cloudera apache kudu updatable analytical storage for modern data platform
TRANSCRIPT

1 © Cloudera, Inc. All rights reserved.
Apache Kudu Updatable Analytical Storage for Modern Data Platform
Sho Shimauchi | Sales Engineer | Cloudera

2 © Cloudera, Inc. All rights reserved.
Who Am I?
Sho Shimauchi Sales Engineer / Technical Evangelist Joined Cloudera in 2011
The First Employee in Cloudera APJ Email: [email protected] Twitter: @shiumachi

3 © Cloudera, Inc. All rights reserved.
• Founded in 2008
• 1600+ Clouderans
• Machine learning and analytics platform
• Shared data experience
• Cloud-native and cloud-differentiated
• Open-source innovation and efficiency

4 © Cloudera, Inc. All rights reserved.
Rakuten Card replaced Mainframe to Cloudera Enterprise in 2017 Apache Spark improved performance of the batch processes >2x Please join Cloudera World Tokyo 2017 to see Kobayashi-san’s Keynote!
www.clouderaworldtokyo.com
Rakuten Card + Cloudera

5 © Cloudera, Inc. All rights reserved.
Why Kudu? Use Cases and Motivation

6 © Cloudera, Inc. All rights reserved. 6
The modern platform for machine learning and analytics optimized for the cloud
EXTENSIBLE SERVICES
CORE SERVICES DATA
ENGINEERING OPERATIONAL
DATABASE ANALYTIC DATABASE
DATA CATALOG
INGEST & REPLICATION SECURITY GOVERNANCE WORKLOAD
MANAGEMENT
DATA SCIENCE
NEW OFFERINGS
Cloudera Enterprise
Amazon S3 Microsoft ADLS HDFS KUDU STORAGE SERVICES

7 © Cloudera, Inc. All rights reserved.
HDFS
Fast Scans, Analytics and Processing of
Stored Data
Fast On-Line Updates &
Data Serving
Arbitrary Storage (Active Archive)
Fast Analytics (on fast-changing or
frequently-updated data)
Unchanging
Fast Changing Frequent Updates
HBase
Append-Only
Real-Time
Kudu Kudu fills the Gap Modern analytic applications often require complex data flow & difficult integration
work to move data between HBase & HDFS
Analytic Gap
Pace of Analysis
Pace
of D
ata
Filling the Analytic Gap

8 © Cloudera, Inc. All rights reserved.
Apache Kudu: Scalable and fast structured storage
Scalable • Tested up to 300+ nodes (PBs cluster) • Designed to scale to 1000s of nodes and tens of PBs
Fast • Millions of read/write operations per second across cluster • Multiple GB/second read throughput per node
Tabular • Represents data in structured tables like a relational database
• Strict schema, finite column count, no BLOBs • Individual record-level access to 100+ billion row tables

9 © Cloudera, Inc. All rights reserved.
Apache Kudu Community

10 © Cloudera, Inc. All rights reserved.
Can you insert time series data in real time? How long does it take to prepare it for analysis? Can you get results and act fast enough to change outcomes?
Can you handle large volumes of machine-generated data? Do you have the tools to identify problems or threats? Can your system do machine learning?
How fast can you add data to your data store? Are you trading off the ability to do broad analytics for the ability to make updates? Are you retaining only part of your data?
Time Series Data Machine Data Analytics Online Reporting
Why Kudu?

11 © Cloudera, Inc. All rights reserved.
Cheaper and faster every year. Persistent memory (3D XPoint™) Kudu can take advantage of SSD and NVM using Intel’s NVM Library.
RAM is cheaper and bigger every day. Kudu runs smoothly with huge RAM. Written in C++ to avoid GC issues.
Modern CPUs are adding cores and SIMD width, not GHz. Kudu takes advantage of SIMD instructions and concurrent data structures.
Next generation hardware
Solid-state Storage Cheaper, Bigger Memory Efficiency on Modern CPUs

12 © Cloudera, Inc. All rights reserved.
How it Works Replication And Fault Tolerance

