capitulo iii variable dependiente ... - … · capitulo iii variable dependiente cualitativa y...
TRANSCRIPT

CAPITULO III
VARIABLE DEPENDIENTE CUALITATIVA Y LIMITADA
1. MODELOS DE ELECCION DISCRETA
Los modelos de elección discreta consideran una variable indicadora dependiente.Esta variable indicadora podrá tomar dos o más valores, si toma sólo dos valores (ceroo uno) se trata de una variable dicotómica.
Existen numerosos ejemplos de variables explicadas, a saber:
o
Existen también muchos métodos de analizar los modelos de regresión en lo queel valor de la variable dependiente es cero o uno. Por ejemplo: el modelo de probabilidadlineal, la función discriminante, modelo probit y modelo logit.
1.1. MODELO DE PROBABILIDAD LINEAL
Se utiliza para denotar un modelo de regresión en el que la variable dependienteY es dicotómica, y toma el valor de uno o cero. Por simplicidad, asumiremos una solavariable explicativa (X).
La variable Y es una variable indicadora que denota la ocurrencia o no ocurrenciade un evento.
El modelo se describe como:
con .
La esperanza condicional , se interpreta como laprobabilidad de que ocurre el evento, dado .
El valor calculado de Y a partir de la ecuación de regresión ( ) nos dala probabilidad estimada de que ocurre el evento, dado un valor específico para X. Enla práctica, estas probabilidades estimadas pueden encontrarse fuera del rango admisible(0, 1).

78
Las razones por las cuales no se puede aplicar mínimos cuadrados ordinarios son:
1º La no normalidad de las perturbaciones.-
Dado que toma los valores de 1 o 0 entonces los errores en laregresión tomará los valores siguientes:
En realidad los siguen una distribución binomial. Aunque el método demínimos cuadrados ordinarios no requiere esto, se asumen con fines de inferenciaestadística. Por lo tanto, existe un problema con la aplicación de las pruebasusuales de significancia.
El supuesto de normalidad no es tan crítico, porque las estimacionespuntuales de mínimos cuadrados ordinarios siguen siendo insesgados; además,a medida que aumenta indefinidamente el tamaño de la muestra los estimadoresde mínimos cuadrados ordinarios tienden por lo general a tener una distribuciónnormal.
Por lo tanto, para muestras grandes, la inferencia estadística de losmodelos de probabilidad lineal seguirá el procedimiento usual de mínimoscuadrados ordinarios bajo el supuesto de normalidad.
2º La varianza de la perturbación es heterocedástica.-
Las probabilidades respectivas de los eventos son:
se tiene que:
sacando factor común ( ) y simplificando nos da:
también se puede expresar de la siguiente forma:

79
La varianza de es heterocedástica porque depende de la esperanzacondicional de , que depende del valor que tome .
Los estimados de mínimos cuadrados ordinarios de no serán eficientes.Es posible utilizar el procedimiento siguiente para estimar el modelo:
I.- Se estima el modelo (ecuación 1) por mínimos cuadrados ordinarios y acontinuación se calcula .
II.- Se estima por mínimos cuadrados ponderados el modelo transformadosiguiente:
se soluciona el problema heterocedástico, pero subsiste los otros.
3º La predicción cae fuera de los limites ( 0 , 1 ).-
La crítica más importante se refiere a la propia formulación, que laesperanza condicional puede estar fuera de los límites (0,1).
El gráfico de la siguiente página revela la acumulación de puntos sobre y . Es fácil que los valores predichos se encuentren fuera del
intervalo (0,1) y que los errores de predicción sean muy grandes.
Existen dos métodos para saber si los estimadores están efectivamenteentre 0 y 1; son:

80
1.- Estimar el modelo de probabilidad lineal por mínimos cuadradosordinarios y ver si los se encuentran entre 0 y 1, si alguno de ellos es
menor a cero entonces se supone que para estos casos es cero; si sonmayores a 1, se suponen iguales a uno.
2.- Diseñar una técnica de estimación que garantice que las probabilidadescondicionales estimadas de estén entre 0 y 1. Los modelos Logit yProbit garantizarán que todas las probabilidades estimadas se encuentrenentre los límites lógicos 0 y 1.
4º La medida de bondad de ajuste.-
El coeficiente de determinación considerado tiene un valor limitado en losmodelos de respuesta dicotómica.
El coeficiente de determinación será alto, únicamente cuando la dispersiónespecífica esté muy cercana a los puntos A y B del gráfico anterior, puesto queen este caso es fácil fijar la línea recta uniendo los dos puntos. En este caso el predicho está muy cerca de 0 o 1.
John Aldrich y Forrest Nelson plantean que el uso del coeficiente dedeterminación como un estadístico resumen debe evitarse en aquellos modelosque contengan variables dependientes cualitativas.
1.2. EJEMPLO
El modelo especificado es:
Las variables se definen:
NOMBRE DEFINICIÓN UNIDAD DEMEDIDA
CAPAGO CAPACIDAD DE PAGO NUEVOS SOLES
CLIENTE CONDICIÓN DEL CLIENTE PUNTUAL = 1MOROSO = 0
EDAD EDAD DEL CLIENTE AÑOS
GARANTÍA MONTO DE LA GARANTÍA NUEVOS SOLES
INTERÉS TASA DE INTERÉS EFECTIVAMENSUAL
PORCENTAJE

