chapter 12 partitioning: divide and conquer. partitioning introduction partitioning lets you create...
TRANSCRIPT

CHAPTER 12Partitioning: Divide and Conquer

Partitioning Introduction• Partitioning lets you create a logical table or index that
consists of separate segments that can each be accessed and worked on by separate threads of execution.
• Each partition of a table or index has the same logical structure, such as the column definitions, but can reside in separate containers. In other words, you can store each partition in its own tablespace and associated datafiles.
• This allows you to manage one large logical object as a group of smaller, more maintainable pieces.
• Allows for massive scalability.• As a DBA or developer you should know partitioning
concepts and how to manage and maintain.

Partitioning Terminology• Partitioning• Partition key• Partition bound• Single-level partitioning• Composite partitioning• Subpartition• Partition independence• Partition pruning• Partition-wise join• Local partitioned index• Global partitioned index• Global nonpartitioned indexed

What Tables Should Be Partitioned?• Tables that are over 2GB in size.• Tables that have more than 10 million rows, when SQL
operations are getting slower as more data is added.• Tables you know will grow large. It’s better to create a
table as partitioned rather than rebuild it as partitioned after performance begins to suffer as the table grows.
• Tables that have rows that can be divided in a way that facilitates parallel operations like loading, retrieval, or backup and recovery.
• Tables for which you want to archive the oldest partition on a periodic basis, and tables from which you want to drop the oldest partition regularly as data becomes stale.

Looking for Big Objectsselect * from (
select
owner
,segment_name
,segment_type
,partition_name
,sum(extents) num_ext
,sum(bytes)/1024/1024 meg_tot
from dba_segments
group by owner, segment_name, segment_type, partition_name
order by sum(extents) desc)
where rownum <= 10;

Partitioning Strategies• Range• List• Hash• Composite• Interval• Reference• Virtual• System

Partitioning by Range• Commonly used partitioning strategy. • Places rows in partition based on the defined ranges.
create table f_regs(reg_count number,d_date_id number)partition by range (d_date_id)(partition p_2010 values less than (20110101),partition p_2011 values less than (20120101),partition p_max values less than (maxvalue));

One Table, No Partitions, One Tablespace
create table f_sales(
sales_id number
,amt number
,d_date_id number)
tablespace p1_tbsp;
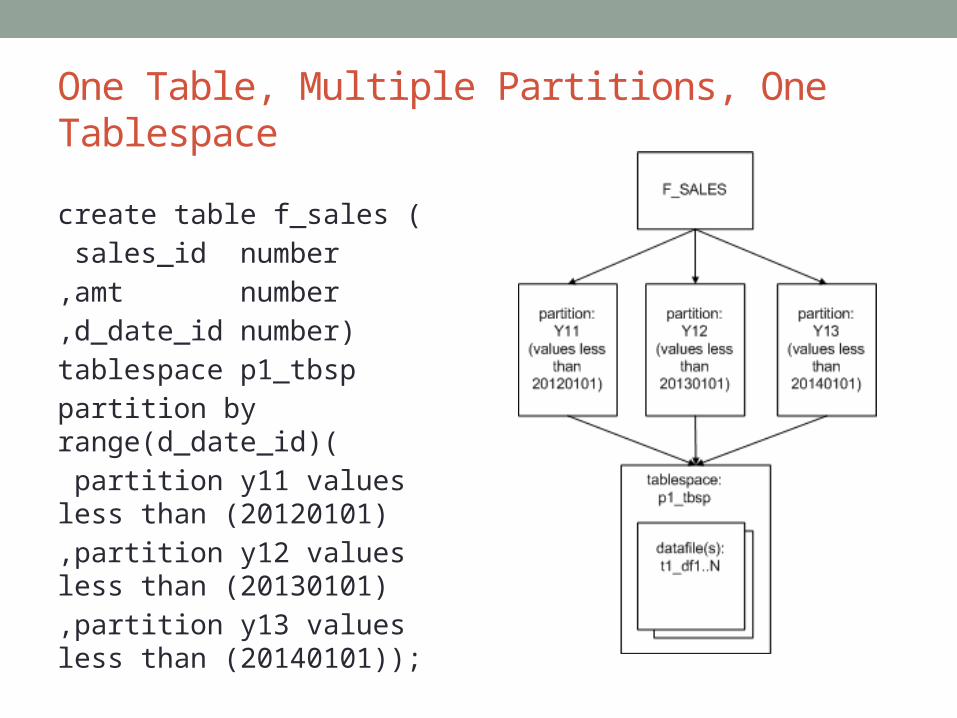
One Table, Multiple Partitions, One Tablespace
create table f_sales (
sales_id number
,amt number
,d_date_id number)
tablespace p1_tbsp
partition by range(d_date_id)(
partition y11 values less than (20120101)
,partition y12 values less than (20130101)
,partition y13 values less than (20140101));

