cloud computing, hadoop and mapreduce
TRANSCRIPT

Cloud Computing, Hadoop and MapReduce

The term ‘Cloud’ refers to a Network or Internet.
Cloud is something which is present at remote location.
Cloud Computing refers to manipulating, configuring and accessing the applications online.
It offers online data storage, infrastructure and applications.
Cloud Computing:

The following definition of cloud computing has been developed by the U.S. National Institute of Standards and Technology (NIST):
“Cloud computing is a model for enabling
convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This cloud model promotes availability and is composed of five essential characteristics, three service models, and four deployment models.”
Definition:

Cloud Architecture:

Deployment models define the type of access to the
cloud i.e, how the cloud is located.
Cloud can have any of the four types of access:
Public Cloud: It allows the systems and servces to be
easily accessible to the general public.
Private cloud: It allows the systems and servces to be
accessible within an organization.
Community Cloud: It allows the systems and servces to
be accessible by a group of organization.
Hybrid Cloud: Hybrid cloud is mixture of public and
private cloud.
Deployment Models:

Service models are the reference models on which
the cloud computing is based.
Three basic service models:-
Infrastructure as a Service(IaaS): IaaS provides
access to fundamental resources such as physical
machines, virtual machines, virtual storage.
Platform as a Service(PaaS): PaaS provides the
runtime environment for applications, dvelopment tools.
Software as a Service(SaaS): SaaS model allows to use
software applications as a service to end users.
Service Models:

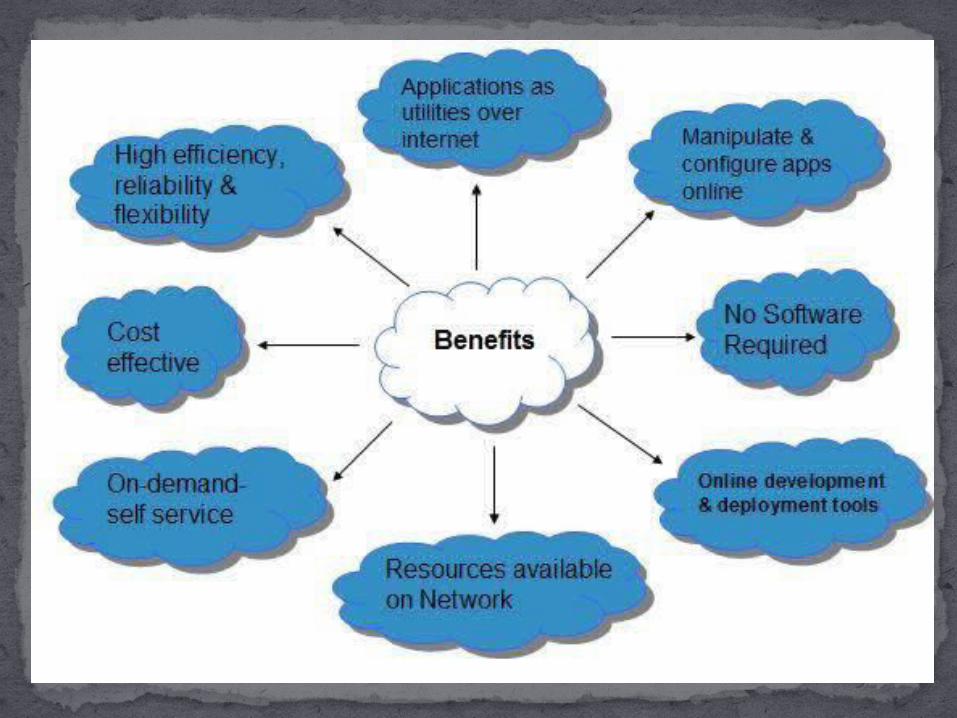
No Software Installation required
Online development and deployment tools
More Reliable and Scalable
More flexible and more secure
Cost effective
Easy maintainance
Offers high efficiency
Fast to get started
On demand self service.
Benefits of Cloud Computing:-

Hadoop is an open-source software framework.
It is used for storing and processing big data in a distributed fashion on large clusters of commodity hardware.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
It accomplishes two tasks: Massive data storage and Faster processing.
Hadoop:
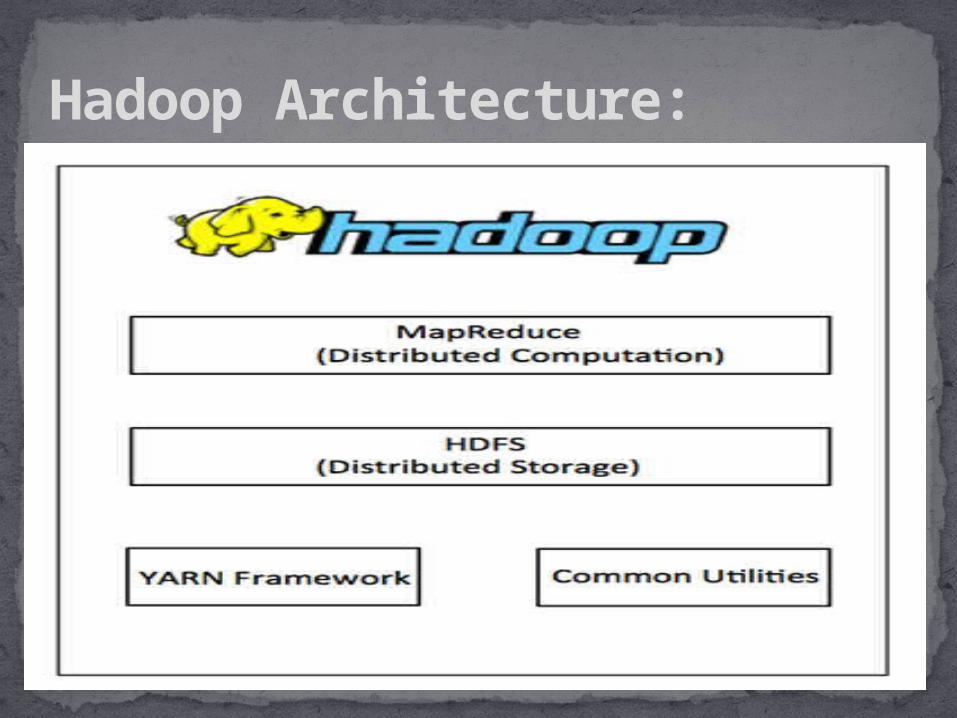
Hadoop Architecture:

