clasificaciÓn y machine learning con … · david chris crisp 1 0 0 0 0 0.24 0.15 0.06 0.01 0.00...
TRANSCRIPT

JoséAntonioSanzUniversidadPúblicadeNavarraEVIA2016
Sistemasdeclasificaciónbasadosenreglasdifusas
CLASIFICACIÓNYMACHINELEARNINGCONTÉCNICASDIFUSAS

Problemadeclasificación[Duda01]
¨ Resolverunproblemadeclasificaciónconsisteenaprenderunaregladedecisiónquepermitadeterminarlaclasedeunnuevoobjetodentrodeunadelasexistentesyconocidas
D:X(E)àC
Alaregladedecisión,D,selellamaclasificadorydebeseróp^maenfuncióndeunciertocriterioquedeterminelacalidaddelclasificador
ElclasificadorDseaprendeu^lizadounconjuntodePejemplos,E={e1,…,eP},llamadoconjuntodeentrenamiento.
CadaunodeestosPejemplos,e,estádescritoporNvalores,unoporcadaatributo/variabledelsistema X(e)={e1,…,eN}
yestáe^quetadoconunadelasMclasesexistentes:C={C1,…,CM}[Duda01]RichardO.Duda,PeterE.Hart,DavidG.Stork,Pahernclassifica^on,Wiley,2001
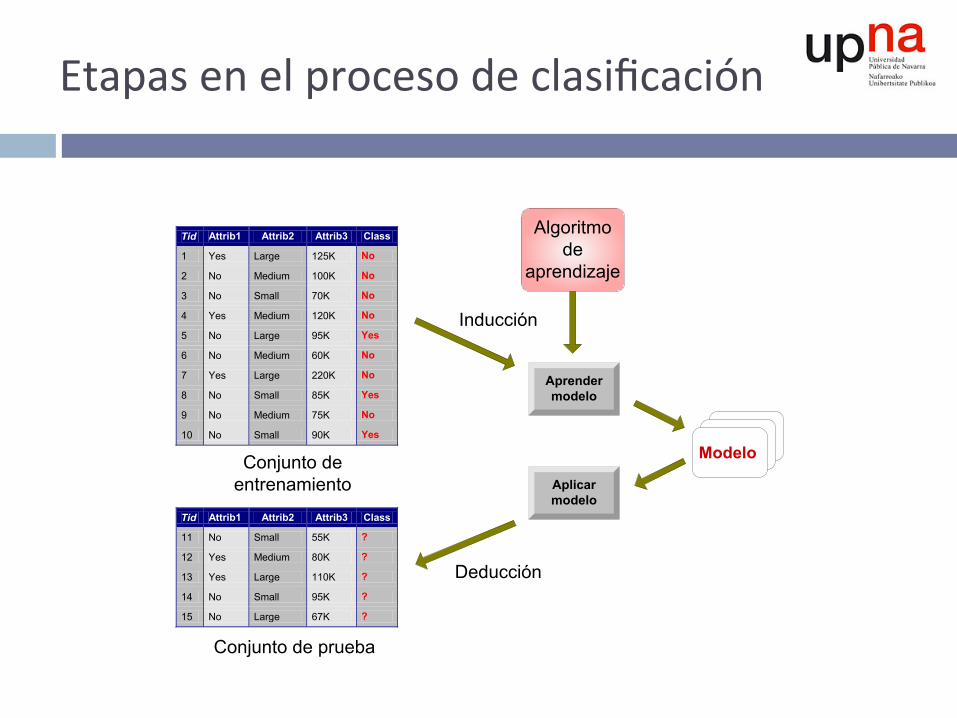
Etapasenelprocesodeclasificación
Inducción
Deducción
Modelo
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Conjunto de prueba
Algoritmo de
aprendizaje
Conjunto de entrenamiento
Aprendermodelo
Aplicarmodelo
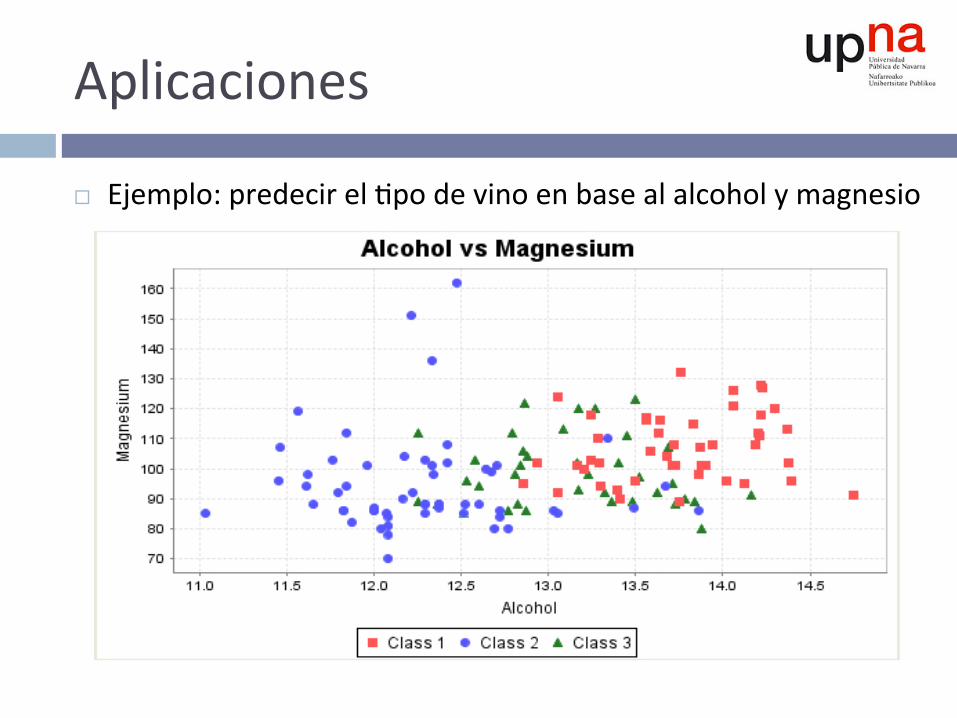
Aplicaciones
¨ Ejemplo:predecirel^podevinoenbasealalcoholymagnesio

Sistemasdeclasificaciónbasadosenreglas
¨ Aprendenunmodelobasadoenreglasu^lizandoelconjuntodeentrenamiento¤ Clasificadorcompuestoporunconjuntodereglas¤ Clasificannuevosejemplosbasándoseenelconocimientoaprendido
¨ Unaregladeclasificaciónestáformadapor¤ Antecedente:con^eneunpredicadoqueseevaluarácomoverdaderoo
falsoconrespectoacadaejemplo¤ Consecuente:con^eneunae^quetadeclase
SIgastos>30.000Yingresos<20.000ENTONCESConcederpréstamo=NO
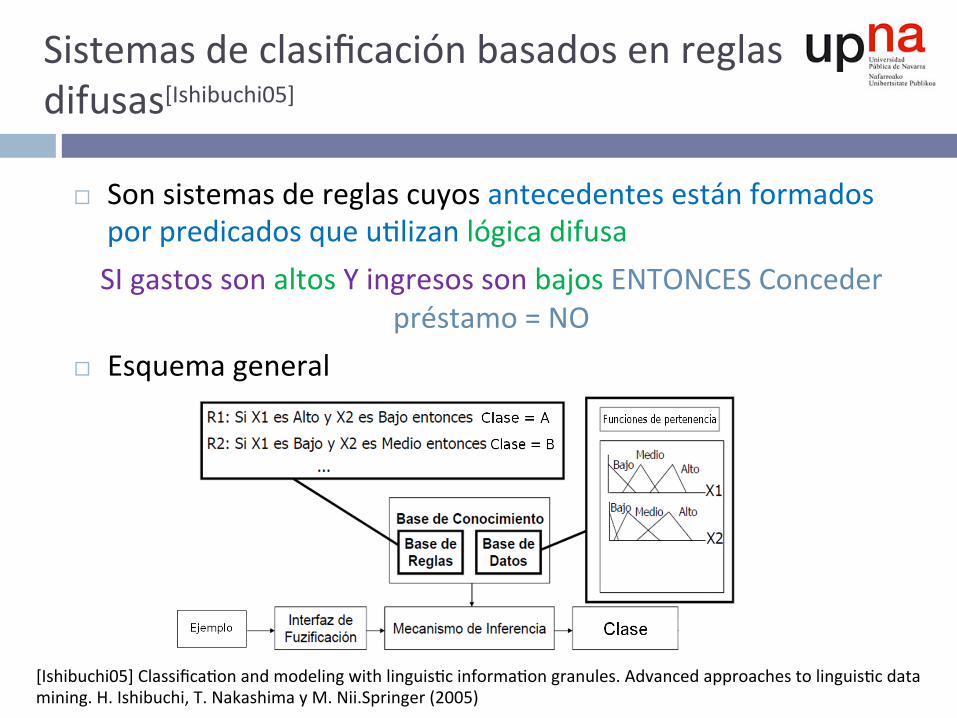
Sistemasdeclasificaciónbasadosenreglasdifusas[Ishibuchi05]
¨ Sonsistemasdereglascuyosantecedentesestánformadosporpredicadosqueu^lizanlógicadifusaSIgastossonaltosYingresossonbajosENTONCESConceder
préstamo=NO¨ Esquemageneral
[Ishibuchi05]Classifica^onandmodelingwithlinguis^cinforma^ongranules.Advancedapproachestolinguis^cdatamining.H.Ishibuchi,T.NakashimayM.Nii.Springer(2005)
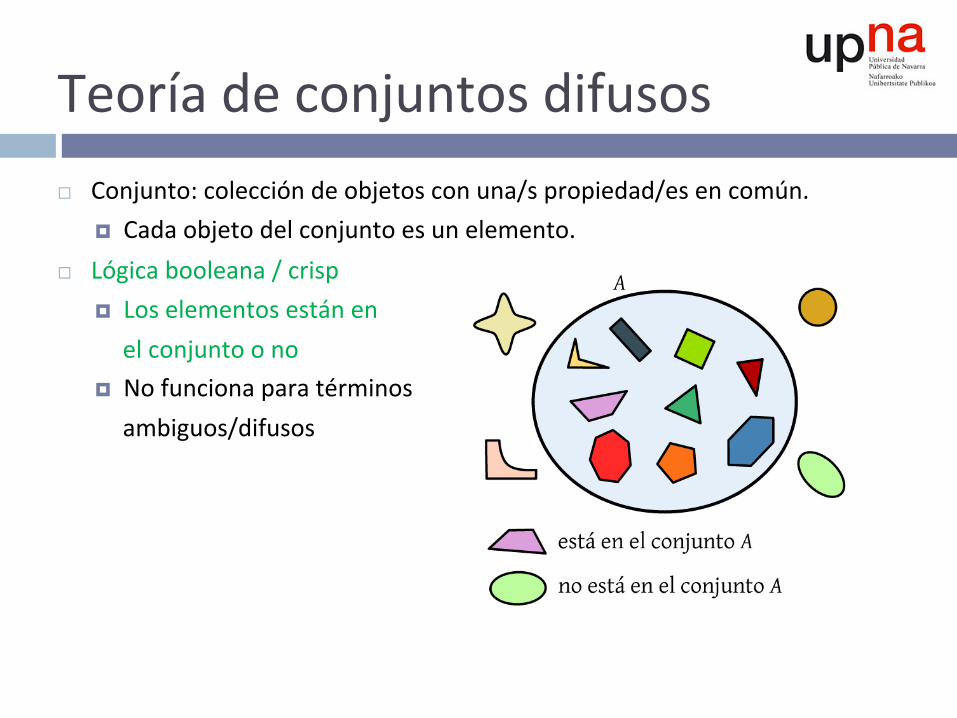
Teoríadeconjuntosdifusos¨ Conjunto:coleccióndeobjetosconuna/spropiedad/esencomún.
¤ Cadaobjetodelconjuntoesunelemento.¨ Lógicabooleana/crisp
¤ Loselementosestánenelconjuntoono¤ Nofuncionaparatérminosambiguos/difusos

Teoríadeconjuntosdifusos¨ Lalógicadifusafuedefinidaen1965porLoqiZadeh
¤ Creadapararepresentarmatemá^camentelaambigüedad/incer^dumbre¤ Ofreceherramientasparatratarlaincer^dumbreintrínsecaenmuchos
problemas¤ Permitemodelartérminoslingüís^cos:personaalta,personabaja,etc…
n Proveeunmodelointerpretablepuestoqueu^lizaellenguajenatural
¤ Basadaenqueloselementospertenecenalconjuntoconungradoen[0,1]
(a) Lógica booleana. (b) Lógica difusa. 0 1 1 0 0.2 0.4 0.6 0.8 1 0 0 1 1 0
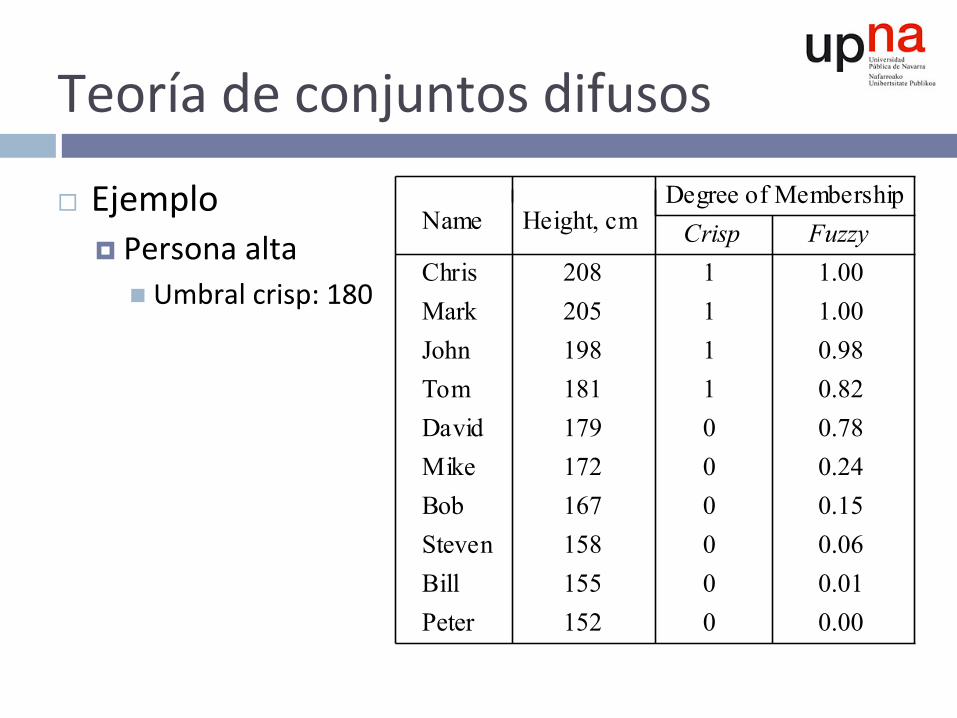
Teoríadeconjuntosdifusos
¨ Ejemplo¤ Personaalta
n Umbralcrisp:180
Degree of MembershipFuzzy
MarkJohnTom
Bob
Bill
11100
1.001.000.980.820.78
Peter
Steven
MikeDavid
ChrisCrisp
1
0000
0.240.150.060.010.00
Name Height, cm
205198181
167
155152
158
172179
208
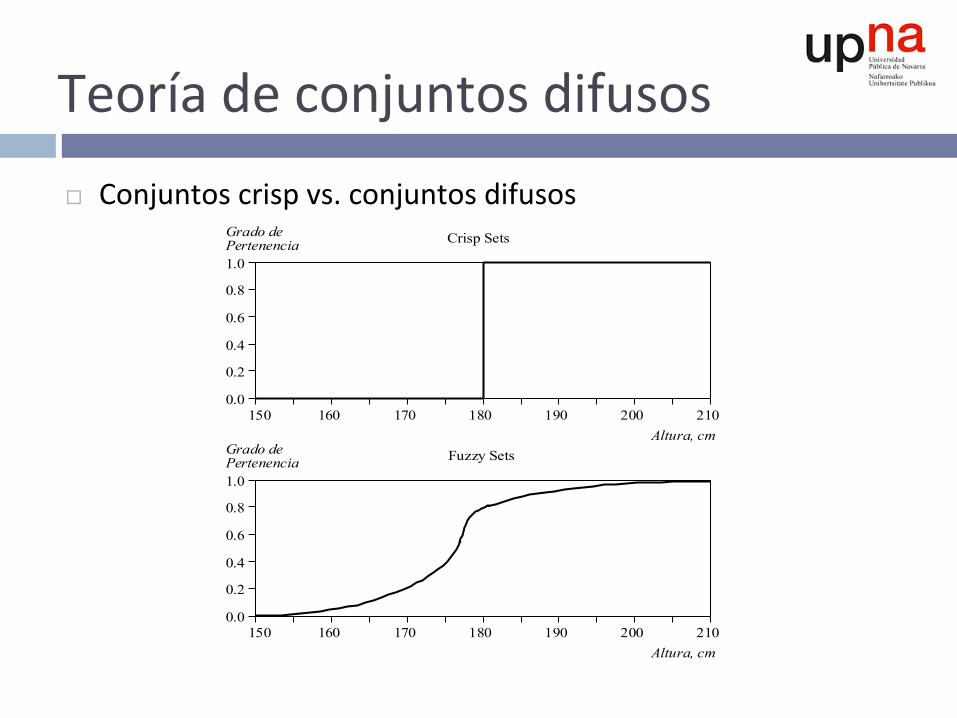
Teoríadeconjuntosdifusos¨ Conjuntoscrispvs.conjuntosdifusos
150 210 170 180 190 200 160
Altura, cm Grado de Pertenencia
Tall Men
150 210 180 190 200
1.0
0.0
0.2
0.4
0.6
0.8
160
Grado de Pertenencia
170
1.0
0.0
0.2
0.4
0.6
0.8
Altura, cm
Fuzzy Sets
Crisp Sets

Teoríadeconjuntosdifusos
¨ Conjuntocrisp
fA(x):Xà{0,1},donde
¨ Conjuntodifuso
µA(x):Xà[0,1],donde µA(x)=1sixestátotalmenteenA; µA(x)=0sixnoestáenA; 0<µA(x)<1sixestáparcialmenteenA.
1, si ( )
0,si A
x Af x
x A∈⎧
= ⎨∉⎩
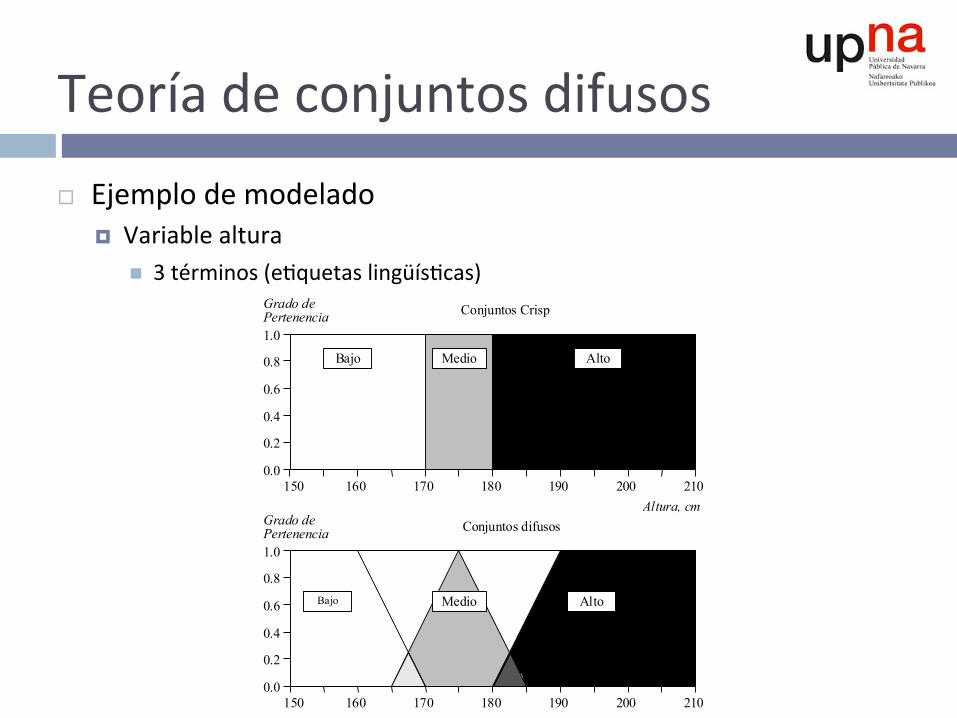
Teoríadeconjuntosdifusos¨ Ejemplodemodelado
¤ Variablealturan 3términos(e^quetaslingüís^cas)
150 210 170 180 190 200 160
Altura, cm Grado de Pertenencia
Tall Men
150 210 180 190 200
1.0
0.0
0.2
0.4
0.6
0.8
160
Grado de Pertenencia
Bajo Medio Short Alto
170
1.0
0.0
0.2
0.4
0.6
0.8
Conjuntos difusos
Conjuntos Crisp
Bajo Medio
Tall
Alto

