinds of strategies, and the learning of control skills for real-time, event-driven systems with long time lag. A computer
simulation model is presented that merges cognitive and control theory
models, ond that simulates the process of strotegy development.
Due to recent developments in hardware technology, the human operator’s task in complex systems turns more and more from physical labor to cogni- tive behavior. A typical instance of such an environment is a real-time, event-driven control system that is controllable in some aspects manually by a human operator. Examples of such systems include vehicle driving
*This paper was written while the author held a visiting faculty position at Department of Psychology, Carnegie-Mellon University. It is an offspring of research done at two remote communities, one in the West and the other in the East; the cognitive psychology research com- munity at Carnegie-Mellon University, and the human engineering research group headed by
Yoshio Hayashi at Keio University. I appreciate all the people who have enabled me to work in this remarkable environment. Special thanks are due to Donald Norman and Herbert Simon for their valuable comments on various earlier versions of this paper. This research was sup- ported by Research Grant MH-07722 from the National Institute of Mental Health. Corre- spondence and requests for reprints should be sent to Dr. Ytdchiro Anzai, Faculty of Science and Technology, Keio University, 3-14-3, Hiyoshi, Kohoku, Yokohoma 223, Japan.
221

222 ANZAI
systems, pursuit tracking systems, plant control systems, display-oriented interactive systems in educational technology, and various kinds of video games.
Control theorists have long been concerned with systems in which human operators participate (e.g., Sheridan & Johannsen, 1976). However, work in control theory and human engineering has not emphasized the operator’s cognitive process. For instance, in spite of the effort in control theory to formalize internal states of systems including human operators (Jagacinski & Miller, 1978; Kleinman, Baron, & Levison, 1971; Kleinman, Pattipati, & Ephrath, 1980), there is almost nothing in common between this characterization and the analyses of cognitive processes common in cognitive science. Studies of internal representations and procedural knowl- edge are central issues in cognitive science. Accordingly, by working on problems in manual control through the eyes of cognitive science, we may open up new research areas for both control theorists and cognitive scien- tists.
This paper addresses one particular issue along this direction: giving an information-processing explanation for the development of cognitive strategies for manually controlling real-time, event-driven systems with long time lag. Systems with long lag are convenient for study. Slowly responding systems, such as systems with long lag, are known to be difficult to control manually (Conklin, 1957; Goldstein & Newton, 1962). It suggests that the process of learning cognitive strategies for such systems may be slow enough to analyze in detail.
I start with the description and some analysis of the task used in this paper. Simplified simulators of the steering of a large ship, a typical system with long time lag, were used as the task environment, one of the original motivations of this study having come from practical application to ship manufacturing industries. Next, I describe experiments that show the differ- ences in strategies employed by subjects of different abilities, and the development of strategies by one naive subject. Third, I describe a theoreti- cal explanation for the development of strategies by extending the theory of learning by doing of Anzai and Simon (1979). The theoretical exploration is accompanied by a computer model that simulates the possible strategy de- velopment process, and an example of simulation results.
TASK ANALYSIS
In this paper, I am concerned with a pair consisting of a physical system and a human operator, linked by a control interface. In this section, 1 provide brief descriptions of the physical system, and the operator’s task.

COGNITIVE CONTROL 223
Dynamics of the Physical System
Real-time, event-driven systems in the real world are best formulated in analog terms, particularly in differential equations. For example, the mo- tion of a ship can be described by the following set of equations if the ship’s speed (V) is assumed to be constant:
Tdf/dt + f(t) = u(t), j(0) = f,
g(t) = I b fh)dr + g(O), g(O) - g,
ak/dt = Vsing(t), x(0) =x,
dyidt = Vcosg(t), y(O) = yo,
where T is the time constant, g(t) is the direction angle (with respect to north) at time t, f(t) is angular velocity, and u(t) is the steering angle.’
Operator’s Task
The task of the pilot, or of subjects in the experiments described in the next section, is to control the steering angle u(t), in such a way as to make the ship go through a series of gates located in the x- y plane as fast as possible. Because the ship’s speed, V, is constant, minimum-time control is equiva- lent to shortest-route control. An example gate configuration is shown in Figure 1. The dynamic system was realized as a hardware circuit with an x-y penrecorder or a display, as shown also in Figure 1 .2 In this simulation environment, the ship’s location is shown as a moving point on the display and each gate is given as a pair of fixed points. The task may be regarded as a simplified simulation of steering a large tanker into a narrow harbor. After the ship starts, it navigates according to the dynamics, but the operator can alter its direction by manipulating the control dial, and thus by changing the value of u(t).
Difficulties in the Task
In spite of the apparent simplicity of the environment, the task is difficult. There are at least the following four sources of difficulties.
‘The behavior of a ship can be described more precisely by a set of equations including a third-order nonlinear differential equation, which contains the linear equation presented here as a special case. However, our equation is sufficient for our purpose, and the more complex equation is not used in this paper.
‘The values of control input, u, and x- and y-coordinates, x and y, of the output trajec- tory were transformed linearly in the apparatus to provide a perceptually natural setting.
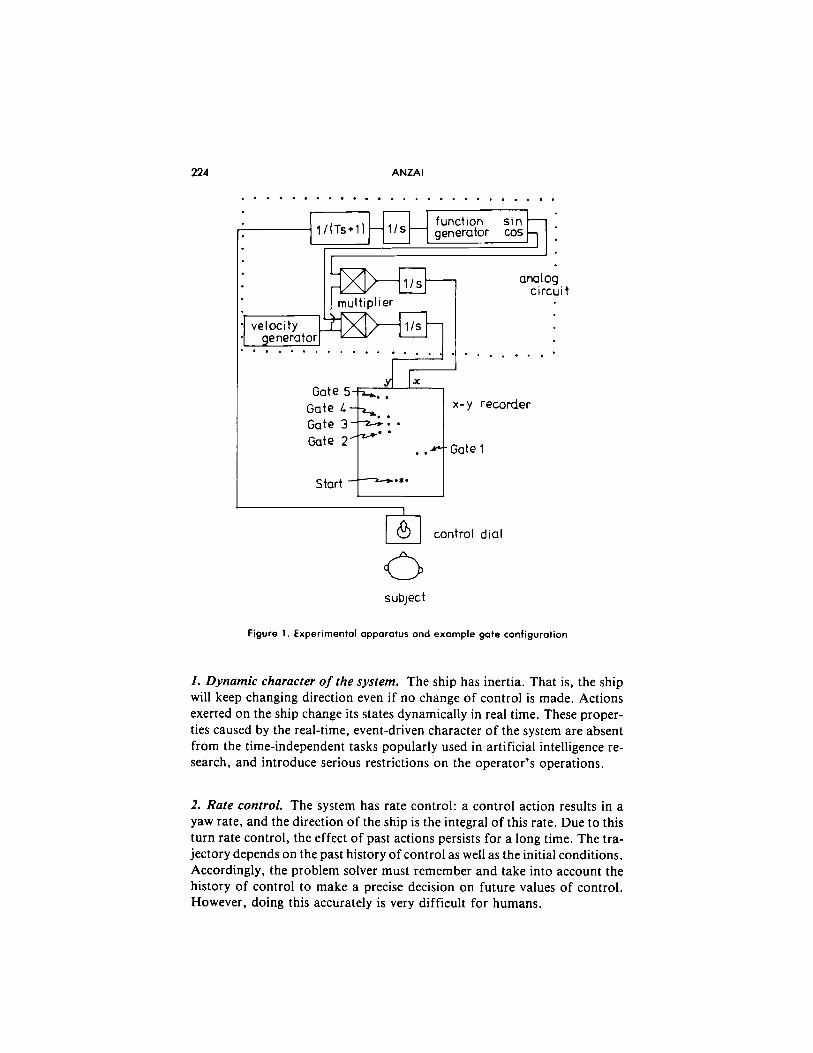
224 ANZAI
. . . . . . . . . . . , *
‘-7 control dial
0
subject
Figure 1. Experimental apparatus and example gate configuration
1. Dynamic character of the system. The ship has inertia. That is, the ship will keep changing direction even if no change of control is made. Actions exerted on the ship change its states dynamically in real time. These proper- ties caused by the real-time, event-driven character of the system are absent from the time-independent tasks popularly used in artificial intelligence re- search, and introduce serious restrictions on the operator’s operations.
2. Rare control. The system has rate control: a control action results in a yaw rate, and the direction of the ship is the integral of this rate. Due to this turn rate control, the effect of past actions persists for a long time. The tra- jectory depends on the past history of control as well as the initial conditions. Accordingly, the problem solver must remember and take into account the history of control to make a precise decision on future values of control. However, doing this accurately is very difficult for humans.

