big data, beyond the data center
TRANSCRIPT

Big Data, Beyond the Data Center
Gilles Fedak
INRIA, University of Lyon, France
Cluj Economics and Business Seminar Series (CEBSS)University Babes-Bolyai Faculty of Economics and Business
AdministrationCluj-Napoca, Romania
6/11/2014

AVALON Team
I Located in Lyon, FranceI Joint Research Group
I INRIA : French National Institute for Research in InformaticsI ENS-Lyon : Ecole Normale SuprieureI University of Lyon
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

AVALON Members
2
Avalon Members @ April 1st, 2014 Faculty Members (8) (4 INRIA, 1 CNRS, 2 UCBL, 1 ENSL) • Eddy Caron, MCF ENS Lyon, HDR (80%) • Frédéric Desprez, DR INRIA, HDR (30%) • Gilles Fedak, CR INRIA • Jean-Patrick Gelas, MCF UCBL • Olivier Glück, MCF UCBL • Laurent Lefèvre, CR INRIA, HDR • Christian Perez, DR INRIA, HDR, Project leader • Frédéric Suter, CR CNRS
PhD students (6) • Maurice-Djibril Faye, ENS-Lyon / Université
Gaston Berger (Sénégal) • Sylvain Gault, MapReduce, INRIA • Anthony Simonet, MapReduce, INRIA • Vincent Lanore, ENSL • Arnaud Lefray, SEED4C, ENSIB • Daniel Balouek, CIFRE New Generation SR
Engineers (3+4+1) • Simon Delamare, IR CNRS (80%) • Jean-Christophe Mignot, IR CNRS (20%) • Matthieu Imbert, INRIA SED (40%)
• Sylvain Bernard, CloudPower • François Rossigneux, XCLOUD • Guillaume Verger, SEED4C • Yulin Zhang Huaxi, SEED4C
• Laurent Pouilloux (AE Héméra)
Postdoc • Jonathan Rouzaud-Cornabas, CNRS Temporary Teacher-Researcher • Ghislain Landry Tsafack, UCBL
Assistant • Evelyne Blesle, INRIA
Avalon Team Overview G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
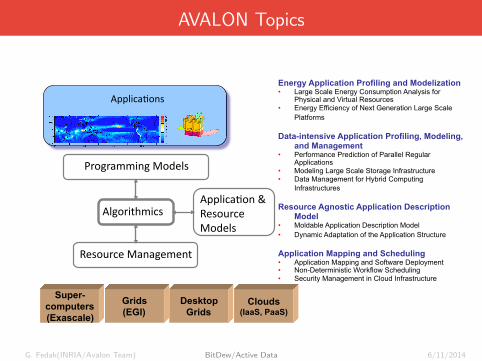
AVALON Topics
3
Avalon: Research Activities
!"#$"%&&'($)*#+,-.)
/00-'1%2#()3)4,.#5"1,)*#+,-.)
4,.#5"1,)*%(%$,&,(6)
/-$#"'67&'1.)
Super- computers (Exascale)
Desktop Grids
Clouds (IaaS, PaaS)
Grids (EGI)
Avalon Team Overview
Energy Application Profiling and Modelization • Large Scale Energy Consumption Analysis for
Physical and Virtual Resources • Energy Efficiency of Next Generation Large Scale
Platforms
Data-intensive Application Profiling, Modeling, and Management
• Performance Prediction of Parallel Regular Applications
• Modeling Large Scale Storage Infrastructure • Data Management for Hybrid Computing
Infrastructures
Resource Agnostic Application Description Model
• Moldable Application Description Model • Dynamic Adaptation of the Application Structure
Application Mapping and Scheduling • Application Mapping and Software Deployment • Non-Deterministic Workflow Scheduling • Security Management in Cloud Infrastructure
/00-'1%2#(.)
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Big Data ...
I Huge and growing volume of information originating frommultiple sources.
!"#$%&'("$#) *+'&,-./"#)0+1)*2+("2() 34(")5-$-)!"$(%"($)
I Impacts many scientific disciplines and industry branchesI Large Scientific Instruments (LSST, LHC, OOOI), but not only
(Sequencing machines)I Internet and Social Network (Google, Facebook, Twitter, etc.)I Open Data (Open Library, Governemental, Genomics)
→ impacts the whole process of scientific discovery (4th paradigmof science)
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

... or Big Bottlenecks ?
I Big Data creates several challenges :
I how to scale the infrastructure ?I end-to-end performance improvement, inter-system
optimization.
I how to improve productivity of data-intensive scientist ?I workflow, programming language, quality of data provenance.
I how to enable collaborative data science ?I incentive for data publication, data-sets sharing, collaborative
workflow.
I New models and software are needed to represent andmanipulate large and distributed scientific data-sets.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

BitDew: Large Scale DataManagement
Haiwu He (CAS/CNIC), Franck Cappello (ANL, UIUC)
I G. Fedak, H. He, and F. Cappello. BitDew: A Programmable Environment for Large-Scale DataManagement and Distribution. In Proceedings of the ACM/IEEE SuperComputing Conference (SC08),pages 112, Austin, USA, November 2008.
I BitDew: A Data Management and Distribution Service with Multi-Protocol and Reliable File Transfer. G.Fedak, H. He, and F. Cappello Journal of Network and Computer Applications, 32(5):961–975, 2009.
I H. He, G. Fedak, B. Tran, and F. Cappello. BLAST Application with Data-aware Desktop GridMiddleware. In Proceedings of 9th IEEE International Symposium on Cluster Computing and the GridCCGRID09, pages 284291, Shanghai, China, May 2009.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

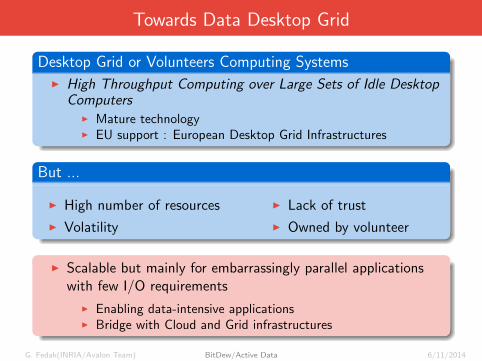
Towards Data Desktop Grid
Desktop Grid or Volunteers Computing Systems
I High Throughput Computing over Large Sets of Idle DesktopComputers
I Mature technologyI EU support : European Desktop Grid Infrastructures
But ...
I High number of resources
I Volatility
I Lack of trust
I Owned by volunteer
I Scalable but mainly for embarrassingly parallel applicationswith few I/O requirements
I Enabling data-intensive applicationsI Bridge with Cloud and Grid infrastructures
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Towards Data Desktop Grid
Desktop Grid or Volunteers Computing Systems
I High Throughput Computing over Large Sets of Idle DesktopComputers
I Mature technologyI EU support : European Desktop Grid Infrastructures
But ...