Teoríadeconjuntosdifusos
¨ Lasfuncionesdepertenenciamodelanalase^quetaslingüís^cas/términoslingüís^cos
¨ Ejemplos¤ Triangular𝜇(𝑥)={█0&𝑠𝑖&𝑥<𝑎 𝑜 𝑥>𝑏@𝑥−𝑎/𝑚−𝑎 &𝑠𝑖&𝑎≤𝑥≤𝑚@𝑏−𝑥/𝑏−𝑚 &𝑠𝑖&𝑚≤𝑥≤𝑏 ¤ Trapezoidal𝜇(𝑥)={█0&𝑠𝑖&𝑥<𝑎 𝑜 𝑥>𝑑@█𝑥−𝑎/𝑏−𝑎 @1@𝑑−𝑥/𝑑−𝑐 &█𝑠𝑖@𝑠𝑖@𝑠𝑖 &█𝑎≤𝑥≤𝑏@𝑏≤𝑥≤𝑐@𝑐≤𝑥≤𝑑 ¤ Gaussiana𝜇(𝑥)= 𝑒↑− (𝑥−𝑚)↑2 /2𝜎↑2
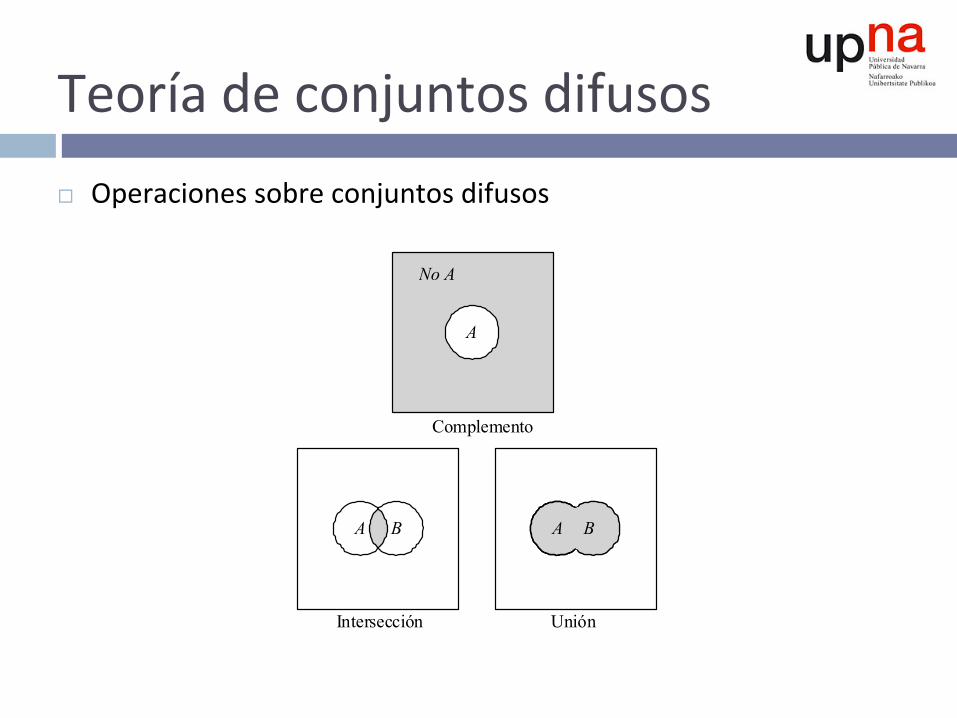
Teoríadeconjuntosdifusos¨ Operacionessobreconjuntosdifusos
Intersección Unión
Complemento
No A
A
B A B A A B
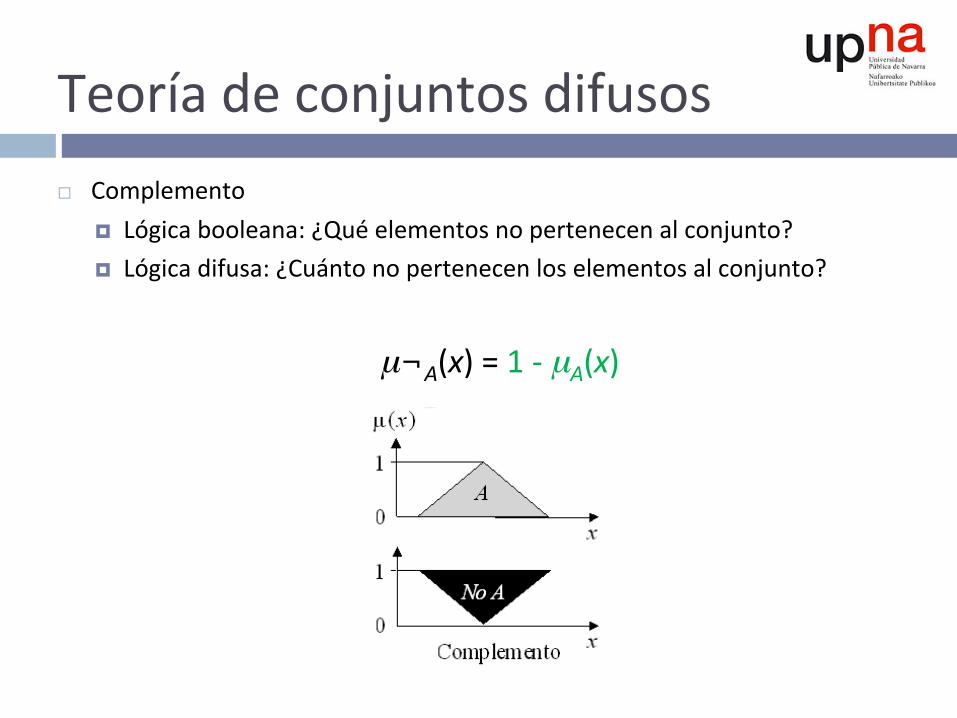
Teoríadeconjuntosdifusos¨ Complemento
¤ Lógicabooleana:¿Quéelementosnopertenecenalconjunto?¤ Lógicadifusa:¿Cuántonopertenecenloselementosalconjunto?
µ¬A(x)=1-µA(x)

Teoríadeconjuntosdifusos¨ Intersección
¤ Lógicabooleana:¿Perteneceelelementoaambosconjuntos?¤ Lógicadifusa:¿Cuántoperteneceelelementoaambosconjuntos?
n Ejemplosdet-normassonelproductoyelmínimo(comúnmenteu^lizadas)
µA∩B(x)=T[µA(x),µB(x)]=µA(x)∩µB(x)

Teoríadeconjuntosdifusos¨ Unión
¤ Lógicabooleana:¿Perteneceelelementoacualquierconjunto?¤ Lógicadifusa:¿Cuántoperteneceelelementoacualquierconjunto?¤ Unejemplodet-conormaeselmáximo(comúnmenteu^lizada)
µA∪B(x)=S[µA(x),µB(x)]=µA(x)∪µB(x)
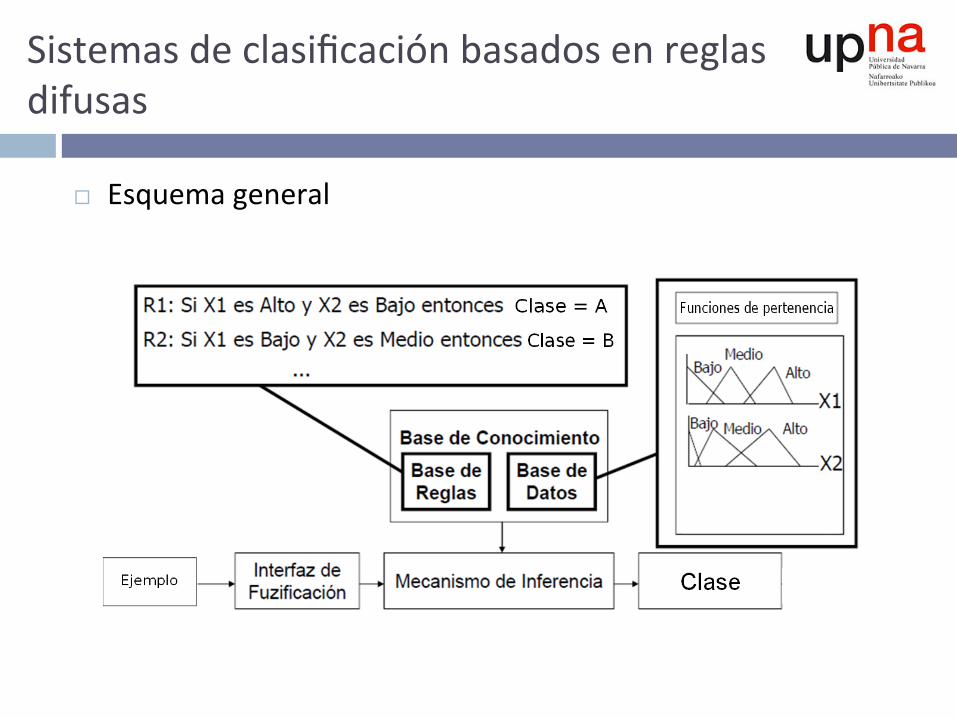
Sistemasdeclasificaciónbasadosenreglasdifusas
¨ Esquemageneral
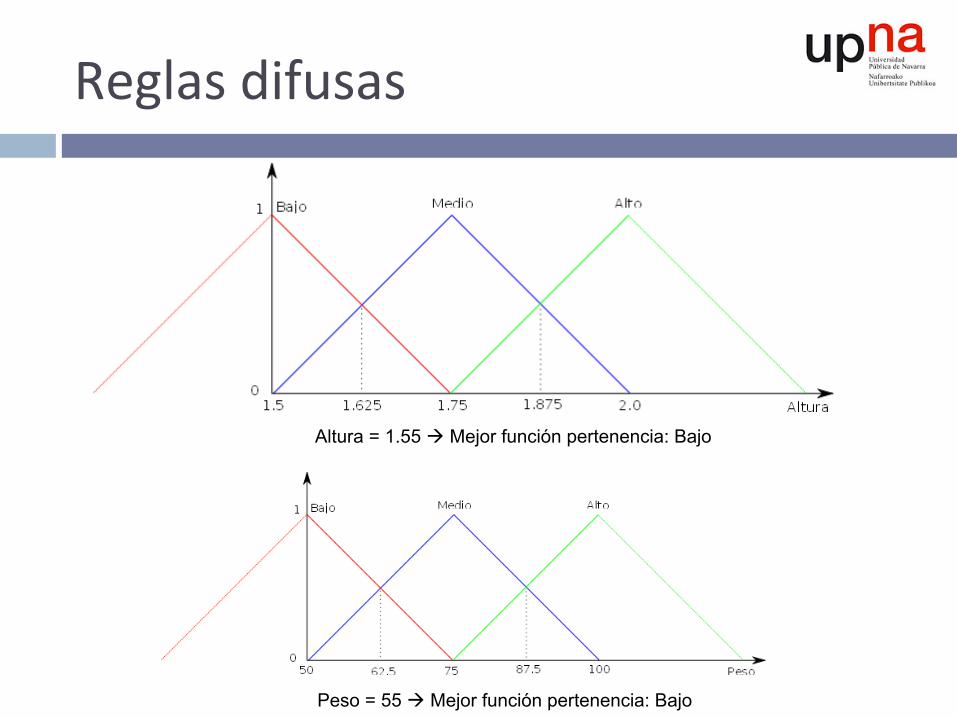
Reglasdifusas
Altura = 1.55 à Mejor función pertenencia: Bajo
Peso = 55 à Mejor función pertenencia: Bajo
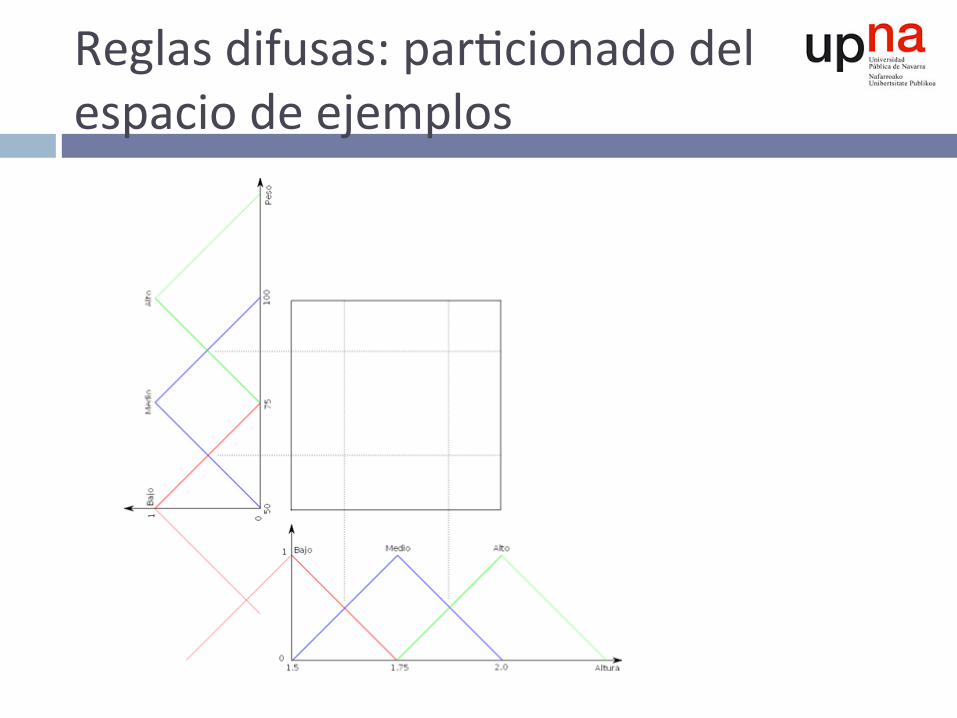
Reglasdifusas:par^cionadodelespaciodeejemplos
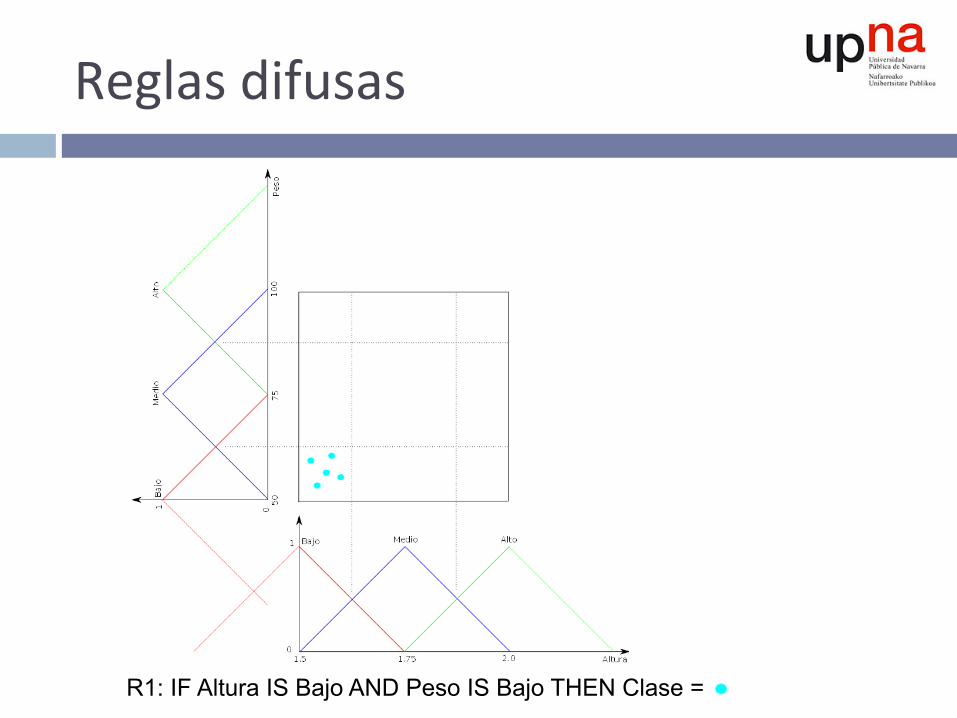
Reglasdifusas
R1: IF Altura IS Bajo AND Peso IS Bajo THEN Clase =
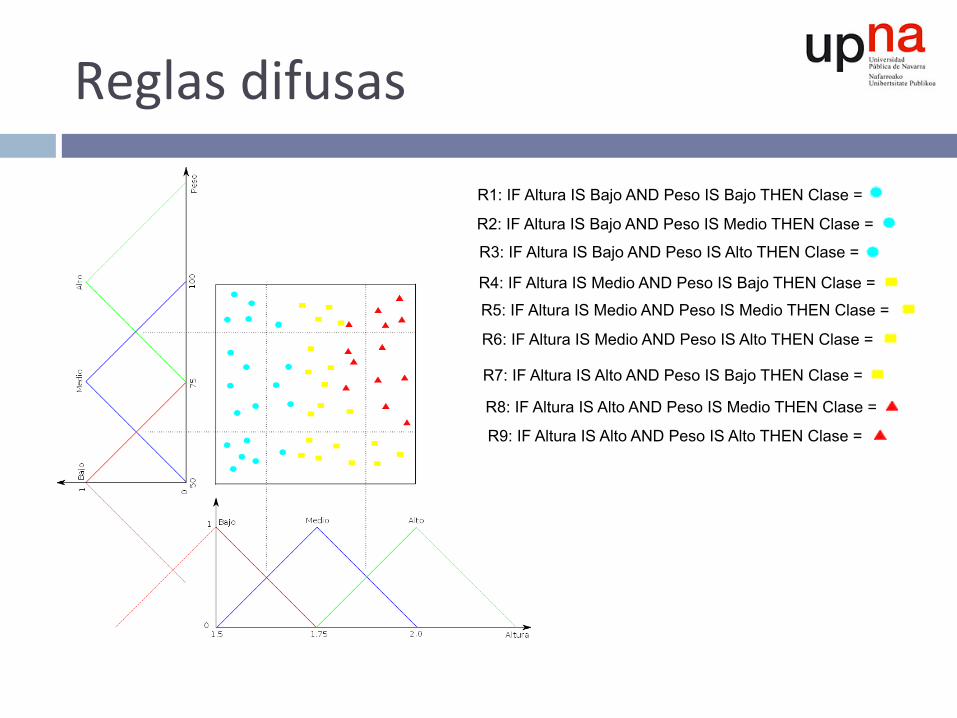
Reglasdifusas
R1: IF Altura IS Bajo AND Peso IS Bajo THEN Clase =
R2: IF Altura IS Bajo AND Peso IS Medio THEN Clase =
R3: IF Altura IS Bajo AND Peso IS Alto THEN Clase =
R4: IF Altura IS Medio AND Peso IS Bajo THEN Clase =
R5: IF Altura IS Medio AND Peso IS Medio THEN Clase =
R6: IF Altura IS Medio AND Peso IS Alto THEN Clase =
R7: IF Altura IS Alto AND Peso IS Bajo THEN Clase =
R8: IF Altura IS Alto AND Peso IS Medio THEN Clase =
R9: IF Altura IS Alto AND Peso IS Alto THEN Clase =
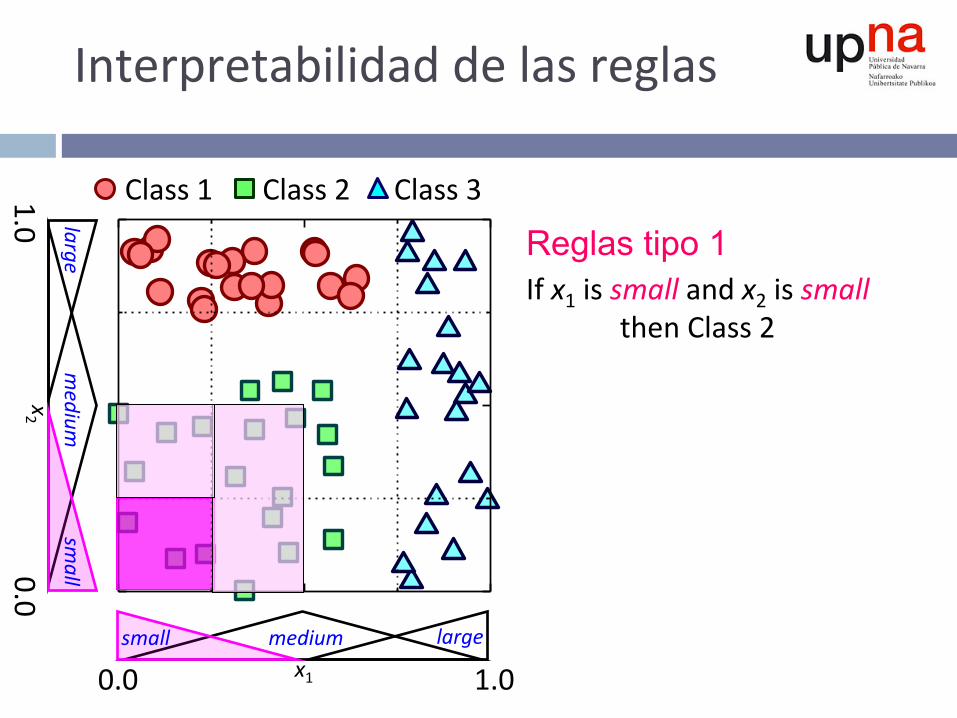
Interpretabilidaddelasreglas
Reglas tipo 1 Ifx1issmallandx2issmallthenClass2
1.0
small medium large
0.0 1.0x1
Class1 Class2 Class3
0.0x2
largemedium
sm
all
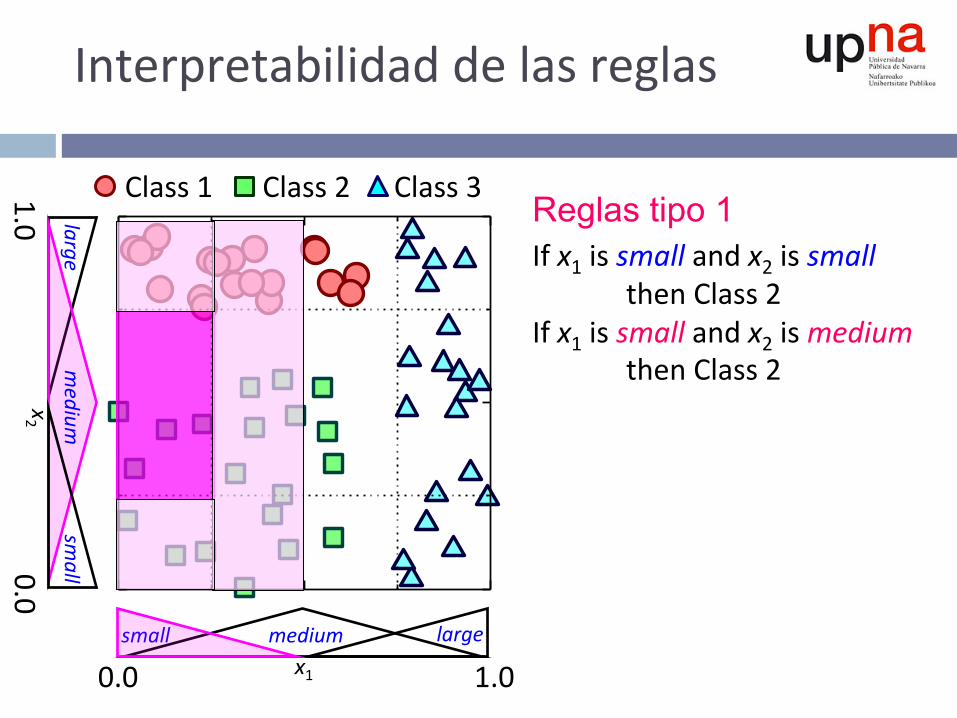
Interpretabilidaddelasreglas
Reglas tipo 1 Ifx1issmallandx2issmallthenClass2Ifx1issmallandx2ismediumthenClass2
x2
1.0
small medium large
0.0 1.0x1
Class1 Class2 Class3
0.0large
medium
sm
all
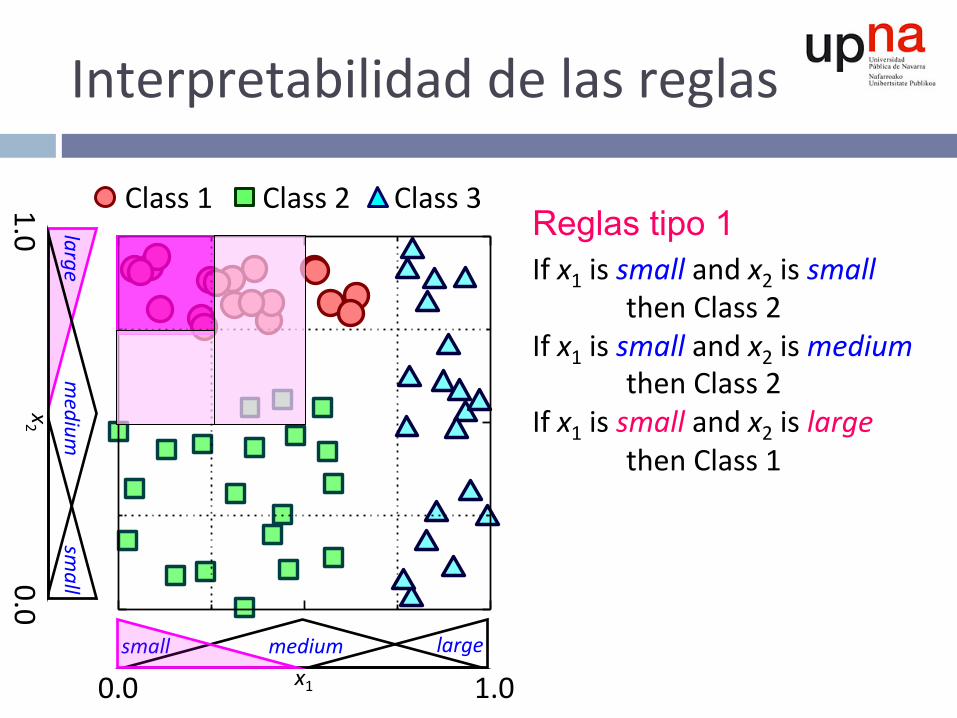
Interpretabilidaddelasreglas
Reglas tipo 1 Ifx1issmallandx2issmallthenClass2Ifx1issmallandx2ismediumthenClass2Ifx1issmallandx2islargethenClass1
1.0
small medium large
0.0 1.0x1
Class1 Class2 Class3
0.0x2
largemedium
sm
all
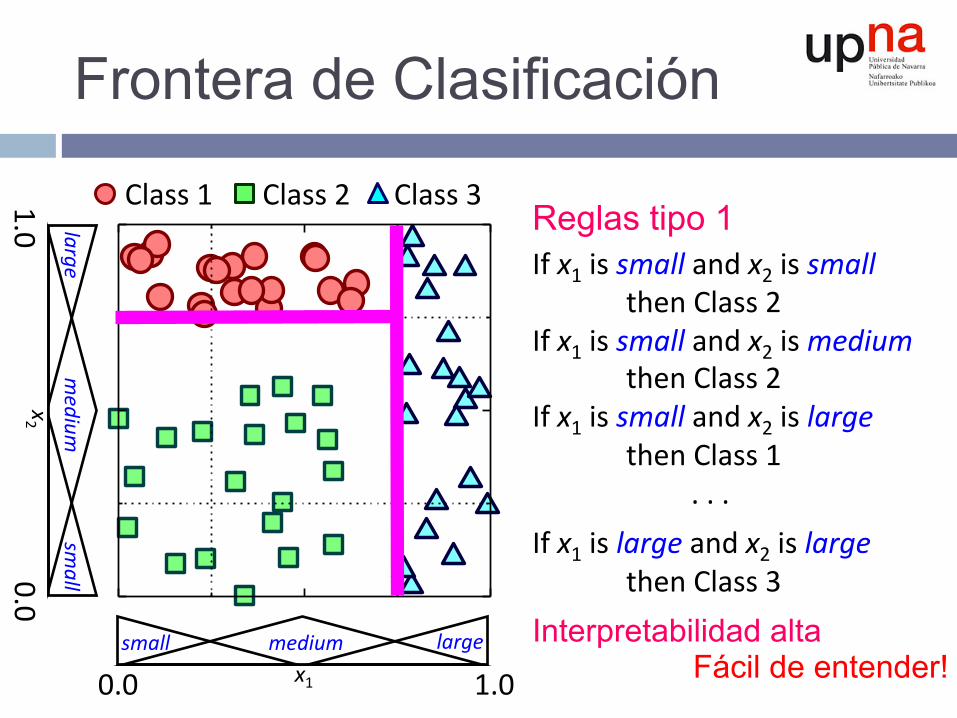
Frontera de Clasificación
1.0
small medium large
0.0 1.0x1
Class1 Class2 Class3
0.0x2
largemedium
sm
all
Reglas tipo 1 Ifx1issmallandx2issmallthenClass2Ifx1issmallandx2ismediumthenClass2Ifx1issmallandx2islargethenClass1...Ifx1islargeandx2islargethenClass3Interpretabilidad alta
Fácil de entender!
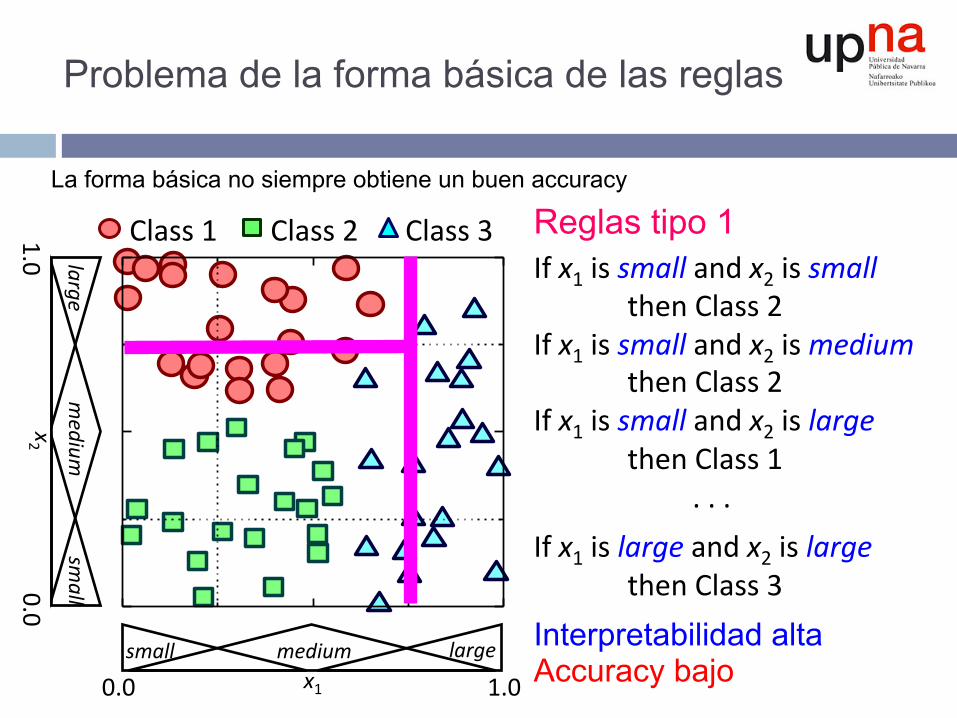
Problema de la forma básica de las reglas
Reglas tipo 1 Ifx1issmallandx2issmallthenClass2Ifx1issmallandx2ismediumthenClass2Ifx1issmallandx2islargethenClass1...Ifx1islargeandx2islargethenClass3Interpretabilidad alta Accuracy bajo
1.0
small medium large
0.0 1.0x1
Class1 Class2 Class3
0.0x2
largemedium
sm
all
La forma básica no siempre obtiene un buen accuracy