COGNITIVE CONTROL 225
3. Response time lag caused by the time-constant T. The time constant, T, in our first equation is the time required for the system’s output to reach 63% of its steady state value. As T gets larger, the exponential lag becomes longer and it takes more time to make a perceivable change on the direction of the ship. This requires the operator to plan ahead. In control theory, this is known as the Preview Problem. It has been treated in the context of tradi- tional control theoretical research (e.g., Tomizuka & Whitney, 1976). From the cognitive viewpoint, the operator’s internal processes call for cognitive functions such as the internal construction of a causal relationship between the control action and the perceived trajectory pattern that appears very slowly after the action.
4. Difficulty of steering straight. Note that the ship’s direction angle and the steering angle are not necessarily the same. This is because the steering dial is controlled as if it were located inside the ship, but the display that is viewed by the observer is an external view, not the view that would be seen from inside the ship. Therefore, if the ship is moving in a straight line in some direction different from north (say north-east), the steering angle must be held at a position straight ahead (toward north), not in the direction of the ship movement (north-east).
An expert for the task probably knows all of the above four difficul- ties, if not the theories behind them. He is an expert because he has already acquired some cognitive strategies to cope with each of them. One who has never tried the task knows virtually nothing, not even about what sort of response would appear for a control input. A large portion of an unskilled operator’s time must be devoted to the acquisition of causal knowledge that associates a control action with a perceived change of the ship’s trajectory. Then, using the knowledge, the operator must acquire efficient cognitive strategies for overcoming the difficulties.
One such strategy, called the locating strategy in this paper, deals with the difficulty caused by response lag by predicting future trajectories on the basis of acquired causal knowledge. The strategy is to locate an appropriate future turning point mentally, then to decide the control value for making a turn there. Another strategy, the canceling strategy, copes with the diffi- culty of going straight by generating a sequence of future control values such as turning the control dial to the right, then left, and then straight. Still another strategy, the subgoal strategy, takes advantage of spatial subgoals to determine the route in the distant future. The subgoals may include not only physical gates given on the display, but also imaginary points that in- dicate locations good for the ship to go through to pass the upcoming phy- sical gates from appropriate directions. These mentally generated spatial subgoals are called mental gates since they are used similarly to physical gates as intermediate destinations in navigation plans, though they are not pairs of points like physical gates.

226 ANZAI
EXPERIMENTS
The process of skill development can be characterized as the unskilled operator’s trying to acquire new strategies to cope with the difficulties de- scribed in the preceding section. In this section, I provide some experimen- tal results which suggest that this process is actually the one that occurs in the course of learning. In the following experiment, I examine the cognitive differences in control skills between experts and novices.
EXPERIMENT 1: PROTOCOL ANALYSIS OF EXPERT
AND NOVICE PERFORMANCE
Subjects and Procedure
Four subjects of different levels of experience on the task participated in the experiment. All the subjects were male undergraduate and graduate stu- dents at a science and engineering school. The experiment was conducted for each subject individually, using the apparatus and the gate configura- tion shown in Figure 1. The values of T and V were set to 5 s and 0.3 cm/s, respectively. Each subject was instructed to manipulate the control dial to move the display of the ship from its initial position at the starting gate toward the final gate, Gate 5, going though the intermediate gates, I, 2, 3 and 4, in order. The subject was told that the system had some response time lag in behavior, but was not told explicitly the technical term “time- constant.” The subject was instructed to think aloud during the experiment.
Before the experimental trial, all four subjects tried training trials with the time constant set to zero four times consecutively, once for each of four different gate configurations, while thinking aloud. These training trials were conducted to let the subjects become accustomed to a verbal protocol experiment. The level of experience for the subjects was different in the fol- lowing way. Subject Sl had no experience on the task except for the four training trials. S2 was asked after the training trials to work on four other gate configurations with T= 5 s, twice for each configuration; thus, S2 had experience of trying eight trials with a large time-constant value. S3’s expe- rience before the training trials was estimated to be the order of 100 trials over a period of about 4 years for various configurations, and values of T and I’. S4’s trials before training was estimated to be more than 1000 during a 4-year period, for various conditions.
Thus, Sl, S2, S3, and S4 were regarded respectively as a complete novice, a novice with a little experience, a moderately experienced subject, and an expert, for our task. No gate configuration used for the training trials was the same as the one for the experiment, and thus Sl and S2 had no

COGNITIVE CONTROL 227
experience on the particular experimental condition. S3 and S4 said that they had never tried on the same condition.
Results and Discussion
The resulting trajectories, shown in Figure 2, reveal the difference of skills of the four subjects. The times consumed for attaining the final goal were about 5 ‘10’ for Sl, 2 ‘36” for S2, 2 ‘10’ for S3 and 2 ‘06’ for S4. Less ex- perienced subjects spent longer times, and generated longer and meandered trajectories.
Figure 2. Troiectories of Sl, S2, S3, ond 54 in Experiment 1

228 ANZAI
Protocol analysis. Most of the protocol segments could be considered as indicating attention to results of actions, prediction of future states, or various kinds of control decisions. Therefore, the protocol data were seg- mented, and each segment was classified into one or more of the following categories:
/Result/: Attending to physical or mental state information that was causally attributed to a control action (mostly the most recent action). (Immediate]: Predicting, or expecting, a physical or mental state of an immediate future. [Distant]: Predicting, expecting, or planning physical or mental states of a distant future. /Decision/: Refers to active decision on an immediate future. For ex- ample, “I should go straight.” [Locate]: The strategy that makes decision for a control action well before the planned turning point for overcoming the difficulty caused by the large value of the time-constant. (Cancel/:The strategy that generates a sequence of control decisions to make the ship go straight. For example, a pilot can make the ship go straight when it is turning to the right, by turning the control dial to the left, turning it back to the right, and then turning it back to the straight direction. /Extreme]: Refers to decision for a control action that takes an ex- treme value of control.
Among the categories, [result/, [immediate], and [distant/ are con- cerned with attention to physical or mental state information. In terms of control theory, they are related to estimation of system states. On the other hand, [decision], [IocateJ, Icancel/, and [extreme/ represent control deci- sions or strategies. Those categories are related to control of system states in control theory.
As an example of the protocol data, part of Sl’s protocol is shown in Table I. For example, Segment 1 in Table I, “It will be wrong with this,” was an [immediate] since it suggests that Sl expected what would happen in an immediate future. Segment 2, “What?“, was an utterance of surprise generated when he saw the gradual turning of the trajectory. So it was classi- fied as a /result/. Segment 3, “It started to turn at last ,” was also considered as a [result]. Since Segment 6, “I should make it straight. It’s difficult,” was apparently a decision for an immediate future direction, it was classi- fied as a [decision].
Table II shows the result from classifying the four subjects’ protocol segments in the above manner. The data suggest the qualitative difference among the cognitive processes employed by the subjects.

