class project due at end of finals week essentially anything you want, so long as it’s ai related...
TRANSCRIPT

Class Project Due at end of finals week Essentially anything you want, so
long as it’s AI related and I approve Any programming language you
want In pairs or individual Email me by Wednesday,
November 3

Projects Implementing Knn to Classify Bedform Stability
Fields Blackjack Using Genetic Algorithms Computer game players:Go, Checkers, Connect
Four, Chess, Poker Computer puzzle solvers: Minesweeper, mazes Pac-Man with intelligent monsters Genetic algorithms:
blackjack strategy Automated 20-questions player Paper on planning Neural network spam filter Learning neural networks via GAs

Projects Solving neural networks via backprop Code decryptor using Gas Box pushing agent (competing against
an opponent)

What didn’t work as well Too complicated games: Risk, Yahtzee, Chess,
Scrabble, Battle Simulation Got too focused in making game work I sometimes had trouble running the game Game was often incomplete Didn’t have time to do enough AI
Problems that were too vague Simulated ant colonies / genetic algorithms Bugs swarming for heat (emergent intelligence never
happened) Finding paths through snow
AdaBoost on protein folding data Couldn’t get boosting working right, needed more time
on small datasets (spent lots of time parsing protein data)

Reinforcement Learning Game playing: So far, we have told
the agent the value of a given board position.
How can agent learn which positions are important? Play whole bunch of games, and
receive reward at end (+ or -) How to determine utility of states that
aren’t ending states?
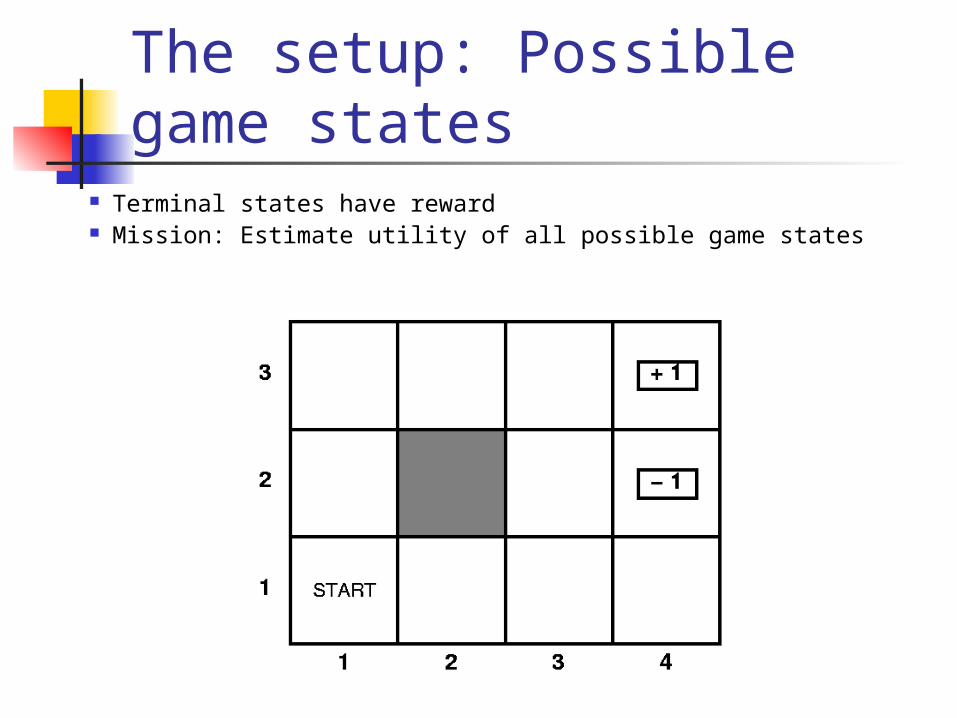
The setup: Possible game states
Terminal states have reward Mission: Estimate utility of all possible game states