Basedereglas
¨ Almacenaelconjuntodereglasdifusas(R={R1,…,RL})u^lizadaspararepresentarelconocimientodelproblema
¨ Tiposdereglas:1. ReglaRj:Six1esAj1y...yxnesAjnentoncesClase=Cj2. ReglaRj:Six1esAj1y...yxnesAjnentoncesClase=CjconRWj
3. ReglaRj:Six1esAj1y...yxnesAjnentoncesRW1,…,RWM
¨ Lasreglasdel^po3generalizanalas2anteriores¤ SiRWj=1yRWi=0conj≠i,entoncestenemosunaregla^po1¤ SiRWj=RWjyRWi=0conj≠i,entoncestenemosunaregla^po2

Gradodecompa^bilidad
¨ Midelocompa^blequeesunejemploconunaregla.Sealaregla𝑞yelejemplo 𝑥↓𝑝 ,elgradodecompa^bilidades
𝜇↓𝐴↓𝑞 (𝑥↓𝑝 )=𝑇(𝜇↓𝐴↓𝑞1 (𝑥↓𝑝1 ), …, 𝜇↓𝐴↓𝑞𝑛 (𝑥↓𝑝𝑛 ))¨ SiAlturaesBajoYPesoesBajoEntoncesClase=
¤ Instancia:altura(1’55)ypeso(55)¤ Compa^bilidad:T(0,9,0,7)=0,63àT-normaproducto
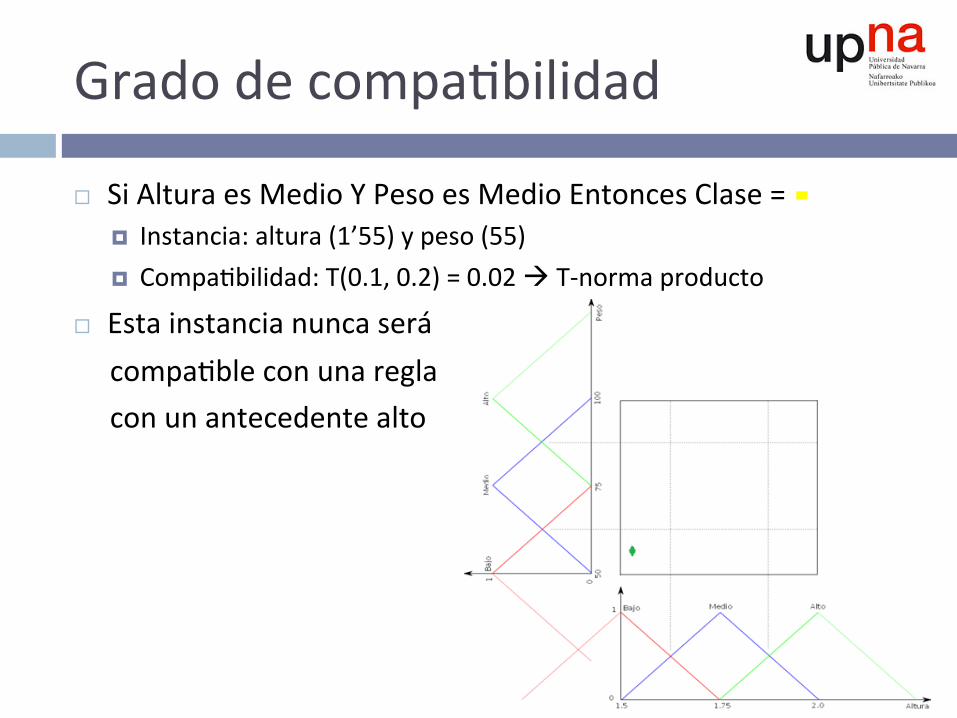
Gradodecompa^bilidad
¨ SiAlturaesMedioYPesoesMedioEntoncesClase=¤ Instancia:altura(1’55)ypeso(55)¤ Compa^bilidad:T(0.1,0.2)=0.02àT-normaproducto
¨ Estainstancianuncaserácompa^bleconunareglaconunantecedentealto

Pesodelasreglas[Ishibuchi01]
¨ Soportedelaregla𝑞𝑆𝑜𝑝(𝐴↓𝑞 →𝐶↓𝑞 )= ∑𝑥↓𝑝∈𝐶𝑙𝑎𝑠𝑠 𝐶↓𝑞 ↑▒𝜇↓𝐴↓𝑞 (𝑥↓𝑝 ) /|𝑁|
¤ 𝑁eselnúmerodeejemplosdeentrenamiento
¨ Confianzadelaregla𝑞𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓𝑞 )= ∑𝑥↓𝑝∈𝐶𝑙𝑎𝑠𝑠 𝐶↓𝑞 ↑▒𝜇↓𝐴↓𝑞 (𝑥↓𝑝 ) /∑𝑝=1↑𝑁▒𝜇↓𝐴↓𝑞 (𝑥↓𝑝 )
[Ishibuchi01] H. Ishibuchi and T. Nakashima, “Effect of rule weights in fuzzy rule-based classification systems,” IEEE Trans. Fuzzy Syst., vol. 9, no. 4, pp. 506–515, Aug. 2001

Pesodelasreglas
¨ Confianzapenalizadaconlaconfianzamediadelrestodeclases
𝐶𝑜𝑛𝑓↓2 =𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓𝑞 )− 𝐶𝑜𝑛𝑓↓𝑚𝑒𝑑𝑖𝑎 𝐶𝑜𝑛𝑓↓𝑚𝑒𝑑𝑖𝑎 = 1/𝑀−1 ∗∑█ℎ=1ℎ≠ 𝐶↓𝑞 ↑𝑀▒𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓ℎ ) ¨ Confianzapenalizadaconlasegundamayorconfianza
𝐶𝑜𝑛𝑓↓3 =𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓𝑞 )− 𝐶𝑜𝑛𝑓↓𝑠𝑒𝑔𝑢𝑛𝑑𝑎 𝐶𝑜𝑛𝑓↓𝑠𝑒𝑔𝑢𝑛𝑑𝑎 =⋁█ℎ=1ℎ≠ 𝐶↓𝑞 ↑𝑀▒𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓ℎ )

Pesodelasreglas
¨ Confianzapenalizadaconlasumadelaconfianzadelrestodeclases¤ Factordecertezapenalizado
𝐶𝑜𝑛𝑓↓4 =𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓𝑞 )− 𝐶𝑜𝑛𝑓↓𝑠𝑢𝑚𝑎 𝐶𝑜𝑛𝑓↓𝑠𝑢𝑚𝑎 =∑█ℎ=1ℎ≠ 𝐶↓𝑞 ↑𝑀▒𝐶𝑜𝑛𝑓(𝐴↓𝑞 →𝐶↓ℎ ) ¨ Observaciones
¤ Las3confianzaspenalizadassonequivalentessielnúmerodeclaseses2
¤ Enlasconfianzaspenalizadaselresultadopuedesernega^voporloqueesareglanoseríagenerada
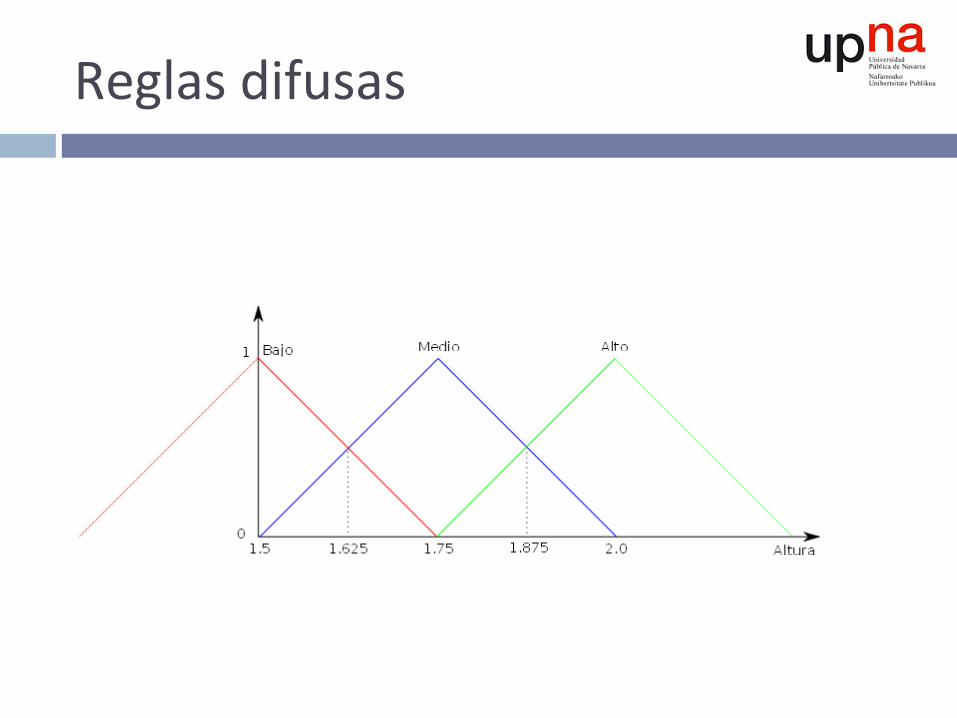
Reglasdifusas
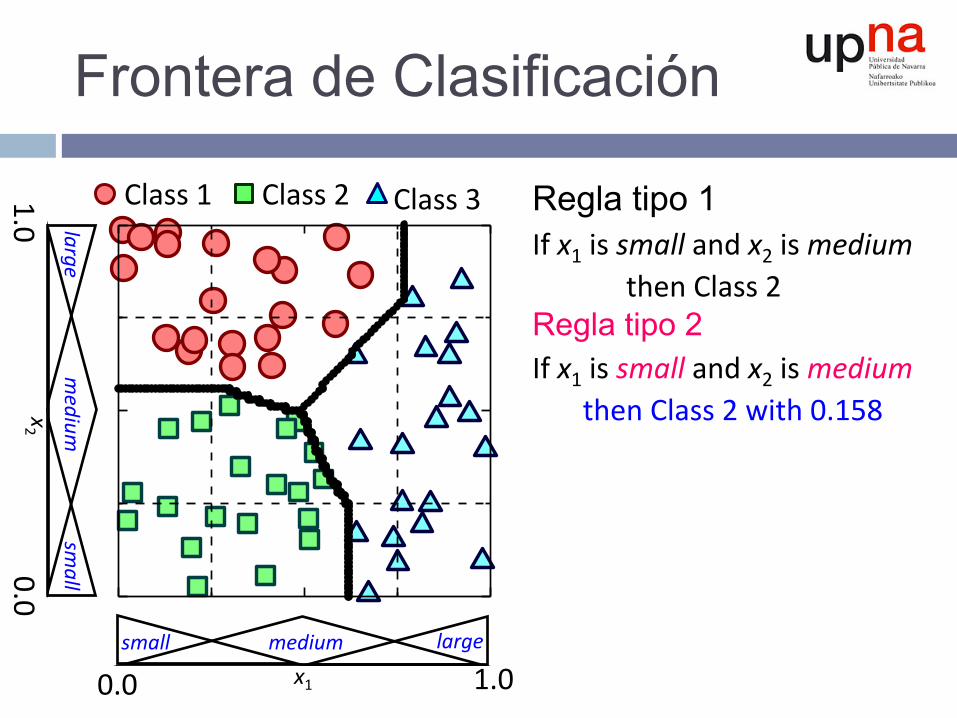
Frontera de Clasificación
Class3
x2
Regla tipo 1 Ifx1issmallandx2ismediumthenClass2Regla tipo 2 Ifx1issmallandx2ismediumthenClass2with0.158
1.0
0.0 1.0x1
Class1 Class2
0.0
small medium large
largemedium
sm
all

AlgoritmodegeneracióndereglasdeChi[Chi96]
¨ WangyMendelproponenunmétododegeneracióndereglasdifusasparaproblemasdecontrol
¨ Chiyotroslosex^endenaproblemasdeclasificación¨ Algoritmo
1. Calcularlaspar^cionesdifusasasociadasalasvariablesdeentrada2. Generarunaregladifusaparacadaejemplodeentrenamiento
i. Calcularlosgradosdepertenenciadelejemploalasdiferentesfuncionesdepertenencia
ii. Asignarelejemploalasfuncionesdepertenenciaquedevuelvanelmayorgradodepertenenciaparacadavariable
iii. Generarlaregla.Elantecedenteeslaconjuncióndelasfuncionesdepertenenciayelconsecuenteeslaclasedelejemplo
iv. Silasreglassondel^po2o3,calcularelpesodelaregla
¨ Reglasconelmismoantecedenteydiferenteclase:conservarlademayorpeso
[Chi96]Z.Chi,H.Yan,T.Pham,FuzzyAlgorithmswithApplica^onstoImageProcessingandPahernRecogni^on,WorldScien^fic,1996

Métododerazonamientodifuso[Cordón99]
¨ Procedimientodeinferenciaqueusalainformacióndelabasedeconocimientoparapredecirlaclasedeunejemplonoclasificado¤ Clasificacióndeejemplos
¨ Determinalaformadeu^lizarlainformacióncontenidaenlasreglas
[Cordón99] O. Cordón, M. J. del Jesus, and F. Herrera, “Aproposal on reasoning methods in fuzzy rule-based classification systems,” Int. J. Approx. Reason., vol. 20, no. 1, pp. 21–45, 1999