TABLE I
Initial Part of Sl’s Verbal Protocol in Experiment 1
1. It will be wrong with this.
2. What?
3. It started to turn here at last.
4. I thought the former ones were oil slow, but this is slower.
5. <unknown >
6. I should make it straight. It’s difficult.
7. <unknown >
8. Go round, go round!
9. Fine.
10. Oh, it might miss.
11. Itpassed...
12. h’s difficult. , this is.
13. The gool was cleared, you agree?
(Experimenter: Continue please.)
14. I turned it a little bit too much.
15. I turned too much to the opposite.
16. Ho, ha! What’s this? I get mad!
17. What?
18. What?
19. This will also turn too much. I’m sure.
20. This is a mess!
21. I began to be confused.
TABLE II
Results from Protocol Analysis:
Percentage Distributions of Protocol Segment Cotegories
cotegory Characterlstlcs Sl
Subled 52 s3 s4
[Result]
[Immediate]
[Distant]
[Decision]
[Locate]
[Cancel]
[Extreme]
N of segments
Attention to o result of control
Prediction or expectation for an
immediate future
Prediction, expectation, or
plonning for a distant future
Active decision on an immediate
future control action or trajectory
Locating a proper point far control
decision to make a future turn
Going straight by concelling past
control
Taking an extreme value of
control
44 12 32 33
18 27 15 8
7 10 24 21
4 17 21 21
0 7 9 0
0 25 12 4
0 7 0 13
45 41 34 24
Each segment may be classified into more than one category. or into no category, among
the seven categories. and thus the percent sums do not necessarily make 100%.
229

230 ANZAI
SI: a complete novice. The domination of /result/s in Sl’s data in Table II. suggests that he attended mostly to his immediate results of control, rather than to a distant future or to using strategies. Also, note that the words “make” and “keep” seldom appeared in Sl’s protocol, which suggests that Sl’s control decisions and planning strategies were not active in the task. It is also worth noting that the word “here,” which often indicates attention to a specific turning point, was uttered only once, in Segment 3, in the pro- tocol. This suggests that Sl did not yet consider how the time lag in motion could be handled by new strategies. These data suggest that Sl worked on the system without actively controlling it, and tried to find, or rather pas- sively found, causal relations between his actions and the system’s behavior. The dominant process was the acquisition of causal relations that may be summarized in the form of “when I did it at that situation, then the situa- tion changed to this. ”
S2: a novice with a little experience. Table II shows that the number of /result/s was relatively smaller, and the number of [immediate/s was larger for S2 than for Sl. Also, it was found from the protocol that S2 uttered “then” often, and “if” sometimes. These results suggest that S2 thought often about prediction and expectation of moves in an immediate future. Also, Table II shows that the number of IcancelJs was relatively large for S2. Actually, in the protocol, S2 frequently said, “I cancel by this (control ac- tion).” These statements were likely to correspond to his turning the control dial back to an opposite position to cancel the influence of the past control. It suggests that he could make use of the canceling strategy for making the ship go straight. Besides, active decision for a future path was verbalized relatively frequently as shown in Table II ([decision]), as indicated by the subject’s frequent announcement of the word “make” in the protocol. Also, the locating strategy (IlocateJ), which is best estimated by the word “here” in the protocol, was frequently used by S2. Thus, we may assume that, un- like Sl, S2 acquired the locating and canceling strategies and tried to apply them in his new trial. The locating strategy can be formulated generally as “to get a particular response at a specific situation, take a particular action, ” whereas the canceling strategy is a combination of sequential con- trol decisions and the application of the locating strategy. S2’s strategies, however, seemed to be still local: he was not likely to have employed any global plan, or goal-oriented procedures.
S3: a moderately experienced subject. S3’s cognitive process was different from both Sl and S2. As shown in Table II, the critical difference was the emergence of a large number of /distantJs. That is, S3 was likely to have considered a distant future, or distant subgoals, much more than the two novice subjects. This may be suggested also from S3’s protocol: the initial

COGNITIVE CONTROL 231
part of it is listed in Table III. For instance, Segment 9 in Table III said, “I turn to the left, taking (Gate) 2 into account.” The point at which he made this utterance was even before Gate 1. Segments 18 and 19 in Table III pro- vide “Well, as I want to enter straight from outside, outside of 2,” and “Make it straight. . . . ” This implies that the decision of taking a straight direction was made to attain the cognitive subgoal of entering straight from outside. These kinds of goal-based decisions were verbalized frequently in the protocol. Thus, S3 seems to have learned the subgoal strategy. That is, he could use the procedure “to attain a particular subgoal, take a particular action. ” It seems that subgoals used in S3’s plan included not only physical gates, but also mental gates. Points for starting actions for generating out- in curves are typical examples of mental gates.
TABLE III
Initial Part of %3’s Verbal Protocol in Experiment 1
1. Turn to the right.
2. Well, this might be sufficient.
3. Beginning to go..
4. Going to the horizontal direction approximately.
5. Now turn it back, ond turn upwords..
6. It began to go upwards.
7. Well, OS it went a little bit too left, I turn it back to the right.
8. Maybe as I can go through by this..
9. I turn to the left, taking 2 into account.
10. Well, about this. _.
11. Did I do too much?
12. Well, what shall I do? Make it go straight, or turn it back downwards?
13. Well. oh, it’s turning back.
14. Now let me start to turn to the right.
15. Turn amply, and I’ll ga as straight as possible.
16. Making it upwards..
17. Ummm..
18. Well, as I want to enter straight from outside, outside of 2.
19. Make it straight.
20. And starting to turn about here, I want to make it go through 3, too.
21. Whot?
22. Well, now it will go through 3, too.
23. I turn, taking 4 into account.
3’4: an experienced subject. In comparison with the above three subjects, S4’s cognitive strategy appeared to be more automated. His protocol was relatively clean, i.e., composed mostly of well-formed short sentences, dif- ferent from the other subjects’ protocols. As Table II shows, almost no ver-

232 ANZAI
balization was made for [IocateJ or (cancel/. This may imply, along with the cleanness of the protocol sentences, that S4’s strategies were relatively auto- mated. But since the experimental trial was his first trial on that particular condition of the time-constant and gate configuration, he needed to adjust his procedures to adapt to the new environment. This should have caused him to evaluate his own behavior frequently. The relatively high percentage of [result] may indicate his attention to the evaluation.
The cognitive differences in expert and novice performance analyzed above suggest that knowledge acquisition by doing our tasks may develop through the initial stage of acquisition of causal knowledge, followed by ac- quisition of the locating and canceling strategies, which is followed further by acquisition of the subgoal strategy. It should be noted that, although ac- quisition of causal knowledge dominated the naive subject’s process, it may be natural to assume that the knowledge was acquired also by the other, more advanced subjects.
In Experiment 2 below, I provide an evidence of this strategy develop- ment process, generated by one person.
EXPERIMENT 2: ONE NAIVE SUBJECT’S LEARNING BY REPEATED TRIALS
Here, we consider how one complete novice for the task learns strategies while repeating trials on the same configuration of gates. The purpose of the experiment was to examine whether we may generalize the results ob- tained in Experiment 1 to one person’s learning process.
Subject and Procedure
The subject was a female college graduate who had neither been told about the task, nor seen the experimental apparatus, before the experiment. The relative gate configuration, the value of the time-constant and the ship’s speed were the same as in Experiment 1, except that the relative distances between the gates were a little smaller.
The subject worked on the same configuration 20 times consecutively, thinking aloud. She was also asked to give a retrospective report after each trial about what kind of strategies she tried to use in that trial.
Results and Discussion
The time consumed for one trial decreased from 2 ‘56’ for the first trial to 1 ‘09” for the 20th trial. The number of passed gates was not significantly

COGNITIVE CONTROL 233
improved. In none of the 20 trials did the subject succeed in passing all five gates.
Three distinct strategies could be identified from the thinking-aloud and retrospective data for coping with each of the following situations: first, deciding what to do after turning the control dial to the right after the start, or, more generally, deciding where to turn; second, trying to find how to go straight; third, deciding which route to take when near a gate. During Trials l-10, most of the subject’s thinking-aloud protocol data included only the first strategy for locating where to turn. This strategy corresponds to the locating strategy mentioned earlier. After Trial 11, she noted the sec- ond strategy for going straight: the canceling strategy. Around Trial 16, she discovered the subgoal strategy for detouring, i.e., making an out-in curve to enter a gate.
The development of strategies can also be identified from the generated trajectories, some of which are illustrated in Figure 3. Note that it was not until Trial 5 that the trajectory did not turn back soon after the start. This suggests that the subject began around in Trial 5 to use the locating strategy of turning the control dial back to the left or straight before the ship over- shot to the right.
The canceling strategy started to be used for going straight around Trial 9. Straight sailing is not as easy as might be thought, for it requires deliberate decisions on control when the ship is still moving toward a seem- ingly (but fallaciously) desirable direction. Also, note that, similar to the result from Experiment 1, the subject could sail straight by the canceling strategy only after the acquisition of the locating strategy.
The trajectory shapes of the later trials in Figure 3 suggest clearly the development of the subgoal strategy for planning an out-in curve to enter the first gate. The strategy is likely to have been acquired around Trial 16. However, it was only around Trial 20 when the strategy began to.be applied to the second gate. The subject seemed to be able to generate mental gates and use them along with physical gates around these trials.
The above results fit those from Experiment 1 well. We may conclude that the subject was able to make use of efficient strategies after around 20 trials, though they were not yet as elaborate as ones used by the advanced subjects in Experiment 1.
It is possible to explain the process of strategy development observed in the experiments by extending the theory of learning presented by Anzai and Simon (1979). Let me present this theoretical exploration in the follow- ing section.
PROCESS OF STRATEGY DEVELOPMENT
In this section, I describe briefly a theoretical exploration into an explana- tion of the strategy development process by unifying three different theories