13 © Cloudera, Inc. All rights reserved.
Tables, tablets, and tablet servers • Each table is horizontally partitioned into tablets
• Range or hash partitioning • PRIMARY KEY (host, metric, timestamp) DISTRIBUTE BY
HASH(timestamp) INTO 100 BUCKETS • Each tablet has N replicas (3 or 5) with Raft consensus
• Automatic fault tolerance • MTTR (mean time to repair): ~5 seconds
• Tablet servers host tablets on local disk drives • Master services metadata operations
• Create/drop tables and tablets • Locate tablets

14 © Cloudera, Inc. All rights reserved.
Metadata Replicated master
Acts as a tablet directory Acts as a catalog (which tables exist, etc) Acts as a load balancer (tracks TS liveness, re-replicates under-replicated tablets)
Caches all metadata in RAM for high performance Client configured with master addresses
Asks master for tablet locations as needed and caches them

15 © Cloudera, Inc. All rights reserved.
Client
Hey Master! Where is the row for ‘tlipcon’ in table “T”?
It’s part of tablet 2, which is on servers {Z,Y,X}. BTW, here’s info on other tablets you might care about: T1, T2, T3, …
UPDATE tlipcon SET col=foo
Meta Cache T1: … T2: … T3: …

16 © Cloudera, Inc. All rights reserved.
Raft consensus
TS A
Tablet 1 (LEADER)
Client
TS B
Tablet 1 (FOLLOWER)
TS C
Tablet 1 (FOLLOWER)
WAL
WAL WAL
2b. Leader writes local WAL
1a. Client->Leader: Write() RPC
2a. Leader->Followers: UpdateConsensus() RPC
3. Follower: write WAL
4. Follower->Leader: success
3. Follower: write WAL
5. Leader has achieved majority
6. Leader->Client: Success!

17 © Cloudera, Inc. All rights reserved.
How it Works Columnar Storage

18 © Cloudera, Inc. All rights reserved.
Row Storage
Scans have to read all the data, no encodings
{23059873, newsycbot, 1442865158, Visual exp…} {22309487, RideImpala, 1442828307, Introducing …} …
Tweet_id, user_name, created_at, text

19 © Cloudera, Inc. All rights reserved.
{25059873, 22309487, 23059861, 23010982}
Tweet_id
{newsycbot, RideImpala, fastly, llvmorg}
User_name
{1442865158, 1442828307, 1442865156, 1442865155}
Created_at
{Visual exp…, Introducing .., Missing July…, LLVM 3.7….}
text
Columnar Storage

20 © Cloudera, Inc. All rights reserved.
SELECT COUNT(*) FROM tweets WHERE user_name = ‘newsycbot’;
{25059873, 22309487, 23059861, 23010982}
Tweet_id
1GB
{newsycbot, RideImpala, fastly, llvmorg}
User_name
Only read 1 column
2GB
{1442865158, 1442828307, 1442865156, 1442865155}
Created_at
1GB
{Visual exp…, Introducing .., Missing July…, LLVM 3.7….}
text
200GB
Columnar Storage

21 © Cloudera, Inc. All rights reserved.
{1442825158, 1442826100, 1442827994, 1442828527}
Created_at
Created_at Diff(created_at)
1442825158 n/a
1442826100 942
1442827994 1894
1442828527 533
64 bits each 11 bits each
Columnar Compression
Many columns can compress to a few bits per row! Especially:
Timestamps Time series values Low-cardinality strings
Massive space savings and throughput increase!

22 © Cloudera, Inc. All rights reserved.
How it Works Write and Read Paths

23 © Cloudera, Inc. All rights reserved.
LSM vs Kudu LSM – Log Structured Merge (Cassandra, HBase, etc)
Inserts and updates all go to an in-memory map (MemStore) and later flush to on-disk files (HFile/SSTable)
Reads perform an on-the-fly merge of all on-disk HFiles Kudu
Shares some traits (memstores, compactions) More complex. Slower writes in exchange for faster reads (especially scans)

24 © Cloudera, Inc. All rights reserved.
LSM Insert Path
MemStore INSERT
Row=r1 col=c1 val=“blah” Row=r1 col=c2 val=“1”
HFile 1 Row=r1 col=c1 val=“blah” Row=r1 col=c2 val=“1”
flush

25 © Cloudera, Inc. All rights reserved.
LSM Insert Path
MemStore INSERT
Row=r1 col=c1 val=“blah2” Row=r1 col=c2 val=“2”
HFile 2 Row=r2 col=c1 val=“blah2” Row=r2 col=c2 val=“2”
flush
HFile 1 Row=r1 col=c1 val=“blah” Row=r1 col=c2 val=“1”

26 © Cloudera, Inc. All rights reserved.
LSM Update path
MemStore UPDATE
HFile 1 Row=r1 col=c1 val=“blah” Row=r1 col=c2 val=“2”
HFile 2 Row=r2 col=c1 val=“v2” Row=r2 col=c2 val=“5”
Row=r2 col=c1 val=“newval”
Note: all updates are “fully decoupled” from reads. Random-write workload is transformed to fully sequential!