Métododerazonamientodifuso
¨ Sea={,…,}elejemploaclasificar.={,…,}elconjuntodeclasesy={,…,}elconjuntodereglas.
¨ LospasosdelMRDson:¤ Gradodecompa^bilidad
𝑅↑𝑘 (𝑒)=𝑇(𝜇↓𝐴↓𝑘1 (𝑒↓1 ), …, 𝜇↓𝐴↓𝑘𝑛 (𝑒↓𝑛 )), 𝑘={1, …, 𝐿}¤ Gradodeasociación
𝑏↓𝑗↑𝑘 (𝑒)=ℎ(𝑅↑𝑘 (𝑒), 𝑅𝑊↓𝑗↑𝑘 ), 𝑘={1, …, 𝐿}, 𝑗={1, …, 𝑀}¤ Ponderación
𝐵↓𝑗↑𝑘 (𝑒)=𝑔( 𝑏↓𝑗↑𝑘 (𝑒)) , 𝑘={1, …, 𝐿}, 𝑗={1, …, 𝑀}¤ Gradodeasociaciónporclases
𝑎↓𝑗 =𝑓( 𝐵↓𝑗↑𝑘 (𝑒)| 𝐵↓𝑗↑𝑘 (𝑒)>0, 𝑘={1, …, 𝐿})¤ Clasificación
𝐶𝑙𝑎𝑠𝑒= arg max┬𝑖=1, …, 𝑀 ( 𝑎↓𝑖 )

Métododerazonamientodifuso
n Gradodecompa^bilidadn T-normas
n Mínimon Producto
¨ Gradodeasociaciónn Implicaciones
n Mínimon Producto
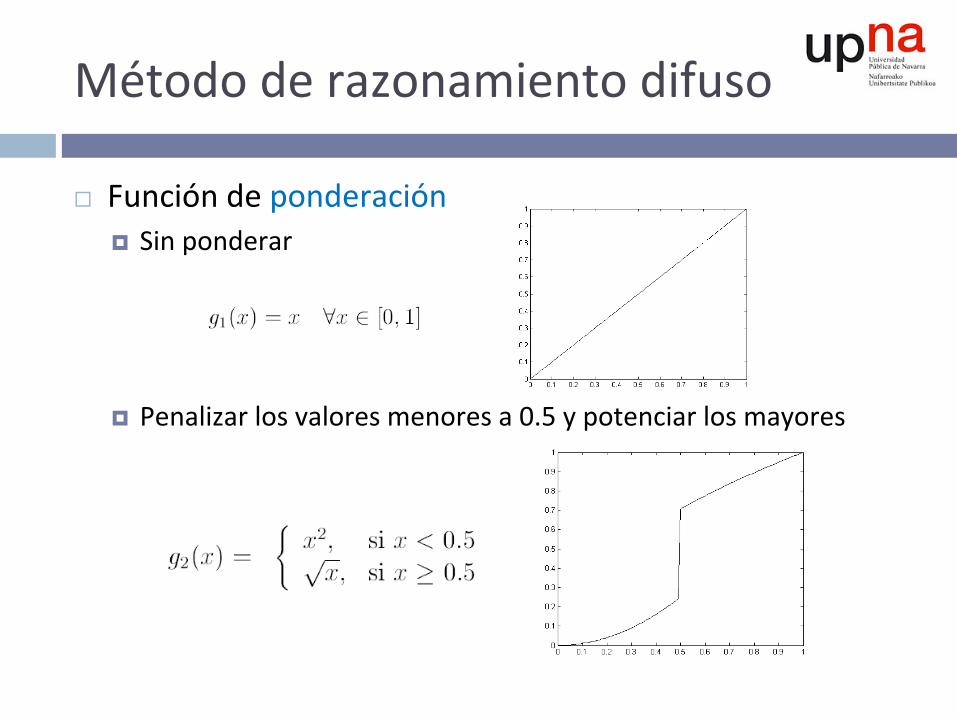
Métododerazonamientodifuso
¨ Funcióndeponderación¤ Sinponderar
¤ Penalizarlosvaloresmenoresa0.5ypotenciarlosmayores

Métododerazonamientodifuso
¨ Gradodeasociaciónporclases𝑎↓𝑗 =𝑓( 𝐵↓𝑗↑𝑘 (𝑒)| 𝐵↓𝑗↑𝑘 (𝑒)>0, 𝑘={1, …, 𝐿})
¤ Funcionesdeagregación,𝑓,(consideran1regla)n Máximo(MRDdelareglaganadora)
¤ Funcionesdeagregación,𝑓,(considerantodaslasreglasdisparadas)n Sumaadi^va(MRDdelacombinaciónadi^va)n Mediaaritmé^ca
¤ Funcionesdeagregación,𝑓,(seleccionanreglas)n OWA

CLASIFICACIÓNYMACHINELEARNINGCONTÉCNICASDIFUSAS
Ensemblesbasadosendescomposición
EVIA2016MikelGalarUniversidadPúblicadeNavarra
Introducción
¨ Clasificación¤ Dos-posdeproblemas
n Binariosn Diagnós^comédico(si/no)
n Mul--clasen Reconocimientodedígitos(1,2,…)
¤ Problemasbinariosgeneralmentemássencillos
¤ Algunosclasificadoresnosoportanmúl^plesclasesn SVM,PDFC…
Object recognition
100
Automated protein classification
50
300-600
Digit recognition
10
Phoneme recognition

Ensemblesbasadosendescomposición
¨ Obje-vo¤ Afrontarproblemasmul^-claseconclasificadoresbinarios
¨ Funcionamiento¤ Descomponerunproblemamul^-clase
n Enproblemasbinarios(mássencillosderesolver)¤ Aprenderunclasificadorparacadasubproblema¤ Paraclasificarunanuevainstancia
n Agregarlassalidasdelosclasificadoresbase
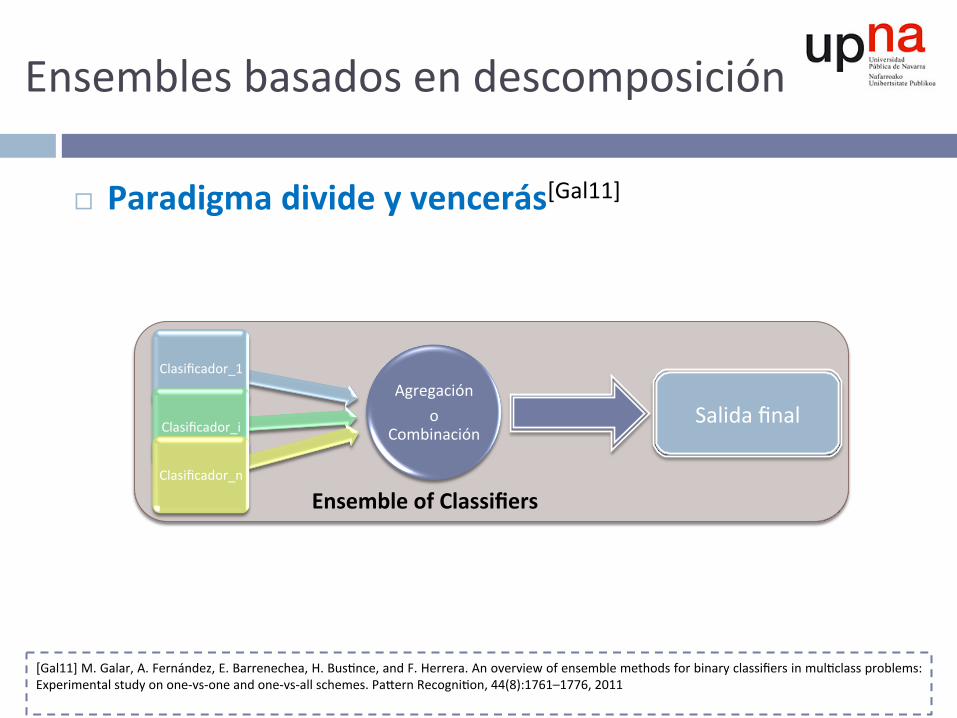
Ensemblesbasadosendescomposición
¨ Paradigmadivideyvencerás[Gal11]
Agregacióno
Combinación
Clasificador_1
Clasificador_i
Clasificador_n
Salidafinal
EnsembleofClassifiers
[Gal11]M.Galar,A.Fernández,E.Barrenechea,H.Bus^nce,andF.Herrera.Anoverviewofensemblemethodsforbinaryclassifiersinmul^classproblems:Experimentalstudyonone-vs-oneandone-vs-allschemes.PahernRecogni^on,44(8):1761–1776,2011
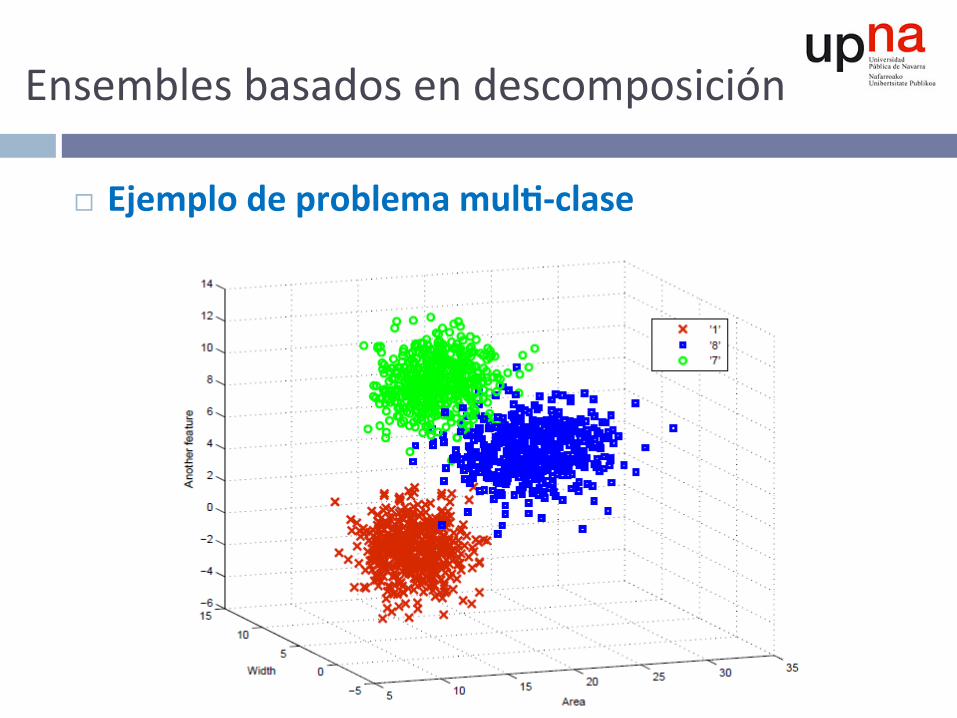
Ensemblesbasadosendescomposición
¨ Ejemplodeproblemamul--clase
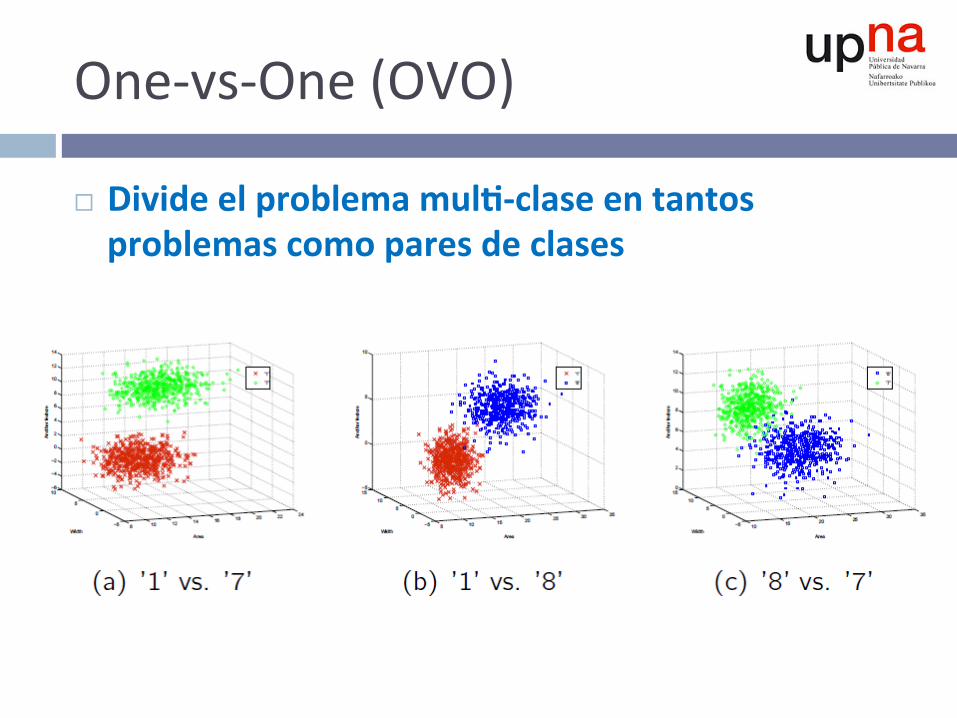
One-vs-One(OVO)
¨ Divideelproblemamul--claseentantosproblemascomoparesdeclases
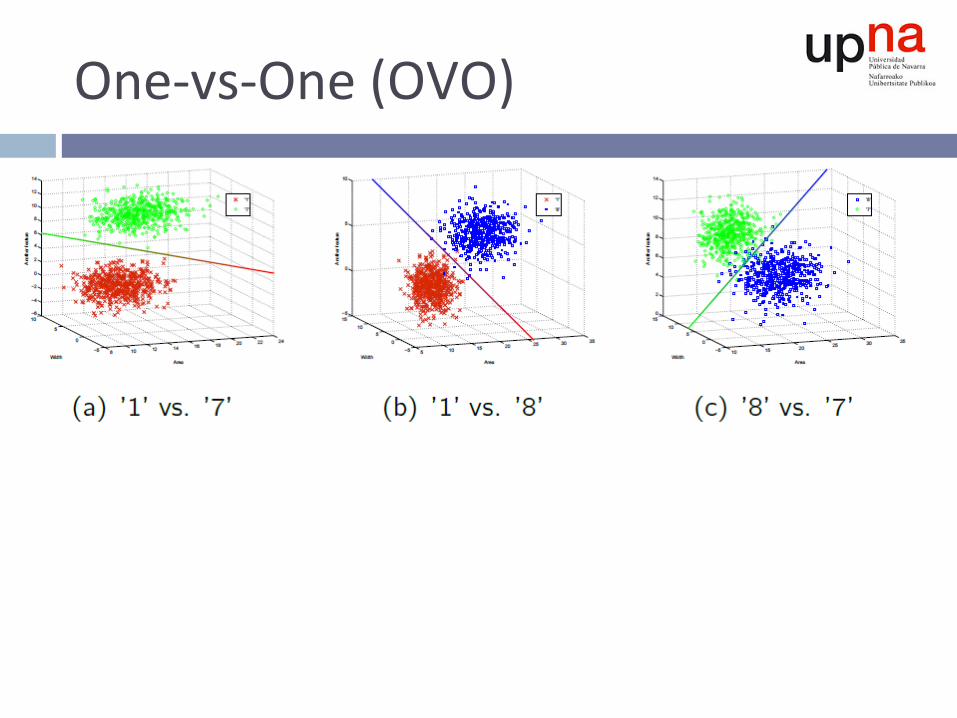
One-vs-One(OVO)
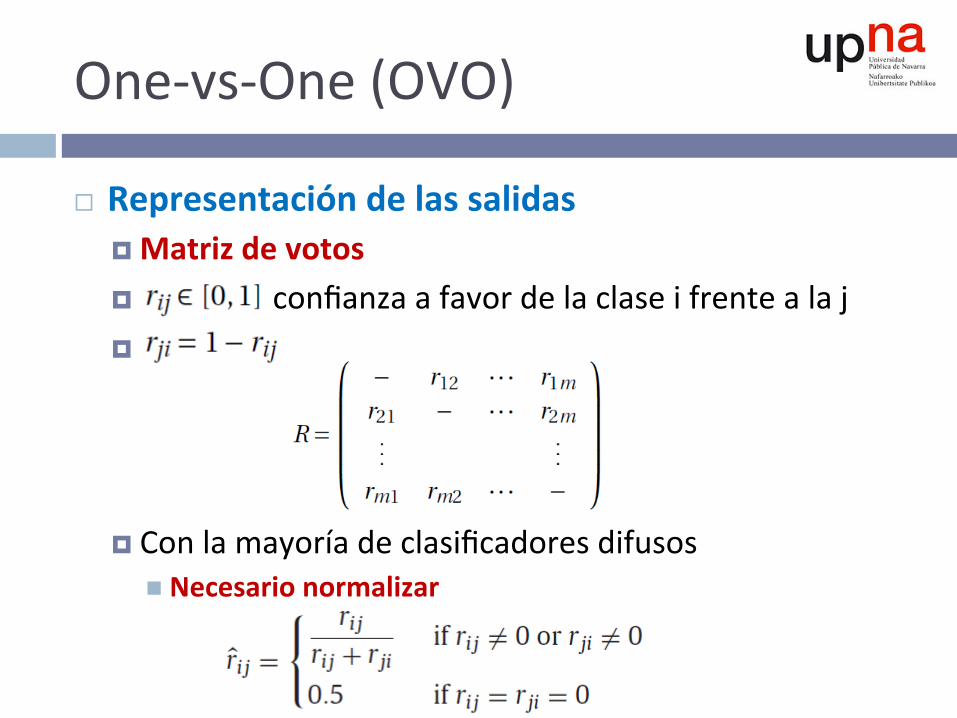
One-vs-One(OVO)
¨ Representacióndelassalidas¤ Matrizdevotos¤ confianzaafavordelaclaseifrentealaj¤ .
¤ Conlamayoríadeclasificadoresdifusosn Necesarionormalizar

One-vs-One(OVO)
¨ Agregacionesmáscomunes¤ Voto(VOTE)[Friedman96]
n Cadaclasificadorvotaporlaclasepredicha
n dondees1siy0enotrocaso¤ Votoponderado(WV)
n Cadaclasificadorvotaconciertaconfianzaacadaclase
¤ Enamboscasos,laclaseconmayorconfianzaeslaquesepredice
[Friedman96] J. H. Friedman, Another approach to polychotomous classifica^on, Tech. rep.,DepartmentofSta^s^cs,StanfordUniversity(1996).

One-vs-One(OVO)
¨ Agregacionesbasadasenlateoríadifusa¤ LearningValuedPreferenceforClassifica-on(LVPC)
n Matrizdevotos=Relacióndepreferenciafuzzyn Sedescomponeentresrelacionesdiferentes
n Preferenciaestricta
n Conflicton Ignorancia
n Ladecisiónfinalsebasaenunvotousandolastresrelaciones
n whereNiisthenumberofexamplesofclassiintraining
[Hüllermeier08] E. Hüllermeier and K. Brinker. Learning valued preference structures for solvingclassifica^onproblems.FuzzySetsandSystems,159(18):2337–2352,2008.
[Hüllermeier08,Huhn09]

¨ Agregacionesbasadasenlateoríadifusa¤ Non-DominanceCriterion(ND)[Fernandez10]
n Tomadedecisiónymodeladodelapreferencia[Orlovsky78]n Matrizdevotos=Relacióndepreferenciafuzzy
n rji=1–rij,sinoànormalizarn Calcularelelementoconmáximogradodenodominancia
n Construirlarelacióndepreferenciaestrictan Calcularelgradodenodominancia
§ Elgradoenelquelaclaseiestádominadaporningunadelasclasesrestantes
n Output
One-vs-One(OVO)
[Fernandez10] A. Fernández, M. Calderón, E. Barrenechea, H. Bus^nce, F. Herrera, Solving mult-class problems withlinguis^cfuzzyrulebasedclassifica^onsystemsbasedonpairwiselearningandpreferencerela^ons,FuzzySetsandSystem161:23(2010)3064-3080,[Orlovsky78]S.A.Orlovsky,Decision-makingwithafuzzypreferencerela^on,FuzzySetsandSystems1(3)(1978)155–167.
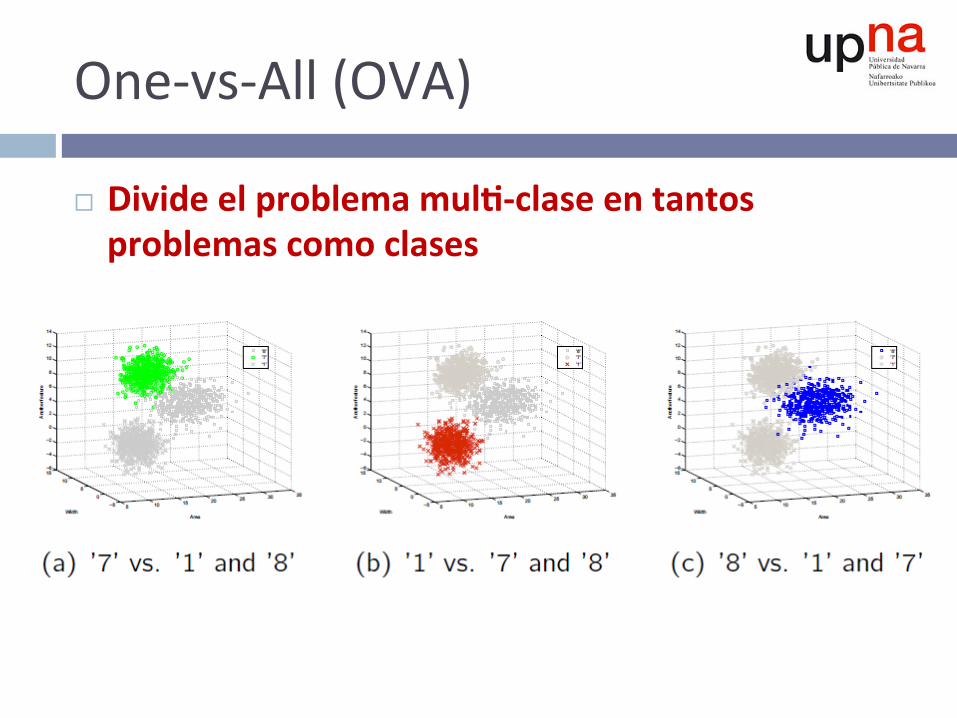
One-vs-All(OVA)
¨ Divideelproblemamul--claseentantosproblemascomoclases
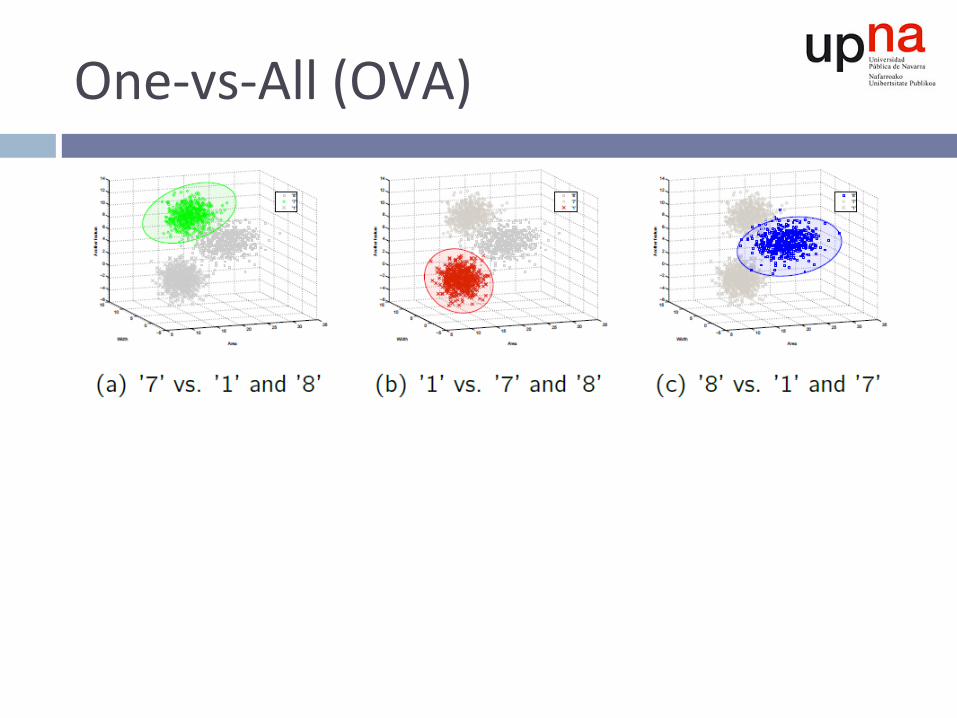
One-vs-All(OVA)