In 3 . ‘C . + 4
. . . . .
22 . . - 3 * . ia . . . . 3 -4P & - . . . . . .
. 3 . ;;A + . . . . . . . . .
“2 _ . .
(5, . z +
:;r/\l . . . . . .
ti ?!
6 IL
234

COGNITIVE CONTROL 235
developed in cognitive psychology and control theory: understanding in problem solving, learning by doing, and two-level adaptive architecture for learning systems. The point of the unification is that, if we formulate our task in the information-processing paradigm of human problem solving, we can explain (1) the process of causal knowledge acquisition by the theory of understanding in problem solving first developed by Hayes and Simon (1974), (2) incremental acquisition of strategies by our theory of learning by doing in problem solving, and (3) the underlying problem solving and knowledge acquisition mechanisms by the two-level architecture.
Control Task as Problem Solving
First, we need to suppose that our task is a problem solving task with a well- defined problem space. The following two assumptions suffice for that.
Assumption I: Problem-solving tusk. Our task is a problem-solving task, where the operator’s task is to make a decision about what kind of control to take at a problem state, constrained by the goal of going through all the upcoming gates and by the external constraints imposed by the control in- terface and the physical system.
Assumption 2: Mental well-structuredness of the task. Although the prob- lem space includes a virtually infinite number of states and operators, the capacity for the operator’s encoding of their internal representation is re- stricted severely by the real-time character of the physical system, which imposes much cognitive demand. Thus, he is forced to regard the task as a well-structured problem, and has procedural knowledge for encoding only a relatively simple, well-defined problem structure.
These assumptions enable us to apply the following three theoretical constructs, all based on well-structuredness of problems, to our task.
Understanding in Problem Solving
Based on Assumptions 1 and 2, and following the theory of Hayes and Simon (1974) that understanding in problem solving is generation of inter- nal representation for the problem space, acquisition of causal knowledge in our problem-solving task can be regarded as internal construction of new operator application rules for the problem. This is assured by the following assumption.
Assumption 3: Competence for learning operator application rules. The operator has procedural knowledge for mentally constructing operator ap- plication rules in the form of a triple of the present problem state, a control

236 ANZAI
action or a sequence of actions to be applied to the present state, and the resulting end state in which the operator notices the effect of the cause, i.e., the action he took.
Each triple constructed by the operator based on Assumption 3 cor- responds exactly to a piece of what we have called the operator’s causal knowledge. A triple specifies what kind of state transition is made when particular actions are applied to a specific state. Thus, acquisition of these triples enables the operator to compare the present mental states and sub- goals with those in the triples to eva!uate and predict the ship’s behavior, and accordingly to develop new strategies.
A possible form of a triple, or a piece of causal knowledge, which is actually used in the simulation model to be described in the next section, is shown in Figure 4 as an attribute-value pattern of result. Among the attributes for the result in Figure 4, initial-distance-to-goal, initial-angle-difference, initial-trajectory-pattern and rotational-direction-to-goal refer respectively to the distance from the ship to the nearest gate, the difference between the ship’s direction to the gate and its present direction, the feature pattern of the trajectory, and the rotational direction (i.e., right, straight, or left) to the gate, all at the present state. They constitute the information facet for the present state encoded by the operator. Also, applied-mental-control and applied-time-period denote the value of control, and its intended duration. They indicate the facet of the operator’s mental actions applied to the pre- sent state. The attributes mental-time-delay, final-trajectory-pattern, i-f- distance-difference, curvature-of-trajectory, and i-f-direction-difference refer to the facet of the end state, and denote respectively the perceived time lag between the application of control and the start of a change of the tra- jectory pattern, the trajectory pattern at the end state, the difference be- tween the distances from the end state and from the present state to the nearest gate, the perceived curvature of the resulting trajectory, and the dif- ference between the ship’s directions at the initial and end states.
Name Attribute Value
(result name
initial-distance-to-goal
initial-ongle-difference
initial-trajectory-pattern
rotational-direction-to-goal
applied-mental-control
opplied-time-period
mental-time-delay
final-trajectory-pattern
i-f-distance-difference
curvature-of-trajectory
i-f-direction-difference
<integer >
<close, , very-for, too-for>
<n, nne. ne. e, . . . . ssw, s>
<right, straight, left >
<right, straight, left >
<right, straight, left >
< integer >
< integer >
<right, straight, left >
<close, , very-for, too-for >
<dose, , very-far, too-far>
<close, , very-far, too-far>)
Figure 4. Internal representation of a piece of causal knowledge

COGNITIVE CONTROL 237
Learning by Doing
The incremental acquisition of new strategies in the strategy development process may be explained under the following assumption, derived directly from the theory of learning by doing (Anzai & Simon, 1979).
Assumption 4: Competence for learning strategies by doing. The problem solver has procedural knowledge for generating the following process of strategy acquisition. First, the problem solver uses weak strategies like trial and error search to solve the problem, and often detects bad moves by heur- istic knowledge. Then, he constructs procedures for avoiding those bad moves, which gradually make smaller the search demand in problem solv- ing. This may result in encountering good moves or subgoals for the solu- tion. Then, organizing those subgoals provides goal-directed strategies. These new strategies may be chunked to build macro procedures.
The assumption presupposes a problem-solving task with a well-struc- tured problem space. From Assumptions 1 and 2, our control task is qualified at this point, and, as described below, it explains well the human operator’s strategy development process for our task.
A novice operator of our task initially works on the problem by using (incorrect) general heuristics such as “The ship is going straight, but the next gate is at the right, so 1 turn the control dial to the right.” This heuris- tic does not work immediately because of the system’s response lag. Appli- cation of the heuristic results in an unexpected course of the ship, which is perceived as an error caused by the steering action.
Then, the detection of this kind of error, or bad move, leads to con- struction of error-avoiding procedures which we called the locating strategy, predicting a future trajectory and managing the rudder well before the planned turning point. Another example of errors caused by a weak heuris- tic is “meandering” produced by trying too late to cancel overshooting. An action for avoiding such an error appears typically in countersteering before or immediately after the system starts turning in response to the present ac- tion. This strategy is the canceling strategy.
The operator can avoid turning at wrong points, or overshooting, and keep good trajectory pattern at least for a while, by using the locating and canceling strategies. It provides him or her opportunities for perceiving good moves for, or subgoals of, detouring well before the next gate, and entering it from outside to inside. This leads to the subgoal strategy investi- gated in the previous section. Chunking into macro procedures was not ob- vious in the experimental results, though S4’s protocol in Experiment 1 has a flavor of it.
Two-level Adaptive Functional Architecture
Assumption 2 guarantees that, though the physical task structure is ill- defined, the operator encodes it as a well-structured problem. For instance,

