biomedical search
TRANSCRIPT

BioTALA group, NICTA Victoria Research Laboratory
Tagging and Genomics Information Retrieval
Sarvnaz Karimi
Genomics Information Retrieval
TREC genomics defined a TEXT retrieval task in which a user seeks infomration in a sub-area of biology linked with genomics information.

Task Definition
TREC 2006 and 2007 Genomics:
Passage retrieval Collection was full-text articles
(12GB) from 49 medical journals.
Queries were medical questions.
Evaluation based on passages, documents, and aspect level.

Queries
Questions were based on the Generic Topic Types (GTTs)
2006: Five different GTTS, such as “Find articles describing the role of a gene involved in a given disease.”
e.g. What is the role of DRD4 in alcoholism?
2007: Questions asking for a specific entity type based on controlled terminologies (14 types).
e.g. What [DISEASES] are associated with lysosomal abnormalities in the nervous system?
Relevance Judgements: Human experts idetified the relevant passages, and the relevant concepts.

Can Tagging Entity Types Help Retrieval?
Tagging: Manual or automatic association of a tag from a controlled vocabulary to a term or phrase in a text.
Controlled vocabulary: set of entity types as defined for the TREC tasks.
e.g. What is the role of DRD4 in alcoholism? What is the role of DRD4 [GENE] in alcoholism [DISEASE]?
Possible benefits: disambiguation: e.g. nur-77 can refer to a gene or
protein. Increase the chance of retrieving a document by
increasing the common terms it has with the query.

Inside the Text Collection
Distribution of tag terms (entity type) in the documents:
Large majority of documents contain more than one distinct tag (57.4% for 2006, and 94.6% for 2007)
for the 2006 collection, on average 46.5% of the irrelevant documents contain the tag terms, compared to 63.4% of the relevant documents. For 2007, these numbers are 47.8% and 80.3%, respectively.
the proportion of relevant documents that would not be retrieved without tagging. For the 2006 collection, this holds for only 0.4% of relevant documents; for 2007, it is only 0.005%.

Inside the Text Collection: Conclusion 1
• Tag terms occur somewhat more frequently in relevant documents compared to irrelevant documents (No extra information/disambiguation is expected with tagging).
• In case of no annotation, the relevant documents would nearly all still be retrievable because of other term overlap between the queries and documents.

Inside the Text Collection: IR Flavoured
Recall versus documents sorted based on the descending frequency of the tag words:

Inside the Text Collection: Conclusion 2
• A small correlation (ρ=0.09) between the number of distinct tags and the likelihood that a document is relevant.
• Tag frequency appears to be related to relevance (ρ=0.84) for most tags.
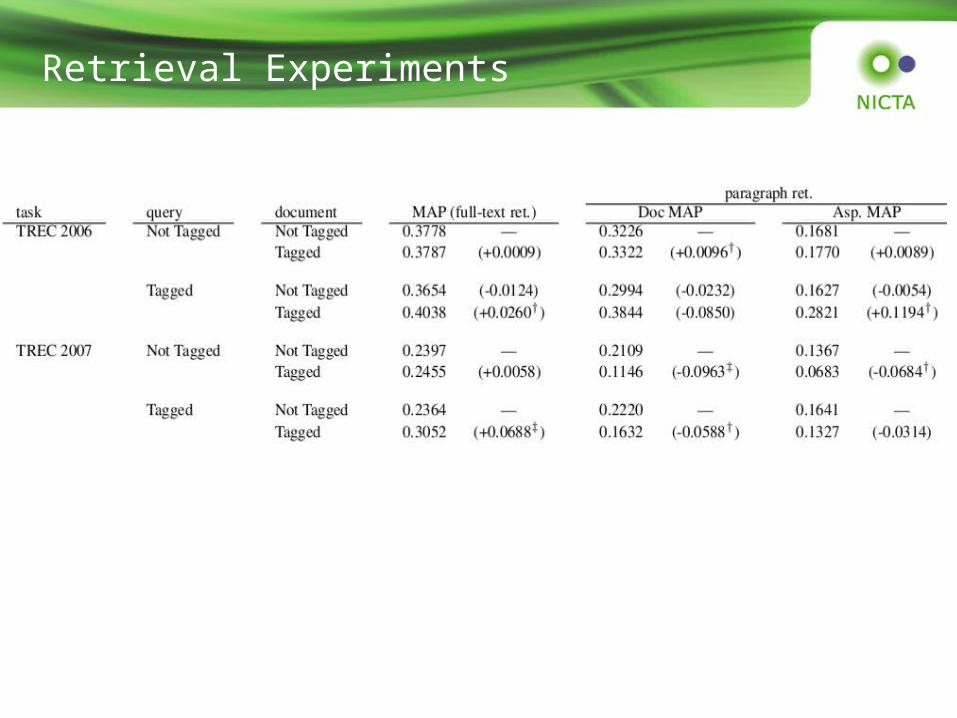
Retrieval Experiments