One-vs-All(OVA)
¨ Representacióndelassalidas¤ Vectordevotos¤ confianzaafavordelaclasei
¤ Normalizaciónn Respectoalvectordeconfianzasparalaclasenega^va
¤ Agregaciónn Máximo
n Clasedesalida=claseconmayorconfianza

OVOvs.OVA
¨ VentajasOVO¤ Problemasmássencillos¤ Problemasmáspequeños¤ Computacionalmentemásrápido¤ Generalmente,máspreciso
¨ DesventajasOVO¤ Regiónnoclasificable(Voto)¤ Clasificadoresnocompetentes¤ Crecimientocuadrá-coenelnúmerodeclasificadores
OVOvs.OVA
¨ VentajasOVA¤ U^lizatodoslosejemplos
n Nohayclasificadoresnocompetentes
¤ Agregacionesmássimples¤ Crecimientolinealenelnúmerodeclasificadores
¨ DesventajasOVA¤ Problemasnobalanceados¤ Problemasmáscomplejos¤ Computacionalmentemáscostoso
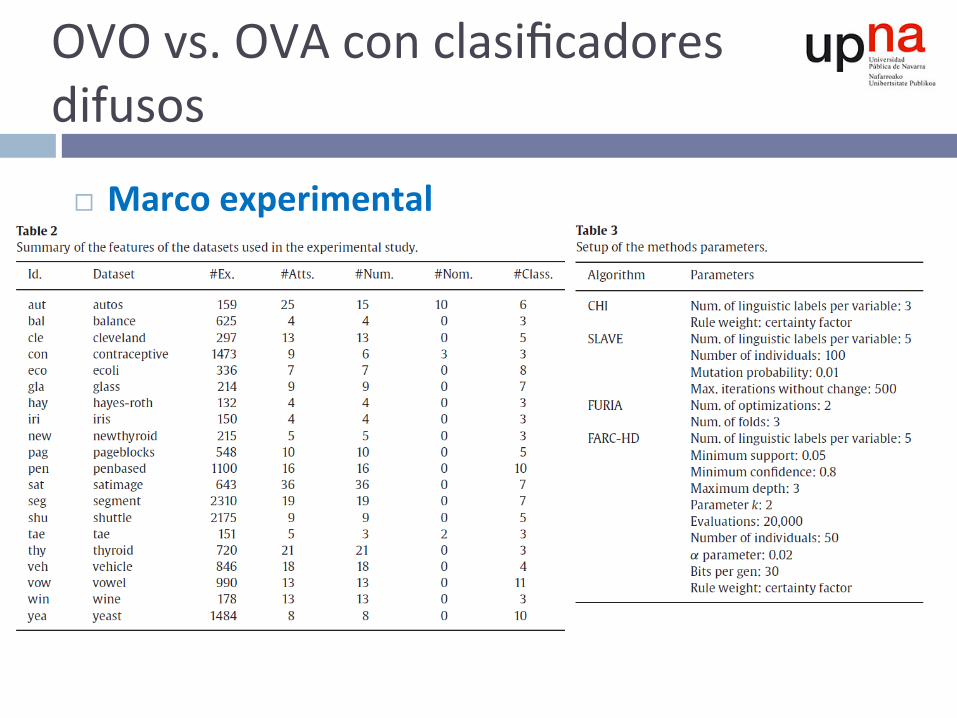
OVOvs.OVAconclasificadoresdifusos
¨ Marcoexperimental
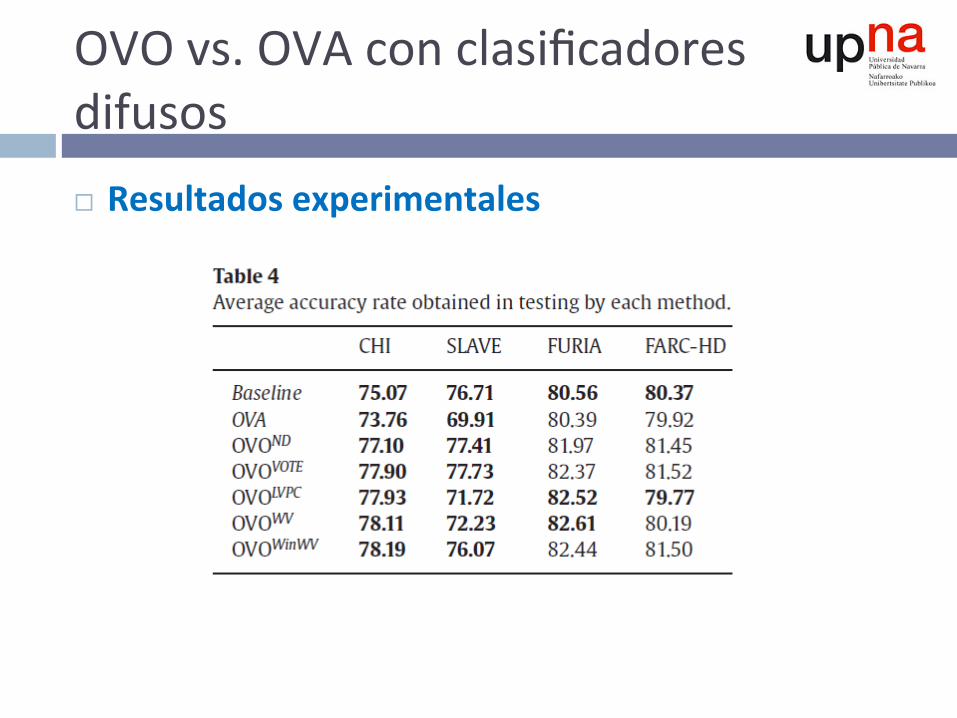
OVOvs.OVAconclasificadoresdifusos¨ Resultadosexperimentales
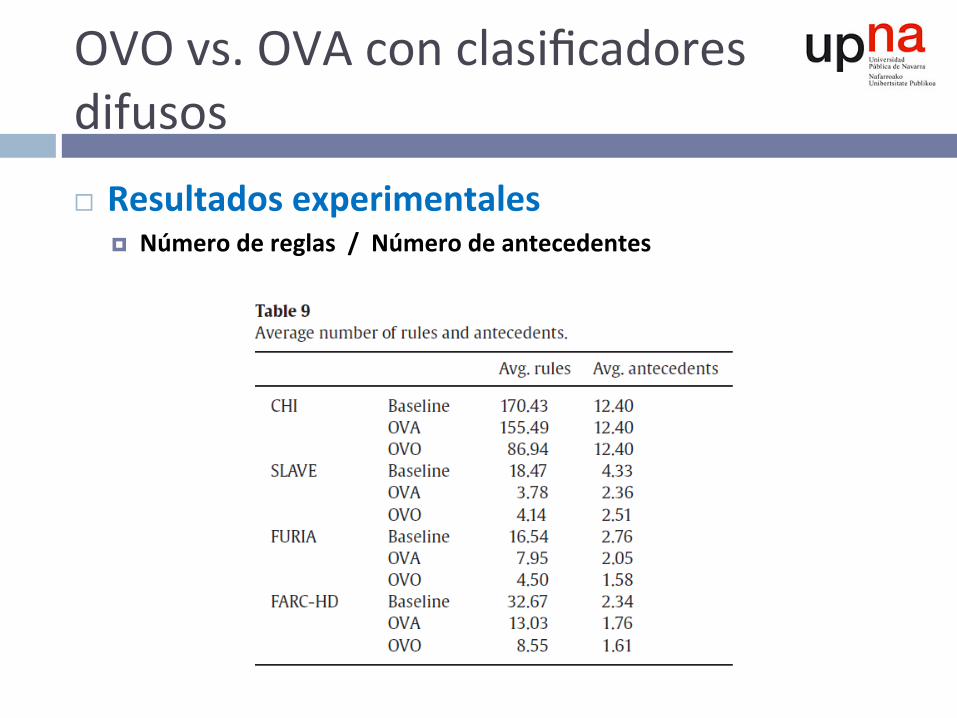
OVOvs.OVAconclasificadoresdifusos¨ Resultadosexperimentales
¤ Númerodereglas/Númerodeantecedentes

AlbertoFernándezHilarioUniversidaddeGranadaEVIA2016
Modelosyescenariosavanzadosparaclasificaciónconsistemasdifusos
CLASIFICACIÓNYMACHINELEARNINGCONTÉCNICASDIFUSAS

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData3. FuzzySystemsinBigDataandDataScience
62

Índice
1. Interval-valuedFuzzyRuleBasedSystems1. HowFRBCSaddressdifficultproblems2. ImprovingtheperformanceofFRBCSusingInterval-
ValuedFuzzySets3. CasestudywithIVTURS
2. Classifica^onwithImbalancedData3. FuzzySystemsinBigDataandDataScience
63
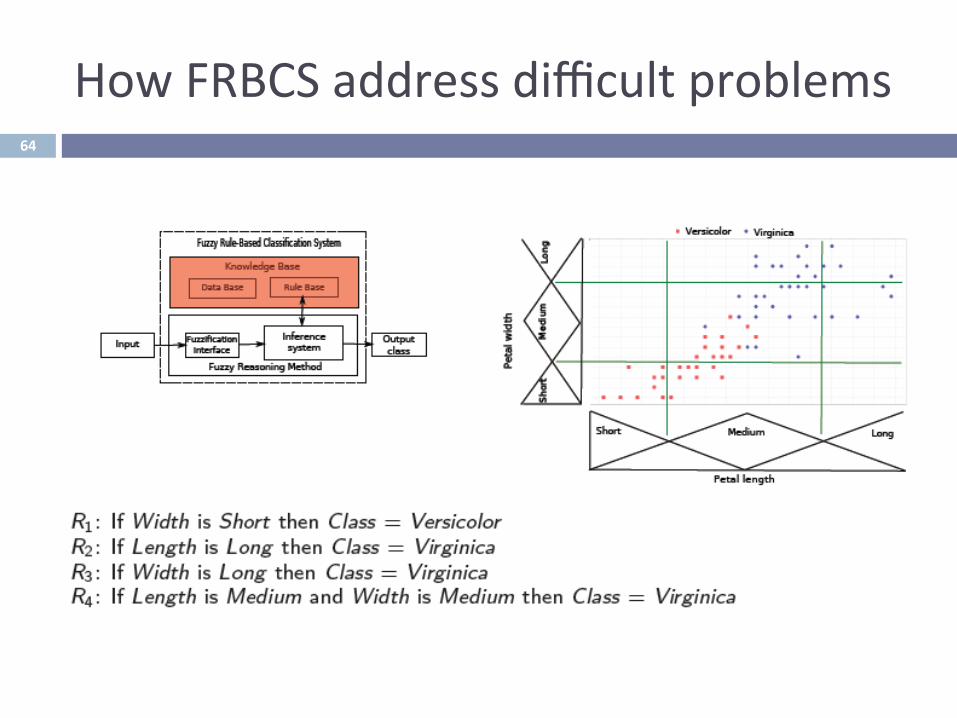
TheProblem:Classifica-on,FRBCSs,Mo-va-onHowFRBCSaddressdifficultproblems64
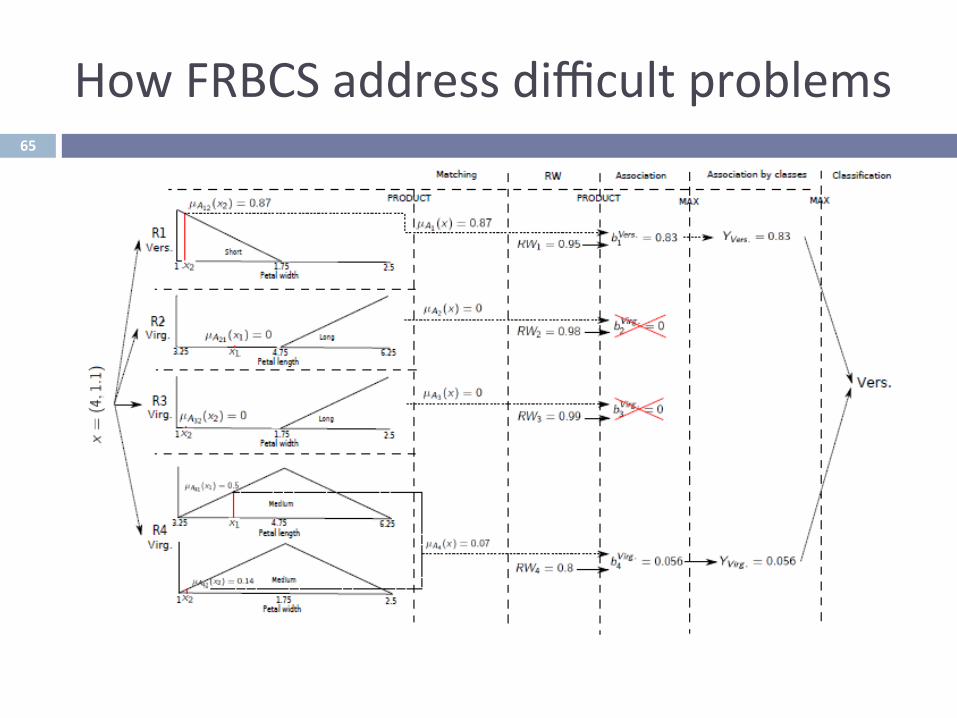
TheProblem:Classifica-on,FRBCSs,Mo-va-onHowFRBCSaddressdifficultproblems65

TheProblem:Classifica-on,FRBCSs,Mo-va-on
DegreeofignoranceontheexactMembershipdegree.ItmaybeusefultoconsiderandmodelittoimprovetheFRBCS
HowFRBCSaddressdifficultproblems66

TheProblem:Classifica-on,FRBCSs,Mo-va-on
Wecanconsidertheintervallengthtorepresentandmodeltheignorance.
HowFRBCSaddressdifficultproblems67

Índice
1. Interval-valuedFuzzyRuleBasedSystems1. HowFRBCSaddressdifficultproblems2. ImprovingtheperformanceofFRBCSusingInterval-
ValuedFuzzySets3. CasestudywithIVTURS
2. Classifica^onwithImbalancedData3. FuzzySystemsinBigDataandDataScience
68

TheProblem:Classifica-on,FRBCSs,Mo-va-onImprovingtheperformanceofFRBCSusingInterval-ValuedFuzzySets¨ Interval-valuedfuzzysets:tomodeldedegreeofignorance related to the defini^on of themembershipfunc^ons.
¨ Gene-calgorithms:toop^mizethevaluesofthemodel’sparameters.
¨ Withthisaim,itisnecessaryto:¤ Definemethodsforconstruc^nginterval-valuedfuzzysets.¤ Extendthefuzzyreasoningmethods.¤ Designnewgene^ctuningapproaches.
69

IntervalValuedFuzzySetsInterval-ValuedFuzzySets(IVFS)70

OntheuseofIntervalValuedFuzzySetsinFRBCSsIVFS:Construc^onMethod71

Gednginteres-ngmodels:StateoftheartinFRBCSs?
References:A.Jurio,M.Pagola,D.Paternain,C.Lopez-Molina,P.Melo-Pinto:Interval-valuedrestrictedequivalencefunc^onsappliedonClusteringTechniques.ProceedingsofIFSA2009,pp.831-836(2009)M.Galar,J.Fernandez,G.Beliakov,H.Bus^nce“Interval-ValuedFuzzySetsAppliedtoStereoMatchingofColorImages”IEEETrans.ImageProcessing,vol.20(7),1939-1949,2011.
IVFS:RestrictedEquivalenceFunc^ons
¨ IV-REFsareusedtoquan^fytheequivalencedegreebetweentwointervals
¨ Weuseaconstruc^onmethodbasedonautomorphisms
72

Gednginteres-ngmodels:StateoftheartinFRBCSs?
Thegoalistoshowhowequivalentaretheintervalmembershipdegreesoftheantencedentoftherulestotheidealintervalmembership[1,1].
IVFS:ExtensionoftheFRM73

Gednginteres-ngmodels:StateoftheartinFRBCSs?IVFS:ExtensionoftheFRM
Instep4weusetheordergivenbyYagerandXu.
74

Gednginteres-ngmodels:StateoftheartinFRBCSs?
The selec-on of a suitable IV-REF tomeasure the equivalencedegree in eachvariable could lead to an improvementontheFRBCS’behaviour.
Gene^cTuningoftheIV-REF75

Índice
1. Interval-valuedFuzzyRuleBasedSystems1. HowFRBCSaddressdifficultproblems2. ImprovingtheperformanceofFRBCSusingInterval-
ValuedFuzzySets3. CaseStudywithIVTURS
2. Classifica^onwithImbalancedData3. FuzzySystemsinBigDataandDataScience
76
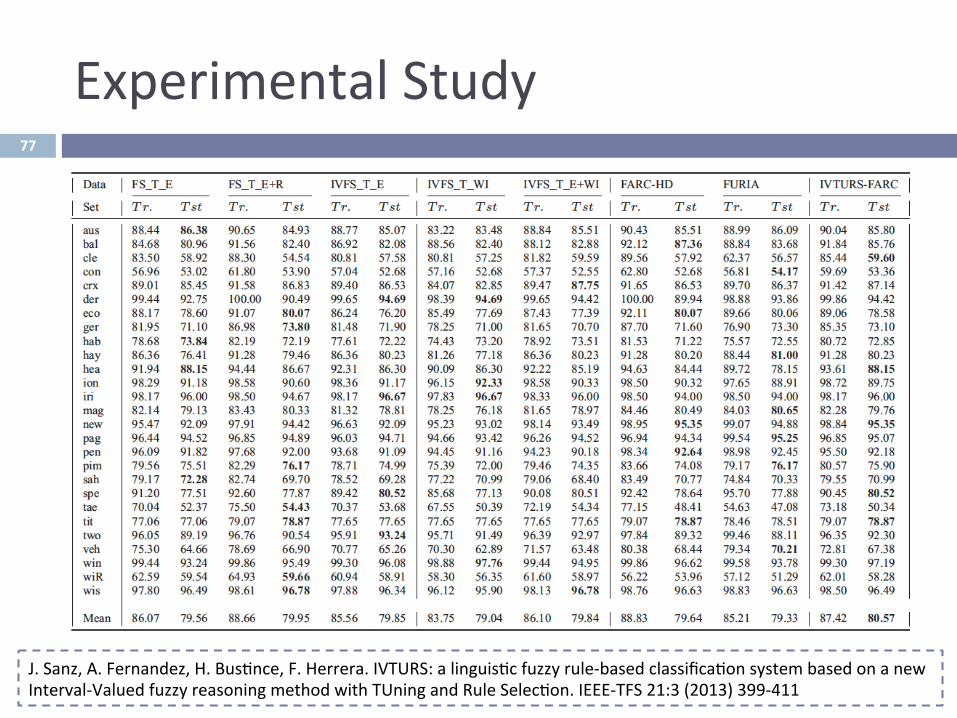
ExperimentalStudy
J.Sanz,A.Fernandez,H.Bus^nce,F.Herrera.IVTURS:alinguis^cfuzzyrule-basedclassifica^onsystembasedonanewInterval-ValuedfuzzyreasoningmethodwithTUningandRuleSelec^on.IEEE-TFS21:3(2013)399-411
77
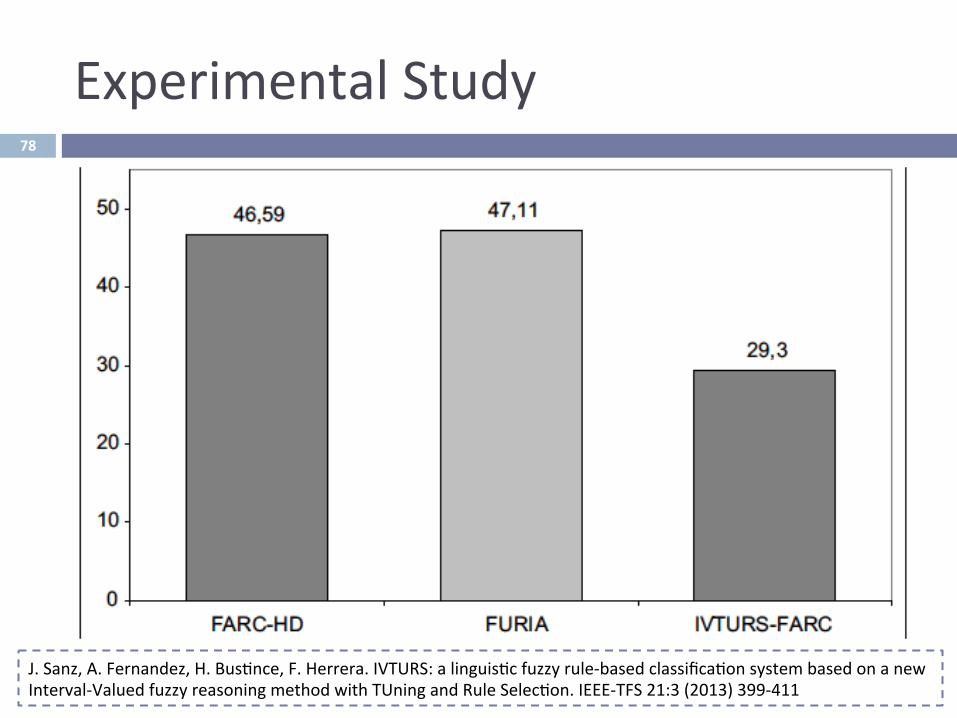
ExperimentalStudy
J.Sanz,A.Fernandez,H.Bus^nce,F.Herrera.IVTURS:alinguis^cfuzzyrule-basedclassifica^onsystembasedonanewInterval-ValuedfuzzyreasoningmethodwithTUningandRuleSelec^on.IEEE-TFS21:3(2013)399-411
78