238 ANZAI
the operator mentally uses, constrained by his or her perceptual thresholds and motor limits, only several discrete levels, perhaps three or five, of con- trol values. By doing so, he or she encodes the problem as a simple one with a finite set of possible problem operators. However, to compensate for this cognitive simplification of the task, a major device is necessary. It is the sophisticated perceptual-motor system working semiconsciously under the cognitive process. The following assumption assures us the adaptive coordi- nation of cognitive and perceptual-motor mechanisms for problem solving and strategy development.
Assumption 5: Two-level adaptive architecture. A two-level adaptive system performs the task, acquires causal knowledge, and develops new strategies. The lower level is concerned with automatic perceptual-motor and normal cognitive functioning that links perception of the present state directly to application of an appropriate steering action. The upper level administers cognitive functions such as detection of errors, detection of good moves, prediction of future states, evaluation of past states, and acquisition of causal knowledge and new strategies, all concerned with construction of complex internal representations and procedural knowledge that can not be dealt with by the simple lower-level mechanisms.
This two-level architecture functionally corresponds to the inner and outer loop control in control theory (Donges, 1978). Our formulation pro- vides a possible underlying cognitive structure of the control loops and their functional relations.
Thus, we may explain the process of strategy development as it pro- ceeds through understanding the task (Assumption 3), and learning by do- ing (Assumption 4), based on the two-level adaptive system (Assumption 5). All the assumptions are well articulated in the problem solving framework: we are able to incorporate in the adaptive problem solving system compe- tent knowledge for encoding problem spaces for solving the problem, and for learning by doing, so that the resulting structure provides a mechanism for generating the strategy development process that we expect to have. A detailed description of the explanation, however, needs richer tools. In the following section, I present a computer simulation model of the process for this purpose.
SIMULATION MODEL OF STRATEGY DEVELOPMENT
The model to be described here is a set of productions, which is written in a production system language OPSS (Forgy, 1981). In general, some past, current, and future physical states of the man-machine system and mental states of the human operator, with other control elements, are stored in

COGNITIVE CONTROL 239
working memory. Rules for transformation of physical states, and the operator’s procedural knowledge, are represented as productions. The pro- cess of navigating to achieve the task goal is simulated by the recognize-act cycle of the production system.
The decision to use a production system was made mainly for two reasons. One is that it allows relatively easy formulation of the strategy development process, which is assumed to be incremental acquisition of procedural knowledge. The other is that, at our level of explanation for the higher mental process, internal manipulation of symbols may be formalized by pairs of internal situations and corresponding actions, best stated by pro- ductions, and packing more basic perceptual and motor mechanisms up in those actions. There is no necessity for choosing particularly OPSS for our purpose. But the speed, efficiency, and attribute-value notation have helped the development of the program.
I. A Glimpse of the Model’s Representation
The model consists of a set of productions and the initial working memory. Production-generating actions are included in right-hand sides of some pro- ductions, and, when they are fired, new productions are generated and added to the production set. This incremental generation and use of new productions models acquisition of strategies in the strategy development process.
The model’s structure is constrained by the following basic represen- tational elements:
I-I. Declarative representation. Each condition in the left-hand side of the production is represented as a list of an atom and attribute-value pairs asso- ciated with it. It is either a physical state, a physical operator, a mental state, or a mental operator. Examples of those declarative elements are presented later in this section. Working memory elements have the same form as those conditions, except that the memory elements do not contain unbound varia- bles. A production may fire whenever all conditions in its left-hand side match elements in working memory.
I-2. Basic procedures. Each action in the right-hand side of a production is a function that either deposits information in memory, modifies informa- tion in memory, or deletes information from memory. Though the top-level procedures for actions are this simple, each action may include various basic computational procedures.
For example, comparing two directions mentally and deciding whether the difference between them is large or small is such a computa-

240 ANZAI
tional procedure. Also, perceptual encoding of the distance between two separate points is one of those procedures. Each procedure must be complex at the physiological or perceptual level. But at the level of our analysis and modelling, it is reasonable to assume that they can be represented as pack- aged functions, black boxes, whose inside may not be dissected. There are about 25 of those basic procedures in the current version of the program.
I-3. Production representation. A production in our model consists of con- ditions represented by basic declarative elements, and actions defined as functions that possibly contain basic procedures.
The model includes about 100 productions. Generally, the produc- tions can be divided functionally into three groups: physical transformation of the ship’s motion; lower-level perceptual, motor, and normal cognitive functioning; and higher-level complex cognitive functioning. The latter two represent the procedural knowledge possibly possessed by the human operator. The last contains procedures for generating new procedures for advanced strategies. Examples of the productions from those groups are ex- plained later in this section.
II. Detailed Description of Declarative and Production Representations
ll-1. Representation of basic declarative elements. II-I-I. Space and time. In the model, time is represented by integers.
The model also assumes the discreteness of spatial perception. Sixteen direc- tions are distributed in the x-y plane, and designated as n, nne, ne, . . . , ssw and s. Distances are divided into nine categories, designated close, very-near, near, medium-near, medium, medium-far, far, very-far, and too-far.
At the same time, the model includes higher-level representations of space. For example, far, very-far, or too-far can be represented as long- way, and other distances as short-way. Nne, ne, ene, e, ese, se or sse can be represented as right, n as straight, and nn w, n w, . . . , or ssw as left: these global directions are defined relative to north and independent of the opera- tor’s view from inside the ship, and were introduced for the requirements of implementation.
U-1-2. Representation of physical states and operators. States of the physical system, i.e., the ship’s locations and the gate configurations, and physical operators, i.e., the values of control, are represented in the model in the following manner:
@state time < present time> X c numerical x-coordinate of the ship> Y <numerical y-coordinate of the ship> direction c numerical direction of the ship> )

COGNITIVE CONTROL 241
hxwte name c name of the gate> X < numerial x-coordinate of the gate> Y < numerical y-coordinate of the gate> )
(pcontrol time <present time> value < numerical control value> ).
In the preceding three list representations, pstate denotes the physical state of the ship at the time of <present time> , pgate indicates the name and the location of a gate, and pcontrol refers to the value of control taken at <present time> . Though time is discrete, x, y and value allow real numbers.
11-l-3. Representation of mental states and operators. The model as- sumes that mental states and operators are encoded in memory from physi- cal states and operators. An mstate is defined as the set of the following four declarative elements:
(mstate time Ii@ direction rotation
shape distance angle cliff-angle
(mcontrol time value duration
(mgate
h3Od
name P&m X
Y
name m-1 direction shape distance value duration
< present time> c name of the next gate> < symbolic direction of the ship> c symbolic rotational direction to the next
gate > < symbolic shape of the present trajectory> < symbolic distance to the next gate> < symbolic direction to the next gate> <symbolic difference of “angle” and “direction” > )
< present time> <symbolic value of control> < temporal duration of the value> )
c name of the mental gate> c name of the next physical gate> c numerical x-coordinate of the mental gate> < numerical y-coordinate of the mental gate> )
c name of the goal > <name of the next physical gate> c symbolic direction to go from the goal> c symbolic shape to be realized at the goal> < symbolic distance from “goal” to “pgoal”> < symbolic value of mental control> <temporal duration of the mental control
value> ).
Mstate differs from pstate by being mostly symbolic. For example, the attributes, direction and angle, of an mstate take 16 discrete directional symbols as values; rotation and shape are bound to be either left, straight,

242 ANZAI
or right; distance takes one of the nine discrete values; and diff-angle is either positive, zero, or negative.
Mstate is the encoded internal representation of a pstate, extended with information related to goals and trajectory pattern. Mcontrol refers to the encoded representation of a pcontrol, with the time duration.
Mgate is the representation of a mental gate: we assume that, under the subgoal strategy, the operator often generates internally a mental gate, which is defined as a point in the x-y plane where no physical gate is located, but where he or she thinks it convenient to pass to clear subsequent physical gates. We refer to both physical and mental gates as gates, though a mental gate is a point rather than a pair of points, since we use both as spatial sub- goals for the ship’s intermediate destinations. Although the coordinates of a mental gate are represented numerically in the running system, they are used quite roughly, in the sense that the neighborhood of the gate defined for checking whether the ship reached it or not is much larger than a physical gate.
Basic subgoals considered in the model are physical and mental gates. However, the representations of those gates include only its name and loca- tion, and the destined physical gate when it is a mental gate. A subgoal must include more information; for example, the shape of the expected trajectory at a physical or mental gate, and the direction from a physical or mental gate to the (physical or mental) gate next to it. Goal is the internal represen- tation of the additional information. It is coupled with each physical or mental gate.
While sailing the ship, a pair of a pgafe and a goal, or a pair of an mgate and a goal, is possibly created by a plan generated by the subgoal strategy. It is eliminated when the ship gets across the physical gate repre- sented by a pgate, or near the mental gate represented by an mgate, or the y-coordinate of the ship exceeds that of the physical or the mental gate. Generation and deletion of subgoals are performed while the ship is run- ning, and depend heavily on situations encountered: a plan is not specified completely before the ship starts, but is situation-dependent.
11-I-4. Representation of causal knowledge. Each piece of causal knowl- edge is encoded while working on the task. Basically, the model always tries to find a causal relation between a sequence of applied mental control values and the internally represented shape of a resulting trajectory. The model memorizes the values, and updates the duration, of the present mcontrol until a different value is encoded. Also it keeps a record in memory of the shape of the present trajectory as long as the same pattern is generated. These two kinds of duration information are stored in memory, and related together to build a result represented as shown earlier in Figure 4, as soon as they match the following knowledge embedded in the model: if