I High number of resources
I Volatility
I Lack of trust
I Owned by volunteer
I Scalable but mainly for embarrassingly parallel applicationswith few I/O requirements
I Enabling data-intensive applicationsI Bridge with Cloud and Grid infrastructures
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Large Scale Data Management
22/06/08 07:48bitdew.svg
Page 1 sur 1file:///Users/fedak/shared/projects/bitdew/trunk/doc/bitdew.svg
BitDew : a Programmable Environment for Large Scale DataManagement
Key Idea 1: provides an API and a runtime environment whichintegrates several P2P technologies in a consistentway
Key Idea 2: relies on metadata (Data Attributes) to drivetransparently data management operation :replication, fault-tolerance, distribution, placement,life-cycle.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
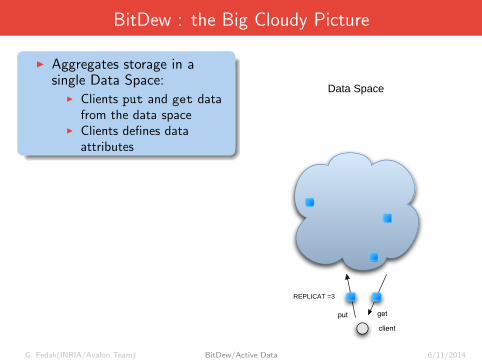
BitDew : the Big Cloudy Picture
I Aggregates storage in asingle Data Space:
I Clients put and get datafrom the data space
I Clients defines dataattributes
I Distinguishes service nodes(stable), client and Workernodes (volatile)
I Service : ensure faulttolerance, indexing andscheduling of data toWorker nodes
I Worker : stores data onDesktop PCs
I push/pull protocol betweenclient → service ← Worker
Data Space
getput
client
REPLICAT =3
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
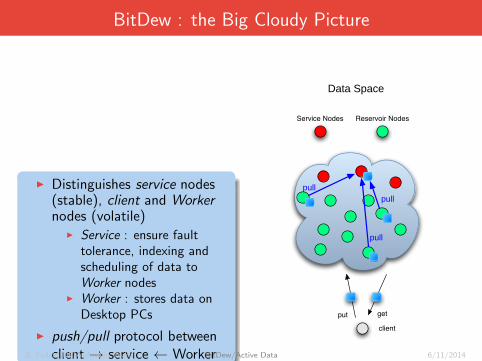
BitDew : the Big Cloudy Picture
I Aggregates storage in asingle Data Space:
I Clients put and get datafrom the data space
I Clients defines dataattributes
I Distinguishes service nodes(stable), client and Workernodes (volatile)
I Service : ensure faulttolerance, indexing andscheduling of data toWorker nodes
I Worker : stores data onDesktop PCs
I push/pull protocol betweenclient → service ← Worker
Reservoir NodesService Nodes
Data Space
getput
client
pull
pull
pull
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Data Attributes
replica : indicates how many occurrences of data should be available atthe same time in the system
resilience : controls the resilience of data in presence of machine crashlifetime : is a duration, absolute or relative to the existence of other data,
which indicates when a datum is obsoleteaffinity : drives movement of data according to dependency rules
transfer protocol : gives the runtime environment hints about the file transfer pro-tocol appropriate to distribute the data
distribution : which indicates the maximum number of pieces of Data with thesame Attribute should be sent to particular node.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
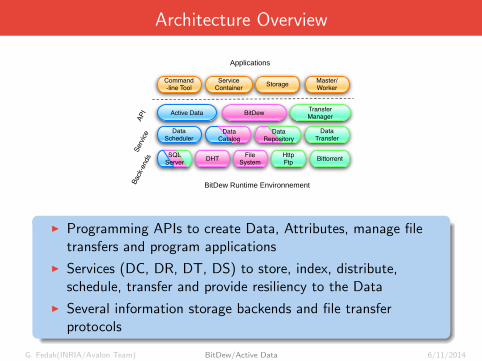
Architecture Overview
File System
Http Ftp Bittorrent
Data Scheduler
Data Transfer
Active Data BitDew Transfer Manager
Command-line Tool
Service Container Storage Master/
Worker
Back
-end
sSe
rvice
API
Applications
DataCatalog
DataRepository
SQLServer
BitDew Runtime Environnement
DHT
I Programming APIs to create Data, Attributes, manage filetransfers and program applications
I Services (DC, DR, DT, DS) to store, index, distribute,schedule, transfer and provide resiliency to the Data
I Several information storage backends and file transferprotocols
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Examples of BitDew Applications
I Data-Intensive ApplicationI DI-BOT : data-driven master-worker Arabic characters
recognition (M. Labidi, University of Sfax)I MapReduce vs Hadoop, (X. Shi, L. Lu HUST, Wuhan China)
I Data Management UtilitiesI File Sharing for Social Network (N. Kourtellis, Univ. Florida)I Distributed Checkpoint Storage (F. Bouabache, Univ. Paris XI)I Grid Data Stagging (IEP, Chinese Academy of Science)
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

MapReduce for Hybrid DistributedComputing Infrastructures
Haiwu He (CAS/CSNET), Bing Tang (WUST), Xunhua Shi & Lu Lu(HUST), Mircea Moca & Gheorghe Silaghi (Univ Babes Bolay)
I Towards MapReduce for Desktop Grid Computing .B. Tang, M. Moca, S. Chevalier, H. He, and G. Fedak.In Fifth International Conference on P2P, Paral lel, Grid, Cloud and Internet Computing (3PGCIC’10),Fukuoka, Japan, November 2010.
I Distributed Results Checking for MapReduce on Volunteer Computing Mircea Moca, Gheorghe CosminSilaghi and Gilles Fedak, in 4th Workshop on Desktop Grids and Volunteer Computing Systems (PCGrid2010) IPDPS’2011, Anchorage Alaska.
I Assessing MapReduce for Internet Computing: a Comparison of Hadoop and BitDew-MapReduce Lu Lu,Hai Jin, Xuanhua Shi and Gilles Fedak in the 13th ACM/IEEE International Conference on Grid Computing(Grid 2012), Beijing, China, 2012
I Data-Intensive Computing on Desktop Grids, H. Lin and W.-C. Feng and G. Fedak Book Chapter inDesktop Grid Computing Book, CRC Press, 2012
I Parallel Data Processing in Dynamic Hybrid Computing Environment Using MapReduce, Bing Tang, HaiwuHe, Gilles Fedak, 4th International Conference on Algorithms and Architectures for Parallel Processing(ICA3PP’14), LNCS/Springer Verlags, August 24-27, Dalian, China, 2014
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

What is MapReduce ?
I Programming Model for data-intense applicationsI Proposed by Google in 2004I Simple, inspired by functionnal programming
I programmer simply defines Map and Reduce tasks
I Building block for other parallel programming toolsI Strong open-source implementation: HadoopI Highly scalable
I Accommodate large scale clusters: faulty and unreliableresources
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and SanjayGhemawat, in OSDI’04: Sixth Symposium on Operating System Design andImplementation, San Francisco, CA, December, 2004.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
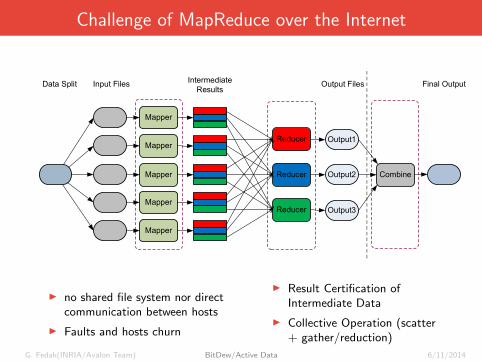
Challenge of MapReduce over the Internet
Reducer
Combine
Mapper
Input FilesIntermediate
ResultsOutput Files
Output1
Mapper
Mapper
Reducer
Final OutputData Split
MapperReducer
Mapper
Output2
Output3
I no shared file system nor directcommunication between hosts
I Faults and hosts churn
I Result Certification ofIntermediate Data
I Collective Operation (scatter+ gather/reduction)
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
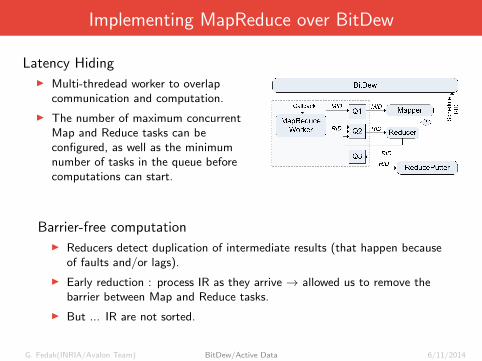
Implementing MapReduce over BitDew
Latency HidingI Multi-thredead worker to overlap
communication and computation.
