canonical formatted address data
TRANSCRIPT

Canonical Formatted Address Data
Concept to clean noisy address data and correct spelling errors
© msg systems ag, August 2014 1

© msg systems ag, August 2014 2
The challenge is to clean noisy data from free texts in table format. This is still a
matter of research. But there are some approaches that can lead to the desired
outcome.
Therefore we build a Language Model that „understands“ the language used based
on probabilities. This will be used to improve misspelled inputs and brings it into a
canonical format. The Language Model consist of a Lucene word index and a
corresponding MultiMap. To improve performance Bloom Filters and caches are
considered useful.
Canonical Formatted Address Data

© msg systems ag, August 2014 3
Additionally we take a classifier to strip all the not needed descriptions from the
address information texts.
The NeeText instances holds valuable information on texts. NEE means
Native Expression Enhancement where „native“ refers to any natural language.
Canonical Formatted Address Data

© msg systems ag, August 2014 4
Raw Input Data

© msg systems ag, August 2014 5
• Take all free text columns into consideration
• Texts contain off street names and often have
human-readable descriptions
• The challenge to strip those human-readable descriptions to get a canonical
format: suitable for Business Intelligence classification tasks
• Is like getting a location‘s reverse-hash: identical fingerprints for nearby places
from differing texts
Raw Input Data

© msg systems ag, August 2014 6
Regular Expression
• Verbatim Word as is in text /^\S{2,}$/
Must have at least two characters
• Normalized /^[a-z]{2,}$/
Verbatim word in lower case,
language-specific replacements,
dropped any other special character & numbers
Language-specific replacements may be • ñ n (Spanish)
• ç c (French)
• é ee (French)
• à aa (French)
• ø o (Norwegian, Danish, etc.)
• ä ae (German)
• ß ss (German)
• Stemmed /^[a-z]+$/
Applied Porter Stemmer algorithm to normalized word Guarantees faster word lookups from MultiMap
Lifecycle Of Words

© msg systems ag, August 2014 7
Building The Language Model

© msg systems ag, August 2014 8
Character-leveled sequence learning
• Training a Hidden Markov Model to evaluate words as unigrams
• Transition probabilities for each character Every red dot is a character
The single yellow dot indicates the word‘s end to train word lengths as well
The transition probabilities matrix in the HMM is a 27 by 27 matrix (|a-z| + word‘s end)
Both transition and initial probabilities will be trained
Guarantees to yield identical results when model is immutable onto run • Good choice for canonical format
• Does not guarantee to yield the correct spelled word by dictionary (but the „correct-looking“ one)
Sequence Model

© msg systems ag, August 2014 9
MultiMap<StemmedWord, PriorityQueue<NeeText>>
• Allows fast word lookup
• Counts each word‘s occurrences
• Parsed NeeText instances knows: Verbatim word
Normalized word
(lower case and replaced special characters like ñ, ç, é, à, ø, ä, etc.)
Stemmed word
Likelyhood being a correct term in this language (from HMM model)
MultiMap Word Index

© msg systems ag, August 2014 10
• Allows fuzzy word lookups
• Scores for best approximate match
• Points to parsed NeeTexts in MultiMap to score words by occurrence counts
Lucene Word Index

© msg systems ag, August 2014 11
• In the end: compact both word indices by filtering out outliers
• Improves word lookup times – shrinks indices‘ sizes
Filtering / Compaction

© msg systems ag, August 2014 12
• Consist of HMM model
MultiMap
Lucene word index (referencing MultiMap for indepth information)
Bloom Filters
Guava Caches
• Language Model can be trained based on Unigrams from Peter Norvig / Google,
Address dataset itself, or
Any text
• Language in training data has only to match test / productive data set‘s native
language
Language Model

© msg systems ag, August 2014 13
Train Language Model
• Mappers Default / identity mappers
• 1 Reducer Trains words as unigrams to Hidden Markov Model
Feed corrected words to Lucene Word Index and reference to MultiMap entry
Compact Language Model
Emit Language Model
MapReduce

© msg systems ag, August 2014 14
Address Information Classification

© msg systems ag, August 2014 15
• Stanford Named Entity Recognizer (NER) From Natural Language Processing group at The Farm
Supervised Learning – so approach will need some training data
Classify Address Information

© msg systems ag, August 2014 16
Classify Address Information

© msg systems ag, August 2014 17
• Picks only relevant address information and discards the rest
Classify Address Information

© msg systems ag, August 2014 18
Train Markov Random Field Classifier
• Mappers Default / identity mappers
• 1 Reducer Markov Random Field learns relevant address information from training dataset
Emit MRF classifier
MapReduce