81
NOMBRE DEFINICIÓN UNIDAD DEMEDIDA
NUMCUOTA NÚMERO DE CUOTAS
PERÍODO DURACIÓN DEL PRÉSTAMO MESES
PRÉSTAMO MONTO DEL PRÉSTAMO NUEVOS SOLES
SEXO SEXO MASCULINO = 1FEMENINO = 0
VALCUOTA VALOR DE LA CUOTA NUEVOS SOLES
Para estimarlo se dispone de información estadística recopilada de una instituciónfinanciera del Departamento de Piura.
El método de estimación es mínimos cuadrados ponderados y el procedimientoa seguir es el siguiente:
1º Estimar el modelo por mínimos cuadrados ordinarios
Se escribe en el Eviews:LS CLIENTE C EDAD PRESTAMO SEXO PERIODO
a continuación se oprime ENTER y nos da el resultado siguiente:
Dependent Variable: CLIENTE Method: Least Squares Sample: 1 60 Included observations: 60 =========================================================== Variable Coefficient Std. Error z-Statistic Prob. =========================================================== C -0.815473 0.306770 -2.658258 0.0103 EDAD 0.014550 0.005161 2.819315 0.0067 PRESTAMO 1.89E-05 9.95E-06 1.895651 0.0633 SEXO 0.159441 0.110854 1.438297 0.1560 PERIODO 0.064383 0.022997 2.799581 0.0070===========================================================R-squared 0.332861 Mean dependent var 0.516667Adjusted R-squared 0.284341 S.D. dependent var 0.503939S.E. of regression 0.426316 Akaike info criteri 1.212381Sum squared resid 9.995971 Schwarz criterion 1.386910Log likelihood -31.37144 F-statistic 6.860387Durbin-Watson stat 1.511575 Prob(F- statistic) 0.000149===========================================================

82
2º Se realiza la estimación de la probabilidad de la siguiente forma:
Abrir la ecuación Procs Forecast OK y se muestra un gráfico y el⇒ ⇒ ⇒software crea un icono con el nombre que se le colocó a la estimación(CLIENTEF).
Para observar los resultados de la variable CLIENTEF se da dos clic ypaquete nos muestra lo siguiente:
CLIENTEF==========================================================
Modified: 1 60 // fit(f=actual) clientef 1 0.417364 1.104751 0.155492 0.803627 0.554091 6 0.814965 0.515421 0.486014 0.909758 0.899076 11 0.475652 0.765374 0.770710 1.321578 0.987106 16 0.536256 0.575847 1.014905 0.341672 0.405989 21 0.230938 0.643846 0.488985 0.437800 0.606510 26 0.259805 0.262450 0.206271 0.085420 0.620479 31 0.717948 -0.136817 0.397171 0.315820 0.243069 36 0.389929 0.804237 0.755200 0.045541 0.188897 41 0.618349 0.155769 0.417060 0.830059 0.278586 46 1.075758 0.486799 0.248942 0.408926 0.518848 51 0.317095 0.186445 0.067943 0.465541 0.483412 56 0.673622 0.643638 0.507839 0.651220 0.545000==========================================================
3º Estimamos la varianza generándola de la siguiente forma:GENR W = CLIENTEF * ( 1 - CLIENTEF )
y el Eviews nos da el siguiente resultado:
W=====================================================
Modified: 1 60 // w=clientef*(1-clientef) 1 0.243171 -0.115724 0.131314 0.157811 0.247074 6 0.150797 0.249762 0.249804 0.082099 0.090738 11 0.249407 0.179577 0.176716 -0.424990 0.012728 16 0.248686 0.244247 -0.015127 0.224932 0.241162 21 0.177606 0.229308 0.249879 0.246131 0.238656 26 0.192306 0.193570 0.163723 0.078124 0.235485 31 0.202498 -0.155536 0.239426 0.216078 0.183987 36 0.237884 0.157440 0.184873 0.043467 0.153215 41 0.235993 0.131505 0.243121 0.141061 0.200976 46 -0.081498 0.249826 0.186970 0.241706 0.249645 51 0.216546 0.151683 0.063327 0.248813 0.249725 56 0.219855 0.229368 0.249939 0.227132 0.247975=====================================================
83
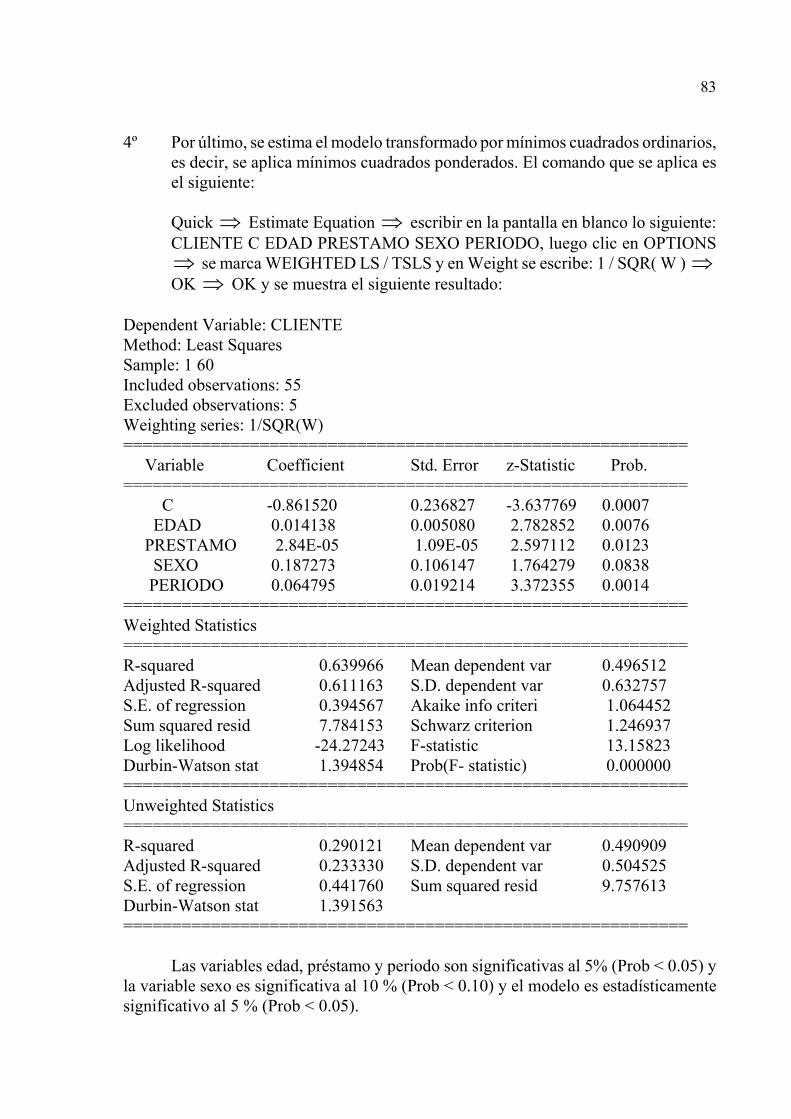
4º Por último, se estima el modelo transformado por mínimos cuadrados ordinarios,es decir, se aplica mínimos cuadrados ponderados. El comando que se aplica esel siguiente:
Quick Estimate Equation escribir en la pantalla en blanco lo siguiente:⇒ ⇒CLIENTE C EDAD PRESTAMO SEXO PERIODO, luego clic en OPTIONS
se marca WEIGHTED LS / TSLS y en Weight se escribe: 1 / SQR( W ) ⇒ ⇒OK OK y se muestra el siguiente resultado:⇒
Dependent Variable: CLIENTE Method: Least Squares Sample: 1 60 Included observations: 55Excluded observations: 5Weighting series: 1/SQR(W) ========================================================== Variable Coefficient Std. Error z-Statistic Prob. ========================================================== C -0.861520 0.236827 -3.637769 0.0007 EDAD 0.014138 0.005080 2.782852 0.0076 PRESTAMO 2.84E-05 1.09E-05 2.597112 0.0123 SEXO 0.187273 0.106147 1.764279 0.0838 PERIODO 0.064795 0.019214 3.372355 0.0014==========================================================Weighted Statistics==========================================================R-squared 0.639966 Mean dependent var 0.496512Adjusted R-squared 0.611163 S.D. dependent var 0.632757S.E. of regression 0.394567 Akaike info criteri 1.064452Sum squared resid 7.784153 Schwarz criterion 1.246937Log likelihood -24.27243 F-statistic 13.15823Durbin-Watson stat 1.394854 Prob(F- statistic) 0.000000==========================================================Unweighted Statistics==========================================================R-squared 0.290121 Mean dependent var 0.490909Adjusted R-squared 0.233330 S.D. dependent var 0.504525S.E. of regression 0.441760 Sum squared resid 9.757613Durbin-Watson stat 1.391563==========================================================
Las variables edad, préstamo y periodo son significativas al 5% (Prob < 0.05) yla variable sexo es significativa al 10 % (Prob < 0.10) y el modelo es estadísticamentesignificativo al 5 % (Prob < 0.05).