IVFSs-FRBCSs:FinalCommentsSummary
¨ Methodologytofacedifficultclassifica^onproblems.¨ TheignorancedegreeismodeledbymeansofIVFS.¨ IVFSarebuiltbymeansofREFs¨ Fuzzy reasoning methods are extended in a naturalwaytoworkwithIVFS
¨ There is a posi^ve coopera^on between the tuningapproaches.
¨ The model obtains high quality results that can becomparedwiththestateoftheartinthetopic.
79
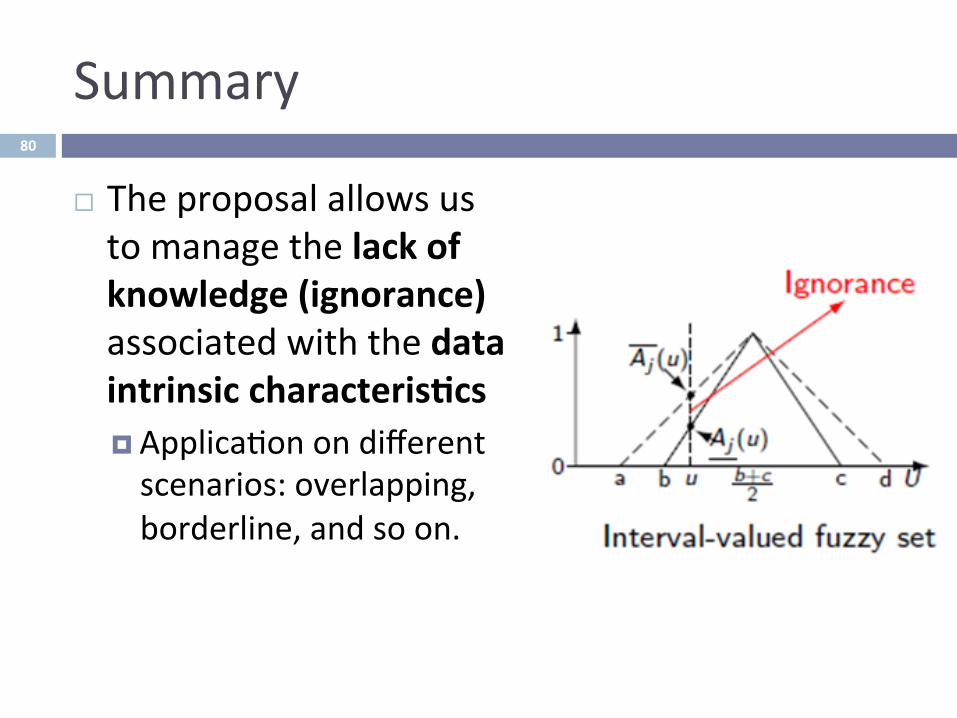
Gednginteres-ngmodels:StateoftheartinFRBCSs?Summary
¨ Theproposalallowsustomanagethelackofknowledge(ignorance)associatedwiththedataintrinsiccharacteris-cs¤ Applica^onondifferentscenarios:overlapping,borderline,andsoon.
80

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData
1. Proper^esofimbalanceddatasets2. Addressingimbalanceddatawithfuzzysystems3. CasestudywithGP-COACH-H
3. FuzzySystemsinBigDataandDataScience
81

Classifica^onwithImbalancedData
o Realapplica^onareasinengineeringcharacterisedbyhavingaverydifferentdistribu^onofexamplesamongtheirclasses.
o Intrinsictotheproblemorduetolimita^onsduringthedatacollec^onprocess.
o Someexamples:o Medicaldiagnosis/Frauddetec^ono Objectsiden^fica^on/Bioinforma^cs
o Problemof imbalanceddata-sets: it setsahandicapfor thecorrectiden^fica^onofthedifferentconceptstobelearnt.
o Posi^ve class oqen represents the concept of the highestinterest for the problem, whereas the nega^ve classrepresentscounter-examples.
82

Proper^esofimbalancedproblems
Learner
Dataset Knowledge Model
Minimizelearningerror+
maximizegeneraliza/on
Why learning from imbalanced data-sets might be difficult? 1. Searchprocessguidedbyglobalerrorrates.2. Classifica^on rules over the posi^ve class are highly
specialized.3. Classifierstendtoignoresmallclassesconcentra^ngon
classifyinglargeonesaccurately
83
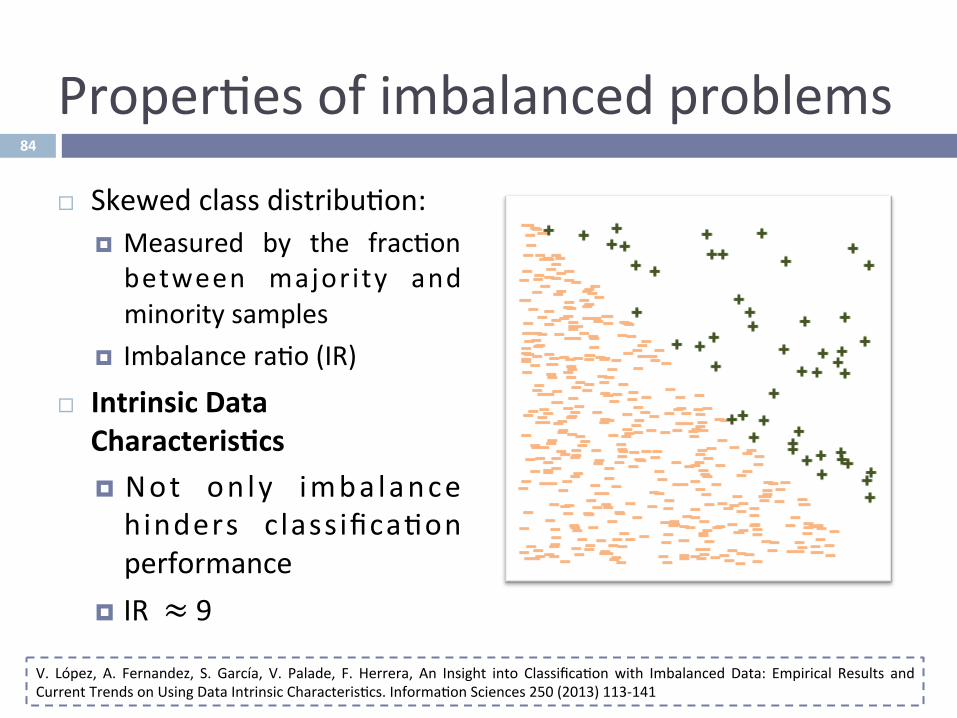
Proper^esofimbalancedproblems
¨ Skewedclassdistribu^on:¤ Measured by the frac^onbetween majority andminoritysamples
¤ Imbalancera^o(IR)
¨ IntrinsicDataCharacteris-cs¤ Not on ly imbalancehinders classifica^onperformance
¤ IR≈9
V. López, A. Fernandez, S. García, V. Palade, F. Herrera, An Insight into Classifica^onwith Imbalanced Data: Empirical Results andCurrentTrendsonUsingDataIntrinsicCharacteris^cs.Informa^onSciences250(2013)113-141
84
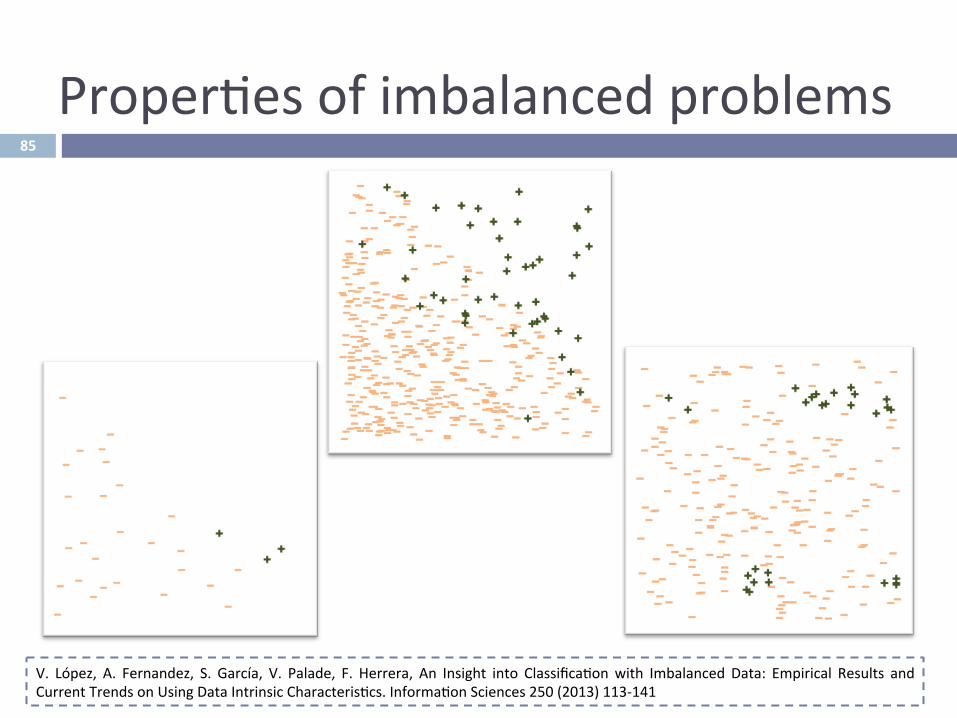
Proper^esofimbalancedproblems
V. López, A. Fernandez, S. García, V. Palade, F. Herrera, An Insight into Classifica^onwith Imbalanced Data: Empirical Results andCurrentTrendsonUsingDataIntrinsicCharacteris^cs.Informa^onSciences250(2013)113-141
85

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData
1. Proper^esofimbalanceddatasets2. Addressingimbalanceddatawithfuzzysystems3. CasestudywithGP-COACH-H
3. FuzzySystemsinBigDataandDataScience
86

Addressingimbalanceddata-sets
¨ Strategies to deal with imbalanced datasets: 1. Data level: instance preprocessing (re-sampling). 2. Algorithm level: change the behaviour of the
algorithm itself.
3. Cost-Sensitive learning: considers the varying costs of different misclassification types, given by a cost matrix. Mix of strategies
87
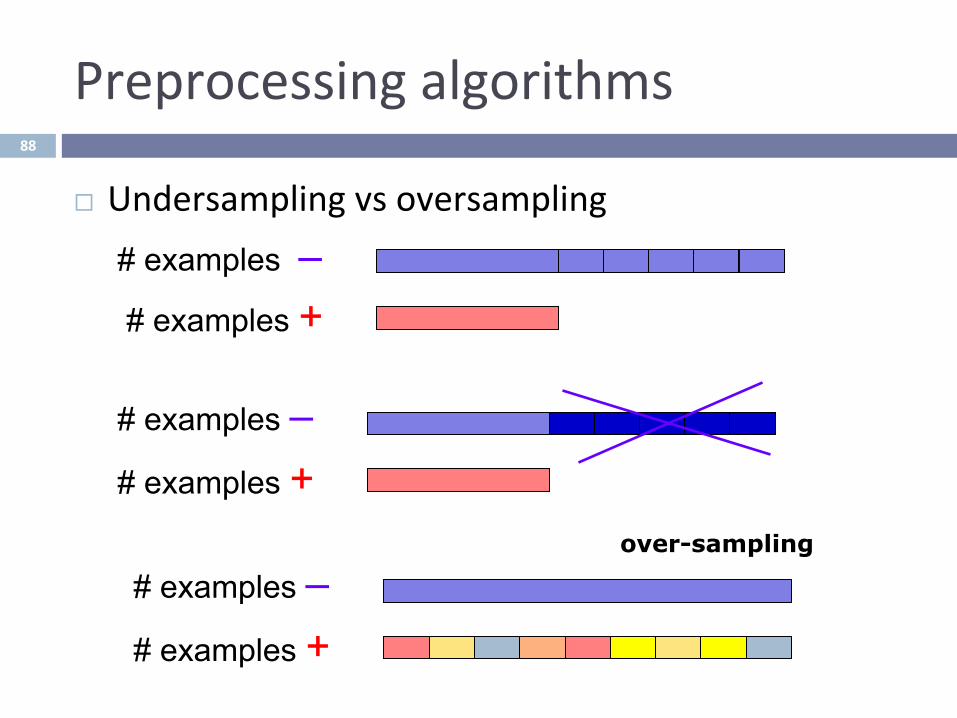
Preprocessingalgorithms
¨ Undersamplingvsoversampling# examples – # examples +
# examples – # examples +
# examples – # examples +
over-sampling
88

Preprocessingalgorithms:SMOTE
¨ Synthe^cMinorityOver-samplingTEchniqueandSMOTErelatedapproaches:¤ Genera-onofnewminorityclassexamples
¤ Interpola^onamongseveralminorityclassinstancesthatlietogether
¤ Somedrawbacks:n Problemofover-generaliza-on
n Lackofflexibility
N.V. Chawla, K.W. Bowyer, L.O. Hall, W.P. Kegelmeyer. SMOTE: synthe^c minority over-sampling technique. Journal of Ar^ficialIntelligenceResearch16(2002)321-357
Foreachminoritysample• Finditsk-nearestminorityneighbours• Randomlyselectjneighbours• Randomly generate synthe^c samples along
the lines joining the minority sampleselectedanditsjneighbours
(jdependsontheamountofoversamplingdesired)
89

Preprocessing+FRBCS
¨ Goodsynergyamongbothtechniques*¨ Many Evolu^onary Fuzzy Systems (EFS) inconjunc^onwithpreprocessing(SMOTE):¤ Adap^veinferencesystem¤ Linguis^cadjustmentbasedon2-tuples¤ Analysisforlowqualitydata¤ ApriorilearningoftheDataBase:featureselec^on+granularity
¤ StudyofthebehaviorofEFSwithdatasetshiq
*A.Fernandez,S.García,M.J.delJesus,F.Herrera.AStudyoftheBehaviourofLinguis^cFuzzyRuleBasedClassifica^onSystemsintheFrameworkofImbalancedDataSets.FuzzySetsandSystems,159:18(2008)2378-2398
90

Fuzzyalgorithmlevelapproaches
¨ FuzzyLogicAndGene^calgorithmsforImbalancedDatasets(FLAGID):¤ To create ad hoc membership func^ons for theposi^veclass
¨ Hierarchicalfuzzyrulebasedclassifica^onsystem:¤ Different granularity levels: higher for borderlineinstances
¨ IVTURSforimbalancedclassifica^on:¤ Rule weight rescaling method regarding the posi^veclass
91

Cost-sensi^velearning 92
¨ Errorsmadeonminority classexampleshigher than thoseof themajorityclassincompu^ngtrainingerror.
¨ Needsacostmatrix,whichencodesmisclassifica^onpenalty.¨ Considerthecost-matrixthroughoutthebuildingofthemodelfor
achievingthelowestcost.¨ Directmethods:
¤ Introduce and use misclassifica^on costs into the learningalgorithms.
¨ Meta-learning:¤ Preprocessingmechanismfortrainingdataorpost-processingoftheoutput.Theoriginallearningalgorithmisnotmodified:n Sampling:assigninginstanceweightsn Thresholding based on the Bayes decision theory: assign instances to class with
minimumexpectedcost.
C. Elkan, The founda^ons of cost-sensi^ve learning, in: Proceedings of the 17th Interna^onal Joint Conference on Ar^ficialIntelligence,2001,pp.973–978

Cost-sensi^vefuzzylearning
¨ Includeweightsduringthelearningstage:¤ Evalua^onfunc^onofgene^crulelearningprocedure
¨ Ac^ngonthecomputa^onoftheruleweight¤ Valuesare“weighted”regardingclassdistribu^on
¨ Modifyingtheinferenceprocess¤ Consider the compa^bility degree of the example andthefuzzylabeltogetherwiththecostassociatedtothatexample
93

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData
1. Proper^esofimbalanceddatasets2. Addressingimbalanceddatawithfuzzysystems3. CasestudywithGP-COACH-H
3. FuzzySystemsinBigDataandDataScience
94

GP-COACH-H:AHierarchicalGene^cProgrammingFuzzyRule-BasedClassifica^onSystemwithRuleSelec^onandTuning
¨ Thisproposalcombinesseveralstrategiesthatareabletoobtainagoodsynergybetween:¤ Data preprocessing modifies the input data to ease thelearningprocess
¤ Ahierarchicallinguis-cclassifierextendsthedefini^onofthe KB to model complex search spaces such asimbalanceddatawithharddataintrinsiccharacteris^cs.
¨ Gene-ctuningofKBparameterstoenhancethefinalmodelbyabehercharacteriza^onof theclassesofthedataset
95

Ra^onaleforHierarchicalKB
¨ A standard KB structure has problems for modelingcomplex problems: Imbalanced data with hard dataintrinsiccharacteris^cs¤ Lack of flexibility because of the rigid par^^oning of theinputspace(linguis^clabels).
¤ The size of the RB directly depends on the number ofvariablesandlinguis^ctermsinthesystem
¤ Obtaining an accurate FRBS requires a significantgranularityamount.n Numberofrulestorisesignificantlyn Interpretabilityislost.n Overfi�ngonthetrainingdata
96