© msg systems ag, August 2014 19
Using The Models
© msg systems ag, August 2014 20
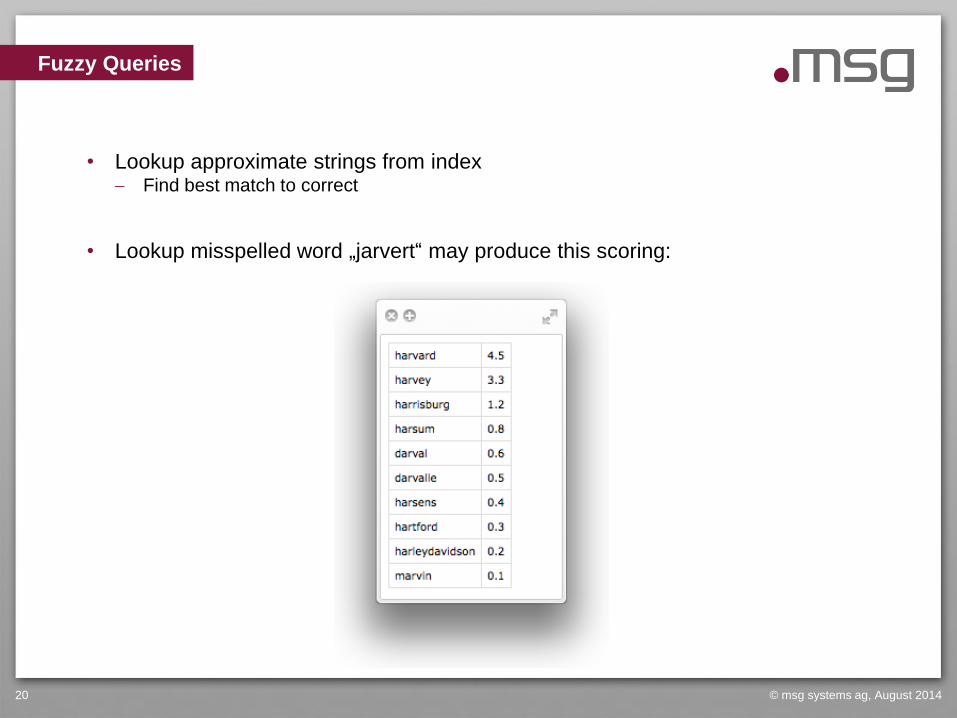
• Lookup approximate strings from index Find best match to correct
• Lookup misspelled word „jarvert“ may produce this scoring:
Fuzzy Queries

© msg systems ag, August 2014 21
• Take best match from custom scoring: „harvard“ here
• Replace the misspelled word „jarvert“ by „harvard“
• Increase occurences count for „harvard“ in backlog buffer
Fuzzy Queries

© msg systems ag, August 2014 22
• Allows over all model improvements
• Hardens the model on any text used Avoids creating a Language Model from a vast sized data set
Model grows by usage
Bare Language Model is immutable as the outcome may otherwise be unstable as
MapReduce may alter the scheduling
• Recently gathered yet unknown words may be merged in or replace the existing
Language Model
Backlog Buffer

© msg systems ag, August 2014 23
Using the Language Model & MRF classifier
• Mappers Fix spelling errors using the Language Model
• Takes Language Model and MRF classifier from distributed cache
• Assign each word a probability of being correct
• Lookup word in the word index and take the best scored of the two
Use the MRF classifier to detect descriptions and remove them
Emit key (city) and value (cleaned data)
• Reducers by city (optional) Fix outliers in cleaned data and in geo coordinates
Emit cleaned data
MapReduce

© msg systems ag, August 2014 24
Solution Approaches

© msg systems ag, August 2014 25
• Porter Stemmer Stems words to improve word lookups & correction
Stemmed words only on indices
Building a MultiMap – MultiMap<StemmedWord, PriorityQueue<NeeTexts>> • Allows fast word lookup
• Counts each word‘s occurrences
• Hidden Markov Model Training model to evaluate strings
Assigns each word a probability of being correct
Improves scoring by taking the most likely string as canonical format
• Markov Random Field Build classifier to remove descriptions from address columns
OpenSource implementation from Stanford University
Our Approach: Statistical Modelling

© msg systems ag, August 2014 26
• Lucene Index Approximate String Matching approach
Fuzzy queries to lookup misspelled words
• Hadoop Once two MapReduce jobs to build statistical models:
• Language Model and
• MRF classifier
One MapReduce job to correct spelling errors & strip description in addresses
(here Reduce phase is optional)
• Backlog Buffer Helps improve the Language Model for future usage
Our Approach: Techniques

© msg systems ag, August 2014 27
• Bloom Filters Probabilistic data structure to avoid fuzzy costly queries
Bloom Filters are used in databases such as Oracle & Cassandra – makes them open
files from disk only iff the desired information might be in there
false negatives not possible
false positives can have any probability greater than zero
• Guava Caches Avoids doing costly computations over and over again
• MultiMap<StemmedWord, PriorityQueue<NeeText>> Allows fast word lookup
Counts each word‘s occurrences
Parsed & compacted NeeText instances only
Our Approach: Performance Improvements

© msg systems ag, August 2014 28
• String Similarity Measures E.g. Levenshtein, Block Distance, Euclidean Distance, etc.
Allow comparison of two string candidates
HMM model may score best match of both candidates
But is one-on-one comparison only so it is expensive to find approximate matches
• String Kernels Allow comparison of two string candidates
Can get the two word‘s common stem
HMM model may score best match of both candidates
But is one-on-one comparison only so it is expensive to find approximate matches
• Support Vector Machines Takes each word as class
Can determine what „correct“ word a misspelled one belongs to
But the expected amount of possible classes is far too high
Additional Approaches

© msg systems ag, August 2014 29
Indices with Lucene

© msg systems ag, August 2014 30
MapReduce

© msg systems ag, August 2014 31
After all the effort:
• Normalizing & stemming each word
• Correcting spelling errors
• Classifying the relevant street name parts
the result will look like …
Final Result

© msg systems ag, August 2014 32
Final Result

© msg systems ag, August 2014 33
• Problem is still a topic of research in Artificial Intelligence
Research

Vielen Dank für Ihre Aufmerksamkeit
© msg systems ag, August 2014 34
Daniel Schulz
GB L / Data Scientist
Telefon: +49 151 613 500 15
www.msg-systems.com