84
Se predice dentro de la muestra con la instrucción siguiente:
Abrir la ecuación Procs Forecast OK y se muestra un gráfico y el software⇒ ⇒ ⇒crea un icono con el nombre que se le colocó a la estimación (CLIENTEF1).
Para observar los resultados de la variable CLIENTEF1 se da dos clic y paquetenos muestra lo siguiente:
CLIENTEF1========================================================= Modified: 1 60 // modproblin.fit(f=actual) clientef1 1 0.453183 1.264643 0.135592 0.836835 0.598836 6 0.850146 0.519971 0.488047 1.081373 0.993891 11 0.530495 0.822073 0.907713 1.590984 0.994447 16 0.531559 0.572147 0.991846 0.311970 0.395700 21 0.185995 0.640793 0.466289 0.421358 0.568752 26 0.200522 0.216839 0.177498 0.057164 0.580712 31 0.705757 -0.186881 0.349757 0.259422 0.188732 36 0.333220 0.805080 0.713630 0.020425 0.178108 41 0.585508 0.103903 0.390143 0.822291 0.239000 46 1.073549 0.468637 0.223544 0.397997 0.464635 51 0.294014 0.161586 0.019346 0.446526 0.426291 56 0.618380 0.623329 0.494666 0.619459 0.525189=========================================================
y los resultados se comparan con los valores observados de la variable endógena,obteniendose 42 predicciones correctas ( 20 para CLIENTE = 1 y 22 PARA CLIENTE= 0) y nos da un Coeficiente de Bondad de Conteo de 70 %.
1.3. MODELO LOGIT Y PROBIT
Un enfoque alternativo es suponer un modelo de regresión:
no se observa ( se conoce como variable " latente " ).
Lo que se observa es una variable indicadora definida por:
La diferencia entre la especificación (2) y el modelo de probabilidad lineal es queen este último se analizan las variables dicotómicas tal como son, en tanto que en (2) sesupone la existencia de una variable latente subyacente para la que se observa una

85
evidencia dicotómica. Ejemplo:
1º la persona tiene o no empleo.
la propensión o capacidad de encontrar empleo.
2º si la persona compra o no un automóvil.
el deseo o capacidad de adquirir un automóvil.
por lo tanto, las variables explicativas de (2) contendrán variables que expliquen amboselementos.
Supongamos que , esto nos permite fijar la escala de .Combinando (2) y (3) obtenemos:
donde F es la función de distribución acumulada de u.
Si la distribución de u es simétrica, entonces , la expresiónanterior se puede escribir:
Los Observados son sólo realizaciones de un proceso binomial cuyasprobabilidades están dadas por (4) y que varían de un ensayo a otro (de pendiendo de
), entonces la función de verosimilitud se puede escribir:
La forma funcional para F en (4) dependerá de la suposición en torno al términode error u.
Se ha creado un problema de estimación porque es no lineal no solamente en sino también en los ; entonces, no se puede estimar mediante mínimos cuadradosordinarios. En esta situación, es preciso recurrir al método de máxima verosimilitud paraestimar los parámetros.
El método de máxima verosimilitud consiste en la maximización de la función deverosimilitud (ecuación 5) para el modelo LOGIT y PROBIT y ésto se logra por mediode métodos no lineales de estimación. La función de verosimilitud es cóncava (no tiene