HierarchicalMul^granularity
¨ Flexibiliza^onoftheKBtobecomeaHierarchicalKB.
¨ Linguis^cvariablesofthelinguis^crulescouldtakevaluesfromfuzzypar^^onswithdifferentgranularitylevels.
¨ Example:DB1becomesalinguis^cpar^^oninDB2.
97
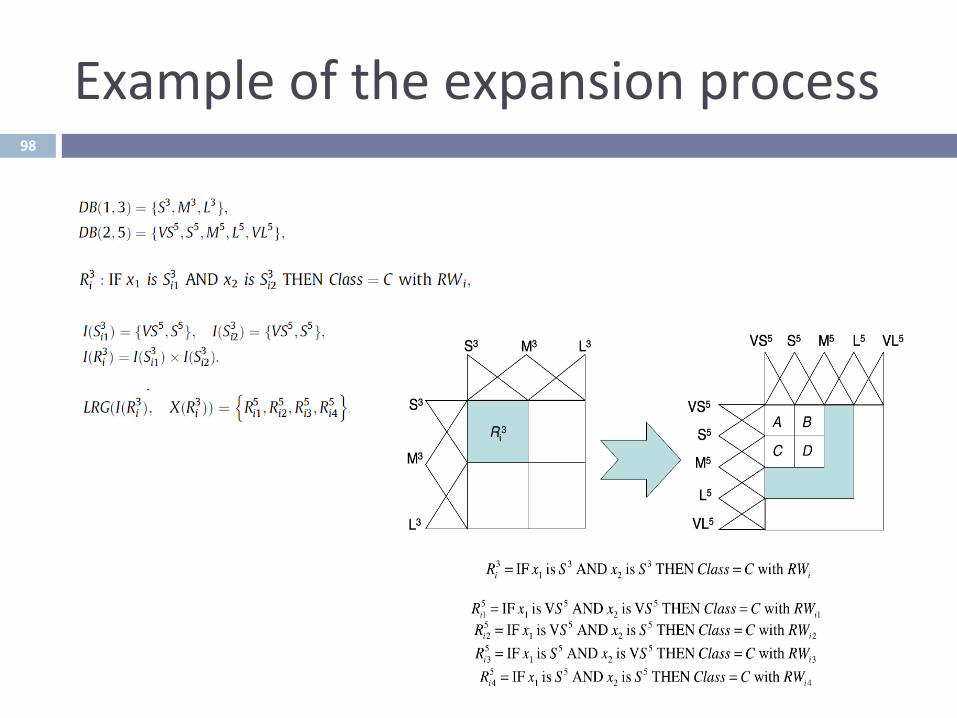
Exampleoftheexpansionprocess98
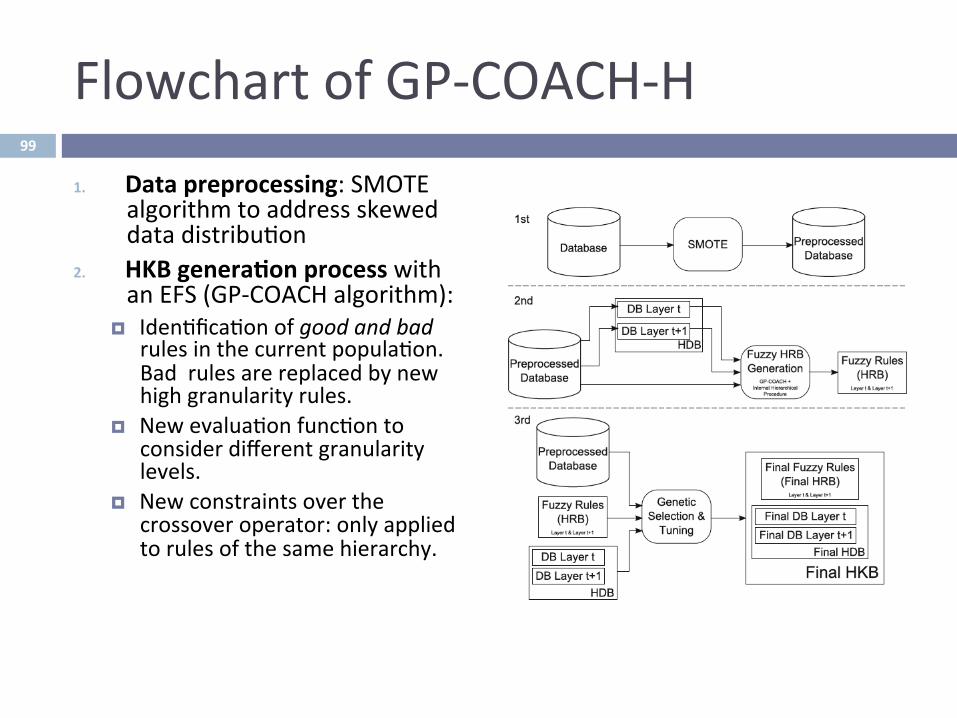
FlowchartofGP-COACH-H
1. Datapreprocessing:SMOTEalgorithmtoaddressskeweddatadistribu^on
2. HKBgenera-onprocesswithanEFS(GP-COACHalgorithm):
¤ Iden^fica^onofgoodandbadrulesinthecurrentpopula^on.Badrulesarereplacedbynewhighgranularityrules.
¤ Newevalua^onfunc^ontoconsiderdifferentgranularitylevels.
¤ Newconstraintsoverthecrossoveroperator:onlyappliedtorulesofthesamehierarchy.
99
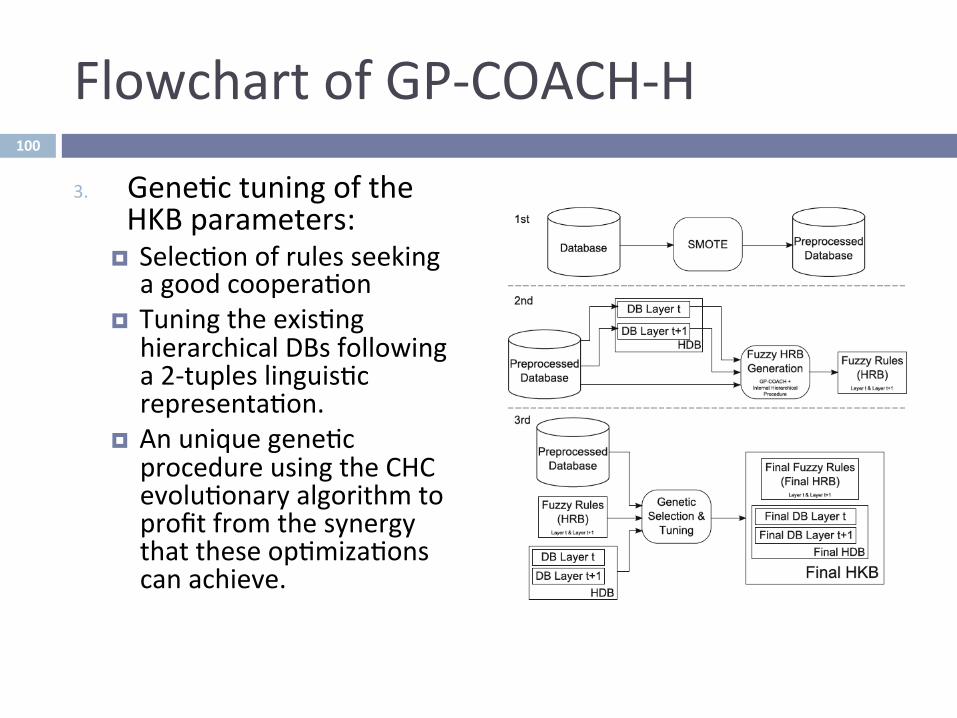
FlowchartofGP-COACH-H
3. Gene^ctuningoftheHKBparameters:
¤ Selec^onofrulesseekingagoodcoopera^on
¤ Tuningtheexis^nghierarchicalDBsfollowinga2-tupleslinguis^crepresenta^on.
¤ Anuniquegene^cprocedureusingtheCHCevolu^onaryalgorithmtoprofitfromthesynergythattheseop^miza^onscanachieve.
100
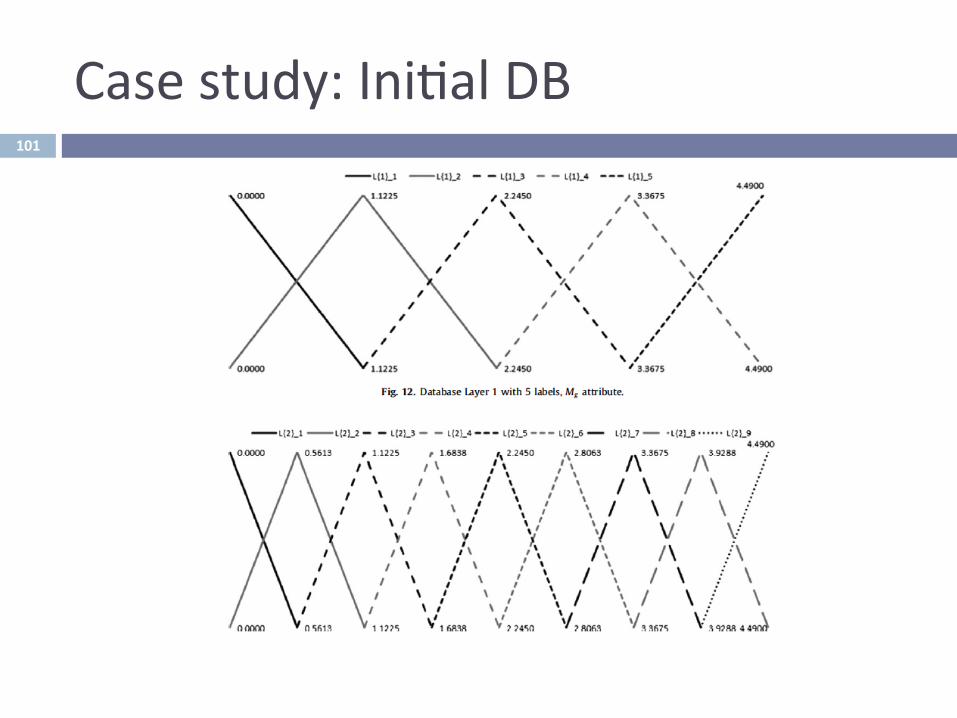
Casestudy:Ini^alDB101

Casestudy:Ini^alRB102
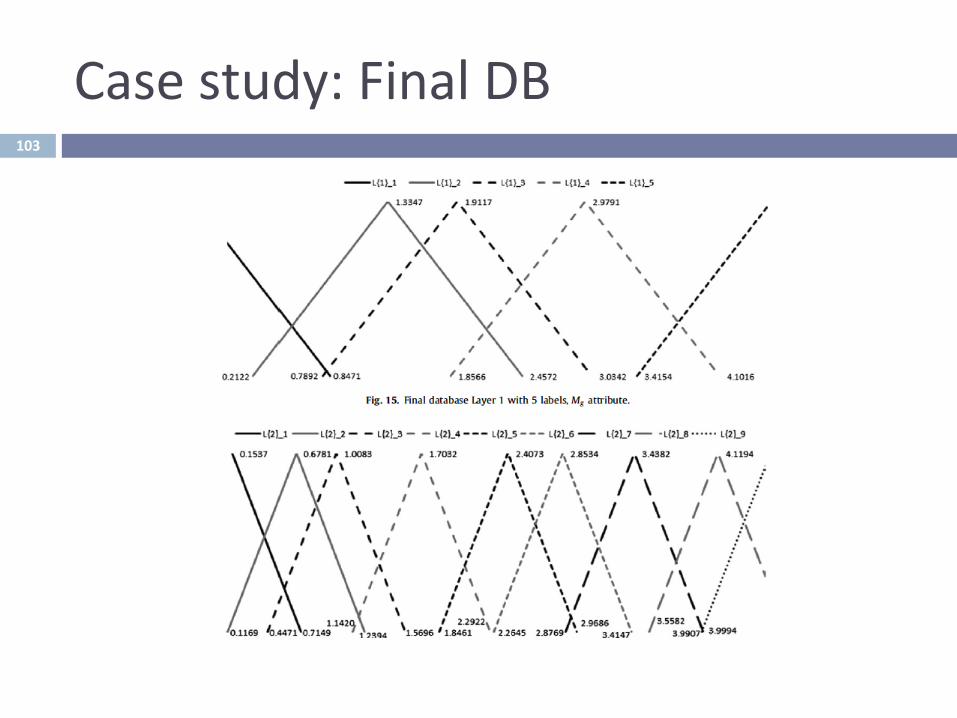
Casestudy:FinalDB103
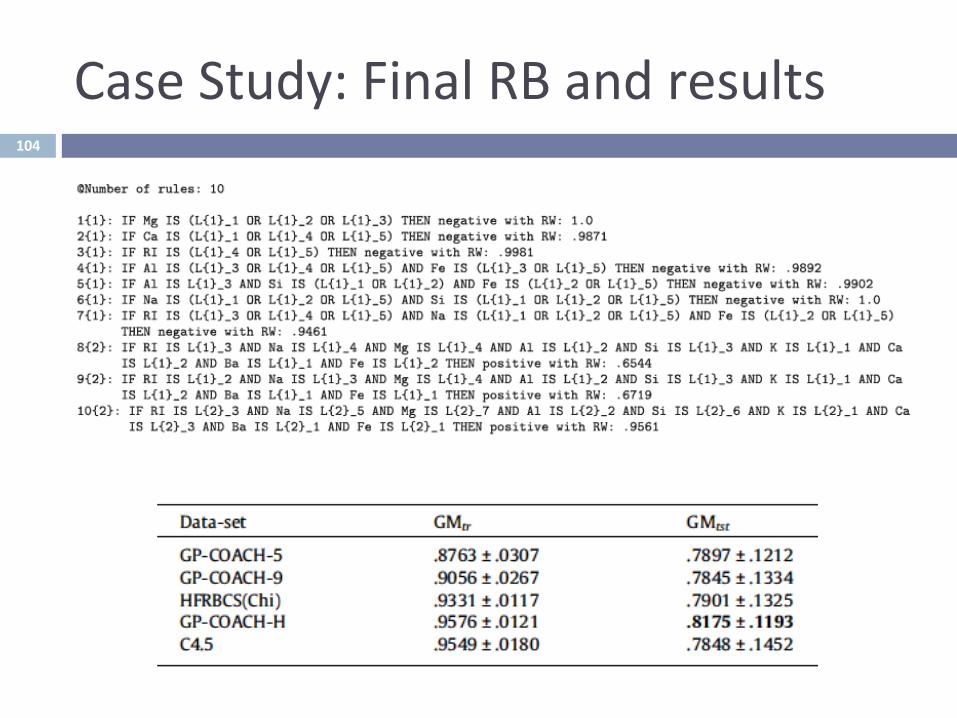
CaseStudy:FinalRBandresults104

ClassImbalance:Data-sets&algorithms105

ClassImbalance:Data-sets&algorithms
¨ 145datasetsincluded:¤ 100for2classes,¤ 15formul^pleclasses¤ 30fornoiseandborderline.
¨ Preprocessedpar^^onsarealsoavailable.
106

Thema^cWebsite
¨ hhp://sci2s.ugr.es/imbalanced/¨ Thewebisorganizedaccordingtothefollowingsummary:
¤ Introduc^ontoClassifica^onwithImbalancedDatasets
¤ ImbalancedDatasetsinClassifica^onn Theproblemofimbalanceddatasets
n Evalua^oninimbalanceddomains
¤ Problemsrelatedwithintrinsicdatacharacteris^cs
¤ AddressingClassifica^onwithimbalanceddata:preprocessing,cost-sensi^velearningandensembletechniquesn Preprocessingimbalanceddatasets:resamplingtechniques
n Cost-sensi^velearning
n Ensemblemethods
n ExperimentalResults
¤ Solware,AlgorithmImplementa-onsandDatasetRepository
¤ Literaturereviewn Papersofinterest:surveysandhighlightedstudies
n SCI2SRelatedApproaches
107

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData3. FuzzySystemsinBigData
1. BigDataandMapReduce2. InherentproblemsofMapReduceandgoodnessof
fuzzysystems3. Casestudy:Chi-FRBCS-BigData
108
A.Fernandezetal.BigDatawithCloudCompu^ng:AnInsightontheCompu^ngEnvironment,MapReduceandProgrammingFrameworks.WIREsDMKD4:5(2014)380-409.doi:10.1002/widm.1134
109
SistemasDifusosenBigData Analy^cs

110
DataFragmenta^onwithParallelProcessing+Modelfusion
MapReduce
SistemasDifusosenBigDataAnaly^cs
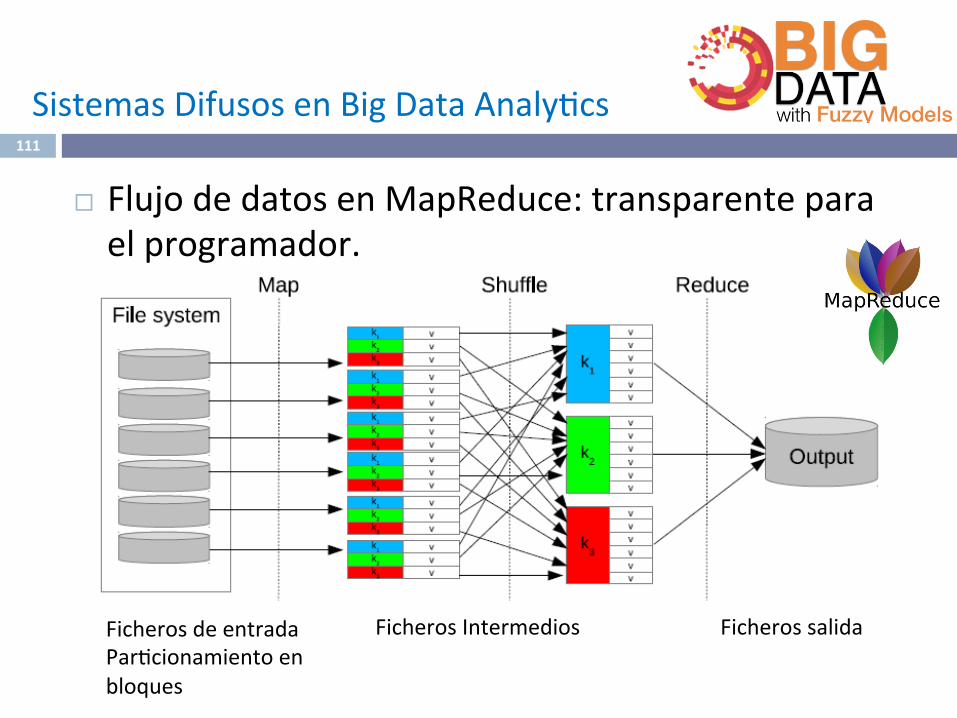
FicherosdeentradaPar^cionamientoenbloques
FicherosIntermedios Ficherossalida
¨ FlujodedatosenMapReduce:transparenteparaelprogramador.
111
SistemasDifusosenBigDataAnaly^cs

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData3. FuzzySystemsinBigData
1. BigDataandMapReduce2. InherentsproblemsofMapReduceandgoodnessof
fuzzysystems3. Casestudy:Chi-FRBCS-BigData
112
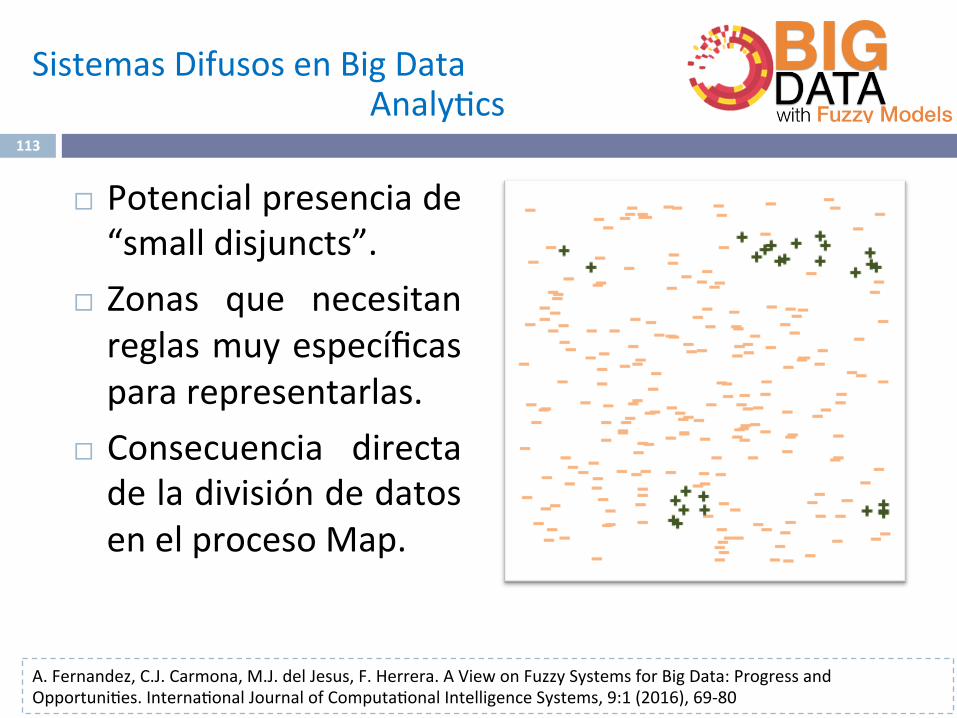
¨ Potencialpresenciade“smalldisjuncts”.
¨ Zonas que necesitanreglasmuyespecíficaspararepresentarlas.
¨ Consecuencia directadeladivisióndedatosenelprocesoMap.
113
A.Fernandez,C.J.Carmona,M.J.delJesus,F.Herrera.AViewonFuzzySystemsforBigData:ProgressandOpportuni^es.Interna^onalJournalofComputa^onalIntelligenceSystems,9:1(2016),69-80
SistemasDifusosenBigData Analy^cs
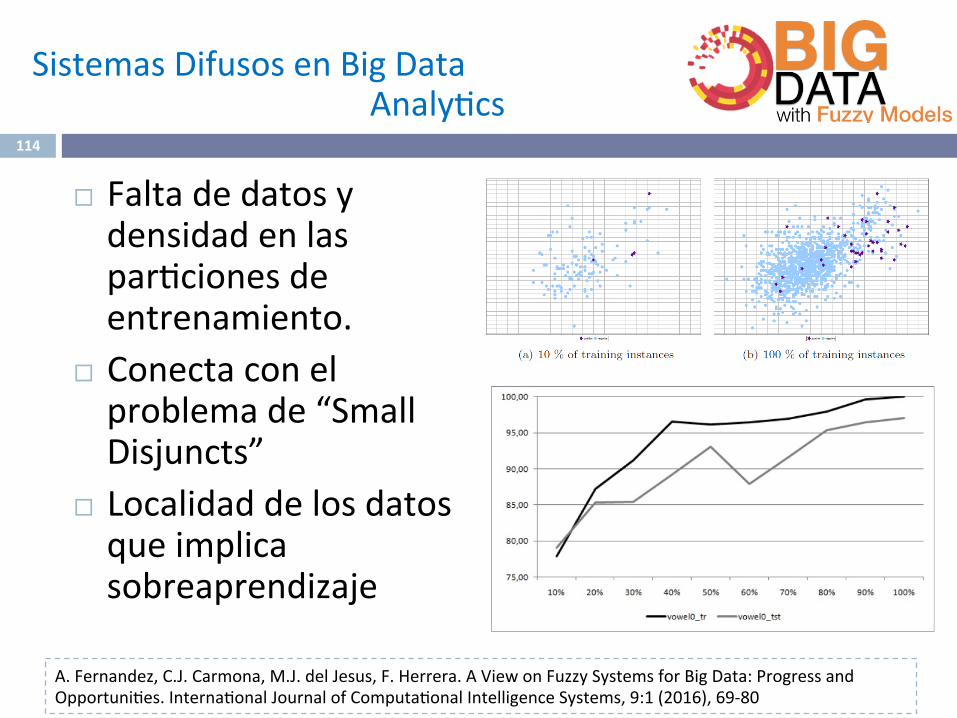
¨ Faltadedatosydensidadenlaspar^cionesdeentrenamiento.
¨ Conectaconelproblemade“SmallDisjuncts”
¨ Localidaddelosdatosqueimplicasobreaprendizaje
114
A.Fernandez,C.J.Carmona,M.J.delJesus,F.Herrera.AViewonFuzzySystemsforBigData:ProgressandOpportuni^es.Interna^onalJournalofComputa^onalIntelligenceSystems,9:1(2016),69-80
SistemasDifusosenBigData Analy^cs