I The number of maximum concurrentMap and Reduce tasks can beconfigured, as well as the minimumnumber of tasks in the queue beforecomputations can start.
Barrier-free computationI Reducers detect duplication of intermediate results (that happen because
of faults and/or lags).
I Early reduction : process IR as they arrive → allowed us to remove thebarrier between Map and Reduce tasks.
I But ... IR are not sorted.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Scheduling and Fault-tolerance
2-level scheduling
1. Data placement is ensured by the BitDew scheduler, which is mainlyguided by the data attribute.
2. Workers periodically report to the MR-scheduler, running on the masternode the state of their ongoing computation.
3. The MR-scheduler determines if there are more nodes available thantasks to execute which can avoid the lagger effect.
Fault-tolerance
I In Desktop Grid, computing resources have high failure rates :
→ during the computation (either execution of Map or Reducetasks)
→ during the communication, that is file upload and download.
I MapInput data and ReduceToken token have the resilient attributeenabled.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
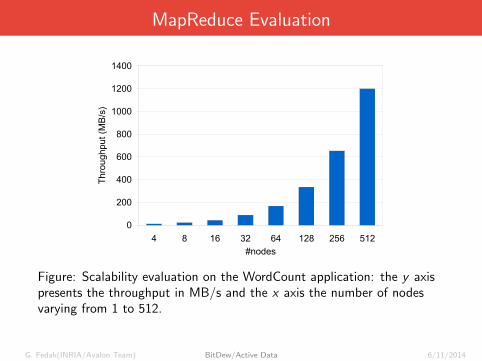
MapReduce Evaluation
!
"!!
#!!!
#"!!
$!!!
$"!!
%!!!
# & ' #$ #( $& %$ &' (& '! )( #$'
*+,-./
012.3/4
56,7-87/9:012.:3;0<4
56,7-87/9:012.:35190,66.+94
=8799.6:012.
>79?.6:012.
Figure 5. Execution time of the Broadcast, Scatter, Gather collective for a 2.7GBfile to a varying number of nodes.
The next experiment evaluates the performance of the collectivefile operation. Considering that we need enough chunks to measurethe Scatter/Gather collective, we selected 16MB as the chunks sizefor Scatter/Gather measurement and 48MB for the broadcast. Thebenchmark consists of the following: we prepare a 2.7GB large fileinto chunks and measure the time to transfer the chunks to all of thenodes according to the collective scheme. Broadcast measurementis conducted using both FTP and BitTorrent, while FTP protocol isused for Scatter/Gather measurement. The broadcast, scatter, gatherresults are presented respectively in the Figure 5. The time to broad-cast the data linearly increases with the number of nodes becausenodes compete for network bandwidth, and using BitTorrent obtainsa better efficiency than using FTP in the same number of nodes. Withrespect to the gather/scatter, each node only downloads/uploads partof all chunks, and the time remain constant because the amount ofdata transferred does not increase with the number of nodes.
B. MapReduce Evaluation
We evaluate now the performance of our implementation ofMapReduce. The benchmark used is the WordCount application,which is a representative example of MapReduce application,adapted from the Hadoop distribution. WordCount counts the num-ber of occurrences of each word in a large collection of documents.The file transfer protocol used is HTTP protocol.
The first experiment evaluates the scalability of our implementa-tion when the number of nodes increases. Each node has a different5GB file to process, splitted into 50 local chunks. Thus, when thenumber of nodes doubles, the size of the whole document counteddoubles too. For 512 nodes2, the benchmark processes 2.5TB of dataand executes 50000 Map and Reduce tasks. Figure 6 presents thethroughput of the WordCount benchmark in MB/s versus the numberof worker nodes. This result shows the scalability of our approachand illustrates the potential of using Desktop Grid resources toprocess a vast amount of data.
The next experiment aims at evaluating the impact of a varyingnumber of mappers and reducers. Table II presents the time spentin Map function, the time spent in Reduce function and the totalmakespan of WordCount for a number of mappers varying from 4to 32 and a number of reducers varying from 1 to 16. As expected,the Map and Reduce time decreases when the number of mappersand reducers increases. The difference between the makespan and
2GdX has 356 double core nodes, so to measure the performance on 521 nodeswe run two workers per node on 256 nodes.
!
$!!
&!!
(!!
'!!
#!!!
#$!!
#&!!
& ' #( %$ (& #$' $"( "#$
*+,-./
0?6,@A?B@9:3C5D/4
Figure 6. Scalability evaluation on the WordCount application: the y axis presentsthe throughput in MB/s and the x axis the number of nodes varying from 1 to 512.
Table IIEVALUATION OF THE PERFORMANCE ACCORDING TO THE NUMBER OF MAPPERS
AND REDUCERS.
#Mappers 4 8 16 32 32 32 32#Reducers 1 1 1 1 4 8 16Map (sec.) 892 450 221 121 123 121 125
Reduce (sec.) 4.5 4.5 4.3 4.4 1 0.5Makespan (sec.) 473 246 142 146 144 150
the Map plus Reduce time is explained by the communication andtime elapsed in waiting loops. Although the Reduce time seemsvery low compared to the Map time, this is typical of MapReduceapplication. A survey [16] of scientific MapReduce applications atthe research Yahoo cluster showed that more than 93% of the codeswhere Map-only or Map-mostly applications.
C. Desktop Grid Scenario
In this section, we emulate a Desktop Grid on the GdX clusterby confronting our prototype to scenarios involving host crashes,laggers hosts and slow network connection.
The first scenario aims at testing if our system is fault tolerant,that is, if a fraction of our system fails, the remaining participantsare able to terminate the MapReduce application. In order todemonstrate this capacity, we propose a scenario where workerscrash at different times: the first fault (F1) is a worker node crashwhile downloading a map input file, the second fault (F2) occursduring the map phase and the third crash (F3) happens after theworker has performed the map and reduce tasks. We execute thescenario and emulate worker crash by killing the worker process.In Figure 7 we report the events as they were measured during theexecution of the scenario in a Gantt chart. We denote w1 ! w5 theworkers and m the master node. The execution of our experimentbegins with the master node uploading and scheduling two reducetoken files: Ut1 and Ut2 . Worker w1 receives t1 and worker w2receives t2. Then, the master node uploads and schedules the mapinput files (chunks) (UC1!5). Each worker downloads one suchchunk, denoted with DC1!5. Node w4 fails (F1) while downloadingmap input chunk DC4 . As the BitDew scheduler periodically checkswhether participants are still present, after a short moment followingthe failure, node w4 is considered to be failed. This conveys to therescheduling of C4 to node w2. Node w3 fails (F2) while performingthe map task M(C3). Then, chunk C3 is rescheduled to node w5.At F3, node w1 fails after having already performed the map taskM(C1) and several reduce tasks: RF1,1 , RF1,2 and RF1,5 . The notationRFp,k refers to the reduce task which takes as input the intermediate
Figure: Scalability evaluation on the WordCount application: the y axispresents the throughput in MB/s and the x axis the number of nodesvarying from 1 to 512.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Data Security and Privacy
Distributed Result CheckingI Traditional DG or VC projects implements result checking on
the server.I IR are too large to be sent back to the server→ distributed result checking
I replicates the MapInput and ReducersI select correct results by majority voting
!"
!#
!$
%" &%"'"
(%
!)*+"
(a) No replica (b) Map replica
Figure 1. Dataflow
RF = {xi|xi = {fi,k|k = 1, rm}, i ∈ N}, to a set of rm
distinct workers as input for Map task. Consequently, theReducer receives a set of rm versions of intermediate filescorresponding to a map input fi. After receiving rm
2 + 1identical versions, the Reducer considers the respectiveresult correct and further, accepts it as input for a Reducetask.