COGNITIVE CONTROL 243
a sequence of mcontrols take the values right (straight, left), then the shape of the trajectory-generated by the sequence must be right (straight, left).
For example, if the values of mcontrols are all right from the time 1 to 5 and then the value is changed to another, and if the shape of the trajectory is right from the time 3 to 7 and then changed to another value, the model relates the two kinds of information, and generates a result in which the control value is right, the duration is 5, the trajectory shape is right, and the cause-effect time lag is 2.
l7-2. Representation of productions. Generally, the procedures represented by productions can be classified functionally into three groups; physical transformation of the ship’s motion; lower-level perceptual, motor, and normal cognitive processing; and higher-level complex cognitive function- ing.
11-2-l. Transformation of physical states. The operator’s cognitive system for manual control is supposed to be related to the physical system through the human-machine interface. The physical side of the total system is represented in the model as a set of productions. For example, one of the productions for physical transformation is represented as:
If the present pstate is given and if the value of pconfrol is provided,
Then recompute the psrafe by applying pcontrol and delete the present pcontrol from memory.
The above production involves computing the set of differential equa- tions for the ship’s behavior, but is not concerned with mental processes of the operator. In this respect, the mental and physical systems are separated in the model, and are interrelated only via the encoding mechanism dis- cussed below.
11-2-2. Lower-levelprocedures. A physical state must be perceptually encoded in memory for any mental processing. Lower-level procedures organize and use the encoded information in forms effecive for their func- tioning.
II-2-2-l. Encoding physical to mental states and operators. For exam- ple, onepstate includes only one-point information for the present time, but perception of the shape of a trajectory needs more information about the past location of the ship. Thus, the perceptual procedure for encoding the present mstate calls for the past pstate information. A representative pro- cedure can be stated as:
If the present and the past psfates are given and if the next pgate is also given,

244 ANZAI
Then create the present mstate by computing values of attributes for the mstote using basic procedures.
Encoding mstates for mental gates is performed by similar procedures. An mcontrol can be encoded either by the lower-level or upper-level-
procedures. Here we are concerned with the former. The latter is described later. It is assumed that, whenever an mstate is to be encoded, the model tries to perceive the difference between the ship’s direction to the next gate and the present direction. This is one of the basic perceptual procedures embedded in the model, and, using the results of this perception, automatic decision for the values of mcontrols is made simply by executing the follow- ing procedure:
If there is in memory the present mslote, in which the value of “diff-angle”, i.e., the difference between the direction to the next gate and the ship’s own direction, is <po.sibve,zero,negalive> ,
Then encode mcontrol with the value < righl,straight,lefr> into memory.
For example, if the direction to the next gate is north-west, but if the ship’s present direction is north-east, then the model generates the value of left for the next mcontrof when no intervention of the upper-level procedures occurs. The upper-level system is able to consider more complex patterns of mcontrofs for the future, as will be described later.
Also, we assume that possible values for mcontrofs are restricted to three levels, right, straight, and left. This assumption is based on the obser- vations that novice subjects for the task appear to use only about three levels of control values. Control of experienced subjects is usually more elaborate, and permits no less than five levels.
II-2-2-2. Decoding mental to physical states and operators. Once the mstate (and the mcontrol to be applied to it) is encoded in memory, the model is ready to convert the value of mcontrol to one for pcontrol, which is to be applied directly to the ship to make a physical transformation. The conversion is made by a few productions. An important side-effect of those productions is to initiate record-keeping for the sequence of applied mcon- trols for generation of a result in which the causal relation between the pres- ent mcontrol and the shape of the future trajectory will be represented. An example of the production is this:
If the present mstate is in memory and if there also is in memory the mcontrol to be
applied but if recording of the sequence of mcontrols is not yet
initiated for the present mcontrol,

COGNITIVE CONTROL 245
Then decode the present mcontrol to generate a pcontrol and initiate recording of the sequence of mconlrols.
11-2-3. Higher-level procedures. The higher-level procedures in the model are responsible for the following four processes: acquisition of causal knowledge, evaluation of problem states and generation of actions deter- mined by the evaluation, creating procedures for avoiding bad actions, and creating procedures for generating subgoals.
11-2-3-Z. Acquisition of causal knowledge. The collection of informa- on for generating a result, e.g., the piece of causal knowledge shown earlier in Figure 4, needs a sequence of mcontrols and a corresponding trajectory pattern. A set of productions, including the control-interface procedure mentioned above, is responsible for the collection. They work on recording an mcontrol sequence (the cause), recording the shape of a trajectory (the effect), updating the information sequences for the cause and the effect, and coupling them into a result. The following is a production for creating a result:
If there is in memory a sequence of past mcontrols of the same value
and if there is also in memory a sequence of past mstafes of the same value for the attribute “shape”
and if the values for the mcontrols and the mstates match and if the sequence of mslafes started after, and ended after,
the sequence of mcontrols,
Then construct a result in memory from the information in the sequences of mcontrols and msfafes by using basic procedures
and delete the two sequences from memory.
The model stores a result, possibly in a slightly generalized form. When two different results share the same initial distance to the next gate, rotational direction to the gate, difference between the direction to the gate and the ship’s direction, initial shape of the trajectory, and value of control, then the values of the other attributes for those two results are averaged, and the new result with averaged values is stored into memory. The old two results are eliminated at this time. This generalization is performed by a procedure represented as a production.
11-2-3-2. Complex evaluation of the present situation. The simplest procedure for evaluating the present state and generating a new mcontrol was described earlier. There, the result of the evaluation was the difference between the goal and present directions, and a corresponding action was im- mediately generated from the evaluation. However, the evaluation can be more complex, and may lead to more complex types of decision on mcon- trols .

246 ANZAI
One such case may arise when the model compares not two directions, but two differences of directions. The first difference is the one between the direction to the next gate and the present direction. The second is the differ- ence between a possible future direction and the present one of the ship. A future direction of the ship may be determined if a result whose initial state matches the present mental state is stored at present in memory. With such a result, the operator can internally extrapolate the ship’s direction under the action specified in the result, and can predict the end state. That end-state information includes a possible future direction of the ship. The procedure for evaluating the difference between the two differences of directions looks like the following:
If the present msfote is in memory and if there also is in memory a result
whose initial state matches the msfafe,
Then evaluate the difference between (a) the difference of the direction to the next gate and the ship’s direction, and (b) the difference of the ship’s future direction specified by the end state of the resulf and the ship’s present direction.
The result of the evaluation is either small, medium, or large. If the result is small, the mcontrol recommended in the result in the condition side of the above production can be encoded directly. If it is medium or large, the model modifies the mcontrol provided by the result to encode mcon- trols. For instance, if the difference between the goal and the present direc- tion is approximately half of the difference between the future direction specified in the result and the present direction, then the mcontrol retrieved from the result may be applied for half of the time duration specified in the result.
11-2-3-3. Generating the locating and canceling strategies. Experi- enced pilots may know elaborate procedures for modification of predicted actions. In the simulation model, there exist productions which, based on the evaluation of the difference of future and present mental states, create new productions for preventing erroneous actions. In these productions, the mcontrol for some future duration is computed in a way similar to the above example. However, to compensate for predicted errors in future tra- jectories, the mcontrol of the value opposite to the one just computed, or neutral (i.e., straight), is appended to the computed sequence of the mcon- trols. If the result of the evaluation is large, the opposite value is taken. If it is medium, the neutral value is employed. For example, if the difference be- tween the present and future directions and the difference between the goal and present directions are both positive, and if the former difference is about two-thirds of the latter, then the planned sequence of the mcontrols is such that the control values will be right for the initial two-thirds of the in-