One Table, Multiple Partitions, Multiple Tablespacescreate table f_sales (
sales_id number
,amt number
,d_date_id number)
tablespace p1_tbsp
partition by range(d_date_id)(
partition y11 values less than (20120101)
tablespace p1_tbsp
,partition y12 values less than (20130101)
tablespace p2_tbsp
,partition y13 values less than (20140101)
tablespace p3_tbsp);

Partitioning by List• Works well for partitioning unordered and unrelated sets of data.• For example: state codes
create table f_sales
(reg_sales number
,d_date_id number
,state_code varchar2(20)
)
partition by list (state_code)
( partition reg_west values ('AZ','CA','CO','MT','OR','ID','UT','NV')
,partition reg_mid values ('IA','KS','MI','MN','MO','NE','OH','ND')
,partition reg_rest values (default)
);

Partitioning by Hash• Table doesn’t contain an obvious column by which to partition the
table.• Surrogate key used for primary key and partition by PK.• Or partitioning by a value like SSN.
create table f_sales(
sales_id number primary key
,sales_amt number)
partition by hash(sales_id)
partitions 2 store in(p1_tbsp, p2_tbsp);
Note: Oracle recommends using a power of two (2, 4, 8, 16, and so on) for the number of hash partitions. This ensures the optimal distribution of rows throughout hashed partitions.

Blending Different Partitioning Methods
• Partition a table using multiple partitioning strategies.
create table f_sales(
sales_amnt number
,reg_code varchar2(3)
,d_date_id number
)
partition by range(d_date_id)
subpartition by list(reg_code)
(partition p2010 values less than (20110101)
(subpartition p1_north values ('ID','OR')
,subpartition p1_south values ('AZ','NM')
),
partition p2011 values less than (20120101)
(subpartition p2_north values ('ID','OR')
,subpartition p2_south values ('AZ','NM')
)
);

Types of Combined Partitioning Strategies Available• Range-hash (8i): Appropriate for ranges that can be
subdivided by a somewhat random key, like ORDER_DATE and CUSTOMER_ID.
• Range-list (9i): Useful when a range can be further partitioned by a list, such as SHIP_DATE and STATE_CODE.
• Range-range: Appropriate when you have two distinct partition range values, like ORDER_DATE and SHIP_DATE.
• List-range: Useful when a list can be further subdivided by a range, like REGION and ORDER_DATE.
• List-hash: Useful for further partitioning a list by a somewhat random key, such as STATE_CODE and CUSTOMER_ID.
• List-list: Appropriate when a list can be further delineated by another list, such as COUNTRY_CODE and STATE_CODE.

Creating Partitions on Demand• Oracle can automatically add partitions to range-partitioned tables.• Use the INTERVAL clause
create table f_sales(
sales_amt number
,d_date date
)
partition by range (d_date)
interval(numtoyminterval(1, 'YEAR'))
store in (p1_tbsp, p2_tbsp, p3_tbsp)
(partition p1 values less than (to_date('01-jan-2012','dd-mon-yyyy'))
tablespace p1_tbsp);

Partitioning to Match a Parent Table• Use the PARTITION BY REFERENCE clause to specify
that a child table should be partitioned in the same way as its parent.
• This allows a child table to inherit the partitioning strategy of its parent table.

Partitioning on a Virtual Column• Recall that a virtual column is based on an expression.• You can partition a table based on a virtual column.
create table emp (
emp_id number
,salary number
,comm_pct number
,commission generated always as (salary*comm_pct)
)
partition by range(commission)
(partition p1 values less than (1000)
,partition p2 values less than (2000)
,partition p3 values less than (maxvalue));

Giving an Application Control over Partitioning
• Use the PARTITION BY SYSTEM clause to allow an INSERT statement to specify into which partition to insert data.
create table apps
(app_id number
,app_amnt number)
partition by system
(partition p1
,partition p2
,partition p3);
SQL> insert into apps partition(p1) values(1,100);