Figure 1b illustrates the dataflow corresponding to aMapReduce execution with rm = 3.
In order to activate the checking mechanism for the resultsreceived from Reducers, the Master node schedules theReduceTokens T , with the attribute replica = rn (rn >2, rn ∈ N). Consequently, the BitDew services distributea set of copies of T , RT = {yj |yj = {tj,p|p = 1, rn}},to a set of rn distinct nodes. As effect, rn workers willperform Reduce tasks with identical input, for the partitiontj . Finally, the Master node receives rn versions for a resultrfj , and selects the correct one.
In figure 2a we present the dataflow corresponding to aMapReduce execution where the system checks the resultsproduced by both Mappers and Reducers. In this scenariowe consider rm = 3 and rn = 3.
It is possible that some malicious workers send super-fluous intermediate results, in the sense that the interme-diate result is entirely fabricated thus not being the outputcorresponding to a Map input fn. Reducers could easilyinhibit this type of behavior by filtering received intermedi-ate results. Hence, we implement a naming scheme whichallows the Reducer to check whether an intermediate resultcorresponds to a Map input fn.
We continue the discussion by presenting the naming
scheme mechanism. Before distributing the Map input F toworkers the Master, creates a set of codes K = {kn, kn =δ(FileName(fn))}, where kn represents a code (such asgiven by a MD5 Hashing function) corresponding to fn. Thelist accompanies each tj scheduled to workers, as discussedearlier in this section. Further, for each fn received, theMapper computes the code kn and attaches this value toifn,m, which is sent to the appropriate Reducer. Finally,the Reducer checks whether the accompanying code kn ofa received intermediate result is present in its own codes listK, ignoring failed results.
D. Evaluation Of The Results Checking Mechanism
In this section we describe the model for characteriz-ing errors while applying the majority voting method forMapReduce in Desktop Grids.
Notations:
• f : the fraction of error-prone nodes; such a nodesrandomly produce erroneous results, independently ofthe behavior of other nodes. The probability to selectsuch a faulty worker is 0 < f < 0.5.
• s: the sabotage rate of faulty / malicious workers.Given that a worker is faulty, it produces an erroneousresult with probability 0 < s < 1. Thus, in general,the probability of having an erroneous result from allworkers is fs.
• NT : is the number of ReduceTokens. For a giveninput fn, a Mapper outputs a result value for each tokentj .
• NF is the number of distinct input files (F ).
(a) No replication
!"
!#
!$
%" &%"'"
(%
!)*+"
(a) No replica (b) Map replica
Figure 1. Dataflow
RF = {xi|xi = {fi,k|k = 1, rm}, i ∈ N}, to a set of rm
distinct workers as input for Map task. Consequently, theReducer receives a set of rm versions of intermediate filescorresponding to a map input fi. After receiving rm
2 + 1identical versions, the Reducer considers the respectiveresult correct and further, accepts it as input for a Reducetask.
Figure 1b illustrates the dataflow corresponding to aMapReduce execution with rm = 3.
In order to activate the checking mechanism for the resultsreceived from Reducers, the Master node schedules theReduceTokens T , with the attribute replica = rn (rn >2, rn ∈ N). Consequently, the BitDew services distributea set of copies of T , RT = {yj |yj = {tj,p|p = 1, rn}},to a set of rn distinct nodes. As effect, rn workers willperform Reduce tasks with identical input, for the partitiontj . Finally, the Master node receives rn versions for a resultrfj , and selects the correct one.
In figure 2a we present the dataflow corresponding to aMapReduce execution where the system checks the resultsproduced by both Mappers and Reducers. In this scenariowe consider rm = 3 and rn = 3.
It is possible that some malicious workers send super-fluous intermediate results, in the sense that the interme-diate result is entirely fabricated thus not being the outputcorresponding to a Map input fn. Reducers could easilyinhibit this type of behavior by filtering received intermedi-ate results. Hence, we implement a naming scheme whichallows the Reducer to check whether an intermediate resultcorresponds to a Map input fn.
We continue the discussion by presenting the naming
scheme mechanism. Before distributing the Map input F toworkers the Master, creates a set of codes K = {kn, kn =δ(FileName(fn))}, where kn represents a code (such asgiven by a MD5 Hashing function) corresponding to fn. Thelist accompanies each tj scheduled to workers, as discussedearlier in this section. Further, for each fn received, theMapper computes the code kn and attaches this value toifn,m, which is sent to the appropriate Reducer. Finally,the Reducer checks whether the accompanying code kn ofa received intermediate result is present in its own codes listK, ignoring failed results.
D. Evaluation Of The Results Checking Mechanism
In this section we describe the model for characteriz-ing errors while applying the majority voting method forMapReduce in Desktop Grids.
Notations:
• f : the fraction of error-prone nodes; such a nodesrandomly produce erroneous results, independently ofthe behavior of other nodes. The probability to selectsuch a faulty worker is 0 < f < 0.5.
• s: the sabotage rate of faulty / malicious workers.Given that a worker is faulty, it produces an erroneousresult with probability 0 < s < 1. Thus, in general,the probability of having an erroneous result from allworkers is fs.
• NT : is the number of ReduceTokens. For a giveninput fn, a Mapper outputs a result value for each tokentj .
• NF is the number of distinct input files (F ).
(b) Replication of the Map tasks
(a) Map and Reduce replica
Figure 2. Dataflow
• rM : is the replica degree of Map input files F . AReducer receives rM versions of the intermediate resultcorresponding to fn, in order to accept it as correct.Thus, rM distinct nodes are needed to Map the fn
input.• rR: is the replica degree of the intermediate results.
Thus, rR distinct nodes Reduce rR versions of anintermediate result.
In the following we present the probabilistic schema thatwe apply for our system. Supposing that the Reducer is hon-est (does not sabotage) and computes the result verificationfor rM versions of intermediate results corresponding to aMap input fn. The probability for the Reducer to report anerroneous result after applying MVM is [2]:
�M (f, s, rM ) =
rM�
j=rM2 +1
�rM
j
�(fs)j(1− fs)rM−j (1)
If this error happens for at least one fn Map input, theReducer produces an error. Thus, for the set of input filesF , the probability for an honest reducer to produce an erroris:
�NF
1
��NF
(1−�NF)NF −1+
�NF
2
��2NF
(1−�NF)NF −2+· · ·+
�NF
NF
��NF
NF= �T
(2)If now we assume that the Reducer sabotages, then
regardless of whether the incoming intermediate results arecorrect or not, it will produce an error.
Further, the Master validates by majority voting setsof rR versions of the final results corresponding to eachReduceToken tj .
The probability that a replica of an intermediate resultis scheduled to a erroneous Reducer is fs, and to anhonest Reducer is (1 − fs). Also, the probability that thehonest Reducer reports an erroneous result due to obtainingerroneous intermediate results from Mappers is �T . Further,the probability that an honest Reducer produces an error is�T (1 − fs). Consequently, the probability that a Reduceroutputs an erroneous result is �R = fs + �T (1 − fs). Theerror rate for majority voting when checking the final resultscorresponding to a partition tj is then:
� =
rR�
j=rR2 +1
�rR
j
�(�R)j(1− �R)rR−j (3)
Now, if we suppose that the general (aggregated) errorrate E is obtained if at least one of the validations for tj iserroneous, then:
E =
�NT
1
��(1−�)NT −1+
�NT
2
��2(1−�)NT −2+· · ·+
�NT
NT
��NT
(4)
IV. EXPERIMENTS AND RESULTS
In this section we present the results of the theoreticalevaluation of our model employing the MVM method.We drive the evaluation by following the variation of theaggregated error rate E while modifying the key parameters
(c) Replication of both Map and Reduce tasks
Figure 2. Dataflows in the MapReduce implementation
distinct workers as input for Map task. Consequently, thereducer receives a set of rm versions of intermediate filescorresponding to a map input fi. After receiving rm
2 + 1identical versions, the reducer considers the respective resultcorrect and further, accepts it as input for a Reduce task.