What is a state? For chess: state is a combination of
position on board and location of opponents Half of your transitions are controlled
by you (your moves) Other half of your transitions are
probabilistic (depend on opponent) For now, we assume all moves are
probabilistic (probabilities unknown)
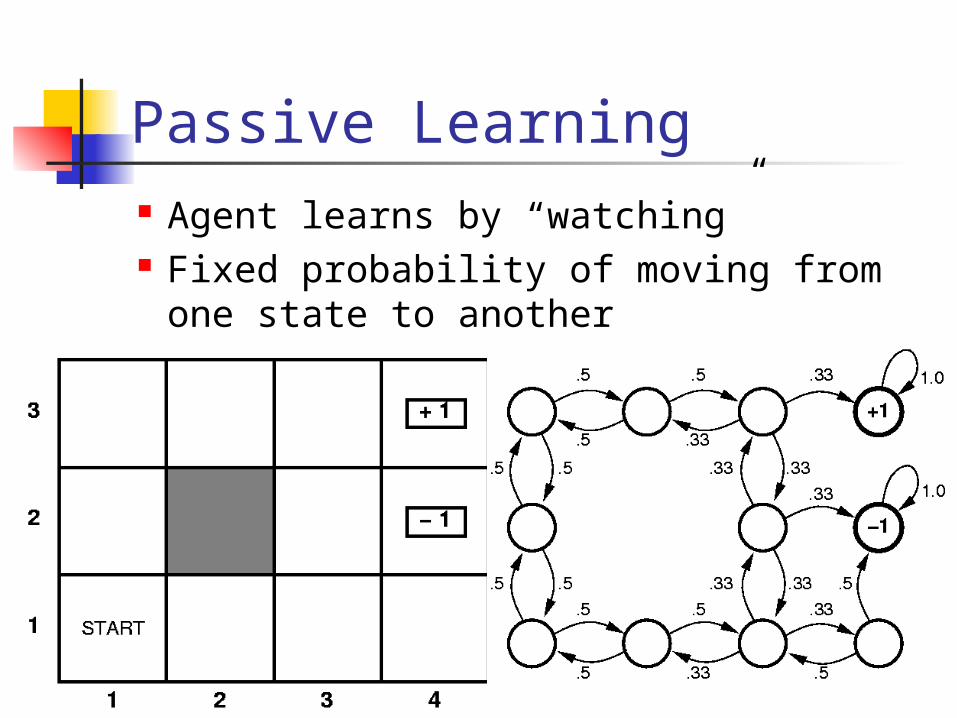
Passive Learning Agent learns by “watching” Fixed probability of moving from one
state to another
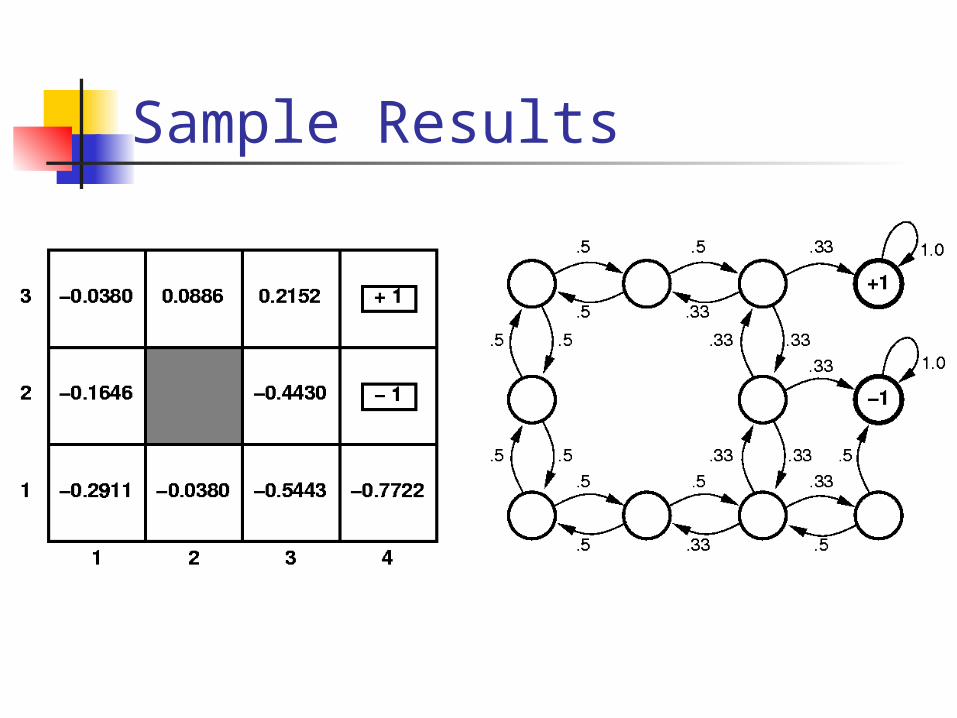
Sample Results