Falta de datos: Pima data sets, C4.5, Backpropagation
T. Jo, N. Japkowicz. Class imbalances versus small disjuncts. SIGKDD Explorations 6:1 (2004) 40-49
El mal comportamiento inicial de los clasificadores es reparado cuando aumenta el tamaño del conjunto de datos.
SistemasDifusosenBigData Analy^cs
115
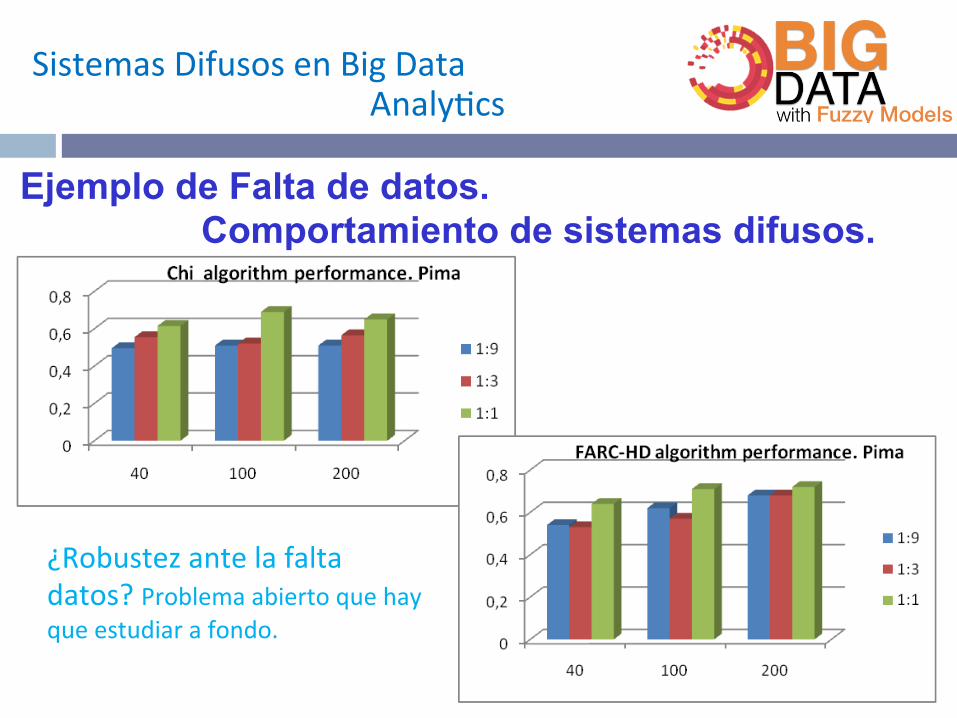
Ejemplo de Falta de datos. Comportamiento de sistemas difusos.
¿Robustezantelafaltadatos?Problemaabiertoquehayqueestudiarafondo.
SistemasDifusosenBigData Analy^cs
116

BigData:Imprecisióneincer-dumbre
¨ Laimprecisiónylaincer^dumbreesinherenteaBigDatadebidoa:¤ Origenheterogéneodelosdatos¤ Variedadde-podedatos¤ DatosImperfectos/incompletos/densidadbajadedatos
¨ Lossistemasdifusospuedenmanejar:¤ Incer-dumbre¤ Imprecisión¤ Densidadbajadedatos,faltadedatos/fragmentacióndelosdatos
SistemasDifusosenBigData Analy^cs
117

118
¨ El uso de variables lingüís^cas ofrece grandesventajasenelmarcodetrabajodeBigData¤ Permitensimplicidadyflexibilidadenelmodeladodelassoluciones.
¤ Ges^ón intrínseca de la variedad (heterogeneidad),veracidad,ynocomple^tud/imperfeccióndelosdatos
¤ El solapamiento de e^quetas difusas facilita lacoberturadelespaciodelproblema:muy importanteenprocesamientoMapReduce(smalldisjuncts!)
A.Fernandez,C.J.Carmona,M.J.delJesus,F.Herrera.AViewonFuzzySystemsforBigData:ProgressandOpportuni^es.Interna^onalJournalofComputa^onalIntelligenceSystems,9:1(2016),69-80
SistemasDifusosenBigData Analy^cs

Índice
1. Interval-valuedFuzzyRuleBasedSystems2. Classifica^onwithImbalancedData3. FuzzySystemsinBigData
1. BigDataandMapReduce2. InherentproblemsofMapReduceandgoodnessof
fuzzysystems3. Casestudy:Chi-FRBCS-BigData
119

Chi-FRBCS(extensión:Wang&Mendelmodel)
¨ “RuleRj:IFx1ISA1jAND…ANDxnISAn
jTHENClass=CjwithRWj”
¨ Buildsthefuzzypar^^onusingequallydistributedtriangularmembershipfunc^ons
¨ BuildstheRBcrea^ngafuzzyruleassociatedtoeachexample
¨ Ruleswiththesameantecedentmaybecreated:¤ Sameconsequent→Deleteduplicatedrules¤ Differentconsequent→Preservehighestweightrule
Z.Chi,H.YanandT.Pham,Fuzzyalgorithmswithapplica-onstoimageprocessingandpaoernrecogni-on,WorldScien^fic,1996.
SistemasDifusosenBigData Analy^cs
120
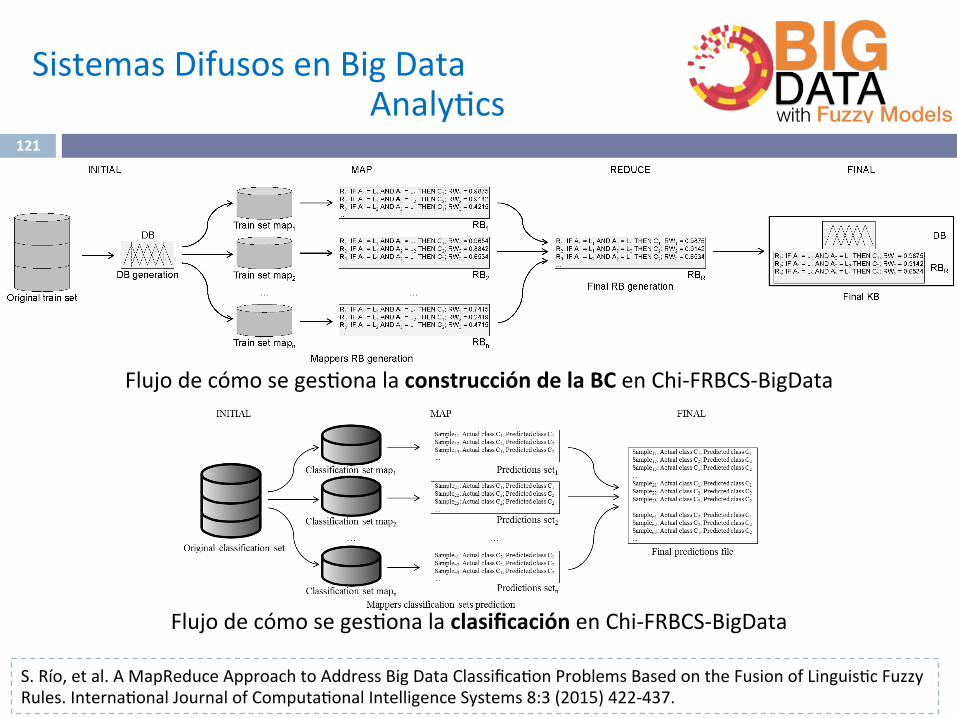
Flujodecómoseges^onalaconstruccióndelaBCenChi-FRBCS-BigData
S.Río,etal.AMapReduceApproachtoAddressBigDataClassifica^onProblemsBasedontheFusionofLinguis^cFuzzyRules.Interna^onalJournalofComputa^onalIntelligenceSystems8:3(2015)422-437.
Flujodecómoseges^onalaclasificaciónenChi-FRBCS-BigData
121
SistemasDifusosenBigData Analy^cs
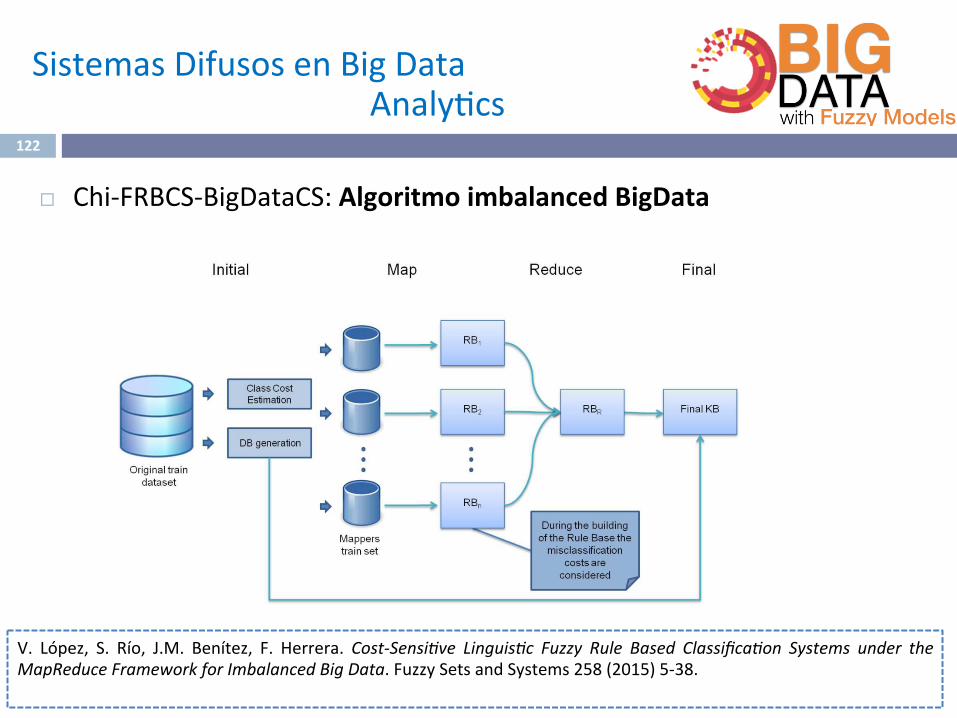
¨ Chi-FRBCS-BigDataCS:AlgoritmoimbalancedBigData
V. López, S. Río, J.M. Benítez, F. Herrera. Cost-SensiJve LinguisJc Fuzzy Rule Based ClassificaJon Systems under theMapReduceFrameworkforImbalancedBigData.FuzzySetsandSystems258(2015)5-38.
SistemasDifusosenBigData Analy^cs
122
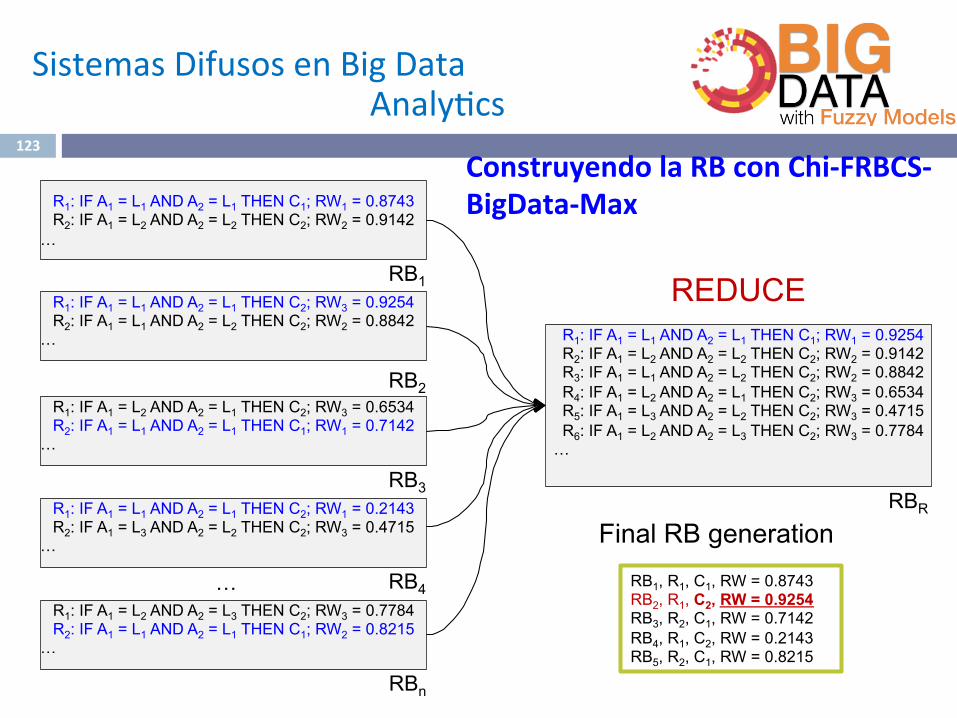
REDUCE R1: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.9254 R2: IF A1 = L2 AND A2 = L2 THEN C2; RW2 = 0.9142 R3: IF A1 = L1 AND A2 = L2 THEN C2; RW2 = 0.8842 R4: IF A1 = L2 AND A2 = L1 THEN C2; RW3 = 0.6534 R5: IF A1 = L3 AND A2 = L2 THEN C2; RW3 = 0.4715 R6: IF A1 = L2 AND A2 = L3 THEN C2; RW3 = 0.7784 …
RBR
Final RB generation
…
R1: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.8743 R2: IF A1 = L2 AND A2 = L2 THEN C2; RW2 = 0.9142
…
RB1 R1: IF A1 = L1 AND A2 = L1 THEN C2; RW3 = 0.9254 R2: IF A1 = L1 AND A2 = L2 THEN C2; RW2 = 0.8842
…
RB2 R1: IF A1 = L2 AND A2 = L1 THEN C2; RW3 = 0.6534 R2: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.7142
…
RB3 R1: IF A1 = L1 AND A2 = L1 THEN C2; RW1 = 0.2143 R2: IF A1 = L3 AND A2 = L2 THEN C2; RW3 = 0.4715
…
RB4 R1: IF A1 = L2 AND A2 = L3 THEN C2; RW3 = 0.7784 R2: IF A1 = L1 AND A2 = L1 THEN C1; RW2 = 0.8215
…
RBn
RB1, R1, C1, RW = 0.8743 RB2, R1, C2, RW = 0.9254 RB3, R2, C1, RW = 0.7142 RB4, R1, C2, RW = 0.2143 RB5, R2, C1, RW = 0.8215
ConstruyendolaRBconChi-FRBCS-BigData-Max
SistemasDifusosenBigData Analy^cs
123

REDUCE R1: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.8033 R2: IF A1 = L2 AND A2 = L2 THEN C2; RW2 = 0.9142 R3: IF A1 = L1 AND A2 = L2 THEN C2; RW2 = 0.8842 R4: IF A1 = L2 AND A2 = L1 THEN C2; RW3 = 0.6534 R5: IF A1 = L3 AND A2 = L2 THEN C2; RW3 = 0.4715 R6: IF A1 = L2 AND A2 = L3 THEN C2; RW3 = 0.7784
…
RBR
Final RB generation … RB1, R1, C1, RW = 0.8743
RB2, R1, C2, RW = 0.9254 RB3, R2, C1, RW = 0.7142 RB4, R1, C2, RW = 0.2143 RB5, R2, C1, RW = 0.8215
RC1, C1, RWave = 0.8033 RC2, C2, RWave = 0.5699
R1: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.8743 R2: IF A1 = L2 AND A2 = L2 THEN C2; RW2 = 0.9142 …
RB1 R1: IF A1 = L1 AND A2 = L1 THEN C2; RW3 = 0.9254 R2: IF A1 = L1 AND A2 = L2 THEN C2; RW2 = 0.8842 …
RB2 R1: IF A1 = L2 AND A2 = L1 THEN C2; RW3 = 0.6534 R2: IF A1 = L1 AND A2 = L1 THEN C1; RW1 = 0.7142 …
RB3
R1: IF A1 = L1 AND A2 = L1 THEN C2; RW1 = 0.2143 R2: IF A1 = L3 AND A2 = L2 THEN C2; RW3 = 0.4715 …
RB4
R1: IF A1 = L2 AND A2 = L3 THEN C2; RW3 = 0.7784 R2: IF A1 = L1 AND A2 = L1 THEN C1; RW2 = 0.8215 …
RBn
ConstruyendolaRBconChi-FRBCS-BigData-Ave
SistemasDifusosenBigData Analy^cs
124
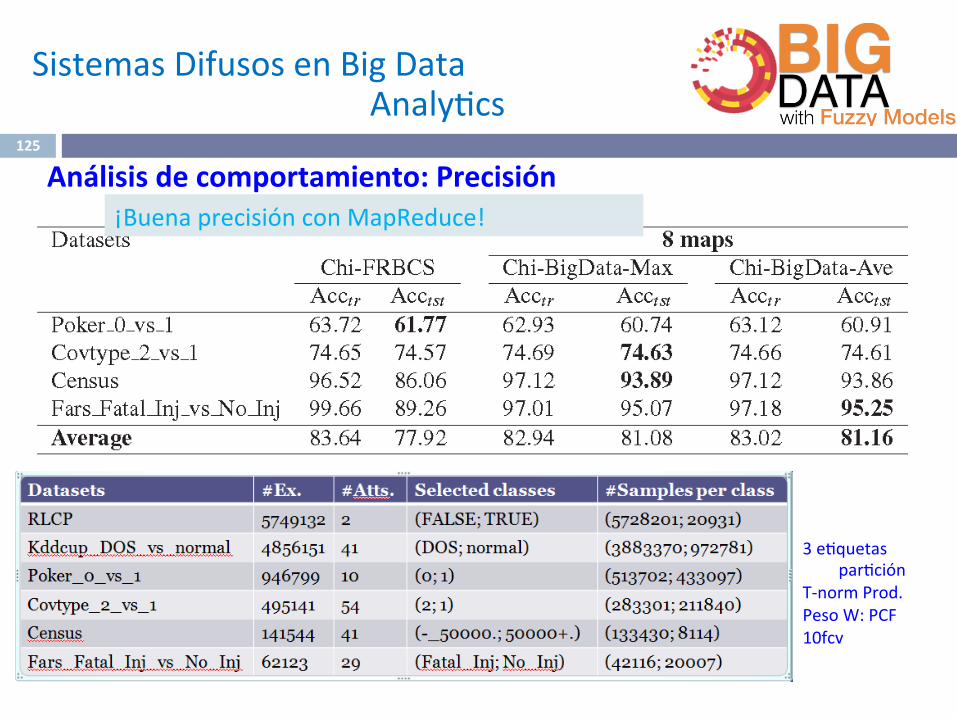
Análisisdecomportamiento:Precisión¡BuenaprecisiónconMapReduce!
SistemasDifusosenBigData Analy^cs
3e^quetaspar^ción
T-normProd.PesoW:PCF10fcv
125
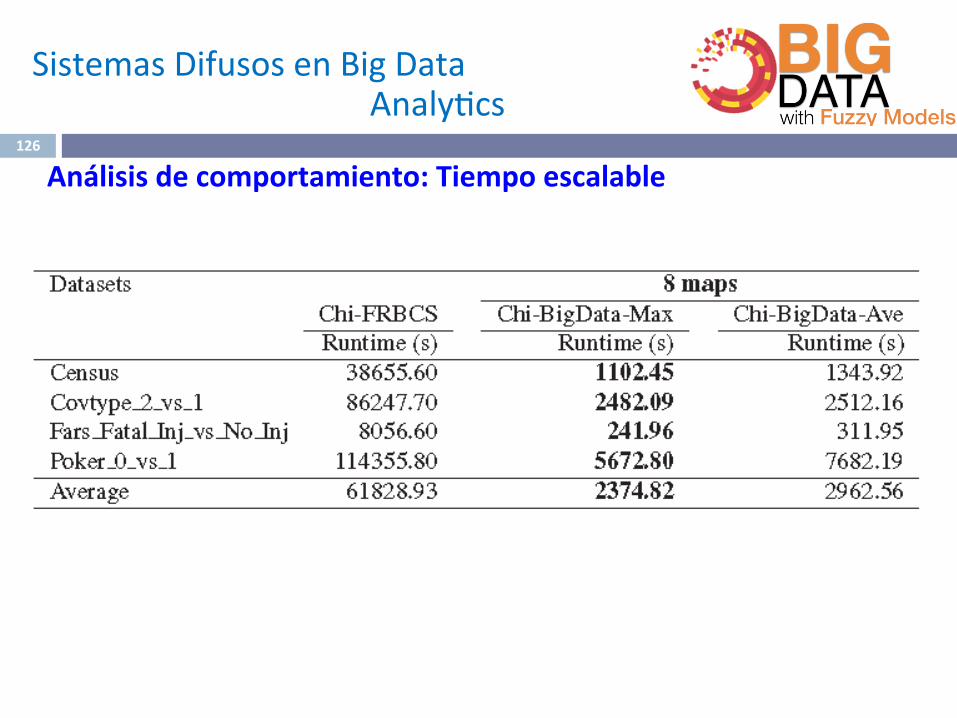
Análisisdecomportamiento:Tiempoescalable
SistemasDifusosenBigData Analy^cs
126

¨ Caracterís-casadestacar:Resultadosprometedores¤ Esfac^bleprocesargrandesvolúmenesdedatos¤ Sepuedemantenerunabuenaprecisión¤ Respuestarápida(incrementandoelnúmerodeMaps)
¨ Retosyestudiosarealizar:Muchosinterrogantes¤ ¿Cómodiseñarmodelosnolingüís^cos?¤ Análisis“ensemblesvsfusionderules”¿Sonú^leslosensembleslingüís^cos?Losensemblesdeárboles(RandomForest)sonmodelosimportantes,permitenconocerlaimportanciadelasvariables,precisión,…
¤ Análisisdelos“smalldisjuncts”víapreprocesamientoygranularidaddelaspar^cioneslingüís^cas.
¤ ¿Cómoabordarproblemasdealtadimensionalidad?
SistemasDifusosenBigData Analy^cs
127

Graciasporsuatención
¨ ¿Preguntas?128

JoséAntonioSanzyMikelGalarUniversidadPúblicadeNavarra
AlbertoFernándezHilarioUniversidaddeGranada
EVIA2016
Sistemasdeclasificaciónbasadosenreglasdifusas:Fundamentos,Mul^-clasificaciónyaspectosavanzados
CLASIFICACIÓNYMACHINELEARNINGCONTÉCNICASDIFUSAS