Figure 2b illustrates the dataflow corresponding to aMapReduce execution where rm = 3.
In order to activate the checking mechanism for theresults received from reducers, the master node schedules theReduceTokens T , with the attribute replica = rr (rr >2, rr ∈ N). Consequently, the BitDew services distribute aset of copies of T , RT = {yj |yj = {tj,p|p = 1, rn}}, to aset of rr distinct nodes. As effect, rr workers will performReduce tasks with same input, for the partition tj . Finally,the master receives rr versions for a result rfj , and selectsthe correct one by applying a verification method.
In figure 2c we present the dataflow corresponding to aMapReduce execution where the system checks the resultsproduced by both mappers and reducers. In this scenario weconsider rm = 3 and rn = 3.
It is possible that some malicious workers send super-fluous intermediate results, in the sense that the intermedi-ate result is entirely fabricated thus not being the outputcorresponding to a Map input fn. reducers could easilyinhibit this type of behavior by filtering received intermedi-ate results. Hence, we implement a naming scheme whichallows the reducer to check whether an intermediate resultcorresponds to a Map input fn.
We continue by presenting the naming scheme mech-anism. Before distributing the Map input F to workersthe master, creates a set of codes K = {kn, kn =δ(FileName(fn))}, where kn represents a code (such asgiven by a MD5 Hashing function) corresponding to fn. Thelist accompanies each tj scheduled to workers, as discussedearlier in this section. Further, for each fn received, themappers compute the code kn and attaches this value toifn,m, which is sent to the appropriate reducer. Finally, thereducer checks whether the accompanying code kn of a
received intermediate result is present in its own codes listK, ignoring failed results.
IV. EVALUATION OF THE RESULTS CHECKINGMECHANISM
In this section we describe the model for characteriz-ing the errors produced by the MapReduce algorithm inVolunteer Computing. We assume that workers sabotageindependently of one another, thus we do not take intoconsideration the colluding nodes behavior. We employ theMVM both for the verification of the results produced bymappers and by reducers.
We give the following notations:• f : the fraction of error-prone nodes; such a nodes
randomly produce erroneous results, independently ofthe behavior of other nodes. The probability to selectsuch a faulty worker is 0 < f < 0.5.
• s: the sabotage rate of faulty / malicious workers.Given that a worker is faulty, it produces an erroneousresult with probability 0 < s < 1. Thus, in general,the probability of having an erroneous result from allworkers is fs.
• NT : is the number of ReduceTokens. For a giveninput fn, a mapper outputs a result value for each tokentj .
• NF is the number of distinct input files (F ).• rm: is the replication degree of Map input files F . A
reducer receives rM versions of the intermediate resultcorresponding to fn, in order to accept it as correct.Thus, rM distinct nodes are needed to Map the fn
input.• rr: is the replication degree of the intermediate results.
Thus, rR distinct nodes Reduce rR versions of anintermediate result.
• �acc is the acceptable error rate.The acceptable error rate is a threshold for the calculated
system error rate, and it can be assessed according to theapplication type running in Volunteer Computing. Error rates
Ensuring Data PrivacyI Use a hybrid infrastructure : composed of private and public resources
I Use IDA (Information Dispersal Algorithms) approach to distribute andstore securely the data
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Active Data: Data Life-CycleManagement
Anthony Simonet (INRIA), Matei Ripeanu (UCB), Samer Al-Kiswany(UCB)
I Active Data: A Data-Centric Approach to Data Life-Cycle Management Anthony Simonet, Gilles Fedak,Matei Ripeanu and Samer Al-Kiswany. 8th Parallel Data Storage Workshop (PDSW’13), Proceedings ofSC13 workshops, Denver, November, 2013 (position paper 5 pages)
I Active Data: A Programming Model for Data Life-Cycle Management on Heterogeneous Systems andInfrastructures. Anthony Simonet, Gilles Fedak and Matei Ripeanu. Technical Report under evaluation.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
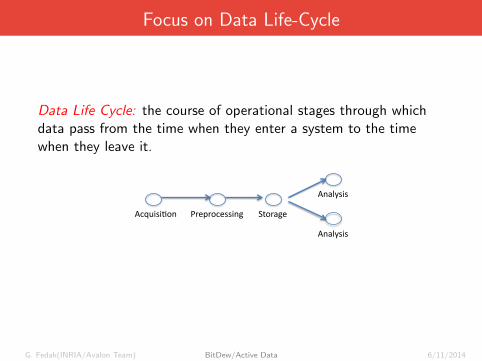
Focus on Data Life-Cycle
Data Life Cycle: the course of operational stages through whichdata pass from the time when they enter a system to the timewhen they leave it.
!"#$%&%'()* +,-.,("-&&%)/* 01(,2/-*
!)234&%&*
!)234&%&*
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Use Case : The Advanced Photon Source
I 3 to 5 TB of data per week on this detector
I Raw data are pre-processed and registered in the GlobusCatalog :
I Data are curated by several applications
I Data are shared amongst scientific user
Instrument(Beamline) LocalStorageTransfer
MetadataCatalog
Extract &Register Metadata
RemoteData Center
Transfer
AcademicCluster
Analysis
More analysis
Upload result
Register resu
ltmetadata
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Objectives
We’re aiming at :
I A model to capture the essential life cycle stages andproperties: creation, deletion, faults, replication, errorchecking . . .
I Allows legacy systems to expose their intrinsic data life cycle.
I Allow to reason about data sets handled by heterogeneoussoftware and infrastructures.