27 © Cloudera, Inc. All rights reserved.
LSM Read path
MemStore
HFile 1 Row=r1 col=c1 val=“blah” Row=r1 col=c2 val=“2”
HFile 2
Row=r2 col=c1 val=“v2” Row=r2 col=c2 val=“5”
Row=r2 col=c1 val=“newval”
Merge based on string row keys
R1: c1=blah c2=2 R2: c1=newval c2=5 ….
CPU intensive!
Must always read rowkeys
Any given row may exist across multiple HFiles: must
always merge!
The more HFiles to merge, the slower it reads

28 © Cloudera, Inc. All rights reserved.
Kudu storage – Inserts and Flushes MemRowSet
INSERT (“todd”, “$1000”,”engineer”)
name pay role
DiskRowSet 1
flush

29 © Cloudera, Inc. All rights reserved.
Kudu storage – Inserts and Flushes MemRowSet
name pay role
DiskRowSet 1
name pay role
DiskRowSet 2
INSERT (“doug”, “$1B”, “Hadoop man”)
flush

30 © Cloudera, Inc. All rights reserved.
Kudu storage - Updates MemRowSet
name pay role
DiskRowSet 1
name pay role
DiskRowSet 2 Delta MS
Delta MS
Each DiskRowSet has its own DeltaMemStore to accumulate updates
base data
base data
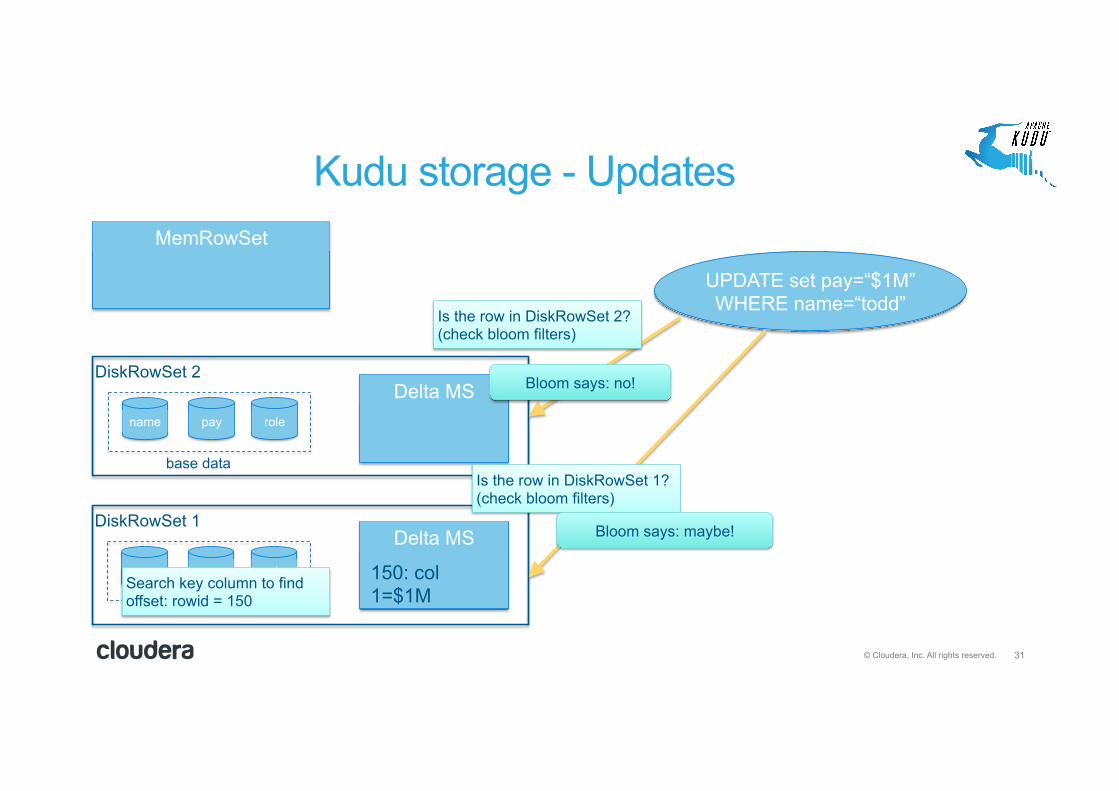
31 © Cloudera, Inc. All rights reserved.
Kudu storage - Updates MemRowSet
name pay role
DiskRowSet 1
name pay role
DiskRowSet 2 Delta MS
Delta MS
UPDATE set pay=“$1M” WHERE name=“todd”
Is the row in DiskRowSet 2? (check bloom filters)
Is the row in DiskRowSet 1? (check bloom filters)
Bloom says: no!
Bloom says: maybe!
Search key column to find offset: rowid = 150
150: col 1=$1M
base data