MapReduce is a processing technique and a program model used by google for distributed computing based on java.
It is used for processing and generating large
data sets.
Two basic operations on the input: Map:
Accepts input key/value pairs.
Emits intermediate key/value pairs. Reduce:
Accepts intermediate key/value pairs.
Emits output key/value pairs.
MapReduce:
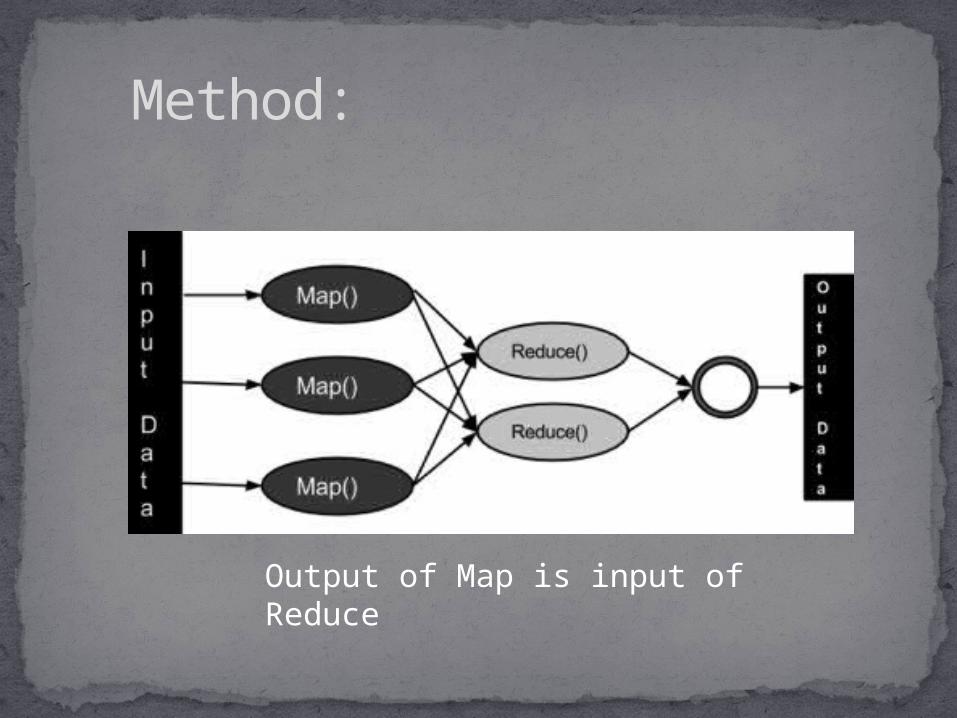
Method:
Output of Map is input of Reduce

The prototypical MapReduce example counts the appearance of each word in a set of documents:
function map(String name, String document):
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
sum=0;
for each pc in partialCounts:
sum += ParseInt(pc) ;
emit (word, sum)
A simple program: Wordcount

First create HDFS directory wordcount/input. hadoop fs -mkdir wordcount
hadoop fs -mkdir wordcount/input
Now create some files and we will count the number of words in the files:
echo "Data Science Class & Data Science HW" > file0
echo "Nice Class Nice Project & Nice program" > file1
Notice that the files are created in the Linux file system. We need to copy them to HDFS:
hadoop fs -put file* wordcount/input
Make sure that files are copied properly: hadoop fs -ls wordcount/input
Demonstration of wordcount problem

Now create a directory in Linux system where we will build the java archive:
mkdir wordcount_classes
Create the jar: jar -cvf wordcount.jar -C wordcount_classes/ .
Now run the application. The following command will create an output directory in HDFS:
hadoop jar wordcount.jar WordCount wordcount/input wordcount/output
Now check the output of the program. Notice a file named part-00000 is created in output directory:
hadoop fs -cat wordcount/output/part-00000

The expected output is: < Data 2>
< Science 2> < Nice 3> < Project 1> < program 1> < Class 2> < HW 1> < & 2>

Thank You !!
Submitted by:Pratik Jain