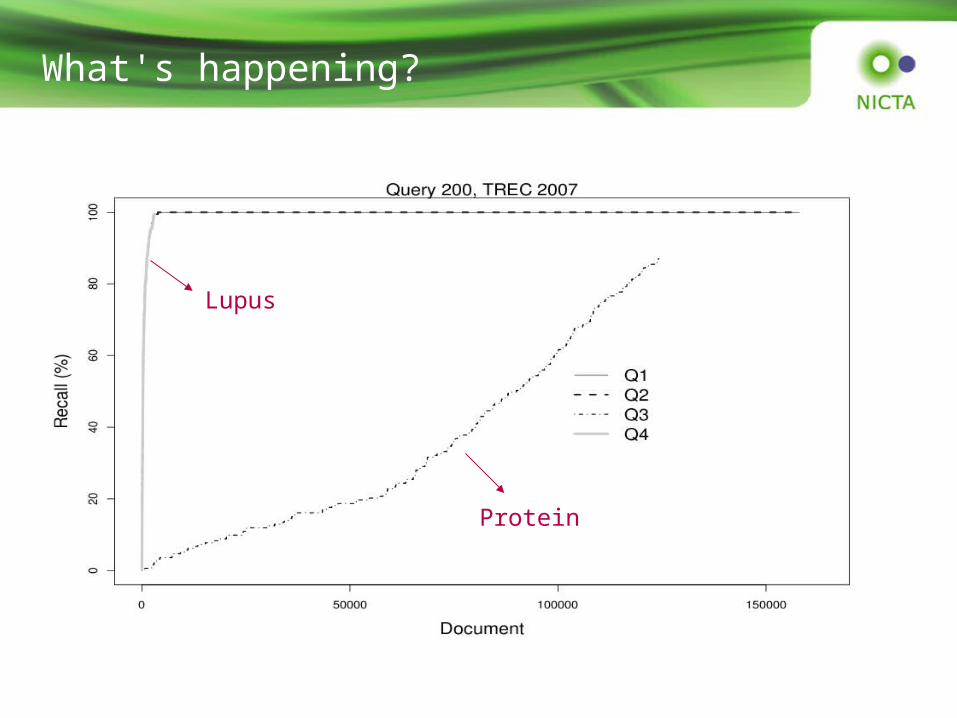
What's happening?
• An example query:– Q1. What serum [PROTEINS] change expression in association
with high disease activity in lupus? (original query)– Q2. What serum change expression in association with high
disease activity in lupus– Q3. proteins– Q4. lupus
What's happening?
Protein
Lupus

Conclusions
Does tagging help a text retrieval task? We still dont have a strong evidence to prove it does.
Maybe tags are too general to be discriminative enough.
What level of accuracy a tagger should have to be beneficial?
In the explained framework we could not define a threshold. Even randon assignment of tags improved MAP over the baseline.