COGNITIVE CONTROL 247
tended duration, and left or straight (depending on the result of the evalua- tion) for the latter one-third of the duration.
As soon as production-generating actions are executed, newly built productions are placed in the original production set, and become usable. This procedure-generating process does not simulate the details of the proc- ess of learning new procedures, but simulates the gross, stagewise develop- ment of strategies for the manual control task, as exemplified in the next section. An example of the production-generating productions for the locat- ing strategy is shown below:
If the present msfufe is in memory and if there is in memory a resulf whose initial state
matches the mstate and if the evaluated result of the difference between the two
directional differences is /urge,
Then build a production of the form:
If an msfate is in memory and if there is in memory a result whose initial
state matches the mstate,
Then evaluate the difference between the two directional differences,
and build a production of the form:
If an msfate is in memory and if there is in memory a result whose initial
state matches the mstate and if the evaluated error for the difference between the
two directional differences is lurge
Then set the value of future mcontrol to the one recommended in the result, and compute its “duration” by basic procedures and extend the duration to the intended length
by appending mcontrols of the opposite value and deposit into memory the sequence of the future
mcontrol values.
The procedures briefly described above are ones for coping with late locating and overshooting actions made frequently by novices. The newly generated procedures constitute the locating and canceling strategies ob- served in the experiments.
U-2-3-4. Complex evaluation of the present situation related to sub- goals. The model includes another set of productions for evaluation and production generation. Those productions identify erroneous actions of go- ing through a gate in a wrong direction, i.e., a direction very different from the direction to the next target gate. The evaluation of the ship’s direction in this case is performed when the mstate is updated after passing through a

248 ANZAI
gate, and is simply a comparison between the ship’s direction to the updated next gate and its present direction. The following is a production for the evaluation:
If the ship succeeded in passing through a pgare and if the next pgafe exists and if the present msfate is in memory.
Then evaluate the difference between the ship’s direction to the next pgafe and the present direction given in the mstute.
11-2-3-j. Generating the subgoal strategy. When the difference of the two directions is found to be large, the model tries to create productions for generating subgoals. A subgoal is a mental gate, generated by those new productions with the help of causal knowledge. This time, the desired direc- tion for entering the next physical gate and the trajectory pattern desired at that gate are computed initially and matched against the end state of a result in memory. If a matchable result exists, its initial state is retrieved and con- verted to an mgate and its associated goal. Since the state information in a result does not include the numerical coordinates of the state, generation of a new mental gate calls for relatively complex computation. Then, the pro- cedure is used recursively, by regarding a generated mental gate as the original gate, to create a sequence of mental gates. Although the recursive generation of new gates can be continued as long as relevant causal knowl- edge can be retrieved, the number of mental gates generated at one time is limited to three in the present version of the program.
To create subgoals recursively, there must be a production for generat- ing the first subgoal, and another production for recursive construction of other subgoals. The first subgoal, i.e., a mental gate located nearest to the target physical gate, is created such that its location is close to and prior to the physical gate, and its direction is toward the physical gate next to the target one. The second subgoal is generated by matching this first subgoal with the end state of a result, and identifying its initial state with the second subgoal. Here is an example of productions that build productions for gen- erating these subgoals:
If the result of evaluation for the difference between the goal and the present directions after passing through a pgute is large
and if the next pgufe exists and if the present mstute is in memory,
Then build a production of the form:
If two consecutive pgutes, pgutel and pgute2, exist and if the present msfufe is in memory

COGNITIVE CONTROL 249
but if no goal is created in memory for pgatel, the current target physical gate,
Then generate a goal by computing values for the attributes by basic procedures, using the information in the two pgates, pgafel and pgate2, and the mstate,
and build a production of the form:
If a goal is in memory and if there is in memory a result whose end state
matches the goal and if there are two consecutive pgates and if the present msfate is in memory,
Then generate another goal by computing the values of the attributes by basic procedures, using the information in the existing goal, the result, the mstate, and the two pgates.
Note that, as shown in the above production-generating productions, the procedures for a new strategy are embedded themselves in the action side of a production-generating production, and no sophisticated procedure learning mechanism is involved.
I do not claim that the mode1 is a mode1 of the detailed learning proc- ess. Rather, it is a simulator of the stagewise development of new strategies. However, although the model simulates only the gross feature of the stage- wise development of strategies, it captures some facts from the empirical observations. In particular, the model, by accumulation of results as causal knowledge and by working on them using a number of genera1 heuristics, develops new strategies fairly quickly. This reflects the fact that the rate of initial cognitive learning is pretty fast for our task: the understanding process specified as the process for acquiring causal knowledge, i.e., state transition rules, plays a decisive role in the strategy development. Also, the stagewise development of strategies by the mode1 fits well the theory of learning by doing of Anzai and Simon (1979): the locating and canceling strategies must be created first by detection of serious errors in actions, which enables the ship to go along better routes, and leads to acquisition of the subgoal strategy.
In the next section, I provide a brief example of the simulation results.
SIMULATION
The purpose of the simulation was to test whether the mode1 generates a process of strategy development similar to the one observed empirically. I describe an example result of the simulation, in which the same gate con-

250 ANZAI
figuration as in Figure 1 was used, except that the final gate 5 was eliminated in the simulation. The elimination was made in order to save computation time, and does not seem to affect the qualitative results of the simulation.
In the simulation, six trials were run successively, each using the pro- ductions and causal knowledge acquired in the past trials. It was assumed that control was limited to a few discrete levels. Because novices seemed to use only about three levels of control, while experienced subjects seemed to use more levels, the mode was limited to three levels in the first three trials and to five in the latter three.
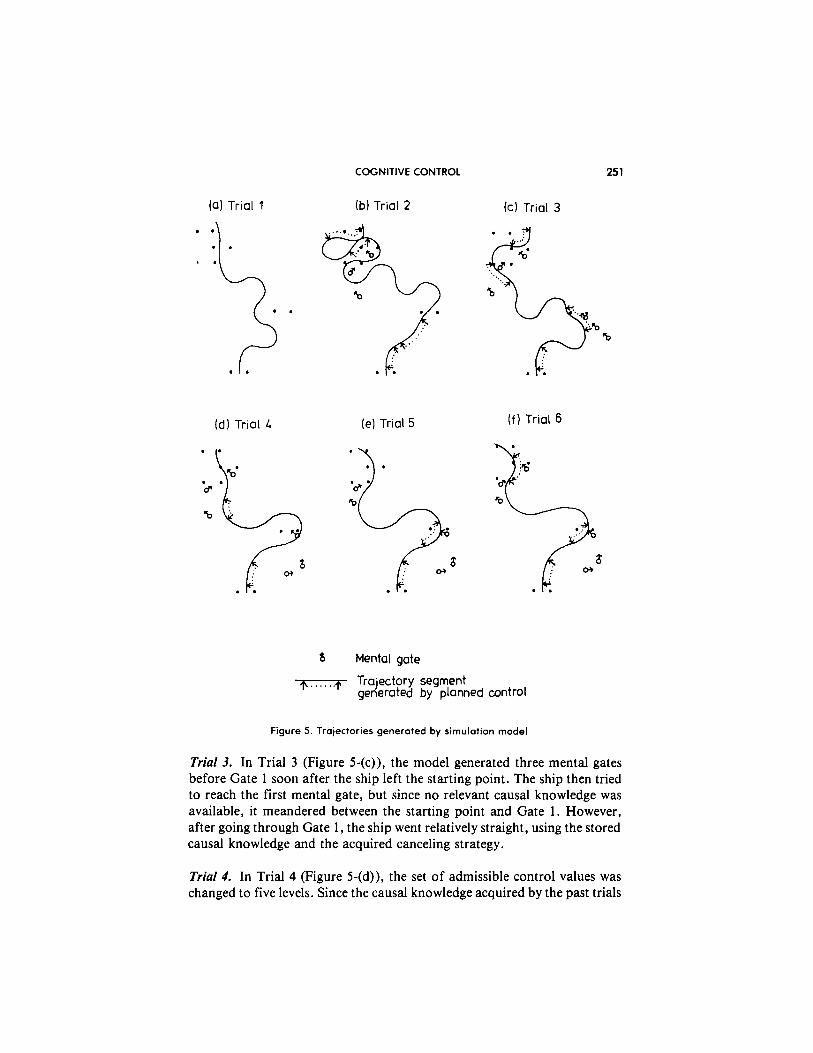
Figure 5 shows the results of trajectories generated by the model for the six trials. The dotted lines bound by small arrows indicate the places where the model used planned actions. That is, the model found that a state similar to the present state had been encountered before, and that some piece of causal knowledge could be used there, and so it generated a suitable sequence of control values to be applied in future.
Each small circle with an arrow in Figure 5 indicates the location of a mental gate and the desirable direction at the gate generated by the model while steering the ship. A mental gate could be created as a subgoal when the subgoal strategy was already available, and there resided in memory a piece of causal knowledge whose initial state matched the mental gate, and the end state matched the upcoming physical gate or another mental gate already generated as a subgoal. Each mental gate was used as an intermedi- ate destination of the ship, but was deleted from memory when the ship went past its neighborhood, or went across the y-coordinate of that gate.
Trial I. The trajectory generated in Trial 1, shown in Figure 5-(a), was more curved between the starting point and Gate 1 than in later trials. The model was somewhat better than the initial trials by humans (such as in Figures 2 and 3), probably because the model had better perceptual-motor skills for simple error detection and control decisions.
Trial 2. In the trajectory for Trial 2 (Figure 5-(b)), the curves between the starting gate and Gate 1 were mostly eliminated, because the causal knowl- edge acquired during Trial 1 was utilized successfully for predicting the ship’s future states. The model developed the locating and canceling strate- gies based on this ability for prediction, and used them to go straight toward Gate 1 and to pass straight through. But when the ship passed Gate 1, it was going in the wrong direction: it should have moved toward Gate 2 when it went though Gate 1. The recognition of this error led the model to create a subgoal strategy for generating mental gates, which produced two mental gates located below Gate 2. The ship tried to reach the first mental gate without succeeding in doing so, and the remaining trajectory for Trial 2 went disasterously.
(a1 Trial 1
IdI Trial 4
COGNITIVE CONTROL
(b) Trial 2
(e) Trial 5
(c) Trial 3
(f) Trial 6
8 Mental gate
-n Trajectory segment generated by planned control
Figure 5. Trajectories generated by simulation model
Trial .?. In Trial 3 (Figure 5-(c)), the model generated three mental gates before Gate 1 soon after the ship left the starting point. The ship then tried to reach the first mental gate, but since no relevant causal knowledge was available, it meandered between the starting point and Gate 1. However, after going through Gate 1, the ship went relatively straight, using the stored causal knowledge and the acquired canceling strategy.
Trial 4. In Trial 4 (Figure 5-(d)), the set of admissible control values was changed to five levels. Since the causal knowledge acquired by the past trials