86
Cliente X ui i i= + +α β
múltiples máximos) y, por lo tanto, cualquier valor inicial de los parámetros será útil. Escostumbre comenzar las iteraciones para el modelo logit y probit con los estimados delmodelo de probabilidad lineal.
Si la información disponible es sobre familias individuales, donde si una
familia posee una casa y si no la posee; entonces el modelo a estimar es (5) porel método de máxima verosimilitud.
1.3.1. CONSTRUCCIÓN DE UN MODELO LOGIT O PROBIT
Los requisitos para la construcción de un modelo logit o probit son:
1º Contar con una muestra representativa de clientes cumplidos e incumplidos, cuyotamaño mínimo se establece vía criterios estadísticos.
2º Contar con suficiente información de los clientes contenida en sus solicitudes decrédito o expedientes.
3º Seleccionar las posibles variables explicativas de la probabilidad de default de losclientes, en base al conocimiento o experiencia previa y a procedimientosestadísticos (test de significancia individual).
4º Escoger el modelo más apropiado en base a tests estadísticos sobre la "bondad deajuste" o "calidad predictiva" del modelo.
El procedimiento a seguir es:
1º El significado de las variables aparece en el ítem 1.2.
2º Buscar el mejor modelo explicativo de la probabilidad de default (cumplimiento)de los clientes, en base al siguiente procedimiento general:
2.1. Realización de regresiones bivariables y selección de variables explicativas segúnsigno y significancia estadística individual (escogemos las de probabilidad menordel 10 por ciento).
Se estiman varias regresiones de la siguiente forma:
para seleccionar la variable se requiere analizar: el signo correcto, la significanciade (si es altamente significativo, significativo o relativamente significativo)βy el (debe estar entre 0.2 y 0.6).R2
2.2. Comparación de correlaciones entre variables a fin de eliminar el problema de

87
multicolinealidad. Entre las variables correlacionadas optamos por la de mayorR2 de Mc Fadden.
Una vez identificadas las variables más relevantes a partir de modelosbivariables, podemos descartar algunas de ellas en base a su correlaciones.Variables altamente correlacionadas (con coeficientes de correlación mayores a0.5) resultan redundantes, es decir, basta con que me quede con una de ellas enel modelo, ya que si las incluyo todas sus significancias estadísticas individualestienden a ser bajas (no se puede distinguir el impacto de cada una de ellas sobrela variable dependiente). El criterio práctico es eliminar las variablescorrelacionadas con menor significancia estadística individual en las regresionesbivariables, con menor R2 (Mc Fadden).
Para obtener la Matriz de Correlaciones entre variables, aplico:Quick/Group Statistics/Correlations
y se escribe el nombres de las variables seleccionadas en el ítem anterior.
2.3. Construcción de modelos multivariables en sus versiones logit, probit y linealincorporando las variables escogidas luego de los pasos 1 y 2. Los modelos sevan perfilando para dejar sólo las variables estadísticamente significativas(probabilidad menor del 10 por ciento).
Con las variables explicativas escogidas, luego de los pasos 2.1. y 2.2. seestima el modelo en su versión logit, probit o lineal. El modelo se perfila paradejar sólo las variables con signos adecuados y estadísticamente significativas(prob < 0.10).
2.4. Evaluación de los modelos alternativos en base a siguientes criterios arrojadospor el programa E-views:
1.- Signo correcto de los coeficientes.2.- Significancia estadística individual de los parámetros de acuerdo al
z-statistic y su probabilidad correspondiente.3.- Significancia conjunta del modelo.4.- Bondad de ajuste en base a R2 de Mc Fadden, Expectation-Prediction
Table, Goodness-of-Fit Test (Hosmer-Lemeshow).
A) Bondad de ajuste: La regla práctica nos dice que este valor debeencontrarse entre 0.2 y 0.6 para considerarseaceptable en el contexto de la modelación deprobabilidades.
Se han sugerido varias medidas de bondad de ajuste paraeste tipo de modelos, por ejemplo:
1.- La correlación entre CALF y CALFF al cuadrado:

88
2.- Basada en la suma de cuadrados residual:
3.- Amemiya:
4.- Mc - Fadden:
= Función de Máxima Verosimilitud conrespecto a todos los parámetros.
= Función de Máxima Verosimilitud cuando sehace con la restricción
5.- Cragg - Uhler:
6.- R2 de conteo:
B) Expecation-Prediction Table: Esta prueba nos permite averiguarcuál es el porcentaje de acierto en laspredicciones que obtiene el modelo.