I Simplify the programming of applications that implement datalife cycle management.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
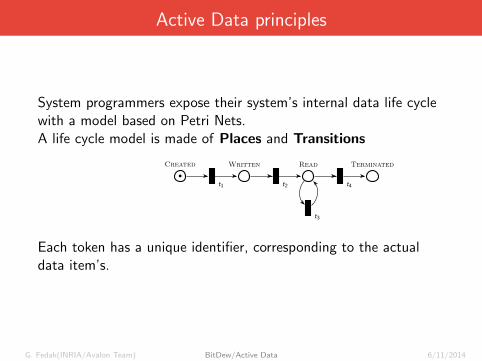
Active Data principles
System programmers expose their system’s internal data life cyclewith a model based on Petri Nets.A life cycle model is made of Places and Transitions
•Created
t1
Written
t2
Read
t3
t4
Terminated
public void handler () {
compressFile ();
}
Each token has a unique identifier, corresponding to the actualdata item’s.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
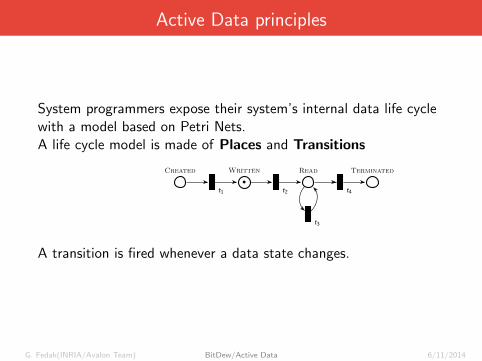
Active Data principles
System programmers expose their system’s internal data life cyclewith a model based on Petri Nets.A life cycle model is made of Places and Transitions
Created
t1
•Written
t2
Read
t3
t4
Terminated
public void handler () {
compressFile ();
}
A transition is fired whenever a data state changes.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
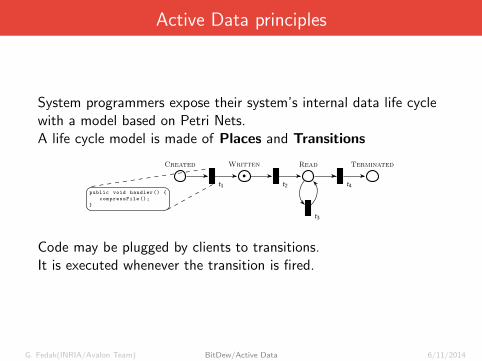
Active Data principles
System programmers expose their system’s internal data life cyclewith a model based on Petri Nets.A life cycle model is made of Places and Transitions
Created
t1
•Written
t2
Read
t3
t4
Terminated
public void handler () {
compressFile ();
}
Code may be plugged by clients to transitions.It is executed whenever the transition is fired.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Active Data features
The Active Data programming model and runtime environment:
I Allows to react to life cycle progression
I Exposes transparently distributed data sets
I Can be integrated with existing systems
I Has scalable performance and minimum overhead overexisting systems
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
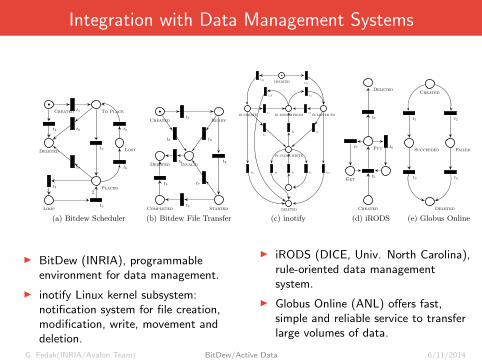
Integration with Data Management Systems
Created t1 To Place
t2
Deletedt3
Placedt4
Loopt5
2
t6
t7
Lost
t8
t9
(a) Bitdew Scheduler
Createdt1
Ready
t2
Startedt3
Completed
t4
Deleted Invalidt5
t6
t7
t8
(b) Bitdew File Transfer
IN CREATEt1
IN MOVED FROM
t2
t3IN MOVED TO
t4
IN CLOSE WRITE
t5t6
t7 t8t9 t10t11
DELETED
t14
t13CREATEDt12
(c) inotify
Get
Put
Created
t5
t6t7
t8
Deleted
(d) iRODS
Created
t1 t2
Succeeded Failed
t3 t4
Deleted
(e) Globus Online
Figure 3: Data life cycle models for four data management system.
structed from its documentation.Reading the source code of BitDew, we observe that data
items are managed by instances of the Data class, and thisclass has the status variable which holds the data itemstate. Therefore, we simply deduce from the enumeration ofthe possible value of status the set of corresponding placesin the Petri Net (see Figure 2a and 2b). By further analyz-ing the source code, we construct the model and summarizehow high level DLM features are modelized using ActiveData model:
Scheduling and replication Part of the complexity ofthe data life cycle in BitDew comes from the Data Schedulerthat schedules data on nodes. Whenever a data item isscheduled on a node, a new replica is created. We representreplicas with a loop on the scheduled state that creates anadditional token every time a token passes through it.
Fault tolerance Because one of BitDew’s target archi-tectures is Desktop Grids, it must deal with frequent faults,i.e. nodes going offline. When a data item is scheduled to anode, and the node disappears from the system, it is markedwith a Lost state and will be scheduled to an other node.This is represented by the loop Placed, Lost, tosched-ule.
Composition of File Transfer and Data SchedulerIn BitDew, the Data Scheduler and File Transfer Service areclosely related, and so are their life cycles. A file transfercannot exist without an associated data item, and a deleteddata item cannot be transferred. To connect the two PetriNets we need to define the start and stop places as explainedin section 3. In BitDew, a new file transfer can be startedfor a Data object in any state, except Deleted, Lost andLoop. To represent this, we define all the places but thethree mentioned above as start places and connect them tothe transfer life cycle model.
5. EXPERIMENTAL EVALUATIONIn this section we report on experimental evaluation of
the prototype using micro-benchmarks and use-case scenar-ios. Experiments are run on a cluster of the Grid’5000 ex-perimental platform [5] composed of 92 2-CPU nodes. EachCPU is an Intel Xeon L5420 with 4 cores running at 2.5Ghz.Each node is equipped with 16GB of RAM and a 320GB
Figure 4: Average number of transitions per second handledby the Active Data Service
Sata II hard drive. Nodes are interconnected with GigabitEthernet and are running Linux 2.6.32.
5.1 Performance EvaluationTo evaluate the performance in terms of throughput, la-
tency and overhead, we conduct a set of benchmarks basedon the version 0.1.2 of the prototype1.
Throughput is measured as the number of transitions thatActive Data is able to handle per second. In order to stressthe system we run one Active Data server and a varyingnumber of clients (one per cluster node), which publish 10,000transitions in a loop without a pause between the iterations.Figure 3 plots the average number of transitions processedper second against the number of clients. Once saturated,the Active Data Service can handle up to 32,000 transitionsper second.
We evaluate the latency, i.e the time to create of a newlife cycle and to publish a transition, and the overhead, i.ethe additional time incurred by the Active Data runtime en-vironment. We use the BitDew file transfer operation as areference to measure the overhead. The experiment consistsin creating and uploading 1,000 files (1KB to stress the sys-
1Active Data is free software, available under the GPL li-cence http://active-data.gforge.inria.fr
I BitDew (INRIA), programmableenvironment for data management.
I inotify Linux kernel subsystem:notification system for file creation,modification, write, movement anddeletion.
I iRODS (DICE, Univ. North Carolina),rule-oriented data managementsystem.