252 ANZAI
was for control with three levels of values, it did not fit well the five-level control. As a result, the ship failed to go through Gates 1 and 2.
Trials 5 and 6. The ship’s behavior became much better in Trial 5 (Figure 5-(e)), because relevant causal knowledge was learned in Trial 4. Then, in Trial 6, the ship succeeded in going through all the four gates (Figure 5-(f)).
The result of the simulation shows that the model developed new strat- egies based on the relevant causal knowledge accumulated while working on the task. In the process of strategy development, the model first generated the locating strategy for determining a good decision point to make a future turn, then developed the canceling strategy for going straight by canceling the past control history, and finally acquired the subgoal strategy for creat- ing and using mental gates, all utilizing the acquired causal knowledge.
CONCLUDING REMARKS
Research on manual control of real-time, event-driven systems has a long tradition in psychology, control theory and human engineering. However, detailed analysis of the cognitive process involved in it has been largely neglected. One major reason for this is that manual control research has been dominated by work on rapid motor tasks such as tracking control of rapidly moving objects, where perceptual-motor mechanisms have been considered more important than cognitive functions. As a result, in an enor- mous literature, not much work can be found concerned with the cognitive process in control of real-time, event-driven systems.
The work presented here, by using a slowly responding system as a task environment, enabled us to analyze some cognitive aspects in controlling such systems. The major results were (1) the finding of the strategy develop- ment process, which starts with trying to understand human-machine inter- action and represent causal knowledge in memory, then gets concerned with the generation of locating and canceling strategies that use local informa- tion, and then with the development of the subgoal strategy that utilizes information from more global perception; and (2) the proposal of an infor- mation-processing explanation and computational model of the process.
Broadbent, in his F. C. Bartlett lecture, asserted in the context of motor control research the necessity of study of multi-level adaptive systems (Broadbent, 1977). He correctly pointed out that internal modification of structure is an indispensable concept in modelling motor control processes: internal modification of structure means that the model itself includes the competence of self-modification.
Adaptive models such as proposed by Broadbent are still scarce in psychology-oriented studies, although they have been a part of control

COGNITIVE CONTROL 253
theory for some time (e.g., Young, 1969). It is necessary for constructing adaptive models to unify the two-level architecture and the competent mechanisms for generating new procedures, since only a little information fed to the perceptual-motor system may trigger the cognitive system, which then may evoke the mechanism of generating new procedures. Such models may contain in them the plausible hypothesis that the operator’s mecha- nisms for strategy development are very sensitive to perceptual and motor information meaningful for him or her: for example, information like a subtle change of the ship’s direction might evoke mechanisms for knowl- edge acquisition. Productions in our model can be divided functionally into the higher and lower levels. In the model, not only does the higher level process control the lower, but the lower level triggers processing of the higher level. This mechanism incorporates the operator’s sensitivity to his or her semantic context into the model.
As shown in this paper, we need a rich representation scheme includ- ing symbolic representations for modelling the operator’s complex internal representation and mechanisms for generating it. The work presented here is one of the first attempts to consider the human operator in control of real- time, event-driven systems as a symbolic information-processing system. With the development of cognitive psychology and artificial intelligence, we already have in hand a basis for bridging gaps lying between the symbolic information-processing and the cybernetic approaches. There are already some efforts in the direction of eliminating the gaps from the side of engi- neering (e.g., Johannsen & Rouse, 1979). There are many issues in this new field, one of which is the development of cognitive strategies treated in this paper, that can be attacked from the side of cognitive science.
REFERENCES
Anzai, Y., & Simon, H. A. (1979). The theory of learning by doing. Psychological Review, 86,
124-140. Broadbent, D. E. (1977). Levels, hierarchies, and the locus of control. Quarferly Journal of
Experimental Psychology, 29, 181-201. Conklin, J. E. (1957). Effect of control lag on performance in a tracking task. Journul of&-
perimental Psychology, 53, 261-268.
tinges, E. (1978). A two-level model of driver steering behavior. Humun Fuctors, 20, 691-707. Forgy, C. L. (1981). OPSS User’s Manual. Report No. CMU-CS-81-135, Pittsburgh, PA:
Department of Computer Science, Carnegie-Mellon University. Goldstein, D. A., & Newton, J. M. (1962). Transfer of training as a function of task difficulty
in a complex control situation. Journal of Experimentul Psychology, 63. 370-375. Hayes, J. R.. & Simon, H. A. (1974). Understanding written problem instructions. In L. W.
Gregg (Ed.), Knowledge unnd cognition, Potomac, MD: Erlbaum. Jagacinski, R. J., &Miller, R. A. (1978). Describing the human operator’s internal model of a
dynamic system. Human Factors, 20, 425-433.
Johannsen. G.. & Rouse, W. B. (1979). Mathematical concepts for modeling human behavior

254 ANZAI
in complex man-machine systems. Human Factors, 21, 733-747. Kleinman, D. L.. Baron, S.. & Levinson, W. H. (1971). A control theoretic approach to
manned-vehicle system analysis. IEEE Transactions on Automatic Control, AC-16,
824-832. Kleinman, D. L., Pattipati, K. R., & Ephrath, A. R. (1980). Quantifying an internal model of
target motion in a manual tracking task. fEEE Transactions on Systems, Man and Cybernetics, SMC-IO, 624-636.
Sheridan, T. B.. & Johannsen, G. (1976). Monitoring behavior and supervisory control. New York: Plenum.
Tomizuka, M.. & Whitney, D. E. (1976). The human operator in manual preview tracking (an
experiment and its modeling via optimal control). Transactions oJASME, Journal of Dynamic Systems, Measurement. Control, 407-443.
Young, L. R. (1969). On adaptive manual control. Ergonomics, 12, 635-675.