89
C) Goodness-of-Fit Test: (test de Hosmer-Lemeshow). Esta pruebaparte de agrupar las observaciones enquantiles y evalúa el desempeño del modeloen cada uno de ellos en términos del númerode observaciones que predice el modelo quedeben ubicarse en cada quantil vs el númerode observaciones real.
Por defecto, me indica que lainformación se va a agrupar en 10 quantiles ogrupos según niveles. Lo ideal es que elnúmero total de observaciones por quantil seael más grande posible (prueba para muestrasgrandes).
Se recomienda hacer esta prueba conel mayor número posible de observacionesposible en cada quantil.
5.- Criterio de Hannan Quinn (por ser una "función de pérdida", convieneminimizarlo frente a los modelos alternativos).
Este es un criterio para comparar modelos alternativos. La regla esescoger el modelo con menor H-Q (no se aplica al MLP).
6.- Curva de Respuesta de Probabilidad de cada variable explicativa del
modelo.
Esta prueba es ratificatoria del test de significancia estadísticaindividual de las variables explicativas. Nos permite evidenciar medianteun gráfico ad hoc si cada una de estas variables tiene poder paradiscriminar entre buenos y malos pagadores, partiendo de un valor "c"como parámetro de corte entre quienes se consideran dentro de ambascategorías; usualmente este valor se sitúa en 0.5, es decir, quienes tienenuna probabilidad de cumplir menor o igual que 0.5 (50 por ciento), seasumen como malos clientes y los que tienen una mayor, buenos clientes.
2.5. Selección del modelo final en base a la perfomance relativa de éste al comparar,entre modelos alternativos, los resultados de los test sugeridos en el ítemanterior.
Lo primero que cabe destacar es que, en el caso del MLP, los efectosmarginales de las variables explicativas son constantes para todos los individuos,mientras que en los casos del logit y el probit, estos efectos son diferentes paracada individuo, dependiendo de los valores de las variables explicativas que locaracterizan.
Usualmente, en los modelos logit y probit se calculan los efectos

90
marginales de una variable o regresor para cada individuo, a fin de tener una ideadel rango de variación de dichos efectos y se asume que el promedio de estosefectos individuales es una buena aproximación al "efecto marginal global" dela variable (si se quiere tener un número - resumen), lo cual, desde luego, partede la premisa de que se cuenta con una muestra suficientemente representativa.
Pese a que los parámetros j de cada regresor, en los modelos logit yprobit, no nos miden, por sí solos el, efecto marginal de dicho regresor, si nosindican la dirección (signo) del cambio inducido en la probabilidad por lavariable explicativa.
2.6. Una vez elegido el modelo final, cálculo de los efectos marginales respectivos
Los efectos de los cambios en las variables explicativas sobre lasprobabilidades de que cualquier observación pertenezca a uno de los dos grupos,son proporcionados por:
donde: y es la función de densidad normal
estándar.
1.3.2. MODELO LOGIT PARA DATOS AGRUPADOS
Si la distribución acumulada de es logística, se tiene el llamado modeloLOGIT, es decir:
donde
Las probabilidades son:

91
El cociente entre ambas probabilidades es:
aplicando logaritmo neperiano, nos da:
En el modelo de probabilidad lineal se supone como función lineal de lasvariables explicativas; aquí, la razón logarítmica de momios o logit es una función linealde las variables explicativas.
Tiene las siguientes características:
1.- Dado que P va de 0 a 1, es decir, a medida que Z varía entre y el logitestá entre y . En otras palabras, aunque las probabilidades se encuentranentre 0 y 1, los logit no tienen estos límites.
2.- Aunque el logit es lineal en X, las probabilidades mismas no lo son, en contrastecon el modelo de probabilidad lineal, donde las probabilidades aumentanlinealmente con X.
3.- La interpretación del modelo logit es: mide el cambio en logit por un cambiounitario en X, es decir, nos muestra cómo varía la factibilidad del logit en favorde poseer una casa a medida que X cambia en una unidad.
Si es relativamente grande y si cada observación en una clase de , estádistribuida en forma independiente como una variable binomial, entonces:
por lo tanto, el término de perturbación en el modelo logit es heterocedástico y el métodode estimación adecuado es mínimos cuadrados ponderados.
El procedimiento para estimar una regresión logit (7) es:

92
( 1 ) Para cada nivel de , se calcula la probabilidad estimada de poseer una casa
como .
( 2 ) Para cada valor de , obténgase el logit como:
( 3 ) Para solucionar el problema de heterocedasticidad, se transforma así:
donde las ponderaciones , porque se distribuye normal
con varianza igual a si es suficientemente grande.
( 4 ) Estimar el modelo transformado utilizando mínimos cuadrados ordinarios (es unmodelo sin intercepto).
( 5 ) Establecer los intervalos de confianza y/o las pruebas de hipótesis en el marcousual de mínimos cuadrados ordinarios, pero manteniendo en mente que todas lasconclusiones serán validas, si la muestra es razonablemente grande. Parapequeñas muestras los resultados estimados deben interpretarse cuidadosamente.
1.3.3. MODELO PROBIT PARA DATOS AGRUPADOS
Si los errores siguen una distribución normal, se tiene un modelo PROBIT (oNORMIT), es decir:
donde es un índice de conveniencia no observable que está determinado por una ovarias variables explicativas, así:
y t es la variable normal estandarizada, es decir, t se distribuye .
Es razonable suponer que para cada familia hay un nivel crítico o umbral delíndice, , tal que si excede a , ocurre el evento, de lo contrario no sucederá. El

93
umbral al igual que no es observable, pero si se supone que esta distribuidonormalmente con la misma media y varianza. Por lo tanto, es posible estimar losparámetros y los valores del índice no observable. Es decir, la probabilidad sería:
Como representa la probabilidad de que un evento ocurra, P se mide por elárea de la curva normal estándar desde hasta . Para obtener la información de , como también de y , tomamos el inverso de la función de distribuciónprobabilística acumulada normal.
Se ha creado un problema de estimación porque es no lineal no solamente en sino también en los ; entonces, no se puede estimar mediante mínimos cuadradosordinarios.
Si es relativamente grande y si cada observación en una clase de , estádistribuida en forma independiente como una variable binomial, entonces:
por lo tanto, el término de perturbación en el modelo probit es heterocedástico y elmétodo de estimación adecuado es mínimos cuadrados ponderados.
El procedimiento para estimar una regresión probit es:
( 1 ) Para cada nivel de , se calcula la probabilidad estimada de poseer una casa
como .
( 2 ) Dado , obténgase el índice de utilidad como:
( 3 ) Para solucionar el problema de heterocedasticidad, se transforma así:

94
donde las ponderaciones , porque se distribuye normal
con varianza igual a si es suficientemente grande.
( 4 ) Estimar el modelo transformado utilizando mínimos cuadrados ordinarios (es unmodelo sin intercepto).
( 5 ) Establecer los intervalos de confianza y/o las pruebas de hipótesis en el marcousual de mínimos cuadrados ordinarios, pero manteniendo en mente que todas lasconclusiones serán validas, si la muestra es razonablemente grande. Parapequeñas muestras los resultados estimados deben interpretarse cuidadosamente.
Si la información esta agrupada o replicada (observaciones repetidas), entoncesse puede obtener información sobre la variable dependiente y el índice de utilidad; porlo tanto, el modelo a estimar se aplica mínimos cuadrados ponderados.
1.3.4. MODELO LOGIT VERSUS MODELO PROBIT
Desde el punto de vista teórico, la diferencia entre ambos modelos es ladistribución de probabilidades (normal para el modelo probit y logística para el modelologit); ambas distribuciones están muy próximas entre sí, excepto en los extremos, lalogística tiene colas ligeramente más planas, es decir, la curva normal o probit se acercaa los ejes más rápidamente que la curva logística. Por esta razón, no es probable obtenerresultados muy diferentes, a menos que las muestras sean grandes.
Sin embargo, los estimados de los parámetros de ambos métodos no son
directamente comparables; porque la distribución logística tiene una varianza y la
distribución normal tiene una varianza de 1. Entonces ambos coeficientes se relacionande la siguiente forma:
Amemiya sugiere multiplicar los estimados LOGIT por 1/1.6 = 0.625 porque estatransformación produce una aproximación más cercana entre la distribución logística yla función de distribución normal estándar. Es decir, la relación sería:
También sugiere que los coeficientes del modelo de probabilidad lineal

95
y los coeficientes del modelo logit se relacionan así:
Aplicando regla de tres simple logramos encontrar la relación entre loscoeficientes del modelo probit y el modelo de probabilidad lineal, que nos da:
Si se tiene muestras de tamaños desiguales, no se afectan la estimación de loscoeficientes de la variables explicativas del modelo logit, pero si se afecta el términoconstante. Este resultado no es valido para el modelo probit ni para el modelo deprobabilidad lineal. Si el modelo estimado se utiliza para propósitos de predicción, esnecesario ajustar el término constante.
Desde el punto de vista práctico, es generalmente utilizado con preferencia elmodelo logit sobre el modelo probit.
2. MODELOS DE ELECCIÓN MÚLTIPLE
Existen varias formas en que se pueden analizar este problema:
1º Con datos no ordenados: se utiliza cuando las alternativas que presenta lavariable endógena no indican ningún orden. Puedenser:
1.1. Multinomial, se utiliza cuando los regresores del modelo hacen referencia a lasobservaciones muestrales, por lo que varían entre observaciones pero no entrealternativas.
1.2. Condicional, se utiliza cuando los regresores del modelo hacen referencia a lasalternativas, por lo que sus valores varían entre alternativas pudiendo hacerlo ono entre observaciones.
2º Con datos ordenados: se utiliza cuando las alternativas de la variableendógena representan un orden entre ellas.
Generalizaremos los resultados anteriores a casos en los que los individuos hacenelecciones entre tres o más alternativas mutuamente excluyentes.
Un modelo multinomial de respuesta cualitativa se define de la siguiente forma:

96
( ) ( )P Y j F X i n y j mi Y i= = = =* , ; , ,..., , ,..., .θ 1 2 1 2
Ysi Y jsi Y j i n y j mij
i
i i
= == ≠ = =⎧⎨⎩
10 1 2 1 2; , ..., , ,..., .
ln lnL Y Fijj
m
i
n
ij
i
===∑∑
01
∂∂θln .L = 0
( ) ( )P Y j X p S j= =,θ
Asume que la variable dependiente toma valores {0, 1, 2, ..., }, entoncesYi mi + 1 miel modelo multinomial vendrá dado:
donde y son vectores de variables independientes y parámetros respectivamente.X * θDe esta forma, depende de un i en particular cuando los individuos tienen diferentesmiconjuntos de elección. Para definir el estimador de en el modelo usualmente seθdefinen variables binarias, de la forma:Σ i
n = 1 ( )mi + 1
La función de verosimilitud viene definida como:
donde el estimador insesgado de se define como una solución a la ecuación:$θ θ
Los modelos multinomiales de respuestas cualitativas se pueden clasificar enmodelos ordenados y no ordenados.
2.1. MODELOS ORDENADOS
Un modelo ordenado se define como:
para alguna medida de probabilidad p, sobre X y , y una secuencia finita de intervalosθsucesivos que depende sobre X y tal que .{ }S j θ U Sj j = ℜ
En los modelos ordenados, los valores que Y toma, corresponden a una particiónsobre la línea real. A diferencia de modelo no ordenado, donde la particióncorrespondería a particiones no sucesivas sobre la línea real o a particiones dedimensiones mayores sobre el espacio euclidiano. En la mayoría de las aplicaciones, elmodelo ordenado toma la forma:

97
( ) ( ) ( )P Y j X F X F X j mj j j j m= = − ′ − − ′ = = −∞ ≤ = ∞+ + +, , ; , ,..., ; ; ;α β α β α β α α α α1 0 1 10 1
( ) ( ) ( )P Y j X X i n y j mi ijk
m
ij i
i
= = ′⎡
⎣⎢
⎤
⎦⎥ ′ = =
=
−
∑ exp exp ; , ,..., , ,...,β β0
1
1 2 0 1
U con jij ij ij= + =µ ε , , ,0 1 2
( ) ( )( ) ( )
( ) ( )( ) ( ) ( )
P Y P U U U U
P Y P
P Y
i i i i i
i
ii
i i i
= = > >
= = + − > + − >
= =+ +
2
2
2
2 1 2 0
2 2 1 1 2 2 0 0
2
0 1 2
,
,
expexp exp exp
ε µ µ ε ε µ µ εµ
µ µ µ
Para alguna distribución F, se puede definir un modelo Logit ordenado o Probitordenado.
2.1.1. MODELO LOGIT
El modelo logit multinomial se define como:
Mc Fadden (1974) considera el siguiente modelo multiecuacional derivado delproblema del consumidor. Considere a un individuo i cuyas utilidades están asociadascon tres alternativas, de la forma siguiente:
donde no es una función estocástica sino deterministica. Por otro lado, es el usualUij ε ijtérmino aleatorio de error. De esta forma, el individuo elige aquella alternativa en la queobtiene la mayor utilidad. El multinomial logit se puede derivar del problema demaximizar la utilidad sí y sólo sí los son independientes y la función de distribuciónε ijde viene dada por De esta manera, la probabilidad de que el iε ij ( )[ ]exp exp .ε ijindividuo elija una alternativa j, será:
y tomará una forma parecida a la definición del modelo logit multinomial sí hacemos y .µ µ βi i iX2 0 2− = ′ µ µ βi i iX1 0 1− = ′
2.2. MODELOS NO ORDENADOS
Se enfocara el caso en que las alternativas no están ordenadas.

98
P X P X P Xi i i i i i1 1 1 2 2 2 3 3 3= + = + = +α β α β α β
( )Prob Y j P e
ei ij
X
X
j
j
j i
j i
= = =′
′
=
−
∑
β
β
0
1
Pe e
P ee e
P ee e
X X
X
X X
X
X X
i i
i
i i
i
i i
0 0
0
11 1
1
1 1 2 2
1 1
1 1 2 2
1 1
1 1 2 2
=+ +
=+ +
=+ +
+ +
+
+ +
+
+ +
α β α β
α β
α β α β
α β
α β α β
2.2.1. MODELO LINEAL DE PROBABILIDAD
Si asumimos que hay tres opciones j = 1, 2, 3, escribimos el modelo:
es la probabilidad de que el individuo i elegirá la j ésima opción, mientras que Pji Xies el valor de X para el j ésimo individuo.
Para estimar cada una de las tres ecuaciones en el modelo por mínimos cuadradosordinarios, no es necesario ejecutar las tres regresiones lineales de probabilidad.
Dado que las probabilidades estimadas están restringidas para sumar 1, losinterceptos estimados para sumar 1 y los parámetros de pendiente para sumar 0.
Entonces, sólo se necesita ejecutar dos de las tres regresiones de mínimoscuadrados. La solución para los parámetros de la tercera ecuación se deriva de lasprimeras dos.
2.2.2. MODELO LOGIT
En este tipo de modelos las alternativas de la variable respuesta indican lapertenencia de las observaciones a un determinado grupo sin incorporar informaciónordinal. La formulación de un Logit Multinomial queda recogida a través de la siguienteecuación:
Donde para el caso sencillo de un modelo en el que la variable endógena presentatres posibles alternativas de elección y sólo existe una variable explicativa en lamodelización, la probabilidad asociada a cada una de las alternativas posibles de eleccióntomarían las siguientes expresiones:
con .P P P0 1 2 1+ + =

99
( ) ( )( )f X X af Xob X a
> =>Pr
( ) ( )Prob X a a> = − −⎛⎝⎜
⎞⎠⎟
= −1 1Φ Φµσ
α
( ) ( )( )
( )( )
( ) ( )f X X af X e
XX
> =−
=−
=
⎛⎝⎜
⎞⎠⎟
−⎛⎝⎜
⎞⎠⎟
−
− − − −
12
1
1
1
21
2 2
2
2
Φ Φ Φαπσ
ασ
φ µσα
µσ
3. MODELO CON VARIABLE DEPENDIENTE LIMITADA
Existen un gran número de datos cuya observación nos muestra que estánlimitados o acotados de alguna forma. Este fenómeno lleva a dos tipos de efectos: eltruncamiento y la censura.
El efecto de truncamiento ocurre cuando la muestra de datos es extraídaaleatoriamente de una población de interés, por ejemplo, cuando se estudia el ingreso yla pobreza se establece un valor sobre el cual el ingreso se encuentra por encima o pordebajo del mismo.. De esta forma, algunos individuos podrán no ser tenidos en cuenta.
Por otro lado, censurar es un procedimiento en el cual los rangos de una variableson limitados a priori por el investigador; este procedimiento produce una distorsiónestadística similar al proceso de truncamiento.
3.1. MODELO TRUNCADO
Una distribución truncada es la parte de una distribución no truncada antes odespués de un valor específico; imagínese por ejemplo que nosotros deseamos conocerla distribución de los ingresos anteriores a 100,000 o el número de viajes a una zonamayores de 2, ésta será tan sólo una parte de la distribución total.
Si una variable continua aleatoria X, tiene una función de densidad deprobabilidades, y a es una constante, entonces:
si X tiene una distribución normal con media y desviación estándar , entonces:µ σ
donde y es función de densidad acumulativa, entonces laα µσ
= −a ( )Φ α
distribución normal truncada será:
donde será la función de densidad de probabilidades normal estándar. La distribuciónφnormal estándar truncada con y para a igual a -0.5, 0 y 0.5, será:µ = 0 σ = 1