I Globus Online (ANL) offers fast,simple and reliable service to transferlarge volumes of data.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
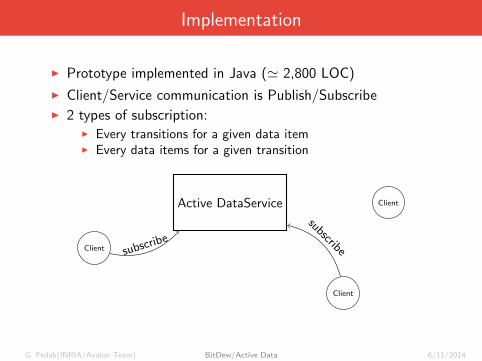
Implementation
I Prototype implemented in Java (' 2,800 LOC)
I Client/Service communication is Publish/SubscribeI 2 types of subscription:
I Every transitions for a given data itemI Every data items for a given transition
Active DataService Client
Client
subscribeClient subscribe
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
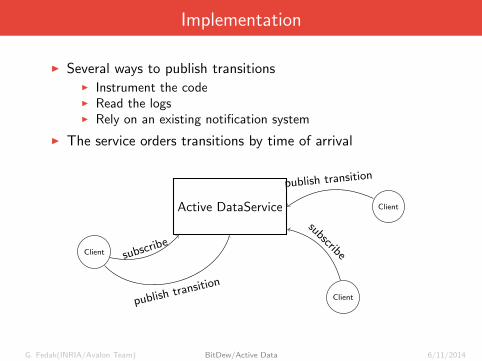
Implementation
I Several ways to publish transitionsI Instrument the codeI Read the logsI Rely on an existing notification system
I The service orders transitions by time of arrival
Active DataService Client
publish transition
Client
subscribeClient subscribe
publish transition
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
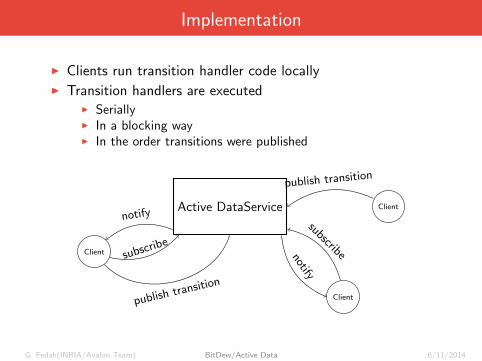
Implementation
I Clients run transition handler code locallyI Transition handlers are executed
I SeriallyI In a blocking wayI In the order transitions were published
Active DataService Client
publish transition
Client
subscribenotify
Client subscribe
notify
publish transition
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Data Surveillance FrameWork for APS
Anthony Simonet (INRIA), Kyle Chard (ANL), Ian Foster (ANL/UC)
I A. Simonet, K. Chard, G. Fedak, I. Foster Active Data to Provide Smart Data Surveillance to E-ScienceUsers In Proceedings of EuromicroPDP’15, Turku Finland, March 4-6, 2015
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
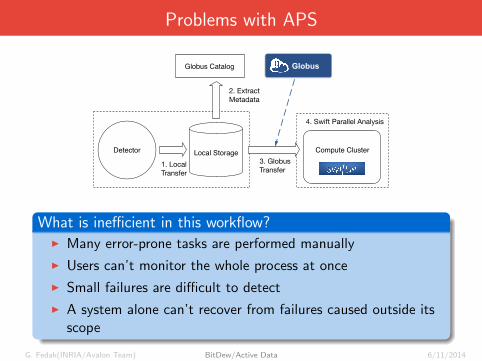
Problems with APS
Globus Catalog Globus
Detector Local Storage Compute Cluster
1. LocalTransfer
2. ExtractMetadata
3. GlobusTransfer
4. Swift Parallel Analysis
What is inefficient in this workflow?I Many error-prone tasks are performed manually
I Users can’t monitor the whole process at once
I Small failures are difficult to detect
I A system alone can’t recover from failures caused outside itsscope
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Data Surveillance Framework
4 goals (that would otherwise require a lot of scripting andhacking):
I Monitoring Data Set Progress
I Better Automation
I Sharing & Notification
I Error Discovery & Recovery
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
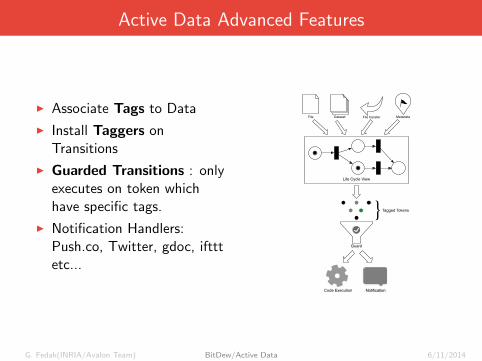
Active Data Advanced Features
I Associate Tags to Data
I Install Taggers onTransitions
I Guarded Transitions : onlyexecutes on token whichhave specific tags.
I Notification Handlers:Push.co, Twitter, gdoc, iftttetc...
A. Progress Monitoring
Scientists require mechanisms to monitor their workflowsfrom a high level, generate reports on progress, and identifypotential errors without painstakingly auditing every dataset.Monitoring is not limited to estimating completion time, butalso: i) receiving a single relevant notification when severalrelated events occurred in different systems; ii) quickly notic-ing that an operation failed within the mass of operations thatcompleted normally; iii) identifying steps that take longer torun than usual, backtracking the chain of causality, fixing theproblem at runtime and optimizing the workflow for futureexecutions; iv) accelerating data sharing with the communityby pushing notifications to collaborators and colleagues.
B. Automation
The APS workflow, like many scientific workflows, re-quires explicit human intervention to progress between stagesand to recover from unexpected events. Such interventionsinclude running scripts on generated datasets on the sharedcluster, registering datasets in the Globus catalog, and execut-ing Swift analysis scripts on the compute cluster Such inter-ventions cannot be easily integrated in a traditional workflowsystem, because they reside a level of abstraction above theworkflow system. In fact, they are the operations that start theworkflow systems.
C. Sharing and Notification
Scientific sharing can be made more efficient by allowingother scientists to be notified of new datasets availability(in the catalog) with powerful filters to extract only thenotifications they need, and even to start processes as soonas files are available. We believe the best way for scientiststo automatically integrate new datasets in their workflows isto rely on widely used dissemination mechanisms—such asTwitter. Twitter is an efficient notification mechanism that iscommonly used by scientists. It also can be simply integratedvia its APIs.
D. Error Discovery and Recovery
Each system participating in the APS experiment hasonly a partial picture of the entire process, which impairstheir ability to recover from unexpected events. Thus, whensuch events occur, systems often fail ungracefully, leavingthe scientists as the only one able to resolve the problemthrough costly manipulations. For example, if a Swift scriptfails when processing a file, it will simply report the error ina log file and return. Later, the when inspecting the outputfiles, a scientist may see that some results are missing, theywill then read the log and discover the faulty file. A quicklook at the file will tell them it was corrupted and their onlymeasure will be to again transfer the file to the computingcluster and re-start the analysis. In cases where entire datasetsare left unprocessed the process for error identification is lessclear. This requirement for low level human intervention andmanipulation delays workflow completion, places a burden onscientists and wastes valuable computing resources. Moreover,such approaches are also prone to human error. Automatingthese steps would improve each of these aspects.
Life Cycle View
File transferFile Dataset Metadata
Guard
Code Execution
} Tagged Tokens
Notification
Fig. 2: Data surveillance framework design
IV. SYSTEM DESIGN
We next present the data surveillance framework that wedesigned to satisfy the APS users’ needs presented above. Wealso elaborate on the design of specific features.
A. Data surveillance framework
Fig. 2 shows the main features of the data surveillanceframework; the framework is able to track any data object(such as files and sets of files) as well as elements related todata (such as file transfers and metadata). The frameworksreceives events from different systems and integrates theidentifiers of data and related elements from them in a singleglobal namespace. Data replicas and their current state areexposed as tokens in a unified identifier used across systems.Tokens provide a model for linking together related data indifferent systems. The framework allows users to be notifiedof the progress of their data and to automatically run customcode at many operational stages of the life cycle. execution ona subset of events, according to user choice.
B. Active Data
The complexity of implementing the surveillance frame-work comes from a lack of integration, impairing tight coor-dination between loosely coupled systems. Such coordinationis incredibly challenging because, in order to be efficient, itmust be as noninvasive as possible. Additional challenges stemfrom the lack of feedback derived from the systems, that aremostly regarded as black boxes from the user perspective.
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
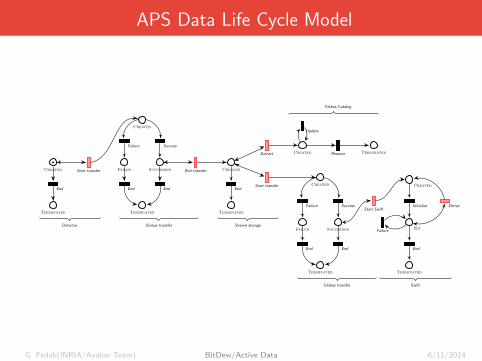
APS Data Life Cycle ModelAvalon Daniel Arnaud Anthony Vincent
Use-case: APS data life cycle model
Created Start transfer
Terminated
End
Detector
Created
SuccessFailure
SucceededFailed
EndEnd
Terminated
End transfer
Globus transfer
Created
End
Terminated
Start transfer
Shared storage
Created
SuccessFailure
SucceededFailed
EndEnd
Terminated
Start Swift
Globus transfer
CreatedExtract
Update
TerminatedRemove
Globus Catalog
Created
Initialize
Set
End
Failure
Terminated
Derive
Swift
Data life cycle model composed of 6 systems.
Avalon June 3rd, 2014 22/30
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Exemple: Data Provenance
Definition
Complete history of data derivations and operations
I Assess dataset quality
I Records the context of data acquisition and transformation
I PASS: Provenance Aware Storage Systems
−→ What about heterogeneous systems?