Numerous Partition Related Views• Used to troubleshoot, manage, and maintain partioned tables
and indexes.
• DBA/ALL/USER_PART_TABLES• DBA/ALL/USER_TAB_PARTITIONS• DBA/ALL/USER_TAB_SUBPARTITIONS• DBA/ALL/USER_PART_KEY_COLUMNS• DBA/ALL/USER_SUBPART_KEY_COLUMNS• DBA/ALL/USER_PART_COL_STATISTICS• DBA/ALL/USER_PART_HISTOGRAMS• DBA/ALL/USER_SUBPART_HISTOGRAMS• DBA/ALL/USER_PART_INDEXES• DBA/ALL/USER_IND_PARTITIONS

Moving a Partition• Storage requirements change, and you want to move a
partition to a different tablespace.
SQL> alter table f_sales move partition reg_west tablespace p1_tbsp;
Automatically Moving Updated Rows• Updating a record and as a result it should be located in a
different partition.• First enable row movement, then update the record.
SQL> alter table f_regs enable row movement;
SQL> update f_regs set d_date_id = 20100901 where d_date_id = 20090201;

Partitioning an Existing Table• There is no “automated” way to alter a regular table into a
partitioned table.• Several manual options:
• CREATE <new_part_tab> AS SELECT * FROM <old_tab>• INSERT /*+ APPEND */ INTO <new_part_tab> SELECT * FROM
<old_tab>• Data Pump EXPDP old table; IMPDP new table • Create partitioned <new_part_tab>; exchange partitions with
<old_tab>• Use the DBMS_REDEFINITION package • Create CSV file or external table; load <new_part_tab> with
SQL*Loader

Adding a Partition• For a range-partitioned table, if the table’s highest bound
isn’t defined with a MAXVALUE, you can use the ALTER TABLE...ADD PARTITION statement to add a partition to the high end.
• For a list-partitioned table, you can add a new partition only if there isn’t a DEFAULT partition defined.
• Check status of any indexes after adding a partition. Make sure they’re still valid. If not, rebuild.

Exchanging a Partition with an Existing Table
• Exchanging a partition is a common technique for loading new data into large partitioned tables.
• This feature allows you to take a stand-alone table and swap it with an existing partition (in an already-partitioned table).
• Doing that lets you transparently add fully loaded new partitions without affecting the availability or performance of operations against the other partitions in the table.
• Very powerful and flexible feature for loading data into data warehouse environments.

Renaming a Partition• Rename a partition to conform to naming standards or
rename it before dropping it (to better ensure it’s not used).
SQL> alter table f_regs rename partition reg_p_1 to reg_part_1;
SQL> alter index f_reg_dates_fk1 rename partition reg_p_1 to reg_part_1;

Splitting a Partition• Take an existing partition and make it into two. • Allows you to evenly distribute rows.
alter table f_sales split partition reg_mid values ('IA','KS','MI','MN') into
(partition reg_mid_a,
partition reg_mid_b);

Merging Partitions• Allows you to merge two partitions into one to more
evenly distribute data.
SQL> alter table f_regs merge partitions reg_p_1, reg_p_2 into partition reg_p_2;

Dropping a Partition• If a partition isn’t being used, you can drop it.
SQL> alter table f_sales drop partition p_2008;

Generating Statistics for a Partition• After loading large amounts of data, generate statistics so
that the query optimizer can create a more optimal execution plan.
exec dbms_stats.gather_table_stats(ownname=>'STAR',-
tabname=>'F_SALES',-
partname=>'P_2012');

Removing Rows from a Partition• Truncate or delete rows per partition.
SQL> alter table f_sales truncate partition p_2008;
SQL> delete from f_sales partition(p_2008);

Manipulating Data within a Partition• If you know the data you’re after is in a specific partition,
select rows from a specific partition:
SQL> select * from f_sales partition (y11);
• Selecting from multiple specific partitions:
select * from f_sales partition (y11)
union
select * from f_sales partition (y12);

Partitioning an Index to Follow Its Table
• SQL> create index f_sales_fk1 on f_sales(d_date_id) local;

Partitioning an Index Differently than Its Table
create index f_sales_gidx1 on f_sales(sales_amt)
global partition by range(sales_amt)
(partition pg1 values less than (25)
,partition pg2 values less than (50)
,partition pg3 values less than (maxvalue));

Partition Pruning• Partition pruning can greatly improve the performance of
queries executing against partitioned tables.• If a SQL query specifically accesses a table on a partition
key, Oracle only searches the partitions that contain data the query needs.
• This feature can have huge performance implications.

Summary• Partitioning allows you to store an object in multiple
database segments.• This allows for massive scalability.• Oracle provides a robust set of partitioning features.• DBAs and developers working with large databases must
be familiar with partitioning.