Technique #1: Naive Updating Also known as Least Mean Squares
(LMS) approach Starting at home, obtain sequence of
states to terminal state Utility of terminal state = reward loop back over all other states
utility for state i = running average of all rewards seen for state i

Naive Updating Analysis Works, but converges slowly
Must play lots of games Ignores that utility of a state
should depend on successor

Technique #2: Adaptive Dynamic Programming
Utility of a state depends entirely on the successor state If a state has one successor, utility
should be the same If a state has multiple successors,
utility should be expected value of successors
) to from transition(
)(
)terminal()terminal(
)(
jiPM
UMiU
rewardU
ij
isuccessorsjjij

Finding the utilities To find all utilities, just solve equations
Set of linear equations, solveable Changes each iteration as you learn
probabilities Completely intractable for large
problems: For a real game, it means finding actual
utilities of all states
)(
)(isuccessorsj
jijUMiU

Technique 3: Temporal Difference Learning
Want utility to depend on successors, but want to solve iteratively
Whenever you observe a transition from i to j:
))()(()()(
)terminal()terminal(
iUjUiUiU
rewardU
= learning rate difference between successive states =
temporal difference Converges faster than Naive updating

Active Learning Probability of going from one state
to another now depends on action ADP equations are now:
) to from transition(
max)(
)terminal()terminal(
)(
jiPM
UMiU
rewardU
ij
isuccessorsjj
aij
a

Active Learning Active Learning with Temporal Difference
Learning: works the same way (assuming you know where you’re going)
Also need to learn probabilities to eventually make decision on where to go
(terminal) (terminal)
( ) ( ) ( ( ) ( ))
U reward
U i U i U j U i

Exploration: where should agent go to learn utilities?
Suppose you’re trying to learn optimal game playing strategies Do you follow best utility, in order to win? Do you move around at random, hoping to
learn more (and losing lots in the process)? Following best utility all the time can get
you stuck at an imperfect solution Following random moves can lose a lot

Where should agent go to learn utilities?
f(u,n) = exploration function depends on utility of move (u), and number
of times that agent has tried it (n) One possibility: instead of using utility
to decide where to go, use
Try a move a bunch of times, then eventually settle
otherwiseu
Nnifnumberbignuf ),(

Q-learning Alternative approach for temporal
difference learning No need to learn probabilities:
considered more desirable sometimes Instead, looking for “quality” of (state,
action) pair
'
( , terminal) (terminal)
( , ) ( , ) (max ( ', ') ( , ))
where ' is the state that action a leads to from a
Q a reward
Q a s Q a s Q a s Q a s
s s

Generalization in Reinforcement Learning
Maintaining utilities for all seen states in a real game is intractable.
Instead, treat it as a supervised learning problem
Training set consists of (state, utility) pairs Or, alternatively, (state, action, q-value) triples
Learn to predict utility from state This is a regression problem, not a classification
problem Radial basis function neural networks (hidden nodes
are Gaussians instead of sigmoids) Support vector machines for regression Etc…

Other applications Applies to any situation where
something is to learn from reinforcement
Possible examples: Toy robot dogs Petz That darn paperclip “The only winning move is not to play”