100
[ ] ( )E X truncamiento = +µ σλ α
[ ] ( )( )var X truncamiento = −σ δ α2 1
( ) ( )( )
( ) ( )( )
λ αφ α
α
λ αφ α
α
=−
>
=−−
<
1
1
Φ
Φ
si el truncamiento ocurre en X a
si el truncamiento ocurre en X a
( )( ) ( )ln ln ln lnL n Y Xa X
i ii
i
n
i=
−+ − − ′ − −
− ′⎛⎝⎜
⎞⎠⎟
⎡
⎣⎢⎤
⎦⎥=∑∑2
2 12
122
2
1π σ
σβ β
σΦ
Si con constante, entonces la media vendrá dada por:[ ]X N≈ µ σ, 2 µ
y la varianza por:
donde . Por otro lado, nosotros observamos que:( )α µ σ= −a /
Tomando el logaritmo de la distribución normal truncada, y al realizar la suma delos logaritmos de estas densidades, se obtiene:
Las condiciones necesarias para maximizar ln L serán:

101
( )
∂∂β
βσ
λσ
∂∂σ σ
βσ
ασ
ln
ln
L Y XX
L Y X X
i i i
i
n
i
i i i i
i
n
=− ′ −⎡
⎣⎢⎤⎦⎥
=
=−
+− ′
−⎡
⎣⎢⎢
⎤
⎦⎥⎥
=
=
=
∑
∑
21
2 2
2
4 21
0
12 2 2
0
Y si Y Y Y si Y= ≤ = >0 0 0* * *
( ) ( )Pr Pr *ob Y ob Y= = ≤ = −⎛⎝⎜
⎞⎠⎟
= − −⎛⎝⎜
⎞⎠⎟
0 0 1Φ Φµσ
µσ
donde y .α βσii ia X= − ( )
( )λφ α
αii
i=
−1 Φ
3.2. MODELO CENSURADO
Un procedimiento normal con datos microeconómicos, consiste en censurar lavariable dependiente. Cuando la variable dependiente es censurada, los valores en undeterminado rango son todos transformados a un valor singular. De esta forma, sidefinimos una variable aleatoria y transformada de la variable original como:
El gráfico de la distribución censurada es:
La distribución correspondiente a será: ( )Y N* ,≈ µ σ 2
si y tiene la densidad de , entonces la distribución tiene partes discretas yY * > 0 Y *

102
( ) ( )( )E Y a= + − +Φ Φ1 µ σλ
( ) ( ) ( ) ( )[ ]Var Y = − − + −σ δ α λ2 21 1Φ Φ
y x u si mi
i i i= + + ≥⎧⎨⎩
β β0 1 ym si y < m
i*
i i*
i
continuas, donde la probabilidad total será de 1como se requiere. Para lograr esto, seasigna la probabilidad total en la región censurada al punto de censuramiento.
La media de una variable censurada vendrá dada por:
y la varianza:
d o n d e : ; ;( ) ( )Φ Φ Φa ob Y a−⎡⎣⎢
⎤⎦⎥
= = ≤ =µσ
α Pr * λ φ=−1 Φ
.δ λ λα= −2
3.3. MODELO TOBIT
El modelo Tobit se originó en el estudio de consumo de bienes no perecederos porparte de las economías domésticas; el importe dedicado al consumo de estos bienes seanula en el caso de familias que no pueden dedicar un mínimo de renta a la adquisiciónde este tipo de productos. Así, el modelo Tobit es de la forma:
en el que el valor es el límite mínimo por debajo del cual la variable endógena nomipuede caer. Este modelo puede considerarse como uno de elección binaria, en el que lavariable endógena toma valores dependientes de las exógenas o bien un mínimo que nodepende de éstas.
Supongamos que se observa si , y no si . Entonces, sedefinirá como:
asume que .

103
Se le llama modelo Tobit o probit de Tobin o modelo censurado de regresiónnormal, debido a que se censura (no se permite observar) algunas observaciones de (aquellas que ). El objetivo es estimar los parámetros y .
Ejemplo
1.- Se especifica la demanda de automóviles de la siguiente forma:
donde Son los gastos en automóviles y x el ingreso. En la muestra habríaun gran número de observaciones para las cuales los gastos en automóviles soncero. El modelo censurado de regresión se puede especificar como:
2.- Si existen observaciones sobre varias personas, de las cuales sólo algunas tienenempleo, podemos especificar el modelo:
Caso horas trabajadas,•
Caso salarios,•
Método de estimación
La estimación de y mediante mínimos cuadrados ordinarios no se puedeβ σutilizar con observaciones positivas , pues cuando se escribe el modelo:
el término de error no tiene media cero. Dado que las observaciones con se omiten, esto supone que sólo se incluyen en la muestra las observaciones para las

104
cuales . Por lo tanto, la distribución de es normal truncada y su media noes cero. La Distribución normal truncada es:
donde la función de densidad estándar normal es:
y la función de distribución acumulada estándar normal es:
Un método de estimación que se sugiere comúnmente es el de máximaverosimilitud, que es el siguiente:
si maximizamos la función de verosimilitud con respecto a y , obtendremos losβ σestimados de máxima verosimilitud de estos parámetros.
Los modelos Tobit se refiere a modelos censurados o truncados donde el rangode la variable dependiente se restringe de alguna forma.
Dado el creciente uso de los modelos tipo Tobit, Amemiya realizó la laboriosatarea de clasificar, los modelos Tobit de acuerdo con similitudes en la función deverosimilitud. La caracterización de los tipos de modelos Tobit es la siguiente:

105
TIPO VARIABLE DEPENDIENTE
Y1 Y2 Y3
1 CENSURADO - -
2 BINARIO CENSURADO -
3 CENSURADO CENSURADO -
4 CENSURADO CENSURADO CENSURADO
5 BINARIO CENSURADO CENSURADO