Outline Introduction Active Data Etude de cas : Framework de surveillance des donnees pour APS Discussion Conclusion
Exemple: Data Provenance
DefinitionHistorique complete des derivations et des operations sur unedonnee
� Estimer la qualite du jeu de donnees� Garder les conditions d’acquisition et de transformation des
donnees� PASS: Provenance Aware Storage Systems
−→What about heterogeneous systems?
Example with Globus Online and iRODS
File transfer service Data store and metadata catalog
G. Fedak(INRIA/UBC) Active Data Vichy 2014 20/28
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Exemple: Data Provenance
Definition
Complete history of data derivations and operations
I Assess dataset quality
I Records the context of data acquisition and transformation
I PASS: Provenance Aware Storage Systems−→ What about heterogeneous systems?
Outline Introduction Active Data Etude de cas : Framework de surveillance des donnees pour APS Discussion Conclusion
Exemple: Data Provenance
DefinitionHistorique complete des derivations et des operations sur unedonnee
� Estimer la qualite du jeu de donnees� Garder les conditions d’acquisition et de transformation des
donnees� PASS: Provenance Aware Storage Systems
−→What about heterogeneous systems?
Example with Globus Online and iRODS
File transfer service Data store and metadata catalog
G. Fedak(INRIA/UBC) Active Data Vichy 2014 20/28
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Exemple: Data Provenance
Definition
Complete history of data derivations and operations
I Assess dataset quality
I Records the context of data acquisition and transformation
I PASS: Provenance Aware Storage Systems−→ What about heterogeneous systems?
Outline Introduction Active Data Etude de cas : Framework de surveillance des donnees pour APS Discussion Conclusion
Exemple: Data Provenance
DefinitionHistorique complete des derivations et des operations sur unedonnee
� Estimer la qualite du jeu de donnees� Garder les conditions d’acquisition et de transformation des
donnees� PASS: Provenance Aware Storage Systems
−→What about heterogeneous systems?
Example with Globus Online and iRODS
File transfer service Data store and metadata catalog
G. Fedak(INRIA/UBC) Active Data Vichy 2014 20/28
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
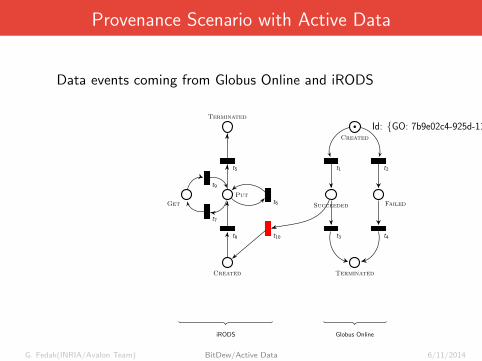
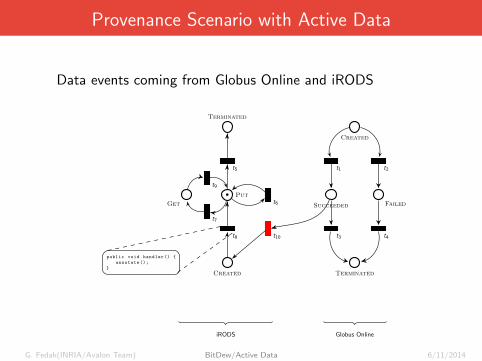
Provenance Scenario with Active Data
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Data events coming from Globus Online and iRODS
Created
Get
Put
Terminated
t5
t9
t6
t7
t8 t10
iRODS
Id: {GO: 7b9e02c4-925d-11e2,iRODS: 10032}public void handler () {
annotate ();
}
•Created
t1 t2
Succeeded Failed
t3 t4
Terminated
Globus Online
Id: {GO: 7b9e02c4-925d-11e2}
public void handler () {
iput (...);
}
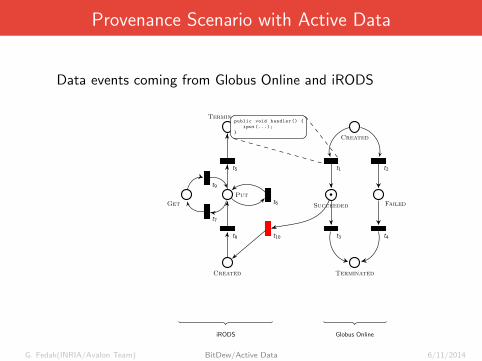
Provenance Scenario with Active Data
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Data events coming from Globus Online and iRODS
Created
Get
Put
Terminated
t5
t9
t6
t7
t8 t10
iRODS
Id: {GO: 7b9e02c4-925d-11e2,iRODS: 10032}public void handler () {
annotate ();
}
Created
t1 t2
•Succeeded Failed
t3 t4
Terminated
Globus Online
Id: {GO: 7b9e02c4-925d-11e2}
public void handler () {
iput (...);
}
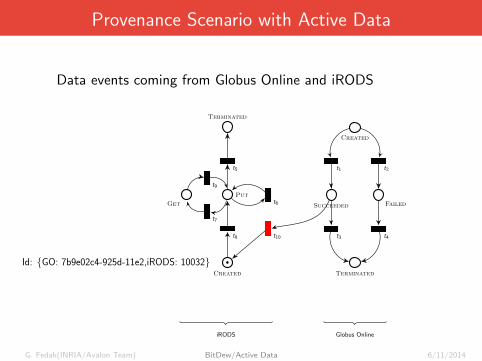
Provenance Scenario with Active Data
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Data events coming from Globus Online and iRODS
•Created
Get
Put
Terminated
t5
t9
t6
t7
t8 t10
iRODS
Id: {GO: 7b9e02c4-925d-11e2,iRODS: 10032}
public void handler () {
annotate ();
}
Created
t1 t2
Succeeded Failed
t3 t4
Terminated
Globus Online
Id: {GO: 7b9e02c4-925d-11e2}public void handler () {
iput (...);
}
Provenance Scenario with Active Data
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014
Data events coming from Globus Online and iRODS
Created
Get
• Put
Terminated
t5
t9
t6
t7
t8 t10
iRODS
Id: {GO: 7b9e02c4-925d-11e2,iRODS: 10032}
public void handler () {
annotate ();
}
Created
t1 t2
Succeeded Failed
t3 t4
Terminated
Globus Online
Id: {GO: 7b9e02c4-925d-11e2}public void handler () {
iput (...);
}

iRODS Provenance Result
$ imeta ls -d test/out_test_4628
AVUs defined for dataObj test/out_test_4628:
attribute: GO_FAULTS
value: 0
----
attribute: GO_COMPLETION_TIME
value: 2013 -03 -21 19:28:41Z
----
attribute: GO_REQUEST_TIME
value: 2013 -03 -21 19:28:17Z
----
attribute: GO_TASK_ID
value: 7b9e02c4 -925d-11e2 -97ce -123139404 f2e
----
attribute: GO_SOURCE
value: go#ep1/~/ test
----
attribute: GO_DESTINATION
value: asimonet#fraise /~/ out_test_4628
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Conclusion
We proposed several approaches to handle Big Data on hybriddistributed computing infrastructures : data management, dataprocessing and programming model.
Next
I Data Collection & Data Stream
I Incentive systems for collaborative data science
Want to learn more ?I Book on Desktop Grid Computing ed. C.Cerin and G.Fedak CRC Press
I Home page for the Big Data class : http://graal.ens-lyon.fr/gfedak/pmwiki-lri/pmwiki.php/Main/MarpReduceClass
I our websites : http://www.bitdew.net and http://www.xtremweb-hep.org
G. Fedak(INRIA/Avalon Team) BitDew/Active Data 6/11/2014

Thank you!
Questions?