32 © Cloudera, Inc. All rights reserved.
Kudu storage – Read path MemRowSet
name pay role
DiskRowSet 1
name pay role
DiskRowSet 2 Delta MS
Delta MS 150: pay=$1M
Read rows in DiskRowSet 2
Then, read rows in DiskRowSet 1
Any row is only in exactly one DiskRowSet– no need to merge
cross-DRS!
Updates are merged based on ordinal offset within DRS: array indexing, no string compares
base data
base data

33 © Cloudera, Inc. All rights reserved.
Kudu storage – Delta flushes MemRowSet
name pay role
DiskRowSet 1
name pay role
DiskRowSet 2 Delta MS
Delta MS
0: pay=foo REDO DeltaFile Flush
A REDO delta indicates how to transform between the ‘base data’ (columnar) and a later
version
base data
base data

34 © Cloudera, Inc. All rights reserved.
Kudu storage – Major delta compaction
name pay role
DiskRowSet(pre-compaction) Delta MS
REDO DeltaFile REDO DeltaFile REDO DeltaFile
Many deltas accumulate: lots of delta application work on reads
name pay role
DiskRowSet(post-compaction) Delta MS
Unmerged REDO deltas UNDO deltas
If a column has few updates, doesn’t need to be re-written: those deltas maintained in new DeltaFile
Merge updates for columns with high update percentage
base data

35 © Cloudera, Inc. All rights reserved.
Kudu storage – RowSet Compactions DRS 1 (32MB)
[PK=alice], [PK=joe], [PK=linda], [PK=zach]
DRS 2 (32MB) [PK=bob], [PK=jon], [PK=mary] [PK=zeke]
DRS 3 (32MB)
[PK=carl], [PK=julie], [PK=omar] [PK=zoe]
DRS 4 (32MB) DRS 5 (32MB) DRS 6 (32MB) [alice, bob, carl, joe] [jon, julie, linda, mary] [omar, zach, zeke, zoe]
Reorganize rows to avoid rowsets with overlapping key ranges
Writes for “chris” have to perform bloom lookups on all 3 RS

36 © Cloudera, Inc. All rights reserved.
Kudu Storage - Compactions Main Idea: Always be compacting!
Compactions run continuously to prevent IO storms ”Budgeted” RS compactions: What is the best way to spend X MBs IO? Physical/Logical decoupling: different replicas run compactions at different times

37 © Cloudera, Inc. All rights reserved.
Conclusion

38 © Cloudera, Inc. All rights reserved.
Getting Started On the web: https://www.cloudera.com/documentation/kudu/latest.html, https://www.cloudera.com/downloads.html, https://blog.cloudera.com/?s=Kudu, kudu.apache.org • Apache project user mailing list: [email protected] • Quickstart VM
• Easiest way to get started • Impala and Kudu in an easy-to-install VM
• CSD and Parcels • For installation on a Cloudera Manager-managed cluster
Training classes available: https://www.cloudera.com/more/training.html

39 © Cloudera, Inc. All rights reserved.
Nov 7, 2017 Tue ANA Intercontinental Hotel
Estimated Attendees #: 1000
E-1: Apache Kudu on Analytical Data Platform
Register Now! www.clouderaworldtokyo.com
Cloudera World Tokyo 2017
